A data mining technique for detecting malignant mesothelioma cancer using multiple regression analysis
-
Abdulla Mousa Falah Alali
 and
Isaac Ofori
and
Isaac Ofori

Abstract
Lung cancer is a substantial health issue globally, and it is one of the main causes of mortality. Malignant mesothelioma (MM) is a common kind of lung cancer. The majority of patients with MM have no symptoms. In the diagnosis of any disease, etiology is crucial. MM risk factor detection procedures include positron emission tomography, magnetic resonance imaging, biopsies, X-rays, and blood tests, which are all necessary but costly and intrusive. Researchers primarily concentrated on the investigation of MM risk variables in the study. Mesothelioma symptoms were detected with the help of data from mesothelioma patients. The dataset, however, included both healthy and mesothelioma patients. Classification algorithms for MM illness diagnosis were carried out using computationally efficient data mining techniques. The support vector machine outperformed the multilayer perceptron ensembles (MLPE) neural network (NN) technique, yielding promising findings. With 99.87% classification accuracy achieved using 10-fold cross-validation over 5 runs, SVM is the best classification when contrasted to the MLPE NN, which achieves 99.56% classification accuracy. In addition, SPSS analysis is carried out for this study to collect pertinent and experimental data.
1 Introduction
It is widely accepted that all malignant mesotheliomas (MMs) are rare, serious malignancies with a clear connection to asbestos exposure. Additionally, a “genetic predisposition” and a previous “simian virus 40” infection are likely related to it. In some Turkish regions where low concentrations of erionite, a naturally fibrous substance that belongs to the group of minerals known as zeolites, are prevalent, the frequency of MM is extremely high. In Turkey, atmospheric “asbestos exposure and MM” are two of the most serious public health issues. The formation of mesothelioma can sometimes be linked to molecular pathways. Staying in the country has been associated with the emergence of mesothelioma. Asbestos-containing soil combinations referred to as “white soil” or “corak” may be observed in Anatolia, Turkey, Luto, and Greece. MM is a deadly cancer that is becoming more common as a result of asbestos exposure. Individual patients may benefit from chemotherapeutic, radiation, or immunotherapy, and some patients may benefit from surgical treatment and multimodality therapy. In the overall population, MM is an uncommon illness with an estimated “incidence of 1–2 per million” each year. In developed nations, MM in women varies from 1 to 5 per million annually, whereas in men it varies between 10 and 30 per million each year [1]. It is possible that asbestos exposure could be the reason for the higher occurrence rates in developed nations. MMs are estimated to be associated with 15,000–20,000 fatalities every year throughout the world, according to current research. In Turkey, approximately 1,000 individuals are diagnosed with MM each year.
The diagnosis of myeloma is mostly dependent on blood and urine testing. Myeloma cells typically release M protein, an antigen known as monoclonal immunoglobulin. The amount of M protein in a patient’s blood and urine is used to determine the illness’ severity, monitor the efficacy of treatment, and observe for disease progression or recurrence. To examine the number of antibodies in the blood, immunoglobulin levels are tested. Blood tests are used to determine the serum levels of albumin and 2-M. Lactase dehydrogenase (LDH) is a protein-type enzyme, and almost all body tissues contain it. An X-ray produces a picture of the interior of the body’s organs using a low amount of radiation. X-ray of the patient’s bones for a doctor’s evaluation of their skeletal system is often the initial step in the analysis of the bones when myeloma is found or diagnosed. Instead of using X-rays, magnetic resonance imaging (MRI) creates precise pictures of the body using magnetic fields. Particularly in the skull, spine, and pelvis, an MRI can reveal if the healthy bone marrow has been replaced with myeloma cells or by a plasmacytoma. A plasma cell tumor called a plasmacytoma develops in bone or soft tissue. Fine-grained imaging could potentially reveal spinal compression fractures or a tumor pushing against the nerve roots. A comprehensive cross-sectional image of soft tissue anomalies or cancers can be obtained by computed tomography (CT) scan. A computer then combines the photos to produce a three-dimensional model of the interior of the body. It is crucial to stress that people with multiple myeloma should avoid intravenous contrast dye, which is frequently used in CT scans for other types of malignancies.
A positron emission tomography (PET) scan, often known as a PET-CT scan, is a combination of PET and a CT scan. A PET scan is a technique for creating images of organs and tissues inside the body. Aspiration and biopsy of bone marrow are the two procedures comparable and are frequently performed concurrently to check the bone marrow. Bone marrow is composed of both solid and liquid components. A needle is used to extract a sample of the bone marrow fluid. A needle biopsy of the bone marrow is the removal of a tiny quantity of solid tissue. This is critical in making a diagnosis of myeloma. The material is next examined by a pathologist. A pathologist is a physician who specializes in the interpretation of laboratory tests and the evaluation of cells, tissues, and organs to diagnose illness. To assess the genes in myeloma, cytogenetics and a specific test known as fluorescence in situ hybridization are performed. These tests determine the genetic makeup of the myeloma and whether it is high or low risk. Additionally, samples may be examined using genomic sequencing to determine exactly the deoxyribonucleic acid (DNA) changes that have occurred in the cancer cells. A bone marrow extraction and biopsy are frequently performed on the pelvic bone, which is located in the lower back near the hip. Anesthesia is used to numb the skin in that location first. The perception of pain may also be suppressed using other anesthetic techniques.
1.1 Background of research
The planet’s average lifespan increased in the later part of the twentieth century. Revolutionary therapies for infectious illnesses, such as dengue fever and cholera, as well as improved sanitation practices, have significantly reduced health hazards. Cancer, on the other hand, continues to be a major global health concern. According to records, there have been 23,869 fatalities in America, 12,012 mortalities in Asia, and 49,779 casualties in Europe due to MM in 2018. MM is caused by mesothelial cells attacking the peritoneal, alveoli, and endocardium. Inflammatory and infectious diseases are two common MM symptoms. From 1980 to 2020, the worldwide death rate owing to MM increased to a catastrophic level [2]. After the first asbestos exposure, mesothelioma symptoms might take 10–50 years to appear. Early identification might be more difficult by symptoms that are frequently confused with less severe conditions. Patients should seek medical assistance as soon as symptoms appear since early discovery may improve the prognosis for mesothelioma. Chest discomfort or abdominal pain, shortness of breath, lack of appetite, blood clots, coughing up blood, fluid accumulation, fatigue, fever and night sweats, and weight loss are all common symptoms of mesothelioma. Dry coughing, chest discomfort, breathlessness, pulmonary edema, and joint stiffness are also frequent early signs. Weight loss, excessive sweating, tiredness, difficulty breathing, temperature, swallowing, and cerebral hypoxia are also indications of the later stages. In general, etiology examines the link between illness and the variables that influence it, such as nutrition, climate, genetic makeup, and lifestyle. Finding valuable information from a large amount of data via manual calculation is difficult. Previous research has shown that association rule mining may be used to derive disease risk variables. The huge amount of biostatistics and medicinal data has made data analysis more difficult and time-consuming for medical practitioners and scientists [3]. Bioinformatics potential is expanded by improved DNA scanning and machine intelligence tools. In addition to medicine, biomedical research, training, automation, commerce, and machine learning approaches are frequently employed. Data mining (DM) is the process of extracting usable information from the data. Segmentation, categorization, analysis, and DM techniques are some of the methodologies and algorithms used in DM. In medical statistics, there is a large class discrepancy. Categories are not reflected evenly in medical diagnostic systems. Minority categories have several minor instances that are pervasive in health diagnosing procedures. The targeted category, patient/malignant, appears substantially less often in such scenarios than genuine/normal specimens [4]. DM is a method for extracting knowledge from data. For effective knowledge retrieval, it applies a variety of techniques and algorithmic techniques to pre-process, cluster, classify, and associate the data. Examining and interpreting the hazy medical data provide outstanding and huge potential for DM. The basic medical data, however, are many, geographically distributed, and of various forms. These data must be compiled in an orderly manner. Thanks to DM’s creativity and intelligence, a customer may deal with contemporary and obscure patterns in the data. There are several advantages to using DM in a medical context and it has many applications, the most important among which is that it leads to better medical treatment at a lower cost. Because DM algorithms provide a learning-rich environment that can improve the accuracy of therapeutic decisions, they are mostly utilized in the detection and treatment of cancer. DM techniques are often divided into two categories: unsupervised learning, or descriptive models, which explore the relationships between qualities and find patterns in the data, and supervised learning; or predictive models, which predict future outcomes based on past behavior. Condensing a theory, acquiring data, pre-handling, evaluating the model, and interpreting the model are all integrated within the DM method.
The lower categories are mostly ignored by traditional classifiers, which focus on the larger ones. “Typically, a large number of current solutions are suggested at the database level, whereas just a small number of existing algorithms are proposed.” Those services are based on interpolation, such as oversampling as well as under-sampling approaches, at the database level.
Whenever a patient visits the hospital to have their symptoms examined, they are frequently diagnosed and treated. Shortness of breath, heart or back discomfort, pain, chronic coughing, and a variety of other signs may be experienced by patients, neither of which instantly alert the clinician to mesothelioma. Numerous clinical investigations on MM illness have been conducted in southeast Turkey. Many studies employing artificial intelligence approaches, including probability neural networks (PNNs), learning vector quantization (LVQ), artificial immune system (AIS), and multilayer neural network (MLNN) incorporating prospective information, have been conducted on MM illness diagnosis. The PNN structures use a methodology known as Bayesian classifiers, which was created in statistics, to offer a generic answer to pattern classification issues. Within a pattern layer, the PNN creates distribution functions using a supervised training set. Compared to other ANN structures, PNN training is a lot easier. However, if the categorization of the categories is different while also being quite similar in certain regions, the pattern layer may be rather large. PNN is suitable for disease diagnosis systems because it provides a general solution to pattern categorization issues. The LVQ neural network (NN) topology is classified according to how much the unknown data resemble these prototypes. An LVQ NN consists of a linear output layer and a competitive layer. The capability to classify input vectors is picked up by the competitive layer. The linear output layer transforms the classes of the competitive layer into user-defined target categories. Target classes for the linear output layer are the classes it learns, whereas subclasses for the competitive layer are the classes it learns. The LVQ network design has been successful for disease diagnosis systems. The most prevalent NN structure that has been employed effectively for illness diagnostic systems is the MLNN structure. The back-propagation technique is a well-known and effective tool for MLNN structure training. Drugs are used in immunotherapy to boost a person’s immune system so it can more effectively detect and eliminate cancer cells. An essential component is the immune system’s ability to stop attacking healthy body cells. “Checkpoints,” which are proteins on immune cells, need to be activated for an immune response to occur (or off). Cancer cells occasionally employ these checkpoints to stave off immune system assaults. Restoring the immune response against cancer cells may benefit from the use of checkpoint inhibitors, more contemporary drugs that directly target these checkpoint proteins.
The diagnosis of MM illness is a crucial classification problem. In many different professions, such as healthcare, categorization is a vital element of the process [5]. Artificial intelligence approaches are increasingly being used in medical diagnostics. The most essential components in diagnosing are, undoubtedly, the analyses of data collected from patients and professional choices. Therefore, multiple artificial intelligence approaches may be required to categorize illnesses at times. DM is used extensively in clinical uses such as diagnostics, prediction, and treatment. Medical information extraction is the term for using DM in healthcare applications (CDM). For practical knowledge-building, healthcare decisions, and critical evaluation, CDM entails the conceptualizing, acquisition, evaluation, and assessment of accessible clinical data. DM focuses on clinical diagnostics among the many clinical applications [6]. Diagnosing a disease is determining if an affected person has a certain problem based on medical indications, behaviors, and testing. Clinical decision support systems (CDSSs), or more particularly diagnosing decision support systems, are computer programs that assist with this process. A number of computerized and non-computerized tools and treatments are included in clinical decision support (CDS). To fully benefit from electronic health records (EHRs) and automated physician order input, high-quality CDSSs, also known as computerized CDS, are required. A CDSS may consider all data included in the EHR, making it feasible to recognize changes outside the purview of the expert and recognize changes particular to a particular patient, within reasonable bounds. Clinical data are increasing in quantity and quality and can be found in EHRs, disease registrations, patient surveys, and information exchanges. However, improved patient care is not necessarily a result of digitization and big data. A number of studies have found that just installing an EHR along with computerized physician order entry (CPOE) greatly increased the number of some errors and dramatically decreased the frequency of others. High-quality CDS is therefore essential if healthcare organizations are to benefit fully from EHRs and CPOE.
Support vector machine (SVM), one of the most widely used supervised learning algorithms, is used to handle classification and regression issues. Nonetheless, it is largely employed in machine learning classification issues. The SVM method seeks to construct the optimum line or decision boundary that can partition n-dimensional space into classes in order to quickly categorize fresh data points in the future. A hyperplane is a name given to this perfect decision boundary. SVM is used to choose the extreme vectors and points that contribute to the hyperplane. Support vectors, which are used to describe these extreme scenarios, are used in the SVM technique. A well-established study area in pattern recognition and machine learning is the combination of numerous classifiers (also known as an ensemble of classifiers, a committee of learners, a mixing of experts, etc.). It is understood that using many classifiers as opposed to a single classifier often increases overall predicted accuracy. Even while the ensemble may not produce results that are superior to the “best” single classifier in some circumstances, it may reduce or even remove the risk associated with selecting an insufficient single classifier. In order to create an ensemble, numerous separate classifiers must first be trained, and their predictions must then be combined. SVMs often have better prediction accuracy by default than multilayer perceptron. SVMs may take longer to execute because they need complex computations, such as applying kernel functions to translate an n-dimensional space. However, it consistently makes excellent forecasts. The complexity of MLP classifiers is managed by keeping the number of hidden units low, whereas the complexity of SVM classifiers is independent of the dimension of the tested data sets. SVMs employ empirical risk minimization, whereas MLP classifiers are based on the minimizing of structural risk. As a result, SVMs are effective and produce close to the best classification since they are able to obtain the ideal separation surface, which performs well on previously unknown data points.
The main goal of this research is to develop the best classification for MM illness diagnosis utilizing powerful DM approaches, as well as to try to uncover the relevant input factors for MM diagnosis of diseases. Several authors utilized different classification algorithms in this dataset to diagnose MM illness, although SVM and MPLE were most likely not utilized as a part of well-related capabilities. This study has the greatest categorization average accuracy (as compared to previous studies) and has a substantial variable input significance chart for MM illness diagnosis.
2 Literature review
MM is a malignancy that arises from mesothelial cells in the pleural membrane surface and intraperitoneal regions and is particularly aggressive. MM, which was once thought to be unusual, is becoming more common, with a maximum occurrence expected around 2010 and 2025. Even though the condition is uncommon, it is extremely serious, with a mean survival rate of only 7 months. Because the disease can take up to 50 years to manifest after asbestos exposure, indications are hazy, and diagnostic instruments are not sensitive or precise enough just to identify the illness until it becomes late. As a result, innovative MM early recognition and screening technologies are critically required to improve MM care [7]. A rare kind of cancer called mesothelioma is largely caused by asbestos exposure. After asbestos exposure, cancer may take decades to manifest, but once it does, the illness spreads swiftly. The majority of those who get mesothelioma have had jobs where asbestos fibers were inhaled. After a person is initially exposed to asbestos, the latency period – the interval between exposure and diagnosis – can be anywhere between 20 and 50 years. The pleural membranes of the body are affected by this form of malignancy. The stomach and chest chambers are lined with these membranes. Up to four out of every five occurrences of malignant mesothelioma involve the chest membranes. The fibers in asbestos are quite small and enter into the extreme ends of tiny air channels in the lungs when individuals inhale them in. The pleural membranes of the chest cavity can be reached by the fibers from there. They may be ingested and may ultimately find their way to the membranes lining the abdominal cavity after spending time in the stomach or other internal organs. Asbestos fibers induce inflammation and scarring after they have made contact with the membranes. This may result in DNA alterations and unchecked cell development, both of which increase the risk of cancer, including mesothelioma. Six distinct minerals that are found in the environment naturally are known as asbestos. Mesothelioma does not always occur in asbestos-exposure victims. The largest risk of contracting the disease is among those who have spent more than a year in employment involving a high level of asbestos exposure. However, mesothelioma can develop after just a few days of exposure. A membrane cancer called malignant mesothelioma is caused by asbestos exposure. Cancer that spreads to other parts of the body can originate anywhere. On the pleural membrane, it can develop tumors that resemble mesothelioma. Cancer that has migrated from its original site to another portion of the body is referred to as metastatic cancer or metastatic carcinoma, and usually, the lymphatic system is involved. After entering the lymph nodes, cancer cells can spread throughout the body and begin new tumors. The pleura is a membrane where pleural mesothelioma first appears. Metastatic cancer on the pleura and mesothelioma have extremely similar appearances. However, the medications used to treat pleural tumors caused by metastatic breast or colon cancer differ from those used to treat pleural mesothelioma. All cancers, including mesothelioma and metastatic cancer, show their origin. Typically, these are proteins. These indicators are known as “biomarkers” by scientists. Biomarkers might be observed in the tissue, blood, or other bodily fluids. All MMs displayed double negativity and all metastatic carcinomas displayed double positivity.
Even though MM must be distinguished from innocuous pleural disorder or metastatic spread of many other principal types of cancer toward the pleura, existing intrusive recognition processes, such as “pleural fluid cytogenetics acquired via thoracentesis,” syringe “biopsy of pleural muscle under CT guidance,” and “accessible thoracotomy,” possess poor susceptibility, varying from 0% with a solitary sample selection to 64% with sequential samplings. Utilizing molecular biomarkers to create a suitable and “non-invasive cancer diagnostic” test has shown to become a very appealing but tough undertaking. Several MM tumor indicators have been discovered. The majority are circulation proteins/antigens, which are either produced or degraded remains of tumor tissue and may be tested therapeutically using immunoassays. The most often used antigenic tumor determinants for identifying MM are soluble mesothelin-related protein (SMRP), megakaryocyte potentiating factor (MPF), and mesothelin (MSLN) variations. In the clinic, SMRP levels can now be measured, although the specificity and sensitivity are still low at 50 and 72%, respectively. MPF and MSLN research showed sensitivity and particularities of 74.2 and 90.4%, respectively, and 59.3 and 86.2% [8]. Even though these indicators have a high sensitivity and specificity, their sensitivity makes them ineffective as an MM diagnostic test.
According to the 2015 World Health Organization classification, patients are now divided into three classic histopathologic types: epithelioid MM (EMM), sarcomatoid MM (SMM), and biphasic MM (BMM), with BMM consisting of a mix of sarcomatoid and epithelioid features. The prognosis is greatest for patients with EMM (median overall survival [OS] of 16 months), worst for those with SMM (OS of 5 months), and in the middle for patients with BMM. This histological categorization is useful for prognosis and treatment, but it is inadequate to account for the wide range of clinical characteristics and health experiences in MM patients. This emphasizes the critical need for innovative strategies to uncover prognostic indicators that are reliably linked to survival. With the increase of deep learning as well as the accessibility of thousands of histological slides, a great beginning to reassess traditional techniques for diagnosis and patient outcome prediction has arisen [9]. Furthermore, this method is frequently regarded as a black box, with visual elements leading to projections that are difficult to understand. To overcome these restrictions, researchers created MesoNet, a deep learning method designed exclusively for analyzing huge photos, such as whole-slide images (WSIs), without the need for pathologists to annotate them locally [10]. Researchers developed a newly disclosed method particularly designed to meet this problem by creating MesoNet. The technique develops a deep learning algorithm using WSIs with only international data labeling to construct a forecasting model. “WSI’s from MM patients” were first normalized and separated into little “112 × 112 µm squares (224 × 224 pixels)” known as “tiles.” Throughout an adaptive learning experience, these tiles were supplied into the network infrastructure, which allocated a survival score to every tile. Ultimately, the model chose the most significant tiles from each WSI for the forecast and utilized this limited handful of tiles to forecast patient OS [11].
The purpose of most DM projects is to create a model from the data supplied. As a result, DM systems are scientific rather than subjective, as they are based on existing facts. Predictive DM incorporates a variety of approaches to create classification and regression models, including decision trees, random forests, boosting, SVMs, linear regression, and NNs. Cluster analysis and classification approach modeling are used in descriptive DM [12].
Three hundred- and twenty-four-MM patients were diagnosed and managed in this study. The files were analyzed and the data were examined retrospectively. All samples in the “dataset have 34 attributes” since the doctor believes it is more helpful than other factor subsets [13]. Age, gender, city, asbestos exposure, type of MM, period of asbestos exposure, prognosis method, keep side, cytology, the severity of symptoms, dyspnea, ache on chest, loss of strength, smoking habit, efficiency status, white blood cell count, hemoglobin, platelet count, sedimentation, blood lactic dehydrogenases (LDHs), alkaline phosphatase (ALP), protein content, total protein, glucose, pleural LDHs are all included. [14]. Each patient’s diagnostic tests were documented. The dataset for this work was obtained from the UCI Machine Learning Repository [15].
2.1 MM illness detection with DM methods
DM is a multi-step procedure that must be iterated. The “CRISP-DM,” an industry-supported “tool-neutral technique” (e.g., SPSS, DaimlerChrysler), splits a DM project into “six phases” (Figure 1).
![Figure 1
CRISP-DM tool [15].](/document/doi/10.1515/biol-2022-0746/asset/graphic/j_biol-2022-0746_fig_001.jpg)
CRISP-DM tool [15].
This work addresses steps 4 and 5, with an emphasis on applying NNs and SVMs to solve classification and regression issues. Both goals need supervised learning, where a model is developed using examples from a dataset to translate my input into a target. Models that deal with categorization produce a probability p(c) for each possible class c, such that
Common criteria for judging classifier models include the ROC area (AUC), a confusion matrix, efficiency (ACC), and actual positive/negative rates (TPR/TNR). High ACC, true positive rate (TPR), TNR, and AUC values are desirable in a classification method. To measure the generalization performance of the model, the endurance verification (i.e., train/test split) or even the more robust k-fold cross-validation is typically utilized [17]. This is far more resilient, but it takes roughly k times as long to compute because there are k hypotheses to fit.
2.2 MLP and multilayer perceptron ensembles (MLPE) NN model
The famous multilayer perceptron is referred to as NN in DM approaches (MLP). MLPs are a good solution to address classification problems. The attempt to determine the correct network for a particular application due to susceptibility to the beginning circumstances and overfitting and underfitting difficulties that restrict their generalization potential is a fundamental worry in their utilization. Furthermore, in the search for a single ideal system, time and technology restrictions may severely limit the levels of flexibility. MLP ensembles are a potential solution to substantially address these problems; aggregating and voting approaches are widely utilized in conventional statistical pattern classification and may be successfully used in MLP classifications [17,18]. MLPEs, which are mixtures of MLP algorithms, are being used to solve frameworks for analysis, and it has been discovered that MPLEs outperform single MLP designs in many cases. The results of this study suggest that MLPEs outperform MLPs. One hidden state of H neurons with exponential functionalities is included in this system (Figure 2, left). The whole model is written as follows:
![Figure 2
MLP NN (left) and SVM (right) [18].](/document/doi/10.1515/biol-2022-0746/asset/graphic/j_biol-2022-0746_fig_002.jpg)
MLP NN (left) and SVM (right) [18].
The platform’s response for component i,
While
Learning is the combination of numerous classifiers (also known as an ensemble of classifiers, a committee of learners, a mixing of experts, etc.). It is understood that using many classifiers as opposed to a single classifier often increases overall predicted accuracy. Even while the ensemble may not produce results that are superior to the “best” single classifier in some circumstances, it may reduce or even remove the risk associated with selecting an insufficient single classifier. To create an ensemble, numerous separate classifiers must first be trained, and their predictions must then be combined.
2.3 SVM model
One benefit SVMs have over NNs is the absence of local minima during the learning process. The core concept is to use a regressive approach to project the input x into a high-dimensional feature collection. The SVM then identifies the optimal linear divergence hyperplane in the training dataset and connects it to a collection of vector support points (Figure 2, right). The conversion (x) is determined by a kernel function. The widely used Gaussian kernel, which has fewer variables than other kernels (such as polynomial), is employed in SVM as part of the sequential minimum optimization (SMO) learning technique:
Two hyper-parameters influence the performance of the classifier: C is a penalty component and K is a kernel criterion. The conditional SVM outcome is as follows:
where m denotes the number of “support vectors,”
The NN and SVM model parameters (e.g., H,
2.4 Sensitivity analysis
The susceptibility assessment is a basic process that assesses the system behaviors when a particular input is altered after the development operation. Let us accept the output produced by maintaining all input parameters at their average numbers
The variable effect characteristic (VEC) curve has now been developed for a more precise examination, which depicts the
2.5 Measures of performance evolution
2.5.1 Classification accuracy (ACC)
The capacity of the algorithm to properly anticipate the class levels of new or previously unknown data is referred to as classification results. The proportion (percentage) of assessment collection samples successfully categorized by the classification is known as classification results. The accuracy level can be used to evaluate categorization performance. That is
such that
The performance development assessment in this section is mostly dependent on the classification results provided in equations (5) and (6). In addition, certain other performance indicators are examined. Following are some quick explanations of additional measurements [19].
2.5.2 AUC and ROC curve
AUC is a useful measure for evaluating classification model operations. When the value for categorizing an item as 0 or 1 is increased from 0 to 1, a plot of the TPR vs the false-positive rate is displayed. If the classification is really strong, the TPR will rapidly increase and the AUC will be close to 1. The AUC is useful for measuring detector performance on skewed data since it is independent of the percentage of the given population that falls into category 0 or 1. The AUC is useful for testing classifier performance on unbalanced data because of this attribute [19]. TPR (responsiveness) is determined as a function of the false-positive frequency at various ROC curve breaking points (100-specificity). Each position on the ROC curve indicates a sensitivity/responsiveness pair, or TPR/TNR, for a certain decision criterion.
The goal of this study was to determine the most accurate categorization and crucial input factors for MM disease identification. Tables 1–3 and Figures 3–5 present the results of applying DM methods. Table 1 shows that SVM and MLPE gave nearly identical results in all cases of efficiency development measurements. After 5 runs and 10-fold cross-validation, SVM has a classification performance of 99.87%, whereas MLPE NN has a classification performance of 99.56%. SVM produces 0.9999 for the AUC measure; however, MLPE returns 0.9998, which is substantially comparable to the SVM result. The remaining performance metrics follow a similar pattern of results. SVM obtained 99.8245 and 100% accuracy rates, whereas MLPE scored 99.5614 and 99.5416% true-positive and true-negative levels, respectively. Finally, the SVM value for the F1 score is 99.9560%, and the MLPE result is 99.6485% [20]. After examining the data in Table 1, it is evident that SVM is a more accurate classification than MLPE NN for all performance measures. Table 2 allows for the evaluation of the classification performance of SVM and MLPE run-wise findings. With a result of 99.87%, Table 3 demonstrates that SVM (with 10-fold cross-validation and 5-run architecture) achieved the best overall classification results. This is a great outcome for the diagnostic problem with MM’s condition. With a score of 99.56%, the MLPE NN (with 5 runs, 2 hidden layers, and 10-fold cross-validation) generated the second-best classification accuracy results. These two strategies make up all the methods discussed in this section. The third-best classification accuracy results were generated by AIS using only 10-fold cross-validation and no study repetitions. The PNN and MLNN are also effective in identifying MM illness diagnoses. The LIFT plot in Figure 3 illustrates a comparison of SVM and MLPE NN. Accordingly, the input important bar chart and VEC are displayed in the LIFT plot for the MM disease dataset’s MM sickness diagnosis utilizing SVM and MLPE NN. The input significance bar chart depicts the relative importance of each input variable to the response variable (measured as a score ranging from 0 to 1). For a more thorough analysis, a VEC plot is employed, which displays the most important input variable versus the response variations according to the x- and y-axis. The LIFT plot contrasts SVM with MLPE NN. Because each of these methods takes a similar amount away from the beginning position, the two lines are parallel. Both approaches extract roughly the same amount of data from the foundation, which is why the two lines are nearly identical. Figure 4 shows input significance bar graphs for 34 input parameters in the MM illness database. It yields some fascinating outcomes for this MM illness diagnostic issue. The most essential input parameter for diagnosing MM illness is ALP [21]. Figure 4 clearly shows that the parameter “City” is an essential element in prognosis. The patient’s situation is crucial in this situation. The parameter “City” file contains information further about the patient’s region. Asbestos exposure is generally known to be one of the leading causes of MM illness. So, it is crucial to know where the person comes from and if he or she has ever been exposed to mesothelioma [22]. Furthermore, Figure 5 shows the VEC plot for even the most external factors that are favorable, ALP. Patients with an ALP value of 300–500 have the best likelihood of developing MM illness.
SVM and MLPE algorithms for MM illness diagnosis are compared
| Performance evolution | |||||
|---|---|---|---|---|---|
| Methods | ACC (%) | AUC (0–1) | TPR (%) | TNR (%) | F1 (%) |
| SVM | 99 | 0.9988 | 99.8215 | 99 | 99.9590 |
| MLPE | 99 | 0.9968 | 99.5615 | 98.5417 | 99.6445 |
Average of MM illness classification accuracy
| Results (%) per run (average of 10-fold cross-validation outputs in each run) | ||||||
|---|---|---|---|---|---|---|
| Methods | 1st | 2nd | 3rd | 4th | 5th | Average |
| SVM | 99 | 99 | 98 | 99 | 98 | 98.6 |
| MLPE | 99 | 99 | 99 | 99 | 99 | 99 |
Comparison of several performance measurement techniques
| Methods | Number of fold cross-validation | Number of runs | ACC (%) |
|---|---|---|---|
| SVM* | 9 | 4 | 99 |
| MLPE* | 9 | 4 | 99 |
| AIS | 9 | — | 9 |
| NN | 9 | — | 91 |
| PNN | 3 | — | 96 |
| MLNN | 2 | — | 94 |
| LVQ | 2 | — | 91 |
* symbol is used to address the models presented in this research.
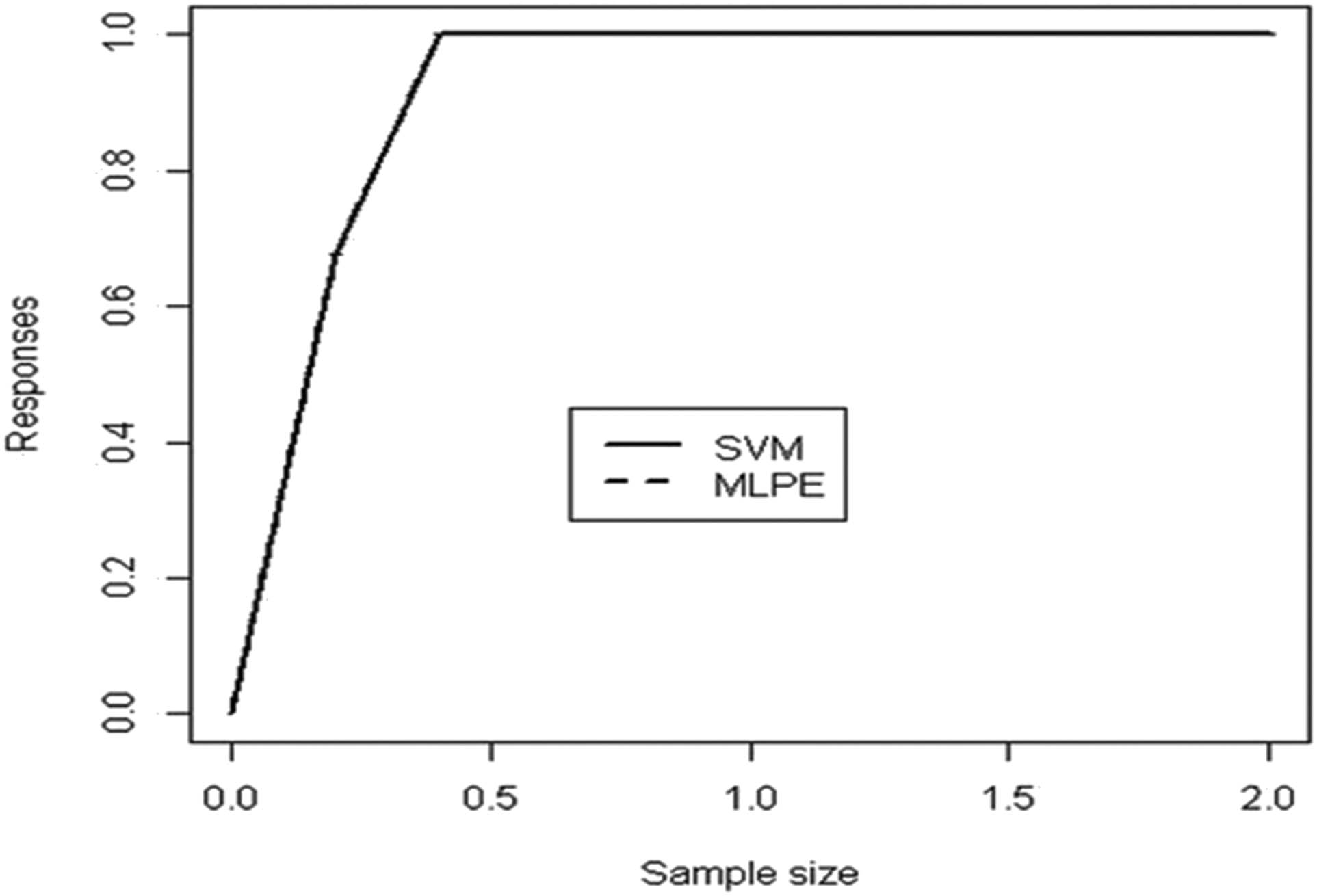
LIFT plot for the detection of MM illness.
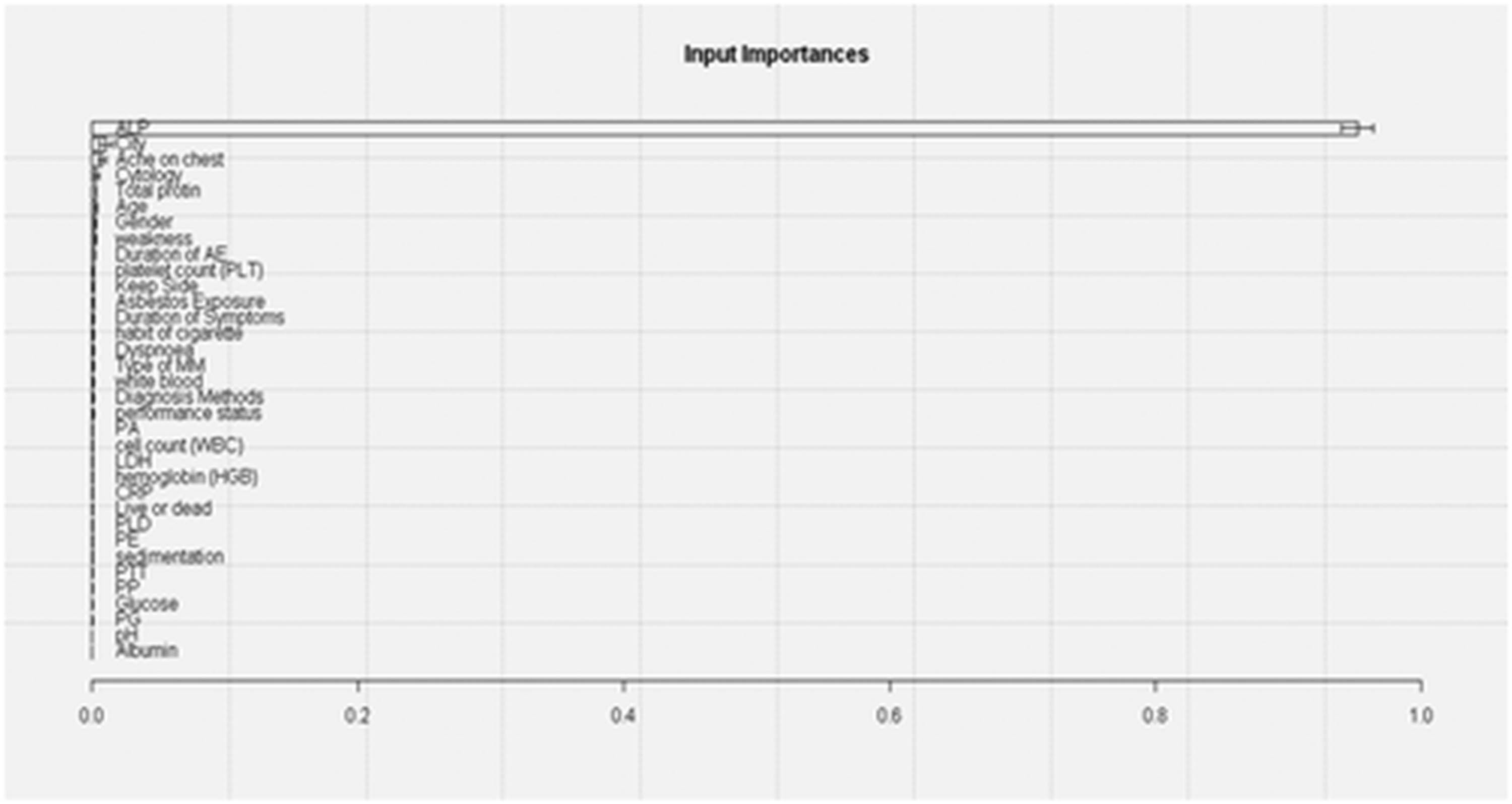
Important bar charts for the diagnosis of MM illness.
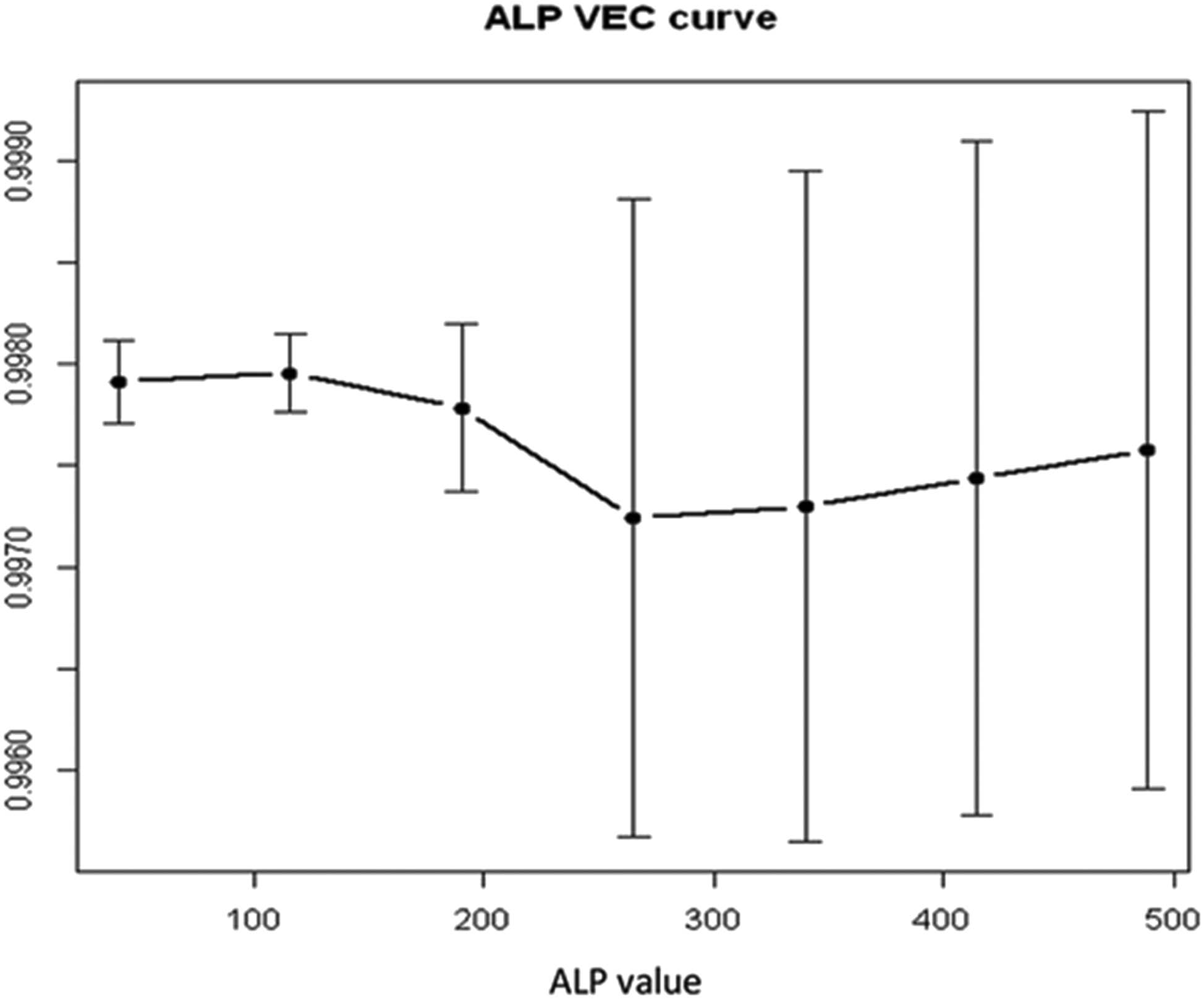
For the input variable ALP, the variable effect curve.
3 Methodology
The research follows a quantitative approach to accomplish the research objectives. The objective of the current research is to identify the number of input variables of the disease MM that develop the maximum accuracy. Apart from this, the research also identifies the number of cross-validation folds and the number of runs at which the DM model gives the maximum accuracy. SVM will be used for feeding the input MM variables and the change in accuracy was evaluated through multiple regression analysis. One of the most crucial statistical methods used in analytical epidemiology is regression modeling. Regression models can be used to examine the impact of one or more explanatory factors (such as exposures, subject characteristics, or risk factors) on a response variable like mortality or cancer. Adjusted effect estimates that account for possible confounders can be derived using multiple regression models. Regression techniques are a fundamental tool for data analysis in epidemiology since they may be used in all types of epidemiologic research designs. Regression models of many types have been created depending on the study’s design and the measurement scale for the response variable. The most crucial techniques are logistic regression for binary outcomes, Cox regression for time-to-event data, Poisson regression for frequencies and rates, and linear regression for continuous outcomes. Statistical Package for Social Sciences (SPSS) by IBM was used for conducting the multiple regression analysis. An inductive research approach has been followed to interpret the research hypotheses. The hypotheses are
H0: The number of input MM variables does have a statistically significant relationship with the classification accuracy.
Cross-validation folds and the number of runs do not affect the classification accuracy of data mining when using SVM.
H1: Increasing the number of input MM variables increases the classification accuracy.
Cross-validation folds and the number of runs have a significant impact on the classification accuracy of data mining when using SVM.
In that context, the input independent variables for multiple regression analysis are (1) the number of input variables for SVM (MM disease); (2) cross-validation folds; and (3) the number of SVM runs. Concerning this, the dependent variable is the classification accuracy of DM using SVM.
4 Analysis and interpretation
SVM has been used with different numbers of folds and runs to evaluate the change in accuracy. To investigate the change in classification accuracy, multiple regression analysis was used. The results are tabulated in Table 4.
Tabular representation of descriptive statistics output
| Statistics | |||||
|---|---|---|---|---|---|
| Number of input variables of MM disease | Cross-validation folds | Number of runs | Classification accuracy of DM | ||
| N | Valid | 15 | 15 | 15 | 15 |
| Missing | 0 | 0 | 0 | 0 | |
| Mean | 18.87 | 7.00 | 4.27 | 97.1773 | |
| Median | 23.00 | 7.00 | 4.00 | 97.1500 | |
| Std. deviation | 10.921 | 4.472 | 2.251 | 2.33371 | |
| Variance | 119.267 | 20.000 | 5.067 | 5.446 | |
| Minimum | 2 | 0 | 1 | 92.35 | |
| Maximum | 34 | 14 | 8 | 99.68 | |
Table 4 shows the descriptive statistics output where it can be observed that a total of 15 experiments were performed and from them, 0 outputs are missing. Nevertheless, the mean number of input variables is 18.87, and corresponding with that, the classification accuracy was 97.1773%. It can be observed that a total of 34 input variables of MM diseases were fed to the SVM and a minimum of 2 variables were entered. Subsequently, the lowest classification accuracy was 92.35% and the highest accuracy was 99.68%. Besides, a complete 14 validation folds were used along with 8 runs (serially). However, the descriptive output cannot determine whether the independent variables are affecting the classification accuracy or not. Thus, the analyses in Table 5 demonstrate the multiple regression output.
Coefficient analysis at 95% confidence level
| Coefficients a | ||||||||
|---|---|---|---|---|---|---|---|---|
| Unstandardized coefficients | Standardized coefficients | t | Sig. | 95.0% confidence interval for B | ||||
| Model | B | Std. error | Beta | Lower bound | Upper bound | |||
| 1 | (Constant) | 93.861 | 0.810 | 115.868 | 0.000 | 92.078 | 95.644 | |
| Number of input variables of MM disease | 0.024 | 0.118 | 0.111 | 0.201 | 0.844 | −0.237 | 0.284 | |
| Cross-validation folds | 0.572 | 0.527 | 1.095 | 1.084 | 0.302 | −0.589 | 1.733 | |
| Number of runs | −0.266 | 0.843 | −0.257 | −0.315 | 0.758 | −2.122 | 1.590 | |
a. Dependent variable: classification accuracy of DM.
Table 5 shows the coefficient variable at a 95% confidence level. The t-test value shows that a value of 0.201 has been observed between the “number of input variables” and the “classification accuracy of DM”. This shows that a smaller difference exists between the two variables. The significance value between these two variables has been observed at 0.844, which shows a low statistical significance (>0.05). A value of 1.095 has been observed between the variable “cross-validation folds” and “classification accuracy of DM”. This shows a greater difference exists between the two variables. The significance value of 0.302 shows a high statistical significance (<0.05). The difference value between “number of runs” and “classification accuracy of DM” has been observed at −0.315, which shows that very little difference and high similarities exist between the two variables. The significance value was observed at 0.758, which shows a low statistical significance (>0.05).
Table 6 shows the regression ANOVA analysis between the dependent and independent variables. The results have shown that a significance value of 0.000 has been observed, which shows a high statistical significance between the dependent and independent variables. The f statistical value has been observed at 34.822, which is a low value and indicates a low statistical significance.
ANOVA regression analysis
| ANOVA a | ||||||
|---|---|---|---|---|---|---|
| Model | Sum of squares | Degree of freedom | Mean square | F | Sig. | |
| 1 | Regression | 68.983 | 3 | 22.994 | 34.822 | 0.000b |
| Residual | 7.264 | 11 | 0.660 | |||
| Total | 76.247 | 14 | ||||
a. Dependent variable: classification accuracy of DM.
b. Predictors: (constant), number of runs, number of input variables of MM disease, cross-validation folds.
Table 7 shows the model summary statistics and the results show that the R-value is 0.951 and the R square value has been observed at 0.905. This shows that a high R and R-square value has been observed between the dependent and independent variables and indicates a high statistical significance. The adjusted R square value has been observed at 0.879 and the estimated standard error has been observed at 0.81261, which indicates a statistically significant relationship between the independent and dependent variables.
Model summary
| Model summary a | ||||
|---|---|---|---|---|
| Model | R | R square | Adjusted R square | Std. error in the estimate |
| 1 | 0.951b | 0.905 | 0.879 | 0.81261 |
a. Dependent variable: Classification accuracy of DM.
b. Predictors: (constant), number of runs, number of input variables of MM disease, cross-validation folds.
Figure 6 shows the effective graphical representation between the variable “classification of DM accuracy” and “the number of cross-validation folds.” This shows that as the number of cross-validation folds increases the overall accuracy for DM efficiency increases. However, after some time the accuracy reaches a saturation point, and here as the cross-validation fold increases the accuracy of DM remains the same.
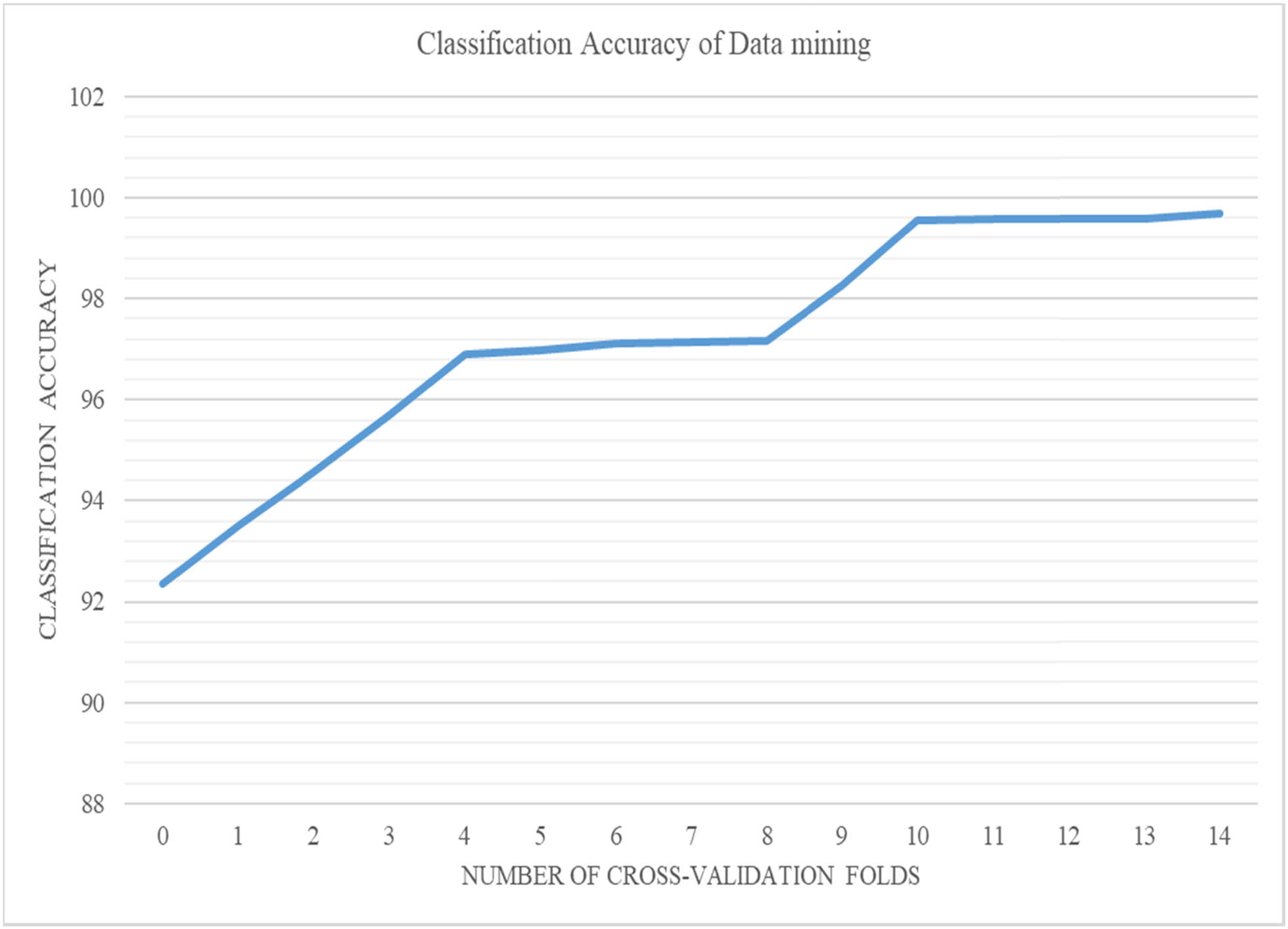
Graphical representation between the variable “Classification of DM accuracy” and “number of cross-validation folds.”
Figure 7 shows the graphical representation of the overall number of variables that are entered and the total accuracy of MM classification. This shows that as the number of input variables increases, the overall classification accuracy of MM increases.
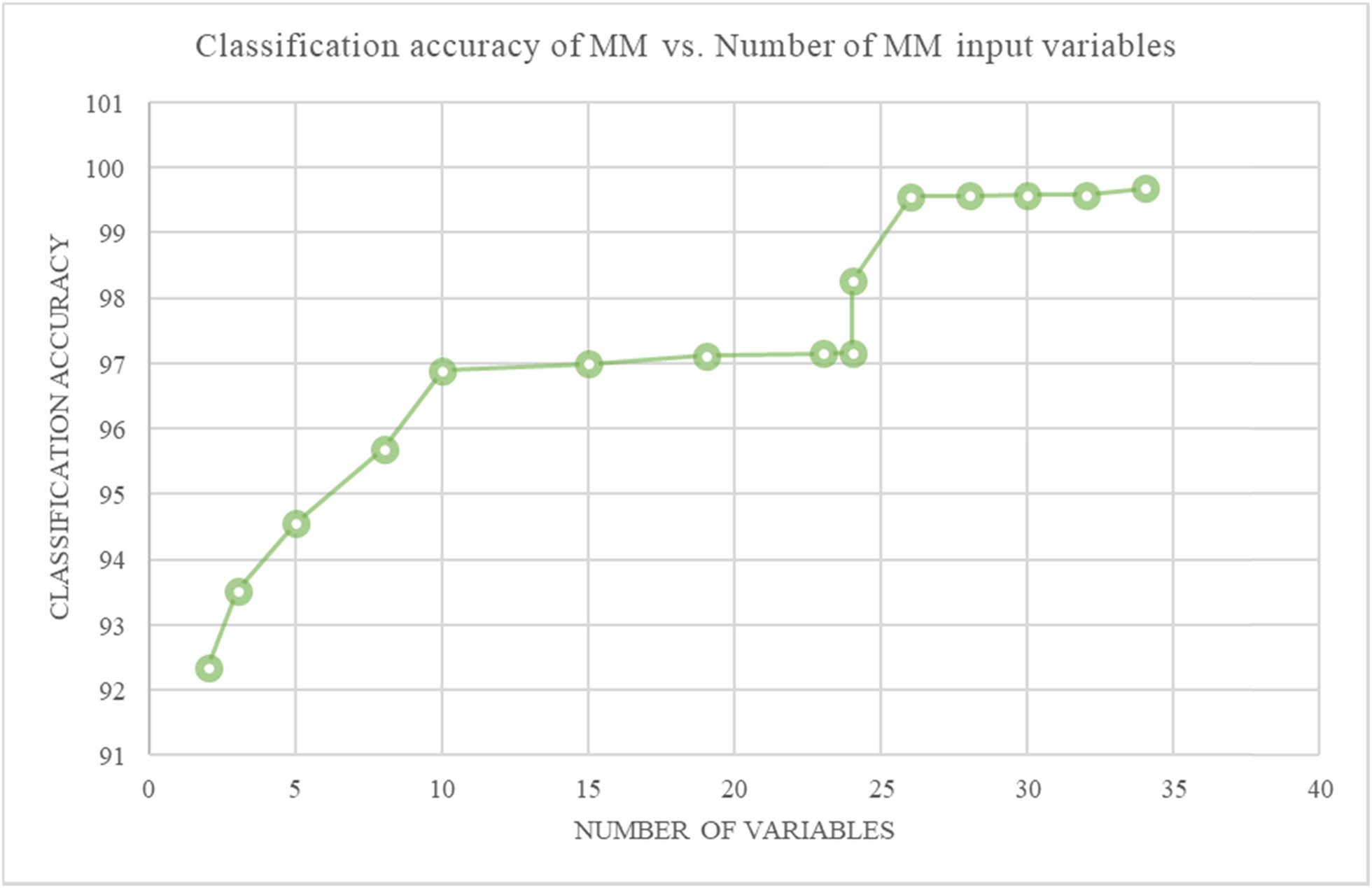
Graphical representation between the number of variables entry and accuracy of MM classification.
The regression analysis has shown that to effectively classify the malignant tissues, the increase in the number of inputs and the number of cross-validation folds are necessary as it helps in determining tissue culture analysis. The coefficient analysis at a 95% confidence level has shown that a statistically significant relationship exists between the cross-validation folds and the DM accuracy. Again, the graphical representations have shown that as the number of input variables increases, the overall accuracy for DM also increases.
Therefore, from the above data analysis, it can be stated that the accuracy level of MM classification depends on the number of input variables and the number of cross-validation folds. These data help researchers and healthcare professionals in successfully analyzing the accuracy level of MM classification. This is required for the proper diagnosis of malignant cells and helps in maintaining the patient’s well-being.
5 Conclusion
In this work, two alternative DM approaches for the MM illness diagnostic problem were used on an identical dataset. As demonstrated in this study, a person can be classified as having or not having MM illness. As per the final performance, the most stable and accurate DM approaches for categorizing MM data are SVM as well as MLPE NN architectures. It can be seen that a total of 15 tests were carried out, with 0 outputs missing. Nonetheless, the average number of input variables is 18.87, and the classification accuracy is 97.1773%. It can be seen that a total of 34 MM illness input variables were supplied to the SVM, with a minimum of 2 variables inputted. As a result, the lowest accuracy of the classification was 92.35% and the best classification accuracy was 99.68%. In addition, 14 validation folds and 8 runs were employed (serially). The regression analysis revealed that increasing the number of inputs and cross-validation folds is required to properly categorize malignant tissues, as it aids in deciding tissue culture analysis. The cross-validation folds and the DM efficiency are statistically related, according to the coefficient analysis at a 95% confidence level. In addition, the graphical displays have demonstrated that as the amount of input variables increases, so does the total accuracy for DM. Finally, ANN structures may be used as a learning-based DSS to aid physicians in making diagnoses. In addition, it is established from this study that the key input variables have a significant impact on virtually any illness diagnosis issue. All other ANN features were shown to be effective in assisting in the diagnosis of MM illness. Since only a few instances were incorrectly classified by the algorithm, this classification performance is quite trustworthy for such a situation. For the identification of MM illness, a ten-fold cross-validation approach with a repeating experimental procedure is more suited than any other traditional evaluation process. Finally, ANN frameworks may be used as a learning-based DSS to aid clinicians in making diagnosis judgments. Moreover, this study has revealed that crucial input components or variables have a significant impact on any form of illness diagnosing the problem. The most crucial input parameter for MM illness detection is ALP, according to this study. ALP is an excellent diagnostic in the event of liver illness, and an increased quantity of ALP in the patient’s psyche can induce cancer. Other characteristics that are crucial for MM disease rearrangement include city, chest pain, seniority, and gender of the client, according to scenario analysis and input significance bar chart. This section of the research might be extremely helpful to physicians in their assessment.
-
Funding information: Authors state no funding involved.
-
Author contributions: All authors have equally contributed to the research.
-
Conflict of interest: Authors state no conflict of interest.
-
Data availability statement: The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
[1] Mukherjee S. Malignant mesothelioma disease diagnosis using data mining techniques. Applied Artificial Intelligence. Vol. 32, Informa UK Limited; 2018. p. 293–308. 10.1080/08839514.2018.1451216.Search in Google Scholar
[2] Latif MZ, Shaukat K, Luo S, Hameed IA, Iqbal F, Alam TM. Risk factors identification of malignant mesothelioma: A data mining based approach. 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE). Istanbul, Turkey: IEEE; 2020. 10.1109/ICECCE49384.2020.9179443.Search in Google Scholar
[3] Alam TM, Shaukat K, Mahboob H, Sarwar MU, Iqbal F, Nasir A, et al. A machine learning approach for identification of malignant mesothelioma etiological factors in an imbalanced dataset. The Computer Journal. 2021;65:1740–51. 10.1093/comjnl/bxab015.Search in Google Scholar
[4] Alam TM, Shaukat K, Hameed IA, Khan WA, Sarwar MU, Iqbal F, et al. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed Signal Process Control. 2021;68:102726. 10.1016/j.bspc.2021.102726.Search in Google Scholar
[5] Gupta S, Gupta MK. Computational model for prediction of malignant mesothelioma diagnosis. The Computer Journal. 2021;66:86–100. 10.1093/comjnl/bxab146.Search in Google Scholar
[6] Win KY, Maneerat N, Choomchuay S, Sreng S, Hamamoto K. Suitable supervised machine learning techniques for malignant mesothelioma diagnosis. 2018 11th Biomedical Engineering International Conference (BMEiCON). Chiang Mai, Thailand: IEEE; 2018. 10.1109/BMEiCON.2018.8609935.Search in Google Scholar
[7] Jain A, Yadav AK, Shrivastava Y. Modelling and optimization of different quality characteristics in electric discharge drilling of titanium alloy sheet. Materials Today: Proceedings. 2020;21:1680–4. 10.1016/j.matpr.2019.12.010.Search in Google Scholar
[8] Jain A, Kumar Pandey A. Modeling and optimizing of different quality characteristics in electrical discharge drilling of titanium alloy (Grade-5) sheet. Materials Today: Proceedings. 2019;18:182–91. 10.1016/j.matpr.2019.06.292.Search in Google Scholar
[9] Alam TM. Identification of malignant mesothelioma risk factors through association rule mining. Preprints. 2019;2019110117. 10.20944/preprints201911.0117.v1.Search in Google Scholar
[10] Rouka E, Beltsios E, Goundaroulis D, Vavougios GD, Solenov EI, Hatzoglou C, et al. In silico transcriptomic analysis of wound-healing-associated genes in malignant pleural mesothelioma. Medicina. 2019;55(6):267. 10.3390/medicina55060267.Search in Google Scholar PubMed PubMed Central
[11] Choudhury A. Identification of cancer: Mesothelioma’s disease using logistic regression and association rule. J Eng Appl Sci. 2018;11:1310–9. 10.3844/ajeassp.2018.1310.1319.Search in Google Scholar
[12] Chikh MA, Saidi M, Settouti N. Diagnosis of diabetes diseases using an artificial immune recognition system2 (AIRS2) with fuzzy k-nearest neighbor. J Med Syst. 2012;36:2721–9. 10.1007/s10916-011-9748-4.Search in Google Scholar PubMed
[13] Müller KM, Fischer M. Malignant pleural mesotheliomas: An environmental health risk in southeast Turkey. Respiration. 2000;67:608–9. 10.1159/000056288.Search in Google Scholar PubMed
[14] Jain A, Pandey AK. Multiple quality optimizations in electrical discharge drilling of mild steel sheet. Materials Today: Proceedings. 2017;4:7252–61. 10.1016/j.matpr.2017.07.054.Search in Google Scholar
[15] Panwar V, Kumar Sharma D, Pradeep Kumar KV, Jain A, Thakar C. Experimental investigations and optimization of surface roughness in turning of en 36 alloy steel using response surface methodology and genetic algorithm. Materials Today: Proceedings. 2021;46:6474–81. 10.1016/J.Matpr.2021.03.642.Search in Google Scholar
[16] Jain A, Kumar CS, Shrivastava Y. Fabrication and machining of metal matrix composite using electric discharge machining: A short review. Evergreen. 2021;8:740–9. 10.5109/4742117.Search in Google Scholar
[17] Jain A, Kumar CS, Shrivastava Y. Fabrication and machining of fiber matrix composite through electric discharge machining: A short review. Materials Today: Proceedings. 2022;51:1233–7. 10.1016/j.matpr.2021.07.288.Search in Google Scholar
[18] Thakar CM, Parkhe SS, Jain A, Phasinam K, Murugesan G, Ventayen RJM. 3d printing: Basic principles and applications. Materials Today: Proceedings. 2022;51:842–9. 10.1016/j.matpr.2021.06.272.Search in Google Scholar
[19] Wagner JC, Sleggs CA, Marchand P. Diffuse pleural mesothelioma and asbestos exposure in the North Western Cape Province. Br J Ind Med. 1960;17(4):260–71. 10.1136/oem.17.4.260.Search in Google Scholar PubMed PubMed Central
[20] Lorena AC, de Carvalho ACPLF, Gama JMP. A review on the combination of binary classifiers in multiclass problems. Artif Intell Rev. 2008;30(19):19–37. 10.1007/s10462-009-9114-9.Search in Google Scholar
[21] Şenyiğit A, Bayram H, Babayiğit C, Topçu F, Nazaroğlu H, Bilici A, et al. Malignant pleural mesothelioma caused by environmental exposure to asbestos in the Southeast of Turkey: CT findings in 117 patients. Respiration. 2000;67:615–22. 10.1159/000056290.Search in Google Scholar PubMed
[22] Omari A. A knowledge discovery approach for breast cancer management in the Kingdom of Saudi Arabia. Healthc Informatics: Int J. 2013;2:1–7. 10.5121/hiij.2013.2301.Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Biomedical Sciences
- Systemic investigation of inetetamab in combination with small molecules to treat HER2-overexpressing breast and gastric cancers
- Immunosuppressive treatment for idiopathic membranous nephropathy: An updated network meta-analysis
- Identifying two pathogenic variants in a patient with pigmented paravenous retinochoroidal atrophy
- Effects of phytoestrogens combined with cold stress on sperm parameters and testicular proteomics in rats
- A case of pulmonary embolism with bad warfarin anticoagulant effects caused by E. coli infection
- Neutrophilia with subclinical Cushing’s disease: A case report and literature review
- Isoimperatorin alleviates lipopolysaccharide-induced periodontitis by downregulating ERK1/2 and NF-κB pathways
- Immunoregulation of synovial macrophages for the treatment of osteoarthritis
- Novel CPLANE1 c.8948dupT (p.P2984Tfs*7) variant in a child patient with Joubert syndrome
- Antiphospholipid antibodies and the risk of thrombosis in myeloproliferative neoplasms
- Immunological responses of septic rats to combination therapy with thymosin α1 and vitamin C
- High glucose and high lipid induced mitochondrial dysfunction in JEG-3 cells through oxidative stress
- Pharmacological inhibition of the ubiquitin-specific protease 8 effectively suppresses glioblastoma cell growth
- Levocarnitine regulates the growth of angiotensin II-induced myocardial fibrosis cells via TIMP-1
- Age-related changes in peripheral T-cell subpopulations in elderly individuals: An observational study
- Single-cell transcription analysis reveals the tumor origin and heterogeneity of human bilateral renal clear cell carcinoma
- Identification of iron metabolism-related genes as diagnostic signatures in sepsis by blood transcriptomic analysis
- Long noncoding RNA ACART knockdown decreases 3T3-L1 preadipocyte proliferation and differentiation
- Surgery, adjuvant immunotherapy plus chemotherapy and radiotherapy for primary malignant melanoma of the parotid gland (PGMM): A case report
- Dosimetry comparison with helical tomotherapy, volumetric modulated arc therapy, and intensity-modulated radiotherapy for grade II gliomas: A single‑institution case series
- Soy isoflavone reduces LPS-induced acute lung injury via increasing aquaporin 1 and aquaporin 5 in rats
- Refractory hypokalemia with sexual dysplasia and infertility caused by 17α-hydroxylase deficiency and triple X syndrome: A case report
- Meta-analysis of cancer risk among end stage renal disease undergoing maintenance dialysis
- 6-Phosphogluconate dehydrogenase inhibition arrests growth and induces apoptosis in gastric cancer via AMPK activation and oxidative stress
- Experimental study on the optimization of ANM33 release in foam cells
- Primary retroperitoneal angiosarcoma: A case report
- Metabolomic analysis-identified 2-hydroxybutyric acid might be a key metabolite of severe preeclampsia
- Malignant pleural effusion diagnosis and therapy
- Effect of spaceflight on the phenotype and proteome of Escherichia coli
- Comparison of immunotherapy combined with stereotactic radiotherapy and targeted therapy for patients with brain metastases: A systemic review and meta-analysis
- Activation of hypermethylated P2RY1 mitigates gastric cancer by promoting apoptosis and inhibiting proliferation
- Association between the VEGFR-2 -604T/C polymorphism (rs2071559) and type 2 diabetic retinopathy
- The role of IL-31 and IL-34 in the diagnosis and treatment of chronic periodontitis
- Triple-negative mouse breast cancer initiating cells show high expression of beta1 integrin and increased malignant features
- mNGS facilitates the accurate diagnosis and antibiotic treatment of suspicious critical CNS infection in real practice: A retrospective study
- The apatinib and pemetrexed combination has antitumor and antiangiogenic effects against NSCLC
- Radiotherapy for primary thyroid adenoid cystic carcinoma
- Design and functional preliminary investigation of recombinant antigen EgG1Y162–EgG1Y162 against Echinococcus granulosus
- Effects of losartan in patients with NAFLD: A meta-analysis of randomized controlled trial
- Bibliometric analysis of METTL3: Current perspectives, highlights, and trending topics
- Performance comparison of three scaling algorithms in NMR-based metabolomics analysis
- PI3K/AKT/mTOR pathway and its related molecules participate in PROK1 silence-induced anti-tumor effects on pancreatic cancer
- The altered expression of cytoskeletal and synaptic remodeling proteins during epilepsy
- Effects of pegylated recombinant human granulocyte colony-stimulating factor on lymphocytes and white blood cells of patients with malignant tumor
- Prostatitis as initial manifestation of Chlamydia psittaci pneumonia diagnosed by metagenome next-generation sequencing: A case report
- NUDT21 relieves sevoflurane-induced neurological damage in rats by down-regulating LIMK2
- Association of interleukin-10 rs1800896, rs1800872, and interleukin-6 rs1800795 polymorphisms with squamous cell carcinoma risk: A meta-analysis
- Exosomal HBV-DNA for diagnosis and treatment monitoring of chronic hepatitis B
- Shear stress leads to the dysfunction of endothelial cells through the Cav-1-mediated KLF2/eNOS/ERK signaling pathway under physiological conditions
- Interaction between the PI3K/AKT pathway and mitochondrial autophagy in macrophages and the leukocyte count in rats with LPS-induced pulmonary infection
- Meta-analysis of the rs231775 locus polymorphism in the CTLA-4 gene and the susceptibility to Graves’ disease in children
- Cloning, subcellular localization and expression of phosphate transporter gene HvPT6 of hulless barley
- Coptisine mitigates diabetic nephropathy via repressing the NRLP3 inflammasome
- Significant elevated CXCL14 and decreased IL-39 levels in patients with tuberculosis
- Whole-exome sequencing applications in prenatal diagnosis of fetal bowel dilatation
- Gemella morbillorum infective endocarditis: A case report and literature review
- An unusual ectopic thymoma clonal evolution analysis: A case report
- Severe cumulative skin toxicity during toripalimab combined with vemurafenib following toripalimab alone
- Detection of V. vulnificus septic shock with ARDS using mNGS
- Novel rare genetic variants of familial and sporadic pulmonary atresia identified by whole-exome sequencing
- The influence and mechanistic action of sperm DNA fragmentation index on the outcomes of assisted reproduction technology
- Novel compound heterozygous mutations in TELO2 in an infant with You-Hoover-Fong syndrome: A case report and literature review
- ctDNA as a prognostic biomarker in resectable CLM: Systematic review and meta-analysis
- Diagnosis of primary amoebic meningoencephalitis by metagenomic next-generation sequencing: A case report
- Phylogenetic analysis of promoter regions of human Dolichol kinase (DOLK) and orthologous genes using bioinformatics tools
- Collagen changes in rabbit conjunctiva after conjunctival crosslinking
- Effects of NM23 transfection of human gastric carcinoma cells in mice
- Oral nifedipine and phytosterol, intravenous nicardipine, and oral nifedipine only: Three-arm, retrospective, cohort study for management of severe preeclampsia
- Case report of hepatic retiform hemangioendothelioma: A rare tumor treated with ultrasound-guided microwave ablation
- Curcumin induces apoptosis in human hepatocellular carcinoma cells by decreasing the expression of STAT3/VEGF/HIF-1α signaling
- Rare presentation of double-clonal Waldenström macroglobulinemia with pulmonary embolism: A case report
- Giant duplication of the transverse colon in an adult: A case report and literature review
- Ectopic thyroid tissue in the breast: A case report
- SDR16C5 promotes proliferation and migration and inhibits apoptosis in pancreatic cancer
- Vaginal metastasis from breast cancer: A case report
- Screening of the best time window for MSC transplantation to treat acute myocardial infarction with SDF-1α antibody-loaded targeted ultrasonic microbubbles: An in vivo study in miniswine
- Inhibition of TAZ impairs the migration ability of melanoma cells
- Molecular complexity analysis of the diagnosis of Gitelman syndrome in China
- Effects of maternal calcium and protein intake on the development and bone metabolism of offspring mice
- Identification of winter wheat pests and diseases based on improved convolutional neural network
- Ultra-multiplex PCR technique to guide treatment of Aspergillus-infected aortic valve prostheses
- Virtual high-throughput screening: Potential inhibitors targeting aminopeptidase N (CD13) and PIKfyve for SARS-CoV-2
- Immune checkpoint inhibitors in cancer patients with COVID-19
- Utility of methylene blue mixed with autologous blood in preoperative localization of pulmonary nodules and masses
- Integrated analysis of the microbiome and transcriptome in stomach adenocarcinoma
- Berberine suppressed sarcopenia insulin resistance through SIRT1-mediated mitophagy
- DUSP2 inhibits the progression of lupus nephritis in mice by regulating the STAT3 pathway
- Lung abscess by Fusobacterium nucleatum and Streptococcus spp. co-infection by mNGS: A case series
- Genetic alterations of KRAS and TP53 in intrahepatic cholangiocarcinoma associated with poor prognosis
- Granulomatous polyangiitis involving the fourth ventricle: Report of a rare case and a literature review
- Studying infant mortality: A demographic analysis based on data mining models
- Metaplastic breast carcinoma with osseous differentiation: A report of a rare case and literature review
- Protein Z modulates the metastasis of lung adenocarcinoma cells
- Inhibition of pyroptosis and apoptosis by capsaicin protects against LPS-induced acute kidney injury through TRPV1/UCP2 axis in vitro
- TAK-242, a toll-like receptor 4 antagonist, against brain injury by alleviates autophagy and inflammation in rats
- Primary mediastinum Ewing’s sarcoma with pleural effusion: A case report and literature review
- Association of ADRB2 gene polymorphisms and intestinal microbiota in Chinese Han adolescents
- Tanshinone IIA alleviates chondrocyte apoptosis and extracellular matrix degeneration by inhibiting ferroptosis
- Study on the cytokines related to SARS-Cov-2 in testicular cells and the interaction network between cells based on scRNA-seq data
- Effect of periostin on bone metabolic and autophagy factors during tooth eruption in mice
- HP1 induces ferroptosis of renal tubular epithelial cells through NRF2 pathway in diabetic nephropathy
- Intravaginal estrogen management in postmenopausal patients with vaginal squamous intraepithelial lesions along with CO2 laser ablation: A retrospective study
- Hepatocellular carcinoma cell differentiation trajectory predicts immunotherapy, potential therapeutic drugs, and prognosis of patients
- Effects of physical exercise on biomarkers of oxidative stress in healthy subjects: A meta-analysis of randomized controlled trials
- Identification of lysosome-related genes in connection with prognosis and immune cell infiltration for drug candidates in head and neck cancer
- Development of an instrument-free and low-cost ELISA dot-blot test to detect antibodies against SARS-CoV-2
- Research progress on gas signal molecular therapy for Parkinson’s disease
- Adiponectin inhibits TGF-β1-induced skin fibroblast proliferation and phenotype transformation via the p38 MAPK signaling pathway
- The G protein-coupled receptor-related gene signatures for predicting prognosis and immunotherapy response in bladder urothelial carcinoma
- α-Fetoprotein contributes to the malignant biological properties of AFP-producing gastric cancer
- CXCL12/CXCR4/CXCR7 axis in placenta tissues of patients with placenta previa
- Association between thyroid stimulating hormone levels and papillary thyroid cancer risk: A meta-analysis
- Significance of sTREM-1 and sST2 combined diagnosis for sepsis detection and prognosis prediction
- Diagnostic value of serum neuroactive substances in the acute exacerbation of chronic obstructive pulmonary disease complicated with depression
- Research progress of AMP-activated protein kinase and cardiac aging
- TRIM29 knockdown prevented the colon cancer progression through decreasing the ubiquitination levels of KRT5
- Cross-talk between gut microbiota and liver steatosis: Complications and therapeutic target
- Metastasis from small cell lung cancer to ovary: A case report
- The early diagnosis and pathogenic mechanisms of sepsis-related acute kidney injury
- The effect of NK cell therapy on sepsis secondary to lung cancer: A case report
- Erianin alleviates collagen-induced arthritis in mice by inhibiting Th17 cell differentiation
- Loss of ACOX1 in clear cell renal cell carcinoma and its correlation with clinical features
- Signalling pathways in the osteogenic differentiation of periodontal ligament stem cells
- Crosstalk between lactic acid and immune regulation and its value in the diagnosis and treatment of liver failure
- Clinicopathological features and differential diagnosis of gastric pleomorphic giant cell carcinoma
- Traumatic brain injury and rTMS-ERPs: Case report and literature review
- Extracellular fibrin promotes non-small cell lung cancer progression through integrin β1/PTEN/AKT signaling
- Knockdown of DLK4 inhibits non-small cell lung cancer tumor growth by downregulating CKS2
- The co-expression pattern of VEGFR-2 with indicators related to proliferation, apoptosis, and differentiation of anagen hair follicles
- Inflammation-related signaling pathways in tendinopathy
- CD4+ T cell count in HIV/TB co-infection and co-occurrence with HL: Case report and literature review
- Clinical analysis of severe Chlamydia psittaci pneumonia: Case series study
- Bioinformatics analysis to identify potential biomarkers for the pulmonary artery hypertension associated with the basement membrane
- Influence of MTHFR polymorphism, alone or in combination with smoking and alcohol consumption, on cancer susceptibility
- Catharanthus roseus (L.) G. Don counteracts the ampicillin resistance in multiple antibiotic-resistant Staphylococcus aureus by downregulation of PBP2a synthesis
- Combination of a bronchogenic cyst in the thoracic spinal canal with chronic myelocytic leukemia
- Bacterial lipoprotein plays an important role in the macrophage autophagy and apoptosis induced by Salmonella typhimurium and Staphylococcus aureus
- TCL1A+ B cells predict prognosis in triple-negative breast cancer through integrative analysis of single-cell and bulk transcriptomic data
- Ezrin promotes esophageal squamous cell carcinoma progression via the Hippo signaling pathway
- Ferroptosis: A potential target of macrophages in plaque vulnerability
- Predicting pediatric Crohn's disease based on six mRNA-constructed risk signature using comprehensive bioinformatic approaches
- Applications of genetic code expansion and photosensitive UAAs in studying membrane proteins
- HK2 contributes to the proliferation, migration, and invasion of diffuse large B-cell lymphoma cells by enhancing the ERK1/2 signaling pathway
- IL-17 in osteoarthritis: A narrative review
- Circadian cycle and neuroinflammation
- Probiotic management and inflammatory factors as a novel treatment in cirrhosis: A systematic review and meta-analysis
- Hemorrhagic meningioma with pulmonary metastasis: Case report and literature review
- SPOP regulates the expression profiles and alternative splicing events in human hepatocytes
- Knockdown of SETD5 inhibited glycolysis and tumor growth in gastric cancer cells by down-regulating Akt signaling pathway
- PTX3 promotes IVIG resistance-induced endothelial injury in Kawasaki disease by regulating the NF-κB pathway
- Pancreatic ectopic thyroid tissue: A case report and analysis of literature
- The prognostic impact of body mass index on female breast cancer patients in underdeveloped regions of northern China differs by menopause status and tumor molecular subtype
- Report on a case of liver-originating malignant melanoma of unknown primary
- Case report: Herbal treatment of neutropenic enterocolitis after chemotherapy for breast cancer
- The fibroblast growth factor–Klotho axis at molecular level
- Characterization of amiodarone action on currents in hERG-T618 gain-of-function mutations
- A case report of diagnosis and dynamic monitoring of Listeria monocytogenes meningitis with NGS
- Effect of autologous platelet-rich plasma on new bone formation and viability of a Marburg bone graft
- Small breast epithelial mucin as a useful prognostic marker for breast cancer patients
- Continuous non-adherent culture promotes transdifferentiation of human adipose-derived stem cells into retinal lineage
- Nrf3 alleviates oxidative stress and promotes the survival of colon cancer cells by activating AKT/BCL-2 signal pathway
- Favorable response to surufatinib in a patient with necrolytic migratory erythema: A case report
- Case report of atypical undernutrition of hypoproteinemia type
- Down-regulation of COL1A1 inhibits tumor-associated fibroblast activation and mediates matrix remodeling in the tumor microenvironment of breast cancer
- Sarcoma protein kinase inhibition alleviates liver fibrosis by promoting hepatic stellate cells ferroptosis
- Research progress of serum eosinophil in chronic obstructive pulmonary disease and asthma
- Clinicopathological characteristics of co-existing or mixed colorectal cancer and neuroendocrine tumor: Report of five cases
- Role of menopausal hormone therapy in the prevention of postmenopausal osteoporosis
- Precisional detection of lymph node metastasis using tFCM in colorectal cancer
- Advances in diagnosis and treatment of perimenopausal syndrome
- A study of forensic genetics: ITO index distribution and kinship judgment between two individuals
- Acute lupus pneumonitis resembling miliary tuberculosis: A case-based review
- Plasma levels of CD36 and glutathione as biomarkers for ruptured intracranial aneurysm
- Fractalkine modulates pulmonary angiogenesis and tube formation by modulating CX3CR1 and growth factors in PVECs
- Novel risk prediction models for deep vein thrombosis after thoracotomy and thoracoscopic lung cancer resections, involving coagulation and immune function
- Exploring the diagnostic markers of essential tremor: A study based on machine learning algorithms
- Evaluation of effects of small-incision approach treatment on proximal tibia fracture by deep learning algorithm-based magnetic resonance imaging
- An online diagnosis method for cancer lesions based on intelligent imaging analysis
- Medical imaging in rheumatoid arthritis: A review on deep learning approach
- Predictive analytics in smart healthcare for child mortality prediction using a machine learning approach
- Utility of neutrophil–lymphocyte ratio and platelet–lymphocyte ratio in predicting acute-on-chronic liver failure survival
- A biomedical decision support system for meta-analysis of bilateral upper-limb training in stroke patients with hemiplegia
- TNF-α and IL-8 levels are positively correlated with hypobaric hypoxic pulmonary hypertension and pulmonary vascular remodeling in rats
- Stochastic gradient descent optimisation for convolutional neural network for medical image segmentation
- Comparison of the prognostic value of four different critical illness scores in patients with sepsis-induced coagulopathy
- Application and teaching of computer molecular simulation embedded technology and artificial intelligence in drug research and development
- Hepatobiliary surgery based on intelligent image segmentation technology
- Value of brain injury-related indicators based on neural network in the diagnosis of neonatal hypoxic-ischemic encephalopathy
- Analysis of early diagnosis methods for asymmetric dementia in brain MR images based on genetic medical technology
- Early diagnosis for the onset of peri-implantitis based on artificial neural network
- Clinical significance of the detection of serum IgG4 and IgG4/IgG ratio in patients with thyroid-associated ophthalmopathy
- Forecast of pain degree of lumbar disc herniation based on back propagation neural network
- SPA-UNet: A liver tumor segmentation network based on fused multi-scale features
- Systematic evaluation of clinical efficacy of CYP1B1 gene polymorphism in EGFR mutant non-small cell lung cancer observed by medical image
- Rehabilitation effect of intelligent rehabilitation training system on hemiplegic limb spasms after stroke
- A novel approach for minimising anti-aliasing effects in EEG data acquisition
- ErbB4 promotes M2 activation of macrophages in idiopathic pulmonary fibrosis
- Clinical role of CYP1B1 gene polymorphism in prediction of postoperative chemotherapy efficacy in NSCLC based on individualized health model
- Lung nodule segmentation via semi-residual multi-resolution neural networks
- Evaluation of brain nerve function in ICU patients with Delirium by deep learning algorithm-based resting state MRI
- A data mining technique for detecting malignant mesothelioma cancer using multiple regression analysis
- Markov model combined with MR diffusion tensor imaging for predicting the onset of Alzheimer’s disease
- Effectiveness of the treatment of depression associated with cancer and neuroimaging changes in depression-related brain regions in patients treated with the mediator-deuterium acupuncture method
- Molecular mechanism of colorectal cancer and screening of molecular markers based on bioinformatics analysis
- Monitoring and evaluation of anesthesia depth status data based on neuroscience
- Exploring the conformational dynamics and thermodynamics of EGFR S768I and G719X + S768I mutations in non-small cell lung cancer: An in silico approaches
- Optimised feature selection-driven convolutional neural network using gray level co-occurrence matrix for detection of cervical cancer
- Incidence of different pressure patterns of spinal cerebellar ataxia and analysis of imaging and genetic diagnosis
- Pathogenic bacteria and treatment resistance in older cardiovascular disease patients with lung infection and risk prediction model
- Adoption value of support vector machine algorithm-based computed tomography imaging in the diagnosis of secondary pulmonary fungal infections in patients with malignant hematological disorders
- From slides to insights: Harnessing deep learning for prognostic survival prediction in human colorectal cancer histology
- Ecology and Environmental Science
- Monitoring of hourly carbon dioxide concentration under different land use types in arid ecosystem
- Comparing the differences of prokaryotic microbial community between pit walls and bottom from Chinese liquor revealed by 16S rRNA gene sequencing
- Effects of cadmium stress on fruits germination and growth of two herbage species
- Bamboo charcoal affects soil properties and bacterial community in tea plantations
- Optimization of biogas potential using kinetic models, response surface methodology, and instrumental evidence for biodegradation of tannery fleshings during anaerobic digestion
- Understory vegetation diversity patterns of Platycladus orientalis and Pinus elliottii communities in Central and Southern China
- Studies on macrofungi diversity and discovery of new species of Abortiporus from Baotianman World Biosphere Reserve
- Food Science
- Effect of berrycactus fruit (Myrtillocactus geometrizans) on glutamate, glutamine, and GABA levels in the frontal cortex of rats fed with a high-fat diet
- Guesstimate of thymoquinone diversity in Nigella sativa L. genotypes and elite varieties collected from Indian states using HPTLC technique
- Analysis of bacterial community structure of Fuzhuan tea with different processing techniques
- Untargeted metabolomics reveals sour jujube kernel benefiting the nutritional value and flavor of Morchella esculenta
- Mycobiota in Slovak wine grapes: A case study from the small Carpathians wine region
- Elemental analysis of Fadogia ancylantha leaves used as a nutraceutical in Mashonaland West Province, Zimbabwe
- Microbiological transglutaminase: Biotechnological application in the food industry
- Influence of solvent-free extraction of fish oil from catfish (Clarias magur) heads using a Taguchi orthogonal array design: A qualitative and quantitative approach
- Chromatographic analysis of the chemical composition and anticancer activities of Curcuma longa extract cultivated in Palestine
- The potential for the use of leghemoglobin and plant ferritin as sources of iron
- Investigating the association between dietary patterns and glycemic control among children and adolescents with T1DM
- Bioengineering and Biotechnology
- Biocompatibility and osteointegration capability of β-TCP manufactured by stereolithography 3D printing: In vitro study
- Clinical characteristics and the prognosis of diabetic foot in Tibet: A single center, retrospective study
- Agriculture
- Biofertilizer and NPSB fertilizer application effects on nodulation and productivity of common bean (Phaseolus vulgaris L.) at Sodo Zuria, Southern Ethiopia
- On correlation between canopy vegetation and growth indexes of maize varieties with different nitrogen efficiencies
- Exopolysaccharides from Pseudomonas tolaasii inhibit the growth of Pleurotus ostreatus mycelia
- A transcriptomic evaluation of the mechanism of programmed cell death of the replaceable bud in Chinese chestnut
- Melatonin enhances salt tolerance in sorghum by modulating photosynthetic performance, osmoregulation, antioxidant defense, and ion homeostasis
- Effects of plant density on alfalfa (Medicago sativa L.) seed yield in western Heilongjiang areas
- Identification of rice leaf diseases and deficiency disorders using a novel DeepBatch technique
- Artificial intelligence and internet of things oriented sustainable precision farming: Towards modern agriculture
- Animal Sciences
- Effect of ketogenic diet on exercise tolerance and transcriptome of gastrocnemius in mice
- Combined analysis of mRNA–miRNA from testis tissue in Tibetan sheep with different FecB genotypes
- Isolation, identification, and drug resistance of a partially isolated bacterium from the gill of Siniperca chuatsi
- Tracking behavioral changes of confined sows from the first mating to the third parity
- The sequencing of the key genes and end products in the TLR4 signaling pathway from the kidney of Rana dybowskii exposed to Aeromonas hydrophila
- Development of a new candidate vaccine against piglet diarrhea caused by Escherichia coli
- Plant Sciences
- Crown and diameter structure of pure Pinus massoniana Lamb. forest in Hunan province, China
- Genetic evaluation and germplasm identification analysis on ITS2, trnL-F, and psbA-trnH of alfalfa varieties germplasm resources
- Tissue culture and rapid propagation technology for Gentiana rhodantha
- Effects of cadmium on the synthesis of active ingredients in Salvia miltiorrhiza
- Cloning and expression analysis of VrNAC13 gene in mung bean
- Chlorate-induced molecular floral transition revealed by transcriptomes
- Effects of warming and drought on growth and development of soybean in Hailun region
- Effects of different light conditions on transient expression and biomass in Nicotiana benthamiana leaves
- Comparative analysis of the rhizosphere microbiome and medicinally active ingredients of Atractylodes lancea from different geographical origins
- Distinguish Dianthus species or varieties based on chloroplast genomes
- Comparative transcriptomes reveal molecular mechanisms of apple blossoms of different tolerance genotypes to chilling injury
- Study on fresh processing key technology and quality influence of Cut Ophiopogonis Radix based on multi-index evaluation
- An advanced approach for fig leaf disease detection and classification: Leveraging image processing and enhanced support vector machine methodology
- Erratum
- Erratum to “Protein Z modulates the metastasis of lung adenocarcinoma cells”
- Erratum to “BRCA1 subcellular localization regulated by PI3K signaling pathway in triple-negative breast cancer MDA-MB-231 cells and hormone-sensitive T47D cells”
- Retraction
- Retraction to “Protocatechuic acid attenuates cerebral aneurysm formation and progression by inhibiting TNF-alpha/Nrf-2/NF-kB-mediated inflammatory mechanisms in experimental rats”
Articles in the same Issue
- Biomedical Sciences
- Systemic investigation of inetetamab in combination with small molecules to treat HER2-overexpressing breast and gastric cancers
- Immunosuppressive treatment for idiopathic membranous nephropathy: An updated network meta-analysis
- Identifying two pathogenic variants in a patient with pigmented paravenous retinochoroidal atrophy
- Effects of phytoestrogens combined with cold stress on sperm parameters and testicular proteomics in rats
- A case of pulmonary embolism with bad warfarin anticoagulant effects caused by E. coli infection
- Neutrophilia with subclinical Cushing’s disease: A case report and literature review
- Isoimperatorin alleviates lipopolysaccharide-induced periodontitis by downregulating ERK1/2 and NF-κB pathways
- Immunoregulation of synovial macrophages for the treatment of osteoarthritis
- Novel CPLANE1 c.8948dupT (p.P2984Tfs*7) variant in a child patient with Joubert syndrome
- Antiphospholipid antibodies and the risk of thrombosis in myeloproliferative neoplasms
- Immunological responses of septic rats to combination therapy with thymosin α1 and vitamin C
- High glucose and high lipid induced mitochondrial dysfunction in JEG-3 cells through oxidative stress
- Pharmacological inhibition of the ubiquitin-specific protease 8 effectively suppresses glioblastoma cell growth
- Levocarnitine regulates the growth of angiotensin II-induced myocardial fibrosis cells via TIMP-1
- Age-related changes in peripheral T-cell subpopulations in elderly individuals: An observational study
- Single-cell transcription analysis reveals the tumor origin and heterogeneity of human bilateral renal clear cell carcinoma
- Identification of iron metabolism-related genes as diagnostic signatures in sepsis by blood transcriptomic analysis
- Long noncoding RNA ACART knockdown decreases 3T3-L1 preadipocyte proliferation and differentiation
- Surgery, adjuvant immunotherapy plus chemotherapy and radiotherapy for primary malignant melanoma of the parotid gland (PGMM): A case report
- Dosimetry comparison with helical tomotherapy, volumetric modulated arc therapy, and intensity-modulated radiotherapy for grade II gliomas: A single‑institution case series
- Soy isoflavone reduces LPS-induced acute lung injury via increasing aquaporin 1 and aquaporin 5 in rats
- Refractory hypokalemia with sexual dysplasia and infertility caused by 17α-hydroxylase deficiency and triple X syndrome: A case report
- Meta-analysis of cancer risk among end stage renal disease undergoing maintenance dialysis
- 6-Phosphogluconate dehydrogenase inhibition arrests growth and induces apoptosis in gastric cancer via AMPK activation and oxidative stress
- Experimental study on the optimization of ANM33 release in foam cells
- Primary retroperitoneal angiosarcoma: A case report
- Metabolomic analysis-identified 2-hydroxybutyric acid might be a key metabolite of severe preeclampsia
- Malignant pleural effusion diagnosis and therapy
- Effect of spaceflight on the phenotype and proteome of Escherichia coli
- Comparison of immunotherapy combined with stereotactic radiotherapy and targeted therapy for patients with brain metastases: A systemic review and meta-analysis
- Activation of hypermethylated P2RY1 mitigates gastric cancer by promoting apoptosis and inhibiting proliferation
- Association between the VEGFR-2 -604T/C polymorphism (rs2071559) and type 2 diabetic retinopathy
- The role of IL-31 and IL-34 in the diagnosis and treatment of chronic periodontitis
- Triple-negative mouse breast cancer initiating cells show high expression of beta1 integrin and increased malignant features
- mNGS facilitates the accurate diagnosis and antibiotic treatment of suspicious critical CNS infection in real practice: A retrospective study
- The apatinib and pemetrexed combination has antitumor and antiangiogenic effects against NSCLC
- Radiotherapy for primary thyroid adenoid cystic carcinoma
- Design and functional preliminary investigation of recombinant antigen EgG1Y162–EgG1Y162 against Echinococcus granulosus
- Effects of losartan in patients with NAFLD: A meta-analysis of randomized controlled trial
- Bibliometric analysis of METTL3: Current perspectives, highlights, and trending topics
- Performance comparison of three scaling algorithms in NMR-based metabolomics analysis
- PI3K/AKT/mTOR pathway and its related molecules participate in PROK1 silence-induced anti-tumor effects on pancreatic cancer
- The altered expression of cytoskeletal and synaptic remodeling proteins during epilepsy
- Effects of pegylated recombinant human granulocyte colony-stimulating factor on lymphocytes and white blood cells of patients with malignant tumor
- Prostatitis as initial manifestation of Chlamydia psittaci pneumonia diagnosed by metagenome next-generation sequencing: A case report
- NUDT21 relieves sevoflurane-induced neurological damage in rats by down-regulating LIMK2
- Association of interleukin-10 rs1800896, rs1800872, and interleukin-6 rs1800795 polymorphisms with squamous cell carcinoma risk: A meta-analysis
- Exosomal HBV-DNA for diagnosis and treatment monitoring of chronic hepatitis B
- Shear stress leads to the dysfunction of endothelial cells through the Cav-1-mediated KLF2/eNOS/ERK signaling pathway under physiological conditions
- Interaction between the PI3K/AKT pathway and mitochondrial autophagy in macrophages and the leukocyte count in rats with LPS-induced pulmonary infection
- Meta-analysis of the rs231775 locus polymorphism in the CTLA-4 gene and the susceptibility to Graves’ disease in children
- Cloning, subcellular localization and expression of phosphate transporter gene HvPT6 of hulless barley
- Coptisine mitigates diabetic nephropathy via repressing the NRLP3 inflammasome
- Significant elevated CXCL14 and decreased IL-39 levels in patients with tuberculosis
- Whole-exome sequencing applications in prenatal diagnosis of fetal bowel dilatation
- Gemella morbillorum infective endocarditis: A case report and literature review
- An unusual ectopic thymoma clonal evolution analysis: A case report
- Severe cumulative skin toxicity during toripalimab combined with vemurafenib following toripalimab alone
- Detection of V. vulnificus septic shock with ARDS using mNGS
- Novel rare genetic variants of familial and sporadic pulmonary atresia identified by whole-exome sequencing
- The influence and mechanistic action of sperm DNA fragmentation index on the outcomes of assisted reproduction technology
- Novel compound heterozygous mutations in TELO2 in an infant with You-Hoover-Fong syndrome: A case report and literature review
- ctDNA as a prognostic biomarker in resectable CLM: Systematic review and meta-analysis
- Diagnosis of primary amoebic meningoencephalitis by metagenomic next-generation sequencing: A case report
- Phylogenetic analysis of promoter regions of human Dolichol kinase (DOLK) and orthologous genes using bioinformatics tools
- Collagen changes in rabbit conjunctiva after conjunctival crosslinking
- Effects of NM23 transfection of human gastric carcinoma cells in mice
- Oral nifedipine and phytosterol, intravenous nicardipine, and oral nifedipine only: Three-arm, retrospective, cohort study for management of severe preeclampsia
- Case report of hepatic retiform hemangioendothelioma: A rare tumor treated with ultrasound-guided microwave ablation
- Curcumin induces apoptosis in human hepatocellular carcinoma cells by decreasing the expression of STAT3/VEGF/HIF-1α signaling
- Rare presentation of double-clonal Waldenström macroglobulinemia with pulmonary embolism: A case report
- Giant duplication of the transverse colon in an adult: A case report and literature review
- Ectopic thyroid tissue in the breast: A case report
- SDR16C5 promotes proliferation and migration and inhibits apoptosis in pancreatic cancer
- Vaginal metastasis from breast cancer: A case report
- Screening of the best time window for MSC transplantation to treat acute myocardial infarction with SDF-1α antibody-loaded targeted ultrasonic microbubbles: An in vivo study in miniswine
- Inhibition of TAZ impairs the migration ability of melanoma cells
- Molecular complexity analysis of the diagnosis of Gitelman syndrome in China
- Effects of maternal calcium and protein intake on the development and bone metabolism of offspring mice
- Identification of winter wheat pests and diseases based on improved convolutional neural network
- Ultra-multiplex PCR technique to guide treatment of Aspergillus-infected aortic valve prostheses
- Virtual high-throughput screening: Potential inhibitors targeting aminopeptidase N (CD13) and PIKfyve for SARS-CoV-2
- Immune checkpoint inhibitors in cancer patients with COVID-19
- Utility of methylene blue mixed with autologous blood in preoperative localization of pulmonary nodules and masses
- Integrated analysis of the microbiome and transcriptome in stomach adenocarcinoma
- Berberine suppressed sarcopenia insulin resistance through SIRT1-mediated mitophagy
- DUSP2 inhibits the progression of lupus nephritis in mice by regulating the STAT3 pathway
- Lung abscess by Fusobacterium nucleatum and Streptococcus spp. co-infection by mNGS: A case series
- Genetic alterations of KRAS and TP53 in intrahepatic cholangiocarcinoma associated with poor prognosis
- Granulomatous polyangiitis involving the fourth ventricle: Report of a rare case and a literature review
- Studying infant mortality: A demographic analysis based on data mining models
- Metaplastic breast carcinoma with osseous differentiation: A report of a rare case and literature review
- Protein Z modulates the metastasis of lung adenocarcinoma cells
- Inhibition of pyroptosis and apoptosis by capsaicin protects against LPS-induced acute kidney injury through TRPV1/UCP2 axis in vitro
- TAK-242, a toll-like receptor 4 antagonist, against brain injury by alleviates autophagy and inflammation in rats
- Primary mediastinum Ewing’s sarcoma with pleural effusion: A case report and literature review
- Association of ADRB2 gene polymorphisms and intestinal microbiota in Chinese Han adolescents
- Tanshinone IIA alleviates chondrocyte apoptosis and extracellular matrix degeneration by inhibiting ferroptosis
- Study on the cytokines related to SARS-Cov-2 in testicular cells and the interaction network between cells based on scRNA-seq data
- Effect of periostin on bone metabolic and autophagy factors during tooth eruption in mice
- HP1 induces ferroptosis of renal tubular epithelial cells through NRF2 pathway in diabetic nephropathy
- Intravaginal estrogen management in postmenopausal patients with vaginal squamous intraepithelial lesions along with CO2 laser ablation: A retrospective study
- Hepatocellular carcinoma cell differentiation trajectory predicts immunotherapy, potential therapeutic drugs, and prognosis of patients
- Effects of physical exercise on biomarkers of oxidative stress in healthy subjects: A meta-analysis of randomized controlled trials
- Identification of lysosome-related genes in connection with prognosis and immune cell infiltration for drug candidates in head and neck cancer
- Development of an instrument-free and low-cost ELISA dot-blot test to detect antibodies against SARS-CoV-2
- Research progress on gas signal molecular therapy for Parkinson’s disease
- Adiponectin inhibits TGF-β1-induced skin fibroblast proliferation and phenotype transformation via the p38 MAPK signaling pathway
- The G protein-coupled receptor-related gene signatures for predicting prognosis and immunotherapy response in bladder urothelial carcinoma
- α-Fetoprotein contributes to the malignant biological properties of AFP-producing gastric cancer
- CXCL12/CXCR4/CXCR7 axis in placenta tissues of patients with placenta previa
- Association between thyroid stimulating hormone levels and papillary thyroid cancer risk: A meta-analysis
- Significance of sTREM-1 and sST2 combined diagnosis for sepsis detection and prognosis prediction
- Diagnostic value of serum neuroactive substances in the acute exacerbation of chronic obstructive pulmonary disease complicated with depression
- Research progress of AMP-activated protein kinase and cardiac aging
- TRIM29 knockdown prevented the colon cancer progression through decreasing the ubiquitination levels of KRT5
- Cross-talk between gut microbiota and liver steatosis: Complications and therapeutic target
- Metastasis from small cell lung cancer to ovary: A case report
- The early diagnosis and pathogenic mechanisms of sepsis-related acute kidney injury
- The effect of NK cell therapy on sepsis secondary to lung cancer: A case report
- Erianin alleviates collagen-induced arthritis in mice by inhibiting Th17 cell differentiation
- Loss of ACOX1 in clear cell renal cell carcinoma and its correlation with clinical features
- Signalling pathways in the osteogenic differentiation of periodontal ligament stem cells
- Crosstalk between lactic acid and immune regulation and its value in the diagnosis and treatment of liver failure
- Clinicopathological features and differential diagnosis of gastric pleomorphic giant cell carcinoma
- Traumatic brain injury and rTMS-ERPs: Case report and literature review
- Extracellular fibrin promotes non-small cell lung cancer progression through integrin β1/PTEN/AKT signaling
- Knockdown of DLK4 inhibits non-small cell lung cancer tumor growth by downregulating CKS2
- The co-expression pattern of VEGFR-2 with indicators related to proliferation, apoptosis, and differentiation of anagen hair follicles
- Inflammation-related signaling pathways in tendinopathy
- CD4+ T cell count in HIV/TB co-infection and co-occurrence with HL: Case report and literature review
- Clinical analysis of severe Chlamydia psittaci pneumonia: Case series study
- Bioinformatics analysis to identify potential biomarkers for the pulmonary artery hypertension associated with the basement membrane
- Influence of MTHFR polymorphism, alone or in combination with smoking and alcohol consumption, on cancer susceptibility
- Catharanthus roseus (L.) G. Don counteracts the ampicillin resistance in multiple antibiotic-resistant Staphylococcus aureus by downregulation of PBP2a synthesis
- Combination of a bronchogenic cyst in the thoracic spinal canal with chronic myelocytic leukemia
- Bacterial lipoprotein plays an important role in the macrophage autophagy and apoptosis induced by Salmonella typhimurium and Staphylococcus aureus
- TCL1A+ B cells predict prognosis in triple-negative breast cancer through integrative analysis of single-cell and bulk transcriptomic data
- Ezrin promotes esophageal squamous cell carcinoma progression via the Hippo signaling pathway
- Ferroptosis: A potential target of macrophages in plaque vulnerability
- Predicting pediatric Crohn's disease based on six mRNA-constructed risk signature using comprehensive bioinformatic approaches
- Applications of genetic code expansion and photosensitive UAAs in studying membrane proteins
- HK2 contributes to the proliferation, migration, and invasion of diffuse large B-cell lymphoma cells by enhancing the ERK1/2 signaling pathway
- IL-17 in osteoarthritis: A narrative review
- Circadian cycle and neuroinflammation
- Probiotic management and inflammatory factors as a novel treatment in cirrhosis: A systematic review and meta-analysis
- Hemorrhagic meningioma with pulmonary metastasis: Case report and literature review
- SPOP regulates the expression profiles and alternative splicing events in human hepatocytes
- Knockdown of SETD5 inhibited glycolysis and tumor growth in gastric cancer cells by down-regulating Akt signaling pathway
- PTX3 promotes IVIG resistance-induced endothelial injury in Kawasaki disease by regulating the NF-κB pathway
- Pancreatic ectopic thyroid tissue: A case report and analysis of literature
- The prognostic impact of body mass index on female breast cancer patients in underdeveloped regions of northern China differs by menopause status and tumor molecular subtype
- Report on a case of liver-originating malignant melanoma of unknown primary
- Case report: Herbal treatment of neutropenic enterocolitis after chemotherapy for breast cancer
- The fibroblast growth factor–Klotho axis at molecular level
- Characterization of amiodarone action on currents in hERG-T618 gain-of-function mutations
- A case report of diagnosis and dynamic monitoring of Listeria monocytogenes meningitis with NGS
- Effect of autologous platelet-rich plasma on new bone formation and viability of a Marburg bone graft
- Small breast epithelial mucin as a useful prognostic marker for breast cancer patients
- Continuous non-adherent culture promotes transdifferentiation of human adipose-derived stem cells into retinal lineage
- Nrf3 alleviates oxidative stress and promotes the survival of colon cancer cells by activating AKT/BCL-2 signal pathway
- Favorable response to surufatinib in a patient with necrolytic migratory erythema: A case report
- Case report of atypical undernutrition of hypoproteinemia type
- Down-regulation of COL1A1 inhibits tumor-associated fibroblast activation and mediates matrix remodeling in the tumor microenvironment of breast cancer
- Sarcoma protein kinase inhibition alleviates liver fibrosis by promoting hepatic stellate cells ferroptosis
- Research progress of serum eosinophil in chronic obstructive pulmonary disease and asthma
- Clinicopathological characteristics of co-existing or mixed colorectal cancer and neuroendocrine tumor: Report of five cases
- Role of menopausal hormone therapy in the prevention of postmenopausal osteoporosis
- Precisional detection of lymph node metastasis using tFCM in colorectal cancer
- Advances in diagnosis and treatment of perimenopausal syndrome
- A study of forensic genetics: ITO index distribution and kinship judgment between two individuals
- Acute lupus pneumonitis resembling miliary tuberculosis: A case-based review
- Plasma levels of CD36 and glutathione as biomarkers for ruptured intracranial aneurysm
- Fractalkine modulates pulmonary angiogenesis and tube formation by modulating CX3CR1 and growth factors in PVECs
- Novel risk prediction models for deep vein thrombosis after thoracotomy and thoracoscopic lung cancer resections, involving coagulation and immune function
- Exploring the diagnostic markers of essential tremor: A study based on machine learning algorithms
- Evaluation of effects of small-incision approach treatment on proximal tibia fracture by deep learning algorithm-based magnetic resonance imaging
- An online diagnosis method for cancer lesions based on intelligent imaging analysis
- Medical imaging in rheumatoid arthritis: A review on deep learning approach
- Predictive analytics in smart healthcare for child mortality prediction using a machine learning approach
- Utility of neutrophil–lymphocyte ratio and platelet–lymphocyte ratio in predicting acute-on-chronic liver failure survival
- A biomedical decision support system for meta-analysis of bilateral upper-limb training in stroke patients with hemiplegia
- TNF-α and IL-8 levels are positively correlated with hypobaric hypoxic pulmonary hypertension and pulmonary vascular remodeling in rats
- Stochastic gradient descent optimisation for convolutional neural network for medical image segmentation
- Comparison of the prognostic value of four different critical illness scores in patients with sepsis-induced coagulopathy
- Application and teaching of computer molecular simulation embedded technology and artificial intelligence in drug research and development
- Hepatobiliary surgery based on intelligent image segmentation technology
- Value of brain injury-related indicators based on neural network in the diagnosis of neonatal hypoxic-ischemic encephalopathy
- Analysis of early diagnosis methods for asymmetric dementia in brain MR images based on genetic medical technology
- Early diagnosis for the onset of peri-implantitis based on artificial neural network
- Clinical significance of the detection of serum IgG4 and IgG4/IgG ratio in patients with thyroid-associated ophthalmopathy
- Forecast of pain degree of lumbar disc herniation based on back propagation neural network
- SPA-UNet: A liver tumor segmentation network based on fused multi-scale features
- Systematic evaluation of clinical efficacy of CYP1B1 gene polymorphism in EGFR mutant non-small cell lung cancer observed by medical image
- Rehabilitation effect of intelligent rehabilitation training system on hemiplegic limb spasms after stroke
- A novel approach for minimising anti-aliasing effects in EEG data acquisition
- ErbB4 promotes M2 activation of macrophages in idiopathic pulmonary fibrosis
- Clinical role of CYP1B1 gene polymorphism in prediction of postoperative chemotherapy efficacy in NSCLC based on individualized health model
- Lung nodule segmentation via semi-residual multi-resolution neural networks
- Evaluation of brain nerve function in ICU patients with Delirium by deep learning algorithm-based resting state MRI
- A data mining technique for detecting malignant mesothelioma cancer using multiple regression analysis
- Markov model combined with MR diffusion tensor imaging for predicting the onset of Alzheimer’s disease
- Effectiveness of the treatment of depression associated with cancer and neuroimaging changes in depression-related brain regions in patients treated with the mediator-deuterium acupuncture method
- Molecular mechanism of colorectal cancer and screening of molecular markers based on bioinformatics analysis
- Monitoring and evaluation of anesthesia depth status data based on neuroscience
- Exploring the conformational dynamics and thermodynamics of EGFR S768I and G719X + S768I mutations in non-small cell lung cancer: An in silico approaches
- Optimised feature selection-driven convolutional neural network using gray level co-occurrence matrix for detection of cervical cancer
- Incidence of different pressure patterns of spinal cerebellar ataxia and analysis of imaging and genetic diagnosis
- Pathogenic bacteria and treatment resistance in older cardiovascular disease patients with lung infection and risk prediction model
- Adoption value of support vector machine algorithm-based computed tomography imaging in the diagnosis of secondary pulmonary fungal infections in patients with malignant hematological disorders
- From slides to insights: Harnessing deep learning for prognostic survival prediction in human colorectal cancer histology
- Ecology and Environmental Science
- Monitoring of hourly carbon dioxide concentration under different land use types in arid ecosystem
- Comparing the differences of prokaryotic microbial community between pit walls and bottom from Chinese liquor revealed by 16S rRNA gene sequencing
- Effects of cadmium stress on fruits germination and growth of two herbage species
- Bamboo charcoal affects soil properties and bacterial community in tea plantations
- Optimization of biogas potential using kinetic models, response surface methodology, and instrumental evidence for biodegradation of tannery fleshings during anaerobic digestion
- Understory vegetation diversity patterns of Platycladus orientalis and Pinus elliottii communities in Central and Southern China
- Studies on macrofungi diversity and discovery of new species of Abortiporus from Baotianman World Biosphere Reserve
- Food Science
- Effect of berrycactus fruit (Myrtillocactus geometrizans) on glutamate, glutamine, and GABA levels in the frontal cortex of rats fed with a high-fat diet
- Guesstimate of thymoquinone diversity in Nigella sativa L. genotypes and elite varieties collected from Indian states using HPTLC technique
- Analysis of bacterial community structure of Fuzhuan tea with different processing techniques
- Untargeted metabolomics reveals sour jujube kernel benefiting the nutritional value and flavor of Morchella esculenta
- Mycobiota in Slovak wine grapes: A case study from the small Carpathians wine region
- Elemental analysis of Fadogia ancylantha leaves used as a nutraceutical in Mashonaland West Province, Zimbabwe
- Microbiological transglutaminase: Biotechnological application in the food industry
- Influence of solvent-free extraction of fish oil from catfish (Clarias magur) heads using a Taguchi orthogonal array design: A qualitative and quantitative approach
- Chromatographic analysis of the chemical composition and anticancer activities of Curcuma longa extract cultivated in Palestine
- The potential for the use of leghemoglobin and plant ferritin as sources of iron
- Investigating the association between dietary patterns and glycemic control among children and adolescents with T1DM
- Bioengineering and Biotechnology
- Biocompatibility and osteointegration capability of β-TCP manufactured by stereolithography 3D printing: In vitro study
- Clinical characteristics and the prognosis of diabetic foot in Tibet: A single center, retrospective study
- Agriculture
- Biofertilizer and NPSB fertilizer application effects on nodulation and productivity of common bean (Phaseolus vulgaris L.) at Sodo Zuria, Southern Ethiopia
- On correlation between canopy vegetation and growth indexes of maize varieties with different nitrogen efficiencies
- Exopolysaccharides from Pseudomonas tolaasii inhibit the growth of Pleurotus ostreatus mycelia
- A transcriptomic evaluation of the mechanism of programmed cell death of the replaceable bud in Chinese chestnut
- Melatonin enhances salt tolerance in sorghum by modulating photosynthetic performance, osmoregulation, antioxidant defense, and ion homeostasis
- Effects of plant density on alfalfa (Medicago sativa L.) seed yield in western Heilongjiang areas
- Identification of rice leaf diseases and deficiency disorders using a novel DeepBatch technique
- Artificial intelligence and internet of things oriented sustainable precision farming: Towards modern agriculture
- Animal Sciences
- Effect of ketogenic diet on exercise tolerance and transcriptome of gastrocnemius in mice
- Combined analysis of mRNA–miRNA from testis tissue in Tibetan sheep with different FecB genotypes
- Isolation, identification, and drug resistance of a partially isolated bacterium from the gill of Siniperca chuatsi
- Tracking behavioral changes of confined sows from the first mating to the third parity
- The sequencing of the key genes and end products in the TLR4 signaling pathway from the kidney of Rana dybowskii exposed to Aeromonas hydrophila
- Development of a new candidate vaccine against piglet diarrhea caused by Escherichia coli
- Plant Sciences
- Crown and diameter structure of pure Pinus massoniana Lamb. forest in Hunan province, China
- Genetic evaluation and germplasm identification analysis on ITS2, trnL-F, and psbA-trnH of alfalfa varieties germplasm resources
- Tissue culture and rapid propagation technology for Gentiana rhodantha
- Effects of cadmium on the synthesis of active ingredients in Salvia miltiorrhiza
- Cloning and expression analysis of VrNAC13 gene in mung bean
- Chlorate-induced molecular floral transition revealed by transcriptomes
- Effects of warming and drought on growth and development of soybean in Hailun region
- Effects of different light conditions on transient expression and biomass in Nicotiana benthamiana leaves
- Comparative analysis of the rhizosphere microbiome and medicinally active ingredients of Atractylodes lancea from different geographical origins
- Distinguish Dianthus species or varieties based on chloroplast genomes
- Comparative transcriptomes reveal molecular mechanisms of apple blossoms of different tolerance genotypes to chilling injury
- Study on fresh processing key technology and quality influence of Cut Ophiopogonis Radix based on multi-index evaluation
- An advanced approach for fig leaf disease detection and classification: Leveraging image processing and enhanced support vector machine methodology
- Erratum
- Erratum to “Protein Z modulates the metastasis of lung adenocarcinoma cells”
- Erratum to “BRCA1 subcellular localization regulated by PI3K signaling pathway in triple-negative breast cancer MDA-MB-231 cells and hormone-sensitive T47D cells”
- Retraction
- Retraction to “Protocatechuic acid attenuates cerebral aneurysm formation and progression by inhibiting TNF-alpha/Nrf-2/NF-kB-mediated inflammatory mechanisms in experimental rats”