
A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
-
Jianqiao Liu


Abstract
The neural collaborative filtering recommendation algorithm widely serves as personalized recommendations of users, which further applies deep learning to a recommendation system. It is a universal framework in the neural collaborative filtering recommendation algorithm; however, it does not regard the impact of important features on recommendation results, nor does it regard the issues of data sparsity and long tail distribution of items. To settle these issues, this article proposes a recommendation algorithm based on the attention mechanism and contrastive learning, which focuses on more important features through the attention mechanism and increases the quantity of samples to achieve data augmentation through contrastive learning; therefore, it enhances recommendation performance. The experimental results on two benchmark datasets show that the algorithm proposed in this article has further enhanced recommendation performance compared to other benchmark algorithms.
1 Introduction
With the rapid development of information technology, today’s community has accessed the age of informatization, generating a large amount of data every moment. How to quickly and accurately obtain messages that the user is interested in from these data is a challenge, and recommendation systems can effectively settle this problem. At present, recommendation systems have been used in e-business, social networks, news communication, and other domains [1,2,3]. Recommendation algorithms are an important component of recommendation systems, and the performance of recommendation algorithms has a significant impact on recommendation results. Currently, collaborative filtering recommendation algorithms are a widely used recommendation algorithm that recommends items of interest to users by calculating their user's similarity and item’s similarity [4]. Among various collaborative filtering recommendation algorithms, matrix factorization is one of the popular ones. Matrix factorization decomposes user and item interaction data into two low-dimensional user matrices and item matrix, obtains the latent contact among users and items, and recommends items of interest to the user through the product of the user matrix and item matrix [5]. Recently, deep learning has also developed promptly, and neural networks in deep learning have realized enormous success in many domains. Many studies have attempted to employ neural networks in the domain of recommendation and have realized some good results, among which the neural collaborative filtering recommendation algorithm is one of them [6]. The neural collaborative filtering recommendation algorithm is a recommendation algorithm that applies neural networks to matrix factorization. It is a universal recommendation algorithm framework with both linear and nonlinear modeling abilities, which can learn stronger user and item representation abilities and has good recommendation performance.
Recently, with the continuous increase in data, it has been difficult to label data, and many data do not have labels. Contrastive learning belongs to self-supervised learning, which can learn from unlabeled data and extract important features from unlabeled data. Contrastive learning has made tremendous achievements in many application domains [7,8,9]. In the domain of the recommendation system, contrastive learning can transform positive samples, add new samples to the sample space, and enhance the representation of data. The self-supervised graph learning model proposed by Wu et al. [10] generates contrastive views on user–item interaction graphs using three methods: node dropout, edge dropout, and random walk and maximizes the consistency of different views of the same node. The SimGCL proposed by Yu et al. [11] creates contrastive views by adding noise to the embedding space, rather than directly modifying the graph structure. This strategy does not change the original user–item interaction graph but improves recommendation performance by enhancing node representation. By using contrastive learning, the performance of the recommendation system can be effectively enhanced. The attention mechanism simulates human attention, focusing more on important things and less on unimportant things. In the recommendation system, utilizing the attention mechanism can provide more attention and weight to important users and items, rather than treating all users and items equally [12,13,14]. Wang et al. [15] proposed a product recommendation model based on self-attention mechanism and attribute heterogeneous information network embedding. The model learns low-dimensional embedding representations of users and items through attribute heterogeneous information network embedding and uses a self-attention mechanism to consider the varying degrees of influence of different attribute information on recommendation results, overcoming the limitations of traditional attribute heterogeneous information network embedding recommendation models. He et al. [1] proposed a recommendation model based on a dual-layer attention mechanism, which improves the interpretability of recommendation results by introducing local attention and mutual attention to learn the potential correlations between users and comments. The attention mechanism can obtain important messages, grasp key sections, better train models, and enhance models’ performance. Therefore, we propose an improved neural collaborative filtering recommendation algorithm, which integrates attention mechanism and contrastive learning on the foundation of the neural collaborative filtering algorithm. This algorithm uses an attention mechanism to adjust the weights of important items, concentrate more attention on important items, and use contrastive learning to add new samples for data augmentation. Experiments were guided on benchmark datasets, and the results showed that the proposed algorithm in this article is effective. Compared with other recommendation algorithms, the proposed algorithm has better performance of recommendation.
The contributions of this article can be concluded as follows:
This article proposes an improved neural collaborative filtering recommendation algorithm, which integrates attention mechanism and contrastive learning on the foundation of the neural collaborative filtering algorithm. Use an attention mechanism to adjust the weights of important items and focus more attention on important items. Use contrastive learning to add new samples for data augmentation.
Experiments were conducted on public datasets, and the experimental results showed that the proposed algorithm in this article is effective. Compared with other benchmark algorithms, our proposed algorithm has better recommendation performance.
The rest of this article is organized as next. In Section 2, we introduced the neural collaborative filtering model. In Section 3, we provided a detailed introduction to our proposed algorithm. In Section 4, we guide experiments on two public datasets to validate the validity of our proposed algorithm. In Section 5, we gave a summary of this article.
2 Neural collaborative filtering (NCF)
Recently, neural networks have developed promptly and realized enormous prosperity in image processing, voice recognition, natural language processing, and other domains. NCF is a collaborative filtering commendation algorithm based on neural network technology, which replaces traditional vector inner product operations with neural networks to achieve matrix factorization and calculate user ratings for items, and provide personalized commendations to users. NCF is a general framework based on neural networks for personalized recommendations, consisting of two sections: generalized matrix factorization (GMF) and multi-layer perceptron (MLP). It has the linear modeling ability of GMF and the nonlinear modeling ability of MLP, which can finer learn the latent contact among users and items. In GMF, users and items are encoded into user and item vectors, and the linear latent contact among users and items is described through the inner product operation of user and item vectors. In the MLP, users and items are encoded, and neural networks are used to learn the deep nonlinear latent contacts among users and items. GMF has linear modeling ability, while MLP has nonlinear modeling ability. The combination of these two models has stronger study ability and can finer learn the deep latent contact among users and items [16–18].
In the NCF framework, the matrix factorization model can be easily extended and learned from data, resulting in a variant of matrix factorization. Therefore, matrix factorization is widely served as practical applications. There is also an extension method that uses nonlinear functions to set the nonlinearity of matrix factorization and learn the latent contact among users and items from logarithmic loss data. By using nonlinear functions, not only the model can be represented nonlinearly, but also its expressive power can be enhanced, thereby obtaining the nonlinear contact between users and items and improving the performance of the model. The linear model is generally difficult to obtain deep latent contacts between users and items; therefore, matrix factorization is not very effective in improving collaborative filtering. In the NCF framework, MLP has nonlinear modeling capabilities and enormous flexibility, enabling them to learn the deep latent contacts among users and items. MLP is discriminative from GMF, which can only use the inner product of fixed user and item features. A MLP can gradually reduce the quantity of neurons from the import layer to the export layer, using fewer neurons at the higher layer to learn more abstract features of users and items. MLP generally has multiple hidden layers, each with a discriminative quantity of neurons, so that they can process information and complete various tasks. MLP has nonlinear modeling abilities and can learn nonlinear contacts in data. The combination of nonlinear and linear models can further enhance the performance of the recommendation.
3 Methodology
3.1 Problem definition
The main notations and their descriptions used in the article are shown in Table 1.
Notations and descriptions
| Notations | Descriptions |
|---|---|
| U | User set |
| I | Item set |
| u | User |
| i | Item |
|
|
Attention value |
|
|
Temperature coefficient |
|
|
True value |
|
|
Prediction value |
| f | Prediction function |
Generally,
where
where
3.2 Framework diagram
The proposed algorithm in this article is a recommendation algorithm that applies neural networks to collaborative filtering and has realized enormous success. However, the neural collaborative filtering algorithm handles all items equally and does not regard the important impacts of important items on the recommendation results. The neural collaborative filtering recommendation algorithm also did not regard the sparsity of user and item interaction data and the long tail effect. Therefore, we integrate attention mechanism and contrastive learning based on the neural collaborative filtering recommendation algorithm to enhance the performance of the recommendation algorithm. By using an attention mechanism to assign discriminative weights to important items, more attention is given to important items. Through contrastive learning, transform the original samples to construct new ones, achieve data augmentation, and optimize model performance. The framework diagram of the neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning (NCF-AC) proposed in this article is shown in Figure 1.
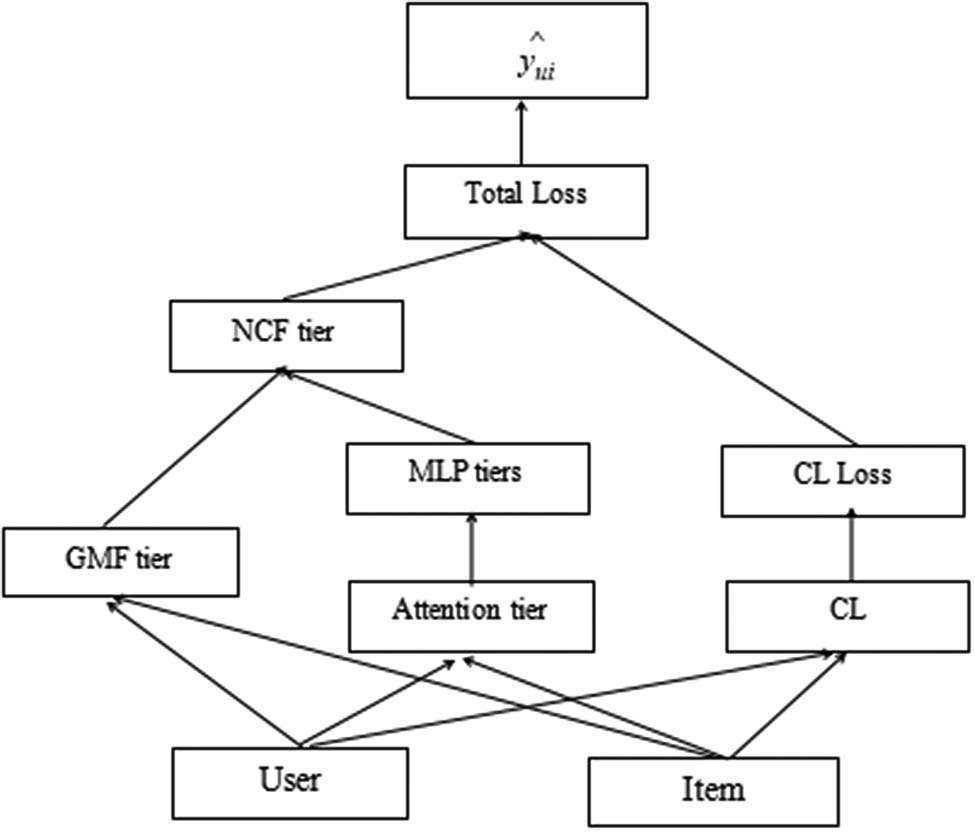
NCF-AC model framework.
The following section provides a detailed introduction to attention mechanisms and contrastive learning.
3.3 Attention mechanism
Attention mechanism is a technique that simulates human attention, which assumes that humans have discriminative levels of attention toward important items, pay more attention to important items, and do not pay too much attention to unimportant items. The attention mechanism believes that important items will have discriminative impacts on the results, and all items should not be treated equally. The important items need to be given higher weights. Attention mechanism can help us select important and useful messages from a large amount of messages, play more weight into these messages, and enhance our work efficiency. In the proposed algorithms, adopting attention mechanism can finer handle the interaction among users and items, focus more attention on important users and items, enhance the accuracy of recommendation results, and achieve personalized recommendations. The attention mechanism can learn from user behavior which items are more important to the user and which items are not important to the user in order to better recommend items that the user is interested in [19,20]. The calculation of attention in this article is explained in formula (3), which assigns higher weights to discriminative vectors to finer match the user’s preference for items. This can enhance the accuracy of recommending items to user and finer meet their personalized needs
where
The attention mechanism can capture the attention of user u to item i and assign higher weights to discriminative items. When performing feature fusion, the ultimate interaction features among users and items are learned through
3.4 Contrastive learning
Contrastive learning is a self-supervised learning and has been widely used in domains such as natural language processing, image processing, and computer vision. Contrastive learning constructs variants of the samples that are similar to the samples through transformation processing and adds new samples to the sample space. The enhanced samples should be as close as possible in space, and discriminative samples should be as far apart as possible in space. The core of contrastive learning is data augmentation. In the domain of the recommendation system, user and item features are high-dimensional sparse data, and there are connections among users and items. The interaction data among users and items is a positive sample, and in general, there are relatively few positive samples. Therefore, constructing more positive samples through contrastive learning is a key issue in contrastive learning [21,22]. The contrastive learning served in this article is to add random noise to positive samples to construct new samples and achieve data augmentation. For a sample
where add noise vectors
Add noise to the original sample. Rotate the original sample at a small angle, with each rotation corresponding to a new sample. By rotating multiple times, multiple new samples can be obtained, achieving data augmentation. Because the original sample is rotated at a relatively small angle, the resulting sample maintains a certain difference from the original sample after rotation, while also retaining the majority of the message of the original sample. The noise added to the original sample is random and discriminative. The calculation of contrastive loss
where
3.5 Model optimization
The loss function of the algorithm proposed in this article consists of two parts, one of which is the loss function
Loss
where
After obtaining the loss
where
3.6 Algorithm description
Algorithm: An NCF-AC
Step 1: Preprocess the data. Generate embedding vectors for users and items, generate user–item interaction matrices, and divide them into training and testing sets.
Step 2: Build the model. Use attention mechanisms to capture information between users and items, assigning different weights to different features; use contrastive learning for data augmentation to improve recommendation performance.
Step 3: Train the model. Train the model using the training set data, adjust the model parameters by minimizing the loss function, and select an optimizer to optimize the loss.
Step 4: Predict the score. For each user and item pair in the test set, input the test set into the trained model to obtain the predicted score. And sort the scores, returning the top N items with the highest scores as the recommendation results.
Step 5: Model evaluation. Use various evaluation metrics such as hit ratio (HR) and normalized discounted cumulative gain (NDCG) to assess the performance of the model.
4 Experimental results and analysis
In this section, we guide experiments on public datasets to confirm the performance of our proposed algorithm. These experiments mainly answer the following questions:
RQ1: How is the overall performance of our proposed recommendation algorithm compared with other recommendation algorithms?
RQ2: What is the impact of the key parameters of our proposed recommendation algorithm on recommendation performance?
RQ3: What is the impact of adding attention and contrastive learning modules to the neural collaborative filtering recommendation algorithm on recommendation performance?
First, we introduce the datasets, evaluation metrics, and benchmark algorithms we use and then answer the upper questions separately. Analyze the overall performance of the algorithm proposed in this article, analyze the impact of key parameters on recommendation performance, and confirm the impact of different modules on recommendation performance through ablation experiments.
4.1 Datasets
In order to confirm the performance of the recommendation algorithm proposed in this article, the experiments were guided on two public datasets, and the detailed information on these two public datasets are as follows:
Movielens dataset: The Movielens dataset is a commonly used machine study dataset used to assess the performance of recommendation algorithms. This dataset is collected through an online movie rating website, which includes user data, movie data, and user rating data for movies. Regardless of the specific rating given by the user to the movie, a grade of 1–5 will be uniformly marked as 1 (with interaction), and in other cases, it will be marked as 0. The data is preprocessed. We deleted user data with less than 20 interactions among users and movies.
Pinterest dataset: The Pinterest dataset is also a commonly used dataset for evaluating the performance of recommendation algorithms. It is a communal and large-scale image recommendation dataset. This dataset contains approximately 50,000 users and 1.58 million interactions among users and items. In order to ensure the quality of the dataset, we also preprocessed the dataset, retaining only user data with 20 or more interactions among users and items.
4.2 Evaluation metrics
HR is a commonly used metric to assess the performance of recommendation algorithms and used to assess the hit rate of recommendation systems. HR behalf the proportion of items that users actually like in the recommendation list. The range of HR values is generally between 0 and 1. The higher the HR value, the more accurate the recommendation.
NDCG is the normalized discounted cumulative gain, which is also a commonly served indicator to assess the performance of recommendation algorithms. NDCG regards the impact on the ranking order of recommended items by users. Items with higher rankings have higher obtained, while items with lower rankings need to compromise their obtained. Items with discriminative ranking orders have an important impact on recommendation performance, with the top items having a greater impact and the bottom items having a smaller impact. The range of NDCG values is between 0 and 1, and the higher the value, the better the recommendation performance. NDCG is a comprehensive evaluation metric for the performance of recommendation algorithms.
4.3 Benchmark algorithms
Item KNN (Item K-nearest neighbors): is a recommendation algorithm based on collaborative filtering, which obtains a set of similar items to the target item based on the user’s historical behavior interaction of the items. Based on the set of similar items, the algorithm estimates the user’s rating on the target items. The algorithm is simple and efficient.
BPR: BPR (Bayesian personalized ranking) is a recommendation algorithm based on matric factorization, which learns the latent features of users and items through Bayesian analysis, optimizes using stochastic gradient descent, and then recommends to the user based on the ranking consequences of items. The algorithm has advantages in selecting a very small amount of data for recommendation in massive amounts of data.
GMF: This is a GMF recommendation algorithm that behalf user and items as a low-dimensional user matrix and item matrix through matrix factorization. Then, the user matrix and item matrix are dot products, and item recommendations are made based on the dot product calculation results. The algorithm is a relatively effective method in both explicit and implicit feedback recommendations.
MLP: This is a recommendation algorithm based on neural networks, which has a hidden layer or multiple hidden layers. There are multiple neurons in the hidden layer, and the next layer receives import from the previous layer. The layers are converted through nonlinear activation features. The algorithm has good recommendation performance, but its training process is relatively time-consuming.
NCF: This is a recommendation algorithm that applies neural networks to matrix factorization, consisting of two parts: GMF and MLP. It has linear and nonlinear modeling abilities and can finer learn the deep latent contact among users and items, with good recommendation performance. The algorithm is a neural network-based collaborative filtering algorithm for implicit feedback data and is a widely used recommendation algorithm.
4.4 Performance analysis
In order to confirm the validity of the NCF-AC proposed in this article, extensive experiments were guided on two public datasets with other benchmark algorithms to compare the recommendation performance. In the experiments, this article sets the quantity of layers for the MLP to 3, the vector size to 64, the temperature coefficient to 0.1, the Top-K to 10, and the training frequency to 20. The benchmark algorithms are set according to the original references. The experimental results are shown in Table 2. It can be seen from Table 2 that on the Movielens dataset, the recommendation algorithm proposed in this article has a higher evaluation metric HR than other benchmark algorithms, and a higher evaluation metric NDCG than other benchmark algorithms. This indicates that adding attention mechanisms and contrastive learning on the basis of neural collaborative filtering recommendation algorithms is effective in improving the performance of recommendation algorithms. For the Pinterest dataset with a large amount of data, the recommendation algorithm proposed in this article also performs well in terms of recommendation performance, with higher evaluation metrics HR and NDCG than other benchmark algorithms. This indicates that the recommendation algorithm proposed in this article is also effective for other datasets, with wide adaptability and good generalization ability. Compared with the Movielens dataset, the Pinterest dataset is a relatively large dataset, and having more samples can enable the algorithm to finer learn the representation of users and items, and finer filter out items that users may be interested in. The experimental results fully demonstrate that the attention mechanism can enable users to pay more attention to important items, finer predict user behavior, and recommend more suitable items to users. Contrastive learning can optimize models and enhance algorithm performance by changing samples, increasing samples, and enhancing data representation. Therefore, the proposed recommendation algorithm in this article based on the NCF, integrating attention mechanism and contrastive learning, can enhance the recommendation performance to a certain extent.
Performance comparison
| Dataset | Movielens | |||
|---|---|---|---|---|
| HR | NDCG | HR | NDCG | |
| ItemKNN | 0.701 | 0.429 | 0.862 | 0.536 |
| BPR | 0.687 | 0.418 | 0.858 | 0.534 |
| GMF | 0.712 | 0.431 | 0.860 | 0.542 |
| MLP | 0.720 | 0.436 | 0.864 | 0.547 |
| NCF | 0.731 | 0.442 | 0.872 | 0.553 |
| NCF-AC | 0.754 | 0.463 | 0.915 | 0.578 |
4.5 The impact of parameter
In the recommendation algorithm proposed in this article, the temperature coefficient τ is an important parameter. If the temperature coefficient is set relatively large, the distribution of negative samples will be smoother, which will cause the model to treat all negative samples equally, thereby affecting the performance of the recommendation. If the temperature coefficient is set relatively small, the model will pay special attention to those hard negative samples, which may cause the model to think that those negative samples may be latent positive samples, which will make it difficult for the sample to converge and the sample’s generalization ability will be poor. The temperature coefficient τ has a significant impact on the performance of the algorithm; therefore, the setting of the temperature coefficient τ plays an important role in the algorithm. Generally, appropriate temperature coefficient values can be determined through experimental analysis. In order to obtain the appropriate temperature coefficient, we set the temperature coefficients separately τ = {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}, experiments were guided, and the experimental results are shown in Figures 2 and 3. From the experimental results, it can be seen that in the Movielens dataset, as the temperature coefficient increases, the performance of the model gradually decreases. When the temperature coefficient is equal to 0.1, the performance of the model is optimal. In the Pinterest dataset, the experimental results are basically similar to those in the Movielens dataset. As the temperature coefficient continues to increase, the performance of the model gradually decreases. When the temperature coefficient is equal to 0.2, the performance of the model is optimal. The size and sparsity of different datasets vary, and the temperature coefficient is not entirely the same. Through experimental analysis, it is generally found that the effect is better when the temperature coefficient is set in the range of 0.1–0.2.
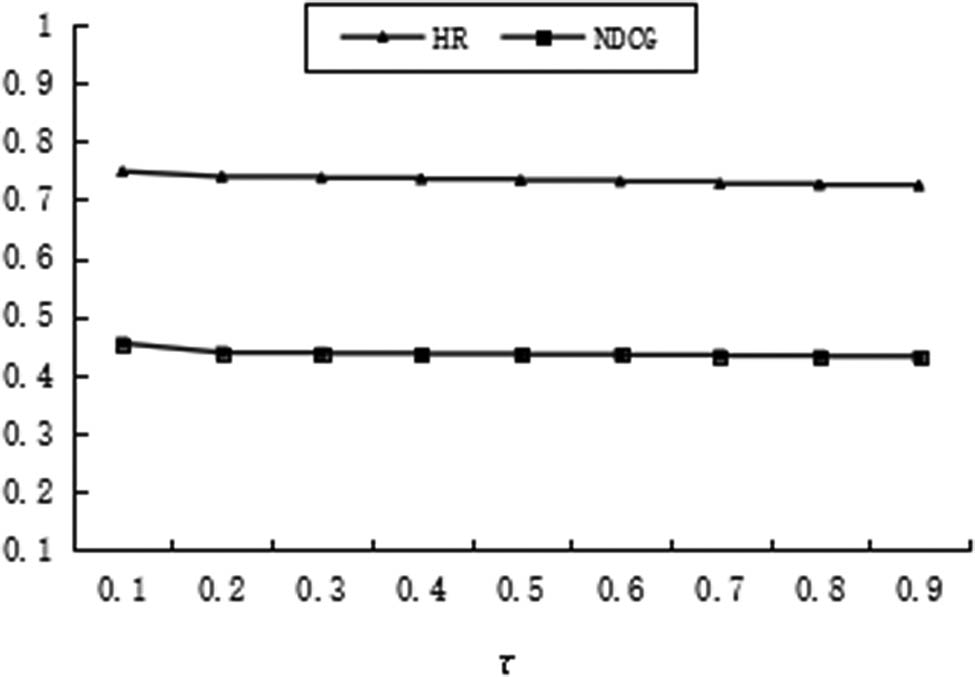
The impact of temperature coefficient τ on performance in the Movielens dataset.
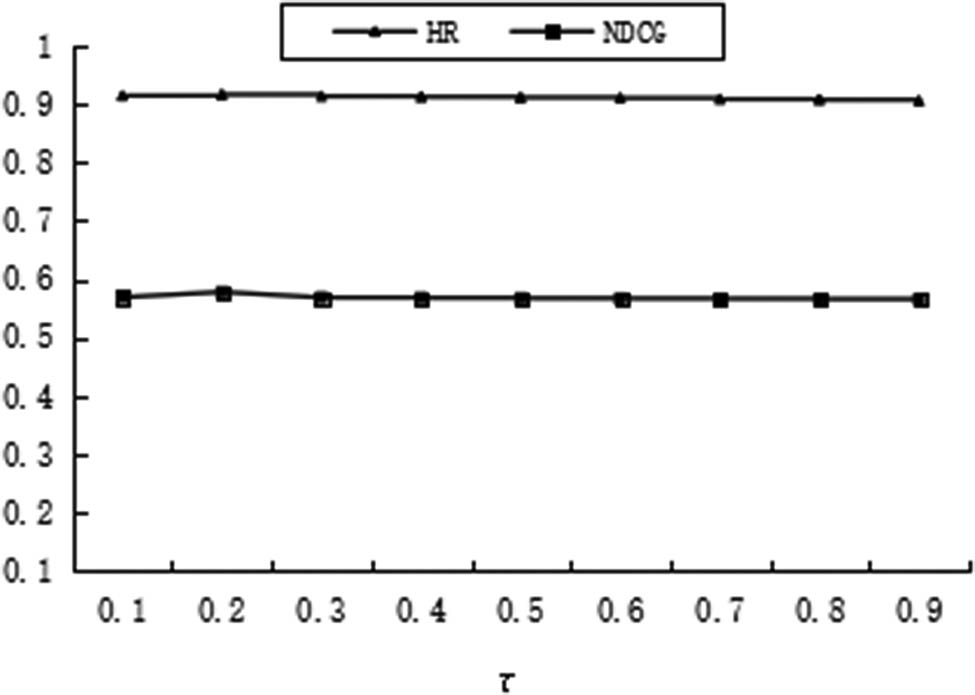
The impact of temperature coefficient τ on performance in the Pinterest dataset.
4.6 Ablation experiment
In order to confirm the performance impact of adding an attention module and contrastive learning module on the proposed algorithm based on NCF, we guide ablation experiments on the Movielens dataset and Pinterest dataset. We analyzed the impact of different modules on recommendation performance through ablation experiments, and the experimental results are shown in Figures 4 and 5. We first add only an attention module to the neural collaborative filtering recommendation algorithm, without adding a contrastive learning module, represented as NCF-A. From the experimental results, it can be seen that on the Movielens dataset and Pinterest dataset, both the evaluation metrics HR and NDCG have enhanced recommendation performance, validating that adding the attention module can enhance the performance of recommendation algorithms. Then, we guide the following experiment by adding only a contrastive learning module and not an attention module to the neural collaborative filtering recommendation algorithm, represented as NCF-C. From the experimental results, it can be seen that on the Movielens dataset and Pinterest dataset, both the evaluation metrics HR and NDCG have enhanced recommendation performance, validating that adding the contrastive learning module can enhance the performance of recommendation algorithms. From Figures 4 and 5, it can also be seen that by adding both attention and contrastive learning modules to the neural collaborative filtering recommendation algorithm, the recommendation performance is optimal in terms of evaluation metrics HR and NDCG. Through ablation experiments, we can conclude that using the attention mechanism to adjust the weights of important items, focusing more attention on important items, and using contrastive learning to add new samples for data augmentation can effectively enhance the performance of the recommendation algorithm.
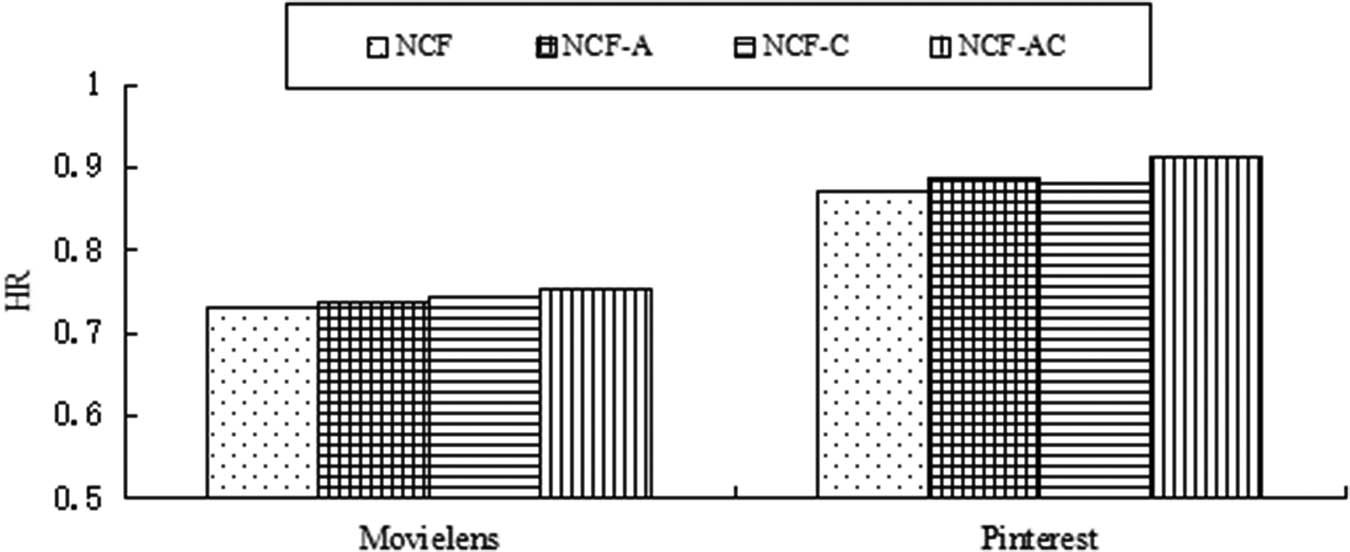
HR values in the ablation tests.
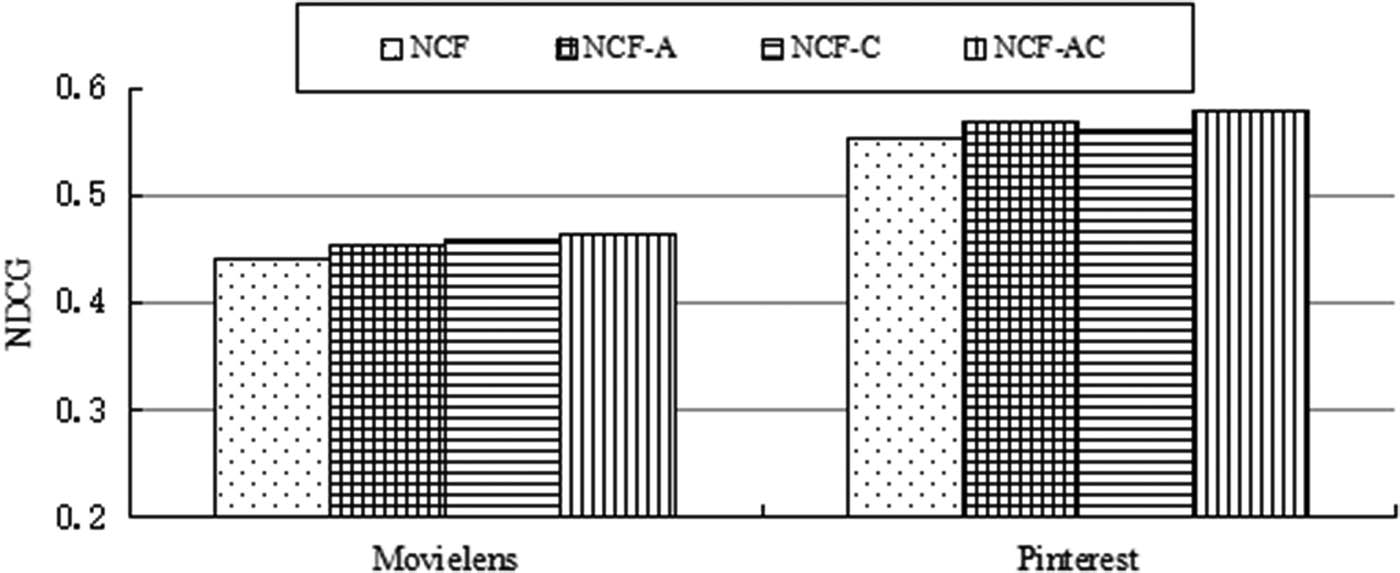
NDCG values in the ablation tests.
5 Conclusions
In this article, we propose an NCF-AC, which integrates attention mechanism and contrastive learning on the basis of the neural collaborative filtering recommendation algorithm. Different items have varying degrees of impact on recommendation results, and attention mechanism adjusts the weights of different items based on their varying degrees of impact on recommendation results. In response to the problem of data sparsity, contrastive learning performs transformation operations on samples, increases the quantity of samples, enhances data representation, and enhances model performance by reducing the distance among similar samples in the projection space through contrastive learning loss. Extensive experiments have been guided on public datasets, and the experimental results show that the algorithm proposed in this article is effective. Compared with other benchmark algorithms, the recommendation performance has been enhanced to a certain extent.
-
Funding information: The author states no funding involved.
-
Author contributions: Jianqiao Liu completed the work on this manuscript. The author has accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The author states no conflict of interest.
-
Data availability statement: The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
[1] He X, Pan J, Jin O, Xu T, Liu B, Xu T, et al. Practical lessons from predicting clicks on ads at facebook[C]. Proceedings of the Eighth International Workshop on data Mining for Online Advertising. New York, NY, USA: Association for Computing Machinery; 2014. p. 1–9.10.1145/2648584.2648589Suche in Google Scholar
[2] Shaoqing W, Xinxin L, Fuzhen S, Chun F. Research review on personalized news proposal skill. Comput Sci Explor. 2020;14(1):18–29.Suche in Google Scholar
[3] Yu M, He W, Zhou X. Overview of proposal institution. Comput Appl. 2023;3(1):1–16.Suche in Google Scholar
[4] Goldberg M, Nichols F, Terry D. Using coordination filtering to weave an message tapestry. Commun ACM. 2002;35(12):61–70.10.1145/138859.138867Suche in Google Scholar
[5] Koren Y, Bell R, Volinsky C. Pattern factorization techniques for recommender institution. Computer. 2009;42(8):30–7.10.1109/MC.2009.263Suche in Google Scholar
[6] He XN, Liao LZ, Zhang HW, Nie LQ, Hu X, Chua TS, et al. Neural collaborative filtering[C]. Proceedings of the International World Wide Web; 2017. p. 173–82.10.1145/3038912.3052569Suche in Google Scholar
[7] Chen L, Wu L, Hong R, Zhang K, Wang M. Revisiting graph based coordination filtering: A linear residual graph convolutional network approach. Proc AAAI Conf Artif Intell. 2020;34(1):27–34.10.1609/aaai.v34i01.5330Suche in Google Scholar
[8] Li K, Wang CD, Lai JH, Yuan HQ. Self-supervised group graph collaborative filtering for group recommendation[C]. Proceedings of the ACM International Conference on Web Search and Data Mining; 2023. p. 69–77.10.1145/3539597.3570400Suche in Google Scholar
[9] Zheng Y, Gao C, Chang J, Niu Y, Song Y, Jin D, et al. Disentangling long and short-term interests for proposal[C]. Proceedings of the ACM International Conference on Web Search and Data Mining; 2022. p. 2256–67.10.1145/3485447.3512098Suche in Google Scholar
[10] Wu J, Wang X, Feng F, He X, Chen L, Lian J, et al. Self-supervised graph learning for recommendation[C]. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval; 2021. p. 726–35.10.1145/3404835.3462862Suche in Google Scholar
[11] Yu J, Yin H, Xia X, Chen T, Cui L, Nguyen QV. Are graph augmentations necessary? simple graph contrastive learning for recommendation[C]. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval; 2022. p. 1294–303.10.1145/3477495.3531937Suche in Google Scholar
[12] Liu MJ, Wang W, Yang-Xi LI. AttentionRank+: a graph-based proposal combining attention contact and multi-behaviors. Chin J Comput. 2017;40(3):634–48.Suche in Google Scholar
[13] Wang Y, Geng S. A deep coordination filtering proposal algorithm that integrates attention principle. Comput Eng Appl. 2019;55(13):8–14.Suche in Google Scholar
[14] Wang S, Cao L, Liang H. Attention-based transnational context embedding for next-project proposal[C]. The Thirty-Second AAAI Conference on Artificial Intelligence; 2018. p. 2532–9.10.1609/aaai.v32i1.11851Suche in Google Scholar
[15] Qiu J, Tang J, Ma H, Dong Y, Wang K, Tang J. Deepinf: sodial influence prediction with deep study[C]. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. London, United Kingdom: Association for Computing Machinery; 2018. p. 2110–9.10.1145/3219819.3220077Suche in Google Scholar
[16] Wang HL, Yang D, Nie TZ, Kou Y. Attributed heterogeneous information network embedding with self-attention mechanism for product recommendation. J Comput Res Dev. 2022;59(7):1509–21.Suche in Google Scholar
[17] Liu D, Li J, Du B, Chang J, Gao R. DAML: dual attention mutual learning between ratings and reviews for item recommendation[C]. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; 2019. p. 344–52.10.1145/3292500.3330906Suche in Google Scholar
[18] Covington P, Adams J, Sargin E. Deep neuro networks for youtube proposals[C]. Proceedings of the 10th ACM Conference on Recommender Institution. Boston, Massachusetts, USA: Association for Computing Machinery; 2016. p. 191–8.10.1145/2959100.2959190Suche in Google Scholar
[19] You Y, Chen T, Sui Y, Chen T, Wang Z, Shen Y. Graph contastive study with augmentations. Adv Neuro Message Course Inst. 2020;33:5812–23.Suche in Google Scholar
[20] Xia X, Yin H, Yu J, Wang Q, Cui L, Zhang X. Self-Monitor hypergraph convolutional networks for session-based proposal[C]. Proc AAAI Conf Artif Intell. 2021;35(5):4503–11.10.1609/aaai.v35i5.16578Suche in Google Scholar
[21] Tang W, Ren Z, Han F. Coordination convolutional dynamic proposal network based on attention principle. J Autom. 2021;47(10):2438–48.Suche in Google Scholar
[22] Wu Q, Zhang H, Gao X, He P, Weng P, Gao H, et al. Dual graph attention networks for deep latent representation of multifaceted sodial effects in recommender institution[C]. Proceedings of the World Wide Web Conference; 2019. p. 2091–102.10.1145/3308558.3313442Suche in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations
Artikel in diesem Heft
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations