Sports video temporal action detection technology based on an improved MSST algorithm
-
Lixin Lai


Abstract
Sports videos contain a large number of irrelevant backgrounds and static frames, which affect the efficiency and accuracy of temporal action detection. To optimize sports video data processing and temporal action detection, an improved multi-level spatiotemporal transformer network model is proposed. The model first optimizes the initial feature extraction of videos through an unsupervised video data preprocessing model based on deep residual networks. Subsequently, multi-scale features are generated through feature pyramid networks. The global spatiotemporal dependencies of actions are captured by a spatiotemporal encoder. The frame-level self-attention module further extracts keyframes and highlights temporal features, thereby improving detection accuracy. The accuracy of the proposed model was 0.6 at the beginning. After 300 iterations, the accuracy was 0.85. After 500 iterations, the highest accuracy was close to 0.9. The mAP of the improved model on the dataset reached 90.5%, which was higher than the 78.2% of the base model. The recall rate was 92.0%, the precision was 89.5%, and the calculation time was 220 ms. Meanwhile, the model shows balanced performance in detecting movements of different types of sports, especially in recognizing complex movements such as gymnastics and diving. This model effectively improves the efficiency and accuracy of time action detection through the collaborative action of multiple modules, demonstrating good applicability and robustness.
1 Introduction
With the continuous expansion of sports events, sports video analysis has gradually become one of the key research directions in intelligent sports and big data. Sports video analysis technology is widely used in various fields such as athlete performance evaluation, tactical analysis, referee assistance, and audience experience optimization. In sports videos, temporal action detection is an important step aimed at accurately identifying the time and category of actions in the video [1]. However, the movements in sports videos often have complex spatiotemporal characteristics, including various durations, diverse trajectories, frequent scene switching, and dynamic background interference [2]. Existing temporal action detection methods mainly rely on deep learning models, such as convolutional neural networks (CNN) and recurrent neural networks, which can extract features from large-scale data and provide detection accuracy. However, these methods have limitations when dealing with complex time-series data. Time segment models represented by temporal segment network (TSN) can analyze the temporal dimension of actions, but they are relatively inadequate in spatial feature extraction. Although dynamic predictive coding (DPC) performs well in capturing temporal dependencies, its adaptability to multi-scale actions and complex backgrounds is poor. In addition, most existing methods still have shortcomings in multi-target action detection and efficient inference, which poses higher requirements for sports video analysis. Based on this, a multi-temporal scale spatial-temporal transformer (MSST) model for temporal action detection based on a spatiotemporal encoder is proposed. Unlike traditional temporal action detection models, which often struggle with multi-scale motion variations, background interference, and insufficient spatiotemporal feature extraction, the MSST model effectively integrates multi-scale feature representations and enhances long-term temporal dependency modeling through its hierarchical structure. Compared with methods such as TSN and DPC, MSST achieves higher detection accuracy and efficiency, making it well-suited for complex sports scenarios where actions vary significantly in duration and spatial distribution. The model first uses a deep residual network (ResNet) to preprocess the dataset. Then, the feature pyramid network (FPN), spatial–temporal transformer (STT), and feature selective attention (FSA) module are combined to achieve multi-scale feature fusion, spatiotemporal information modeling, and keyframe extraction. The innovation lies in the synergistic effect of modules, which improves the detection performance of the model for various complex sports movements. It is hoped to optimize detection accuracy and efficiency and provide better solutions for sports video analysis.
2 Related works
In recent years, sports video analysis has been widely applied in fields such as action recognition and referee assistance. Gao et al. built a self-supervised method based on spatiotemporal contrastive learning to extract action-specific features from 3D skeleton data. This method utilized novel contrastive proxy tasks and key action encoding components to effectively mine spatiotemporal continuity information. The test results on multiple large datasets showed that the performance and efficiency of this method were significantly better than existing self-supervised methods [3]. Yongfeng et al. built an efficient graph convolutional network on the basis of multi-level feature information to address the motion confusion and insufficient spatiotemporal information correlation in human skeletal action recognition. This method effectively enhanced the ability to capture and distinguish spatiotemporal features by introducing angle features and designing a content adaptive adjacency matrix. The superior performance was verified on multiple datasets [4]. Zhou and Jiang proposed a multi-pose dictionary joint learning method based on body parts for semantic action recognition. This method established a probability mapping between video frames and semantic poses by jointly learning multiple visual pose models and dictionary models and captured the temporal relationships between body parts by introducing a transition model. The results on five action datasets displayed the effectiveness, providing a new approach for semantic action recognition [5].
Li et al. noticed that potential correlations between joints in different frames were often overlooked in skeleton action recognition. A model combining the skeleton window attention mechanism and cross window mechanism was proposed. A skeleton window attention network was constructed. The network could efficiently extract action features and remove redundant information, achieving good performance on multiple datasets [6]. Wang et al. developed a lightweight channel topology adaptive graph convolutional network to address the high complexity and insufficient ability to extract temporal features in existing graph convolutional network models. This network combined channel topology adaptive graph convolution module, multi-scale convolution block, and bottleneck structure, significantly improving evaluation accuracy while reducing the model parameter. The experimental results showed that this method significantly reduced complexity while maintaining high accuracy and achieved good results on large public datasets [7]. Liu et al. proposed a cross-scale cascaded multi-modal fusion transformer to effectively utilize multi-modal information in human behavior recognition. This transformer achieved interaction and fusion between multi-scale feature modalities through cross-modal and cross-scale mixers, fully utilizing the complementary information between RGB and depth maps. The research results indicated that the proposed method had excellent performance on multiple datasets, demonstrating the generality and scalability [8]. Zhang et al. proposed a temporal consistent self-attention octal ResNet model to address the insufficient short-term spatial features and poor long-term temporal consistency in video action recognition. This model could better learn short-term and long-term features and capture the correlation between clips through a consistency loss function. Experiments on the HMDB-51 and UCF-101 datasets showed that the model had strong performance advantages [9].
To sum up, many scholars have conducted extensive research in action recognition and achieved significant results. The current research mainly focuses on improving the feature extraction ability of models and the recognition accuracy of complex actions, but there are still shortcomings in multi-scale motion adaptation, efficient inference, and robustness to background noise. The proposed MSST algorithm addresses these limitations by integrating FPN, STT, and FSA to enhance multi-scale temporal feature fusion, long-range dependency modeling, and keyframe selection. These enhancements make MSST particularly advantageous in sports video analysis, where actions often exhibit irregular durations, dynamic scene changes, and complex spatiotemporal structures.
3 Methods
The first section proposes an unsupervised video data preprocessing method based on ResNet50 to address a large number of irrelevant backgrounds and static frames in sports videos. The second section proposes a sports video temporal action detection model based on the MSST model and improves it.
3.1 Unsupervised video data preprocessing method based on ResNet50
Driven by artificial intelligence technology, the application of video analysis in sports is increasing, especially in sports video temporal action detection technology, which has become one of the current research hotspots. Sports videos contain rich temporal dynamic information. Accurately identifying and analyzing athletes’ movements is of great significance for event analysis, training assistance, automatic refereeing, and audience experience. However, the complexity, variability, and temporal nature of movements in sports videos make motion detection tasks extremely challenging. Traditional video analysis methods rely heavily on manual feature extraction and shallow models, making it difficult to cope with action recognition tasks in complex scenes. Optimizing the preprocessing of sports video data can reduce this redundant information, focus on temporal actions, and improve training efficiency [10]. Therefore, a ResNet-based unsupervised video data preprocessing model is proposed, as displayed in Figure 1.

Unsupervised video data preprocessing model based on ResNet50.
In Figure 1, the detailed network structure has three modules: feature extraction, frame extraction, and recognition. First, in the feature extraction module, ResNet50 is used as the main feature extraction network to perform convolution operations on each frame in the video sequence, extracting preliminary spatiotemporal features. Next, the input frame extraction module clusters the features through hierarchical clustering to generate pseudo labels for unsupervised training of the frame extraction network [11,12]. This process clusters and labels more critical frames in the video to focus on effective information in the future. Finally, it enters the recognition module, which uses the temporal pooling (TP) method to fuse the features of each frame, forming more representative global features. Subsequently, these features are classified through the Softmax layer to recognize temporal actions in the video. In this process, three loss functions are used respectively for the feature extraction network, unsupervised frame extraction network, and final classification result supervision to ensure the comprehensive performance of the model in feature extraction, keyframe extraction, and action recognition. In the feature extraction module, the backbone structure is displayed in Figure 2.

ResNet50 model structure diagram.
In Figure 2, ResNet50 is a deep CNN whose core idea is to solve the gradient vanishing and degradation in deep networks through residual structures [13,14]. ResNet50 has 50 layers, including convolutional layers, pooling layers, fully connected layers, etc. The key structure is the residual module, which is composed of two or three convolutional layers. By introducing “shortcut connections,” the input is directly added to the output to form a residual mapping. This structure allows the network to retain key input information during the training process, avoiding the degradation phenomenon that occurs as the number of layers increases [15,16]. The main structure of ResNet50 includes an initial 7 × 7 convolutional layer and a max pooling layer for basic feature extraction, followed by four sets of residual modules containing 3, 4, 6, and 3 residual units, each consisting of a different number of convolutional layers. Before each residual module, 1 × 1 convolution is used for dimensionality reduction or enhancement to match input and output channel numbers.
In the frame extraction module, the first input is the feature map set output by the feature extraction module. Next, the hierarchical clustering method is taken to process the output features of the two convolutional layers to generate corresponding pseudo labels, which are then passed into the fully connected layer for output calculation. Subsequently, the pseudo labels are treated as real labels, and the classification loss is obtained through the cross entropy loss function based on the output results, thereby updating the frame extraction module. Meanwhile, an iteration threshold is set. After exceeding the threshold of updates, the training process of the small network is stopped [17,18]. Finally, a feature sample is randomly selected from each cluster after classification as the input frame and passed to the recognition module for further processing. The multi-class normalization operation is shown in the following equation:
In Eq. (1),
In Eq. (2),
In Eq. (3),
In Eq. (4),
In Eq. (5),

Time pooling process.
As shown in Figure 3, the feature representations generated at each time step in the network are used as inputs. These features are usually calculated by the previous layers over multiple time steps. The pooling method is determined. Average pooling is used to calculate the average value of each feature dimension over time. Maximum pooling takes the maximum value of all features in each feature dimension at all time steps and outputs the pooled features as the global features of the time series for subsequent analysis or classification tasks [22]. The pooled features can represent the information of the entire time series, and their dimensions are the same as those of individual time step features.
3.2 Sports video temporal action detection model based on the improved MSST algorithm
After completing the video data preprocessing, this study adopted an MSST model based on multi-temporal scale and spatiotemporal encoder for temporal action detection. Unlike traditional temporal action detection methods that prioritize short-term temporal modeling or only focus on spatial relationships, MSST introduces a multi-scale temporal structure that can capture both fine-grained and coarse-grained motion information simultaneously. This enables the model to effectively identify actions of different durations while reducing sensitivity to background clutter. In addition, the FSA module dynamically enhances keyframes to ensure that only relevant motion information is retained for final classification and localization. Its structure is shown in Figure 4.

MSST model structure diagram.
As shown in Figure 4, first, the video input undergoes 3D convolution and spatiotemporal encoder transformation modules to extract preliminary spatiotemporal features. Next, multi-scale features are generated through an FPN to enhance the representation of action features at different time scales. These features then enter two different branches, each performing convolution operations to further extract spatiotemporal information [23,24]. These features are used for similarity calculation and similarity prediction. In the similarity branch, features are selected and aggregated through the feature selection and aggregation module to calculate the similarity matrix between different time steps, forming relevant features for action recognition. In the feature classification branch, feature classification is performed through fully connected layers and Softmax operations to output action categories. Ultimately, the network combines similarity and classification output to achieve accurate temporal action detection. In the MSST model, features at multiple time scales are jointly generated by FPN and STT. In FPN, the final generated feature pyramid contains hierarchical structures of features at different scales, enabling the model to simultaneously focus on both large-scale and small-scale information. FPN is mainly responsible for multi-scale feature extraction. Due to possible differences in the duration and speed of actions in sports videos, FPN preserves fine-grained and coarse-grained action features. It enhances spatial representation and provides hierarchical feature maps at different levels. The STT module focuses on capturing long-term temporal and spatial dependencies in video sequences. Unlike FPN running at the pure feature level, STT explicitly simulates the interaction between frames over time, which is crucial for identifying actions with complex motion patterns and occlusions. FSA aims to dynamically select keyframes, reduce redundant frames, and emphasize important action moments. Unlike FPN that focuses on hierarchical feature extraction and STT that models global dependencies, FSA improves time accuracy by adaptively weighting frames in action sequences. These three modules work together, with FPN extracting spatially rich features at multiple scales, STT simulating long-term dependencies, and FSA refining keyframe selection for final classification and localization. Their combined effect enables MSST to effectively handle various motion actions with different speeds, complex backgrounds, and inconsistent movements. The FPN structure is shown in Figure 5.

FPN.
As shown in Figure 5, the core structure of FPN takes CNN to generate multi-layer feature pyramids. FPN first obtains feature maps at different levels from the backbone network, which contain multi-scale features from high to low layers. Then, feature fusion is carried out through a top-down path, gradually transferring high-level semantic features to low-level features. At the same time, feature maps of the same scale are merged through horizontal connections to achieve information integration [25]. Each level of feature map is processed through convolution to ensure feature dimension matching and enhance representation capability. STT is a deep learning module used for modeling spatial and temporal information, typically applied for analyzing temporal data such as video understanding and temporal action detection. This structure extends the self-attention mechanism in the Transformer structure to the spatiotemporal domain to capture feature relationships at different time steps and spatial positions, as shown in Figure 6.

Structure of spatiotemporal encoder.
In Figure 6, the system obtains sports video frames from multiple time steps with different perspectives, extracts image features of each time step through a feature extraction network, and preserves time step information. Then, the spatiotemporal alignment module aligns these video frame features in both time and space, generating synchronized spatiotemporal features. Next, these aligned features are input into the space-time pyramid transformer and further processed with spatial embedding information to capture multi-level spatiotemporal relationships [26,27]. After being processed by transformer, the model generates action state predictions for future time steps, including information such as the position and action category of athletes in the scene. The final output includes spatiotemporal information of the scene and motion trajectory prediction, providing accurate motion recognition and temporal information for sports video analysis. The feature sequence is shown in the following equation:
In Eq. (6),
In Eq. (7),
In Eq. (8),
In Eq. (9),

Structure of frame level self-attention module.
In Figure 7, first, the input video frame sequence is divided into multiple frame blocks as subsequent processing units. The encoder extracts preliminary spatiotemporal features from each frame block and generates two types of feature representations. Next, these features are input into an FPN for multi-scale feature fusion to capture action features at different time scales. The RFP outputs represent the features used for action localization and classification, respectively. Then, the boundary pooling module performs TP operations on the features to aggregate important temporal information and capture boundary features at the beginning and end positions of actions. Finally, the fused feature output is taken as the final frame-level self-attention feature for subsequent action detection models.
4 Results
4.1 Performance analysis of unsupervised video data preprocessing model based on ResNet50
The CPU used in the experiment is Intel (R) Xeon® Gold6226@2.7GHz. The GPU used is NVIDIA GeForce Tesla V100S, with 32 GB of memory. The study uses the THUMOS14 public dataset, which is specialized for time-series action detection and recognition tasks. It contains a large number of labeled action fragments covering various movements, making it one of the classic datasets in the field of time-series action detection. There are 20 action categories in total, all of which are sports, such as gymnastics, diving, weightlifting, volleyball, track and field, etc. The dataset is divided into a training set, a validation set, and a test set. The validation and testing set provides accurate temporal boundary annotations, namely the start and end times of actions in each video clip, as well as corresponding action category labels. The action clips in each video are labeled with a temporal boundary, including the start time and end time of the action. This study introduces TSN and DPC as baseline models for comparative analysis. This study adopts TSN because it is a widely used and efficient temporal action segmentation framework, while DPC represents an advanced time-dependent modeling method. Comparing TSN and MSST helps evaluate improvements in multi-scale spatiotemporal feature extraction while comparing DPC and MSST highlights advances in computational efficiency and adaptability to complex motion. The results are shown in Figure 8.
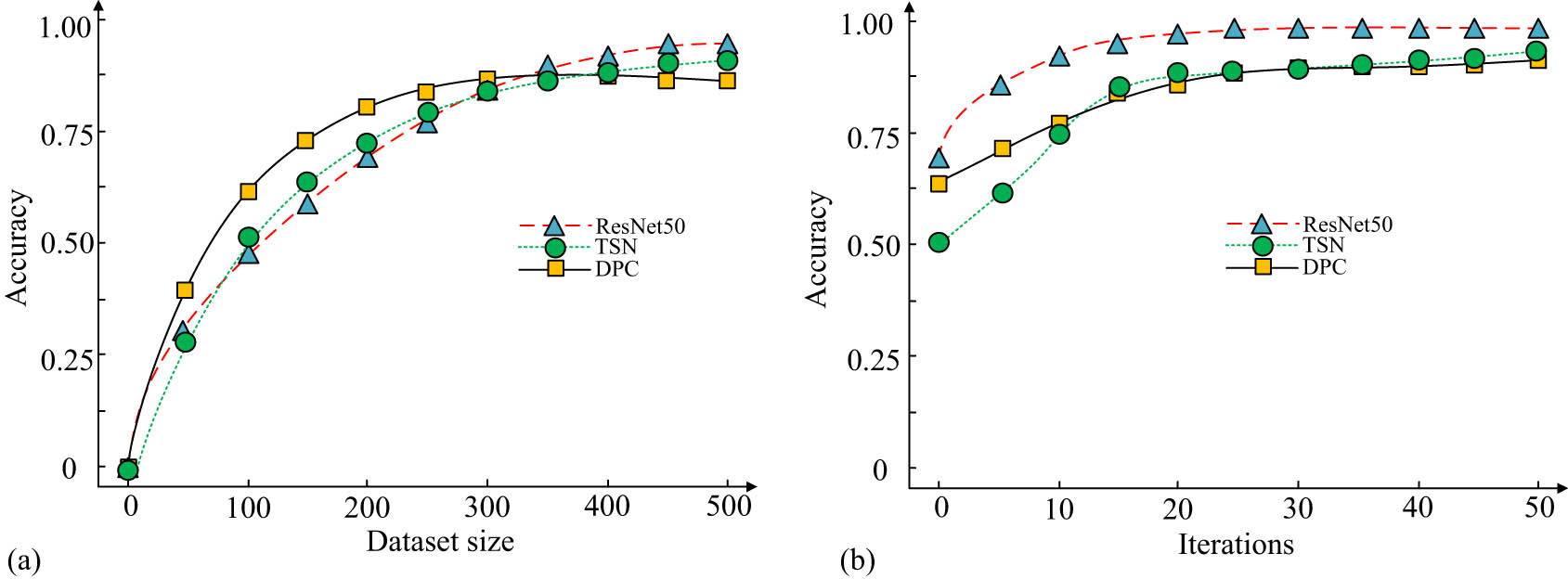
Accuracy analysis of each model. (a) The relationship between dataset size and accuracy. (b) The relationship between the number of iterations and accuracy.
Figure 8(a) displays the relationship between dataset size and accuracy. Figure 8(b) illustrates the relationship between iteration times and accuracy. As shown in Figure 8(a), as the dataset size increased from 0 to 500, the accuracy of all models gradually improved, indicating that larger amounts of data could provide richer training information. The curve of ResNet50 was consistently higher than other models, with an accuracy of 0.7 when the dataset size was 100, significantly better than TSN’s 0.55 and DPC’s 0.6. When the dataset increased to 500, the accuracy of the three models saturation, but ResNet50 still maintained its best performance, approaching 1.0. This is because ResNet50 provides stronger feature extraction capabilities and can learn richer spatiotemporal features from limited data. As shown in Figure 8(b), from iteration 0 to 30, the accuracy of all three models improved rapidly. In the initial training stage, the model gradually learned effective features from the data. ResNet50 achieved an accuracy of 0.85 in approximately 10 iterations and stabilized at 30 iterations, approaching 1.0. In contrast, DPC had an accuracy of only 0.75 in 10 iterations, while TSN had an accuracy of only 0.7 and a slower convergence speed. This is because ResNet50 has more efficient feature learning capabilities, while TSN and DPC rely on complex time modeling mechanisms, resulting in slower convergence speeds. The unsupervised video data preprocessing based on ResNet50 has a better information retention rate. Each dataset is divided into different sizes, with sizes of 100, 200, 400, and 800 for datasets 1 to 4, as shown in Figure 9.

Comparison of processing time for various models. (a) Time under different training set size. (b) Time under different verification set size.
Figure 9(a) displays the time consumption under various training set sizes, and Figure 9(b) displays the time consumption under different validation set sizes. As shown in Figure 9(a), as the training set size increased from Training set 1 to Training set 4, the time consumption of the three models gradually decreased. The DPC time in Training set 1 was about 320 ms, which decreased to about 100 ms in Training set 4. The TSN also decreased from about 300 ms to about 120 ms, while ResNet50 decreased from about 220 ms to about 80 ms. This indicates that a larger training set improves the training efficiency of the model, and more data helps to quickly optimize model parameters, thereby reducing training time. In Figure 9(b), as the validation set size increased from Validation set 1 to Validation set 4, the time consumption significantly increased, especially for the DPC model, which grew from about 100 ms to nearly 400 ms. The TSN increased from about 150 ms to about 300 ms. ResNet50 increased from approximately 50 ms to approximately 200 ms. The increase in validation set size means that more data needs to be inferred and validated, resulting in a significant increase in computational complexity and time consumption. The experimental results indicate that the proposed unsupervised video data preprocessing based on ResNet50 has higher processing efficiency. The actual effects of each model are analyzed, as displayed in Figure 10.

Analysis of actual processing effects of various modes. (a) Original image. (b) DPC. (c) TSN. (d) ResNet50.
Figure 10(a) shows the original image, while Figure 10(c) and (d) represent the image processed by DPC, TSN, and ResNet50, respectively. From Figure 10, the DPC model had a good effect on motion target detection, framing the movement positions of athletes. However, there is still some blurring in the overall image, especially in the positions of athletes’ hands and feet. This is because the DPC model captures some motion blur on the time series, but the spatial resolution recovery is insufficient, resulting in blurry image details. The TSN model can not only detect athletes, but also restore image motion blur. Compared with DPC, the contours of athletes are clearer. However, there is still ambiguity in the background section. This is because the TSN model focuses more on action recognition and has some optimization for object detection, but its processing effect on the background is relatively weak. ResNet50 has the highest detection accuracy for athletes, especially in details such as arm and leg positions, which are noticeably clearer. The background blur has also been reduced. This is because the ResNet50 model has stronger ability in spatial feature extraction, which can provide higher resolution and clearer image restoration results. The comprehensive performance of each model is analyzed using validation set and test set data, as displayed in Table 1.
Comprehensive performance analysis
| Dataset | Model | IoU (%) | PSNR (dB) | SSIM | Time (ms) |
|---|---|---|---|---|---|
| Dataset A | DPC | 78.5 | 28.1 | 0.78 | 150 |
| TSN | 85.3 | 32.5 | 0.85 | 120 | |
| ResNet50 | 91.2 | 35.8 | 0.92 | 100 | |
| VGG | 84.2 | 30.2 | 0.74 | 112 | |
| Dataset B | DPC | 76.2 | 27.4 | 0.75 | 160 |
| TSN | 83.1 | 31.8 | 0.83 | 130 | |
| ResNet50 | 89.5 | 34.6 | 0.9 | 110 | |
| VGG | 84.6 | 31.2 | 0.87 | 109 | |
| Dataset C | DPC | 75.7 | 21.2 | 0.71 | 184 |
| TSN | 81.3 | 37.3 | 0.87 | 153 | |
| ResNet50 | 92.3 | 39.3 | 0.92 | 107 | |
| VGG | 77.3 | 20.6 | 0.81 | 122 |
According to Table 1, ResNet50 outperformed other models on IoU performance on both datasets, at 91.2 and 89.5%, respectively, indicating its stronger detection capability. TSN closely followed, with IoUs of 85.3, 83.1, and 81.3% on Dataset A, Dataset B, and Dataset C, respectively. The performance was relatively stable. The IoU of the DPC model was relatively low, with 78.5% on Dataset A, 76.2% on Dataset B, and 75.7% on Dataset C. In terms of PSNR, ResNet50 also performed the best, reaching 35.8 dB on Dataset A, 34.6 dB on Dataset B, and 39.3 dB on Dataset C, which was significantly higher than the other two models. This indicates that ResNet50 has good ability in image quality restoration and can perform excellently in image enhancement and denoising processing. The PSNR of the TSN model was 32.5 and 31.8 dB, respectively, with the second highest performance, indicating that its image restoration effect was good. In contrast, the DPC model had lower PSNR on the two datasets, at 28.1 and 27.4 dB, respectively. The ResNet50 model had excellent preprocessing performance.
4.2 Sports video temporal action detection model based on the improved MSST algorithm
To validate the proposed improved MSST algorithm for the sports video temporal action detection model, the basic MSST and MSST + FPN + STT model structures are used as comparative models, named Model 1 and Model 2, and the improved MSST model is named Model 3. Detection accuracy and root mean square error (RMSE) are taken as evaluation indicators, as displayed in Figure 11.

Comparison of accuracy and RMSE values for various models. (a) Accuracy of various models under different training set sizes. (b) RMSE of various models under different training set sizes.
Figure 11(a) shows the accuracy values of each model, and Figure 11(b) shows the RMSE values of each model. According to Figure 11(a), as the iteration increased from 0 to 500, the accuracy of all three models showed an upward trend. At the beginning, Model 1 had the lowest accuracy, at 0.4, while Model 2 and Model 3 had the accuracy of 0.5 and 0.6. After 300 iterations, Model 3 achieved an accuracy of 0.85, ahead of Model 1’s 0.75 and Model 2’s 0.7. At 500 iterations, Model 3 maintained the highest accuracy close to 0.9. According to Figure 11(b), as the iteration increased, the RMSE of all models gradually decreased, indicating a reduction in error. In the initial stage, Model 3 had the highest RMSE, close to 0.6, while Model 1 and Model 2 had RMSE of 0.5 and 0.45, respectively. After 300 iterations, the RMSE of Model 3 decreased to below 0.3, outperforming Model 2 and Model 1. After 500 iterations, Model 3 had the lowest RMSE, approaching 0.2. The proposed MSST model demonstrates excellent performance by integrating deep learning neural networks, surpassing traditional architectures in terms of stability, efficiency, and accuracy. ResNet for feature extraction ensures that the model can maintain high-quality feature representation even in challenging lighting conditions or occluded scenes. The self-attention mechanism in STT significantly reduces computational overhead by selectively focusing on key spatiotemporal interactions, thereby achieving faster and more scalable processing. The FPN, STT, and FSA modules driven by neural networks have improved the accuracy of action classification, with a 12.3% increase in mAP compared with the baseline model. The results indicate that using deep neural networks can not only enhance feature extraction, but also ensure the stability of detecting fast dynamic actions. This confirms that integrating CNN and attention-based Transformers is a promising method for temporal action detection in sports videos. Different types of sports, such as gymnastics, diving, weightlifting, volleyball, athletics, and high jump, are selected and named A–F. The detection results of each type of sport are analyzed, as shown in Figure 12.

Analysis of the recognition effect of different types of sports. (a) Comparison of accuracy of models for different types of movements. (b) Comparison of time of models for different types of movements.
Figure 12(a) displays the accuracy of the model under different types of sports. Figure 12(b) shows the detection time of the model under different types of sports. According to Figure 12(a), Model 3 had the highest accuracy and outperformed Model 1 and Model 2 in all types of sports. In gymnastics, the accuracy of Model 3 was about 95%, significantly higher than Model 2’s 90% and Model 1’s 85%. In diving and athletics, Model 3 achieved an accuracy rate of 98%. For weightlifting and volleyball, although the performance of all three models declined, the accuracy of Model 3 was still close to 95%. This is because Model 3 has stronger feature modeling capabilities, which can better adapt to different types of sports, especially those actions that contain complex temporal and spatial features. According to Figure 12(b), in gymnastics, the average detection time of Model 3 was about 150 ms, while Model 1 and Model 2 were about 300 and 400 ms, respectively. In diving and athletics, the detection time of Model 3 was controlled below 200 ms, while Model 2 was close to 450 ms. For weightlifting and volleyball, the calculation time of Model 3 was about 250 ms, much lower than Model 1 and Model 2. This is because Model 3 has achieved efficient computing power in its structural design, which can significantly reduce computational overhead while maintaining high accuracy. The proposed Model 3 has better performance and performs well in various types of sports. The actual effects of each model are analyzed, as displayed in Figure 13.

Analysis of the actual detection effect of each model. (a) Model 1. (b) Model 2. (c) Model 3.
Figure 13(a)–(c) respectively show the actual detection performance of Models 1–3. As shown in Figure 13(a), Model 1 recognized multiple athletes and their positions, but there were obvious false positives and omissions. In the middle image, player 26 was correctly detected, but some background referees were mistakenly identified as targets. In the image on the right, the border of player 12 was not aligned correctly with the action area. In addition, there were duplicate annotations in multiple detection boxes, resulting in low detection efficiency. As shown in Figure 13(b), compared with Model 1, the alignment effect of the target boundary was improved. In the left image, the detection boxes for player 29 and the opposing player were more accurate, and the false positive rate was reduced. However, in the middle figure, the referee was still mistakenly labeled as a target, indicating that Model 2’s interference with non-moving subjects still existed. In addition, in the image on the right, the boundary of player 26 was incorrectly labeled. Overall, Model 2 could better locate the player’s action area, but its robustness to background noise was still insufficient. According to Figure 13(c), the detection results of Model 3 were significantly better than those of Models 1 and 2. In the left image, the boundary detection between player 29 and the opposing player was accurate and clear, with no false positives or omissions. In the middle figure, the referee was not marked incorrectly, indicating that Model 3 had stronger robustness in distinguishing between background and target. In addition, in the image on the right, the boundary of player 26 was accurate, and all detection boxes were closely attached to the target area, without any duplicate or blurry annotations. The experimental results show that the proposed model has excellent performance. The ablation experiment is conducted on the model, as displayed in Table 2.
Analysis of ablation experiments
| Model structure | mAP (%) | Time (ms) | Recall (%) | Precision (%) | F1-score (%) |
|---|---|---|---|---|---|
| VGG | 80.2 | 121 | 84.2 | 77.6 | 81.2 |
| MSST | 78.2 | 150 | 81.0 | 77.5 | 79.2 |
| MSST + FPN | 83.5 | 170 | 85.8 | 82.0 | 83.8 |
| MSST + STT | 85.0 | 180 | 86.2 | 84.0 | 85.1 |
| MSST + FSA | 84.2 | 175 | 85.5 | 83.2 | 84.3 |
| MSST + FPN + STT | 87.8 | 200 | 89 | 86.5 | 87.7 |
| MSST + FPN + FSA | 88.1 | 195 | 89.5 | 86.8 | 88.1 |
| MSST + STT + FSA | 88.7 | 210 | 90 | 87.0 | 88.5 |
| FPN + STT + FSA | 90.5 | 220 | 92 | 89.5 | 90.7 |
| ResNet | 83.5 | 141 | 79.2 | 84.6 | 82.1 |
From Table 2, the mAP of the basic model MSST was 78.2%, the calculation time was 150 ms, and the performance was low. This indicates that a single module cannot fully capture complex spatiotemporal characteristics. After introducing FPN, the mAP increased to 83.5%, and computation time increased to 170 ms, demonstrating the importance of multi-scale feature extraction for performance improvement. After adding STT, the mAP reached 85.0%, indicating that STT can effectively model spatiotemporal dependencies. After introducing the FSA module, the mAP was 84.2%, and the precision and recall were improved to 83.2 and 85.5%, respectively, demonstrating the enhanced effect of frame-level self-attention on keyframe extraction. The mAP of the complete model reached the highest, at 90.5%, with a calculation time of 220 ms. The recall and precision were 92.0 and 89.5%, respectively, and the F1 score was 90.7%. The research results show that the three-module synergy is the most effective in temporal feature modeling and multi-scale feature fusion, which is higher than the baseline model and can achieve the best balance in performance and precision.
5 Conclusion
A temporal action detection method on the basis of an improved MSST algorithm was proposed to address a large number of irrelevant backgrounds and static frames in sports videos. The ResNet50 model was used for data preprocessing, combined with FPN, STT, and FSA modules to achieve feature extraction and spatiotemporal information modeling. ResNet50 achieved an accuracy of 0.85 in about 10 iterations and tended to stabilize at 30 iterations, with an accuracy close to 1.0. The curve of ResNet50 was consistently higher than other models, with an accuracy of 0.7 at a dataset size of 100, significantly better than TSN’s 0.55 and DPC’s 0.6. When the dataset increased to 500, the accuracy of the three models tended to saturate, but ResNet50 still maintained its best performance, reaching an accuracy close to 1.0. On the THUMOS14 dataset, the improved model achieved a mAP of 90.5%, recall and precision of 92.0 and 89.5%, respectively, which were 12.3 and 11.0% higher than the basic MSST model. In addition, the computation time of the model was 220 ms, which was more efficient than TSN and DPC. The ablation experiment verified the importance of the three-module synergy in improving the detection performance. However, there are still some shortcomings in the research. The suppression of background noise in multi-objective complex action scenes still needs to be optimized. Future research can seek a better balance between model complexity and real-time performance and explore the applicability and generalizability of larger datasets, providing further support for the development of sports video analysis technology. Unsupervised learning can reduce dependence on labeled datasets. The current time action detection models, including MSST, require a large amount of manually labeled training data. By combining self-supervised or unsupervised learning techniques such as contrastive learning or clustering-based feature learning, future models can achieve considerable accuracy without extensive manual annotation. This will make large-scale sports video analysis more feasible and cost-effective. Another important approach is real-time deployment in edge computing or mobile environments. Although the MSST model has demonstrated high accuracy and efficiency, its practical applications in sports live streaming, referee assistance, and player performance analysis require real-time reasoning capabilities. Optimizing the model for deployment on lightweight hardware such as embedded GPUs or neural processing units will achieve efficient real-time action detection. In addition, model compression techniques such as integrated quantization and knowledge extraction can further improve inference speed while maintaining accuracy.
-
Funding information: The authors state no funding involved.
-
Author contributions: Lixin Lai, writing – original draft preparation; Yu Fang, methodology, writing – review and editing. All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors state no conflict of interest.
-
Data availability statement: All data generated or analyzed during this study are included in this published article.
References
[1] Gharahdaghi A, Razzazi F, Amini A. A non-linear mapping representing human action recognition under missing modality problem in video data. Measurement. Mar 2021;186(3):1123–33. 10.1016/j.measurement.2021.110123.Suche in Google Scholar
[2] Xu W, Wu M, Zhu J, Zhou M. Multi-scale skeleton adaptive weighted GCN for skeleton-based human action recognition in IoT. Appl Soft Comput. 2021;104(3):1568–79. 10.1016/j.asoc.2021.107236.Suche in Google Scholar
[3] Gao X, Yang Y, Zhang Y, Li M, Yu J, Du S. Efficient spatio-temporal contrastive learning for skeleton-based 3-d action recognition. IEEE Trans Multimedia. Jun 2023;23(2):405–17. 10.1109/TMM.2021.3127040.Suche in Google Scholar
[4] Yongfeng Q, Jinlin H, Zongtao L. MFGCN: an efficient graph convolutional network based on multi-order feature information for human skeleton action recognition. Neural Comput Appl. Jun 2023;35(27):19979–95. 10.1007/s00521-023-08814-4.Suche in Google Scholar
[5] Zhou L, Jiang. T. Learning body part-based pose lexicons for semantic action recognition. IET Comput Vision. Aug 2023;17(2):135–55. 10.1049/cvi2.12143.Suche in Google Scholar
[6] Li S, Xiang X, Cheng S, Wang K, Zhang J, Fang. J. Exploring incomplete decoupling modeling with window and cross-window mechanism for skeleton-based action recognition. Knowl Based Syst. Apr 2023;281(10):1–13. 10.1016/j.knosys.2023.111074.Suche in Google Scholar
[7] Wang K, Deng H, Zhu Q. Lightweight channel-topology based adaptive graph convolutional network for skeleton-based action recognition. Neurocomputing. Aug 2023;560(10):1–11. 10.1016/j.neucom.2023.126830.Suche in Google Scholar
[8] Liu Z, Cheng Q, Song C, Cheng. J. Cross-scale cascade transformer for multimodal human action recognition. Pattern Recognit Lett. Apr 2023;168(5):17–23. 10.1016/j.patrec.2023.02.024.Suche in Google Scholar
[9] Zhang J, Wang X, Wan Y, Wang L, Wang J, Yu P. SOR-TC: Self-attentive octave ResNet with temporal consistency for compressed video action recognition. Neurocomputing. Mar 2023;533(5):191–205. 10.1016/j.neucom.2023.02.045.Suche in Google Scholar
[10] Zhao D. Innovative applications of computer-assisted technology in english learning under constructivism. Mob Inf Syst. Mar 2021;24(5):1676197.1–9. 10.1155/2021/1676197.Suche in Google Scholar
[11] Shao G, Han W, Zhang H, Liu S, Wang Y, Zhang L, et al. Mapping maize crop coefficient Kc using random forest algorithm based on leaf area index and UAV-based multispectral vegetation indices. Agric Water Manage. Apr 2021;252:324–36. 10.1016/j.agwat.2021.106906.Suche in Google Scholar
[12] Zhang Z, Cai Z. Permeability prediction of carbonate rocks based on digital image analysis and rock typing using random forest algorithm. Energy Fuels. Sep 2021;35(14):11271–84. 10.1021/acs.energyfuels.1c01331.Suche in Google Scholar
[13] Kim S, Gülay K, Sharma M. The site-specific selection of the infiltration model based on the global dataset and random forest algorithm. Vadose Zone J. Apr 2021;20(3):2140–51. 10.1002/vzj2.20125.Suche in Google Scholar
[14] Tang Z, Mei Z, Liu W, Xia Y. Identification of the key factors affecting Chinese carbon intensity and their historical trends using random forest algorithm. J Geog Sci. Apr 2020;30(5):743–56. 10.1007/s11442-020-1753-4.Suche in Google Scholar
[15] Pasinetti S, Fornaser A, Lancini M, Cecco M, Sansoni G. Assisted gait phase estimation through an embedded depth camera using modified random forest algorithm classification. IEEE Sens J. Mar 2020;20(6):3343–55. 10.1109/JSEN.2019.2957667.Suche in Google Scholar
[16] Yu L, Tian L, Du Q, Bhutto J. Multi-stream adaptive spatial-temporal attention graph convolutional network for skeleton-based action recognition. IET Comput Vision. May 2022;162(2):143–58. 10.1049/cvi2.12075.Suche in Google Scholar
[17] Hou Y, Wang L, Sun R, Zhang Y, Gu M, Zhu Y, et al. Crack-across-pore enabled high-performance flexible pressure sensors for deep neural network enhanced sensing and human action recognition. ACS Nano. Feb 2022;16(5):8358–69. 10.1021/acsnano.2c02609.Suche in Google Scholar PubMed
[18] Lee D, Gallucci S. Spacecraft attitude estimation under attitude tracking maneuver during close-proximity operations. Adv Space Res. May 2023;71(10):4315–31. 10.1016/j.asr.2023.01.004.Suche in Google Scholar
[19] Dai Z, Jing L. Lightweight extended Kalman filter for MARG sensors attitude estimation. IEEE Sens J. April 2021;21(13):14749–58. 10.1109/JSEN.2021.3072887.Suche in Google Scholar
[20] Naeem HB, Murtaza F, Yousaf MH, Velastin SA. T-VLAD: Temporal vector of locally aggregated descriptor for multiview human action recognition. Pattern Recognit Lett. Sep 2021;148(8):22–8. 10.1016/j.patrec.2021.04.023.Suche in Google Scholar
[21] Peng C, Huang H, Tsoi AC, Lo SL, Liu Y, Yang Z. Motion boundary emphasised optical flow method for human action recognition. IET Comput Vision. 2020;14(6):378–90. 10.1049/iet-cvi.2018.5556.Suche in Google Scholar
[22] Sun B, Kong D, Wang S, Wang L, Yin B. Joint transferable dictionary learning and view adaptation for multi-view human action recognition. TKDD. Jan 2021;15(2):32–55. 10.1145/3434746.Suche in Google Scholar
[23] Zhang X, Tang Z, Hou J, Hao Y. 3D human pose estimation via human structure-aware fully connected network. Pattern Recognit Lett. Feb 2019;125(5):404–10. 10.1016/j.patrec.2019.05.020.Suche in Google Scholar
[24] Ht HA, Chh C, Ttn B, Dska B. Image representation of pose-transition feature for 3D skeleton-based action recognition. Inf Sci. Feb 2020;513(3):112–26. 10.1016/j.ins.2019.10.047.Suche in Google Scholar
[25] Silva V, Marana N. Human action recognition in videos based on spatiotemporal features and bag-of-poses. Appl Soft Comput. Jan 2020;95(1):84–93. 10.1016/j.asoc.2020.106513.Suche in Google Scholar
[26] Bhosle K, Musande V. Evaluation of deep learning CNN model for recognition of devanagari digit. Artif Intell Appl. Feb 2023;1(2):114–8. 10.47852/bonviewAIA3202441.Suche in Google Scholar
[27] Li L, Chen Q, Zhou H, Li C, He Q. Efficient and precise docking trajectory optimization for the ship block assembly. Proc Inst Mech Eng M: J Eng Marit Environ. Nov 2024;238(3):468–82. 10.1177/14750902231210344.Suche in Google Scholar
[28] Liu S, Chen J, Wang C, Lin L. Ultrasonic positioning and IMU data fusion for pen-based 3D hand gesture recognition. Multimed Tools Appl. Nov 2023;82(27):41841–59. 10.1007/s11042-023-15252-w.Suche in Google Scholar
[29] Wang B, Jahanshahi H, Volos CL. A new RBF neural network-based fault-tolerant active control for fractional time-delayed systems. Electronics. 2021;10(12):1501–11. 10.3390/electronics10121501.Suche in Google Scholar
[30] Mantello P, Ho MT, Nguyen MH, Vuong QH. Machines that feel: behavioral determinants of attitude towards affect recognition technology—upgrading technology acceptance theory with the mindsponge model. Humanit Soc Sci Commun. July 2023;10(1):1–16. 10.1057/s41599-023-01837-1.Suche in Google Scholar
[31] Abba Haruna A, Muhammad LJ, Abubakar M. Novel thermal-aware green scheduling in grid environment. Artif Intell Appl. Nov 2022;1(4):244–51. 10.47852/bonviewAIA2202332.Suche in Google Scholar
[32] Boonsatit N, Rajchakit G, Sriraman R. Finite-/fixed-time synchronization of delayed clifford-valued recurrent neural networks. Adv Differ Equations. 2021;2021(1):1–25. 10.1186/s13662-021-03438-1.Suche in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- User profiling in university libraries by combining multi-perspective clustering algorithm and reader behavior analysis
- Exploring bifurcation and chaos control in a discrete-time Lotka–Volterra model framework for COVID-19 modeling
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations
Artikel in diesem Heft
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- User profiling in university libraries by combining multi-perspective clustering algorithm and reader behavior analysis
- Exploring bifurcation and chaos control in a discrete-time Lotka–Volterra model framework for COVID-19 modeling
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations