Intelligent accounting question-answering robot based on a large language model and knowledge graph
-
 and
and

Abstract
In the wave of digital transformation, enterprises have an increasing demand for fast and accurate access to financial information. The conventional accounting service model often relies on manual operations, which are not only inefficient but also susceptible to errors. This study aims to design an intelligent accounting question-answering robot based on a large language model and knowledge graph. To build a complete knowledge graph, this study uses the attention mechanism and convolutional neural network to build a connection prediction model and completes the accounting question-answering knowledge graph. After that, the bidirectional gated loop unit is used to improve the large language model so as to further improve the correlation between knowledge and explore potential information. The results denoted that the developed method had a question-answering accuracy of 94.6%, and the answers covered 95.2% of the domain range. The response time was only 120 ms, which was faster than other models and enhanced the user experience. Moreover, the user satisfaction score of Model 1 was 9.2 points. It is expected that the designed bot will be helpful for enterprises to obtain quick financial information and improve accounting service efficiency.
1 Introduction
With the rapid development of information technology, the accounting industry is undergoing unprecedented changes. As an advanced stage of accounting informatization, the core of intelligent accounting lies in utilizing advanced technologies such as big data and artificial intelligence (AI) to raise the efficiency and quality of accounting work [1,2]. Therefore, it is particularly critical to build an intelligent system that can automatically process accounting problems and provide accurate answers. Many scholars have begun to conduct in-depth research on question-answering systems. Rogers et al. found that there were research gaps in the field of question answering and reading comprehension and conducted a survey on existing research in this area. It classified existing materials according to standards such as “skills” and “format.” The results indicated that current research on question answering and reading comprehension mainly focused on the English language, but there were relatively few multilingual resources and unit resources outside of English [3]. Zaib et al. organized and presented a unified overview of the current application status and related work of question answering systems. It comprehensively reviewed recent review papers and the latest research trends in intelligent question answering (IQA). It was found that the current focus of IQA systems was single-turn question answering. Moreover, with the expansion of the data scale and the advancement of pre-trained language models, the field of multi-turn question answering has also received significant attention [4]. To improve the efficiency of enterprise audit work, Estep et al. proposed an AI-based financial report decision-making method. The method incorporated AI information into financial reporting decision-making and continuously improves the accuracy of the model by learning training corpus. Experimental results showed that this method could effectively improve the quality of financial reports and provide reliable data support for corporate auditing [5]. Mogaji and Nguyen found that in order for banks to provide more reliable financial services, they need to further improve the efficiency of business processing. In view of this, it proposed an AI-based financial services marketing service intelligent robot. The robot works by building a knowledge map of financial services and providing effective information to workers during business processing. The results showed that after the application of this method, the banking business processing efficiency was increased by 20% [6].
A large language model (LLM) is composed of neural networks with many parameters. It uses supervised learning or semi-supervised learning to train a large amount of unlabeled text and can effectively solve tasks such as text classification, etc. [7]. Duong and Solomon compared ChatGPT with 1364 human participants in answering 85 questions about human genetics to evaluate the learning ability and language processing differences in the biomedical field. It was found that the accuracy of ChatGPT reached 68.2%, while the accuracy of humans was 66.6% [8]. Romera-Paredes et al. introduced the process of matching LLM models with system evaluators to explore the ability of LLM models to solve complex tasks. When using the LLM model to analyze cap set problems and algorithm problems, it could effectively find suitable solutions [9]. Knowledge graph has unique advantages in information extraction, knowledge reasoning, etc. If it can be applied to language problems, it will further improve the intelligence of language processing [10]. Yu et al. proposed a detection model based on a knowledge graph and GNN for detecting adverse data in drug-drug interaction datasets. This model established a knowledge graph in the medical field and associated knowledge points. Afterward, GNNs were introduced to screen and identify data with low correlation with other data in the dataset. The outcomes showed that the detection accuracy of this method reached 89.38% [11]. Qin et al. developed a recommendation model based on a knowledge graph and GNN to recommend personalized product content to users on e-commerce platforms. This model used supervised signal detection methods to reveal the hierarchical structure of positions and node entanglement representation learning to exploit the hierarchical structure. Then, graph convolutional neural networks were utilized to extract recommended items. The outcomes showed that the recommendation accuracy of this method reached over 90% [12]. Fell et al. developed a song corpus knowledge base to improve the browsing, classification, and recommendation advantages of music platforms and used the lyrics and audio in these online music databases to build a knowledge graph. These knowledge graphs were applied to various music programs. The results indicated that the knowledge graph established by this corpus could effectively improve the accuracy of browsing classification and recommendation [13].
According to the existing research content, although there are many studies on IQA methods based on LLM models and knowledge graphs, the modeling ability of neural models for knowledge graphs is still not ideal [14,15]. In response to this, the study aims to develop an IQA system that integrates an LLM and a knowledge graph by utilizing a global pointer network (GPN), bidirectional gated recurrent unit (Bi-GRU), and bidirectional encoder representation from transformers (BERT) model. The goal is to overcome the limitations of existing research and achieve more efficient and accurate accounting problem-solving. The innovation of the research lies in using Bi-GRU to improve the traditional BERT model, further mining contextual information between sequences, and enhancing the intelligence of question-answering robots. Moreover, graph connection prediction methods are utilized to complete the extracted incomplete knowledge, ensuring the training quality in subsequent studies.
The research is divided into four parts. Part 1 is the introduction, which summarizes the current research conditions of LLMs, knowledge graphs, and question-answering systems and then identifies the main research directions. Part 2 is the methodology section, which provides a detailed introduction to the IQA method of the proposed intelligent accounting question-answering robot. Part 3 is the experiment analysis section, which analyzes and discusses the effectiveness of the raised IQA method through a series of experiments. Part 4 is the conclusion section, which summarizes the content of the previous parts and looks forward to future research work.
2 Methods and materials
To improve the intelligence of accounting question-answering robots, research was conducted on using attention mechanisms and convolutional neural networks to establish a complete accounting knowledge graph. Then, GPN and Bi-GRU were used to achieve timely responses and answers to accounting-related questions, improving the efficiency of accounting services for enterprises.
2.1 Knowledge graph completion based on self-attention mechanisms and convolutional neural network
Knowledge graph presents the real world in the form of graphs, which can process and display heterogeneous data from multiple sources and their complex relationships. It is one of the core cognitive intelligence technologies driven by both data and knowledge. In the daily service of intelligent accounting question-answering robots, it is necessary to match the relevant knowledge points of the questions raised in a timely manner and then query to obtain appropriate answer content. A complete and accurate accounting knowledge graph is required as data support in this process. However, things themselves have diversity and variability. The knowledge obtained through automatic or semi-automatic knowledge extraction techniques is usually incomplete. If the knowledge graph is incomplete, it will further affect the learning effectiveness of the neural network and reduce the question-answering intelligence of the question-answering robot [16]. Therefore, the study considered introducing attention mechanisms and convolutional neural networks to predict unknown information and complete the knowledge graph. Convolutional neural networks capture the interaction information between entities and relationships through simple and efficient convolution operations, mine and extract the potential semantic information of triplets, and obtain more accurate representations of entity and relationship vectors. This type of method usually seeks rich interaction information between entities and relationships within triplets to enhance the expressive power of the model. To further enhance the ability of convolutional neural network models to obtain rich interactive information, a self-attention mechanism (SAM) was introduced to improve them while retaining the translation features of triplets and the global features of the same dimension. The vector representation process of SAM is shown in Figure 1.
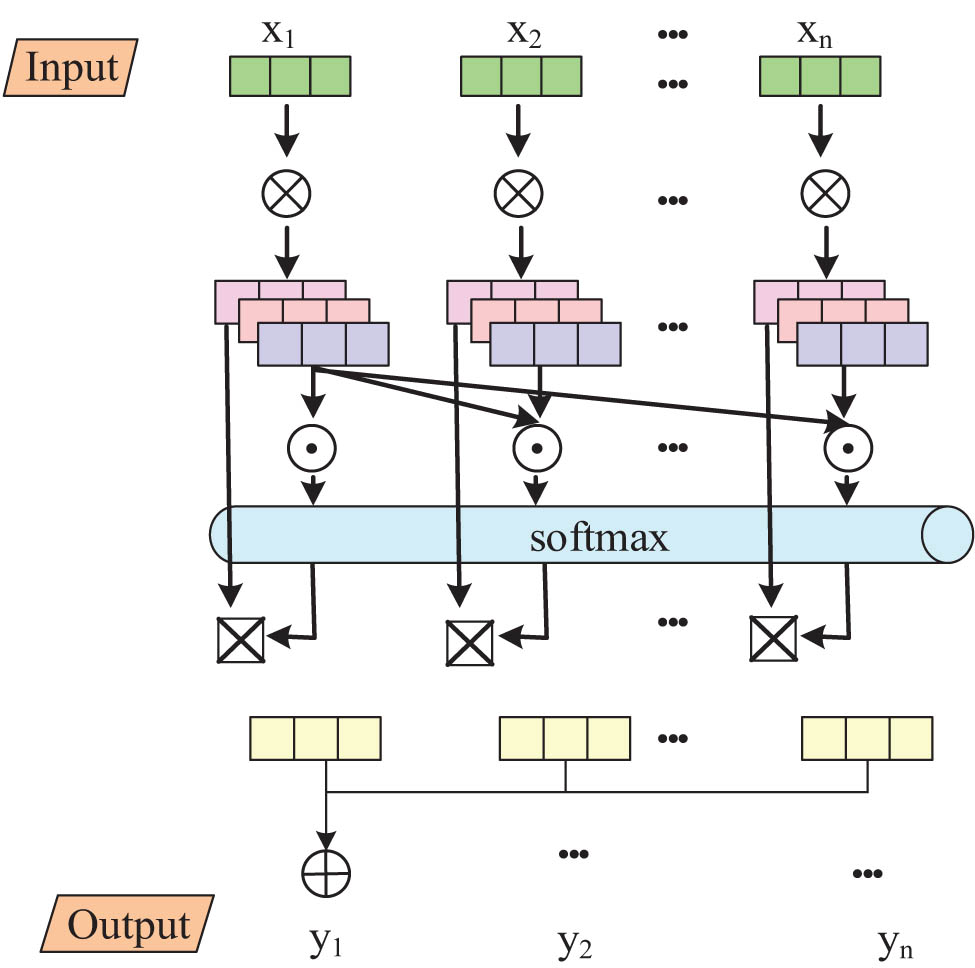
Vector representation process of SAM.
In Figure 1, the SAM models the interdependence of different positions in the input sequence by creating three vectors: Query, Key, and Value for each input vector, and then calculating the attention score using these three vectors. The calculation method of attention value is denoted in the following equations:
In Eq. (1),
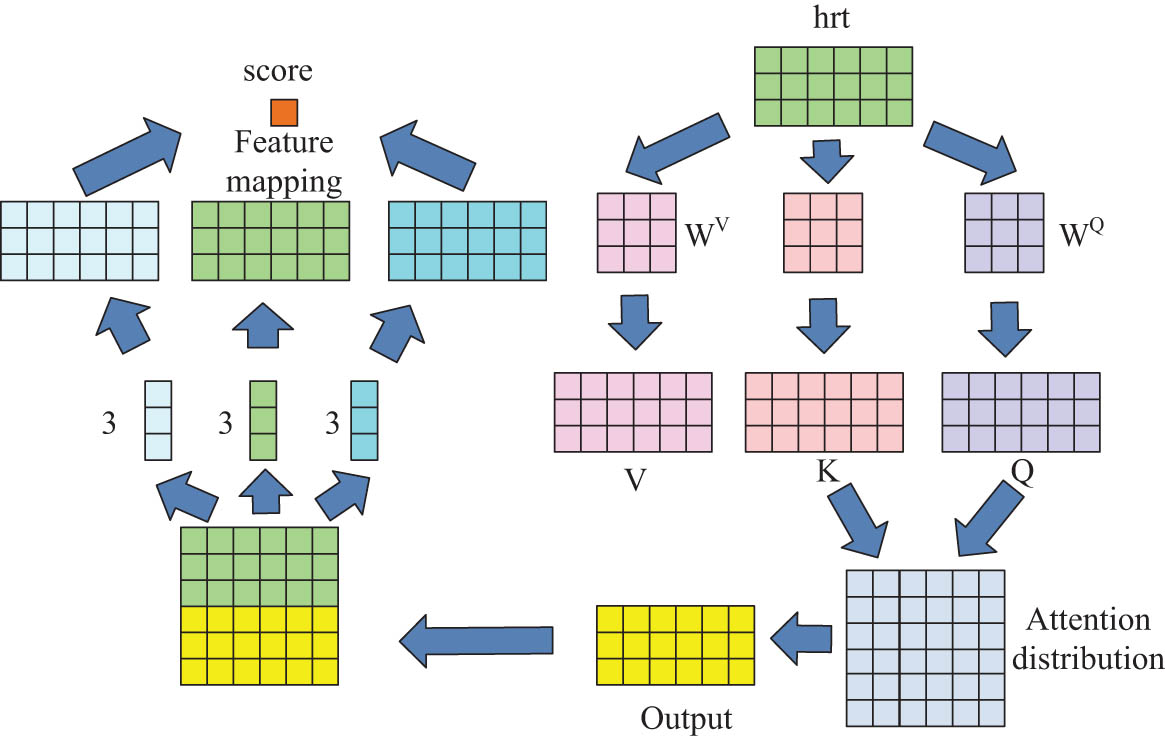
The structure of the knowledge graph link prediction model.
In Figure 2, the study concatenated the initial embeddings of entities and relationships and generated Query, Key, and Value matrices using a mapping matrix of three vectors. Afterward, the transpose of the Query matrix and Key matrix were used to perform matrix multiplication operation. Afterward, the attention distribution matrix was obtained through normalization processing. The obtained attention distribution matrix and Value matrix were multiplied to obtain the Output matrix. Finally, the initial Embedding matrix was merged and the Output matrix obtained using SAM was concatenated to obtain a new matrix, which was used as the input of the convolutional layer. Finally, the convolutional layer was applied to extract semantic information and overall features from the triplet, concatenate all feature matrices, and calculate the score of the triplet. Based on the predicted scoring results of each triplet link, it selected the most suitable completion content to establish a knowledge graph. The scoring function is specifically denoted in the following equation:
In Eq. (2),
2.2 Text information named entity classification and recognition based on improved GPN
After establishing a knowledge graph, textual information was extracted to provide a foundation for subsequent IQA. Named entity recognition is an important subtask in information extraction, which can effectively enable computers to understand professional accounting terminology and provide intelligent answers to accounting-related questions. In professional terminology texts, long nesting and complex structures often occur, which makes it difficult for traditional named entity recognition methods to effectively address. Therefore, the study considered introducing GPN for named entity recognition. The BERT model, as a high-performance model in LLMs, provides a solid foundation for named entity recognition with its powerful pre-training and context-understanding capabilities. Therefore, the study combined it with GPN and achieved named entity recognition by classifying multi-label text. The overall process of the named entity recognition model raised in the study is shown in Figure 3.
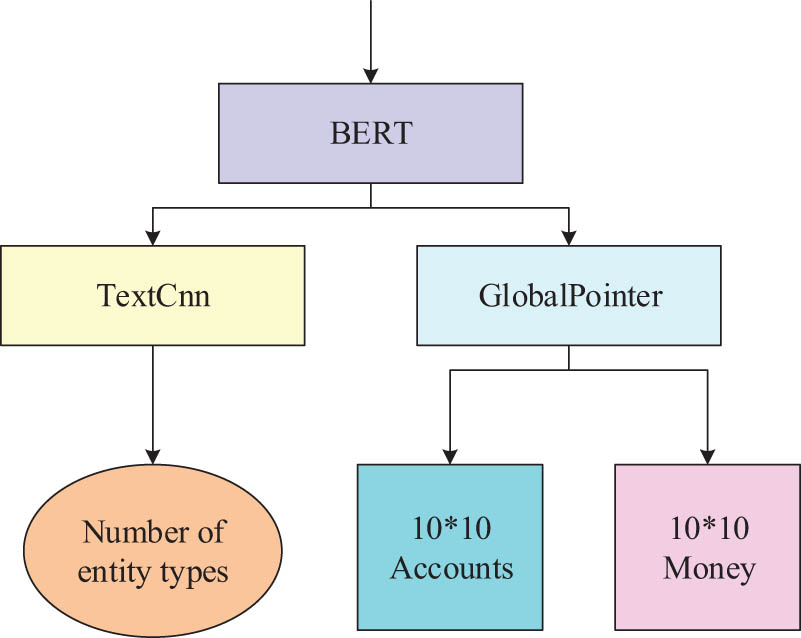
The whole process of the named entity recognition model.
In Figure 3, the study inputs text questions raised by users into the LLM BERT, which consists of two components: text convolution and GPN. Text convolution classifies the text, while GPN annotates the text to obtain a labeled matrix. GPN, as the core component, was designed to process the vector sequence output by BERT models. GPN is a decoding method that utilizes global normalization and span classification to annotate different types and entities by constructing a matrix form. The global-to-local memory pointer network (GLMP) combined the GPN and memory mechanism to strengthen the model’s ability to capture long-distance dependencies and nested structures in text by constructing a global-to-local memory mapping. Based on the vector sequence output by the BERT model, GLMP further explored the contextual information and associations between entities in the text, raising the accuracy and efficiency of named entity recognition. GPN captured and marked potential entity boundaries and types in vector sequences through a global pointer mechanism. On this basis, GLMP utilized memory networks to store and integrate long-distance information, helping the model better understand complex structures and nested relationships in text. The structure of GLMP is shown in Figure 4.
Structure of GLMP.
In Figure 4, GLMP first constructed a global memory matrix to store all possible entities and their related information in the text. Then, during the decoding process, GLMP used the preliminary entity labels generated by the GPN as guidance to retrieve and integrate relevant information from the memory matrix to generate more accurate and complete entity recognition results. This global-to-local memory mapping mechanism enabled the model to maintain high recognition accuracy and efficiency when dealing with long texts and complex structures. Based on the above content, a long nested named entity recognition model was established using GLMP and BERT, which combine GPN and memory mechanisms.
2.3 Intelligent accounting question-answering method based on Bi-GRU and knowledge graph
After establishing a knowledge graph and extracting information, research was conducted to improve the BERT LLM using Bi-GRU, further enhancing the ability of IQA robots to extract correlated information from sequences. The research decomposed the intelligent accounting question-answering method into three tasks: named entity recognition, relationship vector representation, and entity vector representation. As mentioned earlier, the study utilized GLMP and BERT to identify named entities. The BERT model’s structure is indicated in Figure 5.
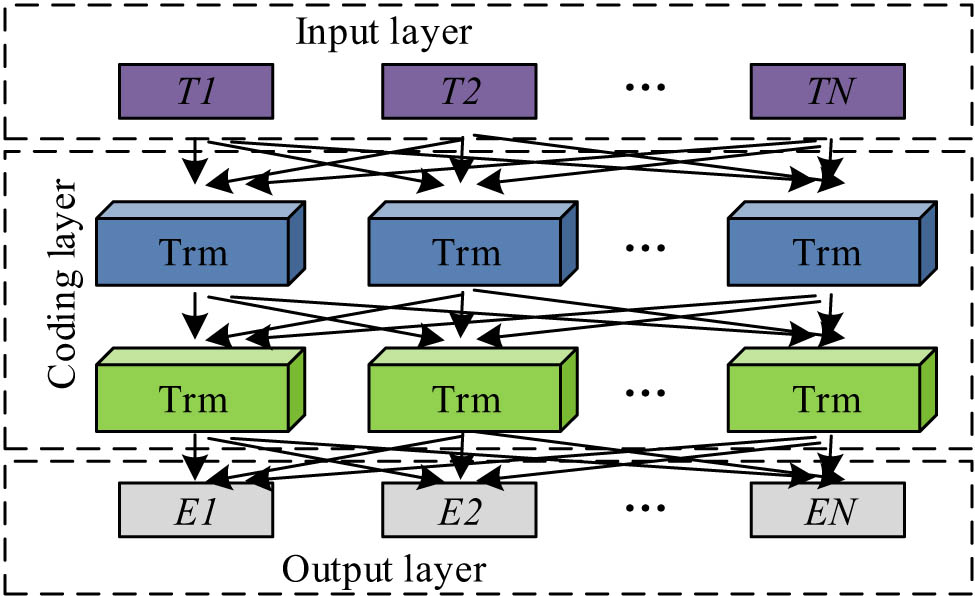
Structure of large language model BERT.
However, traditional BERT models have not fully explored the correlation information in named exercise encoding and vector representation. To improve the accuracy of the three tasks and answer search tasks, Bi-GRU was introduced to improve the traditional BERT model. Research further processed the vector sequence output by the BERT model using Bi-GRU to strengthen the model’s ability to capture correlated information in text. Bi-GRU is a recurrent neural network that combines bidirectional structure and gating mechanism, which can simultaneously consider the contextual information of text, thus performing well in sequence modeling. After adding the Bi-GRU layer to the output of BERT, the BERT model first encoded the input text through a multi-layer transformer structure to generate a vector sequence containing rich semantic information. Subsequently, these vector sequences were fed into the Bi-GRU layer, which utilized its bidirectional structure and gating mechanism to further mine the associated information in the text and generate more refined vector representations. The specific structure and process of the integration of Bi-GRU and BERT are as follows. In this study, Bi-GRU was taken as the next layer structure of the BERT output layer, in which context information was captured and output, and text association information was further mined. The task of named entity recognition is a crucial step in intelligent accounting question-answering systems, which directly affects the accuracy of subsequent relationship vector representations and entity vector representations. The study applied named entity recognition results to answer retrieval tasks, calculated the degree of match between the retrieved answer and the recognition result, scored them, and finally selected the best answer for response. The calculation process is shown in the following equation:
In Eq. (3),
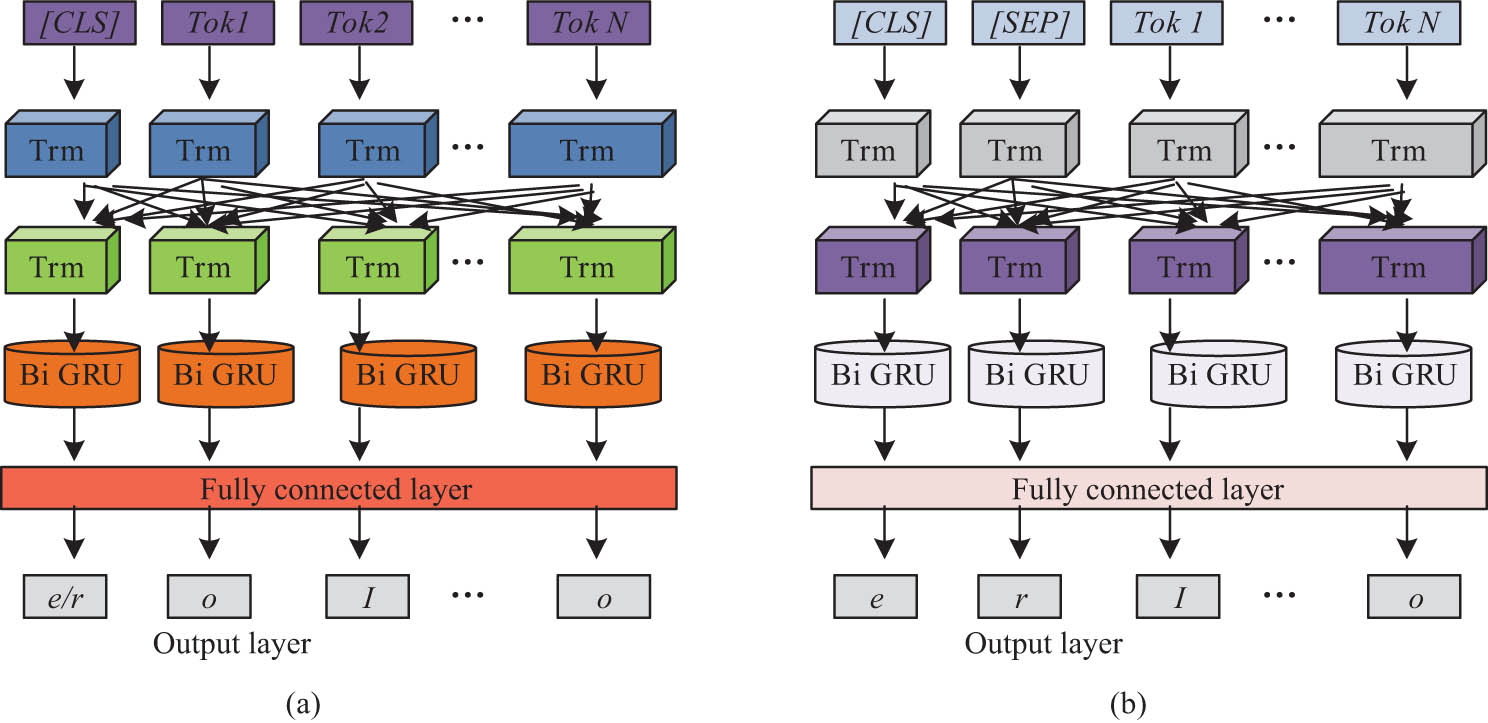
The model structure of the improved BERT model in single-task and multi-task cases: (a) single task and (b) multi-task.
In Figure 6(a), in a single-task scenario, the improved BERT model received text as input and first encoded it through BERT’s multi-layer transformer structure. By encoding, semantic information in the text was captured, and vector representations of each word were generated. Subsequently, these vectors were fed into the Bi-GRU layer to capture the associations and dependencies between words. As shown in Figure 6(b), in a multi-task scenario, the model added a delimiter (SEP) on top of the single task to distinguish different task inputs. Each task had its specific context and objectives, and the model could use this delimiter to distinguish and process different tasks. In multi-task learning, the model was able to learn multiple tasks simultaneously. By sharing the underlying BERT and Bi-GRU structures, different tasks could share semantic information and features, thereby improving overall learning performance and generalization ability.
3 Results
To test the effectiveness of the raised method, massive experiments were organized to analyze and compare it. Moreover, the database was established using knowledge data from the accounting-sharing platform.
3.1 Performance analysis of knowledge graph completion method based on SAM convolutional neural network
To prove the rationality of the raised knowledge graph completion method, the model was experimentally assessed on datasets FB15k-237 and WN18RR. The study introduced mean reciprocal ranking (MRR), mean ranking (MR), and hyperlink-induced topic search (Hits) as evaluation metrics for knowledge graphs. The knowledge graph completion method (Method 1) of the application link prediction method was compared with the traditional knowledge graph extraction method (Method 2), which does not apply the completion method. The comparison results are shown in Figure 7.
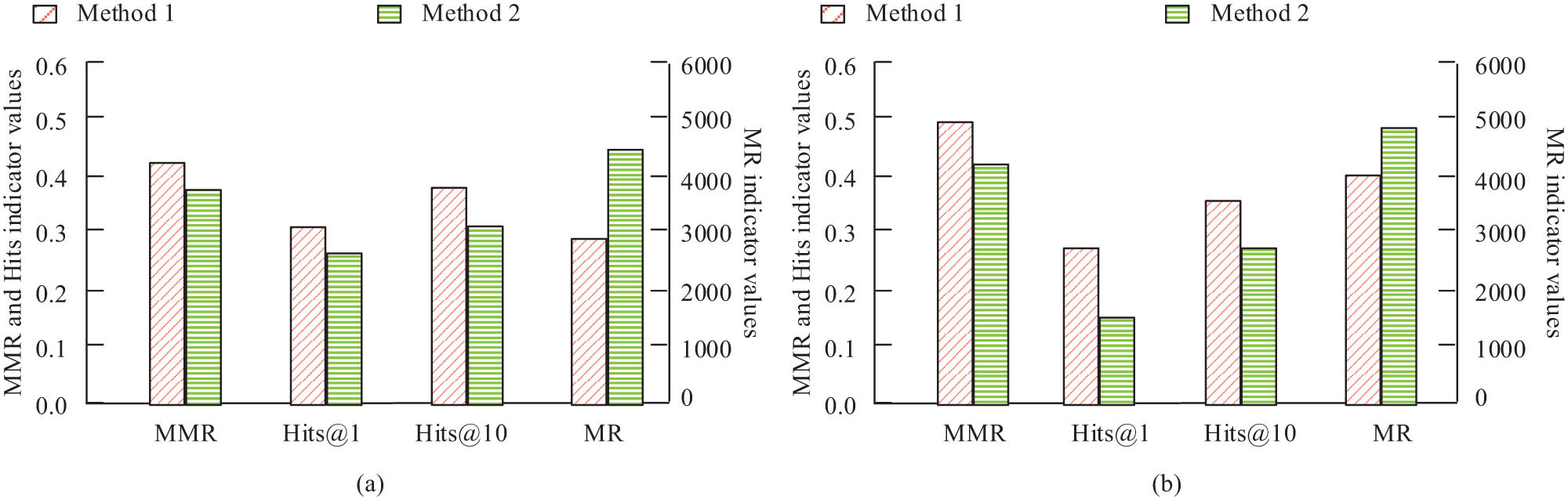
Comparison of the effect of knowledge graph establishment before and after applying knowledge graph completion method: (a) FB15k-237 and (b) WN18RR.
In Figure 7(a) and (b), in both datasets, the MRR, MR indices, and Hits index values of Method 1 were significantly better than those of Method 2. On the FB15k-237 dataset, the MRR of Method 1 improved by about 15% compared to Method 2, while the MR decreased by about 30%, Hits@10 increased by nearly 10%. On the WN18RR dataset, the improvement of various indices was also significant, further verifying the performance of the method.
To test the rationality of introducing SAM in the study, the training of IQA models under knowledge graph extraction results before and after introducing SAM was compared, as shown in Figure 8.
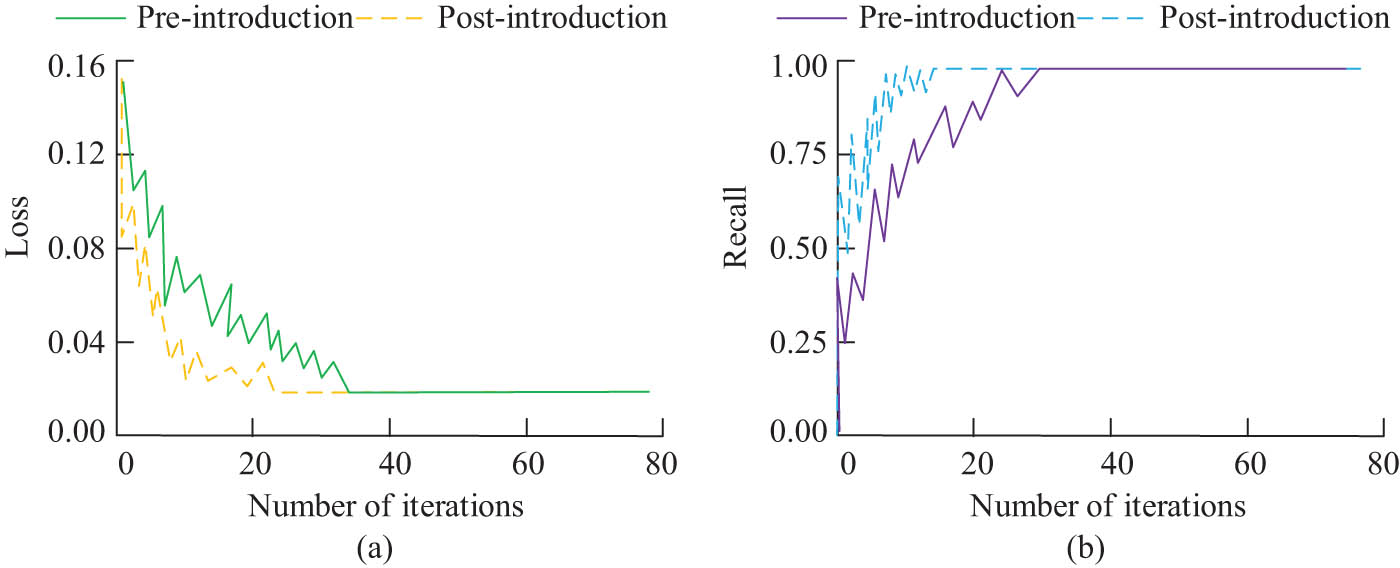
The training situation of the IQA model under the knowledge graph extraction results before and after the introduction of the attention mechanism: (a) loss and (b) recall.
In Figure 8(a), after introducing the attention mechanism, the model had better training iteration convergence and could reach the optimal loss value faster. After the introduction, the number of iterations to convergence of the model decreased by 6 compared to before the introduction. As shown in Figure 8(b), the model achieved the optimal recall rate after only 15 iterations and converged faster compared to the model before introduction.
To further validate the superiority of the raised knowledge graph-building method (Method A), the study compared it with the knowledge graph-building methods (Method B) in ref. [17], (Method C) in ref. [18], and (Method D) in ref. [19]. The comparison findings are indicated in Table 1.
Comparison of performance of several knowledge graph construction methods
| Method | MRR | MR | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|---|
| Method A | 0.539 | 144.0 | 46.2 | 57.3 | 66.4 |
| Method B | 0.300 | 204.2 | 21.2 | 33.1 | 48.2 |
| Method C | 0.516 | 210.0 | 43.2 | 50.7 | 60.8 |
| Method D | 0.350 | 305.4 | 26.8 | 39.2 | 54.1 |
In Table 1, the MRR value of Method A was 0.539, which was significantly improved compared to Method B’s 0.300 and Method D’s 0.350. Meanwhile, the MR value of Method A was only 144.0, far lower than other methods, indicating that its predicted results ranked higher, that is, it was more likely to find the correct answer. On Hits@1, Hits@3, and Hits@10 indicators, Method A also performed well and outperformed other comparative methods.
3.2 Performance analysis of the IQA method based on GPN and Bi-GRU
Research aimed to address the deficiencies of the convolutional LLM BERT and improve it using Bi-GRU. To test the improvement effect of the language model, the comparison results of the model before and after improvement were studied in the named entity recognition task (Mission 1), relationship vector representation task (Mission 2), entity vector representation task (Mission 3), and answer retrieval task (Mission 4), as shown in Figure 9.
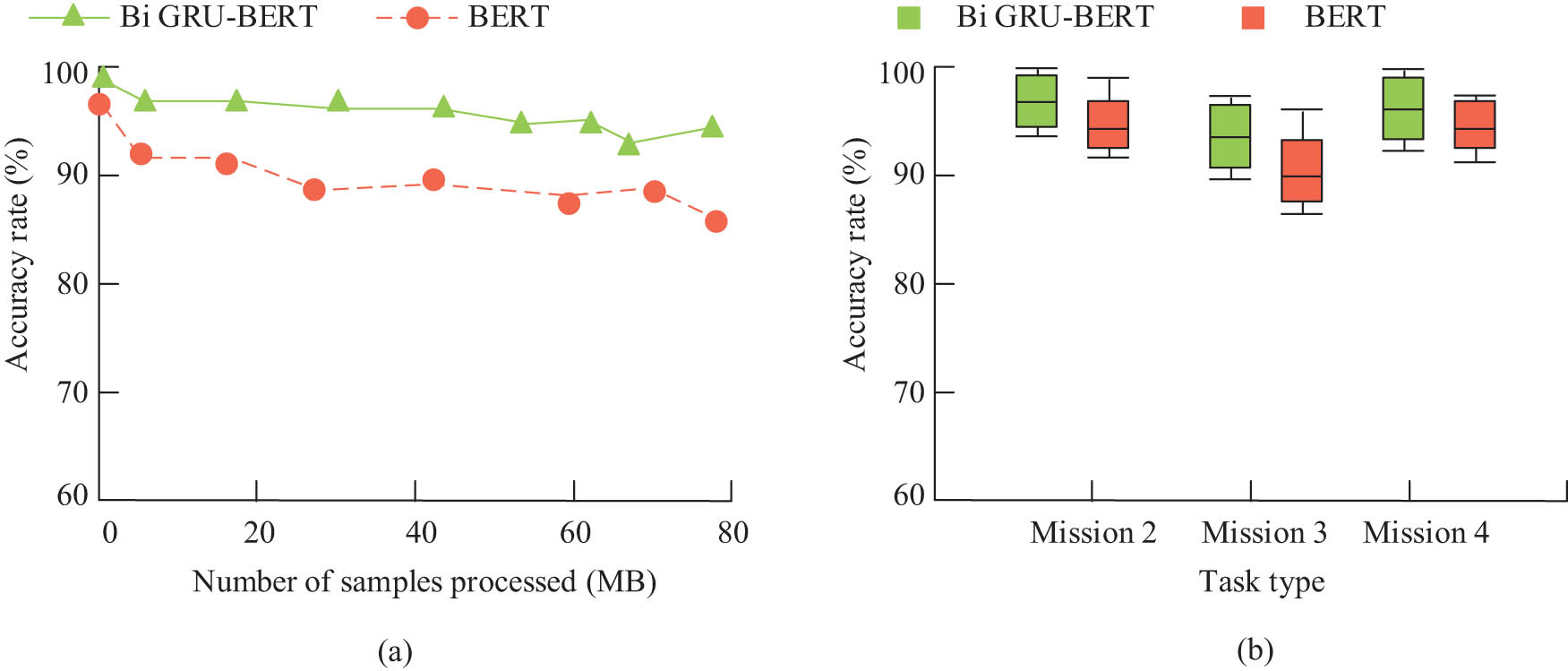
The application effect of the model before and after improvement in three tasks: (a) named entity recognition task accuracy and (b) relational vector representation and entity vector representation, accuracy of answer retrieval task.
In Figure 9(a), in Mission 1, the improved model achieved higher recognition accuracy, reaching 93.48%, an increase of 5.24% compared to before the improvement. As shown in Figure 9(b), the Mission 2, Mission 3, and Mission 4 exceeded 90%. Compared to the previous model, the improvements were 2.54, 4.58, and 3.15%, respectively.
When annotating text tags, research improved GPN by combining it with memory mechanisms to further enhance the recognition of named entities. To validate the performance of the raised improvement method, experiments were organized to compare the changes in recognition accuracy before and after the improvement. The specific results are shown in Figure 10.
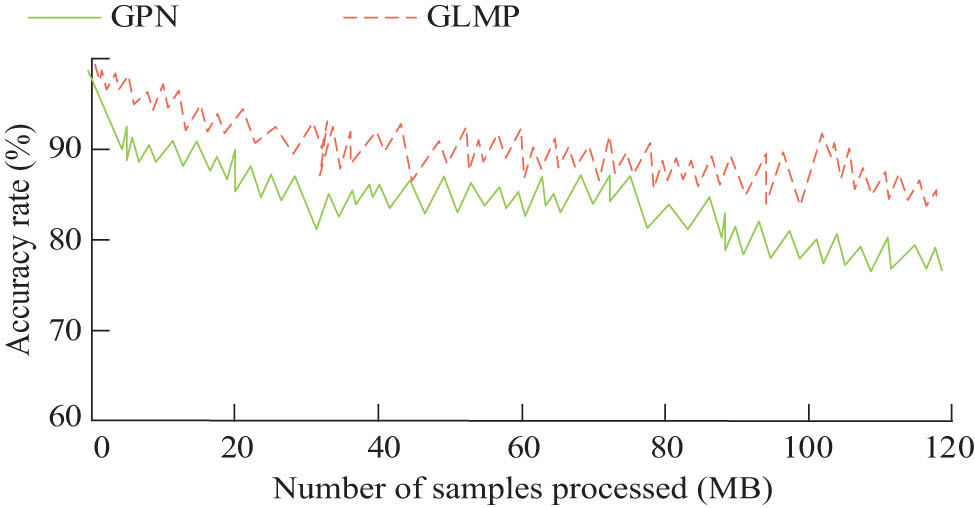
The change of recognition accuracy of the named entity recognition method before and after improvement.
In Figure 10, as the number of named entities to be recognized increased, the recognition accuracy of both methods decreased. The improved method GLMP proposed in the study had the smallest decrease in accuracy and an average accuracy of over 90%. Compared to GPN, the average recognition accuracy increased by 8.47%.
To further prove the efficacy of the raised IQA model (Model 1), the study compared it with the IQA models: Model 2 in ref. [20], Model 3 in ref. [21], and Model 4 in ref. [22]. The study applied these four models to the customer service departments of three different financial institutions in Place A to learn and apply them in business consulting, transaction problems, loan consulting, and other work tasks. The application period was 3 months, and the answer accuracy, coverage percentage, response time, and user satisfaction of the four models were recorded during the experiment. Among them, user satisfaction was the result of the questionnaire completed by the customers who came to the financial institution for consultation each time during the application period. During the experiment, a total of 684 customers evaluated the intelligent question-and-answer system after consulting, and the evaluation results were obtained in the form of average scores, as shown in Table 2.
Comparison of performance of several IQA models
| Model | Answer accuracy (%) | Percentage of coverage area (%) | Response time (ms) | User satisfaction (score out of 10) |
|---|---|---|---|---|
| Model 1 | 94.6 | 95.2 | 120.0 | 9.2 |
| Model 2 | 88.3 | 89.7 | 150.1 | 8.5 |
| Model 3 | 90.1 | 91.4 | 135.2 | 8.8 |
| Model 4 | 85.9 | 87.6 | 180.0 | 8.1 |
In Table 2, the answer accuracy of Model 1 was 94.6%, significantly higher than Model 2, Model 3, and Model 4, indicating that the model was more effective in accurately answering user queries. In addition, Model 1 covered 95.2% of the coverage area, demonstrating its comprehensive ability to handle a wide range of problems. In terms of response time, Model 1 had a response time of only 120 ms, which was faster than other models and enhanced the user experience. Finally, the user satisfaction score for Model 1 was 9.2 points.
To further emphasize the excellent performance of the model designed in the study in practical financial applications, the study compared it with the most advanced question-and-answer model published this year. The experimental scenario was the customer service department of three different financial institutions in Place A. The experiment included a variety of customer consultation scenarios, including account inquiry, transaction questions, loan consultation, etc. The experiment lasted for 10 months. The comparison models included the question-and-answer models in ref. [23], ref. [24], and ref. [25]. The comparison indicators included the model’s answer accuracy, business processing time, MRR, and F1 score. The specific results are shown in Table 3. The comparison results are shown in Table 3.
Comparison of performance of IQA models in financial applications
| Model | Answer accuracy (%) | Business processing time (s) | MRR | F1 score | |
|---|---|---|---|---|---|
| 1–3 months | Model 1 | 94.58 | 15.23 | 0.90 | 0.92 |
| Model [23] | 90.11 | 22.40 | 0.84 | 0.88 | |
| Model [24] | 82.43 | 26.74 | 0.77 | 0.80 | |
| Model [25] | 85.44 | 24.00 | 0.81 | 0.82 | |
| 4–6 months | Model 1 | 96.75 | 13.15 | 0.92 | 0.94 |
| Model [23] | 91.52 | 21.58 | 0.85 | 0.89 | |
| Model [24] | 84.14 | 25.11 | 0.81 | 0.81 | |
| Model [25] | 85.79 | 23.48 | 0.82 | 0.83 | |
| 7–10 months | Model 1 | 98.14 | 11.86 | 0.94 | 0.95 |
| Model [23] | 92.00 | 21.02 | 0.86 | 0.90 | |
| Model [24] | 85.20 | 24.35 | 0.82 | 0.83 | |
| Model [25] | 86.02 | 22.97 | 0.84 | 0.85 | |
In Table 3, Model 1 outperformed other comparison models on all evaluation indicators, especially in terms of response accuracy and MRR. With the progress of the experiment, the indicators of the four models have been significantly improved, of which Model 1 had the largest improvement. This showed that it could continuously improve its function in the process of continuous learning. Model 1 showed significant advantages at every stage of the experiment. This showed that Model 1 not only provided more accurate answers when handling question-and-answer tasks in the financial sector but also performed better in terms of user satisfaction. In addition, Model 1 also excelled in business processing time, with average processing time significantly lower than other models. This showed that Model 1 could respond to customer needs faster in practical applications and improve customer service efficiency. The comparison results of F1 score further confirmed the superiority of Model 1 in considering accuracy and recall rate comprehensively.
4 Discussion and conclusion
A smart IQA method based on an LLM and knowledge graph was proposed to address the issues of low-quality answer content and low response efficiency in intelligent accounting question-answering robots. This method aimed to improve the intelligence of the robots. The results indicated that the MRR, MR, and Hits index values of the knowledge graph establishment method proposed in the study were significantly better than those of Method 2. On the FB15k-237 dataset, the MRR of Method 1 improved by about 15% compared to Method 2, while the MR decreased by about 30%, and Hits@10 increased by nearly 10%. In Mission 1, the improved model achieved higher recognition accuracy, reaching 93.48%, an increase of 5.24% compared to before the improvement. The accuracy in Mission 2, Mission 3, and Mission 4 exceeded 90%. Compared to the previous model, the improvements were 2.54, 4.58, and 3.15%, respectively. In the comparative experiments of existing advanced IQA models, the answer accuracy of Model 1 was 94.6%, significantly higher than Model 2, Model 3, and Model 4. Model 1 covered 95.2% of the geographical area. In terms of response time, Model 1 had a response time of only 120 ms. The user satisfaction score of Model 1 was 9.2 points. In the study of the IQA system, Mihalache et al. [26] and Bhuvan et al. [27] discussed the application of different technologies in improving the performance of question-answering robots. Mihalache et al. [26] demonstrated the potential of AI chatbots in the field of medical education by evaluating the performance of the upgraded version of ChatGPT-4 in the American Medical Licensing Examination. However, Bhuvan et al. [27] proposed an SExpSMA algorithm based on the T5 model to generate question answers and interference items, which is innovative in the field of intelligent decision technology. Model 1 further optimized the IQA system by combining the research results of Mihalache et al. [26] and Bhuvan et al. [27]. By integrating advanced natural language processing technology and deep learning algorithms, Model 1 not only achieved significant improvements in question and answer accuracy but also excelled in processing speed and user interaction experience. When dealing with problems in the financial sector, Model 1 was able to accurately understand the user’s query intent and provide relevant and accurate answers. Based on the above content, the proposed IQA method can ensure high answer quality and improve question-answering efficiency. In future research, more diverse methods of triplet concatenation and interaction can be further considered to achieve multi-angle fusion of information.
-
Funding information: The research was supported by 2023 Guangdong Province Ordinary University Characteristic Innovation Project: “Research on Intelligent Accounting Question Answering Robot Based on Large Language Model and Knowledge Graph” (Project No. 2023KTSCX207), 2022 Guangdong Province Ordinary University Characteristic Innovation Project: “Research on the Design of Cloud Integrated Financial Robot Based on Big Data Analysis” (Project No. 2022KTSCX181), 2022 Zhanjiang University of Science and Technology Campus level Research Project: “Research on Intelligent Quantitative Trading Based on Reinforcement Learning and Big Data” (Project No. ZKXJKY2022005), and 2022 Zhanjiang University of Science and Technology Campus level Research Project: “Prediction of Company Net Asset Return Rate and Sensitivity Analysis of Indicators under Big Data Management” (Project No. ZKXJKY2022015).
-
Author contributions: SY Shi: conceptualization, methodology development, writing the original draft. GX Li: data collection, formal analysis, funding acquisition; writing – review and editing. Y Wang: validation, visualization; data curation; review and editing. All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: Authors state no conflict of interest.
-
Data availability statement: All data generated or analyzed during this study are included in this published article.
References
[1] Zhang H, Sun A, Jing W, Zhen L, Zhou JT, Goh RSM. Natural language video localization: A revisit in span-based question answering framework. IEEE Trans Pattern Anal Mach Intell. 2021;44(8):4252–66.10.1109/TPAMI.2021.3060449Search in Google Scholar PubMed
[2] Ji S, Pan S, Cambria E, Marttinen P, Philip SY. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans Neural Netw Learn Syst. 2021;33(2):494–514.10.1109/TNNLS.2021.3070843Search in Google Scholar PubMed
[3] Rogers A, Gardner M, Augenstein I. QA dataset explosion: A taxonomy of NLP resources for question answering and reading comprehension. ACM Comput Surv. 2023;55(10):1–45.10.1145/3560260Search in Google Scholar
[4] Zaib M, Zhang WE, Sheng QZ, Mahmood A, Zhang Y. Conversational question answering: A survey. Knowl Inf Syst. 2022;64(12):3151–95.10.1007/s10115-022-01744-ySearch in Google Scholar
[5] Estep C, Griffith EE, MacKenzie NL. How do financial executives respond to the use of artificial intelligence in financial reporting and auditing? Rev Acc Stud. 2024;29(3):2798–831.10.1007/s11142-023-09771-ySearch in Google Scholar
[6] Mogaji E, Nguyen NP. Managers’ understanding of artificial intelligence in relation to marketing financial services: Insights from a cross-country study. Int J Bank Mark. 2022;40(6):1272–98.10.1108/IJBM-09-2021-0440Search in Google Scholar
[7] Zhu C, Yang Z, Xia X, Li N, Zhong F, Liu L. Multimodal reasoning based on knowledge graph embedding for specific diseases. Bioinformatics. 2022;38(8):2235–45.10.1093/bioinformatics/btac085Search in Google Scholar PubMed PubMed Central
[8] Duong D, Solomon BD. Analysis of large-language model versus human performance for genetics questions. Eur J Hum Genet. 2024;32(4):466–8.10.1038/s41431-023-01396-8Search in Google Scholar PubMed PubMed Central
[9] Romera-Paredes B, Barekatain M, Novikov A, Balog M, Kumar MP, Dupont E, et al. Mathematical discoveries from program search with large language models. Nature. 2024;625(7995):468–75.10.1038/s41586-023-06924-6Search in Google Scholar PubMed PubMed Central
[10] Castro Nascimento CM, Pimentel AS. Do large language models understand chemistry? A conversation with ChatGPT. J Chem Inf Model. 2023;63(6):1649–55.10.1021/acs.jcim.3c00285Search in Google Scholar PubMed
[11] Yu Y, Huang K, Zhang C, Glass LM, Sun J, Xiao C. SumGNN: Multi-typed drug interaction prediction via efficient knowledge graph summarization. Bioinformatics. 2021;37(18):2988–95.10.1093/bioinformatics/btab207Search in Google Scholar PubMed PubMed Central
[12] Qin Y, Gao C, Wei S, Wang Y, Jin D, Yuan J, et al. Learning from hierarchical structure of knowledge graph for recommendation. ACM Trans Inf Syst. 2023;42(1):1–24.10.1145/3595632Search in Google Scholar
[13] Fell M, Cabrio E, Tikat M, Michel F, Buffa M, Gandon F. The WASABI song corpus and knowledge graph for music lyrics analysis. Lang Res Eval. 2023;57(1):89–119.10.1007/s10579-022-09601-8Search in Google Scholar
[14] Baidoo-Anu D, Ansah LO. Education in the era of generative artificial intelligence (AI): Understanding the potential benefits of ChatGPT in promoting teaching and learning. J Artif Intell. 2023;7(1):52–62.10.61969/jai.1337500Search in Google Scholar
[15] Mihalache A, Popovic MM, Muni RH. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol. 2023;141(6):589–97.10.1001/jamaophthalmol.2023.1144Search in Google Scholar PubMed PubMed Central
[16] Arroyo-Machado W, Torres-Salinas D, Costas R. Wikinformetrics: Construction and description of an open Wikipedia knowledge graph data set for informetric purposes. Quant Sci Stud. 2022;3(4):931–52.10.1162/qss_a_00226Search in Google Scholar
[17] Gaur M, Faldu K, Sheth A. Semantics of the black-box: Can knowledge graphs help make deep learning systems more interpretable and explainable? IEEE Internet Comput. 2021;25(1):51–9.10.1109/MIC.2020.3031769Search in Google Scholar
[18] Rillig MC, Ågerstrand M, Bi M, Gould KA, Sauerland U. Risks and benefits of large language models for the environment. Environ Sci Technol. 2023;57(9):3464–6.10.1021/acs.est.3c01106Search in Google Scholar PubMed
[19] Li Q, Wang D, Feng S, Niu C, Zhang Y. Global graph attention embedding network for relation prediction in knowledge graphs. IEEE Trans Neural Netw Learn Syst. 2021;33(11):6712–25.10.1109/TNNLS.2021.3083259Search in Google Scholar PubMed
[20] Chen Z, Mao H, Li H, Jin W, Wen H, Wei X, et al. Exploring the potential of large language models (LLMs) in learning on graphs. ACM SIGKDD Explor Newsl. 2024;25(2):42–61.10.1145/3655103.3655110Search in Google Scholar
[21] Myers D, Mohawesh R, Chellaboina VI, Sathvik AL, Venkatesh P, Ho YH, et al. Foundation and large language models: Fundamentals, challenges, opportunities, and social impacts. Clust Comput. 2024;27(1):1–26.10.1007/s10586-023-04203-7Search in Google Scholar
[22] Preethi P, Mamatha HR. Region-based convolutional neural network for segmenting text in epigraphical images. Artif Intell Appl. 2023;1(2):119–27.10.47852/bonviewAIA2202293Search in Google Scholar
[23] Qian J, Jin Z, Zhang Q, Cai G, Liu B. A liver cancer question-answering system based on next-generation intelligence and the large model Med-PaLM 2. Int J Comput Sci Inf Technol. 2024;2(1):28–35.10.62051/ijcsit.v2n1.04Search in Google Scholar
[24] Gao X, Li J, Sun K. The analysis of smarter future: Innovations and legal risk in visual question answering technology in home automation. J Organ End User Comput. 2024;36(1):1–20.10.4018/JOEUC.357249Search in Google Scholar
[25] Suárez A, Díaz-Flores García V, Algar J, Gómez Sánchez M, Llorente de Pedro M, Freire Y. Unveiling the ChatGPT phenomenon: Evaluating the consistency and accuracy of endodontic question answers. Int Endod J. 2024;57(1):108–13.10.1111/iej.13985Search in Google Scholar PubMed
[26] Mihalache A, Huang RS, Popovic MM, Muni RH. ChatGPT-4: An assessment of an upgraded artificial intelligence chatbot in the United States Medical Licensing Examination. Med Teach. 2024;46(3):366–72.10.1080/0142159X.2023.2249588Search in Google Scholar PubMed
[27] Bhuvan TN, Jisha G, Shamna NV. SExpSMA-based T5: Serial exponential-slime mould algorithm based T5 model for question answer and distractor generation. Intell Decis Technol. 2024;18(2):1447–62.10.3233/IDT-230629Search in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- User profiling in university libraries by combining multi-perspective clustering algorithm and reader behavior analysis
- Exploring bifurcation and chaos control in a discrete-time Lotka–Volterra model framework for COVID-19 modeling
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations
Articles in the same Issue
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- User profiling in university libraries by combining multi-perspective clustering algorithm and reader behavior analysis
- Exploring bifurcation and chaos control in a discrete-time Lotka–Volterra model framework for COVID-19 modeling
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations