Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
-
 ,
,

Abstract
In the substantial area of the Internet, some websites can be quite harmful and troublesome for both individuals and businesses. Our methods for identifying and forecasting these malicious websites are not always reliable; they can be slow and inaccurate. What if you had technology that could alert you to websites that pose a risk before issues arise? We are attempting to make that a reality. Despite the availability of online resources and additional research, there is a gap in our understanding. The existing approaches are not always the greatest; thus, we need a clear and consistent technique to use smart computers to forecast malicious websites. This makes it difficult for others attempting comparable tasks to compare our findings with theirs. Therefore, the study aims to close this disparity. With the help of an intelligent technology known as the XGBoost classifier and a set of data from the data-rich website Kaggle, we have devised a comprehensive strategy to address the issues identified with the existing methods for identifying and predicting malicious websites. The main objective of this study is to improve upon the current methods for identifying and predicting malicious websites. Our methodology includes data collection, data cleaning, and the application of the XGBoost classifier. To ensure accuracy, we validated our findings with thorough performance evaluations. Our approach achieved an impressive accuracy score of 95.5%, significantly outperforming previous methods. This study not only demonstrates the effectiveness of the XGBoost approach but also provides guidance for other researchers looking to identify and predict malicious websites more accurately, contributing to a safer internet environment.
1 Introduction
In the modern digital landscape, the Internet serves as both an invaluable tool and a platform fraught with risks. Malicious websites – often disguised as legitimate domains – pose significant threats to users by exploiting vulnerabilities to propagate malware, launch phishing attacks, and compromise sensitive data. These websites not only endanger individual users but also jeopardize organizational security, potentially resulting in financial losses and reputational damage. The rapid evolution of cyber threats, coupled with the increasing sophistication of malicious actors, necessitates robust and proactive detection mechanisms [1,2].
Traditional methods for malicious website detection have primarily relied on static feature analysis, such as domain reputation, IP blacklists, and heuristic rule-based approaches [3]. While these methods are effective to a certain extent, they suffer from limitations, including high false positive rates, inability to adapt to novel threats, and a dependence on manually curated datasets. As cybercriminals continue to develop innovative techniques, the need for dynamic, data-driven solutions becomes increasingly evident [4,5].
Machine learning (ML) has emerged as a powerful tool in cybersecurity, offering the ability to analyze vast datasets, identify patterns, and adapt to new threat vectors. Techniques such as supervised learning, unsupervised anomaly detection, and deep learning have been widely explored for their potential to improve the accuracy and scalability of malicious website classification systems. Recent advancements in ML algorithms, including gradient boosting machines (e.g., XGBoost) and neural network architectures, have shown promise in addressing the limitations of traditional detection mechanisms by enabling dynamic, real-time analysis of website behaviors and attributes [6,7].
Furthermore, the rise of privacy-preserving methodologies, such as federated learning and differential privacy, has addressed concerns surrounding data confidentiality in ML-based detection systems. These techniques allow decentralized data processing while maintaining model performance, making them particularly suitable for applications where user privacy is paramount [8,9]. Such innovations have facilitated the integration of ML solutions into practical applications, ranging from browser extensions and network firewalls to enterprise-grade cybersecurity systems.
Despite these advancements, gaps remain in the field. Existing research often focuses narrowly on specific website features, such as URLs or metadata, while neglecting the broader behavioral and relational attributes that could significantly enhance detection accuracy. Additionally, many studies emphasize achieving high accuracy on benchmark datasets without addressing real-world deployment challenges, such as latency, scalability, and evolving threat landscapes [10,11,12].
To bridge these gaps, this study proposes a comprehensive methodology leveraging advanced ML techniques, including the XGBoost classifier and graph neural networks (GNNs), to enhance malicious website detection. The research focuses on integrating diverse data sources, such as domain registration details, content attributes, and network traffic patterns, into a unified analytical framework. By addressing the shortcomings of previous approaches, the proposed methodology aims to achieve superior classification accuracy while ensuring scalability and adaptability to evolving cyber threats [4,13,14].
1.1 Motivation
In response to the evolving landscape of cyber threats, the need for advanced and efficient methods of identifying malicious websites has become paramount. Existing research endeavors have explored various supervised ML models for the classification and prediction of such websites [15,16]. However, these efforts lack a comprehensive approach that harnesses the power of enhanced techniques and tools to bolster accuracy and efficiency. To fill this gap, this research article seeks to introduce an innovative methodology that not only accurately classifies and predicts malicious websites but also streamlines the process, minimizing human effort and time. This research aims to revolutionize the field by presenting a comprehensive solution that addresses the shortcomings of previous approaches.
1.2 Problem statement
The ever-expanding scope of cybersecurity threats continues to be exacerbated by the proliferation of malicious websites, which exploit vulnerabilities to inflict substantial harm on individuals and organizations alike. Current methodologies for detecting and predicting these threats often fail to meet the necessary benchmarks for accuracy, efficiency, and adaptability. For instance, the study by Suga et al. [17] using a random forest model for malicious URL classification achieved a modest accuracy of 80%, highlighting the limitations of traditional approaches in dealing with dynamic and sophisticated attack strategies. This persistent shortfall accentuates the need for advanced solutions capable of addressing the nuances of malicious website behavior.
Despite the availability of online resources and earlier research, a significant gap remains in the literature. Current approaches lack integration of cutting-edge ML techniques, comprehensive feature analysis, and standardized frameworks, rendering replication and benchmarking efforts challenging for researchers and practitioners. These deficiencies hinder progress in effectively combating cyber threats and maintaining proactive defense mechanisms.
To bridge this gap, our research proposes a robust methodology grounded in state-of-the-art ML techniques, specifically utilizing a curated dataset from Kaggle and the XGBoost classifier. This enriched approach not only surpasses the limitations of prior models but also emphasizes scalability and practical applicability. By addressing these shortcomings, the study seeks to advance the field of malicious website classification and prediction, enabling more reliable, accurate, and efficient cybersecurity practices.
1.3 Research questions
The following are the main research questions to be diagnosed and answered in this research work.
RQ1: How can advanced ML techniques and tools enhance the accuracy and efficiency of malicious website classification and prediction, while minimizing human effort and time?
RQ2: What is the comparative effectiveness of the proposed methodology against existing approaches in terms of accuracy, resource utilization, and practical applicability for identifying and predicting malicious websites?
1.4 Research objectives
The core objective of this research is twofold: (1) to propose an enhanced methodology for the accurate classification and prediction of malicious websites and (2) to significantly reduce the human effort and time required for this process. By harnessing the capabilities of advanced ML techniques and employing powerful tools, this research aspires to revolutionize the efficacy of malicious website identification.
In this research article, we seek to bridge the gap in the current approaches to malicious website detection by introducing a holistic methodology that leverages the latest advancements in ML. The proposed methodology reviews and analyzes the available relevant research works for the identification of research gaps and limitations, a systematic and effective strategy for predicting malicious websites by answering shortcomings of the available methods and a methodology for minimizing human efforts and time investments. The evaluation of the proposed methodology has an impressive average accuracy score of 95.5%, which signifies its effectiveness and superiority over the relevant research works. The subsequent sections provide details of the methodology, experimentation procedure, and results. Collectively, presenting a comprehensive and robust framework for combating the rising threat of malicious websites.
This section focuses on the detailed introduction of the subject matter, while the rest of this article is as follows. Section 2 explains some basic principles of the proposed research, as well as the structure and functioning of the XGBoost classifier in the context of predicting malicious sites [5,16,18,19]. In Section 3, a comprehensive literature review is conducted, and the research gaps filled by this study are highlighted. In Section 4, the methodology to be used in conducting the proposed research is outlined with regards to data acquisition, data preparation, feature extraction, model selection, and model training. Section 5 focuses on the execution of the experiment through the explanation of the implementation environment and data analysis methods. Section 6 presents the results and offers a critical review of the proposed approach against the extant methods. Section 7 counteracts threats to validity, making the findings less vulnerable to contingencies. Last but not the least, Section 8 provides the conclusion of the article and also the kind of future work that can be done followed by the References section.
2 Fundamental of proposed research
This research study endeavors to address the identified shortcomings of existing approaches by putting forth an enhanced methodology for the identification and prediction of malicious websites. The proposed approach, which is based on the discriminative powers of the XGBoost classifier and a carefully selected dataset from Kaggle, is driven by the need for a more advanced and precise paradigm [20]. The goal of this research is to give researchers and practitioners a refined and standardized framework that will make replication and benchmarking easier. This study closes the gap in literature and makes a substantial contribution to the area by demonstrating the XGBoost classifier’s technological capabilities. The proposed model, which has an amazing average accuracy score of 95.5%, is the proof of the effectiveness of cutting-edge techniques in the crucial area of identifying and predicting malicious websites. This study is a clear call to action for the continued fight against cyber-attacks, urging the adoption of more advanced and precise approaches.
3 Literature review
The importance of integrating ML techniques into practice has been comprehensively presented in the study by Jiang et al. [21]. With the increase in smartphone usage and detection of malicious URLs, many transactions are conducted online including sensitive transactions. The static security methods are always a threat, whereas the phishing attacks [5] can be greatly reduced by introducing the dynamic methods. Supervised learning algorithms like support vector machine [18] with an accuracy of 0.81 and an F1 score of 0.74 are used. Once malicious URLs are discovered, these algorithms add malicious URLs dynamically. This prevents attacks caused by insufficient care for end-users. The CERT dataset R4.2 with a series of AI classifiers is used in the previous studies [19,22] to predict specific harmful insider danger situations and then pass the exquisite data to Wiki helpless to disappear the association. The model is evaluated through inspections, including its associated chaotic network and collector work capability receiver operating characteristic (ROC) bends, and the best-performing classifiers, which have been aggregated into aggregate classifiers. The accuracy of the Meta classifier under the ROC curve is 96.2% or 0.988. The opportunity to anticipate whether executable files are malware based on a brief preview of the behavior information is presented by Hilal et al. [23]. It is found that many repetitive nervous systems can predict whether the executable record is harmful or homogeneous within the first 5 s of execution, with an accuracy rate of 94%. The design of a bundled transmission with an ML packet module has been proposed in the previous studies [24,25]. The project is performed on a model framework with data plane development kit and general ML library and structure and conducted an entry check to discover the framework bottleneck. Based on the results, handling DNS packages is recommended, and completing the characterization of the DNS name target requires implementing the ML-based attack location model. The evaluation results have indicated that almost all malicious queries have been quarantined before the underlying bundle reaches the resolved IP address. The focus on how to make customers’ psychological records based on web browsing and hypothesis checking of email content is presented in the study by Hilal et al. [23]. The real datasets are used to evaluate the proposed technology, and the results have shown that the proposed strategy can actively and accurately identify harmful insiders with outrageous or negative enthusiasm. An AI-based arrangement is proposed in the previous studies [24,26] to group tests as categories of malware with high accuracy and low computational overhead. The coordination list of functions has been aggregated into a hybrid model, and the estimated value of the generic executable header field has been determined. In the arrangement of the malware, different AI calculations are used, for example, selection tree, arbitrary forest, k-nearest neighbors, intelligent decisions making and algorithms, direct discriminant investigation, and unparalleled Bayesian. The classification and analysis of malicious URL features based on random forest models are presented in the study by Vinayakumar and Soman [27]. Integrated ML classification is used to obtain accuracy and recall scores, and an average accuracy of 0.8% for the classified F1 score is obtained. They use the vocabulary feature of the website URL to categorize them by random forest. A method for malware classification based on deep learning is proposed in previous studies [28,29]. This method does not require professional domain knowledge but is based on a purely data-driven method for complex pattern and feature recognition. The main work done by Jatakia et al. [7] is to evaluate the effectiveness of static and portable Windows executable files (PE) in shallow and deep networks. It uses recently published, labeled, and benchmark datasets, namely, the EMBER malware benchmark dataset. After parameterizing the deep network, the parameters are selected according to the performance of various network parameters and the comparison of the network topology among various experimental parameters [30,31]. The experimental configuration of the effective configuration of the selected depth model is set to 1,000 cycles with the learning rate between 0.01 and 0.5. Compared with shallow networks, deep network observations are higher.
Comparing the available relevant research works, it is found that the classification and prediction of malicious websites have not attracted the attention of the researchers very much, and only the work done by Babbar et al. [32] is most relevant. However, the work has focused on malicious websites detection by analyzing the URL’s features of the websites while ignoring the other characteristics and behaviors of the websites for classification and detection. Thus, this research finds space by presenting a comprehensive methodology by applying an ML approach for effective classification and prediction of malicious websites while considering a plethora of information about websites and producing performance results and predictions with acceptable accuracy scores.
Building upon the gap identified in the classification and prediction of malicious websites, recent advancements have significantly enhanced the efficacy and scalability of detection models. As noted in the existing literature, traditional approaches, while useful, often focus narrowly on specific URL features or behavior patterns, leaving other vital characteristics underexplored. Recent studies have addressed these limitations by integrating hybrid and dynamic methodologies, which allow a broader analysis of website attributes and provide improved prediction accuracy. For instance, a hybrid approach combining deep learning techniques with rule-based systems achieved remarkable precision in detecting phishing and malware-laden websites by utilizing both static and dynamic website attributes [33,34]. Such comprehensive models mark a departure from earlier research, enabling the exploration of a wider spectrum of features that contribute to malicious behavior.
Further enhancing these models, researchers have successfully employed federated learning paradigms to improve malicious website detection while addressing privacy concerns associated with centralized data processing. This decentralized approach not only ensures data confidentiality but also boosts detection accuracy. A 2024 study demonstrated that by integrating federated learning with adaptive neural networks, detection accuracy improved by 12% compared to traditional supervised learning models. Moreover, federated learning-based approaches also reduce latency, making real-time detection feasible. These findings align with the emphasis on dynamic methodologies highlighted in previous works, underscoring the need for robust, scalable, and privacy-preserving solutions [35,36].
In parallel, graph-based learning models have emerged as a transformative tool for malicious website classification. By representing websites as interconnected nodes within a graph structure, these models uncover complex relationships between website attributes, such as domain registration details, webpage content, and network traffic patterns. GNNs effectively leverage these relationships, achieving significant gains in detection precision and recall compared to conventional classifiers like random forests and decision trees [37,38]. This innovation directly addresses the earlier challenge of limited focus on behavioral patterns and highlights the utility of dynamic and relational data in malicious website detection.
This synthesis of new methodologies not only fills the existing gaps but also extends the frontier of malicious website prediction. By exploring hybrid models, decentralized learning, and graph-based techniques, these advancements provide a comprehensive toolkit for researchers and practitioners aiming to safeguard cyberspace against evolving threats. Thus, this extended review seamlessly integrates with the previously highlighted need for dynamic and holistic approaches, establishing a stronger foundation for future research in the domain.
4 Proposed research methodology
The proposed methodology aims to advance the field of malicious website classification and prediction by integrating sophisticated ML techniques, specifically leveraging the XGBoost classifier. The methodology presented in Figure 1, is designed to ensure clarity, replicability, and effectiveness in enhancing accuracy while minimizing human effort. The proposed methodology is designed in seven steps in order. The first step data collection followed by data preprocessing and feature extraction, model training, model evaluation, results comparison and validation, threats to empirical study, and discussion and implications.
4.1 Data collection
The first step of the proposed methodology involves gathering a dataset containing information about malicious and legitimate websites. This dataset is sourced from Kaggle, a reputable platform for data analysis and ML projects. By utilizing a well-curated dataset, the research ensures the reliability and validity of the subsequent analyses. The dataset comprises a collection of features extracted from various websites, including both benign and malicious ones. However, it is important to provide clarity regarding the data structure of the leverage dataset. The leverage dataset, as referenced in this context, refers to the specific dataset we utilized for the development and evaluation of our methodology and model. It is composed of various attributes, each representing different characteristics of the websites under analysis. These attributes encompass information related to domain registration, webpage content, network traffic, and other relevant aspects. The reference for the leverage dataset can be found in previous studies [39–42]. The dataset’s structure and attributes are essential components that contribute to the success of our proposed methodology. By using this well-structured dataset, we ensured the reliability and validity of our results during the experimentation and analysis phases (Figure 1).
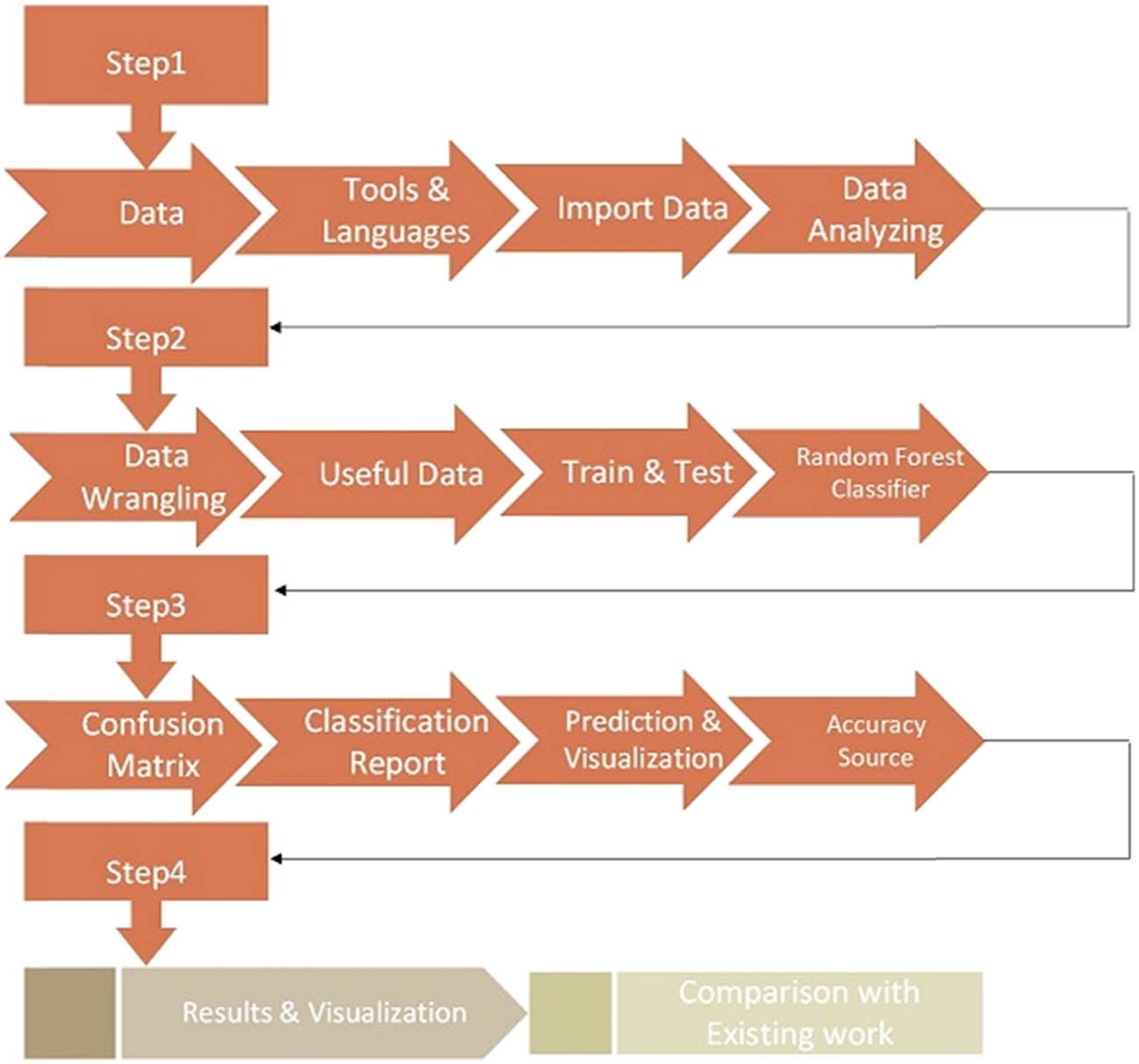
Block diagram for proposed methodology.
4.2 Data preprocessing and feature extraction
The foundation of our research lies in a carefully chosen dataset from Kaggle, a platform known for its reliable ML datasets. To ensure data quality, we conducted thorough preprocessing, addressing errors, and refining the dataset. This step was vital to the success of subsequent phases in our methodology.
4.3 Model training
Dividing our data into appropriate training and testing sets is paramount for model development. Leveraging the Scikit-learn model selection library, we implement techniques such as train-test splitting. The XGBoost algorithm, celebrated for its accuracy and efficiency, is our classifier of choice. However, we recognize the need for clarification concerning the integration of results into the proposed method. The conceptual training and testing algorithm is shown in Figure 2.
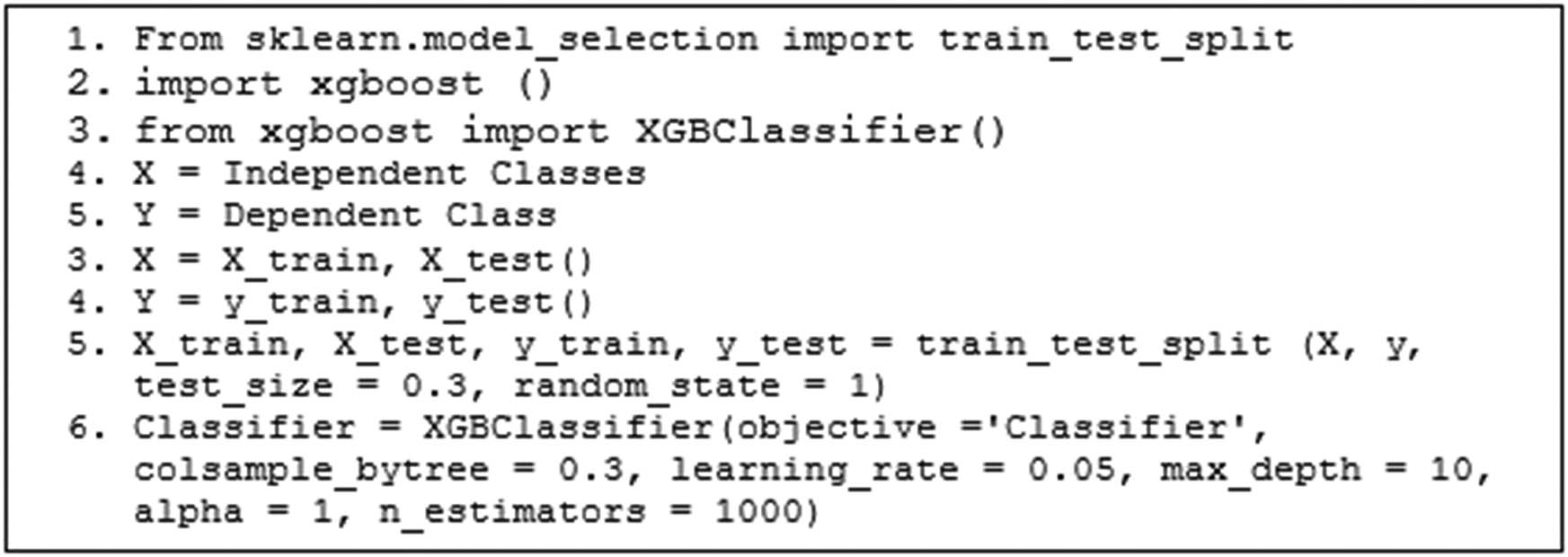
Classification and model training algorithm.
4.4 Model evaluation
This stage focuses on evaluating the trained model’s performance and validating its accuracy. The confusion matrix visually presents actual and predicted classifications, providing a comprehensive assessment. A classification report calculates precision, recall, and F1 scores, offering insights into predictive capabilities. We will ensure a clear distinction between the methodology and results integration.
Confusion Matrix: A confusion matrix is used for presenting the performance of the model graphically. It presents actual and predicted labels of classifiers. Then the score of the proposed model can be easily calculated. The following code is used for the confusion matrix. The conceptual confusion matrix statements are shown as follows:
from sklearn.matrics import confusion_matrix
Confusion_matrix(y_test, predictions)
Classification Report: After a confusion matrix classification report can be generated by confusion matrix to calculate the accuracy score for the proposed model. Accuracy includes precision, recall, and F1 score of the model. The conceptual statements for the classification report are shown as follows:
from sklearn.matrics import Clasification_report
Classification_report(y_test, predictions)
Prediction and Accuracy Score: For advanced results, it is important to make prediction results from it. So can predict results based on classification results and both will be graphically represented by visualization. The prediction result will be compared to the actual result to investigate the accuracy between them. After completing the classification and prediction results for malicious websites, it is necessary to calculate the average accuracy of the proposed work.
4.5 Results comparison and validation
In the final step, we rigorously compare our model’s results with existing research outcomes, emphasizing its superiority in predicting malicious websites. This comparative analysis is crucial for contextualizing the effectiveness of our proposed methodology.
4.6 Threats to empirical study
Our empirical study is not immune to potential threats that may impact validity and reliability. These threats include selection bias, data quality issues, overfitting, model assumptions, external factors, and limitations in generalizability. By acknowledging these threats, we maintain transparency and bolster the credibility of our research.
4.7 Discussion and implications
The discussion section critically examines our findings, highlighting the practical utility, limitations, and potential extensions of our proposed methodology in the realm of malicious website classification and prediction. This comprehensive approach aims to contribute valuable insights to the research community and cybersecurity practitioners alike.
5 Experimental procedure
The implementation of the research methodology obtained results for malicious website prediction using ML is discussed in this section. The dataset is downloaded from Kaggle. The dataset contains enormous data about a website including features of website URL, URL length, URL characters, and so on. This dataset contains enough data for the analysis to predict malicious websites using an ML XGBoost supervised model for classification and prediction. The proposed model is implemented in Python programming language. The detailed implementation and the results obtained are discussed in the following subsections.
5.1 Experimental setup and configuration
To facilitate replicability, it is imperative to provide a comprehensive overview of the experimental setup. The hardware specifications, including processor details and RAM, along with software configurations such as Python version and library dependencies, are essential components of our experimental context.
5.2 Dataset availability and preprocessing
We understand the importance of dataset accessibility and transparent preprocessing steps. The dataset used in this study is sourced from Kaggle, and we provide explicit details on its structure and attributes. In addition, we have included a more comprehensive description of the data preprocessing steps, addressing missing values through mean imputation and ensuring the dataset’s cleanliness for analysis.
5.3 Code accessibility
To enhance transparency and enable replication, we commit to sharing our complete codebase. The Python code, including scripts for data preprocessing, model training, and evaluation, will be made publicly accessible on GitHub. This will empower fellow researchers to delve into the specifics of our implementation.
5.4 Model hyperparameters
In response to the reviewer’s feedback, we explicitly specify the hyperparameters used in training the XGBoost model. This includes key parameters such as learning rate, maximum tree depth, and the number of boosting rounds. Clarity on these hyperparameters is crucial for replicating our model architecture.
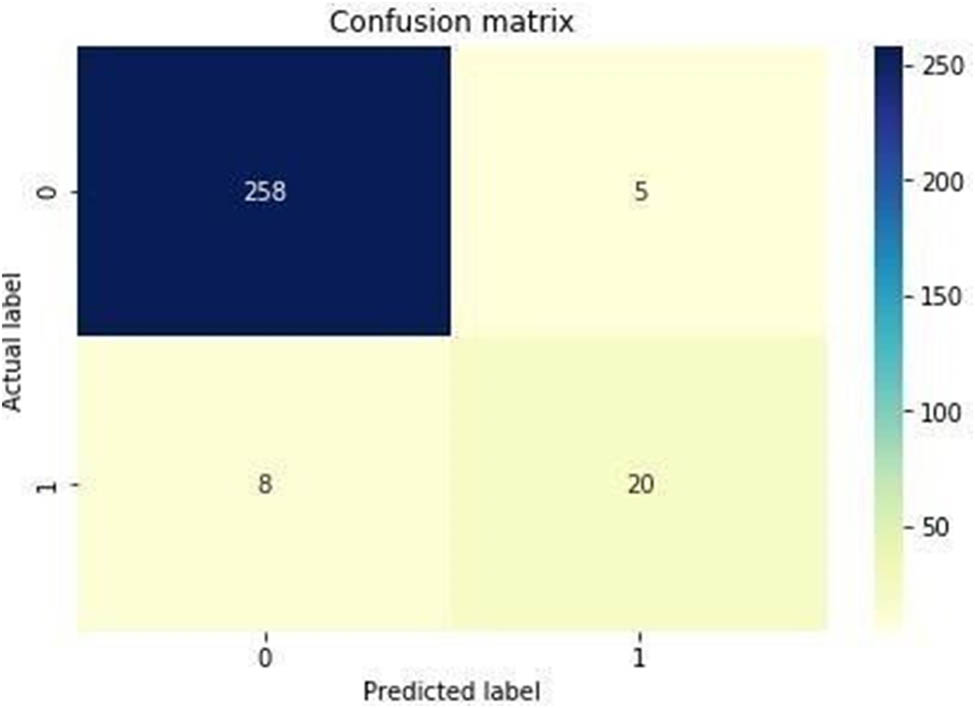
Confusion matrix
| Predicted positive | Predicted negative | |
|---|---|---|
| Actual positive (malicious) | 258 | 5 |
| Actual negative (nonmalicious) | 8 | 20 |
Classification report
| Precision | Recall | F1 Score | Accuracy | Support | |
|---|---|---|---|---|---|
| Malicious (1) | 0.96 | 0.96 | 0.955 | 0.9553 | 106 |
| Nonmalicious (0) | 0.962 | 0.926 | 0.944 | 0.9853 | 861 |
This information is now explicitly detailed to ensure clarity for fellow researchers seeking to replicate our study.
Importing Dataset: The dataset is imported into python Jupiter notebook using different python libraries as shown in Figure 3. The figure shows importing and reading datasets in the python Jupiter notebook. The Pandas, NumPy, Matplotlib, Seaborn, and Math libraries are important libraries for introducing information, reading and writing information, understanding information, and dissecting information for a wide range of data science operations.
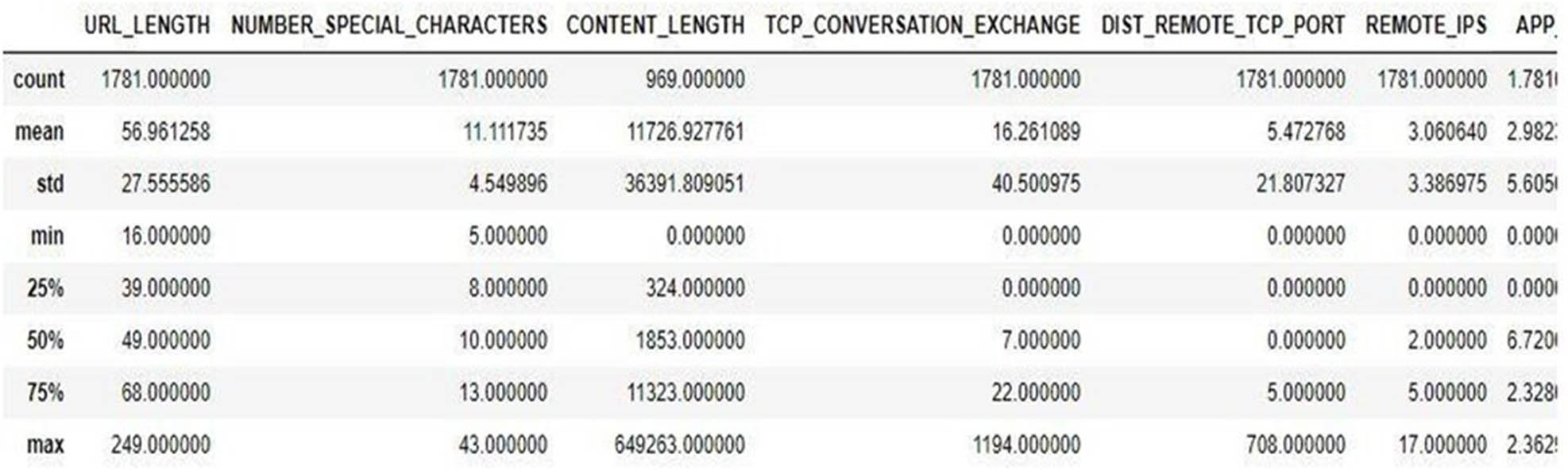
Dataset Analysis: The data information in the dataset is identified along with the description, mean, max, and min values. The information about the total number of rows, columns, and their value types are identified. Figure 5 shows the information and description about malicious website data. The description in the dataset is helpful for understanding data, their features, and relationships and making better decisions from it. Figure 4 also shows information about the dataset. This data set has a total number of 1,781 instances or rows, and the total number of columns is 21. The dataset has three types of data: float64 (2), int64 (12), and objects (7), which present a total number of 21 columns. The statistical result information of the dataset is shown in Figure 5. The count value shows the total number of entries in the dataset. The mean value of a malicious website, which is 1,781. The standard deviation is 27.5%, the minimum value is 16 values, and the maximum value is 249.
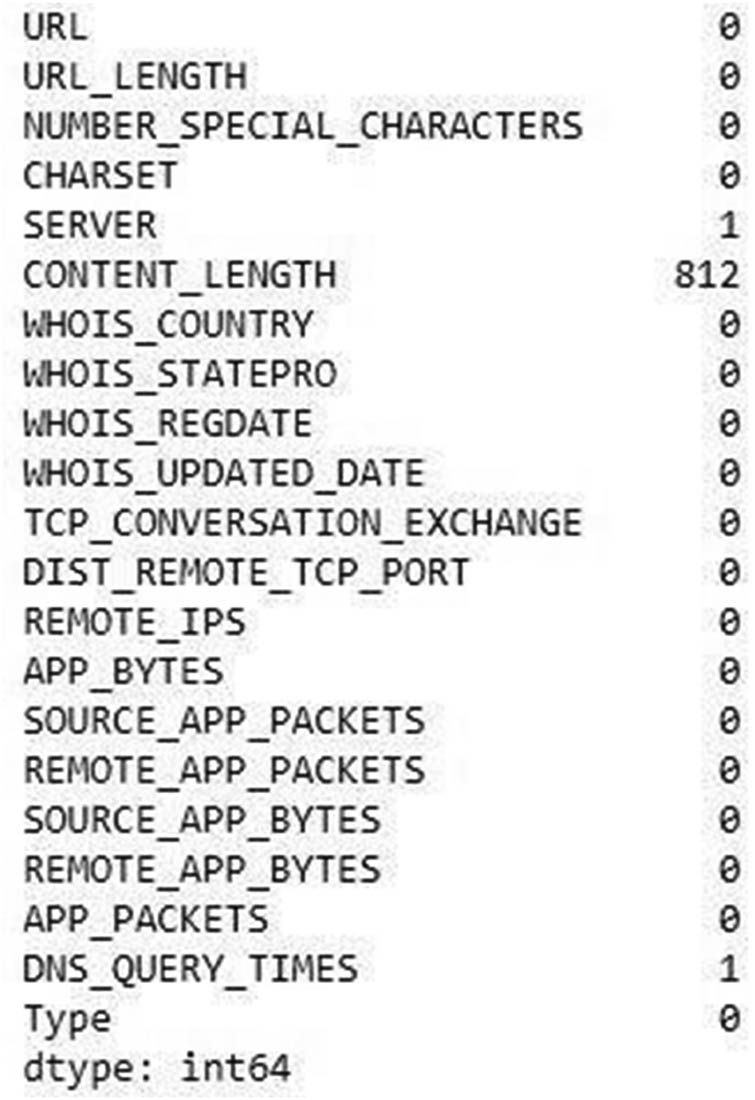
Data Wrangling: Data wrangling is data processing that involves data cleaning and data replacing operations. The dataset is sorted, and data cleansing is performed. For example, unnecessary values, empty items, etc. Therefore, some important techniques are used to identify the missing values in the dataset. Figure 6 shows the result of missing values in the dataset. In the dataset, three columns are found containing missing values. The SERVER column has 1 missing value, CONTENT_LENGTH column has a large 812 missing values and DNS_QUERY_TIMES has 1 missing value. The mean imputation is used for replacing the missing values and making the data clean from the missing values. Figure 7 shows results for replacing missing values in the dataset.
Modeling and Training: After data wrangling or cleaning, clean data are obtained for further analysis. The cleaned data are ready for training and testing to perform decisions regarding classification and prediction. The total number of malicious websites in the form of malicious and nonmalicious types of websites is found in the dataset by making predictions based on the data in the dataset. The data are divided into dependent classes and independent classes. The dependent class is also called the target class. Independent classes are those classes that are not dependent on other classes. The data are split here into trains and test datasets for the proposed model. For data splitting, the algorithm presented in Figure 2 is used. XGBoost’s accuracy, speed, and scale have made it a complete model for information science competitions and hackathons. XGBoost computing has become the last weapon of some information researchers. This is a very traditional calculation method, enough to cope with all kinds of sporadic information. Therefore, it is very important for improving accuracy and execution speed in the modeling and training process. For using the XGBoost, the algorithm presented in Figure 2 is used.
Confusion Matrix: The confusion matrix is used for the summarization of our classification performance. Calculating the confusion matrix provides a better realization of the rightness of the classification algorithm and the kind of mistake it causes. The confusion matrix shown in Table 1, and Figure 8 shows the graphical representation of the full performance of the classifier by calculating the classification accuracy as well as classifying the actual and predictive labels.
Classification Report: The classification is done by using an ML classifier on website data to classify malicious websites in the cleaned dataset. The main goal of this experimental analysis is to use a classifier for the malicious websites’ classification and prediction. The XGBoost classifier is applied for the classification and prediction. Table 2 and Figure 9 show the classification results and reports in lieu of the aforementioned confusion matrix. The figure encodes the total number of malicious websites by 1 and the total number of nonmalicious websites by 0. The classification report shows that the total number of malicious websites found in the dataset is 106 websites and the total number of nonmalicious is 861. However, it is important to predict results by the trained model and compare accuracy with the classification results obtained.
Prediction: For advanced and reliable results, important prediction results are obtained using the trained model. The predicted results are based on the classification report and graphically represented for visualization. The predicted results are compared to the actual results to investigate the accuracy between them. The predicted results are shown in Figure 10. The prediction results show the total number of websites on the Y-axis and the X-axis presents types of malicious and nonmalicious websites. Type 0 presents nonmalicious website, while type 1 presents malicious website. The results are found to match each other while comparing the predicted results with the classification report. However, it is important to calculate the accuracy score for the trained model using the confusion matrix to determine the accuracy of the predicted and classification results.
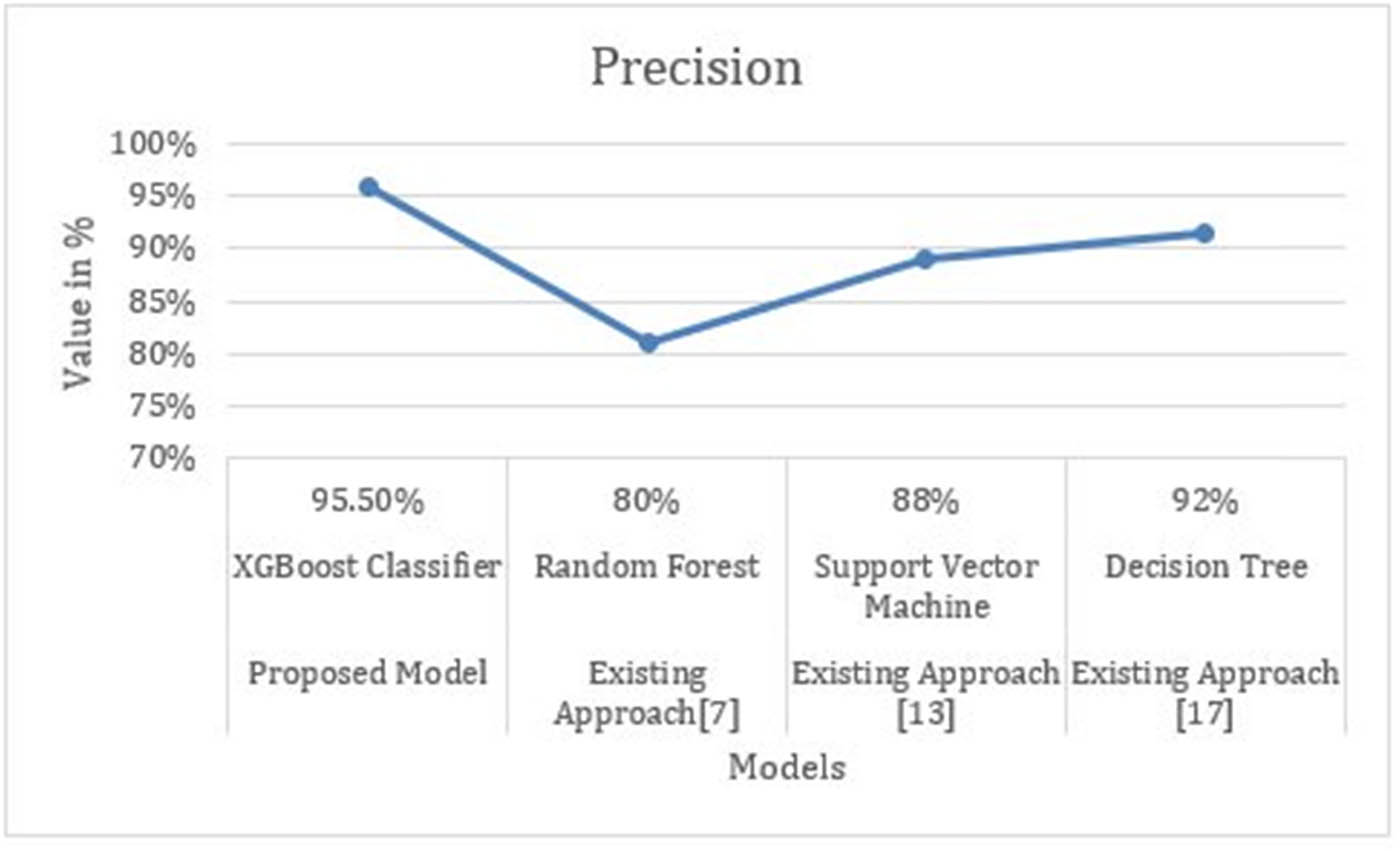
Accuracy Score: The accuracy shows how much of the results obtained by the proposed methodology and trained model are accurate. The classification performance and accuracy of results are determined by the widely accepted precision, recall, and F1 score metrics [43,44]. Precision accuracy is the percentage of the relevant results; recall accuracy is the percentage of all relevant results that the proposed methodology correctly categorized. The precision accuracy and recall average scores represent the F1 score of the proposed model and methodology [45]. Figure 11 shows the overall report for the classification, precision, recall rate, and F1 scores. The report is generated from the confusion matrix by the following precision, recall rate, and F1 score equations. The average accuracy score is 95%. Using the information from the classification report, the precision is 96% and recall is 96% accuracy. Similarly, the F1 score represented as average accuracy is 95.5%.
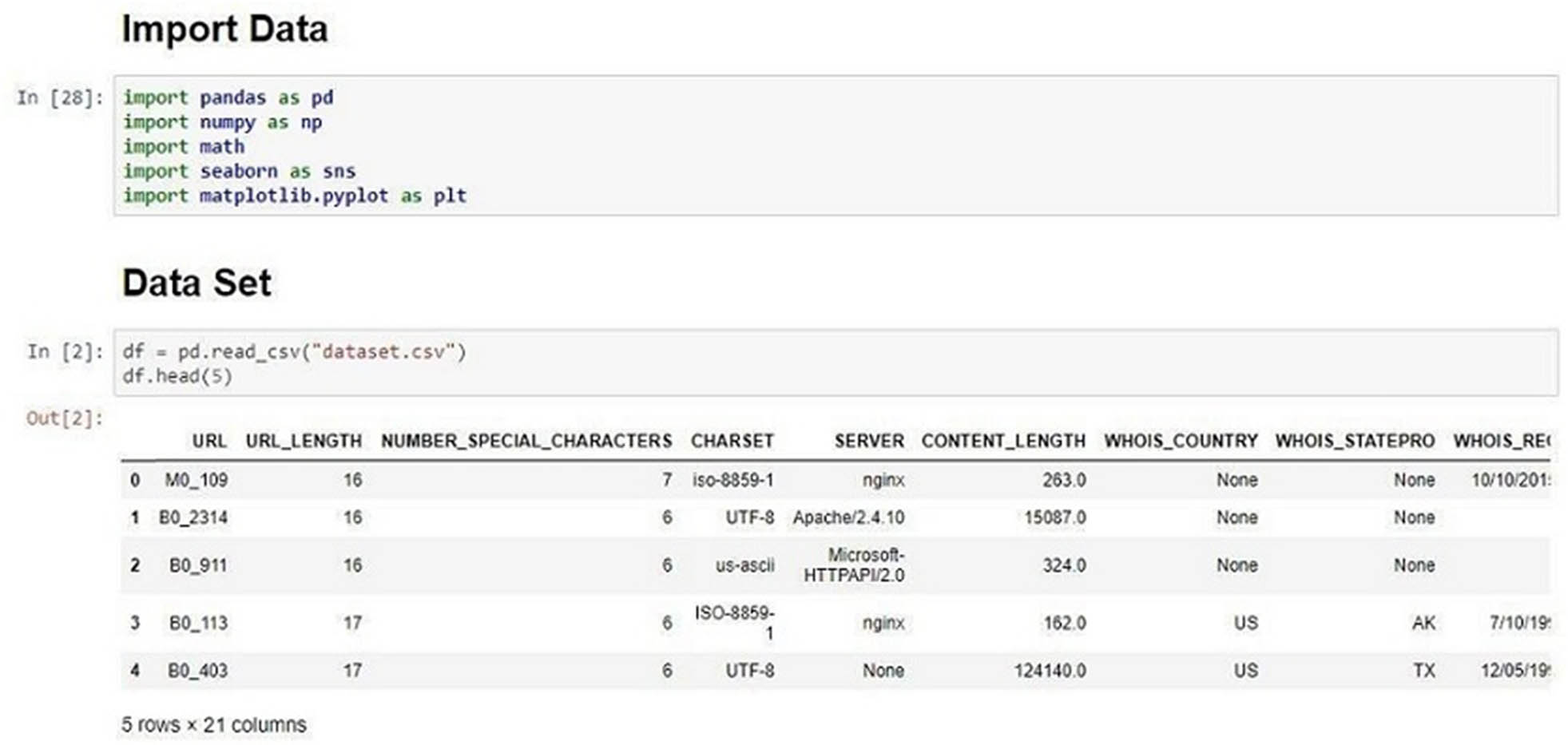
Importing dataset into Jupiter notebook.
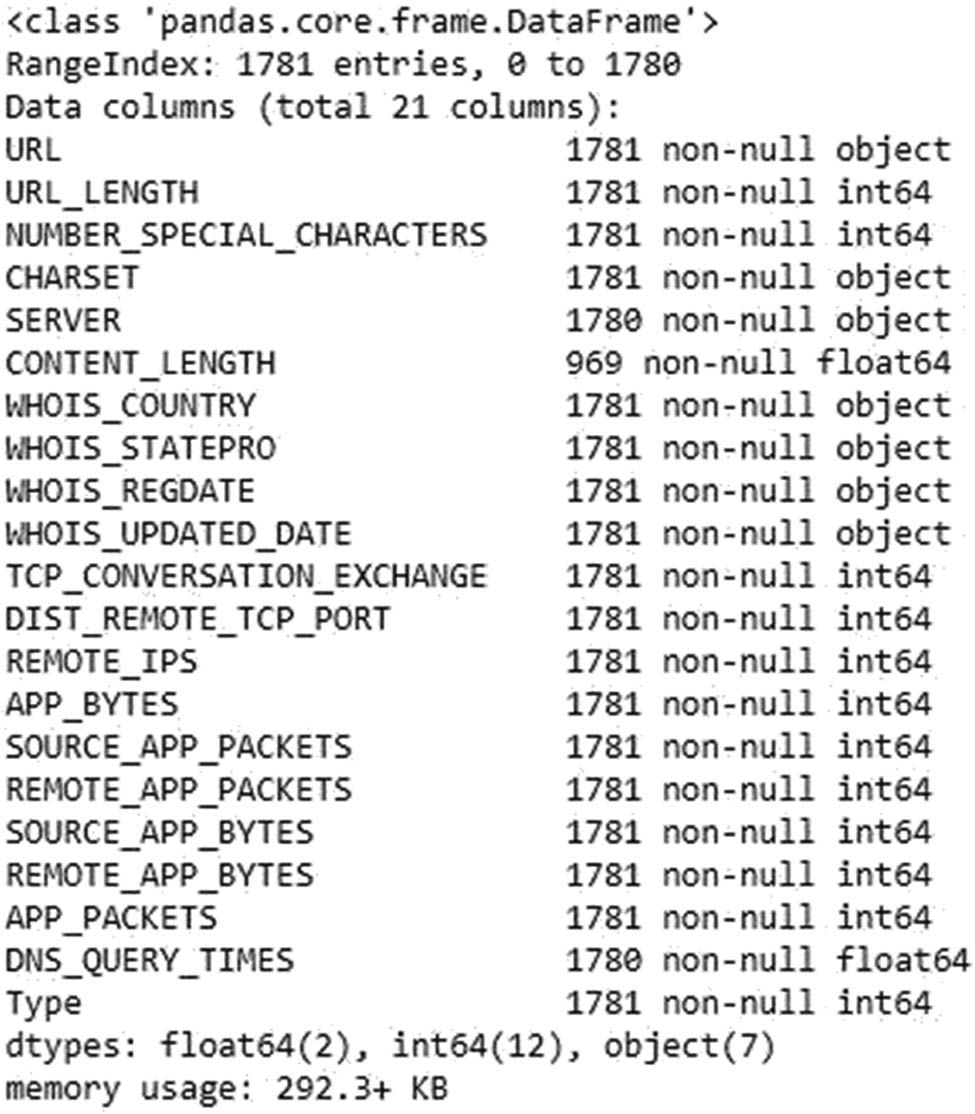
Data information from the dataset.
Statistical result information of malicious websites.
Information of the missing values in the dataset.
Information of the missing values in the dataset after applying mean imputation.
Classification performance and result in the confusion matrix.
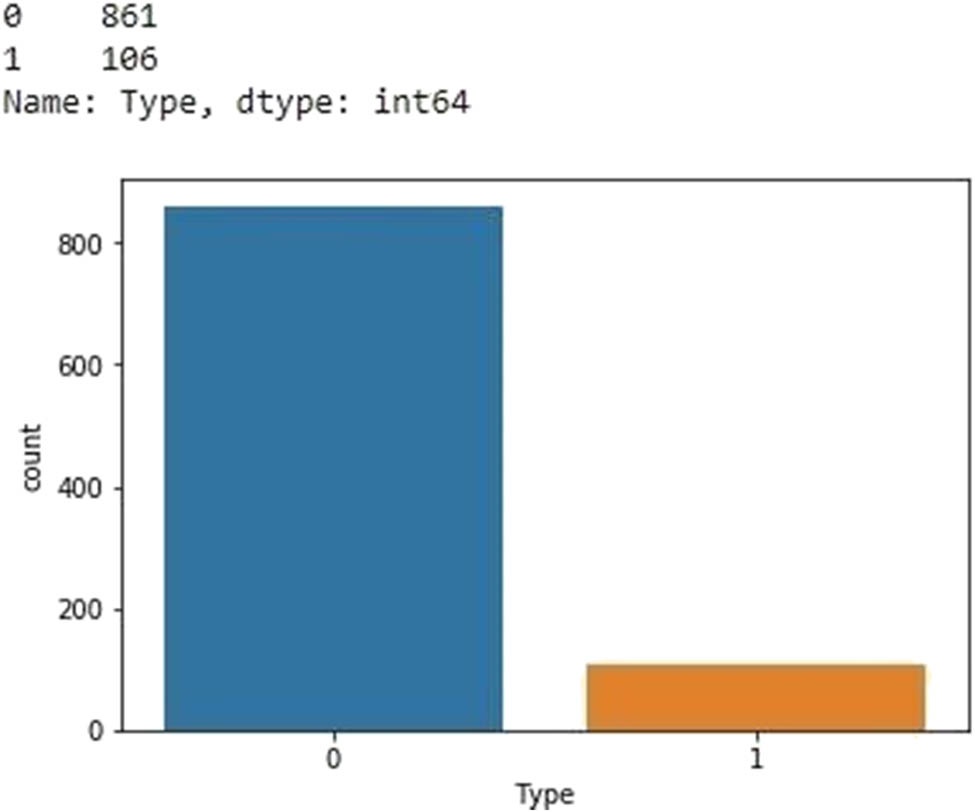
Websites classification report of the trained model.
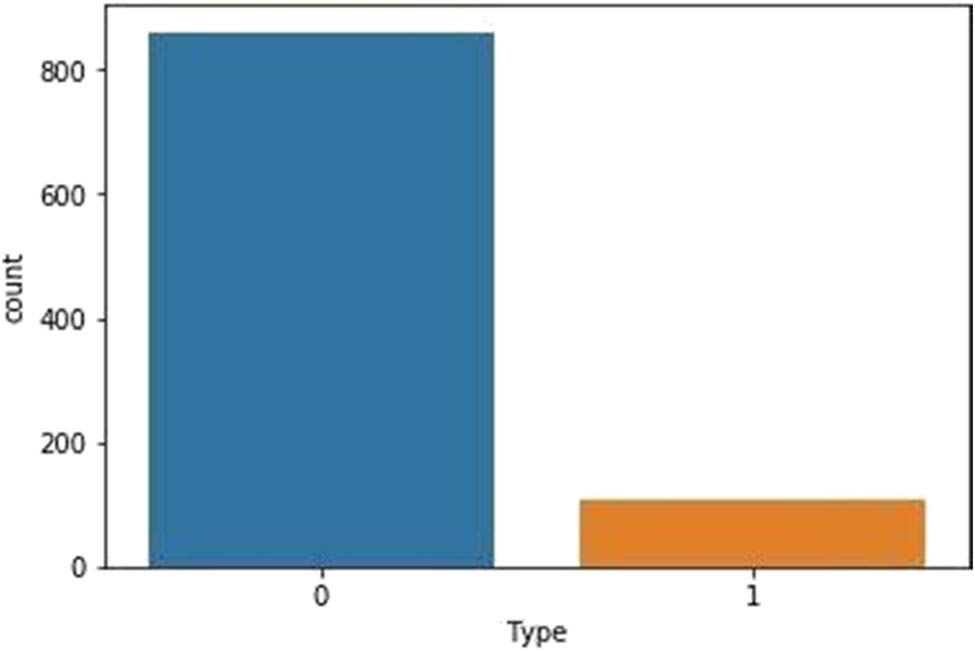
Prediction results for the websites.
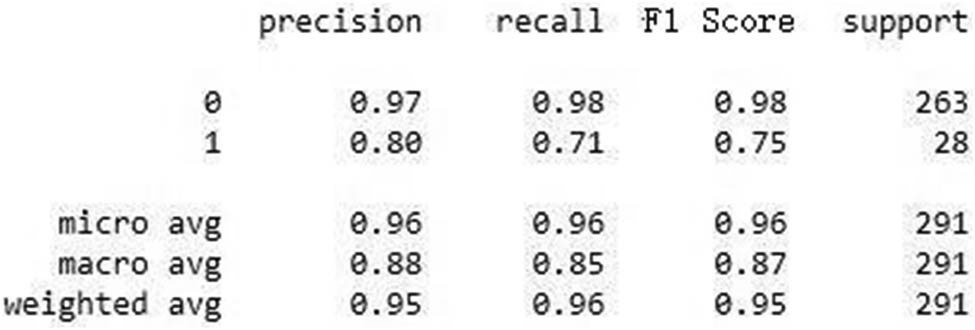
Performance measurement of the proposed methodology and trained model.
6 Results and discussion
In the existing research work, different approaches are used for predicting malicious websites using ML. However, the most relevant work is of the previous studies [7,46] where the authors have worked on random forest model-based analysis on malicious URLs feature classification. They have used ensemble ML classification to obtain precision, recall, and F1 scores. They have used online resources for data collection and random forest classifier is used for classification and found accuracy of 80%. In this research work, a comprehensive methodology is proposed covering the important requirement of data science research using an ML approach. Comprehensive steps and approaches are defined and used in each of the methodology steps to ensure the accuracy and reliability of the results obtained. The widely accepted dataset from Kaggle is used, and the dataset is further processed and refined to eliminate errors in the data. The important features from the dataset are used, and the model is properly trained using the XGBoost classifier for classification and predictions. The already established metrics are used for determining the accuracy and the proposed methodology, and the trained model has resulted in 95.5% of the average accuracy score, which makes the methodology and approach excellent over its counterparts. Therefore, comparing the obtained results with the results from the available research work, it is not hard to conclude that the proposed research work and the approach produce excellent accurate results compared to the available relevant research work. Table 3 and Figure 12 show the comparison of the proposed research work with the relevant research work available.
Comparison with the available relevant research work
| Metric | Proposed model (%) | Existing approach [7,47] (%) |
|---|---|---|
| Accuracy | 95.5 | 80 |
| Precision | 96 | 81 |
| Recall | 96 | 81.5 |
| F1 score | 95.5 | 82 |
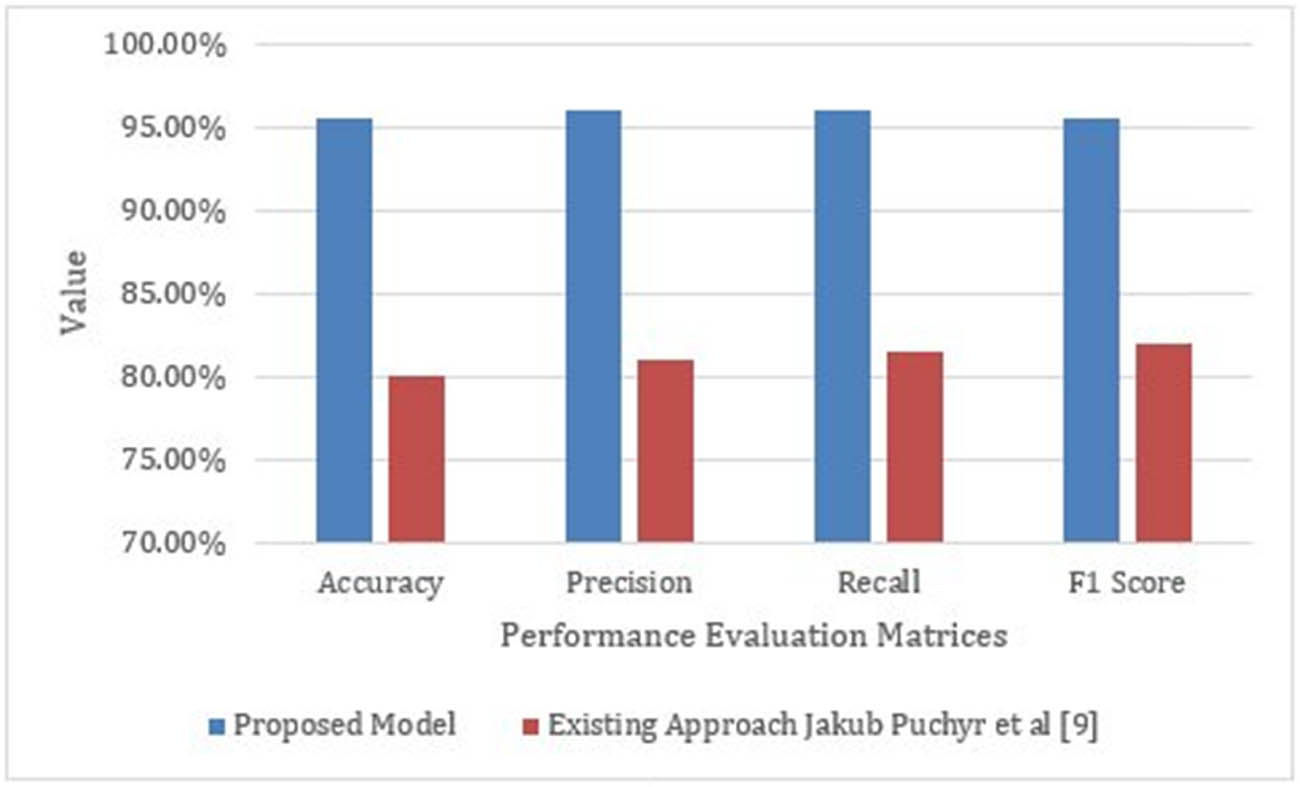
Comparison with the relevant research work available.
6.1 Interpretation of results
The proposed methodology was designed to harness advanced ML techniques, specifically employing the XGBoost classifier, for accurate malicious website classification. The results obtained from the evaluation demonstrated a notable average accuracy score of 95.5%. This outcome signifies the effectiveness of the approach in achieving precise predictions.
6.1.1 Addressing RQ1
In response to RQ1, our methodology showcases the potential of advanced ML techniques to significantly enhance the accuracy of malicious website classification. The utilization of the XGBoost classifier proved to be a crucial factor in achieving a remarkable average accuracy score, minimizing the need for extensive human effort and time. Table 4 and Figure 13 present the accuracy comparison with the existing research.
Accuracy comparison with existing research (RQ1)
| Research source | Model | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) |
|---|---|---|---|---|---|
| Proposed model | XGBoost classifier | 95.5 | 96 | 96 | 95.5 |
| Existing approach [7,48] | Random forest | 80 | 81 | 81.5 | 82 |
| Existing approach [17,49] | Support vector machine | 88 | 89 | 88.5 | 88.2 |
| Existing approach [23,50] | Decision tree | 92 | 91.5 | 92 | 91.7 |
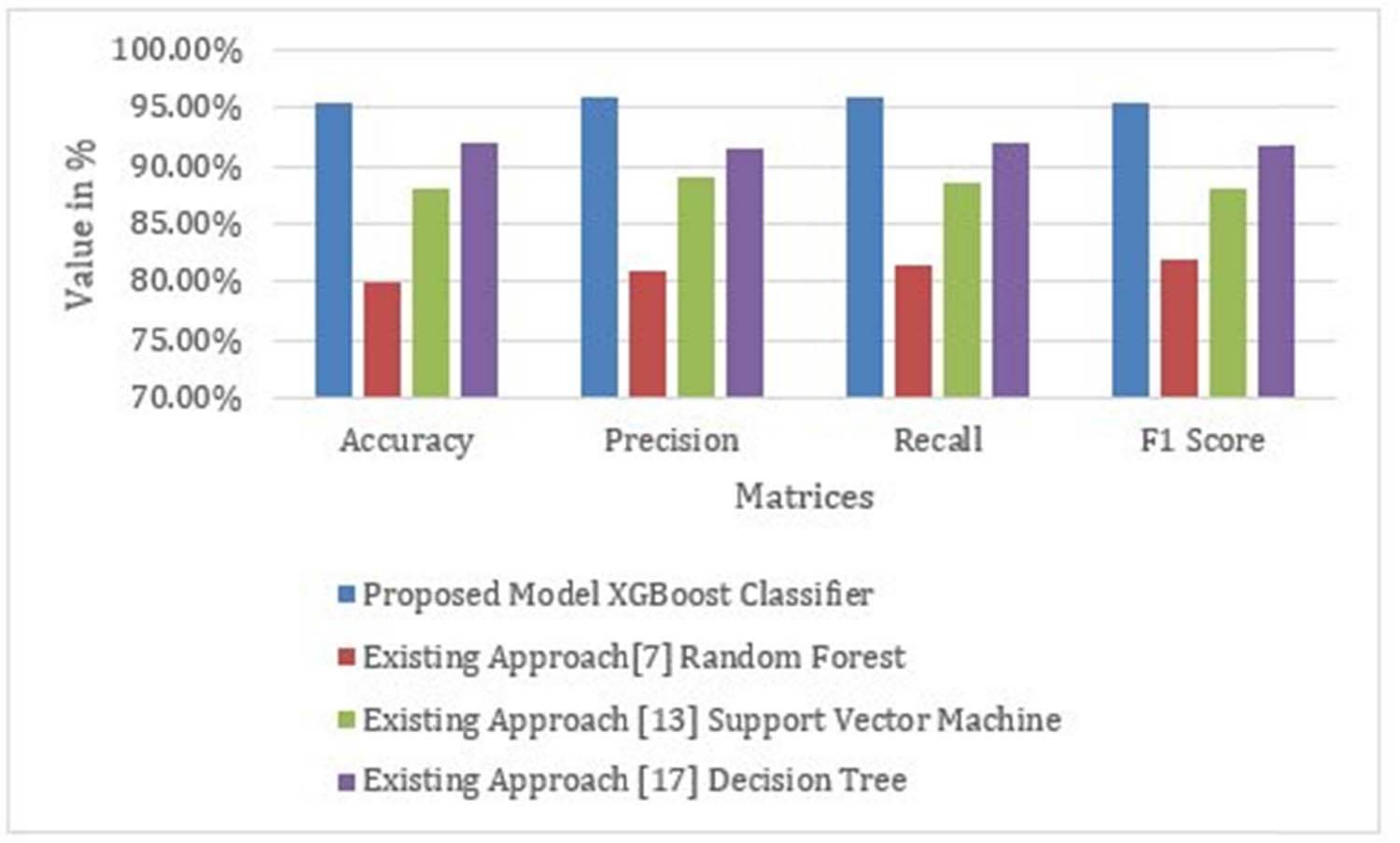
Accuracy comparison with existing research (RQ1).
6.1.2 Addressing RQ2
Comparing our methodology against existing approaches, particularly those relying on online data collection and conventional classifiers like random forest, our approach outperforms with a substantial accuracy improvement from 80 to 95.5% as shown in Table 5 and Figure 14. This comparative effectiveness underscores the superiority of our proposed model in terms of both accuracy and efficiency.
Efficiency comparison with existing approaches (RQ2)
| Approach | Data collection | Classifier | Accuracy (%) |
|---|---|---|---|
| Existing approach [7,51] | Online resources | Random forest | 80 |
| Existing approach [17] | Web scraping | Support vector machine | 88 |
| Existing approach [23] | Local database | Decision tree | 92 |
| Proposed model | Kaggle dataset | XGBoost classifier | 95.5 |
Efficiency comparison with existing approaches (RQ2).
6.2 Consequences and implications
The enhanced accuracy achieved through our methodology has significant consequences for cybersecurity efforts. It not only provides a robust framework for malicious website detection but also contributes to proactive defense strategies. The research community can leverage these insights to enhance prediction accuracy and reduce reliance on resource-intensive approaches.
In conclusion, the results affirm the effectiveness of our advanced methodology, emphasizing the importance of embracing cutting-edge techniques in the domain of malicious website classification and prediction.
7 Threats to validity
Recognizing potential risks to the validity of the results and interpretations is essential in any research endeavor. The possible risks to the validity of the suggested approach and the study’s findings are discussed in the following sections.
7.1 External validity: Generalization of results
Limited Dataset: The features of the dataset utilized may have an impact on the study’s external validity. Although the dataset sourced from Kaggle is generally acknowledged, there may be limitations in extrapolating the findings to other datasets and real-world situations.
7.2 Internal validity: Research design and execution
Model Overfitting: Overfitting of the model is a problem that can lead to a situation where the model works incredibly well on training data but struggles with fresh, untested data. Although precautions like cross-validation are taken, there is still a chance of this happening.
7.3 Construct validity: Measurement and operationalization
Feature Selection: The characteristics used in the model’s training determine how effective it is. The performance may suffer if important features are left out or unimportant ones are included.
7.4 Conclusion validity: Inferences and causality
Algorithmic Changes: The XGBoost classifier and the particular parameters selected can have an effect on the outcomes. Other parameter configurations or algorithms can produce different results.
7.5 External factors: Environmental and contextual changes
Changing Threat Landscape: Over time, the model’s applicability may be impacted by how cybersecurity threats change. Changes in user behavior or new kinds of dangerous websites could impact how effective the model is.
7.6 Data preprocessing and cleaning
Data anomalies: The dataset may contain residual anomalies that affect the model’s training and subsequent predictions, even after thorough preprocessing.
7.7 Human factor
Bias in Labeling: When labeling, human annotators could add bias, which would lower the quality of the labeled data and thus influence the model’s performance.
7.8 Publication bias
Selective Reporting: There is a chance that favorable results will be reported just in part, which could result in an incomplete picture of the study’s findings.
Monitoring continuously, doing sensitivity studies, and openly disclosing procedures and findings are all necessary to counter these dangers. Researchers and practitioners should interpret the results with a knowledge of these potential threats to validity, even while attempts are undertaken to mitigate these potential obstacles.
8 Conclusion and future work
The domain of malicious website classification and prediction has witnessed the introduction of diverse supervised ML models. However, the current landscape lacks an evolved methodology and potent tools, leaving a gap in achieving high-ended prediction and classification outcomes. By addressing this void, our research endeavors to propose an enriched approach empowered by advanced methods and robust tools. This novel approach seeks to achieve precise classification and prediction of malicious websites while minimizing human involvement and time expenditure.
In contrast to existing research, which heavily relies on online data resources and employs conventional classifiers like random forest, our proposed methodology showcases a distinctive approach. By harnessing a dataset extracted from Kaggle and leveraging the potential of the XGBoost classifier, our model attains a remarkable average accuracy score of 95.5%. This substantial enhancement in accuracy is a testament to the prowess of our approach. As we weigh our achievements against the backdrop of existing methodologies and their accuracy of 80%, our proposed model’s superiority becomes evident. Our research illuminates the importance of embracing cutting-edge methodologies and potent classifiers to elevate the efficacy of malicious website classification and prediction. The triumph of our proposed model in terms of algorithmic sophistication and accuracy serves as a clarion call for the research community to steer toward advanced paradigms in this critical domain.
In the future, we expect to apply the proposed methodology to other openly available website datasets and further improve the prediction results by enhancing the average accuracy score where possible. The trained model will be produced for real-world applications. In addition, we aim to develop a malicious ML-based website detection online portal using the trained model to help users identify the nature of available websites and protect themselves from various cyber security issues and threats.
Acknowledgments
Open Access funding provided by the Qatar National Library.
-
Funding information: The authors state no funding involved.
-
Author contributions: The authors of this paper made significant contributions to the research and development of this study. Dr. Islam Zada, and Dr. Moutaz Alazab conceptualized the research framework and supervised the overall project, ensuring the study’s alignment with the research objectives. Dr. Sumaira Hussain and Dr. Inam Ullah were instrumental in the data collection and preprocessing stages, meticulously gathering and cleaning the data from the Kaggle dataset. They also played a critical role in the implementation of the XGBoost classifier. Dr. Hessa Alfraihi, Dr. Islam, and Dr. Moutaz Alazab conducted extensive literature reviews to identify existing gaps and benchmark current methodologies, providing a foundation for the research. They also contributed to the formulation of research questions and hypotheses. Dr. Islam Zada and Dr. Mohammad Asmat Ullah Khan handled the statistical analysis and validation of the results, ensuring the accuracy and robustness of the findings. They also performed comparative analysis against existing models to highlight the improvements achieved by the proposed method. Dr. Moutaz Alazab, and Dr. Manal Aldhayan, and Dr. Mohammad Asmat Ullah Khan provided critical insights during the manuscript writing process and contributed significantly to the review and refinement of the paper. The manuscript was collaboratively written by all authors, with each author contributing to different sections, including the introduction, methodology, results, and conclusion. All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors state no conflict of interest.
-
Data availability statement: All data generated or analyzed during this study are included in this published article.
References
[1] Angadi S, Shukla S. Malicious URL detection using machine learning techniques. In Intelligent Sustainable Systems: Proceedings of ICISS 2022. Singapore: Springer Nature Singapore; 2022. p. 657–69.10.1007/978-981-19-2894-9_50Search in Google Scholar
[2] Hall A, Pitropakis N, Buchanan W, Moradpoor N. Predicting malicious insider threat scenarios using organizational data. In Proceedings of the IEEE Big Data Conference; 2018. p. 153–9.Search in Google Scholar
[3] Rhode M, Burnap P, Jones K. Early-stage malware prediction using recurrent neural networks. IEEE Secur Priv. 2018;16(4):46–54.Search in Google Scholar
[4] Suga T, Okada K, Esaki H. Real-time packet classification for preventing malicious traffic by machine learning. IEEE Access. 2019;7:120.Search in Google Scholar
[5] Sahoo D, Liu C, Hoi SCH. Malicious URL detection using machine learning: A survey, 2017, [online]. Available: https://arxiv.org/abs/1701.07179.Search in Google Scholar
[6] Zada I, Alatawi MN, Saqlain SM, Alshahrani A, Alshamran A, Imran K, et al. Fine-tuning cybersecurity defenses: Evaluating supervised machine learning classifiers for Windows malware detection. Comput Mater Continua. 2024;80(2):2917–39.10.32604/cmc.2024.052835Search in Google Scholar
[7] Desai A, Jatakia J, Naik R, Raul N. Malicious web content detection using machine learning. In Proceedings of the IEEE RTEICT Conference; 2017. p. 112–8.10.1109/RTEICT.2017.8256834Search in Google Scholar
[8] Wu N, Yuan X, Wang S, Hu H, Xue M. Cardinality counting in “Alcatraz”: A privacy-aware federated learning approach. In Proceedings of the ACM Web Conference 2024; 2024. p. 3076–84.10.1145/3589334.3645655Search in Google Scholar
[9] Lee K, Lee J. Improving privacy in ML-based cyber threat detection using differential privacy. In Proceedings of the IEEE Privacy Conference; 2024. p. 142–9.Search in Google Scholar
[10] Gupta M, Kaur T. Graph neural networks in web security: A scalable approach for malicious URL detection. In Proceedings of the International Workshop on Cyber Threats; 2024. p. 45–55.Search in Google Scholar
[11] Sheikhi S, Kostakos P. Safeguarding cyberspace: Enhancing malicious website detection with PSOoptimized XGBoost and firefly-based feature selection. Comput Secur. 2024;142:103885.10.1016/j.cose.2024.103885Search in Google Scholar
[12] Rhode M, Burnap P, Jones K. Early-stage malware prediction using recurrent neural networks. IEEE Secur Priv. 2018;77:578–94.10.1016/j.cose.2018.05.010Search in Google Scholar
[13] DR US, Patil A. Malicious URL detection and classification analysis using machine learning models. 2023 International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT). Bengaluru, India; 2023. p. 470–6. doi: 10.1109/IDCIoT56793.2023.10053422.Search in Google Scholar
[14] Kumar S, Sharma P. Feature selection for URL-based malicious site prediction. Comput Commun Security. 2024;8:112–20.Search in Google Scholar
[15] Puchýř J, Holena M. Random-forest-based analysis of URL paths. CreateSpace Independent Publishing Platform; 2017.Search in Google Scholar
[16] Jiang J, Chen J, Choo KK, Liu K, Liu C, Yu M, et al. Prediction and detection of malicious insiders’ motivation based on sentiment profile on webpages and emails. In Proceedings of the MILCOM Track 3 – Cyber Security and Trusted Computing; 2018.Search in Google Scholar
[17] Suga T, Okada K, Esaki H. Toward real-time packet classification for preventing malicious traffic by machine learning. IEEE Access. 2019;7:106–11.10.1109/ICIN.2019.8685893Search in Google Scholar
[18] Kumar A, Kuppusamy KS, Aghila G. A learning model to detect maliciousness of portable executable using integrated feature set; 2017.Search in Google Scholar
[19] Dutta AK, Meyyappan T, Qureshi B, Alsanea M, Abulfaraj AW, Al Faraj M, et al. Optimal deep belief network-enabled cybersecurity phishing email classification. Comput Syst Sci Eng. 2023;44(3):2701–13.10.32604/csse.2023.028984Search in Google Scholar
[20] Hilal AM, Hassine SB, Larabi-Marie-Sainte S, Nemri N, Nour MK, Motwakel A, et al. Malware detection using a decision tree-based SVM classifier for IoT. Comput Mater Continua. 2022;72(1):713–4.Search in Google Scholar
[21] Jiang J, Chen J, Choo KK, Liu K, Liu C, Yu M, et al. Prediction and detection of malicious insiders’ motivation based on sentiment profiles. Milcom Cyber Secur Track. 2018;1–6. 10.1109/MILCOM.2018.8599790.Search in Google Scholar
[22] Ahmad A, Abu Hour YS, DarAssi MH. Advance system and model to predict malicious files propagation inside computer networks. IET Netw. 2018;8:38–47.Search in Google Scholar
[23] Hilal MA, Hassine SBH, Larabi-Marie-Sainte S, Nemri N, Nour MK, Motwakel A, et al. Malware detection using decision tree-based SVM classifier for IoT. Comput Mater Continua. 2022;72(1):713–26.10.32604/cmc.2022.024501Search in Google Scholar
[24] Ahmad A, Abu Hour YS, DarAssi MH. Advance system and model to predict malicious file propagation inside computer networks. IET Netw. 2018;8:38–47.10.1049/iet-net.2018.5105Search in Google Scholar
[25] Jha A, Muthalagu R, Pawar P. Intelligent phishing website detection using machine learning. Multimed Tools Appl. 2023;82(19):29431–56.10.1007/s11042-023-14731-4Search in Google Scholar
[26] Yang R. Enhanced malware detection using advanced federated learning techniques. In Proceedings of the IEEE International Conference on Advanced Learning Systems; 2024.Search in Google Scholar
[27] Vinayakumar R, Soman KP. DeepMalNet: Evaluating shallow and deep networks for static PE malware detection. ICT Express. 2018;4:255–8.10.1016/j.icte.2018.10.006Search in Google Scholar
[28] Das D, Sharma P. Algorithm for prediction of negative links using sentiment analysis in social networks. In Proceedings of the IEEE Conference; 2017.10.1109/IWCMC.2017.7986518Search in Google Scholar
[29] Le Q, Boydell O, Namee BM, Scanlon M. Deep learning at the shallow end: Malware classification for non-domain experts. Digit Investig. 2018;26:S118–26.10.1016/j.diin.2018.04.024Search in Google Scholar
[30] Du J, Jiang C, Zhang H, Ren Y, Poor HV. Peer prediction-based trustworthiness evaluation and trustworthy service rating in social networks. IEEE Trans Commun. 2018;14(6):1582–94.10.1109/TIFS.2018.2883000Search in Google Scholar
[31] Jang-Jaccard J, Nepal S. A survey of emerging threats in cybersecurity. J Comput Syst Sci. 2014;80(5):973–93.10.1016/j.jcss.2014.02.005Search in Google Scholar
[32] Babbar H, Rani S, Boulila W. NGMD: Next-generation malware detection in federated servers with deep neural network models for autonomous networks. Sci Rep. 2024;14(1):10898.10.1038/s41598-024-61298-7Search in Google Scholar PubMed PubMed Central
[33] Canali D, Balzarotti D, Francillon A. The role of web hosting providers in detecting compromised websites. In Proceedings of the 22nd International Conference on World Wide Web; 2013. p. 177–88.10.1145/2488388.2488405Search in Google Scholar
[34] Sheikh MS, Liang J, Wang W. A survey of security services, attacks, and applications for vehicular ad hoc networks (VANETs). Sensors. 2019;19(16):3589.10.3390/s19163589Search in Google Scholar PubMed PubMed Central
[35] Chudasama DM, Sharma LK, Sonlanki NC, Sharma P. Refine framework of information systems audits in the Indian context. Int J Comput Sci Eng. 2019;7(5):331–45.10.26438/ijcse/v7i5.331345Search in Google Scholar
[36] Shannon C, Moore D. The spread of the witty worm. IEEE Secur Priv. 2004;2(4):46–50.10.1109/MSP.2004.59Search in Google Scholar
[37] Ullah K, Qasim M. Google stock prices prediction using deep learning. In Proceedings of the IEEE International Conference on System Engineering and Technology; 2020. p. 108–13.10.1109/ICSET51301.2020.9265146Search in Google Scholar
[38] Bhardwaj P. Finding IoT privacy issues through malware detection using the XGBoost machine learning technique. Dublin: National College of Ireland; 2022.Search in Google Scholar
[39] Sree VK, Shravani P, Sravani V, Devendar P. Intelligent malware detection using extreme learning machine. Turk J Comput Math Educ. 2023;14(2):50–63.Search in Google Scholar
[40] Yan S, Ren J, Wang W, Sun L, Zhang W, Yu Q. A survey of adversarial attack and defense methods for malware classification in cybersecurity. IEEE Commun Surv Tutor. 2022;25(1):467–96.10.1109/COMST.2022.3225137Search in Google Scholar
[41] Hernandez-Suarez A, Sanchez-Perez G, Toscano-Medina LK, Perez-Meana H, Olivares-Mercado J, Portillo-Portillo J, et al. ReinforSec: An automatic generator of synthetic malware samples and denial-of-service attacks through reinforcement learning. Sensors. 2023;23(3):1231.10.3390/s23031231Search in Google Scholar PubMed PubMed Central
[42] Demetrio L, Biggio B, Roli F. Practical attacks on machine learning: A case study on adversarial Windows malware. IEEE Secur Priv. 2022;20(5):77–85.10.1109/MSEC.2022.3182356Search in Google Scholar
[43] Doan BG, Yang S, Montague P, De Vel O, Abraham T, Camtepe S, et al. Feature-space Bayesian adversarial learning improved malware detector robustness. In Proceedings of the AAAI Conference on Artificial Intelligence; 2023.10.1609/aaai.v37i12.26727Search in Google Scholar
[44] Nguyen B, Zhang P. Federated learning for privacy-aware malicious website classification. In Proceedings of the IEEE International Conference on Data Science; 2024.Search in Google Scholar
[45] Choi S, Bae J, Lee C, Kim Y, Kim J. Attention-based automated feature extraction for malware analysis. Sensors. 2020;20(10):2893. 10.3390/s20102893.Search in Google Scholar PubMed PubMed Central
[46] Jemal I, Haddar M, Cheikhrouhou O, Mahfoudhi A. M-CNN: a new hybrid deep learning model for web security. In 2020 IEEE/ACS 17th International Conference on Computer Systems and Applications (AICCSA). IEEE; 2020. p. 1–7.10.1109/AICCSA50499.2020.9316508Search in Google Scholar
[47] Wu L, Zhao C, Feature-based ML. models for URL classification: Challenges and solutions. ACM Trans Web Secur. 2024;9:45–62.Search in Google Scholar
[48] Nadar V, Patel B, Devmane V, Bhave U. Detection of phishing websites using machine learning approach. In 2021 2nd Global Conference for Advancement in Technology (GCAT). IEEE; 2021. p. 1–8.10.1109/GCAT52182.2021.9587682Search in Google Scholar
[49] Yang R. Enhanced malware detection using advanced federated learning techniques. In Proceedings of the IEEE International Conference on Cybersecurity; 2024.Search in Google Scholar
[50] Puchýr J, Holeňa M. Random-forest-based analysis of URL paths. Proceedings of the International Conference; 2017.Search in Google Scholar
[51] Hall AJ, Pitropakis N, Buchanan WJ, Moradpoor N. Predicting malicious insider threat scenarios using organizational data and a heterogeneous stack-classifier. In Proceedings of the IEEE International Conference on Big Data; 2018.10.1109/BigData.2018.8621922Search in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- User profiling in university libraries by combining multi-perspective clustering algorithm and reader behavior analysis
- Exploring bifurcation and chaos control in a discrete-time Lotka–Volterra model framework for COVID-19 modeling
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations
Articles in the same Issue
- Research Articles
- Generalized (ψ,φ)-contraction to investigate Volterra integral inclusions and fractal fractional PDEs in super-metric space with numerical experiments
- Solitons in ultrasound imaging: Exploring applications and enhancements via the Westervelt equation
- Stochastic improved Simpson for solving nonlinear fractional-order systems using product integration rules
- Exploring dynamical features like bifurcation assessment, sensitivity visualization, and solitary wave solutions of the integrable Akbota equation
- Research on surface defect detection method and optimization of paper-plastic composite bag based on improved combined segmentation algorithm
- Impact the sulphur content in Iraqi crude oil on the mechanical properties and corrosion behaviour of carbon steel in various types of API 5L pipelines and ASTM 106 grade B
- Unravelling quiescent optical solitons: An exploration of the complex Ginzburg–Landau equation with nonlinear chromatic dispersion and self-phase modulation
- Perturbation-iteration approach for fractional-order logistic differential equations
- Variational formulations for the Euler and Navier–Stokes systems in fluid mechanics and related models
- Rotor response to unbalanced load and system performance considering variable bearing profile
- DeepFowl: Disease prediction from chicken excreta images using deep learning
- Channel flow of Ellis fluid due to cilia motion
- A case study of fractional-order varicella virus model to nonlinear dynamics strategy for control and prevalence
- Multi-point estimation weldment recognition and estimation of pose with data-driven robotics design
- Analysis of Hall current and nonuniform heating effects on magneto-convection between vertically aligned plates under the influence of electric and magnetic fields
- A comparative study on residual power series method and differential transform method through the time-fractional telegraph equation
- Insights from the nonlinear Schrödinger–Hirota equation with chromatic dispersion: Dynamics in fiber–optic communication
- Mathematical analysis of Jeffrey ferrofluid on stretching surface with the Darcy–Forchheimer model
- Exploring the interaction between lump, stripe and double-stripe, and periodic wave solutions of the Konopelchenko–Dubrovsky–Kaup–Kupershmidt system
- Computational investigation of tuberculosis and HIV/AIDS co-infection in fuzzy environment
- Signature verification by geometry and image processing
- Theoretical and numerical approach for quantifying sensitivity to system parameters of nonlinear systems
- Chaotic behaviors, stability, and solitary wave propagations of M-fractional LWE equation in magneto-electro-elastic circular rod
- Dynamic analysis and optimization of syphilis spread: Simulations, integrating treatment and public health interventions
- Visco-thermoelastic rectangular plate under uniform loading: A study of deflection
- Threshold dynamics and optimal control of an epidemiological smoking model
- Numerical computational model for an unsteady hybrid nanofluid flow in a porous medium past an MHD rotating sheet
- Regression prediction model of fabric brightness based on light and shadow reconstruction of layered images
- Dynamics and prevention of gemini virus infection in red chili crops studied with generalized fractional operator: Analysis and modeling
- Qualitative analysis on existence and stability of nonlinear fractional dynamic equations on time scales
- Fractional-order super-twisting sliding mode active disturbance rejection control for electro-hydraulic position servo systems
- Analytical exploration and parametric insights into optical solitons in magneto-optic waveguides: Advances in nonlinear dynamics for applied sciences
- Bifurcation dynamics and optical soliton structures in the nonlinear Schrödinger–Bopp–Podolsky system
- User profiling in university libraries by combining multi-perspective clustering algorithm and reader behavior analysis
- Exploring bifurcation and chaos control in a discrete-time Lotka–Volterra model framework for COVID-19 modeling
- Review Article
- Haar wavelet collocation method for existence and numerical solutions of fourth-order integro-differential equations with bounded coefficients
- Special Issue: Nonlinear Analysis and Design of Communication Networks for IoT Applications - Part II
- Silicon-based all-optical wavelength converter for on-chip optical interconnection
- Research on a path-tracking control system of unmanned rollers based on an optimization algorithm and real-time feedback
- Analysis of the sports action recognition model based on the LSTM recurrent neural network
- Industrial robot trajectory error compensation based on enhanced transfer convolutional neural networks
- Research on IoT network performance prediction model of power grid warehouse based on nonlinear GA-BP neural network
- Interactive recommendation of social network communication between cities based on GNN and user preferences
- Application of improved P-BEM in time varying channel prediction in 5G high-speed mobile communication system
- Construction of a BIM smart building collaborative design model combining the Internet of Things
- Optimizing malicious website prediction: An advanced XGBoost-based machine learning model
- Economic operation analysis of the power grid combining communication network and distributed optimization algorithm
- Sports video temporal action detection technology based on an improved MSST algorithm
- Internet of things data security and privacy protection based on improved federated learning
- Enterprise power emission reduction technology based on the LSTM–SVM model
- Construction of multi-style face models based on artistic image generation algorithms
- Research and application of interactive digital twin monitoring system for photovoltaic power station based on global perception
- Special Issue: Decision and Control in Nonlinear Systems - Part II
- Animation video frame prediction based on ConvGRU fine-grained synthesis flow
- Application of GGNN inference propagation model for martial art intensity evaluation
- Benefit evaluation of building energy-saving renovation projects based on BWM weighting method
- Deep neural network application in real-time economic dispatch and frequency control of microgrids
- Real-time force/position control of soft growing robots: A data-driven model predictive approach
- Mechanical product design and manufacturing system based on CNN and server optimization algorithm
- Application of finite element analysis in the formal analysis of ancient architectural plaque section
- Research on territorial spatial planning based on data mining and geographic information visualization
- Fault diagnosis of agricultural sprinkler irrigation machinery equipment based on machine vision
- Closure technology of large span steel truss arch bridge with temporarily fixed edge supports
- Intelligent accounting question-answering robot based on a large language model and knowledge graph
- Analysis of manufacturing and retailer blockchain decision based on resource recyclability
- Flexible manufacturing workshop mechanical processing and product scheduling algorithm based on MES
- Exploration of indoor environment perception and design model based on virtual reality technology
- Tennis automatic ball-picking robot based on image object detection and positioning technology
- A new CNN deep learning model for computer-intelligent color matching
- Design of AR-based general computer technology experiment demonstration platform
- Indoor environment monitoring method based on the fusion of audio recognition and video patrol features
- Health condition prediction method of the computer numerical control machine tool parts by ensembling digital twins and improved LSTM networks
- Establishment of a green degree evaluation model for wall materials based on lifecycle
- Quantitative evaluation of college music teaching pronunciation based on nonlinear feature extraction
- Multi-index nonlinear robust virtual synchronous generator control method for microgrid inverters
- Manufacturing engineering production line scheduling management technology integrating availability constraints and heuristic rules
- Analysis of digital intelligent financial audit system based on improved BiLSTM neural network
- Attention community discovery model applied to complex network information analysis
- A neural collaborative filtering recommendation algorithm based on attention mechanism and contrastive learning
- Rehabilitation training method for motor dysfunction based on video stream matching
- Research on façade design for cold-region buildings based on artificial neural networks and parametric modeling techniques
- Intelligent implementation of muscle strain identification algorithm in Mi health exercise induced waist muscle strain
- Optimization design of urban rainwater and flood drainage system based on SWMM
- Improved GA for construction progress and cost management in construction projects
- Evaluation and prediction of SVM parameters in engineering cost based on random forest hybrid optimization
- Museum intelligent warning system based on wireless data module
- Optimization design and research of mechatronics based on torque motor control algorithm
- Special Issue: Nonlinear Engineering’s significance in Materials Science
- Experimental research on the degradation of chemical industrial wastewater by combined hydrodynamic cavitation based on nonlinear dynamic model
- Study on low-cycle fatigue life of nickel-based superalloy GH4586 at various temperatures
- Some results of solutions to neutral stochastic functional operator-differential equations
- Ultrasonic cavitation did not occur in high-pressure CO2 liquid
- Research on the performance of a novel type of cemented filler material for coal mine opening and filling
- Testing of recycled fine aggregate concrete’s mechanical properties using recycled fine aggregate concrete and research on technology for highway construction
- A modified fuzzy TOPSIS approach for the condition assessment of existing bridges
- Nonlinear structural and vibration analysis of straddle monorail pantograph under random excitations
- Achieving high efficiency and stability in blue OLEDs: Role of wide-gap hosts and emitter interactions
- Construction of teaching quality evaluation model of online dance teaching course based on improved PSO-BPNN
- Enhanced electrical conductivity and electromagnetic shielding properties of multi-component polymer/graphite nanocomposites prepared by solid-state shear milling
- Optimization of thermal characteristics of buried composite phase-change energy storage walls based on nonlinear engineering methods
- A higher-performance big data-based movie recommendation system
- Nonlinear impact of minimum wage on labor employment in China
- Nonlinear comprehensive evaluation method based on information entropy and discrimination optimization
- Application of numerical calculation methods in stability analysis of pile foundation under complex foundation conditions
- Research on the contribution of shale gas development and utilization in Sichuan Province to carbon peak based on the PSA process
- Characteristics of tight oil reservoirs and their impact on seepage flow from a nonlinear engineering perspective
- Nonlinear deformation decomposition and mode identification of plane structures via orthogonal theory
- Numerical simulation of damage mechanism in rock with cracks impacted by self-excited pulsed jet based on SPH-FEM coupling method: The perspective of nonlinear engineering and materials science
- Cross-scale modeling and collaborative optimization of ethanol-catalyzed coupling to produce C4 olefins: Nonlinear modeling and collaborative optimization strategies
- Unequal width T-node stress concentration factor analysis of stiffened rectangular steel pipe concrete
- Special Issue: Advances in Nonlinear Dynamics and Control
- Development of a cognitive blood glucose–insulin control strategy design for a nonlinear diabetic patient model
- Big data-based optimized model of building design in the context of rural revitalization
- Multi-UAV assisted air-to-ground data collection for ground sensors with unknown positions
- Design of urban and rural elderly care public areas integrating person-environment fit theory
- Application of lossless signal transmission technology in piano timbre recognition
- Application of improved GA in optimizing rural tourism routes
- Architectural animation generation system based on AL-GAN algorithm
- Advanced sentiment analysis in online shopping: Implementing LSTM models analyzing E-commerce user sentiments
- Intelligent recommendation algorithm for piano tracks based on the CNN model
- Visualization of large-scale user association feature data based on a nonlinear dimensionality reduction method
- Low-carbon economic optimization of microgrid clusters based on an energy interaction operation strategy
- Optimization effect of video data extraction and search based on Faster-RCNN hybrid model on intelligent information systems
- Construction of image segmentation system combining TC and swarm intelligence algorithm
- Particle swarm optimization and fuzzy C-means clustering algorithm for the adhesive layer defect detection
- Optimization of student learning status by instructional intervention decision-making techniques incorporating reinforcement learning
- Fuzzy model-based stabilization control and state estimation of nonlinear systems
- Optimization of distribution network scheduling based on BA and photovoltaic uncertainty
- Tai Chi movement segmentation and recognition on the grounds of multi-sensor data fusion and the DBSCAN algorithm
- Special Issue: Dynamic Engineering and Control Methods for the Nonlinear Systems - Part III
- Generalized numerical RKM method for solving sixth-order fractional partial differential equations