Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
-
Wasan Saad Ahmed
 ,
Ziyad Tariq Mustafa AL-Ta’I
,
Ziyad Tariq Mustafa AL-Ta’I

Abstract
In the face of escalating cyber threats, a real-time automated security evidence collection system for cloud-based digital forensics investigations is essential for identifying and mitigating malicious activities. However, the substantial volumes of data generated by modern cloud-based digital systems pose difficulties in collecting and analyzing evidence promptly and systematically. To address these challenges, this research introduces an architecture that combines a security lake and a modern data lake. The primary objective of this architecture is to overcome the obstacles associated with gathering evidence from multiple cloud-based accounts and regions while ensuring the flexibility and scalability required to manage the ever-expanding data volumes encountered in cloud-based digital forensics investigations. This work focuses on gathering security events from multiple accounts and regions within a cloud environment in real-time while maintaining the integrity of the evidence and storing them in lakes, providing investigators with the flexibility to move between these lakes for analysis to get quick results. This is achieved through the utilization of security lake and modern data architecture. To validate the system, we tested it within a university system comprising numerous accounts spread across different regions within an AWS environment. Overall, the proposed system effectively gathers evidence from various sources and consolidates all data lakes into a single account. These lakes were then utilized for analyzing the evidence using Athena and Wazuh.
1 Introduction
Nowadays, cloud computing has become more commonly used within organizations over the years due to the numerous services provided to the user. As the utilization of cloud resources continues to grow, it also draws the attention of more advanced adversaries to exploit its potential. Cybercriminals have recognized the significant value proposition that cloud platforms offer, enabling them to scale up their operations and execute sophisticated attacks. A survey conducted between March 2022 and March 2023 among cybersecurity leaders of worldwide organizations revealed that, on average, 66% of organizations worldwide fell victim to a ransomware attack [1]. The estimated cost of cybercrime is expected to increase from 2023 to 2028, reaching a total of 5.7 trillion USD (+69.94%) [2]. Attackers can gain access to critical areas, such as cloud computing services, by using stolen credentials. This unauthorized access allows them to compromise the confidentiality, integrity, and availability of these services. In response to such crimes involving the cloud, investigators must conduct forensic investigations within the cloud environment. Cloud forensics, a subset of network forensics, becomes essential in these scenarios. By identifying, gathering, preserving, examining, and reporting digital evidence, cloud forensics applies scientific principles, practices, and procedures to reconstruct the events. The field of forensics is rapidly evolving, extending traditional digital forensics to encompass cloud-based environments and services [3]. According to the definition provided in [4], cloud forensics refers to the implementation of digital forensic science techniques within the context of cloud computing environments.
Digital forensics investigations require the collection and analysis of a large amount of data from various sources, including cloud infrastructure [5]. Analyzing this data is crucial for detecting attack tactics and techniques, identifying attack behaviors, determining the types of attacks, and uncovering issues related to malware and vulnerabilities [6]. To meet the increasing demand for effective data collection and analysis, investigators must leverage new technologies capable of gathering and analyzing information from multiple sources to uncover insights that were previously unattainable. The coming of the data lake concept has empowered security organizations with the ability to aggregate all data, making it readily accessible at any given time [7]. However, collecting evidence, especially logs from cloud infrastructure, poses significant challenges due to the exponential growth of digital data generated by organizations. Investigators need to be able to efficiently collect, store, and analyze this data while maintaining its integrity in digital forensics investigations [8]. The difficulties arise because security evidence is allocated across different servers in various regions, available in heterogeneous formats from different cloud layers, and must maintain data integrity in a multi-tenant environment. To overcome these challenges, previous research studies [9,10,11] have introduced different models for evidence collection and ensuring the integrity of the evidence. Other studies [12,13,14] focus more on analysis, emphasizing data collection techniques that enhance efficiency and ease of analysis, particularly for small companies. However, none of these studies address the issue of evidence collection in the context of organizations operating across multiple accounts and regions and how to centralize all the ingested data and keep it in one format. As organizations expand and require scalable infrastructure across various accounts and regions, investigators face increasing complexity in collecting evidence. The challenges come from the necessity to centralize all security evidence resources shared among accounts in different regions. The process of centralizing evidence involves copying data from various accounts with different formats and consolidating it, which is time-consuming. Time is a critical factor in digital forensics, adding pressure to the investigation process. Additionally, maintaining the integrity of evidence when resources are shared among multiple accounts, spread across various locations, and accessible by various parties without breaching the confidentiality of others, presents further challenges.
Furthermore, the unprecedented growth of data volumes from terabytes to petabytes, and even exabytes, further compounds this challenge [15]. Traditional on-premises data analytics approaches are inadequate for handling these volumes due to their limited scalability and high costs. In general, investigators must have the capability to readily retrieve and examine various forms of data, including structured, semi-structured, unstructured, and real-time streaming data, To conduct thorough and effective analyses, they also need to get and move data between their centralized data lakes and the surrounding purpose-built data services in a seamless, secure, and compliant way, to get insights with speed and agility.
Currently, cloud providers offer services that can be utilized to develop advanced systems for forensic investigators. In this article, we introduce a system that automates the collection and storage of evidence, providing investigators with a robust and secure platform for conducting thorough investigations efficiently and promptly. This system will leverage various cloud services provided by the AWS environment. Initially, the system will utilize services to gather logs from different accounts. Subsequently, it will employ the capabilities of a security lake and modern data lake architecture to serve as a centralized repository for security-related data and analytics, along with a design for scalable and flexible data storage, processing, and analysis.
The proposed Digital Forensics Architecture for Real-Time Automated Evidence Collection and Centralization by using Security Lake and Modern Data Architecture makes significant contributions to digital forensics investigation by gathering security evidence from multiple accounts and regions automated in real time. The main contributions of this work are listed below:
The system enables investigators to quickly gather, store, and analyze relevant data from multiple accounts within the organization and centralize it all in real time.
The system reduces the complexity associated with accessing data from individual accounts separately.
Centralized storage eliminates the need for separate storage systems for individual data sources or accounts, resulting in reduced storage costs and simplified data management.
Enhanced security because the components offer secure data storage, encryption, control access, and permission.
It gives seamless scalability, accommodating the growth of data over time without significant infrastructure investments. This scalability reduces costs associated with infrastructure expansion and ensures the system can manage increasing data volumes efficiently.
This article is organized into seven sections. The second section discusses related works. The third section provides preliminary knowledge about Amazon cloud services. The fourth section describes the proposed architecture and its components. The fifth section presents the implementation and evaluation of the proposed architecture. In Section 6, the results are analyzed and the limitation is presented. Finally, in Section 7, the conclusion is presented.
2 Related works
In recent years, researchers have directed their focus toward digital forensics within the cloud environment to ensure security against cyberattacks. Numerous significant research works have been conducted, with specific emphasis on digital forensics and data lake technology. Alex and Kishor attempted to address evidence collection in cloud forensics, aiming to tackle issues arising under the control of cloud service providers (CSPs) [16]. To overcome these challenges, Alex and Kishor proposed collecting all evidence outside the CSP’s control, specifically in the forensic monitoring plane. However, relying on a single forensic server as the storage location for all evidence can create a failure in a single point, leaving the evidence vulnerable to alteration and deletion if the forensic server is compromised by an attacker.
Alternatively, several researchers proposed an architecture that collects and preserves evidence for an Infrastructure-as-a-Service cloud in a blockchain, distributed among multiple peers [3,17] However, these approaches increase the complexity of data movement between analytical tools, requiring additional coordination and effort. It involves retrieving data from different peers, ensuring data consistency, and adapting it to the requirements of specific analytical tools, potentially hindering the efficiency and effectiveness of the investigation process. The model of Secure Logging as a Service (Secale’s) was introduced to establish a cloud forensics architecture that ensures the collection of various logs without loss of integrity [18]. To uphold integrity, a hash chain scheme was implemented, and periodic publication of proofs of past logs to cloud providers. However, the complexity of analyzing logs increases when they are collected in a centralized manner.
To address the problem of dependence on a CSP, the model of Forensic Acquisition and Analysis System (FAAS) was presented [19]. This agent-assisted system enables the control of all preserved evidence by an agent manager and coordinator, rather than the CSP. However, FAAS is not able to keep data provenance, which is a critical component in cloud forensics. Additionally, the involvement of multiple agents contributes to the complexity of the system. The model log aggregation was proposed for a digital forensic architecture, which includes several processes such as log extraction, acquisition, indexing, normalization, correlation, sequencing, and presentation [20]. All logs that were gathered were deposited into a central evidentiary log repository with the intent of carrying out additional analysis. Nonetheless, this centralized repository is vulnerable to attacks and can be compromised by attackers easily, as it lacks built-in security features such as access controls, encryption, and monitoring to protect against unauthorized access and suspicious activities. Once attackers gain access to the repository, they can modify or delete the logs, making it challenging to conduct accurate and reliable forensic investigations.
A forensic acquisition approach based on fuzzy-based data mining was proposed in Santra et al. [21]. The approach involved the use of a fuzzy expert system for monitoring, analyzing, and generating evidence for cloud logs. The CSP maintained control over the storage and management of all evidence. However, since the CSP cannot be entirely trusted in a cloud environment, the reliability of the evidence is reduced. To address the dynamic configuration challenges of cloud architecture, a proposal for an adaptive evidence-collection mechanism was introduced in Pasquale et al. [22]. This mechanism considers three distinct scenarios: vulnerable databases, security breaches, and cloud configuration. By considering these scenarios, the evidence-collection process is dynamically adjusted to adapt to the specific circumstances. While this approach demonstrates adaptiveness, it falls short in terms of providing comprehensive data provenance and ensuring evidence integrity.
Since cloud computing has spread, central logging is another potential approach. Because of virtualization, data distribution, and replication, identifying and gathering data in the cloud is not an easy operation. Investigators can quickly and effectively identify and gather evidence of artifacts utilizing a single storage place through central logging [23]. Several publications have also emphasized the significance of cloud computing which is forensics-enabled and the requirement for a distinct model that gathers forensics evidence. Kebande and Venter proposed Cloud Forensics Readiness Evidence Analysis System which is designed to leverage distributed hardware clusters within the cloud environment utilizing the MapReduce framework. This System is composed of various modules, such as a forensic Database that operates through the MapReduce process. These modules include Forensics logs, hypervisor error logs virtual images, which are then stored in the forensics database [24]. Patrascu and Patriciu proposed cloud architecture with forensics capabilities to monitor various activities within a cloud environment. They introduced a cloud forensics module designed to collect all forensic evidence and logs from virtual machines, through interaction with the underlying hypervisor [25].
Despite recent research efforts, there remains a significant gap in addressing the challenges of evidence collection for organizations operating across multiple accounts and regions. Specifically, no studies have thoroughly examined how to automate the collection of security evidence in real time, centralize data lakes, and standardize ingested data from diverse sources. Additionally, the seamless movement of data between lakes and the surrounding purpose-built data services has not been adequately explored. Therefore, the architecture for automating collection and centralization while maintaining the integrity of evidence in complex environments remains a major concern in cloud forensics.
3 Preliminary knowledge to Amazon
3.1 Amazon Security Lake
During the latest Reinvent conference on November 29, 2022, AWS introduced a new managed security service called Amazon Security Lake [26]. This service automatically gathers security data from various sources, including integrated AWS services, SaaS providers, on-premises systems, the cloud, and third-party sources. The collected data are centralized into a data lake stored in S3 storage within the AWS account. Amazon Security Lake transforms ingested data into the Open Cybersecurity Schema Framework (OCSF), a widely used open-source schema, as well as the Apache Parquet format. With OCSF support, security lake integrates and normalizes security data from various enterprise sources, including AWS.
In digital forensics, security lake can be of utmost importance in the preservation of the integrity and availability of the collected data. All security events that are collected with security lake automatically encrypted by using AWS Key Management Service (AWS KMS) and Stored in S3 bucket in the account that delegate. Also, all data in transit between AWS services are encrypted. Additionally, security lake includes built-in security features such as access controls and monitoring to protect against unauthorized access and suspicious activities. Security lake can be used to store different types of security-related data, including logs, network traffic, and configuration information. These data can be analyzed and visualized using various tools and services offered by AWS, such as Amazon Athena, QuickSight, and Sage Maker [27].
Security lake is a powerful service that plays a crucial role in gathering events and security logs from different services in AWS and third-party while offering centralized access and lifecycle management. It employs an automated process to partition and transform incoming data into a format that is optimized for efficient querying. This compatibility extends to allow for easier integration with various analysis tools and services offered by AWS and third-party providers. By normalizing the data, the security lake enables multiple security solutions to consume it concurrently, with customizable access levels and configurations. It spans across multiple AWS accounts and regions, facilitating data consolidation to meet compliance requirements, and offering flexibility for tailored log collection from specific sources, accounts, and regions. Its architecture encompasses the collection of data not only from standard AWS services but also from custom sources, making it a versatile and essential component for effective security management [27].
Security Lake gathers data from custom sources as well as from the following AWS services: AWS CloudTrail management and data events (S3, Lambda), Amazon Route 53 Resolver query logs, AWS Security Hub findings, and Amazon Virtual Private Cloud (VPC) flow logs [28].
3.2 Modern data lake architected
The rapid increase in data generated by various data platforms and applications has necessitated the use of a centralized data lake for more efficient storage and analysis of large volumes of unstructured and structured data to derive meaningful insights. However, analyzing this data requires moving it between different lakes and purpose-built stores, which can be challenging due to the continuous growth of data. As a solution, AWS introduced modern data architecture to address persona-centric usage patterns [30]. This architecture enables seamless and secure data transfer between centralized data lakes and specialized analytics stores, ensuring compliance while facilitating rapid insights and adaptability. Modern data architecture represents an advancement from data lake-based and warehouse solutions. Modern data management approaches known as modern data lakes have gained popularity as an alternative solution. Data lakes provide a contemporary framework for storing and processing several types of data and empower organizations to efficiently extract valuable insights from their data assets [29,30].
The concept of data lake architecture was introduced by Giebler et al. [31] to encompass the holistic design of a data lake, encompassing various components such as data storage, infrastructure, data modeling, data flow, data organization, metadata management, data processes data security, and privacy, and data quality. In this architecture, data security and privacy, as well as the quality of data, are considered conceptual aspects, while the other components have both conceptual and system-specific physical dimensions. A data lake typically exhibits a physical and logical organization, representing the structure and storage of data within the system [31,32].
The modern data lakes incorporate five key elements that distinguish them from traditional storage systems. First, data lakes must be scalable to efficiently manage large data volumes while allowing for seamless expansion. Second, they utilize specialized tools and platforms designed to meet specific data processing requirements. Third, seamless data movement facilitates the smooth transfer of data between systems or storage repositories without interruptions. Fourth, unified governance involves implementing consistent rules, policies, and procedures to ensure data quality, security, and compliance across the organization. Lastly, performant and cost-effective solutions deliver high-performance levels while maintaining reasonable expenses. Together, these elements form the foundation of modern data lakes, enabling organizations to effectively manage and leverage their data assets [29].
3.3 AWS organizations
AWS organizations is a comprehensive account management service designed to streamline the management of multiple AWS accounts. It allows organizations to consolidate their AWS accounts under a central management structure. With AWS organizations, administrators can create new accounts within the organization and invite existing accounts to join. This centralized approach offers several benefits, including improved budget management, enhanced security measures, and simplified compliance adherence. By leveraging the capabilities of AWS Organizations, businesses can effectively meet their operational requirements while maintaining a secure and scalable cloud infrastructure [33,34].
4 Proposed architecture and methodology
In this section, we introduce the architectures of the system we have implemented after considering the above-explained problems. We have implemented a system to gather data from multiple accounts and regions in real time and store the evidence in a modern architected data lake to ensure the investigator can analyze these data with more flexibility. We also implement access controls and permissions to keep the evidence more secure by controlling who accesses the data as shown in Figure 1.
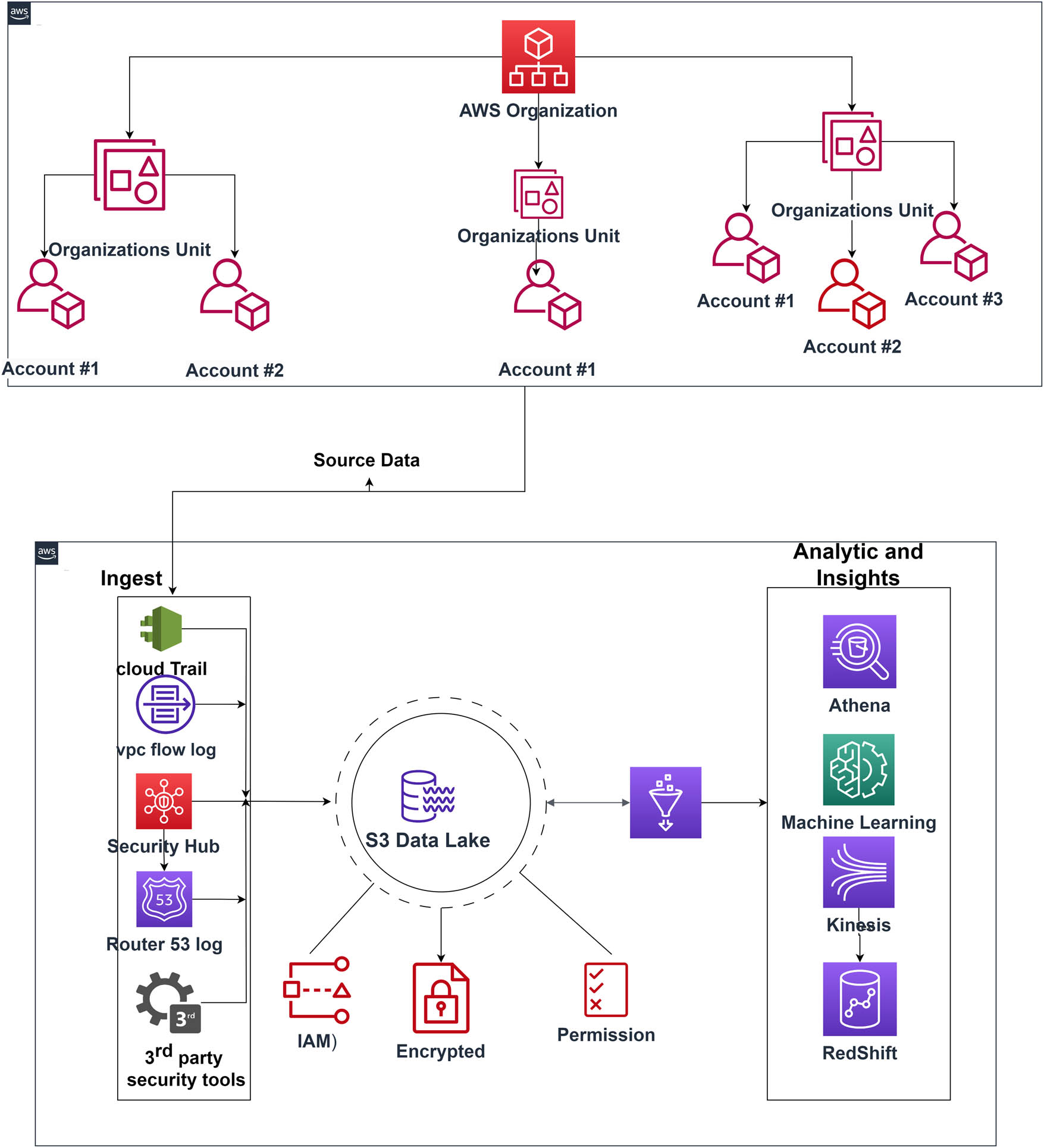
Architecture of the proposed system.
The collection of evidence from cloud-based systems, as followed in this architectural framework, depends on the following workflow steps shown in Figure 2.

Process of evidence collection from cloud-based environment.
The architecture of the proposed forensic system consists of the following main components:
4.1 Amazon Security Lake
After conducting thorough research across various papers, applications, and company journals, we have discovered a more cost effect solution to collect data from AWS organizations and centralize and normalize issues. AWS provides a diverse range of services, including a security lake service that meets the requirements of the above mentions Amazon Security Lake is a comprehensive, fully managed security data lake service that allows organizations to effectively manage and utilize security-related log and event data at scale. It simplifies and streamlines the process of consolidating security logs and events from various sources, including AWS, on-premises systems, and other cloud providers, in a cost-effective manner. With Amazon Security Lake, the collection of security-related log and event data is automated from integrated AWS services and third-party sources, and the lifecycle of that data is managed with customizable retention settings, rolling up to preferred AWS regions. The data are then transformed into a standardized, open-source format called the OCSF. Organizations can utilize the security data stored and accessed in modern data lakes for incident response and security data analytics [35].
4.2 Modern data architected
After successfully gathering the logs and evidence from various sources, it is now essential to develop a system that can store all the database operations and easily move data around for analysis purposes. We propose a modern data architecture that stores all the information in the lake and guarantees the security and flexibility of movement of the data between sources for analysis without having to build multiple copies of data. AWS’s modern data architecture emphasizes the integration of a data lake and purpose-built data services to facilitate the development of analytics workloads that offer speed and agility at a large scale.
The modern data lake architecture is designed based on the five pillars outlined in its framework [36]. First, data at any scale are achieved by leveraging Amazon S3 as the primary storage solution, offering scalability and flexibility to accommodate large volumes of data. Second, seamless data access is facilitated through the use of AWS Glue, enabling the smooth movement of data across diverse data sources. Third, unified governance is established using AWS Lake Formation, allowing for effective management of data quality, metadata, and access control policies within the data lake. Fourth, machine learning and artificial intelligence capabilities are harnessed by utilizing purpose-built AI services like Amazon Personalize, empowering the creation of personalized recommendations. Lastly, the best price performance is attained by leveraging the built-in data service. By adhering to these architectural principles, the modern data lake architecture provides a robust and efficient framework for managing and leveraging data at any scale, ensuring seamless access, maintaining unified governance, incorporating advanced AI capabilities, and optimizing cost-effectiveness.
4.3 Security Hub
Security Hub is a powerful security data aggregation platform that gathers security information from various sources, including AWS accounts, services, and supported third-party partner products. It plays a crucial role that security organizations getting a complete view of their security environment and identifying trends, even when the security findings originate from multiple sources. The most significant advantage of Security Hub, however, is its integration with CloudWatch, which allows for the automation of mitigation processes for identified security concerns. Security Hub has been introduced as a centralized management tool for various security products in an AWS environment. Inspector and GuardDuty are two examples of products that can be integrated with Security Hub. Security Hub processes security alerts and issues in bulk and organizes them based on customizable configurations. Furthermore, it conducts automated compliance checks in the background and raises findings if they do not comply with best practices [37,38].
4.4 CloudTrail
It captures and logs events that represent activities occurring within an AWS account. These events can be actions performed by Identity and Access Management (IAM) identities or monitorable services. CloudTrail records a comprehensive history of both API and non-API account activity, including actions executed through the AWS Management Console, AWS SDKs, command line tools, and other AWS services. There are three categories of events that can be tracked and logged in CloudTrail: management events, data events, and CloudTrail Insights events. By default, CloudTrail trails record management events, while data events and Insights events are not logged unless specifically configured to do so [39].
4.5 Amazon Route 53
Route 53 provides valuable data in various aspects: first, it captures DNS query data, including domain name, source IP address, query type, response code, and timestamp, allowing analysis of traffic patterns and DNS infrastructure performance. Second, it collects health check data by regularly evaluating resource health, and providing information on endpoints’ status, response times, and any issues encountered. Third, when utilizing Route 53 Traffic Flow, it gathers data on DNS traffic routing based on configured policies and health checks, optimizing routing decisions. Lastly, if query logging is enabled for VPC Resolver endpoints, Route 53 collects resolver query logs, including source IP address, domain name, query type, and response code, within the VPC [40].
4.6 Security
The integration of the security lake and modern data lake architecture provides a comprehensive security framework for data storage. One of the key components is the Access Control and Permissions feature, which leverages Amazon IAM to manage user roles, permissions, and authentication mechanisms. This enables fine-grained access control, ensuring that only authorized users and services can interact with the security lake and its components [41]. Furthermore, security lake offers server-side encryption, allowing data to be encrypted at rest. This ensures that the data remains protected even when it is not actively being accessed. In addition, data transfer to and from the security lake is secured through transport layer security (TLS) encryption [42]. This encryption mechanism ensures that data remain confidential and protected during transit, safeguarding it from unauthorized interception or tampering. By combining these security measures, the system ensures that data stored within the security lake remain confidential, protected, and secure throughout its lifecycle. The access control and permissions feature, along with server-side encryption and TLS encryption, collectively contribute to establishing a robust security framework for the storage and handling of sensitive digital evidence [43].
5 Implementation and evaluation
In this section, we will explain how the proposed system is implemented to collect and store evidence in centralized lakes automatically in real time while maintaining the integrity of evidence. This is achieved by combining security lake and modern architecture with other various services from the AWS cloud environment and building the modern data lake architecture with its key elements. We will also discuss how it was tested with a university system in AWS and integrated with third-party tools for advanced analysis. The implementation process involves several steps, each of which is detailed below.
Step 1: Create a delegate account which is the forensics account to manage the security lake and centralized lakes and add group users with permissions access.
Step 2: Identify security events and log sources to ingest from all supported and integrate services and enable them and specify the accounts and regions from which data should be collected.
CloudTrail: collect log API calls and user activities across all AWS accounts.
Security Hub: Security Hub is activated to aggregate security findings from various AWS services.
VPC Flow Logs: VPC Flow Logs are enabled to capture information about IP traffic to and from network interfaces within the VPC.
Route S3: Logging for DNS queries is enabled in Route 53.
To configure log source collection.
Step 3: Create an IAM role that gives security lake permission to gather data from all sources and add them to data lake.
Step 4: Set up storage preferences for the data and specify rollup Regions for data consolidation.
Step 5: Add subscribers to the users outside of the group in forensics account who want to access the lakes for security with less privilege.
Step 6: Establishing a modern data architecture.
This process entails cataloging the data using AWS Glue, following a series of outlined steps. First, a data catalog is created by subjecting the data sources to a crawling process, which automatically generates a catalog containing metadata that describes the data. This metadata facilitates easy exploration and querying.
Second, a schema is defined for the data once the catalog is created. This schema establishes the structure of the data, simplifying the analysis process.
Third, a Glue job is generated to extract data from the data sources, transform it, and load it into the desired data store. Glue data connectors are utilized to establish connectivity with various data sources, including Amazon S3, Amazon RDS, Amazon Redshift, and other data stores, and then scheduled the Glue job to ensure that the data remain consistently up-to-date and readily available for analysis purposes.
Finally, implementing data governance and compliance in a modern data architecture is crucial. It involves defining data governance policies that cover data handling, access control, data quality, data retention, and compliance requirements, ensuring alignment with relevant regulatory and industry standards. Robust access controls and authorization are implemented to restrict access to specific data assets within the data lake, utilizing AWS IAM for user roles, permissions, and authentication, as shown in Figure 3.
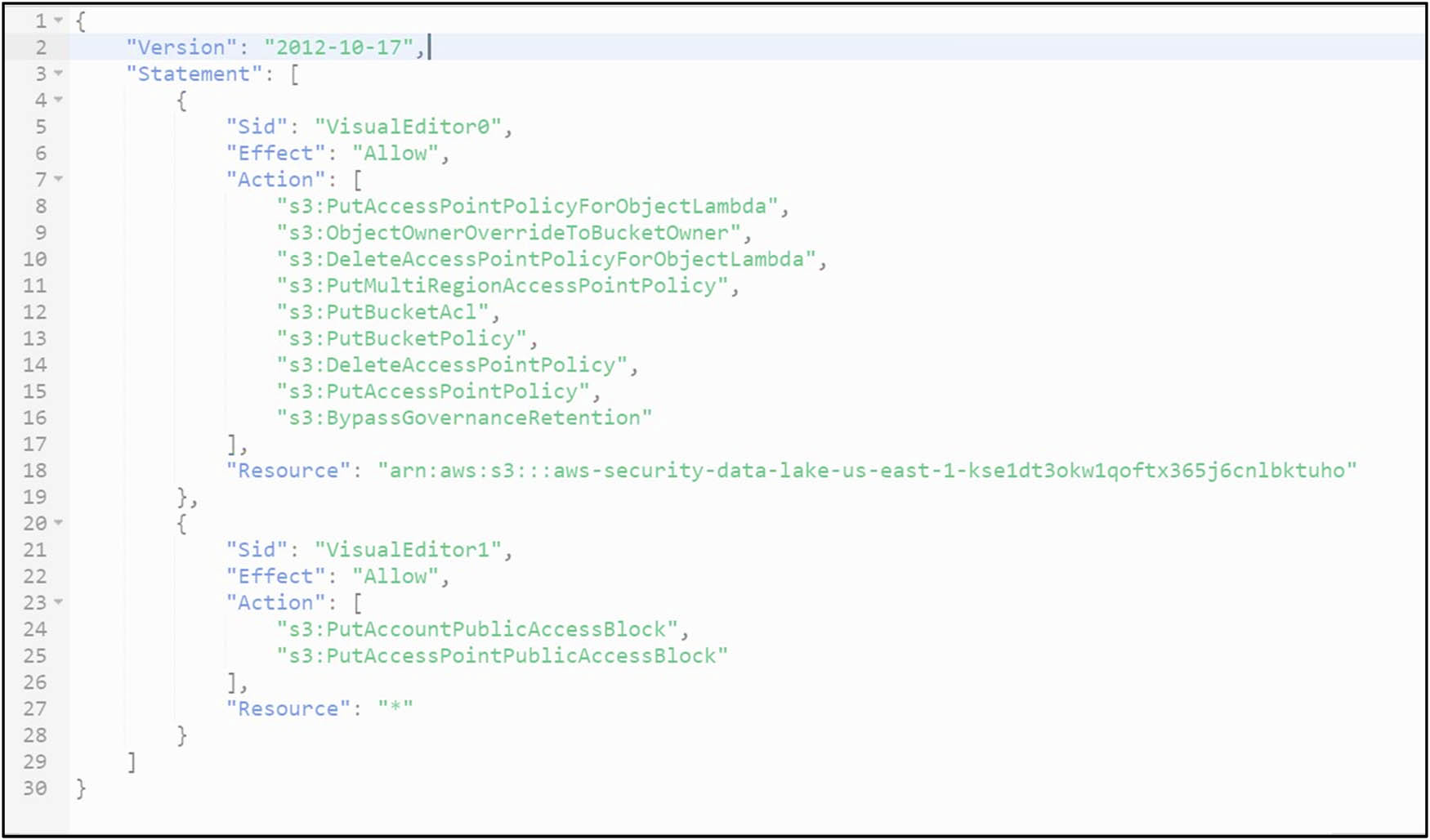
JSON file for policy.
The principle of least privilege should be followed to grant access based on job roles. Furthermore, data encryption mechanisms are deployed to protect data at rest and in transit, leveraging AWS services such as Amazon S3 Server-Side Encryption and AWS KMS for encryption key management, with a focus on sensitive data to prevent unauthorized access.
To evaluate the system, we conducted tests using a university system built on an AWS environment. This system comprises a management account, which serves as the root account, and utilizes the AWS Organizations service to create different organizational units (OUs) for various college and department accounts. Additionally, we created an account named the forensics account to collect and centralize all the lakes for all chosen accounts. We set up the experiment by selecting accounts from this organization across different regions to utilize the proposed system for automated real-time collection of security events across multiple accounts and centralization in lakes within the forensics account. To facilitate easy and rapid analysis of the data stored in these lakes, we utilized Amazon Athena and AWS Lake Formation to view and query the evidence. Furthermore, we integrated these lakes with Wazuh, an open-source Security Information and Event Management (SIEM) solution, to perform more advanced analysis.
6 Results and discussion
After testing the proposed system, we proceed to analyze the performance of the forensic architecture. In this section, we will first introduce the results obtained from implementing the system within the university. Then, we will compare our proposed approach with the previous centralized log collection approach.
Once the system was implemented and the regions and accounts were selected from which to collect security evidence, along with specifying the types of logs to be collected and enabling the services accordingly, the results, as shown in Figure 4, that eight lakes were created centralized within a single account. Additionally, one lake was created for the chosen roll-up region to consolidate all selected regions and accounts inside it. This is considered a significant advantage because it allows for one lake designated for each region, facilitating localized data management and analysis. Simultaneously, the consolidated lake encompassing all regions enables broader analysis and correlation across the entire environment. This approach offers flexibility and scalability in managing and analyzing security evidence.
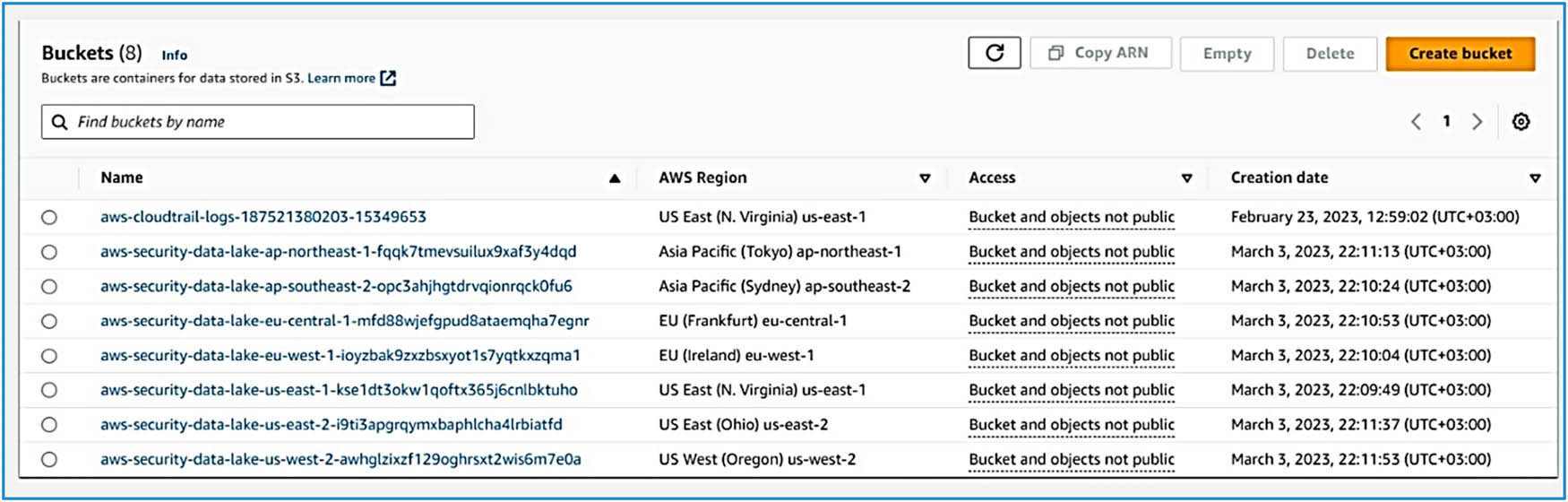
Lakes for each chosen region.
The analysis of creation time indicates that the initialization of lakes happened simultaneously, which is nearly identical to real-time as shown in Figure 5. In digital forensics, where timeliness and accuracy are crucial, this demonstrates the system’s capability of collecting evidence from multiple accounts and regions in real time. This capability is highly advantageous in forensic investigations, as it enables prompt collection, storage, and analysis of evidence, empowering investigators to quickly respond to security incidents or potential threats.
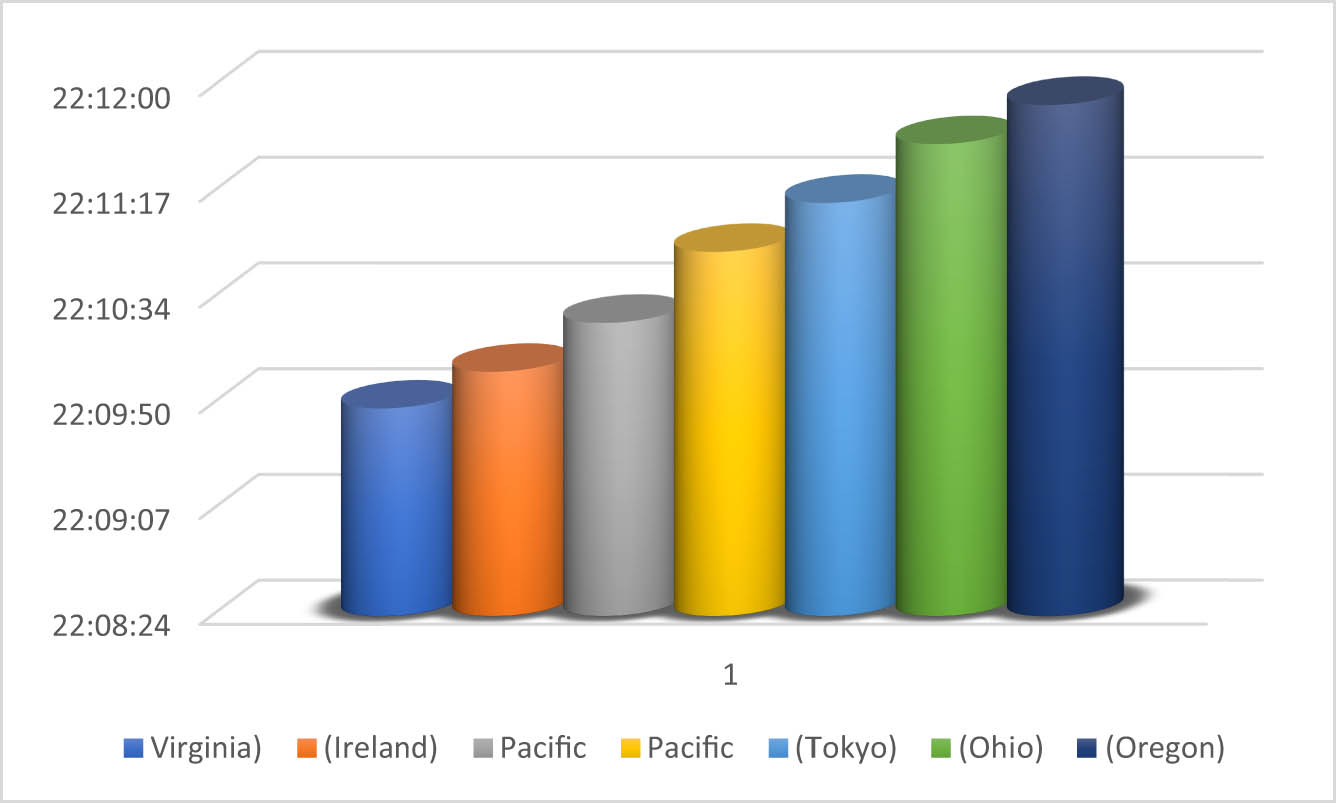
Corresponding time to create the lakes.
If we investigate deeper into each lake, we will find folders corresponding to each service enabled for log collection, along with folders for each selected account. Specifically, folders are created within the chosen region’s bucket for each service and each account that has the service enabled. For example, in this environment, CloudTrail and Security Hub findings are enabled. Figure 6 is shown in two folders: one for Security Hub and another for CloudTrail. Inside these folders, the accounts we selected to collect evidence from are included, and all the evidence is ingested inside the account folder in partial hourly intervals, as shown in Figure 7.
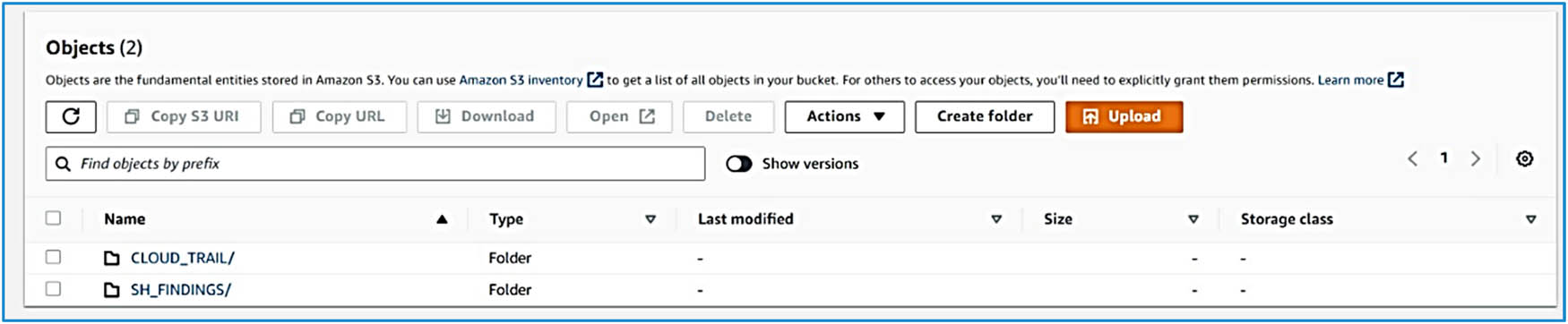
Folder for each service.
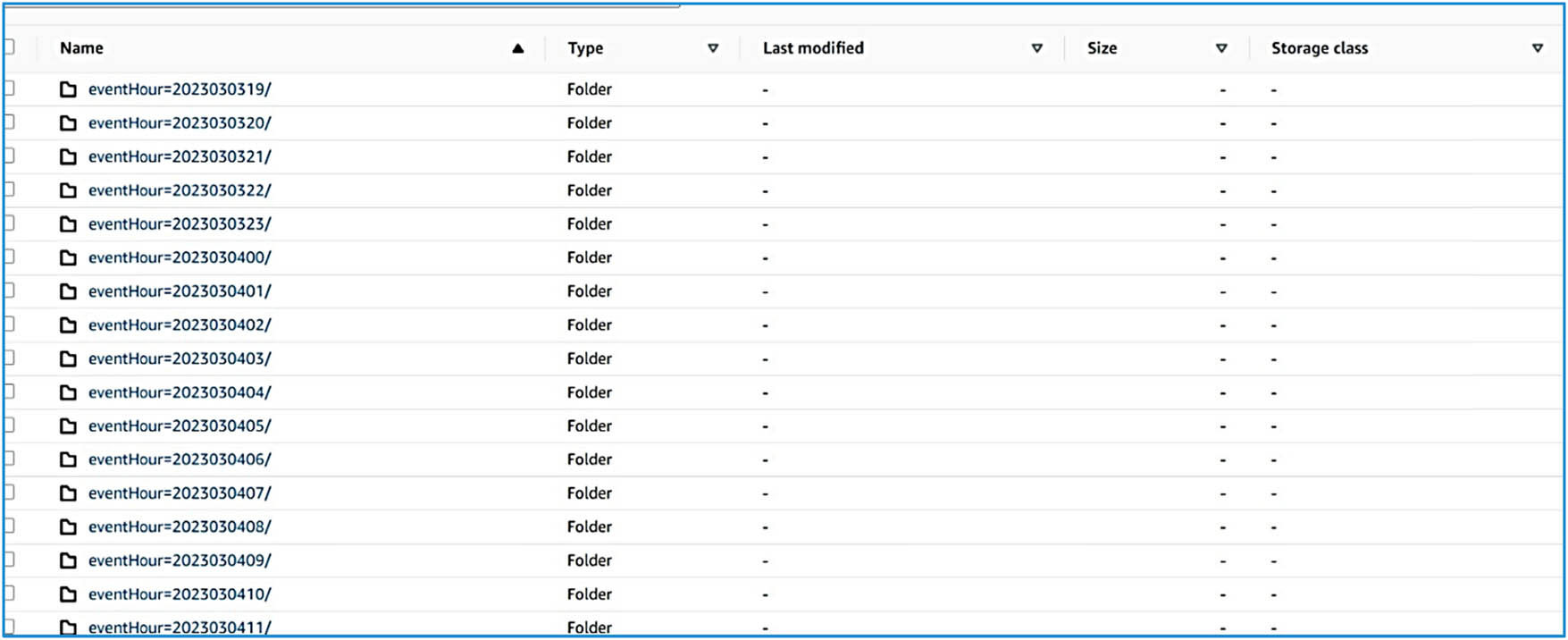
Evidence hourly partition.
If we go through all account folders, we will find that all evidence is automatically collected in real time (within about 2 min) from each account and sent to the respective S3 bucket assigned to each account, in addition to the roll-up area. This evidence is collected and organized in a unified format from all accounts, as shown in Figures 8 and 9. Although the data is collected from different sources and layers within the cloud, this approach solves the problem of having evidence available in heterogeneous formats from various cloud layers. By organizing all collected evidence into a unified format, investigators can quickly and efficiently analyze the data without needing to convert or normalize it from multiple formats. This reduces the time and effort required for data preparation.

Evidence collected with services.
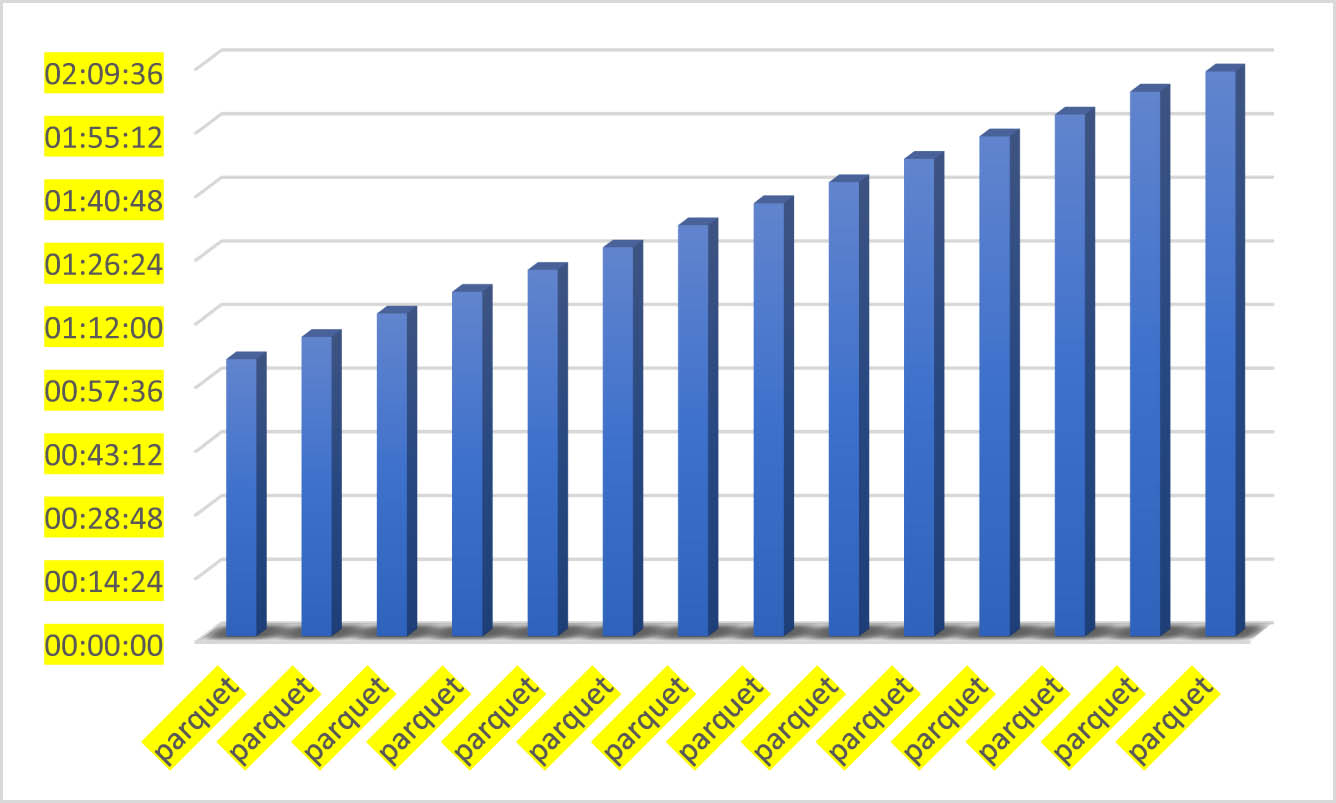
Evidence collected from services in minutes.
The data and evidence have been successfully ingested into the S3 data buckets. To establish a data catalog for each service, AWS Glue is utilized. To extract valuable insights from the data stored in the S3 buckets, a crawler is created and configured. Before setting up the crawler, it is important to create an AWS IAM role that has both S3 Full Access and Glue Service Role policies enabled.
Once the crawler is launched and subsequently stopped, tables are added to the database based on the raw data captured during the crawling process, as illustrated in Figure 10. The raw data are then cataloged within AWS Glue. At this point, investigators can effectively query or analyze the data using tools such as Amazon Athena, Amazon SageMaker, and Amazon Recognition which significantly enhance the capabilities of digital forensics by automating analysis, identifying patterns, and extracting valuable insights from forensic data.
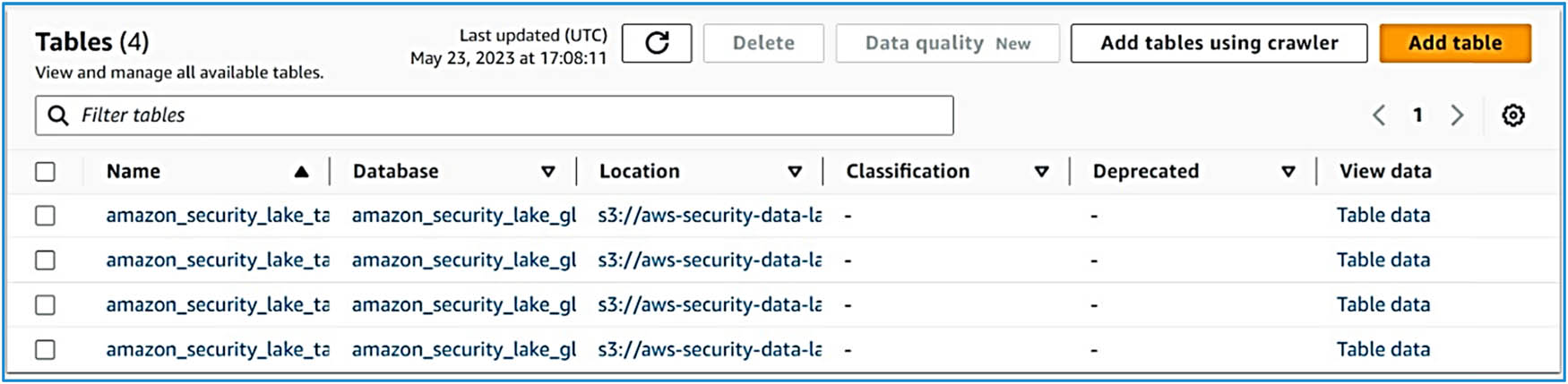
Tables for data.
For integration with third-party services, it was integrated with the Wazuh which is SIEM solution as shown in Figure 11.
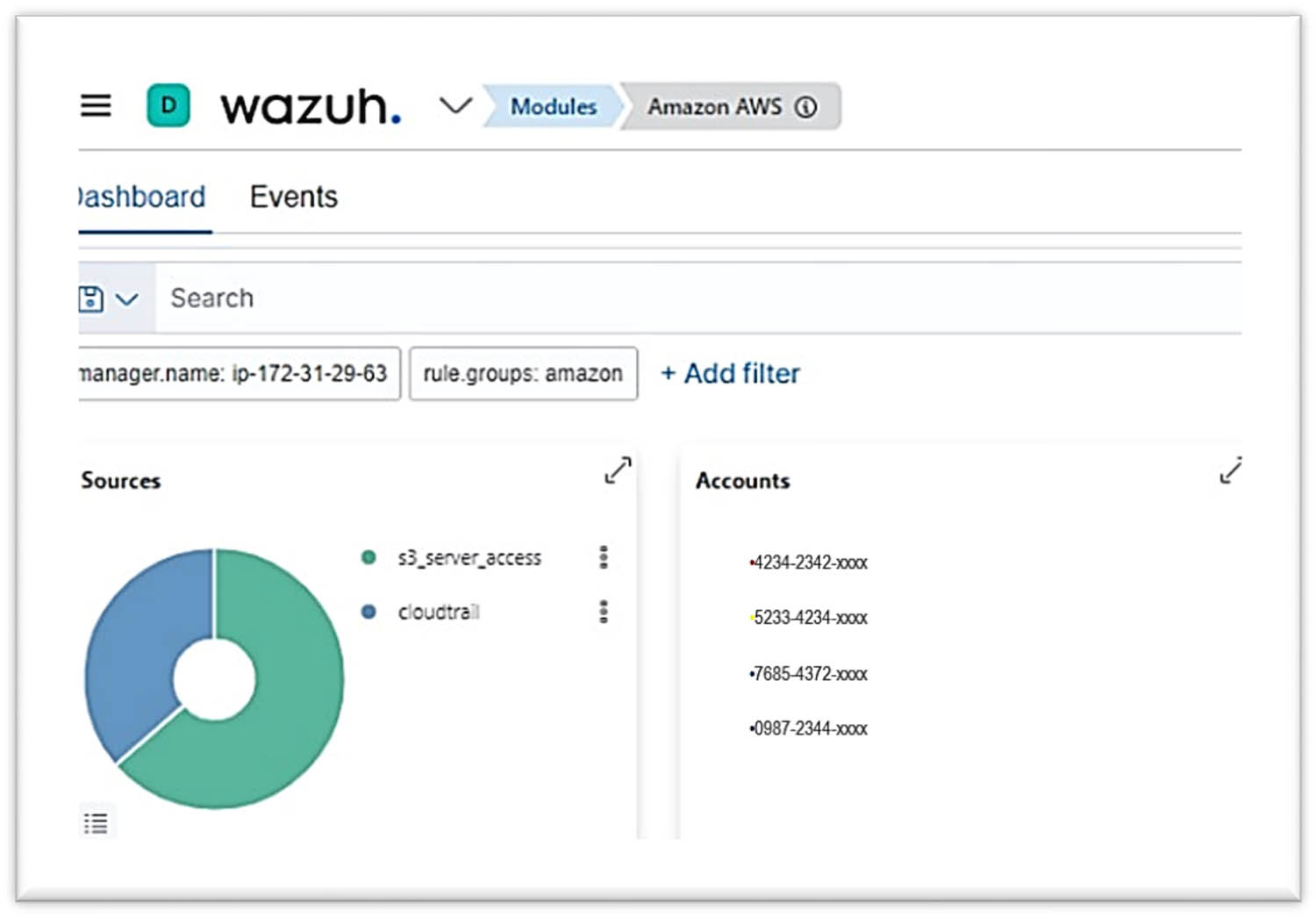
Integrated with the Wazuh.
The above results show that the proposed forensics system has the capability to collect and centralize evidence in real time by using security lake and modern data architecture. Furthermore, the integration of the system assists investigators in analyzing and answering investigation questions. This characteristic is the main strength of this system compared to other frameworks. Table 1 depicts the comparison of the proposed system and other frameworks based on these characteristics.
Characteristics of each forensic framework
| Publications | Collecting evidence | Storage | Integrates AWS services or third-party products | Integrity | Real time | ||
|---|---|---|---|---|---|---|---|
| One account | Multi-accounts and regions | Traditional Storage | Lakes | ||||
| Alex and Kishore [16] | ✓ | × | Not specify | × | × | × | × |
| Pourvahab and Ekbatanifard [3] | ✓ | × | ✓ | × | × | ✓ | × |
| Awuson-David et al. [17] | ✓ | × | ✓ | × | × | ✓ | × |
| Zawoad et al. [18] | ✓ | × | ✓ | × | × | ✓ | × |
| Alqahtany et al. [19] | ✓ | × | Not specify | × | × | × | × |
| Ahmed Khan and Ullah [20] | ✓ | × | Not specify | × | × | × | × |
| Santra et al. [21] | Not specify | × | ✓ | × | x | × | × |
| Pasquale et al. [22] | ✓ | × | ✓ | × | x | × | × |
| Trenwith and Venter [23] | ✓ | × | ✓ | × | x | × | × |
| Baror et al. [24] | ✓ | × | ✓ | × | x | × | × |
| Patrascu and Patriciu [25] | ✓ | × | Decentralize | × | x | × | ✓ |
| Proposed System | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
6.1 Limitation
The system is limited to working only with the AWS environment; all accounts must be belonged to the same organization. If AWS Organizations is not utilized, adjustments to specific policies, like the S3 bucket policy, are necessary to enable authorization from the AWS IAM roles associated with each account.
7 Conclusion
The main goal of this research was to develop a system for cloud forensics investigation that provides investigators with the ability to collect security evidence from multiple accounts and regions within a cloud-based system, store data in centralized lakes, maintain its integrity, and make analysis easier for investigators. The proposed system, based on combining Amazon Security Lake and modern data architecture, serves as a centralized repository that preserves evidence by ingesting events and logs from various regions and accounts. Additionally, these lakes can integrate with third-party tools such as Wazuh, Splunk, and Athena, facilitating advanced analysis and reporting for investigators. The automation in collecting and centralizing data, along with seamless real-time analysis, strengthens this system compared to others in cloud digital forensics. This system was evaluated using an organization built on AWS with multiple OUs and one dedicated account for forensics. The proposed system successfully created all the lakes, collected evidence from multiple accounts and regions in real time, and centralized it in one account. Future research can explore building this system in different cloud environments and integrating it with SIEM solutions for enhanced cloud security monitoring.
-
Funding information: The research does not have any funds.
-
Author contributions: Wasan Saad Ahmed: conceptualization, methodology, validation, formal analysis, resources, writing – original draft, visualization, investigation. Ziyad Tariq Mustafa AL-Ta’I: conceptualization, resources, writing – review and editing, supervision, project administration, funding acquisition. Tamirat Abegaz: writing – review and editing, supervision, project administration. Ghassan Sabeeh Mahmood: writing – review and editing, visualization.
-
Conflict of interest: Authors declare they do not have a conflict of interest.
-
Data availability statement: This research does not include any data.
References
[1] “Ransomware attacks worldwide by country 2022,” Statista. Accessed: Feb. 27, 2024. [Online]. Available: https://www.statista.com/statistics/1246438/ransomware-attacks-by-country/.Search in Google Scholar
[2] “Global cybercrime estimated cost 2028,” Statista. Accessed: Feb. 27, 2024. [Online]. Available: https://www.statista.com/forecasts/1280009/cost-cybercrime-worldwide.Search in Google Scholar
[3] Pourvahab M, Ekbatanifard G. Digital forensics architecture for evidence collection and provenance preservation in IaaS cloud environment using SDN and blockchain technology. IEEE Access. 2019;7:153349–64. 10.1109/ACCESS.2019.2946978.Search in Google Scholar
[4] Zawoad S, Hasan R. Trustworthy digital forensics in the cloud. Computer (Long Beach Calif). 2016;49(3):78–81. 10.1109/MC.2016.89.Search in Google Scholar
[5] Abbas TMJ, Abdulmajeed AS. Identifying digital forensic frameworks based on processes models. Iraqi J Sci. 2021;249–58. 10.24996/ijs.2021.Search in Google Scholar
[6] Kessler GC. Book Review: Casey, E. (2004). Digital evidence and computer crime: Forensics science, computers and the internet (2nd ed.). Amsterdam: Elsevier Academic Press. 690 pp. Crim Justice Rev. 2007;32(3):280. 10.1177/0734016807304840.Search in Google Scholar
[7] Kachaoui J, Belangour A. Challenges and benefits of deploying big data storage solution. ACM International Conference Proceeding Series; Mar 2019. 10.1145/3314074.3314097.Search in Google Scholar
[8] Mell P, Grance T, Grance T. The NIST definition of cloud computing recommendations of the National Institute of Standards and Technology. National Institute of Standards and Technology, Information Technology Laboratory. Vol. 145; 2011. 10.6028/NIST.SP.800-145.Search in Google Scholar
[9] Orr DA, White P. Current state of forensic acquisition for IaaS cloud services cloud background and needed forensic solution. J Forensic Sci Crim Inves. 2018;10(1):1–10. 10.19080/JFSCI.2018.10.555778.Search in Google Scholar
[10] Lizarti N, Sudyana D. Digital evidence acquisition system on iaas cloud computing model using live forensic method. Sci J Inform. 2019;6(1):2407–7658. 10.15294/sji.v6i1.18424.Search in Google Scholar
[11] Rathore NK, Khan Y, Kumar S, Singh P, Varma S. An evolutionary algorithmic framework cloud based evidence collection architecture. Multimed Tools Appl. Mar 2023;82(26):39867–95. 10.1007/S11042-023-14838-8/METRICS.Search in Google Scholar
[12] Almadhoor L, Bd El-Aziz AA, Hamdi H. Detecting malware infection on infrastructure hosted in IaaS cloud using cloud visibility and forensics. Int J Adv Comput Sci Appl. 2021;12(6):2021. 10.14569/IJACSA.2021.01206106.Search in Google Scholar
[13] Akilal A, Kechadi MT. An improved forensic-by-design framework for cloud computing with systems engineering standard compliance. Forensic Sci Int: Digital Invest. Mar 2022;40:301315. 10.1016/j.fsidi.2021.301315.Search in Google Scholar
[14] Hakim AR, Ramli K, Gunawan TS, Windarta S. A novel digital forensic framework for data breach investigation. IEEE Access. 2023;11:42644–59. 10.1109/ACCESS.2023.3270619.Search in Google Scholar
[15] Sol Kavanagh, “Forensic investigation environment strategies in the AWS Cloud,” AWS Security Blog. Accessed: May 23, 2023. [Online]. Available: https://aws.amazon.com/blogs/security/forensic-investigation-environment-strategies-in-the-aws-cloud/.Search in Google Scholar
[16] Alex ME, Kishore R. Forensics framework for cloud computing. Comput Electr Eng. May 2017;60:193–205. 10.1016/j.compeleceng.2017.02.006.Search in Google Scholar
[17] Awuson-David K, Al-Hadhrami T, Alazab M, Shah N, Shalaginov A. BCFL logging: An approach to acquire and preserve admissible digital forensics evidence in cloud ecosystem. Future Gener Comput Syst. Sep 2021;122:1–13. 10.1016/J.FUTURE.2021.03.001.Search in Google Scholar
[18] Zawoad S, Dutta AK, Hasan R. Towards building forensics enabled cloud through secure logging-as-a-service. IEEE Trans Dependable Secure Comput. Mar 2016;13(2):148–62. 10.1109/TDSC.2015.2482484.Search in Google Scholar
[19] Alqahtany S, Clarke N, Furnell S, Reich C. A forensic acquisition and analysis system for IaaS: Architectural model and experiment. Proceedings – 2016 11th International Conference on Availability, Reliability and Security, ARES 2016; Dec 2016. p. 345–54. 10.1109/ARES.2016.58.Search in Google Scholar
[20] Ahmed Khan MN, Ullah SW. A log aggregation forensic analysis framework for cloud computing environments. Comput Fraud Secur. Jul 2017;2017(7):11–6. 10.1016/S1361-3723(17)30060-X.Search in Google Scholar
[21] Santra P, Roy P, Hazra D, Mahata P. Fuzzy data mining-based framework for forensic analysis and evidence generation in cloud environment. Adv Intell Syst Comput. 2018;696:119–29. 10.1007/978-981-10-7386-1_10/COVER.Search in Google Scholar
[22] Pasquale L, Hanvey S, McGloin M, Nuseibeh B. Adaptive evidence collection in the cloud using attack scenarios. Comput Secur. Jun 2016;59:236–54. 10.1016/J.COSE.2016.03.001.Search in Google Scholar
[23] Trenwith PM, Venter HS. Digital forensic readiness in the cloud. 2013 Information Security for South Africa – Proceedings of the ISSA 2013 Conference; 2013. 10.1109/ISSA.2013.6641055.Search in Google Scholar
[24] Baror SO, Ikuesan RA, Venter HS. Functional architectural design of a digital forensic readiness cybercrime language as a service. Eur Conf Cyber Warf Secur. Jun. 2023;22(1):73–82. 10.34190/ECCWS.22.1.1240.Search in Google Scholar
[25] Patrascu A, Patriciu VV. Logging system for cloud computing forensic environments. J Control Eng Appl Inform. Mar 2014;16(1):80–8. 10.61416/CEAI.V16I1.2181.Search in Google Scholar
[26] “Document history for the Amazon Security Lake User Guide,” Amazon Security Lake. Accessed: Dec. 18, 2023. [Online]. Available: https://docs.aws.amazon.com/security-lake/latest/userguide/doc-history.html.Search in Google Scholar
[27] “What is Amazon Security Lake?” Amazon Security Lake. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/security-lake/latest/userguide/what-is-security-lake.html.Search in Google Scholar
[28] “Collecting data from AWS services,” Amazon Security Lake. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/security-lake/latest/userguide/internal-sources.html.Search in Google Scholar
[29] Nambiar A, Mundra D. An overview of data warehouse and data lake in modern enterprise data management. Big Data Cognit Comput. 2022;6(4):132. 10.3390/bdcc6040132.Search in Google Scholar
[30] Zagan E, Danubianu M. Data lake approaches: A survey. 2020 15th International Conference on Development and Application Systems, DAS 2020 – Proceedings; May 2020. p. 189–93. 10.1109/DAS49615.2020.9108912.Search in Google Scholar
[31] Giebler C, Gröger C, Hoos E, Schwarz H, Mitschang B. A zone reference model for enterprise-grade data lake management. 2020 IEEE 24th International enterprise distributed object computing conference (EDOC), Eindhoven, Netherlands; 2020. p. 57–66, 10.1109/EDOC49727.2020.00017.Search in Google Scholar
[32] Wieder P, Nolte H. Toward data lakes as central building blocks for data management and analysis. Front Big Data. 2022;5:945720. 10.3389/fdata.2022.945720.Search in Google Scholar PubMed PubMed Central
[33] “What is AWS Organizations?” AWS Organizations. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/organizations/latest/userguide/orgs_introduction.html.Search in Google Scholar
[34] “AWS Organizations terminology and concepts,” AWS Organizations. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/organizations/latest/userguide/orgs_getting-started_concepts.html.Search in Google Scholar
[35] “Open Cybersecurity Schema Framework (OCSF),” Amazon Security Lake. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/security-lake/latest/userguide/open-cybersecurity-schema-framework.html.Search in Google Scholar
[36] “Modern Data Architecture on AWS,” Amazon Web Services. Accessed: May 29, 2023. [Online]. Available: https://aws.amazon.com/big-data/datalakes-and-analytics/modern-data-architecture/.Search in Google Scholar
[37] “What is AWS Security Hub?” AWS Security Hub. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/securityhub/latest/userguide/what-is-securityhub.html.Search in Google Scholar
[38] “Logging AWS Security Hub API calls with AWS CloudTrail,” AWS Security Hub. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/securityhub/latest/userguide/securityhub-ct.html.Search in Google Scholar
[39] “What Is AWS CloudTrail?” AWS CloudTrail. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-user-guide.html.Search in Google Scholar
[40] “What is Amazon Route 53?” Amazon Route 53. Accessed: May 29, 2023. [Online]. Available: https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/Welcome.html.Search in Google Scholar
[41] “Identity and access management for Amazon Security Lake,” Amazon Security Lake. Accessed: Jun. 11, 2023. [Online]. Available: https://docs.aws.amazon.com/security-lake/latest/userguide/security-iam.html.Search in Google Scholar
[42] “Data protection in Amazon Security Lake,” Amazon Security Lake. Accessed: Jun. 11, 2023. [Online]. Available: https://docs.aws.amazon.com/security-lake/latest/userguide/data-protection.html.Search in Google Scholar
[43] “Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation,” AWS Big Data Blog. Accessed: Jun. 11, 2023. [Online]. Available: https://aws.amazon.com/blogs/big-data/create-a-secure-data-lake-by-masking-encrypting-data-and-enabling-fine-grained-access-with-aws-lake-formation/.Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations