Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
-
Yan Wang


Abstract
As the number of online news texts continues to increase, the algorithm of automatic keyword extraction becomes a key content in facilitating users’ fast access to the desired content. This article first introduced two common algorithms: term frequency–inverse document frequency (TF–IDF) and TextRank. Then, the calculation of news title weight was added to the TF–IDF algorithm according to the characteristics of network news text. Moreover, a new automatic extraction algorithm was designed by applying Word2vec to extract semantics. The experimental results demonstrated that on the ACE2005 dataset, as the quantity of automatically extracted keywords increased, the accuracy of the TF–IDF, TextRank, and the semantics-combined TF–IDF algorithms gradually decreased, and the recall rates gradually increased. When five keywords were extracted, the gap of the semantics-combined TF–IDF algorithm with the other two algorithms was the largest, and its accuracy, recall rate, and F-measure were 72.77, 78.64, and 75.59%, respectively. Finally, the F-measure of the semantics-combined TF–IDF algorithm reached 81% for network news texts. The experimental results prove the performance of the semantics-combined TF–IDF algorithm in automatically extracting keywords from network news texts, and it will have promising applications in practice.
1 Introduction
The term “online news text” refers to news texts that are disseminated through the Internet, which have a faster dissemination speed and wider coverage compared to traditional news texts. With the Internet’s ongoing evolution, there has been a significant increase in the number of news texts in the network, which facilitates people to get news information more quickly and directly but also makes it more difficult for people to find the news they want. The use of keywords can help readers quickly comprehend the main content of a text and thus improve search efficiency, which has a significant role in various fields, such as text categorization and information retrieval [1]. With the massive growth of information, the traditional way of manual annotation has become increasingly difficult to meet current needs; thus, algorithms for automatic keyword extraction have been widely studied [2]. Compared with ordinary texts, network news texts are different in terms of text structure and writing techniques, so the present algorithms for automatic keyword extraction are not fully applicable. In this article, the traditional term frequency–inverse document frequency (TF–IDF) method was combined with the Word2vec word vector model to improve semantic extraction, and the performance of this combined approach was proved through experiments on a dataset. The research in this article provides a new reliable method for automatically extracting keywords from online news texts, which can serve as the foundation for classifying and retrieving online news texts, thereby further enhancing the efficiency of processing such texts.
2 Related works
Thiyagarajan et al. [3] studied three popular keyword extraction techniques: the rapid automatic keyword extraction, TF–IDF, and semantic fingerprinting algorithms, and found through experiments that the TF–IDF algorithm had the strongest correlation with the human assessment. Li et al. [4] designed a new unsupervised method for Weibo texts by combining two hashtag enhancement algorithms and found through experiments that the method was accurate. Yang et al. [5] introduced a word network based on the relationship between sentences. A new word-sentence approach proposed by them was found to be superior to the classical TF–IDF and TextRank algorithms in aspects of precision and recall rate through experiments. Hassani et al. [6] conducted a study on video text mining and proposed a new key phrase extraction method that considered the local and global features of every candidate phrase and conducted experiments on five datasets in English and Persian and found that the method performed better in aspects such as precision. Okada et al. [7] extended a multi-keyword pattern matching machine, called the Aho and Corasick machine, and proposed an effective substring search method to achieve keyword extraction. The simulation results showed that the method had good performance. Azcarraga et al. [8] put forward an approach called liGHtSOM, based on analyzing how weights distribute in the weight vector of the training graph and simple operations of the random projection matrix applied for input data compression. The experiment showed that the keywords obtained by the approach were highly accurate. Tixier et al. [9] introduced an unsupervised technique using the degradation of graphs, carried out experiments on documents of different sizes, and obtained good performance. Campos et al. [10] proposed YAKE, a lightweight unsupervised keyword extraction approach that uses statistical characteristics of the text from a single document to select the most significant keywords within it, and demonstrated the advantages of the method through experiments on 20 datasets. Yan et al. [11] integrated eye movement signals with electroencephalogram (EEG) signals and utilized neural networks to automatically extract keywords from microblogs. They verified the collaborative effect of EEG and eye movement signals through experiments. Zhang and Zhang [12] introduced a method that utilizes human reading time for keyword extraction. They extracted fixation durations from publicly available language resources and designed two neural network models for keyword extraction. The effectiveness of the proposed method was demonstrated through both quantitative and qualitative experiments. Zhang et al. [13] developed a neural framework for extracting keyphrases, which obtains indicative representations through conversation context encoders and inputs them into the keyphrase table to extract important words. The experiment found that this method had better performance than previous models.
3 Automatic keyword extraction algorithm combined with semantics
Keywords refer to the words that have an important role in the text [14], and they are useful in helping people to quickly understand the content of the full text and find the text they need more quickly. Keywords are widely used in academic papers and also have good performance in various online texts.
The TF–IDF algorithm is an earlier and frequently used algorithm for automatic keyword extraction [15]. This algorithm considers that the significance of a word is directly proportional to how often it appears in the document but inversely proportional to its frequency in the corpus. TF refers to the term frequency. The calculation method of TF is
where
IDF refers to inverse document frequency
where
The TF–IDF value is obtained by
If a word has a high TF value and a low IDF value, the word is considered to have great criticality [16], and this method is simple to operate and widely used [17].
The TextRank algorithm is a refined version of the PageRank algorithm [18]. The principle of PageRank is that if a web page is linked to many other web pages, it indicates that the web page is relatively important, which means its PageRank value is high. PageRank is calculated using the following equation:
where
TextRank is an algorithm for ranking based on graphs. It treats sentences or words in a text as nodes of a graph, treats the relationships between them as edges, and determines their importance by calculating the weights between the nodes.
The calculation formula of the PageRank-based TextRank algorithm is
where
A text is segmented into sentences. Candidate keyword graph G = (V, E) is built after preprocessing. V is the set of nodes, i.e., the obtained candidate keywords, and E is the edge between two points, which indicates the co-occurrence relationship. Subsequently, the node weight is calculated according to the above formula to obtain the most important T words.
Most of the ordinary texts are single texts, while online news texts are generally composed of titles and bodies. According to the characteristics of news texts, the titles are usually a high summary of the main content of the news. To further enhance the performance of automatic keyword extraction from online news texts, this article improves the TF–IDF algorithm by combining semantics.
First, consideration of the title is added when calculating the importance of words:
where
The TF–HF–IDF is combined with the Word2vec model [19] to improve the extraction of semantics. Suppose there is text
where
The specific process of the method is as follows. After processing the text by word segmentation and stop word elimination, the TF–HF–IDF value is computed, and then the individual words are represented by Word2vec word vectors. After that, the semantic-based similarity of the processed words is calculated. The set of semantic topic concepts is obtained by the hierarchical clustering algorithm [20], i.e., the set of words with similar semantics. Finally, the comprehensive weight value is calculated:
where
Finally, according to the comprehensive weight of words, the word with the highest weight in every semantic topic concept set is used as a keyword to obtain the keyword set of the document.
4 Experimental analysis
The experiments were conducted on a Windows 7 system with 4 GB memory. The word separation system was Institute of Computing Technology, Chinese Lexical Analysis System [21]. The algorithm was implemented through Java language programming. The experimental dataset came from the ACE2005 corpus [22], containing news reports from Xinhua News Agency and China National Radio. Table 1 presents the statistics of the corpus.
ACE2005 corpus
| 1.5 characters = 1 word | |
|---|---|
| Broadcast | 20,000 words |
| Newswire | 20,000 words |
| Weblog | 10,000 words |
There were 500 texts in the dataset. The semantics-combined TF–IDF algorithm was compared with TF–IDF and TextRank algorithms. The evaluation indexes as follows.
Precision: P = A/B, where A is the quantity of keywords extracted correctly by the algorithm and B is the quantity of all keywords extracted by the algorithm.
Recall rate: R = A/C, where C is the actual total number of keywords.
F-measure: F-measure = 2PR/(P + R), indicating the overall performance of an algorithm.
First, for Word2vec, the chosen dimension of word vectors will affect the results. Under other consistent conditions, the performance of the proposed method with different dimensions (64-dimensional, 96-dimensional, 128-dimensional, and 200-dimensional) was compared. Five keywords were extracted, and the outcomes are presented in Table 2.
The effect of word vector dimensions on the algorithm performance
| Training time (min) | Accuracy (%) | |
|---|---|---|
| 64 Dimensions | 8.32 | 68.92 |
| 96 Dimensions | 9.73 | 67.34 |
| 128 Dimensions | 10.67 | 71.16 |
| 200 Dimensions | 12.24 | 71.77 |
It was seen that with the gradual increase in word vector dimension, the training time of the algorithm gradually increased. When the dimension was 200, the training time of the algorithm was 12.24 min, which was increased by 14.71% compared to that when the dimension was 128, and the accuracy was 71.77%, which was increased by 0.61% compared to that when the dimension was 128. This indicated that the training time was significantly increased, but the improvement of the accuracy was limited. Therefore, the word vector dimension was set as 128 in the following experiments.
The impact of the quantity of keywords on the algorithm performance was compared. The number of keywords sampled was 1–10, and the precision variation is presented in Figure 1.
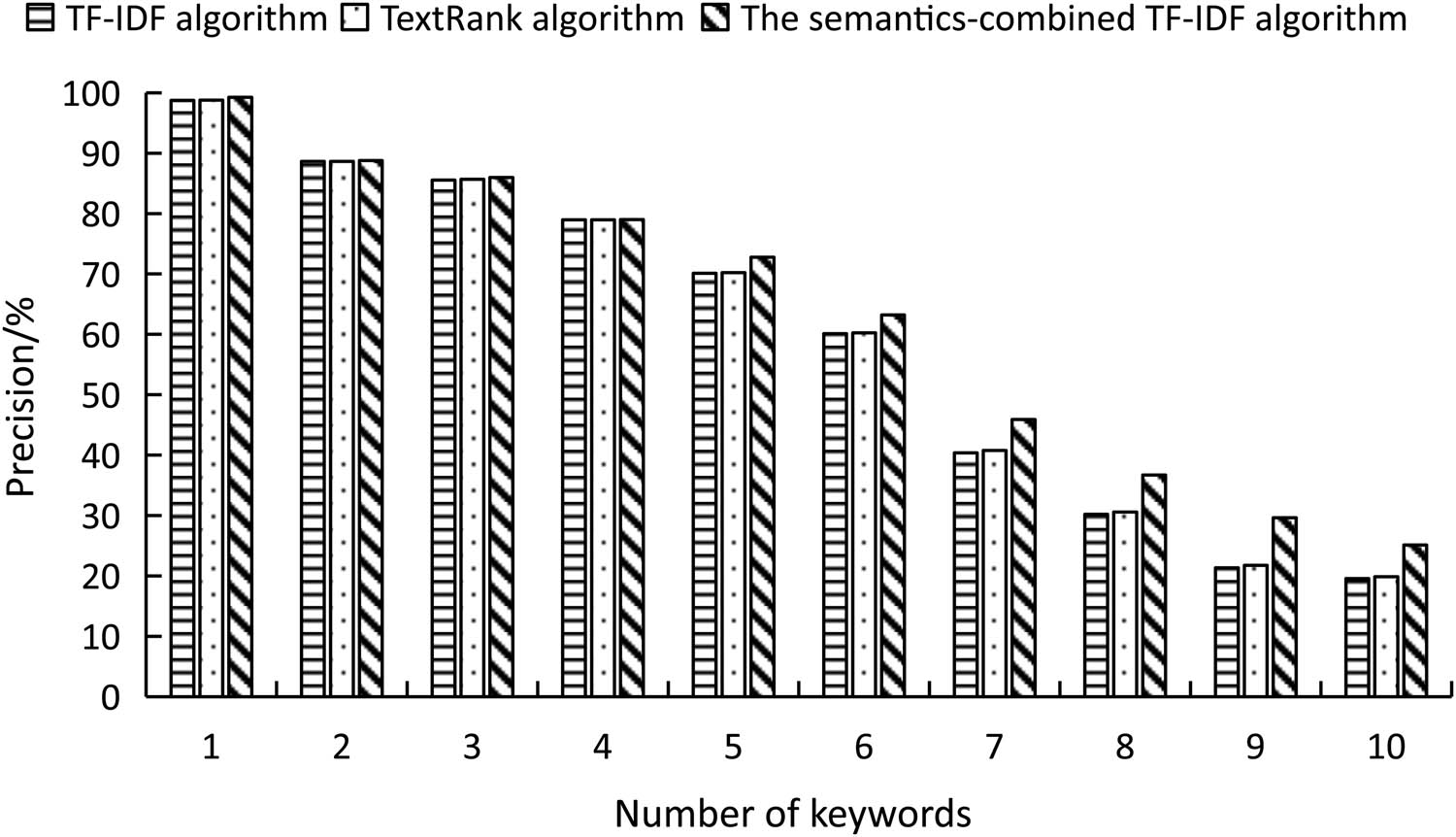
Comparison of precision between different algorithms.
It was seen from Figure 1 that when only one keyword was extracted, the precision of all three algorithms was close to 100%, indicating that all three algorithms performed good when only one keyword was extracted. When the number of extracted keywords reached five, the gap between the semantics-combined TF–IDF algorithm and the TF–IDF and TextRank algorithms started to increase; at this moment, the precision of TF–IDF and TextRank algorithms were 70.12 and 70.23%, respectively, while the precision of the semantics-combined algorithm reached 72.77%, which was improved by 2.65 and 2.54%, respectively. When the number of keywords reached ten, all three algorithms achieved their minimum accuracy levels, 19.56, 19.87, and 25.12%, respectively.
The variation of the recall rate of different algorithms is shown in Figure 2.
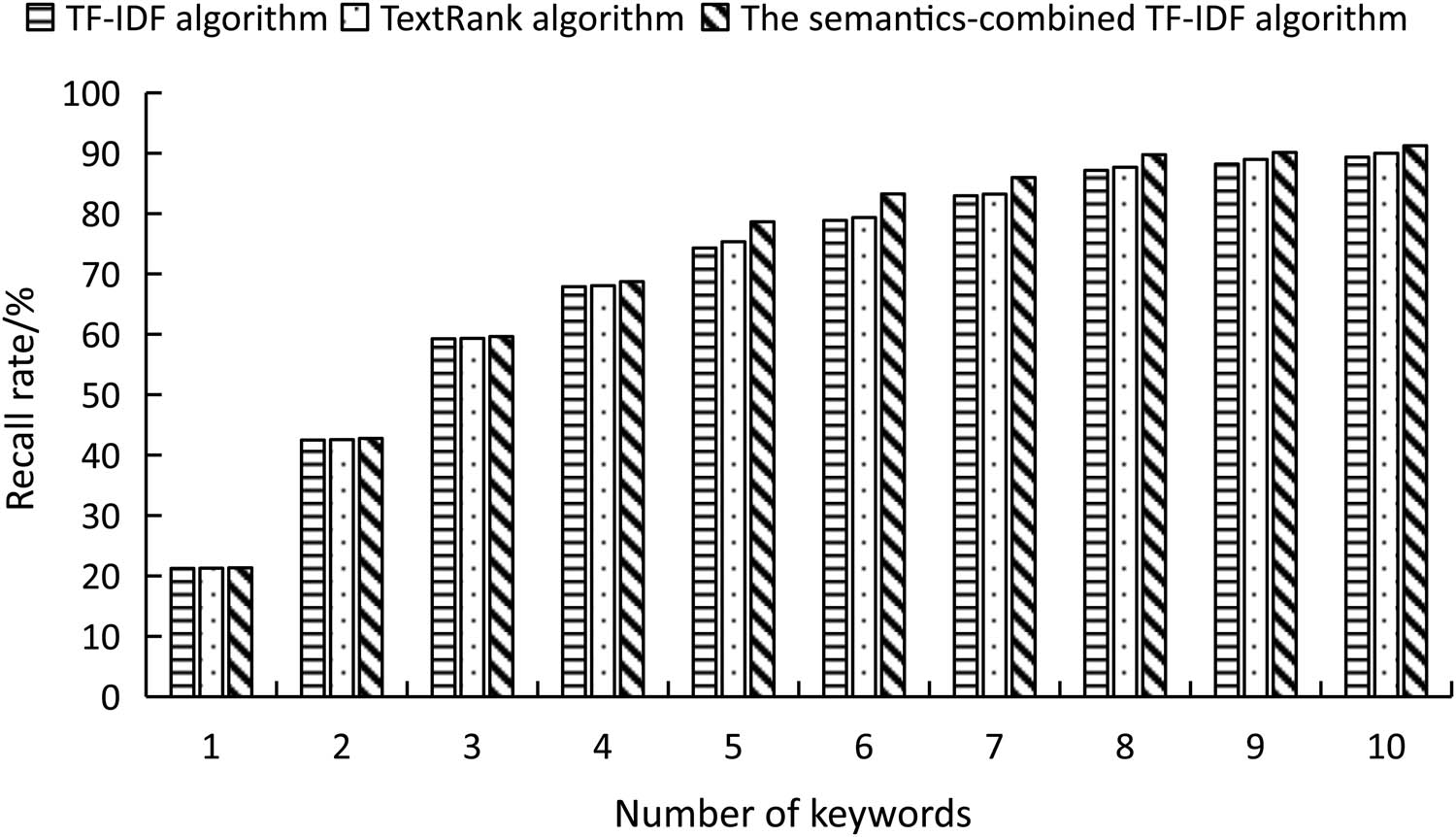
Comparison of recall rates of different algorithms.
It was seen from Figure 2 that contrary to the precision, the recall rates of different algorithms gradually improved as the number of keywords automatically extracted increased, but similar to the precision, the gap between algorithms started to become obvious when the number of keywords reached five; at this moment, the recall rate of TF–IDF and TextRank algorithms were 74.28 and 75.34%, respectively, while the recall rate of the semantics-combined algorithm was 78.64%, which was improved by 4.36 and 3.3%, respectively. When the number reached ten, the recall rate of all three algorithms was around 90%.
Finally, the F-measure of different algorithms was compared, as shown in Figure 3.
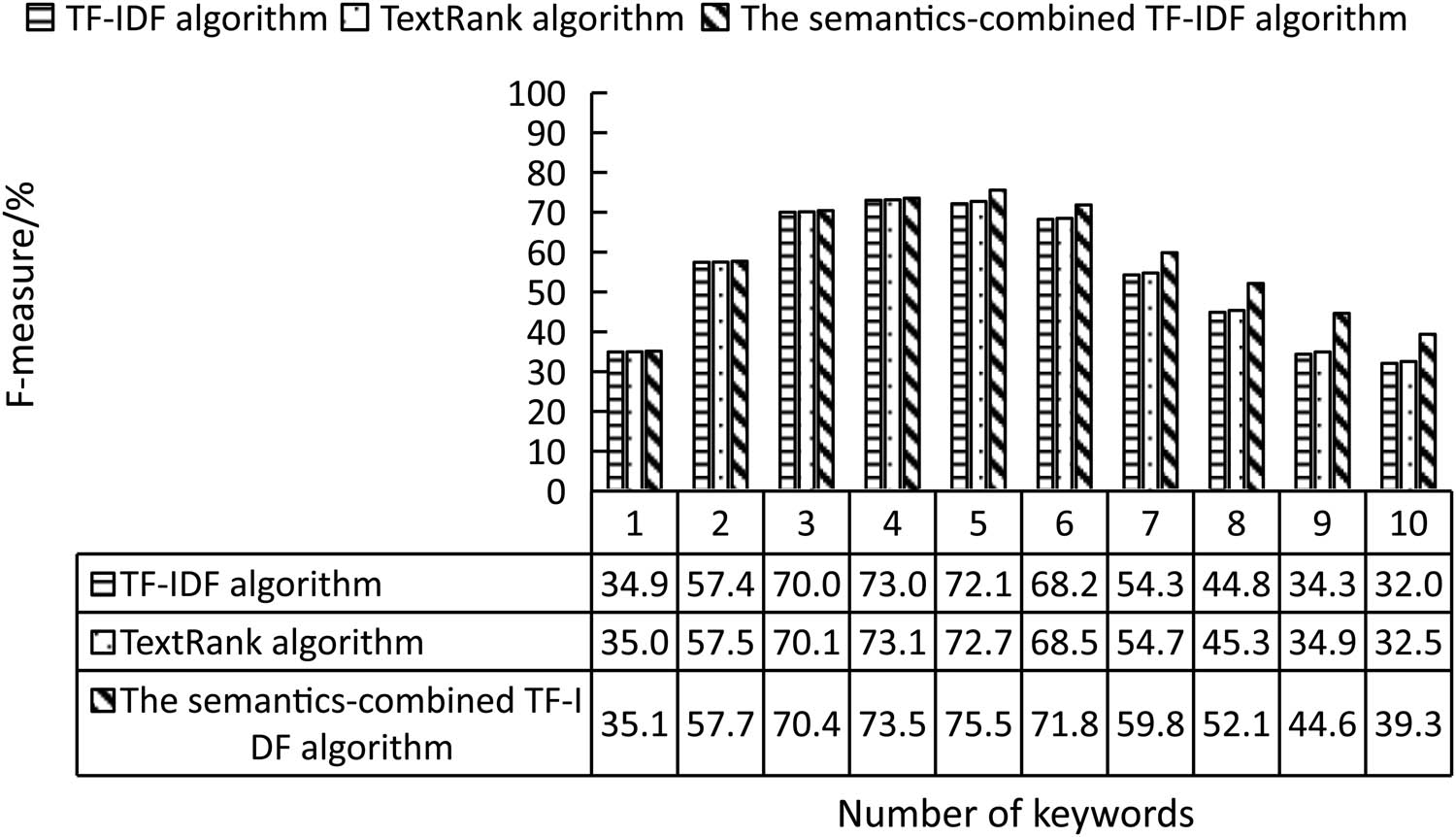
Comparison of F-measure between different algorithms.
It was seen from Figure 3 that when the number of keywords was small, the difference in the F-measure was not obvious and almost the same. When five keywords were extracted, the F-measure of the semantics-combined algorithm was 3.45 and 2.89% higher than the other two algorithms, respectively. When the number of keywords reached ten, the F-measure of TF–IDF and TextRank algorithms were 32.09 and 32.55%, respectively, while the F-measure of the semantics-combined algorithm was 39.39%. Finally, it was concluded from Figures 1–3 that the semantics-combined algorithm had the best performance when the number of extracted keywords was five.
In order to further understand the effect of the semantics-combined TF–IDF algorithm on the automatic extraction of keywords from web news texts, 500 articles were crawled from news web pages based on the Scrapy framework through a crawler tool for experiments. Ten keywords were manually labeled. Under different numbers of extracted keywords, the comparison of the F-measure is presented in Figure 4.

Comparison of F-measure between different algorithms for the automatic extraction of keywords from online news texts.
From Figure 4, it can be found that the F-measure of the semantics-based approach was higher than the other approaches in automatically extracting keywords from 500 crawled online news texts; when five keywords were extracted, the F-measure of the proposed algorithm reached the highest, 81.13%, which was 13.06% higher than the TF–IDF approach and 7.8% higher than the TextRank approach, further proving the performance of the proposed method.
Wen et al. [23] proposed an optimized weighted TextRank algorithm to extract keywords. When five keywords were extracted, the outcomes are displayed in Table 3.
Comparison between the TextRank and weighted TextRank methods
| Result | ||||
|---|---|---|---|---|
| Weight value | Precision | Recall rate | F-measure | |
| TextRank | — | 0.25656 | 0.48452 | 0.33548 |
| Weighted TextRank | 0.3 | 0.28575 | 0.53687 | 0.37298 |
| 0.5 | 0.28616 | 0.53772 | 0.37353 | |
| 0.7 | 0.28575 | 0.53636 | 0.37286 | |
In Table 3, for the weighted TextRank approach, the precision, recall rate, and F-measure value were the highest in keyword extraction when the weight value was taken as 0.5. When five keywords were extracted, the comparison of the growth amplitude of different indicators of the weighted TextRank method and the semantics-based TF–IDF method compared to the TextRank method is presented in Table 4.
Comparison between the weighted TextRank method and the semantics-based TF–IDF method
| Precision | Recall rate | F-measure | ||
|---|---|---|---|---|
| The study of literature [23] | TextRank | 0.25656 | 0.48452 | 0.33548 |
| Weighted TextRank | 0.28616 (+0.0296) | 0.53772 (+0.0532) | 0.37353 (+0.03805) | |
| This study | TextRank | 0.75216 | 0.71526 | 0.73325 |
| The semantics-based TF–IDF method | 0.82916 (+0.077) | 0.79323 (+0.07797) | 0.81125 (+0.078) | |
In Table 4, the object of the study in the literature [23] was 500 news crawled from Sohu news, and the object of this article was 500 randomly crawled online news. The amount of data in the two datasets was similar. The weighted TextRank method was improved by 0.0296, 0.0532, and 0.03805 in precision, recall rate, and F-measure compared to the TextRank method, respectively; the semantics-based TF–IDF method was improved by 0.077, 0.07797, and 0.078 in precision, recall rate, and F-measure compared to the TextRank method, respectively. Comparisons revealed that the growth rate of the semantics-based TF–IDF approach was higher than that of the TextRank approach, indicating that the semantics-based TF–IDF method was more beneficial to improving the keyword extraction effect than the weighted TextRank method.
Taking one of the online news texts entitled “iPhone 14 fastest price drop: record-breaking speed” as an example, the keyword extraction effect of the semantics-based TF–IDF method was analyzed. The text content is as follows.
After the iPhone 14 full series went on sale, the offline price of two models in the standard version was lower than the initial offer price. Even with the value of heavy upgrades such as the Spirit Island and 48 million pixels, the premium for the two models in the Pro version also fell rapidly after the launch, spot goods at the original price were available for some models and colors offline, and the service break can be expected soon.
Judging by the price trend in the last 2 days, iPhone 14 has seen a big drop in the e-commerce platform, and the offline spot price has also seen a new low. iPhone 14 has dropped by about 600 yuan, iPhone 14 plus has dropped by about 800 yuan, iPhone 14 Pro has also dropped slightly, and the price of the high-capacity version has dropped a little more.
After analysis, experts believe that compared to the iPhone 12 and iPhone 13 series in the previous 2 years, the lack of price reduction in the last month after the release means that the iPhone 14 is the model with the fastest price reduction in recent years.
The manually labeled keywords and the keywords extracted by the TF–IDF, TextRank, and semantics-based TF–IDF methods are shown in Table 5.
Example of automatic keyword extraction results
| Manual labeling | The TF–IDF algorithm | The TextRank algorithm | The semantics-combined TF–IDF algorithm |
|---|---|---|---|
| iPhone 14 | iPhone 14 | iPhone 14 | iPhone 14 |
| Price reduction | Price reduction | Price reduction | Price reduction |
| Model | Model | Model | Model |
| Drop | Price | Premium | Drop |
| E-commerce | Offline | Price | E-commerce |
It is seen from Table 5 that when automatically extracting keywords from this online news text, three keywords were correctly extracted by the TF–IDF and TextRank approaches, and the other two were different from the manually labeled results, but the keywords extracted by the semantics-combined algorithm were consistent with the manually labeled ones, which further proved the reliability of the TF–IDF algorithm combined with semantics.
5 Conclusion and future works
This article designed a TF–IDF algorithm combining semantics by combining title weights and Word2vec word vector model to improve the algorithm performance for automatic extraction of keywords. It was found through experiments that this method had advantages in precision and recall rate. This method showed greater enhancement in precision, recall rate, and F-measure than existing methods when extracting keywords. The case study showed that the extracted keywords had a better match with the manually labeled keywords. The semantics-combined TF–IDF algorithm can be further applied in the real world. However, this study also has some limitations, such as the small number of languages studied and the small number of texts. In future work, the applicability of the proposed method will be investigated in more languages and the scale of experiments will be further expanded to determine the reliability of the method.
-
Funding information: Author states no funding involved.
-
Author contributions: The author confirms the sole responsibility for the conception of the study, presented results, and manuscript preparation.
-
Conflict of interest: Author states no conflict of interest.
-
Data availability statement: The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
[1] Ahadh A, Binish GV, Srinivasan R. Text mining of accident reports using semi-supervised keyword extraction and topic modeling. Process Saf Environ Prot Part B. 2021;155:455–65.10.1016/j.psep.2021.09.022Search in Google Scholar
[2] Zhou Q, Shi X, Ge L. Predicting mental disorder from noisy questionnaires: an anomaly detection approach based on keyword extraction and machine learning techniques. J Intell Fuzzy Syst: Appl Eng Technol. 2021;41:7167–79.10.3233/JIFS-211044Search in Google Scholar
[3] Thiyagarajan G, Prasanna S, Uma B. Automation of discussion board evaluation through keyword extraction techniques: a comparative study. IOP Conference Series: Materials Science and Engineering. vol. 1131; 2021. p. 1–7.10.1088/1757-899X/1131/1/012017Search in Google Scholar
[4] Li L, Liu J, Sun Y, Xu G, Yuan J, Zhong L. Unsupervised keyword extraction from microblog posts via hashtags. J Web Eng. 2018;17:97–124.Search in Google Scholar
[5] Yang L, Li K, Huang H. A new network model for extracting text keywords. Scientometrics: An Int J All Quant Asp Sci Sci Policy. 2018;116:339–61.10.1007/s11192-018-2743-5Search in Google Scholar
[6] Hassani H, Ershadi MJ, Mohebi A. LVTIA: A new method for keyphrase extraction from scientific video lectures. Inf Process Manage: Libr Inf Retr Syst Commun Networks: An Int J. 2022;59:1–21.10.1016/j.ipm.2021.102802Search in Google Scholar
[7] Okada M, Lee SS, Hayashi Y, Aoe J, Ando K. An efficient substring search method by using delayed keyword extraction. Inf Process Manag. 2021;37:741–61.10.1016/S0306-4573(00)00050-9Search in Google Scholar
[8] Azcarraga AP, Yap T, Chua TS. Comparing keyword extraction techniques for WEBSOM text archives. Int J Artif Intell Tools. 2008;11:219–32.10.1142/S0218213002000861Search in Google Scholar
[9] Tixier A, Malliaros F, Vazirgiannis M. A graph degeneracy-based approach to keyword extraction. Conference on Empirical Methods in Natural Language Processing, (Austin, Texas), Association for Computational Linguistics; 2016, Nov 1-5. p. 1860–70.10.18653/v1/D16-1191Search in Google Scholar
[10] Campos R, Mangaravite V, Pasquali A, Jorge AM, Nunes C, Jatowt A. YAKE! keyword extraction from single documents using multiple local features. Inf Sci. 2020;509:257–89.10.1016/j.ins.2019.09.013Search in Google Scholar
[11] Yan X, Zhang Y, Zhang C. Utilizing cognitive signals generated during human reading to enhance keyphrase extraction from microblogs. Inf Process Manag. 2024;61:103614.10.1016/j.ipm.2023.103614Search in Google Scholar
[12] Zhang Y, Zhang C. Enhancing keyphrase extraction from microblogs using human reading time. J Assoc Inf Sci Technol. 2021;72:611–26.10.1002/asi.24430Search in Google Scholar
[13] Zhang Y, Zhang C, Li J. Joint modeling of characters, words, and conversation contexts for microblog keyphrase extraction. J Assoc Inf Sci Technol. 2020;71:553–67.10.1002/asi.24279Search in Google Scholar
[14] Chen J, Hou H, Gao J. Inside importance factors of graph-based keyword extraction on chinese short text. ACM Trans Asian Low-Resour Lang Inf Process (TALLIP). 2020;19:63.1–15.10.1145/3388971Search in Google Scholar
[15] Jones KS. A statistical interpretation of term specificity and its application in retrieval. J Doc. 1972;28:11–21.10.1108/eb026526Search in Google Scholar
[16] Ramezani R. A language-independent authorship attribution approach for author identification of text documents. Expert Syst Appl. 2021;180:1–21.10.1016/j.eswa.2021.115139Search in Google Scholar
[17] Li S, Ou J. Multi-label classification of research papers using multi-label k-nearest neighbour algorithm. J Phys: Conf Ser. 2021;1994:1–10.10.1088/1742-6596/1994/1/012031Search in Google Scholar
[18] Mihalcea R, Tarau P. TextRank: Bringing Order into Texts. Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing; 2004. p. 404–11.Search in Google Scholar
[19] Sumayasuhana S, Ashokkumar S. An enhancement in machine learning approaches for novel data mining serendipitous drug usage to reduce false positive rate from social media comparing word2vec Algorithm. ECS Trans. 2022;107:13329–44.10.1149/10701.13329ecstSearch in Google Scholar
[20] Sun H. RETRACTED: business data analysis based on hierarchical clustering algorithm in the context of big data. J Phys: Conf Ser. 2021;1744:1–7.10.1088/1742-6596/1744/4/042135Search in Google Scholar
[21] Xu W. A chinese keyword extraction algorithm based on TFIDF method. Inf Studies: Theory Appl. 2008;31:298–302.Search in Google Scholar
[22] Shi X, Zeng X, Wu J, Hou M, Zhu H. Context event features and event embedding enhanced event detection. ACAI 2020: 2020 3rd International Conference on Algorithms, Computing and Artificial Intelligence, (Sanya China). Association for Computing Machinery; 2020, Dec 24–26. p. 1–6.10.1145/3446132.3446397Search in Google Scholar
[23] Wen Y, Yuan H, Zhang P. Research on keyword extraction based on Word2Vec weighted TextRank. 2016 2nd IEEE International Conference on Computer and Communications (ICCC). Chengdu, China: IEEE; 2016, Oct 14–17. p. 2109–13.10.1109/CompComm.2016.7925072Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations