Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
-
Tingting Liu
 ,
Qiyuan Liu
,
Qiyuan Liu

Abstract
As the information technology develops, educational resource recommendation system has become an indispensable part of the education field. At the same time, people’s demand for personalised educational resources is also growing; therefore, how to accurately predict user demand and provide personalised recommendations has become an important issue. In this study, a fuzzy predictive control model on the grounds of neural network is proposed to optimise the design of educational resource recommendation in the context of information technology. After experimental testing, the model recommendation fit reached 95.16 and 92.91% on the two test datasets, which are significantly higher than the control model. The average F1 values of the proposed model also reached 95.21 and 88.77%, which are higher than the control model. In other control experiments, the proposed model of this study also has a better performance. The relevant outcomes showcase that the predictive performance and recommendation effect of the model can be further enhanced by improving the structure of the neural network and the parameter optimisation method. Meanwhile, the proposed model has high performance in information overload and personalised demand, which offers a useful reference for the optimal design of educational resource recommendation system.
1 Introduction
With the advent of the information age, the ways in which educational resources are obtained and utilised have undergone tremendous changes. The traditional way of obtaining educational resources can no longer satisfy people’s requirements, and the development of information technology provides new opportunities for the establishment and optimisation of educational resource recommendation systems. Although there are various educational resource recommendation systems available on the market, there are still some shortcomings in the current educational resource recommendation systems. First, the problem of information overload makes it difficult for users to find suitable resources among numerous resources, resulting in low efficiency. Second, traditional recommendation algorithms are difficult for satisfying the diverse requirements of users [1,2]. Therefore, how to accurately predict user needs and make personalised recommendations has become an important direction of research in educational resource recommendation systems [3]. Neural networks, as a powerful pattern recognition and learning method, can extract useful features from a large amount of data. Especially the generalised matrix factorisation (GMF) algorithm, which has the advantages of general neural networks and can reduce the dimensionality of data [4]. The fuzzy predictive control (FPC) algorithm, on the other hand, is able to deal with uncertainty and ambiguity, improving the robustness and adaptability of the system. Therefore, this research combines GMF and FPC techniques to construct an accurate personalised educational resource recommendation model. There are two innovations in this research: first, the research uses a rolling optimisation algorithm to optimise the FPC algorithm, which solves the problem of the prediction time window limitation; second, using GMF for dimensionality reduction enables the FPC algorithm to maintain high accuracy in processing high-dimensional data. The structure of the article includes four parts, the first part is related work, which looks for a large number of research-related literature to make theoretical preparations for this study; the second part is the methodology, which constructs an educational resource recommendation model through FPC and GMF; the third part is the model performance test, which proposes the application performance of the model through experimental tests; the fourth part is the conclusion, which summarises the achievements and significance of this study, and points out the shortcomings of the research.
2 Related works
FPC is one of the most common types of prediction algorithms, and a number of researchers have conducted in-depth studies and explored this algorithm. For example, Fei and Liu [5] proposed a real-time nonlinear model predictive control method on the grounds of a self-feedback recursive fuzzy neural network estimator. The method integrates the advantages of fuzzy system and recurrent neural network, and significantly improves the dynamic performance through the self-feedback structure. And a gradient descent based optimisation method is utilised for solving the optimal control problem. The relevant outcomes demonstrate that the method has better performance compared to existing methods in both steady state and dynamic states. Shan et al. [6] proposed a predictive voltage and current control strategy for microgrids formed by clusters of shunt-connected distributed generating units in islanded and grid-connected modes of operation. The strategy achieves islanded and grid-connected operation and smooth transition through a unified cost function without changing the control architecture. Test results show that this control strategy outperforms the conventional method. Long et al. [7] presented a new control method that combines fuzzy control with a model predictive controller (MPC). The method makes full use of the regulation capability of the swing equation, and uses the MPC method to modify the optimal power rating of the VSG to enhance the support of the energy storage system (ESS) for power demand. The relevant outcomes verify the effectiveness of the method, which can significantly improve the frequency performance of the system. Zha et al. [8] proposed a hierarchical stability control strategy for the stability problem of four-wheel independent drive (4WID) electric vehicles. The strategy includes a fuzzy controller in the upper level, a torque distribution optimisation controller in the middle level, and a motor torque controller in the lower level. It is validated by a joint simulation platform on the grounds of Carsim and Simulink software, and the outcomes showcase that the proposed control strategy not only meets the driving dynamics requirements, but also improves the stability and security of the 4WID electric vehicle. Gao et al. [9] proposed a trajectory tracking control scheme for solving the lateral motion problem of an unmanned aerial vehicle. The scheme works on the grounds of model predictive control and linearises the nonlinear lateral motion model through small angle approximation. For the lateral motion problem, a new bounded equivalence function is proposed for solving the trajectory tracking control using the vehicle kinematics model and Taylor series expansion. The model predictive control ensures robustness and control accuracy. The relevant outcomes verify the effectiveness of the method in the real environment.
Recently, as the boost of the information technology, neural network-based prediction, and recognition models have been gradually introduced in different aspects, contributing greatly to the advancement of the corresponding industries. A new taxonomy is proposed by researchers such as Zhang et al. [10]. The taxonomy is organised along three dimensions, which are the type of participation, the type of interpretation, and the focus. The taxonomy provides a meaningful three-dimensional view as two of the dimensions are not simply categorised but allow for ordered subcategories. The proposed method is experimentally verified to be significantly useful in black-box attribute classification and effectively improves the efficiency of black-box attribute classification. Cui et al. [11] proposed a feed-forward neural network based battery charging state detection method for solving the problem of effective charging of lithium batteries. The method analyses the charging state of lithium battery in real time through feed-forward on the neural network feature extraction and fitting ability, so as to determine whether there is any abnormality in the charging state. The relevant outcomes proved that the proposed method possess excellent performance and advanced in practical applications. Hizlisoy et al. [12] presented a music emotion recognition method for music recognition and classification. The method provides features obtained by logarithmic Mel filterbank energy and Mel-frequency cepstrum coefficients through the convolutional neural network layer. The classification results show that the best performance is obtained when the new feature set is combined with standard features using long and short-term memory and a deep neural network classifier. Liu et al. [13] proposed a programmable diffractive deep neural network architecture on the grounds of a multilayer array of digitally coded meta-surfaces. The architecture acts as an active artificial neuron on the grounds of the integration of each meta-atom on the neuron surface with two amplifier chips, providing a dynamic modulation range of 35 dB (from −22 to 13 dB). The experiment shows that the framework has good dynamic adjustment ability. Hu et al. [14] proposed a solution to process videos using deep neural network visual analytics. The proposed solution aims to detect communication users that can be augmented or substituted in practice activities. The results indicated that this method had great potential in improving the effectiveness of data logging and ultimately enhancing complementarity.
In summary, the education resource recommendation model on the grounds of neural networks and FPC has great potential in improving the learning effectiveness of learners and meeting personalised needs, but further research and improvement are still essential for enhancing the accuracy, practicality, and adaptability of the model. Therefore, this study attempts to introduce new methods to improve FPC and GMF technologies, aiming to construct an efficient and accurate educational resource recommendation model.
3 Construction of an education resource recommendation model on the ground of GMF and FPC
In the current education sector, recommender systems play an important role in helping students access personalised educational resources. However, traditional recommendation methods often fail to accurately capture students’ interests and needs. Therefore, this research uses advanced generalised matrix decomposition techniques and FPC models to upgrade the educational resource recommendation model.
3.1 Research on personalised recommendation model on the ground of FPC
The demand for education has diverse and personalised characteristics, and the existing educational resources are showing an explosive growth trend. Its query efficiency and recommendation efficiency face many challenges. FPC algorithm plays a crucial role in educational resource recommendation, and its feedback correction mechanism can continuously update the correction prediction values during the process of educational resource recommendation, achieving good recommendation results [15]. The basic idea of FPC algorithm is to describe the dynamic behaviour by constructing a fuzzy rule base and to use fuzzy inference and fuzzy controller for prediction and control. The construction of FPC model requires the definition of fuzzy set, where each element has a certain degree of affiliation within a particular range of variables [16]. Therefore, the study chose FPC as the main method to explore the key challenges in educational resource recommendation systems. FPC, with its ability to handle system uncertainty and ambiguity, provides effective solutions for diverse educational needs. The RO algorithm overcomes the prediction time window limitation by optimising FPC, thereby enhancing the robustness of the system. The combination of FPC and RO enables the system to more accurately predict user needs, achieve personalised educational resource recommendations, and provide higher quality educational resource services. The construction of the FPC model requires the definition of a fuzzy set, which refers to a specific range of variables where each element has a certain degree of membership [17]. The degree of affiliation indicates how similar an element is to that fuzzy set and is usually expressed as a real value between 0 and 1. The value of the degree of affiliation is determined by the affiliation function and the expression defining the affiliation function of a fuzzy set is shown in equation (1).
where
where
where
where
where
where
Feedback correction is also an important module of the FPC algorithm, which measures and compares the output of the system, and adjusts and corrects the input of the system according to the measurement results for making the output close to the desired value. The feedback correction module contains two parts: the feedback control loop and the feed-forward positive path, and its structure is shown in Figure 1.
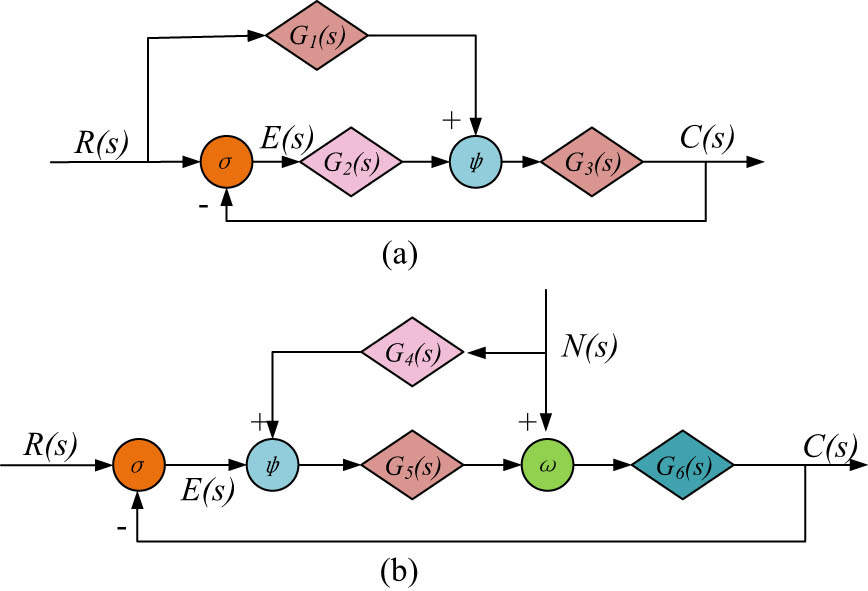
Structural diagram of feedback correction module. (a) Feedback control loop. (b) Feedforward positive path.
The feedback correction module possesses an essential influence on control systems. It can not only significantly enhance the performance of the control system and make it more comfortable in the face of uncertainty and change but also broaden the utilisation areas of the control system. The addition of the feedback correction module effectively alleviates the problem of information overload in the educational resources recommendation model. After adding the feedback correction, the construction of a more complete FPC model is basically completed, and the structure is showcased in Figure 2.
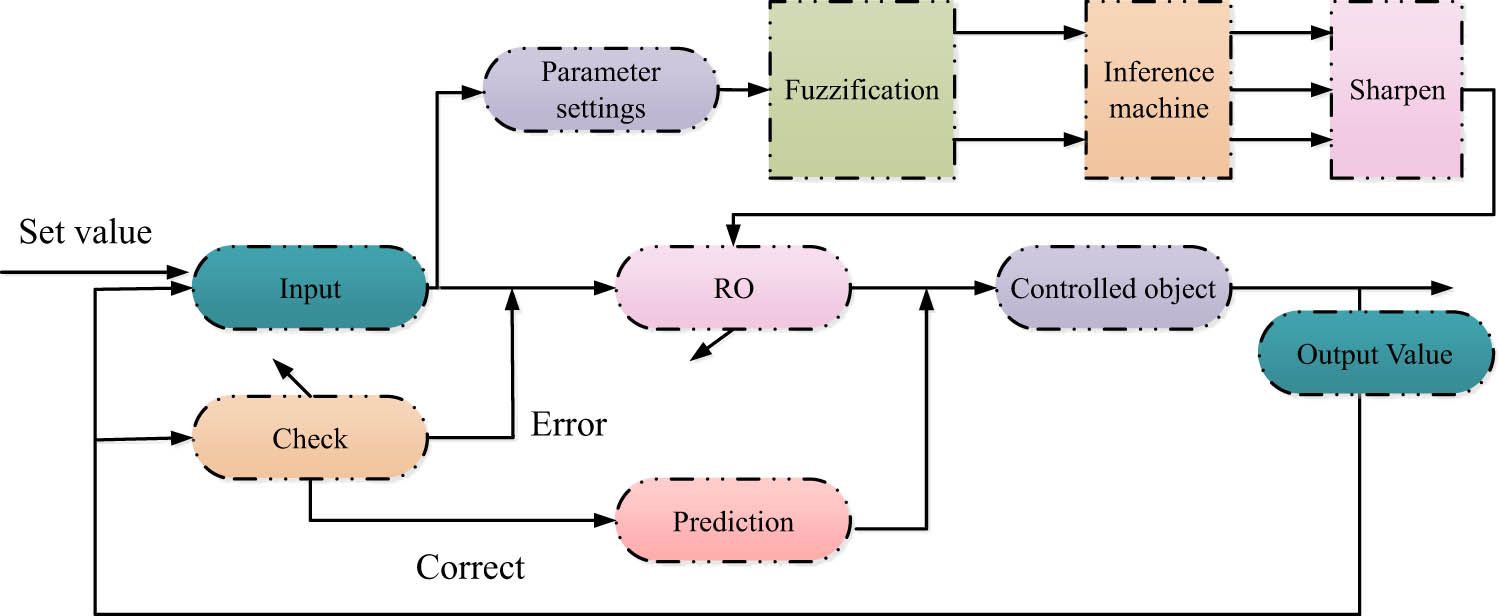
Structure diagram of FPC model.
Since the FPC model cannot handle high-dimensional data, the output accuracy of the algorithm often fails to meet the needs of personalised recommendation when facing multi-attribute optimal selection. To address the above shortcomings, the FPC model also needs to be improved by dimensionality reduction.
3.2 Construction of FPC education resource recommendation model integrating GMF algorithm
The GMF algorithm is a technique for dimensionality reduction of high-dimensional matrices, which disassembles the original high-dimensional matrix into the product of multiple matrices for achieving the influence of dimensionality reduction [19]. Therefore, the study uses the GMF algorithm to improve the FPC model and thus reach the influence of dimensionality reduction. Matrix decomposition is an important concept in linear algebra, which has an extensive range of applications in many fields [20]. Among the many matrix decomposition methods, singular value decomposition, eigenvalue decomposition, and Cholesky decomposition are well known and widely used. However, these traditional matrix decomposition methods are significantly different from the decomposition of GMF algorithm. The matrix decomposition of GMF algorithm is showcased in Figure 3.
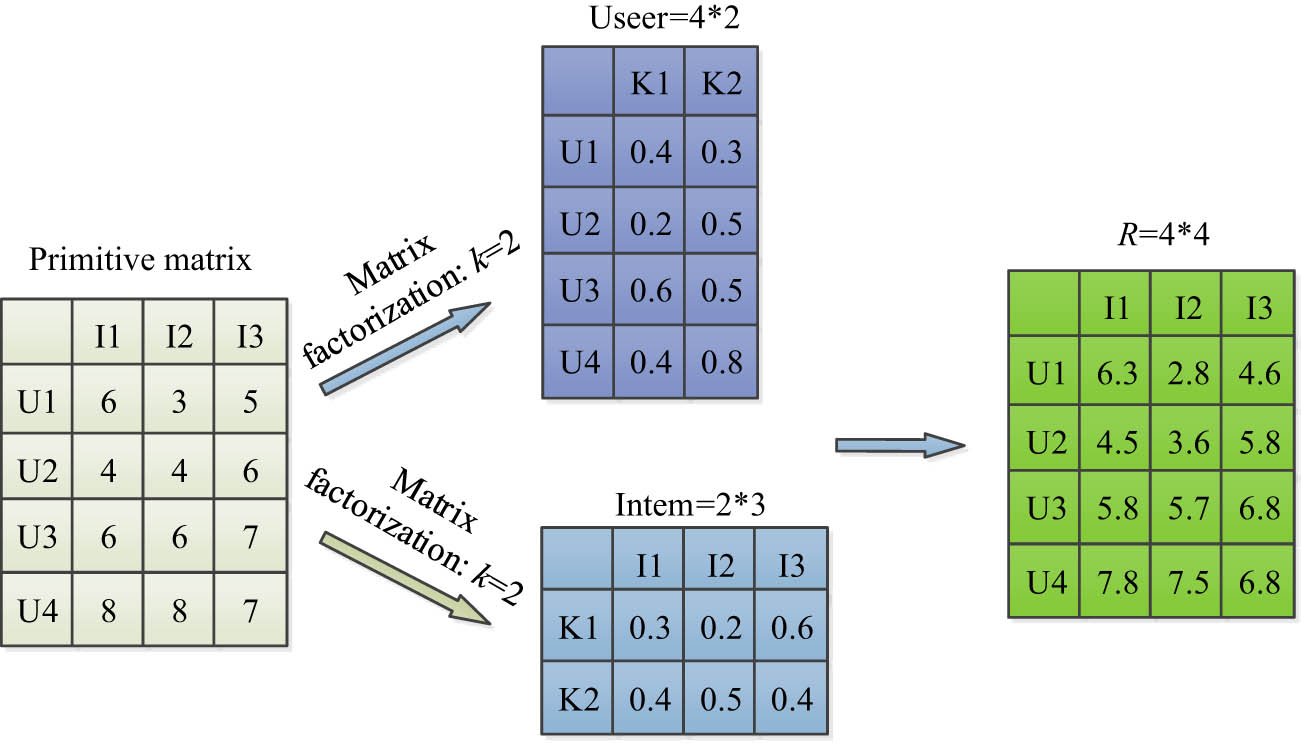
Matrix decomposition process of GMF algorithm.
The decomposition expression of the GMF algorithm is showcased in equation (8).
where
where
where
where
where
where
where
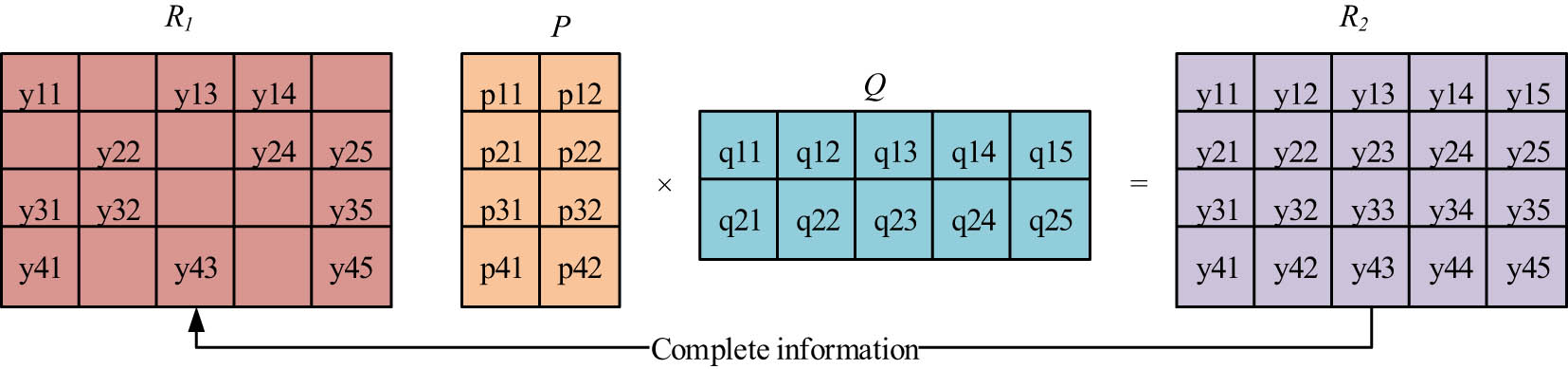
Process of improving feature information.
Aiming at obtaining the predicted values in the user and educational resource scarcity matrices in Figure 4, it is necessary to decompose the matrix
where
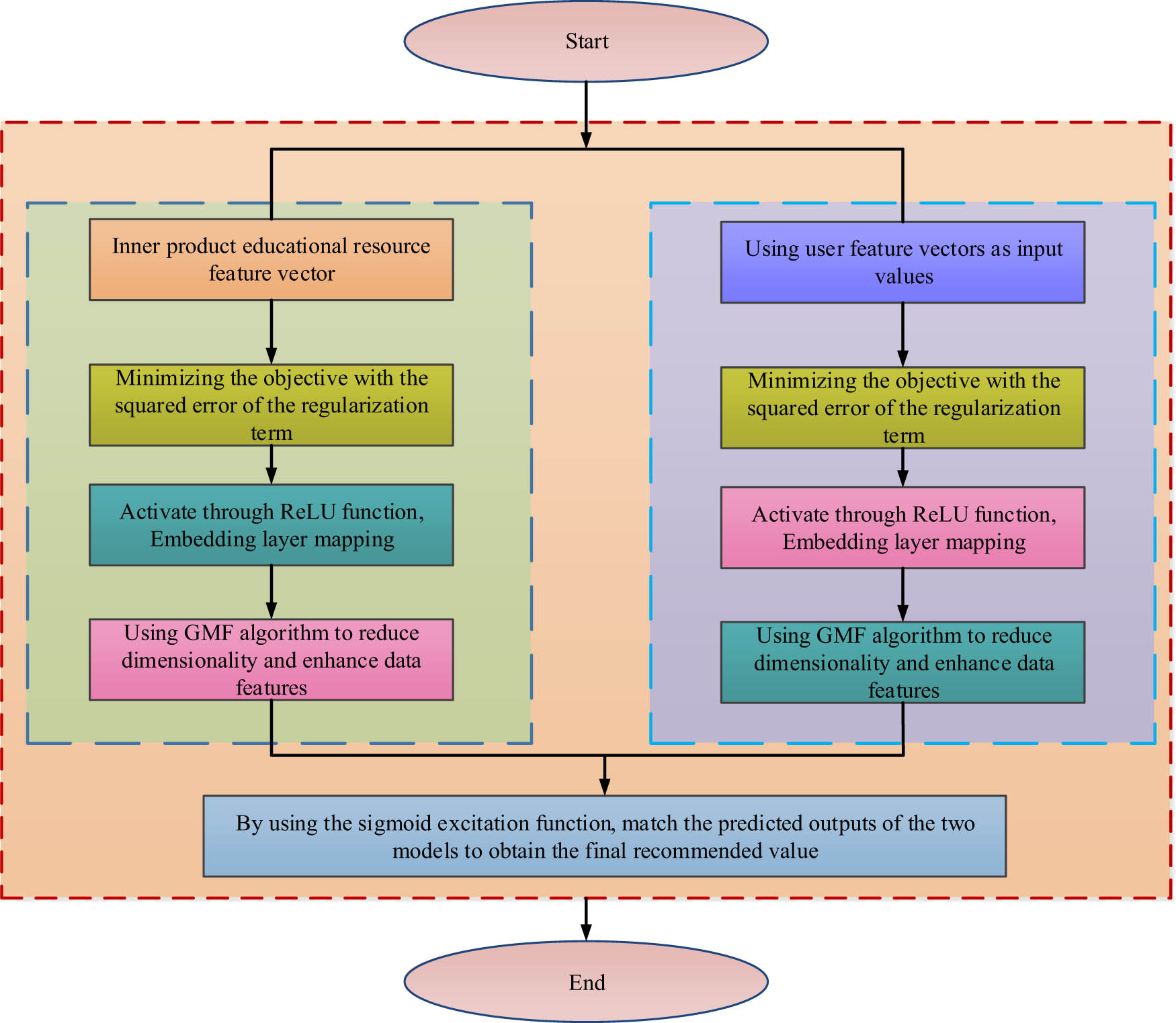
Technical framework of G-FPC model.
4 Performance analysis of G-FPC model
The study comprehensively analyses the performance of content-based recommendation (CBR), G-FPC, and collaborative filtering (CF) models on the air quality and energy efficiency datasets to evaluate the effectiveness of different models in recommendation systems. The indicators involved in the experiment include model fit, loss rate, recall rate, time complexity, F1 value, and root mean square error (RMSE). The selected comparison models include CF and CBR.
4.1 Analysis of G-FPC model classification performance and loss rate
The equipment used for this experiment is a desktop computer with 16GB of operating memory, i7-13700K CPU, and GeForce GTX 470 graphics card; the system resource is Windows 11; the data processing and analysis tool is Pandas; the editor is PyCharm; the experimental datasets are air quality and energy efficiency dataset; the control models are CF, CBR. The fit between the recommended resources output from the models and the actual user preferences is the core index of this study. This experiment takes the air quality and energy efficiency datasets as inputs, and compares the fit between the recommended resources output from the three models CBR, G-FPC, and CF and the actual user preferences, and the outcomes are showcased in Figure 6. Figure 6(a) represents the relation in the fit of each model on the air quality dataset and the number of training times. Figure 6(b) represents the relationship between the fit of each model on the energy efficiency dataset and the number of training times. The figure indicates that the fit of the G-FPC model outperforms the control model on both datasets, and the fit of the G-FPC model on the air quality dataset reaches a maximum of 95.16%, and that on the energy efficiency dataset reaches a maximum of 92.91%.
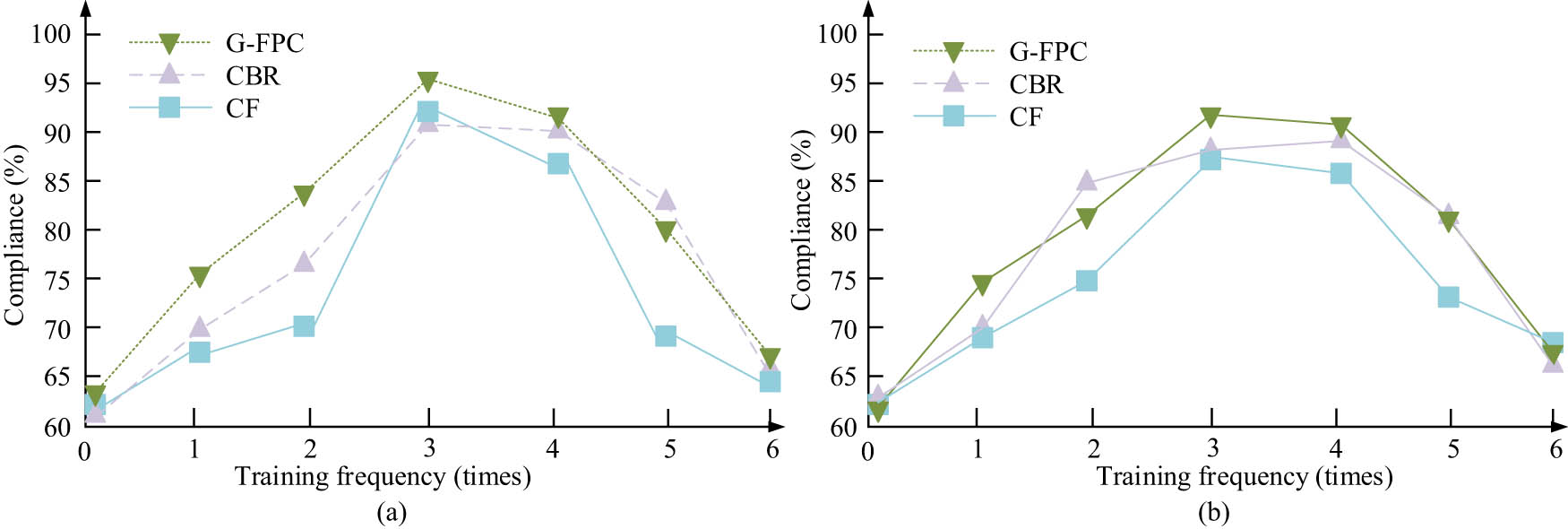
Comparison of fit between different models. (a) The fit of the model on the air quality dataset. (b) The fit of the model on the energy efficiency dataset.
Aiming at verifying the classification effect on educational resources, this experiment assumes various types of data in the energy efficiency dataset as different types of educational resources as inputs, and compares the classification effects of the CBR model and the G-FPC model. The outcomes are showcased in Figure 7. Figure 7(a) represents the classification effect of the CBR model, which has a low classification density and an error in the locating classification centre after classification. Figure 7(b) represents the classification performance of the CF model, which can have better classification performance compared to CBR, but also has the disadvantages of inaccurate classification centre position and low classification density. Figure 7(c) shows the classification effect of the G-FPC model, which classifies with high density and also locates the classification centre more accurately.
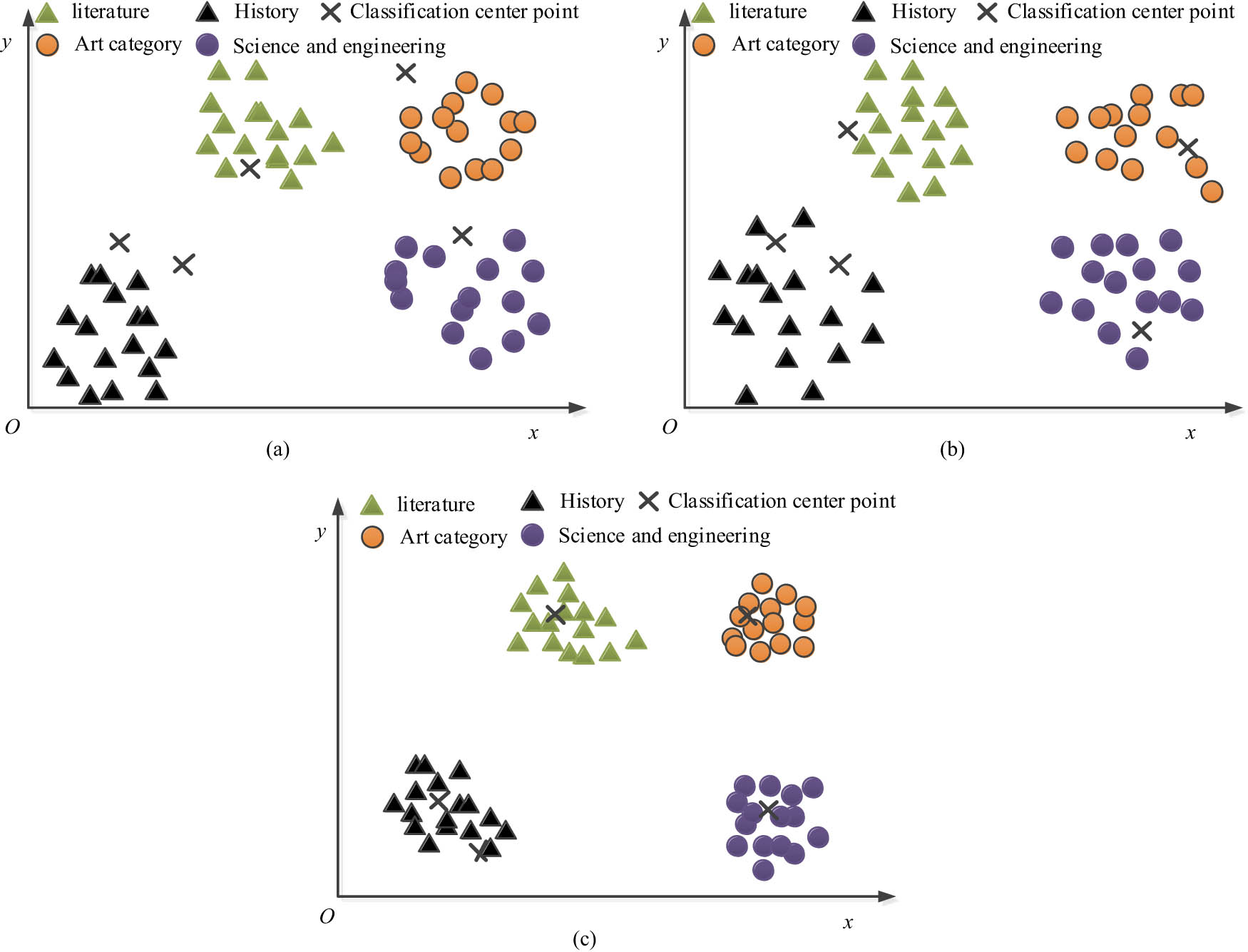
Comparison of model classification effects. (a) CBR model classification performance. (b) CF model classification performance. (c) G-FPC model classification performance.
In order to analyse the relationship between the loss rate and the number of iterative steps, this experiment uses the air quality dataset as input and compares the loss rate of the CBR and G-FPC models and the average loss rate calculated after three experiments, and the outcomes are showcased in Figure 8. Figure 8(a) represents the relation in the loss rate and the number of iteration steps for the first experiment of the CBR and G-FPC model; Figure 8(b) represents the relation in the average loss rate and the number of iteration steps after repeating the three experiments. From the figure, it can be seen that the trend of the change in the loss rate and the change in the average loss rate of the first experiment are basically the same. The G-FPC model possesses a lower loss rate with the same number of iterative steps, and at the same time, the number of convergence steps of the G-FPC model is smaller than that of the CBR model.
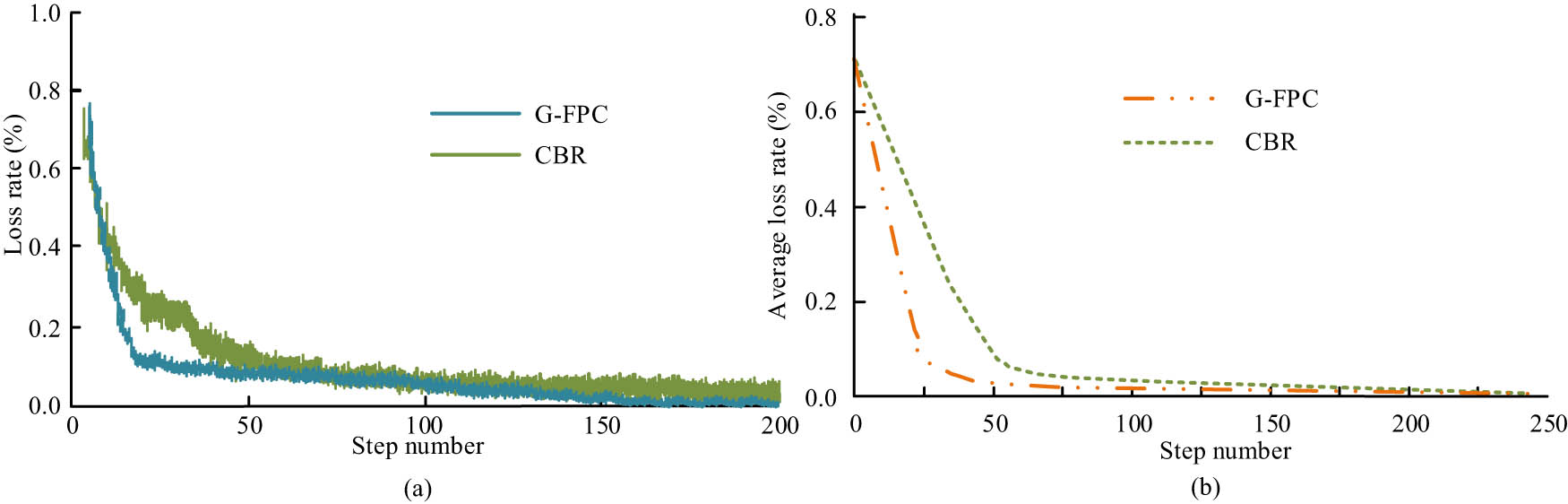
Comparison of loss rates of various models. (a) Loss rate. (b) Average loss rate.
4.2 Training and application analysis of G-FPC Model
Recall is a metric that reflects the relationship between positive and negative samples in a model run, and is one of the metrics commonly used in machine learning class of algorithms. This experiment uses the air quality dataset as input, and compares the recall and average recall of the three models CBR, G-FPC, and CF, and the outcomes are showcased in Figure 9. Figure 9(a) represents the relation in the recall and the number of training times for the three models CBR, G-FPC, and CF; Figure 9(b) represents the average recall of the three models for multiple training times. The figure reveals that the recall of the G-FPC model exceeds the control model except for the second training. In addition, the average recalls of the three models CBR, G-FPC and CF are 88.71, 93.09, and 79.24%, respectively, so the G-FPC model performs better than the control model in the F1 test.
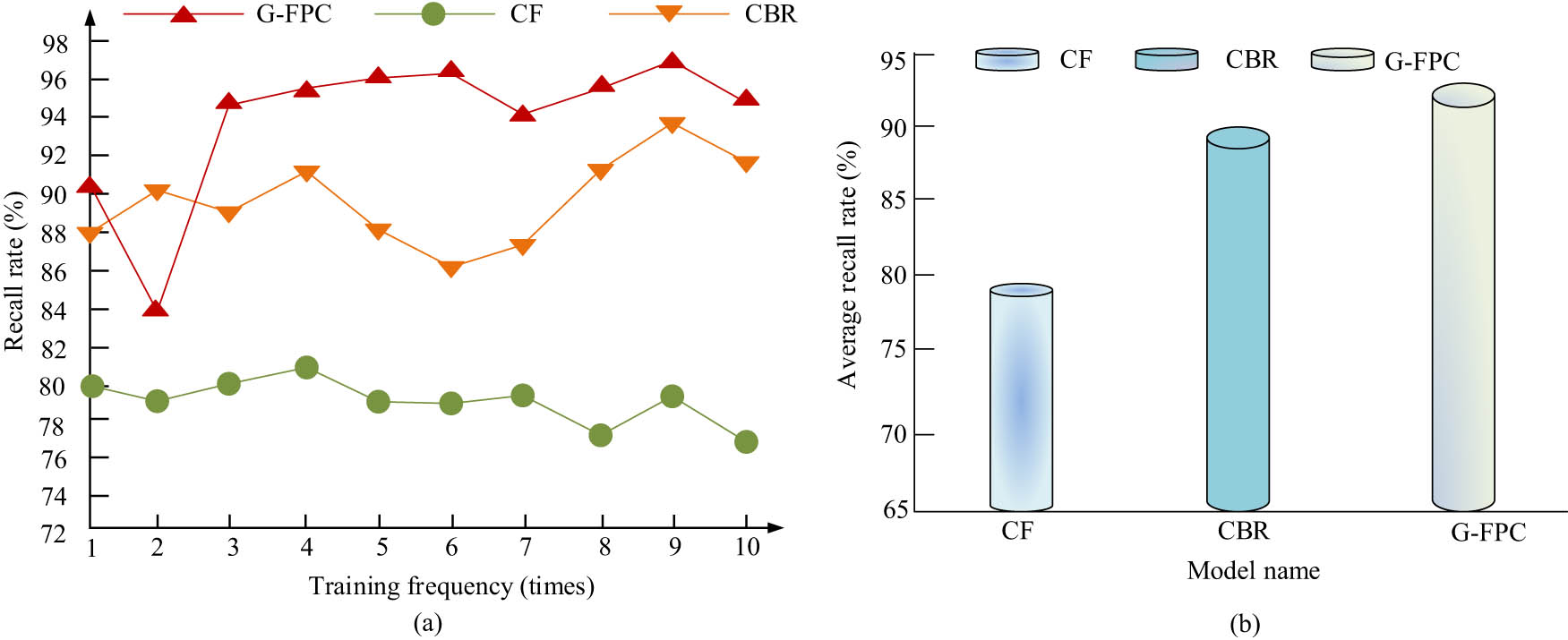
Comparison of recall rates among different models. (a) Comparison chart of recall rates among different models. (b) Comparison of F1 values among different models.
Time complexity is a measure used in algorithm analysis of how fast the execution time of an algorithm grows with the size of the input. It describes the relationship between the algorithm running time and the problem size. Aiming at verifying the time complexity, this experiment uses two datasets, air quality and energy efficiency, as inputs to compare the relationship between the number of information and time complexity of the three models, CBR, G-FPC, and CF, and the outcomes are showcased in Figure 10. Figure 10(a) represents the time complexity comparison of each model on the air quality dataset; Figure 10(b) represents the time complexity comparison of each model on the energy efficiency dataset. The figure reveals that the time complexity of G-FPC model is below other control models on both datasets, so the G-FPC model is advanced in terms of time complexity, and also verifies the advantage of high computational efficiency of G-FPC model from the side.
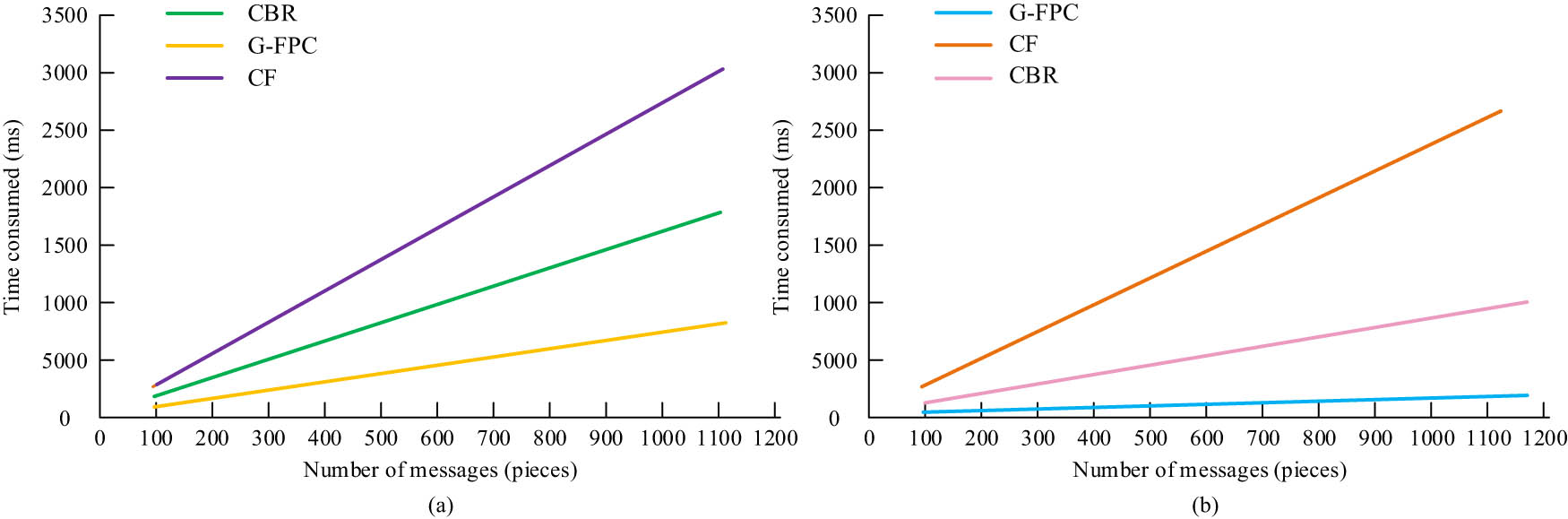
Comparison of time complexity of various models. (a) Comparison of time complexity on the air quality dataset. (b) Comparison of time complexity on the energy efficiency dataset.
The F1 value is a comprehensive indicator that takes into account both accuracy and recall, and is also one of the commonly used indicators for model evaluation. This experiment compares the F1 values of the three models CBR, G-FPC, and CF on the air quality and energy efficiency datasets, and the experiment will be repeated three times for avoiding the influence of chance factors. The relevant outcomes are showcased in Figure 11. Figure 11(a) represents the F1 values of the models on the air quality dataset; Figure 11(b) represents the F1 values of the models on the energy efficiency dataset. The figure reveals that the F1 values on the air quality and energy efficiency datasets are G-FPC model, CBR model, and CF model in descending order. The average F1 of the proposed model on the two datasets of air quality and energy efficiency is 95.21 and 88.77%, respectively.
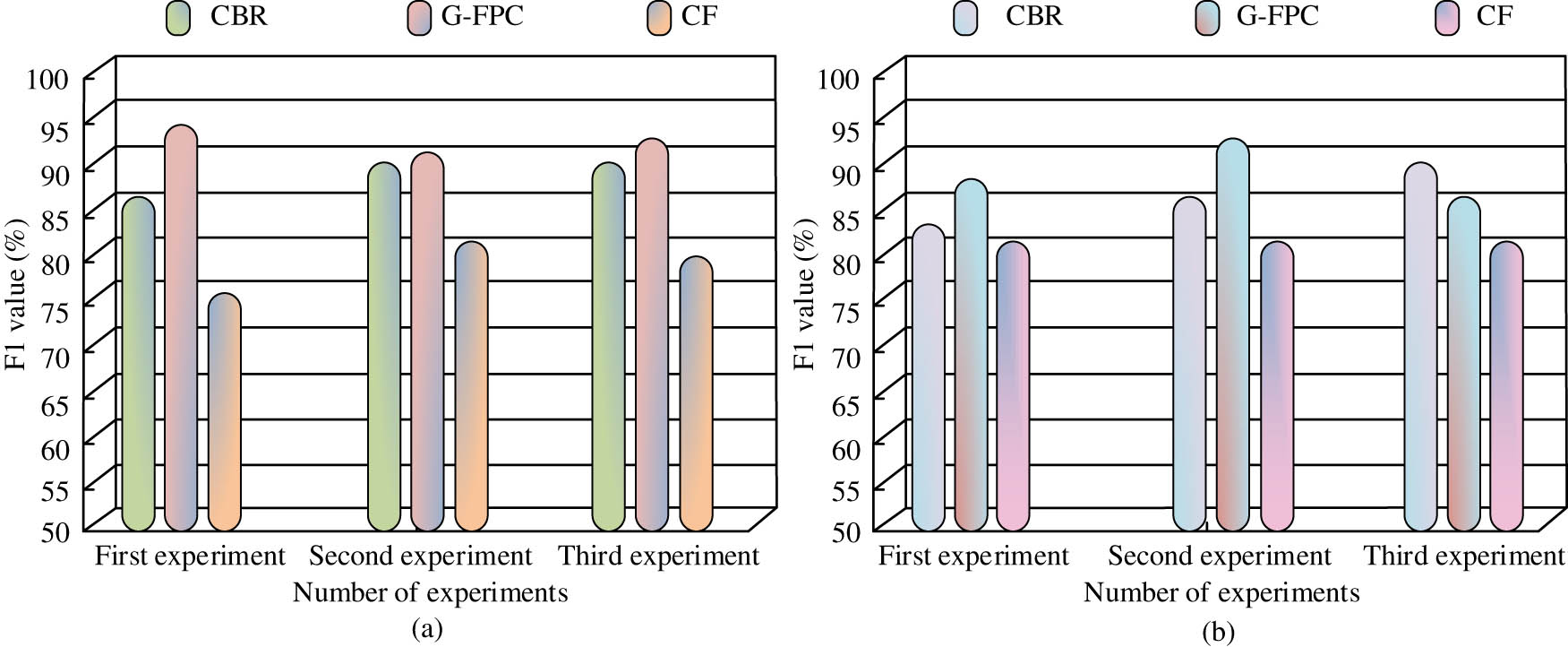
Comparison of F1 values among different models. (a) Comparison of F1 values on the air quality dataset. (b) Comparison of F1 values on the energy efficiency dataset.
RMSE is a commonly utilised statistical measure of the degree of difference between predicted and observed values. In this experiment, the air quality and energy efficiency datasets are used as inputs to compare the RMSE of the two models G-FPC and CF, and the outcomes are showcased in Figure 12. Figure 12(a) serves as the RMSE values of the models on the air quality dataset; Figure 12(b) serves as the RMSE values of the models on the energy efficiency dataset. The trends of the RMSE values of the models on the two datasets are generally the same, but the fluctuation of the RMSE values on the energy efficiency dataset is more obvious. The RMSE values of the two models, G-FPC and CF, on the air quality dataset are 0.131 and 0.186, respectively, after the models have reached a stable level, while the RMSE values of the energy efficiency dataset are 0.134 and 0.20, respectively, after the models have reached a stable level.
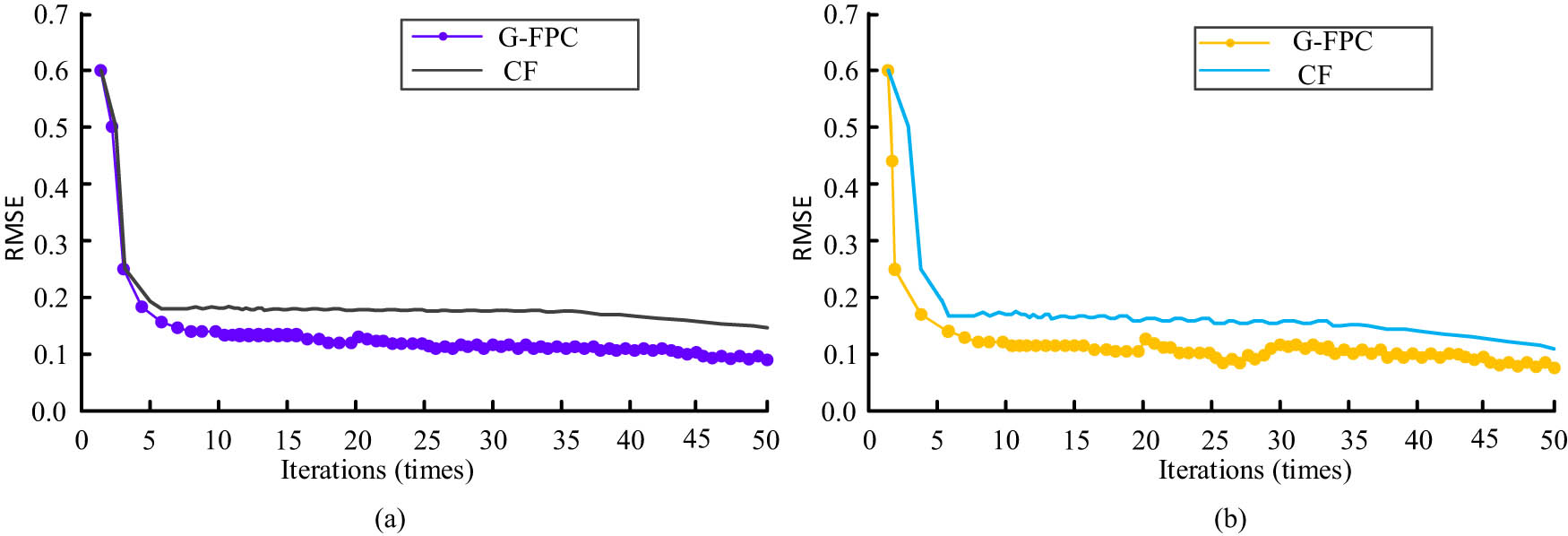
Comparison of RMSE values of various models. (a) RMSE comparison on the air quality dataset. (b) RMSE comparison on the energy efficiency dataset.
5 Conclusion
In today’s education field, people are facing a massive amount of educational resources, which cover multiple sources such as schools, online platforms, and training institutions. Due to the lack of fully functional classification recommendation systems on the market, how to quickly and efficiently recommend personalised educational courses from these chaotic and diverse resources has been an urgent issue that the industry needs to solve. Consequently, this study presents a personalised education resource recommendation model that incorporates the GMF algorithm and FPC, and designs experiments for validating its performance. The relevant outcomes showcase that the proposed model achieves a recommendation fit of 95.16 and 92.91% on the test dataset, an average F1 value of 95.21 and 88.77%, and a recall rate of 93.09%. These data indicate that the proposed model possesses high accuracy and recall in recommendation tasks and can effectively provide personalised recommendation services to users. In addition, the proposed model demonstrated a low RMSE on the test dataset, proving its high prediction accuracy. Meanwhile, this means that the model can accurately predict user behaviour and interests, providing users with more accurate recommendations and ensuring a good user experience. During the experiment, it was also found that the proposed model had shortcomings, such as slow convergence and poor performance in processing complex data. The subsequent research can decrease the complexity of the input data by pre-processing the data before inputting it, so as to improve the efficiency of the model recommendation.
-
Funding information: The work was supported by National Social Science Foundation (21BKS056), “Research on the labor concept in the New Era”.
-
Author contributions: Tingting Liu: data curation, formal analysis, writing—original draft preparation, writing—review and editing. Qiyuan Liu, Xiaobei Wang: formal analysis, validation. Yang Yang: software, visualization.
-
Conflict of interest: The authors declare that there are no conflicts of interest to report regarding the present study.
-
Data availability statement: All data generated or analysed during this study are included in this published article.
References
[1] Gao P, Li J, Liu S. An introduction to key technology in artificial intelligence and big data driven e-learning and e-education. Mob Netw Appl. 2021;26(5):2123–6.10.1007/s11036-021-01777-7Search in Google Scholar
[2] Alexei LA, Alexei A. Cyber security threat analysis in higher education institutions as a result of distance learning. Int J Int J Sci Technol Res. 2021;3:128–33.Search in Google Scholar
[3] Gladstone DJ, Lindsay MP, Douketis J, Smith EE, Dowlatshahi D, Wein T. Canadian Stroke Consortium. Canadian stroke best practice recommendations. Secondary prevention of stroke update 2020. Can J Neurol Sci. 2022;49(3):315–37.10.1017/cjn.2021.127Search in Google Scholar PubMed
[4] Teede HJ, Tay CT, Laven JJE, Dokras A, Moran LJ, Piltonen TT, et al. Recommendations from the 2023 international evidence-based guideline for the assessment and management of polycystic ovary syndrome. Eur J Endocrinol. 2023;189(2):G43–64.Search in Google Scholar
[5] Fei J, Liu L. Real-time nonlinear model predictive control of active power filter using self-feedback recurrent fuzzy neural network estimator. IEEE Trans Ind Electron. 2021;69(8):8366–76.10.1109/TIE.2021.3106007Search in Google Scholar
[6] Shan Y, Hu J, Chan KW, Islam S. A unified model predictive voltage and current control for microgrids with distributed fuzzy cooperative secondary control. IEEE Trans Ind Inform. 2021;17(12):8024–34.10.1109/TII.2021.3063282Search in Google Scholar
[7] Long B, Liao Y, Chong KT, Rodríguez J, Guerrero JM. Enhancement of frequency regulation in AC microgrid: A fuzzy-MPC controlled virtual synchronous generator. IEEE Trans Smart Grid. 2021;12(4):3138–49.10.1109/TSG.2021.3060780Search in Google Scholar
[8] Zha Y, Quan X, Ma F, Liu G, Zheng X, Yu M. Stability control for a four-wheel-independent-drive electric vehicle based on model predictive control. sae. Int J Veh Dyn Stab NVH. 2021;5(10-05-02-0013):191–204.10.4271/10-05-02-0013Search in Google Scholar
[9] Gao H, Kan Z, Li K. Robust lateral trajectory following control of unmanned vehicle based on model predictive control. IEEE/ASME Trans Mechatron. 2021;27(3):1278–87.10.1109/TMECH.2021.3087605Search in Google Scholar
[10] Zhang Y, Tiňo P, Leonardis A, Tang K. A survey on neural network interpretability. IEEE Trans Emerg Top Comput Intell. 2021;5(5):726–42.10.1109/TETCI.2021.3100641Search in Google Scholar
[11] Cui Z, Wang L, Li Q, Wang K. A comprehensive review on the state of charge estimation for lithium-ion battery based on neural network. Int J Energy Res. 2022;46(5):5423–40.10.1002/er.7545Search in Google Scholar
[12] Hizlisoy S, Yildirim S, Tufekci Z. Music emotion recognition using convolutional long short term memory deep neural networks. Eng Sci Technol Int J. 2021;24(3):760–7.10.1016/j.jestch.2020.10.009Search in Google Scholar
[13] Liu C, Ma Q, Luo ZJ, Hong QR, Xiao Q, Zhang HC, et al. A programmable diffractive deep neural network based on a digital-coding metasurface array. Nat Electron. 2022;5(2):113–22.10.1038/s41928-022-00719-9Search in Google Scholar
[14] Hu G, Chen SHK, Mazur N. Deep neural network-based speaker-aware information logging for augmentative and alternative communication. J Artif Intell Technol. 2021;1(2):138–43.10.37965/jait.2021.0017Search in Google Scholar
[15] Yu T, Zhang L, Zhang Y. PRMF: Point of interest recommendation method integrating multiple factors. Int J Web Eng Technol. 2023;18(1):45–61.10.1504/IJWET.2023.131141Search in Google Scholar
[16] Wang F, Li J, Li Z, Ke D, Du J, Garcia C, et al. Design of model predictive control weighting factors for PMSM using Gaussian distribution-based particle swarm optimisation. IEEE Trans Ind Electron. 2021;69(11):10935–46.10.1109/TIE.2021.3120441Search in Google Scholar
[17] Hebbi C, Mamatha H. Comprehensive dataset building and recognition of isolated handwritten kannada characters using machine learning models. Artif Intell Appl. 2023;1(3):179–90.10.47852/bonviewAIA3202624Search in Google Scholar
[18] Mokayed H, Quan TZ, Alkhaled L, Sivakumar V. Real-time human detection and counting system using deep learning computer vision techniques. Artif Intell Appl. 2023;1(4):221–9.10.47852/bonviewAIA2202391Search in Google Scholar
[19] Liu H, Wang Y, Lin H, Xu B, Zhao N. Mitigating sensitive data exposure with adversarial learning for fairness recommendation systems. Neural Comput Appl. 2022;34(20):18097–111.10.1007/s00521-022-07373-4Search in Google Scholar
[20] Gawlikowski J, Tassi CRN, Ali M, Lee J, Humt M, Feng J, et al. A survey of uncertainty in deep neural networks. Artif Intell Rev. 2023;56(Suppl 1):1513–89.10.1007/s10462-023-10562-9Search in Google Scholar
[21] Dastres R, Soori M. Artificial neural network systems. Int J Imaging Robot. 2021;21(2):13–5.Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations