Application and research of English composition tangent model based on unsupervised semantic space
-
Rihong Tang


Abstract
Nowadays, major enterprises and schools vigorously promote the combination of information technology and subject teaching, among which automatic grading technology is more widely used. In order to improve the efficiency of English composition correction, the study proposes an unsupervised semantic space model for English composition tangent, using a Hierarchical Topic Tree Hybrid Semantic Space to achieve topic representation and clustering in English composition; adopts a feature dimensionality reduction method to select a set of semantic features to complete the optimization of the feature semantic space; and combines the tangent analysis algorithm to achieve intelligent scoring of English composition. The experimental data show that the accuracy and F-value of the English composition tangent analysis method based on the semantic space are significantly improved, and the Pearson correlation coefficient between the unsupervised semantic space English composition tangent model and the teacher’s manual grading is 0.8936. The results show that the unsupervised semantic space English composition tangent model has a higher accuracy rate, is more applicable, and can efficiently complete the English composition grading task: essay review task.
1 Introduction
As the popularity of English has increased, the ability to teach English has gradually improved and students’ English standards have also improved significantly [1]. Writing occupies an important place in the English learning process, reflecting students’ ability to use language and express themselves in writing. Students’ English composition reflects the extent to which they have mastered the basics of vocabulary and grammar, as well as their overall mastery of sentence and paragraph structure and the logic of the text [2,3]. English composition writing is commonly found in subject examinations, Level 4 and 6 examinations and major English competitions, and is a comprehensive reflection of students’ English writing ability. Many experts and scholars agree that writing is an important way of assessing students’ ability to use language. However, there are many problems with the current traditional English teaching model, such as the overwhelming number of students resulting in a heavy task of reviewing essays, and the difficult task of teachers resulting in untimely feedback on review information, all of which can lead to a failure to improve students’ writing skills quickly and efficiently [4]. To address these problems, researchers have proposed an automated English grading system that combines technologies such as natural language processing and machine learning to reduce teachers’ physical and mental workload [5,6]. However, this field still faces some challenges, such as how to accurately evaluate students’ writing abilities and how to handle complex language structures and semantics. Therefore, this study designed a semantic space English composition topic analysis model based on unsupervised methods. The main innovation lies in the use of relational triples as carriers for topic clustering and distributed representation, and proposed topic analysis algorithms, topic coherence algorithms, and topic viewpoint algorithms for multi-dimensional topic analysis of English composition content. Through experimental verification, this model has high accuracy and application value in scoring the quality of relevance to the topic. The main contribution of the research is to propose a method for constructing a hierarchical topic tree (HTT) mixed semantic space and to extend topic relevance analysis from shallow semantic analysis to potential topic semantic analysis, improving the accuracy and granularity of topic relevance semantic analysis.
2 Related works
2.1 Semantic space analysis
Semantic space is an important concept in the study of communication effectiveness, and a prerequisite for communication to be realized is a common semantic space between the transmitter and the receiver. Xiao et al. addressed the problem of low accuracy of scene migration by proposing a simulated realistic decision model based on feature semantic space, combining environment representation, policy optimization, and intelligent decision modules to shorten the difference between real and virtual scenes. It is verified that the method has good stability in practical applications [7]. To optimize the semantic space of text, Kherwa et al. adopted the three-level weight model to distribute the weight of terms, documents, and corpora, so as to achieve the generation of semantic similarity and context clustering [8]. Yu’s research group addressed the convolutional neural network neural-style conversion problem, proposed a multi-scale style conversion algorithm based on deep semantic matching, combined with spatial segmentation and contextual illumination information to construct a deep semantic space, and used the loss function of nearest neighbour search to optimize the effect of deep-style migration, and the experimental results show that the algorithm synthesizes a more reasonable spatial structure image [9]. To optimize the conversion method of semantic space, Yu proposed a semantic space-based and automatic bibliographic classification algorithm based on conversion, combining text preprocessing and word vectors to achieve automatic classification of bibliographic semantic vectors. Experimental data show that the accuracy of this algorithm is higher than that of traditional classification algorithms [10]. Orhan et al. proposed an embedding method for learning word vectors through weighted semantic relations, finding the best weight for them by semantic relations and adjusting the Euclidean distance to obtain word vectors of synonymous sets. Experimental results show that the method is able to find word-level semantic similarities and weights [11].
2.2 Automatic scoring technology
With the development of the times and the progress of technology, major enterprises and schools vigorously promote the combination of information technology and subject teaching, forming the concept of Internet + education, among which the application of automatic scoring technology is more common. Zhao used English automatic scoring algorithm and English sentence feature scoring algorithm to achieve intelligent online scoring and elegant sentence extraction of English composition, and the experimental results show that the algorithm can reduce the workload of English and the experimental results show that the algorithm can reduce the workload of scoring English essays [12]. Wang et al. proposed an improved P-means-based automatic scoring algorithm for Chinese fill-in-the-blank questions, combining semantic lexicon matching and semantic similarity calculation to build an automatic scoring framework, using the improved P-means model to generate standard answers and sentence vectors and calculate semantic similarity, and the experimental data show that the highest accuracy rate of the algorithm is 94.3% [13]. Yuan’s research group proposed an automatic essay scoring system based on a linear regression machine learning algorithm, combining linguistic features in a multiple regression approach to complete essay evaluation and model performance analysis [14]. Xia et al. proposed an automatic essay scoring model based on a neural network structure, which includes a long- and short-term memory layer and an attention mechanism layer; using pre-trained generated word vectors to calculate the experimental data showed that the quadratic weighted kappa coefficients of this model outperformed the bidirectional long- and short-term memory model [15]. Saihanqiqige proposed a multi-model fusion algorithm based on word vectors in order to improve the accuracy of English proficiency assessment, combining the text representation method of word vector clustering and the word vector space model to complete the automatic scoring of English composition [16].
In summary, many researchers have designed many algorithms and models for semantic space and automatic scoring, but the accuracy of these algorithms and models has yet to be improved. Therefore, the study proposes an unsupervised semantic space-based English composition tangent model, which is expected to improve the accuracy of automatic English composition scoring and reduce teachers’ workload.
3 Designing a model for English composition tangents in unsupervised semantic space
3.1 Unsupervised semantic space and tangent analysis algorithm design
The unsupervised semantic space, namely, the Hierarchical Topic Tree Hybrid Semantic Space (HTTHSS), is proposed for implementing topic representation and clustering in English composition. The hierarchical tree topic tree hybrid space is mainly composed of a ternary hierarchical theme plants (HTP) model, a distributed vector group of topic relationships, and a topic semantic space based on a knowledge base [17]. The monads in the HTP model are replaced by relational triads to achieve a thematic semantic representation of sentence semantics and structural components, and Figure 1 illustrates the triad hierarchical tree topic model.
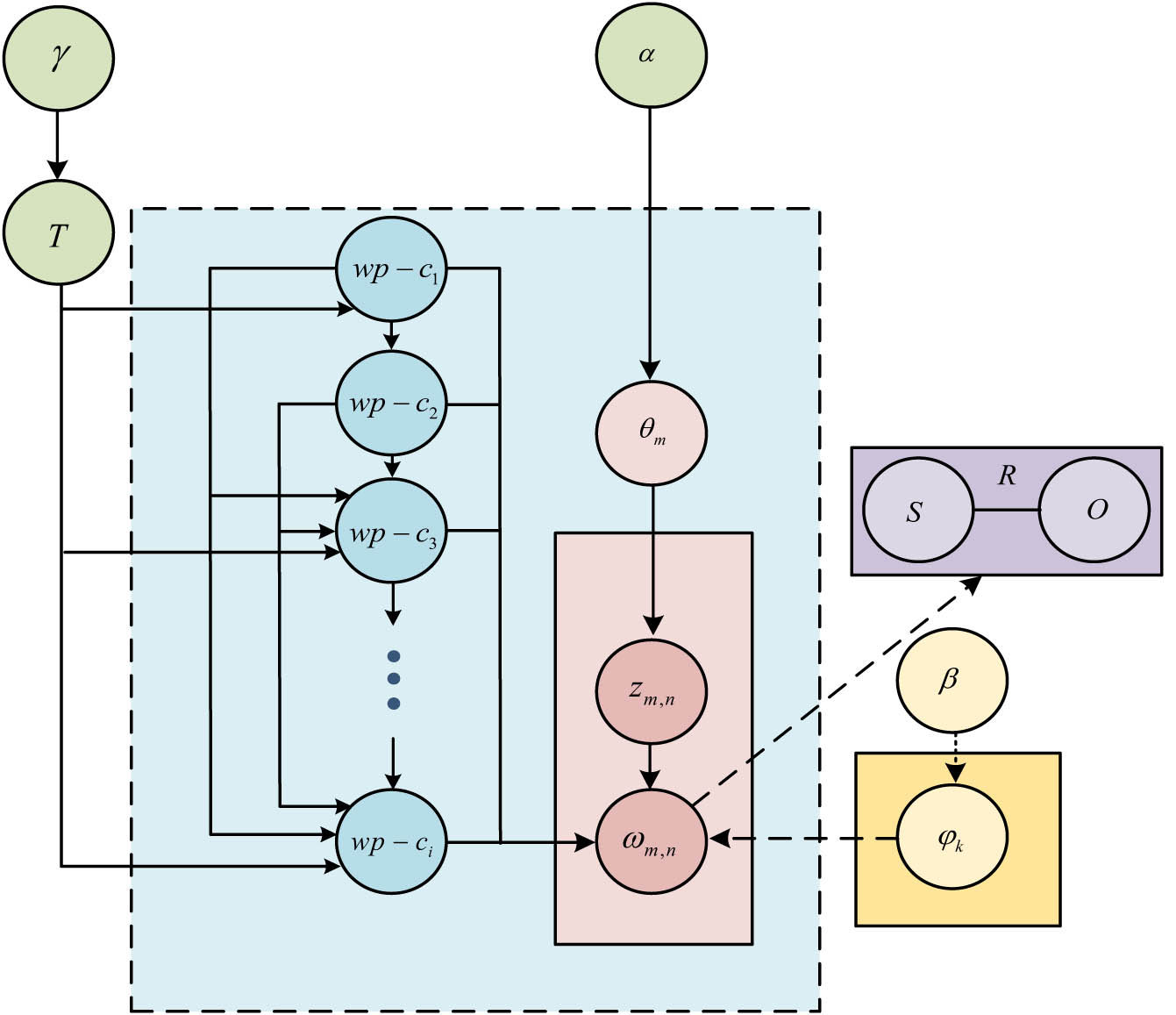
Relational triple hierarchical tree theme model.
In Figure 1, the hyperparameters controlling the probability of a new path are
where
where the new sampling path is
where the subject, relation, and object hyperparameters are
where the list of the first
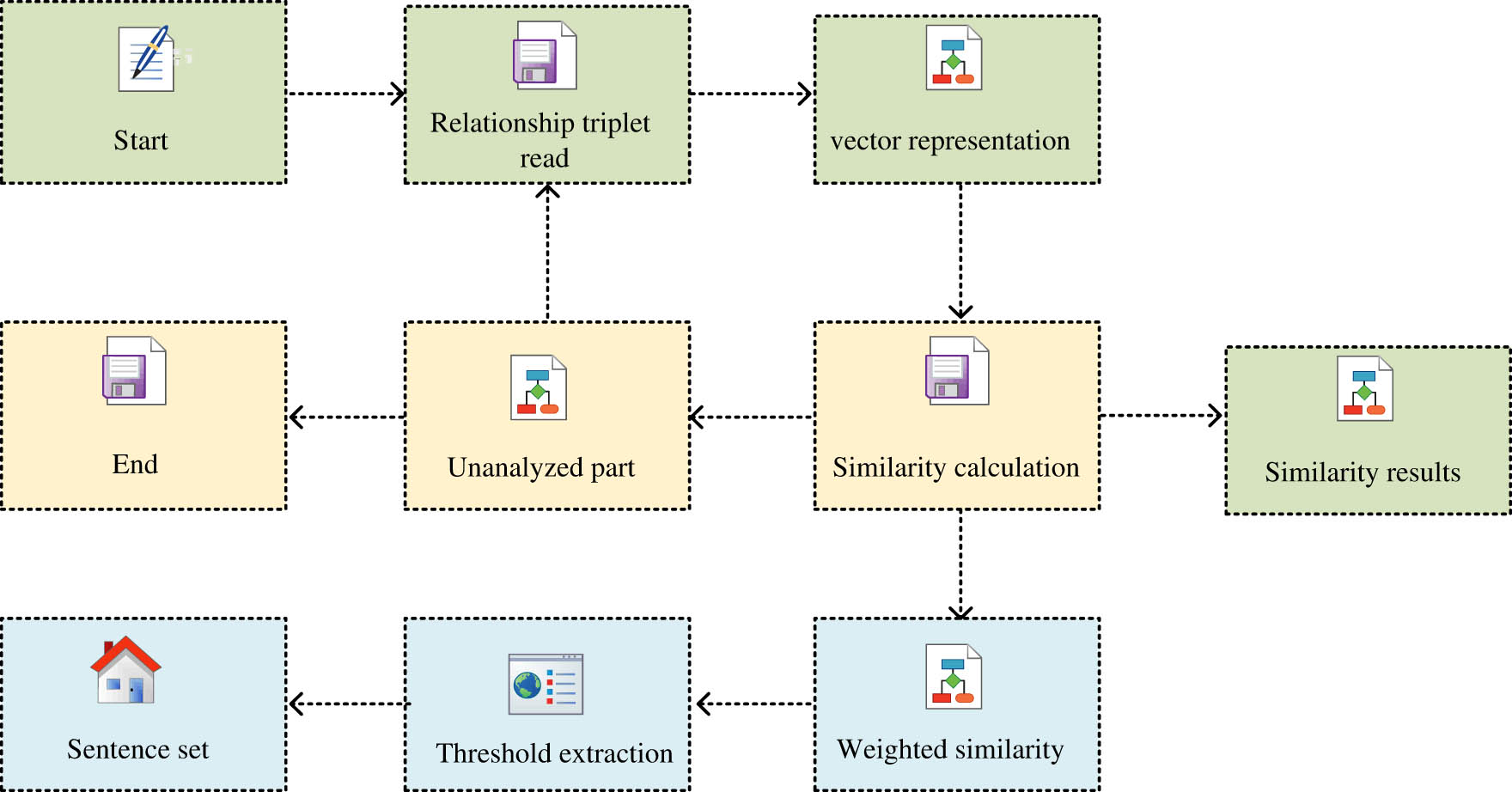
Process of relevance analysis algorithm.
The HTTHSS represents the English composition topics as a topic relation triplet distributed vector. Let the relation triplet contain
where the hyperparameters are
where
where the vector dimension is, the sentence distributed vector mean is, the topic distributed vector mean is
where the sentence cut semantic similarity is
3.2 Design of English composition tangent model in unsupervised semantic space
The English composition cut model in unsupervised semantic space generates cut analysis results through English composition pre-processing, semantic space establishment, English composition cut analysis, and English composition cut quality analysis, and the processing flow of the English composition cut model in unsupervised semantic space as presented in the figure in the articles [19].
The basic link of text analysis is pre-processing, which has an important role in the semantic analysis later on. Using natural language processing tools, special character filtering, segmentation, sentence division, word division, and information extraction are completed [19]. The special characters and Chinese characters that appear in the English writing process can affect the segmentation, sentence, and word division of English compositions. The study establishes a special character set for English composition writing, combines regular expressions to filter special characters, and then slices the filtered English compositions in a global to partial manner to obtain sliced paragraphs, sentences, and words. The deactivated word set is then used to delete words in the sentences that do not affect the semantics, and then, the words in the composition are converted to their initial state for subsequent processing operations.
Words with the same grammatical properties belong to the same lexical property. There are 10 types of English lexical properties, and 2 special lexical properties are transitive and intransitive. The lexical property of each word needs to be labelled to facilitate the subsequent building of a dependency syntactic tree [20]. The study uses a recurrent dependency neural network lexical annotator, which obtains lexical labels through symmetric inference, relying on the existence of correlations between each node in the neural network and neighbouring nodes, and obtains conditional similarity maximization of node training data through local model training, to prepare for English text processing and analysis. The study injects a large number of rare word set features into the lexical annotator to achieve correct annotation of unknown words.
Information extraction is a text processing technique that extracts factual information such as entities, relations, and events of specified types from natural language text and forms structured data output. The relational triad form contains subjects, relations, and objects. The relationships between words in a sentence are realized through dependency syntactic analysis, and the dependency syntactic tree expression is shown in the following equation:
where the textual dependency arc is
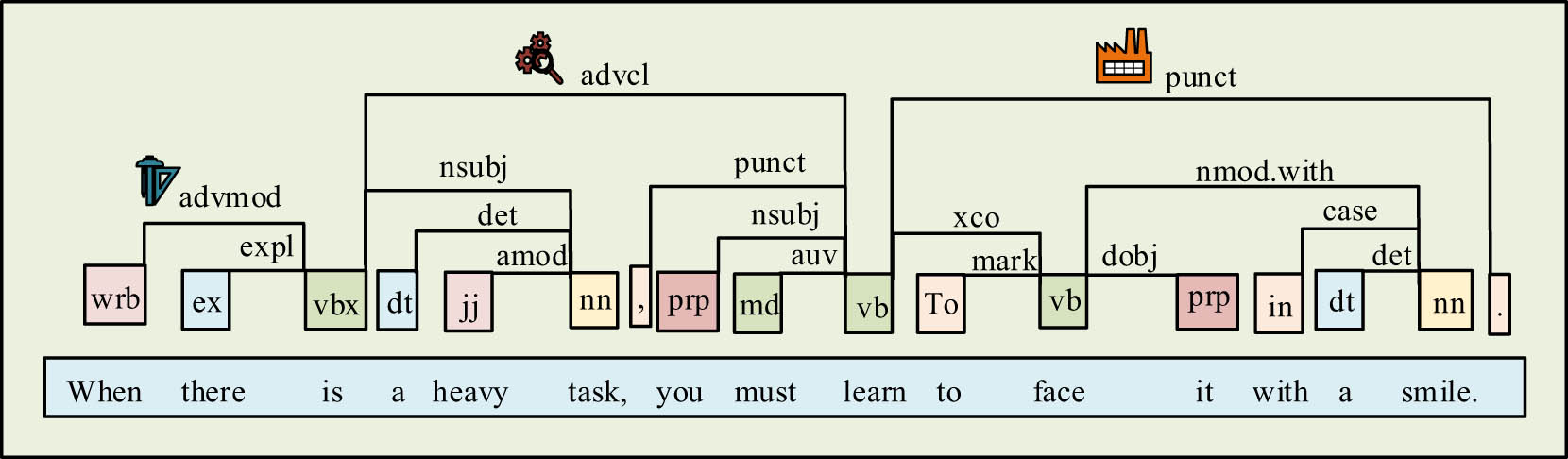
Dependency parsing results.
The study comprehensively analyses the quality of English composition tangency by calculating the semantics of English composition sentences and composition topics, the semantics of sentences and composition paragraphs, the semantics of paragraphs and topic topics, and the semantic similarity of full text and topic topics, and analyses the quality of composition topics and opinion expressions by combining the topic coherence algorithm and the topic opinion algorithm. The formula for calculating the cut score of English composition is shown in the following equation:
where the hyperparameter is
where the thematic coherence score of the English composition is
where the topic perspective score of English composition is
where the English composition cut quality score is
4 Experimentation and analysis of English composition tangent model in unsupervised semantic space
4.1 Experimental test sets and assessment criteria
The relational triad HTP model’s parameters were optimized by the Wikipedia corpus, The International Corpus Network of Asian Learners of English (ICNALE), and the Chinese learner English corpus. The HTP model’s parameters were optimized by setting the topic smoothing distribution to 10, the predictive clustering parameter of the topic-relational triad to 1, and the relational triad smoothing distribution to 0.1. The test set data are shown in Figure 4.
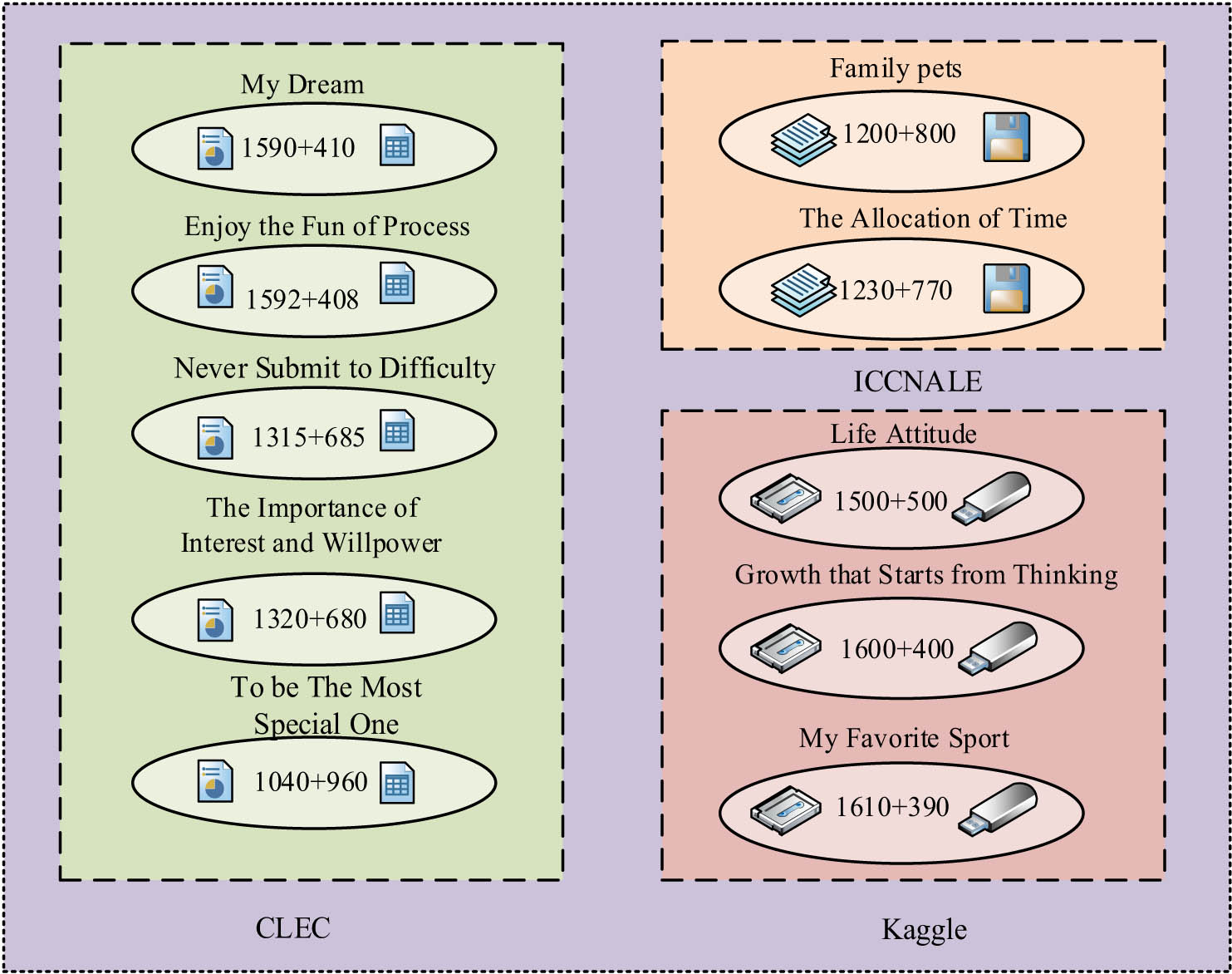
Test set data.
A corresponding number of run-on essays were added to each topic in the test set. The sentence test set was a random selection of 16,010 sentences from 1,000 essays under two essay topics from ICNALE, including 6,930 tangential sentences and including 5,200 thematically incoherent sentences. The number of samples with positive model and manual assessment is
Evaluation criteria for the degree of relevance in English compositions
| Score | Evaluation criterion |
|---|---|
| 90–100 | Content to the point; good thematic coherence |
| Express clearly and fluently | |
| 80–90 | Content to the point; good thematic coherence; express opinions clearly |
| Minor language errors | |
| 70–80 | Content is basically relevant to the topic; theme is generally coherent |
| Inadequate expression of thematic viewpoints | |
| 60–70 | Content is basically relevant to the topic; poor thematic coherence and expression of thematic viewpoints |
| 0–60 | Content is not well organized; poor thematic coherence; chaotic expression of thematic viewpoints |
The experiment reflects the relevance of the two by evaluating the degree of tangibility of the English composition through the model and calculating the correlation index Pearson’s correlation coefficient by combining the results of the teachers’ evaluation. The Pearson correlation coefficient is
4.2 Analysis of model experimental data
The experimental test set consisted of 22,000 English essays under ten topics in the corpus, of which 15,000 were tangential essays as well as 7,000 run-on essays. Table 2 indicates the experimental results of the research that proposed a semantic space-based approach to the analysis of tangential English essays.
Experimental results of relevance analysis method
| Composition title | P (%) | R (%) | F (%) |
|---|---|---|---|
| My dream | 94.01 | 87.21 | 90.48 |
| Enjoy the fun of process | 94.86 | 86.97 | 90.74 |
| Never submit to difficulty | 93.42 | 88.31 | 90.79 |
| The importance of interest and willpower | 94.56 | 89.01 | 91.70 |
| To be the most special one | 94.89 | 88.78 | 91.73 |
| Family pets | 92.18 | 88.12 | 90.10 |
| The allocation of time | 94.78 | 87.03 | 90.74 |
| Life attitude | 89.96 | 87.54 | 88.73 |
| Growth that starts from thinking | 90.36 | 89.82 | 90.09 |
| My favourite sport | 90.93 | 87.56 | 89.21 |
Analysis of the experimental data in Table 2 shows that the highest value of accuracy of the semantic space-based English composition tangent analysis algorithm is 94.86%, the average accuracy is 93.00%, the highest value of recall is 89.82%, the average recall is 88.04%, the highest F-value is 91.73%, and the average F-value is 90.43%. Due to the study’s extended topic set, the effectiveness of the tangential analysis method was stable under different lengths of English composition topics. The experiments were conducted to verify the effectiveness of the analysis of the hybrid semantic space of HTP (marked as D) by Word2Vec + topic hierarchical tree semantic space (marked as A), Word2Vec + improved topic hierarchical tree semantic space (marked as B), and Word2Vec + topic hierarchical tree + knowledge base semantic space (marked as C) as comparisons, and the experimental results are shown in Figure 5.
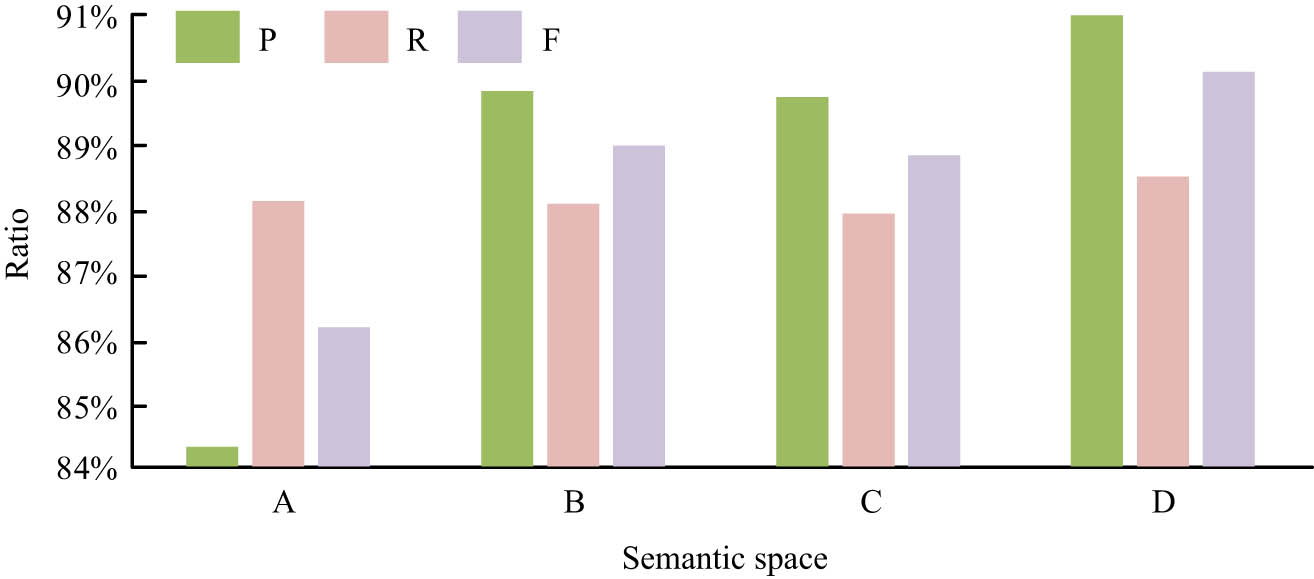
Experimental results of semantic space relevance analysis.
As can be seen in Figure 5, the recall rates of the four semantic spaces for cut-topic analysis do not differ much, all remaining around 88%, but the recall rate under the HTTHSS is slightly higher at 88.53%. The accuracy rate of English tangent analysis in the HTTHSS was 91.65% with an F-value of 90.08%, indicating that the experiment was effective. The experiments compared the WEDVRM (marked as A), the LDA + WEDVRM (marked as B) with the research proposed semantic space-based English composition tangent analysis algorithm (marked as C) for 5,000, 10,000, 15,000, and 20,000 compositions in the test set, respectively, and the experimental results are shown in Figure 6.
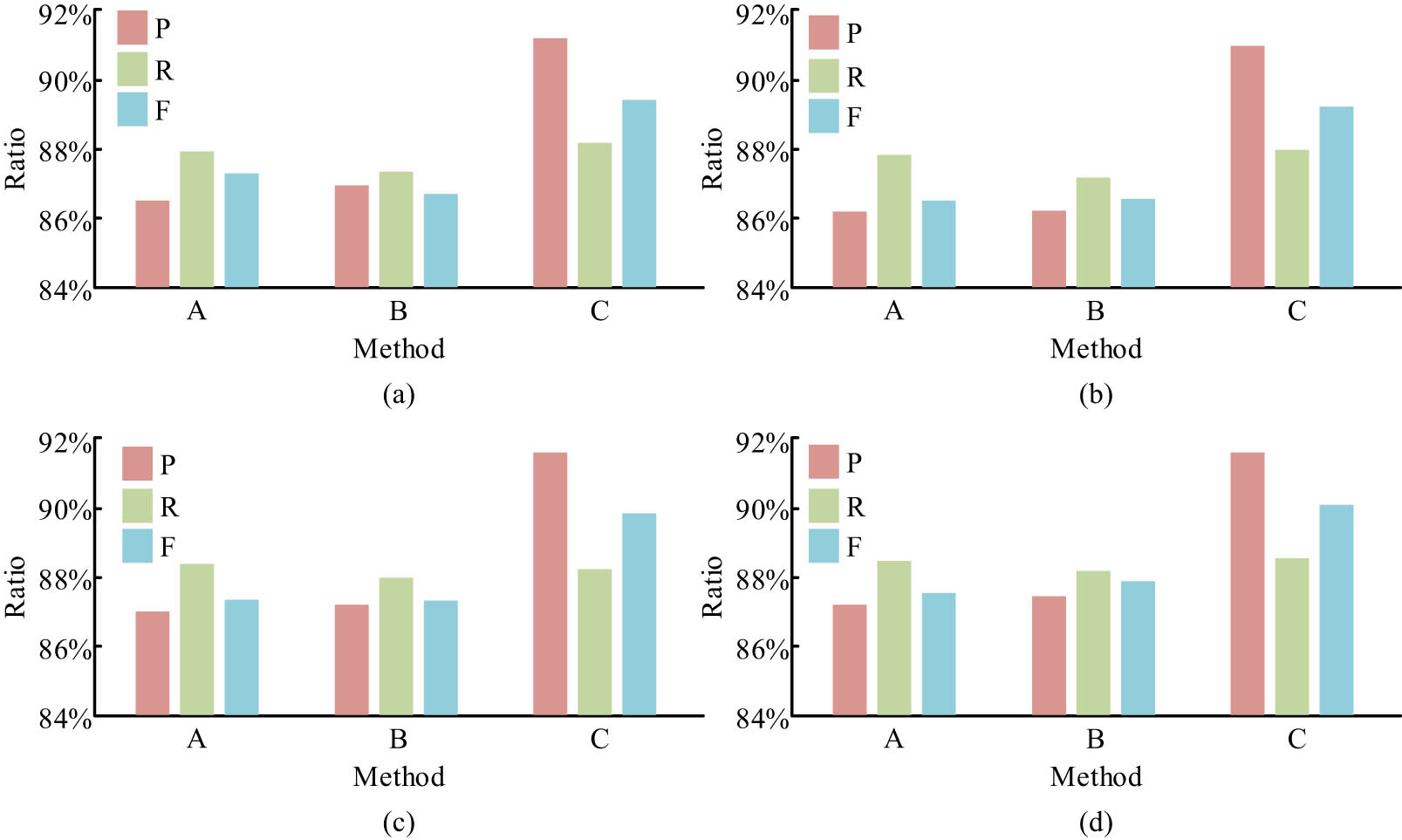
Comparison of experimental results of different relevance analysis methods. (a) 5,000 essays, (b) 10,000 essays, (c) 15,000 essays, and (d) 20,000 essays.
As can be seen from Figure 6, the three indicators corresponding to the three algorithms increased as the number of compositions increased, indicating that the more English compositions were analysed, the more stable the performance of the tangential analysis algorithm became. The accuracy and F-value of the semantic space-based English composition tangent analysis algorithm were significantly higher than those of the Word Embedding Distributed Vector Representation Method (WEDVRM) and the LDA + WEDVRM, with an accuracy and F-value of 91.65 and 90.12%, respectively, when 20,000 English compositions were analysed, increasing the accuracy and F-value of the tangent analysis algorithm by 5 and 3%, respectively. The recall rates for the three algorithms did not differ significantly, all remaining at around 88%. The tangent analysis model analysed 16,010 sentences (which included 6,930 marked tangent sentences) from 1,000 essays, with different tangent thresholds set in the tangent experiments, and the experimental results are shown in Figure 7.
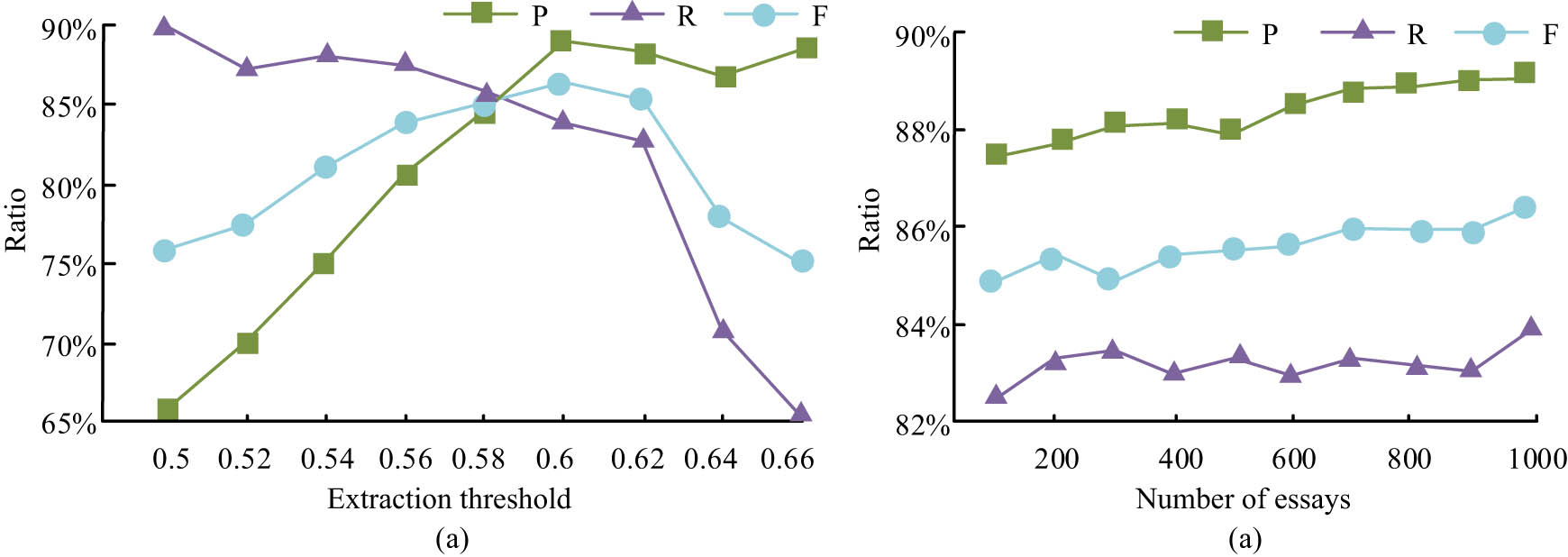
Experimental results of topic analysis models under different extraction thresholds for topic specific sentences. (a) Results of extracting relevant sentences and (b) the threshold is 0.6 for extracting results.
Figure 7(a) shows the experimental results of the tangent analysis model under different tangent sentence extraction thresholds. Analysis of the experimental data shows that the highest F-value of the tangent analysis algorithm is 86.67% when the threshold is 0.6, and the tangent sentence extraction effect is more satisfactory at this time. When the extraction threshold was low, the recall rate of tangent extraction was higher but the accuracy rate was lower; when the extraction threshold was high, the accuracy rate of tangent extraction was higher but the recall rate was lower, both of which could not complete the task of tangent extraction stably. Figure 7(b) shows the experimental results of the model’s tangential sentence extraction of 1,000 articles when the tangential extraction threshold is set to 0.6. Analysis of the experimental data shows that when the quantity of English essays increases, the precision of the tangential analysis algorithm also increases, with the highest accuracy rate being 89.12% and the recall rate being basically stable, with the mean value of F being 86.67%. The model analysed 16,010 sentences (which included 5,200 marked thematically incoherent sentences) from 1,000 essays, and the experiments were also set to different thresholds, and the results are shown in Figure 8.
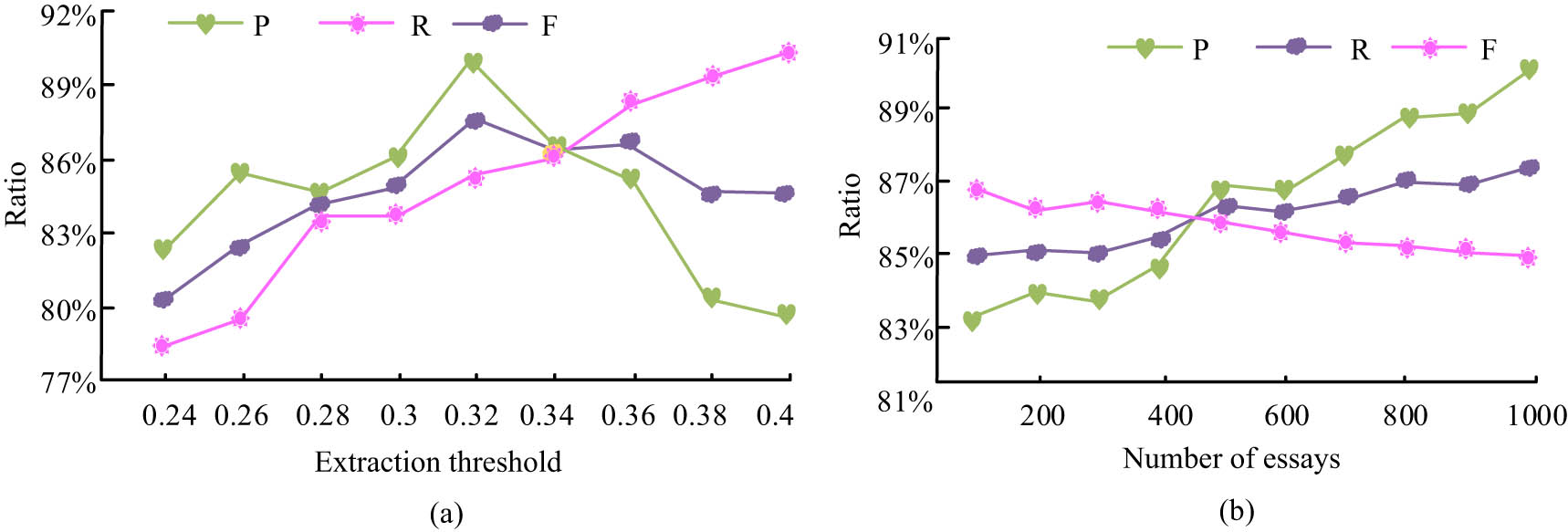
Analysing the results of disconnected sentences on the topic. (a) Incoherent sentence extraction result and (b) extracting incoherent sentences with a threshold of 0.32.
Analysis of the experimental data in Figure 8 shows that the highest F-value of 87.68% was achieved when the extraction threshold for thematically incoherent sentences was 0.32. When the quantity of English compositions increases, the precision of the tangential analysis algorithm also increases, with a maximum accuracy of 90.16% and a decrease in the recall rate. To verify the practical application of the English composition tangent model in unsupervised semantic space, the experiments used the professional English teachers’ ratings as a comparison and scored 1,000 English compositions tangentially, respectively, and the experimental results are shown in Figure 9.
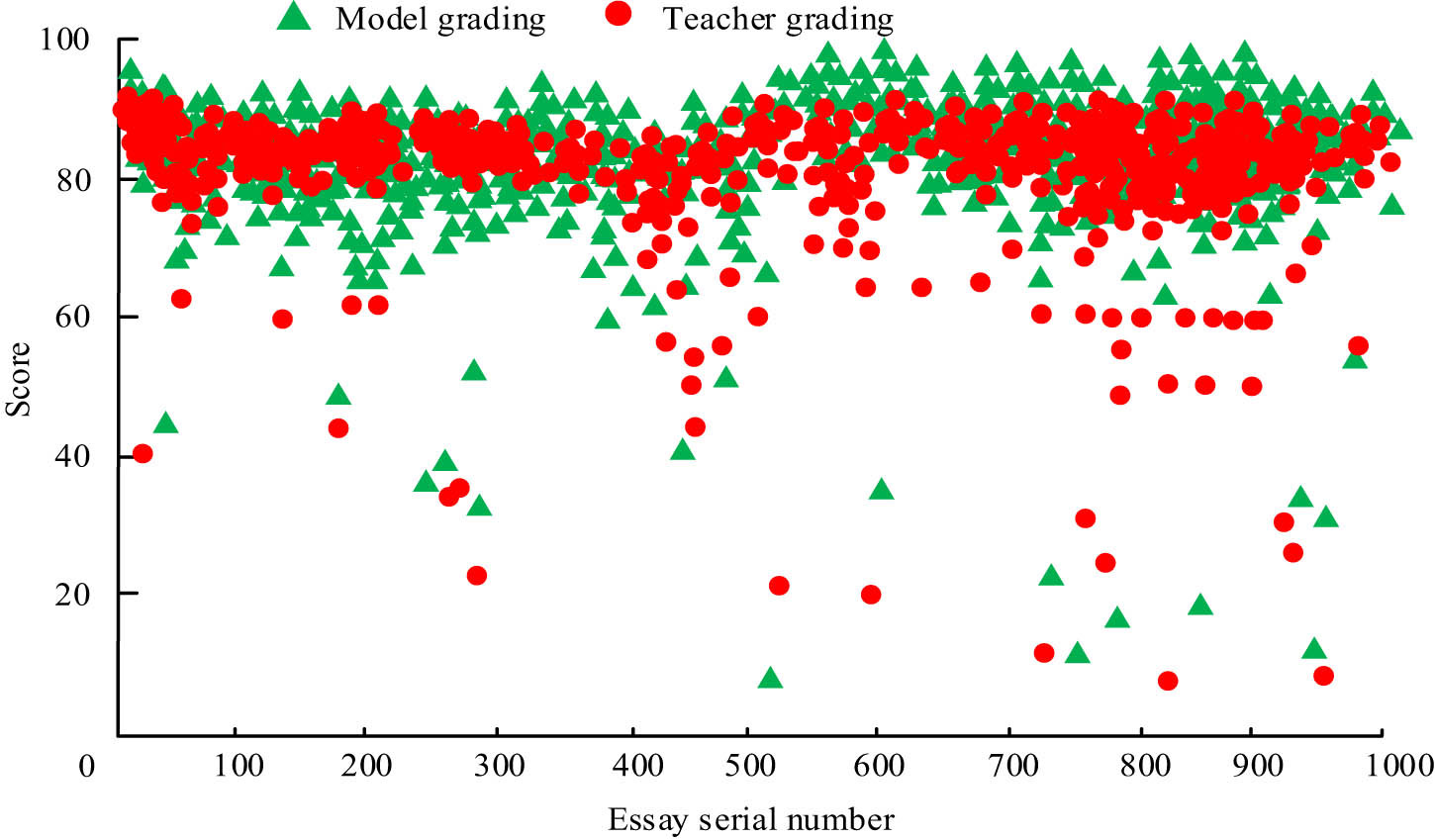
Comparison of model scoring and teacher scoring results.
In Figure 9, the results of the model scoring and teacher scoring are mainly concentrated between 80 and 90 points. Analysis of the experimental data shows that the mean value of the English composition tangent model scoring 1,000 English compositions under unsupervised semantic space is 83.56 points and the mean value of teacher scoring is 82.36 points, and the difference between the two scores as well as the Pearson correlation coefficient are 1.2 points and 0.8936 points, respectively, with a strong correlation grade. The experiment shows that the English composition tangent model under unsupervised semantic space has high credibility and practicality.
5 Conclusion
In the form of globalization, English occupies a major position as a common language, and various English examinations and competitions usually involve the writing of English essays, and the marking of essays is also a big project. To improve the efficiency of English composition correction, the study proposes an unsupervised semantic space-based English composition tangent model, combining a relational triad hierarchical tree topic model with a tangent analysis algorithm to achieve intelligent scoring of English compositions. The experimental data show that the accuracy and F-value of the semantic space-based English composition tangent analysis method are significantly higher than those of the WEDVRM and the LDA + WEDVRM, and the precision and F-value are 91.65 and 90.12%, respectively, when 20,000 English compositions are analysed: 86.67%, which is a good result for tangential sentence extraction. The highest F-value of 87.68% was obtained for a threshold of 0.32 for the extraction of thematically incoherent sentences. When the quantity of English compositions increases, the precision of the tangential analysis algorithm also increases, with a maximum accuracy of 90.16%. The mean score of the English composition tangent model in unsupervised semantic space for 1,000 English compositions was 83.56, and the mean score of the teacher’s score was 82.36, and the difference between the two scores and the Pearson correlation coefficient were 1.2 and 0.8936, respectively. The results show that the English composition tangent model in unsupervised semantic space is more stable and applicable, and can accurately and efficiently complete the English composition criticism task. The study is a tangential analysis of the topics, sentences, and paragraphs of English composition, and the tangential analysis can be further improved subsequently by combining features such as chapter structure.
-
Funding information: The research was supported by National level, A Study on the construction and promotion of Jiaodong Culture into English Quality Courses in Higher Vocational Colleges (No. WYW2022A03).
-
Author contributions: Rihong Tang: methodology, conceptualization, Writing – Original Draft, Writing – Review & Editing.
-
Conflict of interest: The author reports there are no competing interests to declare.
-
Data availability statement: The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
References
[1] Cowen AS, Keltner D. Semantic space theory: A computational approach to emotion. Trends Cognit Sci. 2021;25(2):124–36.10.1016/j.tics.2020.11.004Search in Google Scholar PubMed
[2] Sato N, Matsumoto R, Shimotake A, Matsuhashi M, Otani M, Kikuchi T, et al. Frequency-dependent cortical interactions during semantic processing: an electrocorticogram cross- spectrum analysis using a semantic space model. Cereb Cortex. 2021;31(9):4329–39.10.1093/cercor/bhab089Search in Google Scholar PubMed
[3] Huang GM, Zhang XW. An analysis model of potential topics in English essays based on semantic space. J Comput. 2022;33(1):151–64.10.53106/199115992022023301014Search in Google Scholar
[4] Neumeyer L, Franco H, Digalakis V, Weintraub M. Automatic scoring of pronunciation quality. Speech Commun. 2000;30(2–3):83–93.10.1016/S0167-6393(99)00046-1Search in Google Scholar
[5] Nimrah S, Saifullah S. Context-free word importance scores for attacking neural networks. J Comput Cognit Eng. 2022;1(4):187–92.10.47852/bonviewJCCE2202406Search in Google Scholar
[6] Waziri TA, Yakasai BM. Assessment of some proposed replacement models involving moderate fix-up. J Comput Cognit Eng. 2023;2(1):28–37.10.47852/bonviewJCCE2202150Search in Google Scholar
[7] Xiao W, Luo X, Xie S. Feature semantic space-based sim2real decision model. Appl Intell. 2023;53(3):4890–906.10.1007/s10489-022-03566-5Search in Google Scholar
[8] Kherwa P, Bansal P. Three level weight for latent semantic analysis: an efficient approach to find enhanced semantic themes. Int J Knowl Learn. 2023;16(1):56–72.10.1504/IJKL.2023.127328Search in Google Scholar
[9] Yu J, Jin L, Chen J, Xiao Y, Tian Z, Lan X. Deep semantic space guided multi-scale neural style transfer. Multimed Tools Appl. 2022;81(3):3915–38.10.1007/s11042-021-11694-2Search in Google Scholar
[10] Yu HF. Bibliographic automatic classification algorithm based on semantic space transformation. Multimed Tools Appl. 2020;79(13):9283–97.10.1007/s11042-019-7400-3Search in Google Scholar
[11] Orhan U, Tulu CN. A novel embedding approach to learn word vectors by weighting semantic relations: semspace. Expert Syst Appl. 2021;180:115146–53.10.1016/j.eswa.2021.115146Search in Google Scholar
[12] Zhao Y. Research and design of automatic scoring algorithm for english composition based on machine learning. Sci Program. 2021;3429463–72.10.1155/2021/3429463Search in Google Scholar
[13] Wang H, Zhao Y, Lin H, Zuo X. Automatic scoring of Chinese fill-in-the-blank questions based on improved P-means. J Intell Fuzzy Syst. 2021;40(3):5473–82.10.3233/JIFS-202317Search in Google Scholar
[14] Yuan Z. Interactive intelligent teaching and automatic composition scoring system based on linear regression machine learning algorithm. J Intell & Fuzzy Syst. 2021;40(2):2069–81.10.3233/JIFS-189208Search in Google Scholar
[15] Xia L, Luo D, Liu J, Guan M, Zhang Z, Gong A. Attention-based two-layer long short-term memory model for automatic essay scoring. J Shenzhen Univ Sci Eng. 2021;37(6):559–66.10.3724/SP.J.1249.2020.06559Search in Google Scholar
[16] Saihanqiqige HE. Application research of english scoring based on TF-IDF clustering algorithm. IOP Conf Ser: Mater Sci Eng. 2020;750(1):12215–301.10.1088/1757-899X/750/1/012215Search in Google Scholar
[17] Lewis M, Marsden D, Sadrzadeh M. Semantic spaces at the intersection of NLP, physics, and cognitive science. FLAP. 2020;7(5):677–82.Search in Google Scholar
[18] Shi L, Du J, Liang M, Kuo F. Dynamic topic modeling via self-aggregation for short text streams. Peer-to-Peer Netw Appl. 2019;12(1):1403–17.10.1007/s12083-018-0692-7Search in Google Scholar
[19] Kou F, Du J, Lin Z, Liang M, Li H, Shi L, et al. A semantic modeling method for social network short text based on spatial and temporal characteristics. J Comput Sci. 2018;28(1):281–93.10.1016/j.jocs.2017.10.012Search in Google Scholar
[20] Shi L, Song G, Cheng G, Liu X. A user-based aggregation topic model for understanding user’s preference and intention in social network. Neurocomputing. 2020;413(1):1–13.10.1016/j.neucom.2020.06.099Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations