
Real-time segmentation of short videos under VR technology in dynamic scenes
-
Zichen He
 and
Danian Li
and
Danian Li

Abstract
This work addresses the challenges of scene segmentation and low segmentation accuracy in short videos by employing virtual reality (VR) technology alongside a 3D DenseNet model for real-time segmentation in dynamic scenes. First, this work extracted short videos by frame and removed redundant background information. Then, the volume rendering algorithm in VR technology was used to reconstruct short videos in dynamic scenes in 3D. It enriched the detailed information of short videos, and finally used the 3D DenseNet model for real-time segmentation of short videos in dynamic scenes, improving the accuracy of segmentation. The experiment compared the performance of High resolution network, Mask region based convolutional neural network, 3D U-Net, Efficient neural network models on the Densely annotation video segmentation dataset. The experimental results showed that the segmentation accuracy of the 3D DenseNet model has reached 99.03%, which was 15.11% higher than that of the ENet model. The precision rate reached 98.33%, and the average segmentation time reached 0.64 s, improving the segmentation accuracy and precision rate. It can adapt to various scene situations and has strong robustness. The significance of this research lies in its innovative approach in tackling these issues. By integrating VR technology with advanced deep learning models, we can achieve more precise segmentation of dynamic scenes in short videos, enabling real-time processing. This has significant practical implications for fields such as video editing, VR applications, and intelligent surveillance. Furthermore, the outcomes of this research contribute to advancing computer vision in video processing, providing valuable insights for the development of future intelligent video processing systems.
1 Introduction
As virtual reality (VR) technology advances rapidly alongside the surge of short video platforms like TikTok, they are becoming increasingly integrated into people’s daily lives, creating a significant cultural phenomenon. However, one notable challenge lies in the real-time segmentation of short video content, particularly in dynamically changing scenes. This is particularly evident in fast-paced motion scenes within TikTok videos, where achieving accurate segmentation becomes difficult. As a result, the real-time segmentation of short videos suffers from poor accuracy, ultimately impacting the overall user experience. Efficient real-time segmentation of short videos in dynamic scenes can provide users with an immersive experience and promote the development of interactive digital media.
The acceleration of social informatization has led to the rapid rise of the short video field, and many researchers have conducted research on real-time segmentation of short videos. To explore the problem of short video object segmentation, scholars such as Yao et al. conducted a survey to elaborate on different object segmentation methods and evaluation indicators [1]. Scholars such as Lu et al. introduced attention networks to solve the problem of inaccurate separation of objects and backgrounds in videos, achieving object and scene segmentation in videos [2,3]. Tang et al. used short tube connection algorithms for real-time monitoring of dynamic objects in order to segment the objects in the video, which improved the accuracy by 8.8% [4]. Scholars such as Zhou et al. used the Motion attentive transition network (MATNet) for zero sample video object segmentation, achieving improved segmentation performance [5]. Yang et al. used a combination of multi-scale matching structure and Collaborative foreground background integration for collaborative video object segmentation, achieving an accuracy of 82.9% [6]. Zhuo et al. proposed a new unsupervised online video object segmentation framework to explore video segmentation in dynamic scenes [7]. In order to solve the efficiency problem of short video segmentation processing, Hu et al. introduced the SiamMask framework and achieved a rate of 55 frames per second [8]. The above scholars have improved the segmentation accuracy of short videos to some extent, but the segmentation scenarios for short videos are too limited to adapt to complex scene changes.
With the country’s emphasis on VR technology and the development of the online entertainment industry, many researchers have introduced it to study the performance improvement of real-time segmentation of short videos. Yaqoob introduced the combination of VR technology and short videos to explore the immersive experience effect of videos, providing reference for future research [9,10,11]. Scholars such as Gonzalez et al. have achieved automatic medical imaging segmentation through 3D modeling and the introduction of VR technology [12,13,14]. Kim et al. used 360° videos to investigate immersive VR content and explore its impact on students’ learning outcomes [15]. In order to fully consider the real-time requirements of short videos, scholars such as Gionfrida et al. used a combination of 3D Convolutional Neural Network (3D CNN) and short-term memory units for real-time segmentation of gesture videos [16]. Liu et al. learned to use a 3D CNN model for real-time segmentation of vehicle monitoring videos, improving the real-time monitoring performance [17]. The above scholars introduced VR technology for 3D modeling of scenes, enriching the detailed information of short videos. In summary, it is feasible to combine VR technology with 3D CNN model for real-time segmentation of short videos in dynamic scenes.
In order to address the scene limitations and low segmentation accuracy of short video segmentation, this work adopts VR technology and 3D DenseNet model to perform real-time segmentation of short videos in dynamic scenes. First, this study extracts the original short video by frame and removes redundant background information. Its random selection and cropping of video preprocessing operations, and then the introduction of VR technology’s volume rendering algorithm for 3D reconstruction of short videos, enrich the detailed information of short videos. It uses a 3D DenseNet model for real-time segmentation of short videos. Finally, by comparing the performance of High-resolution network (HRNet), Mask region based CNN Mask R-CNN, 3D U-Net, and Efficient neural network (ENet) models on the DAVIS dataset, the 3D DenseNet model achieved a segmentation accuracy of 99.03%, an improvement of 15.11%, and a precision rate of 98.33%, an improvement of 3.76% compared to the 3D U-Net model. The average segmentation time reaches 0.64 s, and the impact on the segmentation using VR technology reaches 58.33%. This has achieved improvements in segmentation accuracy and robustness, which to some extent enhances real-time performance.
2 Experimental related data
2.1 Experimental dataset
This experimental dataset is sourced from the dense annotated video segmentation dataset DAVIS, which contains high-quality and high-resolution dense annotated video segmentation datasets at resolutions of 480p and 1,080p. It has a total of 50 video sequences, with 3,455 densely annotated frames at the pixel level. The duration of short videos ranges from 5 to 40 s. The video includes information about people, animals, cars, and other objects, as well as various competition videos. This work randomly selects 42 video sequences and divides them into training and testing sets using the ten-fold cross validation method. It divides all the data in the image into ten subsets, with three being the test set and seven being the training set. This work takes turns conducting experiments and the average of the results is taken as the final evaluation criterion.
2.2 Data preprocessing
2.2.1 Short video extraction by frame
To facilitate the processing of the model, this study now extracts short videos by frame and extracts actions from multiple consecutive time periods. Each time period corresponds to an action, and then it is integrated into a time series. In the first row, there is a picture of a big bear strolling, while in the second row, there is a picture of a car passing through an intersection. The third row shows a woman pushing a child’s car to go shopping, the fourth row shows a middle-aged woman swinging, and the fifth row shows a man playing tennis.
2.2.2 Image enhancement
To balance the dataset, this work uniformly performs random rotation and cropping operations on the segmented images [18,19]. Now, the segmented images of short videos are uniformly rotated counterclockwise by 30°.
2.2.3 Removing redundant backgrounds
This experiment combines the fuzzy C-means clustering algorithm [20,21] with motion window technology to generate a motion window based on the frame difference information of the short video in the dynamic scene after 3D reconstruction. It calculates the color Euclidean distance of each pixel and each cluster center corresponding to each point in the short video frame difference template in the dynamic scene after 3D reconstruction. If the random distance between a certain pixel and each cluster center exceeds a certain threshold, then the pixel is treated as a background pixel and removed to obtain a dynamic scene short video object after 3D reconstruction [22,23].
3 VR technology
VR technology utilizes computers to generate a simulated environment, immersing users in this environment. It is widely used in the fields of intelligent transportation and intelligent healthcare [24,25]. The establishment of a virtual environment is the core content of a VR system. Its main task is to obtain three-dimensional data of the actual environment and establish corresponding virtual environment models according to the needs of the application. This experiment introduces VR technology for 3D reconstruction of short videos to improve the real-time segmentation accuracy of short videos. It uses VR technology to process 2D short videos with multiple video frames containing single information into 3D short videos containing complex volume data. It enriches the detailed information of the target object in short videos to a certain extent, providing accurate data for segmentation implementation.
In this experiment, the volume rendering algorithm in VR technology was used for 3D reconstruction of short videos. In dynamic scenarios, data format conversion and redundant data removal operations are performed on the 3D spatial volume data of short videos, and reasonable color and transparency values are added for each data type after conversion. Rays from each pixel is emitted on the screen in the specified direction, passing through the video frame data. Sampling operations are performed on the ray at a uniform spacing, using 8-pixel color and opacity values adjacent to one of the sampling points, and then the color and opacity values of the sampling point are obtained using linear interpolation. Finally, the color and transparency values of all sampling points on the ray are obtained, and all sampling points are synthesized in a specific way to obtain a 3D short video.
Color assignment is a key step in 3D modeling. This work now distinguishes all objects within a short video by assigning color values. When the opacity is set to 1, it indicates that the object belongs to an opaque object, so that subsequent objects would be obscured. When the opacity is set to 0, it indicates that the object belongs to a transparent object, and the object is invisible. Another short video contains multiple objects, each with a different background color, so the color of the object is determined by the various substances contained together. In this experiment, R, G, and B are used to represent the components of the three-dimensional grayscale information of each frame of a short video sequence in a dynamic scene. The calculation of the color value of an object is shown in formula (1), and the color representation of a substance is shown in formula (2) [26].
where
After color assignment, the short video is synthesized using image synthesis method, using the viewpoint as the initial position of the ray. It starts from the viewpoint and projects toward the farthest point, synthesizing all pixel color and transparency values in the ray along the farthest direction from the viewpoint to the projection point, ending at the farthest projection point. The corresponding 3D video synthesis formula in this experiment is shown in formula (3).
where
4 3D DenseNet model
In this experiment, a cutting-edge approach employing a 3D DenseNet model is utilized to tackle the real-time segmentation challenges within dynamic scenes depicted in short videos. Unlike traditional methods, this model leverages 3D CNNs, which excel in capturing both temporal and spatial intricacies inherent in videos. By analyzing information from three consecutive frames, this advanced model delves deeper into the nuances of motion and context within the video footage.
Furthermore, the integration of 3D reconstruction techniques enhances the model’s understanding of the dynamic scene, allowing for more accurate segmentation results. By reconstructing the scene in three dimensions, the model gains a richer understanding of the spatial relationships between objects and their movements over time.
At the same time, each feature map in the convolutional layer is connected to the previous layer structure to fully extract motion information in the video scene. The formula for the specific convolutional layer in convolution is given below [27]:
where (x, y, z) represents the position coordinates of the feature map, tanh() is the convolution function, and
The 3D CNN extends the traditional DenseNet convolutional kernel from 2D to 3D. It adopts a dense connection method, connecting each layer of network with all the networks in the previous layer. The 3D convolution kernel convolves input feature maps similar to 2D convolution in space, while modeling the temporal dependencies between consecutive video frames in a neat manner. The 3D pooling layer downsamples the size of the input feature map in space and time, where the kernel sizes of the 3D convolutional layer and pooling layer are both s * s * d, s is the size of the space, and d is the depth or length of the input video frame.
For 3D DenseNet, the features of each layer are directly connected to the subsequent layers in the 3D DenseBlock through element level addition. Therefore, for a block in lth layer, this study summarizes the existence of l (l + 1)/2 connections, and may contain multiple convolutional kernels between the lth layer and the (l – 1)th layer. The input of the lth layer is the output of all 3D Dense-Blocks before the lth layer, and the output of the lth layer is xl. The process is briefly described by formula (5).
where H (.) is a nonlinear transformation function, which is a composite function of the BN ReLU-3DConv (Batch Normalization Rectified Linear Unit 3D Convolution) combination operation.
5 Real-time segmentation experiment for short videos in dynamic scenes
5.1 Experimental environment
This experiment is based on the Windows 10 system and implemented using the TensorFlow framework in Python. It uses Intel Core i7-6800k central processing unit, NvidiaTITAN Xp (12GB) graphics card, and 16GB memory.
5.2 Experimental process
This experiment first uses short videos from the dataset as input to the model. After inputting the videos, the video frames are uniformly sampled, and redundant information is removed, randomly cropped, and rotated. On the training set, this work first trains all samples 40 times (epoch = 40), dynamically expands the number of training times when adjusting parameters, and adds a batch normalization layer by stacking in multiples of two. This study sets the initial learning rate to 0.001 and the weight attenuation coefficient for training to 0.0003. Finally, this study fine-tunes the parameters on the validation set and compares the segmentation accuracy, precision rate, segmentation duration, robustness of different segmentation models, as well as verifies the experimental results from the perspective of the impact of VR technology on segmentation effectiveness.
6 Experimental results of video segmentation
This study evaluated the results using accuracy, precision, recall, comprehensive evaluation indicators f1 score, intersection over union (IOU), etc. The article evaluates the real-time segmentation performance of short videos in dynamic environments using the 3D DenseNet model.
Accuracy rate: The proportion of all correct judgments made by the model to the total [28].
Precision rate: The proportion of all predictions that are truly correct to be positive.
Recall rate: The proportion of true correctness to all actual positives.
F1 score: The f1 value is the arithmetic mean divided by the geometric mean. The larger the result, the better. The f1 value has weighted both the precision rate and recall rate, and the f1 score is in the range of 0–1. In this model, 1 represents the best segmentation performance, while 0 represents the worst.
IOU [29]: IOU is the standard performance measure for object class segmentation problems. IOU can measure the similarity between the predicted area and the ground truth area of objects present in a set of images.
TP represents true positive; FP represents false positive, and FN represents false negative count.
7 Experimental discussion on real-time segmentation of short video in dynamic scenes
7.1 Image analysis after video segmentation
Taking a holistic view of the original image, there is a notable resemblance in color between the goat and the mountainous terrain. However, post-VR 3D modeling, there is a significant enhancement in color detail, effectively accentuating the subject – the goat. Through segmentation, it is evident that the goat has been accurately isolated. In scene number 16, we witness a football being kicked into grass. Initially, the football rests beside a substantial tree within the grassy landscape. Despite some overlapping perspectives, the model adeptly discerns the ball’s contour and the surrounding imagery, especially under varying lighting conditions influenced by the grass. In summary, the model demonstrates commendable performance in segmenting short videos within dynamic scenes.
7.2 Analysis of accuracy and F1 value of different segmentation models
The comparison of segmentation accuracy and F1 index between different models is shown in Figure 1. The light yellow bar chart in Figure 1 represents segmentation accuracy, while the green line chart represents F1 value. From the perspective of segmentation accuracy, the 3D DenseNet model corresponds to the highest bar graph, reaching 99.03%, with the best performance, which is 2.46% higher than the HRNet model. The segmentation accuracy of the 3D U-Net model and ENet model is poor, with the 3D U-Net model achieving 94.48%. The ENet model only achieved 83.92% segmentation accuracy, which decreased by 15.11% compared to the 3D DenseNet model. From the F1 value, HRNet reached 0.95, a decrease of 0.03 compared to the 3D DenseNet model, Mask R-CNN model reached 0.93, and ENet model had the worst performance of only 0.80. In summary, it can be seen that the 3D DenseNet model has achieved good results in high share accuracy and F1 value.

Accuracy and F1 value of different segmentation models.
7.3 Analysis of recall and precision rates for different segmentation models
The comparison of recall and precision rates among different segmentation models is shown in Figure 2. In Figure 2, the light green bar chart represents the precision rate, and the light red bar chart represents the recall rate. From the precision rate, the 3D DenseNet model has the longest bar, reaching 98.33%, which is 2.95% higher than the Mask R-CNN model. The ENet model is the worst, only 81.24%, which is 17.09% lower than the 3D DenseNet model. It can be seen that the 3D DenseNet model has a significant advantage in improving the precision rate and has powerful advantages. From the perspective of recall rate, the 3D U-Net model reached 86.10%, which is 16.75% higher than the ENet model. The best one is the 3D DenseNet model, which reached 97.39%. Overall, both the 3D DenseNet model and HRNet model perform well in precision rate and recall rate.
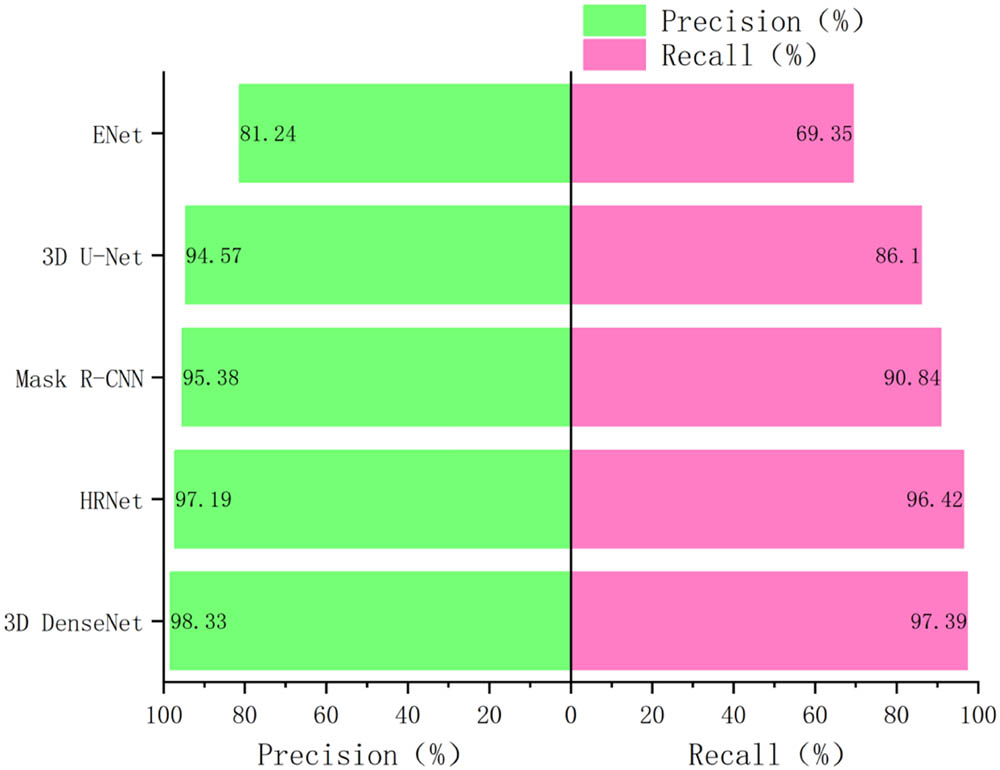
Recall rate and precision rate of different segmentation models.
7.4 Real-time segmentation result analysis
In order to explore the real-time segmentation effect more clearly, this work presents it in detail.

The real-time effect of object segmentation.
Figure 3 shows the real-time effect of object segmentation in some videos, and the first row shows the scene of a big bear walking, which is very obvious from the four feet of the big bear. Comparing the first and second images, the soles of the big bear pass through the stone area and there is some obstruction. As the bear strolls forward, in the fourth image, the outline of the bear’s front foot is completely obscured. Visible real-time segmentation is obvious, providing users with a more immersive experience of details and immersion. The second row of Figure 3 shows the scene of a bus passing through an intersection. From the first image to the sixth image, it can be seen that the road sign reference in the current perspective changes with the relative movement of the bus as it moves forward. The third row of Figure 3 shows the scene of a woman pushing a child while going shopping. Although it may not be obvious from the child’s car, it can be seen from the contour of the woman’s forward footsteps that both her left and right feet have taken a step forward in sequence. The fourth row of Figure 3 shows the scene of a middle-aged woman swinging on a swing. Compared to the original image, it can be seen that the wooden pillars of the swing may have some obstruction from the current perspective. From the real-time details of the rope and the woman’s hands and feet after segmentation, it can be seen that the rope and wooden stakes are accurately separated in the first image. In the second picture, the rope is segmented due to the woman’s initial forward movement to a certain extent. In the third to sixth images, apart from the rope changes, some features of the feet and hands, especially those obstructed by wood, a certain degree of obstruction is seen. In the fifth row of Figure 3, there is a scene where a man plays volleyball. From the specific details of his footsteps, the model can also achieve good real-time segmentation results. In summary, it can be seen that the model can adapt well to real-time recognition in dynamic situations.
For the real-time performance of specific video segmentation, this work now presents experimental data from several representative videos selected. The analysis of segmentation time for different model parts is shown in Table 1. In video number 1, having video duration of 5 s, the ENet model has the shortest processing time, only 0.30 s, while the HRNet model has the longest processing time, reaching 0.52 s. The 3D DenseNet model achieved 0.35 s, which requires an additional 0.05 s compared to the ENet model. However, compared to the HRNet model, it consumes 0.17 s less and can achieve good results. In video number is 5, having video duration of 15 s, the 3D DenseNet model reaches 0.77 s, which is 0.12 s more expensive than the 3D U-Net model. The video number is 8, and the video duration is 35 s. The ENet model only takes 0.75 s, followed by the 3D U-Net model which takes 0.79 s, which is only 0.04 s more than the ENet model. In addition, the 3D DenseNet model achieved 0.86 s, which is 0.11 s more expensive than the ENet model. Overall, the average segmentation time of the ENet model is the lowest, only 0.55 s, while the average segmentation time of the 3D DenseNet model is 0.64 s. The average segmentation time of the HRNet model reached a maximum of 0.76 s. In summary, it can be seen that the ENet model adopts a lightweight construction, achieving the best results in segmentation time. Based on its segmentation accuracy and precision, it can be seen that although it has an advantage in segmentation time, it sacrifices a lot of segmentation accuracy related performance, while the 3D DenseNet model only consumes 0.09 s more on average segmentation time.
Partial segmentation duration of different models
| Video number | Video duration (s) | 3D DenseNet | HRNet | Mask R-CNN | 3D U-Net | ENet |
|---|---|---|---|---|---|---|
| 1 | 5 | 0.35 | 0.52 | 0.46 | 0.33 | 0.30 |
| 2 | 8 | 0.44 | 0.56 | 0.48 | 0.40 | 0.37 |
| 3 | 10 | 0.55 | 0.58 | 0.60 | 0.52 | 0.48 |
| 4 | 13 | 0.57 | 0.69 | 0.63 | 0.53 | 0.51 |
| 5 | 15 | 0.77 | 0.87 | 0.79 | 0.65 | 0.62 |
| 6 | 20 | 0.79 | 0.89 | 0.81 | 0.71 | 0.65 |
| 7 | 27 | 0.82 | 0.94 | 0.89 | 0.76 | 0.69 |
| 8 | 35 | 0.86 | 1.06 | 0.97 | 0.79 | 0.75 |
7.5 Customer satisfaction analysis of different models
To further evaluate the real-world applicability of the model, it has been seamlessly integrated into an intelligent transportation vehicle system. Its effectiveness is gauged through a comprehensive questionnaire survey involving 300 users. The survey meticulously assesses performance based on key indicators including segmentation accuracy, responsiveness, and visual quality. Each criterion is meticulously scored using a standardized system, culminating a total score out of 30 points. The comprehensive scores of different segmentation models are shown in Figure 4. Light orange represents the actual segmentation effect, light green represents response speed, and light purple represents the image quality after segmentation. From the perspective of segmentation performance, the 3D DenseNet model has the highest score, reaching 9 points, followed by HRNet and Mask R-CNN models both achieving 8 points. The worst rated model is the ENet model, with only 4 points. From the perspective of response speed, the ENet model scored the highest, reaching 9 points, while the 3D DenseNet model only scored 7 points. From the perspective of image quality after segmentation, both the 3D DenseNet and HRNet models achieved 8 points, while the ENet and 3D U-Net models were the worst, with only 6 points. Overall, the 3D DenseNet model has the highest score, reaching 24 points, while the ENet model only has 19 points. Overall, it can be seen that the 3D DenseNet model is more favored by users.
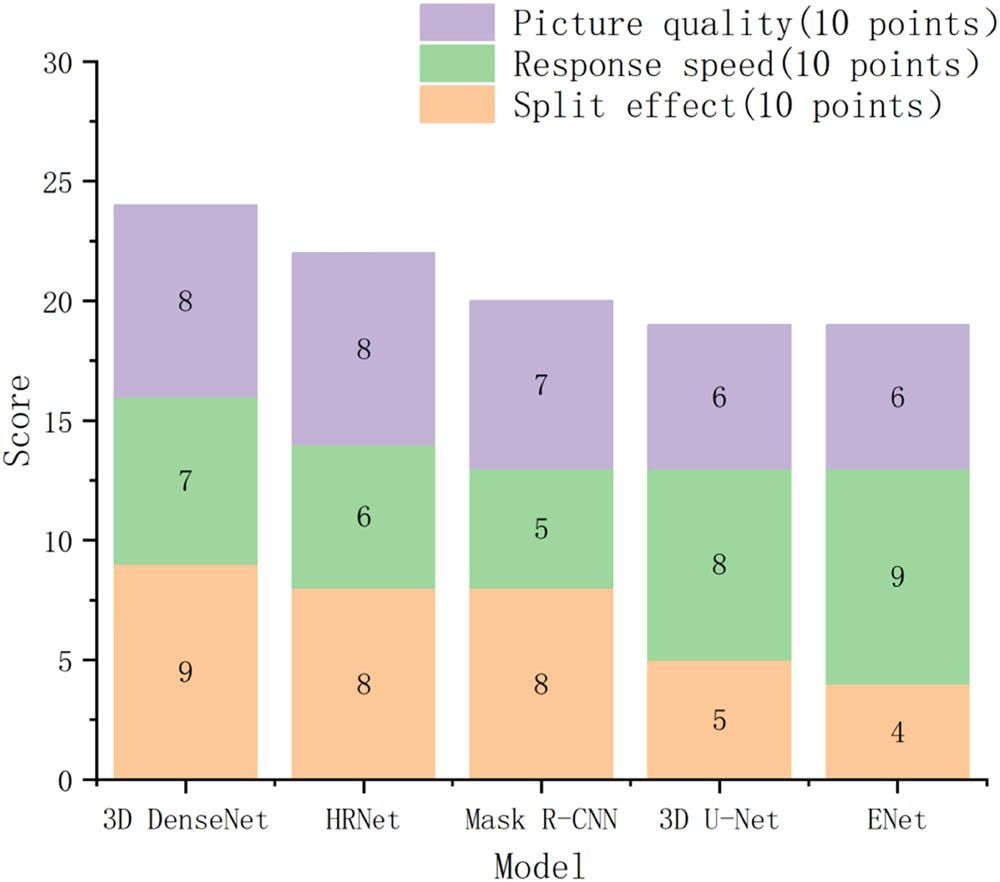
User satisfaction evaluation of different segmentation models.
7.6 Robustness analysis
In order to further verify the robustness of this model, it compared the segmentation accuracy and speed under five scenarios: normal, occlusion, strong light, fast motion, and complex background. The specific comparison is shown in Figure 5. The gray line graph in Figure 5 represents the segmentation accuracy. The red line chart represents the segmentation speed. From the perspective of segmentation accuracy, the accuracy of video segmentation under occlusion reached 98.81%, which is only 0.22% lower than the normal situation, and the impact is minimal. Under complex background conditions, the segmentation accuracy decreased to 94.49%, with a decrease of 4.54%, indicating the greatest impact. From the perspective of segmentation speed, under strong lighting conditions, the time consumption reached 0.67 s, which is only 0.03 s more than normal. In the case of complex background processing, the time consumption reached 1.14 s, which is 0.5 s more than normal. Overall, the fluctuations in various situations are within an acceptable range, meeting good practical application requirements.
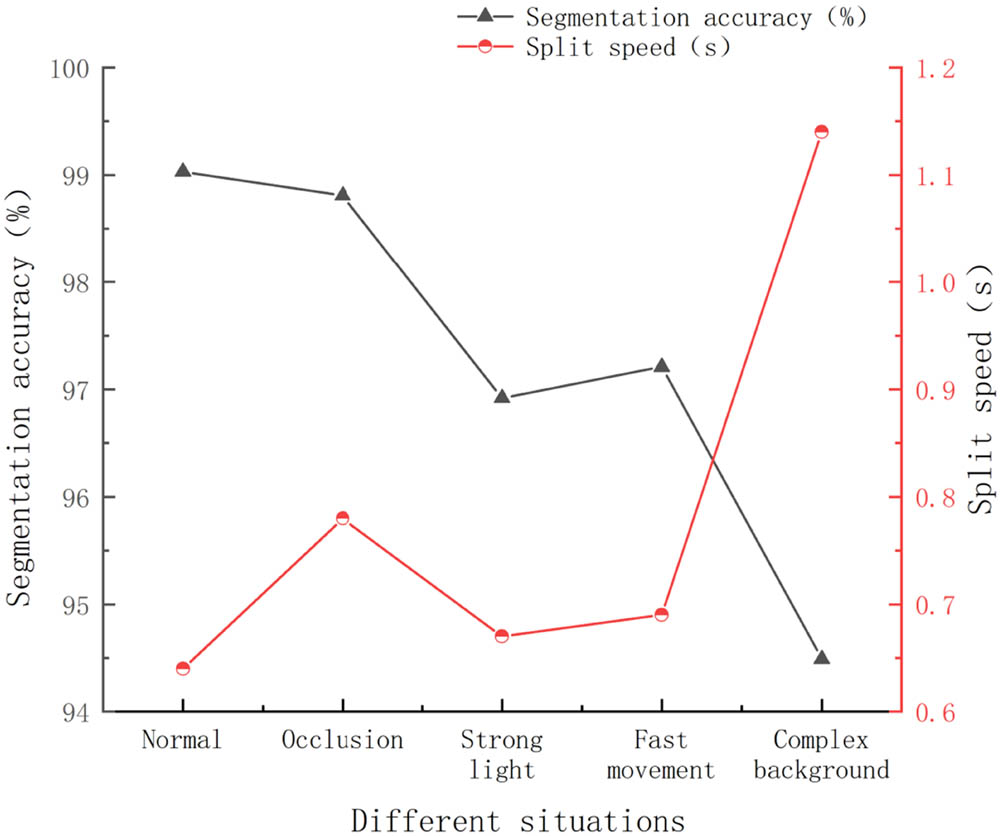
Robustness analysis.
7.7 Analysis of the impact of VR technology 3D modeling on segmentation effect
The comparison of the impact of VR technology 3D modeling on segmentation results is shown in Figure 6. This experiment compares and analyzes the degree of 3D modeling restoration and the use of VR technology to enrich scene information. The degree of restoration can be divided into the restoration of shape, size, color depth, and multi perspective information. Enriched scene information can be divided into rich lighting changes, textures, motion trajectories, and perspective projection effects. In Figure 6, those using VR technology are represented by a light purple bars, while those not using VR technology are represented by a light blue bars. From the perspective of restoration degree, after using VR technology to restore the shape, the IOU reached 0.96, the impact degree reached 18.52%, and the restored object size IOU reached 0.98. The degree of impact reached 30.67%, with the largest impact being the restoration of multi perspective information, with an IOU of 0.95 and an impact degree of 58.33%. From the perspective of rich scene information, the IOU reached 0.86 after the adoption of VR technology with rich lighting changes, and the impact degree reached 50.88%. After enriching the texture, the degree of influence is only 19.40%, and after enriching the motion trajectory, it is only 9.41%. Overall, the use of VR technology has had a good impact on real-time segmentation in dynamic scenes, improving the model’s ability to extract object features to a certain extent.
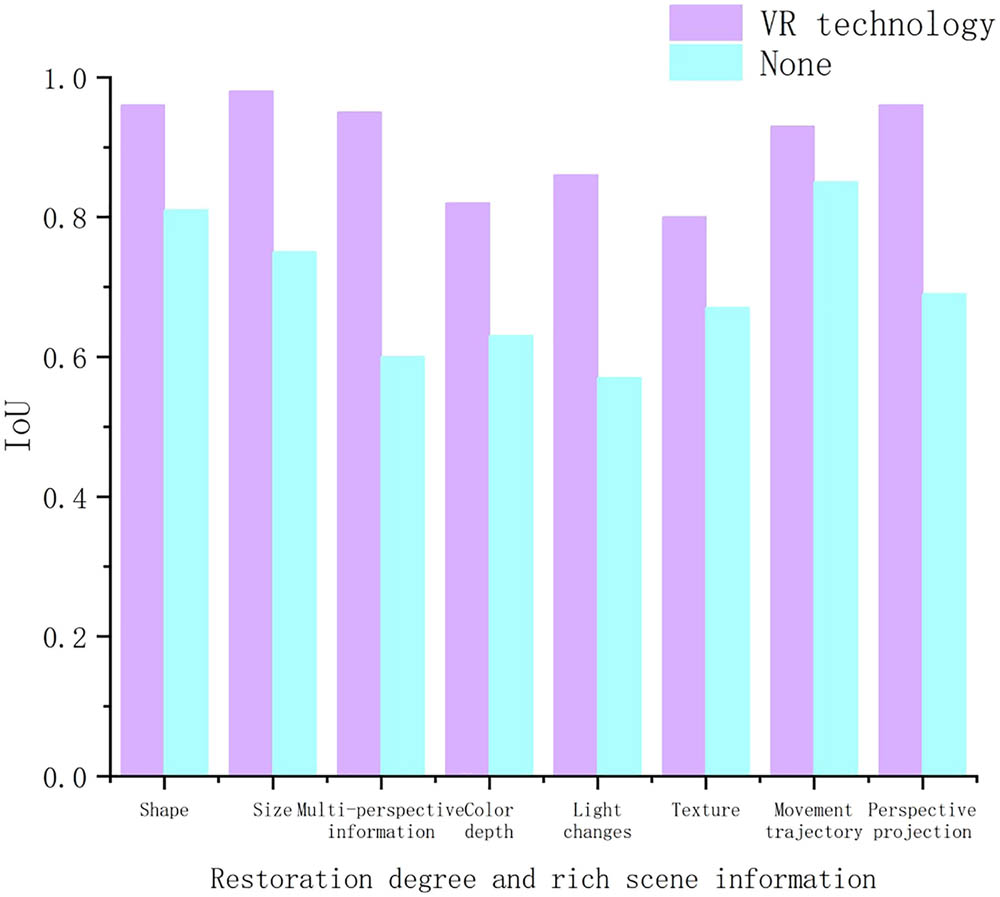
Impact of VR technology 3D modeling on segmentation effect.
8 Conclusion
This study presents a novel approach that integrates VR technology with a 3D DenseNet model to facilitate real-time segmentation of short videos within dynamic scenes. The process involves initial preprocessing of the original video, followed by the application of volume rendering algorithms from VR technology to reconstruct the short videos in dynamic 3D scenes. Subsequently, a 3D DenseNet model is employed for real-time segmentation. The experimental findings highlight the effectiveness of this combined approach in achieving high segmentation accuracy and robustness, while also contributing to a reduction in segmentation time. However, it is acknowledged that the complexity of the model is somewhat elevated, and there exists a challenge in fully balancing segmentation accuracy with real-time performance. Looking ahead, future research directions may involve conducting experiments aimed at streamlining the process involved, potentially leading to the development of more lightweight models. This would address the current shortcomings and further enhance the practical applicability of the approach in real-world settings.
-
Funding information: The authors state no funding involved.
-
Author contributions: Z.C.H. played a key role in authoring the manuscript, designing the research framework, developing the model, analyzing data, revising the language, and editing images. D.N.L. is mainly responsible for language proofreading, data analysis and organization, and model design. All authors have read and agreed to the published version of the manuscript.
-
Conflict of interest: The author(s) declare(s) that there is no conflict of interest regarding the publication of this article.
-
Data availability statement: The data used to support the findings of this study are available from the corresponding author upon request.
References
[1] Yao R, Lin G, Xia S, Zhao J, Zhou Y. Video object segmentation and tracking: A survey. ACM Trans Intell Syst Technol (TIST). 2020;11(4):1–47. 10.1145/3391743.Search in Google Scholar
[2] Lu X, Wang W, Shen J, Crandall D, Luo J. Zero-shot video object segmentation with co-attention siamese networks. IEEE Trans Pattern Anal Mach Intell. 2020;44(4):2228–42. 10.1109/TPAMI.2020.3040258.Search in Google Scholar PubMed
[3] Fu J, Liu J, Jiang J, Li Y, Bao Y, Lu H. Scene segmentation with dual relation-aware attention network. IEEE Trans Neural Netw Learn Syst. 2020;32(6):2547–60. 10.1109/TNNLS.2020.3006524.Search in Google Scholar PubMed
[4] Tang P, Wang C, Wang X, Liu W, Zeng W, Wang J. Object detection in videos by high quality object linking. IEEE Trans Pattern Anal Mach Intell. 2019;42(5):1272–8. 10.1109/TPAMI.2019.2910529.Search in Google Scholar PubMed
[5] Zhou T, Li J, Wang S, Tao R, Shen J. Matnet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Trans Image Process. 2020;29:8326–38. 10.1109/TIP.2020.3013162.Search in Google Scholar PubMed
[6] Yang Z, Wei Y, Yang Y. Collaborative video object segmentation by multi-scale foreground-background integration. IEEE Trans Pattern Anal Mach Intell. 2021;44(9):4701–12. 10.1109/TPAMI.2021.3081597.Search in Google Scholar PubMed
[7] Zhuo T, Cheng Z, Zhang P, Wong Y, Kankanhalli M. Unsupervised online video object segmentation with motion property understanding. IEEE Trans Image Process. 2019;29:237–49. 10.1109/TIP.2019.2930152.Search in Google Scholar PubMed
[8] Hu W, Wang Q, Zhang L, Bertinetto L, Torr P. Siammask: A framework for fast online object tracking and segmentation. IEEE Trans Pattern Anal Mach Intell. 2023;45(3):3072–89. 10.1109/TPAMI.2022.3172932.Search in Google Scholar PubMed
[9] Yaqoob A, Bi T, Muntean GM. A survey on adaptive 360° video streaming: Solutions, challenges and opportunities. IEEE Commun Surv & Tutor. 2020;22(4):2801–38. 10.1109/COMST.2020.3006999.Search in Google Scholar
[10] Montagud M, Li J, Cernigliaro G, Ali AE, Fernandez S, Cesar P. Towards socialVR: Evaluating a novel technology for watching videos together. Virtual Real. 2022;26(4):1593–1613. 10.1007/s10055-022-00651-5.Search in Google Scholar PubMed PubMed Central
[11] Huang J, Huang A, Wang L. Intelligent video surveillance of tourist attractions based on virtual reality technology. IEEE Access. 2020;8:159220–33. 10.1109/ACCESS.2020.3020637.Search in Google Scholar
[12] Gonzalez Izard S, Sanchez Torres R, Alonso Plaza O, Mendez J, Garcia-Penalvo F. Nextmed: Automatic imaging segmentation, 3D reconstruction, and 3D model visualization platform using augmented and virtual reality. Sensors. 2020;20(10):2962. 10.3390/s20102962.Search in Google Scholar PubMed PubMed Central
[13] Pires F, Costa C, Dias P. On the use of virtual reality for medical imaging visualization. J Digital Imaging. 2021;34(1):1034–48. 10.1007/s10278-021-00480-z.Search in Google Scholar PubMed PubMed Central
[14] Pajaziti E, Schievano S, Sauvage E, Cook A, Capelli C. Investigating the feasibility of virtual reality (VR) for teaching cardiac morphology. Electronics. 2021;10(16):1889–99. 10.3390/electronics10161889.Search in Google Scholar
[15] Kim J, Kim K, Kim W. Impact of immersive virtual reality content using 360-degree videos in undergraduate education. IEEE Trans Learn Technol. 2022;15(1):137–49. 10.1109/TLT.2022.3157250.Search in Google Scholar
[16] Gionfrida L, Rusli WMR, Kedgley AE, Bharath AA. A 3DCNN-LSTM multi-class temporal segmentation for hand gesture recognition. Electronics. 2022;11(15):2427–39. 10.3390/electronics11152427.Search in Google Scholar
[17] Liu Y, Zhang T, Li Z. 3DCNN-based real-time driver fatigue behavior detection in urban rail transit. IEEE Access. 2019;7:144648–62. 10.1109/ACCESS.2019.2945136.Search in Google Scholar
[18] Maharana K, Mondal S, Nemade B. A review: Data pre-processing and data augmentation techniques. Glob Transit Proc. 2022;3(1):91–9. 10.1016/j.gltp.2022.04.020.Search in Google Scholar
[19] Antink CH, Ferreira JCM, Paul M, Lyra S, Heimann K, Karthik S. Fast body part segmentation and tracking of neonatal video data using deep learning. Med & Biol Eng Comput. 2020;58:3049–61. 10.1007/s11517-020-02251-4.Search in Google Scholar PubMed PubMed Central
[20] Khang TD, Vuong ND, Tran MK, Fowler M. Fuzzy C-means clustering algorithm with multiple fuzzification coefficients. Algorithms. 2020;13(7):158–68. 10.3390/a13070158.Search in Google Scholar
[21] Chowdhary CL, Mittal M, PK, Pattanaik PA, Marszalek Z. An efficient segmentation and classification system in medical images using intuitionist possibilistic fuzzy C-mean clustering and fuzzy SVM algorithm. Sensors. 2020;20(14):3903–22. 10.3390/s20143903.Search in Google Scholar PubMed PubMed Central
[22] Cho J, Kang S, Kim K. Real-time precise object segmentation using a pixel-wise coarse-fine method with deep learning for automated manufacturing. J Manuf Syst. 2022;62:114–23. 10.1016/j.jmsy.2021.11.004.Search in Google Scholar
[23] Yang X, Jiang X. A hybrid active contour model based on new edge-stop functions for image segmentation. Int J Ambient Comput Intell (IJACI). 2020;11(1):87–98. 10.4018/IJACI.2020010105.Search in Google Scholar
[24] Lv Z, Guo J, Singh AK, Lv H. Digital twins based VR simulation for accident prevention of intelligent vehicle. IEEE Trans Veh Technol. 2022;71(4):3414–28. 10.1109/TVT.2022.3152597.Search in Google Scholar
[25] Minopoulos GM, Memos VA, Stergiou CL, Stergiou KD, Plageras AP, Koidou MP, et al. Exploitation of emerging technologies and advanced networks for a smart healthcare system. Appl Sci. 2022;12(12):5859–86. 10.3390/app12125859.Search in Google Scholar
[26] Cong ZC, Ning H, Qixiang S, Xiaojie Y. 3D DenseNet human body movement recognition method based on attention mechanism. Computer Eng. 2021;47(11):313–20. 10.19678/j.issn.1000-3428.0059640.Search in Google Scholar
[27] Qu M, Cui J, Su T, Deng G, Shao W. Video visual relation detection via 3D convolutional neural network. IEEE Access. 2022;10:23748–56. 10.1109/ACCESS.2022.3154423.Search in Google Scholar
[28] Ammar S, Bouwmans T, Zaghden N, Neji M. Deep detector classifier (DeepDC) for moving objects segmentation and classification in video surveillance. IET Image Process. 2020;14(8):1490–501. 10.1049/iet-ipr.2019.0769.Search in Google Scholar
[29] Mei J, Wang M, Yang Y, Li Y, Liu Y. Fast real-time video object segmentation with a tangled memory network. ACM Trans Intell Syst Technol. 2023;14(3):1–21. 10.1145/3585076.Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations
Articles in the same Issue
- Research Articles
- A study on intelligent translation of English sentences by a semantic feature extractor
- Detecting surface defects of heritage buildings based on deep learning
- Combining bag of visual words-based features with CNN in image classification
- Online addiction analysis and identification of students by applying gd-LSTM algorithm to educational behaviour data
- Improving multilayer perceptron neural network using two enhanced moth-flame optimizers to forecast iron ore prices
- Sentiment analysis model for cryptocurrency tweets using different deep learning techniques
- Periodic analysis of scenic spot passenger flow based on combination neural network prediction model
- Analysis of short-term wind speed variation, trends and prediction: A case study of Tamil Nadu, India
- Cloud computing-based framework for heart disease classification using quantum machine learning approach
- Research on teaching quality evaluation of higher vocational architecture majors based on enterprise platform with spherical fuzzy MAGDM
- Detection of sickle cell disease using deep neural networks and explainable artificial intelligence
- Interval-valued T-spherical fuzzy extended power aggregation operators and their application in multi-criteria decision-making
- Characterization of neighborhood operators based on neighborhood relationships
- Real-time pose estimation and motion tracking for motion performance using deep learning models
- QoS prediction using EMD-BiLSTM for II-IoT-secure communication systems
- A novel framework for single-valued neutrosophic MADM and applications to English-blended teaching quality evaluation
- An intelligent error correction model for English grammar with hybrid attention mechanism and RNN algorithm
- Prediction mechanism of depression tendency among college students under computer intelligent systems
- Research on grammatical error correction algorithm in English translation via deep learning
- Microblog sentiment analysis method using BTCBMA model in Spark big data environment
- Application and research of English composition tangent model based on unsupervised semantic space
- 1D-CNN: Classification of normal delivery and cesarean section types using cardiotocography time-series signals
- Real-time segmentation of short videos under VR technology in dynamic scenes
- Application of emotion recognition technology in psychological counseling for college students
- Classical music recommendation algorithm on art market audience expansion under deep learning
- A robust segmentation method combined with classification algorithms for field-based diagnosis of maize plant phytosanitary state
- Integration effect of artificial intelligence and traditional animation creation technology
- Artificial intelligence-driven education evaluation and scoring: Comparative exploration of machine learning algorithms
- Intelligent multiple-attributes decision support for classroom teaching quality evaluation in dance aesthetic education based on the GRA and information entropy
- A study on the application of multidimensional feature fusion attention mechanism based on sight detection and emotion recognition in online teaching
- Blockchain-enabled intelligent toll management system
- A multi-weapon detection using ensembled learning
- Deep and hand-crafted features based on Weierstrass elliptic function for MRI brain tumor classification
- Design of geometric flower pattern for clothing based on deep learning and interactive genetic algorithm
- Mathematical media art protection and paper-cut animation design under blockchain technology
- Deep reinforcement learning enhances artistic creativity: The case study of program art students integrating computer deep learning
- Transition from machine intelligence to knowledge intelligence: A multi-agent simulation approach to technology transfer
- Research on the TF–IDF algorithm combined with semantics for automatic extraction of keywords from network news texts
- Enhanced Jaya optimization for improving multilayer perceptron neural network in urban air quality prediction
- Design of visual symbol-aided system based on wireless network sensor and embedded system
- Construction of a mental health risk model for college students with long and short-term memory networks and early warning indicators
- Personalized resource recommendation method of student online learning platform based on LSTM and collaborative filtering
- Employment management system for universities based on improved decision tree
- English grammar intelligent error correction technology based on the n-gram language model
- Speech recognition and intelligent translation under multimodal human–computer interaction system
- Enhancing data security using Laplacian of Gaussian and Chacha20 encryption algorithm
- Construction of GCNN-based intelligent recommendation model for answering teachers in online learning system
- Neural network big data fusion in remote sensing image processing technology
- Research on the construction and reform path of online and offline mixed English teaching model in the internet era
- Real-time semantic segmentation based on BiSeNetV2 for wild road
- Online English writing teaching method that enhances teacher–student interaction
- Construction of a painting image classification model based on AI stroke feature extraction
- Big data analysis technology in regional economic market planning and enterprise market value prediction
- Location strategy for logistics distribution centers utilizing improved whale optimization algorithm
- Research on agricultural environmental monitoring Internet of Things based on edge computing and deep learning
- The application of curriculum recommendation algorithm in the driving mechanism of industry–teaching integration in colleges and universities under the background of education reform
- Application of online teaching-based classroom behavior capture and analysis system in student management
- Evaluation of online teaching quality in colleges and universities based on digital monitoring technology
- Face detection method based on improved YOLO-v4 network and attention mechanism
- Study on the current situation and influencing factors of corn import trade in China – based on the trade gravity model
- Research on business English grammar detection system based on LSTM model
- Multi-source auxiliary information tourist attraction and route recommendation algorithm based on graph attention network
- Multi-attribute perceptual fuzzy information decision-making technology in investment risk assessment of green finance Projects
- Research on image compression technology based on improved SPIHT compression algorithm for power grid data
- Optimal design of linear and nonlinear PID controllers for speed control of an electric vehicle
- Traditional landscape painting and art image restoration methods based on structural information guidance
- Traceability and analysis method for measurement laboratory testing data based on intelligent Internet of Things and deep belief network
- A speech-based convolutional neural network for human body posture classification
- The role of the O2O blended teaching model in improving the teaching effectiveness of physical education classes
- Genetic algorithm-assisted fuzzy clustering framework to solve resource-constrained project problems
- Behavior recognition algorithm based on a dual-stream residual convolutional neural network
- Ensemble learning and deep learning-based defect detection in power generation plants
- Optimal design of neural network-based fuzzy predictive control model for recommending educational resources in the context of information technology
- An artificial intelligence-enabled consumables tracking system for medical laboratories
- Utilization of deep learning in ideological and political education
- Detection of abnormal tourist behavior in scenic spots based on optimized Gaussian model for background modeling
- RGB-to-hyperspectral conversion for accessible melanoma detection: A CNN-based approach
- Optimization of the road bump and pothole detection technology using convolutional neural network
- Comparative analysis of impact of classification algorithms on security and performance bug reports
- Cross-dataset micro-expression identification based on facial ROIs contribution quantification
- Demystifying multiple sclerosis diagnosis using interpretable and understandable artificial intelligence
- Unifying optimization forces: Harnessing the fine-structure constant in an electromagnetic-gravity optimization framework
- E-commerce big data processing based on an improved RBF model
- Analysis of youth sports physical health data based on cloud computing and gait awareness
- CCLCap-AE-AVSS: Cycle consistency loss based capsule autoencoders for audio–visual speech synthesis
- An efficient node selection algorithm in the context of IoT-based vehicular ad hoc network for emergency service
- Computer aided diagnoses for detecting the severity of Keratoconus
- Improved rapidly exploring random tree using salp swarm algorithm
- Network security framework for Internet of medical things applications: A survey
- Predicting DoS and DDoS attacks in network security scenarios using a hybrid deep learning model
- Enhancing 5G communication in business networks with an innovative secured narrowband IoT framework
- Quokka swarm optimization: A new nature-inspired metaheuristic optimization algorithm
- Digital forensics architecture for real-time automated evidence collection and centralization: Leveraging security lake and modern data architecture
- Image modeling algorithm for environment design based on augmented and virtual reality technologies
- Enhancing IoT device security: CNN-SVM hybrid approach for real-time detection of DoS and DDoS attacks
- High-resolution image processing and entity recognition algorithm based on artificial intelligence
- Review Articles
- Transformative insights: Image-based breast cancer detection and severity assessment through advanced AI techniques
- Network and cybersecurity applications of defense in adversarial attacks: A state-of-the-art using machine learning and deep learning methods
- Applications of integrating artificial intelligence and big data: A comprehensive analysis
- A systematic review of symbiotic organisms search algorithm for data clustering and predictive analysis
- Modelling Bitcoin networks in terms of anonymity and privacy in the metaverse application within Industry 5.0: Comprehensive taxonomy, unsolved issues and suggested solution
- Systematic literature review on intrusion detection systems: Research trends, algorithms, methods, datasets, and limitations