
Dynamic load balancing algorithm for large data flow in distributed complex networks
-
Zhuo Zhang


Abstract
Information society brings convenience to people, but also produces a lot of data. Relational databases are not suitable for processing big data due to architecture defects. The most commonly used system to store and process large amounts of data is the NoSQL (Not only Structured Query Language) database. Obviously, it is very important to cooperate with these independent computers to accomplish processing tasks efficiently, which is the function of load balancing. This paper studies the commonly used NoSQL database and load balancing algorithms, and designs and implements a more efficient load balancing algorithm. By introducing the relationship between nodes and the children of their brother nodes, we reduce the height of the whole sorted binary tree. The time cost of the algorithm is reduced versus the commonly used weighted polling algorithm O(N) to O(log N), while the spatial cost remains unchanged. The equalization algorithm synthetically utilizes the characteristics of big data processing systems and has good performance. At the same time, the algorithm can quickly find the sub-optimal nodes when the optimal nodes have been occupied, so it is very suitable for load balancing in highly concurrent systems. Finally, the effectiveness of the proposed load balancing algorithm is verified by simulation.
1 Introduction
For a long time, relational databases have been the main tools for data storage. Relational databases were first put forward by IBM researcher F. Codd. Their theoretical basis is relational algebra, which was then gradually developed into a more mature relational database supporting transaction processing. Before the 1990s, the number of visits to a website was generally small, and mainly to static web pages. Relational databases became the mainstream storage technology [1].
With the rapid development of Web2.0, the amount of information generated by the Internet is growing rapidly. Search engine companies, such as Google, and social network companies have produced huge amounts of data information.However, the traditional relational database architecture cannot meet the needs of large quantities of processing [2]. First of all, the extensibility of the relational database schema is insufficient, and it is not suitable for big data storage. Because reading data from memory is much faster than reading data from disk, traditional relational databases speed up data access by putting indexes and caches into memory. Then a complex optimization algorithm is used to avoid reading the data directly from the disk and returning it to the client after receiving the user’s request [3]. But this approach is often ineffective in big data processing, because big data indexes tend to be several orders of magnitude larger than the average server’s memory capacity. Disk access is often the bottleneck of the whole system, which greatly reduces the response speed of the system. Second, although the use of mainframes or supercomputers can to some extent make up for the shortcomings of the above methods, they requires high operating and maintenance costs [4]. It’s hard for most free Internet applications to afford such a high cost. At the same time, having a mainframe as a centralized system does not provide as strong robustness and availability as distributed systems, and downtime accidents will seriously affect user experience. In the face of more and more homogeneous competition, this disadvantage can be said to be fatal.
Finally, big data processing systems tend to simply read and write data without the need for more complex features such as ACID (Atomicity, Consistency, Isolation, Durability), which provides these functions at the expense of performance degradation [5]. Since databases have become synonymous with storage systems, they are often referred to as NoSQL databases. In less than a decade, there have been dozens of NoSQL database products. Almost all large Internet companies use NoSQL database as one of their databases. Even Oracle, a relational database giant, has developed NoSQL database products based on Hadoop. The NoSQL database has become an important supplement to relational databases.
Load balancing is the distribution of workload between multiple computers, clusters of computers, or other resources to achieve optimal resource utilization, maximum throughput, minimum response time, and avoidance of overload. It is widely used in network systems and distributed systems. Load balancing is an important part of the NoSQL system [6]. How to design an efficient load balancing algorithm to deal with a large number of data requests is the key to the performance of the whole system. A good load balancing algorithm should select the most suitable node to handle the request according to the performance difference of each node in the system.
The common algorithms in commercial systems are the random method, polling method, and fastest connection method. In addition, even some artificial intelligence algorithms such as the genetic algorithm are still under study. However, such algorithms are either too complex or too difficult to implement, and the performance advantages are limited, or rough, failing to take into account the speed and performance of the node itself [7]. In this paper, we design a new algorithm to make the value of the largest weight always in the position of the first element without traversing the whole array to find the node with the maximum weight, which maintains the data structure while requiring less time cost.
2 A Survey of distributed mass data storage systems and load balancing algorithms
2.1 Summary of distributed mass data storage system
As mentioned above, the development of distributed mass data storage systems is the inevitable result of the development of the information age. Due to the limitations of hardware technology, the frequency of CPUs is closer to the theoretical limit of 4GHz under the existing architecture, and the space for performance improvement is not much while the cost is huge. Centralized systems face great challenges in dealing with rapidly expanding data storage and processing. Meanwhile, distributed systems have attracted much attention because of their high cost performance, good fault tolerance and robustness. On the other hand, relational databases also face great challenges. For example, when Internet applications produce huge amounts of data which can’t even be indexed into memory, traditional relational databases can’t do anything about it. And Internet applications often surge in a large number of visits in a short period of time with social hot spots and festivals, but these applications do not have high requirements for consistency [8]. Poor support for scalability can significantly increase overhead and response speed in relational databases. Therefore, a new distributed mass data storage system emerges as the times require. It makes full use of the advantages of the distributed system, and achieves high response speed and availability through cooperation between independent nodes. Because databases have been synonymous with storage systems for decades, these distributed mass data storage systems are often referred to as NoSQL databases.
At present, there is no uniform definition of NoSQL database, which is generally considered as the general term for any non-relational database. A NoSQL database can be described as follows:
Extensible loosely coupled data model
Cross-node data distribution, horizontal dynamic expansion
Data persistence capability in memory or disk
Supporting non-SQL statement interfaces for data access
The results of the comparison of NoSQL databases which satisfy true distribution and automated fragmentation are shown in Table 1. Many NoSQL databases are not included because they do not meet these Ellis prerequisites.
Classification of NoSQL
| Data storage | Support for transparently added machines | Multi-data center support |
|---|---|---|
| Cassandra | No | No |
| HBase | No | Yes |
| Riak | No | Yes |
| Scalaris | No | Yes |
| Voldemort | Yes | Need some code |
We believe that persistence design is important for good runtime of a database. Memory databases are fast but easily lost. This strategy is fast and avoids the vulnerability of pure memory databases. The B-tree can provide robust index support in the database, but it does not perform well due to the need to read and write more disks. The document database CouchDB uses a B-tree and only appends writes, thus avoiding excessive disk IO.
2.2 Distributed mass data storage system
Memcached is a distributed cache system developed by danga.com which is used to dynamically reduce database load and improve system performance. It is widely used in NoSQL databases. Memcached implements network connections based on the libevent library and itself provides services as a stand-alone application or daemon. It uses a simple protocol for communication, built-in memory storage for storage [9]. The NoSQL data model and query API are given in Table 2.
NoSQL data model and query API
| Database | Data model | Query API |
|---|---|---|
| Cassandra | List | Thrift |
| CouchDB | Documents | Map/reduce view |
| HBase | List | Thrift, REST |
| MongoDB | Documents | cursor |
| Neo4j | Diagram | Diagram |
| Redis | set | set |
| Riak | Documents | Inline hash |
| calaris | Key/value | Get/put |
| Tokyo Cabinet | Key/value | Get/put |
| Voldemort | Key/value | Get/put |
Sorting NoSQL with persistent storage is given in Table 3. Memcached is usually used as a cache for the front end of the database, and is used only to manage data in memory, not to include more time-consuming operations such as SQL parsing and disk operations. Therefore, it can provide better performance than direct reading of traditional relational databases, and it is widely used in mass data storage systems. In addition, Memcached is often used as a medium for sharing data between servers [10], shared by multiple applications. Because Memcached uses memory to store and manage data, other means are needed to persist the data. At the same time, memory is very expensive and storage space is extremely limited, so using this way to store data is not extensible.
Sorting NoSQL with persistent storage
| Database | Durable design |
|---|---|
| Cassandra | Memtable / SSTable |
| CouchDB | Append B tree |
| HBase | Memtable / SSTable on HDFS |
| MongoDB | B tree |
| Neo4j | Disk link list |
| Redis | RAM |
| Riak | uncertain |
| calaris | RAM |
| Tokyo Cabinet | Hash or B-tree |
| Voldemort | Pluggable (mainly BDB My SQL) |
A key-value storage database is a database where data is stored in memory and disk as keys and values. There is a common simple data model for key-value storage: a mapping/dictionary that allows clients to request and push values through keys. One of the more famous databases for key-value storage is AmazonDynamo. Itwas used for many purposes along with other databases at Amazon, and as one of NoSQL’s earliest products had a significant impact on later NoSQL databases.
Dynamo is an extensible, highly available key-value storage system developed internally by Amazon. Instead of being exposed directly to the outside, Dynamo is used to support a portion of Amazon’s web services. Many of the technologies used in Dynamo are based on the research of distributed systems and operating systems in the past few years. The techniques used by Dynamo and their advantages are shown in Table 4.
Dynamo Use Technology and Benefits
| Problem | Solution | Advantage |
|---|---|---|
| Partition | Consistency hash | Improve scalability |
| High-availability write operations | Vector Clock | Version decoupling |
| Handling temporary failure | Loose election mechanism | High availability and durability |
| Recover from persistent failure | Anti-entropy | Background consistency replication |
| Failure detection | Heartbeat protocol | Avoid centralized registration |
The advantages and disadvantages of Dynamo are summarized in Table 5.
The advantages and disadvantages of Dynamo
| Advantages | Shortcomings |
|---|---|
| No master | Non-open source software |
| Supports high availability write operations | Clients need smarter |
| Read or write tuning | No compression |
| Simple | Do not support unified operation of columns Do not support range queries and batch operations |
2.3 Commonly used theory
2.3.1 Consistency theory
CAP means consistency, availability and partitioning fault tolerance. According to CAP theory, at most, only two of the three can be strictly satisfied. Consistency is whether and how the system is in a consistent state after performing an operation. If all read operations after a write operation can see their update operations in shared data resources, the distributed system can be considered consistent. Availability, or high availability, means that a system is implemented in away that allows continuous operation, even if some nodes or hardware fail due to upgrades [11]. Partitioning fault tolerance refers to the ability of the system to support continuous operation in the case of network partitioning. This occurs when two or more isolated nodes are not connected. Others think that partitioning fault tolerance refers to the ability to dynamically add or remove nodes. CAP applied to the system is given in Table 6.
CAP applied to the system
| Select | Features | Example |
|---|---|---|
| Consistency, availability (sacrificing | Two-phase commit, cache | Single database, cluster database |
| partition fault tolerance) | verification protocol | LDAP, xFS file system |
| Consistency, Partition Fault | Negative lock, making a few | Distributed Databases, Distributed |
| Tolerance (Sacrificing Availability) | partitions unavailable | Locks, Most Distributed Protocols |
| Availability, Partition Fault Tolerance | Conflict resolution, optimistic | Coda, DNS |
| (Sacrifice Consistency) | locking |
These applications often improve availability and reliability through a certain degree of redundancy.
2.3.2 Partition fault tolerance
If the data in a large-scale system exceeds the capacity of a single machine, then the system needs to consider replication to ensure reliability, load balancing and data partitioning to improve scalability. Depending on the size of the system and other factors, there are several different options [12].
This can be viewed as a partitioned memory database. These systems copy used data frequently into memory and then distribute it to the client, thus avoiding a large amount of disk IOs and significantly improving efficiency. In the case of Memcached, the memory cache contains a set of processes that have allocated memory, and these servers connect by configuring the network. The Memchched protocol, which can be implemented in multiple languages, provides a simple key-value storage API. It hashes objects that need to be stored into the configured in-memory cache instance. If a node is unable to connect due to a hardware failure, the object needs to be relocated through a secondary hash [13]. Because these are all in-memory operations, they are fast. Because memory bars are much more expensive than disks, they are expensive, or are not extensible at a certain cost. Database server clustering is another way of transparently partitioning data. However, this approach can only be used based on distributed database management systems with poor performance [14].
2.4 Load balancing
Load balancing is a set of methods to adjust and control resources in a distributed system to improve the performance of the system. It has a significant impact on the performance of the system under the established hardware environment. Load balancing mechanisms are typically triggered during initialization and redistribution [15]. The load balancing algorithm can either separate the two or deal with them together. The mechanisms of the two methods are similar, and the redistribution phase requires more load balancing. This paper focuses on the re-distribution phase of the load balancing mechanism.
Load balancing can be classified differently according to different criteria. For example, according to the implementation method, it can be divided into software and hardware load balancing. According to the scope of load balancing, it can be divided into local and global load balancing. It can also be divided into link layer, transport layer and application layer load balancing [16].
Software and hardware load balancing
Software load balancing uses a software method to deal with load balancing, while hardware load balancing uses a hardware method. Software load balancing serves to distribute the traffic through a certain load balancing algorithm at the interface of the distributed software system to realize a reasonable flow of the traffic. Hardware load balancing by connecting a load balancer is responsible for forwarding and regulating network traffic. Because the hardware equipment has the characteristics of high speed, stability, reliability and so on, the backstage of a large website generally uses this load balancing method to control access.
Local and global load balancing
Technology for load balancing by region can be divided into partial load balancing and global load balancing. Partial load balancing consists generally of the dynamic distribution of load in LAN, and most of the load balancing belongs is of this type at present. Because of the high speed of local area networks, we can think of network delay as a secondary factor. At this time, the main consideration is the matching degree between the task and the server node itself. On the other hand, global load balancing is used to distribute the load at multiple sites in a cross-region.
Network layer load balancing
This method distributes different packets by parsing network protocol packets. At present, it is mainly divided into link layer, transmission layer and application layer balancing.
3 Design and implementation of load balancing algorithm
3.1 Load problem description
Due to the limitation of CPU frequency, memory reading speed and Von Neumann system structure, the performance of a single computer is limited to a certain extent, so people use multiple computers to improve performance. Distributed systems can be divided into three types: shared memory, shared disk, and no shared resources, as shown in Figure 1.
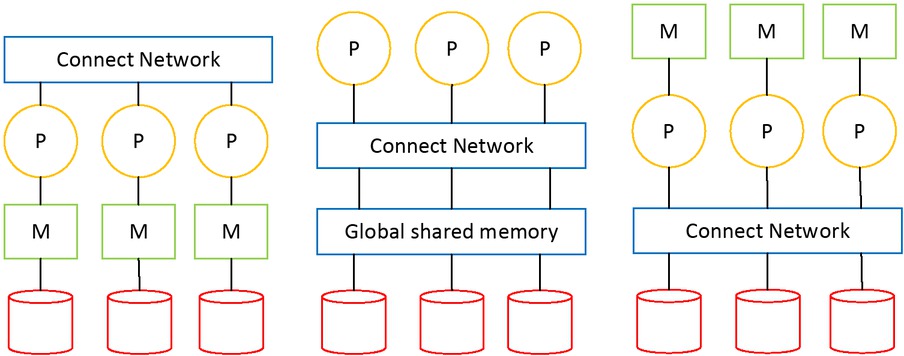
Three common structures of distributed databases
Multiple processors of a shared memory system are connected over a network and have access to common memory. Shared disk storage systems are such that each processor has its own independent memory, but can directly access all hard disks over the network. Without a shared resource system, each processor has its own memory and disk, and there is no common resource, and all communication between different processors is done over the network. Shared memory and shared disk structure are prone to resource conflicts. With increase in number of processors, system performance improvement is limited. Non-shared resource systems are considered to be the best structure for scalable large-scale data processing systems, obtaining approximately linear performance improvement.
Load balancing is mainly responsible for adjusting the load between partition servers so that the resources managed by each load can be balanced as much as possible. When the load is not balanced, the task handled by the heavier node can be dynamically transferred to the lighter load node [6]. Load balancing plays an important role in distributed systems. Application scenarios typically focus on communication within the same data center, that is, connections between these servers over local area networks, regardless of the connection between servers over a wide area network when communicating across data centers. Therefore, it is generally believed that network transmission speed will not become the bottleneck of the system.
3.2 Design of load balancing algorithm
The key for load balancing algorithms is to design an algorithm to quickly and accurately find the node with light load and assign the task to such node. As mentioned earlier, static algorithms ignore the differences between nodes and the load tilt caused by task execution, which has obvious efficiency disadvantages compared with dynamic algorithms [8].
The balanced tree is a data structure commonly used in computer science. It usually adjusts the structure of the general ordered binary tree when it meets some conditions by certain constraints to keep the relative equilibrium between its left and right subtrees. The time cost of operations such as insertion and deletion of binary tree is closely related to the height of the tree. Therefore, the key to improving the efficiency of the binary tree is to add appropriate constraints to maintain balance of the binary tree through simple and efficient operation.
In this paper, a constraint condition is introduced for binary trees by combining balanced binary trees with the Fibonacci sequence. The cost of time O(logN) is reduced, and only a few operations are required to make binary trees that do not satisfy this condition satisfy this constraint condition. The algorithm stores node information in the ordered binary tree, adds an element to the sorted binary tree to count the number of nodes, and then rotates the tree to the left and right, so that the binary tree always keeps the height of O(log N).
For the convenience of the following description, define as follows: T means node, left [T] means left child of T, right [T] means right child of T. size [T] denotes the number of nodes in a subtree of which T is the root node. In addition to satisfying the properties of ordinary ordered binary trees, we also satisfy the following two properties:
Size [T] and these two properties are very important for reducing the height of the ordered binary tree, which is the key to improving the efficiency of the algorithm. In the worst case, the common ordered binary tree is reduced to a linked list, and the time cost is the same as the time cost of polling in the worst case. It will be shown later that by introducing the above two properties, O(log N) can make the sorted binary tree as high as possible in any case. The above two properties are not always satisfied in the establishment of ordered binary trees. Through the Maintain operation, the previously unsatisfied nodes satisfy these two properties. Because these two properties are symmetric, there are two situations:
1) Situation 1
It is assumed here that T’s left and right children are satisfied with the above properties. Assuming that a node is inserted so that size[A] > size[R] is in violation of Property 1. A node which is not satisfied with that property can be made satisfied by the right-hand rotation operation shown in Figure 2. If the T node or L node of the binary tree does not satisfy the above two properties, then the Maintain operation is performed on them again. The size values of the T node and L node are recalculated. It is clear that after the Maintain operation, all nodes satisfy the above two properties.
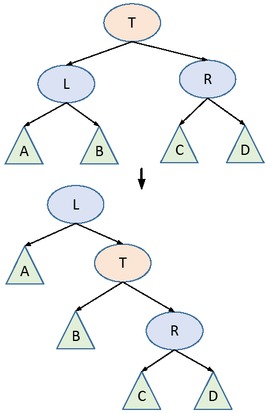
Right-handed operation of T node
2) Situation 2
Assuming that the insertion node causes size [B] > size [R] to violate Property 1, then we first perform a left-handed operation on the L node and then a right-handed operation on the T node. The left-handed operation of the L node has been discussed in the case of 2) as shown in Figure 3. At this point, the B subtree may satisfy Property 1, and sometimes this Maintain operation needs to be performed on the B point. At this point, all nodes satisfy two properties.
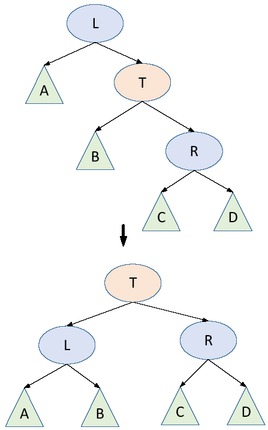
Left-handed operation of L node
We organize the nodes into one of the above binary tree structures so that the most suitable node can be taken out at a time cost to execute the load balancing plan. When the power value changes, the binary tree can also be maintained over time by swapping with the left child or the right child. Adding or deleting nodes also takes time to complete.
At initialization, the binary tree is sorted in the normal way, and then the nodes that do not satisfy Properties 1 and 2 are rotated. When the data structure is set up, only a few nodes need to be adjusted, so it is not necessary to reorder all the nodes, but only to adjust the individual nodes. The time cost of reordering is maximum when using the old polling algorithm, but the whole time cost of this algorithm is what is required, and it may be much smaller than this worst time cost in practice.
3.3 Common operation of algorithm
The key for this algorithm is to count the number of nodes and limit the height of the binary tree by the constraint relationship between the number of nodes. The pseudo code for the statistics node size is as follows:
When the two introduced properties are not satisfied, the structure of the tree is changed by the Maintain operation to re-satisfy the condition. The operation is a recursive operation—that is, the operation is premised on the child nodes satisfying Properties 1 and 2. The pseudocode for left rotation and left rotation in Maintain operations is as follows:
The pseudocode for RightRotateroot to the right is as follows:
The pseudocode for maintaining operations, Maintainroot, for Properties 1 and 2 is as follows:
The pseudocode for looking for a precursor, FindPre-decessorroot, looks like this:
In high concurrency big data processing systems, it is also very important to find the sub-optimal and the third optimal nodes in order to improve the throughput when the optimal nodes have already been allocated. The pseudocode for finding the k maximum value FindRank(root, k) is as follows:
In short, using the above operations, you can maintain a more balanced binary tree in time.
3.4 Implementation of load-balancing weighting algorithm
Load balancing evaluation index has an important impact on load balancing. A good evaluation index can accurately reflect the system load situation and processing ability. Common load metrics include processor occupancy, processor ready queue length, main memory usage, IO speed, and so on.
The load balancing algorithm is usually in the load balancer, where the trigger condition of load balancing is satisfied, and the load balancer finds out the responding node to schedule the load according to the load balancing algorithm. The communication between nodes can be done by means of TCP or UDP. when the client’s read-write request arrives, the load balancer distributes the load in real time according to the load of the load server and the balancing strategy. The communication between the client and the load server is forwarded through the load balancer. The advantage of this method is that it is convenient for centralized management and easy to configure. The weakness is that the requirements of load balancer are high and it’s easy for the the equalizer to become the bottleneck of the system when the task is large. The client first communicates with the load balancer to obtain the address of the load server that can process its requests. The load balancer selects an appropriate balancing server based on the state information and load balancing policy of the maintained load balancer and returns the IP address and port number of the load server to the client. The client then establishes a communication connection directly with the load server. The advantages of this approach are ease of expansion, good robustness, and the lack of system bottlenecks in the architecture itself. Therefore, this method is the mainstream method to achieve load balancing; the test system of this paper also adopts this structure.
Figure 4 is a general frame diagram of the load balancing algorithm. When the load is tilted, the load balancing plan is executed, the optimal load node is selected to process the request, and finally the data transfer and metadata modification are carried out.
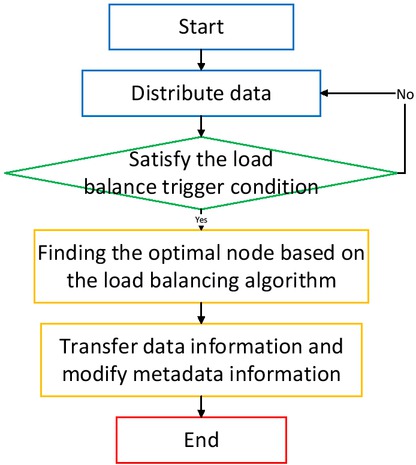
Load balancing algorithm flow chart
4 Test and analysis
4.1 Test environment
The load balancing algorithm and memory optimization described in this paper are applied to the distributed mass data storage system developed by the Institute of Computing of the Chinese Academy of Sciences. In order to test the performance of the algorithm and memory optimization, a distributed system platform is built. The architecture of the system is shown in Figure 5, and the IP addresses of the primary server and partition server are shown in Table 7.
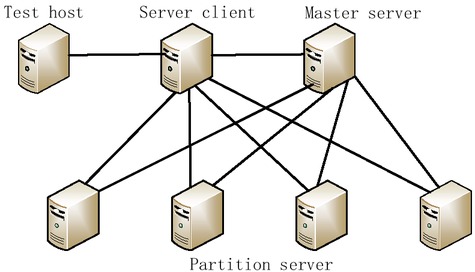
Test System Architecture
text
| Name of server | LAN IP address |
|---|---|
| Master server | 192.168.0.121 |
| Partition server 1 | 192.168.0.134 |
| Partition server 2 | 192.168.0.135 |
| Partition server 3 | 192.168.0.136 |
| Partition server 4 | 192.168.0.137 |
The whole distributed system is divided into three parts: server client, primary server and partition server. Metadata storage and distributed lock management is a cluster of primary server nodes in the metadata storage subsystem in Figure 5. This mainly provides a metadata persistence storage function, metadata consistency maintenance function, and metadata access management function based on the above mentioned metadata.
4.2 Improved binary tree performance test
The core of this algorithm is to maintain the balance of the binary tree by left rotation and right rotation operations, so as to ensure finding at O(log N) the node with high weight in any data application. One of the important differences between this algorithm and other balanced binary trees is the introduction of a simple constraint relationship so that the binary tree needs only a few operations to maintain a better balance. The balance of a binary tree can be roughly measured by the average depth and height. The binary tree test flow chart is given in Figure 6.
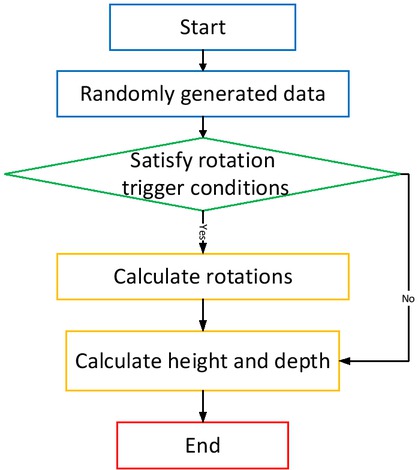
Binary tree test flow chart
2000000 random data are generated and inserted by the random number generator, and then the efficiency differences between the data structure designed by this algorithm and other classical binary tree data structures are compared, as shown in Table 8. You can count the number and average depth of rotation by setting global variables. Because rotation is a more complex operation, the more the rotation times are, the more unbalanced the binary tree is, so the algorithm with less rotation times is often more efficient. Because the time cost of many operations of a binary tree is related to its height, the smaller the height or depth of the tree is, the faster the query, insertion, and deletion of the binary tree is.
The proposed Binary Tree is compared with other binary trees
| Types | Binary Tree | AVL tree | Treap | Random binary tree | Stretching tree |
|---|---|---|---|---|---|
| Average depth | 19.35 | 19.58 | 26.54 | 25.68 | 38.2 |
| height | 25 | 26 | 51 | 56 | 81 |
| Number of rotations | 1.58 million | 1.55 million | 4.01 million | 4.03 million | 25.21 million |
It can be seen that this data structure has some advantages compared with other classical data structures in terms of the height of the tree and the number of times of rotation. It is only slightly higher than the AVL tree in the number of times of rotation, and the overall efficiency is very high. The effect is satisfactory.
4.3 Memory optimization test
In the process of reading and writing the system, the memory detection tool Valgrind is used to detect the memory and find that there are a lot of memory fragments in Cell-Cache. The management of CellCache through memory pool can improve the efficiency of the system. The memory fragment size usually ranges from a few bytes to a few hundred bytes, so the test environment for this article changes the input data to a large number of small data repeated insert operations. A 40 tasks performance comparison chart is given in Figure 7.
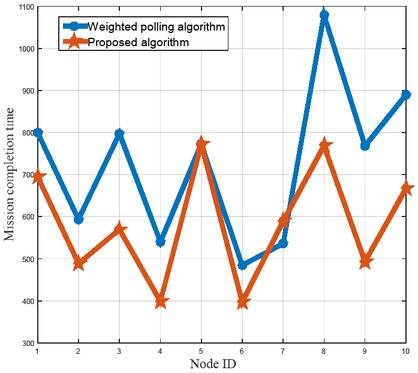
40 tasks performance comparison chart
After testing, there has been a significant increase in efficiency with the optimized memory pool rewriting configuration, as shown in Figure 8. The two lines in the figure represent the default allocation of STL, the insert process under the four allocation modes directly using memory pool, and the comparison of memory usage. As you can see, memory fragmentation on the partition server has been significantly reduced through memory pool management of CellCache.
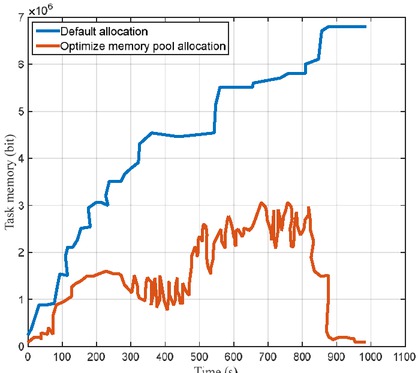
Comparison of results before and after memory optimization
As seen from Figure 7 and Figure 8, using the proposed load balancing algorithm can effectively reduce the system memory footprint. Simulation validates the effectiveness of the proposed method.
5 Conclusion
Based on the research into the NoSQL database and the current mainstream load balancing algorithm, this paper designs an efficient load balancing algorithm for mass data storage systems. On the basis of a polling algorithm and weighted algorithm, the algorithm adds information about the number of statistical nodes. The height of the sorted binary tree is maintained at O(log N) by rotation operations, so that the time cost of accessing the node can be reduced from the time cost of the node to O(log N), which is helpful to improving the throughput of the big data system. The algorithm can also recursively find sub-optimal nodes and their successors and support load balancing of high concurrent systems and parallel processing systems.
Acknowledgement
Supported by the Natural Science Foundation of Heilongjiang Province of China (Grant No.A201413).
References
[1] Cui L., Yu F.R., Yan Q., When big data meets software-defined networking: SDN for big data and big data for SDN, IEEE network, 2016, 30, 58-65.10.1109/MNET.2016.7389832Search in Google Scholar
[2] Kreutz D., Ramos F.M., Verissimo P.E., Rothenberg C.E., Azodolmolky S., Uhlig S., Software-defined networking: A comprehensive survey, Proceedings of the IEEE, 2015, 103, 14-76.10.1109/JPROC.2014.2371999Search in Google Scholar
[3] Jo M., Maksymyuk T., Strykhalyuk B., Cho C.H., Device-to-device-based heterogeneous radio access network architecture for mobile cloud computing, IEEE Wireless Communications, 2015, 22, 50-58.10.1109/MWC.2015.7143326Search in Google Scholar
[4] Shaofei W., A Traffic Motion Object Extraction Algorithm, International Journal of Bifurcation and Chaos, 2015, 25, 18-27.10.1142/S0218127415400398Search in Google Scholar
[5] Capitanescu F., Ochoa L.F., Margossian H., Hatziargyriou N.D., Assessing the potential of network reconfiguration to improve distributed generation hosting capacity in active distribution systems, IEEE Transactions on Power Systems, 2015, 30, 346-356.10.1109/TPWRS.2014.2320895Search in Google Scholar
[6] He X., Ai Q., Qiu R.C., Huang W., Piao L., Liu H., A big data architecture design for smart grids based on random matrix theory, IEEE transactions on smart Grid, 2017, 8, 674-686.10.1109/TSG.2015.2445828Search in Google Scholar
[7] Hu F., Hao Q., Bao K., A survey on software-defined network and openflow: From concept to implementation, IEEE Communications Surveys and Tutorials, 2014, 16, 2181-2206.10.1109/COMST.2014.2326417Search in Google Scholar
[8] Mijumbi R., Serrat J., Gorricho J.L., Bouten N., De T.F., Boutaba R., Network function virtualization: State-of-the-art and research challenges, IEEE Communications Surveys and Tutorials, 2016, 18, 236-262.10.1109/COMST.2015.2477041Search in Google Scholar
[9] Yan Q., Yu F.R., Gong Q., Li J., Software-defined networking (SDN) and distributed denial of service (DDoS) attacks in cloud computing environments: A survey, some research issues and challenges, IEEE Communications Surveys and Tutorials, 2016, 18, 602-622.10.1109/COMST.2015.2487361Search in Google Scholar
[10] Diamantoulakis P.D., Kapinas V.M., Karagiannidis G.K., Big data analytics for dynamic energy management in smart grids, Big Data Research, 2015, 2, 94-101.10.1016/j.bdr.2015.03.003Search in Google Scholar
[11] Jarraya Y., Madi T., Debbabi M., A survey and a layered taxonomy of software-defined networking, IEEE Communications Surveys and Tutorials, 2015, 16, 1955-1980.10.1109/COMST.2014.2320094Search in Google Scholar
[12] Syahputra R., Robandi I., Ashari M., Performance Improvement of Radial Distribution Network with Distributed Generation Integration Using Extended Particle Swarm Optimization Algorithm, International Review of Electrical Engineering, 2015, 10, 293-304.10.15866/iree.v10i2.5410Search in Google Scholar
[13] Liu Q., Cai W., Shen J., Fu Z., Liu X., Linge N., A speculative approach to spatial-temporal efficiency with multi-objective optimization in a heterogeneous cloud environment, Security and Communication Networks, 2016, 9, 4002-4012.10.1002/sec.1582Search in Google Scholar
[14] Yang C., Zhang X., Zhong C., Liu C., Pei J., Ramamohanarao K., et al., A spatiotemporal compression based approach for efficient big data processing on cloud, J. Comp. Sys. Sci., 2014, 80, 1563-1583.10.1016/j.jcss.2014.04.022Search in Google Scholar
[15] Chen T., Matinmikko M., Chen X., Zhou X., Ahokangas P., Software defined mobile networks: concept, survey and research directions, IEEE Communications Magazine, 2015, 53, 126-133.10.1109/MCOM.2015.7321981Search in Google Scholar
[16] Yi X., Liu F., Liu J., Jin H., Building a network highway for big data: architecture and challenges, IEEE Network, 2014, 28, 5-13.10.1109/MNET.2014.6863125Search in Google Scholar
© 2018 Zhuo Zhang, published by De Gruyter
This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 License.
Articles in the same Issue
- Regular Articles
- A modified Fermi-Walker derivative for inextensible flows of binormal spherical image
- Algebraic aspects of evolution partial differential equation arising in the study of constant elasticity of variance model from financial mathematics
- Three-dimensional atom localization via probe absorption in a cascade four-level atomic system
- Determination of the energy transitions and half-lives of Rubidium nuclei
- Three phase heat and mass transfer model for unsaturated soil freezing process: Part 1 - model development
- Three phase heat and mass transfer model for unsaturated soil freezing process: Part 2 - model validation
- Mathematical model for thermal and entropy analysis of thermal solar collectors by using Maxwell nanofluids with slip conditions, thermal radiation and variable thermal conductivity
- Constructing analytic solutions on the Tricomi equation
- Feynman diagrams and rooted maps
- New type of chaos synchronization in discrete-time systems: the F-M synchronization
- Unsteady flow of fractional Oldroyd-B fluids through rotating annulus
- A note on the uniqueness of 2D elastostatic problems formulated by different types of potential functions
- On the conservation laws and solutions of a (2+1) dimensional KdV-mKdV equation of mathematical physics
- Computational methods and traveling wave solutions for the fourth-order nonlinear Ablowitz-Kaup-Newell-Segur water wave dynamical equation via two methods and its applications
- Siewert solutions of transcendental equations, generalized Lambert functions and physical applications
- Numerical solution of mixed convection flow of an MHD Jeffery fluid over an exponentially stretching sheet in the presence of thermal radiation and chemical reaction
- A new three-dimensional chaotic flow with one stable equilibrium: dynamical properties and complexity analysis
- Dynamics of a dry-rebounding drop: observations, simulations, and modeling
- Modeling the initial mechanical response and yielding behavior of gelled crude oil
- Lie symmetry analysis and conservation laws for the time fractional simplified modified Kawahara equation
- Solitary wave solutions of two KdV-type equations
- Applying industrial tomography to control and optimization flow systems
- Reconstructing time series into a complex network to assess the evolution dynamics of the correlations among energy prices
- An optimal solution for software testing case generation based on particle swarm optimization
- Optimal system, nonlinear self-adjointness and conservation laws for generalized shallow water wave equation
- Alternative methods for solving nonlinear two-point boundary value problems
- Global model simulation of OH production in pulsed-DC atmospheric pressure helium-air plasma jets
- Experimental investigation on optical vortex tweezers for microbubble trapping
- Joint measurements of optical parameters by irradiance scintillation and angle-of-arrival fluctuations
- M-polynomials and topological indices of hex-derived networks
- Generalized convergence analysis of the fractional order systems
- Porous flow characteristics of solution-gas drive in tight oil reservoirs
- Complementary wave solutions for the long-short wave resonance model via the extended trial equation method and the generalized Kudryashov method
- A Note on Koide’s Doubly Special Parametrization of Quark Masses
- On right-angled spherical Artin monoid of type Dn
- Gas flow regimes judgement in nanoporous media by digital core analysis
- 4 + n-dimensional water and waves on four and eleven-dimensional manifolds
- Stabilization and Analytic Approximate Solutions of an Optimal Control Problem
- On the equations of electrodynamics in a flat or curved spacetime and a possible interaction energy
- New prediction method for transient productivity of fractured five-spot patterns in low permeability reservoirs at high water cut stages
- The collinear equilibrium points in the restricted three body problem with triaxial primaries
- Detection of the damage threshold of fused silica components and morphologies of repaired damage sites based on the beam deflection method
- On the bivariate spectral quasi-linearization method for solving the two-dimensional Bratu problem
- Ion acoustic quasi-soliton in an electron-positron-ion plasma with superthermal electrons and positrons
- Analysis of projectile motion in view of conformable derivative
- Computing multiple ABC index and multiple GA index of some grid graphs
- Terahertz pulse imaging: A novel denoising method by combing the ant colony algorithm with the compressive sensing
- Characteristics of microscopic pore-throat structure of tight oil reservoirs in Sichuan Basin measured by rate-controlled mercury injection
- An activity window model for social interaction structure on Twitter
- Transient thermal regime trough the constitutive matrix applied to asynchronous electrical machine using the cell method
- On the zagreb polynomials of benzenoid systems
- Integrability analysis of the partial differential equation describing the classical bond-pricing model of mathematical finance
- The Greek parameters of a continuous arithmetic Asian option pricing model via Laplace Adomian decomposition method
- Quantifying the global solar radiation received in Pietermaritzburg, KwaZulu-Natal to motivate the consumption of solar technologies
- Sturm-Liouville difference equations having Bessel and hydrogen atom potential type
- Study on the response characteristics of oil wells after deep profile control in low permeability fractured reservoirs
- Depiction and analysis of a modified theta shaped double negative metamaterial for satellite application
- An attempt to geometrize electromagnetism
- Structure of traveling wave solutions for some nonlinear models via modified mathematical method
- Thermo-convective instability in a rotating ferromagnetic fluid layer with temperature modulation
- Construction of new solitary wave solutions of generalized Zakharov-Kuznetsov-Benjamin-Bona-Mahony and simplified modified form of Camassa-Holm equations
- Effect of magnetic field and heat source on Upper-convected-maxwell fluid in a porous channel
- Physical cues of biomaterials guide stem cell fate of differentiation: The effect of elasticity of cell culture biomaterials
- Shooting method analysis in wire coating withdrawing from a bath of Oldroyd 8-constant fluid with temperature dependent viscosity
- Rank correlation between centrality metrics in complex networks: an empirical study
- Special Issue: The 18th International Symposium on Electromagnetic Fields in Mechatronics, Electrical and Electronic Engineering
- Modeling of electric and heat processes in spot resistance welding of cross-wire steel bars
- Dynamic characteristics of triaxial active control magnetic bearing with asymmetric structure
- Design optimization of an axial-field eddy-current magnetic coupling based on magneto-thermal analytical model
- Thermal constitutive matrix applied to asynchronous electrical machine using the cell method
- Temperature distribution around thin electroconductive layers created on composite textile substrates
- Model of the multipolar engine with decreased cogging torque by asymmetrical distribution of the magnets
- Analysis of spatial thermal field in a magnetic bearing
- Use of the mathematical model of the ignition system to analyze the spark discharge, including the destruction of spark plug electrodes
- Assessment of short/long term electric field strength measurements for a pilot district
- Simulation study and experimental results for detection and classification of the transient capacitor inrush current using discrete wavelet transform and artificial intelligence
- Magnetic transmission gear finite element simulation with iron pole hysteresis
- Pulsed excitation terahertz tomography – multiparametric approach
- Low and high frequency model of three phase transformer by frequency response analysis measurement
- Multivariable polynomial fitting of controlled single-phase nonlinear load of input current total harmonic distortion
- Optimal design of a for middle-low-speed maglev trains
- Eddy current modeling in linear and nonlinear multifilamentary composite materials
- The visual attention saliency map for movie retrospection
- AC/DC current ratio in a current superimposition variable flux reluctance machine
- Influence of material uncertainties on the RLC parameters of wound inductors modeled using the finite element method
- Cogging force reduction in linear tubular flux switching permanent-magnet machines
- Modeling hysteresis curves of La(FeCoSi)13 compound near the transition point with the GRUCAD model
- Electro-magneto-hydrodynamic lubrication
- 3-D Electromagnetic field analysis of wireless power transfer system using K computer
- Simplified simulation technique of rotating, induction heated, calender rolls for study of temperature field control
- Design, fabrication and testing of electroadhesive interdigital electrodes
- A method to reduce partial discharges in motor windings fed by PWM inverter
- Reluctance network lumped mechanical & thermal models for the modeling and predesign of concentrated flux synchronous machine
- Special Issue Applications of Nonlinear Dynamics
- Study on dynamic characteristics of silo-stock-foundation interaction system under seismic load
- Microblog topic evolution computing based on LDA algorithm
- Modeling the creep damage effect on the creep crack growth behavior of rotor steel
- Neighborhood condition for all fractional (g, f, n′, m)-critical deleted graphs
- Chinese open information extraction based on DBMCSS in the field of national information resources
- 10.1515/phys-2018-0079
- CPW-fed circularly-polarized antenna array with high front-to-back ratio and low-profile
- Intelligent Monitoring Network Construction based on the utilization of the Internet of things (IoT) in the Metallurgical Coking Process
- Temperature detection technology of power equipment based on Fiber Bragg Grating
- Research on a rotational speed control strategy of the mandrel in a rotary steering system
- Dynamic load balancing algorithm for large data flow in distributed complex networks
- Super-structured photonic crystal fiber Bragg grating biosensor image model based on sparse matrix
- Fractal-based techniques for physiological time series: An updated approach
- Analysis of the Imaging Characteristics of the KB and KBA X-ray Microscopes at Non-coaxial Grazing Incidence
- Application of modified culture Kalman filter in bearing fault diagnosis
- Exact solutions and conservation laws for the modified equal width-Burgers equation
- On topological properties of block shift and hierarchical hypercube networks
- Elastic properties and plane acoustic velocity of cubic Sr2CaMoO6 and Sr2CaWO6 from first-principles calculations
- A note on the transmission feasibility problem in networks
- Ontology learning algorithm using weak functions
- Diagnosis of the power frequency vacuum arc shape based on 2D-PIV
- Parametric simulation analysis and reliability of escalator truss
- A new algorithm for real economy benefit evaluation based on big data analysis
- Synergy analysis of agricultural economic cycle fluctuation based on ant colony algorithm
- Multi-level encryption algorithm for user-related information across social networks
- Multi-target tracking algorithm in intelligent transportation based on wireless sensor network
- Fast recognition method of moving video images based on BP neural networks
- Compressed sensing image restoration algorithm based on improved SURF operator
- Design of load optimal control algorithm for smart grid based on demand response in different scenarios
- Face recognition method based on GA-BP neural network algorithm
- Optimal path selection algorithm for mobile beacons in sensor network under non-dense distribution
- Localization and recognition algorithm for fuzzy anomaly data in big data networks
- Urban road traffic flow control under incidental congestion as a function of accident duration
- Optimization design of reconfiguration algorithm for high voltage power distribution network based on ant colony algorithm
- Feasibility simulation of aseismic structure design for long-span bridges
- Construction of renewable energy supply chain model based on LCA
- The tribological properties study of carbon fabric/ epoxy composites reinforced by nano-TiO2 and MWNTs
- A text-Image feature mapping algorithm based on transfer learning
- Fast recognition algorithm for static traffic sign information
- Topical Issue: Clean Energy: Materials, Processes and Energy Generation
- An investigation of the melting process of RT-35 filled circular thermal energy storage system
- Numerical analysis on the dynamic response of a plate-and-frame membrane humidifier for PEMFC vehicles under various operating conditions
- Energy converting layers for thin-film flexible photovoltaic structures
- Effect of convection heat transfer on thermal energy storage unit
Articles in the same Issue
- Regular Articles
- A modified Fermi-Walker derivative for inextensible flows of binormal spherical image
- Algebraic aspects of evolution partial differential equation arising in the study of constant elasticity of variance model from financial mathematics
- Three-dimensional atom localization via probe absorption in a cascade four-level atomic system
- Determination of the energy transitions and half-lives of Rubidium nuclei
- Three phase heat and mass transfer model for unsaturated soil freezing process: Part 1 - model development
- Three phase heat and mass transfer model for unsaturated soil freezing process: Part 2 - model validation
- Mathematical model for thermal and entropy analysis of thermal solar collectors by using Maxwell nanofluids with slip conditions, thermal radiation and variable thermal conductivity
- Constructing analytic solutions on the Tricomi equation
- Feynman diagrams and rooted maps
- New type of chaos synchronization in discrete-time systems: the F-M synchronization
- Unsteady flow of fractional Oldroyd-B fluids through rotating annulus
- A note on the uniqueness of 2D elastostatic problems formulated by different types of potential functions
- On the conservation laws and solutions of a (2+1) dimensional KdV-mKdV equation of mathematical physics
- Computational methods and traveling wave solutions for the fourth-order nonlinear Ablowitz-Kaup-Newell-Segur water wave dynamical equation via two methods and its applications
- Siewert solutions of transcendental equations, generalized Lambert functions and physical applications
- Numerical solution of mixed convection flow of an MHD Jeffery fluid over an exponentially stretching sheet in the presence of thermal radiation and chemical reaction
- A new three-dimensional chaotic flow with one stable equilibrium: dynamical properties and complexity analysis
- Dynamics of a dry-rebounding drop: observations, simulations, and modeling
- Modeling the initial mechanical response and yielding behavior of gelled crude oil
- Lie symmetry analysis and conservation laws for the time fractional simplified modified Kawahara equation
- Solitary wave solutions of two KdV-type equations
- Applying industrial tomography to control and optimization flow systems
- Reconstructing time series into a complex network to assess the evolution dynamics of the correlations among energy prices
- An optimal solution for software testing case generation based on particle swarm optimization
- Optimal system, nonlinear self-adjointness and conservation laws for generalized shallow water wave equation
- Alternative methods for solving nonlinear two-point boundary value problems
- Global model simulation of OH production in pulsed-DC atmospheric pressure helium-air plasma jets
- Experimental investigation on optical vortex tweezers for microbubble trapping
- Joint measurements of optical parameters by irradiance scintillation and angle-of-arrival fluctuations
- M-polynomials and topological indices of hex-derived networks
- Generalized convergence analysis of the fractional order systems
- Porous flow characteristics of solution-gas drive in tight oil reservoirs
- Complementary wave solutions for the long-short wave resonance model via the extended trial equation method and the generalized Kudryashov method
- A Note on Koide’s Doubly Special Parametrization of Quark Masses
- On right-angled spherical Artin monoid of type Dn
- Gas flow regimes judgement in nanoporous media by digital core analysis
- 4 + n-dimensional water and waves on four and eleven-dimensional manifolds
- Stabilization and Analytic Approximate Solutions of an Optimal Control Problem
- On the equations of electrodynamics in a flat or curved spacetime and a possible interaction energy
- New prediction method for transient productivity of fractured five-spot patterns in low permeability reservoirs at high water cut stages
- The collinear equilibrium points in the restricted three body problem with triaxial primaries
- Detection of the damage threshold of fused silica components and morphologies of repaired damage sites based on the beam deflection method
- On the bivariate spectral quasi-linearization method for solving the two-dimensional Bratu problem
- Ion acoustic quasi-soliton in an electron-positron-ion plasma with superthermal electrons and positrons
- Analysis of projectile motion in view of conformable derivative
- Computing multiple ABC index and multiple GA index of some grid graphs
- Terahertz pulse imaging: A novel denoising method by combing the ant colony algorithm with the compressive sensing
- Characteristics of microscopic pore-throat structure of tight oil reservoirs in Sichuan Basin measured by rate-controlled mercury injection
- An activity window model for social interaction structure on Twitter
- Transient thermal regime trough the constitutive matrix applied to asynchronous electrical machine using the cell method
- On the zagreb polynomials of benzenoid systems
- Integrability analysis of the partial differential equation describing the classical bond-pricing model of mathematical finance
- The Greek parameters of a continuous arithmetic Asian option pricing model via Laplace Adomian decomposition method
- Quantifying the global solar radiation received in Pietermaritzburg, KwaZulu-Natal to motivate the consumption of solar technologies
- Sturm-Liouville difference equations having Bessel and hydrogen atom potential type
- Study on the response characteristics of oil wells after deep profile control in low permeability fractured reservoirs
- Depiction and analysis of a modified theta shaped double negative metamaterial for satellite application
- An attempt to geometrize electromagnetism
- Structure of traveling wave solutions for some nonlinear models via modified mathematical method
- Thermo-convective instability in a rotating ferromagnetic fluid layer with temperature modulation
- Construction of new solitary wave solutions of generalized Zakharov-Kuznetsov-Benjamin-Bona-Mahony and simplified modified form of Camassa-Holm equations
- Effect of magnetic field and heat source on Upper-convected-maxwell fluid in a porous channel
- Physical cues of biomaterials guide stem cell fate of differentiation: The effect of elasticity of cell culture biomaterials
- Shooting method analysis in wire coating withdrawing from a bath of Oldroyd 8-constant fluid with temperature dependent viscosity
- Rank correlation between centrality metrics in complex networks: an empirical study
- Special Issue: The 18th International Symposium on Electromagnetic Fields in Mechatronics, Electrical and Electronic Engineering
- Modeling of electric and heat processes in spot resistance welding of cross-wire steel bars
- Dynamic characteristics of triaxial active control magnetic bearing with asymmetric structure
- Design optimization of an axial-field eddy-current magnetic coupling based on magneto-thermal analytical model
- Thermal constitutive matrix applied to asynchronous electrical machine using the cell method
- Temperature distribution around thin electroconductive layers created on composite textile substrates
- Model of the multipolar engine with decreased cogging torque by asymmetrical distribution of the magnets
- Analysis of spatial thermal field in a magnetic bearing
- Use of the mathematical model of the ignition system to analyze the spark discharge, including the destruction of spark plug electrodes
- Assessment of short/long term electric field strength measurements for a pilot district
- Simulation study and experimental results for detection and classification of the transient capacitor inrush current using discrete wavelet transform and artificial intelligence
- Magnetic transmission gear finite element simulation with iron pole hysteresis
- Pulsed excitation terahertz tomography – multiparametric approach
- Low and high frequency model of three phase transformer by frequency response analysis measurement
- Multivariable polynomial fitting of controlled single-phase nonlinear load of input current total harmonic distortion
- Optimal design of a for middle-low-speed maglev trains
- Eddy current modeling in linear and nonlinear multifilamentary composite materials
- The visual attention saliency map for movie retrospection
- AC/DC current ratio in a current superimposition variable flux reluctance machine
- Influence of material uncertainties on the RLC parameters of wound inductors modeled using the finite element method
- Cogging force reduction in linear tubular flux switching permanent-magnet machines
- Modeling hysteresis curves of La(FeCoSi)13 compound near the transition point with the GRUCAD model
- Electro-magneto-hydrodynamic lubrication
- 3-D Electromagnetic field analysis of wireless power transfer system using K computer
- Simplified simulation technique of rotating, induction heated, calender rolls for study of temperature field control
- Design, fabrication and testing of electroadhesive interdigital electrodes
- A method to reduce partial discharges in motor windings fed by PWM inverter
- Reluctance network lumped mechanical & thermal models for the modeling and predesign of concentrated flux synchronous machine
- Special Issue Applications of Nonlinear Dynamics
- Study on dynamic characteristics of silo-stock-foundation interaction system under seismic load
- Microblog topic evolution computing based on LDA algorithm
- Modeling the creep damage effect on the creep crack growth behavior of rotor steel
- Neighborhood condition for all fractional (g, f, n′, m)-critical deleted graphs
- Chinese open information extraction based on DBMCSS in the field of national information resources
- 10.1515/phys-2018-0079
- CPW-fed circularly-polarized antenna array with high front-to-back ratio and low-profile
- Intelligent Monitoring Network Construction based on the utilization of the Internet of things (IoT) in the Metallurgical Coking Process
- Temperature detection technology of power equipment based on Fiber Bragg Grating
- Research on a rotational speed control strategy of the mandrel in a rotary steering system
- Dynamic load balancing algorithm for large data flow in distributed complex networks
- Super-structured photonic crystal fiber Bragg grating biosensor image model based on sparse matrix
- Fractal-based techniques for physiological time series: An updated approach
- Analysis of the Imaging Characteristics of the KB and KBA X-ray Microscopes at Non-coaxial Grazing Incidence
- Application of modified culture Kalman filter in bearing fault diagnosis
- Exact solutions and conservation laws for the modified equal width-Burgers equation
- On topological properties of block shift and hierarchical hypercube networks
- Elastic properties and plane acoustic velocity of cubic Sr2CaMoO6 and Sr2CaWO6 from first-principles calculations
- A note on the transmission feasibility problem in networks
- Ontology learning algorithm using weak functions
- Diagnosis of the power frequency vacuum arc shape based on 2D-PIV
- Parametric simulation analysis and reliability of escalator truss
- A new algorithm for real economy benefit evaluation based on big data analysis
- Synergy analysis of agricultural economic cycle fluctuation based on ant colony algorithm
- Multi-level encryption algorithm for user-related information across social networks
- Multi-target tracking algorithm in intelligent transportation based on wireless sensor network
- Fast recognition method of moving video images based on BP neural networks
- Compressed sensing image restoration algorithm based on improved SURF operator
- Design of load optimal control algorithm for smart grid based on demand response in different scenarios
- Face recognition method based on GA-BP neural network algorithm
- Optimal path selection algorithm for mobile beacons in sensor network under non-dense distribution
- Localization and recognition algorithm for fuzzy anomaly data in big data networks
- Urban road traffic flow control under incidental congestion as a function of accident duration
- Optimization design of reconfiguration algorithm for high voltage power distribution network based on ant colony algorithm
- Feasibility simulation of aseismic structure design for long-span bridges
- Construction of renewable energy supply chain model based on LCA
- The tribological properties study of carbon fabric/ epoxy composites reinforced by nano-TiO2 and MWNTs
- A text-Image feature mapping algorithm based on transfer learning
- Fast recognition algorithm for static traffic sign information
- Topical Issue: Clean Energy: Materials, Processes and Energy Generation
- An investigation of the melting process of RT-35 filled circular thermal energy storage system
- Numerical analysis on the dynamic response of a plate-and-frame membrane humidifier for PEMFC vehicles under various operating conditions
- Energy converting layers for thin-film flexible photovoltaic structures
- Effect of convection heat transfer on thermal energy storage unit