BOF steelmaking endpoint carbon content and temperature soft sensor model based on supervised weighted local structure preserving projection
-
YunKe Su
 ,
FuGang Chen
,
FuGang Chen

Abstract
Endpoint control stands as a pivotal determinant of steel quality. However, the data derived from the BOF steelmaking process are characterized by high dimension, with intricate nonlinear relationships between variables and diverse working conditions. Traditional dimension reduction does not fully use non-local structural information within manifold shapes. To address these challenges, the article introduces a novel approach termed supervised weighting-based local structure preserving projection. This method dynamically includes label information using sparse representation and constructs weighted submanifolds to mitigate the influence of irrelevant labels. Subsequently, trend match is employed to establish the same distribution datasets for the submanifold. The global and local initial neighborhood maps are then constructed, extracting non-local relations from the submanifold by analyzing manifold curvature. This process eliminates interference from non-nearest-neighbor points on the manifold while preserving the local geometric structure, facilitating adaptive neighborhood parameter change. The proposed method enhances the adaptability of the model to changing working conditions and improves overall performance. The carbon content prediction maintains a controlled error range of within ±0.02%, achieving an accuracy rate of 82.50%. The temperature prediction maintains a controlled error range of within ±10°C, achieving an accuracy rate of 79.00%.
1 Introduction
The basic oxygen furnace (BOF) steelmaking method employs high-purity oxygen as an oxidant, harnessing both the physical heat generated by molten iron and the chemical heat from oxidation to fulfill steelmaking requirements [1]. BOF has emerged as the predominant steelmaking process due to its high capacity, cost-effectiveness, rapid equipment deployment, and superior product quality. During BOF steelmaking, oxygen is introduced into molten iron, followed by slagging operations and a sequence of physicochemical reactions, culminating in the attainment of the desired steel composition and temperature, termed the endpoint. Efficient and environmentally friendly production necessitates precise endpoint control, with carbon content and temperature serving as pivotal indicators of steel quality. Endpoint control methods in BOF steelmaking encompass both contact measurement and non-contact indirect observation techniques. Due to cost considerations, manual observation remains prevalent, with operators relying on visual cues from the BOF flame, albeit susceptible to factors like operator skill and experience. In recent years, the development of distributed control systems has facilitated data acquisition and analysis, enhancing precision and minimizing human subjectivity in process monitoring.
Advancements in computer technology have enabled the flexible application of soft sensor methods across diverse industrial processes, optimizing production costs while ensuring stability, and effectively solving the problem of the traditional method that makes it difficult to measure the target variable continuously and accurately [2,3,4]. However, the dynamic nature of steel production, combined with varying raw material quality, presents challenges. Fluctuations in scrap iron quality and the inherent complexity of process mechanisms result in nonlinear characteristics, necessitating adaptive operating strategies [5,6]. Variations in impurity content, chemical composition, and melting points of raw materials directly influence furnace reactions, leading to a change in working conditions that necessitates adjustments to parameters such as oxygen pressure and gas-blowing volume. Consequently, constructing a static single model with high prediction accuracy becomes challenging due to disparities between furnace samples and the nonlinear nature of chemical processes [7].
To address the aforementioned challenges, this study employs a localized modeling approach to capture the dynamic fluctuations within process data. Just-in-time learning (JITL), representing a standard framework in local modeling, employs similarity metrics to select the most relevant historical samples for query samples from a historical database. It then constructs a local model for output prediction and adapts the model in real time as new query samples arise [8]. Yu [8] introduced the JITL based on data-driven (JITL-DD) strategy for process monitoring, entailing the construction of a nonlinear model and residual calculation to derive monitoring outcomes. Yang et al. [9] argued that a time series consists of a potential trend and a rapidly changing sequence of stochastic residuals. Building on this, the present study integrates the JITL concept with a trend match (TM) module, dynamically constructing a similar trend dataset based on sample trend characteristics.
JITL modeling performance is intricately linked to the metrics. However, in the context of BOF steelmaking, which involves multiple input variables, the model’s data point requirements increase with dimension, leading to longer algorithm runtimes [10]. Moreover, metric effectiveness diminishes with rising data dimension, and the accuracy of DD soft sensors relies heavily on the similarity of sample distributions in training and test sets [7]. To address this issue, a dimension reduction model is introduced to simplify data complexity. Manifold learning aims to preserve the spatial geometric structure of the dataset, with classical algorithms such as Laplacian Eigenmap (LE) utilized to maintain local neighborhood structures by minimizing distances between projections of neighboring data points. The locally conserved nature of the LE algorithm renders it relatively robust to outliers and noise, thereby emphasizing natural data clustering [11]. Previous research by Liu et al. [12] demonstrated the utility of the LE algorithm in hyperspectral image dimension reduction, highlighting enhanced resolution and correlation representation post-reduction. Similarly, Zhang et al. [11] applied LE for nonlinear dimension reduction in near-infrared spectral data, resulting in higher prediction accuracy and adept handling of nonlinear variable relationships.
However, the direct application of the LE algorithm to BOF process data is hindered by inherent variability resulting from process perturbations, control differences, sensor drift, equipment degradation, and environmental fluctuations. Even under identical raw material input and operating conditions, variability across different furnaces impedes complete production replication [13]. As a distance-based analysis method, K-nearest neighbor (KNN) uses Euclidean distance to determine the nearest neighbor. The LE algorithm uses KNN to construct the adjacency matrix. Consequently, direct application of LE to BOF process data yields suboptimal performance, with local relationships among original data points compromised in low-dimensional embeddings. Li and Liu [14] proposed an adaptive LE algorithm that dynamically adjusts neighborhood parameters based on sampling density and manifold curvature, enhancing adaptability and robustness. Moreover, LE, as an unsupervised algorithm, overlooks label information, measuring similarity solely based on label-independent data characteristics [15]. Kanghua and Chunheng [16] imposed strict constraints on KNN graph construction, limiting neighboring points to those within the same category. However, in sparsely sampled scenarios, this method fails to adequately explore manifold geometry [17]. Additionally, the BOF steelmaking process necessitates distinguishing production data with diverse characteristics, such as mean, variance, and correlation, corresponding to different production requirements [18]. While Li et al. [15] proposed that assuming data located on a single manifold has the same labels, data belonging to different manifolds will be labeled differently. For example, a person’s face image is considered on one manifold, while another person’s face image will be distributed on another manifold. Raducanu and Dornaika [19] introduced label information to split the Laplacian graph into intraclass and interclass graphs, using the average distances between each sample and all the samples as a threshold for determining class membership. However, this approach overlooks non-local relationships within the same labeled data and fails to analyze relationships between corresponding manifolds of differently labeled data [20]. Despite considering label differences, this method does not fully capture similarity within class-labeled data or dissimilarity between classes.
Drawing from the aforementioned analysis, introduces a novel supervised weighted local structure preserving projection (SWLSPP) algorithm designed to extract the most pertinent labels relevant to the current query sample via sparse representation (SR). Subsequently, weights are assigned to these labels based on their degree of relevance. Leveraging the outcomes of these relevant labels, TM is executed following the extraction of the pertinent submanifold. This process constructs a uniformly and dense distributed dataset with similar data characteristic performance, thereby facilitating the construction of global and local initial neighborhood graphs. Subsequently, the non-local characteristics of the manifolds are elucidated through curvature analysis, enabling the removal of non-nearest neighbors on the manifolds to optimize neighbor selection. The resultant optimization outcomes serve as inputs for the dimension reduction model, thereby resolving the issues encountered with the original LE algorithm, including the tendency to include non-nearest neighbors on the manifolds during neighborhood matrix construction and the lack of label information for weight assignment.
The contributions of this study can be summarized as follows:
In response to the absence of label information in the original LE algorithm, the frequent fluctuations in BOF conditions, and the differences in data characteristics across different batches, an adaptive supervised neighborhood graph construction strategy is proposed. This strategy extracts submanifold relevant to new query samples based on their characteristics, eliminates the influence of irrelevant samples through TM, and retains data exhibiting similar trends to construct the initial neighborhood graph.
To address the issue of including non-nearest neighbors in the construction of the adjacency matrix, a manifold curvature analysis (MCA) strategy is proposed. This strategy involves adaptive optimization of neighborhood parameters to accurately preserve local geometric structures.
An experimental investigation using actual BOF steelmaking process data is conducted to validate the effectiveness of the proposed method through ablation experiments and comparisons with other soft sensor methods.
The remainder of the article is structured as follows: Section 2 provides a review of relevant knowledge pertaining to the proposed method and its underlying motivation. Section 3 elucidates the structural arrangement of the proposed method, offering a detailed exposition of its algorithmic components. Section 4 delineates the soft sensor model for BOF steelmaking process data based on SWLSPP. Section 5 presents experimental results and analyses. Finally, Section 6 offers conclusions.
2 Relevant theories and research motivations
Section 2 delineates the components of the proposed algorithm and its rationale. By providing a description of how the SR and LE work, their mechanisms, the motivation for their introduction, and how they work together within the framework are explained.
2.1 Sparse representation (SR)
The SR posits that a given sample can be expressed as a linear combination of other samples, where the sparse coefficients denote the extent to which other samples contribute to reconstructing the given sample. Higher coefficients indicate stronger similarity. Consequently, the reconstruction coefficients serve as a measure of sample similarity [21]. Additionally, SR offers the benefits of few parameters and robustness to data noise. The SR process is shown in Figure 1. The darker the color of
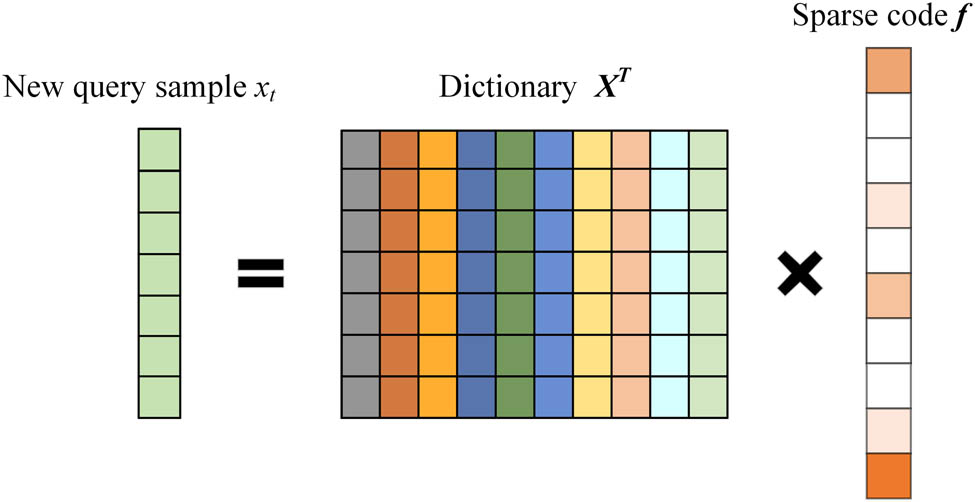
Schematic diagram of the SR.
Given a sample set
where
2.2 Laplacian eigenmap (LE)
LE, as one of the representative nonlinear manifold learning methods, finds the low-dimensional embedding of the original data by preserving the similarity relationship between local points, which can better explain the geometric structure of nonlinear manifolds [15,19].
The steps for realization are as follows.
(1) Create a closest neighbor graph G using nodes as data points and edges generated by the k-NN method.
(2) Create a weight matrix W. Using a heat kernel, compute the edge weights
where
(3) Feature Mapping. To find the low-dimensional embedding, the eigenvalues and related eigenvectors are calculated. The eigenvalue decomposition is applied on the Laplace matrix
The traditional LE algorithm is only suitable for dealing with uniformly distributed flat manifolds, so for sparsely distributed or highly distorted manifolds [14], it is easy to mistakenly include the non-nearest neighbor points on the manifolds into the adjacency graphs, which incorrectly extracts the local geometric structures and interferes with the regression modeling. Meanwhile, the traditional LE algorithm, as an unsupervised dimension reduction method, lacks the use of label information, and different labels do not reflect the differences in weight assignment when constructing the neighborhood graph.
3 Supervised weighted local structure preserving projection (SWLSPP)
The LE algorithm is a locality-preserving manifold learning approach designed to uncover a low-dimensional representation of high-dimensional data by maintaining the local geometry among the original data points [15]. However, numerous experiments have demonstrated that the efficacy of dimension reduction heavily relies on accurately setting the neighborhood size. Furthermore, LE fails to leverage labeled data information. When utilizing the original LE algorithm to construct the nearest-neighbor graph, samples with disparate labels may exhibit shorter Euclidean distances than those with identical labels, leading to the inability to differentiate points with distinct labels in the dimension reduction outcomes [15].
To tackle the aforementioned challenges, the article introduces an SWLSPP algorithm for BOF steelmaking production process data. Its objective is to derive a low-dimensional embedding of the high-dimensional data, which serves as input for the regression model. A diagram of the SWLSPP algorithm is shown in Figure 2, where the left part of the diagram corresponds to Sections 3.1 and 3.2, and the right part corresponds to Section 3.3.

SWLSPP.
3.1 Supervised sparse weights (SSW)
Supervisory information significantly influences feature extraction [15]. Utilizing labels allows for the categorization of data with the same or similar labels, facilitating the extraction of differentiation information concealed within the original data. While the original LE algorithm can extract the low-dimensional embedding of high-dimensional data if all data points are situated on a single continuous manifold, BOF steel production process data typically exhibit various operational conditions, resulting in a complex nearest-neighbor relationship among data clusters. Assuming that data with identical or similar labels reside on distinct manifolds, the dataset manifests a multi-manifold structure, necessitating the extraction of information from corresponding manifolds for data with different labels [15,19].
Although raw LE adeptly captures and preserves local manifold shape information within the dataset, it falls short in segregating differently labeled data. To address this limitation, this section introduces an SSW module. Using label information, this module divides the historical dataset into relevantly and irrelevantly labeled subsets based on the characteristics of current query samples. Subsequently, it quantifies the relevance of each labeled set by assigning weights, thereby emphasizing label information.
Definition 1
Supervised sparse weighting module (SSW)
Step 1: The current query sample
Step 2: The labels of the historical samples corresponding to the index are extracted based on the non-zero terms in the sparse coefficient
Step 3: Removing duplicate labels gives the set of related labels
Step 4: The non-zero values of the sparsity coefficients corresponding to the statistics
An SSW module is employed to disentangle historical sample sets from the influence of irrelevantly labeled data clusters, particularly in scenarios with complex distributions and multiple working conditions. This module quantifies the degree of association among relevantly labeled data sets, thereby mitigating the interference of irrelevant information on subsequent processing.
3.2 Trend match (TM)
While process data from distinct stages may exhibit varying numerical performances due to differences in initial conditions of the BOF and raw material batches, it is theoretically expected that the autocorrelation and inter-correlation among process variables within each stage adhere to intrinsic mechanistic relationships [22]. In the context of regression tasks, capturing similar trend samples is crucial for preserving their shared characteristics and production trends.
To address this, we introduce the TM module. This module identifies historical data with analogous trends in data sets associated with different relevant labels for the query sample

Schematic of SSW and TM.
Definition 2
Trend match module (TM).
Step 1: A quantitative evaluation of the degree of synchronization of the change trends and the degree of similarity of the base shapes between the historical samples and the query samples
where
where
Step 2: The historical samples
where
This results in a TM result, i.e., dataset
3.3 Manifold curvature analysis and adjacency matrix construction (MCA & AMC)
Traditional LE algorithms hinge on the accurate reflection of internal manifold structure by local neighborhood settings [14]. Oversized parameters are prone to eliminating small-scale manifold structures, leading to short-circuiting, while undersized parameters may result in manifold splitting [23]. The k-NN often generates distorted neighborhood structures for sparse and noisy data [23], exacerbating the short-circuiting phenomenon. Short-circuiting refers to the proximity of folding surfaces on the manifold, causing the search for nearest neighbors to include points from different folding surfaces rather than neighboring points on the manifold, thereby necessitating neighborhood optimization.
As depicted in Figure 4, the red circle illustrates the neighborhood range constructed by the traditional distance metric, wherein point a serves as the origin, and points c and d from the other folded plane are erroneously included. Even when employing solely geodesic distance as the distance metric, depicted in the gray section of the figure, point c, not residing in the same local linear plane, may still be considered a neighboring point. Hence, both metrics must collaborate in analyzing the curvature of the manifold in high-dimensional space to accurately construct neighborhoods. Given the non-uniform distribution of BOF steelmaking process data, the traditional k-NN can construct oversized neighborhoods in sparse regions. To address this, we introduce the MCA module in this section. This module incorporates geodesic distance proximity and subsequently filters out non-nearest neighbors after computing the curvature of local manifold shapes, enabling adaptive adjustment of neighborhood parameters to enhance model performance. Subsequently, the corresponding weights from the SSW module for each labeled dataset are merged and applied to each local neighborhood matrix. These matrices are then fused with the global neighborhood map to derive the fused neighborhood map for participation in dimension reduction.

Schematic diagram of MCA.
Definition 3
MCA module
Step 1: The k neighborhood of any point
Step 2: Solve for the geodesic distance
Step 3: Using
Step 4: Adjust the neighborhood parameters based on the manifold curvature. Calculate the ratio of
When
Definition 4
AMC module
Step 1: For the current query sample
Step 2: The different labeled sets
Step 3: The globally optimized neighborhood graph
4 A soft sensor model of carbon temperature at the end of BOF steelmaking with SWLSPP
The data from BOF steelmaking processes exhibit high dimension, multiple working conditions, and uneven distribution. Given the limited performance of the traditional model, this part proposes a SWLSPP soft sensor model for predicting carbon temperature at the endpoint of BOF steelmaking, built upon traditional LE algorithms. The overall soft sensor modeling steps are delineated as follows:
Step 1: Utilize SR to identify the most relevant labels and their corresponding weights for the query samples, thereby eliminating interference from irrelevant labels.
Step 2: Apply TM within each valid label’s data set to extract samples akin to the working conditions of the query samples, filtering them for participation in modeling.
Step 3: Based on the TM outcomes, introduce the MCA module to adaptively optimize neighborhood parameters. This facilitates the construction of both globally optimized neighborhood graph
Step 4: Generate predictions for the endpoint carbon content and temperature of the current query sample.
The algorithm pseudo-code is shown below. Meanwhile, the experiments were done in MATLAB2021a and run on a computer equipped with i7-12700H (Intel(R) Core (TM) @ 2.3 GHz) CPU and 16 GB RAM.
Algorithm:
Soft sensor model of endpoint carbon content and temperature in converter steelmaking based on SWLSPP
Input: Historical Sample Set
Output: Endpoint carbon temperature prediction
1: The SR finds the set of related labels
2: FOR
3: Perform TM on the datasets corresponding to
4: Sequentially integrate the filtering results
5: END FOR
6: FOR k
7: Calculate
8: Iteratively calculate all
9: Curvature of a manifold
10: Optimization of neighborhood parameters by removing non-nearest neighbors on the manifold according to the threshold
11: END FOR
12: MCA of global similar trend dataset, tuning parameters
13: Weighting
14: Fused neighborhood graph
15: Dimensionality reduction to obtain low-dimensional embeddings
16: Regression prediction, output endpoint carbon temperature prediction.
5 Experiments and analyses
To validate the efficacy of the proposed method, simulation experiments are conducted using real BOF steelmaking process data, following the modeling process outlined in Section 4.
5.1 Evaluation indicators
In order to evaluate the prediction performance, regression accuracy (RA), root mean square error (RMSE), and mean absolute percentage error (MAPE) are used as metrics in this article, among which RA is the most important, which indicates the prediction accuracy of the model for the test set within the allowable error. The formula for RA is as follows:
where
RMSE and MAPE are used to assess the regression model performance; the smaller the value, the better the model performance; the formula is as follows:
5.2 Data introduction and parameter setting
The experimental data were obtained from actual BOF steelmaking production data at a steel plant, with the target variables being the endpoint carbon content and temperature, i.e., the output variables. These samples were collected under different production conditions due to changes in raw material origins leading to quality differences between batches, adjustments in raw material ratios and furnace parameters, and changes in production conditions. First, the original dataset is checked and processed for missing data and outliers, and the corresponding samples are removed. Then, using the min–max scale, each variable to the range [0,1] using its minimum and maximum values, as shown in equation (14). Normalization is a preprocessing step crucial and effective for distance-based algorithms, equalizes the influence and importance of feature scales and thus prevents wide ranges or higher magnitudes from having a greater influence on learning [26]
where
A total of 3,000 furnace samples under normal operating conditions are collected in the experimental process, and 2,800 furnaces are randomly divided into 2,800 furnaces as the training set and 200 furnaces as the test set. As the raw process data contains a large number of redundant features. Therefore, based on previous research, 33-dimensional raw features are selected as input variables for the model according to feature importance [24,25] (Table 1).
Detailed information on the data set of the BOF steel production process
| Dataset | No. of input variables | Sample size | Output range |
|---|---|---|---|
| Carbon content | 33 | 3,000 | [0.05, 0.14] (%) |
| Temperature | 33 | 3,000 | [1,590, 1,690] (
|
Table 2 shows the optimal parameter values corresponding to the experiments.
Experimental parameter settings
| Parameter | Parameter value (carbon content) | Parameter value (temperature) |
|---|---|---|
| TM threshold
|
0.001 | 0.0006 |
| Nearest neighbor points
|
24 | 11 |
| Curvature analysis threshold
|
0.9 | 0.88 |
| Low dimensionality
|
6 | 7 |
| Tolerance error
|
|
|
5.3 Performance comparison of methods
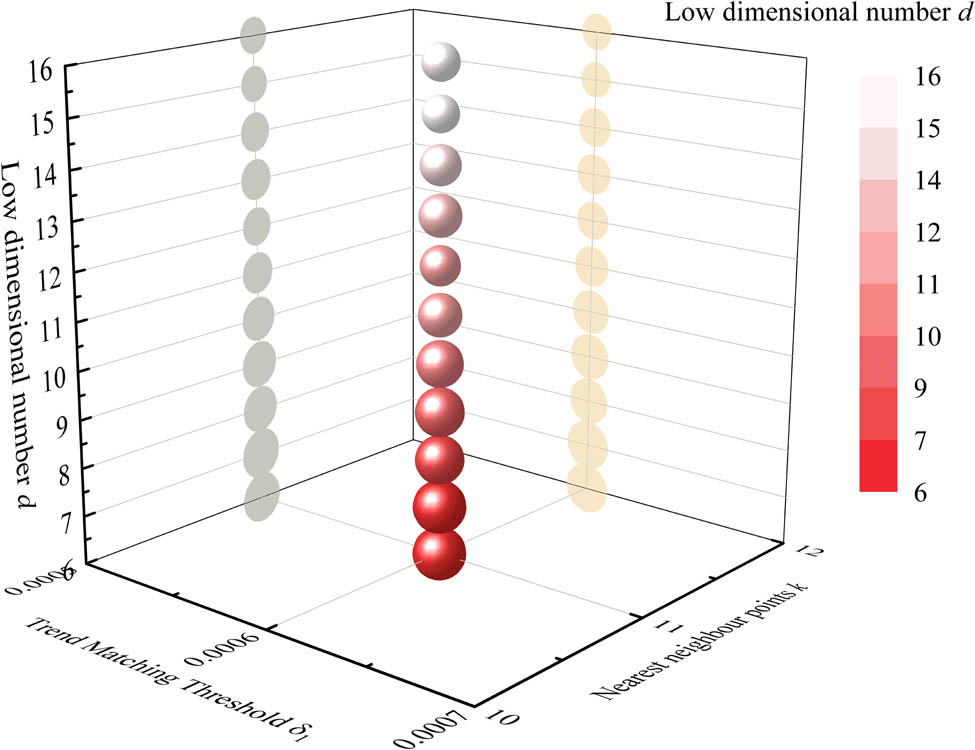
5.3.1 Impact of TM thresholds and curvature analysis thresholds
The TM threshold

RMSE and RA results for different threshold values (carbon content). (a) Matching threshold
For the prediction of temperature, the interval of

RMSE and RA results for different threshold values (temperature). (a) Matching threshold
5.3.2 Impact of the number of nearest neighbor points
The LE algorithm is used as a local dimension reduction model, and the local geometry of the manifold shape is usually constructed based on the k-NN [15]. For carbon content prediction, the experiments were carried out in the interval [16,30] to determine the value of the number of nearest neighbor points k, and for temperature prediction, the experiments were carried out in the interval [10,24] to determine the value of the number of nearest neighbor points k, with a step size of 1. It was verified experimentally that, under the optimal settings of other parameters, the best performance of carbon content and temperature prediction was achieved with the values of the number of nearest neighbor points k being 24 and 11, respectively. Figures 7–10 show some of the experimental results. Table 3 shows some of the experimental results; the larger the sphere volume, higher the RA generated based on the corresponding parameters.

Effect of different numbers of nearest neighbor points k on the model. The larger the volume of the sphere in the figure, the higher the accuracy of the regression (carbon content).

Effect of different numbers of nearest neighbor points k on the model (carbon content).

Effect of different numbers of nearest neighbor points k on the model. The larger the volume of the sphere in the figure, the higher the accuracy of the regression (temperature).

Effect of different numbers of nearest neighbor points k on the model (temperature).
Effect of different numbers of nearest neighbor points k and low dimensionality d on RA
| Output variable | Nearest neighbor points
|
Low dimension number
|
RA (%) |
|---|---|---|---|
| Steel carbon content
|
19 | 7 | 72.50 |
| 20 | 12 | 75.50 | |
| 21 | 13 | 78.50 | |
| 22 | 10 | 80.00 | |
| 23 | 10 | 77.50 | |
| 24 | 6 | 82.50 | |
| 25 | 7 | 79.50 | |
| 26 | 6 | 77.50 | |
| 27 | 6 | 78.50 | |
| 28 | 6 | 78.00 | |
| Steel temperature (
|
10 | 6 | 76.50 |
| 11 | 7 | 79.00 | |
| 12 | 6 | 74.00 | |
| 13 | 6 | 77.00 | |
| 14 | 9 | 71.00 | |
| 15 | 6 | 68.00 | |
| 16 | 7 | 68.50 | |
| 17 | 7 | 69.00 | |
| 18 | 6 | 65.50 | |
| 19 | 6 | 65.50 |
Bold values represent the best parameter settings and its experiment results.
From Figures 7 and 8, it can be seen that with the adjustment of the number of nearest neighbor points k, the RA of the model shows an increasing and then decreasing trend when predicting the carbon content and reaches a peak at k = 24. It shows that when k = 24, the dimension reduction results retain sufficient data structure information, so that the model can better capture the neighbor relationship between data points. As the k value continues to increase, the performance of the model begins to decline. Setting a larger value of the nearest neighbor point may increase the sensitivity of the noise, so that the low-dimensional embedding extraction results are greatly affected by the noise.
For Figures 9 and 10, as the number of nearest neighbor points k increases, the irrelevant information contained in the construction of the adjacency matrix gradually increases, and the RA tends to decrease significantly. With the increase of the number of neighboring points, the model will search for adjacent points more widely in the high-dimensional space, resulting in the points far away from each other participating in the construction of the adjacency matrix, which contains irrelevant information and reduces the RA.

Effect of different low dimension d on the model. The larger the volume of the sphere in the figure, the higher the accuracy of the regression (carbon content).
5.3.3 Impact of low dimension
Accurate parameter setting of low dimension can effectively retain the spatial geometric information of the data and improve the performance of the dimension reduction model. The experiments were carried out in the interval [6,16] to determine the value of the low dimension d, with a step size of 1. It was experimentally verified that the best prediction of carbon content and temperature with the optimal settings of the other parameters was achieved with the values of 6 and 7 for the low dimension d (Figure 11). Some of the results of the experiments are shown in Figures 12 and 13, where the greater the volume of the sphere, the greater the accuracy of the regressions generated based on the corresponding parameters (Table 4).
Effect of different low dimension d on the model. The larger the volume of the sphere in the figure, the higher the accuracy of the regression (temperature).

Results of ablation experiments: (a) carbon content, (b) temperature.
Effect of different low dimension d on RA
| Output variable | Low dimension number
|
RA(%) |
|---|---|---|
| Steel carbon content
|
6 | 82.50 |
| 7 | 77.50 | |
| 8 | 78.00 | |
| 9 | 76.50 | |
| 10 | 75.00 | |
| 11 | 76.00 | |
| 12 | 74.00 | |
| 13 | 76.00 | |
| 14 | 75.00 | |
| 15 | 73.50 | |
| 16 | 68.00 | |
| Steel temperature (
|
6 | 78.50 |
| 7 | 79.00 | |
| 8 | 72.50 | |
| 9 | 72.50 | |
| 10 | 69.00 | |
| 11 | 64.00 | |
| 12 | 59.00 | |
| 13 | 62.50 | |
| 14 | 59.50 | |
| 15 | 54.00 | |
| 16 | 55.00 |
Bold values represent the best parameter settings and its experiment results.
Comparison of carbon content and temperature prediction result of ablation experiments
| Output variables |
|
RA (%) | |||
|---|---|---|---|---|---|
| TM_MCA&AMC | SSW_MCA&AMC | SSW_TM_AMC | The proposed method | ||
| Steel carbon content (
|
0.01% | 30.50 | 28.00 | 45.00 | 44.00 |
| 0.02% | 68.00 | 57.50 | 73.00 | 82.50 | |
| 0.03% | 89.50 | 85.00 | 88.00 | 97.00 | |
| Steel temperature (
|
5
|
41.00 | 31.50 | 45.00 | 54.50 |
| 10
|
66.50 | 54.00 | 72.00 | 79.00 | |
| 15
|
84.50 | 75.00 | 88.50 | 89.00 | |
Bold values represent the proposed method has the highest prediction accuracy compared with other algorithms.
5.3.4 Ablation experiment
Ablation experiments are conducted to validate the effectiveness of the proposed method. The regression model remains unchanged throughout the experiments, with model prediction performance contingent on the TM efficacy, neighborhood parameter optimization, and integration of SSWs. To assess the efficacy of the SWLSPP model, it undergoes ablation along the following lines:
Ablation of SSWs using the TM and MCA & AMC, which eliminates the interference of widely varying samples and manifolding non-nearest neighbors. However, it lacks the utilization of label information and differentiation between sets of differently labeled data. This ablation experiment is denoted as TM_MCA & AMC (Table 5).
For the ablation of TM, although the SSW module introduces labeling information, it lacks a mechanism to remove interference from irrelevant working condition sample information. This ablation experiment is denoted as SSWs_MCA & AMC.
For MCA ablation, the screening of non-nearest-neighbor points on the manifold is omitted. This ablation experiment is denoted as SSWs_TM_AMC.
Subsequent experiments are based on production process data, model parameters of methods adjusted to optimum values.
As depicted in Figures 13 and 14, the SSW_MCA&AMC configuration lacks the TM module to filter out samples with significant discrepancies. Consequently, the model extracts information with greater interference, resulting in the poorest fitting performance observed in Figure 14(b), particularly evident in larger errors during true predicted value jumps.

Comparison of results from ablation experiments (carbon content on the left, temperature on the right). (a) TM_MCA&AMC, (b) SSW_MCA&AMC, and (c) SSW_TM_AMC.
Conversely, TM_MCA&AMC effectively eliminates irrelevant information but fails to distinguish and analyze submanifold. It relies on the spatial geometric information of the overall dataset, neglecting the internal geometric structures unique to submanifold within each dataset labeled differently. This distinction is crucial for a comprehensive understanding of the dataset.
Meanwhile, SSW_TM_AMC augments information by incorporating features from the former two configurations. However, it overlooks the removal of non-nearest-neighbor points within neighborhoods, adversely impacting the model’s performance.
5.4 Experimental comparison results with other algorithms and analysis
In this section, the proposed SWLSPP algorithm is compared with other dimension reduction soft sensors including LE, Cosine Similarity and Jensen Shannon Divergence-Supervised Local Linear Embedding (CJS-SLLE), Supervised LE (S-LE1), and LE with adaptive neighborhood parameters (S-LE2). The parameters of all comparison algorithms have been tuned to the optimum in the experiments.
Analyzing Tables 6 and 7, Figures 15 and 16, reveal the following insights:
The LE algorithm, lacking mechanisms to reject irrelevant information and utilize labeling data, struggles to adapt to varying conditions when handling query samples with different working conditions. Consequently, it fails to accurately extract intrinsic data information, as evidenced in Figure 16(a).
The CJS-SLLE algorithm incorporates label information into similarity metrics, while S-LE2 determines the number of nearest neighbors for each sample based on data density and adopts the geodesic line distance as the distance metric. However, both methods lack submanifold analysis of differently labeled data sets, impeding accurate extraction of intrinsic differences manifested in various labeled data sets. Although the modules for removing irrelevant information in CJS-SLLE and S-LE2 effectively enhance model performance by 20 and 23% for carbon content prediction and 20 and 20.5% for temperature prediction, respectively. However, the neglect of difference information still leads to the limited improvement of fitting degree. as shown in Figure 16(b) and (d).
For the S-LE1 algorithm, the average value of the distance between each sample and all samples is used as the threshold for judging the set of similar nearest neighbors and the set of dissimilar nearest neighbors when constructing the nearest neighbor graph, which does not take into account the similarity between the samples within a class and the differences between dissimilar samples very well, and at the same time, it will result in the increase of the computational cost, and the algorithm targets classification problems and performs poorly in regression tasks. Compared with S-LE2, S-LE1 lacks the consideration of folded surfaces and manifold curvature in the high-dimensional space and includes non-nearest neighbor points when constructing the nearest-neighbor map, which leads to the dispersion of the denser regions in the original data into multiple parts, affecting the accuracy of the dimension reduction results. From the experimental results, in the BOF steelmaking process data, compared with the original LE algorithm, S-LE1 improves by 16% and 11.5% when predicting carbon content and temperature, respectively.
According to Figures 15 and 16, the comparison between the real value and the predicted value of each soft sensor model shows that the SWLSPP model has the smallest error between the real value and the predicted value compared with the models of other methods, thus reflecting the effectiveness of the soft sensor modeling, and realizing the real-time accurate prediction of the carbon content and temperature of the endpoint of BOF steelmaking.
Table 7 shows the experimental results of the SWLSPP algorithm proposed in this article and other comparative algorithms for endpoint prediction, of the 78 furnace samples obtained. Due to the differences in data distribution between the new furnace dataset and the original training and test sets, the regression accuracies of some algorithms are reduced by 1.73–2.46% compared with Table 6. Meanwhile, the new dataset has a smaller number of samples, which may lead to the inability to fully evaluate the performance of the model.
Comparison of carbon content and temperature prediction result of comparison experiments
| Output Variables |
|
RA (%) | ||||
|---|---|---|---|---|---|---|
| LE | CJS-SLLE [25] | S-LE1 [19] | S-LE2 [14] | The proposed method | ||
| Steel carbon content (
|
0.01% | 25.00 | 34.50 | 32.00 | 36.00 | 44.00 |
| 0.02% | 48.00 | 68.00 | 64.00 | 71.00 | 82.50 | |
| 0.03% | 75.00 | 85.50 | 84.50 | 91.50 | 97.00 | |
| RMSE | 0.026573 | 0.019033 | 0.021027 | 0.018577 | 0.014859 | |
| MAPE | 2.8106 × 10−1 | 1.9750 × 10−1 | 2.2102 × 10−1 | 2.0050 × 10−1 | 1.5797 × 10 −1 | |
| Steel temperature (
|
5
|
23.00 | 41.50 | 36.50 | 42.00 | 54.50 |
| 10
|
48.50 | 68.50 | 60.00 | 69.00 | 79.00 | |
| 15
|
70.50 | 84.00 | 79.00 | 84.00 | 89.00 | |
| RMSE | 13.565055 | 10.410257 | 12.094537 | 10.485176 | 8.637297 | |
| MAPE | 6.8669 × 10−3 | 4.9232 × 10−3 | 5.8087 × 10−3 | 4.8864 × 10−3 | 3.8867 × 10 −3 | |
Bold values represent the proposed method has the highest prediction accuracy compared with other algorithms.
Comparison of carbon content and temperature prediction result of comparison experiments (the new furnace dataset contains 78 samples)
| Output Variables |
|
RA (%) | ||||
|---|---|---|---|---|---|---|
| LE | CJS-SLLE [25] | S-LE1 [19] | S-LE2 [14] | The proposed method | ||
| Steel carbon content (
|
0.01% | 25.64 | 32.05 | 30.77 | 35.90 | 44.87 |
| 0.02% | 50.00 | 70.51 | 61.54 | 69.23 | 80.77 | |
| 0.03% | 79.49 | 91.03 | 94.87 | 87.18 | 98.72 | |
| RMSE | 0.022450 | 0.018589 | 0.018533 | 0.018508 | 0.015127 | |
| MAPE | 2.5650 × 10−1 | 2.1095 × 10−1 | 2.1582 × 10−1 | 2.0996 × 10−1 | 1.7039 × 10 −1 | |
| Steel temperature (
|
5
|
28.21 | 44.87 | 33.33 | 50.00 | 51.28 |
| 10
|
51.28 | 69.23 | 58.97 | 67.95 | 76.92 | |
| 15
|
74.36 | 87.18 | 75.64 | 84.62 | 93.59 | |
| RMSE | 12.191638 | 10.389208 | 11.799098 | 9.745768 | 8.488916 | |
| MAPE | 6.1175 × 10−3 | 4.7421 × 10−3 | 5.6987 × 10−3 | 4.4810 × 10−3 | 4.0060 × 10 −3 | |
Bold values represent the proposed method has the highest prediction accuracy compared with other algorithms.

Comparison results with other algorithms: (a) carbon content and (b) temperature.

Comparison results with other algorithms (carbon content on the left, temperature on the right). (a) LE, (b) CJS-SLLE, (c) S-LE1, (d) S-LE2, and (e) the proposed method.
6 Conclusion
Addressing the challenges posed by the high dimension and varying working conditions of BOF steelmaking process data, traditional static models often struggle to adapt to changing conditions. To overcome this limitation, the article proposes a soft sensor model for predicting carbon content and temperature at the endpoint of BOF steelmaking. Using SWLSPP, this model aims to achieve accurate predictions.
By integrating label information into the dimension reduction process, the SWLSPP model mitigates interference from irrelevant data, ensuring precise preservation of local spatial structures through analysis of non-local relationships within data sets corresponding to different labels. Through comprehensive modeling and simulation of BOF steelmaking process data, the proposed SWLSPP model undergoes ablation experiments and comparative analysis against alternative dimension reduction soft sensor algorithms. Evaluation across various criteria on carbon content and temperature datasets demonstrates the superior performance of the proposed algorithm compared to others. When the error range of carbon content prediction is controlled within
Acknowledgements
The authors are grateful to the National Natural Science Foundation of China (No. 62263016) and the Applied Basic Research Foundation of Yunnan Province (No. 202401AT070375) for funding to support this research.
-
Funding information: This work was supported by the National Natural Science Foundation of China (No. 62263016) and the Applied Basic Research Foundation of Yunnan Province (No. 202401AT070375).
-
Author contributions: YunKe Su: conceptualization, methodology, software, validation, writing-original draft, writing-review and editing, and visualization; Hui Liu: conceptualization, methodology, supervision, project administration, and funding acquisition; Fugang Chen: data curation, investigation, and formal analysis; JianXun Liu: data curation, formal analysis, investigation, writing-review and editing; Heng Li: investigation; Xiaojun Xue: investigation.
-
Conflict of interest: The authors state no conflict of interest.
-
Data availability statement: The data is obtained from the actual steelmaking plant, but the data is not available due to privacy.
References
[1] Yu, X. The simulation of multiphase flow behavior in BOF, Vol. 72, University of Science and Technology, Liaoning, 2018.Search in Google Scholar
[2] Han, M. and L. Jiang. Endpoint prediction model of basic oxygen furnace steelmaking based on PSO-ICA and RBF neural network, IEEE, 2010 International Conference on Intelligent Control and Information Processing, Dalian, China, 2010.10.1109/ICICIP.2010.5565236Search in Google Scholar
[3] He, F. and L. Zhang. Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network. Journal of Process Control, Vol. 66, 2018, pp. 51–58.10.1016/j.jprocont.2018.03.005Search in Google Scholar
[4] Liu, Z., S. Cheng, and P. Liu. Prediction model of BOF end-point temperature and carbon content based on PCA -GA- BP neural network. Metallurgical Research & Technology, Vol. 119, No. 6, 2022, pp. 7039–7043.10.1051/metal/2022091Search in Google Scholar
[5] Wang, X., M. Han, and J. Wang. Applying input variables selection technique on input weighted support vector machine modeling for BOF endpoint prediction. Engineering Applications of Artificial Intelligence, Vol. 23, No. 6, 2010, pp. 1012–1018.10.1016/j.engappai.2009.12.007Search in Google Scholar
[6] Shao, W., Z. Ge, H. Li, and Z. Song. Semisupervised dynamic soft sensing approaches based on recurrent neural network. Journal of Electronic Measurement And Instrumentation, Vol. 33, No. 11, 2019, pp. 7–13.Search in Google Scholar
[7] Alakent, B. Online tuning of predictor weights for relevant data selection in just-in-time-learning. Chemometrics and Intelligent Laboratory Systems, Vol. 203, 2020, id. 104043.10.1016/j.chemolab.2020.104043Search in Google Scholar
[8] Yu, H. A just-in-time learning approach for sewage treatment process monitoring with deterministic disturbances, Yokohama, Japan, 2015.10.1109/IECON.2015.7392965Search in Google Scholar
[9] Yang, X., F. Yu, W. Pedrycz, and Z. Li. Clustering time series under trend-oriented fuzzy information granulation. Applied Soft Computing, Vol. 141, 2023, id. 110284.10.1016/j.asoc.2023.110284Search in Google Scholar
[10] Bader, J., D. Nelson, T. Chai-Zhang, and W. Gerych. Neural network for nonlinear dimension reduction through manifold recovery, Elke Rundensteiner, Cambridge, 2019.10.1109/URTC49097.2019.9660541Search in Google Scholar
[11] Zhang, X., Z. Chen, S. Yi, and J. Liu. Rapid detection of lignin content in corn straw based on Laplacian Eigenmaps. Infrared Physics & Technology, Vol. 133, 2023, id. 104787.10.1016/j.infrared.2023.104787Search in Google Scholar
[12] Liu, D., L. Wang, and J.A. Benediktsson. An object-oriented color visualization method with controllable separation for hyperspectral imagery. Applied Sciences-Basel, Vol. 10, No. 10, 2020.10.3390/app10103581Search in Google Scholar
[13] Qian, Q. Process monitoring and quality prediction of basicoxygen furnace steelmaking process based on functional data analysis, Vol. 169, University of Science and Technology, Beijing, 2023.Search in Google Scholar
[14] Li, Y. and L. Binghan. Self-regulation of neighborhood parameter for Laplacian eigenmaps. Journal of Fuzhou University (Natural Science Edition), Vol. 41, No. 2, 2013, pp. 153–157.Search in Google Scholar
[15] Li, B., Y. Li, and X. Zhang. A survey on Laplacian eigenmaps based manifold learning methods. Neurocomputing, Vol. 335, 2019, pp. 336–351.10.1016/j.neucom.2018.06.077Search in Google Scholar
[16] Kanghua, H. and W. Chunheng. Clustering-based locally linear embedding, Tampa, FL, USA, 2008.10.1109/ICPR.2008.4761293Search in Google Scholar
[17] Li, B., J. Liu, Z.Q. Zhao, and W.S. Zhang. Locally linear representation Fisher criterion, Dallas, TX, USA, 2013.10.1109/IJCNN.2013.6706985Search in Google Scholar
[18] Yang, L., H. Liu, and F. Chen. Soft sensor method of multimode BOF steelmaking endpoint carbon content and temperature based on vMF-WSAE dynamic deep learning. High Temperature Materials and Processes, Vol. 42, No. 1, 2023, id. 20220270.10.1515/htmp-2022-0270Search in Google Scholar
[19] Raducanu, B. and F. Dornaika. A supervised non-linear dimensionality reduction approach for manifold learning. Pattern Recognition, Vol. 45, No. 6, 2012, pp. 2432–2444.10.1016/j.patcog.2011.12.006Search in Google Scholar
[20] Wang, N. Research on class-preserving laplacian eigenmaps for dimensionality reduction, Harbin Engineering University, Harbin, China, 2017.10.1109/FSKD.2016.7603204Search in Google Scholar
[21] Zhang, J., J. Wang, and X. Cai. Sparse locality preserving discriminative projections for face recognition. Neurocomputing, Vol. 260, 2017, pp. 321–330.10.1016/j.neucom.2017.04.051Search in Google Scholar
[22] Ji, C. and W. Sun. A review on data-driven process monitoring methods: characterization and mining of industrial data. Processes, Vol. 10, No. 2, 2022, id. 335.10.3390/pr10020335Search in Google Scholar
[23] Wen, G. Dynamically determining neighborhood parameter for locally linear embedding. Journal of Software, Vol. 19, No. 7, 2008, pp. 1666–1673.10.3724/SP.J.1001.2008.01666Search in Google Scholar
[24] Xiong, Q. Study on the soft measurement method of carbon temperature at the end of blowing based on the integrated learning of converter steelmaking production process data, Vol. 83, Kunming University of Science and Technology, Kunming, China, 2021.Search in Google Scholar
[25] Zhao, A., H. Liu, F. Chen, X. Liu, and D. Zhang. Soft sensor method of endpoint carbon content and temperature of BOF steelmaking based on CJS-SLLE and just-in-time learning. Control Theory and Applications, 2023, Vol. 40, No. 10, pp. 1–11.Search in Google Scholar
[26] Tawakuli A., B. Havers , V. Gulisano , D. Kaiser, and T. Engel. Survey: time-series data preprocessing: a survey and an empirical analysis. Journal of Engineering Research, 2024.10.1016/j.jer.2024.02.018Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- De-chlorination of poly(vinyl) chloride using Fe2O3 and the improvement of chlorine fixing ratio in FeCl2 by SiO2 addition
- Reductive behavior of nickel and iron metallization in magnesian siliceous nickel laterite ores under the action of sulfur-bearing natural gas
- Study on properties of CaF2–CaO–Al2O3–MgO–B2O3 electroslag remelting slag for rack plate steel
- The origin of {113}<361> grains and their impact on secondary recrystallization in producing ultra-thin grain-oriented electrical steel
- Channel parameter optimization of one-strand slab induction heating tundish with double channels
- Effect of rare-earth Ce on the texture of non-oriented silicon steels
- Performance optimization of PERC solar cells based on laser ablation forming local contact on the rear
- Effect of ladle-lining materials on inclusion evolution in Al-killed steel during LF refining
- Analysis of metallurgical defects in enamel steel castings
- Effect of cooling rate and Nb synergistic strengthening on microstructure and mechanical properties of high-strength rebar
- Effect of grain size on fatigue strength of 304 stainless steel
- Analysis and control of surface cracks in a B-bearing continuous casting blooms
- Application of laser surface detection technology in blast furnace gas flow control and optimization
- Preparation of MoO3 powder by hydrothermal method
- The comparative study of Ti-bearing oxides introduced by different methods
- Application of MgO/ZrO2 coating on 309 stainless steel to increase resistance to corrosion at high temperatures and oxidation by an electrochemical method
- Effect of applying a full oxygen blast furnace on carbon emissions based on a carbon metabolism calculation model
- Characterization of low-damage cutting of alfalfa stalks by self-sharpening cutters made of gradient materials
- Thermo-mechanical effects and microstructural evolution-coupled numerical simulation on the hot forming processes of superalloy turbine disk
- Endpoint prediction of BOF steelmaking based on state-of-the-art machine learning and deep learning algorithms
- Effect of calcium treatment on inclusions in 38CrMoAl high aluminum steel
- Effect of isothermal transformation temperature on the microstructure, precipitation behavior, and mechanical properties of anti-seismic rebar
- Evolution of residual stress and microstructure of 2205 duplex stainless steel welded joints during different post-weld heat treatment
- Effect of heating process on the corrosion resistance of zinc iron alloy coatings
- BOF steelmaking endpoint carbon content and temperature soft sensor model based on supervised weighted local structure preserving projection
- Innovative approaches to enhancing crack repair: Performance optimization of biopolymer-infused CXT
- Structural and electrochromic property control of WO3 films through fine-tuning of film-forming parameters
- Influence of non-linear thermal radiation on the dynamics of homogeneous and heterogeneous chemical reactions between the cone and the disk
- Thermodynamic modeling of stacking fault energy in Fe–Mn–C austenitic steels
- Research on the influence of cemented carbide micro-textured structure on tribological properties
- Performance evaluation of fly ash-lime-gypsum-quarry dust (FALGQ) bricks for sustainable construction
- First-principles study on the interfacial interactions between h-BN and Si3N4
- Analysis of carbon emission reduction capacity of hydrogen-rich oxygen blast furnace based on renewable energy hydrogen production
- Just-in-time updated DBN BOF steel-making soft sensor model based on dense connectivity of key features
- Effect of tempering temperature on the microstructure and mechanical properties of Q125 shale gas casing steel
- Review Articles
- A review of emerging trends in Laves phase research: Bibliometric analysis and visualization
- Effect of bottom stirring on bath mixing and transfer behavior during scrap melting in BOF steelmaking: A review
- High-temperature antioxidant silicate coating of low-density Nb–Ti–Al alloy: A review
- Communications
- Experimental investigation on the deterioration of the physical and mechanical properties of autoclaved aerated concrete at elevated temperatures
- Damage evaluation of the austenitic heat-resistance steel subjected to creep by using Kikuchi pattern parameters
- Topical Issue on Focus of Hot Deformation of Metaland High Entropy Alloys - Part II
- Synthesis of aluminium (Al) and alumina (Al2O3)-based graded material by gravity casting
- Experimental investigation into machining performance of magnesium alloy AZ91D under dry, minimum quantity lubrication, and nano minimum quantity lubrication environments
- Numerical simulation of temperature distribution and residual stress in TIG welding of stainless-steel single-pass flange butt joint using finite element analysis
- Special Issue on A Deep Dive into Machining and Welding Advancements - Part I
- Electro-thermal performance evaluation of a prismatic battery pack for an electric vehicle
- Experimental analysis and optimization of machining parameters for Nitinol alloy: A Taguchi and multi-attribute decision-making approach
- Experimental and numerical analysis of temperature distributions in SA 387 pressure vessel steel during submerged arc welding
- Optimization of process parameters in plasma arc cutting of commercial-grade aluminium plate
- Multi-response optimization of friction stir welding using fuzzy-grey system
- Mechanical and micro-structural studies of pulsed and constant current TIG weldments of super duplex stainless steels and Austenitic stainless steels
- Stretch-forming characteristics of austenitic material stainless steel 304 at hot working temperatures
- Work hardening and X-ray diffraction studies on ASS 304 at high temperatures
- Study of phase equilibrium of refractory high-entropy alloys using the atomic size difference concept for turbine blade applications
- A novel intelligent tool wear monitoring system in ball end milling of Ti6Al4V alloy using artificial neural network
- A hybrid approach for the machinability analysis of Incoloy 825 using the entropy-MOORA method
- Special Issue on Recent Developments in 3D Printed Carbon Materials - Part II
- Innovations for sustainable chemical manufacturing and waste minimization through green production practices
- Topical Issue on Conference on Materials, Manufacturing Processes and Devices - Part I
- Characterization of Co–Ni–TiO2 coatings prepared by combined sol-enhanced and pulse current electrodeposition methods
- Hot deformation behaviors and microstructure characteristics of Cr–Mo–Ni–V steel with a banded structure
- Effects of normalizing and tempering temperature on the bainite microstructure and properties of low alloy fire-resistant steel bars
- Dynamic evolution of residual stress upon manufacturing Al-based diesel engine diaphragm
- Study on impact resistance of steel fiber reinforced concrete after exposure to fire
- Bonding behaviour between steel fibre and concrete matrix after experiencing elevated temperature at various loading rates
- Diffusion law of sulfate ions in coral aggregate seawater concrete in the marine environment
- Microstructure evolution and grain refinement mechanism of 316LN steel
- Investigation of the interface and physical properties of a Kovar alloy/Cu composite wire processed by multi-pass drawing
- The investigation of peritectic solidification of high nitrogen stainless steels by in-situ observation
- Microstructure and mechanical properties of submerged arc welded medium-thickness Q690qE high-strength steel plate joints
- Experimental study on the effect of the riveting process on the bending resistance of beams composed of galvanized Q235 steel
- Density functional theory study of Mg–Ho intermetallic phases
- Investigation of electrical properties and PTCR effect in double-donor doping BaTiO3 lead-free ceramics
- Special Issue on Thermal Management and Heat Transfer
- On the thermal performance of a three-dimensional cross-ternary hybrid nanofluid over a wedge using a Bayesian regularization neural network approach
- Time dependent model to analyze the magnetic refrigeration performance of gadolinium near the room temperature
- Heat transfer characteristics in a non-Newtonian (Williamson) hybrid nanofluid with Hall and convective boundary effects
- Computational role of homogeneous–heterogeneous chemical reactions and a mixed convective ternary hybrid nanofluid in a vertical porous microchannel
- Thermal conductivity evaluation of magnetized non-Newtonian nanofluid and dusty particles with thermal radiation
Articles in the same Issue
- Research Articles
- De-chlorination of poly(vinyl) chloride using Fe2O3 and the improvement of chlorine fixing ratio in FeCl2 by SiO2 addition
- Reductive behavior of nickel and iron metallization in magnesian siliceous nickel laterite ores under the action of sulfur-bearing natural gas
- Study on properties of CaF2–CaO–Al2O3–MgO–B2O3 electroslag remelting slag for rack plate steel
- The origin of {113}<361> grains and their impact on secondary recrystallization in producing ultra-thin grain-oriented electrical steel
- Channel parameter optimization of one-strand slab induction heating tundish with double channels
- Effect of rare-earth Ce on the texture of non-oriented silicon steels
- Performance optimization of PERC solar cells based on laser ablation forming local contact on the rear
- Effect of ladle-lining materials on inclusion evolution in Al-killed steel during LF refining
- Analysis of metallurgical defects in enamel steel castings
- Effect of cooling rate and Nb synergistic strengthening on microstructure and mechanical properties of high-strength rebar
- Effect of grain size on fatigue strength of 304 stainless steel
- Analysis and control of surface cracks in a B-bearing continuous casting blooms
- Application of laser surface detection technology in blast furnace gas flow control and optimization
- Preparation of MoO3 powder by hydrothermal method
- The comparative study of Ti-bearing oxides introduced by different methods
- Application of MgO/ZrO2 coating on 309 stainless steel to increase resistance to corrosion at high temperatures and oxidation by an electrochemical method
- Effect of applying a full oxygen blast furnace on carbon emissions based on a carbon metabolism calculation model
- Characterization of low-damage cutting of alfalfa stalks by self-sharpening cutters made of gradient materials
- Thermo-mechanical effects and microstructural evolution-coupled numerical simulation on the hot forming processes of superalloy turbine disk
- Endpoint prediction of BOF steelmaking based on state-of-the-art machine learning and deep learning algorithms
- Effect of calcium treatment on inclusions in 38CrMoAl high aluminum steel
- Effect of isothermal transformation temperature on the microstructure, precipitation behavior, and mechanical properties of anti-seismic rebar
- Evolution of residual stress and microstructure of 2205 duplex stainless steel welded joints during different post-weld heat treatment
- Effect of heating process on the corrosion resistance of zinc iron alloy coatings
- BOF steelmaking endpoint carbon content and temperature soft sensor model based on supervised weighted local structure preserving projection
- Innovative approaches to enhancing crack repair: Performance optimization of biopolymer-infused CXT
- Structural and electrochromic property control of WO3 films through fine-tuning of film-forming parameters
- Influence of non-linear thermal radiation on the dynamics of homogeneous and heterogeneous chemical reactions between the cone and the disk
- Thermodynamic modeling of stacking fault energy in Fe–Mn–C austenitic steels
- Research on the influence of cemented carbide micro-textured structure on tribological properties
- Performance evaluation of fly ash-lime-gypsum-quarry dust (FALGQ) bricks for sustainable construction
- First-principles study on the interfacial interactions between h-BN and Si3N4
- Analysis of carbon emission reduction capacity of hydrogen-rich oxygen blast furnace based on renewable energy hydrogen production
- Just-in-time updated DBN BOF steel-making soft sensor model based on dense connectivity of key features
- Effect of tempering temperature on the microstructure and mechanical properties of Q125 shale gas casing steel
- Review Articles
- A review of emerging trends in Laves phase research: Bibliometric analysis and visualization
- Effect of bottom stirring on bath mixing and transfer behavior during scrap melting in BOF steelmaking: A review
- High-temperature antioxidant silicate coating of low-density Nb–Ti–Al alloy: A review
- Communications
- Experimental investigation on the deterioration of the physical and mechanical properties of autoclaved aerated concrete at elevated temperatures
- Damage evaluation of the austenitic heat-resistance steel subjected to creep by using Kikuchi pattern parameters
- Topical Issue on Focus of Hot Deformation of Metaland High Entropy Alloys - Part II
- Synthesis of aluminium (Al) and alumina (Al2O3)-based graded material by gravity casting
- Experimental investigation into machining performance of magnesium alloy AZ91D under dry, minimum quantity lubrication, and nano minimum quantity lubrication environments
- Numerical simulation of temperature distribution and residual stress in TIG welding of stainless-steel single-pass flange butt joint using finite element analysis
- Special Issue on A Deep Dive into Machining and Welding Advancements - Part I
- Electro-thermal performance evaluation of a prismatic battery pack for an electric vehicle
- Experimental analysis and optimization of machining parameters for Nitinol alloy: A Taguchi and multi-attribute decision-making approach
- Experimental and numerical analysis of temperature distributions in SA 387 pressure vessel steel during submerged arc welding
- Optimization of process parameters in plasma arc cutting of commercial-grade aluminium plate
- Multi-response optimization of friction stir welding using fuzzy-grey system
- Mechanical and micro-structural studies of pulsed and constant current TIG weldments of super duplex stainless steels and Austenitic stainless steels
- Stretch-forming characteristics of austenitic material stainless steel 304 at hot working temperatures
- Work hardening and X-ray diffraction studies on ASS 304 at high temperatures
- Study of phase equilibrium of refractory high-entropy alloys using the atomic size difference concept for turbine blade applications
- A novel intelligent tool wear monitoring system in ball end milling of Ti6Al4V alloy using artificial neural network
- A hybrid approach for the machinability analysis of Incoloy 825 using the entropy-MOORA method
- Special Issue on Recent Developments in 3D Printed Carbon Materials - Part II
- Innovations for sustainable chemical manufacturing and waste minimization through green production practices
- Topical Issue on Conference on Materials, Manufacturing Processes and Devices - Part I
- Characterization of Co–Ni–TiO2 coatings prepared by combined sol-enhanced and pulse current electrodeposition methods
- Hot deformation behaviors and microstructure characteristics of Cr–Mo–Ni–V steel with a banded structure
- Effects of normalizing and tempering temperature on the bainite microstructure and properties of low alloy fire-resistant steel bars
- Dynamic evolution of residual stress upon manufacturing Al-based diesel engine diaphragm
- Study on impact resistance of steel fiber reinforced concrete after exposure to fire
- Bonding behaviour between steel fibre and concrete matrix after experiencing elevated temperature at various loading rates
- Diffusion law of sulfate ions in coral aggregate seawater concrete in the marine environment
- Microstructure evolution and grain refinement mechanism of 316LN steel
- Investigation of the interface and physical properties of a Kovar alloy/Cu composite wire processed by multi-pass drawing
- The investigation of peritectic solidification of high nitrogen stainless steels by in-situ observation
- Microstructure and mechanical properties of submerged arc welded medium-thickness Q690qE high-strength steel plate joints
- Experimental study on the effect of the riveting process on the bending resistance of beams composed of galvanized Q235 steel
- Density functional theory study of Mg–Ho intermetallic phases
- Investigation of electrical properties and PTCR effect in double-donor doping BaTiO3 lead-free ceramics
- Special Issue on Thermal Management and Heat Transfer
- On the thermal performance of a three-dimensional cross-ternary hybrid nanofluid over a wedge using a Bayesian regularization neural network approach
- Time dependent model to analyze the magnetic refrigeration performance of gadolinium near the room temperature
- Heat transfer characteristics in a non-Newtonian (Williamson) hybrid nanofluid with Hall and convective boundary effects
- Computational role of homogeneous–heterogeneous chemical reactions and a mixed convective ternary hybrid nanofluid in a vertical porous microchannel
- Thermal conductivity evaluation of magnetized non-Newtonian nanofluid and dusty particles with thermal radiation