High-altitude satellites range scheduling for urgent request utilizing reinforcement learning
-
 ,
,

Abstract
High-altitude satellites are visible to more ground station antennas for longer periods of time, its requests often specify an antenna set and optional service windows, consequently leaving huge scheduling search space. The exploitation of reinforcement learning techniques provides a novel approach to the problem of high-altitude orbit satellite range scheduling. Upper sliding bound of request pass was calculated, combining customized scheduling strategy with overall antenna effectiveness, a frame of satellite range scheduling for urgent request using reinforcement learning was proposed. Simulations based on practical circumstances demonstrate the validity of the proposed method.
1 Introduction
To ensure the required and reliable satellite-ground communication capability, a set of ground stations are placed over the country and abroad to provide TT&C services, satellite payload data reception services, and launcher tracking services for supported missions. A suite of applications that can cope with satellite range scheduling were developed. These applications are automated and rules based, but the scheduling strategy is evolved in line with the space access requirement of current and future missions. Satellite range scheduling means scheduling communications between satellites in space and antennas on the ground. Satellite communicate with ground station antenna only during visible window. With the arrival of new request for satellite-antenna pass, the scheduling algorithm is in charge of solving conflict among passes. All the requests are expected to be satisfied with certain constraints. Urgent request from satellite reaches the scheduling application due to many kinds of uncertainties, such as random satellite observation, scheduled antenna breakdowns, mission cancellations, and other urgent events. In general, regardless of normal request or urgent request, the ground antennas are oversubscribed, and all the requests cannot be satisfied.
For high-altitude orbit satellites, there are two special situation of satellite-antenna pass in the scheduling problem. First, the visible time is much longer than the low-altitude satellites, but only part of the visible time can be arranged to request satellite. Second, to overcome the congestion issue between the scheduled pass and request in future (before the start time of the scheduled pass), allocated passes may be adjusted in the visible window on different antennas. Since the search space is usually large and with specific constraints, solving the problem of high-altitude satellite range scheduling is very computationally demanding.
In the past decades, various techniques are studied to generate conflict free and high-efficient solutions for the problem of satellite range scheduling (Petelin et al. 2021, Luo et al. 2017, Li et al. 2015, Li et al. 2014, Zufferey et al. 2008, Zufferey and Michel 2015, Ling et al. 2013, Badaloni et al. 2007, Bagchi 2009, Xhafa et al. 2013, Zhang et al. 2014). Heuristics methods provide a solution quickly, but fails to scale to larger and more complex problems. Metaheuristics such as genetic algorithm, simulated annealing and tabu search take more time but output results closer to optimal solution. Barbulescu et al. (2004) proved that satellite range scheduling is NP complete, Marinelli et al. (2011) and Brown et al. (2018) developed a new heuristic method based on Lagrangian relaxation to overcome the difficulty that large-scale variables yield, and the former applied the method to GALILEO constellation. As far as we know, there exist few studies about satellite range scheduling using reinforcement learning.
Reinforcement learning is about learning how to act to achieve a goal in an uncertain environment to maximize the reward in a particular situation, and it is a specialized application of machine learning and deep learning techniques to solve various types of decision making problems (Sutton and Barto 2019, Wiering and Otterlo 2018). The agent is trained to seek a new way to maximize the reword, and by interacting with the environment, a neural network storing experiences improves the performance. The reinforcement learning algorithms are usually classified into three types: value-based approach, policy-based approach and model-based approach. In a value-based reinforcement learning algorithm, the agent will try to maximize a value function and is expecting a long-term return of current state. In a policy-based algorithm, the agent will try to come up with such a policy that the action performed in every state improves the return in the future. In a model-based algorithm, a model was created in every environment and the agent learns to perform in them. Recently, reinforcement learning has also gained more and more attention in scheduling. Cunha et al. (2021) created a novel architecture that incorporates reinforcement learning into scheduling systems. Shyalika et al. (2020) addressed the reinforcement learning techniques used for dynamic task scheduling. Luo (2020) developed a deep Q-network to solve the dynamic job shop scheduling problem. Huang et al. (2021) used deep deterministic policy gradient algorithm to solve the satellite task scheduling problem. Inspired by the aforementioned applications of reinforcement learning in scheduling, solving the problem of satellite range scheduling by using reinforcement learning became feasible.
The main contribution of this article is the proposal of an innovative high-altitude satellite range scheduling method for urgent request by adopting reinforcement learning. We utilized Q learning as the learning model, and Q learning is a value-based algorithm of providing information to inform which action an agent should take (Watkins 1989, Watkins & Dayan 1992). Our article is organized as follows. First, we introduce the background of the problem and several basic definitions. Section 2 is the analysis of high-altitude orbit satellites urgent request scenario. Calculation of sliding bound of request pass is described in Section 3. A novel frame of satellite range scheduling using reinforcement learning is proposed in Section 4. The simulation and discussion are presented in Section 5. Finally, we conclude this study and put forward some future ideas in Section 6.
2 Analysis of high-altitude orbit satellite request for ground antenna
To introduce the problem of satellite range scheduling clearly, several major definitions are listed as follows:
High-altitude orbit satellite request: When a high-altitude orbit satellite need a supported service from an antenna, it will send a resource requests message to the scheduling system. The message mainly includes the least last time (LLT, minimum duration) and the request time (RT), LLT is the shortest service time that the satellite need, RT is a time scope in which the service time should be arranged. There are two types of resource requests, normal request and urgent request. The normal requests are periodic corresponding to the regular service demand, and the urgent request is temporary corresponding to the service demand in an emergency. The present article focuses on the resources scheduling for urgent request. Whenever an urgent request arrives, there was already an antenna work plan generated by the normal request scheduling process.
Resources scheduling system: It is the core system in charge of antenna scheduling for normal and urgent requests, a plan of scheduled passes for all antennas would be generated after scheduling process.
Antenna service switch time: It is the antenna repositioning time between adjacent service time for different satellites, and it is a constant value for all ground station antennas. The constraints of the switch time, minimum elevation, and visibility are taken into account, but they are neglected in the notations for simplicity.
Scheduled pass and request pass: The scheduled passes are the components of the service plan of an antenna, it is the output of resources scheduling system. A request pass is the pass with a length, which is equal to the request LLT in the RT. All the passes must be in the satellite-antenna visible time.
Service conflict: The conflict between two service time is defined by pass conflict that one pass is overlapped with the adjacent one, while the antenna service switch time must be considered.
Sliding operation: In a scheduling environment, a request pass should be arranged on an antenna and then all the scheduled passes should be conflict free. We define the arrange operation as insert. When a pass insert operation causes a conflict, all the passes in the RT should try to move backward (to the earlier time or to the left side) or forward (to the later time or to the right side) to overcome the confliction. The move of pass on an antenna is called slide, the request pass after slide operation should be in the RT, and other pass after slide operation should be in the visible time.
The design of urgent request data is to create an interface for interoperability between the satellite and the scheduling system, and it specifies the service detail that may be provided by an antenna. An urgent request contains the following elements:
a request satellite;
a set of ground station antennas;
request time (RT);
least last time (LLT);
the type of request service.
Calculate the intersection of visible time and request time, that is,
Let W(LEO) denotes the scheduled low-altitude satellite passes in MRT, and we obtain the scheduled high-altitude satellite passes in MRT as
Constraints of the process of urgent request scheduling.
The satellite range scheduling. This will be further illustrated in Section 4.
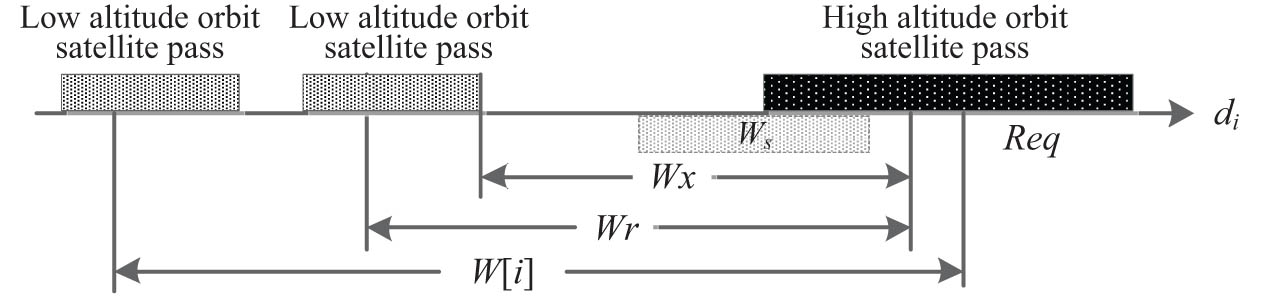
Example of an urgent request scheduling scenario.
3 Calculation of the sliding upper bound
In this section, the sliding bound of the high-altitude satellite request pass will be provided. We call upper bound of sliding operation a maximum time scope, such that in which one high-altitude satellite pass can move. The initial condition for a conflict free scheduling solution is
For the case of sliding backward in Figure 2,

Scheduled high-altitude orbit satellite passes slide backward.
For the case of sliding forward in Figure 3,
Updated values of
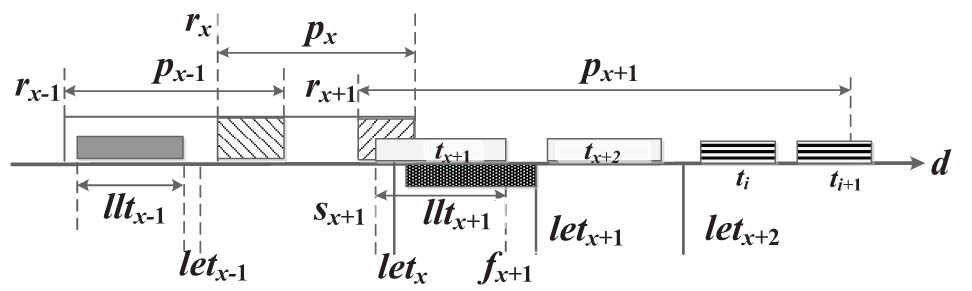
Scheduled high-altitude orbit satellite passes slide forward.
We learn from Eqs. (1) and (2) that the length of the total time window for request pass after sliding on d is
The time length
4 A frame of satellite range scheduling using reinforcement learning
Scheduling strategy is the reference policy for the scheduling method and is the principle of sliding operation (Pinedo 2016, Conway et al. 2003). The strategies describe that how the request pass slide to avoid overlap. We design two scheduling strategies for high-altitude satellite urgent request, mono-layer, and multi-layer scheduling.
Mono-layer scheduling strategy. The request pass is only permitted to be arranged on the current antenna, the scheduled passes in the MRT of the request cannot be transferred to the other antenna belonging to the corresponding request antenna set.
Multi-layer scheduling strategy. The request pass can be arranged on an antenna belonging to the request antenna set, and the scheduled high-altitude satellite passes can be transferred to the any other antenna belonging to the corresponding original request antenna set.
After the discussion of scheduling strategy, we propose an overall antenna effectiveness (OAE) function to represent the benefit of different sliding operations:
where
where
From Eqs. (5) and (6), we find that the value of OAE ranges from
The new satellite range scheduling frame for urgent request of high-altitude orbit satellites begins from some main components of reinforcement learning. The details are as follows:
Agent: There are two types of time windows, LLT and MRT in high-altitude satellite request. These two terms are regarded as entities, which slide forward or backward on an antenna in the scheduling environment.
Action: The action of the agents is sliding from one state to another, which means that the agent can stay still, move forward, or backward on the antenna, and the time scope of sliding operation is limited.
Environment: In a scheduling scenario, there would be one ground station antenna or several antennas, one high-altitude satellite request, and scheduled passes in the request-relevant MRT. To achieve the objective that all the scheduled passes are conflict free after sliding actions, the agents need to slide according to the value of reward. The state of agents will be updated after each sliding. The direction and magnitude of the sliding are the key factors of each action.
State: The state of the scheduling environment consists of the start time and the end time of each time window on the corresponding antenna, and the result of the value function at the end of the sliding action.
Value function: We use overall antenna effectiveness as value function, it is a measure of how well a scheduling operation is utilized in the MRT, compared to full potential of an antenna during the visible time window. It specifies the value of a state, and the agents should be expected maximizing the overall antenna effectiveness in the MRT on an antenna for a high-altitude satellite request. If clashes between two passes are detected, then the value of OAE will be 0.
In Figure 4, we design an architecture to illustrate the scheduling mechanism that employs reinforcement learning techniques. When a new urgent request arrives, visible time, antennas, RT, and LLT will be parsed from request. Mono-layer scheduling strategy is selected if single antenna was requested. Then sliding upper bound is adopted as a basic filter for the following process, which was described at the end of Section 3. User-oriented design of value function makes this frame flexible for various situations, and current design comes from the perspective of service provider. This scheduling frame works as a loop according to the requested antennas, and the process continues with next antenna if the previous antenna failed to output a conflict free window. The scheduling frame breaks out of the loop if a valid result is generated. Two major factors are considered in the real circumstance of satellite range scheduling: the quality of the scheduling result and the time consumed to obtain it. Both the scheduling strategy and the value function of reinforcement learning will react on the objective. The proposed frame of scheduling is not to generate the best solution, but a result good enough that is obtained by an intelligent scheduling system using reinforcement learning.
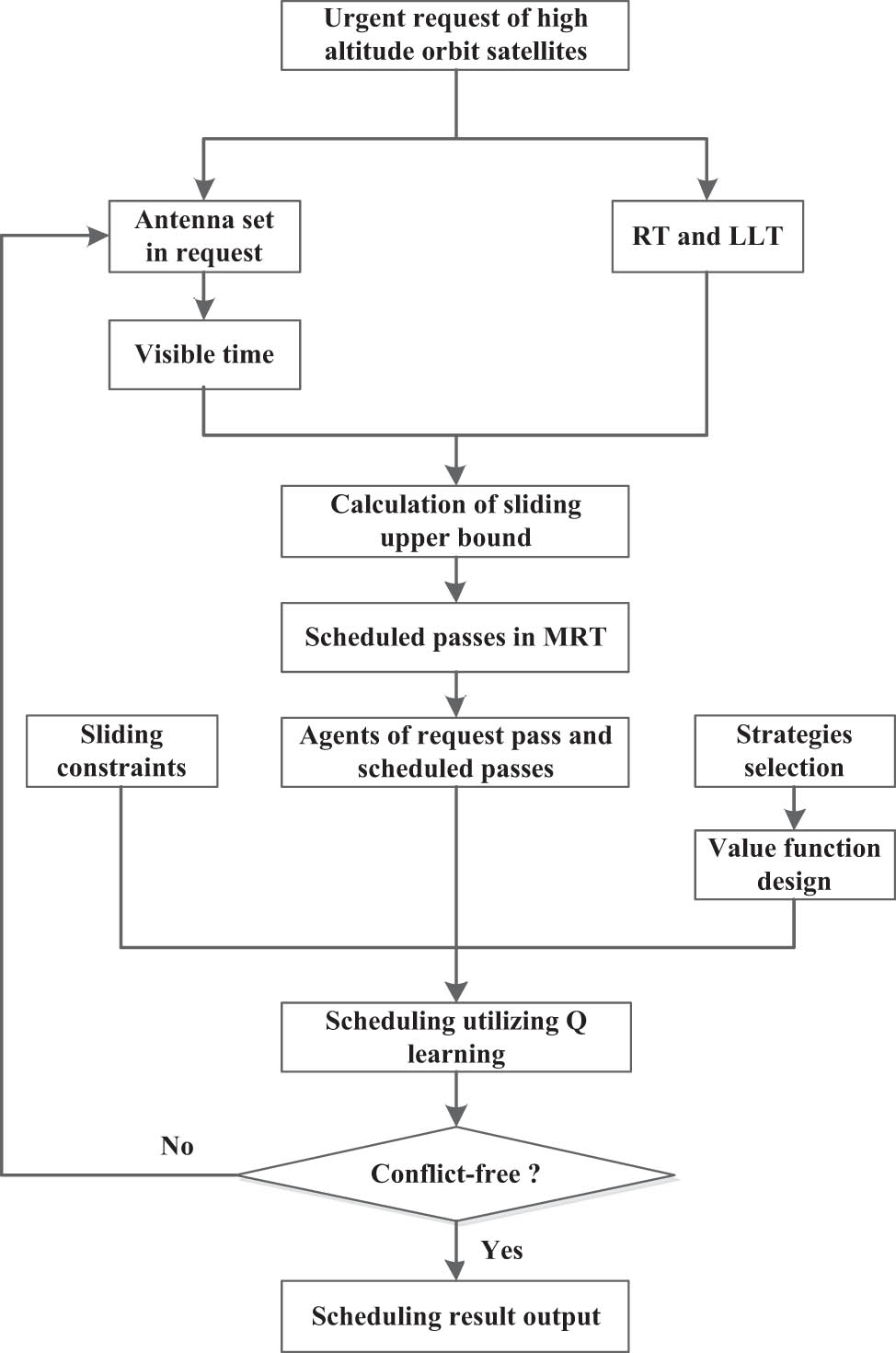
Scheduling procedure utilizing reinforcement learning.
5 Simulation
The simulation is implemented in a real operational context, 30 ground station antennas, 250 satellites including 30 high-altitude orbit satellites, and a plan of scheduled passes for normal requests with a period of 7 days was involved. The data environment for mono-layer strategy scheduling is presented in Table 1, where
Data environment for mono-layer strategy simulation
| Sat | ST/UTC | ET/UTC | LLT/second | Type |
|---|---|---|---|---|
| s_1 | 13:55:00 | 16:33:20 | 900 | Urgent request |
| s_2 | 13:55:12 | 14:10:12 | 900 | Scheduled pass |
| s_2 | 13:55:00 | 16:33:20 | 900 | Original request |
| s_3 | 14:31:19 | 14:41:28 | — | Low altitude |
| s_4 | 14:58:36 | 15:54:06 | 3,330 | Scheduled pass |
| s_4 | 14:58:30 | 16:21:46 | 3,330 | Original request |
| s_5 | 16:35:33 | 20:22:13 | 13,600 | Scheduled pass |
| s_5 | 16:11:40 | 20:50:35 | 13,600 | Original request |
We apply Q learning to the scheduling for urgent request of s_1. The pass of s_3 cannot slide, the reinforcement learning parameters are as follows: initial pass position of s_1 is 13:55:12UTC-14:10:12UTC, learning rate is 0.001, and slide step is 3 s. Figure 5 shows the variation of OAE for different values of training times.

Variation of OAE for different values of training times with mono-layer strategy.
We find from Figure 5 that the maximum value of OAE is 0.632 (the corresponding scheduled result for s_5 is 16:31:09UTC-20:17:49UTC) and lies in the range of
The data environment for multi-layer strategy scheduling is presented in Tables 2 and 3. The request pass and scheduled passes in the MRT of s_1 on the first preferred antenna d_1 are listed in Table 2, The scheduled passes in the MRT of s_2 on the first preferred antenna d_2 except d_1 are listed in Table 3. Five agents are request of s_1, scheduled passes s_2, s_7, s_8, and s_9, learning rate is 0.001, and slide step is 3 s. The training result is shown in Figure 6, due to the failure in the first stage of mono-layer strategy scheduling, s_2 was transferred to d_2 and the multi-layer strategy is implemented. Then the value of OAE equal to
Data environment for multi-layer strategy simulation on d_1
| Sat | ST/UTC | ET/UTC | LLT/second | Type |
|---|---|---|---|---|
| s_1 | 13:55:00 | 15:50:00 | 900 | Urgent request |
| s_2 | 13:45:00 | 14:00:00 | 900 | Scheduled pass |
| s_2 | 12:00:00 | 14:00:00 | 900 | Original request |
| s_3 | 14:08:57 | 14:28:57 | 1,200 | Scheduled pass |
| s_3 | 08:59:57 | 14:57:30 | 1,200 | Original request |
| s_4 | 14:50:58 | 15:10:58 | 1,200 | Scheduled pass |
| s_4 | 14:43:58 | 17:54:49 | 1,200 | Original request |
| s_5 | 15:17:00 | 15:32:00 | 900 | Scheduled pass |
| s_5 | 14:36:00 | 16:31:00 | 900 | Original request |
| s_6 | 15:38:12 | 15:53:12 | 900 | Scheduled pass |
| s_6 | 14:55:00 | 16:50:00 | 900 | Original request |
Data environment for multi-layer strategy simulation on d_2
| Sat | ST/UTC | ET/UTC | LLT/second | Type |
|---|---|---|---|---|
| s_7 | 12:02:06 | 12:11:46 | — | Low altitude |
| s_8 | 12:30:23 | 12:45:23 | 900 | Scheduled pass |
| s_8 | 12:00:00 | 14:00:00 | 900 | Original request |
| s_9 | 13:05:57 | 13:25:57 | 1200 | Scheduled pass |
| s_9 | 13:00:00 | 15:00:00 | 1200 | Original request |
| s_10 | 14:18:58 | 14:30:14 | — | Low altitude |
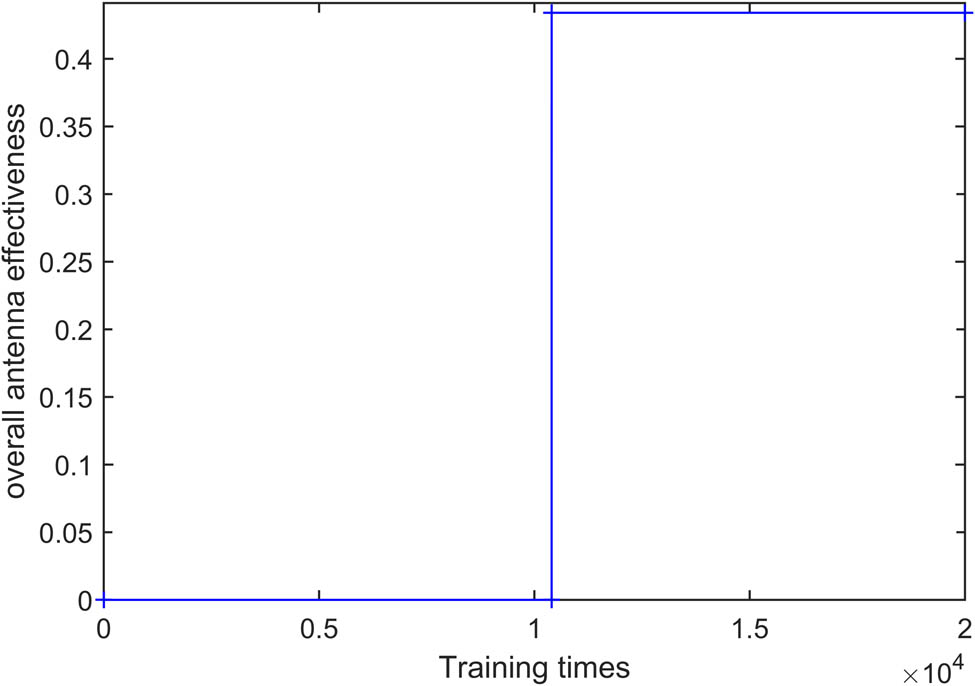
Variation of OAE for different values of training times with multi-layer strategy.
In the experiment with a more larger scale, for example, there are more than 15 high-altitude orbit satellite passes in one MRT, it is difficult to have a good control on the search. An additional high-altitude scheduled pass in MRT can lead to a slightly drawback in run time. On the contrary, a low-altitude scheduled pass in MRT instead of high-altitude pass can result in a similar OAE. Improving the overall performance of the method on large-scale scenario will be an important research topic in the future.
6 Conclusion
This article demonstrates how reinforcement learning can be used in high-altitude satellites range scheduling for urgent request. In the frame of our implementation, calculation of pass sliding bound and overall antenna effectiveness was introduced, Q learning was utilized as the learning model. Two kinds of scheduling strategies make our novel approach feasible to be extended to any other user-oriented scheduling method. The trained model can directly generate a scheduling result without retraining a new instance. Although not considered in our article, the proposed method can easily incorporate urgent request scheduling for request from low-altitude satellites. Numerical experiments are conducted on a large-scale of practical context, and results of simulations prove that the proposed method is feasible.
-
Funding information: This work was supported by the National Natural Science Foundation of China (Grant No. U21B2050).
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors state no conflict of interest.
References
Badaloni S, Falda M, Giacomin M. 2007. Solving temporal over-constrained problems using fuzzy techniques. J Intell Fuzzy Sys. 18:255–265. Search in Google Scholar
Bagchi TP. 2009. Near optimal ground support in multi-spacecraft missions: a GA model and its results. IEEE Trans Aero Elec Sys. 45:950–964. 10.1109/TAES.2009.5259176Search in Google Scholar
Barbulescu L, Watson JP, Whitley LD, Howe AE. 2004. Scheduling space-ground communications for the air force satellite control network. J Scheduling. 7:7–34. 10.1023/B:JOSH.0000013053.32600.3cSearch in Google Scholar
Brown N, Arguello B, Nozick L, Xu N. A heuristic approach to satellite range scheduling with bounds using Lagrangian relaxation. 2018. IEEE Sys J. 12:3828–3836. 10.1109/JSYST.2018.2821094Search in Google Scholar
Conway RW, Maxwell WL, Miller LW. 2003. Theory of scheduling. Mineola (NY), USA: Dover Publications. Search in Google Scholar
Cunha B, Madureira A, Fonseca B, Matos J. 2021. Intelligent scheduling with reinforcement learning. Appl Sci. 11:3710. 10.3390/app11083710Search in Google Scholar
Huang YX, Mu ZC, Wu SF, Cui BJ. 2021. Revising the observation satellite scheduling problem based on deep reinforcement learning. Remote Sens. 13:2377. https://doi.org/10.3390/rs13122377. Search in Google Scholar
Li YQ, Wang RX, Liu Y, Xu MQ. 2015. Satellite range scheduling with the priority constraint: an improved genetic algorithm using a station ID encoding method. Chinese J Aeronaut. 28:789–803. 10.1016/j.cja.2015.04.012Search in Google Scholar
Li YQ, Wang RX, Xu MQ. 2014. An evolution algorithm for satellite range scheduling problem with priority constraint. Appl Mech Mater. 568–570:775–780. 10.4028/www.scientific.net/AMM.568-570.775Search in Google Scholar
Ling XD, Zhu WK, Wu JM, Wu XY. 2013. Research of multi-satellite T&C scheduling problem. Appl Mech Mater. 263–266:476–484. 10.4028/www.scientific.net/AMM.263-266.476Search in Google Scholar
Luo KP, Wang HH, Li YJ, Li Q. 2017. High-performance technique for satellite range scheduling. Comput Oper Res. 85:12–21. 10.1016/j.cor.2017.03.012Search in Google Scholar
Luo S. 2020. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Appl Soft Comput. 91:106208. https://doi.org/10.1016/j.asoc.2020.106208. Search in Google Scholar
Marinelli F, Nocella S, Rossi F, Smriglio S. 2011. A Lagrangian heuristic for satellite range scheduling with resource constraints. Comput Oper Res. 38:1572–1583. 10.1016/j.cor.2011.01.016Search in Google Scholar
Petelin G, Antoniou M, Papa G. 2021. Multi-objective approaches to ground station scheduling for optimization of communication with satellites. Optim Eng. 2021:1–38. https://doi.org/10.1007/s11081-021-09617-z. Search in Google Scholar
Pinedo ML. 2016. Scheduling: theory, algorithms and systems. 5th ed. Berlin Heidelberg, Germany: Springer. 10.1007/978-3-319-26580-3Search in Google Scholar
Shyalika C, Silva T, Karunananda A. 2020. Reinforcement learning in dynamic task scheduling: a review. SN Comput Sci. 1:306. https://doi.org/10.1007/s42979-020-00326-5. Search in Google Scholar
Sutton RS, Barto AG. 2019. Reinforcement learning: an introduction. 2nd ed. Beijing, China: Publishing House of Electronics Industry. Search in Google Scholar
Watkins CJCH. 1989. Learning from delayed rewards, PhD thesis, King’s College, London, UK. Search in Google Scholar
Watkins CJCH, Dayan P. 1992. Q-learning. Mech Learn. 8:279–292. 10.1007/BF00992698Search in Google Scholar
Wiering M, Otterlo M. 2018. Reinforcement learning: state-of-the-art. Beijing, China: China Machine Press. https://doi.org/10.3390/app11083710. Search in Google Scholar
Xhafa F, Herrero X, Barolli A, Barolli L, Takizawa M. 2013. Evaluation of struggle strategy in genetic algorithms for ground stations scheduling problem. J Comput Syst Sci. 79:1086–1100. 10.1016/j.jcss.2013.01.023Search in Google Scholar
Zhang ZJ, Zhang N, Feng ZR. 2014. Multi-satellite control resource scheduling based on ant colony optimization. Expert Syst Appl. 41:2816–2823. 10.1016/j.eswa.2013.10.014Search in Google Scholar
Zufferey N, Amstutz P, Giaccari P. 2008. Graph colouring approaches for a satellite range scheduling problem. J Scheduling. 11:263–277. 10.1007/s10951-008-0066-8Search in Google Scholar
Zufferey N, Michel V. 2015. A generalized consistent neighborhood search for satellite range scheduling problems. Oper Res. 49:99–121. 10.1051/ro/2014027Search in Google Scholar
© 2022 Bo Ren et al., published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Deep learning application for stellar parameters determination: I-constraining the hyperparameters
- Explaining the cuspy dark matter halos by the Landau–Ginzburg theory
- The evolution of time-dependent Λ and G in multi-fluid Bianchi type-I cosmological models
- Observational data and orbits of the comets discovered at the Vilnius Observatory in 1980–2006 and the case of the comet 322P
- Special Issue: Modern Stellar Astronomy
- Determination of the degree of star concentration in globular clusters based on space observation data
- Can local inhomogeneity of the Universe explain the accelerating expansion?
- Processing and visualisation of a series of monochromatic images of regions of the Sun
- 11-year dynamics of coronal hole and sunspot areas
- Investigation of the mechanism of a solar flare by means of MHD simulations above the active region in real scale of time: The choice of parameters and the appearance of a flare situation
- Comparing results of real-scale time MHD modeling with observational data for first flare M 1.9 in AR 10365
- Modeling of large-scale disk perturbation eclipses of UX Ori stars with the puffed-up inner disks
- A numerical approach to model chemistry of complex organic molecules in a protoplanetary disk
- Small-scale sectorial perturbation modes against the background of a pulsating model of disk-like self-gravitating systems
- Hα emission from gaseous structures above galactic discs
- Parameterization of long-period eclipsing binaries
- Chemical composition and ages of four globular clusters in M31 from the analysis of their integrated-light spectra
- Dynamics of magnetic flux tubes in accretion disks of Herbig Ae/Be stars
- Checking the possibility of determining the relative orbits of stars rotating around the center body of the Galaxy
- Photometry and kinematics of extragalactic star-forming complexes
- New triple-mode high-amplitude Delta Scuti variables
- Bubbles and OB associations
- Peculiarities of radio emission from new pulsars at 111 MHz
- Influence of the magnetic field on the formation of protostellar disks
- The specifics of pulsar radio emission
- Wide binary stars with non-coeval components
- Special Issue: The Global Space Exploration Conference (GLEX) 2021
- ANALOG-1 ISS – The first part of an analogue mission to guide ESA’s robotic moon exploration efforts
- Lunar PNT system concept and simulation results
- Special Issue: New Progress in Astrodynamics Applications - Part I
- Message from the Guest Editor of the Special Issue on New Progress in Astrodynamics Applications
- Research on real-time reachability evaluation for reentry vehicles based on fuzzy learning
- Application of cloud computing key technology in aerospace TT&C
- Improvement of orbit prediction accuracy using extreme gradient boosting and principal component analysis
- End-of-discharge prediction for satellite lithium-ion battery based on evidential reasoning rule
- High-altitude satellites range scheduling for urgent request utilizing reinforcement learning
- Performance of dual one-way measurements and precise orbit determination for BDS via inter-satellite link
- Angular acceleration compensation guidance law for passive homing missiles
- Research progress on the effects of microgravity and space radiation on astronauts’ health and nursing measures
- A micro/nano joint satellite design of high maneuverability for space debris removal
- Optimization of satellite resource scheduling under regional target coverage conditions
- Research on fault detection and principal component analysis for spacecraft feature extraction based on kernel methods
- On-board BDS dynamic filtering ballistic determination and precision evaluation
- High-speed inter-satellite link construction technology for navigation constellation oriented to engineering practice
- Integrated design of ranging and DOR signal for China's deep space navigation
- Close-range leader–follower flight control technology for near-circular low-orbit satellites
- Analysis of the equilibrium points and orbits stability for the asteroid 93 Minerva
- Access once encountered TT&C mode based on space–air–ground integration network
- Cooperative capture trajectory optimization of multi-space robots using an improved multi-objective fruit fly algorithm
Articles in the same Issue
- Research Articles
- Deep learning application for stellar parameters determination: I-constraining the hyperparameters
- Explaining the cuspy dark matter halos by the Landau–Ginzburg theory
- The evolution of time-dependent Λ and G in multi-fluid Bianchi type-I cosmological models
- Observational data and orbits of the comets discovered at the Vilnius Observatory in 1980–2006 and the case of the comet 322P
- Special Issue: Modern Stellar Astronomy
- Determination of the degree of star concentration in globular clusters based on space observation data
- Can local inhomogeneity of the Universe explain the accelerating expansion?
- Processing and visualisation of a series of monochromatic images of regions of the Sun
- 11-year dynamics of coronal hole and sunspot areas
- Investigation of the mechanism of a solar flare by means of MHD simulations above the active region in real scale of time: The choice of parameters and the appearance of a flare situation
- Comparing results of real-scale time MHD modeling with observational data for first flare M 1.9 in AR 10365
- Modeling of large-scale disk perturbation eclipses of UX Ori stars with the puffed-up inner disks
- A numerical approach to model chemistry of complex organic molecules in a protoplanetary disk
- Small-scale sectorial perturbation modes against the background of a pulsating model of disk-like self-gravitating systems
- Hα emission from gaseous structures above galactic discs
- Parameterization of long-period eclipsing binaries
- Chemical composition and ages of four globular clusters in M31 from the analysis of their integrated-light spectra
- Dynamics of magnetic flux tubes in accretion disks of Herbig Ae/Be stars
- Checking the possibility of determining the relative orbits of stars rotating around the center body of the Galaxy
- Photometry and kinematics of extragalactic star-forming complexes
- New triple-mode high-amplitude Delta Scuti variables
- Bubbles and OB associations
- Peculiarities of radio emission from new pulsars at 111 MHz
- Influence of the magnetic field on the formation of protostellar disks
- The specifics of pulsar radio emission
- Wide binary stars with non-coeval components
- Special Issue: The Global Space Exploration Conference (GLEX) 2021
- ANALOG-1 ISS – The first part of an analogue mission to guide ESA’s robotic moon exploration efforts
- Lunar PNT system concept and simulation results
- Special Issue: New Progress in Astrodynamics Applications - Part I
- Message from the Guest Editor of the Special Issue on New Progress in Astrodynamics Applications
- Research on real-time reachability evaluation for reentry vehicles based on fuzzy learning
- Application of cloud computing key technology in aerospace TT&C
- Improvement of orbit prediction accuracy using extreme gradient boosting and principal component analysis
- End-of-discharge prediction for satellite lithium-ion battery based on evidential reasoning rule
- High-altitude satellites range scheduling for urgent request utilizing reinforcement learning
- Performance of dual one-way measurements and precise orbit determination for BDS via inter-satellite link
- Angular acceleration compensation guidance law for passive homing missiles
- Research progress on the effects of microgravity and space radiation on astronauts’ health and nursing measures
- A micro/nano joint satellite design of high maneuverability for space debris removal
- Optimization of satellite resource scheduling under regional target coverage conditions
- Research on fault detection and principal component analysis for spacecraft feature extraction based on kernel methods
- On-board BDS dynamic filtering ballistic determination and precision evaluation
- High-speed inter-satellite link construction technology for navigation constellation oriented to engineering practice
- Integrated design of ranging and DOR signal for China's deep space navigation
- Close-range leader–follower flight control technology for near-circular low-orbit satellites
- Analysis of the equilibrium points and orbits stability for the asteroid 93 Minerva
- Access once encountered TT&C mode based on space–air–ground integration network
- Cooperative capture trajectory optimization of multi-space robots using an improved multi-objective fruit fly algorithm