KI in der Smart Factory: Warum Standardanwendungen besser sind
-
Markus Diesner
Dipl.-Ing. (BA) Markus Diesner, Jahrgang 1977, studierte Informationstechnik an der Berufsakademie in Mannheim. Nach verschiedenen Tätigkeiten bei einem großen deutschen IT-Hersteller wechselte er im Juli 2012 zu MPDV in Mosbach, einem führenden Hersteller von Fertigungs-IT. Heute ist er als Principal Marketing Communications zuständig für die Erstellung von fachlichen Inhalten zur Vermarktung der Produkte und Lösungen von MPDV. Darüber hinaus engagiert er sich in diversen Gremien von Fachverbänden sowie in der Normungsarbeit.

Abstract
Künstliche Intelligenz (KI) kann Betreiber einer Smart Factory dabei unterstützen, effizienter zu produzieren, Störungen früher zu erkennen oder sogar vorherzusagen und somit in Summe wettbewerbsfähiger zu werden. Dabei geht es um KI-basierte Analysen, Vorhersagen und die Planung der kompletten Fertigung. Der Beitrag erläutert, was KI in der Smart Factory leisten kann und warum Standardlösungen deutliche Vorteile gegenüber individuellen KI-Projekten bieten.
Abstract
Artificial intelligence (AI) can help the operator of a smart factory produce more efficiently, recognize faults earlier or even predict them, and become more competitive overall. This involves AI-based analyses, predictions, and the planning of the entire production process. The article explains what AI can achieve in the smart factory and why standard solutions offer clear advantages over individual AI projects.
Der Traum von einer Maschine, die in der Lage ist, selbständig intelligente Entscheidungen zu treffen, ist älter als der moderne Computer. Bereits in den 1950er-Jahren gab es erste Vorstöße, die mit heutigen Ansätzen vergleichbar sind [1]. Doch erst in den letzten Jahren hat die Künstliche Intelligenz einen echten Aufschwung erlebt. Denn Computer verfügen mittlerweile über ausreichend viel Rechenleistung und der Einsatz von KI wird von der Gesellschaft immer mehr akzeptiert. Aktuell erleben wir einen neuen Höhepunkt mit ChatGPT und Angeboten, die auf dieser Technologie basieren. Aber bis zu KI-basierten Standardlösungen für die Smart Factory scheint es noch nicht zu reichen.
Wie alles begann
Bei einem Smartphone kann man den integrierten Blitz auf Wunsch zuschalten, um das nähere Umfeld besser auszuleuchten. Aber funktioniert das auch mit Künstlicher Intelligenz? Kann KI ganz einfach zugeschaltet werden, um im Bedarfsfall bessere Ergebnisse zu erzielen?
Der Blick in die Historie gibt wenig Grund zu Optimismus: Das 1996 entwickelte branchenübergreifende Standardverfahren für die Verarbeitung von großen Datenmengen, „Cross Industry Standard Process for Data Mining (CRISP-DM)“ [2], wird auch heute noch in vielen KI-Projekten eingesetzt [3]. Dieses Verfahren beschreibt anwendungsneutral, welche Schritte unternommen werden müssen, um erfolgreich von großen Datenmengen zu profitieren [4]. Es handelt sich um sechs Phasen (Bild 1):
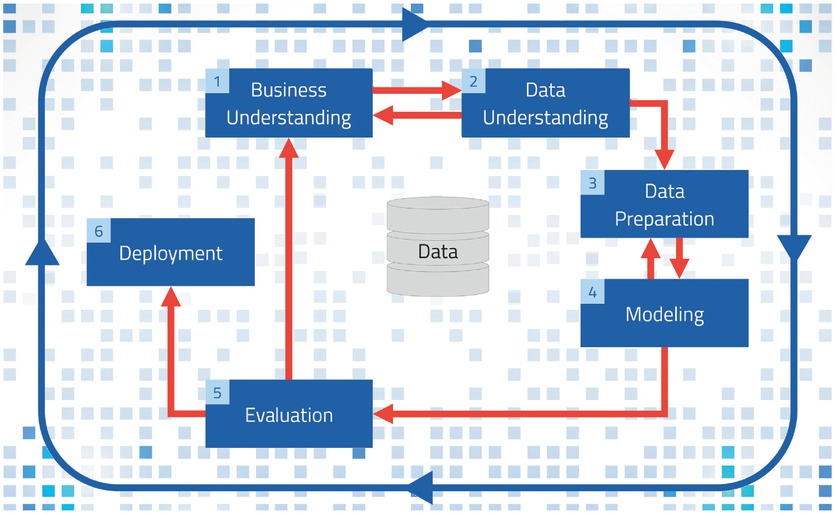
Das Vorgehensmodell Cross Industry Standard Process for Data Mining (CRISP-DM) erklärt, wie man mit großen Datenmengen umgeht (Quelle: MPDV, Adobe Stock, Rawpixel.com, i.A. an Wikipedia)
Business Understanding: Anwendungsfall verstehen,
Data Understanding: Daten verstehen,
Data Preparation: Daten vorbereiten,
Modeling: Modell erstellen,
Evaluation: Modell evaluieren und
Deployment: Modell bereitstellen.
Besonders das Aufbereiten der Daten, also die Schritte 1 bis 3, beansprucht in herkömmlichen KI-Projekten einen erheblichen Anteil an Zeit und Kosten. Ein Data Scientist muss diesen überwiegend manuellen Prozess für jedes einzelne Projekt aufs Neue durchführen. Sobald das KI-Modell fertiggestellt ist, kann es implementiert und verwendet werden. Wenn sich die Umstände stark verändern, kann eine Überarbeitung oder Erweiterung des Modells erforderlich werden. Denn die Künstliche Intelligenz lernt, ähnlich wie bei ChatGPT, nicht automatisch kontinuierlich weiter. Es wäre kostensparender, wenn man sowohl die Erstellung als auch die Erweiterung der KI-Modelle vollständig automatisieren könnte – eine Art „Automated Data Science“. Alternativ könnte man die Daten so bereitstellen, dass die ersten drei Schritte obsolet werden und direkt mit der Modellierung gestartet werden kann.
KI-Standardanwendungen
Daten in geeigneter Form vorzuhalten, ist eine der zentralen Aufgaben der modernen Fertigungs-IT. Begriffe wie „Integrationsplattform“ und „Semantik“ spielen dabei eine wesentliche Rolle. Wenn alle Daten innerhalb einer gemeinsamen Integrationsplattform in einem semantischen Datenmodell strukturiert sind, wird es für KI-Software einfach, auf diese zuzugreifen und sie für die Modellbildung zu nutzen. Kurz erklärt: Ein semantisches Datenmodell ist wie eine Landkarte für Daten, die zeigt, wie verschiedene Informationen miteinander verbunden sind und was sie bedeuten. Es hilft dabei, Daten besser zu verstehen und zu nutzen, indem es die Beziehungen und Bedeutungen der Daten klärt [5].
Ähnlich wie bei der Entwicklung von browserbasierten Computerspielen können stets neue Szenarien erstellt werden, die auf denselben Grundprinzipien basieren. Um bei diesem Vergleich zu bleiben: Für die zugrunde liegende Spiele-Engine ist es unerheblich, ob man eine Raumstation baut und Ressourcen von fremden Planeten sammelt oder ob man einen Bauernhof mit Rinderzucht betreibt. In beiden Szenarien gibt es Rohstoffe, Unterkünfte, Produktionsstätten und eine Währung, mit der man alles handeln kann, was man selbst nicht herstellt. Die zugrunde liegende Datenbasis bleibt identisch, es wird lediglich differenziert, wofür die Daten genutzt werden. Im genannten Beispiel unterschieden sich die Darstellungen Raumstation und Bauernhof nicht aber das Konstrukt dahinter.
Zurück zur Smart Factory: Eine Integrationsplattform stellt umfangreiche Daten bereit, die von verschiedenen Anwendungen genutzt werden können. Ob man analysiert, wie effizient eine Maschine ist oder vorhersagt, wie lange das Rüsten bei einem bestimmten Artikelwechsel dauern wird, ist für die Plattform zunächst unerheblich. Die semantische Strukturierung der Daten gewährleistet, dass jede Anwendung die Daten versteht und für ihren spezifischen Zweck nutzen kann. Dadurch wird der Weg für Standardanwendungen geebnet. Solche Standardanwendungen gibt es bereits auf dem Markt – zum Beispiel von MPDV (siehe Infokasten).
Auch für die KI-Engine ist nicht relevant, welche Art von Daten analysiert wird. Das Prinzip ist immer das Gleiche:
Das System analysiert historische Daten.
Die KI erkennt Muster und ermittelt Einflussfaktoren.
Anhand dieser Erkenntnisse kann das System Zusammenhänge visualisieren beziehungsweise Ergebnisse oder Ereignisse vorhersagen.
Industrielle Anwendung
Mit der AI Suite bietet MPDV aktuell acht Standardanwendungen, die jede für sich gesehen einen Mehrwert in der Smart Factory bietet und für mehr Wettbewerbsfähigkeit sorgt (siehe Bild 2):
AI Planning
AI Workforce Planning
AI-based Setup Time Prediction
AI-based Scrap Analysis
AI-based Capacity Utilization Analysis
AI-based Setup Rate Analysis
AI-based Resource Performance Account Analysis
Predictive Quality
Alle diese Anwendungen nutzen Daten aus der Manufacturing Integration Platform (MIP) und können daher ohne großen Zusatzaufwand eingesetzt werden. Mehr dazu unter https://www.mpdv.com/produkte/ai-suite-kuenstliche-intelligenz-in-der-fertigung

Mit der AI Suite liefert MPDV Standardanwendungen für die Smart Factory (Quelle: MPDV, Adobe Stock, sofi ko14)
Künstliche Intelligenz für die Smart Factory
Der Begriff „Künstliche Intelligenz“ umfasst ein ziemlich großes Feld der Wissenschaft und soll daher zunächst auf ein überschaubares Spektrum eingegrenzt werden. Im Fertigungsumfeld soll die KI den Menschen dabei unterstützen, bestimmte Aufgaben schneller oder auch besser auszuführen. Daher bietet es sich an, das Teilgebiet Machine Learning genauer zu betrachten. Machine Learning bzw. maschinelles Lernen ist ein Oberbegriff für die künstliche Wissensgenerierung: Ein System lernt aus Beispielen und kann diese nach Beendigung der Lernphase verallgemeinern. Dazu bauen Algorithmen beim maschinellen Lernen ein statistisches Modell auf, das auf Trainingsdaten beruht. Machine Learning selbst lässt sich in verschiedene Methoden unterteilen, die je nach Anwendungsfall unterschiedlich wirksam sind. Im Folgenden betrachten wir die drei Bereiche „überwachtes Lernen“, „unüberwachtes Lernen“ und „bestärkendes Lernen“ genauer.
Überwachtes Lernen
Im einfachsten Fall gibt man einem KI-System ein ausreichend großes Datenset zum Trainieren. Man spricht dabei von überwachtem Lernen, da diese Trainingsdaten auch das Ergebnis enthalten, das später vorhergesagt werden soll. Das KI-System erstellt aus diesen Trainingsdaten dann ein Modell, das später angewendet werden kann [6]. Ein konkretes Anwendungsbeispiel dafür ist Predictive Quality. Diese Anwendung soll auf Basis von Prozessparametern die Qualität eines Artikels vorhersagen, der gerade produziert wird. Bei einem ausreichend großen Set an Trainingsdaten aus genau diesen Prozessdaten und der jeweils dazu passend festgestellten Qualität funktioniert das bereits sehr zuverlässig. Genaueres dazu später.
Unüberwachtes Lernen
Einen Schritt weiter geht es, wenn man dem KI-System zwar Trainingsdaten zur Verfügung stellt, die Frage anschließend aber nicht auf die Vorhersage von Ergebnissen abzielt, sondern auf das Finden von Zusammenhängen [6]. Zum Einsatz kommt ein solches Vorgehen zum Beispiel bei der Vorhersage von Rüstzeiten auf Basis verschiedener Einflussfaktoren wie Maschine, Werkzeug, Material und vorherigem Artikel. Im Falle bereits bekannter Kombinationen kommen Methoden des überwachten Lernens zum Einsatz. Wenn jedoch neue Kombinationen oder komplett neue Artikel ins Spiel kommen, muss das KI-System auf Basis von Erfahrungen und erkannten Abhängigkeiten der Einflussfaktoren schätzen, wie hoch der Einfluss eines bestimmten Parameters wirklich ist. Und genau hier beginnen die Methoden des unüberwachten Lernens. Hier gibt der Anwender nicht mehr vor, wie das System lernen soll, sondern überlässt es dem System selbst, Schlüsse aus den verfügbaren Daten zu ziehen.
Bestärkendes Lernen
Eine dritte weit verbreitete Methode des Machine Learning ist das bestärkende Lernen. Bestärkendes Lernen bzw. Reinforcement Learning steht für eine Reihe von Methoden des maschinellen Lernens, bei denen ein System selbständig eine Strategie erlernt, um erhaltene Belohnungen zu maximieren. Dabei wird dem System nicht vorgezeigt, welche Aktion in welcher Situation die beste ist, sondern es erhält zu bestimmten Zeitpunkten eine Belohnung, die auch negativ sein kann. Anhand dieser Belohnungen optimiert das System das Ergebnis [7]. Vergleichbar ist dieses Vorgehen mit der Erziehung eines Hundes durch Belohnung mit Extra-Futter. Immer wenn das Tier etwas richtig gemacht hat, bekommt es eine Belohnung in Form eines Stücks Futter. Der Hund wird folglich versuchen, so viel wie möglich richtig zu machen, um möglichst viel Extra-Futter zu bekommen. Auf ähnliche Weise funktioniert Reinforcement Learning und nähert sich so sukzessive einem Optimum an – nur eben ohne das Extra-Futter. Auch dem menschlichen Lernen kommt diese Vorgehensweise am nächsten. Eingesetzt werden kann Reinforcement Learning unter anderem bei der automatischen Fertigungsplanung.
Funktionsweise und Nutzen am Beispiel von Predictive Quality
Predictive Quality beruht auf der Erkenntnis, dass trotz Einhaltung aller Prozessparameter innerhalb der vorgegebenen Toleranzgrenzen Ausschuss oder Nacharbeit entstehen kann. Dies liegt an den komplexen Wechselwirkungen, die mit der Fertigungstechnologie verbunden sind. In der Praxis wird eine Kombination aus verschiedenen Prozesswerten und der Qualitätseinstufung verwendet, um die Wahrscheinlichkeit zu bestimmen, ob das aktuell hergestellte Produkt einwandfrei oder Ausschuss ist. Hierfür ist eine umfassende Sammlung von Daten notwendig, insbesondere ein breites Spektrum an Prozessdaten, die mit entsprechenden Qualitätsdaten korreliert werden können. Dabei ist es entscheidend, dass die erfassten Prozesswerte synchron zu den Qualitätseinstufungen vorliegen. Sowohl die Menge als auch die Vielfalt der erfassten Daten sind für die Zuverlässigkeit der Vorhersagen wichtig. Einfach ausgedrückt: Je mehr die einzelnen Prozesswerte innerhalb ihrer zulässigen Toleranzen variieren und je mehr Kombinationen unterschiedlicher Extremwerte erfasst werden, desto besser.
Aus diesen Daten entwickelt die Künstliche Intelligenz ein Vorhersagemodell, das mit aktuellen Prozessdaten gespeist werden kann. Das Ergebnis ist einerseits eine Qualitätseinstufung und andererseits eine Einschätzung der Wahrscheinlichkeit, dass diese Einstufung korrekt ist (Bild 3). Dann liegt es in der Verantwortung des Menschen zu entscheiden, wie mit den Ergebnissen umgegangen wird. Beispielsweise könnte man alle Teile, die mit mehr als 60 Prozent Wahrscheinlichkeit Ausschuss sind, sofort recyceln oder überprüfen und Teile, die mit über 90 Prozent als „Gutteil“ eingestuft werden, ungeprüft ausliefern. Je nach Branche und Wert der produzierten Artikel könnten die Ergebnisse von Predictive Quality jedoch auch anders genutzt werden. Diese Entscheidung kann die Künstliche Intelligenz nicht treffen – allerdings kann sie die Analyse der Daten und die Vorhersage von Ergebnissen übernehmen.

Predictive Quality kann die Qualitätseinstufung eines Produkts vorhersagen, das aktuell produziert wird (Quelle: MPDV)
Verglichen mit anderen bekannten Standardanwendungen: Excel liefert Tabellen und Diagramme zu jedem Thema, aber die Nutzung dieser Daten bleibt dem Nutzer überlassen. Excel ist gleichgültig gegenüber der Art der analysierten und visualisierten Daten – es bleibt eine Standardanwendung. Dasselbe gilt für KI-basierte Standardanwendungen.
Zusammenfassung und Handlungsempfehlung
Wie in vielen Anwendungsfällen der Industrie 4.0 gilt auch beim Einsatz von Künstlicher Intelligenz in der Fertigungs-IT: Je eher Unternehmen mit der Umsetzung beginnen, desto früher können sie von den bisher ungenutzten Potenzialen profitieren. Der Einsatz moderner Technologie wie Künstlicher Intelligenz steht jedem Produktionsunternehmen zur Verfügung. Nur diejenigen, die zeitnah, aber dennoch mit Bedacht handeln, werden sich im weltweiten Wettbewerb durchsetzen können. Konjunkturelle Schwächen und andere Unwegsamkeiten scheinen vordergründig gegen eine Investition in die Fertigungs-IT zu sprechen. Jedoch ist eine solche Entscheidung gleichzusetzen mit einer Investition in die Zukunft. Der Weg zur Smart Factory ist nicht immer eben und braucht an einigen Stellen auch Mut. Davon sollten sich zukunftsorientierte Fertigungsunternehmen jedoch nicht abschrecken lassen. Die Smart Factory ist und bleibt ein lohnendes Ziel. Für viele Branchen wird sie zudem die einzige Möglichkeit sein, sich am Markt zu halten.
Es bleibt die Frage zu klären, ob man KI in der Smart Factory einsetzen sollte und wenn ja, wofür. Diese Frage muss jedes Fertigungsunternehmen selbst eruieren und diskutieren. Auch bei der Art und Weise des KI-Einsatzes gilt es, die richtigen Entscheidungen zu treffen. Im Falle einer Standardlösung ist KI so einfach wie der integrierte Blitz beim Smartphone. Mit etwas Licht werden Handybilder heller und mit KI kann man mehr aus seinen Fertigungsdaten herausholen. Viel Erfolg!
Hinweis
Bei diesem Beitrag handelt es sich um einen von den Mitgliedern des ZWF-Advisory Board für dieses Sonderheft wissenschaftlich begutachteten Fachaufsatz (Peer-Review).
About the author
Dipl.-Ing. (BA) Markus Diesner, Jahrgang 1977, studierte Informationstechnik an der Berufsakademie in Mannheim. Nach verschiedenen Tätigkeiten bei einem großen deutschen IT-Hersteller wechselte er im Juli 2012 zu MPDV in Mosbach, einem führenden Hersteller von Fertigungs-IT. Heute ist er als Principal Marketing Communications zuständig für die Erstellung von fachlichen Inhalten zur Vermarktung der Produkte und Lösungen von MPDV. Darüber hinaus engagiert er sich in diversen Gremien von Fachverbänden sowie in der Normungsarbeit.
Literatur
1 Turing, A. M.: Computing Machinery and Intelligence. Mind, New Series, 59 (1950) 236, S. 433–460 DOI:10.1093/mind/LIX.236.43310.1093/mind/LIX.236.433Search in Google Scholar
2 CRoss-Industry Standard Process for Data Mining. (https://cordis.europa.eu/project/id/25959 [Abgerufen am 09.01.2025])Search in Google Scholar
3 CRISP-DM is Still the Most Popular Framework for Executing Data Science Projects. (https://www.datascience-pm.com/crisp-dmstill-most-popular [Abgerufen am 09.01.2025])Search in Google Scholar
4 The Crisp-DM Methodology. (https://almirgouvea.github.io/The-Crisp-DM-Methodology/chapters/intro.html [Abgerufen am 09.01.2025])Search in Google Scholar
5 Berres, B.; Eckhardt, H.; Kletti, J.; Strebel, T.: MIP – Manufacturing Integration Platform: Aufbruch zu neuen Horizonten der Fertigungs-IT. NetSkill Solutions, Köln 2018Search in Google Scholar
6 Frochte, J.: Maschinelles Lernen – Grundlagen und Algorithmen in Python. Carl Hanser Verlag, München 2021 DOI:10.3139/978344646355410.3139/9783446463554Search in Google Scholar
7 Sutton, R. S.: Reinforcement Learning: an Introduction. 2. Auflage, Cambridge, Massachusetts 2018Search in Google Scholar
© 2025 Markus Diesner, publiziert von De Gruyter
Dieses Werk ist lizensiert unter einer Creative Commons Namensnennung 4.0 International Lizenz.
Articles in the same Issue
- Grußwort
- Grußwort
- Inhalt
- Künstliche Intelligenz
- Künstliche Intelligenz (KI)
- Menschzentrierte Einführung von Künstlicher Intelligenz in Produktion und Engineering
- Generative AI and Agentic Architecture in Engineering and Manufacturing
- Intelligent Industry
- Von Piloten zu skalierbaren Lösungen
- KI in Engineering
- KI-Anwendungen im Engineering
- KI-Adaption in der Produktentwicklung
- KI-Transformation im Engineering
- Code the Product – Vision für die Produktentstehung der Zukunft
- Machine Learning in Transmission Design
- AI Enables Data-Driven Product Design
- Optimierung von Entwicklungsprozessen durch KI-gestütztes Generatives Engineering und Design
- Human-AI Teaming in a Digital Twin Model for Virtual Product Development
- Kundenorientierte Innovationspotenziale durch KI
- Scheitert Systems Engineering an seiner eigenen Komplexität?
- AI-Augmented Model-Based Systems Engineering
- Prompt Engineering im Systems Engineering
- Sustainable Product Development and Production with AI and Knowledge Graphs
- AI-Driven ERP Systems
- Optimale Produktion dank Künstlicher Intelligenz
- KI in PLM-Systemen
- KI in Produktion
- Durchblick in der Produktion
- Production of the Future
- Der Use-Case-First-Ansatz zum Einsatz von Künstlicher Intelligenz in der Produktion
- Überwindung der Programmierkluft in der Produktion und Fertigung
- Lean Data – Anwendungsspezifische Reduktion großer Datenmengen im Produktionsumfeld
- KI-Zuverlässigkeit in der Produktion
- KI in der Smart Factory: Warum Standardanwendungen besser sind
- Data-Driven Decision-Making: Leveraging Digital Twins for Reprocessing in the Circular Factory
- Extended Intelligence for Rapid Cognitive Reconfiguration
- Erfahrungsbasierte Bahnoptimierung von Montagerobotern mittels KI und Digitalen Zwillingen
- Integration of Machine Learning Methods to Calculate the Remaining Useful Life of Mandrels
- AI-Driven Load Sensing for Wind Turbine Operations
- ChatPLC – Potenziale der Generativen KI für die Steuerungsentwicklung
- Developing and Qualifying an ML Application for MRO Assistance
- Applying AI in Supporting Additive Manufacturing Machine Maintenance
- Kollaboratives Modelltraining und Datensicherheit
- KI-basierte Partikelgrößenbestimmung in Suspensionen
- Intelligente Prozessüberwachung für die flexible Produktion
- Robuste Bauteilidentifikation mittels digitaler Fingerabdrücke
- Herausforderungen der Digitalisierung in der Klebetechnik
- Vom Webshop zum Shopfloor
- Scoring-Prozess mit Vorhersagemodell
- Automatisierte Optimierung von Metamaterialien im Leichtbau
- KI-gestützte Prozessoptimierung in der Massivumformung
- AI-Supported Process Monitoring in Machining
- Federated Learning in der Arbeitsplanung
- KI in der Kommissionierung
- KI-basiertes Assistenzsystem zur Qualitätskontrolle
- Qualitätssteigerung durch Digitalisierung
- Qualitative und wirtschaftliche Vorteile des KI-gestützten 8D-Prozesses
- KI-gestützte Prognose von Durchlauf- und Lieferzeiten in der Einzel- und Kleinserienfertigung
Articles in the same Issue
- Grußwort
- Grußwort
- Inhalt
- Künstliche Intelligenz
- Künstliche Intelligenz (KI)
- Menschzentrierte Einführung von Künstlicher Intelligenz in Produktion und Engineering
- Generative AI and Agentic Architecture in Engineering and Manufacturing
- Intelligent Industry
- Von Piloten zu skalierbaren Lösungen
- KI in Engineering
- KI-Anwendungen im Engineering
- KI-Adaption in der Produktentwicklung
- KI-Transformation im Engineering
- Code the Product – Vision für die Produktentstehung der Zukunft
- Machine Learning in Transmission Design
- AI Enables Data-Driven Product Design
- Optimierung von Entwicklungsprozessen durch KI-gestütztes Generatives Engineering und Design
- Human-AI Teaming in a Digital Twin Model for Virtual Product Development
- Kundenorientierte Innovationspotenziale durch KI
- Scheitert Systems Engineering an seiner eigenen Komplexität?
- AI-Augmented Model-Based Systems Engineering
- Prompt Engineering im Systems Engineering
- Sustainable Product Development and Production with AI and Knowledge Graphs
- AI-Driven ERP Systems
- Optimale Produktion dank Künstlicher Intelligenz
- KI in PLM-Systemen
- KI in Produktion
- Durchblick in der Produktion
- Production of the Future
- Der Use-Case-First-Ansatz zum Einsatz von Künstlicher Intelligenz in der Produktion
- Überwindung der Programmierkluft in der Produktion und Fertigung
- Lean Data – Anwendungsspezifische Reduktion großer Datenmengen im Produktionsumfeld
- KI-Zuverlässigkeit in der Produktion
- KI in der Smart Factory: Warum Standardanwendungen besser sind
- Data-Driven Decision-Making: Leveraging Digital Twins for Reprocessing in the Circular Factory
- Extended Intelligence for Rapid Cognitive Reconfiguration
- Erfahrungsbasierte Bahnoptimierung von Montagerobotern mittels KI und Digitalen Zwillingen
- Integration of Machine Learning Methods to Calculate the Remaining Useful Life of Mandrels
- AI-Driven Load Sensing for Wind Turbine Operations
- ChatPLC – Potenziale der Generativen KI für die Steuerungsentwicklung
- Developing and Qualifying an ML Application for MRO Assistance
- Applying AI in Supporting Additive Manufacturing Machine Maintenance
- Kollaboratives Modelltraining und Datensicherheit
- KI-basierte Partikelgrößenbestimmung in Suspensionen
- Intelligente Prozessüberwachung für die flexible Produktion
- Robuste Bauteilidentifikation mittels digitaler Fingerabdrücke
- Herausforderungen der Digitalisierung in der Klebetechnik
- Vom Webshop zum Shopfloor
- Scoring-Prozess mit Vorhersagemodell
- Automatisierte Optimierung von Metamaterialien im Leichtbau
- KI-gestützte Prozessoptimierung in der Massivumformung
- AI-Supported Process Monitoring in Machining
- Federated Learning in der Arbeitsplanung
- KI in der Kommissionierung
- KI-basiertes Assistenzsystem zur Qualitätskontrolle
- Qualitätssteigerung durch Digitalisierung
- Qualitative und wirtschaftliche Vorteile des KI-gestützten 8D-Prozesses
- KI-gestützte Prognose von Durchlauf- und Lieferzeiten in der Einzel- und Kleinserienfertigung