Scoring-Prozess mit Vorhersagemodell
-
Stephan Pfeiffer
Stephan Pfeiffer, Geschäftsführer der X-INTEGRATE Software & Consulting GmbH, ist seit vielen Jahren als Architekt, Berater, Projektleiter und Manager im SW-Engineering und in der Technologieberatung tätig


Abstract
Auf Basis aussagekräftiger Daten der Werkzeuge die Qualität der zu fertigenden Produkte sowie den Zustand der Werkzeuge innerhalb der Produktionsmaschinen indirekt vorherzusagen – dies wird möglich durch den Einsatz von Sensorik in vernetzten Industrieanlagen. Die derart gesammelten Daten werden durch Predictive-Analytics-Verfahren ausgewertet, visuell aufbereitet und anschließend für die Planung bereitgestellt.
Abstract
Using sensor technology in networked industrial plants enables manufacturers to indirectly predict the quality of products to be manufactured and the condition of the tools within the production machines, based on meaningful data from the tools. Predictive analytics methods collect the data, evaluate, visualize them and make them available for planning.
Predictive Analytics mit Machine Learning
Die industrielle Fertigung in Deutschland steht aktuell unter starkem Druck durch hohe Energiekosten, globale Lieferkettenprobleme und den Wettbewerb mit Niedriglohnländern. Hinzu kommen steigende Anforderungen an Klimaschutz und Digitalisierung. Dem müssen Unternehmen des produzierenden Gewerbes etwas entgegensetzen. Diversifizierung von Lieferketten und eine stärkere regionale Beschaffung helfen, Abhängigkeiten zu reduzieren. Parallel sind Kostensenkungsmaßnahmen und Effizienzsteigerungen erforderlich.
Qualitätsprüfungen in der Fertigung, Wechsel und Einrichtung von Maschinenkomponenten zum Beispiel sind personalintensive Prozesse und damit Kostentreiber. Klassischerweise entnimmt man dabei in vordefinierten Abständen baugruppenbezogene Teile aus der Fertigungsstraße und überprüft sie. Bei diesem Standardverfahren werden physikalische Größen gemessen und direkt physikalischen Effekten zugeordnet. Herausforderung: Sind die Intervalle zu kurz, kommt es zu häufigen (und kostspieligen) Verzögerungen in der Produktion. Bei zu langen Zwischenräumen wiederum fällt der Verschleiß von Werkzeugen erst auf, wenn die Qualität der Fertigungsteile bereits derart signifikant gesunken ist, dass im schlechtesten Fall nur noch Ausschuss produziert wird.
Um dies zu verhindern, gibt es mittlerweile neue Ansätze der Vernetzung von Produktionsstrecken/Industrieanlagen und der Erfassung von Produktionsdaten durch Sensorik (Bild 1). Dafür werden Messgeräte an den Maschinen angebracht, die innerhalb der Fertigungsstraßen die Qualität der gefertigten Bauteile sowie den Zustand der Werkzeuge kontinuierlich kontrollieren. Es findet also eine indirekte Messung statt. Auf der Basis aussagekräftiger Daten lassen sich die Qualität der zu fertigenden Produkte vorhersagen sowie langfristig verbessern.
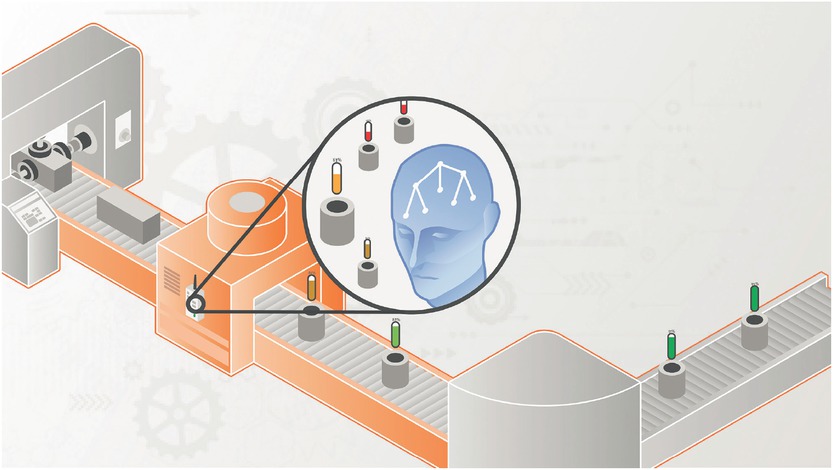
Neue Ansätze der Vernetzung von Produktionsstrecken/Industrieanlagen und Erfassung von Produktionsdaten durch Sensorik (Quelle: X-INTEGRATE)
Vorgehensweise – Einsatz von KI
Ein zentraler Bestandteil von KI ist maschinelles Lernen (ML), das Algorithmen verwendet, um Daten zu analysieren, daraus zu lernen und Erkenntnisse zu gewinnen. Es handelt sich um eine dynamische Technologie, die ihre Leistung kontinuierlich verbessert, je mehr Daten sie analysiert. Mit zunehmendem Umfang der Datensätze verbessern sich also Genauigkeit und Aussagekraft des Modells.
Besonders im Bereich der Wartung und des Service bietet maschinelles Lernen vielversprechende Anwendungen. Ungeplante Stillstände führen zu Produktivitätsverlusten und verursachen hohe Kosten durch notwendige Serviceeinsätze. ML ermöglicht die Analyse historischer und aktueller Anlagendaten, um mögliche zukünftige Ereignisse, wie notwendige Wartungsarbeiten oder drohende Anlagenausfälle, zu prognostizieren (Predictive Analytics). Probleme werden dadurch frühzeitig erkannt und Ineffizienzen identifiziert. Servicekräfte können proaktiv Maßnahmen ergreifen und potenzielle Ausfälle verhindern, bevor sie auftreten.
Ansätze für Vorhersagen
Vorhersagen lassen auf verschiedene Art treffen. Entweder sie basieren auf bestehenden Daten, werden durch kontinuierliches Lernen getroffen oder aber eventuell auftretende Leistungsprobleme werden vorab mittels Simulationen getestet.
Edge Computing
Angesichts prognostizierter Wachstumsraten der Datenmengen erweist sich deren Analyse in der Cloud inzwischen oft als zu unperformant. Hinzu kommen Sicherheitsbedenken. So spricht einiges für eine Zwischenschicht – den Edge.
Das Industrial Internet of Things produziert heute Daten am laufenden Band, bei Maschinen- und Anlagenbauern aller Größen. Sie mittels künstlicher Intelligenz auszuwerten, dafür werden gerne Public-Cloud-Angebote genutzt. Der Grund: KI-Ansätze benötigen Daten als Lernmenge, die in einer Public-Cloud-Lösung naturgemäß größer sind als auf on-premises installierten Systemen. Außerdem kann man auf Out-of-the-Box-Lösungen in der Cloud zugreifen.
Trotzdem zögern viele Unternehmen bei diesem Schritt. Dafür gibt es zwei gewichtige Gründe, rechtlicher wie technischer Art. Zum einen stellt sich in vielen Geschäftsprozessen das Problem, dass die Ausleitung von Daten in die Cloud aus Governance-Gründen untersagt ist. Denn in den IIoT-Daten steckt ein hohes Maß an Intellectual Property, also (geheimes, werthaltiges) Wissen über Produkte und Produktionsverfahren, die man nicht veröffentlichen bzw. teilen möchte oder darf. Denkt man zum Beispiel an die Fertigung von Rüstungsgütern oder Teilen/Werkstücken im Kundenauftrag, wird der schützenswerte Charakter solcher Daten offensichtlich. Zweites Problem ist das immer größere Volumen. Wenn eine Maschine heute mehrere 1.000 Datenpunkte im Millisekundenbereich erzeugt, ist eine Echtzeitverarbeitung in der Cloud aus Latenzgründen kaum mehr möglich.
Vorhersagen auf Basis bestehender Daten
Durch die Kombination von historischen Leistungsdaten, technischen Spezifikationen und Echtzeit-Analysen können benutzerspezifische, zustandsbasierte Alarme und Warnmeldungen erstellt werden. So lassen sich potenzielle Probleme erkennen und beheben, bevor sie auftreten. Diese Methode bildet in der Regel die grundlegende Stufe KI-gestützter Vorhersagen.
Vorhersagen durch kontinuierliches Lernen
Unabhängig vom Reifegrad eines IIoT-Systems kann KI dabei helfen, Daten gezielt zu analysieren und zu verfeinern. Im Laufe der Zeit entstehen so präzisere und effektivere Modelle, die eine Predictive-Maintenance-Strategie unterstützen. Diese baut kontinuierlich Wissen auf und identifiziert Muster, die auf drohende Ausfälle hinweisen und proaktive Maßnahmen ermöglichen.
Simulationen zur Vorhersage
Belastungen und Bedingungen, die während des Entwicklungsprozesses zu Leistungsproblemen führen könnten, lassen sich mithilfe von Simulationen vorab testen. So wird sichergestellt, dass Maschinen realen Einsatzbedingungen standhalten, und vorausschauende Alarm- und Warnpunkte können definiert werden. Daten, die durch KI-gestützte Prozesse gesammelt werden, verbessern diese Simulationen kontinuierlich und liefern zunehmend präzisere Ergebnisse.
In einem Predictive-Analytics-Verfahren tritt an die Stelle klassischer Prüfintervalle ein Scoring-Prozess mithilfe eines Vorhersagemodells auf Basis einer Software für statistische Datenanalyse (Bild 2). Auf diesen Modellen baut Predictive Quality auf. Diese nutzt also Predictive-Analytics-Methoden wie maschinelles Lernen und statistische Modelle, ist aber speziell auf die Qualitätssicherung im Produktionskontext ausgerichtet.
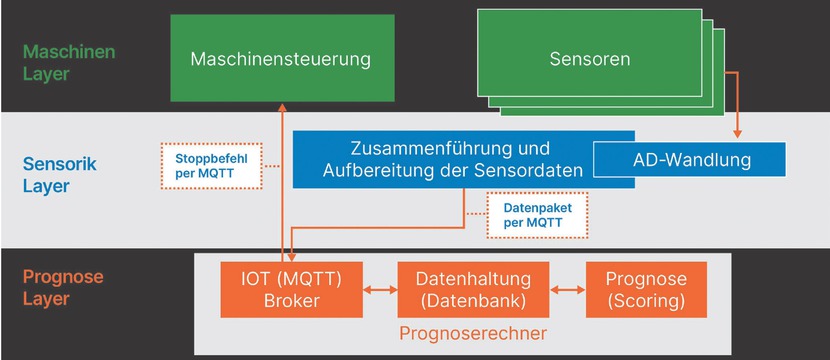
Ebenen der Scoring-Lösung (Quelle: X-INTEGRATE)
Der Prozess findet in einer Docker-Umgebung statt. Docker ist eine auf Open Source basierende Methode zur Isolation von Anwendungen in Containern. Die auf einem Rechner genutzten Ressourcen werden über die Container getrennt und verwaltet. Dies erlaubt einen flexiblen Betrieb in verschiedenen Deploymentmodellen.
Das Docker-Konzept lässt sich mit der Virtualisierung vergleichen. Es vereinfacht die Bereitung von Software (minimalinvasive Softwareimplementierung!) und macht sie unabhängig von der Plattform, da sich die Container leicht transportieren und installieren lassen. Docker wird im beschriebenen Fall verwendet, um die Statistik- und Analyse-Software SPSS der Firma IBM in Kombination mit einem (von X-INTEGRATE entwickelten) mathematischen Modell auf verschiedene Container zu verteilen.
Durch das „Dockerisieren“ der Softwarekomponenten ist es möglich, die gesamte Scoring-Lösung auf einem Edge Gateway – einer gehärteten Hardwarekomponente, die Industrie-Connectivity-Standards unterstützt – zu implementieren und lokal an den Maschinen einer Fertigungsstraße zu installieren. Von „gehärtet“ spricht man, weil ein Edge Gateway weit mehr als ein normaler Router oder Computer ist. Es handelt sich um eine speziell entwickelte Hardware mit hoher physischer und digitaler Widerstandsfähigkeit, die in herausfordernden und oft sicherheitskritischen Umgebungen eingesetzt wird. Unter Berücksichtigung diverser betriebsrelevanter Messwerte, wie z. B. Druck- und Kraftwerten, werden präzise Vorhersagen über die Qualität eines gefertigten Bauteils und den Zustand der Werkzeuge getroffen.
Skalierbare Architekturen im Edge-Cloud-Kontinuum
Edge Computing vereint die Vorteile von Local- und Cloud-Computing. Es lässt sich als Vorbereitung für die Cloud verstehen – eine On-Premises-Lösung auf dem Edge mit Funktionen für Analytik, Vorverarbeitung und dezentrale Intelligenz, die mit der Cloud zusammen eine Art Kontinuum bildet. Near Edge bezeichnet das Edge Computing in Cloudnähe, Far Edge in Maschinennähe. Die Unterscheidung erlaubt im Bedarfsfall skalierbare Architekturen im Edge-Cloud-Kontinuum.
Am Edge lassen sich IoT-Daten so aggregieren und anonymisieren, dass sie in der Cloud verwendet werden können – dies ist der rechtliche Aspekt. Voraussetzung dafür sind Konnektoren zwischen Edge und Cloud zur Datenübertragung sowie Datenmodelle, die auf beiden Seiten Datenintegration unterstützen. Was die technischen Vorteile angeht, lassen sich dank neuer und skalierbarer Technologien auch hohe Datenvolumina am Edge ohne Latenzprobleme bearbeiten. Dadurch werden Echtzeitanalysen erst möglich. Eine Warnung, dass die Maschine aufgrund Überschreitens kritischer Grenzen in wenigen Minuten ausfallen könnte, kommt dann auch wirklich zur rechten Zeit, ebenso wie ein sofortiger Produktionsstopp im Rahmen einer datenbasierten Qualitätskontrolle, die jedes einzelne Werkstück unmittelbar nach seiner Herstellung prüft. Auf diese Weise werden Ausschussmengen reduziert und nebenher nachhaltig Material- und Energiekosten eingespart. In solchen Fällen großer zu analysierender Datenmengen und schnell benötigter Antworten ist Edge Computing im Grunde unumgänglich.
Mustererkennung auf Kraft-/Wirkkurven
Durch mathematische Verfahren und neuronale Netze werden anschließend jene Teile einer Maschine und eines Werkzeuges indirekt geprüft, die erfahrungsgemäß ein Qualitätsproblem aufweisen könnten.
Dieses Modell ist das Herzstück des gesamten Vorhersageprozesses. Es übersetzt abstrakte Daten, die für das menschliche Auge zumeist aussagelos sind, in für den Produktionsprozess relevante Aussagen (Bild 3), zum Beispiel so, dass das produzierte Bauteil einen Defekt aufweist oder die Matrize verschlissen ist und ausgetauscht werden sollte.
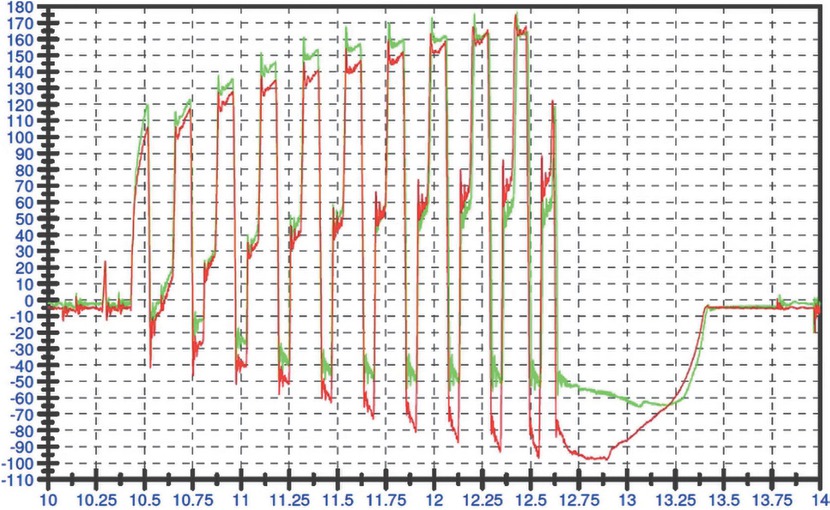
Die bei der Produktion entstehenden Kräfte werden gemessen und als Kraftkurven bereitgestellt (Quelle: X-INTEGRATE)
Hier werden die bei der Produktion entstehenden Kräfte gemessen und als Kraftkurven bereitgestellt. Diese sehen auf den ersten Blick alle gleich aus, unabhängig von dem Zustand der gerade eingesetzten Matrize. Aus diesen Kurven werden weitere Daten wie diskrete Ableitungen, Integrale, Mittel- und Extremwerte generiert.
Realtime Scoring bei Felss
Die Felss Systems GmbH, einer der führenden deutschen Maschinen- und Anlagenproduzenten, setzt ein von X-INTEGRATE entwickeltes Predictive-Analytics-Verfahren ein, um die Effizienz des Fertigungsprozesses und der Qualitätsprüfung auf den Anlagen zu erhöhen, die seine Kunden betreiben. Die Industriemaschinen für die Umformung von Metallen für Getriebewellen, Lenkwellen, Antriebskomponenten und weitere anspruchsvolle Bauteile kommen in vielen Branchen, u. a. der Automobilindustrie, zum Einsatz.
Ein mathematisches Vorhersagemodell, hier ein Neuronales Netz, sagt dann vorher, ob die Matrize oder das Bauteil, zugehörig zu den Daten, in Ordnung ist oder nicht. Die Genauigkeit der Vorhersage liegt dabei initial bei ca. 95 Prozent. Diese und die Robustheit des Modells werden während der fortlaufenden Produktion weiter verbessert. Durch fortwährendes Feedback, beispielsweise durch Beobachtungen der Mitarbeiter, ob ein als fehlerhaft gekennzeichnetes Bauteil tatsächlich fehlerhaft war, wird das Modell weiter trainiert.
Neue, präzisere Kontrollmöglichkeit
Die Anwendung des Scoring-Prozesses führt zu einer sehr hohen Treffsicherheit der nächst nötigen Wartung. Noch bevor es im Fertigungsprozess zu Komplikationen oder Ausfällen kommt, erhält der Maschinist eine visuelle Benachrichtigung an der betroffenen Maschine. Durch die neue, präzisere Kontrollmöglichkeit kann der Maschinenbauer gezielt vorhersagen, wann es zu Qualitätsabfall in einer Produktionskette kommt, und auf Grund dieser Informationen z. B. notwendige Werkzeugwechsel und Bestellvorgänge geplant und durchgeführt werden müssen. In Echtzeit können so Arbeitsschritte flexibel angepasst werden und das Risiko von Qualitätsmängeln oder eines Maschinenausfalls wird minimiert. Innerhalb der Fertigungsstraße sinken damit der Ausschuss der Produkte und die Wahrscheinlichkeit eines ungeplanten Maschinenstopps.
Ebenen der Scoring Lösung
Die Scoring-Lösung besteht aus Systemen, die sich auf unterschiedlichen Ebenen befinden: Die Maschinenebene umfasst die Industriemaschine selbst, die dazugehörige Steuerungseinheit und eine Reihe von Sensoren. Auf der Sensorikebene werden die von den Messgeräten gelieferten Daten zusammengeführt und für eine Auswertung aufbereitet. Der eigentliche KI-Einsatz im Zuge der Datenanalyse findet auf der Prognoseebene statt. Die Ergebnisse der Analyse der aufbereiteten Sensordaten werden anschließend an die Maschinensteuerung gesendet. Diese kann den Ergebnissen entsprechende Maßnahmen einleiten, wie z. B. ein Stoppen der Maschine.
Robustes Vorhersagemodell
Durch kontinuierlichere, präzisere Kontrolle kann der Betreiber der Maschine Arbeitsschritte in Echtzeit anpassen und gezielter vorhersagen, wann für die einzelnen Maschinen in einer Produktionskette ein Werkzeugwechsel oder die Anpassung der Maschinenparameter oder des Maschinenprofils notwendig ist. Innerhalb der Fertigungsstraße sinken damit der Ausschuss der Produkte und die Wahrscheinlichkeit eines ungeplanten Maschinenstopps. Auch die Qualitätskontrolle der Bauteile wird durch das neue Predictive-Analytics-Verfahren erheblich effizienter.
Sehr personalintensive Qualitätsprü-fungsprozesse können nun von der Datenmessung über die Berichterstattung bis hin zur Anpassung des Maschinenprofils automatisch und effizient erledigt und zur weiteren Optimierung des Vorhersagemodells dokumentiert werden.
Systemschnittstellen
Als Schnittstelle zu den Systemen, welche Sensordaten liefern und Vorhersageergebnisse verarbeiten, wird das Open-Source-Nachrichtenprotokoll MQTT eingesetzt. Die Verwendung des Publish/Subscribe-Mechanismus von MQTT stellt sicher, dass die Servicequalität (Quality of Service Level) des jeweiligen Partners unterstützt wird. Außerdem ermöglicht es einen flexiblen Umgang mit weiteren Konsumenten der Sensordaten und der Vorhersageergebnisse.
Datenspeicherung und Processing
Sowohl die Sensordaten als auch die Vorhersageergebnisse werden auf einer Datenbankkomponente (IBM DB2) gespeichert. Dies ermöglicht weitere Optimierungen des Vorhersagemodells, z. B. bei Änderungen und Erweiterungen in der Sensorkonfiguration. Die Datenbankkomponente wird als Docker-Container bereitgestellt. Die maximale Vorhaltezeit der gespeicherten Daten ist durch die anvisierte Hardwarekomponente vorgegeben.
Berechnete maximale Last, die von der Maschine erzeugt werden kann bei einem theoretischen 24×7-Betrieb:
1 Datensatz pro Sensor pro Millisekunde,
pro Minute ca 60.000 kombinierte Datensätze,
pro Tag 86 Mio Datenbankzeilen (5 GB).
Ergebnis ist eine engere Überwachung des Verschleißes von Werkzeugen, vorausschauende Planung sowie in der Folge ein verbessertes Qualitätsmanagement. Zusätzlich kann ein Unternehmen mit der Lösung in Zukunft flexibler auf Ereignisse reagieren und Werkzeugwechselprozesse effizienter gestalten.
Hinweis
Bei diesem Beitrag handelt es sich um einen von den Advisory-Board-Mitgliedern des ZWF-Sonderheftes wissenschaftlich begutachteten Fachaufsatz (Peer-Review).
About the author
Stephan Pfeiffer, Geschäftsführer der X-INTEGRATE Software & Consulting GmbH, ist seit vielen Jahren als Architekt, Berater, Projektleiter und Manager im SW-Engineering und in der Technologieberatung tätig
© 2025 Stephan Pfeiffer, publiziert von De Gruyter
Dieses Werk ist lizensiert unter einer Creative Commons Namensnennung 4.0 International Lizenz.
Articles in the same Issue
- Grußwort
- Grußwort
- Inhalt
- Künstliche Intelligenz
- Künstliche Intelligenz (KI)
- Menschzentrierte Einführung von Künstlicher Intelligenz in Produktion und Engineering
- Generative AI and Agentic Architecture in Engineering and Manufacturing
- Intelligent Industry
- Von Piloten zu skalierbaren Lösungen
- KI in Engineering
- KI-Anwendungen im Engineering
- KI-Adaption in der Produktentwicklung
- KI-Transformation im Engineering
- Code the Product – Vision für die Produktentstehung der Zukunft
- Machine Learning in Transmission Design
- AI Enables Data-Driven Product Design
- Optimierung von Entwicklungsprozessen durch KI-gestütztes Generatives Engineering und Design
- Human-AI Teaming in a Digital Twin Model for Virtual Product Development
- Kundenorientierte Innovationspotenziale durch KI
- Scheitert Systems Engineering an seiner eigenen Komplexität?
- AI-Augmented Model-Based Systems Engineering
- Prompt Engineering im Systems Engineering
- Sustainable Product Development and Production with AI and Knowledge Graphs
- AI-Driven ERP Systems
- Optimale Produktion dank Künstlicher Intelligenz
- KI in PLM-Systemen
- KI in Produktion
- Durchblick in der Produktion
- Production of the Future
- Der Use-Case-First-Ansatz zum Einsatz von Künstlicher Intelligenz in der Produktion
- Überwindung der Programmierkluft in der Produktion und Fertigung
- Lean Data – Anwendungsspezifische Reduktion großer Datenmengen im Produktionsumfeld
- KI-Zuverlässigkeit in der Produktion
- KI in der Smart Factory: Warum Standardanwendungen besser sind
- Data-Driven Decision-Making: Leveraging Digital Twins for Reprocessing in the Circular Factory
- Extended Intelligence for Rapid Cognitive Reconfiguration
- Erfahrungsbasierte Bahnoptimierung von Montagerobotern mittels KI und Digitalen Zwillingen
- Integration of Machine Learning Methods to Calculate the Remaining Useful Life of Mandrels
- AI-Driven Load Sensing for Wind Turbine Operations
- ChatPLC – Potenziale der Generativen KI für die Steuerungsentwicklung
- Developing and Qualifying an ML Application for MRO Assistance
- Applying AI in Supporting Additive Manufacturing Machine Maintenance
- Kollaboratives Modelltraining und Datensicherheit
- KI-basierte Partikelgrößenbestimmung in Suspensionen
- Intelligente Prozessüberwachung für die flexible Produktion
- Robuste Bauteilidentifikation mittels digitaler Fingerabdrücke
- Herausforderungen der Digitalisierung in der Klebetechnik
- Vom Webshop zum Shopfloor
- Scoring-Prozess mit Vorhersagemodell
- Automatisierte Optimierung von Metamaterialien im Leichtbau
- KI-gestützte Prozessoptimierung in der Massivumformung
- AI-Supported Process Monitoring in Machining
- Federated Learning in der Arbeitsplanung
- KI in der Kommissionierung
- KI-basiertes Assistenzsystem zur Qualitätskontrolle
- Qualitätssteigerung durch Digitalisierung
- Qualitative und wirtschaftliche Vorteile des KI-gestützten 8D-Prozesses
- KI-gestützte Prognose von Durchlauf- und Lieferzeiten in der Einzel- und Kleinserienfertigung
Articles in the same Issue
- Grußwort
- Grußwort
- Inhalt
- Künstliche Intelligenz
- Künstliche Intelligenz (KI)
- Menschzentrierte Einführung von Künstlicher Intelligenz in Produktion und Engineering
- Generative AI and Agentic Architecture in Engineering and Manufacturing
- Intelligent Industry
- Von Piloten zu skalierbaren Lösungen
- KI in Engineering
- KI-Anwendungen im Engineering
- KI-Adaption in der Produktentwicklung
- KI-Transformation im Engineering
- Code the Product – Vision für die Produktentstehung der Zukunft
- Machine Learning in Transmission Design
- AI Enables Data-Driven Product Design
- Optimierung von Entwicklungsprozessen durch KI-gestütztes Generatives Engineering und Design
- Human-AI Teaming in a Digital Twin Model for Virtual Product Development
- Kundenorientierte Innovationspotenziale durch KI
- Scheitert Systems Engineering an seiner eigenen Komplexität?
- AI-Augmented Model-Based Systems Engineering
- Prompt Engineering im Systems Engineering
- Sustainable Product Development and Production with AI and Knowledge Graphs
- AI-Driven ERP Systems
- Optimale Produktion dank Künstlicher Intelligenz
- KI in PLM-Systemen
- KI in Produktion
- Durchblick in der Produktion
- Production of the Future
- Der Use-Case-First-Ansatz zum Einsatz von Künstlicher Intelligenz in der Produktion
- Überwindung der Programmierkluft in der Produktion und Fertigung
- Lean Data – Anwendungsspezifische Reduktion großer Datenmengen im Produktionsumfeld
- KI-Zuverlässigkeit in der Produktion
- KI in der Smart Factory: Warum Standardanwendungen besser sind
- Data-Driven Decision-Making: Leveraging Digital Twins for Reprocessing in the Circular Factory
- Extended Intelligence for Rapid Cognitive Reconfiguration
- Erfahrungsbasierte Bahnoptimierung von Montagerobotern mittels KI und Digitalen Zwillingen
- Integration of Machine Learning Methods to Calculate the Remaining Useful Life of Mandrels
- AI-Driven Load Sensing for Wind Turbine Operations
- ChatPLC – Potenziale der Generativen KI für die Steuerungsentwicklung
- Developing and Qualifying an ML Application for MRO Assistance
- Applying AI in Supporting Additive Manufacturing Machine Maintenance
- Kollaboratives Modelltraining und Datensicherheit
- KI-basierte Partikelgrößenbestimmung in Suspensionen
- Intelligente Prozessüberwachung für die flexible Produktion
- Robuste Bauteilidentifikation mittels digitaler Fingerabdrücke
- Herausforderungen der Digitalisierung in der Klebetechnik
- Vom Webshop zum Shopfloor
- Scoring-Prozess mit Vorhersagemodell
- Automatisierte Optimierung von Metamaterialien im Leichtbau
- KI-gestützte Prozessoptimierung in der Massivumformung
- AI-Supported Process Monitoring in Machining
- Federated Learning in der Arbeitsplanung
- KI in der Kommissionierung
- KI-basiertes Assistenzsystem zur Qualitätskontrolle
- Qualitätssteigerung durch Digitalisierung
- Qualitative und wirtschaftliche Vorteile des KI-gestützten 8D-Prozesses
- KI-gestützte Prognose von Durchlauf- und Lieferzeiten in der Einzel- und Kleinserienfertigung