Database Creation and Dialect-Wise Comparative Analysis of Prosodic Features for Punjabi Language
-
Shipra J. Arora
 and
Rishipal Singh
and
Rishipal Singh

Abstract
The paper represents a Punjabi corpus in the agriculture domain. There are various dialects in the Punjabi language and the main concentration is on major dialects, i.e. Majhi, Malwai and Doabi for the present study. A speech corpus of 125 isolated words is taken into consideration. These words are uttered by 100 speakers, i.e. 60 Malwi dialect speakers (30 male and 30 female), 20 Majhi dialect speakers (10 male and 10 female) and 20 Doabi dialect speakers (10 male and 10 female). Tonemes, adhak (geminated) and nasal words are selected from the corpus. Recordings have been processed through two mediums. The paper also elaborates some distinctive features of the corpus. This corpus is of quite significance for the speech recognition system. Prosodic characteristics such as intonation, rhythm and stress create a crucial impact on the speech recognition system. These characteristics vary from language to language as well as various dialects of a language. This paper portrays a comparative analysis of isolated words prosodic features of Malwi, Majhi and Doabi dialects of Punjabi language. Analysis is done using the PRAAT tool. Pitch, intensity, formant I and formant II values are extracted for toneme, adhak, nasal (bindi) and nasal (tippi) words. For all kinds of words, there is a significant variation in pitch (fundamental frequency), intensity, formant I and formant II values of male and female speakers of Malwi, Majhi and Doabi dialects. A detailed analysis has been discussed throughout this paper.
1 Introduction
Agriculture is one of the main occupations of people of Punjab which forms the moral fiber of economy of the Punjab state. The state has the maximum growth rate in production of food. Approximately 1.54% of the country’s geographical area comprises this state. It is surrounded by five rivers and can be considered as one of the most prolific areas on the earth.
There are various ways of communication, and speech is one of the most important and efficient methods of communication between human beings and their other environmental and non-environmental elements. Therefore, manufacturing of an automatic speech recognizer is very desirable and favorable. Speech recognition made it possible for the computers to understand human languages. As information technology has the impact on various aspects of human lives, and in recent years, it has affected a lot on human life, hence it becomes increasingly important to resolve the problem of communication between human beings and information processing devices. In the past, a lot of communication has been done through the usage of keyboards and screens, but speech is the most widely used, natural, convenient and the fastest means of communication for human beings.
Agriculture is the major livelihood of people in Punjab. Normally, farmers do not have scientific information about crops. They do not have interest in visiting an information center or a website to get information about crops. Even they are not capable of typing on computer. The reasons for requirement of Punjabi corpora are as follows:
to alleviate the communication of Punjabi speakers in India and abroad in their native language with smart devices;
to upgrade the Punjabi speaker information retrieval system without the use of a mouse and keyboard;
there is lack of resources;
there is low literacy level; and
visually impaired people find it inconvenient to use a Braille keyboard.
Punjabi speech corpora thus created are helpful to rural people who can be benefitted by automatic speech processing and can communicate with computer in their own native language.
Punjabi language is mainly used in two countries, India (East Punjab) and Pakistan (West Punjab), and on a small scale spoken in few other countries. It is a state language of Punjab in India. It has 10 vowels and 41 letters consisting of 38 consonants and 3 basic vowel sign bearers. Out of 38 consonants, there are 6 consonants with a dot below which are used to represent borrowed words from other languages. It has three conjunct vargs and also three signs, i.e. bindi, tippi and adhak. The script of Punjabi language is Gurumukhi which is based on the one-sound one-symbol rule. Punjabi is a tonal language. Segmental and super-segmental sounds are the taxonomy of speech sounds. Segmental sounds are further classified into vowels and consonants, but super-segmental sounds concentrate on tone, intonation and stress.
2 Related Work
TIFR Mumbai and IIT Bombay created a Marathi language speech database in a noisy environment. Data were recorded by 1500 speakers using cell phones and voice recorders. The database was created for the purpose of the automatic speech recognition system in the agriculture domain [2], [3], [16].
Punjabi University Patiala created a Punjabi language speech database consisting of 3312 syllables in a studio environment using a standard microphone. The database was created for the purpose of the text to speech synthesis system [9], [11].
KIIT, Gurgaon, created a Hindi and Indian English mobile-based speech database in a noise-free environment. Nokia Research Centre, China, sponsored this project. It consisted of 13 prompt sheets, each having 630 phonetically rich sentences. Data were recorded by 100 speakers (60 female and 40 male), using cell phones, and omni-directional and cardioid microphones [3].
TIFR Mumbai and CDAC Noida created a Hindi speech database in a noise-free environment. Data were recorded by 100 speakers using standard microphones. The database consisted of 10 phonetically rich Hindi sentences. It was created for the purpose of the speech recognition system [1], [2], [15].
IIT Hyderabad created a Telugu, Hindi and English speech database in a noise-free environment. Data were recorded by 15 speakers using standard microphones and laptops. Data were divided into the following domains: (i) local travel, (ii) hotel and restaurant transactions, (iii) tourism and (iv) emergency services, to overcome the problems faced by tourists because they were incapable of understanding native language [9], [10].
3 Text and Speech Corpora Collection
The fundamental step of speech recognition is anthology of vocabulary words which is to be recorded by native speakers. The corpus consists of 125 isolated words in the agriculture domain. These words have been recorded by 100 speakers (50 male and 50 female) in different dialects. Recordings have been processed in two recording mediums: laptop-mounted microphone and mobile phone using PRAAT software having a sampling rate of 16 kHz/16 bits. Speech corpora of 12,500 isolated words of 100 speakers have been gathered, processed and organized in totality. Corpora characterize phonemic and phonetic characteristics of speech sounds. The dialect-wise distribution of data is shown in Figure 1.
4 Corpus Features
The text and speech corpora designed so far have many unique features.
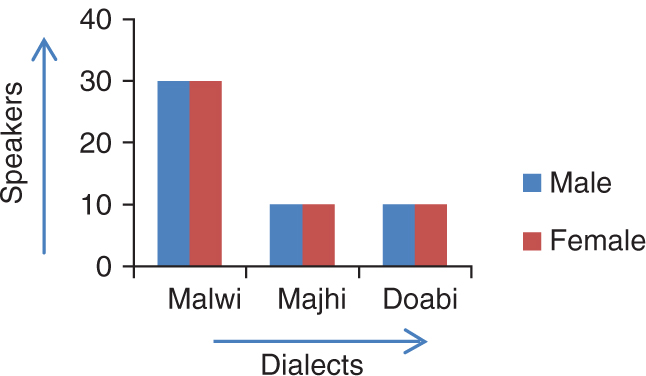
Dialect-Wise Data Distribution – Male and Female Speakers.
4.1 Tonemes
Tone is the distinctive feature of Punjabi language. T. Grahame Bailey stated in 1914, about a century ago: “Variations in the tone of the voice form a very remarkable feature of Punjabi pronunciation. There are two special tones, apart from the ordinary tone of speaking. They occur in stressed syllables only” [15]. Velar (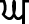 ), Palatal (
), Palatal (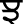 ), Retroflex (
), Retroflex (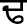 ), Dental (
), Dental (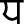 ) and Bilabial (
) and Bilabial (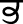 ) are the toneme consonants. When these tonemes are used at the beginning position of words, they are pronounced as Velar (
) are the toneme consonants. When these tonemes are used at the beginning position of words, they are pronounced as Velar (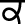 ), Palatal (
), Palatal (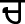 ), Retroflex (
), Retroflex (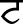 ), Dental (
), Dental (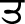 ) and Bilabial (
) and Bilabial (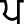 ) with low vowel tone. But when these tonemes are used at the middle or final position of words, they are pronounced as Velar (
) with low vowel tone. But when these tonemes are used at the middle or final position of words, they are pronounced as Velar ( ), Palatal (
), Palatal (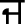 ), Retroflex (
), Retroflex (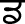 ), Dental (
), Dental (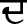 ) and Bilabial (
) and Bilabial (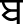 ) with high tone on the vowel before the consonants and low tone on the vowel after the consonants. Some of the toneme words in our corpora are
) with high tone on the vowel before the consonants and low tone on the vowel after the consonants. Some of the toneme words in our corpora are 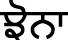 (tʃòna),
(tʃòna), 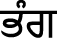 (pƏ̀ng),
(pƏ̀ng), 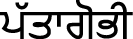 (pƏt̪t̪agobi),
(pƏt̪t̪agobi), 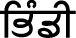 (pìnɖi),
(pìnɖi),  (phƱlgobí), etc.
(phƱlgobí), etc.
If  (h) is used at the beginning of the word, then it is pronounced regularly, but if it is used at the middle and final position of the word, it is pronounced with high tone on the preceding vowel. Some of the words in our corpora are
(h) is used at the beginning of the word, then it is pronounced regularly, but if it is used at the middle and final position of the word, it is pronounced with high tone on the preceding vowel. Some of the words in our corpora are  (tʃá),
(tʃá), 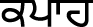 (kƏpá), etc.
(kƏpá), etc.
4.2 Nasal
Nasal phonemes are produced by using tippi and bindi. Tippi is used with vowels 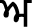 (Mukta),
(Mukta), 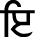 (Sihari),
(Sihari), 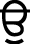 (Onkarh) and
(Onkarh) and 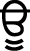 (Dulankarh), while bindi is used with vowels
(Dulankarh), while bindi is used with vowels 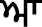 (kanna),
(kanna), 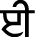 (Bihari),
(Bihari), 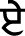 (Lanva),
(Lanva), 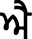 (Dulavan),
(Dulavan), 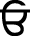 (Horha) and
(Horha) and 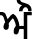 (Kanaorha). Both the tippi and bindi serve the same usage, i.e. used to emphasize nasal sound. Some of the nasal words in our corpora are:
(Kanaorha). Both the tippi and bindi serve the same usage, i.e. used to emphasize nasal sound. Some of the nasal words in our corpora are: 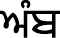 (Əmb),
(Əmb),  (mƱngi),
(mƱngi), 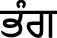 (pƏ́ng),
(pƏ́ng),  (mungfƏli),
(mungfƏli),  (gƏnna),
(gƏnna), 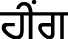 (hing),
(hing), 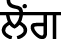 (long), etc.
(long), etc.
4.3 Adhak
Adhak is used to geminate the consonant sound. It is located between two letters. Letter which follows adhak is to be repeated. It is very important. Without it, words have different meaning. For example, 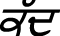 means height and
means height and  means when. Some of the words in our corpora are
means when. Some of the words in our corpora are 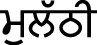 (mƱlƏʈhʈhi),
(mƱlƏʈhʈhi),  (ʃƏkkƏrkƏnd̪i),
(ʃƏkkƏrkƏnd̪i),  (pƏt̪t̪agobí),
(pƏt̪t̪agobí), 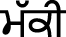 (mƏkki), etc.
(mƏkki), etc.
4.4 Dialects
Punjabi is spoken all over the world. It has various dialects, but major dialects are Majhi, Doabi and Malwai. Majhi is a prominent dialect which is a benchmark of written Punjabi. Major areas are Amritsar, Gurdaspur (districts of Punjab), various states of Haryana, Uttar Pradesh, etc. Doabi dialect is spoken in Doaba Punjab. Doabi means the region between two rivers, i.e. Beas and Satluj. Major areas are Jalandhar, Kapurthla, Hoshiarpur, etc. Malwi dialect is spoken in Malwa province of Punjab. Major areas are Ferozpur, Fazilka, Muktsar, Faridkot, etc. If “v” is used at the beginning of a word, Doabi use letter “b” instead of “v” or otherwise use “o”. Some of the words in the corpus are  (gƏvar),
(gƏvar),  (jƏvar), etc. Doabi speakers use “e” in place of “i”. Words in the corpus are
(jƏvar), etc. Doabi speakers use “e” in place of “i”. Words in the corpus are 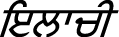 (ɪlatʃi),
(ɪlatʃi), 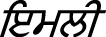 (Imli), etc.
(Imli), etc.
4.5 Speakers Variety According to Age, Sex and Location
Isolated words have been recorded by 50 male and 50 female speakers in the age group of 18–35 years. Speakers belong to different cities and villages of various districts of Malwi, Majhi and Doabi dialects.
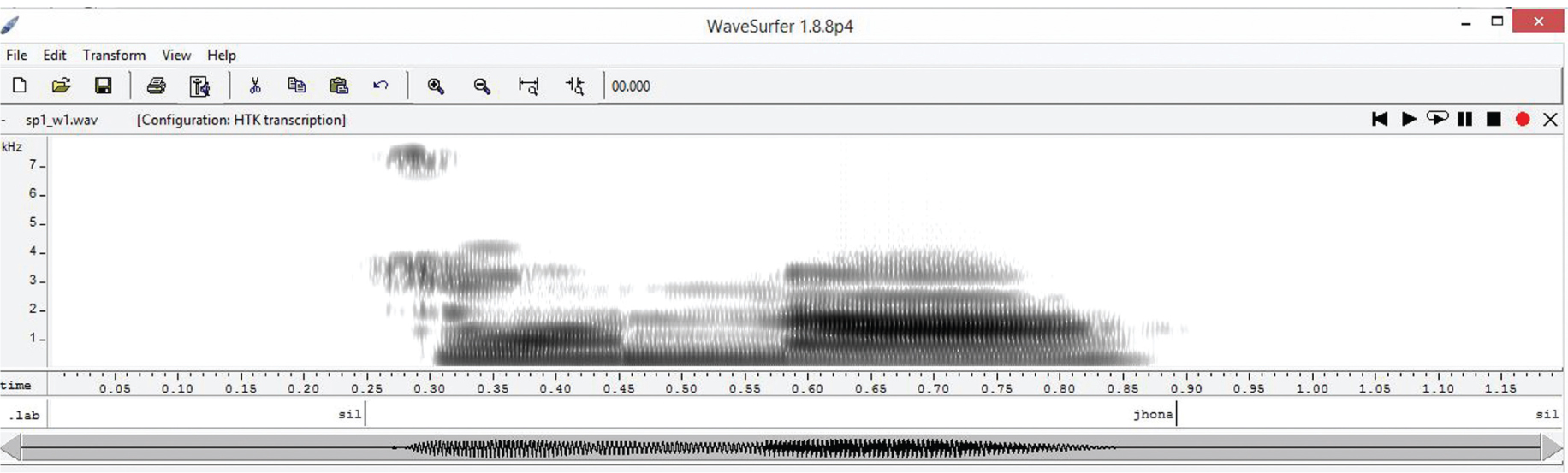
Annotation of Word 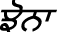 (tʃòna).
(tʃòna).
4.6 Speech Database Annotation
Annotation of speech corpora has been done using wave surfer at the word level. Speech corpora of 125 words spoken by 100 speakers, i.e. 12,500 words, have been segmented and labeled properly in order to study phonetic features further. Durations of segmented data were stored in a lab file. The sample is shown in Figure 2.
4.7 Phonetic Features of Speech Sounds
Man-machine interaction involves the integration of latest technologies for speech input as well as speech output. Speech sounds can be classified into consonants and vowels. Place of articulation refers to restriction of air in the vocal tract. It involves glottis, lip, jaw, teeth, tongue, lungs, larynx and other vocal parts. The manner of articulation refers how close articulators move toward each other, i.e. the way in which air is tailored in the vocal tract. Speech corpora designed so far cover approximately all categories and phonetic features of speech sounds.
5 Speech Databases
Various organizations and institutes are conducting research in the area of speech processing. They have created different speech databases. Databases can be compared on the basis of the following parameters: (a) noisy or noise-free environment, (b) number of speakers, (c) recording devices, (d) languages, (e) speech types and (f) purpose [4], [6].
Most of the speech databases have been created in a noise-free environment. But researchers should also create a speech database in a noisy environment to meet the real-life situations and to build a robust automatic speech recognition system [5], [7], [8]. Speech databases that have been created for text-to-speech synthesis are not quite significant for the speech recognition system. Speech databases that have been recorded using landline and mobile phones are sort of deficient due to network errors. The major work in this area has been done for Hindi, Tamil, Bengali and Marathi languages [12], [13], [14]. A little work has been done for other Indian languages. In order to build up wider language technologies base for all Indian languages, researchers should do more and more work in this area for all languages.
Pitch Variations for Different Types of Words in the Database.
| Words type | Male/female speakers | Malwi dialect | Majhi dialect | Doabi dialect |
|---|---|---|---|---|
| Toneme words | Female | 258.6585 | 261.1291 | 250.9955 |
| Male | 146.3769 | 128.636 | 165.7305 | |
| Adhak words | Female | 252.6602 | 251.9879 | 249.4705 |
| Male | 145.521 | 128.8458 | 166.6938 | |
| Nasal (bindi) words | Female | 252.4579 | 249.7492 | 244.4647 |
| Male | 141.9681 | 128.5487 | 163.6569 | |
| Nasal (tippi) words | Female | 252.4445 | 257.3207 | 245.678 |
| Male | 143.059 | 129.1502 | 163.0176 |
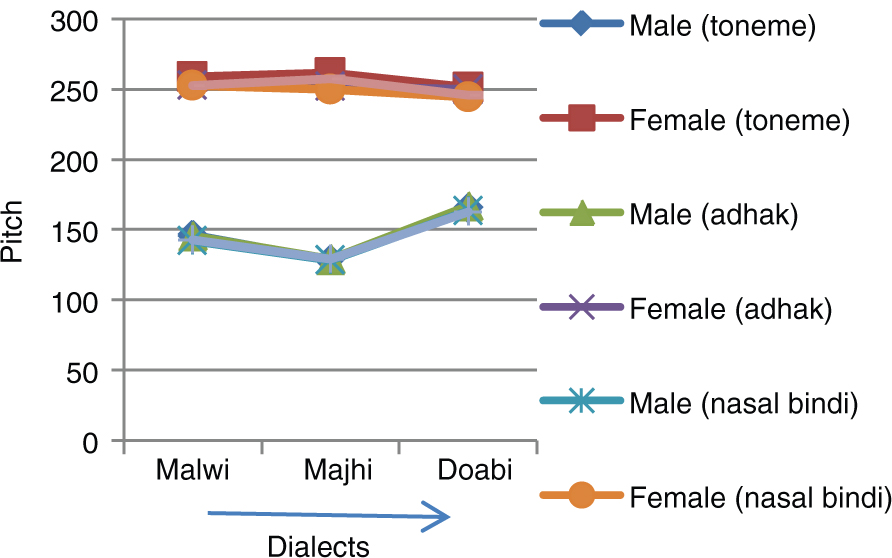
Dialect-Wise Pitch Variation for Tonemes, Adhak, Nasal (Bindi) and Nasal (Tippi) Words.
6 Research Method
The PRAAT tool is used for comparative analysis. Isolated words have been classified into toneme, adhak, nasal (bindi) and nasal (tippi) words. For comparison, these words are spoken by 10 male and 10 female speakers of Malwi, Majhi and Doabi dialects. Pitch, intensity, formant I and formant II values are extracted and compared.
Intensity Variations for Different Types of Words in the Database.
| Words type | Male/female speakers | Malwi dialect | Majhi dialect | Doabi dialect |
|---|---|---|---|---|
| Toneme words | Female | 78.07429 | 74.98018 | 74.37597 |
| Male | 74.14868 | 73.77925 | 73.98708 | |
| Adhak words | Female | 76.74887 | 73.22307 | 71.91624 |
| Male | 73.09751 | 72.60313 | 72.3589 | |
| Nasal (bindi) words | Female | 78.52311 | 74.69312 | 74.48076 |
| Male | 73.81041 | 73.59468 | 74.00996 | |
| Nasal (tippi) words | Female | 77.99654 | 74.06132 | 74.43187 |
| Male | 73.90844 | 73.66547 | 74.07185 |
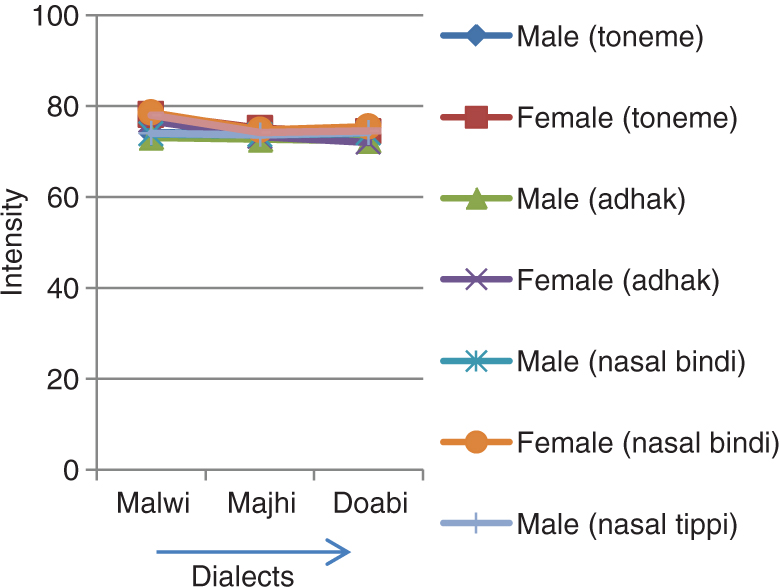
Dialect-Wise Intensity Variation for Tonemes, Adhak, Nasal (Bindi) and Nasal (Tippi) Words.
7 Results and Analysis
It has been observed from Table 1 and Figure 3 that the pitch of male speakers is very less than that of female speakers for Malwi, Majhi and Doabi dialects. In case of female speakers, for toneme words and nasal (tippi) words, pitch variation is the same and as follows: Majhi > Malwi > Doabi. For adhak (geminated) and nasal (bindi) words, pitch variation is the same and as follows: Malwi > Majhi > Doabi. In case of male speakers, for all types of words, pitch variation is the same and as follows: Doabi > Malwi > Majhi.
Formant I Variations for Different Types of Words in the Database.
| Words type | Male/female speakers | Malwi dialect | Majhi dialect | Doabi dialect |
|---|---|---|---|---|
| Toneme words | Female | 584.3751 | 544.1478 | 591.7777 |
| Male | 743.0935 | 567.2225 | 723.4262 | |
| Adhak words | Female | 505.2374 | 492.3279 | 510.929 |
| Male | 630.945 | 513.1304 | 634.4885 | |
| Nasal (bindi) words | Female | 527.9302 | 488.2497 | 544.5416 |
| Male | 688.9413 | 541.2241 | 688.2608 | |
| Nasal (tippi) words | Female | 473.5769 | 453.0424 | 508.958 |
| Male | 622.5815 | 480.2751 | 641.8084 |
It has been observed from Table 2 and Figure 4 that the intensity of male speakers is less than that of female speakers for Malwi, Majki and Doabi dialects. In case of female speakers, for toneme, adhak (geminated) and nasal (bindi) words, intensity variation is the same and as follows: Malwi > Majhi > Doabi. For nasal (tippi) words, intensity variation is as follows: Malwi > Doabi > Majhi. In all cases, there is very little variation in Majhi and Doabi dialect speakers.
In case of male speakers, for nasal (bindi) and nasal (tippi) words, intensity variation is as follows: Doabi > Malwi > Majhi. For toneme words, it is as follows: Malwi > Doabi > Majhi. For adhak (geminated) words, it is as follows: Malwi > Majhi > Doabi. In all cases, there is very little variation in Majhi and Doabi dialect speakers.
It has been observed from Table 3 and Figure 5 that the formant I value of male speakers is greater than that of female speakers for Malwi, Majhi and Doabi dialects. In case of female speakers, for all types of words, Formant I variations are as follows: Doabi > Malwi > Majhi. In case of male speakers, for nasal (bindi) words and toneme words, formant I variations are as follows: Malwi > Doabi > Majhi. For nasal (tippi) words and adhak (geminated) words, the variations are as follows: Doabi > Malwi > Majhi.
It has been observed from Table 4 and Figure 6 that the formant II value of male speakers is greater than that of female speakers for Malwi and Doabi dialects but less than in case of Majhi dialect. In case of female speakers, for toneme and adhak (geminated) words, formant II variations are as follows: Malwi > Majhi > Doabi. For nasal (bindi) and nasal (tippi) words, the variations are as follows: Majhi > Malwi > Doabi.
In case of male speakers, for all kinds of words, formant II variations are as follows: Malwi > Doabi > Majhi.
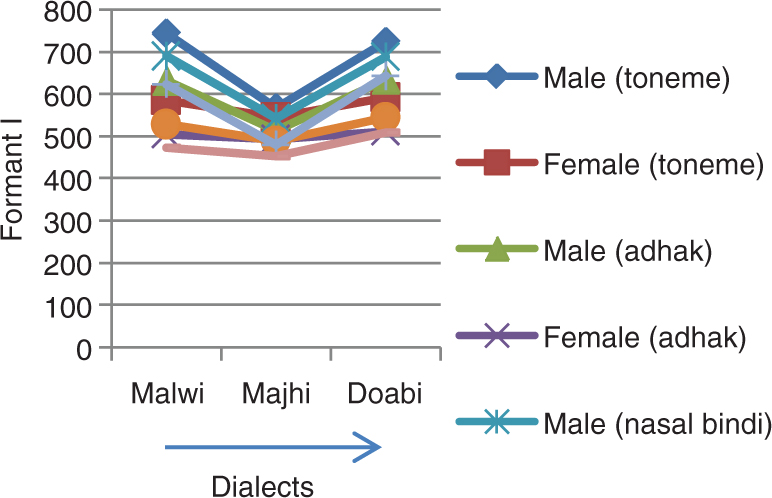
Dialect-Wise Formant I Variation for Tonemes, Adhak, Nasal (Bindi) and Nasal (Tippi) Words.
Formant II Variations for Different Types of Words in the Database.
| Words type | Male/female speakers | Malwi dialect | Majhi dialect | Doabi dialect |
|---|---|---|---|---|
| Toneme words | Female | 1594.738 | 1586.196 | 1534.068 |
| Male | 1690.307 | 1430.97 | 1622.056 | |
| Adhak words | Female | 1649.454 | 1646.245 | 1594.833 |
| Male | 1698.524 | 1533.741 | 1697.627 | |
| Nasal (bindi) words | Female | 1527.631 | 1528.878 | 1493.46 |
| Male | 1640.137 | 1392.773 | 1605.244 | |
| Nasal (tippi) words | Female | 1563.765 | 1577.419 | 1490.581 |
| Male | 1616.112 | 1431.992 | 1653.765 |
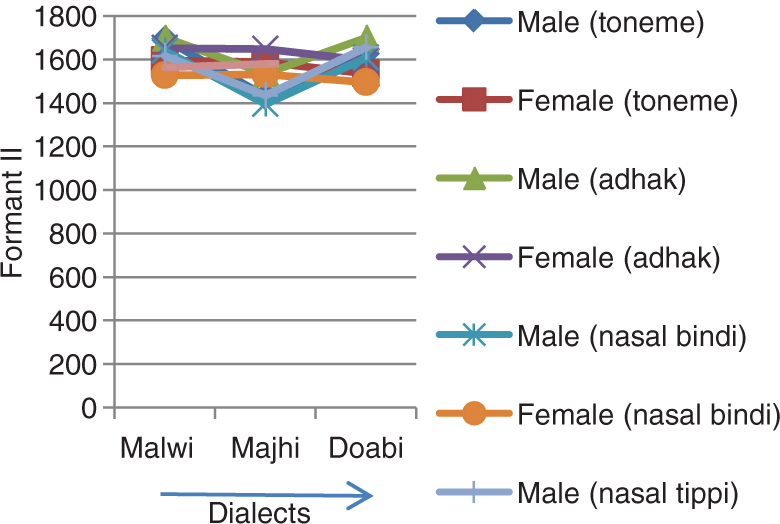
Dialect-Wise Formant II Variation for Tonemes, Adhak, Nasal (bindi) and Nasal (Tippi) Words.
In speech at different levels, dialect-related information is available. Spectral features such as mel-frequency cepstral coefficients and entropy are at the segmental level, and prosodic features such as pitch contour, intensity and duration at the suprasegmental level provide information about dialects. These prosodic features along with spectral features provide discriminating information for dialect identification as well as speaker identification.
8 Conclusions
In this paper, we have created text and speech corpora of about 12,500 words for Punjabi language. In India, there are various Punjabi dialects, but major dialects are Malwi, Majhi and Doabi. This corpus has been designed in context with these dialects. Tonal words have also been taken into consideration in this corpus. The existing database designs are also discussed and compared. This corpus is of quite importance in speech processing work due to its unique features, which makes this corpus a perfect corpus to develop language technology for Punjabi language. The present study also emphasized on the comparative analysis of prosodic features of Malwi, Majhi and Doabi dialects of Punjabi language. It has been found that the pitch of male speakers is very less than that of female speakers for all dialects. There is little variation in the intensity of male and female speakers. For all dialects, the formant I value of male speakers is greater than that of female speakers, but the formant II value of male speakers is greater than that of female speakers for Malwi and Doabi dialect and less for Majhi dialect. These variations are helpful in speaker identification, dialect identification and language identification.
Bibliography
[1] S. S. Agrawal and K. Samudravijaya, (Chief Editors), Text and speech corpora development in Indian languages, In: Proceedings of the International Symposium on Speech technology and Processing Systems (ISTEPS-2004 and Oriental COCOSDA-2004); Vol. II, CDAC, New Delhi, India, pp. 21–27, November 17–19, 2004.Search in Google Scholar
[2] S. S. Agrawal, K. Samudravijaya and K. Arora, Recent advances of speech database development activities, In: International Symposium on Chinese Spoken Language Processing (ISCSLP 2006), 2006.Search in Google Scholar
[3] S. S. Agrawal, S. Sinha, P. Singh and O. Jesper, Development of text and speech database for Hindi and Indian English specific to mobile communication environment, In: Proceeding of International Conference on the Language Resources and Evaluation Conference, LREC, Istanbul, Turkey, 2012.Search in Google Scholar
[4] M. A. Anusuya and S. K. Katti, Front end analysis of speech recognition: a review, Int. J. Speech Technol. 14 (2011), 99–145.10.1007/s10772-010-9088-7Search in Google Scholar
[5] S. J. Arora and R. Singh, Automatic speech recognition: a review, Int. J. Comput. Appl. 60 (2012), 34–44.10.5120/9722-4190Search in Google Scholar
[6] S. J. Arora and R. Singh, Acoustic and phonological analysis of homophones of Punjabi language, Int. J. Comput. Sci. Eng. Inform. Technol. Res. 4 (2014), 95–102.Search in Google Scholar
[7] P. Bhaskararao, Sailent phonetic features of Indian languages in speech technology, In: Sadhana Academy Proceedings in Engineering Sciences, Indian Academy of Sciences, Bangalore, India, Volume 36, Number 5, pp. 587–599, October 2011.10.1007/s12046-011-0039-zSearch in Google Scholar
[8] K. Cini, A survey on speech recognition in Indian languages, Int. J. Comput. Sci. Inform. Technol. 5 (2014) 6169–6175.Search in Google Scholar
[9] S. Dhanjal and S. S. Bhatia, Computerization of the Punjabi language, In: 2nd World Punjabi Conference, Punjab University, Chandigarh, February 24–25, 2009.Search in Google Scholar
[10] S. Dhanjal and S. S. Bhatia, Punjabi Bhasha da Takneekee Bhavikh, In: Silver Jubilee International Punjabi Development Conference, Punjabi University, Patiala, February 3–5, 2009.Search in Google Scholar
[11] S. Dhanjal and S. S. Bhatia, A new corpus for the Punjabi speech processing, In: International Symposium on Frontiers of Research on Music and Speech (FRSM-2012), KIIT Gurgaon, India, pp. 223–227, January 18–19, 2012.Search in Google Scholar
[12] M. Dua, R. K. Aggarwal, V. Kadyan and S. Dua, Punjabi automatic speech recognition using HTK, Int. J. Comput. Sci. 9 (2012) 359–364.Search in Google Scholar
[13] H. Kaur and R. Bhatia, Speech recognition system for Punjabi language, Int. J. Adv. Res. Comput. Sci. Softw. Eng. 5 (2015) 566–573.Search in Google Scholar
[14] K. Kumar and R. K. Aggarwal, Hindi speech recognition system using HTK, Int. J. Comput. Bus. Res. 2 (2011).Search in Google Scholar
[15] S. Nareshkumar, N. Mariappan and K. Thirumoorthy, Database interaction using automatic speech recognition, Int. J. Innov. Res. Sci. Eng. Technol. 3 (2014) 1895–1899.Search in Google Scholar
[16] K. Samudravijaya, P. V. S. Rao and S. S. Agrawal, Hindi speech database, In: Proceeding International Conference on Spoken Language Processing (ICSLP00), Beijing, China, October 2000.10.21437/ICSLP.2000-847Search in Google Scholar
©2020 Walter de Gruyter GmbH, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 Public License.
Articles in the same Issue
- An Optimized K-Harmonic Means Algorithm Combined with Modified Particle Swarm Optimization and Cuckoo Search Algorithm
- Texture Feature Extraction Using Intuitionistic Fuzzy Local Binary Pattern
- Leaf Disease Segmentation From Agricultural Images via Hybridization of Active Contour Model and OFA
- Deadline Constrained Task Scheduling Method Using a Combination of Center-Based Genetic Algorithm and Group Search Optimization
- Efficient Classification of DDoS Attacks Using an Ensemble Feature Selection Algorithm
- Distributed Multi-agent Bidding-Based Approach for the Collaborative Mapping of Unknown Indoor Environments by a Homogeneous Mobile Robot Team
- An Efficient Technique for Three-Dimensional Image Visualization Through Two-Dimensional Images for Medical Data
- Combined Multi-Agent Method to Control Inter-Department Common Events Collision for University Courses Timetabling
- An Improved Particle Swarm Optimization Algorithm for Global Multidimensional Optimization
- A Kernel Probabilistic Model for Semi-supervised Co-clustering Ensemble
- Pythagorean Hesitant Fuzzy Information Aggregation and Their Application to Multi-Attribute Group Decision-Making Problems
- Using an Efficient Optimal Classifier for Soil Classification in Spatial Data Mining Over Big Data
- A Bayesian Multiresolution Approach for Noise Removal in Medical Magnetic Resonance Images
- Gbest-Guided Artificial Bee Colony Optimization Algorithm-Based Optimal Incorporation of Shunt Capacitors in Distribution Networks under Load Growth
- Graded Soft Expert Set as a Generalization of Hesitant Fuzzy Set
- Universal Liver Extraction Algorithm: An Improved Chan–Vese Model
- Software Effort Estimation Using Modified Fuzzy C Means Clustering and Hybrid ABC-MCS Optimization in Neural Network
- Handwritten Indic Script Recognition Based on the Dempster–Shafer Theory of Evidence
- An Integrated Intuitionistic Fuzzy AHP and TOPSIS Approach to Evaluation of Outsource Manufacturers
- Automatically Assess Day Similarity Using Visual Lifelogs
- A Novel Bio-Inspired Algorithm Based on Social Spiders for Improving Performance and Efficiency of Data Clustering
- Discriminative Training Using Noise Robust Integrated Features and Refined HMM Modeling
- Self-Adaptive Mussels Wandering Optimization Algorithm with Application for Artificial Neural Network Training
- A Framework for Image Alignment of TerraSAR-X Images Using Fractional Derivatives and View Synthesis Approach
- Intelligent Systems for Structural Damage Assessment
- Some Interval-Valued Pythagorean Fuzzy Einstein Weighted Averaging Aggregation Operators and Their Application to Group Decision Making
- Fuzzy Adaptive Genetic Algorithm for Improving the Solution of Industrial Optimization Problems
- Approach to Multiple Attribute Group Decision Making Based on Hesitant Fuzzy Linguistic Aggregation Operators
- Cubic Ordered Weighted Distance Operator and Application in Group Decision-Making
- Fault Signal Recognition in Power Distribution System using Deep Belief Network
- Selector: PSO as Model Selector for Dual-Stage Diabetes Network
- Oppositional Gravitational Search Algorithm and Artificial Neural Network-based Classification of Kidney Images
- Improving Image Search through MKFCM Clustering Strategy-Based Re-ranking Measure
- Sparse Decomposition Technique for Segmentation and Compression of Compound Images
- Automatic Genetic Fuzzy c-Means
- Harmony Search Algorithm for Patient Admission Scheduling Problem
- Speech Signal Compression Algorithm Based on the JPEG Technique
- i-Vector-Based Speaker Verification on Limited Data Using Fusion Techniques
- Prediction of User Future Request Utilizing the Combination of Both ANN and FCM in Web Page Recommendation
- Presentation of ACT/R-RBF Hybrid Architecture to Develop Decision Making in Continuous and Non-continuous Data
- An Overview of Segmentation Algorithms for the Analysis of Anomalies on Medical Images
- Blind Restoration Algorithm Using Residual Measures for Motion-Blurred Noisy Images
- Extreme Learning Machine for Credit Risk Analysis
- A Genetic Algorithm Approach for Group Recommender System Based on Partial Rankings
- Improvements in Spoken Query System to Access the Agricultural Commodity Prices and Weather Information in Kannada Language/Dialects
- A One-Pass Approach for Slope and Slant Estimation of Tri-Script Handwritten Words
- Secure Communication through MultiAgent System-Based Diabetes Diagnosing and Classification
- Development of a Two-Stage Segmentation-Based Word Searching Method for Handwritten Document Images
- Pythagorean Fuzzy Einstein Hybrid Averaging Aggregation Operator and its Application to Multiple-Attribute Group Decision Making
- Ensembles of Text and Time-Series Models for Automatic Generation of Financial Trading Signals from Social Media Content
- A Flame Detection Method Based on Novel Gradient Features
- Modeling and Optimization of a Liquid Flow Process using an Artificial Neural Network-Based Flower Pollination Algorithm
- Spectral Graph-based Features for Recognition of Handwritten Characters: A Case Study on Handwritten Devanagari Numerals
- A Grey Wolf Optimizer for Text Document Clustering
- Classification of Masses in Digital Mammograms Using the Genetic Ensemble Method
- A Hybrid Grey Wolf Optimiser Algorithm for Solving Time Series Classification Problems
- Gray Method for Multiple Attribute Decision Making with Incomplete Weight Information under the Pythagorean Fuzzy Setting
- Multi-Agent System Based on the Extreme Learning Machine and Fuzzy Control for Intelligent Energy Management in Microgrid
- Deep CNN Combined With Relevance Feedback for Trademark Image Retrieval
- Cognitively Motivated Query Abstraction Model Based on Associative Root-Pattern Networks
- Improved Adaptive Neuro-Fuzzy Inference System Using Gray Wolf Optimization: A Case Study in Predicting Biochar Yield
- Predict Forex Trend via Convolutional Neural Networks
- Optimizing Integrated Features for Hindi Automatic Speech Recognition System
- A Novel Weakest t-norm based Fuzzy Fault Tree Analysis Through Qualitative Data Processing and Its Application in System Reliability Evaluation
- FCNB: Fuzzy Correlative Naive Bayes Classifier with MapReduce Framework for Big Data Classification
- A Modified Jaya Algorithm for Mixed-Variable Optimization Problems
- An Improved Robust Fuzzy Algorithm for Unsupervised Learning
- Hybridizing the Cuckoo Search Algorithm with Different Mutation Operators for Numerical Optimization Problems
- An Efficient Lossless ROI Image Compression Using Wavelet-Based Modified Region Growing Algorithm
- Predicting Automatic Trigger Speed for Vehicle-Activated Signs
- Group Recommender Systems – An Evolutionary Approach Based on Multi-expert System for Consensus
- Enriching Documents by Linking Salient Entities and Lexical-Semantic Expansion
- A New Feature Selection Method for Sentiment Analysis in Short Text
- Optimizing Software Modularity with Minimum Possible Variations
- Optimizing the Self-Organizing Team Size Using a Genetic Algorithm in Agile Practices
- Aspect-Oriented Sentiment Analysis: A Topic Modeling-Powered Approach
- Feature Pair Index Graph for Clustering
- Tangramob: An Agent-Based Simulation Framework for Validating Urban Smart Mobility Solutions
- A New Algorithm Based on Magic Square and a Novel Chaotic System for Image Encryption
- Video Steganography Using Knight Tour Algorithm and LSB Method for Encrypted Data
- Clay-Based Brick Porosity Estimation Using Image Processing Techniques
- AGCS Technique to Improve the Performance of Neural Networks
- A Color Image Encryption Technique Based on Bit-Level Permutation and Alternate Logistic Maps
- A Hybrid of Deep CNN and Bidirectional LSTM for Automatic Speech Recognition
- Database Creation and Dialect-Wise Comparative Analysis of Prosodic Features for Punjabi Language
- Trapezoidal Linguistic Cubic Fuzzy TOPSIS Method and Application in a Group Decision Making Program
- Histopathological Image Segmentation Using Modified Kernel-Based Fuzzy C-Means and Edge Bridge and Fill Technique
- Proximal Support Vector Machine-Based Hybrid Approach for Edge Detection in Noisy Images
- Early Detection of Parkinson’s Disease by Using SPECT Imaging and Biomarkers
- Image Compression Based on Block SVD Power Method
- Noise Reduction Using Modified Wiener Filter in Digital Hearing Aid for Speech Signal Enhancement
- Secure Fingerprint Authentication Using Deep Learning and Minutiae Verification
- The Use of Natural Language Processing Approach for Converting Pseudo Code to C# Code
- Non-word Attributes’ Efficiency in Text Mining Authorship Prediction
- Design and Evaluation of Outlier Detection Based on Semantic Condensed Nearest Neighbor
- An Efficient Quality Inspection of Food Products Using Neural Network Classification
- Opposition Intensity-Based Cuckoo Search Algorithm for Data Privacy Preservation
- M-HMOGA: A New Multi-Objective Feature Selection Algorithm for Handwritten Numeral Classification
- Analogy-Based Approaches to Improve Software Project Effort Estimation Accuracy
- Linear Regression Supporting Vector Machine and Hybrid LOG Filter-Based Image Restoration
- Fractional Fuzzy Clustering and Particle Whale Optimization-Based MapReduce Framework for Big Data Clustering
- Implementation of Improved Ship-Iceberg Classifier Using Deep Learning
- Hybrid Approach for Face Recognition from a Single Sample per Person by Combining VLC and GOM
- Polarity Analysis of Customer Reviews Based on Part-of-Speech Subcategory
- A 4D Trajectory Prediction Model Based on the BP Neural Network
- A Blind Medical Image Watermarking for Secure E-Healthcare Application Using Crypto-Watermarking System
- Discriminating Healthy Wheat Grains from Grains Infected with Fusarium graminearum Using Texture Characteristics of Image-Processing Technique, Discriminant Analysis, and Support Vector Machine Methods
- License Plate Recognition in Urban Road Based on Vehicle Tracking and Result Integration
- Binary Genetic Swarm Optimization: A Combination of GA and PSO for Feature Selection
- Enhanced Twitter Sentiment Analysis Using Hybrid Approach and by Accounting Local Contextual Semantic
- Cloud Security: LKM and Optimal Fuzzy System for Intrusion Detection in Cloud Environment
- Power Average Operators of Trapezoidal Cubic Fuzzy Numbers and Application to Multi-attribute Group Decision Making
Articles in the same Issue
- An Optimized K-Harmonic Means Algorithm Combined with Modified Particle Swarm Optimization and Cuckoo Search Algorithm
- Texture Feature Extraction Using Intuitionistic Fuzzy Local Binary Pattern
- Leaf Disease Segmentation From Agricultural Images via Hybridization of Active Contour Model and OFA
- Deadline Constrained Task Scheduling Method Using a Combination of Center-Based Genetic Algorithm and Group Search Optimization
- Efficient Classification of DDoS Attacks Using an Ensemble Feature Selection Algorithm
- Distributed Multi-agent Bidding-Based Approach for the Collaborative Mapping of Unknown Indoor Environments by a Homogeneous Mobile Robot Team
- An Efficient Technique for Three-Dimensional Image Visualization Through Two-Dimensional Images for Medical Data
- Combined Multi-Agent Method to Control Inter-Department Common Events Collision for University Courses Timetabling
- An Improved Particle Swarm Optimization Algorithm for Global Multidimensional Optimization
- A Kernel Probabilistic Model for Semi-supervised Co-clustering Ensemble
- Pythagorean Hesitant Fuzzy Information Aggregation and Their Application to Multi-Attribute Group Decision-Making Problems
- Using an Efficient Optimal Classifier for Soil Classification in Spatial Data Mining Over Big Data
- A Bayesian Multiresolution Approach for Noise Removal in Medical Magnetic Resonance Images
- Gbest-Guided Artificial Bee Colony Optimization Algorithm-Based Optimal Incorporation of Shunt Capacitors in Distribution Networks under Load Growth
- Graded Soft Expert Set as a Generalization of Hesitant Fuzzy Set
- Universal Liver Extraction Algorithm: An Improved Chan–Vese Model
- Software Effort Estimation Using Modified Fuzzy C Means Clustering and Hybrid ABC-MCS Optimization in Neural Network
- Handwritten Indic Script Recognition Based on the Dempster–Shafer Theory of Evidence
- An Integrated Intuitionistic Fuzzy AHP and TOPSIS Approach to Evaluation of Outsource Manufacturers
- Automatically Assess Day Similarity Using Visual Lifelogs
- A Novel Bio-Inspired Algorithm Based on Social Spiders for Improving Performance and Efficiency of Data Clustering
- Discriminative Training Using Noise Robust Integrated Features and Refined HMM Modeling
- Self-Adaptive Mussels Wandering Optimization Algorithm with Application for Artificial Neural Network Training
- A Framework for Image Alignment of TerraSAR-X Images Using Fractional Derivatives and View Synthesis Approach
- Intelligent Systems for Structural Damage Assessment
- Some Interval-Valued Pythagorean Fuzzy Einstein Weighted Averaging Aggregation Operators and Their Application to Group Decision Making
- Fuzzy Adaptive Genetic Algorithm for Improving the Solution of Industrial Optimization Problems
- Approach to Multiple Attribute Group Decision Making Based on Hesitant Fuzzy Linguistic Aggregation Operators
- Cubic Ordered Weighted Distance Operator and Application in Group Decision-Making
- Fault Signal Recognition in Power Distribution System using Deep Belief Network
- Selector: PSO as Model Selector for Dual-Stage Diabetes Network
- Oppositional Gravitational Search Algorithm and Artificial Neural Network-based Classification of Kidney Images
- Improving Image Search through MKFCM Clustering Strategy-Based Re-ranking Measure
- Sparse Decomposition Technique for Segmentation and Compression of Compound Images
- Automatic Genetic Fuzzy c-Means
- Harmony Search Algorithm for Patient Admission Scheduling Problem
- Speech Signal Compression Algorithm Based on the JPEG Technique
- i-Vector-Based Speaker Verification on Limited Data Using Fusion Techniques
- Prediction of User Future Request Utilizing the Combination of Both ANN and FCM in Web Page Recommendation
- Presentation of ACT/R-RBF Hybrid Architecture to Develop Decision Making in Continuous and Non-continuous Data
- An Overview of Segmentation Algorithms for the Analysis of Anomalies on Medical Images
- Blind Restoration Algorithm Using Residual Measures for Motion-Blurred Noisy Images
- Extreme Learning Machine for Credit Risk Analysis
- A Genetic Algorithm Approach for Group Recommender System Based on Partial Rankings
- Improvements in Spoken Query System to Access the Agricultural Commodity Prices and Weather Information in Kannada Language/Dialects
- A One-Pass Approach for Slope and Slant Estimation of Tri-Script Handwritten Words
- Secure Communication through MultiAgent System-Based Diabetes Diagnosing and Classification
- Development of a Two-Stage Segmentation-Based Word Searching Method for Handwritten Document Images
- Pythagorean Fuzzy Einstein Hybrid Averaging Aggregation Operator and its Application to Multiple-Attribute Group Decision Making
- Ensembles of Text and Time-Series Models for Automatic Generation of Financial Trading Signals from Social Media Content
- A Flame Detection Method Based on Novel Gradient Features
- Modeling and Optimization of a Liquid Flow Process using an Artificial Neural Network-Based Flower Pollination Algorithm
- Spectral Graph-based Features for Recognition of Handwritten Characters: A Case Study on Handwritten Devanagari Numerals
- A Grey Wolf Optimizer for Text Document Clustering
- Classification of Masses in Digital Mammograms Using the Genetic Ensemble Method
- A Hybrid Grey Wolf Optimiser Algorithm for Solving Time Series Classification Problems
- Gray Method for Multiple Attribute Decision Making with Incomplete Weight Information under the Pythagorean Fuzzy Setting
- Multi-Agent System Based on the Extreme Learning Machine and Fuzzy Control for Intelligent Energy Management in Microgrid
- Deep CNN Combined With Relevance Feedback for Trademark Image Retrieval
- Cognitively Motivated Query Abstraction Model Based on Associative Root-Pattern Networks
- Improved Adaptive Neuro-Fuzzy Inference System Using Gray Wolf Optimization: A Case Study in Predicting Biochar Yield
- Predict Forex Trend via Convolutional Neural Networks
- Optimizing Integrated Features for Hindi Automatic Speech Recognition System
- A Novel Weakest t-norm based Fuzzy Fault Tree Analysis Through Qualitative Data Processing and Its Application in System Reliability Evaluation
- FCNB: Fuzzy Correlative Naive Bayes Classifier with MapReduce Framework for Big Data Classification
- A Modified Jaya Algorithm for Mixed-Variable Optimization Problems
- An Improved Robust Fuzzy Algorithm for Unsupervised Learning
- Hybridizing the Cuckoo Search Algorithm with Different Mutation Operators for Numerical Optimization Problems
- An Efficient Lossless ROI Image Compression Using Wavelet-Based Modified Region Growing Algorithm
- Predicting Automatic Trigger Speed for Vehicle-Activated Signs
- Group Recommender Systems – An Evolutionary Approach Based on Multi-expert System for Consensus
- Enriching Documents by Linking Salient Entities and Lexical-Semantic Expansion
- A New Feature Selection Method for Sentiment Analysis in Short Text
- Optimizing Software Modularity with Minimum Possible Variations
- Optimizing the Self-Organizing Team Size Using a Genetic Algorithm in Agile Practices
- Aspect-Oriented Sentiment Analysis: A Topic Modeling-Powered Approach
- Feature Pair Index Graph for Clustering
- Tangramob: An Agent-Based Simulation Framework for Validating Urban Smart Mobility Solutions
- A New Algorithm Based on Magic Square and a Novel Chaotic System for Image Encryption
- Video Steganography Using Knight Tour Algorithm and LSB Method for Encrypted Data
- Clay-Based Brick Porosity Estimation Using Image Processing Techniques
- AGCS Technique to Improve the Performance of Neural Networks
- A Color Image Encryption Technique Based on Bit-Level Permutation and Alternate Logistic Maps
- A Hybrid of Deep CNN and Bidirectional LSTM for Automatic Speech Recognition
- Database Creation and Dialect-Wise Comparative Analysis of Prosodic Features for Punjabi Language
- Trapezoidal Linguistic Cubic Fuzzy TOPSIS Method and Application in a Group Decision Making Program
- Histopathological Image Segmentation Using Modified Kernel-Based Fuzzy C-Means and Edge Bridge and Fill Technique
- Proximal Support Vector Machine-Based Hybrid Approach for Edge Detection in Noisy Images
- Early Detection of Parkinson’s Disease by Using SPECT Imaging and Biomarkers
- Image Compression Based on Block SVD Power Method
- Noise Reduction Using Modified Wiener Filter in Digital Hearing Aid for Speech Signal Enhancement
- Secure Fingerprint Authentication Using Deep Learning and Minutiae Verification
- The Use of Natural Language Processing Approach for Converting Pseudo Code to C# Code
- Non-word Attributes’ Efficiency in Text Mining Authorship Prediction
- Design and Evaluation of Outlier Detection Based on Semantic Condensed Nearest Neighbor
- An Efficient Quality Inspection of Food Products Using Neural Network Classification
- Opposition Intensity-Based Cuckoo Search Algorithm for Data Privacy Preservation
- M-HMOGA: A New Multi-Objective Feature Selection Algorithm for Handwritten Numeral Classification
- Analogy-Based Approaches to Improve Software Project Effort Estimation Accuracy
- Linear Regression Supporting Vector Machine and Hybrid LOG Filter-Based Image Restoration
- Fractional Fuzzy Clustering and Particle Whale Optimization-Based MapReduce Framework for Big Data Clustering
- Implementation of Improved Ship-Iceberg Classifier Using Deep Learning
- Hybrid Approach for Face Recognition from a Single Sample per Person by Combining VLC and GOM
- Polarity Analysis of Customer Reviews Based on Part-of-Speech Subcategory
- A 4D Trajectory Prediction Model Based on the BP Neural Network
- A Blind Medical Image Watermarking for Secure E-Healthcare Application Using Crypto-Watermarking System
- Discriminating Healthy Wheat Grains from Grains Infected with Fusarium graminearum Using Texture Characteristics of Image-Processing Technique, Discriminant Analysis, and Support Vector Machine Methods
- License Plate Recognition in Urban Road Based on Vehicle Tracking and Result Integration
- Binary Genetic Swarm Optimization: A Combination of GA and PSO for Feature Selection
- Enhanced Twitter Sentiment Analysis Using Hybrid Approach and by Accounting Local Contextual Semantic
- Cloud Security: LKM and Optimal Fuzzy System for Intrusion Detection in Cloud Environment
- Power Average Operators of Trapezoidal Cubic Fuzzy Numbers and Application to Multi-attribute Group Decision Making