Aspect-Oriented Sentiment Analysis: A Topic Modeling-Powered Approach
-
V.S. Anoop
 and
S. Asharaf
and
S. Asharaf

Abstract
Because of exponential growth in the number of people who purchase products online, e-commerce organizations are vying for each other to offer innovative and improved services to its customers. Current platforms give its customers innovative services such as product recommendations based on their purchase histories and location, product comparison, and most importantly, a platform for expressing their experience and feedback. It is important for any e-commerce organization to analyze this feedback and to find out the sentiment of the customers for giving them better products and services. As large reviews may contain feedback in a mixed manner where a customer gives his opinion on different product features in the same review, finding out the exact sentiment is tedious. This work proposes aspect-specific sentiment analysis of product reviews using a well-sophisticated topic modeling algorithm called latent Dirichlet allocation (LDA). The topic words, thus, extracted are mapped with various aspects of an entity to perform the aspect-specific sentiment analysis on product reviews. Experiments with synthetic and real dataset show promising results compared to existing methods of sentiment analysis.
1 Introduction
Platforms such as social networks, micro-blogs, online reviews, and discussion forums are growing very fast, and thus, the need for analyzing the sentiments of the users are also increasing. Sentiment analysis proves to be very effective in businesses and social domains because opinions matter and is critical for all human activities, and thus, they have become the key influence of human behavior. There are two broadly categorized types of the textual representation: one is fact; another is opinion. While facts are objective expressions about entities, events, and their properties, opinions are subjective expressions that describe people’s sentiments toward entities or events. Product reviews in e-commerce platforms help the customer to analyze the product and take better judgments based on its previous usage history.
Sentiment analysis is the process of extracting subjective information from natural language text, and it also expresses the opinion or view of a user toward a topic. Sentiment means feelings, and it includes attitudes, emotions, and opinions, and sentiment is a subjective impression, not a fact. Sentiment analysis can be done by applying natural language processing, statistical methods, or machine learning techniques to identify, extract, or characterize the sentiment content of a text unit. The insights and applications from sentiment analysis were useful in other areas, like politics, law, policy making, sociology, and psychology. In general, humans are subjective creatures, and opinions are important, and being able to interact with people on that level has many advantages for the information system.
The main challenges in sentiment analysis are that people express their opinions in complex ways and the relevance of lexical content in text. There are many possibilities for classification such as users, texts, words, sentences, etc. The words or short phrases are the building blocks of the sentiment expressed. The next step is to find the polarity keywords to identify the sentiment behind them. For example, there will be some relation between the words and positive reviews, and such keywords can be found out by data-driven methods for better accuracy. In the case of social networks like Twitter and Facebook, sentiment is most succinctly represented with emotions or smileys, and in such scenario, emotion recognition is performed to capture the sentiment expressed in them [35]. Therefore, customers are not only interested in the whole quality of the product but also some specific aspects of the product also. For example, considering a laptop as an example, customers are not only interested in the whole product but also into some other aspects such as “screen quality”, “processor generation”, or “random-access memory (RAM) speed”. This leads to the extraction of various aspects of a product [31] to perform sentiment analysis of product reviews. For each class of products, there is a set of very general categorical aspects that are common to all products in that class. Aspects can be identified either manually or through an appropriate automated method. This work aims to identify aspects and then perform the sentiment analysis of product reviews using topic modeling. The main contributions of this paper are summarized as follows:
Outlines a brief explanation of aspect-oriented sentiment analysis and topic modeling, which are well-studied and addressed areas in text mining.
Proposes a topic modeling-powered approach for aspect extraction and aspect-based sentiment analysis from unstructured product reviews expressed by users of various products.
Verify experimentally the effectiveness and usefulness of proposed algorithms in extracting aspect-oriented sentiments from real-world and dynamic datasets.
Organization of this paper: The remainder of this paper is organized as follows. Section 2 describes the state-of-the-art in sentiment analysis; Section 3 throws light on some background of latent Dirichlet allocation (LDA), which is a widely used topic modeling algorithm. The experimental setup used in this work is explained in Section 5, and Section 6 presents the results and a detailed evaluation of the same. The author concludes the paper, and some interesting future dimensions are given in Section 7.
2 Related Work
In this section, we discuss some of the very recent works on sentiment analysis from unstructured text specifically focusing on aspect-specific sentiment analysis. Sentiment analysis is an ever-evolving research area, and this caused rapid generation of a vast array of research publications. Because of space constraints, we, here, mention some of the prominent works that are closely related to our proposed method. Shelke et al. [30] proposed an approach for domain-independent aspect-oriented sentiment analysis for product reviews. This unsupervised approach uses SentiWordNet lexical resource to determine the polarity of identified features. A client perception-based product feature mining algorithm was introduced by Li et al. [14] that makes use of sentiment orientation. The feature and sentiment orientation of products are sorted by the weights of user interest that help customers access review orientation more effectively. Another notable approach in aspect-oriented sentiment analysis was introduced in the literature by Akhtar et al. [1] that is composed of a two-step approach, viz., aspect term extraction and sentiment classification. Their pruned, compact set of features performed better compared to the chosen baselines that uses a complete set of features for sentiment classification. An ensemble-based particle swarm optimization they construct in the second phase using maximum entropy, conditional random field and support vector machine outperformed the baseline.
A linguistic rule-based approach for aspect-level sentiment analysis for movie reviews was reported in the literature, which was devised by Piryani et al. [25]. Their method used a linguistic rule-based approach, which identifies the aspects from movie reviews, locates opinion about that aspect, and computes the sentiment polarity of that opinion using linguistic approaches. The system then generates an aspect-level opinion summary, and the authors claim that the system shows good accuracy, and this can be deployed in an integrated opinion profiling system. Another interesting work that finds out aspect-level sentiment analysis on tweets about diabetes was introduced by Salas-Zárate et al. [28]. The authors calculate the sentiment of aspects by considering the words around the aspects using n-gram-based approach. They claim that this approach showed a precision of 81.93 % and an f-measure of 81.24 %.
A very recent comprehensive survey on text sentiment analysis from opinion to emotion mining by Yadollahi et al. [34] was reported in the literature very recently. The authors present the state-of-the-art methods in this area and proposes a taxonomy of sentiment analysis, a survey on polarity classification methods, emotion theories, and emotion mining research. Schouten et al. [29] proposed a novel approach for supervised and unsupervised aspect category detection for sentiment analysis with co-occurrence data. Their proposed approach applies association rule mining on co-occurrence frequency data to find aspect categories. An approach for aspect-based rating prediction on reviews using sentiment strength analysis was introduced by Wang et al. [32]. Previous works on sentiment analysis used reviewer’s sentiment orientation, and in this work, the authors focus on the sentiment strength users expressed in the reviews.
A feature selection approach using multi-objective optimization for aspect-based sentiment analysis was reported by Akhtar et al. [2] in which the authors incorporated the concepts of multi-objective optimization, distributional thesaurus, and unsupervised lexical induction. This work uses support vector machines for sentiment classification and conditional random fields for aspect term and opinion target expression extraction tasks. Their experiments on benchmark setups of SemEval-2014 and SemEval-2016 shared tasks show that the proposed method achieved the state-of-the-art on aspect-based sentiment analysis for several languages. Another comprehensive and systematic literature review on opinion types and sentiment analysis techniques was contributed in the literature by Qazi et al. [27] in which the authors identified nine practices of review types, eight standard machine learning classification techniques, and seven practices of concept learning Sentic computing techniques. Their review offers insights on promising concept-based approaches to SA, which leverage commonsense knowledge and linguistics for tasks such as polarity detection. In addition to this, the practical implications of the methods are also explained in this review.
Ontology-based approach for enhancing aspect extraction process by identifying features pertaining to implicit entities was reported recently, which was proposed by Marstawi et al. [19]. Their Ontology-Based Product Sentiment Summarization (OBPSS) method outperformed other existing summarization systems in terms of aspect extraction and sentiment scoring. Our proposed method devise algorithms for aspect-oriented sentiment analysis, which are guided by topic modeling algorithm. This method model topics from product reviews and the obtained “topics” are mapped to corresponding aspects. Then, the polarity of these aspects are computed to summarize the overall sentiment of customers toward a product.
Very recently, Hazarika et al. proposed an approach for modeling inter-aspect dependencies for aspect-based sentiment analysis [9]. Majority of the present neural-based approaches largely ignore the inter-aspect dependencies and only capture aspect and its contextual information. In their proposed work, authors incorporated the inter-aspect pattern by simultaneous classification of all aspects in a sentence along with temporal dependency processing of their corresponding sentence representations using recurrent networks [9]. Another recent work that proposed a general two-stage approach for target-based sentiment analysis was introduced by Wang et al. [33]. In this approach, the first stage extract and group target-related words, and the second stage separates aspect and opinions from these identified groups. The proposed method showed better performance when there were no sufficient labeled data was available.
3 Background: Latent Dirichlet Allocation (LDA)
Topic modeling is a method for analyzing large quantities of unlabeled text data. A topic is a probability distribution over a collection of words, and a topic model is a formal statistical relationship between a group of observed and latent random variables that specifies a probabilistic procedure to generate the topics – a generative model [5]. LDA is the most popular and simplest topic model. It is a generative for text and other collections of discrete data that generalizes or improves on several previous models including PLSI (probabilistic latent semantic indexing). LDA is a generative probabilistic model for collections of discrete data such as text corpora. It is a three-level hierarchical Bayesian model, in which each item of a collection is modeled as a finite mixture over an underlying set of topics. Each topic is, in turn, modeled as an infinite mixture over an underlying set of topic probabilities, and the topic probabilities provide an explicit representation of a document in the context of topic modeling [6]. In LDA, we represent a word as the basic unit of discrete data, defined to be an item from a vocabulary indexed by {1…V}. A document is a sequence of N words denoted by w = (w1, … wn), where wn is the nth word in the sequence, and a corpus is a collection of “M” documents denoted by D = W1 … Wm. The generative process for each document “w” in a corpus “D” is represented as follows [5]:
Choose N ∼ Poisson (ξ)
Choose θ ∼ Dir (α)
For each of the N words wn:
Choose a topic zn ∼ Multinomial (θ)
(Choose a word wn from p(wn — zn, β), a multinomial probability conditioned on the topic zn.
A k-dimensional Dirichlet random variable θ can take values in the (k − 1) simplex (a k-vector θ lies in the (k − 1) simplex if θi ≥ 0,
where the parameter α is a k-vector with components αi > 0, and where Γ(x) is the γ function. Given the parameters α and β, the joint distribution of a topic mixture θ, a set of N topics z, and a set of N words w, is given by:
where P(zn—θ) is simply θi for the unique i such zn = 1. Integrating over θ and summing over z, we obtain the marginal distribution of a document as follows:
Finally, taking the product of the marginal probabilities of single documents, we obtain the probability of a corpus as:
4 Aspect-Oriented Sentiment Analysis: A Topic Modeling-Powered Approach
In this section, we describe our proposed framework for finding aspect-oriented sentiment of product reviews expressed by customers. Those reviews mostly contain mixed opinions so that individual word-level polarity computation may not be useful. Our topic modeling-powered approach first models topics from customer reviews, which are a collection of word uni-grams and then extracts aspects from it. Based on the probability, we map these topics to corresponding aspects, and then aspect-level polarity is computed, and using Naive Bayes classifier, we classify sentiments. The overall work flow of the proposed approach is shown in Figure 1. In this work, we used Amazon product review dataset, which consists of a large collection of review texts on mobile phones. Pre-processing is performed for converting raw text file into a well-defined sequence of linguistically meaningful units. This is an essential part of this system, as the characters, words, and sentences identified at this stage are the basic elements passed to all other processing stages. The words such as “and”, “the”, “but”, and other punctuation and hyperlinks are removed from the reviews. Then, the LDA algorithm is executed on top of this cleansed dataset to generate topics. In the case of hundreds of review documents from this dataset, topic modeling will be a good approach to understand something of what the archive contains without reading every document and this will be helpful for extracting aspects from the review texts. Table 1 represents some topics that are extracted by topic modeling.

Overall Workflow of the Proposed Approach for Topic Modeling-Guided Aspect-Oriented Sentiment Analysis.
Topics Extracted by LDA Algorithm (Because of Space Constraints, We Show Only the First Five Topics Generated).
| Topic | Topic keywords |
|---|---|
| Topic 1 | Software treo palm keyboard blackberry device pda data email pc sync computer windows web internet mobile version support contacts |
| Topic 2 | Charger car cable work usb works plug charging power fine cord adapter charge worked device port doesn plugged connection |
| Topic 3 | Buy money worth love cheap thing blue bought quot buying don people dont color waste paid cost cool wanted |
| Topic 4 | Phone phones cell motorola nokia razr samsung lg reception features flip dropped calls drop basic sanyo vx razor krzr |
| Topic 5 | Small size pocket design makes bit feel find big large nice hand easily carry fact easier smaller style buttons |
Algorithm 1 takes the product review corpus as the input, and the output will be aspect-specific sentences. First of all, the review corpus is pre-processed by removing stop-words and symbols. Then, LDA is performed on the pre-processed corpus to do topic modeling, and thus, topics are extracted. Each topic is then mapped to a particular aspect, and for each aspect, the algorithm scans the pre-processed corpus to find a match with topic words to extract aspect-specific sentences. Thus, for each aspect, the aspect-specific sentences will be written to a text file.

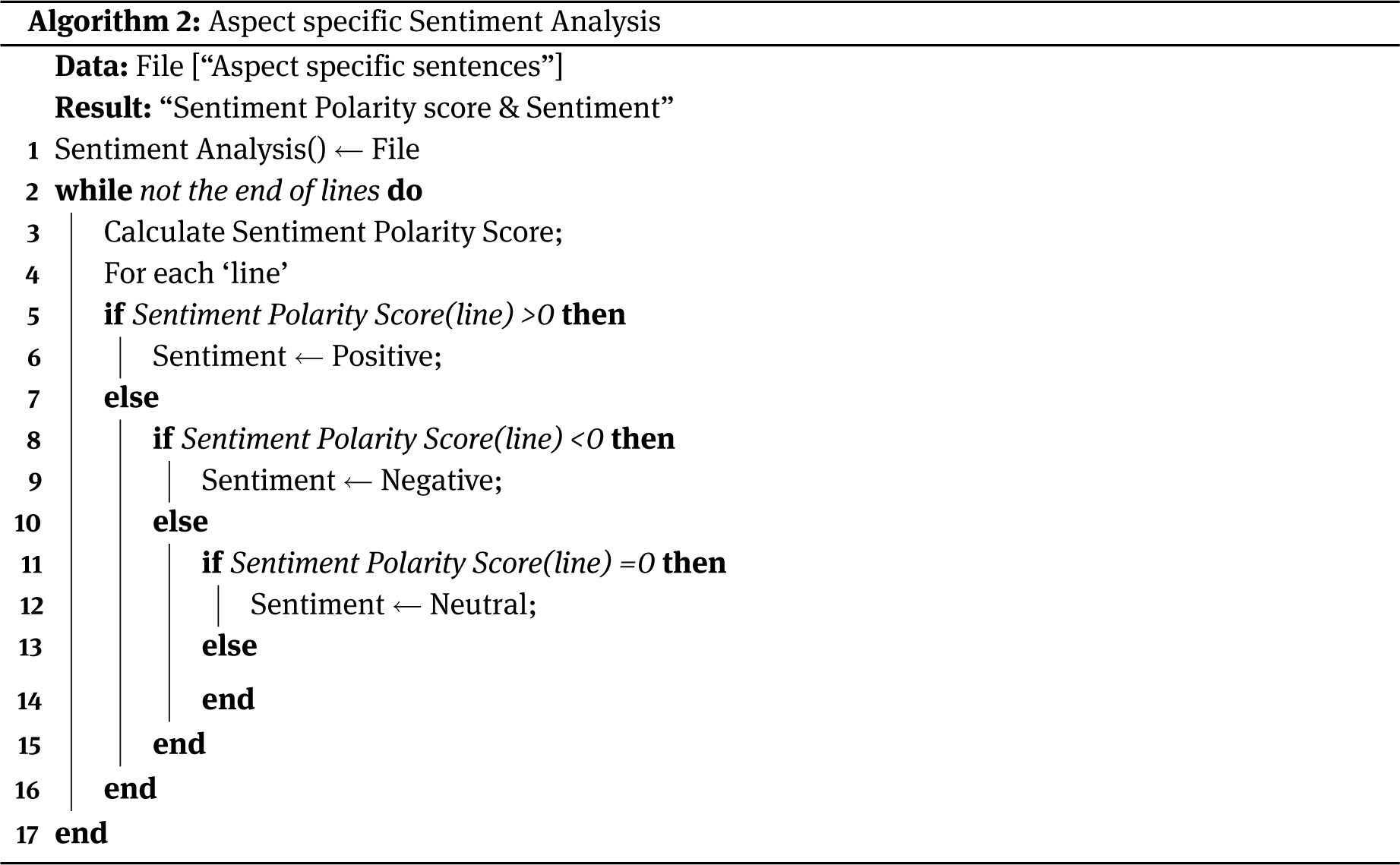
Algorithm 2 takes the file containing aspect-specific sentences as the input, and it calculates the polarity score for each such sentence. The polarity score determines the sentiment of the sentence. If the polarity score of a sentence is greater than zero, the sentiment is “Positive”, and if the polarity score is less than zero, then the sentiment is “Negative”. If the polarity score is equal to zero, then, the sentiment toward the particular sentence is said to be “Neutral”.

Algorithm 3 takes the total polarity count of aspect-specific sentences as the input, and it expresses the sentiment on that particular aspect. If the total positive polarity count is higher than the negative and neutral polarity counts, then the sentiment toward the particular aspect is said to be “Positive”. Similarly, if the total negative polarity count is higher than the positive and neutral polarity counts, then the sentiment toward a particular aspect is said to be “Negative”. If the total neutral count is higher than the positive and negative polarity counts, then the sentiment toward the particular aspect is said to be “Neutral”.
5 Experimental Setup
This section details the experimental setup we have used for implementing proposed algorithms on Amazon product reviews available on public web. A brief description of datasets used in this experiment and the experimental testbed details are discussed below.
5.1 Dataset Description
We use Amazon product review dataset available at the url http://jmcauley.ucsd.edu/data/amazon/links.html. This dataset contains product reviews and associated metadata from Amazon, including 142.8 million reviews spanning for the period May 1996 to July 2014. This dataset includes reviews (ratings, text, helpfulness votes), product metadata (descriptions, category information, price, brand, and image features), and links (also viewed/also bought). It contains reviews for a variety of product categories such as books, electronics, beauty, automotive, etc. For this current experiment, we used “Cell Phones and Accessories” category and used 194,439 reviews for our experiment.
5.2 Experimental Testbed
All algorithms discussed in this paper were implemented on a server configured with AMD Opteron 6376 @ 2.3 GHz having 16 core processor and 16 GB of main memory. These algorithms were programmed using Python 2.7 and removal of stopwords and other pre-processing were done using Python NLTK (Natural Language Tool Kit) [4], and stopword list for English language was used. We also removed punctuation, URLs, and other special characters to make the experimental ready copy of our dataset. We observed that the user reviews contain emojis, which plays an important role in expressing the user sentiment, but those emojis cannot be handled by our topic modeling algorithm. We also removed emojis from the dataset and considered only text as our input to the LDA algorithm. For topic modeling, we used MALLET (MAchine Learning for LanguagE Toolkit), which is freely available at the url http://mallet.cs.umass.edu/. For modeling topics, we chose 300 as the number of iterations in Gibbs sampling as by trail and error method we found that Gibbs sampling approaches the target distribution after 300 rounds of iterations. The α and β parameters of LDA was set to 50/Z and 0.01, respectively.
Result of Topic–Aspect Mapping.
| Topic | Topic words | Aspect |
|---|---|---|
| Topic 1 | Software treo palm keyboard blackberry device pda data email pc sync computer windows web internet mobile version support contacts | Network |
| Topic 2 | Charger car cable work usb works plug charging power fine cord adapter charge worked device port doesn plugged connection | Battery |
| Topic 3 | Buy money worth love cheap thing blue bought quot buying don people dont color waste paid cost cool wanted | Price |
| Topic 4 | Phone phones cell motorola nokia razr samsung lg reception features flip dropped calls drop basic sanyo vx razor krzr | Body |
| Topic 5 | Small size pocket design makes bit feel find big large nice hand easily carry fact easier smaller style buttons | Battery |
Based on the number of words that are related to an aspect, we map the entire topic to the corresponding aspect.
Polarity Score and Sentiment of Review Texts for the Aspect “Battery”.
| 1 | The first battery, from a different vendor was not good and needed charging daily | −0.025 | Neg | Correct |
| 2 | The battery gets hot when charging so I would not use this as my main battery | 0.20 | Pos | Wrong |
| 3 | The battery was charging all night long, and then, this morning the battery died | −0.05 | Neg | Correct |
| 4 | Powerful battery, needs charging once in 3–4 days | 0.3 | Pos | Correct |
Polarity Count for Various Aspects.
| Aspect | Total | Pos | Neg | Neu |
|---|---|---|---|---|
| Battery | 26,323 | 7890 | 5591 | 12,842 |
| Body | 23,840 | 14,446 | 4148 | 5246 |
| Display | 18,421 | 10,332 | 3451 | 4638 |
| Network | 17,884 | 1577 | 14,075 | 2232 |
| Price | 34,135 | 18,333 | 5816 | 9986 |
| Service | 37,323 | 7701 | 16,302 | 13,320 |
| Sound | 67,514 | 42,366 | 12,142 | 13,006 |
5.3 Baselines
We compare our proposed algorithms with two state-of-the-art methods available in the literature for aspect-oriented sentiment analysis. The first baseline [19] is an approach that uses ontology for extraction of aspects and eliminates lexicon-based sentiment scoring issues. Thus, they claim that this will improve the accuracy of sentiment analysis. The second baseline [25] is a linguistic rule-based approach for aspect-level sentiment analysis of movie reviews. The authors devised a linguistic rule-based approach, which identifies the aspects from movie reviews, locates opinion about that aspect, and computes the sentiment polarity of that opinion using linguistic approaches [25]. We chose these two baselines as we found these methods closely associated with our proposed algorithms. A comparison result in terms of Precision, Recall, and Accuracy is given in the experimental results section.
Result of Aspect-Oriented Sentiment Analysis.
| No | Aspect | Sentiment |
|---|---|---|
| 1 | Battery | Neutral |
| 2 | Body | Positive |
| 3 | Display | Positive |
| 4 | Network | Negative |
| 5 | Price | Positive |
| 6 | Service | Negative |
| 7 | Sound | Positive |
6 Results and Evaluation
In this section, we present the results obtained from the experimental setup discussed in Section 5. The topics generated by the LDA algorithm is shown in Table 1. Because of space constraints, we show only the first five topics generated by the LDA, which are word unigrams. Each of these topics are then mapped to aspects identified from the product descriptions such as Network, Battery, Price, etc., and the results of such mappings are shown in Table 2. In Table 3, we show the polarity score and sentiment of the review text for the “Battery” aspect of the product. Various polarity counts for such identified aspects are given in Table 4. In Table 5, we outline the result of our aspect-oriented sentiment analysis algorithm. For further analysis and interpretation, we plot the true positive rate (TPR) and false positive rate (FPR) using the receiver operating characteristics (ROC) plot, and such graphs for the aspects “Battery and Body”, “Display and Network”, “Price and Service” are shown in Figures 2–4, respectively. Figures 5 and 6 shows the charts depicting the precision, recall, and f-measure comparisons of our proposed method with the chosen baselines for the aspects “Battery and Body”, “Display and Network”, “Price and Service”. We compare our proposed algorithms with two state-of-the-art methods for establishing the usefulness and better accuracy of our proposed algorithms. The results in terms of precision, recall, and f-measure are given in Table 6, and the data clearly shows that our proposed method outperforms our chosen
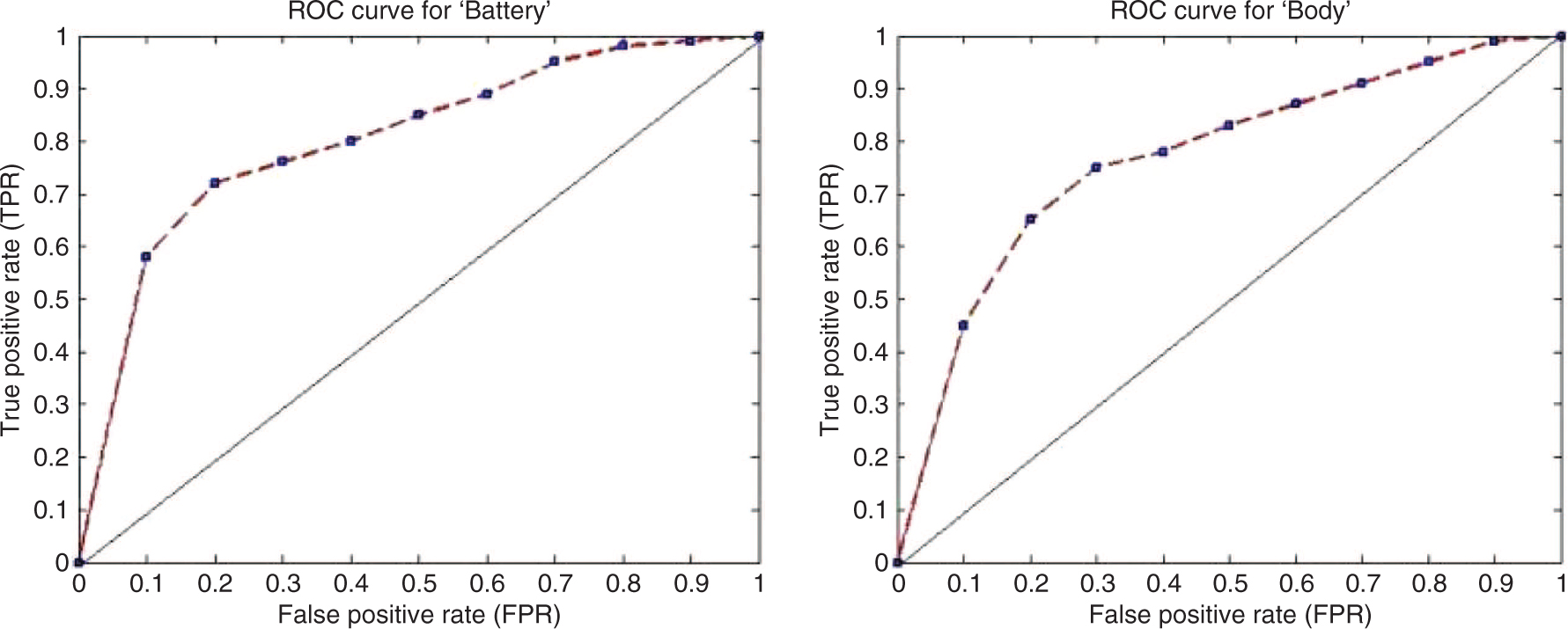
ROC Plots for “Battery” and “Body”.
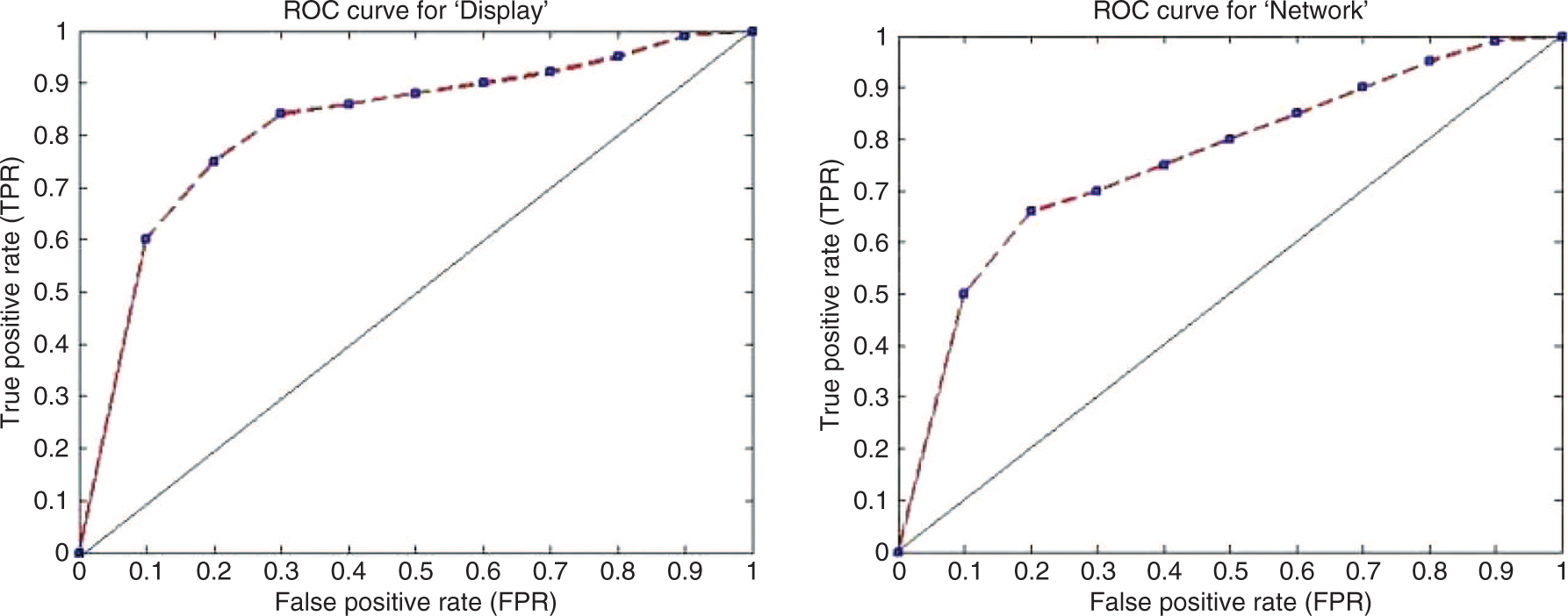
ROC Plots for “Display” and “Network”.
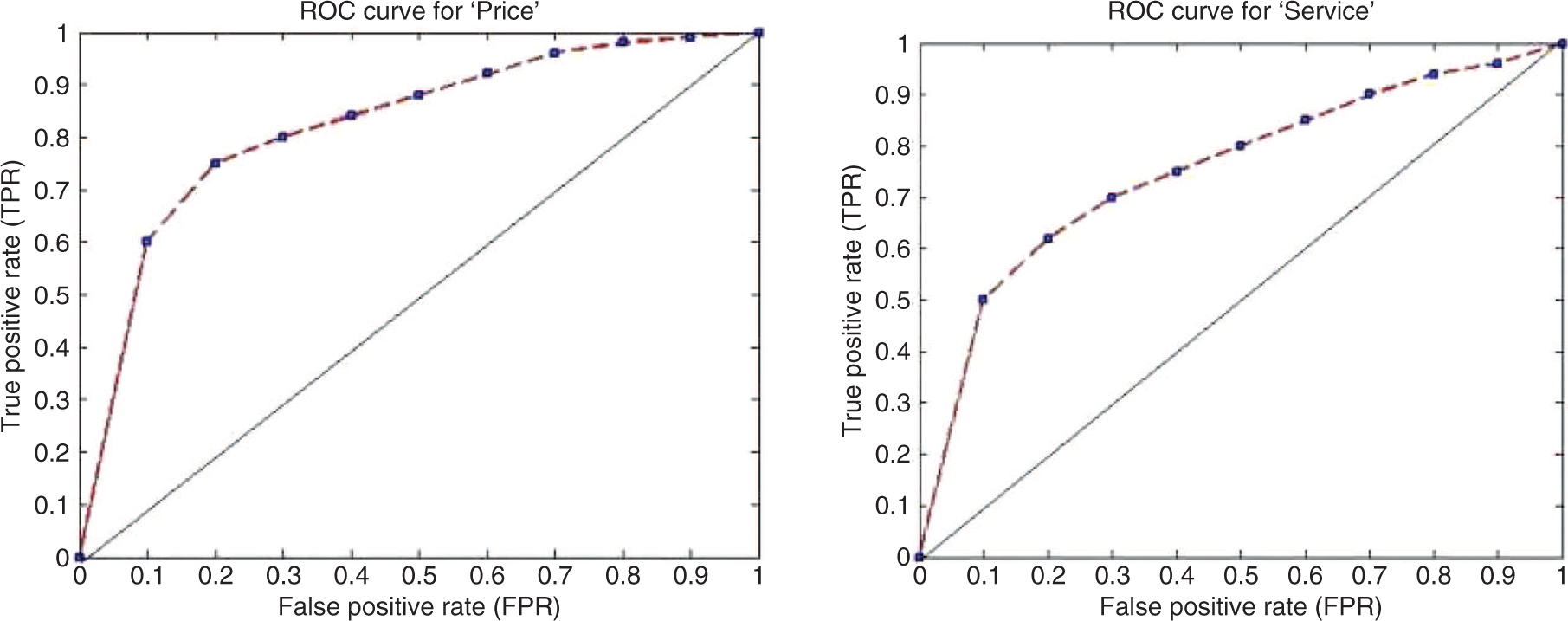
ROC Plots for “Price” and “Service”.
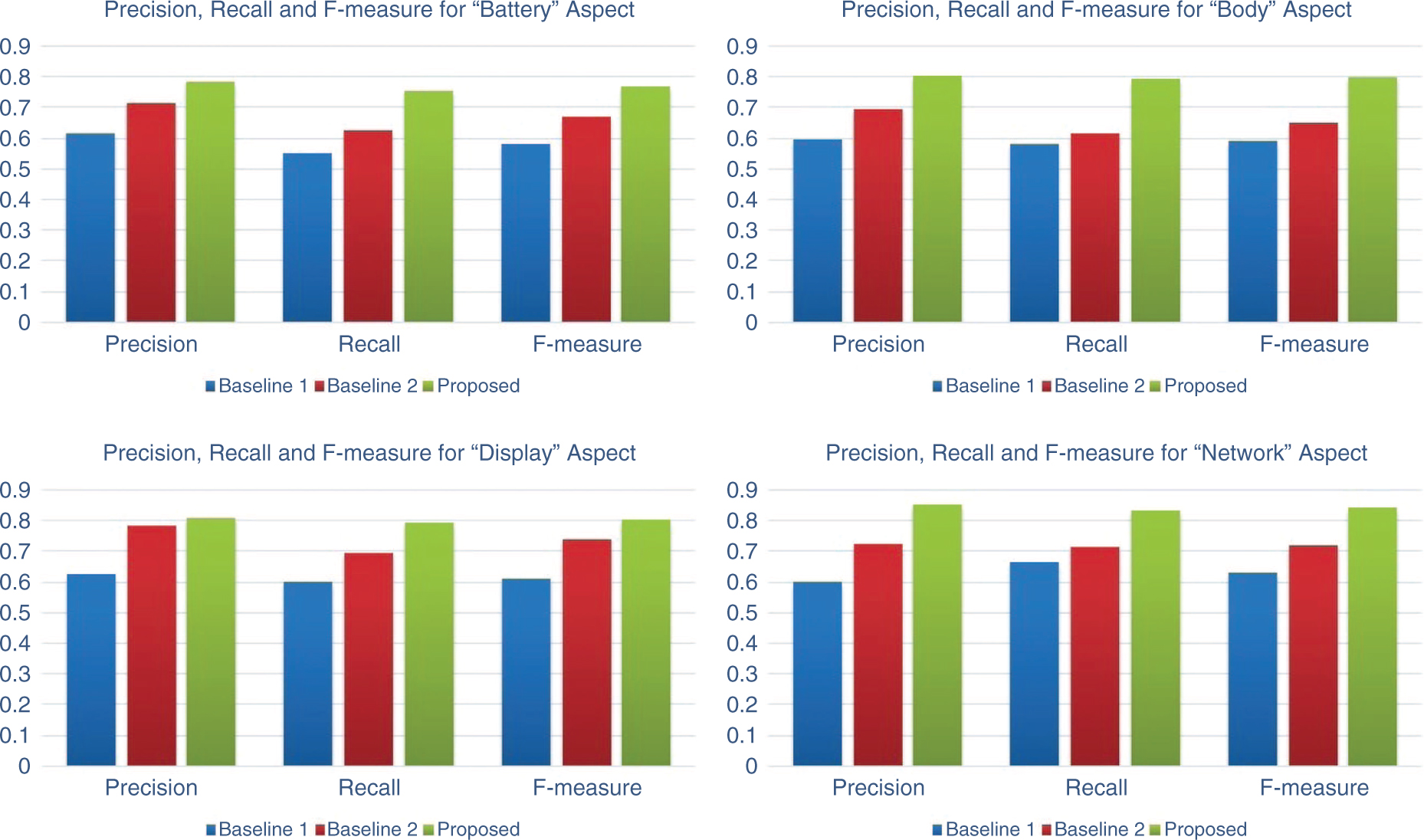
Graph Showing Precision, Recall, and f-Measure for Various Aspects.
baselines for all the aspects we have considered. Figure 7 shows the screenshot of a web application we have developed to visualize the results of our aspect-oriented sentiment analysis framework implemented on real-time data. The current screenshot shows the result of aspect-based sentiment analysis for the mobile Xiaomi Redmi Note 3, and the corresponding user reviews are collected from the famous customer review platform called MouthShut. Our proposed algorithms could clearly show the user sentiments on different aspects of the mobile, and the algorithms were found to be highly scalable. This system has already been implemented for some e-commerce vendors, and they are using it as a pilot version.
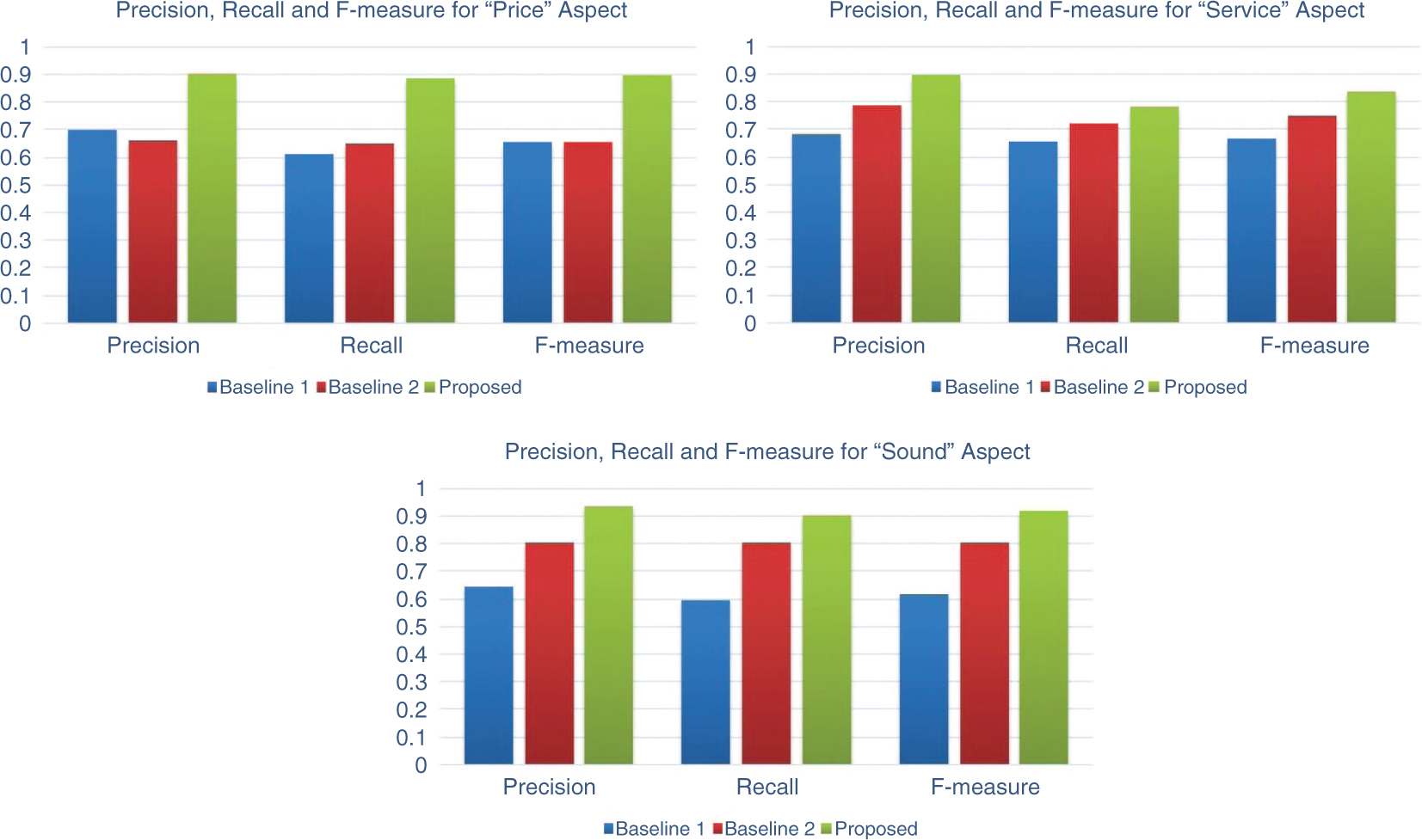
Graph Showing Precision, Recall, and f-Measure for Various Aspects.
Performance of our Proposed Aspect-Oriented Sentiment Analysis When Compared with Chosen Baselines [25], [19].
| Aspect | Baseline 1 [19] |
Baseline 2 [25] |
Proposed method |
||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | |
| Battery | 0.6158 | 0.5485 | 0.5802 | 0.7155 | 0.6252 | 0.6673 | 0.7845 | 0.7544 | 0.7691 |
| Body | 0.5952 | 0.5812 | 0.5881 | 0.6925 | 0.6152 | 0.6515 | 0.8012 | 0.7955 | 0.7983 |
| Display | 0.6266 | 0.5984 | 0.6121 | 0.7852 | 0.6951 | 0.7374 | 0.8101 | 0.7920 | 0.8009 |
| Network | 0.6011 | 0.6652 | 0.6315 | 0.7241 | 0.7129 | 0.7184 | 0.8522 | 0.8311 | 0.8415 |
| Price | 0.7010 | 0.6123 | 0.6536 | 0.6612 | 0.6522 | 0.6566 | 0.9054 | 0.8856 | 0.8953 |
| Service | 0.6840 | 0.6551 | 0.6692 | 0.7852 | 0.7210 | 0.7517 | 0.8995 | 0.7845 | 0.8380 |
| Sound | 0.6450 | 0.5963 | 0.6196 | 0.8021 | 0.8045 | 0.8032 | 0.9388 | 0.9012 | 0.9196 |
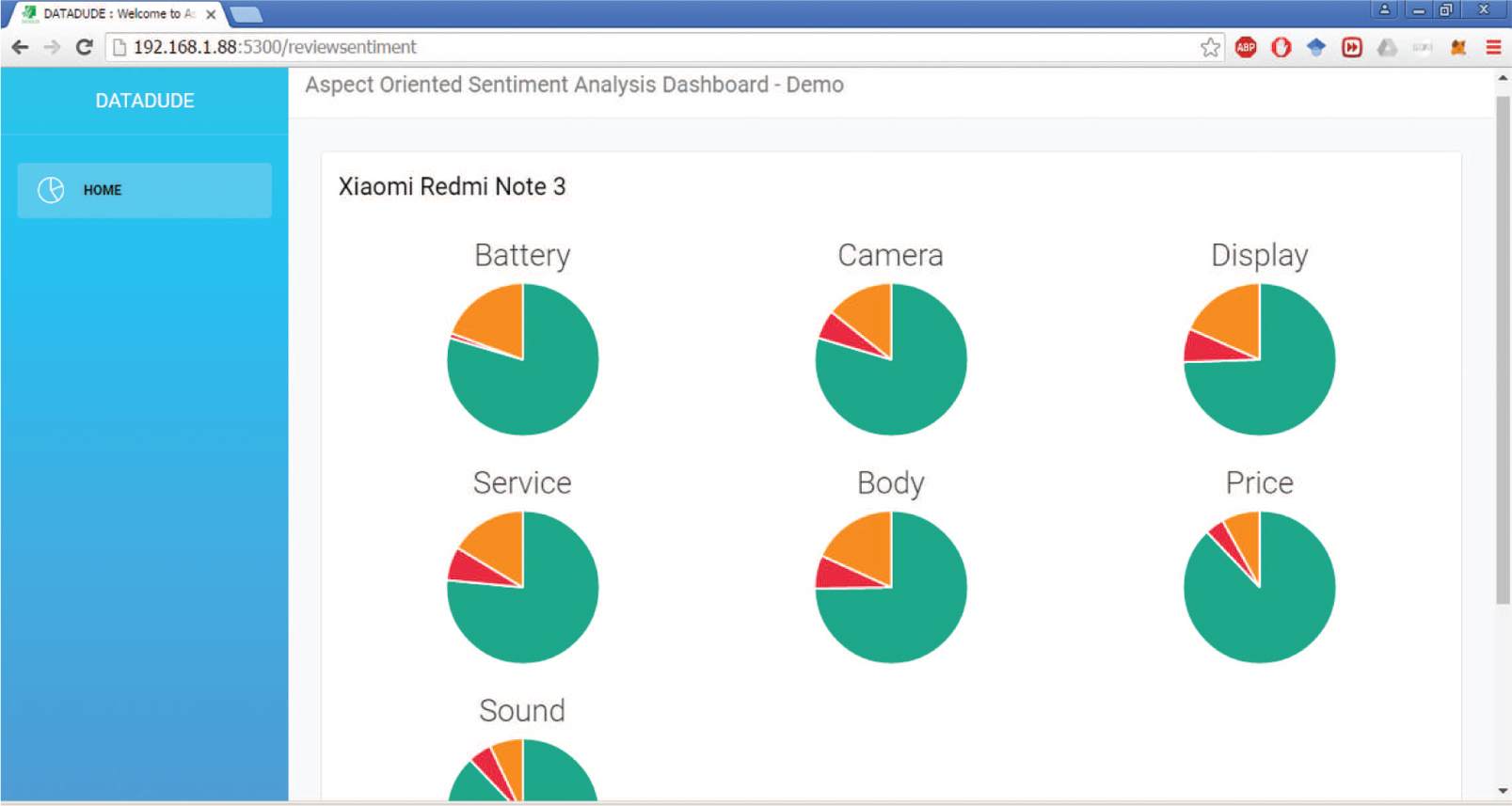
Screenshot of Web Application Developed for Finding Aspect-Oriented Sentiment of Customers for Mobile Phones and Accessories Using Proposed Algorithms. This system was extended to production level, and a number of vendors are already using a pilot version of the same.
7 Conclusions and Future Work
This paper proposed a novel approach for aspect-oriented sentiment analysis of e-commerce product reviews, which are publicly available in the form of unstructured text. This approach make use of LDA algorithm to perform topic modeling on top of the dataset to bring out hidden themes as “topics”, and then these topics are mapped to various aspects of the product. Then, an aspect specific sentiment analysis is implemented using machine learning techniques. The proposed method shows accuracy ranges from 74 % to 81 % for each aspect and also outperforms some of the state-of-the-art methods on sentiment analysis.
In this work, the aspects from the vendor websites are collected and then topics are assigned to certain aspects, which requires manual effort. As the end results are promising, the authors would like to work on the dimensions of extracting aspects automatically, and algorithmic techniques can be developed to map the topics into extracted aspects. That may certainly improve the efficiency of the proposed algorithms, and the authors would like to work on these dimensions in the future. Studying and improving the scalability aspects of the algorithms are another potential future work.
Acknowledgment
The authors would like to thank staffs and researchers at Data Engineering Lab, Indian Institute of Information Technology and Management – Kerala (IIITM-K) for their valuable suggestions and comments that significantly improved the quality of this paper. The authors also thank Dr. Julian McAuley (Assistant Professor, UC San Diego) for providing the complete datasets for this experiment. On behalf of all the authors, the corresponding author states that there is no conflict of interest.
Bibliography
[1] M. S. Akhtar, D. Gupta, A. Ekbal, and P. Bhattacharyya, Feature selection and ensemble construction: a two-step method for aspect based sentiment analysis, Knowl. Based Syst. 125 (2017), 116–135.10.1016/j.knosys.2017.03.020Search in Google Scholar
[2] M. S. Akhtar, S. Kohail, A. Kumar, A. Ekbal and C. Biemann, Feature selection using multi-objective optimization for aspect based sentiment analysis, in: International Conference on Applications of Natural Language to Information Systems, pp. 15–27, Springer, Cham., Liege, Belgium, 2017.10.1007/978-3-319-59569-6_2Search in Google Scholar
[3] D. Bespalov, B. Bai, Y. Qi and A. Shokoufandeh, Sentiment classification based on supervised latent n-gram analysis, in: Proceedings of the 20th ACM International Conference on Information and Knowledge Management, pp. 375–382, ACM, Glasgow, Scotland, UK, 2011.10.1145/2063576.2063635Search in Google Scholar
[4] S. Bird and E. Loper, NLTK: the natural language toolkit, in: Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions, p. 31, Association for Computational Linguistics, July 2004. Available at http://www.aclweb.org/anthology/P04-303110.3115/1219044.1219075Search in Google Scholar
[5] D. M. Blei, A. Y. Ng and M. I. Jordan, Latent Dirichlet allocation, J. Mach. Learn. Res. 3 (2003), 993–1022.Search in Google Scholar
[6] Colorado Reed, Latent Dirichlet allocation: towards a deeper understanding, January 2012.Search in Google Scholar
[7] S. C. Deerwester, S. T. Dumais, T. K. Landauer, G. W. Furnas and R. A. Harshman, Indexing by latent semantic analysis. JAsIs 41 (1990), 391–407.10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9Search in Google Scholar
[8] W. Ding, X. Song, Y. Shang, J. Zhu, L. Guo, X. Hu, Similarity dependency dirichlet process for aspect-based sentiment analysis.Search in Google Scholar
[9] D. Hazarika, S. Poria, P. Vij, G. Krishnamurthy, E. Cambria and R. Zimmermann, Modeling inter-aspect dependencies for aspect-based sentiment analysis, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, Volume 2, Short Papers, pp. 266–270, 2018.10.18653/v1/N18-2043Search in Google Scholar
[10] T. Hofmann, Probabilistic latent semantic analysis, in: Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, pp. 289–296, Morgan Kaufmann Publishers Inc., Stockholm, Sweden, 1999.10.1145/312624.312649Search in Google Scholar
[11] J. Huang, J. Lu and C. X. Ling, Comparing naive Bayes, decision trees, and SVM with AUC and accuracy, in: Data Mining, 2003. ICDM 2003, Third IEEE International Conference on, IEEE, Melbourne, FL, USA, 2003.Search in Google Scholar
[12] S. Kim, J. Zhang, Z. Chen, A. H. Oh and S. Liu, A hierarchical aspect-sentiment model for online reviews, in: AAAI, Bellevue, WA, USA, 2013.10.1609/aaai.v27i1.8700Search in Google Scholar
[13] H. Li, H. Y. Chen, H. Ji, S. Muresan and D. Zheng, Combining social cognitive theories with linguistic features for multi-genre sentiment analysis, in: Proceedings of the 26th Pacific Asia Conference on Language, Information, and Computation, Bali, Indonesia, pp. 127–136, 2012.Search in Google Scholar
[14] J. J. Li, H. Yang and H. Tang, Feature mining and sentiment orientation analysis on product, in: Management Information and Optoelectronic Engineering: Proceedings of the 2016 International Conference on Management, Information and Communication (ICMIC2016) and the 2016 International Conference on Optics and Electronics Engineering (ICOEE2016), p. 79, World Scientific, Guilin, China, 2017.10.1142/9789813202689_0011Search in Google Scholar
[15] T. Li, Y. Zhang and V. Sindhwani, A non-negative matrix tri-factorization approach to sentiment classification with lexical prior knowledge, in: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Volume 1, Association for Computational Linguistics, Suntec, Singapore, 2009.10.3115/1687878.1687914Search in Google Scholar
[16] B. Liu, Sentiment analysis and opinion mining, in: Synthesis Lectures on Human Language Technologies, Morgan & Claypool Publishers, San Rafael, CA, USA, 2012.10.2200/S00416ED1V01Y201204HLT016Search in Google Scholar
[17] A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng and C. Potts, Learning word vectors for sentiment analysis, in: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Volume 1, pp. 142–150, Association for Computational Linguistics, Portland, OR, USA, 2011.Search in Google Scholar
[18] R. Malouf and T. Mullen, Taking sides: user classification for informal online political discourse, Internet Res. 18 (2008), 177–190.10.1108/10662240810862239Search in Google Scholar
[19] A. Marstawi, N. M. Sharef, T. N. M. Aris and A. Mustapha, Ontology-based aspect extraction for an improved sentiment analysis in summarization of product reviews, in: Proceedings of the 8th International Conference on Computer Modeling and Simulation, pp. 100–104, ACM, Canberra, ACT, Australia, 2017.10.1145/3036331.3036362Search in Google Scholar
[20] J. McAuley and J. Leskovec, Hidden factors and hidden topics: understanding rating dimensions with review text, in: Proceedings of the 7th ACM Conference on Recommender systems, ACM, Hong Kong, China, 2013.10.1145/2507157.2507163Search in Google Scholar
[21] A. K. McCallum, MALLET: a machine learning for language toolkit, 2002. Available at: http://mallet.cs.umass.edu.Search in Google Scholar
[22] A. Neviarouskaya, H. Prendinger and M. Ishizuka, Affect analysis model: novel rule-based approach to affect sensing from text. Nat. Lang. Eng. 17 (2011), 95–135.10.1017/S1351324910000239Search in Google Scholar
[23] G. Paltoglou and M. Thelwall, A study of information retrieval weighting schemes for sentiment analysis, in: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pp. 1386–1395, Association for Computational Linguistics, Uppsala, Sweden, 2010.Search in Google Scholar
[24] B. Pang, L. Lee and S. Vaithyanathan, Thumbs up?: sentiment classification using machine learning techniques, in: Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, Volume 10, pp. 79–86, Association for Computational Linguistics, Stroudsburg, PA, USA, 2002.10.3115/1118693.1118704Search in Google Scholar
[25] R. Piryani, V. Gupta, V. K. Singh and U. Ghose, A linguistic rule-based approach for aspect-level sentiment analysis of movie reviews, in: Advances in Computer and Computational Sciences, pp. 201–209, Springer, Singapore, 2017.10.1007/978-981-10-3770-2_19Search in Google Scholar
[26] S. Poria, A. Gelbukh, B. Agarwal, E. Cambria and N. Howard, Sentic demo: a hybrid concept-level aspect-based sentiment analysis toolkit, in: ESWC 2014, 2014.10.1007/978-3-319-12024-9_5Search in Google Scholar
[27] A. Qazi, R. G. Raj, G. Hardaker and C. Standing, A systematic literature review on opinion types and sentiment analysis techniques: tasks and challenges, Internet Res. 27 (2017), 608–630.10.1108/IntR-04-2016-0086Search in Google Scholar
[28] M. D. P. Salas-Zárate, J. Medina-Moreira, K. Lagos-Ortiz, H. Luna-Aveiga, M. A. Rodríguez-García and R. Valencia-García, Sentiment analysis on tweets about diabetes: an aspect-level approach, Comput. Math. Methods Med. 2017 (2017). Article ID: 5140631.10.1155/2017/5140631Search in Google Scholar PubMed PubMed Central
[29] K. Schouten, O. van der Weijde, F. Frasincar and R. Dekker, Supervised and unsupervised aspect category detection for sentiment analysis with co-occurrence data, IEEE Trans. Cybern. 48 (2018), 1263–1275.10.1109/TCYB.2017.2688801Search in Google Scholar PubMed
[30] N. Shelke, S. Deshpande, and V. Thakare, Domain independent approach for aspect oriented sentiment analysis for product reviews, in: Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications, pp. 651–659, Springer, Bhubaneswar, India, 2017.10.1007/978-981-10-3156-4_69Search in Google Scholar
[31] A. Shen, Aspect-specific ranking of product reviews using topic modeling. Available online at: https://cs.brown.edu/research/pubs/theses/masters/2012/shen.pdfSearch in Google Scholar
[32] Y. Wang, Y. Huang and M. Wang, Aspect-based rating prediction on reviews using sentiment strength analysis, in: International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, pp. 439–447, Springer, Cham. Arras, France, 2017.10.1007/978-3-319-60045-1_45Search in Google Scholar
[33] S. Wang, M. Zhou, S. Mazumder, B. Liu and Y. Chang, Disentangling aspect and opinion words in target-based sentiment analysis using lifelong learning, 2018, arXiv preprint arXiv:1802.05818.Search in Google Scholar
[34] A. Yadollahi, A. G. Shahraki and O. R. Zaiane, Current state of text sentiment analysis from opinion to emotion mining, ACM Comput. Surv. (CSUR) 50 (2017), 25.10.1145/3057270Search in Google Scholar
[35] H. Yu and V. Hatzivassiloglou, Towards answering opinion questions: separating facts from opinions and identifying the polarity of opinion sentences, in: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 129–136, Association for Computational Linguistics, Honolulu, HI, USA, 2003.10.3115/1119355.1119372Search in Google Scholar
©2020 Walter de Gruyter GmbH, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 Public License.
Articles in the same Issue
- An Optimized K-Harmonic Means Algorithm Combined with Modified Particle Swarm Optimization and Cuckoo Search Algorithm
- Texture Feature Extraction Using Intuitionistic Fuzzy Local Binary Pattern
- Leaf Disease Segmentation From Agricultural Images via Hybridization of Active Contour Model and OFA
- Deadline Constrained Task Scheduling Method Using a Combination of Center-Based Genetic Algorithm and Group Search Optimization
- Efficient Classification of DDoS Attacks Using an Ensemble Feature Selection Algorithm
- Distributed Multi-agent Bidding-Based Approach for the Collaborative Mapping of Unknown Indoor Environments by a Homogeneous Mobile Robot Team
- An Efficient Technique for Three-Dimensional Image Visualization Through Two-Dimensional Images for Medical Data
- Combined Multi-Agent Method to Control Inter-Department Common Events Collision for University Courses Timetabling
- An Improved Particle Swarm Optimization Algorithm for Global Multidimensional Optimization
- A Kernel Probabilistic Model for Semi-supervised Co-clustering Ensemble
- Pythagorean Hesitant Fuzzy Information Aggregation and Their Application to Multi-Attribute Group Decision-Making Problems
- Using an Efficient Optimal Classifier for Soil Classification in Spatial Data Mining Over Big Data
- A Bayesian Multiresolution Approach for Noise Removal in Medical Magnetic Resonance Images
- Gbest-Guided Artificial Bee Colony Optimization Algorithm-Based Optimal Incorporation of Shunt Capacitors in Distribution Networks under Load Growth
- Graded Soft Expert Set as a Generalization of Hesitant Fuzzy Set
- Universal Liver Extraction Algorithm: An Improved Chan–Vese Model
- Software Effort Estimation Using Modified Fuzzy C Means Clustering and Hybrid ABC-MCS Optimization in Neural Network
- Handwritten Indic Script Recognition Based on the Dempster–Shafer Theory of Evidence
- An Integrated Intuitionistic Fuzzy AHP and TOPSIS Approach to Evaluation of Outsource Manufacturers
- Automatically Assess Day Similarity Using Visual Lifelogs
- A Novel Bio-Inspired Algorithm Based on Social Spiders for Improving Performance and Efficiency of Data Clustering
- Discriminative Training Using Noise Robust Integrated Features and Refined HMM Modeling
- Self-Adaptive Mussels Wandering Optimization Algorithm with Application for Artificial Neural Network Training
- A Framework for Image Alignment of TerraSAR-X Images Using Fractional Derivatives and View Synthesis Approach
- Intelligent Systems for Structural Damage Assessment
- Some Interval-Valued Pythagorean Fuzzy Einstein Weighted Averaging Aggregation Operators and Their Application to Group Decision Making
- Fuzzy Adaptive Genetic Algorithm for Improving the Solution of Industrial Optimization Problems
- Approach to Multiple Attribute Group Decision Making Based on Hesitant Fuzzy Linguistic Aggregation Operators
- Cubic Ordered Weighted Distance Operator and Application in Group Decision-Making
- Fault Signal Recognition in Power Distribution System using Deep Belief Network
- Selector: PSO as Model Selector for Dual-Stage Diabetes Network
- Oppositional Gravitational Search Algorithm and Artificial Neural Network-based Classification of Kidney Images
- Improving Image Search through MKFCM Clustering Strategy-Based Re-ranking Measure
- Sparse Decomposition Technique for Segmentation and Compression of Compound Images
- Automatic Genetic Fuzzy c-Means
- Harmony Search Algorithm for Patient Admission Scheduling Problem
- Speech Signal Compression Algorithm Based on the JPEG Technique
- i-Vector-Based Speaker Verification on Limited Data Using Fusion Techniques
- Prediction of User Future Request Utilizing the Combination of Both ANN and FCM in Web Page Recommendation
- Presentation of ACT/R-RBF Hybrid Architecture to Develop Decision Making in Continuous and Non-continuous Data
- An Overview of Segmentation Algorithms for the Analysis of Anomalies on Medical Images
- Blind Restoration Algorithm Using Residual Measures for Motion-Blurred Noisy Images
- Extreme Learning Machine for Credit Risk Analysis
- A Genetic Algorithm Approach for Group Recommender System Based on Partial Rankings
- Improvements in Spoken Query System to Access the Agricultural Commodity Prices and Weather Information in Kannada Language/Dialects
- A One-Pass Approach for Slope and Slant Estimation of Tri-Script Handwritten Words
- Secure Communication through MultiAgent System-Based Diabetes Diagnosing and Classification
- Development of a Two-Stage Segmentation-Based Word Searching Method for Handwritten Document Images
- Pythagorean Fuzzy Einstein Hybrid Averaging Aggregation Operator and its Application to Multiple-Attribute Group Decision Making
- Ensembles of Text and Time-Series Models for Automatic Generation of Financial Trading Signals from Social Media Content
- A Flame Detection Method Based on Novel Gradient Features
- Modeling and Optimization of a Liquid Flow Process using an Artificial Neural Network-Based Flower Pollination Algorithm
- Spectral Graph-based Features for Recognition of Handwritten Characters: A Case Study on Handwritten Devanagari Numerals
- A Grey Wolf Optimizer for Text Document Clustering
- Classification of Masses in Digital Mammograms Using the Genetic Ensemble Method
- A Hybrid Grey Wolf Optimiser Algorithm for Solving Time Series Classification Problems
- Gray Method for Multiple Attribute Decision Making with Incomplete Weight Information under the Pythagorean Fuzzy Setting
- Multi-Agent System Based on the Extreme Learning Machine and Fuzzy Control for Intelligent Energy Management in Microgrid
- Deep CNN Combined With Relevance Feedback for Trademark Image Retrieval
- Cognitively Motivated Query Abstraction Model Based on Associative Root-Pattern Networks
- Improved Adaptive Neuro-Fuzzy Inference System Using Gray Wolf Optimization: A Case Study in Predicting Biochar Yield
- Predict Forex Trend via Convolutional Neural Networks
- Optimizing Integrated Features for Hindi Automatic Speech Recognition System
- A Novel Weakest t-norm based Fuzzy Fault Tree Analysis Through Qualitative Data Processing and Its Application in System Reliability Evaluation
- FCNB: Fuzzy Correlative Naive Bayes Classifier with MapReduce Framework for Big Data Classification
- A Modified Jaya Algorithm for Mixed-Variable Optimization Problems
- An Improved Robust Fuzzy Algorithm for Unsupervised Learning
- Hybridizing the Cuckoo Search Algorithm with Different Mutation Operators for Numerical Optimization Problems
- An Efficient Lossless ROI Image Compression Using Wavelet-Based Modified Region Growing Algorithm
- Predicting Automatic Trigger Speed for Vehicle-Activated Signs
- Group Recommender Systems – An Evolutionary Approach Based on Multi-expert System for Consensus
- Enriching Documents by Linking Salient Entities and Lexical-Semantic Expansion
- A New Feature Selection Method for Sentiment Analysis in Short Text
- Optimizing Software Modularity with Minimum Possible Variations
- Optimizing the Self-Organizing Team Size Using a Genetic Algorithm in Agile Practices
- Aspect-Oriented Sentiment Analysis: A Topic Modeling-Powered Approach
- Feature Pair Index Graph for Clustering
- Tangramob: An Agent-Based Simulation Framework for Validating Urban Smart Mobility Solutions
- A New Algorithm Based on Magic Square and a Novel Chaotic System for Image Encryption
- Video Steganography Using Knight Tour Algorithm and LSB Method for Encrypted Data
- Clay-Based Brick Porosity Estimation Using Image Processing Techniques
- AGCS Technique to Improve the Performance of Neural Networks
- A Color Image Encryption Technique Based on Bit-Level Permutation and Alternate Logistic Maps
- A Hybrid of Deep CNN and Bidirectional LSTM for Automatic Speech Recognition
- Database Creation and Dialect-Wise Comparative Analysis of Prosodic Features for Punjabi Language
- Trapezoidal Linguistic Cubic Fuzzy TOPSIS Method and Application in a Group Decision Making Program
- Histopathological Image Segmentation Using Modified Kernel-Based Fuzzy C-Means and Edge Bridge and Fill Technique
- Proximal Support Vector Machine-Based Hybrid Approach for Edge Detection in Noisy Images
- Early Detection of Parkinson’s Disease by Using SPECT Imaging and Biomarkers
- Image Compression Based on Block SVD Power Method
- Noise Reduction Using Modified Wiener Filter in Digital Hearing Aid for Speech Signal Enhancement
- Secure Fingerprint Authentication Using Deep Learning and Minutiae Verification
- The Use of Natural Language Processing Approach for Converting Pseudo Code to C# Code
- Non-word Attributes’ Efficiency in Text Mining Authorship Prediction
- Design and Evaluation of Outlier Detection Based on Semantic Condensed Nearest Neighbor
- An Efficient Quality Inspection of Food Products Using Neural Network Classification
- Opposition Intensity-Based Cuckoo Search Algorithm for Data Privacy Preservation
- M-HMOGA: A New Multi-Objective Feature Selection Algorithm for Handwritten Numeral Classification
- Analogy-Based Approaches to Improve Software Project Effort Estimation Accuracy
- Linear Regression Supporting Vector Machine and Hybrid LOG Filter-Based Image Restoration
- Fractional Fuzzy Clustering and Particle Whale Optimization-Based MapReduce Framework for Big Data Clustering
- Implementation of Improved Ship-Iceberg Classifier Using Deep Learning
- Hybrid Approach for Face Recognition from a Single Sample per Person by Combining VLC and GOM
- Polarity Analysis of Customer Reviews Based on Part-of-Speech Subcategory
- A 4D Trajectory Prediction Model Based on the BP Neural Network
- A Blind Medical Image Watermarking for Secure E-Healthcare Application Using Crypto-Watermarking System
- Discriminating Healthy Wheat Grains from Grains Infected with Fusarium graminearum Using Texture Characteristics of Image-Processing Technique, Discriminant Analysis, and Support Vector Machine Methods
- License Plate Recognition in Urban Road Based on Vehicle Tracking and Result Integration
- Binary Genetic Swarm Optimization: A Combination of GA and PSO for Feature Selection
- Enhanced Twitter Sentiment Analysis Using Hybrid Approach and by Accounting Local Contextual Semantic
- Cloud Security: LKM and Optimal Fuzzy System for Intrusion Detection in Cloud Environment
- Power Average Operators of Trapezoidal Cubic Fuzzy Numbers and Application to Multi-attribute Group Decision Making
Articles in the same Issue
- An Optimized K-Harmonic Means Algorithm Combined with Modified Particle Swarm Optimization and Cuckoo Search Algorithm
- Texture Feature Extraction Using Intuitionistic Fuzzy Local Binary Pattern
- Leaf Disease Segmentation From Agricultural Images via Hybridization of Active Contour Model and OFA
- Deadline Constrained Task Scheduling Method Using a Combination of Center-Based Genetic Algorithm and Group Search Optimization
- Efficient Classification of DDoS Attacks Using an Ensemble Feature Selection Algorithm
- Distributed Multi-agent Bidding-Based Approach for the Collaborative Mapping of Unknown Indoor Environments by a Homogeneous Mobile Robot Team
- An Efficient Technique for Three-Dimensional Image Visualization Through Two-Dimensional Images for Medical Data
- Combined Multi-Agent Method to Control Inter-Department Common Events Collision for University Courses Timetabling
- An Improved Particle Swarm Optimization Algorithm for Global Multidimensional Optimization
- A Kernel Probabilistic Model for Semi-supervised Co-clustering Ensemble
- Pythagorean Hesitant Fuzzy Information Aggregation and Their Application to Multi-Attribute Group Decision-Making Problems
- Using an Efficient Optimal Classifier for Soil Classification in Spatial Data Mining Over Big Data
- A Bayesian Multiresolution Approach for Noise Removal in Medical Magnetic Resonance Images
- Gbest-Guided Artificial Bee Colony Optimization Algorithm-Based Optimal Incorporation of Shunt Capacitors in Distribution Networks under Load Growth
- Graded Soft Expert Set as a Generalization of Hesitant Fuzzy Set
- Universal Liver Extraction Algorithm: An Improved Chan–Vese Model
- Software Effort Estimation Using Modified Fuzzy C Means Clustering and Hybrid ABC-MCS Optimization in Neural Network
- Handwritten Indic Script Recognition Based on the Dempster–Shafer Theory of Evidence
- An Integrated Intuitionistic Fuzzy AHP and TOPSIS Approach to Evaluation of Outsource Manufacturers
- Automatically Assess Day Similarity Using Visual Lifelogs
- A Novel Bio-Inspired Algorithm Based on Social Spiders for Improving Performance and Efficiency of Data Clustering
- Discriminative Training Using Noise Robust Integrated Features and Refined HMM Modeling
- Self-Adaptive Mussels Wandering Optimization Algorithm with Application for Artificial Neural Network Training
- A Framework for Image Alignment of TerraSAR-X Images Using Fractional Derivatives and View Synthesis Approach
- Intelligent Systems for Structural Damage Assessment
- Some Interval-Valued Pythagorean Fuzzy Einstein Weighted Averaging Aggregation Operators and Their Application to Group Decision Making
- Fuzzy Adaptive Genetic Algorithm for Improving the Solution of Industrial Optimization Problems
- Approach to Multiple Attribute Group Decision Making Based on Hesitant Fuzzy Linguistic Aggregation Operators
- Cubic Ordered Weighted Distance Operator and Application in Group Decision-Making
- Fault Signal Recognition in Power Distribution System using Deep Belief Network
- Selector: PSO as Model Selector for Dual-Stage Diabetes Network
- Oppositional Gravitational Search Algorithm and Artificial Neural Network-based Classification of Kidney Images
- Improving Image Search through MKFCM Clustering Strategy-Based Re-ranking Measure
- Sparse Decomposition Technique for Segmentation and Compression of Compound Images
- Automatic Genetic Fuzzy c-Means
- Harmony Search Algorithm for Patient Admission Scheduling Problem
- Speech Signal Compression Algorithm Based on the JPEG Technique
- i-Vector-Based Speaker Verification on Limited Data Using Fusion Techniques
- Prediction of User Future Request Utilizing the Combination of Both ANN and FCM in Web Page Recommendation
- Presentation of ACT/R-RBF Hybrid Architecture to Develop Decision Making in Continuous and Non-continuous Data
- An Overview of Segmentation Algorithms for the Analysis of Anomalies on Medical Images
- Blind Restoration Algorithm Using Residual Measures for Motion-Blurred Noisy Images
- Extreme Learning Machine for Credit Risk Analysis
- A Genetic Algorithm Approach for Group Recommender System Based on Partial Rankings
- Improvements in Spoken Query System to Access the Agricultural Commodity Prices and Weather Information in Kannada Language/Dialects
- A One-Pass Approach for Slope and Slant Estimation of Tri-Script Handwritten Words
- Secure Communication through MultiAgent System-Based Diabetes Diagnosing and Classification
- Development of a Two-Stage Segmentation-Based Word Searching Method for Handwritten Document Images
- Pythagorean Fuzzy Einstein Hybrid Averaging Aggregation Operator and its Application to Multiple-Attribute Group Decision Making
- Ensembles of Text and Time-Series Models for Automatic Generation of Financial Trading Signals from Social Media Content
- A Flame Detection Method Based on Novel Gradient Features
- Modeling and Optimization of a Liquid Flow Process using an Artificial Neural Network-Based Flower Pollination Algorithm
- Spectral Graph-based Features for Recognition of Handwritten Characters: A Case Study on Handwritten Devanagari Numerals
- A Grey Wolf Optimizer for Text Document Clustering
- Classification of Masses in Digital Mammograms Using the Genetic Ensemble Method
- A Hybrid Grey Wolf Optimiser Algorithm for Solving Time Series Classification Problems
- Gray Method for Multiple Attribute Decision Making with Incomplete Weight Information under the Pythagorean Fuzzy Setting
- Multi-Agent System Based on the Extreme Learning Machine and Fuzzy Control for Intelligent Energy Management in Microgrid
- Deep CNN Combined With Relevance Feedback for Trademark Image Retrieval
- Cognitively Motivated Query Abstraction Model Based on Associative Root-Pattern Networks
- Improved Adaptive Neuro-Fuzzy Inference System Using Gray Wolf Optimization: A Case Study in Predicting Biochar Yield
- Predict Forex Trend via Convolutional Neural Networks
- Optimizing Integrated Features for Hindi Automatic Speech Recognition System
- A Novel Weakest t-norm based Fuzzy Fault Tree Analysis Through Qualitative Data Processing and Its Application in System Reliability Evaluation
- FCNB: Fuzzy Correlative Naive Bayes Classifier with MapReduce Framework for Big Data Classification
- A Modified Jaya Algorithm for Mixed-Variable Optimization Problems
- An Improved Robust Fuzzy Algorithm for Unsupervised Learning
- Hybridizing the Cuckoo Search Algorithm with Different Mutation Operators for Numerical Optimization Problems
- An Efficient Lossless ROI Image Compression Using Wavelet-Based Modified Region Growing Algorithm
- Predicting Automatic Trigger Speed for Vehicle-Activated Signs
- Group Recommender Systems – An Evolutionary Approach Based on Multi-expert System for Consensus
- Enriching Documents by Linking Salient Entities and Lexical-Semantic Expansion
- A New Feature Selection Method for Sentiment Analysis in Short Text
- Optimizing Software Modularity with Minimum Possible Variations
- Optimizing the Self-Organizing Team Size Using a Genetic Algorithm in Agile Practices
- Aspect-Oriented Sentiment Analysis: A Topic Modeling-Powered Approach
- Feature Pair Index Graph for Clustering
- Tangramob: An Agent-Based Simulation Framework for Validating Urban Smart Mobility Solutions
- A New Algorithm Based on Magic Square and a Novel Chaotic System for Image Encryption
- Video Steganography Using Knight Tour Algorithm and LSB Method for Encrypted Data
- Clay-Based Brick Porosity Estimation Using Image Processing Techniques
- AGCS Technique to Improve the Performance of Neural Networks
- A Color Image Encryption Technique Based on Bit-Level Permutation and Alternate Logistic Maps
- A Hybrid of Deep CNN and Bidirectional LSTM for Automatic Speech Recognition
- Database Creation and Dialect-Wise Comparative Analysis of Prosodic Features for Punjabi Language
- Trapezoidal Linguistic Cubic Fuzzy TOPSIS Method and Application in a Group Decision Making Program
- Histopathological Image Segmentation Using Modified Kernel-Based Fuzzy C-Means and Edge Bridge and Fill Technique
- Proximal Support Vector Machine-Based Hybrid Approach for Edge Detection in Noisy Images
- Early Detection of Parkinson’s Disease by Using SPECT Imaging and Biomarkers
- Image Compression Based on Block SVD Power Method
- Noise Reduction Using Modified Wiener Filter in Digital Hearing Aid for Speech Signal Enhancement
- Secure Fingerprint Authentication Using Deep Learning and Minutiae Verification
- The Use of Natural Language Processing Approach for Converting Pseudo Code to C# Code
- Non-word Attributes’ Efficiency in Text Mining Authorship Prediction
- Design and Evaluation of Outlier Detection Based on Semantic Condensed Nearest Neighbor
- An Efficient Quality Inspection of Food Products Using Neural Network Classification
- Opposition Intensity-Based Cuckoo Search Algorithm for Data Privacy Preservation
- M-HMOGA: A New Multi-Objective Feature Selection Algorithm for Handwritten Numeral Classification
- Analogy-Based Approaches to Improve Software Project Effort Estimation Accuracy
- Linear Regression Supporting Vector Machine and Hybrid LOG Filter-Based Image Restoration
- Fractional Fuzzy Clustering and Particle Whale Optimization-Based MapReduce Framework for Big Data Clustering
- Implementation of Improved Ship-Iceberg Classifier Using Deep Learning
- Hybrid Approach for Face Recognition from a Single Sample per Person by Combining VLC and GOM
- Polarity Analysis of Customer Reviews Based on Part-of-Speech Subcategory
- A 4D Trajectory Prediction Model Based on the BP Neural Network
- A Blind Medical Image Watermarking for Secure E-Healthcare Application Using Crypto-Watermarking System
- Discriminating Healthy Wheat Grains from Grains Infected with Fusarium graminearum Using Texture Characteristics of Image-Processing Technique, Discriminant Analysis, and Support Vector Machine Methods
- License Plate Recognition in Urban Road Based on Vehicle Tracking and Result Integration
- Binary Genetic Swarm Optimization: A Combination of GA and PSO for Feature Selection
- Enhanced Twitter Sentiment Analysis Using Hybrid Approach and by Accounting Local Contextual Semantic
- Cloud Security: LKM and Optimal Fuzzy System for Intrusion Detection in Cloud Environment
- Power Average Operators of Trapezoidal Cubic Fuzzy Numbers and Application to Multi-attribute Group Decision Making