Wissensnetz der Zürcher Ehedaten des 16.–18. Jahrhunderts: Eine Anwendung von Semantic-Web-Technologien im Archiv
-
Rebekka Plüss
Rebekka Plüss, M. A.

 and
Roberta Padlina
and
Roberta Padlina
Dr. des. Roberta Padlina

Zusammenfassung
In einem Pilotprojekt hat das Staatsarchiv des Kantons Zürich den Bestand der Zürcher Ehedaten des 16.–18. Jahrhunderts mittels Semantic-Web-Technologien als Wissensnetz aufbereitet. Dabei wurden aus dem swissuniversities Projekt NIE-INE entwickelte Ansätze und Erkenntnisse aufgegriffen und ein modulares Verfahren entwickelt, bei dem Anwendungsfall für Anwendungsfall implementiert wird und an dessen Ende immer ein konsistentes und kontrollierbares Wissensrepräsentationssystem aus Ontologien und Graphdaten steht.
Abstract
In a pilot project, the Zurich State Archives transformed the holdings of Zurich’s sixteenth to eighteenth century marriage data into a knowledge graph using Semantic Web technologies. In the process, approaches and findings developed from the swissuniversities’ NIE-INE project were taken up and a modular procedure was developed, in which use case after use case is implemented and at the end of which there is always a consistent and controllable knowledge representation system of ontologies and graph data.
1 Anwendung von Semantic-Web-Technologien in Archiven
Von Baumstrukturen hin zu Netzstrukturen: Diskussionen zu neuen Wegen, Archivdaten aufzubereiten und miteinander zu verlinken, prägen die letzten Jahre. Zahlreiche Pilotprojekte und Workshops werden zum Thema Linked Open Data durchgeführt. Mit dem Konzeptmodell und der Ontologie Records in Contexts (RiC),[1] die von der Experts Group on Archival Description (EGAD) des International Council on Archives (ICA) konzipiert wurden, steht den Archiven nun ein Standard für ihre Archivverzeichnisdaten zur Repräsentation in Graphstrukturen zur Verfügung. Mit dem Linked Data Service LINDAS[2] hat das Schweizerische Bundesarchiv eine Infrastruktur zur Datenkonvertierung, -integration, -visualisierung und -publikation von Linked Open Data entwickelt. Noch besteht aber Unsicherheit, wie Archive Semantic-Web-Technologien im Sinne ihres Kerngeschäfts, dem Zugänglichmachen ihrer immensen Wissensbestände, nutzen und mitgestalten können. Denn Semantic-Web-Technologien können nicht nur bei Archivverzeichnisdaten, sondern auch bei digital aufbereiteten Beständen bzw. Online-Editionen, zur Aufwertung von HTML-Seiten oder zur Aufbereitung und Anreicherung strukturierter Quellenbestände zum Einsatz kommen. Um über die diesbezüglichen Möglichkeiten mehr Klarheit zu erhalten, hat das Staatsarchiv des Kantons Zürich in einem Pilotprojekt die Zürcher Ehedaten des 16.–18. Jahrhunderts als Linked Open Data aufbereitet.[3]
Semantic-Web-Technologien stellen ein breites Set an Werkzeugen (Modelle und formale Sprachen) zur Verfügung, um ein erweiterbares, in sich konsistentes und kontrollierbares Wissensrepräsentationssystem zu erstellen. Mittels geeigneten formalen Vokabulars (Ontologien) kann das Wissen eines spezifischen Wissensbereichs (Domäne) identifiziert, modelliert und mit anderen Domänen verlinkt werden. So entsteht ein maschinen- und menschenlesbares System, in welchem Datenmodell und Daten eine Einheit bilden. Dabei basiert alles auf der Methodik, Aussagen als sogenannte Tripel zu Graph- oder Netzstrukturen zu kombinieren. Die Anwendung von Semantic-Web-Technologien geht aber über den Aspekt der Datenverlinkung im Netz hinaus. Dank Machine Reasoning ist es beispielsweise möglich, über das Definieren von Regeln aus bestehenden Tripeln weitere Tripel herzuleiten. Ein wesentlicher Vorteil von Semantic-Web-Technologien für Archive ist zudem, dass es damit möglich wird, eigene Datenmodelle zu erstellen und dennoch externe Ontologien einzubinden. Somit werden die Daten interoperabel mit anderen geeigneten Datensätzen, und ein Archiv ist dennoch unabhängig in der Entwicklung und Anwendung seines Datenmodells. Das Ehedatenprojekt des Staatsarchivs Zürich bedient sich hier eines Ansatzes, wie er im Projekt NIE-INE entwickelt wurde.
2 Entwicklung von Semantic Web Ontologien im Projekt NIE-INE
Als Teil des swissuniversities P-5 Programms für wissenschaftliche Information hatte das Projekt Nationale Infrastruktur für Editionen (NIE-INE, 2016–2020)[4] als Hauptziel die Entwicklung eines Web-Frameworks für digitale wissenschaftliche Editionen aus geisteswissenschaftlichen Projekten in der Schweiz formuliert. NIE-INE kooperierte mit mehr als 15 Editionsprojekten, die zusammen ein sehr breites Spektrum an Texten abdecken, die aus verschiedenen historischen Epochen und Sprachräumen stammen und sehr unterschiedlicher Natur sind. Die Infrastruktur sollte den spezifischen Bedürfnissen umfangreicher und komplexer Editionsprojekte gerecht werden und die digitale Repräsentation und Publikation von Forschungsdaten und -ergebnissen gewährleisten. Die technologischen Lösungen mussten einfach zu benutzen, flexibel und in hohem Maße wiederverwendbar sein.
Die gewählten Kerntechnologien waren die Standards des Semantic Web, eine der modernsten Technologien für die Repräsentation und den Austausch von Daten und Wissen, die viele Vorteile hat (unter anderem Unabhängigkeit von natürlichen Sprachen, Datentransparenz und -qualität, Möglichkeit des Machine Reasoning). Der Einsatz der Semantic-Web-Technologien erleichtert den Aufbau von formalen verknüpften Daten, die die FAIR-Prinzipien (Findable, Accessible, Interoperable, Reusable) unterstützen. Tatsächlich ermöglicht das Semantic Web die Verknüpfung und semantische Interoperabilität von Daten aus unterschiedlichen Quellen und Wissensgebieten, wodurch Fachwissen hinzugefügt und somit die Wiederverwendung sowie die Interdisziplinarität gefördert wird.
NIE-INE hat verschiedene Dienstleistungen und Produkte im Zusammenhang mit dem Semantic Web geliefert, insbesondere die Unterstützung bei der formalen Darstellung von Forschungsdaten durch die Entwicklung eines Netzes von hochgradig voneinander abhängigen Ontologien.[5] Da die Ontologien in formalen Standardsprachen zum Ausdruck gebracht werden und einen Konsens aufweisen, werden sie zu in hohem Maße wiederverwendbaren Modellen, die eine semantische Interoperabilität ermöglichen. Das stellt einen klaren Vorteil für andere oder zukünftige Projekte dar, denn es ermöglicht beispielsweise über dasselbe SPARQL-Abfragesystem auf die RDF-Datenbanken verschiedener Projekte zuzugreifen. Die Erstellung von Ontologien umfasst die Konvertierung von bestehenden oder neuen wissenschaftlichen Datenmodellen und Forschungsdaten in explizite, formale, selbstbeschreibende und maschineninterpretierbare Ausdrücke, die langfristig aufbewahrt und maschinell weiterverarbeitet werden können.
Die formale Modellierung von Ontologien ist keine leichte Aufgabe, da sie explizit und präzise sein muss und eine komplexe Gruppe von Abhängigkeiten aufweist: projektgetriebene (ursprüngliches Datenmodell, Daten und Domain Knowledge), aber auch formale (W3C-Standards, Normen, bestehende Standardontologien und grundlegende Modellierungsmuster). Bei der Modellierung geht es oft darum, das richtige Gleichgewicht zu finden. Ein wesentlicher Aspekt der Modellierung im Semantic Web ist die Interaktion von lokalen und globalen (oder eigenen und externen) Ontologien. Die Ausdruckskraft des Semantic Web wird durch die Tatsache erheblich erhöht, dass jeder eine eigene lokale Ontologie als Teil des globalen semantischen Raums erstellen kann. Wir können also jede beliebige Äußerung zum Ausdruck bringen, aber damit sie einen Sinn ergibt, muss sie auch gemäß gemeinsamer und geteilter Ontologien ausgedrückt werden, die, da sie allgemeiner und abstrakter sind, als „Klebstoff“ fungieren und die Überschneidung und Verbindung der verschiedenen Reden und sogar widersprüchlicher Interpretationsmodelle ermöglichen. Daher wird die Interoperabilität durch die Verwendung gleicher externer, gemeinsamer und übergeordneter Ontologien gewährleistet, die als Zwischensprache zwischen den verschiedenen Ontologien dienen. Solche Modelle, die im Konsens zustande kommen, sind notwendig, um projektspezifische semantische Silos zu vermeiden, in denen dieselben Konzepte immer wieder für verschiedene Projekte modelliert werden, was zu einer Vervielfachung von Aufwand und Kosten führt. Die Kombinier- und Erweiterbarkeit von Ontologien ermöglicht gleichzeitig eine Anpassung an projektspezifische Bedürfnisse.
Diese Flexibilität wirft jedoch das Problem der Entwicklung neuer Ontologien bei gleichzeitiger Maximierung der Wiederverwendung bestehender Ontologien auf. Eine Ontologie dient in erster Linie dazu, Wissen darzustellen, um es gemeinsam nutzen zu können. Es stellt sich die Frage, welche und wie man bereits vorhandene Ontologien ganz oder teilweise nutzen kann. Im Allgemeinen ist dies ein Problem, für das es keine einfache Lösung gibt. Die Modellierung steht vor der Herausforderung, die richtige Balance zwischen Grundelementen und Details zu finden. Eine tiefe Verankerung wird durch sehr grundlegende oder übergeordnete Ontologien erreicht. Am anderen Ende des Spektrums steht die eher projektspezifische Modellierung auf eigenständige Weise. Der von NIE-INE gewählte Ansatz, die middle-out-Modellierung, beginnt mit einigen erforderlichen Tiefen- und Detailpunkten in einer Weise, die es ermöglicht, Ontologien zu erweitern. Im Gegensatz zu einem bottom-up-Ansatz (der einen hohen Detaillierungsgrad aufweist) und einem top-down-Ansatz (der mit High-Level-Kategorien beginnt), definiert der middle-out-Ansatz die grundlegendsten Begriffe in jedem Arbeitsbereich, bevor er zu abstrakteren und spezifischeren Begriffen innerhalb eines Arbeitsbereichs übergeht. Ein middle-out-Ansatz sorgt für ein Gleichgewicht in Bezug auf die Detailtiefe und bietet Gemeinsamkeit und Stabilität. Obwohl der Anwendungsbereich einer lokalen Ontologie enger ist, das heißt stärker projektorientiert, können die Entitäten gegebenenfalls in einem anderen Kontext wiederverwendet werden, so dass sie nicht auf einen bestimmten Bereich beschränkt sein müssen. NIE-INE Ontologien basieren auf mehreren übergeordneten externen Standardontologien, insbesondere dem Conceptual Reference Model des International Commitee for Documentation (CIDOC CRM)[6] und den Functional Requirements for Bibliographic Records (FRBRoo).[7]
Ein weiteres Problem ist die Art der Wiederverwendung externer Ontologien, weil es mehrere Ansätze für die Wiederverwendung gibt: direkte, indirekte (mit Ausrichtung) oder hybride (die beides kombinieren).[8] Obwohl schneller, hat die direkte Wiederverwendung von externen Ontologien mehrere Nachteile (Abhängigkeit, Instabilität, Risiko von Unstimmigkeiten), die bei der indirekten Wiederverwendung vermieden werden. Aus diesem Grund befürwortet NIE-INE die Erstellung eigener lokaler Ontologien und die indirekte Wiederverwendung externer Ontologien durch die Eigenschaft rdfs:subClassOf: lokale Klassen werden als Unterklassen von externen Ontologien deklariert. Die Verwendung externer Ontologien verdeutlicht die Bedeutung des Konsenses bei der Wissensdarstellung. Die Modellierungsarbeit umfasst nicht nur formale und technische, sondern auch soziale und pragmatische Aspekte.
3 Die Zürcher Ehedaten des 16.–18. Jahrhunderts
In einem Pilotprojekt hat das Staatsarchiv Zürich, wie bereits erwähnt, die im Projekt NIE-INE entwickelten Ansätze und Erkenntnisse aufgegriffen und den Bestand der Zürcher Ehedaten des 16.–18. Jahrhunderts als Wissensnetz aufbereitet. Wie präsentierte sich die Ausgangslage?
Die Zürcher Ehedaten des 16.–18. Jahrhunderts vielmehr die Zürcher Pfarrbücher sind ein Vermächtnis der Institutionalisierung bzw. vermehrten administrativen Tätigkeiten der Zürcher Kirche im Zuge der Reformation. Sie umfassen knapp 300 000 Eheeinträge und nähern sich der Grundgesamtheit der Zürcher Bevölkerung der Frühen Neuzeit an.[9] Abbildung 1 zeigt zur Veranschaulichung einige der ersten Einträge.

Die ersten Eheeinträge im Grossmünster-Pfarrbuch in Zürich von 1525 (Quelle: Tauf- und Ehenbuch Grossmünster 1525 bis 1600: https://www.stadt-zuerich.ch/prd/de/index/stadtarchiv/bestaende/pfarrbuecher/Grossmuenster.html, 11.08.2022)
Die Eheeinträge wurden ursprünglich von einem privaten Genealogen über mehrere Jahre transkribiert und systematisch mit dem Ziel erfasst, ein Hilfsmittel für Familienforschende zu erstellen. Das Staatsarchiv Zürich hat die Daten erworben, ergänzt und normalisiert. Ein Datensatz wie dieser ist für die Zeit vor den modernen Volkszählungen im 19. Jahrhundert für die Schweiz einmalig.[10] Die Daten sind jedoch nicht nur inhaltlich für ein Semantic Web-Projekt interessant, sondern auch im Hinblick auf ihre Struktur. Es handelt sich um eine Kombination aus archivischen Primär- und Metadaten. Einerseits sind sie mit den üblichen Informationen im Archivinformationssystem (AIS) des Staatsarchivs Zürich verzeichnet, andererseits beinhalten sie die Transkriptionen der Kirchenbücher. Sie bieten somit die Möglichkeit, zu untersuchen, wie Semantic-Web-Technologien sowohl bei Verzeichnisdaten (Metadaten) als auch bei digital verfügbarem Archivgut (Primärdaten) zur Anwendung kommen könnten. Die Verzeichnung im AIS erfolgte mittels des Standards ISAD(G) in einer hierarchischen Baumstruktur. Die Pfarrbücher, in welchen die Eheeinträge enthalten sind, sind auf der zweituntersten Stufe Dossier, und die einzelnen Eheeinträge auf der untersten Stufe Dokument verzeichnet (vgl. Abbildung 2). Enthält ein Pfarrbuch sehr viele Eheeinträge, wurde noch eine Zwischenstufe Subdossier eingefügt.
Der im AIS des Staatsarchivs Zürich verzeichnete Ehedatensatz gilt für das vorliegende Projekt als Ursprungsversion bzw. Master und wird dies auch zukünftig sein. Änderungen werden im AIS vorgenommen und danach in die anderen Repräsentationen des Datensatzes überführt. Dies sind einerseits PDF-Dateien[11] und andererseits ein Open Government Datensatz (OGD) als einfache CSV-Tabelle.[12] Sowohl die PDF-Dateien als auch der OGD-Datensatz enthalten alle Eheeinträge auf der Stufe Dokument als Listenübersicht mit nahezu denselben Feldern wie im AIS. Namensformen wurden wie erwähnt normalisiert. Die Felder Seite im Band bzw. Pfarrbuch und Zusatzinformationen sind nicht für alle Datensätze vorhanden.
4 Modularer Aufbereitungsprozess des Wissensnetzes
Für die Aufbereitung eines Datensatzes mit Semantic-Web-Technologien gibt es noch keine etablierten Verfahren,[13] aber einige Vorschläge. Ein Ziel des Wissensnetzes der Ehedaten ist seine stetige Erweiterbarkeit. Es lohnt sich daher, diese Idee von Anfang an im Aufbereitungsprozess einfließen zu lassen. Peroni hat dieses Konzept in seinem Vorschlag der Methode Simplified Agile Methodology for Ontology Development (SAMOD) aufgegriffen. Ontologien werden dabei anhand von Testfällen modular aufgebaut.[14] Der Aufbereitungsprozess des Wissensnetzes (vgl. Abbildung 3) wurde anhand dieser Methode und der Resultate aus dem Projekt NIE-INE ausgearbeitet. Abbildung 3 zeigt die konkreten Arbeitsschritte dieses modularen Aufbereitungsprozesses. Ein Durchlauf kann als ein Modul verstanden werden, an dessen Ende immer ein konsistentes Wissensnetz steht.

Hierarchische Verzeichnung der Ehedaten im Archivinformationssystem (AIS) des Staatsarchivs Zürich (Grafik: Staatsarchiv des Kantons Zürich)
Um das Wissen, das in einem Datensatz vorhanden ist, zu erkennen, folgt zunächst eine intensive Auseinandersetzung mit dem Stoff. Es gilt, sich an den klassischen Fragen der historischen Quellenkritik und Quelleninterpretation zu orientieren. Oldman et al. fassen dies so zusammen: „The major role information systems […] can and should play is the support of the epistemological processes, i. e., what knowledge exists, where it comes from, where it has been used, where it can be used, and where it should be used.“[15] Bezüglich der Ehedaten bedeutete dies, zu fragen, was Entstehungskontext und Überlieferungsgeschichte der Pfarrbücher ist. Es gilt, sich mit dem historischen Kontext auseinanderzusetzen und in das Thema Ehe und Heirat im frühneuzeitlichen Zürich einzutauchen. Dies auch, um zu verstehen, welche Quellenbestände, Normdaten und allenfalls digital aufbereiteten Bestände mit den Ehedaten in Verbindung stehen und damit verlinkt werden könnten. So kristallisiert sich heraus, welche Forschungskontexte die Eheeinträge und Pfarrbücher berühren. Welche Fragen können mit den Daten beantwortet werden? Welche nicht?[16] Welche Hypothesen von Historikerinnen und Historikern existieren und könnten mit dem resultierenden Wissensnetz verifiziert werden?
Anhand dieser Analyse werden in einem nächsten Schritt konkrete Anwendungsfälle definiert. Für jeden Anwendungsfall werden Entitäten, Beziehungen und Regeln identifiziert. Um ein klareres Bild zu Normen und Moralvorstellungen im frühneuzeitlichen Zürich zu erhalten, könnte Historikerinnen und Historiker beispielsweise die Frage interessieren, an welchen Wochentagen im frühneuzeitlichen Zürich geheiratet wurde und ob dabei eine zeitliche Entwicklung feststellbar ist (vgl. Abschnitt 7). Identifizierte Entitäten wären hier unter anderem Datum und Wochentag, die diesbezügliche Beziehung wäre Datum hat Wochentag, und die Regel dazu wäre die Formel zur Berechnung des Wochentages aus dem Datum. Anhand der identifizierten Entitäten und Beziehungen wird danach ein Modell erstellt oder das als Resultat aus vorangegangenen Anwendungsfällen bestehende Modell erweitert.
Aus dem Modell wird anschließend die Ontologie gebildet. Nach Vorbild der Ontologien des Projekts NIE-INE wurden dafür im Modell Hauptkonzepte identifiziert. Ein Hauptkonzept wird in der Folge eine Ontologie. Zur Veranschaulichung ein kurzer Vorgriff: Als Resultat aus den Anwendungsfällen 1 und 2 (vgl. Abschnitt 5 und 6) ergeben sich folgende miteinander zusammenhängende Hauptkonzepte bzw. Ontologien: Archiving aus Anwendungsfall 1 und Place, Organization, Date, Marriage, Person aus Anwendungsfall 2. Aus jedem neuen Anwendungsfall ergibt sich also die Frage: Braucht es ein neues Hauptkonzept bzw. eine neue Ontologie oder mehrere? Wenn ja, wo knüpfen diese an die bestehenden Ontologien an? Und wenn nein, in welchen bestehenden Ontologien gilt es, welche Entitäten und Beziehungen hinzuzufügen?

Modularer Aufbereitungsprozess: Arbeitsschritte je Anwendungsfall (Grafik: Staatsarchiv des Kantons Zürich)
Üblicherweise wird erst nach der Erstellung der Ontologien nach entsprechenden Konzepten in externen Ontologien wie Records in Contexts (RiC-O) gesucht. Wenn das primäre Ziel Interoperabilität ist, kann es aber auch sinnvoll sein, externe Ontologien als Vorlage zu nutzen und die lokale Ontologie in Anlehnung an diese zu erstellen.[17] Externe Ontologien werden dabei wie von NIE-INE vorgeschlagen indirekt wiederverwendet. Erwähnenswert ist zudem, dass externe Ontologien auch zu einem späteren Zeitpunkt eingebunden werden können.
Nachdem die Ontologien erstellt sind, gilt es die Rohdaten der/den Ontologie/n zuzuordnen. Im vorliegenden Projekt geschah dies über Python-Skripte und die Python-Bibliothek rdflib.[18] Als Ausgangspunkt diente dabei die CSV-Tabelle des OGD-Datensatzes der Ehedaten. Der OGD-Datensatz wurde durch weitere Quelldaten, beispielsweise über Abfragen im AIS des Staatsarchivs, ergänzt.
In einem nächsten Schritt können die resultierenden Tripel mit Normdaten wie GND[19] (für Personen) und Geonames[20] oder mit externen Daten wie beispielsweise Artikeln im Historischen Lexikon der Schweiz (HLS)[21] verknüpft werden.[22] Diese Verknüpfung ist selten vollautomatisch möglich und mit entsprechendem Zeitaufwand verbunden. Um beispielsweise für Personen in den Ehedaten ihre zugehörigen HLS-Artikel zu finden, wurden Vor- und Nachnamen im entsprechenden Zeitraum der Artikel mittels eines Skripts abgeglichen und mögliche Kandidatinnen und Kandidaten aufgelistet. Die manuelle Überprüfung der Liste war dennoch oft mit zusätzlichem Rechercheaufwand verbunden.
Nach der Aufbereitung der Daten in Tripel werden sie idealerweise auf einen Triplestore geladen und veröffentlicht.[23] Die Tripel und Ontologien können aber auch nur als RDF/XML- oder Turtle-Dateien[24] publiziert werden und in eine lokale SPARQL-Umgebung geladen und dort abgefragt werden.
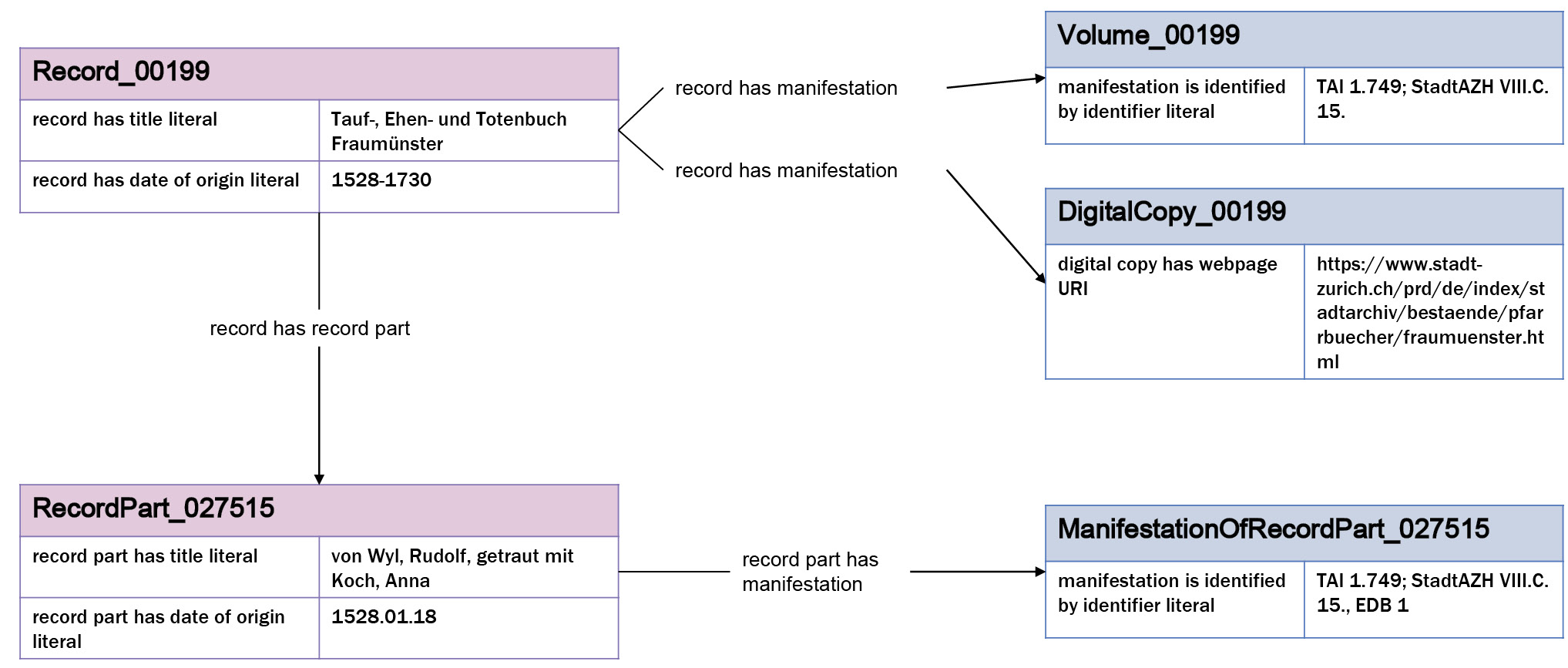
Ein Beispieldatensatz des Konzepts Archiving (Grafik: Staatsarchiv des Kantons Zürich)
Die beschriebenen Schritte (vgl. Abbildung 3) werden wie erwähnt pro Anwendungsfall wiederholt. Dabei läuft die inhaltliche Analyse erfahrungsgemäß immer mit. Resultat ist nach jedem Durchgang ein möglichst kohärentes, angereichertes, erweiterbares System, in welchem bekanntes Wissen explizit gemacht wird. Dieser modulare Aufbereitungsprozess ist im Prinzip nie abgeschlossen. Es können stetig neue Anwendungsfälle (und neues Wissen) umgesetzt werden, um das Wissensnetz weiter auszubauen.
Im vorliegenden Projekt zu den Zürcher Ehedaten stand als erstes Modul bzw. erster Anwendungsfall die Erfassung der Ehedaten in ihrem heutigen Kontext als Archivdaten im Zentrum. Dies bedeutete, von der jetzigen Repräsentation einer hierarchischen Baumstruktur zu einer Graph- bzw. Netzstruktur zu kommen (Abschnitt 5). Als zweites Modul wurden die Ehedaten in ihrem Entstehungskontext erfasst (Abschnitt 6). Anhand eines weiteren Anwendungsfalls möchten wir exemplarisch aufzeigen, wie mit Unsicherheiten in Daten umgegangen werden kann (Abschnitt 7).
5 Ehedaten als Archivverzeichnisdaten
Die Nutzenden, welche die Ehedaten heute abfragen, kennen die Daten als Archivverzeichnisdaten. Daher bietet das resultierende Hauptkonzept Archiving[25] dank eines Wiedererkennungseffekts einen guten Einstieg in das Wissensnetz der Ehedaten. Gleichzeitig orientiert sich die Ontologie Archiving an Records in Contexts und war der erste Praxistest dieses neuen Standards im Staatsarchiv Zürich.
Es stellt sich hier hauptsächlich die Frage, wie die jetzigen ISAD(G)-Felder in Abbildung 2 und deren Beziehungen unter der Verwendung von Records in Contexts in einer Ontologie umgesetzt werden können. Der Umstand, dass sich RiC-O zum Zeitpunkt der Entwicklung des vorliegenden Wissensnetzes mitten in einer Revisionsphase befindet, erschwerte die Umsetzung von Anwendungsfall 1. Andererseits konnte der Pilot sogleich als Praxistest dienen und die daraus resultierenden Verbesserungsvorschläge dem International Council on Archives (ICA) weitergeleitet werden. Hier zeigt sich auch der Vorteil, wenn lokale Ontologien erstellt werden. Gibt es bei RiC-O noch Anpassungen, muss nur die Einbindung überarbeitet werden. Die lokale Ontologie bleibt stabil.
Bei der Entwicklung der Ontologie Archiving orientierten wir uns unter anderem an den von Peroni et al. beobachteten Kernherausforderungen zur Beschreibung von digitalen Ressourcen.[26] Grundlage ihrer Erkenntnisse sind Auswertungen der verzeichneten Objekte in der virtuellen Bibliothek Europeana. Sie betonen dabei, dass es wichtig sei, im Datenmodell die Beziehung zwischen dem originalen physischen Objekt, des Archivales, und dessen digitaler/n Repräsentation/en zu klären. Abbildung 4 zeigt anhand eines Beispieldatensatzes die Umsetzung der hierarchischen Verzeichnung im AIS (Abbildung 2) in die neue Graphstruktur. Archivverzeichniseinheiten der verschiedenen Stufen (Record, RecordPart) mit der Beschreibung des Archivales haben das physische Objekt als Ausprägung (Manifestation) mit dessen Signatur oder dem Weblink des Digitalisates.[27]
Da die hierarchische Beziehung zwischen Pfarrbuch und Eheeintrag umgesetzt wurde, lassen sich in dieser ersten Form des Wissensnetzes bereits Informationen abfragen, welche den anderen Datenrepräsentationen der Ehedaten nicht zu entnehmen wären (der OGD-Datensatz beinhaltet nur die unterste Hierarchiestufe der Eheeinträge). Neben der Interoperabilität, dank Einbindung von RiC-O, stellt dies einen weiteren Mehrwert gegenüber den bestehenden Datenrepräsentationen dar.
6 Ehedaten in ihrem historischen Kontext
Neben der Repräsentation der Ehedaten in ihrem heutigen Kontext als Archivverzeichnisdaten galt es in einem nächsten Schritt, die Ehedaten in ihrer Eigenschaft als historische Quelle zu erfassen. Im Vergleich zum vorhergehenden Kapitel wird dieser Anwendungsfall mittels mehrerer Hauptkonzepte bzw. Ontologien abgebildet, um die spätere Erweiterung des Wissensnetzes zu erleichtern. Beim Modellieren der Ontologien stellt sich die Leitfrage: Was ist das explizite (und das implizite) Wissen, das die Ehedaten als Quelle(n) enthalten? Und wie lässt sich zudem eine Verbindung von den Ehedaten als Archivdaten zu ihrem ursprünglichen Daseinszweck herstellen? Wo knüpft also das zweite Modul an das erste an?
Bei den Ehedaten handelt es sich um Eheeinträge in einem Pfarrbuch, verfasst von einem Pfarrer, dessen Namen wir normalerweise nicht kennen (und darum auch nicht als identifizierte Entität erfassen). Die Entität Eheeintrag steht folglich im Zentrum des Datenmodells. Ein Eheeintrag betrifft dabei nicht zwingend die eigentliche Heirat eines Paares. In den Kirchgemeindebüchern wurden auch Verkündungen von Ehen verzeichnet. Die Zeremonie erfolgte dann in einer anderen Kirchgemeinde. Dieser Fall kam vor, wenn einer der Partner Mitglied der entsprechenden Kirchgemeinde war, jedoch nicht in dieser heiratete. Die Eheschließung eines Paares kann folglich bis zu dreimal in den Ehedaten erscheinen, dies dann, wenn beide aus einer Gemeinde der Stadt oder der Landschaft Zürich stammten, aber in einer nochmals anderen Zürcher Gemeinde heirateten.
Der Eheeintrag befindet sich in einem Pfarrbuch, und dieses Pfarrbuch wurde von einer bestimmten Kirchgemeinde geführt. Diese Kirchgemeinde ist eine Organisation und sie hat gleichzeitig die Rolle des Aktenbildners beziehungsweise der Provenienz der Pfarrbücher. Eine Kirchgemeinde ist also Subklasse der Klasse archiving:Agent (Akteur) in der Ontologie Archiving.
Ein weiterer Anknüpfungspunkt an die Ontologie Archiving ist jener, dass ein archving:RecordPart einen Eheeintrag repräsentiert und ein archving:Record ein Pfarrbuch. Eine Kirchgemeinde hat ihren Sitz an einem geographischen Ort. Eheeinträge sind datiert auf ein bestimmtes Datum, das bis 1700 dem Julianischen, dann dem Gregorianischen Kalender folgt. In manchen Fällen ist die exakte Datierung allerdings nicht bekannt, sondern befindet sich innerhalb einer Datumsperiode. Diese Datumsperiode hat ein Startdatum und ein Enddatum gemäß Julianischem beziehungsweise Gregorianischem Kalender. Sowohl Datum als auch Datumsperiode sind Subkonzepte der Klasse archiving:TimePeriod (Zeitperiode) in der Ontologie Archiving. Ein Eheeintrag registriert Personen, jeweils einen Mann und eine Frau. Der Pfarrer notierte meistens ihre Vor- und Nachnamen. In vielen Fällen ist zudem ihre Herkunft (Ort) angegeben. Zu einem Eheeintrag hat der Pfarrer neben den Namen und der Herkunft der Personen oft noch weitere Bemerkungen vorgenommen. Steht eine Bemerkung neben dem Namen der Frau, so betrifft er auch tatsächlich die Frau. Steht sie neben dem Namen des Mannes, kann sie entweder seine Person oder auch die Heirat als solche betreffen – beispielsweise, welcher Psalm während der Trauung gelesen wurde. Abbildung 5 zeigt das Datenmodell und die Hauptkonzepte, welche aus dem oben Beschriebenen resultieren. Zudem zeigt sie, wie und wo das Modell an die Ontologie Archiving anknüpft.

Datenmodell und Hauptkonzepte resultierend aus Anwendungsfall 2 (Grafik: Staatsarchiv des Kantons Zürich)
7 Heiratswochentag: Ein Beispiel für den Umgang mit Unsicherheiten
Eine Herausforderung bei der Entwicklung eines Wissensnetzes im historischen Bereich ist der Umgang mit Unsicherheiten in den Daten. In der Forschung finden sich noch wenig Hinweise darauf, wie Unsicherheiten konkret in einer Ontologie modelliert werden können. In den meisten Fällen würde es helfen, wenn eine Aussage, repräsentiert in einem Tripel, als nicht gesichert gekennzeichnet werden könnte. Aussagen über ganze Tripel betreffen die Thematik der Reification, welche mittels RDF-Star[28] angegangen wird. Da RDF-Star noch kein Standard ist, mussten im Ehedaten-Projekt andere Wege gefunden werden. Eine mögliche Herangehensweise möchten wir anhand der Erweiterung des Wissensnetzes um den Heiratswochentag diskutieren (vgl. Beispiel-Anwendungsfall in Abschnitt 4).
In Abschnitt 6 wurde bereits erwähnt, dass ein Eheeintrag nicht zwingend die Heirat eines Ehepaares dokumentiert: Er konnte auch die Verkündung einer Eheschließung ein paar Tage vor der eigentlichen Trauung betreffen. In diesem Anwendungsfall gilt es folglich zu ermitteln, welche Eheeinträge eine Verkündung und welche eine Trauung betreffen. Dies ist auch für weitere Anwendungsfälle relevant. Nur mit dieser Unterscheidung kann die tatsächliche Anzahl der Heiraten in einem Zeitraum ermittelt werden, was für viele Fragestellungen maßgebend ist, beispielsweise für Fragen zur Bevölkerungsentwicklung. Aus Anwendungsfall 3 ergibt sich eine Erweiterung des Modells und der Ontologie Date um Wochentag und Jahr. Um den Wochentag aus dem Datum zu berechnen, musste zuerst aus allen Datierungen nach Julianischem Kalender die Datierung nach Gregorianischem Kalender abgeleitet werden. Somit ist das Wissensnetz auch um die Information angereichert, als dass nun für alle Datierungen die gregorianische integriert ist.
Ob ein Eheeintrag eine Heirat oder Verkündung dokumentiert, kann kaum ohne erheblichen Zeitaufwand für alle 300 000 Einträge mit abschließender Sicherheit ermittelt werden. Wir haben aber diesbezügliche Kriterien ermittelt:
Fällt die Datierung eines Eheeintrags auf den Sonntag, so betrifft dieser ab 1620 (Verbot von Sonntagsheiraten) sehr wahrscheinlich eine Verkündung.
Enthält ein Eheeintrag explizit den Vermerk „promulgiert“ oder „proklamiert“ oder versah ihn der Bearbeiter der Daten mit dem Vermerk „Verkünddatum“, so betrifft dieser sehr wahrscheinlich ebenfalls eine Verkündung.
Enthält ein Eheeintrag den Vermerk „getraut zu …“, so betrifft dieser sehr wahrscheinlich ebenfalls eine Verkündung (einer in einer anderen Kirchgemeinde erfolgten Trauung).
Treffen a, b und c nicht zu, so betrifft der Eheeintrag wahrscheinlich die Heirat.
Der vorliegende Fall „Eheeintrag betrifft Verkündung oder Heirat“ ist ein dualer. Es kann sich nur um das eine oder das andere handeln. Daher wurden in der Ontologie Marriage zwei neue Beziehungen eingefügt und zwar: „Eheeintrag dokumentiert Verkündung mit Sicherheitswert“ und „Eheeintrag dokumentiert Heirat mit Sicherheitswert“. Dafür wurde zusätzlich die Ontologie Certainty-Value[29] erstellt, welche es ermöglicht, auf Entitäten wie „wahrscheinlich“ (likely) zu verweisen.

Erweiterung der Ontologie Marriage um Eheverkündung/Heirat (Grafik: Staatsarchiv des Kantons Zürich)

Resultat einer SPARQL-Abfrage zur Entwicklung der Heiratswochentage in den Städten Winterthur und Zürich (Grafik: Staatsarchiv des Kantons Zürich)[31]

Resultat einer SPARQL-Abfrage zur Entwicklung der Heiratswochentage auf der Zürcher Landschaft (Grafik: Staatsarchiv des Kantons Zürich)[32]
Erste Abfrageresultate der Heiratswochentage im Zeitraum von 1525 bis 1800 in den Städten Zürich und Winterthur (vgl. Abbildung 7) und auf der Zürcher Landschaft (vgl. Abbildung 8) zeigen ein klares Bild: In den Städten wurde hauptsächlich am Montag und auf dem Land bis zum Verbot der Sonntagsheirat 1620 am Sonntag und danach am Dienstag geheiratet. Zumindest beim Dienstag handelt es sich offenbar um den Tag des Wochengottesdienstes.[30] Die einzige Ausnahme bildet das Jahr 1700, wo auch auf dem Land der Montag der häufigere Heiratswochentag gewesen zu sein scheint (vgl. Abbildung 8). Da es sich hier um das Jahr vor dem Kalenderwechsel handelt, wäre an einen Umrechnungsfehler zu denken. Ein solcher hätte jedoch andere Auswirkungen auf das Datenbild gehabt. Stichproben weisen auf eine andere Erklärung hin: In diesem Jahr findet sich auf der Zürcher Landschaft bei einigen Einträgen der Vermerk „Samstags“, die Datierung nach Julianischem Kalender ergibt aber den Sonntag.[33] Kam es hier aufgrund des anstehenden Kalenderwechsels zu einer Verwechslung in den Landgemeinden? Es ist durchaus vorstellbar, dass der Vollzug des Kalenderwechsels die Landgemeinden vor Schwierigkeiten stellte.
Die beiden Spitzen 1613 und 1631 erklären sich im Übrigen mit vorangehenden Pestjahren, die einen deutlichen Anstieg der Heiraten zur Folge hatten.[34]
Neben dem Umgang mit Unsicherheiten über eine Beziehung zu einem Sicherheitswert, kann die Unsicherheit auch direkt in die Beziehung mit aufgenommen werden. Beispielsweise hatten die geographischen Orte, die in den Ehedaten vorkommen, in der Frühen Neuzeit oft andere Grenzen als heute, und diese sind selten genau zu ermitteln – wenn sie denn überhaupt exakt bestanden. Um die Orte dennoch mit geographischen Normdaten zu verknüpfen, könnte eine Beziehung wie „entspricht in etwa heutigem Ort“ definiert werden.
8 Publikation der Ehedaten als Linked Open Data
Daten, Ontologien, Konvertierungsskripte und Beispielabfragen zum Wissensnetz der Ehedaten stehen Interessierten auf einem öffentlichen Github-Repository zur Verfügung.[35] Daten und Ontologien konnten während der Projektphase auf die Testumgebung der Linked Open Data Platform LINDAS des Schweizerischen Bundesarchivs[36] geladen und validiert werden. Für eine Publikation von offenen Daten auf LINDAS ist beim Kanton Zürich die OGD-Fachstelle beim Statistischen Amt zuständig. Als Resultat des Austausches mit der Fachstelle im Rahmen dieses Projekts hat sich eine Arbeitsgruppe gebildet, welche eine Publikation der Ehedaten als Linked Open Data gemeinsam mit weiteren geeigneten Datensätzen des Kantons Zürich auf LINDAS anstrebt und in einem ersten Schritt nun die Ehedaten in einer kompakten Version als Linked Open Data abfragbar gemacht hat.[37]
About the authors

Rebekka Plüss, M. A.

Dr. des. Roberta Padlina
© 2022 bei den Autorinnen, publiziert von De Gruyter.
Dieses Werk ist lizensiert unter einer Creative Commons Namensnennung 4.0 International Lizenz.
Articles in the same Issue
- Titelseiten
- Editorial
- Fachbeiträge
- Wissensnetz der Zürcher Ehedaten des 16.–18. Jahrhunderts: Eine Anwendung von Semantic-Web-Technologien im Archiv
- Wie geht bedarfsorientiertes Forschungsdatenmanagement?
- Nutzungsforschung in der Universitätsbibliothek der Freien Universität Berlin: Werkstattbericht zur Beteiligung am internationalen Projekt „Cancelling the Big Deal“
- Die Hochschulbibliotheken in NRW auf dem Weg in die Alma-Cloud
- Auf dem Weg zum Dritten Ort
- Den Lern- und Bildungsraum Hochschulbibliothek gestalten. Zwei neue Campusbibliotheken an der TH Köln
- Die „neue“ Schleswig-Holsteinische Landesbibliothek als Dritter Ort: Konzeptionelle Überlegungen und Umbauplanungen
- Brixen – der lange Weg zur neuen Stadtbibliothek
- Tagungsbericht
- #FreiräumeSchaffen – Der 8. Bibliothekskongress in Leipzig vom 31. Mai bis zum 2. Juni 2022
- LIBER 2022
- Leading Libraries in the World of Openness
- Die Kultur macht den Unterschied – wie macht man einen Unterschied in der Kultur?
- Nachrichten
- Nachrichten
- Produktinformation
- Produktinformationen
- ABI Technik-Frage
- Wie funktioniert eine Wikiversitätsstadt?
- Rezension
- Qualität in der Inhaltserschließung. Hrsg. von Michael Franke-Maier, Anna Kasprzik, Andreas Lendl, Hans Schürmann (Buch- und Informationspraxis; 70). Berlin/Boston: De Gruyter Saur, 2021. VI, 420 S. – ISBN: 9783110691498. € 72,95
- Veranstaltungskalender
- Veranstaltungskalender
Articles in the same Issue
- Titelseiten
- Editorial
- Fachbeiträge
- Wissensnetz der Zürcher Ehedaten des 16.–18. Jahrhunderts: Eine Anwendung von Semantic-Web-Technologien im Archiv
- Wie geht bedarfsorientiertes Forschungsdatenmanagement?
- Nutzungsforschung in der Universitätsbibliothek der Freien Universität Berlin: Werkstattbericht zur Beteiligung am internationalen Projekt „Cancelling the Big Deal“
- Die Hochschulbibliotheken in NRW auf dem Weg in die Alma-Cloud
- Auf dem Weg zum Dritten Ort
- Den Lern- und Bildungsraum Hochschulbibliothek gestalten. Zwei neue Campusbibliotheken an der TH Köln
- Die „neue“ Schleswig-Holsteinische Landesbibliothek als Dritter Ort: Konzeptionelle Überlegungen und Umbauplanungen
- Brixen – der lange Weg zur neuen Stadtbibliothek
- Tagungsbericht
- #FreiräumeSchaffen – Der 8. Bibliothekskongress in Leipzig vom 31. Mai bis zum 2. Juni 2022
- LIBER 2022
- Leading Libraries in the World of Openness
- Die Kultur macht den Unterschied – wie macht man einen Unterschied in der Kultur?
- Nachrichten
- Nachrichten
- Produktinformation
- Produktinformationen
- ABI Technik-Frage
- Wie funktioniert eine Wikiversitätsstadt?
- Rezension
- Qualität in der Inhaltserschließung. Hrsg. von Michael Franke-Maier, Anna Kasprzik, Andreas Lendl, Hans Schürmann (Buch- und Informationspraxis; 70). Berlin/Boston: De Gruyter Saur, 2021. VI, 420 S. – ISBN: 9783110691498. € 72,95
- Veranstaltungskalender
- Veranstaltungskalender