Aspect-based sentiment analysis on multi-domain reviews through word embedding
-
Mukkamula Venu Gopalachari
 ,
Sangeeta Gupta
,
Sangeeta Gupta

Abstract
The finest resource for consumers to evaluate products is online product reviews, and finding such reviews that are accurate and helpful can be difficult. These reviews may sometimes be corrupted, biased, contradictory, or lacking in detail. This opens the door for customer-focused review analysis methods. A method called “Multi-Domain Keyword Extraction using Word Vectors” aims to streamline the customer experience by giving them reviews from several websites together with in-depth assessments of the evaluations. Using the specific model number of the product, inputs are continuously grabbed from different e-commerce websites. Aspects and key phrases in the reviews are properly identified using machine learning, and the average sentiment for each keyword is calculated using context-based sentiment analysis. To precisely discover the keywords in massive texts, word embedding data will be analyzed by machine learning techniques. A unique methodology developed to locate trustworthy reviews considers several criteria that determine what makes a review credible. The experiments on real-time data sets showed better results compared to the existing traditional models.
1 Introduction
It could require a lot of time to conduct online research for product reviews [1]. A consumer must read multiple reviews on various websites to get a feel of a product’s benefits and drawbacks. Customers are looking for a more accurate breakdown of all reviews when they read many testimonials on social media. Making the user’s decision-making process easier would be to provide dependable reviews based on specific criteria. Finding a method for effectively condensing review data would not only assist customers in making wiser judgments but also increase market awareness of quality [2].
In addition, an efficient review analyzer would provide quick input that could be applied to improving services. As a result, the market needs quality keyword extraction and polarity quantifying techniques that would help in the optimal mapping of customers and companies. The use of sentiment analysis is advantageous in a wide range of different industries to sort out business challenges [3]. The main applications include market analysis, consumer opinion analysis, and the analysis of product reviews. They can be applied to many other sectors, such as e-commerce, services, and electronics. E-commerce platforms like Amazon and Flipkart have tried to reflect a product’s features, but the existing techniques are frequently insufficient and lack the weight of more significant criteria because they only employ evaluations from the relevant industry [4]. The fewer data accessible in terms of size or users causes an issue known as “cold start,” which has an impact on the quality of information retrieval [5]. The dynamics of the sentiment analysis over aspects in short text messages or reviews are more sensitive toward a single data source and thus get affected by the volume of the relevant part of the data. For instance, if the volume of reviews related to a particular item in e-commerce is low, it leads to a cold start, which in turn affects the quality of the aspects in sentiment analysis. The field of aspect-based sentiment analysis has had numerous different modifications and crossed many different new eras, thus it is not a straight journey. Researchers have been putting forth a lot of effort to address complex problems with numerous facets in the field of sentiment analysis. With a variety of machine-learning techniques, primarily deep-learning techniques, they have developed comprehensive answers to numerous complex issues with respect to the quality of aspects [6].
In this work, the proposed system develops a framework that effectively gathers product reviews from various e-commerce websites (e.g., Amazon, Flipkart, and Snapdeal) that determine the attributes of the concerned product along with their related adjectives and check for any other structural text discrepancies. In addition, a system to effectively gather product reviews from all three major e-commerce websites is developed, which extracts the features of the products discussed along with their corresponding adjectives while ensuring that there are no other structural text inconsistencies [5].
Aspect extraction (AE), aspect sentiment analysis, and sentiment evolution are the three basic processing phases that can be used to categorize aspect-based sentiment analysis (ABSA) as shown in Figure 1. The extraction of aspects, including explicit aspects, implicit aspects, aspect terms, entities, and opinion target expressions, is the focus of the first phase. The second stage categorizes the polarity of sentiment for a chosen aspect, target, or object. To increase the accuracy of sentiment classification, this phase also formulates interactions, dependencies, and contextual semantic linkages between various data items, such as aspect, entity, target, multi-word target, and sentiment word. Ternary, or fine-gained sentiment, values can be used to categorize the conveyed emotion. The third stage focuses on how the attitudes of people toward certain characteristics (or events) change over time, and sentiment evolution is thought to be mostly caused by social factors and personal experiences [7].

Traditional phases in aspect-based sentiment analysis.
2 Related work
According to studies, SA may often be divided into three levels. To categorize whether a document as a whole, a statement (subjective or objective), or an aspect reflect a feeling, i.e., whether it is positive, negative, or neutral. Comparatively, the ABSA, which places a direct emphasis on sentiments rather than language structure, aids in a better understanding of the SA issue. The core idea of an aspect extends beyond judgment to include thoughts, points of view, ways of thinking, viewpoints, an underlying theme, or a social effect on an occurrence when an aspect is associated with an entity. Hence, ABSA offers a fantastic opportunity to analyze public opinions over time across various media-presented topics. Prior approaches have used a wide range of techniques to assist with the AE component, including parsing, named entity recognizers, bag-of-words, semantic analysis, and domain-specific ones like word clusters [8]. In addition, there are some techniques that focus on identifying the nouns that a viewpoint describes. However, word vectors, which convert words into vectors of a preset length, can be used to efficiently handle issues like the multi-class categorization of words [9]. When word vectors are used, the game changes as there are so many applications. In this work, it is discovered that the most accurate results were produced when this method was used with K-Means clustering.
Many strategies have been put forth in the literature for ABSA, including deep learning-based mode and more conventional feature-based models [10,11]. A few researchers attempted to apply the pre-trained bidirectional encoder representations from transformers model to ABSA in the context of the recent pattern of fine-tuning pre-trained models in natural language processing tasks, and they achieved the most cutting-edge results on multiple benchmark datasets [12]. Despite the substantial improvement, most of these systems mainly rely on textual content and ignore other related modalities, such as images with facial expressions. The input from various methods is crucial for anticipating the sentiment polarities regarding target aspects, as many online forums are becoming more multimodal. This encouraged a number of recent research to propose using beneficial information from images to increase the task performance of ABSA [13].
The phases of the review analysis process that can be separated are AE and multi-domain scraping [14]. The older techniques for extracting online reviews retrieved them from a single website. Multi-domain scraping has trouble identifying products and finding reviews that are hard to find using simple HTML parsers [15,16]. Either single domain scraping or multi domain scraping can handle browsing tasks are usually automated with tools like selenium will use the unique identifiers to search for products will resolve the mentioned concerns.
The accuracy may be further enhanced by recurrent neural network, which handles the context of phrase structures that our suggested system might not be able to recognize [17]. Reviews that are deemed insufficiently trustworthy are filtered using the trustability scores that have been calculated as a threshold. To gain the most reliable perspective on the product, the customer can also consider the reviews with the highest trustability rankings. The user receives a significantly more reliable appraisal of the product and its features because the least reliable scores are taken away [18].
3 Methodology
In order to avoid the cold start problem, the proposed system is modeled in two phases. In the first phase, dynamic multi-domain scraping is done, and in the second phase, product review keyword extraction and trustability scores are determined. The model in Figure 2 depicts the entire system design, which includes the aforementioned phases.

System architecture of multi-domain ABSA.
3.1 Dynamic multi-domain review scraping
The Python package Selenium is used to carry out the review scraping procedure. This package is useful for automated browsing. Selenium enables web page interaction, website browsing, and HTML code parsing. The technique uses the product’s particular model number to look for it on numerous websites. The following three steps are involved.
3.1.1 Individual ID recognition
The system launches a browser and uses Selenium to visit the link from the product’s link. Using the HTML tag ID from the webpage, the product’s distinctive model number is derived. Multiple domains search for the product using the model number. It currently searches Snapdeal and Flipkart.
3.1.2 Finding the product
The product is found by parsing the HTML code of the search result pages and using the links to the appropriate products. The links to the recognized products’ review pages are processed.
3.1.3 Scraping and compiling reviews
On the relevant review sites, Beautiful Soup uses tag IDs to identify the reviews, and then it extracts the review’s text and other information. The data are saved to a .csv file and kept in a Pandas DataFrame. As a result, we automatically compile product reviews from various sources. The following characteristics are present in each review: title, rating, description, and upvotes for the review.
3.2 Review trustability and keyword extraction
The review trustability and keyword extraction stages are made to find credible reviews and, as a result, to extract the characteristics of the product under consideration. All stages of the process are included in the extraction stage.
3.2.1 Review trustability score
The trustworthiness score of a review denotes the degree to which the viewpoint may be relied upon. The four main components of a review that make up the score are as follows:
Length of Sentences – Longer evaluations are frequently more thorough and accurately describe the product. Effectively counted the sentences in each review using the spaCy program.
Readability – Look at the words used, the sentence structures, and other elements to determine readability. It describes how straightforward the text is to read. Reviews that are simpler to read are frequently thought to be more trustworthy. Using the Automated Readability Index technique, we determined the readability score for a particular review. This approach takes word structure into account and is often based on a word list’s percentage of simple words or the average number of syllables per word.
Target words – When looking at a review, a reader focuses mostly on specific words to identify the review’s structure. Each target word has been counted for how many times it appears in each review while also accounting for its benefits, drawbacks, pros, and disadvantages.
The number of votes: Obviously, the reviews with the most votes are the most helpful.
The sum of the points for each component is used to calculate the review’s overall trustworthiness score. The scores have been changed so that they range from [0,1]. Therefore, using the final scores of each review to determine whether a score greater than the threshold (average of normalized scores) applies, we arrive at a conclusion that is communicated at the visualization step.
The score of credibility is defined by considering the textual and sentimental factors of the reviews as follows:
where N(x) stands for the normalization function, resulting in a [0,1] range, V i reflects the value of a certain aspect, and W i denotes the weighting given to various factors based on typical customer behavior.
In the proposed methodology, four factors are defined and weighted, as shown in Table 1.
Textual and sentiment factors with weightages
| S. no. | V i | W i |
|---|---|---|
| 1 | Sentence count | 0.2 |
| 2 | Reading comprehension | 0.3 |
| 3 | Target words | 0.2 |
| 4 | Upvoted votes | 0.3 |
3.2.2 Pre-processing
The review content that has been scraped from numerous different domains is cleaned up by the cleaning software we have created. It gets rid of additional characters, hyperlinks, symbols, spaces, and other text patterns that our algorithms could not handle. We also replaced several period symbols with a single period. We extracted the text description for our study from this cleaned dataset. The other irregularities that predominate in the scraped evaluations are the data type and data organization within their connected attributes. We have tools for both typecasting the data into the format that is absolutely necessary and for removing the extraneous information that is included with the pertinent data.
3.2.3 Extraction of noun–adjective pairs
The first step here is to change the votes information into numeric representation in order to do make better study of attributes. The primary goal of this stage is to extract the attributes and any related modifiers (adjectives). We created a dependency parse tree using the Python tool spaCy in order to extract aspect-adjective pairings based on specific syntactic dependency paths. The result of this stage is a dictionary of these noun–adjectives, which is utilized as an input in the next step of grouping aspects (Figure 3).
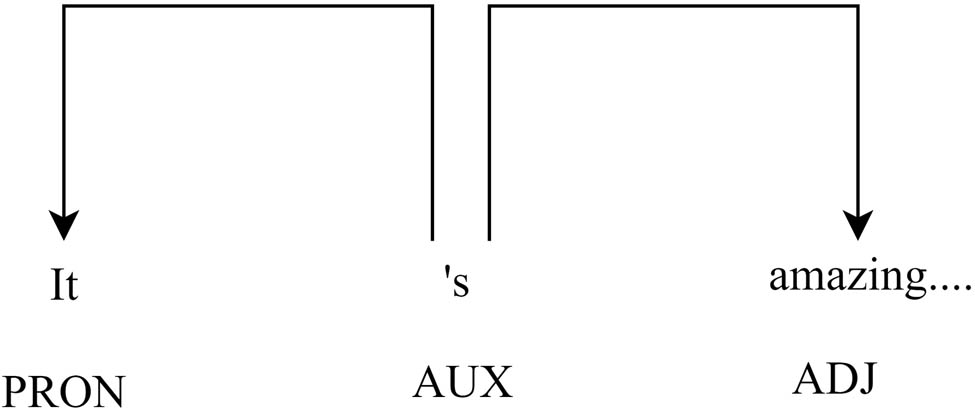
Dependency parse tree.
The rules were constructed from the terms in the parts-of-speech tags of the review text. For example, the phrase’s noun would be a word with the “nsubj” dependence relationship to the verb token, and the noun’s adjective would be a word with the “acomp” dependence relationship. In addition, we replaced every usage of the pronoun “product” with the word “Product,” because, in its general sense, the pronoun refers to the complete product. As a result, this pair would be extracted as a relevant aspect–modifier pair. In the picture below, “A” stands for the aspect, while “M” and “M′” are the appropriate modifiers of the adjective for the aspect. This illustrates some of the ideas we came up with (Figure 4).

Rules explanation.
3.2.4 Grouping aspects
This is done in two steps. First step is aspect generation using word embedding process and the second step is clustering the generated aspects.
3.2.4.1 Word embedded aspects generation
We may detect how similar two words are by comparing the word vectors produced by the integrated high-performance vectorization model of spaCy. Using spaCy for vectorization allows you rapid and simple access to over a million different word vectors, and unlike other libraries like NLTK, its multi-task convolution neural network model is trained on “web” data rather than “newspaper” data.
3.2.4.2 Clustering aspects
SciKit Learn’s K-Means technique is then used to group the word vectors. We obtained effective results for 15 clusters using the K-Means approach, which varies in effectiveness depending on the quantity of data provided. The term that most often appeared in each cluster was used to designate the clusters.
3.2.5 Determining polarity scores
To identify the polarity of the aspect’s adjectives, we utilized the NLTK library’s Vader Sentiment Analysis approach. We chose this method over the spaCy and Text Blob approaches by taking speed and accuracy into consideration. We calculated the compound polarities of the set of derived adjectives and then added them all together to get the final aspect polarity.
3.2.6 Visualization
We utilized the Matplotlib library to display the ABSA results and the review’s credibility. In contrast, the ABSA bar plots display the final most popular subjects across various domains, such as Flipkart, Amazon, and Snapdeal, as positive and negative bars with appropriate polarity values. Review trustability bar plots give information about the demographics and reviews that were assessed.
4 Results and discussions
The technology we built can dynamically extract reviews from many domains. Currently registered domains include Flipkart, Amazon, and Snapdeal. For the majority of the products, there are several reviews available on the most well-known websites, Amazon and Flipkart. Snapdeal continued to create fewer reviews. Getting a specific model number from Flipkart is the first step in the process, which is then utilized to obtain information from Amazon and Snapdeal. After scraping the reviews using the techniques, the keywords of a text are retrieved along with the corresponding adjectives, and the polarity for these qualities is established along with the trustworthiness score for each review. The keywords or elements provide a succinct but impactful grasp of the material by summarizing the information in the text. The example on the “Dell Inspiron Laptop” is discussed further.
4.1 Elements
The system looks up the goods on Amazon, Flipkart, and Snapdeal and displays bar graphs of the analyzed data. Let us examine each experiment performed on Amazon, Flipkart, and Snapdeal for the analysis of product reviews using our method and then compare them all.
The 15 aspects of the product that have received the most attention on Amazon are shown in Figure 5. We can see that the abundance of information is allowing our system to effectively capture many of the reviews posted on Amazon. A few elements have negative and neutral attitudes, while most of the aspects have good opinions.

Amazon’s aspects with corresponding sentiments for “Dell Inspiron Laptop.”
The 15 aspects of the product that have received the most attention on Flipkart are shown in Figure 6. The system effectively identified the topics that were discussed and showed varied behavior among the topics, showing opinions that were both favorable and negative.

Flipkart’s aspects with corresponding sentiments for Dell Inspiron Laptop.
The five components of the product that have received the greatest attention on Snapdeal are shown in Figure 7. The analysis’s capacity to present various features is impacted by the information’s restricted availability, as can be seen in Figures 5 and 6. The well-known cold start issue occurs as a result of insufficient data availability. A user is given confusing reviews and ratings because, unlike Amazon and Flipkart, the elements are largely good. Our suggested system, which takes into account the information from all three of the aforementioned domains and conducts an overall analysis, resolves this.

Snapdeal’s aspects with corresponding sentiments for Dell Inspiron Laptop.
The 15 product features that have received the most attention on Amazon, Flipkart, and Snapdeal are represented in Figure 8. In contrast to current techniques, the characteristics are grouped based on the semantics of the aspects. The most frequent characteristic within each cluster also emerges as the cluster’s final element. In this manner, 15 clusters of various viewpoints produce 15 distinct features that effectively depict the product. This avoids the prejudice of only showing the top 15 often-mentioned features overall and instead displays all pertinent aspects of all the perspectives discussed. By expanding the richness of the aspects and the needs of the consumers, this analysis surpasses all other studies.

Dynamic multi-domain aspects with corresponding sentiments.
The experiments conducted on individual and integral data sources depict the performance of the proposed model w.r.t. the determined aspects and the corresponding sentiment of the particular aspect. For example, the aspect named “user” in Figure 7 is more inclined to positive polarity around 0.6 due to the lower volume of reviews, whereas in Figure 8, it is showing less than 0.2. In addition, a few aspects that exhibit negative sentiment polarity were not actually considerable when the volume of the input increased. This infers that the dynamics in the weightage of the aspects in the reviews improved with a high distribution and less bias.
4.2 Review trustability
One important issue resolved in our research was the reliability of reviews. The important elements of sentence length, readability of review content, amount of upvotes, and target terms have been used to assign a trustability score to each review that is scraped from various domains. We avoid any prejudice that might result from showing the most helpful review based merely on the number of upvotes by taking into account all of these indicators.
The majority of e-commerce companies simply use the number of positive reviews as a quantitative criterion for customers to determine how trustworthy a review is. Figure 9 illustrates how our algorithm evaluates the reliability of reviews using four key metrics (Votes, Sentences, Triggering Words, and Readability). By addressing biases in the current system, this technique can direct customers to reviews that are beneficial. The average of the normalized scores generated yields a threshold.

Example of reviews recognized as per trustability score threshold.
As a result, it can be said that the system created provides the client with relevant information that he might not discover while browsing an e-commerce website and is, for the most part, an improvement over the review presentation method used by those websites (Table 2).
Bottom-most reviews based on the trustability score
| Comment | Trustability |
|---|---|
| ok | 0.00 |
| go for it | 0.056 |
| i love it | 0.066 |
| wow | 0.075 |
| good for 50k | 0.162 |
Customers do not respect reviews that are just a description of a product, as seen in Figure 9, and as a result, the trustworthiness score is lower. Organizations can greatly benefit from this because it expands the field of use for feedback analysis.
5 Conclusion
The proposed work will make a substantial contribution to the removal of bias from the current commercial system. The review corpus expands when more domains are used as extraction sources for a single product. As a result, the product is represented more accurately, and customers have less trouble using different apps. Furthermore, it helps reveal prejudice that is specific to websites. The approach works well for products with a certain model number or ID that are correctly supplied. As a result, the system uses dynamic multi-domain scraping to overcome the cold start problem. The availability of data is one of the scraping’s limitations. The scrape is limited to those things solely because the model number is identified for many significant and tangible goods.
In the phase of AE, noun–adjective pairs are identified by the use of natural language processing techniques. The most effective method of detecting features is through this type of grammatical analysis. The information from many aspects was combined into a much smaller number of aspect clusters once the aspects were clustered. The adjectives in the questions rely on their context, which is important to keep in mind. The polarity values that are generated, which are more accurate than those from context-free sentiment analysis, are built on these context-based adjectives.
Acknowledgments
It would be our pleasure to extend our sincere declaration to the Department of Information Technology at Chaitanya Bharathi Institute of Technology in Hyderabad, India for continuous support in carrying this research.
-
Author contributions: Mukkamula Venu Gopalachari has conceptualised the proposed approach, executed the architecture, performed the experiments, collected, and concluded the results. Sangeeta Gupta and Salakapuri Rakesh has validated the concept of approach, analysed the methodology and results. Dharmana Jayaram and Pulipati Venkateswara Rao audited the whole architecture of the approach and experimental results.
-
Conflict of interest: Authors state no conflict of interest to disclose.
-
Data availability statement: The dataset used for this research is available online and has a proper citation within the article s contents.
References
[1] Ananthajothi K, Karthikayani K, Prabha R. Explicit and implicit oriented aspect-based sentiment analysis with optimal feature selection and deep learning for demonetization in India. Data Knowl Eng. 2022;142:102092.Search in Google Scholar
[2] Alyami S, Alhothali A, Jamal A. Systematic literature review of Arabic aspect-based sentiment analysis. J King Saud Univ - Comput Inf Sci. 2022;34(9):6524–51.Search in Google Scholar
[3] Araque O, Corcuera-Platas I, Sánchez-Rada J, Iglesias C. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst Appl. 2017;77(19):236–46.Search in Google Scholar
[4] Lu Q, Sun X, Sutcliffe R, Xing Y, Zhang H. Sentiment interaction and multi-graph perception with graph convolutional networks for aspect-based sentiment analysis. Knowl Syst. 2022;256:109840.Search in Google Scholar
[5] Dai X, Bikdash M, Meyer B. From social media to public health surveillance: Word embedding based clustering method for Twitter classification. SoutheastCon 2017; 2017. p. 1–7.Search in Google Scholar
[6] Khan M, Alam M, Basheer S, Ansari MD, Kumar N. A map reduce clustering approach for sentiment analysis using big data. Cognit Sci Technol. 2022;1:223–9. 10.1007/978-981-19-2350-0_22.Search in Google Scholar
[7] Venugopalan M, Gupta D. An enhanced guided LDA model augmented with BERT based semantic strength for aspect term extraction in sentiment analysis. Knowl Syst. 2022;246:108668.Search in Google Scholar
[8] Kamkarhaghighi M, Makrehchi M. Content tree word embedding for document representation. Expert Syst Appl. 2017;90:241–9.Search in Google Scholar
[9] Wang W, Pan SJ, Dahlmeier D, Xiao X. Recursive neural conditional random fields for aspect-based sentiment analysis. Proc. Conf. Empirical Methods Natural Lang. Process; 2016. p. 616–26.Search in Google Scholar
[10] Ma Y, Peng H, Khan T, Cambria E, Hussain A. Sentic LSTM: A hybrid network for targeted aspect-based sentiment analysis. Cogn Comput. 2018;10(4):639–50.Search in Google Scholar
[11] Luo H, Li T, Liu B, Wang B, Unger H. Improving aspect term extraction with bidirectional dependency tree representation. IEEE/ACM Trans Audio Speech Lang Process. 2019;27(7):1201–12.Search in Google Scholar
[12] Pontiki M, Galanis D, Papageorgiou H, Manandhar S, Androutsopoulos I. Semeval-2015 task 12: Aspect based sentiment analysis. Proc. 9th Int. Workshop Semantic Evaluation; 2015. p. 486–95.Search in Google Scholar
[13] Yang J, Yang R, Wang C, Xie J. Multi-entity aspect-based sentiment analysis with context, entity and aspect memory. Proceedings of 32nd AAAI Conference on Artificial Intelligence; 2018. p. 6029–36.Search in Google Scholar
[14] Wang J, Li J, Li S, Kang Y, Zhang M, Si L, et al. Aspect sentiment classification with both word level and clause-level attention networks. Proceedings 27th International Joint Conference of Artificial Intelligence; 2018. p. 4439–45.Search in Google Scholar
[15] Angelidis S, Lapata M. Multiple instance learning networks for fine-grained sentiment analysis. Trans Assoc Comput Linguist. 2018;6:17–31.Search in Google Scholar
[16] Chi CGQ, Ouyang Z, Xu X. Changing perceptions and reasoning process: Comparison of residents’ pre-and post-event attitudes. Ann Tour Res. 2018;70:39–53.Search in Google Scholar
[17] Huang H, Zhang B, Jing L, Fu X, Chen X, Shi J. Logic tensor network with massive, learned knowledge for aspect-based sentiment analysis. Knowl Syst. 2022;257:109943.Search in Google Scholar
[18] Yang L, Na J-C, Yu J. Cross-modal multitask transformer for end-to-end multimodal aspect-based sentiment analysis. Inf Process Manag. 2022;59(5):103038.Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique