Intelligent auditing techniques for enterprise finance
-
Chen Peng


Abstract
With the need of social and economic development, the audit method is also continuously reformed and improved. Traditional audit methods have defects of comprehensively considering various risk factors, and cannot meet the needs of enterprise financial work. To improve the effectiveness of audit work and meet the financial needs of enterprises, a solution for intelligent auditing of enterprise finance is proposed, including intelligent analysis of accounting vouchers and of audit reports. Then, Bi-directional Long Short-Term Memory (BiLSTM) neural network is used to classify the audit problems under three text feature extraction methods. The test results show that the accuracy, recall rate, and F1 value of the COWORDS-IOM algorithm in the aggregate clustering of accounting vouchers are 85.12, 83.28, and 84.85%, respectively, which are better than the self-organizing map algorithm before the improvement. The accuracy rate, recall rate, and F1 value of Word2vec TF-IDF LDA-BiLSTM model for intelligent analysis of audit reports are 87.43, 87.88, and 87.66%, respectively. This shows that the proposed method has good performance in accounting voucher clustering and intelligent analysis of audit reports, which can provide guidance for the development of enterprise financial intelligence software to a certain extent.
1 Introduction
With the emergence of massive financial data, the traditional audit method based on sampling can no longer meet the needs of the information age. Intelligent audit of enterprise finance has become a new audit method, which can effectively monitor the efficiency, legality, and authenticity of financial income and expenditure of enterprises [1,2]. At the same time, the continuous development of data mining technology also provides greater possibilities for the realization of intelligent auditing. With the help of data mining technology, it is possible to obtain the intrinsic correlations and rules between financial data, providing valuable information for the auditors to carry out their work smoothly. At present, the domestic and foreign markets lack effective enterprise financial intelligent audit system, and the existing intelligent audit methods have defects in the risk factors and data information extraction process, which cannot identify the enterprise financial situation relatively objectively and reasonably, and the practicability is low. In addition, the research on relevant technologies in this field is still in a relatively blank state, and the technology at this stage is mainly reflected in the data analysis of financial audit [3,4,5]. The research mainly solves the problems of insufficient data feature extraction and low practicality of existing intelligent audit methods, and improves audit efficiency. Therefore, the study proposes how to achieve intelligent analysis of enterprise financial audit with the help of data mining technology, including intelligent analysis of accounting documents and intelligent analysis of audit reports. It is expected to improve the effectiveness and practicability of the existing intelligent audit technology through this method, provide reference basis for the discovery of financial problems of enterprises, and meet the development needs of enterprises.
This article has conducted some research on improving the clustering analysis of accounting abstract vouchers and intelligent analysis of audit reports. The specific contributions are as follows. The first point is to combine word co-occurrence with Self-Organizing Map (SOM) neural network to improve the clustering effect of accounting summary vouchers. Second, based on the feature extraction of word co-occurrence text, the Word2vec TF-IDF LDA Bi-directional Long Short-Term Memory (WTL-BiLSTM) neural network is used to construct the WTL-BiLSTM model for classification of audit problems, with high classification accuracy. The above research results can effectively analyze and audit large-scale financial data, meeting the needs of enterprise economic development. At the same time, it provides more references for the optimization and improvement of intelligent audit methods.
The technical route of the study is shown in Figure 1.

Technical route of the research.
2 Review of the literature
A financial audit of a business is a way of monitoring the economic activities of that business in accordance with the law to ensure that the economic efficiency can be properly run. Erzurumlu et al. calculated the composition and work efficiency of auditors based on the operating loss of the banking industry in a certain place. The results showed that the difference in cultural background and the insufficient funds of the committee may damage the effectiveness of the bank audit committee in reducing operational risk [6]. David and Daniel explored the impact of artificial intelligence on audit services. From the perspective of consumer and industry competition, this impact is transformative, complex, and uncertain [7]. Firnanti and Karmudiandri addressed the lagging factor in audit report submission, using purposive sampling method to sample 204 listed companies. The data showed that in addition to the audit committee itself, the size and operating capacity of the company will have an impact on the lag of audit reports [8]. Lestari et al. studied the relationship between audit expectation gap and company performance. The data show that the change in earnings per share (EPS) and receiver operating characteristic curve mainly lies in the detection of errors and fraud in the audited financial statements and the change in auditors’ opinions. Preventing errors in the audited financial statements has a significant impact on EPS [9]. Ogbonna and Ebimobowei designed a predictive model for audit fraud detection and applied it to audit engagements. By analyzing actual data, this model can identify abnormal transactions, improve the work efficiency and independence of auditors, and enhance audit quality [10]. Singh et al. studied the effect of testing technology as well as environment based on the computer-assisted audit technology (CAAT). The data are analyzed by equation modeling method and least square method. The findings demonstrate that the user abilities have a greater influence on CAAT than technology or the surroundings. There are not many complicated technological procedures needed for the audit process [11].
SOM neural network belongs to unsupervised learning network. It can automatically find the intrinsic connection between samples, so as to change the parameters and structure of the grid adaptively, which has better practicality. Wang et al. used SOM neural network to identify the relevant characteristics of innovation and development among urban clusters in China when analyzing the innovation degree and development status among urban clusters, which provides a reference for coordinated development between regions [12]. Xu et al. constructed an enterprise human resource allocation model based on SOM neural network for enterprise human resource management and adjustment, providing a basis for enterprise human resource optimization [13]. Wu analyzed the characteristics of chain retail enterprises based on SOM neural network and fuzzy neural network. The results showed that the knowledge becomes the core competitiveness of an enterprise. Knowledge-based employees can create more value for the enterprise [14]. Kamimura addressed the problem that network compression cannot be applied to networks with complex components, replaced complex components with common components, and constructed a SOM network model to evaluate this technique. The results show that the approach may compress the network to create the most basic and understandable network [15]. Ma et al. built a SOM-STM based power data detection and repair method to solve the missing data in the power data acquisition and transmission. The experimental findings demonstrate that the SOM-STM model can effectively address the missing data by drastically reducing the mean absolute error and mean square heel error [16]. Liu et al. used multiple SOM neural networks to build a parallel self-organizing map (PSOM) neural network in view of the low contrast and high noise of brain MRI images. Studies demonstrate that the PSOM neural network greatly shortens the time required to segment images and increases segmentation accuracy [17].
From the above analysis, the research on the problems arising in enterprise auditing is rich in content, but there is less research on auditing techniques. The auditing techniques currently used mainly rely on CAAT. Therefore, an intelligent auditing scheme for enterprise finance based on SOM neural network is proposed, which performs intelligent analysis of accounting documents and audit reports. It is expected that this method will improve auditing techniques and enhance audit efficiency.
3 Analysis of intelligent auditing techniques for enterprise financial audit
3.1 Intelligent analysis algorithm for accounting vouchers
As an important part of the implementation of financial intelligence in enterprises, a clustering algorithm combining word co-occurrence and SOM neural network is used to complete the clustering of voucher summaries, which in turn identifies suspicious points for review and provides assistance to auditors’ judgment. The algorithm first obtains co-occurrence resources from the text set and vectorizes the text and then clusters the text using the optimized SOM neural network. Finally, the results based on the clustering are evaluated [18,19]. If the text set is denoted by
where

Co-occurrence network diagram.
If
where the weights of the joint edge of nodes
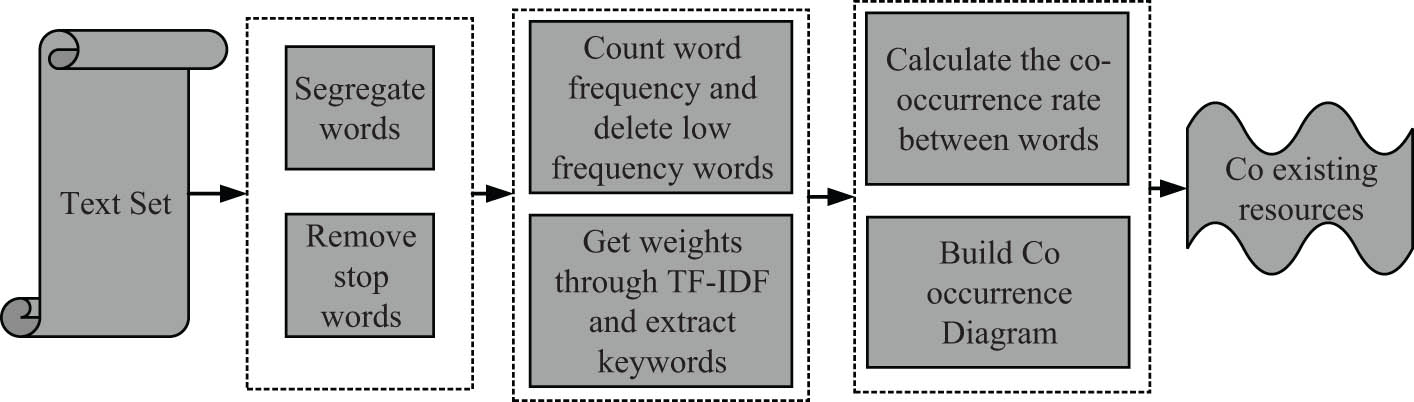
Schematic diagram of co-occurring phrase extraction.
As a competitive learning unsupervised neural network, SOM neural network has the advantages of high objectivity, high accuracy, and few parameters in clustering time and effect. The classical SOM network includes an input layer and an output layer. The input vector and the number of neurons in the input layer have the same dimension. The neurons in the output layer have weight vectors. The SOM network clustering process includes three stages: competition, cooperation, and weight adjustment. Cooperation and weight adjustment refers to the simulation of the inhibitory function that biological cells always produce on the rest of the cells when they are subjected to the stimulation process. The adjustment weights include the winning nodes and the nodes in the domain. The algorithm is prone to dead nodes in more distant regions during training. It is optimized by two methods [22,23]. The first method is to improve the SOM network weight initialization method matrix. The first step is to obtain the average vector of all samples, and then set the initial value of the weight vector as the sum of the average vector and the random number. The second way is to improve the learning rate function in the weight adjustment stage, including the initial stage and the later stage of clustering. In the early stage, exponential function is applied to increase the updating range of weights. In the later stage, linear function is used to optimize weights.
3.2 Intelligent analysis and processing of audit reports
The intelligent analysis of the audit report supports the auditors to deal with the problems in a targeted way. A classification algorithm (WTL-BiLSTM) is proposed to achieve text classification, which involves four parts, namely, text preprocessing, vectorization, neural network layer, and comprehensive classification evaluation. Figure 4 displays the particular flowchart.

Flowchart of the WTL-BiLSTM algorithm.
Vectorization of text is completed through Word2vec, TF-IDF, and LDA. The semantic features of short texts, as well as the integration of textual thematic features and lexical importance features are obtained [24]. Then, the semantic features of the text are obtained from two aspects, respectively, by BiLSTM to solve the gradient disappearance and gradient explosion. Word2vec model sets the window size to 5. The dimension of the word vector is 100, with a quantity of 168,823. The prior parameters of the word distribution in the topic and the topic distribution in the document are set to 0.01 in the LDA topic model. The number of topics is 100, and the number of iterations is 1,000 [25]. The structure of the BiLSTM includes input gates, forgetting gates, and output gates. The structure is shown in Figure 5.

Schematic diagram of the BiLSTM structure.
The function of the forgetting gate
The input gate function determines whether new information is entered and involves two components. One is new content obtained by the Sigmoid function and the other is the alternative content obtained by the Tanh function [26]. The output gate determines whether the information is output or not, and also involves two parts. One is the output content of the information determined by the Sigmoid function. The other is the final output information
To complete the BiLSTM, forward and backward propagations are required. The former is to calculate the output value of each module, and the latter is to calculate the error value of each module, which can transfer the error value of the current time to the upper layer in reverse [27]. The input to the BiLSTM is a character feature vector. It is stitched together in real time with forward and reverse outputs to obtain a bi-directional feature sequence, which can be expressed as
where both
where
4 Effect analysis of enterprise financial intelligence audit
4.1 Performance analysis of the intelligent analysis algorithm for accounting vouchers
To verify the effectiveness of the intelligent audit method proposed in the study, the improved SOM algorithm was tested and compared with TF-IDF SOM and COWORDS SOM algorithms. The experimental parameter settings are shown in Table 1.
Neural network parameter settings
| Parameter | Parameter value |
|---|---|
| SOM network output layer | 2 × 3 two-dimensional matrix |
| Initial neighborhood radius | 2 |
| Dropout | 0.5 |
| Batch size | 500 |
| Epoch size | 35 |
| Initial learning rate | 0.05 |
| Iteration period | T = 400 |
The summary of accounting vouchers corresponding to the accounting subject is selected for auditing. The voucher abstracts include five types of vouchers: payroll payable, accounts receivable, prepayments, short-term investments, and notes receivable. There are 1,485 voucher summaries in total, as shown in Figure 6. The TF-IDF algorithm is used to obtain 1,523 keywords. The word co-occurrence algorithm is used to obtain the top 30 keyword groups in each type of document, totaling 300 keywords. The main co-occurring phrases in the category of payroll payable are month-rent, rent-rent, and year-purchase. The main co-occurring phrases in the category of accounts receivable are register-social, account-cleared, and company-returned. In prepayments category, they are loan-pre-purchase, unit-prepaid, and account-contract. In the category of short-term investments, the main co-occurring phrases are rental-rent, shop-rent, and year-purchase. In the category of notes receivable, the main co-occurring phrases are notes-unit, draft-received, and discount-advance. The five document data are divided into training, testing, and validation sets in a 3:1:1 ratio, with a total of 891, 297, and 435 documents, respectively.

Summary of voucher details for five accounts.
The output layer of the SOM network is set to be a 2 × 3 two-dimensional matrix. The initial neighborhood radius and learning rate are 2 and 1. The performance of the improved SOM algorithm (COWORDS-ISOM), COWORDS-SOM, and TF-IDF-SOM is compared experimentally. The results are shown in Figure 7. The accuracy, recall, and F1 values of the COWORDS-ISOM algorithm are better than the other two algorithms. The accuracy of COWORDS-ISOM, COWORDS-SOM, and TF-IDF-SOM are 85.12, 82.35, and 79.27, respectively. The recall rates are 83.28, 83.14, and 76.34% and the F1 values are 84.85, 82.14, and 77.37%, respectively.

Performance of SOM algorithm before and after optimization.
4.2 Results of intelligent analysis of audit reports
The training data for the Word2vec model is more than 1.5 million economic texts. The final word vectors are obtained. The experimental data used in the study was more than 1,800 audit questions obtained from audit reports. The ratio of training set, testing set, and validation set is 3:1:1. It is finally found that most documents are composed of 100–200 lexical groups. Figure 8 depicts the precise distribution. After the document is standardized, the number of words in each document is 100. If the number exceeds 100, the redundant part is truncated. If the number is insufficient, additional supplement is required.

Details of the number of words in the document.
The experiments are conducted with the help of keras 2.1.1 to build a neural network, including an input layer, a BiLSTM layer, a network layer, a dropout layer, and a fully connected layer. The parameter settings are shown in Table 2.
Parameter settings of LSTM neural network
| Parameter | Parameter value |
|---|---|
| Number of LSTM layer units | 64 |
| Number of fully connected layer units | 40 |
| Training frequency | 37 |
| Dropout | 0.6 |
| Batch size | 500 |
| Initial learning rate | 0.05 |
The performance of the WTL-BiLSTM model, the word vector-oriented bi-directional LSTM model (Word2vec Bi LSTM, W-BiLSTM), and the word vector-oriented LSTM model (Word2vec LSTM, W-LSTM) are compared. The results are presented in Figure 9. On the whole, the three models have high accuracy, recall, and F1 value, which completes short text classification well. However, the WTL-BiLSTM model has better performance. The accuracy, recall, and F1 values are superior to the other two models, with values of 87.43, 87.88, and 87.66%, respectively. The corresponding values of the W-BiLSTM model are 86.76, 85.55, and 85.63%. The corresponding values of the W-LSTM model are 86.03, 82.98, and 84.01%, respectively. Therefore, the WTL-Bi-LSTM model proposed in the study has the best intelligent analysis effect of audit reports.

Comparison of the performance of the three models.
The existing intelligent audit methods commonly used are K-means clustering analysis and Intelligent audit method of fast correlation-based filter (FCBF) algorithm. To compare the application performance of the optimization model, the commonly used K-means and FCBF audit analysis methods are compared with WTL-BiLSTM. The comparison results are shown in Figure 10. The accuracy of K-means method is 83.79%. The accuracy of FCBF model is 85.63%. The accuracy of WTL-BiLSTM model is 87.25%, which is significantly higher than the other existing intelligent audit analysis methods. This shows that the method has good data analysis effect and can provide reference for further optimization of existing audit analysis methods.

Comparison of accuracy of three audit methods.
5 Conclusion
Intelligent auditing of enterprise finance is a topic of close concern for experts in the financial field. Two key techniques are proposed in intelligent auditing of enterprise finance, the intelligent implementation of accounting vouchers, and the intelligent implementation of audit reports. The former achieves clustering of voucher abstract by combining word co-occurrence and SOM neural network algorithm, while the latter completes feature fusion classification of short texts with the help of BiLSTM neural network algorithm. For the intelligent analysis of accounting vouchers, the accuracy rates of COWORDS-ISOM, COWORDS-SOM, and TF-IDF-SOM are 85.12, 82.35, and 79.27%, respectively, and the recall rates are 83.28, 83.14, and 76.34%, respectively. The F1 values are 84.85, 82.14, and 77.37%, respectively. The accuracy, recall, and F1 values of the COWORDS-ISOM algorithm are higher than the other two algorithms. For intelligent analysis of audit reports, the accuracy rates of WTL-Bi LSTM model, W-BiLSTM model, and W-LSTM model are 87.43, 86.76, and 86.06%, respectively. The recall rates are 87.88, 85.55, and 82.98%, respectively. F1 values are 87.66, 85.63, and 84.01%, respectively. The accuracy, recall, and F1 value of WTL-Bi LSTM model are better than the other two models. This shows that the intelligent analysis method of accounting vouchers and the intelligent analysis model of audit report have good performance and can play a good role in the financial audit of enterprises. Limited by our time and energy, the study still has the following two aspects that need to be improved. First, the limited number of data samples used in the study may have an impact on the experimental results. More relevant audit data samples need to be collected for experimentation in subsequent studies. The parameters of the SOM neural network clustering algorithm need further optimization. Genetic algorithms, particle swarm optimization, and ant colony optimization algorithms have good performance in machine learning. In future research, these algorithms can be introduced to optimize the parameters of SOM neural networks and improve the stability of the algorithm.
-
Author contributions: Chen Peng: write original manuscript; Guixian Tian: revise manuscript.
-
Conflict of interest: The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this article.
-
Data availability statement: The authors confirm that the data supporting the findings of this study are available within the article.
References
[1] Bak G. Appraisal is need of re-appraisal: reflections on “Confronting Jenkinson’s canon: reimagining the ‘destruction and selection of modern archives’ through the Auditor-General of South Africa’s financial audit trail. Arch Rec. 2022;43(2):177–9.10.1080/23257962.2022.2051456Search in Google Scholar
[2] Ngoepe M, Kenosi L. Confronting Jenkinson’s canon: reimagining the ‘destruction and selection of modern archives’ through the Auditor-General of South Africa’s financial audit trail. Arch Rec. 2022;43(2):166–76.10.1080/23257962.2022.2048639Search in Google Scholar
[3] Florentin ET, Florian MN. Risk Analysis in Financial Audit using the Trust Function Method. Audit Financiar. 2020;18:159.10.20869/AUDITF/2020/159/018Search in Google Scholar
[4] Melinda TF, Gabriel R. Assurance of financial audit reporting and sustainability reporting. Int J Econ Account. 2022;11(3):213–32.10.1504/IJEA.2022.126276Search in Google Scholar
[5] Katerina M, Vera K, Slavica B, Maja M, Pece N. The Importance of Forensic Audit and Differences in Relation to Financial Audit. Int J Sciences: Basic Appl Res (IJSBAR). 2020;54(2):190–200.Search in Google Scholar
[6] Erzurumlu Y, Avci G. Audit committee member characteristics and committee effectiveness: evidence from Turkish banking sector. Int J Monetary Econ Financ. 2020;13(4):341–61.10.1504/IJMEF.2020.109996Search in Google Scholar
[7] David B, Daniel S. The assessment: artificial intelligence and financial services. Oxf Rev Eco Policy. 2021;37(3):417–34.10.1093/oxrep/grab015Search in Google Scholar
[8] Firnanti F, Karmudiandri A. Corporate governance and financial ratios effect on audit report lag. GATR Account Financ Rev. 2020;5(1):15–21.10.35609/afr.2020.5.1(2)Search in Google Scholar
[9] Lestari D, Mardian S, Firman MA. Why don’t auditors use computer-assisted audit techniques? study at small public accounting firms. The Indonesian. Account Rev. 2020;10(2):105–16.10.14414/tiar.v10i2.1974Search in Google Scholar
[10] Ogbonna GN, Ebimobowei A. Causality of audit expectation gap and corporate performance in Nigeria. Res J Financ Account. 2021;5(9):11–21.Search in Google Scholar
[11] Singh N, Lai KH, Vejvar M, Cheng TE. Data-driven auditing: A predictive modeling approach to fraud detection and classification. J Corp Account Financ. 2019;30(3):64–82.10.1002/jcaf.22389Search in Google Scholar
[12] Wang X, Wan T, Yang Q, Zhang M, Sun Y. Research on innovation non-equilibrium of chinese urban agglomeration based on SOM neural network. Sustainability. 2021;13(17):9506.10.3390/su13179506Search in Google Scholar
[13] Xu J, Wang B, Min G. Research on human resource allocation model based on SOM neural network. Int J Mob Comput Multimed Commun. 2019;10(1):65–76.10.4018/IJMCMC.2019010105Search in Google Scholar
[14] Wu Y. Statistical analysis of chain company employee performance based on SOM neural network and fuzzy model. J Intell Fuzzy Syst. 2019;37(5):6287–300.10.3233/JIFS-179210Search in Google Scholar
[15] Kamimura R. Partially black-boxed collective interpretation and Its application to SOM-based convolutional neural networks. Neurocomputing. 2021;450(6):336–53.10.1016/j.neucom.2021.04.019Search in Google Scholar
[16] Ma YM, Yang JY, Feng JW, Wang HX, Li YL, Li YY. Load data recovery method based on SOM-LSTM neural network. Energy Rep. 2022;8(S1):129–36.10.1016/j.egyr.2021.11.070Search in Google Scholar
[17] Liu L, Hua C, Cheng ZX, Ji YF. Intelligent diagnosis method of MRI brain image using parallel self-organizing feature maps neural network. J Med Imaging Health Inform. 2021;11(2):487–96.10.1166/jmihi.2021.3285Search in Google Scholar
[18] Martin K, Eva V, Robert J, Pavel S. The use of conventional clustering methods combined with SOM to increase the efficiency. Neural Comput Appl. 2021;33(23):1–13.10.1007/s00521-021-06251-9Search in Google Scholar
[19] Daoud L, Marei A, Al-Jabaly SM, Aldaas AA. Moderating the role of top management commitment in usage of computer-assisted auditing techniques. Accounting. 2021;7(2):457–68.10.5267/j.ac.2020.11.005Search in Google Scholar
[20] Arnold T. Bridging conversation islands to connect healthcare: Introducing unique co-occurring word networks to find distinct themes. Proceedings of the International Symposium of Human Factors and Ergonomics in Healthcare. Vol. 11, No. 1, 2022. p. 44–7.10.1177/2327857922111008Search in Google Scholar
[21] Zhang ZW, Jing T, Tian CH, Cui PF, Li XJ, Gao ML. Objects discovery based on co-occurrence word model with anchor-box polishing. IEEE Trans Circuits Syst Video Technol. 2020;30(3):632–45.10.1109/TCSVT.2019.2894363Search in Google Scholar
[22] Jiang WJ, Meng LS, Liu FT, Sheng YZ, Chen SM, Yang JL, et al. Distribution, source investigation, and risk assessment of topsoil heavy metals in areas with intensive anthropogenic activities using the positive matrix factorization (PMF) model coupled with self-organizing map (SOM). Environ Geochem Health. 2023;45(8):6353–70.10.1007/s10653-023-01587-8Search in Google Scholar PubMed
[23] Ding R. Enterprise intelligent audit model by using deep learning approach. Computational Econ. 2022;59(1):1335–54.10.1007/s10614-021-10192-9Search in Google Scholar
[24] Zair M, Rahmoune C, Benazzouz D, Ratni A. Automatic condition monitoring of electromechanical system based on MCSA, spectral kurtosis and SOM neural network. J Vibroengineering. 2019;21(8):2082–95.10.21595/jve.2019.20056Search in Google Scholar
[25] James AK, James RT. Audit process safety for compliance and performance. Chem Eng Prog. 2022;118(8):23–8.10.1201/9781003216162-3Search in Google Scholar
[26] Xiao TS, Geng CX, Yuan C. How audit effort affects audit quality: An audit process and audit output perspective. China J Account Res. 2020;13(1):109–27.10.1016/j.cjar.2020.02.002Search in Google Scholar
[27] Li LM, Zhang MY, Wen ZZ. Dynamic prediction of landslide displacement using singular spectrum analysis and stack long short-term memory network. J Mt Sci. 2021;18(10):2597–611.10.1007/s11629-021-6824-1Search in Google Scholar
[28] Chen Y. Evaluation of teaching effect of internet of things education platform based on long-term and short-term memory network. Int J Continuing Eng Educ Life-Long Learn. 2021;31(1):36–52.10.1504/IJCEELL.2021.111839Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique