Improving binary crow search algorithm for feature selection
-
Zakaria A. Hamed Alnaish


Abstract
The feature selection (FS) process has an essential effect in solving many problems such as prediction, regression, and classification to get the optimal solution. For solving classification problems, selecting the most relevant features of a dataset leads to better classification accuracy with low training time. In this work, a hybrid binary crow search algorithm (BCSA) based quasi-oppositional (QO) method is proposed as an FS method based on wrapper mode to solve a classification problem. The QO method was employed in tuning the value of flight length in the BCSA which is controlling the ability of the crows to find the optimal solution. To evaluate the performance of the proposed method, four benchmark datasets have been used which are human intestinal absorption, HDAC8 inhibitory activity (IC50), P-glycoproteins, and antimicrobial. Accordingly, the experimental results are discussed and compared against other standard algorithms based on the accuracy rate, the average number of selected features, and running time. The results have proven the robustness of the proposed method relied on the high obtained value of accuracy (84.93–95.92%), G-mean (0.853–0.971%), and average selected features (4.36–11.8) with a relatively low computational time. Moreover, to investigate the effectiveness of the proposed method, Friedman test was used which declared that the performance supremacy of the proposed BCSA-QO with four datasets was very evident against BCSA and CSA by selecting the minimum relevant features and producing the highest accuracy classification rate. The obtained results verify the usefulness of the proposed method (BCSA-QO) in the FS with classification in terms of high classification accuracy, a small number of selected features, and low computational time.
1 Introduction
The feature selection (FS) process has an essential effect in solving prediction, regression, and classification problems. It includes detecting and selecting the most appropriate features for each dataset to get the most accurate results [1]. Basically, the main aim of the FS process is to maximize the accuracy and reduce the number of sub-optimal selected features with minimum running time [2]. There are three types of FS algorithms, which are wrappers, filters, and hybrid [3,4]. In the filter method, the classifier is not included in the FS process. So, it is less time-consuming than hybrid and wrapper methods. In the wrapper method, the process of selecting the features depends on the accuracy of the classifier which considers a good evaluation criterion to choose the most related features. The hybrid method combines the techniques of filter and wrapper methods which determine the sub-selected features based on the classifier design [3,4].
Actually, there are many variants of swarm intelligence algorithms that are applied to FS problems such as binary particle swarm optimization (BPSO) [5], binary differential evolution algorithm based on taper-shaped transfer functions (T-NBDE) [6], binary grey wolf optimization (BGWO) [7], binary whale optimization algorithm [8], and binary crow search algorithm (BCSA) [9]. In addition, the following studies explain in more detail about using a swarm intelligence algorithm in solving FS problems. In ref. [10], the authors proposed a novel FS method based on a binary multi-verse optimizer algorithm which is used for solving text clustering problems. Also, in ref. [11], the authors proposed a new FS method based on a BGWO algorithm for solving text clustering problems. In ref. [12], the authors proposed a novel multi-objective binary version of the cuckoo search algorithm to select the optimal EEG channel for person identification. Also, in ref. [13], the authors used a BGWO algorithm to select the optimal EEG channel which will be used as inputs to the hybrid support vector machine with a radial basis function classifier for solving person identification problems. In ref. [14], the authors proposed a new hybrid FS method based on TRIZ-inventive solution and GWO algorithm to solve gene selection for microarray data classification which is classified using support vector machine.
In addition, FS is one of the problems that is solved using CSA algorithm. CSA has been implemented on many fields like medical diagnosing problems [15], usability feature extraction for software quality measurement [16], and home energy management in smart grid [17]. In ref. [18], the authors proposed opposition-based learning strategy based on BCSA to select the most relevant features in classifying a big dataset. Adamu et al. [3] suggested a method called ECCSPSOA using a novel hybrid PSO with binary chaotic CSA for selecting the most relevant features in classification problems [3]. Arora et al. [19] suggested a hybrid method for solving FS problems using the GWO and CSA algorithms. Rodrigo et al. [1] presented a model called V-shaped BCSA to solve FS problem. Also, in ref. [20], the authors proposed a method to enhance the CSA by adapting the awareness probability. The authors proposed a new approach called BCSA-TVFL based on BCSA and time-varying flight length to solve FS problems. In ref. [21], the authors enhanced the efficiency of CSA based on cellular automata model to control the diversity of the search process.
From all the aforementioned studies, the following research question is raised. In spite of the methods being developed for selecting the most optimal features and improved in many previous studies, is there a need to develop and enhance a new FS method [22]? The answer is yes because not all the existing FS techniques produce the best performance in solving different problems with various datasets [20]. Consequently, a robust method to select the most relevant features is still needed. This is the motivation of this study.
Accordingly, it is clear that the CSA algorithm plays an important role in solving the problems that concern FS, but the main problem of the CSA algorithm is trapping in local minima [20]. Thus, the main aim of this study is that there is a crucial need to develop and enhance the efficiency of the CSA algorithm to overcome the mentioned problem which considers the objective of this study.
In this study, the CSA has been selected as a FS method among other optimization algorithms because it is easy to implement, it requires few tuning parameters compared to other swarm optimization algorithms, fast convergence speed, and high efficiency [1,18]. The parameters are the probability of awareness (AP) and flight length (fl). AP parameter balances the trade-off between exploration and exploitation and fl parameter controls the search capability of crows [20]. In the basic CSA, the amount of fl is a constant value which may cause inappropriate searching by the crows in the solution space that results in trapping in the local optima [23]. Also, constant fl does not resemble the natural behavior of crows [20]. Thus, the primary goal of this study is to improve the exploitation and the exploration ability of CSA. So, the main problem of this work is tuning the value of fl. In addition, the FS is a discrete problem and converting the continuous values to discrete values requires transfer function. Thus, the sigmoid function is used to convert the continuous values to discrete values as a part of binary crow search algorithm improvement in solving FS problems. The contributions of this work are as follows:
Propose a new FS technique based on the CSA by tuning the value of fl of crows using the Quasi-Oppositional (QO) method to get the most significant features in order to be more suitable for solving various problems with different datasets.
The performance of the proposed BCSA-QO is tested on four popular datasets using k-nearest neighbors (KNN) as a classifier based on classification accuracy, the minimum number of the selected features, G-mean, and minimum needed CPU time.
Jaccard index is used to measure the consistency of the selected features by the proposed method.
Friedman and Bonferroni tests have been implemented to show the significance of the difference between the obtained results of the proposed method against other existing methods.
The rest of this article is arranged as follows: Section 2 includes the CSA. Section 3 explains the suggested method. The results are explained in Section 4. Finally, Section 5 includes the conclusion.
2 CSA
CSA [24] is an algorithm that belongs to swarm intelligence algorithms that simulate the nature foraging process of the crows in the environment. In summary, the work of CSA depends on the behavior of the crows which includes: living in the swarm, hiding food's locations in memory, following another crow to steal its food, and finally preventing other crows from finding its food location. The implementation of the CSA for solving an optimization problem could be represented as: n
c
is the swarm of crows, and
where each row in matrix crows represents one possible solution.
Then, the crows travel in the search space and attempt to discover and memorize the solution with the best fitness reached so far in the matrix
In standard CSA, the searching process is represented through one of the two cases. In the first case, the owner crow j of food source
where fl represents the distance of the flight of each crow, and t denotes an arbitrary value within [0,1].
In the second case, the crow j realizes that is being followed by crow i. Thus, crow j tries to distract crow i by moving to a different place. So, crow i will update its location randomly. The scenario of searching process could be concluded by equation (2).
where θ denotes a random value within the interval [0, 1], where AP denotes the probability of awareness which balances between exploration and exploitation phases during the searching process. To achieve the FS process, the BCSA is proposed [20,22]. It is a developed version of the standard crow search algorithm [24], but it cooperates with binary search space instead of continuous search space. The value 0 in the search space represents that the feature has not been chosen and value 1 represents that the feature has been chosen. In BCSA, the transformation of the search space from continuous values to binary values {0, 1} is required using a suitable transfer function. In this study, the sigmoid function is used as a transfer function. Figure 1 demonstrates the BCSA solution implementation.
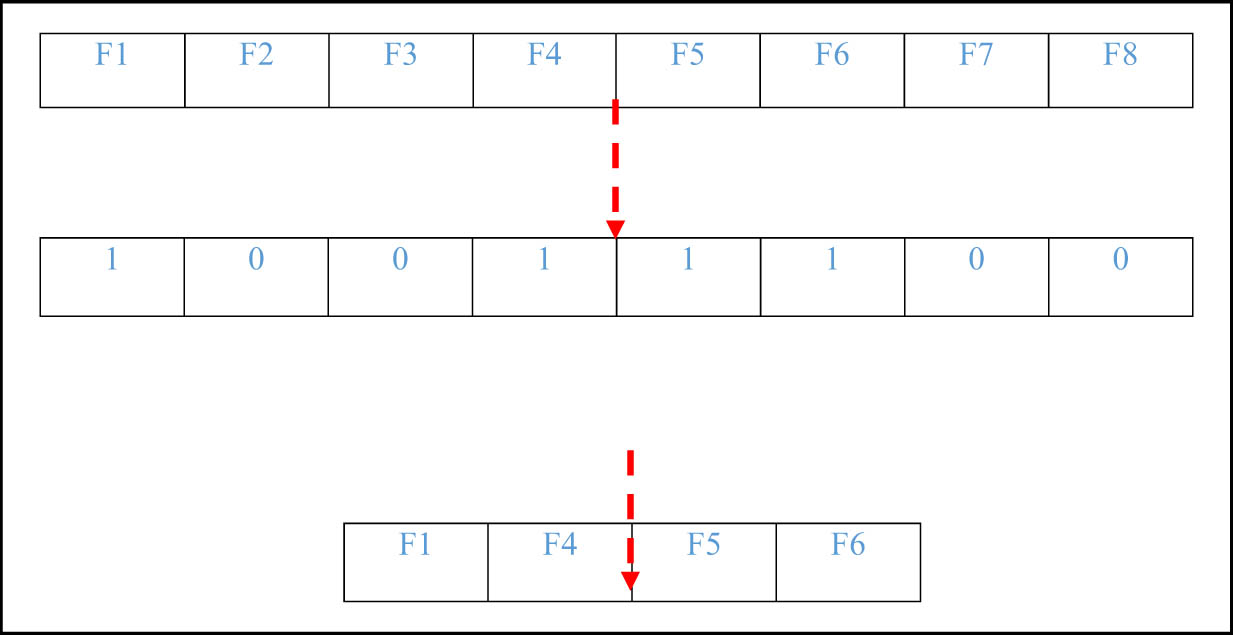
The selected features.
3 The proposed method: BCSA-QO
As mentioned before, CSA depends only on two parameters which are fl and AP to get the best solution [20]. To control the exploration and exploitation, find the optimal solution, and simulate the nature of crows, the value of the fl parameter should not be a constant [20]. So, in this study, the QO method is suggested to tune the value of fl parameter and get the optimal solution. QO method [20] is a developed method that is based on the oppositional-based learning (O-BL) technique [25]. The O-BL technique depends on the opposite number for any number located within a specific interval which can be represented mathematically as follow:
Suppose
If a = 0 and b = 1, then,
Also, in multi-dimensional vectors, suppose that we have a point
where
Thus, the quasi-opposite number
Accordingly, we will get two values, the first value (x) represents the initial random value within the interval
As a result, the fl will be in the interval [flmin, flmax]. The quasi-opposite number (
where
Then, the fitness values for both the initial values of fl and
The following steps explain the proposed approach in detail:
Step 1: Set the values of the number of crows, AP, flmin, flmax, and maximum number of iterations.
Step 2: Convert the values of the positions that represent the features to binary values using the sigmoid function based on equation (8) [20].
where
Step 3: Calculate the fitness value based on the fitness function as shown in equation (10).
where
Step 4: Update the crows' positions based on equation
Step 5: Repeat steps 3 and 4 until the maximum iteration is reached.
| Algorithm 1: (BCSA-QO) 1: start 2: set the initial values of the positions
3: set the initial values of the memory ( 4: calculate the fitness value for the position of each crow 5: convert the positions 6: while maximum iteration (t) has not reached do 7: for i = 1: N (total number of crows) 8: select one of the crows randomly 9: determine the awareness probability (AP) and generate (r i) randomly 10: if r i >= AP 11: 12: convert 13: else 14: 15: end if 16: end for 17: test the feasibility of new positions according to the fitness value 18: assess the new position for all crows 19: modify the memory of crows according to: 20: 21: 22: else 23: 23: end if 21: end while 22: end |
Figure 2 shows the flowchart of the proposed method (BCSA-QO).

Flowchart of the proposed method (BCSA-QO).
4 Implementation of the experiment and results
To evaluate the efficiency of the suggested method (BCSA-QO), four datasets are used which are human intestinal absorption (HIA) [26], HDAC8 inhibitory activity (IC50) [25], P-glycoproteins (P-gp) [26] and antimicrobial [27] as described in Table 1.
Datasets description
| Dataset name | No. of features | No. of instances | Classes |
|---|---|---|---|
| Antimicrobial | 3,657 | 212 | 104 inactive compounds and 108 active compounds |
| HDAC8 | 2,014 | 75 | 37 non-inhibitor and 38 inhibitors |
| HIA | 736 | 196 | 65 non-absorbable HIA– compounds and 131 absorbable HIA+ compounds |
| P-gp | 1,136 | 201 | 85 non-mediums and 116 mediums |
The dataset is split into training and testing groups. The training group includes 70% of the number of instances in each dataset for implementing the training phase and the rest represents the testing group for implementing the testing phase.
In addition, two classification criteria are utilized to evaluate the efficiency of the proposed method and compare it with other methods in the literature in terms of classification accuracy (CA) (G‐mean), and F-measure. The classification accuracy represents the percentage of the classes that are classified correctly which are calculated based on equation (11).
In addition, G-mean was utilized to emphasize the combined efficiency of specificity (SP) and sensitivity (SN) according to equation (12).
where SN represents the probability of positive patterns which are classified as truly positive patterns. SP denotes the probability of negative patterns which are classified as truly negative patterns.
The F-measure is another criterion used in the evaluation. It is defined as
The experimental results are produced by running each method 20 times autonomously. The parameter setting of the crow search algorithm was: (1) the number of crows was 30, (2) the AP was 0.2, and (3) the
The averaged selected features obtained by the used methods (testing or training)
| Datasets | BCSA-QO | M-CSA | S-CSA |
|---|---|---|---|
| HDAC8 | 8.1 ± 1.041 | 11.2 ± 1.238 | 13.7 ± 1.723 |
| Antimicrobial | 11.8 ± 1.053 | 14.1 ± 1.143 | 17.5 ± 1.166 |
| HIA | 4.36 ± 0.077 | 6.81 ± 0.081 | 7.88 ± 0.092 |
| P-gp | 11.7 ± 0.214 | 18.3 ± 0.218 | 25.1 ± 0.221 |
The performance of the proposed method compared with other methods in terms of minimum obtained features is highlighted in bold.
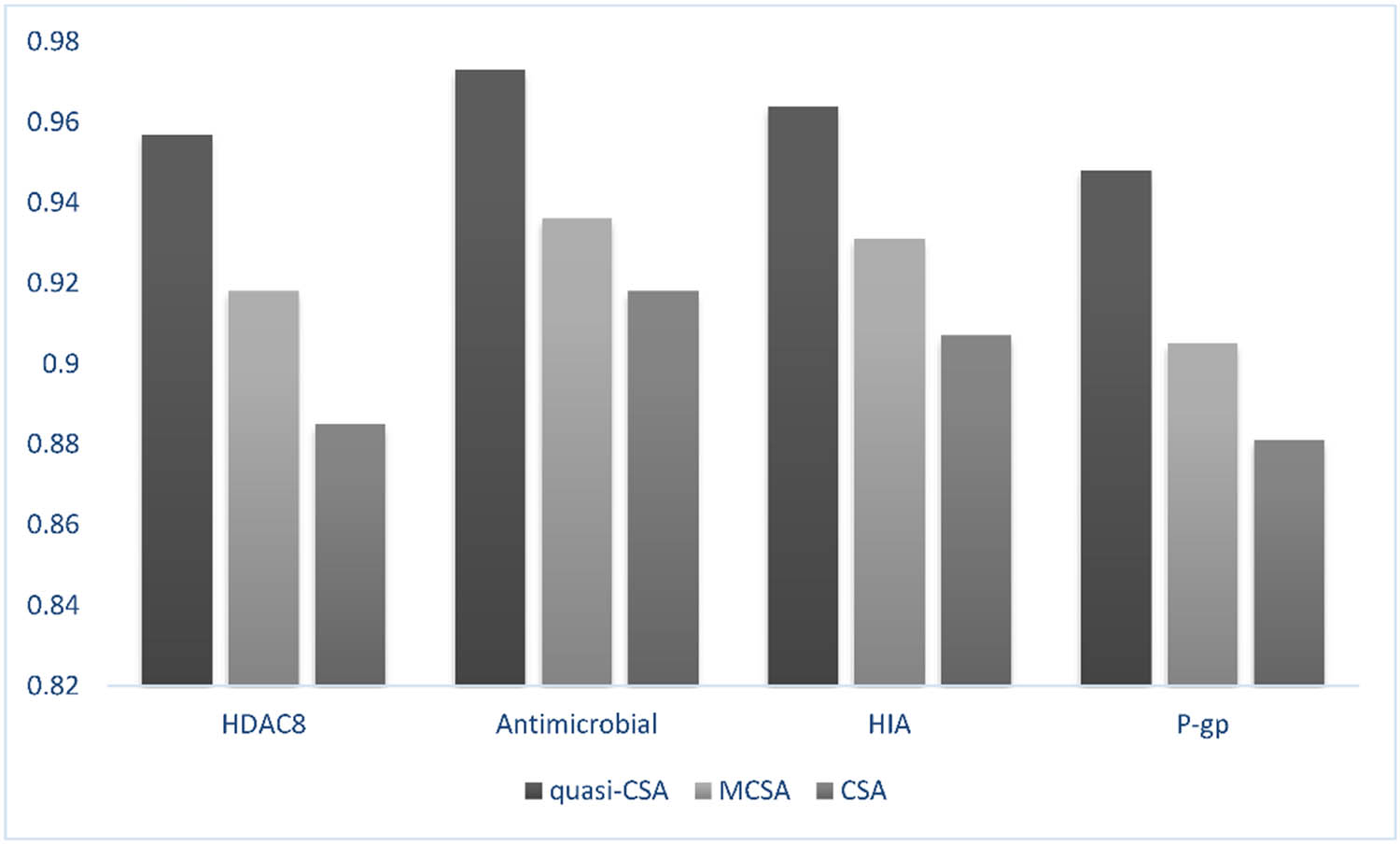
Moreover, to examine the effectiveness of the suggested technique (BCSA-QO), the obtained results are compared against the results that are obtained by S-CSA method [9] and M-CSA in terms of accuracy and G-mean based on the same datasets. As revealed in Table 3, the performance of the BCSA-QO method is higher than the performance of S-CSA and M-CSA in terms of CA and G-mean for both training and testing phases. Regarding the F-measure, quasi-CSA, on average, surpasses the two algorithms in all the used datasets.
Comparison of results of all the methods
| Dataset | Method | Training dataset | Testing dataset | ||
|---|---|---|---|---|---|
| CA | G-mean | F-measure | CA | ||
| HDAC8 | Quasi-CSA | 92.39 ± 0.074 | 0.912 ± 0.023 | 0.923 ± 0.021 | 88.87 ± 0.024 |
| M-CSA | 87.11 ± 0.081 | 0.835 ± 0.028 | 0.841 ± 0.024 | 81.11 ± 0.029 | |
| S-CSA | 81.84 ± 0.093 | 0.801 ± 0.035 | 0.811 ± 0.031 | 78.68 ± 0.032 | |
| Antimicrobial | Quasi-CSA | 98.08 ± 0.017 | 0.971 ± 0.016 | 0.982 ± 0.014 | 95.92 ± 0.018 |
| M-CSA | 93.78 ± 0.021 | 0.923 ± 0.022 | 0.928 ± 0.023 | 90.72 ± 0.023 | |
| S-CSA | 90.63 ± 0.025 | 0.884 ± 0.026 | 0.891 ± 0.024 | 87.28 ± 0.026 | |
| HIA | Quasi-CSA | 86.15 ± 0.018 | 0.853 ± 0.019 | 0.862 ± 0.018 | 84.93 ± 0.020 |
| M-CSA | 81.54 ± 0.021 | 0.808 ± 0.023 | 0.817 ± 0.022 | 78.28 ± 0.027 | |
| S-CSA | 76.81 ± 0.021 | 0.752 ± 0.027 | 0.763 ± 0.025 | 73.74 ± 0.031 | |
| P-gp | Quasi-CSA | 96.87 ± 0.026 | 0.955 ± 0.027 | 0.962 ± 0.026 | 95.39 ± 0.028 |
| M-CSA | 92.24 ± 0.030 | 0.915 ± 0.029 | 0.922 ± 0.028 | 90.84 ± 0.030 | |
| S-CSA | 88.69 ± 0.033 | 0.871 ± 0.031 | 0.883 ± 0.029 | 86.91 ± 0.032 |
The performance of the proposed method compared with other methods in terms of minimum obtained features is highlighted in bold.
Once again, Figure 3 shows the CPU time in seconds of the BCSA-QO, M-CSA, and S-CSA methods. As shown in Figure 3, the BCSA-QO method has less training time than M-CSA and S-CSA methods with all datasets.

The average training time in seconds for the BCSA-QO, M-CSA, and S-CSA methods.
Moreover, to investigate the stability of the proposed method BCSA-QO, Jaccard index is used to measure the consistency of the selected features. The Jaccard index is a proportion of the intersection between two populations and the union between the same populations. For example, J
1 and J
2 are subgroups of the selected features and
For a number of solutions
The higher S.test value is considered more efficient in FS. Figure 4 depicts the proposed method stability against other methods which have been examined by four datasets. As shown in Figure 4, BCSA-QO displays the higher rate of stability than M-CSA and S-CSA
The results of S.test.
For more convincing evidence regarding the performance of the proposed method (BCSA-QO), in choosing the best features that produce the highest classification accuracy, a Friedman test has been used. The Friedman test has been implemented based on the AUC values in training phase. When the alternative hypothesis is accepted, the post hoc of the Bonferroni test is calculated under various critical values (0.01, 0.05, and 0.1). Table 4 shows the outcomes of the applied statistical tests.
Results of Friedman and Bonferroni tests of the methods over all datasets
| Friedman average rank | Friedman test results | Bonferroni test results | |
|---|---|---|---|
| Quasi-CSA | 3.278 |
|
|
| M-CSA | 9.041 | ||
| S-CSA | 9.257 |
Based on these outcomes, the alternative hypothesis is accepted at
5 Conclusion
This study included improving the BCSA by using the QO method in terms of tuning the value of flight length with the aim of overcoming the trapping in local minima. The main purpose of this work is to demonstrate that not all the features for each dataset are relevant to the solution of a problem to get the highest accuracy rate.
Also, it has been applied for solving classification problem with FS. The BCSA-QO method depended on the advantages of both BCSA and the QO methods. The experimental results have shown that the proposed method has produced the highest classification accuracy, the minimum number of the selected features, and the minimum needed CPU time with high stability for all datasets compared to other methods. As a limitation, the performance of the quasi-CSA depends on choosing the lower and the upper bounds. For future works, the following points are suggested:
Propose a new FS technique by hybridization of QO method with other binary optimization algorithms such as binary-PSO, binary-GWO, and binary-TLBO to enhance their performance.
Appling the BCSA-QO technique on a different application such as prediction and clustering with different datasets.
Utilizing another classifier such as a support vector machine and naïve Bayes instead of the KNN.
-
Conflict of interest: Authors state no conflict of interest.
References
[1] De Souza RCT, dos Santos Coelho L, De Macedo CA, Pierezan J. A V-shaped binary crow search algorithm for feature selection. In 2018 IEEE Congress on Evolutionary Computation (CEC). Brazil: IEEE; 2018.10.1109/CEC.2018.8477975Search in Google Scholar
[2] Ghosh M, Guha R, Alam I, Lohariwal P, Jalan D, Sarkar R. Binary genetic swarm optimization: A combination of GA and PSO for feature selection. J Intell Syst. 2020;29(1):1598–610.10.1515/jisys-2019-0062Search in Google Scholar
[3] Adamu A, Abdullahi M, Junaidu SB, Hassan IH. An hybrid particle swarm optimization with crow search algorithm for feature selection. Mach Learn Appl. 2021;6:100108.10.1016/j.mlwa.2021.100108Search in Google Scholar
[4] Gad AG, Sallam KM, Chakrabortty RK, Ryan MJ, Abohany AA, Gad AG, et al. An improved binary sparrow search algorithm for feature selection in data classification. Neural Comput Appl. 2022;34:1–49.10.1007/s00521-022-07203-7Search in Google Scholar
[5] Khanesar MA, Teshnehlab M, Shoorehdeli MA. A novel binary particle swarm optimization. In 2007 Mediterranean Conference on Control & Automation. Athens, Greece: IEEE; 2007.Search in Google Scholar
[6] He Y, Zhang F, Mirjalili S, Zhang T. Novel binary differential evolution algorithm based on Taper-shaped transfer functions for binary optimization problems. Swarm Evolut Comput. 2022;69:101022.10.1016/j.swevo.2021.101022Search in Google Scholar
[7] Emary E, Zawbaa HM, Hassanien AE. Binary grey wolf optimization approaches for feature selection. Neurocomputing. 2016;172:371–81.10.1016/j.neucom.2015.06.083Search in Google Scholar
[8] Hussien AG, Hassanien AE, Houssein EH, Bhattacharyya S, Amin M. S-shaped binary whale optimization algorithm for feature selection. In recent trends in signal and image processing. Singapore: Springer; 2019. p. 79–87.10.1007/978-981-10-8863-6_9Search in Google Scholar
[9] Laabadi S, Naimi M, Amri HE, Achchab B. A binary crow search algorithm for solving two-dimensional bin packing problem with fixed orientation. Procedia Comput Sci. 2020;167:809–18.10.1016/j.procs.2020.03.420Search in Google Scholar
[10] Abasi AK, Khader AT, Al-Betar MA, Naim S, Makhadmeh SN, Alyasseri ZA. A text feature selection technique based on binary multi-verse optimizer for text clustering. In 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT). Amman, Jordan: IEEE; 2019.10.1109/JEEIT.2019.8717491Search in Google Scholar
[11] Abasi AK, Khader AT, Al-Betar MA, Naim S, Makhadmeh SN, Alyasseri ZA. An improved text feature selection for clustering using binary grey wolf optimizer. In Proceedings of the 11th National Technical Seminar on Unmanned System Technology 2019. Singapore: Springer; 2021.10.1007/978-981-15-5281-6_34Search in Google Scholar
[12] Abdi Alkareem Alyasseri Z, Alomari OA, Al-Betar MA, Awadallah MA, Hameed Abdulkareem K, Abed Mohammed M, et al. EEG channel selection using multiobjective cuckoo search for person identification as protection system in healthcare applications. Comput Intell Neurosci. 2022;2022:5974634.10.1155/2022/5974634Search in Google Scholar PubMed PubMed Central
[13] Alyasseri ZAA, Alomari OA, Makhadmeh SN, Mirjalili S, Al-Betar MA, Abdullah S, et al. EEG channel selection for person identification using binary grey wolf optimizer. IEEE Access. 2022;10:10500–13.10.1109/ACCESS.2021.3135805Search in Google Scholar
[14] Alomari OA, Makhadmeh SN, Al-Betar MA, Alyasseri ZAA, Doush IA, Abasi AK, et al. Gene selection for microarray data classification based on Gray Wolf Optimizer enhanced with TRIZ-inspired operators. Knowl Syst. 2021;223:107034.10.1016/j.knosys.2021.107034Search in Google Scholar
[15] Anter AM, Ali M. Feature selection strategy based on hybrid crow search optimization algorithm integrated with chaos theory and fuzzy c-means algorithm for medical diagnosis problems. Soft Comput. 2020;24(3):1565–84.10.1007/s00500-019-03988-3Search in Google Scholar
[16] Gupta D, Rodrigues JJPC, Sundaram S, Khanna A, Korotaev V, de Albuquerque VHC. Usability feature extraction using modified crow search algorithm: a novel approach. Neural Comput Appl. 2020;32(15):10915–25.10.1007/s00521-018-3688-6Search in Google Scholar
[17] Javaid S, Ali I, Mushtaq N, Faiz Z, Sadiq HA, Javaid N. Enhanced differential evolution and crow search algorithm based home energy management in smart grid. In International Conference on Broadband and Wireless Computing, Communication and Applications. Cham: Springer; 2017.Search in Google Scholar
[18] Al-Thanoon NA, Algamal ZY, Qasim OS. Feature selection based on a crow search algorithm for big data classification. Chemom Intell Lab Syst. 2021;212:104288.10.1016/j.chemolab.2021.104288Search in Google Scholar
[19] Arora S, Singh H, Sharma M, Sharma S, Anand P. A new hybrid algorithm based on grey wolf optimization and crow search algorithm for unconstrained function optimization and feature selection. IEEE Access. 2019;7:26343–61.10.1109/ACCESS.2019.2897325Search in Google Scholar
[20] Chaudhuri A, Sahu TP. Feature selection using Binary Crow Search Algorithm with time varying flight length. Expert Syst Appl. 2021;168:114288.10.1016/j.eswa.2020.114288Search in Google Scholar
[21] Awadallah MA, Al-Betar MA, Doush IA, Makhadmeh SN, Alyasseri ZAA, Abasi AK, et al. CCSA: Cellular Crow Search Algorithm with topological neighborhood shapes for optimization. Expert Syst Appl. 2022;194:116431.10.1016/j.eswa.2021.116431Search in Google Scholar
[22] Sayed GI, Hassanien AE, Azar AT. Feature selection via a novel chaotic crow search algorithm. Neural Comput Appl. 2019;31(1):171–88.10.1007/s00521-017-2988-6Search in Google Scholar
[23] Mohammadi F, Abdi H. A modified crow search algorithm (MCSA) for solving economic load dispatch problem. Appl Soft Comput. 2018;71:51–65.28.10.1016/j.asoc.2018.06.040Search in Google Scholar
[24] Askarzadeh A. A novel metaheuristic method for solving constrained engineering optimization problems: crow search algorithm. Comput Struct. 2016;169:1–12.10.1016/j.compstruc.2016.03.001Search in Google Scholar
[25] Cao GP, Arooj M, Thangapandian S, Park C, Arulalapperumal V, Kim Y, et al. A lazy learning-based QSAR classification study for screening potential histone deacetylase 8 (HDAC8) inhibitors. SAR QSAR Environ Res. 2015;26:397–420.10.1080/1062936X.2015.1040453Search in Google Scholar PubMed
[26] Liu F, Zhou Z. A new data classification method based on chaotic particle swarm optimization and least square-support vector machine. Chemom Intell Lab Syst. 2015;147:147–56.10.1016/j.chemolab.2015.08.015Search in Google Scholar
[27] Xing J-J, Liu Y-F, Li Y-Q, Gong H, Zhou Y-P. QSAR classification model for diverse series of antimicrobial agents using classification tree configured by modified particle swarm optimization. Chemom Intell Lab Syst. 2014;137:82–90.10.1016/j.chemolab.2014.06.011Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique