Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
-
Jianing Shen
 and
Yang Zhou
and
Yang Zhou

Abstract
Real-time object detection is an integral part of internet of things (IoT) application, which is an important research field of computer vision. Existing lightweight algorithms cannot handle target occlusions well in target detection tasks in indoor narrow scenes, resulting in a large number of missed detections and misclassifications. To this end, an accurate real-time multi-scale detection method that integrates density-based spatial clustering of applications with noise (DBSCAN) clustering algorithm and the improved You Only Look Once (YOLO)-v4-tiny network is proposed. First, by improving the neck network of the YOLOv4-tiny model, the detailed information of the shallow network is utilized to boost the average precision of the model to identify dense small objects, and the Cross mini-Batch Normalization strategy is adopted to improve the accuracy of statistical information. Second, the DBSCAN clustering algorithm is fused with the modified network to achieve better clustering effects. Finally, Mosaic data enrichment technique is adopted during model training process to improve the capability of the model to recognize occluded targets. Experimental results show that compared to the original YOLOv4-tiny algorithm, the mAP values of the improved algorithm on the self-construct dataset are significantly improved, and the processing speed can well meet the requirements of real-time applications on embedded devices. The performance of the proposed model on public datasets PASCAL VOC07 and PASCAL VOC12 is also better than that of other advanced lightweight algorithms, and the detection ability for occluded objects is significantly improved, which meets the requirements of mobile terminals for real-time detection in crowded indoor environments.
1 Introduction
Dense object detection is one of the special application tasks of computer vision [1]. It has a wide range of application value in fields such as control and identification of suspicious objects [2], intelligent collection of human traffic statistics [3], and abnormal behavior detection [4]. Crowded indoor space is a single background scene that is less influenced by factors such as illumination, angle, and internal structure. The difficulty lies in the fact that when faced with factors such as mutual occlusion between multiple objects and incomplete camera framing, the traditional lightweight algorithms will lead to a great number of missed detections and false alarms, so it is of great research significance to achieve a lightweight detection algorithm that can accurately and quickly detect occluded small targets within crowded indoor spaces in the internet of things (IoT) environment [5].
Taking the elevator car detection application as an example, in the field of elevator safety management, the information provided by the elevator monitoring video is often used as the basis to judge the situation in the car and take corresponding measures. The current elevators generally have video acquisition devices on the top of the car, but this only provides real-time observation, video storage, and evidence collection and does not have functions such as timely warning and real-time monitoring. Although elevator managers can observe the video images and take timely measures after discovering the forbidden objects, managers cannot observe the surveillance video all the time, which may cause omissions in work. Therefore, it is necessary to solve the shortage of human monitoring through image acquisition equipment, processors, and target detection algorithms, that is, to design an intelligent video monitoring system that can detect prohibited objects in elevators throughout the day and realize the detection of prohibited target intrusions based on elevator monitoring video [6]. Through timely alarm to the management personnel, the workloads of relevant personnel are reduced and the elevator riding safety is guaranteed.
Traditional object detection methods rely on manual feature extraction and complete detection tasks through classifiers such as the support vector machine (SVM) [7]. The recognition process of such method is complex and highly subjective, and it is not sensitive to occluded salient regions, which leads to a poor performance in terms of detection accuracy, processing speed, and robustness. Recently, with the continuous progress in convolutional neural network (CNN), the concept of end-to-end framework has been applied to target detection algorithms, such as single shot multibox detector (SSD) [8] and the You Only Look Once (YOLO) series [9]. These algorithms combine the classification process and the regression network into a single stage, which has a significant improvement in the trade-off between detection accuracy and speed and is suitable for deployment on mobile terminals for target detection in crowded indoor spaces.
Existing algorithms such as YOLOv4-tiny network [10] achieve good detection performance in dense scenes, but they also have the following shortcomings:
The backbone network is too lightweight, and the contour evolution of the feature map is insufficient during the layer-by-layer transfer process, making it impossible to effectively learn enough features of the occluded targets in the course of training;
The neck network structure is too simple, with low efficiency when fusing feature maps of different sizes, and it is prone to lose detailed edge information;
The traditional K-means clustering has limitations in the post-processing stage, which can easily lead to missed detection.
The main contributions of the proposed method are listed as follows:
An adaptive multi-scale detection algorithm is proposed by taking the crowded indoor spaces such as the elevator car, bus car, and passenger aircraft cabin as the main research scenarios. Based on the YOLOv4-tiny model which is suitable for embedded hardware platforms, the neck network of the model is improved to improve the recognition accuracy of small targets. The Cross mini-Batch Normalization (CmBN) technique is used to replace the batch normalization (BN) technique from the original YOLOv4-tiny model to ensure the estimation accuracy of statistical information and reduce estimation errors. The Mosaic data enrichment strategy is introduced in the training phase to improve the utilization of feature maps of different scales and alleviate the loss of edge information;
An improved clustering method combining DBSCAN and K-means algorithm is proposed. First, initial clustering is performed by DBSCAN clustering algorithm, and then multi-scale clustering is added to further obtain the local and overall information of the targets. After multi-scale clustering and convolution operations, the initial feature map is obtained. Afterward, the accurate center point position is derived with the K-means algorithm, which effectively accelerates the convergence and improves the classification accuracy for dense small targets. As a result, the classification effect of objects in different datasets and complex environments is improved, and the resistance to noise and interference is also improved.
The remainder of this article is organized as follows. Section 2 introduces the related research, and Section 3 explains the background knowledge of YOLOv4-tiny. Section 4 describes the proposed method specifically, including the improved YOLOv4-tiny network structure and the enhanced clustering algorithm for bounding box determination. In Section 5, the experimental results and discussion are presented. Finally, Section 6 summarizes the full text.
2 Related research
Before the rise of deep learning (DL) methodology, the traditional object recognition technology proposed in the early days mainly utilize the more obvious features including image corners, textures, and contours, and used feature descriptors such as histogram of oriented gradient [11], scale-invariant feature transform [12], speeded up robust features [13], Haar-like features [14], and local binary pattern [15], and the recognition and classification of the extracted object features are performed with template matching [16], boosting [17], SVM, and other methods. However, the traditional recognition algorithms have shortcomings such as relying on manual experience for feature selection and poor robustness in complex application scenarios.
As hardware equipment and DL technology evolve, DL-based frameworks have begun to emerge in the field of object detection. Classic DL models include CNN, deep belief networks, deep residual Networks, and AutoEncoders (AE) [18]. LeCun et al. [19] first applied artificial neural network to recognize handwritten fonts, and the LeNet [20] proposed later was the beginning of research on deep convolutional networks in the area of object recognition. Later, the ALexNet suggested by Krizhevsky et al. [21] achieved the best result of 11% false recognition rate in the visual object classes (VOC) challenge, which greatly improved the practicability of neural networks in the area of target recognition. The VGGNet [22] proposed by Oxford University further deepens the neural network and extracts deeper abstract features of the image. GoogleNet [23] developed by Google improves the computational efficiency of neural networks, and new versions including inception2, inception3, inception4, and Xception [24] were subsequently proposed.
The ResNet [25] developed by He et al. from the Microsoft Research Institute is a 152-layer deep neural network. The model gained the championship in the ImageNet Large Scale Visual Recognition Challenge 2015 competition with significantly lower error rate and reduced number of parameters compared to that of the VGGNet. In addition, there are also some studies on shallow networks and unsupervised DL models. For example, Chen et al. [26] proposed to use an unsupervised sparse AE network to learn from randomly sampled image patches, and finally train a softmax classifier to classify the objects. In 2014, Girshick et al. [27] proposed a regional detection-based CNN (R-CNN) in which a region-selective search algorithm is used to obtain 2,000 candidate bounding boxes and then convolution operations are performed, which reduce the redundant convolution operations and realize the function of multi-target recognition for a single image. So far, the CNN has gained considerable attention in the area of object recognition.
On the basis of the classic networks, by improving the way of obtaining candidate regions and the modification of the network structure, two types of object detection methods have been developed, namely the candidate region-based (also known as two-stage) algorithms, and the regression-based (also known as one-stage) object detection algorithms. In general, the candidate region-based algorithms have better recognition performance, while the regression-based algorithms have faster processing speed [28].
The popular candidate region-based object detection models include Spp-Net [26], Fast R-CNN [29], Faster R-CNN [30], and mask R-CNN [31]. These algorithms mainly involve two tasks: candidate region acquisition and candidate region identification. Spp-Net reduces the computing load of the network through pyramid pooling layers. Fast RCNN and Faster R-CNN improve the network in different aspects to improve the detection speed. The key improvement of Faster R-CNN is to use the region proposal network (RPN) instead of the selection search algorithm, which further improves the detection speed. RPN is currently the most accurate candidate bounding box localization method, so Faster R-CNN has very high localization accuracy. On the basis of Faster R-CNN, researchers have proposed mask R-CNN, RetinaNet [32], etc.
The regression-based (one-stage) object detection algorithms seek a compromise between recognition speed and recognition accuracy; the selection of candidate bounding boxes, feature extraction, object classification and the bounding box predictions are all regressed into the network, and the location and category of the target are obtained explicitly at the output layer, so that the recognition speed improves significantly. The regression-based object recognition algorithms mainly include YOLO [9], SSD [8], and EfficientNet [33]. These are the methods with fast processing speed and great detection accuracy.
In 2016, Redmon et al. proposed the YOLO network [9] which no longer uses the region proposal strategy, but the entire image input is divided into multiple grids. Each grid is responsible for forecasting the object whose center is within the grid. End-to-end prediction can be achieved by running a single CNN operation on an image, which significantly accelerates the speed of object recognition. YOLO also has some shortcomings. Its positioning accuracy is lower than that of the candidate region-based algorithms, it cannot identify small targets well, and its generalization performance is poor. Liu et al. proposed SSD [8] in the European Conference on Computer Vision 2016, in which the RPN structure is used to improve the YOLO network. By mapping objects at different scales through different convolutional layers, the detection accuracy for small targets is enhanced, while retaining the merits of fast computing speed from YOLO and high accuracy from Faster R-CNN. YOLO is superior to the SSD algorithm in terms of detection speed, but there is a problem of missed detections for mutually occluded targets. In addition, researchers have developed simplified versions of YOLOv3-Tiny [34], YOLOv4-tiny [10], and other lightweight models based on the original YOLO network. These models are relatively simple and efficient with fewer parameters, thus significantly reducing storage and computing requirements. Among them, YOLOv4-tiny is significantly better than other lightweight models in terms of training time and detection speed, which are applicable for embedded devices.
3 Yolov4-tiny
In the YOLO series, region classification proposals are integrated into a single neural network for the predictions of bounding boxes and classification probabilities, where the input image is partitioned into
YOLOv4-tiny [10], as a lightweight version of the YOLOv4 model, using CSPDarkNet53-tiny as its backbone network, and the network structure of the YOLOv4-tiny are shown in Figure 1. CSPDarkNet53-tiny uses three simplified CSP blocks with residual modules removed in the CSP network. In order to further reduce computing complexity, the Mish function is replaced by the leaky rectified linear unit as the activation function, and the feature pyramid network is used to extract two feature maps of different sizes to predict the recognition results, reducing the number of model parameters and computational loads, thereby promoting the application in embedded systems and mobile devices. However, due to the simpler network structure, the detection performance of YOLOv4-tiny is also significantly lower than that of the YOLOv4 network, especially for small targets.

Structure of Yolov4-tiny.
4 Proposed method
Based on the original YOLOv4-tiny model, this study designs a dense object recognition model for indoor spaces. The YOLOv4-tiny model has a simplified structure and fast inference speed and is suitable for embedded hardware platforms. However, the recognition accuracy of the model for small targets and overlapping targets within dense scenes needs to be improved, and further optimization and improvement are required.
4.1 Improvement of the network structure
The backbone network of the YOLOv4-tiny model contains three CSP modules, namely CSP1, CSP2, and CSP3. Among them, the CSP2 layer includes precise location information and more specific information, but fewer semantic information. The CSP3 layer includes a larger amount of semantic information but less specific information, the location information is relatively rough, and the position information and detail information of many small targets could be lost. To promote the recognition precision of the YOLOv4-tiny model for densely crowded targets, we propose an improved YOLOv4-tiny model, the detailed structure of which is shown in Figure 2. In the figure, Conv denotes convolutional operation, Leaky is the Leaky Relu activation function, and Maxpool represents max pooling operation. The route module performs concatenation operation, and CSP1, SCP2, and CSP3 are CSP network modules. UP1 and UP2 represent upsampling 1 and upsampling 2 operations, respectively. The input image resolution is 416 × 416. The dimensions of the output feature maps are 13 × 13, 26 × 26, and 52 × 52, respectively.

Structure of improved YOLOv4-tiny model, CBL module, and CSP module.
From Figure 2, it can be seen that the proposed model adds a path connected to the CSP2 layer of the backbone network in the neck network of the original YOLOv4-tiny model, and the detection scales are expanded from two to three. The outputs of the CSP2 layer and the upsampling layer (UP layer) are concatenated in the channel dimensions, the feature maps from two different layers are fused, and then through two CBL modules, the feature map that is downsampled by eight times of the resolution of the input image is finally obtained. For an input image with a resolution of 416 × 416 pixels, the improved YOLOv4-tiny model outputs feature maps at three scales with resolutions of 13 × 13, 26 × 26, and 52 × 52 pixels, respectively. Since the occluded objects have the characteristics of small salient areas, the original YOLOv4-tiny network is prone to lose a lot of edge detail information. In the proposed model, large-scale feature map optimization technique is introduced into the improved backbone network, which enables the network to capture more detailed image information. By improving the resolution of input pictures, the dimensions of the output feature map are changed from 13 × 13, 26 × 26 to 13 × 13, 26 × 26, and 52 × 52, thereby enhancing the learning capability of the shallow network and reducing the information loss of the shallow layers in the training process.
4.2 CmBN strategy
In object detection tasks, due to the limited memory capacity of the video cards, the BN strategy is inaccurate in estimating statistical information, which may easily lead to increased model errors. This drawback will be more pronounced in resource-constrained embedded devices and can significantly degrade model performance. To this end, the CmBN strategy is used to replace the BN strategy in the original YOLOv4-tiny model.
During model training, the batch of image data in the training set is evenly divided into several mini-batches and passed to the model for forward propagation. The weights of the model do not change until a single iteration is completed, so the statistics of different mini-batches in the same batch can be directly accumulated. The execution processes of the CmBN strategy are as follows:
When calculating the mean and standard deviation of the ith batch data, the output information of the convolutional layer of the (i − 1)th mini-batch data in the training set is combined;
The output of the convolution layer of the ith small batch of data is transformed into a normal distribution with a mean of 0 and a variance of 1;
Using learnable parameters, linearly transform the normalized output of the convolutional layers of the ith mini-batch to enhance its expressive ability.
The forward pass calculation process of the CmBN strategy is as follows:
where
4.3 Target bounding box prediction
In the majority of DL-based target detection algorithms, the convolutional layers generally only acquire the features of the targets, and then pass the acquired features to the classifier or regressor for result prediction. The YOLO series of algorithms use a 1 × 1 convolution kernel to complete the target prediction so that the dimension of the obtained prediction map is equal to the dimension of the feature map. The number of target bounding boxes in YOLOv4-tiny is 3, which is determined by each grid cell in the prediction map, and the feature map contains
From Figure 3, it can be seen that the predicted center coordinate is

Schematic diagram of bounding box prediction.
The YOLOv4-tiny algorithm consists of two parts, training and testing. During the training stage, a mass of data needs to be fed into the model, and during the prediction stage, the candidate bounding boxes are used to determine whether any target falls into the candidate box. If a target falls within the bounding box, its probability is as follows:
In the process of object detection, images vary in size and variety. In order to determine the initial positions of the candidate bounding boxes in YOLOv4-tiny, the K-means clustering algorithm is utilized to determine the initial position of the bounding boxes. As an unsupervised learning method, the K-means clustering algorithm performs clustering operations on surrounding objects close to them by specifying a
where
However, the appropriate selection of
In the DBSCAN clustering algorithm, the closeness of the sample distribution in the neighborhood is described by the parameter
In the original YOLOv4-tiny, the seed points of the K-means clustering algorithm are chosen randomly, which increases the randomness of the clustering and will lead to poor clustering effect. This article proposes a strategy to reduce the randomness of seed point selection. First, the K value is obtained through the error sum of squares method, as shown in equation (11), and then the first cluster center is obtained through the K-means algorithm. Afterward, the obtained K clusters are analyzed, and the closest clusters are merged, thereby reducing the number of cluster centers; the corresponding number of clusters will also decrease when the next clustering is performed, obtaining an ideal number of clusters. After several iterations, when the convergence of the evaluation function reaches the expected value, the best clustering effect can be obtained as follows:
In the experiment, 400 random points are selected and tested with the K-means clustering algorithm and the proposed DB-K hybrid clustering algorithm, respectively. In the K-means clustering algorithm, the

Performance comparison of different clustering methods. (a) K-means clustering method and (b) DB-K clustering method.
Therefore, by integrating the DBSCAN clustering algorithm and improving the traditional K-means clustering algorithm, the classification performance of object detection in different datasets and complex environments is enhanced, and the robustness to noise and interference is also improved. With the proposed DB-K clustering algorithm, the performance of neural network in object recognition is significantly improved.
5 Experiment results and analysis
The experiments in this article are conducted in the Linux environment, and the system is configured as Ubuntu18.04, compute unified device architecture (CUDA) 11.0, and CUDA deep neural network library (CUDNN) 8.0. The hardware platform is equipped with an 8-core Intel 10400F CPU and the graphics card is GTX 960, with 16 GB RAM. During the experiment, GPU is used to speed up the training process. The self-made data set is randomly split into training and testing sets in a ratio of 7:3, and multiple groups of ablation experiments are set up to verify the effect of each improved strategy on the model, thus obtaining the optimal model. In order to further authenticate the performance of the proposed algorithm, a comparative experiment with the most commonly used lightweight algorithms was conducted on the PASCAL VOC07 + 12 [37,38] public dataset, and the performance of different algorithms was compared in terms of the average detection accuracy (mAP) and detection speed (FPS).
5.1 Experiment datasets
In order to analyze the recognition performance of the proposed lightweight model in the crowded indoor spaces with occluded objects, two datasets were constructed: the PASCAL VOC07 + 12 public dataset which includes 16,551 training images and 4,952 testing images, and a self-made dataset. The self-made dataset involves four different scenarios, with 10,432 images captured from elevator cars and 9,139 images captured from bus cars, passenger aircraft cabins, and natural scenes. The training, validation, and test sets are partitioned in a ratio of 7:2:1. Among them, 70% of the pictures have the characteristics of mutual occlusion or incomplete camera framing. In this article, such pictures are defined as complex images in the experiment, which can effectively prevent the overfitting caused by the single background in the dense space during training, and improve the generalization capability of the model in crowded indoor scenarios. The dataset defines three detection categories: person, electric-bicycle, and bicycle. Baby carriage, trolley, furniture, other goods, and pets are used as negative samples to enhance the reliability of the model. The LabelImg tool designed by Tzutalin [39] is used to mark the labeling area and picture area of each picture according to a certain proportion, and the aspect ratio of the pictures is limited within 3:1 to make the predicted bounding boxes more fit to the targets. The statistics of the self-built dataset is shown in Table 1.
Statistics of the self-built dataset
| Categories | Positive objects | Negative objects | Total | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Person | Electric bicycle | Bicycle | Baby carriage | Trolley | Furniture | Other goods | Pets | ||
| Number | 24,475 | 16,528 | 7,544 | 1,497 | 1,382 | 864 | 1,497 | 3,801 | 57,588 |
| % | 42.5 | 28.7 | 13.1 | 2.6 | 2.4 | 1.5 | 2.6 | 6.6 | 100 |
Objects in dense indoor scenes such as elevators and carriages are prone to mutual overlap and occlusion, which will seriously affect the accuracy of target recognition. Aiming at the aforementioned problems, this study introduces Mosaic data augmentation technique [40] during model training to improve the model’s capability to recognize occluded objects. The example images after Mosaic process is shown in Figure 5. Before each iteration, the DL framework not only acquires images from the training set, but also generates new images through Mosaic data augmentation, and then the newly generated images and the original images are combined and fed into the model for training. Mosaic data enhancement randomly selects four images from the training set, randomly crops the four selected images, and splices the cropped images in sequence to obtain a new image, and the generated image has the same resolution as the training set image. During random cropping, part of the bounding box of the target in the training set image may be cropped to simulate the effect of the object being occluded. In addition, this study optimizes Mosaic data augmentation, and proposes an improved Mosaic data augmentation, which uses the intersection-over-union (IoU) as an indicator and sets the threshold considering the relevant standards used when calibrating the dataset to filter the objects’ bounding boxes in the newly generated image. The improved Mosaic strategy generates a new image according to the steps of Mosaic data enhancement and filters the object bounding boxes in the newly generated image. If the IoU between the object bounding boxes in the new image and in the corresponding original image is less than the threshold, the object bounding box in the new image will be deleted and it is considered that there is no object here. Otherwise, the object bounding box in the newly generated image will be retained, and it is considered that there is a target here.

Examples of the training data enhancement. (a) Original images and (b) imaged after enhanced Mosaic process.
5.2 Evaluation metric
The inference speed (ms/frame) is used as an evaluation metric for model recognition speed, and the inference speed is the time required for the model to recognize an image. The average precision (AP) is used as the evaluation metric for the model recognition accuracy. AP is calculated based on the precision (P) and recall (R) of the model. P, R, AP, and mAP are calculated as follows:
where TP is the number of correctly detected positive samples, TN is the number of correctly detected negative samples, FP is the number of falsely detected positive samples, and FN is the number of falsely detected negative samples. P represents the percentage of correctly detected positive samples in all detected positive samples. R represents the percentage of correctly detected positive samples in all of the ground-truth positive samples. In the final evaluation result, AP represents the comprehensive evaluation of a certain category, and the greater the AP value is, the better the accuracy of a single category. mAP is an evaluation of the level of the entire network, C is the number of classes contained in the whole dataset, and c denotes a single class.
5.3 Model training parameters
The model parameters in the experiment are set as follows: the input image is 416 × 416; the epoch is set to 300; the batch_size is 128 for the first 70 rounds, and 32 for the last 230 rounds. The learning rate is 1 × 10–3 for the first 70 rounds and 1 × 10–4 for the last 230 rounds. We employed stochastic gradient descent optimization strategy for model training, with an initial learning rate whose momentum was gradually decreased as the degree of gradient descent increased, in order to improve convergence performance. Specifically, we set the momentum parameter to 0.9 to accelerate the convergence rate of the optimization process. The loss curves during training are shown in Figure 6.
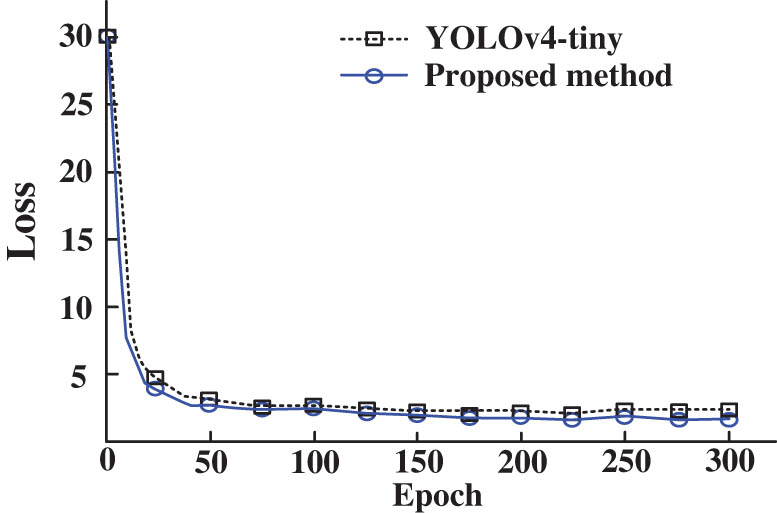
Loss curves during training.
As the epoch continues to increase, the loss values of both modes continue to decrease. After 70 rounds of training, the loss curves tend to be stable, and there is no underfitting or overfitting. The loss values of the original YOLOv4-tiny algorithm and the improved algorithm converge to around 2.3 and 1.9, respectively, which proves that the recognition accuracy of the model is constantly improving, and the hyperparameters of the proposed algorithm are set reasonably.
5.4 Comparison with the original YOLOv4-tiny
The test results of the original YOLOv4-tiny and the proposed model on self-built dataset are shown in Table 2, in which the mAP, inference speed, and model size comparisons are given. Among them, complex images account for 70% of the dataset, which correspond to the situation where the targets are occluded by each other or the camera view is incomplete. The mAP of the original YOLOv4-tiny model for recognizing complex images and all images in the test dataset are 75.47 and 84.25%, respectively, and the proposed model is 7.94 and 8.32% higher than those of the original model, respectively. The neck network of the improved YOLOv4-tiny model reduces the loss of low-level feature map details and location information in the backbone network. The newly added feature maps have a smaller perceptual field for detecting blurred and occluded targets in images and improve the model’s ability to detect small targets. And, the DB-K clustering algorithm is used to further improve the classification effect. Compared with the original Yolov4-tiny, the model size of the proposed model is increased by 2MB, and the inference time per image is increased by 0.37 ms. The improved model only adds three convolutional layers, one upsampling operation, and one connection operation to the neck network, and the backbone network of the model does not change. Therefore, the improved YOLOv4-tiny model maintains a fast inference speed while improving the detection accuracy.
Comparison results on self-build dataset
| Models | mAP (%) | Inference speed (ms/frame) | Model size (MB) | |
|---|---|---|---|---|
| Complex images | All images | |||
| Yolov4-tiny | 75.47 | 84.25 | 3.42 | 23.5 |
| Proposed model | 83.41 | 92.57 | 3.79 | 25.5 |
The mAP curves of the proposed model and the original YOLOv4-tiny on PSACAL VOC dataset are shown in Figure 7. From the figures, it can be observed that with the proposed model, the mAP for recognizing objects of various scales and different categories are improved significantly. For example, compared with the original model, when using the proposed model, the APs for categories containing a large number of small targets such as potted plant, boat, and bird are increased by 7, 4, and 3%, respectively. The results validate that the proposed algorithm has better detection effect when dealing with scenes containing many occluded targets and small targets, which further proves the superiority of the proposed algorithm.

Performance comparison on PASCAL VOC dataset. (a) Original YOLO-v4-tiny and (b) proposed model.
5.5 Ablation study
The ablation analysis is performed based on the original YOLOv4-tiny model and combined with different improvement strategies, and the training and performance evaluation are carried out on the self-built dataset containing four types of scenes, to validate the contribution of each module to the improvement of recognition accuracy under the precondition of guaranteeing real-time performance. The test results of different module combinations are shown in Table 3, all of which are trained using the proposed enhanced Mosaic technology. The effectiveness of each module is analyzed in the table, and it can be seen that each improved module has different degrees of contribution to the overall performance. Among them, the introduction of DBSCAN in Model 4 contributes the most to the network, and the mAP increases by 4.99%, which proves that the proposed clustering algorithm significantly improves the classification effect in complex environments, while increasing the robustness to noise and interference. The mAP value of the original YOLOv4-tiny (model 1) is 84.25%, and the mAP value after using the neck network optimization (model 2) is 86.77%, an increase of 2.52%, indicating that the introduction of this optimization module enables the model to strengthen the extraction of detailed information from shallow layers, which makes the training for occluded objects more in-depth. Model 3 replaces BN with CmBN on the basis of model 2. BN can only use the output features from the convolution layers of the current mini-batch, so the statistic information is not accurate enough, resulting in a poor performance. CmBN, on the other hand, realizes the expansion of samples by accumulating information from different mini-batches and makes the estimation of statistical information more accurate.
Results of the ablation tests
| Models | Original neck network | Improved neck network | BN | CmBN | K-means clustering | Improved DB-K clustering | mAP (%) |
|---|---|---|---|---|---|---|---|
| 1 | √ | √ | √ | 84.25 | |||
| 2 | √ | √ | √ | 86.77 | |||
| 3 | √ | √ | √ | 87.58 | |||
| 4 | √ | √ | √ | 92.57 |
5.6 Comparison with other state-of-the-art models
To further verify the effectiveness of the proposed model, a comparison experiment is carried out on PASCAL VOC07 + 12 public dataset with the proposed model and other state-of-the-art models including Faster RCNN [30], YOLOv4 [36], YOLOv3-tiny [34], and YOLOv4-tiny [10]. In addition, the DL frameworks and the trained models are ported to Jetson nano and Raspberry Pi 4B to test the inference speed of the models on the embedded hardware platforms. The results are listed in Table 4. From Table 4, it can be observed that the advantage of large networks is high detection accuracy. For example, the two-stage algorithm Faster RCNN using Resnet50 as the backbone network and the classic one-stage algorithm YOLOv4 have achieved mAPs of 83.77 and 90.01%, respectively. However, the size of these two models is too large, 330 MB and 256 MB, respectively, making such networks difficult to deploy to mobile terminals with limited computing capacity. The performance of the proposed method is comparable to that of the large network Faster RCNN in mAP, only 1.41% behind, and the size of the proposed model is only 1/13 to that of the faster RNN. Compared with the 64.3 million parameters of the YOLOv4 model, the parameters of the proposed model are only 6.1 million, which is less than 1/10. The advantage of the lightweight network is that the detection speed and accuracy are relatively balanced, and it can perform real-time detection on the mobile terminal, but the performance is relatively poor in complex scenes. Compared with two popular lightweight models YOLOv3-tiny and YOLOv4-tiny, the proposed method has significantly improved mAP performance while satisfying the real-time detection requirements. The proposed model will not introduce too much extra computing power and memory overhead in the inference process. The model retains the advantages of simplified structure and fast inference while ensuring a high recognition accuracy. It proves that the proposed model is applicable for the deployment in embedded hardware platforms.
Comparison results with different methods
| Models | Backbone network | mAP (%) | Model size (MB) | Parameters/million | Inference speed (ms/frame) | ||
|---|---|---|---|---|---|---|---|
| GTX 960 | Jetson nano | Raspberry Pi | |||||
| Faster RCNN | Resnet50 | 83.77 | 330 | 81.7 | 41.55 | — | — |
| YOLOv4 | CSPDarknet53 | 90.01 | 256 | 64.3 | 14.58 | 812 | 19,350 |
| YOLOv3-tiny | Darkent53-tiny | 70.22 | 33.1 | 6.2 | 4.92 | 274 | 3,680 |
| YOLOv4-tiny | CSPDarknet-53-tiny | 75.49 | 23.5 | 5.9 | 3.42 | 152 | 2,177 |
| Proposed method | CSPDarknet-53-tiny | 82.36 | 25.5 | 6.1 | 3.79 | 183 | 2,601 |
6 Conclusion
In order to address the problem of poor performance of the original YOLOv4-tiny algorithm for detection of occluded object in dense indoor scenes, a modified target detection model is proposed based on YOLOv4-tiny algorithm, and three feasible improvements are made: 1) The neck network structure of the original YOLOv4-tiny model is modified so that the model can learn more information from the occluded objects; 2) The CmBN strategy is used instead of the BN strategy, and the model error is reduced by accumulating the outputs of the convolutional layers; 3) The DBSCAN clustering algorithm is incorporated in the proposed network and then the anchor point coordinates are determined through the improved K-means clustering, thus the detection accuracy is further increased. Experimental results show that the mAP values of the proposed algorithm in the PASCAL VOC07 + 12 dataset and the self-built dataset are 92.57 and 82.36%, respectively, which are 8.32 and 6.87% higher than those of the original YOLOV4-tiny model, respectively. It proves that the performance of the proposed algorithm is significantly improved compared with the original YOLOV4-tiny model. The inference speeds of the proposed algorithm on the embedded platforms Jetson nano and Raspberry PI are 183 and 2,601 ms/frame, respectively, indicating that the processing speed of the proposed algorithm can satisfy the requirements of different real-time applications, the occluded target can be detected quickly and accurately, and the proposed model is applicable for practical application of target detection in crowded indoor spaces. There are still some areas for improvement of the proposed method. Although the recognition accuracy of the proposed algorithm has been greatly improved, it is limited by the lightweight nature of the backbone network. When performing detection tasks in general scenes, the detection accuracy of small objects is still lower than that of complex networks. In the future, we will continue to optimize the backbone network. In order to reuse local features and strengthen the fusion of global features, we can try to connect the CBM module and the CBL module in the CSP module in a dense connection structure. The CBM modules in different CSP modules can be tensor spliced after the upsampling operation, which further integrates the feature information of the shallow layer and the deep layer. In addition, an attempt will be made to augment the experimental dataset for small object detection in general scenarios.
-
Funding information: This work was not supported by any fund projects.
-
Author contributions: Jianing Shen: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project, administration, Resources, Software, Supervision, Validation, Visualization; Yang Zhou: Writing – original draft, Writing – review & editing.
-
Conflict of interest: The author declares that there is no conflict of interest regarding the publication of this article.
-
Data availability statement: The data used to support the findings of this study are included within the article.
References
[1] Zou Z, Shi Z, Guo Y, Ye J. Object detection in 20 years: A survey. arXiv preprint arXiv: 1905.05055; 2019.Search in Google Scholar
[2] Meng Z, Zhang M, Wang H. CNN with pose segmentation for suspicious object detection in MMW security images. Sensors. 2020;20(17):4974.10.3390/s20174974Search in Google Scholar PubMed PubMed Central
[3] Teknomo K, Takeyama Y, Inamura H. Tracking system to automate data collection of microscopic pedestrian traffic flow. arXiv preprint arXiv: 1609.01810; 2016.Search in Google Scholar
[4] Ko KE, Sim K. Deep convolutional framework for abnormal behavior detection in a smart surveillance system. Eng Appl Artif Intell. 2018;67:226–34.10.1016/j.engappai.2017.10.001Search in Google Scholar
[5] Murthy CB, Hashmi MF, Bokde ND, Geem ZW. Investigations of object detection in images/videos using various deep learning techniques and embedded platforms – A comprehensive review. Appl Sci. 2020;10(9):3280.10.3390/app10093280Search in Google Scholar
[6] Lan S, Gao Y, Jiang S. Computer vision for system protection of elevators. Journal of Physics: Conference Series. Vol. 1848. Issue 1. IOP Publishing; 2021. p. 012156.10.1088/1742-6596/1848/1/012156Search in Google Scholar
[7] Wang S. A review of gradient-based and edge-based feature extraction methods for object detection. 2011 IEEE 11th International Conference on Computer and Information Technology. IEEE; 2011. p. 277–82.10.1109/CIT.2011.51Search in Google Scholar
[8] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. Ssd: Single shot multibox detector. European Conference on Computer Vision. Cham: Springer; 2016. p. 21–37.10.1007/978-3-319-46448-0_2Search in Google Scholar
[9] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016. p. 779–88.10.1109/CVPR.2016.91Search in Google Scholar
[10] Wang CY, Bochkovskiy A, Liao HYM. Scaled-yolov4: Scaling cross stage partial network. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021. p. 13029–38.10.1109/CVPR46437.2021.01283Search in Google Scholar
[11] Ren H, Li ZN. Object detection using edge histogram of oriented gradient.2014 IEEE international conference on image processing (ICIP). IEEE; 2014. p. 4057–61.10.1109/ICIP.2014.7025824Search in Google Scholar
[12] Gilani SAM. Object recognition by modified scale invariant feature transform. Third International Workshop on Semantic Media Adaptation and Personalization. IEEE; 2008. p. 33–9.10.1109/SMAP.2008.12Search in Google Scholar
[13] Farooq J. Object detection and identification using SURF and BoW model. International Conference on Computing, Electronic and Electrical Engineering (ICE Cube). IEEE; 2016. p. 318–23.10.1109/ICECUBE.2016.7495245Search in Google Scholar
[14] Lienhart R, Maydt J. An extended set of Haar-like features for rapid object detection. Proceedings. International Conference on Image Processing. Vol. 1. IEEE; 2002. p. I.10.1109/ICIP.2002.1038171Search in Google Scholar
[15] Trefný J, Matas J. Extended set of local binary patterns for rapid object detection. Computer Vision Winter Workshop; 2010. p. 1–7.Search in Google Scholar
[16] Mostafa A, Sander OE. Application of template matching for improving classification of urban railroad point clouds. Sensors. 2016;16(12):2112.10.3390/s16122112Search in Google Scholar PubMed PubMed Central
[17] Bühlmann P, Hothorn T. Boosting algorithms: Regularization, prediction and model fitting. Stat Sci. 2007;22(4):477–505.10.1214/07-STS242Search in Google Scholar
[18] Zhao ZQ, Zheng P, Xu ST, Wu X. Object detection with deep learning: A review. IEEE Trans Neural Netw Learn Syst. 2019;30(11):3212–32.10.1109/TNNLS.2018.2876865Search in Google Scholar PubMed
[19] LeCun Y, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W, et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989;1(4):541–51.10.1162/neco.1989.1.4.541Search in Google Scholar
[20] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–324.10.1109/5.726791Search in Google Scholar
[21] Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst. 2012;25:1106–14.Search in Google Scholar
[22] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556; 2014.Search in Google Scholar
[23] Ballester P, Araujo RM. On the performance of GoogLeNet and AlexNet applied to sketches. Thirtieth AAAI Conference on Artificial Intelligence; 2016.10.1609/aaai.v30i1.10171Search in Google Scholar
[24] Chollet F. Xception: Deep learning with depthwise separable convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017. p. 1251–8.10.1109/CVPR.2017.195Search in Google Scholar
[25] He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016. p. 770–8.10.1109/CVPR.2016.90Search in Google Scholar
[26] Chen S, Liu H, Zeng X, Qian S, Yu J, Guo W. Image classification based on convolutional denoising sparse autoencoder. Math Probl Eng. 2017;2017:5218247. 10.1155/2017/5218247.Search in Google Scholar
[27] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014. p. 580–7.10.1109/CVPR.2014.81Search in Google Scholar
[28] Lu X, Li Q, Li B, Yan J. Mimicdet: Bridging the gap between one-stage and two-stage object detection. European Conference on Computer Vision. Cham: Springer; 2020. p. 541–57.10.1007/978-3-030-58568-6_32Search in Google Scholar
[29] Palaniappan K, Kambhamettu C. Hasler, Goldgof. Fast r-cnn. Proceedings of the IEEE International Conference on Computer Vision; 2015. p. 1440–8.Search in Google Scholar
[30] Ren S, He K, Girshick R, Sun J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst. 2015;28.Search in Google Scholar
[31] He K, Gkioxari G, Dollár P, Girshick R. Mask r-cnn. Proceedings of the IEEE International Conference on Computer Vision; 2017. p. 2961–9.10.1109/ICCV.2017.322Search in Google Scholar
[32] Afif M, Ayachi R, Said Y, Pissaloux E, Atri M. An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation. Neural Process Lett. 2020;51(3):2265–79.10.1007/s11063-020-10197-9Search in Google Scholar
[33] Tan M, Le QV. Efficientnet: Rethinking model scaling for convolutional neural networks. International Conference On Machine Learning. PMLR; 2019. p. 6105–14.Search in Google Scholar
[34] Redmon J, Farhadi A. YOLOv3: An Incremental Improvement; 2018, arXiv:1804.02767. [Online]. http://arxiv.org/abs/1804.02767.Search in Google Scholar
[35] Redmon J, Farhadi A. YOLO9000: better, faster, stronger. Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition; 2017. p. 7263–71.10.1109/CVPR.2017.690Search in Google Scholar
[36] Bochkovskiy A, Wang CY, Liao HYM. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934; 2020.Search in Google Scholar
[37] Everingham M, Van Gool L, Williams CK, Winn J. The pascal visual object classes (voc) challenge. Int J Comput Vis. 2010;88(2):303–38.10.1007/s11263-009-0275-4Search in Google Scholar
[38] Shetty S. Application of convolutional neural network for image classification on Pascal VOC challenge 2012 dataset. arXiv preprint arXiv:1607.03785; 2016.Search in Google Scholar
[39] Tzutalin D. LabelImg Is a graphical image annotation tool and label object bounding boxes in images; 2015. URL https://github.com/tzutalin/labelImg.Search in Google Scholar
[40] Yun S, Han D, Chun S, Oh SJ, Yoo Y, Choe J, et al. Cutmix: Regularization strategy to train strong classifiers with localizable features. Proceedings of the IEEE/CVF International Conference on Computer Vision; 2019. p. 6023–32.10.1109/ICCV.2019.00612Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique
Articles in the same Issue
- Research Articles
- Salp swarm and gray wolf optimizer for improving the efficiency of power supply network in radial distribution systems
- Deep learning in distributed denial-of-service attacks detection method for Internet of Things networks
- On numerical characterizations of the topological reduction of incomplete information systems based on evidence theory
- A novel deep learning-based brain tumor detection using the Bagging ensemble with K-nearest neighbor
- Detecting biased user-product ratings for online products using opinion mining
- Evaluation and analysis of teaching quality of university teachers using machine learning algorithms
- Efficient mutual authentication using Kerberos for resource constraint smart meter in advanced metering infrastructure
- Recognition of English speech – using a deep learning algorithm
- A new method for writer identification based on historical documents
- Intelligent gloves: An IT intervention for deaf-mute people
- Reinforcement learning with Gaussian process regression using variational free energy
- Anti-leakage method of network sensitive information data based on homomorphic encryption
- An intelligent algorithm for fast machine translation of long English sentences
- A lattice-transformer-graph deep learning model for Chinese named entity recognition
- Robot indoor navigation point cloud map generation algorithm based on visual sensing
- Towards a better similarity algorithm for host-based intrusion detection system
- A multiorder feature tracking and explanation strategy for explainable deep learning
- Application study of ant colony algorithm for network data transmission path scheduling optimization
- Data analysis with performance and privacy enhanced classification
- Motion vector steganography algorithm of sports training video integrating with artificial bee colony algorithm and human-centered AI for web applications
- Multi-sensor remote sensing image alignment based on fast algorithms
- Replay attack detection based on deformable convolutional neural network and temporal-frequency attention model
- Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation
- Computer technology of multisensor data fusion based on FWA–BP network
- Application of adaptive improved DE algorithm based on multi-angle search rotation crossover strategy in multi-circuit testing optimization
- HWCD: A hybrid approach for image compression using wavelet, encryption using confusion, and decryption using diffusion scheme
- Environmental landscape design and planning system based on computer vision and deep learning
- Wireless sensor node localization algorithm combined with PSO-DFP
- Development of a digital employee rating evaluation system (DERES) based on machine learning algorithms and 360-degree method
- A BiLSTM-attention-based point-of-interest recommendation algorithm
- Development and research of deep neural network fusion computer vision technology
- Face recognition of remote monitoring under the Ipv6 protocol technology of Internet of Things architecture
- Research on the center extraction algorithm of structured light fringe based on an improved gray gravity center method
- Anomaly detection for maritime navigation based on probability density function of error of reconstruction
- A novel hybrid CNN-LSTM approach for assessing StackOverflow post quality
- Integrating k-means clustering algorithm for the symbiotic relationship of aesthetic community spatial science
- Improved kernel density peaks clustering for plant image segmentation applications
- Biomedical event extraction using pre-trained SciBERT
- Sentiment analysis method of consumer comment text based on BERT and hierarchical attention in e-commerce big data environment
- An intelligent decision methodology for triangular Pythagorean fuzzy MADM and applications to college English teaching quality evaluation
- Ensemble of explainable artificial intelligence predictions through discriminate regions: A model to identify COVID-19 from chest X-ray images
- Image feature extraction algorithm based on visual information
- Optimizing genetic prediction: Define-by-run DL approach in DNA sequencing
- Study on recognition and classification of English accents using deep learning algorithms
- Review Articles
- Dimensions of artificial intelligence techniques, blockchain, and cyber security in the Internet of medical things: Opportunities, challenges, and future directions
- A systematic literature review of undiscovered vulnerabilities and tools in smart contract technology
- Special Issue: Trustworthy Artificial Intelligence for Big Data-Driven Research Applications based on Internet of Everythings
- Deep learning for content-based image retrieval in FHE algorithms
- Improving binary crow search algorithm for feature selection
- Enhancement of K-means clustering in big data based on equilibrium optimizer algorithm
- A study on predicting crime rates through machine learning and data mining using text
- Deep learning models for multilabel ECG abnormalities classification: A comparative study using TPE optimization
- Predicting medicine demand using deep learning techniques: A review
- A novel distance vector hop localization method for wireless sensor networks
- Development of an intelligent controller for sports training system based on FPGA
- Analyzing SQL payloads using logistic regression in a big data environment
- Classifying cuneiform symbols using machine learning algorithms with unigram features on a balanced dataset
- Waste material classification using performance evaluation of deep learning models
- A deep neural network model for paternity testing based on 15-loci STR for Iraqi families
- AttentionPose: Attention-driven end-to-end model for precise 6D pose estimation
- The impact of innovation and digitalization on the quality of higher education: A study of selected universities in Uzbekistan
- A transfer learning approach for the classification of liver cancer
- Review of iris segmentation and recognition using deep learning to improve biometric application
- Special Issue: Intelligent Robotics for Smart Cities
- Accurate and real-time object detection in crowded indoor spaces based on the fusion of DBSCAN algorithm and improved YOLOv4-tiny network
- CMOR motion planning and accuracy control for heavy-duty robots
- Smart robots’ virus defense using data mining technology
- Broadcast speech recognition and control system based on Internet of Things sensors for smart cities
- Special Issue on International Conference on Computing Communication & Informatics 2022
- Intelligent control system for industrial robots based on multi-source data fusion
- Construction pit deformation measurement technology based on neural network algorithm
- Intelligent financial decision support system based on big data
- Design model-free adaptive PID controller based on lazy learning algorithm
- Intelligent medical IoT health monitoring system based on VR and wearable devices
- Feature extraction algorithm of anti-jamming cyclic frequency of electronic communication signal
- Intelligent auditing techniques for enterprise finance
- Improvement of predictive control algorithm based on fuzzy fractional order PID
- Multilevel thresholding image segmentation algorithm based on Mumford–Shah model
- Special Issue: Current IoT Trends, Issues, and Future Potential Using AI & Machine Learning Techniques
- Automatic adaptive weighted fusion of features-based approach for plant disease identification
- A multi-crop disease identification approach based on residual attention learning
- Aspect-based sentiment analysis on multi-domain reviews through word embedding
- RES-KELM fusion model based on non-iterative deterministic learning classifier for classification of Covid19 chest X-ray images
- A review of small object and movement detection based loss function and optimized technique