Uncertainty measurement for a three heterogeneous information system based on k-nearest neighborhood: Application to unsupervised attribute reduction
-
Xiaoyan Guo
 and
Yu Li
and
Yu Li

Abstract
The
1 Introduction
1.1 Research background
Uncertainty of datasets, including randomness, fuzziness, vagueness, incompleteness, and inconsistency, is widespread. Uncertainty measurement (UM) can supply new points of view for analyzing data and help us to disclose the substantive characteristics of datasets.
Rough set theory (RST) is a significant tool to deal with uncertainty. This theory only uses internal information, which can be independent of the prior model convention. It can also extract and represent the hidden knowledge in an information system (IS) [1,2]. In rough set theory, knowledge is defined as a family set with indistinguishable relations, so that knowledge has a clear mathematical meaning, then we can use mathematical methods to deal with it. It gives a mathematical method of knowledge discovery.
Information entropy, introduced by Shannon [3], is an important tool for estimating uncertainty. Information granulation is mainly used to study uncertainty of information or knowledge in an IS. All these studies were dedicated to evaluating uncertainty of a set in terms of the partition ability of a knowledge.
Some scholars measured uncertainty of ISs or rough sets by using information entropy and information granulation. For instance, Liang and Qian [4] studied information granules and entropy theory in an IS. Beaubouef et al. [5] came up with a method for measuring the uncertainty of rough sets. Sosa-Cabrera et al. [6] investigated a multivariate approach to the symmetrical UM. Zhao et al. [7] studied complement information entropy for UM in fuzzy rough sets and its applications. Zhang et al. [8] studied UM for interval set information tables based on interval
Attribute reduction or feature selection is considered to be one of the important problems in the research of RST [2]. In recent years, attribute reduction has received much attention and some attribute reduction algorithms have been proposed. Wang et al. [12] discussed attribute reduction for hybrid data based on the fuzzy rough iterative computation model. Thuy and Wongthanavasu [13] gave a novel feature selection method for a high-dimensional mixed decision IS. Zhang et al. [14] researched attribute reduction based on the D-S evidence theory in a hybrid IS. Gao et al. [15] considered granular maximum decision entropy-based monotonic uncertainty measure for attribute reduction. Sun et al. [16] proposed feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Wang et al. [17] studied feature selection and classification based on directed fuzzy rough sets. An et al. [18] gave robust fuzzy rough approximations with
1.2 Motivation and contributions
Neighborhood rough set is an important model for dealing with real-valued data in the rough set theory. The above series of neighborhood rough sets based on neighborhood information granules have the following disadvantage. For ISs with different distribution densities for different attributes (even when rescaled), the neighborhood parameter that controls the size of information granules should be different for the low-density sample distribution region and the high-density sample distribution region. KNN classification algorithm is a theoretically mature method and one of the important machine learning algorithms. The idea of this method is that in the feature space, if most of the
A 3HIS means an IS whose information values contain three types of data (i.e., scaled type, ordinal type, and nominal type). Considering the powerful functionality of KNN, this article studies UM in a 3HIS based on KNN and neighborhood rough set, applying UM to unsupervised attribute reduction. We summarize the major contributions as follows.
The processing method for different types of data in a 3HIS is provided, and a specific distance function is summarized to calculate the distance between any two information values within each single attribute. Based on KNN and neighborhood rough set, KNN in a 3HIS is proposed.
Information granules in a 3HIS are constructed by using KNN. On this basis, four UMs of a 3HIS are discussed.
Dispersion analysis in statistics to compare four UMs. An unsupervised attribute reduction algorithm for a 3HIS based on KNN is designed, and cluster analysis is performed to evaluate the designed unsupervised attribute reduction.
This study will address the uncertainty measure issue in a 3HIS, using the KNN framework and information entropy tools to assess data fuzziness.
This study will construct an improved KNN model that integrates multiple attribute distances to capture local features of heterogeneous data.
This study will propose the ARHentropy attribute reduction algorithm to balance attribute redundancy and discriminability, providing theoretical support for gene expression data analysis.
1.3 Structure and organization
Figure 1 depicts the flowchart of this article.
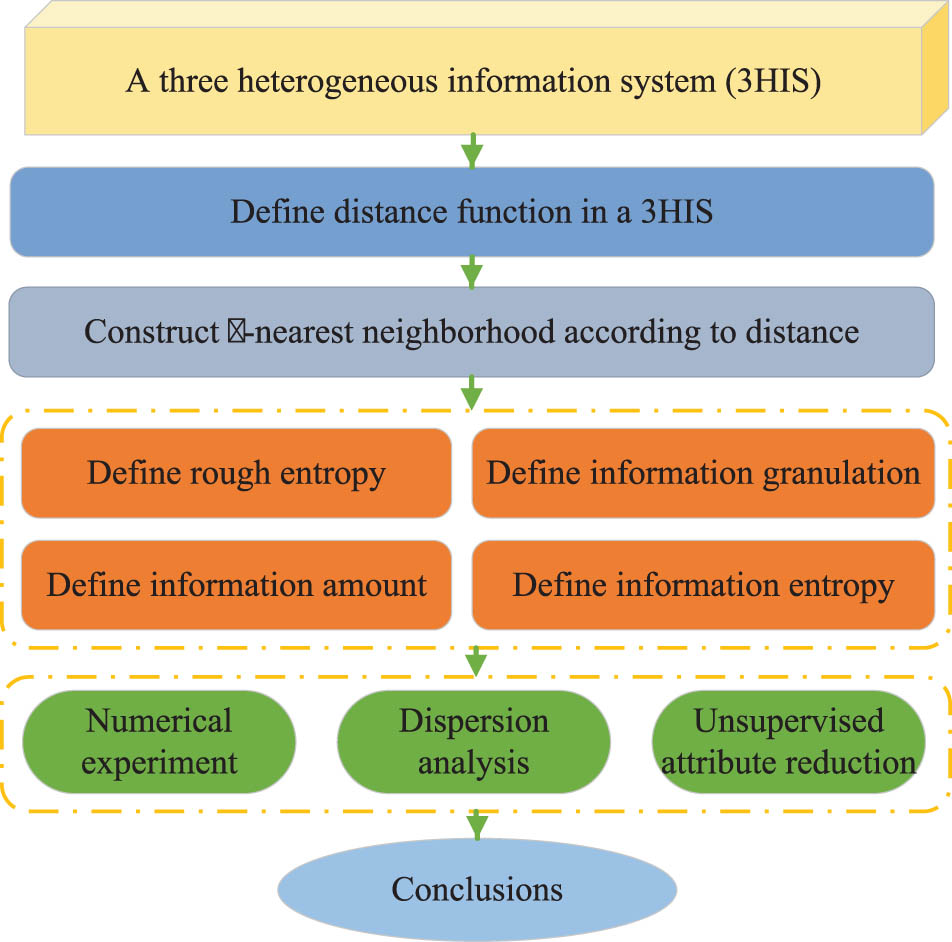
Flowchart of this article. Source: Created by the authors.
The remaining part of this article is organized as follows. Section 2 recalls related concepts about a 3HIS. Section 3 introduces KNN in a 3HIS. Section 4 proposes tools for measuring the uncertainty of a 3HIS based on KNN. Section 5 first conducts numerical experiment to compare four UMs, then executes the dispersion analysis for four UMs, finally presents an unsupervised attribute reduction algorithm, and carries out cluster analysis. Section 6 discusses the advantages and disadvantages of the study. Section 7 summarizes the study.
2 Preliminaries
In this section, we review the notion of fuzzy relations.
Throughout this article,
Definition 2.1
[1] Let
Definition 2.2
Let
Let
Definition 2.3
Let
Otherwise,
Put
Example 2.4
Table 1 illustrates a 3HIS, where
A 3HIS
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
5.08 | 2.67 | Good | Small | Red | China |
|
|
9.92 | 3.31 | Average | Middle | Green | USA |
|
|
7.67 | 4.59 | Good | Big | Blue | USA |
|
|
15.18 | 4.41 | Average | Middle | Blue | China |
|
|
7.81 | 2.09 | Pass | Big | Green | UK |
|
|
18.23 | 6.31 | Average | Big | Blue | China |
|
|
17.05 | 2.76 | Average | Middle | Blue | USA |
|
|
9.63 | 3.17 | Excellent | Small | Red | UK |
First, features
We can obtain that
Definition 2.5
Let
Then
Example 2.6
(Continued from Example 2.4)
Let
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Below, we use
3 KNN in a 3HIS
Definition 3.1
Let
or
where
Define
Obviously,
Definition 3.2
Let
Then
Example 3.3
(Continued from Example 2.4)
Let
KNN of
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Proposition 3.4
Let
If
If
If
Proof
(1) Suppose
Thus,
(2) Suppose
So
Thus,
So
Thus,
Put
Then
4 Measuring the uncertainty of a 3HIS
In this section, we propose some tools for measuring the uncertainty of a 3HIS.
4.1 Granularity measures for a 3HIS
Definition 4.1
Suppose that
Proposition 4.2
Suppose that
If
Proof
Thus,
If
Proposition 4.3
Let
If
If
If
Proof
It can be proved by Proposition 3.4.□
4.2 Entropy measure for a 3HIS
Definition 4.4
Suppose that
Proposition 4.5
Let
If
Proof
Then
Thus,
Proposition 4.6
Let
If
If
If
Proof
(1) Since
Then
By Definition 4.4,
Hence,
(2) Since
Then
By Definition 4.4,
Hence,
(3) Since
Then
By Definition 4.4,
Hence,
Definition 4.7
Let
Theorem 4.8
Let
Proof
By Definitions 4.4 and 4.7,
Then
Corollary 4.9
Let
If
Proof
It can be obtained by Proposition 4.5 and Theorem 4.8.□
Corollary 4.10
Let
If
If
If
Proof
It can be obtained by Proposition 4.6 and Theorem 4.8.□
This corollary shows that the information entropy increases when the information structure becomes finer, and it decreases when information structure becomes coarser.
4.3 Information amount in a 3HIS
Definition 4.11
Let
Example 4.12
(Continued from Examples 2.4 and 3.3)
Let
Uncertainty measures of
|
|
|
|
|
|
|---|---|---|---|---|
|
|
0.5938 | 2.2298 | 0.7702 | 0.4063 |
|
|
0.4219 | 1.7194 | 1.2806 | 0.5781 |
|
|
0.2188 | 0.6981 | 2.3019 | 0.7813 |
|
|
0.1719 | 0.3231 | 2.6769 | 0.8281 |
|
|
0.1406 | 0.1250 | 2.8750 | 0.8594 |
|
|
0.1250 | 0.0000 | 3.0000 | 0.8750 |
Theorem 4.13
Let
Proof
By Definition 4.1,
By Definition 4.11,
Then
So
Corollary 4.14
Let
If
Proof
It can be proved by Proposition 4.2 and Theorem 4.13.□
Corollary 4.15
Let
If
If
If
Proof
It can be obtained by Proposition 4.3 and Theorem 4.13.□
5 Numerical experiments and unsupervised attribute reduction
This section offers several UCI datasets as a 3HIS for evaluating the suggested unsupervised attribute reduction algorithm. It first compares four UMs for each 3HIS, then implements the dispersion analyses, next presents an unsupervised attribute reduction algorithm (
5.1 Numerical experiments
Six datasets from the UCI (Repository of machine learning databases) are selected for a numerical experiment, as shown in Table 5. The details of these datasets are outlined in the table. In addition, four UMs of a 3HIS are compared.
Datasets from UCI
| Datasets | #Objects | #Features | #Scaled | #Ordinal | #Nominal |
|---|---|---|---|---|---|
| Hepatitis [24] | 155 | 20 | 2 | 4 | 14 |
| Automobile [25] | 205 | 26 | 15 | 1 | 10 |
| ILPD [26] | 583 | 11 | 5 | 4 | 2 |
| AIDS [27] | 2,139 | 24 | 8 | 3 | 13 |
| PredictStudents [28] | 4,424 | 37 | 17 | 2 | 18 |
| SUPPORT2 [29] | 9,105 | 45 | 29 | 5 | 11 |
The parameters of four UMs are setup as follows:
The hepatitis dataset may express a 3HIS
The automobile dataset may express a 3HIS
The ILPD dataset may express a 3HIS
The AIDS dataset may express a 3HIS
The PredictStudents dataset may express a 3HIS
The SUPPORT2 dataset may express a 3HIS
Figure 2 illustrates that four measures of uncertainty on six datasets have a similar situation. Namely, the information granulation curves with black and rough entropy curves with red decline with the increase of the cardinality of

Four measures of uncertainty for six 3HISs. Source: Created by the authors.
In addition, Figure 2 also depicts that the alterations in information granulation
5.2 Dispersion analyses
Statistical research often involves studying the dispersion degree of a dataset. The dispersion degree can be measured by difference measures, such as range, point difference, average difference, standard deviation, and dispersion coefficient. This study utilizes the dispersion coefficient to evaluate the dispersion degree of four UMs. The dispersion coefficient is mainly utilized to compare the amount of dispersion between multiple group of data. A high dispersion coefficient indicates a large quantity of data dispersion, while a low dispersion coefficient implies a small degree of data dispersion.
For a given dataset
According to four measures of uncertainty on six datasets, their dispersion coefficient are calculated in terms of the aforementioned formulas. Figure 3 depicts that the
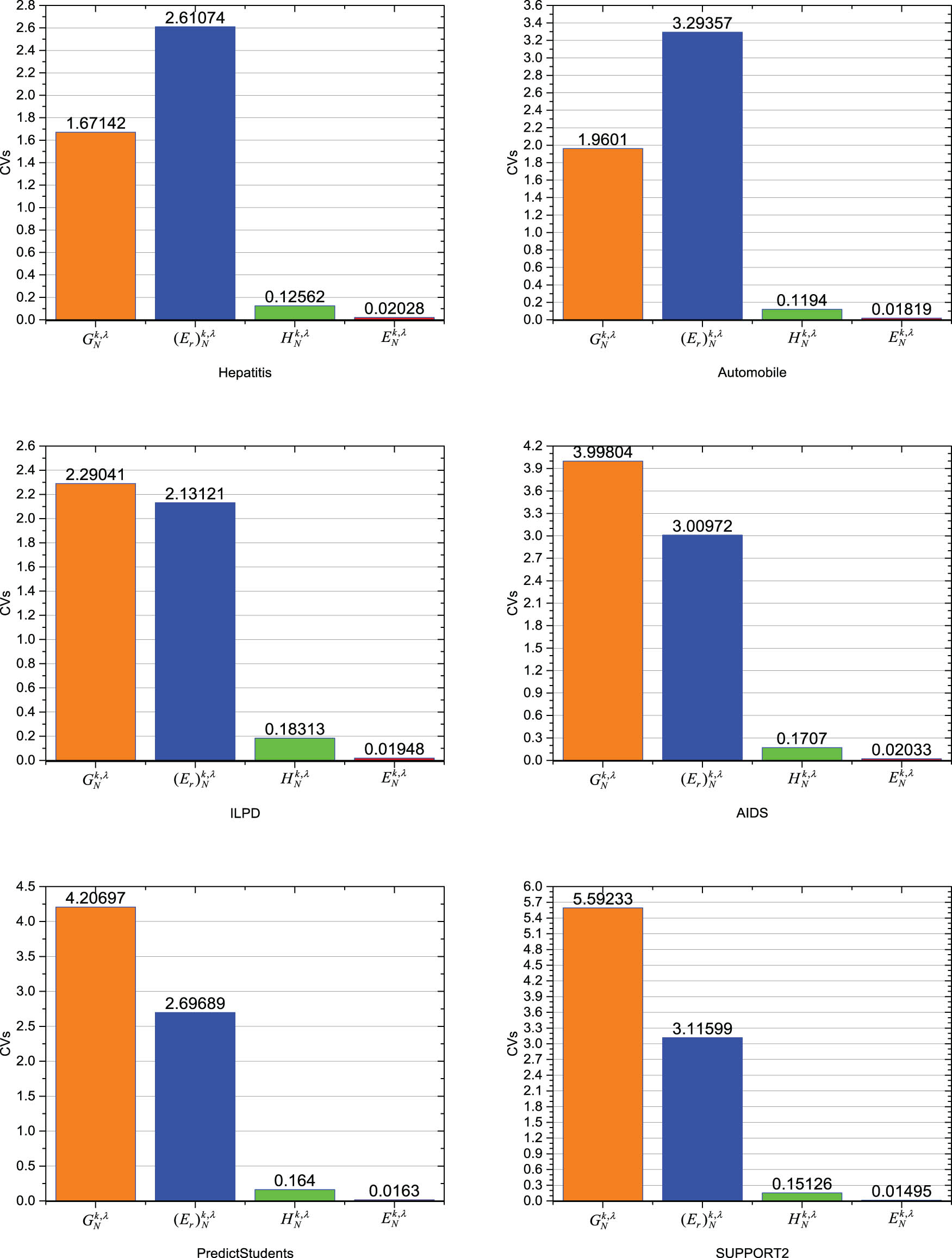
By examining Figure 3, it is evident that the information amount
5.3 Unsupervised attribute reduction
This subsection first presents an unsupervised attribute reduction algorithm (
5.3.1 Unsupervised attribute reduction algorithm in a 3HIS
This subsection introduces an unsupervised attribute reduction algorithm utilizing information entropy and evaluates its cost-effectiveness by examining its time complexity and space complexities.
|
Algorithm 1: Unsupervised attribute reduction in a 3HIS utilizing information entropy (
|
|---|
|
Input: A
|
|
Output: A reduct
|
|
|
|
|
|
for
each
|
|
|
| end |
|
return
|
Algorithm 1 is designed as a heuristic search strategy to obtain one reduct of a 3HIS. It commences with permutation of the sets
To evaluate the cost-effectiveness of an algorithm, its time and space complexities can be taken into account. The big O notation is a commonly used method for quantifying the running time and required storage space of an algorithm, namely, time and space complexities.
Let
5.3.2 Datasets
The subsection selects six datasets of varying complexities from the UCI, namely,
Datasets from UCI,
| Dataset | Object | Attribute | Scaled | Ordinal | Nominal |
|---|---|---|---|---|---|
|
|
148 | 19 | 1 | 2 | 16 |
|
|
155 | 20 | 2 | 4 | 14 |
|
|
205 | 26 | 15 | 1 | 10 |
|
|
583 | 11 | 5 | 4 | 2 |
|
|
125 | 16 | 5 | 1 | 10 |
|
|
2,139 | 24 | 8 | 3 | 13 |
The datasets
5.3.3 Metrics of clustering methods
The study utilizes the below evaluation metrics to evaluate the performance of clustering algorithms.
1. Silhouette coefficient
The Silhouette coefficient (SC) gauges the extent to which samples are clustered with similar ones. A higher SC in a clustering model signifies better performance, while a lower SC indicates the opposite. Assume that
In the case that
Here,
If
If
The SC of
Given a sample set
2. DBI
The DBI is capable of assessing the level of similarity between two comparable clusters. Let
Here,
The similarity of clusters
Here,
Obviously, the DBI represents the average similarity among
The DBI of 0 is considered the optimal score, signifying that all the samples within the same group are accurately clustered together. A DBI that is close to 0 suggests a more favorable assignment outcome. As the DBI decreases, the distance between sample points within the clusters decreases, while the distance between sample points in different clusters increases.
5.3.4 Reducts and cluster analyses
This subsection performs cluster analysis on several datasets and the resulting reducts after applying
The datasets
Reducts of dataset
| Dataset | Reduct | RedR |
|---|---|---|
|
|
|
18.63 |
|
|
18.68 | |
|
|
18.53 | |
|
|
18.58 | |
|
|
18.53 | |
|
|
18.58 | |
|
|
18.53 | |
|
|
18.53 | |
|
|
18.58 | |
|
|
18.58 | |
|
|
|
19.80 |
|
|
19.80 | |
|
|
19.80 | |
|
|
19.80 | |
|
|
19.80 | |
|
|
19.85 | |
|
|
19.80 | |
|
|
19.80 | |
|
|
19.85 | |
|
|
19.85 | |
|
|
|
25.69 |
|
|
25.73 | |
|
|
25.77 | |
|
|
25.73 | |
|
|
25.73 | |
|
|
25.73 | |
|
|
25.73 | |
|
|
25.73 | |
|
|
25.73 | |
|
|
25.73 | |
|
|
|
10.55 |
|
|
10.55 | |
|
|
10.55 | |
|
|
10.55 | |
|
|
10.55 | |
|
|
10.64 | |
|
|
10.64 | |
|
|
10.64 | |
|
|
10.55 | |
|
|
10.64 | |
|
|
|
15.50 |
|
|
15.56 | |
|
|
15.56 | |
|
|
15.56 | |
|
|
15.44 | |
|
|
15.56 | |
|
|
15.56 | |
|
|
15.50 | |
|
|
15.50 | |
|
|
15.56 | |
|
|
|
23.62 |
|
|
23.71 | |
|
|
23.58 | |
|
|
23.67 | |
|
|
23.71 | |
|
|
23.58 | |
|
|
23.54 | |
|
|
23.67 | |
|
|
23.62 | |
|
|
23.67 |
In Table 7,
To illustrate the results of reduction ratio visually, a histogram plot is shown in Figure 4. The horizontal axis represents the datasets, while the vertical axis represents the reduction ratio.

Reduction ratio of raw datasets and their 10 reducts. Source: Created by the authors.
Figure 4 obviously depicts that the reduction ratios of 10 ruducts obtained by the
To assess the effectiveness of the obtained attribute reducts, each dataset and its 10 reducts, respectively, perform the performs
Two evaluation metrics, SC and DBI, are compared to evaluate their clustering performances. The SC metrics are illustrated in Table 8, and DBI metrics are indicated in Table 9.
SC before or after reduction for datasets
| 3HIS |
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
0.1250 | 0.2109 | 0.2797 | 0.5599 | 0.2376 | 0.2605 |
|
|
0.2849 | 0.5332 | 0.6082 | 0.9319 | 0.9756 | 0.4799 |
|
|
0.3283 | 0.7551 | 0.6082 | 0.8240 | 0.6047 | 0.3650 |
|
|
0.2469 | 0.7551 | 0.5941 | 0.9319 | 0.5969 | 0.3535 |
|
|
0.2993 | 0.6596 | 0.5935 | 0.9319 | 0.6052 | 0.4263 |
|
|
0.2274 | 0.7551 | 0.5598 | 0.8241 | 0.9756 | 0.3534 |
|
|
0.2080 | 0.7372 | 0.6082 | 0.9240 | 0.9756 | 0.4064 |
|
|
0.2929 | 0.5333 | 0.5598 | 0.9282 | 0.9756 | 0.4353 |
|
|
0.2774 | 0.5203 | 0.5680 | 0.7623 | 0.9769 | 0.4263 |
|
|
0.2178 | 0.7371 | 0.6072 | 0.9638 | 0.9756 | 0.4352 |
|
|
0.2908 | 0.7372 | 0.5940 | 0.9282 | 0.9769 | 0.4300 |
DBI before or after reduction for datasets
| 3HIS |
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
1.9813 | 1.8299 | 1.3800 | 0.6991 | 1.7249 | 1.5838 |
|
|
1.2477 | 0.6824 | 0.4217 | 0.3289 | 0.3478 | 0.8488 |
|
|
1.1419 | 0.5415 | 0.4218 | 0.4990 | 0.5913 | 1.2127 |
|
|
1.5310 | 0.5415 | 0.4488 | 0.3289 | 0.6006 | 1.2445 |
|
|
1.2607 | 0.6525 | 0.4493 | 0.3289 | 0.5908 | 1.0489 |
|
|
1.5922 | 0.5414 | 0.4908 | 0.4990 | 0.3478 | 1.2446 |
|
|
1.5676 | 0.5568 | 0.4218 | 0.5654 | 0.3478 | 1.0291 |
|
|
1.2067 | 0.6824 | 0.4907 | 0.3323 | 0.3478 | 1.0061 |
|
|
1.4457 | 0.9176 | 0.4717 | 0.6193 | 0.3475 | 1.0489 |
|
|
1.4543 | 0.5570 | 0.4225 | 0.2824 | 0.3478 | 1.0063 |
|
|
1.3320 | 0.5568 | 0.4490 | 0.3324 | 0.3475 | 0.9717 |
Based on Table 8, it is evident that the SC values of the 10 reducts exceed the SC of the original dataset for each of the six datasets. A higher SC denotes improved clustering performance. Consequently, the clustering performances of the 10 reducts outperform that of the original dataset. This indicates that the obtained attribute reducts possess higher effectiveness and that the proposed unsupervised attribute reduction algorithm
In Figure 5, a histogram plot is used to illustrate the results of SC visually. The horizontal axis represents datasets, while the vertical axis represents SC.

SC of raw datasets and their 10 reducts. Source: Created by the authors.
Figure 5 clearly shows that the SC metrics of 10 reducts are superior to that of raw datasets for all datasets. This indicates that the proposed
Reduct
Reducts
Reducts
Reduct
Reducts
Reduct
Table 9 demonstrates that the DBI metrics for 10 reducts are consistently lower than the DBI of the original dataset for all datasets. A DBI of 0 is the optimal score, and a lower DBI indicates a better cluster result. As a result, the clustering results for the 10 reducts are superior to those of the original datasets for all datasets. This further illustrates that the obtained attribute reducts possess higher effectiveness and that the proposed unsupervised attribute reduction algorithm
To visually demonstrate the results of the DBI, a histogram plot is shown in Figure 6. The datasets are represented on the horizontal axis, while the DBI is shown on the vertical axis.

DBI of raw datasets and their 10 reducts. Source: Created by the authors.
Figure 6 shows that the DBI metrics for 10 reducts are consistently better than those of the raw datasets across all datasets. This indicates that the proposed
To sum up, the clustering performances of the reducts generated by the proposed
6 Discussion
According to the aforementioned analyses of numerical experiments, the advantages and disadvantages of the study are outlined as follows:
Advantages
Four UMs (information granulation
The
This study shows a monotonic relationship between uncertainty measure and the number of attributes, demonstrating a decrease in information granulation as the number of features increases and an increase in information entropy. This provides a theoretical basis for modeling heterogeneous data.
Disadvantages
The numerical experiment of this study is solely based on the UCI dataset and does not cover high-dimensional or extremely large-scale heterogeneous data, such as single-cell gene expression data. The generalizability of the
This study does not address the potential impact of complex interactions between attributes in heterogeneous data, such as nonlinear dependencies. This requires further enhancement in the future.
7 Conclusion
The study defines the distance between objects using three types of features, deriving
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions, which have helped immensely in improving the quality of the article.
-
Funding information: This work is supported by 2024 High-Level Talent Project of Yulin Normal University [Grant No. G2024ZK09].
-
Author contributions: Xiaoyan Guo: methodology, investigation, and writing-original draft; Yichun Peng: investigation, software, and writing-original draft; Yu Li: investigation, validation, and editing.
-
Conflict of interest: The authors declare that they have no conflict of interest.
-
Data availability statement: The datasets supporting this study are publicly available and can be obtained from the UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/).
References
[1] Pawlak Z. Rough sets. Int J Comput Inform Sci. 1982;11:341–56. 10.1007/BF01001956.Search in Google Scholar
[2] Pawlak Z. Rough sets: Theoretical aspects of reasoning about data. Dordrecht: Kluwer Academic Publishers; 1991. 10.1007/978-94-011-3534-4.Search in Google Scholar
[3] Shannon CE. A mathematical theory of communication. Bell Syst Tech J. 1948;27:379–423. 10.1002/j.1538-7305.1948.tb01338..Search in Google Scholar
[4] Liang JY, Qian YH. Information granules and entropy theory in information systems. Sci China (Series F). 2008;51:1427–44. 10.1007/s11432-008-0113-2.Search in Google Scholar
[5] Beaubouef T, Petry FE, Arora G. Information-theoretic measures of uncertainty for rough sets and rough relational databases, Inform Sci 1988;109(1–4):185–95. 10.1016/S0020-0255(98)00019-X.Search in Google Scholar
[6] Sosa-Cabrera G, Garcìa-Torres M, Gómez-Guerrero S, Schaerer CE, Divina F. A multivariate approach to the symmetrical uncertainty measure: Application to feature selection problem. Inform Sci. 2019;494:1–20. 10.1016/j.ins.2019.04.046.Search in Google Scholar
[7] Zhao JY, Zhang ZL, Han CZ, Zhou ZF. Complement information entropy for uncertainty measure in fuzzy rough set and its applications. Soft Comput. 2015;19:1997–2010. 10.1007/s00500-014-1387-5.Search in Google Scholar
[8] Zhang YM, Jia XY, Tang ZM, Long XZ. Uncertainty measures for interval set information tables based on interval δ-similarity relation. Inform Sci. 2019;501:272–92. 10.1016/j.ins.2019.06.014.Search in Google Scholar
[9] Navarrete J, Viejo D, Cazorla M. Color smoothing for RGB-D data using entropy information. Appl Soft Comput. 2016;46:361–80. 10.1016/j.asoc.2016.05.019.Search in Google Scholar
[10] Huang ZH, Li JJ. Discernibility measures for fuzzy β-covering and their application. IEEE Trans Cybernet. 2022;52:9722–35. 10.1109/TCYB.2021.3054742.Search in Google Scholar PubMed
[11] Chen YM, Wuuu KS, Chen XH, Tang CH, Zhu QX. An entropy-based uncertainty measurement approach in neighborhood systems. Inform Sci. 2014;279:239–50. 10.1016/j.ins.2014.03.117.Search in Google Scholar
[12] Wang P, He JL, Li ZW. Attribute reduction for hybrid data based on fuzzy rough iterative computation model. Inform Sci. 2023;632:555–75. 10.1016/j.ins.2023.03.027.Search in Google Scholar
[13] Thuy NN, Wongthanavasu S. A novel feature selection method for high-dimensional mixed decision tables. IEEE Trans Neural Netw Learn Syst. 2022;7:1–14. 10.1109/TNNLS.2020.3048080.Search in Google Scholar PubMed
[14] Zhang QL, Qu LD, Li ZW. Attribute reduction based on D-S evidence theory in a hybrid information system. Int J Approx Reason. 2022;148:202–34. 10.1016/j.ijar.2022.06.002.Search in Google Scholar
[15] Gao C, Lai ZH, Zhou J, Wen JJ, Wong WK. Granular maximum decision entropy-based monotonic uncertainty measure for attribute reduction. Int J Approx Reason. 2019;104:9–24. 10.1016/j.ijar.2018.10.014.Search in Google Scholar
[16] Sun L, Zhang XY, Qian YH, Xu JC, Zhang SG. Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Inform Sci. 2019;502:18–41. 10.1016/j.ins.2019.05.072.Search in Google Scholar
[17] Wang CY, Wang CZ, An S, Ding WP, Qian YH. Feature selection and classification based on directed fuzzy rough sets. IEEE Trans Syst Man Cybernet Syst. 2024;55:699–711. 10.1109/TSMC.2024.3492337.Search in Google Scholar
[18] Annn S, Zhang MR, Wang CZ, Ding WP. Robust fuzzy rough approximations with kNN granules for semi-supervised feature selection. Fuzzy Sets Syst 2023;461:108476. 10.1016/j.fss.2023.01.011.Search in Google Scholar
[19] Xu WH, Li YZ. Multi-label feature selection for imbalanced data via KNN-based multi-label rough set theory. Inform Sci. 2025;715:122220. 10.1016/j.ins.2025.122220.Search in Google Scholar
[20] Dai JH, Chen WX, Xia LY. Feature selection based on neighborhood complementary entropy for heterogeneous data. Inform Sci 2024;682:121261. 10.1016/j.ins.2024.121261.Search in Google Scholar
[21] Cui XY, Wang CZ, An S, Qian YH. Adaptive fuzzy neighborhood decision tree. Appl Soft Comput. 2024;167:112435. 10.1016/j.asoc.2024.112435.Search in Google Scholar
[22] Zhang Y, Wang CZ, Huang Y, Ding WP, Qian YH. Adaptive relative fuzzy rough learning for classification. IEEE Trans Fuzzy Syst. 2024;32:6267–76. 10.1109/TFUZZ.2024.3443863.Search in Google Scholar
[23] Yang J, Kuang JC, Wang GY, Zhang QH, Liu YM, Liu Q, et al. Adaptive three-way KNN classifier using density-based granular balls. Inform Sci. 2024;678:120858. 10.1016/j.ins.2024.120858.Search in Google Scholar
[24] Hepatitis, UCI Machine Learning Repository (1988). Search in Google Scholar
[25] Jeffrey S. Automobile, UCI Machine Learning Repository. 1987. Search in Google Scholar
[26] Ramana B, Venkateswarlu N. ILPD (Indian Liver Patient Dataset), UCI Machine Learning Repository. 2012. 10.24432/C5D02C.Search in Google Scholar
[27] Hammer SM, Katzenstein DA, Hughes MD, Gundacker H, Merigan TC. A trial comparing nucleoside monotherapy with combination therapy in HIV-infected adults with CD4 cell counts from 200 to 500 per cubic millimeter. AIDS Clinical Trials Group Study 175 Study Team. N Engl J Med. 1996;335:1081–90. 10.1056/NEJM199610103351501.Search in Google Scholar PubMed
[28] Valentim R, Mónica VM, Jorge M, Luís B. Predict students’ dropout and academic success. UCI Machine Learning Repository. 2021. Search in Google Scholar
[29] Connors AF, Dawson NV, Desbiens NA, Fulkerson WJ, Goldman L, Knaus WA, et al. A controlled trial to improve care for seriously iII hospitalized patients: The study to understand prognoses and preferences for outcomes and risks of treatments (SUPPORT). Jama 1995;274:1591–8. 10.1001/jama.1995.03530200027032.Search in Google Scholar
[30] Zwitter M, Soklic M. Lymphography, UCI Machine Learning Repository. 1988. Search in Google Scholar
[31] Sano C. Japanese Credit Screening, UCI Machine Learning Repository. 1992. 10.24432/C5259N.Search in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Synergistic effect of artificial intelligence and new real-time disassembly sensors: Overcoming limitations and expanding application scope
- Greenhouse environmental monitoring and control system based on improved fuzzy PID and neural network algorithms
- Explainable deep learning approach for recognizing “Egyptian Cobra” bite in real-time
- Optimization of cyber security through the implementation of AI technologies
- Deep multi-view feature fusion with data augmentation for improved diabetic retinopathy classification
- A new metaheuristic algorithm for solving multi-objective single-machine scheduling problems
- Estimating glycemic index in a specific dataset: The case of Moroccan cuisine
- Hybrid modeling of structure extension and instance weighting for naive Bayes
- Application of adaptive artificial bee colony algorithm in environmental and economic dispatching management
- Stock price prediction based on dual important indicators using ARIMAX: A case study in Vietnam
- Emotion recognition and interaction of smart education environment screen based on deep learning networks
- Supply chain performance evaluation model for integrated circuit industry based on fuzzy analytic hierarchy process and fuzzy neural network
- Application and optimization of machine learning algorithms for optical character recognition in complex scenarios
- Comorbidity diagnosis using machine learning: Fuzzy decision-making approach
- A fast and fully automated system for segmenting retinal blood vessels in fundus images
- Application of computer wireless network database technology in information management
- A new model for maintenance prediction using altruistic dragonfly algorithm and support vector machine
- A stacking ensemble classification model for determining the state of nitrogen-filled car tires
- Research on image random matrix modeling and stylized rendering algorithm for painting color learning
- Predictive models for overall health of hydroelectric equipment based on multi-measurement point output
- Architectural design visual information mining system based on image processing technology
- Measurement and deformation monitoring system for underground engineering robots based on Internet of Things architecture
- Face recognition method based on convolutional neural network and distributed computing
- OPGW fault localization method based on transformer and federated learning
- Class-consistent technology-based outlier detection for incomplete real-valued data based on rough set theory and granular computing
- Detection of single and dual pulmonary diseases using an optimized vision transformer
- CNN-EWC: A continuous deep learning approach for lung cancer classification
- Cloud computing virtualization technology based on bandwidth resource-aware migration algorithm
- Hyperparameters optimization of evolving spiking neural network using artificial bee colony for unsupervised anomaly detection
- Classification of histopathological images for oral cancer in early stages using a deep learning approach
- A refined methodological approach: Long-term stock market forecasting with XGBoost
- Enhancing highway security and wildlife safety: Mitigating wildlife–vehicle collisions with deep learning and drone technology
- An adaptive genetic algorithm with double populations for solving traveling salesman problems
- EEG channels selection for stroke patients rehabilitation using equilibrium optimizer
- Influence of intelligent manufacturing on innovation efficiency based on machine learning: A mechanism analysis of government subsidies and intellectual capital
- An intelligent enterprise system with processing and verification of business documents using big data and AI
- Hybrid deep learning for bankruptcy prediction: An optimized LSTM model with harmony search algorithm
- Construction of classroom teaching evaluation model based on machine learning facilitated facial expression recognition
- Artificial intelligence for enhanced quality assurance through advanced strategies and implementation in the software industry
- An anomaly analysis method for measurement data based on similarity metric and improved deep reinforcement learning under the power Internet of Things architecture
- Optimizing papaya disease classification: A hybrid approach using deep features and PCA-enhanced machine learning
- Handwritten digit recognition: Comparative analysis of ML, CNN, vision transformer, and hybrid models on the MNIST dataset
- Multimodal data analysis for post-decortication therapy optimization using IoMT and reinforcement learning
- Predicting early mortality for patients in intensive care units using machine learning and FDOSM
- Uncertainty measurement for a three heterogeneous information system based on k-nearest neighborhood: Application to unsupervised attribute reduction
- Genetic algorithm-based dimensionality reduction method for classification of hyperspectral images
- Power line fault detection based on waveform comparison offline location technology
- Assessing model performance in Alzheimer's disease classification: The impact of data imbalance on fine-tuned vision transformers and CNN architectures
- Review Articles
- A comprehensive review of deep learning and machine learning techniques for early-stage skin cancer detection: Challenges and research gaps
- An experimental study of U-net variants on liver segmentation from CT scans
- Strategies for protection against adversarial attacks in AI models: An in-depth review
- Resource allocation strategies and task scheduling algorithms for cloud computing: A systematic literature review
- Latency optimization approaches for healthcare Internet of Things and fog computing: A comprehensive review
- Explainable clustering: Methods, challenges, and future opportunities
Articles in the same Issue
- Research Articles
- Synergistic effect of artificial intelligence and new real-time disassembly sensors: Overcoming limitations and expanding application scope
- Greenhouse environmental monitoring and control system based on improved fuzzy PID and neural network algorithms
- Explainable deep learning approach for recognizing “Egyptian Cobra” bite in real-time
- Optimization of cyber security through the implementation of AI technologies
- Deep multi-view feature fusion with data augmentation for improved diabetic retinopathy classification
- A new metaheuristic algorithm for solving multi-objective single-machine scheduling problems
- Estimating glycemic index in a specific dataset: The case of Moroccan cuisine
- Hybrid modeling of structure extension and instance weighting for naive Bayes
- Application of adaptive artificial bee colony algorithm in environmental and economic dispatching management
- Stock price prediction based on dual important indicators using ARIMAX: A case study in Vietnam
- Emotion recognition and interaction of smart education environment screen based on deep learning networks
- Supply chain performance evaluation model for integrated circuit industry based on fuzzy analytic hierarchy process and fuzzy neural network
- Application and optimization of machine learning algorithms for optical character recognition in complex scenarios
- Comorbidity diagnosis using machine learning: Fuzzy decision-making approach
- A fast and fully automated system for segmenting retinal blood vessels in fundus images
- Application of computer wireless network database technology in information management
- A new model for maintenance prediction using altruistic dragonfly algorithm and support vector machine
- A stacking ensemble classification model for determining the state of nitrogen-filled car tires
- Research on image random matrix modeling and stylized rendering algorithm for painting color learning
- Predictive models for overall health of hydroelectric equipment based on multi-measurement point output
- Architectural design visual information mining system based on image processing technology
- Measurement and deformation monitoring system for underground engineering robots based on Internet of Things architecture
- Face recognition method based on convolutional neural network and distributed computing
- OPGW fault localization method based on transformer and federated learning
- Class-consistent technology-based outlier detection for incomplete real-valued data based on rough set theory and granular computing
- Detection of single and dual pulmonary diseases using an optimized vision transformer
- CNN-EWC: A continuous deep learning approach for lung cancer classification
- Cloud computing virtualization technology based on bandwidth resource-aware migration algorithm
- Hyperparameters optimization of evolving spiking neural network using artificial bee colony for unsupervised anomaly detection
- Classification of histopathological images for oral cancer in early stages using a deep learning approach
- A refined methodological approach: Long-term stock market forecasting with XGBoost
- Enhancing highway security and wildlife safety: Mitigating wildlife–vehicle collisions with deep learning and drone technology
- An adaptive genetic algorithm with double populations for solving traveling salesman problems
- EEG channels selection for stroke patients rehabilitation using equilibrium optimizer
- Influence of intelligent manufacturing on innovation efficiency based on machine learning: A mechanism analysis of government subsidies and intellectual capital
- An intelligent enterprise system with processing and verification of business documents using big data and AI
- Hybrid deep learning for bankruptcy prediction: An optimized LSTM model with harmony search algorithm
- Construction of classroom teaching evaluation model based on machine learning facilitated facial expression recognition
- Artificial intelligence for enhanced quality assurance through advanced strategies and implementation in the software industry
- An anomaly analysis method for measurement data based on similarity metric and improved deep reinforcement learning under the power Internet of Things architecture
- Optimizing papaya disease classification: A hybrid approach using deep features and PCA-enhanced machine learning
- Handwritten digit recognition: Comparative analysis of ML, CNN, vision transformer, and hybrid models on the MNIST dataset
- Multimodal data analysis for post-decortication therapy optimization using IoMT and reinforcement learning
- Predicting early mortality for patients in intensive care units using machine learning and FDOSM
- Uncertainty measurement for a three heterogeneous information system based on k-nearest neighborhood: Application to unsupervised attribute reduction
- Genetic algorithm-based dimensionality reduction method for classification of hyperspectral images
- Power line fault detection based on waveform comparison offline location technology
- Assessing model performance in Alzheimer's disease classification: The impact of data imbalance on fine-tuned vision transformers and CNN architectures
- Review Articles
- A comprehensive review of deep learning and machine learning techniques for early-stage skin cancer detection: Challenges and research gaps
- An experimental study of U-net variants on liver segmentation from CT scans
- Strategies for protection against adversarial attacks in AI models: An in-depth review
- Resource allocation strategies and task scheduling algorithms for cloud computing: A systematic literature review
- Latency optimization approaches for healthcare Internet of Things and fog computing: A comprehensive review
- Explainable clustering: Methods, challenges, and future opportunities