Application and optimization of machine learning algorithms for optical character recognition in complex scenarios
-
Liming Liu
 and
Juntao Chen
and
Juntao Chen

Abstract
In the era of artificial intelligence, the technology of optical character recognition under complex backgrounds has become particularly important. This article investigated how machine learning algorithms can improve the accuracy of text recognition in complex scenarios. By analyzing algorithms such as scale-invariant feature transform, K-means clustering, and support vector machine, a system was constructed to address the challenges of text recognition under complex backgrounds. Experimental results show that the proposed algorithm achieves 7.66% higher accuracy than traditional algorithms, and the built system is fast, powerful, and highly satisfactory to users, with a 13.6% difference in results between the two groups using different methods. This indicates that the method proposed in this study can effectively meet the needs of complex text recognition, significantly improving recognition efficiency and user satisfaction.
1 Introduction
In the current era of big data explosion, the text processing environment is becoming more and more complex. Ordinary text recognition methods can no longer meet the increasing requirements in terms of speed, accuracy, and completeness when judging and recognizing various complex texts. Machine learning (ML) is an important direction in the field of artificial intelligence (AI) research. Automatic ML can solve complex and computationally intensive problems. With the in-depth development of ML theory, the advantages of automated ML algorithms in data processing are becoming more and more obvious, and they have been applied to various fields and successfully solved various data processing problems. For text recognition in complex backgrounds, it is of far-reaching significance to quickly and efficiently recognize text in a large amount of unstructured text. Scholars have adopted a variety of recognition algorithms for optical character recognition (OCR) problems, but the application and research of ML combined with multiple algorithms such as k-means and support vector machine (SVM) algorithms in this field are relatively small.
In response to the problem of low efficiency of text recognition in the aforementioned complex background, this article uses ML to analyze the text recognition algorithm, simulate the performance of the text recognition algorithm, achieve the highest recognition rate, and reduce the running time. The innovation of this article is to use AI and ML to realize complex text recognition algorithms and systems. Compared with traditional ML algorithms, automated ML algorithms have higher recognition accuracy and more ideal recognition effects. In practical applications, automated machine algorithms oriented to AI can effectively adapt to the recognition needs of different texts, thereby improving user satisfaction and promoting the sustainable development of algorithm applications.
2 Related works
With the increasing application of text recognition, more and more scholars have explored related methods of text recognition. Long et al. [1] studied scene text detection and recognition based on deep learning. Deep learning is a subfield of ML. He used multi-layer neural networks to simulate human learning methods and process complex data patterns. It is particularly suitable for complex tasks such as image and speech recognition. Ranjbarzadeh et al. [2] proposed a deep learning method for robust, multi-directional, and curved text detection. Altwaijry et al. [3] proposed an Arabic note recognition system based on convolutional neural networks. Raisi [4] proposed a Transformer-based architecture recognition method for regular and irregular text image recognition to address the problem of two-dimensional image information loss in traditional recognition algorithms. The Transformer architecture is a model for processing sequence data. It effectively processes the relationship between elements in the sequence through the self-attention mechanisms and performs well in the field of natural language processing. In response to the problem of low image output quality during the recognition process, Petrova O proposed a weighted model for merging the recognition results of each frame and proposed a new weighted merging method and weighting standard for text recognition results [5]. However, these methods have low accuracy and recall in text recognition under complex backgrounds.
ML has achieved good results in improving data tolerance and accuracy [6,7]. Bustillo et al. [8] used data from machine test repetitions to improve the accuracy of ML models. Gong L used ML computational methods to identify disease-related entities from text data sets to understand the molecular mechanisms associated with ASD [9]. Gaye et al. [10] improved the computational rate of traditional ML algorithms to make traditional ML algorithms meet the requirements of the big data era. Jan et al. [11] proposed a distributed sensor fault detection and diagnosis system based on ML algorithms. The proposed model is superior to the classic neural fuzzy and non-fuzzy learning methods. These methods have improved the efficiency and accuracy of text recognition to a certain extent, but their complexity is relatively high.
OCR technology is the key to image text digitization and is widely used in document electronization, license plate recognition, augmented reality, and other fields. With the development of deep learning technology, the accuracy and stability of OCR systems have been significantly improved. Saqib Raza et al. [12] developed an OCR system based on a deep extreme learning machine for Urdu nastalique script, which effectively improved the accuracy of character recognition. Singh et al. [13] introduced an improved Otsu inter-class variance method to enhance image segmentation, which helps to optimize the preprocessing stage of the OCR system. The multi-level threshold algorithm developed by Singh et al. [14] further improved the accuracy of the OCR system by effectively separating the text area from the background clutter. The OCR system based on a deep extreme learning machine proposed by Ranganayakulu et al. [15] not only optimized the separation of text and background but also expanded the application of OCR technology in non-traditional text recognition tasks. Slavin and Arlazarov [16] implemented related algorithms in Tiger and CuneiForm OCR software, demonstrating the practicality of OCR in software solutions. The boundary-constrained image fusion OCR algorithm studied by Xun et al. [17] is particularly suitable for scenes with complex backgrounds or low image quality. Peter et al. [18] explored the application of OCR combined with a naive Bayes classifier in promotional image classification, demonstrating the potential of OCR technology in image classification tasks. Tuyet Hai et al. [19] conducted a comprehensive survey of OCR post-processing methods and emphasized the importance of improving the accuracy and usability of OCR output through post-processing steps.
3 Automated ML algorithms and methods for system implementation
3.1 Content and organization of this article
Technology promotes the rapid change and development of life, and the usage scenarios of text recognition methods are constantly enriched. The defects and deficiencies of traditional text recognition methods are increasingly prominent, so it is very important to improve the efficiency of text recognition methods in complex environments [20-21]. Through the investigation, it is found that the current research on text recognition algorithms and systems in complex backgrounds is not complete enough. Therefore, this paper proposed the research and system construction of text recognition algorithms using ML. This paper analyzed the performance of text recognition and various machine learning algorithms and recognition systems, combining the SIFT algorithm, K-means, and SVM algorithms for text recognition in complex backgrounds, and then proposed new algorithms and systems for text recognition in complex backgrounds. Experiments showed that the method proposed in this paper had a better text recognition effect than ordinary methods.
The full text of this study consists of five parts. The first part mainly introduced the research background of the text recognition problem in the complex background and elicited the problem to be solved to illustrate the purpose and significance of this research. Then, it made a general analysis of the research status in the field of text recognition and the application field of ML and explained the content and innovation of this study. The second part described the organization structure and method of the full text of this research, introduced the related methods of text recognition and ML, and then described the proposed new algorithm and construction of the recognition system. The third part provided a detailed description of the data sources of this article. The fourth part concluded after analyzing the resulting data. The fifth part is the conclusion.
3.2 ML text recognition algorithm and system construction
Text recognition is mainly divided into three steps: acquisition, analysis, and classification. It is mainly achieved through statistical, logical, and grammatical methods, using template matching and feature extraction techniques. Since the appearance features of text such as position, font, and color may change, it is necessary to locate the text before recognition. Text detection models have been developed to handle complex background situations [22]. Text detection is a key preliminary step in recognizing text in an image. However, this process is often affected by factors such as color, character spacing, background, lighting, and text tilt, making it difficult to distinguish text from other image textures [23].
Text recognition is now widely used in image and video search. Thanks to the development of multimedia and network technologies, information is increasingly present in the form of images. This technology overcomes the limitations of traditional keyword search, especially on the Internet, where it helps extract text information from web page images and is also used to filter web page content. Digital image processing is a key technology for recognizing text in images. The current popular image search models mainly rely on feature vectors. This study uses SIFT technology to extract features from photographs. This method can capture the features of images at different scales, thereby better understanding and recognizing text.
In image feature extraction, the scale space of a two-dimensional image can be obtained by convolution with a Gaussian kernel [24], as shown in the following formula:
where
where
The scale space can be implemented in practice using Gaussian pyramids [25]. A Gaussian pyramid can be generated in two steps: the first step is to fold the image using a Gaussian kernel with different scaling parameters; the second step is to perform an interval sampling operation on the processed image. The Gaussian pyramid is shown in Figure 1.

Gaussian pyramid. Source: This figure has been created by the authors.
As shown in Figure 1, the original image pixel interval is sampled multiple times to obtain a continuous image sequence with a smaller size. This sequence is arranged according to the image size from large to small, bottom to top, and is shaped like a pyramid. The original size of the image combined with the final size of the image on the minaret determines the number of layers in the pyramid. When building a Gaussian pyramid in the zoom space, to obtain continuous zooming, a Gaussian filter will be added to the process of building the pyramid. Each layer of the image pyramid will be convolved with a continuously scaled Gaussian kernel to obtain the parameters of the image size. Although a series of identical images with varying degrees of blurring, each layer of the image pyramid contains multiple images [26].
In actual use, it is more convenient to use the DOG operator for extreme value detection, and its expression is shown in the following formula:
Among them, the difference pyramid can be obtained by subtracting adjacent layers. However, the extremum obtained in this way cannot be used as the feature point of the image, and the extremum must be arranged more correctly for precise positioning. This is because there are several extreme points with low response values, and the edge responses produced by the DOG operator are more pronounced.
In this study, the precise position and scale of extreme points are obtained by fitting the scale-space DOG function with a continuous curve. The scale-space expansion is shown in the following formula:
where
Taking the derivative of the equation and making it 0, the offset of the extreme point at the current position is shown in the following formula:
Substitute formula (6) into formula (5) to calculate the value of the equation as shown in the following formula:
The key points need the direction to make the domain range information orderly arranged and only then have the rotation invariance. Using the gradient information of the image to find the main direction in the area, the gradient modulus calculation process is shown in the following formula:
The gradient direction calculation process is shown in the following formula:
where
After the feature point information is clarified, appropriate descriptors should be selected to describe the feature points [27]. Displacement feature description vectors can be generated by analyzing the statistical information in the pixel distribution. The generation of SIFT is based on the gradient histogram of the field, and the required radius of the adjacent field is calculated as shown in the following formula:
where v is the number of sub-regions in each row, and
Then, the gradient information of the pixels of each sub-region is obtained, the amplitudes are accumulated in the gradient direction, an eight-dimensional gradient histogram is generated, and the histograms generated by all the sub-windows are concatenated. In the specific order of generating vectors, vectors are feature vectors that represent feature point information [28].
This study used the k-means algorithm for clustering, but there are some problems with the traditional method. In this study, the initial cluster centers were selected for each range from the K samples with the smallest variance, and then, the initial cluster centers were optimized based on the smallest variance. According to the definition of distribution, the smaller the sample distribution, the denser the data distribution near the sample, the more objective the selection of cluster centers, and the more accurate the clustering results [29].
The average distance between samples and all samples is defined in the following formula:
The variance of the sample is defined in the following formula:
The definition of the average distance of samples in the dataset is shown in the following formula:
where
This study used the SVM learning algorithm to process ML training data, which theoretically can achieve the best classification of linearly separable data [30,31]. It can process high-dimensional data and map it to a high-dimensional space, making it easier for data to be separated in that space, and has good learning ability, and the learned results have good generalization.
If there is training data that can be separated by a hyperplane, the constraints that make all samples classified correctly can be expressed in the following formula:
where
To maximize the classification interval can be achieved by minimizing
To solve the optimal hyperplane, the function to be solved must be defined first, as shown in the following formula:
where
where the optimal solution is
where the linear combination of training sample vectors represented by formula (19) is the solution of the optimal hyperplane, and the conditions it must satisfy are shown in the following formula:
After the final solution, the optimal classification function is obtained as shown in the following formula:
In this study, the aforementioned three algorithms were used in the learning phase to process the text in the image. Based on the above, a text recognition algorithm with a complex background was proposed and tested.
The system is based on the Struts2 and Hibernate frameworks and follows the MVC design pattern. Struts2 is responsible for page navigation and logic processing, while Hibernate handles database interaction. The user interface consists of JSP pages, and the business logic layer integrates ML text recognition algorithms and Microsoft OCR controls. The business log layer interacts with the MySQL database through Hibernate to store information [32].
4 Data sources for automated ML algorithms and system implementations
The data used for this algorithm to learn is to select different pictures automatically generated by the machine. Among them, 1,500 pictures without text were selected, and 1,500 pictures were randomly generated with text in the pictures; the specific grouping attributes of the samples are shown in Table 1.
Examples of learning image sample attributes
| Data set | Sample 1 | Sample 2 | Sample 3 |
|---|---|---|---|
| Word count | 4 | 7 | 2 |
| Font | Microsoft YaHei | Song Dynasty | Young round |
| Shape of words | Regular body | Bold | Italic bold |
| Pixel size | 43 | 62 | 58 |
Among them, the objects in the learning picture set are composed of four attributes, namely, the number of words in each picture, the font of the text in the picture, the shape of the word, and the pixel size of the word.
Then, the extracted key point feature items are clustered, and the test result data is obtained by testing different K values of the K-means algorithm. The specific results are shown in Table 2.
Example of test content for k value influence results
| Value of k | Sample 1 | Sample 2 | Sample 3 |
|---|---|---|---|
| 8 | −1 | 1 | 1 |
| 16 | 1 | 1 | 1 |
| 32 | −1 | −1 | 1 |
| 64 | 1 | −1 | −1 |
Table 2 shows the effect of different K values on three samples when using the K-means algorithm for clustering. The “K value” here determines how many clusters the algorithm divides the data into. The values “−1” and “1” indicate whether the algorithm classifies the sample as containing text under a specific K value, where “1” indicates an image that contains text and “−1” indicates an image that does not contain text or is unclear. As the K value increases, the algorithm’s clustering effect and recognition accuracy will change.
Then, test the data samples to obtain the test results of different numbers of data samples. The specific test results obtained are shown in Table 3.
Sample test result example
| Number of samples | Test content | Number of pictures with text | Number of pictures without text |
|---|---|---|---|
| 200 | Contains text | 124 | 76 |
| 500 | Contains text | 341 | 159 |
| 1,000 | Contains text | 759 | 241 |
From Table 3, it can be seen that when the sample size is 200, the number of images with text is 124, and the number of images without text is 76. When the sample size is 500, the number of images with text is 314, and the number of images without text is 159. When the sample size is 1,000, the number of images with text is 759, and the number of images without text is 241.
After the system performance test is completed, the effect experiment is carried out, and the system effect is judged by issuing a satisfaction questionnaire to the experimental user group. This study randomly selected three users from the experimental user group to participate in this satisfaction survey, among which all three users have different needs for text recognition services. The user satisfaction information collected by the questionnaire is shown in Table 4.
Example of the data content of satisfaction questionnaire survey
| Project | User 1 | User 2 | User 3 |
|---|---|---|---|
| Operation interface | 3.86 | 4.15 | 4.33 |
| Difficulty to use | 4.12 | 4.37 | 5.00 |
| Running speed | 3.89 | 3.66 | 4.17 |
| Recognition accuracy | 4.25 | 4.36 | 3.98 |
| Overall evaluation | 3.96 | 4.08 | 4.43 |
The table shows the satisfaction ratings of three users on the user interface, ease of use, speed, recognition accuracy, and overall evaluation of a project. The scores range from 1 to 5, with 5 indicating the highest satisfaction. Users gave ratings on their experience of different aspects of the system, and these ratings were used to evaluate system performance and user satisfaction, thereby guiding system improvement and optimization.
5 Results and discussion of automated ML algorithms and system implementations
5.1 Accuracy of clustering algorithm before and after improvement
In this article, all the vectors obtained by SIFT are clustered according to the k-means algorithm before and after the improvement, and ML is done using SVM. The test is divided into four groups when k = 8, k = 16, k = 32, and k = 64, and the specific results are shown in Figure 2.

Comparison of accuracy rates of different algorithms: (a) accuracy rate for pictures with words and (b) accuracy rate for pictures without words. Source: This figure has been created by the authors.
As shown in Figure 2, it can be found that the correct rate of the improved algorithm is higher than that of the original algorithm. In the four sets of experiments, when k = 16, the correct rate is the highest, with a correct rate of 94.7% for images with text and 92.2% for images without text. It can be seen that the optimization of the algorithm in this article can effectively improve the accuracy of the image text recognition system.
5.2 Judgment performance of different pictures and texts
In this study, the improved algorithm is used to test the stability of the algorithm in the case of processing complex pictures by using pictures in different states. The test is divided into three groups: rotated pictures, stretched pictures, and real photographs. The text recognition test is carried out on them, and the results are shown in Figure 3.

Different image performance tests: (a) test on the rotated picture, (b) test on pictures after stretching, and (c) test on actual photographs. Source: This figure has been created by the authors.
As shown in Figure 3, in the rotated image test, the image recognition accuracy rate is 88.6% for images with text and 91.5% for images without text. The correct rate is the same as for normal images, consistent with the invariance of SIFT concerning rotation. In the stretched image test, images with text were 91.1% correct, and images without text were 87.2% correct. The correct rate is the same as that of normal images, which is consistent with the invariance of SIFT to scaling. In the real photograph test, the accuracy is 79.7%, which is lower than the accuracy of procedurally generated images.
5.3 System reflection time performance
This study used 200 different pictures to test the system, and the system response time was tested by the time to process these pictures. At the same time, the time of each module in the system was counted to test the performance of different modules. The specific results are shown in Figure 4.

Different module performance: (a) time test results of each module and (b) average running time. Source: This figure has been created by the authors.
As shown in Figure 4, the average time required for the system to determine whether there is text in an image is 0.874 s, the average time for the OCR module is 0.336 s, and the average time for the database operation module is 0.141 s. However, the total recorded time is 1.457 s greater than the sum of the running time of each module. Generally speaking, the speed of this system is still very fast.
5.4 User satisfaction evaluation of different text recognition methods
This article tests and analyzes the user’s satisfaction with the use of the system after the performance test is completed. Through a 1 month experience of users in groups A and B, group A uses the recognition system constructed in this study, and group B uses traditional text recognition methods. After the test is over, the satisfaction evaluation information is collected from the users, and a comparative analysis is carried out, the specific results are shown in Figure 5.
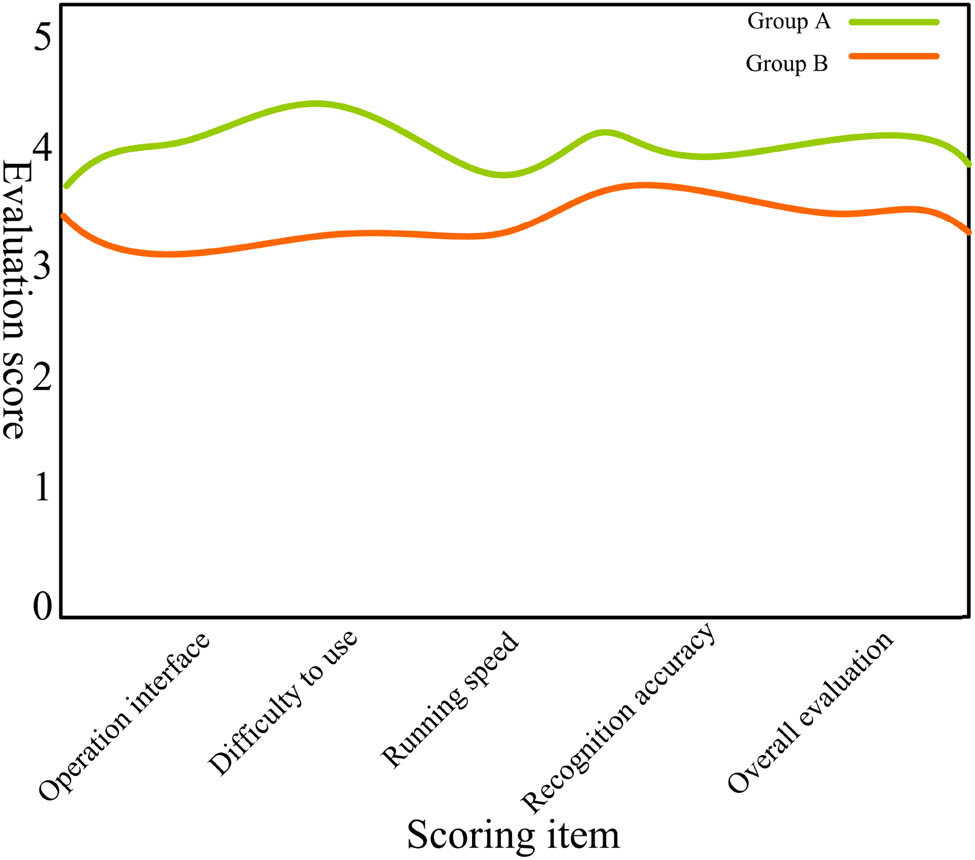
Comparison of satisfaction ratings. Source: This figure has been created by the authors.
It can be seen from Figure 5 that users who have experienced the recognition system constructed in this article have higher satisfaction feedback than users in group B who use the common method. The difference in satisfaction is mainly manifested in practical difficulty and recognition accuracy. Users in group A rated 4.32 and 4.13 points, respectively, while users in group B gave satisfaction ratings of 3.13 and 3.34 points. In contrast, the recognition system proposed in this study outperforms common recognition methods in all aspects, especially in terms of difficulty of use and recognition accuracy. It can be seen that the system can well meet the needs of text recognition users with complex backgrounds. With the support of AI, automated ML algorithms can effectively recognize text in complex scenarios. For users with different recognition needs, the recognition effect of this automated ML algorithm is relatively ideal, which can bring users a better user experience.
The results of OCR by the algorithm proposed in this study are shown in Figure 6 [33].
![Figure 6
OCR results. Source: Image from OCR dataset, https://universe.roboflow.com/muthunithin/ocr-ulmxi-3muzt [33].](/document/doi/10.1515/jisys-2023-0307/asset/graphic/j_jisys-2023-0307_fig_006.jpg)
OCR results. Source: Image from OCR dataset, https://universe.roboflow.com/muthunithin/ocr-ulmxi-3muzt [33].
Figure 6 shows the recognition results of the algorithm for part of the text in this article. It can be seen that the algorithm can efficiently recognize characters while achieving high accuracy.
6 Conclusions
This study significantly improved the accuracy of text recognition in complex scenarios by integrating ML algorithms, meeting the urgent need for efficient and accurate OCR technology in practical applications. The study not only optimized the SIFT, K-means, and SVM algorithms, but also built an automated ML system with rapid response and high user satisfaction, achieving significant improvements over traditional methods. Despite the breakthrough, this study still has room for improvement when processing actual photographs and did not fully consider the scalability of the algorithm and its performance on larger datasets. Future research should focus on improving the robustness of the algorithm, enhancing large-scale data processing capabilities, and application testing in a variety of scenarios to promote the further development and practical application of OCR technology.
-
Funding information: This work was supported by Research on the test strategy of Professional Quality of Students in specialized school in Polytechnic (Characteristic innovation projects of Guangdong Provincial Department of Education, 2019GKTSCX080).
-
Author contributions: Juntao Chen: editing data curation and supervision. Liming Liu and Dexin Yang: writing – original draft preparation.
-
Conflict of interest: The authors declare that there are no conflicts of interest regarding the publication of this paper. The authors declare that there is no conflict of interest with any financial organizations regarding the material reported in this manuscript.
-
Research involving human participants and/or animal: This study does not violate and simultaneously does not involve human participants and/or animal research.
-
Informed consent: All authors were aware of the publication of this manuscript and agreed to its publication.
-
Data availability statement: The data in Figures 6 from the public data Roboflow Universe. This OCR dataset was created by muthunithin and is hosted on the Roboflow Universe platform. It is an open-source dataset intended to support research and development work in Optical Character Recognition (OCR).
References
[1] Long S, He X, Yao C. Scene text detection and recognition: The deep learning era. Int J Comput Vis. 2021;129(1):161–84. 10.1007/s11263-020-01369-0.Search in Google Scholar
[2] Ranjbarzadeh R, Jafarzadeh Ghoushchi S, Anari S, Safavi S, Tataei Sarshar N, Babaee Tirkolaee E, et al. A deep learning approach for robust, multi-oriented, and curved text detection. Cognit Comput. 2024;16(4):1979–91. 10.1007/S12559-022-10072-W.Search in Google Scholar
[3] Altwaijry N, Al-Turaiki I. Arabic handwriting recognition system using convolutional neural network. Neural Comput Appl. 2021;33(7):2249–61. 10.1007/S00521-020-05070-8.Search in Google Scholar
[4] Raisi Z, Naiel MA, Fieguth P, Wardell S, Zelek J. 2D Positional Embedding-based Transformer for Scene Text Recognition. J Comput Vis Imaging Syst. 2021;6(1):1–4. 10.15353/jcvis.v6i1.3533.Search in Google Scholar
[5] Petrova O, Bulatov K, Arlazarov VV, Arlazarov VL. A weighted combination of per-frame recognition results in text recognition in a video stream. Comput Opt. 2021;45(1):77–89. 10.18287/2412-6179-CO-795.Search in Google Scholar
[6] Forootan MM, Larki I, Zahedi R, Ahmadi A. Machine learning and deep learning in energy systems: A review. Sustainability. 2022;14(8):4832–81. 10.3390/su14084832.Search in Google Scholar
[7] Samanta A, Chowdhuri S, Williamson SS. Machine learning-based data-driven fault detection/diagnosis of lithium-ion battery: A critical review. Electronics. 2021;10(11):1309–26. 10.3390/ELECTRONICS10111309.Search in Google Scholar
[8] Bustillo A, Reis R, Machado AR, Yurievich Pimenov D. Improving the accuracy of machine-learning models with data from machine test repetitions. J Intell Manuf. 2022;33(1):203–21. 10.1007/s10845-020-01661-3.Search in Google Scholar
[9] Gong L, Zhang X, Chen T, Zhang L. Recognition of disease genetic information from unstructured text data based on BiLSTM-CRF for molecular mechanisms. Security Commun Netw. 2021;2021(4):1–8. 10.1155/2021/6635027.Search in Google Scholar
[10] Gaye B, Zhang D, Wulamu A. Improvement of support vector machine algorithm in big data background. Math Probl Eng. 2021;2021(1):5594899–908. 10.1155/2021/5594899.Search in Google Scholar
[11] Jan SU, Lee YD, Koo IS. A distributed sensor-fault detection and diagnosis framework using machine learning. Inf Sci. 2021;547:777–96. 10.1016/j.ins.2020.08.068.Search in Google Scholar
[12] Saqib Raza RS, Adnan KM, Sagheer A, Muhammad A, Nida A, Areej F. Deep extreme learning machine-based optical character recognition system for nastalique Urdu-like script languages. Comput J. 2022;65(2):331–44. 10.1093/comjnl/bxaa042.Search in Google Scholar
[13] Singh S, Mittal N, Singh H, Oliva D. Improving the segmentation of digital images by using a modified Otsu’s between-class variance. Multimed Tools Appl. 2023;82(26):40701–43. 10.1007/s11042-023-15129-y.Search in Google Scholar PubMed PubMed Central
[14] Singh S, Mittal N, Singh H. A multilevel thresholding algorithm using HDAFA for image segmentation. Soft Comput. 2021;25(16):10677–708. 10.1007/s00500-021-05956-2.Search in Google Scholar
[15] Ranganayakulu SV, Subrahmanyam KV, Niranjan A. A novel algorithm for convective cell identification and tracking based on optical character recognition neural network. J Electromagnetic Waves Appl. 2021;35(16):2239–55. 10.1080/09205071.2021.1941299.Search in Google Scholar
[16] Slavin OA, Arlazarov VL. Algorithms of the tiger and cuneiform optical character recognition software. Pattern Recognit Image Anal. 2023;33(4):669–84. 10.1134/S1054661823040442.Search in Google Scholar
[17] Xun Z, Jinxiong Z, Wanrong B, Hong Z. Research on optical character recognition algorithm based on boundary-constrained image fusion. Infrared Laser Eng. 2022;51:12. 10.3788/IRLA20220102.Search in Google Scholar
[18] Peter P, Richard S, Derwin S. Classifying promotion images using optical character recognition and Naïve Bayes classifier. Proc Comput Sci. 2021;179:498–506. 10.1016/j.procs.2021.01.033.Search in Google Scholar
[19] Tuyet Hai NT, Adam J, Mickael C, Antoine D. Survey of post-OCR processing approaches. ACM Comput Surv (CSUR). 2021;54(6):1–37. 10.1145/345347.Search in Google Scholar
[20] Abiodun EO, Alabdulatif A, Abiodun OI, Alawida M, Alabdulatif A, Alkhawaldeh RS. A systematic review of emerging feature selection optimization methods for optimal text classification: the present state and prospective opportunities. Neural Comput Appl. 2021;33(22):15091–118. 10.1007/s00521-021-06406-8.Search in Google Scholar PubMed PubMed Central
[21] Abuzaraida MA, Zeki A. Writing on Digital Surfaces, Challenges and Obstacles for Dealing with Text Recognition Systems. Int J Found Comput Sci Technol. 2021;9(1):21–35.Search in Google Scholar
[22] Saloum SS. DAD: A Detailed Arabic Dataset for Online Text Recognition and Writer Identification, a New Type. J Comput Sci. 2021;17(1):19–32. 10.3844/jcssp.2021.19.32.Search in Google Scholar
[23] Khan T, Sarkar R, Mollah AF. Deep learning approaches to scene text detection: a comprehensive review. Artif Intell Rev. 2021;54:3239–98. 10.1007/s10462-020-09930-6.Search in Google Scholar
[24] Ghaderizadeh S, Abbasi-Moghadam D, Sharifi A, Zhao N, Tariq A. Hyperspectral image classification using a hybrid 3D-2D convolutional neural networks. IEEE J Sel Top Appl Earth Observations Remote Sens. 2021;14:7570–88. 10.1109/JSTARS.2021.3099118.Search in Google Scholar
[25] Li Z, Shu H, Zheng C. Multi-scale single image dehazing using Laplacian and Gaussian pyramids. IEEE Trans Image Process. 2021;30:9270–9. 10.1109/TIP.2021.3123551.Search in Google Scholar PubMed
[26] Mei Y, Fan Y, Zhang Y, Yu J, Zhou Y, Liu D, et al. Pyramid attention network for image restoration. Int J Comput Vis. 2023;131(12):3207–25. 10.1007/s11263-023-01843-5.Search in Google Scholar
[27] Sun L, Wang T, Ding W, Xu J, Lin Y. Feature selection using Fisher score and multilabel neighborhood rough sets for multilabel classification. Inf Sci. 2021;578:887–912. 10.1016/j.ins.2021.08.032.Search in Google Scholar
[28] Sumit SS, Rambli DRA, Mirjalili S. Vision-based human detection techniques: a descriptive review. IEEE Access. 2021;9:42724–61. 10.1109/ACCESS.2021.3063028.Search in Google Scholar
[29] Dalmaijer ES, Nord CL, Astle DE. Statistical power for cluster analysis. BMC Bioinforma. 2022;23(1):205–33. 10.1186/s12859-022-04675-1.Search in Google Scholar PubMed PubMed Central
[30] Ovirianti NH, Zarlis M, Mawengkang H. Support vector machine using a classification algorithm. Sink J dan Penelit Tek Inf. 2022;7(3):2103–7. 10.33395/sinkron.v7i3.11597.Search in Google Scholar
[31] Noubigh Z, Mezghani A, Kherallah M. Densely connected layer to improve VGGnet-based CRNN for Arabic handwriting text line recognition. Int J Hybrid Intell Syst. 2021;3:1–15. 10.3233/HIS-210009.Search in Google Scholar
[32] Bonteanu AM, Tudose C. Performance analysis and improvement for CRUD operations in relational databases from java programs using JPA, hibernate, spring data JPA. Appl Sci. 2024;14(7):2743–75. 10.3390/app14072743.Search in Google Scholar
[33] Muthunithin. OCR Dataset. Roboflow Universe, 2024. Available at: https://universe.roboflow.com/muthunithin/ocr-ulmxi-3muzt.Search in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Synergistic effect of artificial intelligence and new real-time disassembly sensors: Overcoming limitations and expanding application scope
- Greenhouse environmental monitoring and control system based on improved fuzzy PID and neural network algorithms
- Explainable deep learning approach for recognizing “Egyptian Cobra” bite in real-time
- Optimization of cyber security through the implementation of AI technologies
- Deep multi-view feature fusion with data augmentation for improved diabetic retinopathy classification
- A new metaheuristic algorithm for solving multi-objective single-machine scheduling problems
- Estimating glycemic index in a specific dataset: The case of Moroccan cuisine
- Hybrid modeling of structure extension and instance weighting for naive Bayes
- Application of adaptive artificial bee colony algorithm in environmental and economic dispatching management
- Stock price prediction based on dual important indicators using ARIMAX: A case study in Vietnam
- Emotion recognition and interaction of smart education environment screen based on deep learning networks
- Supply chain performance evaluation model for integrated circuit industry based on fuzzy analytic hierarchy process and fuzzy neural network
- Application and optimization of machine learning algorithms for optical character recognition in complex scenarios
- Comorbidity diagnosis using machine learning: Fuzzy decision-making approach
- A fast and fully automated system for segmenting retinal blood vessels in fundus images
- Application of computer wireless network database technology in information management
- A new model for maintenance prediction using altruistic dragonfly algorithm and support vector machine
- A stacking ensemble classification model for determining the state of nitrogen-filled car tires
- Research on image random matrix modeling and stylized rendering algorithm for painting color learning
- Predictive models for overall health of hydroelectric equipment based on multi-measurement point output
- Architectural design visual information mining system based on image processing technology
- Measurement and deformation monitoring system for underground engineering robots based on Internet of Things architecture
- Face recognition method based on convolutional neural network and distributed computing
- OPGW fault localization method based on transformer and federated learning
- Class-consistent technology-based outlier detection for incomplete real-valued data based on rough set theory and granular computing
- Detection of single and dual pulmonary diseases using an optimized vision transformer
- CNN-EWC: A continuous deep learning approach for lung cancer classification
- Cloud computing virtualization technology based on bandwidth resource-aware migration algorithm
- Hyperparameters optimization of evolving spiking neural network using artificial bee colony for unsupervised anomaly detection
- Classification of histopathological images for oral cancer in early stages using a deep learning approach
- A refined methodological approach: Long-term stock market forecasting with XGBoost
- Enhancing highway security and wildlife safety: Mitigating wildlife–vehicle collisions with deep learning and drone technology
- An adaptive genetic algorithm with double populations for solving traveling salesman problems
- EEG channels selection for stroke patients rehabilitation using equilibrium optimizer
- Influence of intelligent manufacturing on innovation efficiency based on machine learning: A mechanism analysis of government subsidies and intellectual capital
- An intelligent enterprise system with processing and verification of business documents using big data and AI
- Hybrid deep learning for bankruptcy prediction: An optimized LSTM model with harmony search algorithm
- Construction of classroom teaching evaluation model based on machine learning facilitated facial expression recognition
- Artificial intelligence for enhanced quality assurance through advanced strategies and implementation in the software industry
- An anomaly analysis method for measurement data based on similarity metric and improved deep reinforcement learning under the power Internet of Things architecture
- Optimizing papaya disease classification: A hybrid approach using deep features and PCA-enhanced machine learning
- Handwritten digit recognition: Comparative analysis of ML, CNN, vision transformer, and hybrid models on the MNIST dataset
- Multimodal data analysis for post-decortication therapy optimization using IoMT and reinforcement learning
- Predicting early mortality for patients in intensive care units using machine learning and FDOSM
- Uncertainty measurement for a three heterogeneous information system based on k-nearest neighborhood: Application to unsupervised attribute reduction
- Genetic algorithm-based dimensionality reduction method for classification of hyperspectral images
- Power line fault detection based on waveform comparison offline location technology
- Assessing model performance in Alzheimer's disease classification: The impact of data imbalance on fine-tuned vision transformers and CNN architectures
- Hybrid white shark optimizer with differential evolution for training multi-layer perceptron neural network
- Review Articles
- A comprehensive review of deep learning and machine learning techniques for early-stage skin cancer detection: Challenges and research gaps
- An experimental study of U-net variants on liver segmentation from CT scans
- Strategies for protection against adversarial attacks in AI models: An in-depth review
- Resource allocation strategies and task scheduling algorithms for cloud computing: A systematic literature review
- Latency optimization approaches for healthcare Internet of Things and fog computing: A comprehensive review
- Explainable clustering: Methods, challenges, and future opportunities
Articles in the same Issue
- Research Articles
- Synergistic effect of artificial intelligence and new real-time disassembly sensors: Overcoming limitations and expanding application scope
- Greenhouse environmental monitoring and control system based on improved fuzzy PID and neural network algorithms
- Explainable deep learning approach for recognizing “Egyptian Cobra” bite in real-time
- Optimization of cyber security through the implementation of AI technologies
- Deep multi-view feature fusion with data augmentation for improved diabetic retinopathy classification
- A new metaheuristic algorithm for solving multi-objective single-machine scheduling problems
- Estimating glycemic index in a specific dataset: The case of Moroccan cuisine
- Hybrid modeling of structure extension and instance weighting for naive Bayes
- Application of adaptive artificial bee colony algorithm in environmental and economic dispatching management
- Stock price prediction based on dual important indicators using ARIMAX: A case study in Vietnam
- Emotion recognition and interaction of smart education environment screen based on deep learning networks
- Supply chain performance evaluation model for integrated circuit industry based on fuzzy analytic hierarchy process and fuzzy neural network
- Application and optimization of machine learning algorithms for optical character recognition in complex scenarios
- Comorbidity diagnosis using machine learning: Fuzzy decision-making approach
- A fast and fully automated system for segmenting retinal blood vessels in fundus images
- Application of computer wireless network database technology in information management
- A new model for maintenance prediction using altruistic dragonfly algorithm and support vector machine
- A stacking ensemble classification model for determining the state of nitrogen-filled car tires
- Research on image random matrix modeling and stylized rendering algorithm for painting color learning
- Predictive models for overall health of hydroelectric equipment based on multi-measurement point output
- Architectural design visual information mining system based on image processing technology
- Measurement and deformation monitoring system for underground engineering robots based on Internet of Things architecture
- Face recognition method based on convolutional neural network and distributed computing
- OPGW fault localization method based on transformer and federated learning
- Class-consistent technology-based outlier detection for incomplete real-valued data based on rough set theory and granular computing
- Detection of single and dual pulmonary diseases using an optimized vision transformer
- CNN-EWC: A continuous deep learning approach for lung cancer classification
- Cloud computing virtualization technology based on bandwidth resource-aware migration algorithm
- Hyperparameters optimization of evolving spiking neural network using artificial bee colony for unsupervised anomaly detection
- Classification of histopathological images for oral cancer in early stages using a deep learning approach
- A refined methodological approach: Long-term stock market forecasting with XGBoost
- Enhancing highway security and wildlife safety: Mitigating wildlife–vehicle collisions with deep learning and drone technology
- An adaptive genetic algorithm with double populations for solving traveling salesman problems
- EEG channels selection for stroke patients rehabilitation using equilibrium optimizer
- Influence of intelligent manufacturing on innovation efficiency based on machine learning: A mechanism analysis of government subsidies and intellectual capital
- An intelligent enterprise system with processing and verification of business documents using big data and AI
- Hybrid deep learning for bankruptcy prediction: An optimized LSTM model with harmony search algorithm
- Construction of classroom teaching evaluation model based on machine learning facilitated facial expression recognition
- Artificial intelligence for enhanced quality assurance through advanced strategies and implementation in the software industry
- An anomaly analysis method for measurement data based on similarity metric and improved deep reinforcement learning under the power Internet of Things architecture
- Optimizing papaya disease classification: A hybrid approach using deep features and PCA-enhanced machine learning
- Handwritten digit recognition: Comparative analysis of ML, CNN, vision transformer, and hybrid models on the MNIST dataset
- Multimodal data analysis for post-decortication therapy optimization using IoMT and reinforcement learning
- Predicting early mortality for patients in intensive care units using machine learning and FDOSM
- Uncertainty measurement for a three heterogeneous information system based on k-nearest neighborhood: Application to unsupervised attribute reduction
- Genetic algorithm-based dimensionality reduction method for classification of hyperspectral images
- Power line fault detection based on waveform comparison offline location technology
- Assessing model performance in Alzheimer's disease classification: The impact of data imbalance on fine-tuned vision transformers and CNN architectures
- Hybrid white shark optimizer with differential evolution for training multi-layer perceptron neural network
- Review Articles
- A comprehensive review of deep learning and machine learning techniques for early-stage skin cancer detection: Challenges and research gaps
- An experimental study of U-net variants on liver segmentation from CT scans
- Strategies for protection against adversarial attacks in AI models: An in-depth review
- Resource allocation strategies and task scheduling algorithms for cloud computing: A systematic literature review
- Latency optimization approaches for healthcare Internet of Things and fog computing: A comprehensive review
- Explainable clustering: Methods, challenges, and future opportunities