Edition von frühdigitalem Text: Ein Problemaufriss
-
Torsten Roeder


Abstract
Early born-digital texts from the 1980s and 1990s are increasingly becoming subjects of cultural transmission. Their scholarly editing requires textual criticism on multiple levels. These texts often exist in multimedia, performative environments, and their ephemeral surfaces necessitate the inclusion of underlying logical structures in textual analysis. Both aspects could be incorporated into synoptic forms of scholarly editing in the future. This is illustrated through the example of disk magazines, a type of multimedia electronic periodical from the home computer era.
1. Historische Digitalität
Von der Zeit der ersten Heimcomputer bis zur allgemeinen Verfügbarkeit des Breitbandinternets – ungefähr im Zeitraum der 1980er und 1990er Jahre – wurden digitale Dokumente vorrangig auf magnetischen Datenträgern gespeichert, transportiert und verbreitet. Derartiges Material wird Archivierungs- und Erschließungseinrichtungen mittlerweile häufiger als Nachlass vorgelegt, während zugleich die Expertise im Umgang mit älteren Programmen und Dateiformaten durch den Generationenwechsel schwindet und historische Geräte und Datenträger Korrosions- oder Entsorgungsprozessen ausgesetzt sind.[1] Die auf Expansion und Novität ausgerichteten Hard- und Softwaremärkte unterstützen diese Dynamik, wodurch Digitalität eine kurze Halbwertszeit innezuwohnen scheint, was abgesehen von dem materiellen Verschleiß einiger Komponenten gar nicht zwingend notwendig wäre. Durch diesen Mangel an Nachhaltigkeit auf mehreren Ebenen (Expertise, Markt, Material) ist das digitale Erbe jener Dekaden, und perspektivisch auch das der aktuellen Zeit, potenziell gefährdet oder steht bereits in erheblichen Teilen nicht mehr zur Bewahrung, geschweige denn Beforschung zur Verfügung. Die Selektion der längerfristig zu erhaltenden digitalen Hinterlassenschaften wird aktiv nur punktuell unterstützt und bleibt ansonsten partikularen Interessen oder technischen Notwendigkeiten unterworfen. Insbesondere die Vielfalt und Proprietarität digitaler Medienformate erschweren automatische Mechanismen zum Erhalt von ‘digital heritage’.[2] Hinzu kommen noch urheber- und persönlichkeitsrechtliche Umstände, die sich nicht nur auf die Erzeugnisse, sondern auch auf die Systemarchitekturen beziehen können.[3]
Auch die Editionswissenschaft wird sich zukünftig verstärkt mit Digitalia befassen müssen. Nicht nur Forschungsdaten,[4] Nachlässe[5] und amtliche Daten,[6] sondern auch elektronische Literaturformen[7] rücken das historische digitale Kulturerbe in den Interessenhorizont der Philologie. Schon aus der Zeit der Heimcomputer und magnetischen Datenträger – mediengeschichtlich vorprägende Jahre für aktuelle digitale Kulturformen – liegt eine erhebliche Menge an ‘Born-digital’-Material vor, das aber beispielsweise im Vergleich zu frühen Dokumenten des World Wide Web (man denke nur an die Wayback Machine und andere Webarchive) der Allgemeinheit heute kaum mehr zugänglich ist. Denn jenes Material ist inzwischen, auch wenn es bereits ‚digital‘ angelegt war, bereits so weit historisiert, dass die Übertragung in aktuelle Systeme längst keine triviale Aufgabe mehr darstellt. Zudem gerät im zunehmend ‚postdigitalen‘ Umfeld aus dem Bewusstsein, wie weitreichend Geräte, ihre Systemumgebungen und die darauf laufende Software auch die darauf erstellten digitalen Erzeugnisse determinieren konnten (so wie auch heutige Programme durch ihre Funktionspaletten ebenso bewusst ein Fahrwasser zur Strukturierung und Ausgestaltung digitaler Erzeugnisse vorgeben).
In der Ära der Heimcomputer wurden die Limits häufiger bereits von der Hardware vorgegeben, etwa durch Auswahl und Zahl der Farben, Schriftarten und Soundkanäle oder durch Speicherkapazität und mögliche Bildschirmauflösungen: Grenzen, die einerseits stilprägend wirkten und andererseits zu kreativen Lösungen einluden. Ein weiterer Aspekt sind die zahlreichen historischen Formate und Kodierungsstandards, die oft nicht mehr an heutige Standards anschlussfähig oder von aktuellen Systemen entzifferbar sind. Das Spektrum firmeneigener Standards und die Möglichkeiten individueller Anpassbarkeit waren zudem deutlich ausdifferenzierter im Vergleich zur aktuellen Zeit, in der global verfügbare Internetservices auch globale Kommunikationsstandards benötigen. Die Untersuchung digitalen Kulturerbes erfordert deshalb aber eine vertiefte Auseinandersetzung mit den jeweiligen historischen Bedingungen oder – technisch ausgedrückt – mit den jeweiligen Systemumgebungen. Daraus entstehen Herausforderungen für die Edition digitaler Erzeugnisse einerseits und für die digitale Editorik andererseits: Das ‚Computermaterial‘ ist als Umwelt der Textentstehung einzubeziehen und die ursprüngliche digitale Form des Textes in eine dem jeweiligen Edendum medial angemessene und nachhaltige Präsentation zu überführen.[8]
1.1. Bewahrungsstrategien für Hardware und Software
Bei der näheren Beschäftigung mit digitalen Hinterlassenschaften aus den 1980er und 1990er Jahren wird schnell deutlich, welch fundamentaler Technikwandel in nur wenigen Jahrzehnten stattgefunden hat. Weder Software noch Daten sind heute mit einfachen Mitteln zugänglich, und der Umgang mit originalen Datenträgern und Geräten erfordert Umsicht und Expertise, die zunehmend seltener wird und den Bedarf an archivalischen und bibliothekarischen Spezialisierungen weckt. Im Allgemeinen bieten sich drei Strategien zur Bewahrung früher ‘Born-digital’-Objekte an: Konservierung, Emulation und Migration, denen sehr unterschiedliche Trade-Offs innewohnen.
Die erste, konservatorische Strategie nutzt originale und reparierte, gegebenenfalls auch rekonstruierte Geräte. Dies ist aufwändig und in größerem Rahmen nur institutionalisiert denkbar. An verschiedenen universitären Standorten existieren dazu bereits wissenschaftliche Sammlungen (oft mit Laborcharakter),[9] der größere Teil fällt allerdings den Computermuseen und privaten Sammlungen zu.[10] Dies ermöglicht den authentischen Blick auf die ‘Born-Digital’-Objekte und ist für das buchstäbliche Begreifen der historischen Systemumgebung sogar unerlässlich.[11]
Die zweite Strategie, Emulation, ist für häufigere oder auch breit angelegte und experimentelle Zugriffsmethoden besser geeignet. Dabei wird eine Hardware-Umgebung durch eine Software auf einem (notwendigerweise leistungsstärkeren) System imitiert, während physische Datenträger mit ihren Inhalten in Form einer Container-Datei abgebildet werden. Dies bringt mehrere praktische Vorteile mit sich: Im Emulator lassen sich beispielsweise Speicherzustände von Systemen, in deren Umgebung gerade bestimmte Programme mit bestimmten Inhalten laufen, zu einem beliebigen Zeitpunkt einfrieren (‘snapshot’) und an diesem Punkt später wieder aufrufen. Dies erlaubt es wiederum, einen spezifischen Stand einer laufenden Software zu zitieren.[12] Emulation ist im Browser möglich und bietet damit potenziell der Allgemeinheit einen niederschwelligen Zugang zu frühen digitalen Objekten.[13] Dass bei der Emulation die Abhängigkeit von der Originalhardware beseitigt ist, hat aber nicht nur Vorteile: Die Nutzung eines Emulators zusammen mit einem aktuellen Eingabegerät kann aus mehreren Gründen zu Dissonanzen führen. So ist das heutige Zeicheninventar einer Tastatur möglicherweise nicht deckungsgleich mit der originalen Tastatur, oder es wird ein spezifisches Eingabegerät vorausgesetzt, das heute nicht mehr zum üblichen Inventar gehört, wie zum Beispiel ein Mikroschalter-Joystick. Manchmal wird auch erst anhand der Bauart der ursprünglichen Tastaturen und Eingabegeräte deutlich, warum bestimmte Entscheidungen, die die Bedienung eines Programms betreffen, als besonders naheliegend oder intuitiv betrachtet wurden. Das heißt, die Emulation verzichtet auf die Abbildung einer möglicherweise epistemologisch relevanten Ebene.
Eine dritte Möglichkeit besteht in der Migration,[14] bei der digitale Objekte so transformiert werden, dass sie sich problemlos in eine andere, neuere Umgebung einpassen. Dabei sind Abhängigkeiten zum Ausgangssystem aufzulösen und gleichzeitig die Umgebungsbedingungen des Zielsystems zu erfüllen. Je nach Grad der Abhängigkeiten und der neuen Bedingungen kann dies einfach oder sehr aufwändig sein. So würde beispielsweise die Migration von Schachsymbolen, wie sie auf historischen Atari-Plattformen im nativen Schriftsatz vorhanden sind, voraussetzen, dass diese auf dem Zielsystem ebenfalls vorhanden sind. Mit einem aktuellen System würde dies dank Unicode funktionieren – allerdings nicht bei vielen anderen Sonderzeichen des Atari. Manche Eigenheiten eines Objekts lassen sich möglicherweise nur mit größerem Transformationsaufwand oder mit Kompromissen migrieren, bei hardwareabhängigen Aspekten oft nur mit Verlust. Vorwärtskompatibilität ist indessen als Glücksfall zu betrachten.
Bei dem Migrationsprozess ist das Material nicht nur von der Ausgangsumgebung ab- und an die Zielumgebung anzukoppeln, sondern auch für die Zielumgebung medial zu rekonzipieren. Insofern deckt sich die Migration – wenn dabei die Idee des Bewahrens im Zentrum steht – methodisch mit einem Kerngebiet der Editorik: der Aufbereitung von überliefertem Text in einer allgemein zugänglichen Medienform unter Bewahrung der wesentlichen bedeutungstragenden Merkmale.
1.2. Digitaler Text
‘Born-digital’-Text besitzt im Gegensatz zu seinem analogen Pendant auf materiellen Textträgern keine feste Erscheinungsform außer seinen Datenträgern, die nur mit bestimmten – und durchaus materiellen – Geräten lesbar sind. Die temporäre Sichtbarmachung in ihrer intentionalen Form erfolgt durch Visualisierung der binär gespeicherten Textdaten auf Bildschirmen: etwa durch fluoreszierendes Material, das durch hochfrequente Kathodenstrahlen zum Leuchten gebracht wird (CRT, ‘cathode ray tube’), oder durch polarisierbare, lichtdurchlässige Flüssigkristalle (LCD, ‘liquid crystal display’). Aufgrund der transitorischen Erscheinungsform digitalen Textes – denn seine ‚Lichtform‘ verschwindet mit dem Beenden des dazugehörigen Programms oder dem Ausschalten des Bildschirms – gehört die jeweilige Geräteumgebung als ‚Leseszene‘ zur Textperformanz. Dieser rezeptiven Umgebung ist außerdem die produktive Umgebung, die zur Erzeugung eines Textes verwendet wurde, als ‚Schreibszene‘ gegenüberzustellen.
Der Weg eines digital gespeicherten Textes vom Datenträger auf den Bildschirm – oder informatisch ausgedrückt: von der physikalischen zur konzeptionellen Ebene – ist allerdings keine 1:1-Abbildung, sondern wird erst durch Computerarchitektur, Betriebssystem und passende Programme – die logische Ebene – bereitet, welche die Textdaten für die Darstellung auf dem Bildschirm interpretieren und transformieren. Wenngleich das Grundformat eines gespeicherten Textes oft Einblicke erlaubt, auf welche Weise ein Text dargestellt werden soll, kann die gleichwohl ephemere Bildschirmwiedergabe eines Textes aufgrund ihrer intentionalen Qualität ausschlaggebend für die Textkritik sein. Die Editorik stünde dann aber vor der Herausforderung, für ihre Arbeit eine Textperformanz erzeugen zu müssen, die den originalen Bedingungen der Textrezeption und gegebenenfalls auch der Textproduktion hinreichend nahekommt.
2. Hintergrund: Graue digitale Literatur
2.1. Das Diskmags-Projekt
Den Hintergrund der Überlegungen zum Problemfeld ‚frühdigitaler Text‘ bildet ein Erschließungsprojekt, das sich mit digitalem Kulturerbe der 1980er und 1990er Jahre befasst. Aus diesen Jahrzehnten ist nicht nur eine sehr große Menge an computerbezogenen Printmagazinen überliefert, sondern es existierte auch eine hohe Zahl an digitalen Publikationen, die durch Bibliotheken oder Archive oft nicht erfasst wurde. Dies geschah schon aus dem einfachen Grund, dass digitale Veröffentlichungsformen noch gar nicht etabliert und allein daher nicht im üblichen Sammlungsauftrag der Einrichtungen enthalten waren, aber auch, weil ein erheblicher Anteil dieser Publikationen zur sogenannten grauen Literatur zu zählen ist. Das Projekt, welches durch das NFDI-Konsortium Text+ im Jahr 2023 finanziert wurde,[15] hat sich die Katalogisierung und Texterschließung der sogenannten ‚Diskettenmagazine‘ zum Ziel gesetzt. Es handelt sich dabei um elektronische Zeitschriften aus der frühen Heimcomputerszene, die sich ausschließlich auf den Computersystemen rezipieren lassen, für die sie erzeugt wurden und die per se kein analoges Pendant besitzen, also als ‘born digital’ einzuordnen sind.
Diskettenmagazine sind aus mehreren Gründen ein interessantes Fallbeispiel für den eingangs aufgeworfenen Fragenkomplex. Zunächst stellt sich die Frage, unter welchen Bedingungen Texte, die vor mehreren Dekaden erstellt und gespeichert wurden, auf heutigen Geräten eindeutig wiedergegeben werden können. Und wie lassen sich die digitalen Texte konvertieren, um ein ediertes, durchsuchbares Textkorpus daraus zu erstellen? Hinzu kommt die multimediale Dimension: Diskettenmagazine bestanden primär aus Text, enthielten aber auch Grafiken, Animationen, Klänge, Musik, interaktive Elemente und nicht zuletzt ausführbare Programme. Inwieweit wirkt dieser Kontext auf den Text zurück, und wie ist dies textkritisch und editorisch zu berücksichtigen? Welche Rolle spielen dabei die spezifischen technischen Eigenschaften der jeweiligen Geräte?
2.2. Frühdigitale Periodika und ihre Trägermedien
Während in jener Zeit das Internet im Heimcomputerbereich eine untergeordnete Rolle spielte, stellten magnetische Datenträger das vorrangige Verbreitungsmedium für digitale Publikationen dar. Dazu zählen zunächst Audiokassetten, auf denen Daten akustisch gespeichert wurden (‘datasette’). Auf diesem Medium erschienen ab 1978 Magazine wie CLOAD für den Radio Shack TRS-80 oder CURSOR für den Commodore PET. Die Nutzung von Audiokassetten war für die Etablierung der Heimcomputer hochrelevant, da in den meisten Haushalten bereits kompatible Kassettenrekorder vorhanden waren, so wie man den eigenen Röhrenfernseher häufig auch als Computerbildschirm nutzen konnte. Die Heimcomputer fügten sich somit in die konsumbürgerliche Haushaltsinfrastruktur ein.
Schon in den frühen 1980er Jahren etablierte sich die Diskette (‘floppy disk’) als primäres Speichermedium. Diese bestanden aus rotierbaren, magnetisierbaren Kunststoffscheiben in rechteckigen Schutzhüllen, für den Heimcomputermarkt zunächst im 5,25-Zoll-Format, später im 3,5-Zoll- und seltener auch im 3-Zoll-Format. Während bei Datasetten Lese- und Schreibvorgänge mithilfe eines mechanischen Zählwerks manuell positioniert und gestartet werden mussten (‚Notieren Sie sich jetzt den Zählerstand!‘), konnten Floppy-Laufwerke diese Vorgänge eigenständig und präzise durchführen. Durch die rotierende Scheibe und den beweglichen Lesekopf konnten Zugriffe auf das Dateisystem zudem ohne wahrnehmbare Verzögerung erfolgen. Auf 5,25-Zoll-Diskette erschienen ab 1981 kommerzielle Magazine wie Softdisk für den Apple II (1981–1995) und Loadstar für den Commodore 64 (1984–2010). Später erschienen auch deutschsprachige Magazine wie Magic Disk 64 (1987–1995) oder das Spielemagazin Game On (1988–1995). Darin fanden sich Neuigkeiten über aktuelle Hardware und Software, aber auch Programmierkurse und Elektrobastelanleitungen – und immer wieder kleine oder größere Programme, oft von Personen aus der Heimcomputerszene erstellt. Einige Magazine besaßen einen kleineren Papieranteil, der als Umschlag diente und beispielsweise Gebrauchsanleitungen enthielt. Dies betraf vor allem die frühen Magazine, welche kommerziell betrieben wurden und einen großen Anteil an Software enthielten. Bei größerem Printanteil (‚Heft mit Diskette‘) spricht man deshalb auch von ‚Softwaremagazinen‘, bei denen also nicht das Trägermedium, sondern der Inhalt als Charakteristikum angesetzt wird.
Die erschwinglichen Geräte von Commodore und Atari begünstigten die Herausbildung einer dynamischen Jugendkultur, die ihre Diskettenmagazine bald in Eigenregie erstellte, denn es handelte sich um ein Format, das mit vergleichsweise wenig Geld- und Materialeinsatz erzeugt werden konnte. Tatsächlich entstand der weitaus größere Anteil von Diskettenmagazinen gar nicht in kommerziellen Verlagen, sondern in der Community. Diese kamen ohne Papieranteil aus und verbreiteten sich über Software-Tauschringe zusammen mit meist illegalen Kopien von Spielen und Anwenderprogrammen, aus denen die heute bereits im deutschen und finnischen UNESCO-Verzeichnis des immateriellen Kulturguts geführte Demoszene entstanden ist.[16]
Auf den kompakteren 3,5-Disketten erschienen anschließend unzählige Magazine vor allem für Amiga, Atari und IBM-PC, auf der kuriosen 3-Zoll-Diskette von Amstrad indessen nur einige wenige. Der erst in den 1990er Jahren aufkommenden CD-ROM fiel nur eine untergeordnete Bedeutung für die Diskmags-Szene zu, dafür wiederum umso mehr für kommerzielle Printmagazine als Software-Beileger.
Nach der allgemeinen Verbreitung des Breitbandinternets gegen Ende der 1990er Jahre wurden viele Diskettenmagazine eingestellt. Ein Teil wurde im Internet weitergeführt, nicht selten unter Beibehaltung der Bezeichnung ‚Diskmag‘ im Titel. Einige Magazine wie Digital Talk für den Commodore 64 existieren bis heute und werden weiterhin auf 5,25-Zoll-Disketten verbreitet. Viele Magazine werden aber auch über browserbasierte Emulatoren angeboten, was die aktuell zugänglichste Methode darstellt, historische Programme in ihrer originalen Systemumgebung auszuführen.
Als Zeugnisse einer frühen digitalen Ära sind Diskettenmagazine heute für die Forschung interessant: etwa für die Rezeptionsgeschichte von Computerspielen, für die Rekonstruktion von grenzübergreifenden Jugend-Netzwerken sowie als Studienobjekte für den Umgang mit frühen digitalen Medien (die aus heutiger Sicht in ihren Möglichkeiten stark begrenzt erschienen, aus der historischen Sicht aber ungeahnte Möglichkeiten eröffneten). Während erste Schätzungen von international ca. 300 Titeln ausgingen, kam das oben genannte NFDI-Kooperationsprojekt durch Auswertung verschiedener Datenbanken schon nach wenigen Recherchemonaten auf ca. 2500 nachweisbare Titel mit weit über 10 000 Ausgaben – eine Menge, die nur im Rahmen eines größeren Erschließungsprojekts handhabbar werden könnte. Diese Zahl wird vermutlich noch steigen, da einige Systeme und auch einige Herkunftsländer noch nicht systematisch untersucht wurden, sondern lediglich Informationen aus mehreren verfügbaren Datenbanken zusammengeführt wurden. Bislang existiert kaum eine bibliothekarische Dokumentation der Magazine, weshalb es notwendig erscheint, weiterhin Nachweise im Katalog zu sammeln und außerdem die Inhalte zunächst für Volltextrecherchen aufzubereiten. Für diese inhaltliche Erschließung – eine notwendige Vorstufe einer möglichen editorischen Bearbeitung – wurden automatisierte Textextraktionsverfahren angewendet, deren Entwicklung eine Reihe von Herausforderungen für die Textkritik aufgeworfen hat.
Natürlich sollen auch die urheberrechtlichen Fragen, die sich zweifellos bei dem noch relativ jungen Material stellen, nicht ganz ausgeklammert werden. Allgemein schützt das Gesetz die Erschließung zu Forschungszwecken unter bestimmten Bedingungen (UrhG § 60d: „Text und Data Mining für Zwecke der wissenschaftlichen Forschung“).[17] Ein Textkorpus braucht nicht zwingend in Volltextform veröffentlicht zu werden, sondern kann auch als statistisches Textkorpus mit Stellennachweisen funktionieren. Möchte man Volltexte herausgeben, lässt sich von vielen Urhebern direkt eine Erlaubnis einholen – was durch den Umstand erschwert wird, dass die Klarnamen aufgrund der Verwendung von Pseudonymen oft nur schwer ermittelbar sind – oder eine Risikoabwägung aufstellen, inwieweit Urheber tatsächlich Einwände erheben könnten. Problematischer erscheint eher noch die Behandlung von Musik- und Bildwerken, die oft einen integralen Teil der Magazine bildeten, denn die frühe digitale Pastiche-Kultur adaptierte gern Werke für spezifische Computersysteme.
3. Frühe digitale Texte in ihrem Medium
Die Computersysteme, auf denen die ersten Diskettenmagazine, aber auch viele andere textenthaltende Formate erzeugt und rezipiert wurden, weisen im Vergleich eine Reihe von oft ähnlichen Eigenschaften in der Präsentation von Text auf, die nachfolgend anhand eines typischen Fallbeispiels aufgezeigt werden.
3.1. Fallbeispiel
Zur Anschauung dient hier eine Seite aus der ersten Ausgabe der Magic Disk 64 (s. Abb. 1). Dieses Magazin war im deutschsprachigen Raum sehr populär und erschien meist monatlich von 1987 bis 1995, erhältlich zum Preis von 9,80 DM im Einzelhandel. Es konnte auf dem weit verbreiteten Heimcomputersystem Commodore 64 (und 128) gelesen werden. Enthalten waren aktuelle Nachrichten aus der Computerszene, Software- und Hardware-Rezensionen, Programmierkurse, Elektronik-Bastelanleitungen und nicht zuletzt eine Reihe von Spielen und Anwendungsprogrammen, die man von der gleichen Diskette starten konnte. Abgesehen von einer bunten Titelfolie für die Auslage im Geschäft gibt es keine nennenswerten Printanteile.
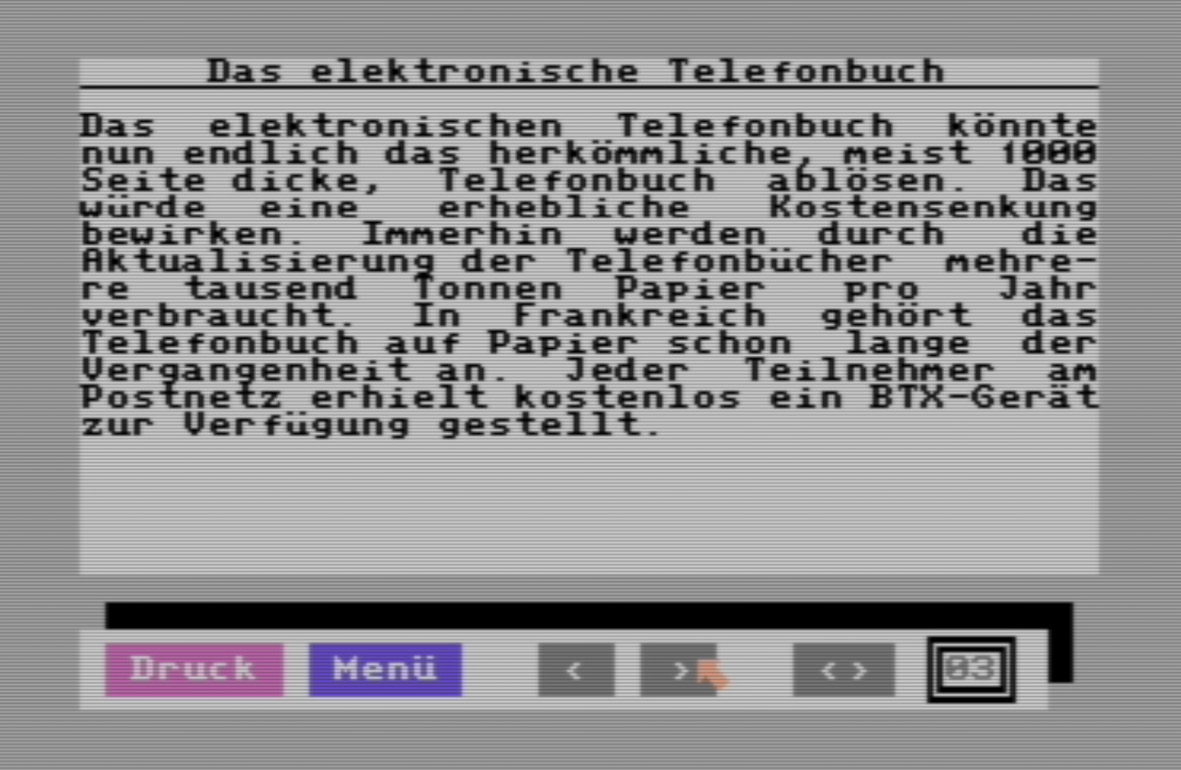
Beispielseite aus der Magic Disk 64, Rubrik „Hardware“, S. 3.
3.2. Bildschirmraster
Betrachtet man die Seite auf einem Commodore 64 oder in einem entsprechenden Emulator, fällt vielleicht sofort eine typische Eigenschaft der Texttopographie älterer Computersysteme auf: Die Schriftzeichen sind in einem regelmäßigen Raster[18] aus 25 Zeilen zu 40 Zeichen angeordnet, also genau 1000 Zeichen pro Bildschirmseite (vgl. Abb. 1). Jedes Schriftzeichen setzt sich wiederum aus einer Rastergrafik von 8×8 Bildpunkten zusammen. Üblicherweise ist die Gestalt der Schriftzeichen vorgegeben, in diesem Fall wurden die Lettern aber leicht angepasst. Typische Hervorhebungsformen wie Fettdruck oder Kursivierung waren unüblich, weil es dazu eigene Schriftzeichen bräuchte – jedoch ist das Zeicheninventar durch begrenzten (weil teuren) Speicherplatz auf 256 Zeichen limitiert. Stattdessen wird hier mit Färbung, Sperrung, Invertierung[19] und auch mit Blockgrafiken[20] gearbeitet, um Textteile hervorzuheben. Das kann außerdem dazu führen, dass die direkte Übernahme der originalen Textkodierung nicht ohne Weiteres möglich ist, da sie zusätzliche Steuerzeichen enthält (beispielsweise zeigt der PETSCII-Code 30 eine Farbänderung des nachfolgenden Textes zu Grün an).[21] Editorisch wäre an dieser Stelle zwischen einem konzeptionellen Befund (‚Wort ist gesperrt‘) und einem logischen Befund (‚zwischen den Buchstaben eines Wortes befindet sich jeweils ein Leerzeichen‘) zu differenzieren.[22] Auch bei Hervorhebungszeichen, die außerhalb des Textflusses liegen (etwa Unterstreichungen durch eine Reihe von Längsstrichen in der darunterliegenden Zeile; s. Abb. 1 in Zeile 2), wäre so zu verfahren. Die editorische Behandlung des Textes kann sich also gleichzeitig an der konzeptionellen Bildschirmpräsentation und an der dahinterliegenden, logischen Repräsentation des Textes im Bildschirmspeicher und dessen Rasterstruktur orientieren. Bei der Herstellung eines edierten Textes besteht dann die Möglichkeit, die Rasterung beizubehalten oder den Textfluss zugunsten der Lesbarkeit anzupassen. Weniger Flexibilität besteht, wenn im Original Blockgrafiken verwendet wurden, die nicht nur der Hervorhebung von Textpassagen oder der Benutzeroberfläche dienen (vgl. Abb. 1 unten), sondern strukturell konstitutiv für das Layout sind, wie etwa Listen, Tabellen und Diagramme. Hier erscheint es sinnvoll, das Textraster prinzipiell auch in verarbeiteten Wiedergabeformaten zu erhalten oder das Layout konzeptionell zu rekonstruieren. Gänzlich in ihrer abgebildeten Form zu bewahren sind schließlich Grafiken, die mithilfe von Blockgrafiken erzeugt wurden.
3.3. Re-Medialisierung
Das Editionsverfahren der Re-Medialisierung wurde versuchsweise bei der ersten Ausgabe der Magic Disk 64 angewendet.[23] Der Wechsel der Medienform zu einer browserbasierten Umgebung kann einige Konsequenzen nach sich ziehen. Während es durchaus möglich wäre, die Präsentation der gesamten Ausgabe einschließlich der ursprünglichen Benutzerführung (mit Pfeilsymbolen zum Blättern, s. Abb. 1, unterer Bereich) nachzuahmen, kann eine solche Mimikry dem Auftrag einer kritischen Edition möglicherweise sogar abträglich sein, da intransparent wird, an welchen Stellen möglicherweise Kompromisse eingegangen wurden. Für eine originalnahe Wiedergabe ist die Version im Emulator zu bevorzugen, während eine browserbasierte Version erstens die historische Distanz zum Original aufzeigen kann und zweitens einige Nutzungsvorteile (wie Hyperlinks und Suchfunktion) mit sich bringt. Am vorliegenden Beispiel bedeutet dies außerdem, die streng seitenorientierte Darstellung des Magazins auf das Schriftrollenprinzip des Hypertexts zu übertragen.
In der Versuchsedition wurden alle Inhalte der Ausgabe – ausgenommen aber die Software – auf eine einzige Webseite transferiert. Die Kodierung mit TEI erlaubt die Trennung zwischen konzeptioneller und logischer Ebene, die auf der Webseite für einen flexiblen Wechsel zwischen ‚diplomatischem‘ Rastertext und Fließtext für komfortables Lesen genutzt wird. Außerdem erschien es sinnvoll, der ‚re-digitalisierten‘ Ausgabe auch Screenshots der originalen Bildschirmseiten beizufügen.[24] Anbieten könnte sich perspektivisch eine Ausgabe, in der Edition und Emulation synoptisch präsentiert werden, in der also die ‚lebendige‘ Originalform des Diskettenmagazins neben einer konzeptionell und systematisch erschlossenen Wiedergabe steht.
4. Textkritik am Byte
Diese am Textraster des Bildschirms orientierte Methode berücksichtigt allerdings noch nicht die Speicherform des Textes, wie sie in der Datei auf der dazugehörigen Diskette abgebildet ist. Idealerweise entspräche das Zeichen auf dem Bildschirm genau dem standardisierten Codepunkt in der Datei, so dass die Datei auch unmittelbar für einen anderen Kontext interpretiert werden könnte – wie etwa zur Erzeugung eines Textkorpus oder einer Edition. Das nachstehende Beispiel zeichnet den Weg einer Zeichenkette vom Datenträger auf den Bildschirm nach – und zeigt auf, dass die Interpretierbarkeit von Textdaten maßgeblich durch die Logik ihrer Umgebung bestimmt wird.
4.1. ASCII, PETSCII, Screencodes, Unicode
Die Grundlage von digital gespeichertem Text sind die sogenannten Bits, die den Wert Null oder Eins annehmen können und auf Datenträgern durch unterschiedliche Signale oder Ladungszustände festhaltbar sind. Acht solcher Bits bilden ein Byte und können 256 unterschiedliche Werte annehmen. Durch Gruppierung mehrerer Bytes erhöht sich der mögliche Wertebereich entsprechend. Die Werte – üblicherweise ausgedrückt durch Dezimalzahlen von ‚0‘ bis ‚255‘ oder in Hexadezimalzahlen[25] von ‚00‘ bis ‚FF‘ – lassen sich aber nicht nur als Zahl, sondern nach feststehenden Standards auch als Schriftzeichen interpretieren. Aus der Notwendigkeit, Daten zwischen unterschiedlichen Computersystemen austauschen zu können, ging schließlich der herstellerübergreifende ASCII-Standard mit einem Vorrat von 128 Zeichen hervor (aus den gleichen Beweggründen wurden beispielsweise Emojis in den Unicode-Standard integriert). Zwischen einem Binärcode auf einem Datenträger und einem dargestellten Zeichen auf dem Anzeigegerät besteht deshalb – unter Standardbedingungen – eine direkte, symbolische Verbindung.
In der historischen Praxis hat diese mathematisch ausgedrückt ‚ein-eindeutige‘ Verbindung viel zur Kompatibilität beim Datenaustausch zwischen unterschiedlichen Gerätefamilien beigetragen, während diese innerhalb von Gerätefamilien aber nie absolut stabil blieb. Firmen wie Apple, Atari, Commodore und Sinclair erweiterten ASCII um weitere 128 Zeichen durch hauseigene Standards, was auch ganz im Sinne des Standards war. Im Fall von Commodore heißt diese Erweiterung PETSCII, welche auf Commodore PET, C64/128 sowie C16/116/Plus4 verwendet wurde. In Unicode sind diese Firmenstandards aber nur teilweise abgebildet und wurden von den Herstellern mit Absicht nicht immer präzise beschrieben, vor allem wenn es sich um grafische Zeichen handelte, deren Einsatzmöglichkeiten durchaus mehrdeutig und kontextabhängig waren. Wenn man also eine Übertragung der herstellerspezifischen Sonderzeichen nach Unicode anstrebt, kann diese nicht immer eindeutig vorgenommen werden.[26] Allerdings lässt sich die Problematik auf die tatsächlich ambivalenten Fälle eingrenzen – bei der maximalen Menge von 256 Zeichen ein fast noch überschaubarer Aufwand.
Ein weiterer Faktor ist der Bildschirmspeicher. Darin wird festgehalten, an welcher Stelle auf dem Bildschirm welches Zeichen wiedergegeben werden soll. Auf älteren Systemen lässt sich der Bildschirmspeicher noch direkt beschreiben. Beispielsweise bewirkt der Speicherbefehl ‚POKE 1024,1‘, dass in der oberen linken Ecke das Zeichen ‚A‘ angezeigt wird. ‚1024‘ adressiert dabei das erste Zeichen des Bildschirmspeichers (entspricht der linken oberen Ecke) und ‚1‘ das Zeichen ‚A‘, das auf diese Adresse geschrieben werden soll.
Ein Blick in den PETSCII-Standard zeigt, dass ‚A‘ dort nicht mit ‚1‘, sondern mit ‚65‘ kodiert ist.[27] Der Grund dafür ist, dass PETSCII sehr viele ASCII-Steuerzeichen enthält, die für die Darstellung eines Zeichens am Bildschirm gar nicht verwendbar waren, wie beispielsweise ‘line feed’ (= neue Zeile) oder ‘return’ (= zurück an den Anfang der Zeile), aber auch Datenübertragungskommandos, die in ASCII für die Rückwärtskompatibilität von Fernschreibergeräten integriert worden waren. Um die Menge von 256 darstellbaren Zeichen aber vollständig ausschöpfen zu können, wurde für den Bildschirmspeicher eine andere Kodierung verwendet, die sich aber nur teilweise mit PETSCII überschneidet, genannt ‘Screencodes’. Auf Datenträgern findet sich nun manchmal Code in PETSCII, manchmal als Screencodes. Deshalb ist im Vorfeld zu ermitteln, welche Kodierungsmethode verwendet wurde, wenn Text aus einer historischen Datei in ein aktuelles Kodierungsformat migriert werden soll.
4.2. Custom Charsets
Schwerer als die begrenzte und schon im Vorfeld behandelbare Problemstellung des Standard-Mappings wiegt der Umstand, dass es auf fast allen Geräten möglich war, die äußere Gestalt des Zeicheninventars individuell anzupassen. Beim C64 etwa konnte die aus 8×8 Bildpunkten bestehende Pixelmatrix jedes Zeichens umgestaltet werden. Das wurde genutzt, um Schrifttypen einen anderen Charakter zu verleihen, aber auch, um nicht im Standard enthaltene Zeichen abbilden zu können – und das konnten nicht nur Sonderzeichen sein, sondern auch frei erfundene sowie kombinierbare Blockgrafiken (vgl. Abb. 2). Das heißt, die Textkodierung konnte durch jedes Programm beliebig weit destandardisiert werden. Dies war von den Herstellern durchaus beabsichtigt, weil es die Möglichkeit schuf, sprachspezifische Zeichen oder technische Symbole zu nutzen. Für solche nutzerseitig eingeführten Zeichen existieren jedoch keine Standard- oder Dokumentationsformate, abgesehen von der internen Speicherstruktur für Zeichensätze.
Für ein korrektes Mapping einer Bytefolge auf die Semantik eines Zeichens ist deshalb ein hinreichendes Wissen sowohl um die firmen- als auch nutzerseitigen Anpassungsmöglichkeiten notwendig, denn sonst kann weder aus der Kodierung auf das intendierte Zeichen geschlossen, noch aus der äußeren Form die Kodierung erschlossen werden. Das bedeutet, dass die Überlieferung von digitalem Text nicht ohne Überlieferung der Textumwelt, hier: der Systemumgebung, erfolgen kann.
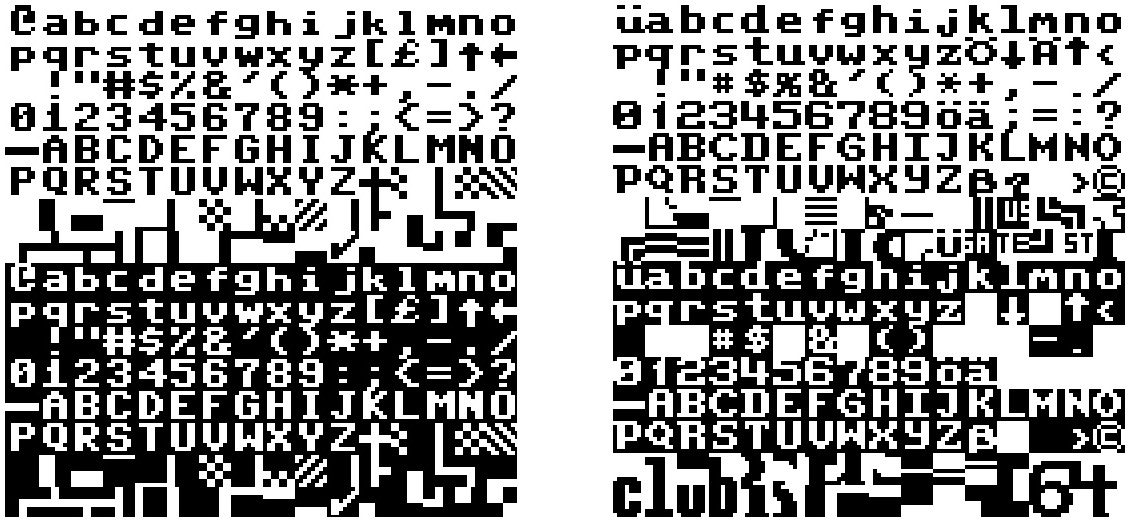
Nativer Zeichensatz des C64, ‘lowercase’-Variante (links) und Zeichensatz der Magic Disk 64 (rechts). Die Zeichen sind jeweils mit den Screencodes von 0 bis 255 adressierbar.
4.3. Vom Dateicode auf den Bildschirm: Wie aus Null ein Ü wird
Betrachten wir das Wort „Telefonbücher“ auf der Beispielseite aus der Magic Disk 64 in der Mitte der achten Bildschirmzeile. In der Datei, welche den Textinhalt dieser Seite enthält, stößt man auf die Bytefolge ‚54 05 0C 05 06 0F 0E 02 00 03 08 05 12‘ (s. Abb. 3). Nach ASCII oder auch nach dem Commodore-hauseigenen PETSCII aufgelöst, würde dies in das Schriftzeichen ‚T‘ und eine daran anschließende Sequenz von Steuerzeichen resultieren, die in dieser Abfolge aber keinen Sinn ergeben. Wertet man die Zeichen nach C64-Screencodes aus, ergibt sich indessen die Zeichenfolge ‚|ELEFONB@CHER‘, was schon nahe dem Wort „Telefonbücher“ ist, aber die Frage nach den Senkrechtbalken und dem ‚at‘-Zeichen aufwirft, die in der obigen Bytefolge durch die Codes ‚54‘ und ‚00‘ abgebildet werden. Der erste Fall erklärt sich dadurch, dass der Commodore 64 zwei Zeichensätze anbietet: Der voreingestellte enthält Großbuchstaben und Blockgrafiken, während der alternative Zeichensatz Groß- und Kleinbuchstaben, aber eine reduzierte Auswahl von Blockgrafiken enthält (vgl. Abb. 2, links). Durch Anwendung des letzteren ergibt sich die Zeichenfolge ‚Telefonb@cher‘, da die native Zeichentabelle des C64 keine Umlaute enthält. Erst aus einer anderen Datei geht hervor, dass die Zeichentabelle so verändert wurde, dass sie deutschsprachige Sonderzeichen abbilden kann (vgl. Abb. 2, rechts). Im Ergebnis repräsentiert das Byte ‚00‘ in der Datei also das Schriftzeichen ‚ü‘.

Bytefolge in der Datei und deren mögliche Interpretationen.
4.4. Konsequenzen
Für eine automatische Re-Digitalisierung bedeutet dies, dass zuerst erschlossen werden muss, welche Kodierungsmethode (ASCII, PETSCII, Screencodes) und welche interne Zeichentabelle verwendet wurde, und anschließend, ob Letztere gegebenenfalls zur Anzeige nicht im Gerätestandard enthaltener Zeichen modifiziert wurde. Auf dieser Grundlage kann im besten Fall ein passgenaues Mapping zu Unicode hergestellt werden. Historischer digitaler Text muss also umkodiert werden, bevor er in einer aktuellen Umgebung weiterverwendet werden kann. Die Umkodierung kann aber nur auf Grundlage der Kenntnis der historischen allgemeinen Standards, spezifischen Gerätestandards und nutzerseitigen Anpassungen erfolgen.
Während in diesem Fall das Mapping noch relativ leicht zu ermitteln ist und sich auch aus dem Kontext erschließen ließe, liegen zahlreiche andere Fälle vor, die mehr Aufwand erfordern. Noch einzubeziehen wären zunächst Kompressionsalgorithmen, die häufig zur Einsparung von Speicherplatz angewendet wurden. Die Algorithmen sind aber oft nicht bekannt und müssen erst rückerschlossen (‘reverse engineered’) werden, um an die originale Zeichenfolge zu kommen. Ferner wurden Zeichentabellen oft nicht nur mit einzelnen Sonderzeichen, sondern mit komplett neuen Schriftsätzen überschrieben. Beides kombiniert – Kompression und extensive Zeichendefinition – findet sich beispielsweise in der Digital Talk, die mithilfe von 256 Codepoints nicht nur acht verschiedene Schriftarten, sondern auch größere Zeichen abbilden kann. Einer der Schriftsätze wird hier mithilfe von zwei zusammengesetzten Zeichen erstellt: Die Erstellung eines Mappings ist in diesem Fall nicht nur quantitativ aufwändiger, sondern muss gegebenenfalls auch zwei Zeilen zusammenfassend betrachten können. Das Magazin Action News geht sogar noch einen Schritt weiter und nutzt Zeichensätze, um damit bewegte Grafiken zu erzeugen (s. Abb. 4a). Die Animation entsteht hier durch schnelles Umschalten des Zeichensatzes. Dadurch löst sich aber die semantische Bindung zwischen Kodierung und Bildschirmdarstellung vollständig auf – relevant ist hier ausschließlich das Erscheinungsbild und nicht mehr der dahinterliegende buchstäbliche Code (s. Abb. 4b).[28]
Das demnach nicht eindeutige Verhältnis zwischen kodiertem Text und seiner Darstellung könnte in einer Edition wiederum synoptisch abgebildet werden, mit einem Verweis auf den kommentierten Programmcode oder die dazugehörigen Zeichensätze.
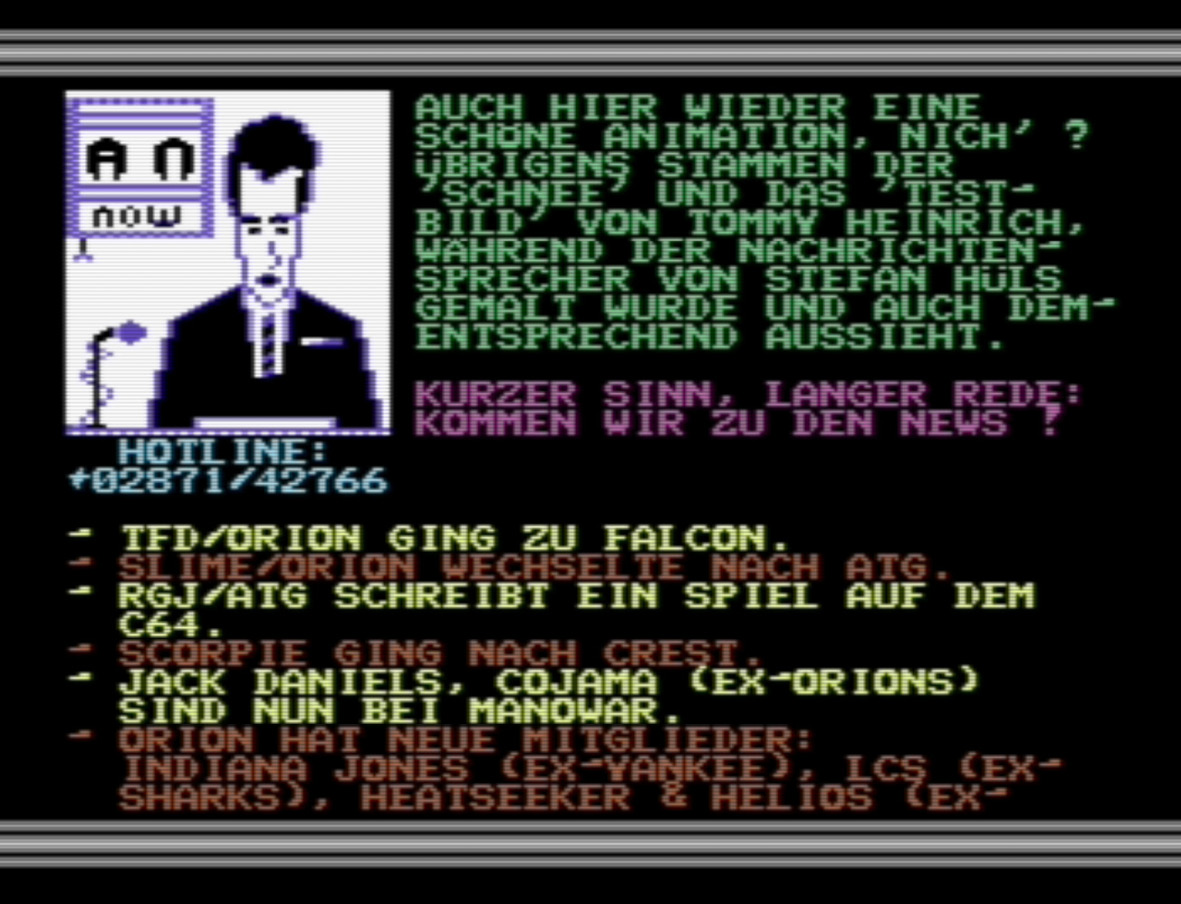
Screenshot von Action News 5, Rubrik „Szenenews“, S. 1, mit Grafik und Text.

Auflösung der oberen Hälfte des Bildschirminhalts (Screencodes) aus Abb. 4a nach ASCII (ohne Invertierungen). Die Grafik ist aus 12×12=144 Zeichen zusammengesetzt, somit bleiben noch 111 Screencodes für Schriftzeichen.
5. Schlussbetrachtung
Digital kodierter Text kann nur unter Standardvoraussetzungen buchstäblich interpretiert werden. Destandardisierbarkeit ist allerdings gewollter und notwendiger Teil von Computersystemen und der dazugehörigen Nutzungspraxis. Wenn aber das Verhältnis zwischen angezeigten Zeichen und deren zugrundeliegender Kodierung nur im individuellen Kontext der originalen Umgebung funktioniert: Was ist dann im Digitalen die Textgrundlage? Ein digital kodierter Text und seine Visualisierung stehen in einem Abhängigkeitsverhältnis zueinander, das durch Code definiert wird, welcher oft individuell gestaltet ist. Kann der jeweilige Code nicht berücksichtigt werden, braucht es die Visualisierung, um daran den digital kodierten Text zu validieren. Das setzt insgesamt drei Rahmenbedingung für Textkritik digitalen Materials: Es bedarf der allgemeinen Berücksichtigung der Kodierung, der Visualisierung und der jeweiligen Verarbeitungsprozesse.
Textkritik an ‘Born-digital’-Objekten sollte an zwei Endpunkten ansetzen: zum einen an der Datengrundlage und zum anderen an der Performanz. Zwischen diesen Endpunkten liegt der Visualisierungsprozess in Form von Programmcode, der nicht Teil des visualisierten Textes ist, aber ebenfalls Gegenstand der Textkritik sein kann.[29] Der digitalen Editorik wiederum fällt die Aufgabe zu, nicht nur passende Beschreibungssystematiken und -praktiken zu entwickeln, sondern auch neue, medial passende Editionsformate zu (er)finden, die sowohl längerfristig erhaltbar als auch allgemeiner verfügbar als die ursprünglichen digitalen Objekte sind. Synoptische Präsentationskonzepte könnten je nach Fall verschiedene Ebenen kombiniert einbeziehen: eine klassische Leseansicht oder eine diplomatische Ansicht nahe am originalen Layout, ein Screenshot als Faksimile oder auch eine Emulation als ‘living document’, eine TEI-Kodierung sowie eine Hexadezimalansicht der zugrundeliegenden Dateien, und schließlich nicht zu vergessen einen Kommentar des Programmcodes. Wie sinnvoll der Einbezug der jeweiligen Aspekte ist, muss allerdings am jeweiligen Gegenstand entschieden werden.
Das Verhältnis zwischen digital kodiertem Text und digital visualisiertem Text wurde in der Geschichte der Computer immer wieder neu organisiert. Textkritik an digitalem Material erfordert, technische Aspekte als Textumwelt zu begreifen, um Digitalität und ihre Anteile an der jeweiligen Textkonstituierung in ihrer jeweiligen historischen Ausprägung nachvollziehen zu können.
© 2024 bei den Autoren, publiziert von Walter de Gruyter GmbH, Berlin/Boston
Dieses Werk ist lizensiert unter einer Creative Commons Namensnennung 4.0 International Lizenz.
Articles in the same Issue
- Titelseiten
- Hin und zurück?
- Transformation und Reduktion von Aufführungswirklichkeit
- Kants Critik der Urtheilskraft – neu ediert
- Kompilation, Transformation, Edition
- Sorabistische Editionspraxis
- Authentische Fassung oder editorisches Konstrukt?
- Edition von frühdigitalem Text: Ein Problemaufriss
- Die interoperable Edition ‚sub specie durationis‘
- Von OCR und HTR bis NER und LLM
- Beiträge aus der Tagung „Fünfzig Jahre ‚Texte und Varianten‘ “ (II)
- Text als System
- Das Modell der Textdynamik und sein Potential für eine Editionswissenschaft jenseits der ‚Schulen‘
- Historisch-kritisch edieren
- Chronologie, Schichtung, Korrektur: Heiner Müllers Nachlass als Herausforderung seines eigenen Werkverständnisses
- Zur Rezeption von (historisch-)kritischen Ausgaben in der aktuellen germanistischen Forschung
- Berichte
- Wandel, Wert und Wirkung von Editionen. 50 Jahre Arbeitsgemeinschaft philosophischer Editionen. Tagung an der Bergischen Universität Wuppertal, 20.–22. September 2023
- Digitales Edieren gestern, heute und morgen. Tagung an der Herzog August Bibliothek, Wolfenbüttel, 25./26. September 2023
- Rezensionen
- Genetic Criticism in Motion. New Perspectives on Manuscript Studies. Hrsg. von Sakari Katajamäki und Veijo Pulkkinen, Associate Editor: Tommi Dunderlin. Helsinki: Finnish Literature Society, SKS 2023 (Studia Fennica. Litteraria. 14), 183 S., auch digital im ‘open access’ zugänglich: https://doi.org/10.21435/sflit.14.
- Philip Kraut: Die Arbeitsweise der Brüder Grimm. Stuttgart: S. Hirzel Verlag 2023, 353 S., auch digital im ‘open access’ zugänglich: https://doi.org/10.3813/9783777633954.
- Mitteilung
- … herausgegeben von … Editores und Edenda
- Anschriften
- Anschriften
- Formblatt zur Einrichtung satzfertiger Manuskripte
- Formblatt zur Einrichtung satzfertiger Manuskripte
Articles in the same Issue
- Titelseiten
- Hin und zurück?
- Transformation und Reduktion von Aufführungswirklichkeit
- Kants Critik der Urtheilskraft – neu ediert
- Kompilation, Transformation, Edition
- Sorabistische Editionspraxis
- Authentische Fassung oder editorisches Konstrukt?
- Edition von frühdigitalem Text: Ein Problemaufriss
- Die interoperable Edition ‚sub specie durationis‘
- Von OCR und HTR bis NER und LLM
- Beiträge aus der Tagung „Fünfzig Jahre ‚Texte und Varianten‘ “ (II)
- Text als System
- Das Modell der Textdynamik und sein Potential für eine Editionswissenschaft jenseits der ‚Schulen‘
- Historisch-kritisch edieren
- Chronologie, Schichtung, Korrektur: Heiner Müllers Nachlass als Herausforderung seines eigenen Werkverständnisses
- Zur Rezeption von (historisch-)kritischen Ausgaben in der aktuellen germanistischen Forschung
- Berichte
- Wandel, Wert und Wirkung von Editionen. 50 Jahre Arbeitsgemeinschaft philosophischer Editionen. Tagung an der Bergischen Universität Wuppertal, 20.–22. September 2023
- Digitales Edieren gestern, heute und morgen. Tagung an der Herzog August Bibliothek, Wolfenbüttel, 25./26. September 2023
- Rezensionen
- Genetic Criticism in Motion. New Perspectives on Manuscript Studies. Hrsg. von Sakari Katajamäki und Veijo Pulkkinen, Associate Editor: Tommi Dunderlin. Helsinki: Finnish Literature Society, SKS 2023 (Studia Fennica. Litteraria. 14), 183 S., auch digital im ‘open access’ zugänglich: https://doi.org/10.21435/sflit.14.
- Philip Kraut: Die Arbeitsweise der Brüder Grimm. Stuttgart: S. Hirzel Verlag 2023, 353 S., auch digital im ‘open access’ zugänglich: https://doi.org/10.3813/9783777633954.
- Mitteilung
- … herausgegeben von … Editores und Edenda
- Anschriften
- Anschriften
- Formblatt zur Einrichtung satzfertiger Manuskripte
- Formblatt zur Einrichtung satzfertiger Manuskripte