Causeries scriptologiques posthumes avec Anthonij Dees : un rapide survol
-
Hans Goebl


Abstract
This article examines two Old French corpora related to the Domaine d’Oïl (Northern France) from a dialectometric and scriptometric perspective, which go back to the Romance scholar Anthonij Dees (1928–2001). These are, on the one hand, his atlas of charters published in 1980 (digiDees 1980) and, on the other hand, an electronic corpus created in Salzburg as recently as 2006 (digiDees 1983). This is based on geolocalisation computations of Old French texts (from the 12th and 13th centuries), which, carried out by Dees in 1983, were only rediscovered by chance in Amsterdam in 2006 and subsequently transferred to Salzburg. In addition to these two medieval datasets, dialect data from the French linguistic atlas ALF (“Atlas linguistique de la France”, 1902–1910) are also analysed, which spatially align with the two medieval datasets. The dialectometric and scriptometric analyses carried out on these three electronic corpora aim primarily to compare the spatial depth structures found in them. For this purpose, the following dialectometric map types were examined: similarity maps, parameter maps and isoglottic syntheses. When comparing them, an astonishing similarity of the spatial profiles visible on them emerges. It should be noted, however, that a time span of 600 years lies between the Old French data analysed by Dees and those of the ALF. The spatial similarity of the depth structures found in them is therefore all the more striking.
1 Remarques préliminaires
Nul médiéviste n’ignore les deux atlas scripturaux (parus respectivement en 1980 et 1987) du romaniste hollandais Anthonij Dees (1928–2001).[1] Leur grande valeur documentaire et leur utilité linguistique se sont révélées à d’innombrables reprises. Quand, en juillet 1980, un exemplaire de son atlas des chartes m’est tombé entre les mains, j’ai tout de suite compris – fort de mes propres expériences scriptologiques et dialectométriques durant la décennie précédente – que cet atlas représentait une excellente « rampe de lancement » pour un vol fascinant sur une grande orbite interdisciplinaire. Le compte rendu que j’en ai rédigé (publié en 1982 dans la Zeitschrift für französische Sprache und Literatur)[2] exprimait clairement cet espoir. Pour différentes raisons, ce « vol interdisciplinaire » n’a pu prendre son départ qu’en 1996. C’est alors que Piet van Reenen, collègue et infatigable collaborateur d’A. Dees, m’a remis les fichiers électroniques non pas de l’Atlas de 1980 en tant que tel, mais d’une base de données « sous-jacente », qui comprenait 85 localités (ou « points d’enquête ») au lieu de 28, et 268 attributs graphiques, qui correspondaient aux cartes 1–268 de l’Atlas de 1980, riche pour leur part de 282 cartes choroplèthes.
Ces dimensions (N = 85 points × p = 268 cartes) excédaient d’un côté celles de l’atlas publié en 1980 – qui reposait sur un réseau de 28 unités spatiales seulement – et négligeaient, de l’autre, 14 des 282 cartes de l’atlas imprimé. Jusqu’à ce jour, j’en ignore les raisons.[3] Toujours est-il que dès l’introduction de son Atlas de 1980 (XII), Dees mentionne l’existence d’un réseau supplémentaire de 85 points, tout en en publiant deux échantillons à titre d’exemple à la fin du livre (370–371).
En 1996, quand les données numérisées « sous-jacentes » de l’atlas de 1980 me furent remises par P. van Reenen sur deux disquettes aujourd’hui complètement obsolètes, mon atelier dialectométrique (DM) salzbourgeois était déjà bien « achalandé », tant du point de vue des méthodes de la DM en tant que telles que de celui de l’informatique à proprement parler. Par la suite, ces disquettes furent confiées à deux de mes anciens collaborateurs de recherche, Guillaume Schiltz et Slawomir Sobota, qui les ont rapidement adaptées aux normes techniques de la panoplie informatique salzbourgeoise de l’époque.
Dans la longue série de mes articles consacrés au « projet Dees »,[4] le premier en date remonte à 1998. Il démontrait clairement que la synthèse dialecto- ou scriptométrique des 268 cartes (ou attributs scripturaux) de l’Atlas de Dees de 1980 révélait des structures « de profondeur » complètement inattendues et de ce fait innovatrices, dont la logique et la régularité spatiales correspondaient d’ailleurs parfaitement à ce qui ressortait de nos analyses DM antérieures de grands atlas linguistiques nationaux tels que l’ALF ou l’AIS.[5]
Fait curieux et tragique à la fois : aux dires des deux biographes d’A. Dees – P. von Reenen et L. Schøsler[6] –, il est très vraisemblable que, vu la détérioration rapide de son état de santé dans les années 1990, Dees n’a jamais pris acte de nos synthèses DM des données de son Atlas scriptologique de 1980, pourtant publiées à partir de 1998, donc trois ans avant sa mort, survenue en 2001.
Soit dit en passant, j’avais rencontré Dees en personne à deux reprises : en 1988 à Amsterdam, lors de la remise de sa Festschrift pour son soixantième anniversaire,[7] et en 1998, à l’occasion du 22e CILPR organisé à Bruxelles. Alors que l’entrevue de 1988 a donné lieu à des entretiens personnels nourris, celle de 1998 était de nature plutôt fortuite. Malheureusement, en 1988, le dépouillement DM de son Atlas de 1980 était encore « ante portas », si bien que ce sujet ne pouvait pas encore être débattu entre nous deux lors des festivités d’Amsterdam.
Alors que les planches 1–4 de cet article reposent sur les données numérisées de l’Atlas de 1980 transférées d’Amsterdam à Salzbourg en 1996, les planches restantes se réfèrent, en dernière analyse, à un « miracle scientifique » : la « trouvaille de Lauterbad ».[8]
Lauterbad est un village idyllique, situé au cœur de la Forêt Noire : c’est là que se sont réunis, du 23 au 26 février 2006 et sur invitation d’Achim Stein (Stuttgart) et de Pierre Kunstmann (Ottawa), plusieurs médiévistes et scriptologues venus discuter de tous les problèmes posés par le « nouveau corpus d’Amsterdam » (NCA).[9] Ce dernier comprend les textes littéraires que Dees avait utilisés et dépouillés dans la préparation de son atlas littéraire de 1987.[10]
Il semble bien que Dees, après la publication de sa thèse sur les pronoms démonstratifs parue en 1971, ait décidé sans tarder d’englober dans ses recherches « géo-oïliques » non seulement les chartes (non littéraires)[11] du XIIIe siècle (qu’il a toujours privilégiées comme témoins linguistiques « fiables » du temps), mais aussi un grand nombre de textes littéraires des XIIe et XIIIe siècles dont il se méfiait pourtant du point de vue géolinguistique, étant donné leur caractère hybride et métissé. C’est ainsi qu’est née en lui l’idée d’utiliser son corpus non littéraire (avec 85 points [= N] et 268 attributs graphiques [= p]) pour la localisation quantitative de quelque 200 textes littéraires dont il avait dépouillé, pour ce genre d’analyses, des échantillons copieux.
Les travaux de localisation se sont déroulés au centre de calcul de l’Université Libre d’Amsterdam (ULA) en novembre 1983[12] avec la participation de Marcel Dekker et Onno Huber, dûment cités au frontispice de l’atlas de 1987.
Or, ces calculs de localisation alors effectués à Amsterdam ont été conservés dans 222 épaisses liasses de papier restées sur place après la mort d’A. Dees (survenue en 2001). En 2006, le décanat de l’ULA, désireux de s’en défaire, confia cette opération à P. van Reenen. Ce dernier eut cependant l’excellente idée d’emporter quelques spécimens de ces liasses à Lauterbad et de me les montrer. Après y avoir jeté un bref coup d’œil, j’eus vite fait de comprendre de quoi il s’agissait et d’entrevoir la valeur DM de ces calculs.
Rentré à Salzbourg, j’ai organisé (et payé) l’envoi postal d’Amsterdam à Salzbourg de sept grandes caisses où étaient entreposées les liasses en question. Après leur arrivée à Salzbourg, le contenu de ces caisses fut méticuleusement analysé par mon collaborateur scientifique Pavel Smečka et moi-même. Suite à cet examen, nous avons décidé d’extraire de chacune de ces 222 liasses une colonne contenant 87 valeurs de similarité[13] et de les utiliser pour la création d’une matrice de données (factice) bidimensionnelle (N × p) avec 87 points « d’enquête » (= N) et 222 vecteurs de similarité (= p).
Cette matrice, réduite en l’occurrence à 85 points, est la base des calculs scriptométriques dont sont issues les planches 5–8, et en partie aussi la planche 9 de cet article.
Par la suite, nous désignerons les deux corpus numérisés de Dees par des sigles particuliers pour bien les distinguer de leurs corollaires imprimés :
digiDees 1980 pour le corpus remis par P. van Reenen en 1996
digiDees 1983 pour le corpus issu en 2006 de la « trouvaille de Lauterbad ».
2 Présentation et interprétation des planches 1–4, issues de digiDees 1980 et de l’ALF (corpus élagué)
2.1 Présentation et interprétation des quatre cartes de la planche 1
Il s’agit d’équivalents choroplèthes polygonisés de quatre cartes tirées de digiDees 1980, toutes relatives aux représentants (graphiques) oïliques (appartenant toujours au groupe 1 « indiqué » dans Dees 1980) de quatre étymons latins : égo (Dees 1980, carte 1 : graphies en ge, gie etc.), illóru (Dees 1980, carte 17 : graphies en ou), hére (Dees 1980, carte 158 : graphies en ei) et séniore (Dees 1980, carte 187 : graphies en eu).
Les chiffres répertoriés dans les colonnes situées dans les marges de gauche des quatre cartes de la planche 1 signalent l’« intensité » [Int(x)j] avec laquelle telle graphie (x) se manifeste dans le polygone respectif (j). Ils sont le résultat d’une mensuration sophistiquée conçue par Dees qui prend en considération, pour chacun des points d’enquête examinés, les grandeurs suivantes :[14]
la somme des chartes (Σch) retenues pour le point examiné j qui comportent au moins une occurrence de l’attribut graphique x répertorié par Dees dans le groupe 1 (« indiqué ») [Σch(x)gr1]
la somme des chartes (Σch) retenues pour le point examiné j qui comportent au moins une occurrence de l’attribut graphique x répertorié (par Dees) dans le groupe 2 (« non indiqué ») [Σch(x)gr2]
La formule « d’intensité » [Int(x)j] que Dees en a tirée est la suivante :
Int(x)j = 100 × Σch(x)gr1/Σch(x)gr1 + Σch(x)gr2
L’indice Int(x)j fournit donc des scores de fréquence situés entre 0 et 100 (%).
Au sein de l’« École dialectométrique de Salzbourg » (EDMS), la polygonisation des réseaux géolinguistiques « dialectométrisés » est de mise. Elle assure la parfaite comparabilité (numérique et visuelle) des profils des cartes de type choroplèthe (= cartes de similarité et cartes à paramètres) avec ceux des cartes de type isarythmique (ou isolinéaire) (= cartes isoglottiques, cartes à rayons).
La visualisation des valeurs calculées [ici : Int(x)j] se sert des couleurs de l’arc-en-ciel, identiques d’ailleurs à celles du spectre solaire. L’algorithme utilisé pour la distribution des six couleurs le plus souvent utilisées sur nos planches (et aussi pour le calcul des seuils numériques respectifs) a pour nom MINMWMAX.[15] Il distribue les 85 (ou 87) scores numériques en question des deux côtés de la moyenne arithmétique [MA ; en allemand : Mittelwert – MW] (i.e. entre le minimum et la MA, et entre la MA et le maximum) à l’intérieur de deux triplets d’intervalles (= 3 × 2 classes), respectivement à largeurs numériques égales.
Cet algorithme, qui fait depuis longtemps partie de la panoplie méthodique de la DM salzbourgeoise, a été pleinement incorporé dans VDM (« Visual DialectoMetry »), le logiciel standard de la DM de Salzbourg, créé en 1999–2000 par mon ami Edgar Haimerl. Précisons en outre que pour la confection des neuf planches de cet article, nous avons utilisé l’interface française du logiciel salzbourgeois VDM.[16]
Le message des profils des quatre cartes est très clair : les teintes (chaudes) en rouge, orange et jaune symbolisent les barycentres des graphies respectives, alors que les teintes (froides) en bleu [foncé et clair] et vert en signalent l’opposé. Les polygones en gris renvoient à des chiffres infimes des graphies prises en compte, alors que les polygones en blanc témoignent de l’absence totale de graphies susceptibles d’être répertoriées dans le groupe 1 (« indiqué »), due soit à des usages scripturaux aberrants soit à l’absence totale d’étymons s’y rapportant dans les textes dépouillés.
Les colonnes qui jouxtent les marges de gauche des quatre cartes de la planche 1 servent de légendes numériques. L’on y trouve les scores (oscillant entre 0 et 100) de l’indice Int(x)j alors que les chiffres présentés entre crochets signalent le nombre des polygones (= points « d’enquête ») affichant la couleur respective. L’addition des chiffres placés entre crochets aboutira toujours au total de 85.[17]
Chacune de ces quatre cartes choroplèthes représente une colonne de la matrice de données (voir la figure 1, en bas, à gauche) du corpus digiDees 1980.
2.2 Présentation et interprétation des quatre cartes de la planche 2
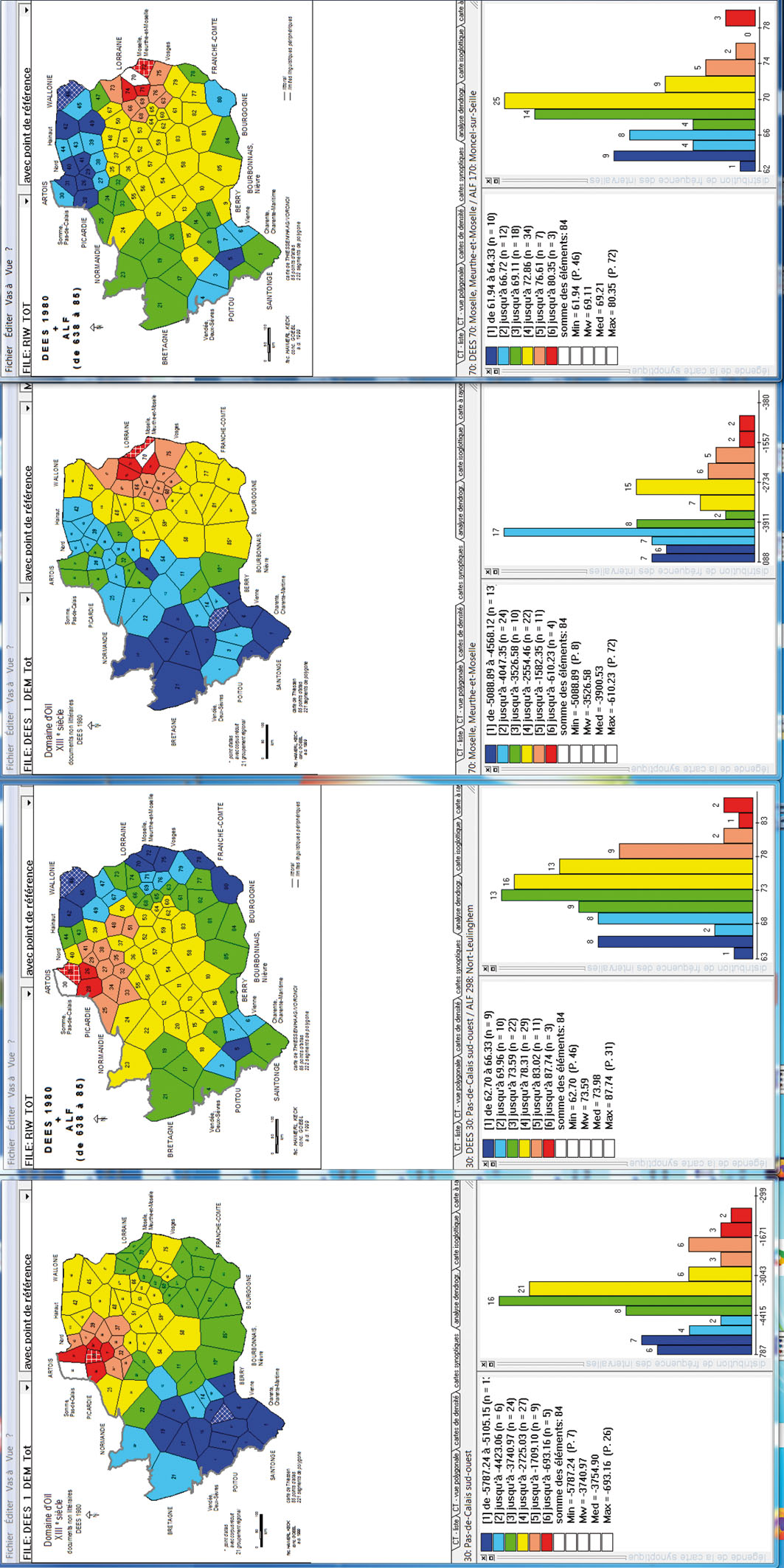
Il s’agit de deux paires de cartes de similarité dont la première (toujours à gauche) est issue de digiDees 1980, alors que la seconde est issue d’une version élaguée de l’ALF. La première des deux paires se réfère au Poitou (Deux-Sèvres, Échiré = P.-ALF 510), la seconde concernant l’Île-de-France (Paris, Le Plessis-Piquet = P.-ALF 226).
D’entrée de jeu, quatre remarques techniques :
a) sur la genèse du corpus « ALF élagué » :
Entre 1995 et 2000, nous avons effectué la « dialectométrisation » d’environ 40% des 1421 cartes originales de la série A de l’ALF. En plus des 638 points réguliers des cartes de l’ALF, le réseau respectif comprenait trois points artificiels : les langues standards du français, de l’italien et du catalan. Sur ces 641 points-ALF à proprement parler, 347 couvrent l’étendue du seul domaine d’oïl.
Toujours au moyen des réseaux polygonisés de la partie oïlique du réseau de l’ALF et de digiDees 1980, nous avons procédé à une superposition pour le domaine d’oïl, en conservant uniquement, sur les 347 polygones oïliques de l’ALF, ceux dont la position géographique coïncidait le plus exactement possible avec celle des 85 polygones de digiDees 1980.
De cette manière, le nombre des « cartes de travail » susceptibles d’être incorporées dans cette matrice de données élaguée, est tombé de 1681 à 1279.[18]
b) sur la mesure de la similarité :
Quant à la saisie quantitative de la similarité interponctuelle, nous avons utilisé, pour les données (qualitatives) tirées de l’ALF, l’« indice relatif d’identité » (IRIjk) [ou, en allemand, « Relativer Identitätswert » (RIWjk)], alors que pour les données (quantitatives) tirées du corpus digiDees 1980, il a fallu utiliser un indice de similarité de nature quantitative. Pour ce faire, nous avons adopté la « Durchschnittliche Euklidische Metrik » (DEMjk), appelée en français « similarité euclidienne moyenne » (SEMjk).[19]
c) concernant la lecture des légendes numériques (toujours en bas, à gauche) :
L’on y trouve non seulement les seuils numériques des six intervalles visualisés, mais aussi le nombre des polygones répertoriés dans les différents intervalles.
d) concernant la lecture des histogrammes (toujours en bas, à droite) :
Les histogrammes servent à la détection de la nature statistique de la distribution de fréquence (ou de similarité, etc.) en question. Pour mieux la faire ressortir, le nombre des intervalles en question a été doublé de 6 à 12.
Notons en outre qu’entre les cartes appariées de la planche 2, il existe un décalage diachronique de quelque 600 ans (= 1300–1900). Il est d’autant plus étonnant de constater la grande ressemblance geógraphique qui s’instaure entre les deux mesures, tant pour le Poitou que pour l’Île-de-France.
Il en résulte que les gestions linguistiques de l’espace par les scribes ou les locuteurs respectifs – de type scriptural à gauche et de type basilectal à droite –, ainsi que les « structures de profondeur » inhérentes à ces stocks de données[20] se sont développées dans la même direction, et que l’impact du « substrat dialectal générateur » sur la genèse de l’écrit non littéraire médiéval a été très sensible dans les deux cas.
Nous allons voir que la même remarque vaut également pour les cartes des planches 3, 4, 6, 7 et 8.
2.3 Présentation et interprétation des quatre cartes de la planche 3
Cette fois-ci, les points de repère des cartes de similarité présentées se trouvent en Picardie et en Lorraine. À nouveau, la gradualité interne des profils choroplèthes et les ressemblances interséculaires (entre 1300 et 1900) laissent rêveur.
2.4 Présentation et interprétation des quatre cartes de la planche 4
Les deux cartes de gauche se réfèrent à la synopse des « coefficients d’asymétrie de Fisher » (CAF)[21] alors que les deux cartes de droite (dites cartes isarythmiques, isolinéaires ou interponctuelles) correspondent, en dernière analyse, à la superposition du tracé d’isoglosses telle qu’elle a été pratiquée à d’innombrables reprises depuis la genèse de la géographie linguistique.[22]
2.4.1 Planche 4 : synopse des scores d’asymétrie (CAF) (dans la moitié gauche)
Le CAF est un des nombreux paramètres « classiques » de toute distribution de fréquence, y compris les distributions de similarité telles qu’elles figurent ici sur les planches 2, 3, 6 et 7. Il permet la saisie quantitative de la symétrie de la silhouette de la distribution de similarité en question tout en oscillant dans un espace numérique situé entre -1 et +1. Or, il s’est avéré, au cours de nos nombreux travaux DM, que les scores négatifs du CAF renvoient le plus souvent à des zones marquées par une forte irradiation linguistique, alors que les scores positifs du CAF révélaient le contraire : des zones géolinguistiquement isolées, plutôt conservatrices ou même autarciques.
Plus une distribution de similarité est symétrique, plus elle s’intègre harmonieusement – de même que le vecteur d’attributs de son point de repère – dans l’ensemble des autres distributions de similarité. Si le contraire intervient et qu’une telle distribution de similarité accuse une certaine asymétrie tout en tendant vers la droite ou la gauche, le point de repère respectif (et son vecteur d’attributs) pourra apparaître – métaphoriquement parlant – comme un « abstentionniste », voire un « trouble-fête ».
Cet état des choses est en relation directe avec une propriété constitutive de tout atlas linguistique et de ses données, à savoir « l’enchevêtrement particulier » des aires linguistiques.[23] Comme ces dernières peuvent considérablement varier par leur taille et leur configuration spatiale, la saisie quantitative des modalités de leur présence, sur les cartes d’un atlas linguistique donné, s’avère très utile et révélatrice pour les linguistes, surtout du point de vue diachronique.
Pour mieux faire ressortir ces propriétés analytiques de la synopse du CAF, nous avons réduit la visualisation des cartes de gauche à l’extrême, c’est-à-dire à seulement deux classes (ou teintes chromatiques).
De la comparaison des deux cartes de gauche, il ressort clairement qu’en plein Moyen Âge et à l’entrecroisement de plusieurs provinces historiques comme le Poitou, la Normandie, la Picardie, la Lorraine ou la Franche-Comté – toutes marquées en rouge –, il s’est formé un carrefour cohérent d’échanges (marqué en bleu) soumis à de nombreuses dynamiques linguistiques de contact et de conflit.
Six siècles plus tard (c’est-à-dire à l’heure de l’ALF), ces dynamiques se sont soldées par un certain « lissage » des interactions linguistiques dans l’Ouest, le Sud-Ouest et le Sud du domaine d’oïl tout en refoulant les aires linguistiques, avec leurs enchevêtrements microchoriques, à la périphérie septentrionale et orientale – à l’exception d’une « extravagance » champenoise signalée en rouge.
Les polygones en rouge, tous marqués par des scores positifs (voir les légendes numériques), occupent les marges périphériques du domaine d’oïl où se trouvent la majorité des provinces historiques qui gardaient encore, vers 1300, leur cachet graph(émat)ique particulier.
Les polygones coloriés en bleu, porteurs en revanche de scores négatifs, se trouvent géographiquement en position intermédiaire ou même centrale et représentent, de ce fait, une espèce de « plateforme d’échange » linguistique commune où, à la suite de nombreux échanges et contacts linguistiques, nombre de traits linguistiques (et graphiques) ont allègrement pu agrandir les superficies de leurs aires respectives.
À la lumière de nos connaissances de l’histoire linguistique du français, l’explication de cet état des choses est simple : à la suite du rayonnement continu du type linguistique francilien entre 1300 et 1900, la « foire linguistique » intermédiaire du Haut Moyen Âge (voir supra) a littéralement explosé « tous azimuts », en créant une nouvelle « orée autonome » aux franges nord-orientales du domaine d’oïl.
2.4.2. Planche 4 : synopse des scores interponctuels[24] (dans la moitié droite)
L’impact visuel du message sémiotique de ces deux cartes de la planche 4 tient à l’interaction combinée de la variabilité du coloriage et de l’épaisseur de 226 (digiDees 1980) ou 225 (ALF élagué) côtés de polygone (ou interpoints). Dans les deux cas, la visualisation recourt à six intervalles (numériques et chromatiques) et à un algorithme de visualisation particulier (MEDMW) qui crée, des deux côtés de la moyenne arithmétique [MA][25] (pour digiDees 1980 : 1805,31 ; pour l’ALF élagué : 17,12), trois intervalles (ou classes) dont les nombres de côtés de polygone cartographiables sont égaux : pour digiDees 1980 : 39–40 au-dessous de la MA, et 35–36 au-dessus de la MA : pour l’ALF (élagué) 36–37 au-dessous de la MA, et 38–39 au-dessus de la MA.
Pour digiDees 1980 l’indice de ressemblance utilisé était la DEM (Durchschnittliche Euklidische Metrik ; en français : SEM = similarité euclidienne moyenne), alors que pour la dialectométrisation des données de l’ALF élagué, nous avons appliqué l’IRI (en all. RIW), à savoir l’indice de similarité standard de l’EDMS.
L’observation globale des deux « compartimentages » fait clairement ressortir que dans l’analyse isolinéaire issue de digiDees 1980, le cœur du domaine d’oïl est encore fortement sillonné de faisceaux d’isoglosses très épais (en bleu foncé), alors que les mêmes zones revêtent un aspect carrément nivelé et aplati dans la perspective de l’ALF élagué.
Il ne fait aucun doute que ceci est dû à l’effet de l’irradiation circulaire évoqué ci-dessus.
3 Présentation et interprétation des planches 5–8, issues de digiDees 1983 et de l’ALF (corpus élagué)
Pour une meilleure compréhension des procédures DM décrites par la suite, on attirera tout d’abord l’attention des lecteurs sur les figures 1 et 2.
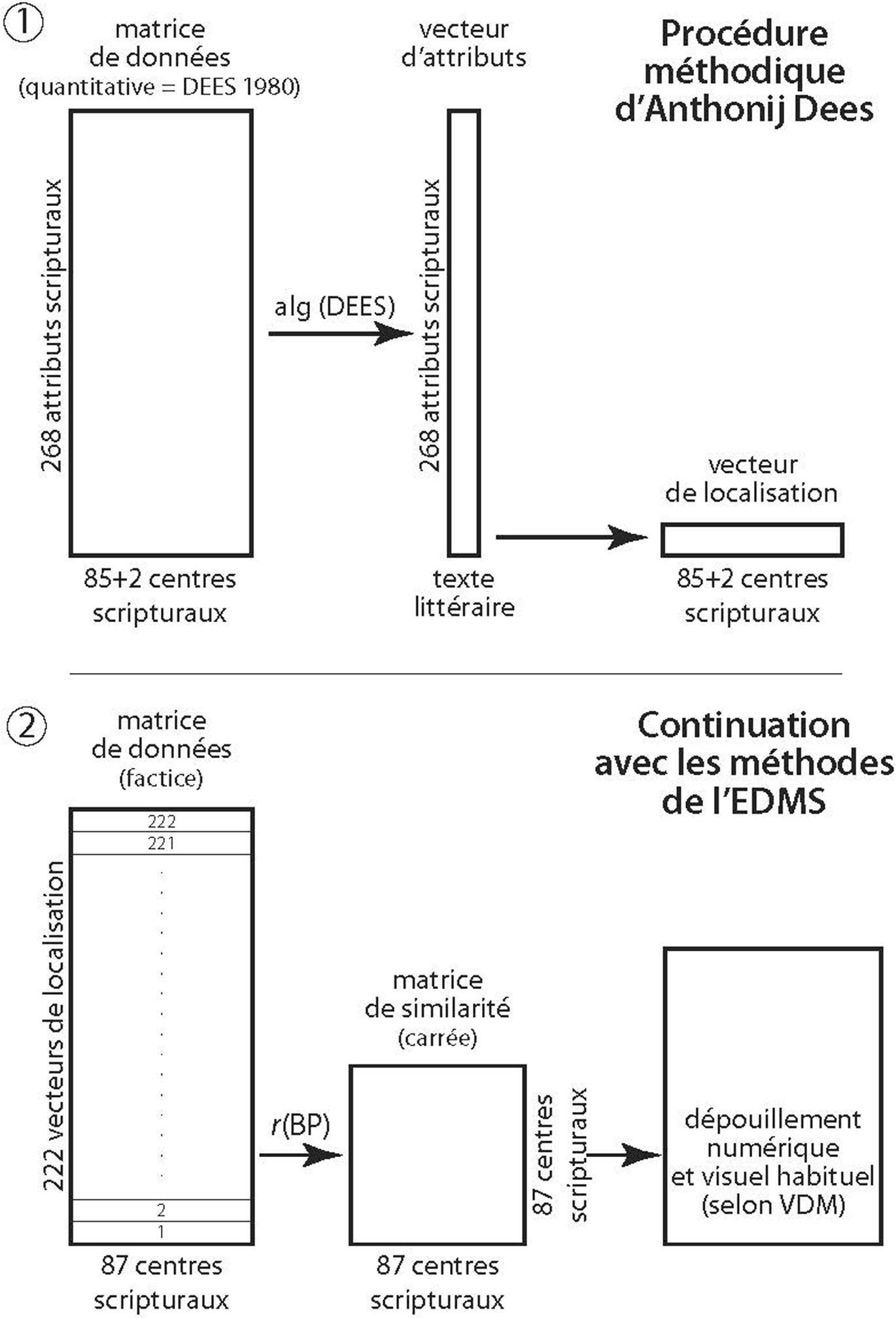
Architecture et enchaînement des méthodes quantitatives d’Anthonij Dees, en haut, et de l’ « École Dialectométrique de Salzbourg » (EDMS), en bas.
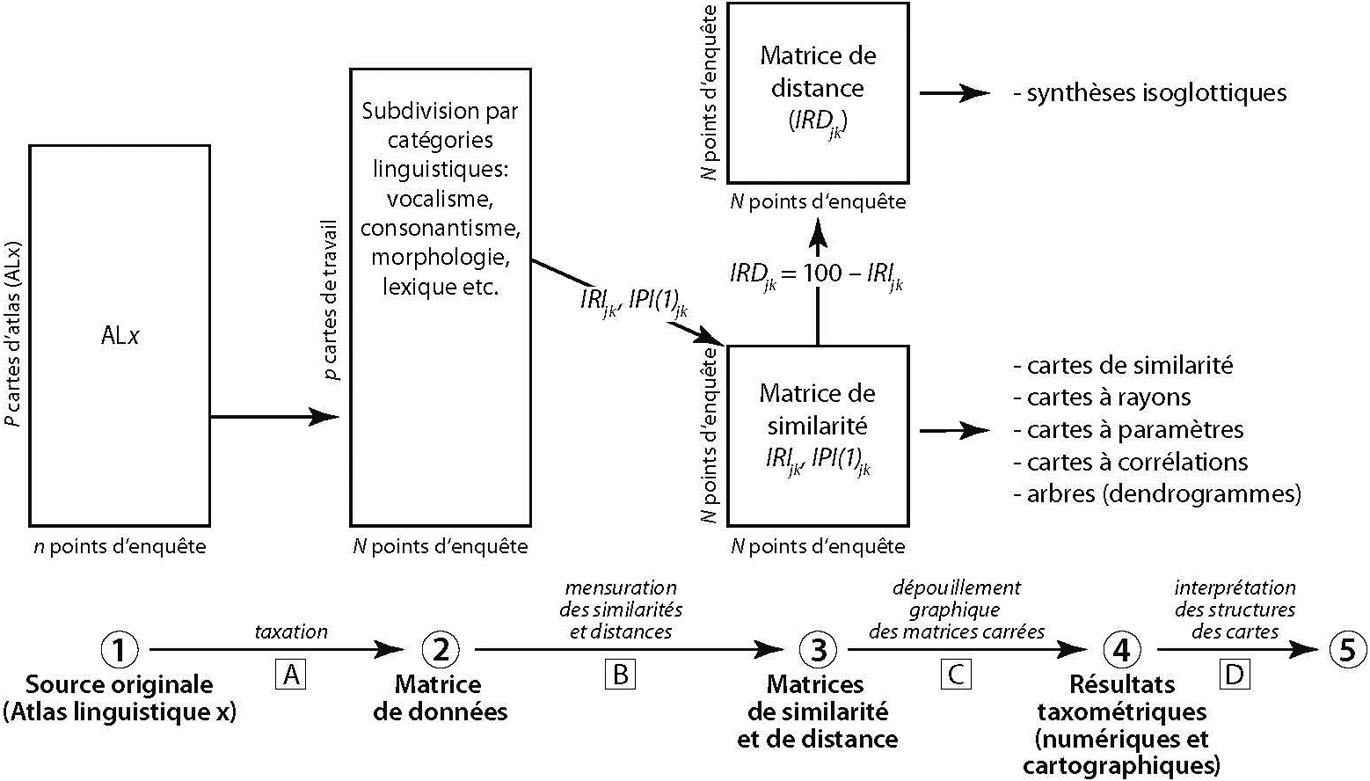
Alignement standard (mode-DM « alpha ») des démarches méthodiques de l’ « École Dialectométrique de Salzbourg ».
La fig. 1 montre, dans sa partie supérieure, la logique des calculs de localisation de 222 textes littéraires en ancien français (datant des XIIe et XIIe siècles) exécutés sous la direction d’A. Dees le 9 novembre 1983 à Amsterdam. Les algorithmes alors appliqués par Dees et son équipe comportaient deux volets : a) un volet destiné à saisir la présence (quantitativement circonstanciée) de 268 attributs graphiques contenus dans digiDees 1980, dans les textes littéraires examinés, et b) un volet algorithmique pour la mesure de la similarité (ou plutôt de la corrélation algorithmique, située entre les pôles numériques -100 et +100)[26] de ces 222 textes avec la matrice de données originale de digiDees 1980.
Il en résultait alors 222 « vecteurs de localisation » pour autant de textes littéraires médiévaux. Grâce à l’aimable médiation de Piet van Reenen, j’ai pu les passer en revue peu de temps après mon retour du séminaire de Lauterbad, sur les liasses de calcul confectionnées en 1983 à Amsterdam. Précisons que chacun de ces 222 « vecteurs de localisation » consistait en 87 scores de corrélation, relatifs à autant de points d’enquête (ou « centres scripturaires ») du réseau (élargi) de digiDees 1980.
La partie inférieure de la fig. 1 montre comment, à partir de ces 222 vecteurs de localisation, nous avons construit à Salzbourg une nouvelle matrice de données – évidemment de nature « factice » – aux dimensions 87 (N : pour les points d’« enquête ») × 222 (p : pour les textes littéraires analysés), et aussi comment cette dernière a servi de point de départ pour l’application des méthodes taxométriques habituelles de l’EDMS.
La fig. 2 renseigne sur l’architecture générale (mode DM « alpha »)[27] des méthodes DM en usage à Salzbourg : elle est surtout utile pour l’explication du traitement DM des données tirées de l’ALF.
3.1 Présentation et interprétation de quatre calculs de localisation : voir la planche 5
Bien que les quatre profils de la planche 5 comportent tous des profils choroplèthes accidentés, ils sont néanmoins tous pourvus d’une gradualité diatopique remarquable. L’on y reconnaît, par le biais des polygones coloriés en rouge, les endroits où la genèse matérielle du texte en question est très probable, alors que les polygones en bleu foncé renvoient aux zones qui, des points de vue graphique et linguistique, sont carrément étrangères au même texte littéraire. Il est également remarquable de constater qu’entre ces deux pôles extrêmes se déploient des transitions finement échelonnées, par le biais de polygones oranges, jaunes, verts et bleu clair.
Les hachures blanches caractérisent respectivement le maximum (en rouge) et le minimum (en bleu) des scores visualisés.
Évidemment, il s’agit ici de localisations faites dans un esprit quantitatif qui opère non pas à l’aide de constats qualitatifs et géographiquement péremptoires, mais au moyen de probabilités changeantes, inscrites dans un espace à granulation discrète prédéfinie.
Il s’agit, de gauche à droite, de localisations quantitatives des textes suivants (représentés par des extraits relativement longs tirés des éditions respectives) :
Les Sermons de Maurice de Sully
Aucassin et Nicolette
Perceval (ms. V)
Lothringischer Psalter (Psautier lorrain)
Connaissant les résultats du total des 222 calculs de localisations entrepris par A. Dees en novembre 1983, je puis affirmer que la clarté de Fous les profils choroplèthes s’y rapportant est parfaitement à la hauteur des quatre échantillons présentés sur la planche 5.
3.2 Présentation et interprétation de deux paires de cartes de similarité : voir la planche 6
Un des buts centraux de l’EDMS est l’analyse des « structures de profondeur » qui se cachent à l’intérieur de la masse des données (angl. mass data) de collections atlantistes de toute sorte, que ce soient des atlas linguistiques à proprement parler tels l’ALF et l’AIS, ou des matrices de données factices comme digiDees 1983. Il en découle la nécessité de pouvoir comparer entre elles différentes « structures de profondeur », en l’occurrence celles qui sous-tendent digiDees 1983 et la version élaguée de l’ALF (avec 85 points d’enquête).
Au vu des deux cartes de similarité appariées (digiDees 1983 et l’ALF élagué), l’une relative à un point de repère poitevin, l’autre à un point de repère picard, il appert qu’entre ces deux espèces de « structures de profondeur », les différences sont relativement faibles, notamment si l’on prend en compte – une fois de plus – le décalage diachronique de quelque 600 ans (de 1300 à 1900) entre ces deux niveaux. Précisons en outre que le même constat émane également d’une comparaison entre une dialectométrisation analogue des données de digiDees 1980 et de l’ALF (élagué) : voir les planches 2–4.
Évidemment, la constatation de cette étonnante constance diachronique est du plus haut intérêt linguistique.
3.3 Présentation et interprétation de deux paires de cartes de similarité : voir la planche 7
Dans ce paragraphe, il est question de deux autres exemples du même type dialecto- ou scriptométrique. Alors que sur la planche 6, les deux paires de cartes de similarité se réfèrent au Sud-Ouest (Poitou) et au Nord (Picardie) du domaine d’oïl, la planche 7 en fournit des échantillons corollaires pour l’Île-de-France et la Franche-Comté.
À nouveau, le parallélisme spatial entre les cartes de similarité appariées (diachroniquement distantes de six siècles) a de quoi surprendre.
3.4 Présentation et interprétation de deux paires de cartes : synopse des « coefficients d’asymétrie de Fisher » (CAF) et synthèse isoglottique (ou interponctuelle) ; voir la planche 8
À l’instar du paragraphe 2.4, il s’agit ici de deux paires de cartes scripto- et dialectométriques, établies selon les mêmes méthodes : la synopse du CAF[28] (à gauche) et l’« analyse isoglottique » (à droite) qui, en dernière analyse, reprend en termes de dialectométrie le tracement combiné d’isoglosses de la géographie linguistique classique.
Par rapport aux cartes de similarité appariées présentées sur les planches 6 et 7, la ressemblance entre les deux paires de cartes présentées sur la planche 8 (toujours diachroniquement distantes de six siècles) est nettement moindre. Et pour cause !
La raison principale réside dans la vertu « mensuratrice » des deux analyses. En effet, chacune avec sa logique statistique particulière, elles saisissent une des propriétés les plus saillantes de tout réseau atlantiste, à savoir l’« enchevêtrement particulier » (EP) d’innombrables aires linguistiques sur les cartes des atlas linguistiques, déjà évoqué au paragraphe 2.4.1.
Signalons que dès l’époque de Jules Gilliéron (1854–1926), Karl Jaberg (1877–1958) et Jakob Jud (1882–1952), il était clair que le véritable « sel innovateur » de la géographie linguistique naissante était la découverte de l’indépendance historique des différentes aires linguistiques et de leur liberté « évolutive » absolue. Il en résulta une nouvelle vision de l’étude du changement linguistique visant à la description et à l’explication – en termes de diachronie et de diatopie – des variations de la taille et de la configuration de nombreuses aires linguistiques telles qu’elles se dégageaient des cartes originales des nouveaux atlas linguistiques.
3.4.1. Planche 8 : présentation et interprétation des deux cartes choroplèthes de gauche ; synopse des « coefficients d’asymétrie de Fisher » (CAF)
Rappelons que les propriétés taxométriques du CAF ainsi que les modalités de leur mise en carte ont déjà été expliquées au paragraphe 2.4.1.
En comparant les deux synopses du CAF, il faut se souvenir du fait qu’il y a entre elles un décalage historique de six siècles ! Or, le profil de gauche, relatif aux XIIe et XIIIe siècles, est caractérisé par la présence d’un « chenal » central (en bleu foncé) qui se faufile entre plusieurs provinces historiques telles que la Normandie, la Picardie, la Franche-Comté, le Poitou et la Saintonge, toutes marquées en rouge.
Nous savons déjà que dans la perspective du CAF, les zones en bleu sont caractérisées par une forte interaction linguistique (et des effets EP de type méga-chorique) alors que les zones en rouge accusent un certain conservatisme linguistique (et des effets EP de type micro-chorique).
Sur la carte issue de l’analyse des données de digiDees 1983, les zones en rouge, toutes situées aux périphéries du domaine d’oïl (et des deux côtés du « chenal » interactif central en bleu foncé) renvoient à plusieurs provinces historiques périphériques qui, aux XIIe et XIIIe siècles, maintenaient encore leurs autonomies graphiques respectives.
Par contre, la carte relative aux données de l’ALF (relevées entre 1897 et 1901), montre un vaste glacis central bleu, émaillé dans le Sud-Est d’une petite butte-témoin en rouge et encadré, à la périphérie nord-orientale, d’un grosse bordure cohérente, également en rouge.
Cet état des choses correspond exactement à ce que nous avons déjà pu constater sur les deux cartes de gauche de la planche 4 : extension spectaculaire, en six siècles (1300–1900), de la superficie du « chenal central interactif » (bleu foncé).
Le même constat émane, en dernière analyse, des deux cartes isolinéaires (ou interponctuelles) de la même planche (à droite).
3.4.2 Planche 8 : présentation et interprétation des deux cartes isolinéaires (ou interponctuelles) de droite ; synthèse isoglottique[29]
Le profil interponctuel de la carte interponctuelle de gauche repose sur les données de digiDees 1983, alors que celui de la carte de droite se fonde sur les données de l’ALF élagué. Il a été calculé à l’aide de l’indice de similarité pondéré GIW (Gewichtender Identitätswert = indice pondéré d’identité – IPI), à la différence du même cliché de la planche 4, qui avait été établi moyennant l’indice de similarité standard RIW (Relativer Identitätswert = indice relatif d’identité – IRI).
L’observation contrastive des deux « compartimentages »[30] fait clairement ressortir que dans l’analyse isolinéaire issue de digiDees 1983, le cœur du domaine d’oïl médiéval est encore fortement sillonné de faisceaux d’isoglosses très épais (en bleu foncé), alors que les mêmes zones revêtent dans la perspective « dix-neuviémiste » de l’ALF élagué un aspect carrément nivelé et aplati. Il ne fait aucun doute que cela est dû à l’effet de l’irradiation pluriséculaire (et continue) de la latinité linguistique de l’Île-de-France.
4. Présentation et interprétation de trois analyses arborescentes (issues de digiDees 1980, digiDees 1983 et de l’ALF élagué)
Au vu de la fig. 2 (secteur D, en bas), l’on constate que la construction d’arbres ou de dendrogrammes fait également partie de l’arsenal standard des méthodes taxométriques de l’EDMS. Une telle analyse présuppose, du point de vue heuristique, la présentation parallèle tant de l’arbre calculé en tant que tel que de son interprétation géographique (« spatialisation »). De plus, il est nécessaire de conférer à ces deux volets heuristiques le même aspect chromatique.
La taxométrie moderne[31] offre un grand nombre d’algorithmes dendrographiques dont l’utilité linguistique reste à déterminer au cas par cas. Au sein de l’EDMS, nous avons fait d’excellentes expériences, pour les objectifs de la linguistique romane, avec un algorithme « ascendant et hiérarchique » proposé en 1963 par le statisticien américain Joe H. Ward, Jr. (1926–2011).
En voici le fonctionnement : l’algorithme de Ward crée une hiérarchie arborescente de N fusions binaires. Ces fusions s’opèrent parmi les N/2 × (N-1) scores de similarité (ou de corrélation) stockés dans une des deux moitiés symétriques de la matrice de similarité carrée respective (N2).
Les fusions binaires débutent avec les valeurs minimales de l’indice de similarité utilisé et s’étendent par la suite jusqu’aux valeurs maximales. Métaphoriquement parlant, les agglomérations binaires commencent au niveau des « feuilles » de l’arbre et finissent par en rejoindre la « racine » (ou le « tronc »). Si l’on regarde la planche 9, il s’agit donc d’un mouvement allant de gauche à droite.
À Salzbourg, les embranchements coloriés à l’intérieur de l’arbre sont appelés « dendrèmes », alors que leurs équivalents géographiques (ou « spatialisés ») portent le nom de « chorèmes ». Il va de soi que leur coloriage respectif doit être identique. Autre nécessité heuristique, pour une comparaison de plusieurs arbres taxométriques, le nombre des dendrèmes-chorèmes (DC) pris en compte doit être égal. Ici, on compte cinq DC.
En règle générale, l’interprétation linguistique des arbres part de la racine (ou du tronc) pour rejoindre les feuilles terminales. Sur la planche 9, ce mouvement va de droite à gauche. Une telle interprétation est le plus souvent d’ordre historique et retrace – évidemment dans une perspective purement modélisante – les étapes de l’éclosion et de la fragmentation d’un champ linguistique donné, en l’occurrence le domaine d’oïl.
Dans de telles circonstances, l’hypothèse générale veut que le champ (ou domaine) en question soit unitaire au début de cet itinéraire diachronique imaginaire, et qu’il subisse, au cours du « temps », des fragmentations binaires hiérarchisées dont les modalités numériques sont dictées par l’algorithme agglomératif utilisé (ici celui de Joe Ward Jr.).
Ajoutons que les différents dendrèmes qui naissent « en cours de route » possèdent une hétérogénéité interne variable : cette dernière est très grande pour les dendrèmes situés près de la racine et diminue au fur et à mesure que ceux-ci s’approchent des feuilles.
Il en résulte que les bifurcations les « plus hautes », situées donc à proximité de la racine, ont la plus grande « importance » linguistique. Au vu des trois arbres de la planche 9, l’on constate que partout les premières bifurcations divisent le domaine d’oïl en deux : en une partie occidentale, coloriée en rouge et jaune, et une partie orientale, coloriée en vert, bleu clair et bleu foncé.
Il est non moins intéressant de voir que les chorèmes relatifs aux sous-dendrèmes issus de la première bifurcation créent dans l’espace des plages très similaires. Ceci est vrai surtout pour les spatialisations relatives à digiDees 1980 et digiDees 1983 (à gauche et au centre), alors que le bilan chorématique relatif à l’ALF (élagué) s’en écarte un peu. Ceci concerne surtout l’étendue sensiblement accrue du chorème figuré en jaune sur la spatialisation de droite (relative à l’ALF élagué), due au rayonnement radial pluriséculaire de la latinité centrale de l’Île-de-France, à l’instar de ce qui a déjà pu être constaté pour les cartes des planches 4 et 8.
5 Bilan et conclusion
Dees espérait pouvoir tirer d’un grand nombre de chartes médiévales de première main (digiDees 1980) des informations « sûres » sur la structure linguistique du domaine d’oïl médiéval, et cet espoir a pu être confirmé une fois de plus. Il en va de même pour un corpus de 222 textes littéraires de la même époque (digiDees 1983) soumis à deux traitements quantitatifs différents : celui d’A. Dees visant à les localiser géographiquement dans les mailles du réseau de digiDees 1980, et celui de l’EDMS visant à découvrir des structures de profondeur inhérentes à ce corpus textuel.
Ce double constat est encore renforcé par l’expérience géotypologique de la grande ressemblance des structures de profondeur scripturales avec celles extraites d’un corpus dialectal tiré de l’ALF, postérieur de six siècles aux données de digiDees 1980 et de digiDees 1983.
Cette constance géotypologique observée au niveau des structures de profondeur est tout à fait remarquable.
6 Abréviations techniques souvent utilisées
| Sigle | Signification | Mention dans le texte |
| CAF | Coefficient d’asymétrie de Ronald A. Fisher [1890–1963] | cf. 2.4 et 3.4 |
| CAH | Classification ascendante hiérarchique | cf. 4 |
| CILPR | Congrès international de linguistique et de philologie romanes | cf. 1 |
| CS | Carte de similarité | Corpus des planches |
| DC | Dendrème et chorème | cf. 4 |
| DEMjk | Distance euclidienne moyenne (entre les points d’atlas j et k)/Durchschnittliche Euklidische Metrik [DEMjk + SEMjk = 100] | cf. 2.2 |
| digiDees 1980 | Ensemble des données de base de l’atlas scriptural d’A. Dees de 1980, remis sous forme électronique par P. van Reenen à H. Goebl en 1996 | passim |
| digiDees 1983 | Ensemble des calculs de localisation effectués par A. Dees le 9 novembre 1983 à Amsterdam (« trouvaille de Lauterbad ») | passim |
| DM | Dialectométrie, dialectométrique, relatif à la dialectométrie | passim |
| EDMS | École dialectométrique de Salzbourg | passim |
| EP | Enchevêtrement particulier | cf. 2.4 et 3.4 |
| EPAL | Enchevêtrement particulier des aires linguistiques | cf. 2.4.1 |
| GIW(1)jk | Gewichtender Identitätswert (facteur de pondération 1) [= IPI(1)jk] | cf. 2.1, 4. et 5 |
| IPI(1)jk | Indice pondéré d’identité (entre les points d’atlas j et k) (facteur de pondération 1) [= GIW(1)jk] | cf. 3.4.2, 5 |
| IRIjk | Indice relatif d’identité (entre les points d’atlas j et k) [= RIWjk] | cf. 2.1 |
| MEDMW | Algorithme d’intervallisation (ou de visualisation) | cf. 3.4.2 |
| MINMWMAX | Algorithme d’intervallisation (ou de visualisation) | cf. 2.1 |
| PMKjk | Produkt-Moment-Korrelationskoeffizient [= r(BP)jk] | cf. 3.4.2 |
| r(BP)jk | Coefficient de corrélation (entre les points d’atlas j et k), proposé par Auguste Bravais [1811–1863] et Karl Pearson [1857–1936] [= PMKjk] | cf. 3.4.2 |
| RIWjk | Relativer Identitätswert [= IRIjk] | cf. 2.2 |
| SEMjk | Similarité euclidienne moyenne [SEMjk + DEMjk = 100] | cf. 2.2 |
| ULA | Université Libre d’Amsterdam | cf. 1 |
| VDM | Visual DialectoMetry (logiciel dialectométrique créé en 1999–2000 par Edgar Haimerl et couramment utilisé depuis à Salzbourg) | passim |
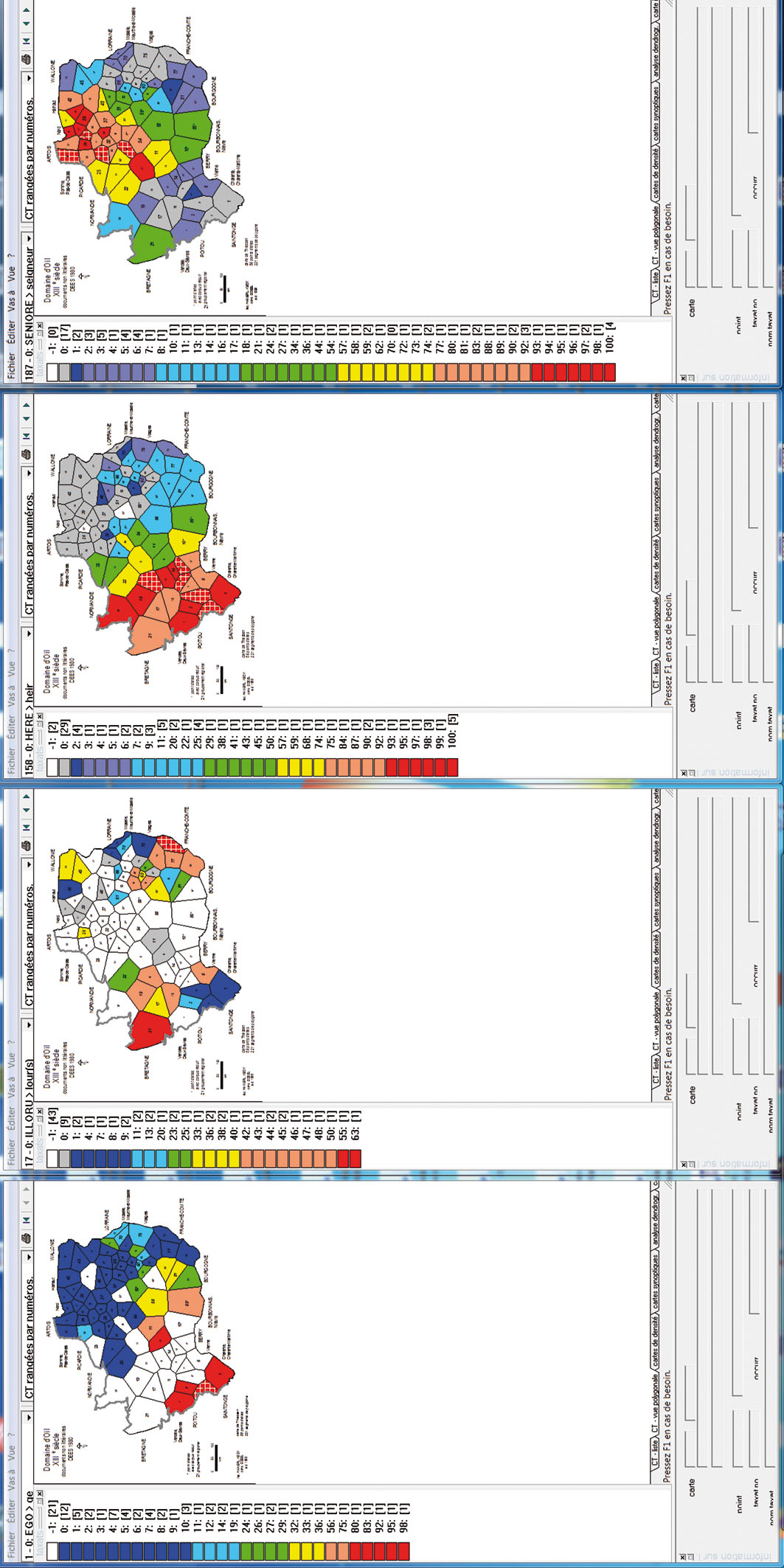
Cartes choroplèthes de la distribution spatiale de quatre traits scripturaires (selon digiDees 1980); MINMWMAX 6-tuple. Carte de gauche: graphies g, ge, gie (etc.) (< lat. ÉGO) « je » cf. Dees 1980, carte 1. Carte du centre gauche: graphie ou (< lat. ILLÓRU) « leur » cf. Dees 1980, carte 17. Carte du centre droite: graphie ei (< lat HÉRE) « hoir »; cf. Dees 1980, carte 158. Carte de droite: graphie eu (< lat. SENIÓRE) « Seigneur »; cf. Dees 1980, carte 187.
![Planche 2 (cf. 2.2) Deux paires de CS selon digiDees 1980 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes) et 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 2 (Deux-Sèvres) de digiDees 1980. Indice de similarité [Ids]: DEMjk = SEMjk. Carte du centre gauche: CS du P. 510 (Échiré) du corpus-ALF réduit. Ids: RIWjk = IRIjk. Carte du centre droite: CS du P. 56 (Paris) de digiDees 1980. Ids: DEMjk = SEMjk. Carte de droite: CS du P. 226 (Le Plessis-Piquet) du corpus-ALF réduit. Ids: RIWjk = IRIjk.](/document/doi/10.1515/zrp-2023-0039/asset/graphic/zrp-2023-0039_fig_004.jpg)
Deux paires de CS selon digiDees 1980 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes) et 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 2 (Deux-Sèvres) de digiDees 1980. Indice de similarité [Ids]: DEMjk = SEMjk. Carte du centre gauche: CS du P. 510 (Échiré) du corpus-ALF réduit. Ids: RIWjk = IRIjk. Carte du centre droite: CS du P. 56 (Paris) de digiDees 1980. Ids: DEMjk = SEMjk. Carte de droite: CS du P. 226 (Le Plessis-Piquet) du corpus-ALF réduit. Ids: RIWjk = IRIjk.
Deux paires de CS selon digiDees 1980 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes) et 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 30 (Pas-de-Calais, sud-ouest) de digiDees 1980. Ids: DEMjk = SEMjk. Carte du centre gauche: CS du P. 289 (Nort-Leulinghem) du corpus-ALF réduit. Ids: RIWjk = IRIjk. Carte du centre droite : CS du P. 70 (Moselle, Meurthe-et-Moselle) de digiDees 1980. Ids: DEMjk = SEMjk. Carte de droite: CS du P. 170 (Moncel-sur-Seille) du corpus-ALF réduit. Ids: RIWjk = IRIjk.
![Planche 4 (cf. 2.4) Asymétrie distributionnelle et cloisonnement isoglottique. MEDMW 2-tuple (→ cartes choroplèthes) et 6-tuple (→ cartes isolinéaires); MEDMW 4-tuple et MEDMW 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: Synopse de 85 scores-CAF selon digiDees 1980 (268 attributs graphiques × 85 centres scripturaires. Ids: DEMjk= SEMjk. Carte du centre gauche: Synopse de 85 scores-CAF selon le corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail). Ids: RIWjk = IRIjk. Carte du centre droite: Carte à cloisons selon digiDees 1980 (268 attributs graphiques × 85 centres scripturaires). Indice de distance [Idd]: 100 - DEMjk (= SEMjk). Carte de droite: Carte à cloisons selon le corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail). Idd: 100 - RIWjk (= IRIjk).](/document/doi/10.1515/zrp-2023-0039/asset/graphic/zrp-2023-0039_fig_006.jpg)
Asymétrie distributionnelle et cloisonnement isoglottique. MEDMW 2-tuple (→ cartes choroplèthes) et 6-tuple (→ cartes isolinéaires); MEDMW 4-tuple et MEDMW 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: Synopse de 85 scores-CAF selon digiDees 1980 (268 attributs graphiques × 85 centres scripturaires. Ids: DEMjk= SEMjk. Carte du centre gauche: Synopse de 85 scores-CAF selon le corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail). Ids: RIWjk = IRIjk. Carte du centre droite: Carte à cloisons selon digiDees 1980 (268 attributs graphiques × 85 centres scripturaires). Indice de distance [Idd]: 100 - DEMjk (= SEMjk). Carte de droite: Carte à cloisons selon le corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail). Idd: 100 - RIWjk (= IRIjk).
![Planche 5 (cf. 3.1) Profils de localisation de quatre textes médiévaux, calculés par A. Dees en novembre 1983, relatifs au Poitou, à la Picardie, à l’Île-de-France et à la Lorraine. MINMWMAX 6-tuple; hachures blanches: scores minimal et maximal. Carte de droite: Sermons de Maurice de Sully (ed. A. Boucherie) [NCA : 258]. Carte du centre gauche: Aucassin et Nicolette (ed. M. Roques, CFMA) [NCA : 022]. Carte du centre droite: Perceval, Ms. V, vs. 1-2000 (ed. R. L. H. Lops) [NCA : inexistant]. Carte de droite: Lothringischer Psalter (ed. F. Apfelstedt, p. 1-23) [NCA : 146].](/document/doi/10.1515/zrp-2023-0039/asset/graphic/zrp-2023-0039_fig_007.jpg)
Profils de localisation de quatre textes médiévaux, calculés par A. Dees en novembre 1983, relatifs au Poitou, à la Picardie, à l’Île-de-France et à la Lorraine. MINMWMAX 6-tuple; hachures blanches: scores minimal et maximal. Carte de droite: Sermons de Maurice de Sully (ed. A. Boucherie) [NCA : 258]. Carte du centre gauche: Aucassin et Nicolette (ed. M. Roques, CFMA) [NCA : 022]. Carte du centre droite: Perceval, Ms. V, vs. 1-2000 (ed. R. L. H. Lops) [NCA : inexistant]. Carte de droite: Lothringischer Psalter (ed. F. Apfelstedt, p. 1-23) [NCA : 146].
![Planche 6 (cf. 3.2) Deux paires de CS selon digiDees 1983 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes); MINMWMAX 12-tuple (→ histogrammes). Ids: PMKjk = r(BP)jk [pour digiDees 1983] et RIWjk = IRIjk [pour l’ALF]); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 1 (Charente, Charente-Maritime) de digiDees 1983. Carte du centre gauche: CS du P. 518 (Chassors) du corpus-ALF réduit. Carte du centre droite: CS du P. 30 (Pas-de-Calais, sud-ouest) de digiDees 1983. Carte de droite: CS du P. 289 (Nort-Leulinghem) du corpus-ALF réduit.](/document/doi/10.1515/zrp-2023-0039/asset/graphic/zrp-2023-0039_fig_008.jpg)
Deux paires de CS selon digiDees 1983 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes); MINMWMAX 12-tuple (→ histogrammes). Ids: PMKjk = r(BP)jk [pour digiDees 1983] et RIWjk = IRIjk [pour l’ALF]); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 1 (Charente, Charente-Maritime) de digiDees 1983. Carte du centre gauche: CS du P. 518 (Chassors) du corpus-ALF réduit. Carte du centre droite: CS du P. 30 (Pas-de-Calais, sud-ouest) de digiDees 1983. Carte de droite: CS du P. 289 (Nort-Leulinghem) du corpus-ALF réduit.
![Planche 7 (cf. 3.3) Deux paires de CS selon digiDees 1983 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes) et 12-tuple (→ histogrammes). Ids: PMKjk = r(BP)jk [pour digiDees 1983] et RIWjk = IRIjk [pour l’ALF]); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 56 (Paris) de digiDees 1983. Carte du centre gauche: CS du P. 226 (Le Plessis-Piquet) du corpus-ALF réduit. Carte du centre droite: CS du P. 78 (Doubs) de digiDees 1983. Carte de droite: CS du P. 53 (Saint-Hippolyte) du corpus-ALF réduit.](/document/doi/10.1515/zrp-2023-0039/asset/graphic/zrp-2023-0039_fig_009.jpg)
Deux paires de CS selon digiDees 1983 et le corpus-ALF réduit. MINMWMAX 6-tuple (→ cartes choroplèthes) et 12-tuple (→ histogrammes). Ids: PMKjk = r(BP)jk [pour digiDees 1983] et RIWjk = IRIjk [pour l’ALF]); hachures blanches: scores minimal et maximal. Carte de gauche: CS du P. 56 (Paris) de digiDees 1983. Carte du centre gauche: CS du P. 226 (Le Plessis-Piquet) du corpus-ALF réduit. Carte du centre droite: CS du P. 78 (Doubs) de digiDees 1983. Carte de droite: CS du P. 53 (Saint-Hippolyte) du corpus-ALF réduit.
![Planche 8 (cf. 3.4) Asymétrie distributionnelle et cloisonnement isoglottique selon digiDees 1983 et le corpus-ALF réduit. MEDMW 2-tuple [→ cartes choroplèthes] et 6-tuple [→ cartes isolinéaires]; MEDMW 4-tuple et 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: Synopse de 87 scores-CAF tirés de digiDees 1983 (222 localisations × 87 points d’atlas. Ids: PMKjk = r(BP)jk. Carte du centre gauche: Synopse de 85 scores-CAF calculés à partir du corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail. Ids: GIWjk= IRIjk. Carte du centre droite: Carte à cloisons calculée à partir de digiDees 1983 (222 localisations × 87 points d’atlas. Idd: 100 - PMKjk [= r(BP)jk]. Carte de droite: Carte à cloisons calculée à partir du corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail. Idd: 100 - GIWjk [= IRIjk].](/document/doi/10.1515/zrp-2023-0039/asset/graphic/zrp-2023-0039_fig_010.jpg)
Asymétrie distributionnelle et cloisonnement isoglottique selon digiDees 1983 et le corpus-ALF réduit. MEDMW 2-tuple [→ cartes choroplèthes] et 6-tuple [→ cartes isolinéaires]; MEDMW 4-tuple et 12-tuple (→ histogrammes); hachures blanches: scores minimal et maximal. Carte de gauche: Synopse de 87 scores-CAF tirés de digiDees 1983 (222 localisations × 87 points d’atlas. Ids: PMKjk = r(BP)jk. Carte du centre gauche: Synopse de 85 scores-CAF calculés à partir du corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail. Ids: GIWjk= IRIjk. Carte du centre droite: Carte à cloisons calculée à partir de digiDees 1983 (222 localisations × 87 points d’atlas. Idd: 100 - PMKjk [= r(BP)jk]. Carte de droite: Carte à cloisons calculée à partir du corpus-ALF réduit (85 P.-ALF × 1279 cartes de travail. Idd: 100 - GIWjk [= IRIjk].
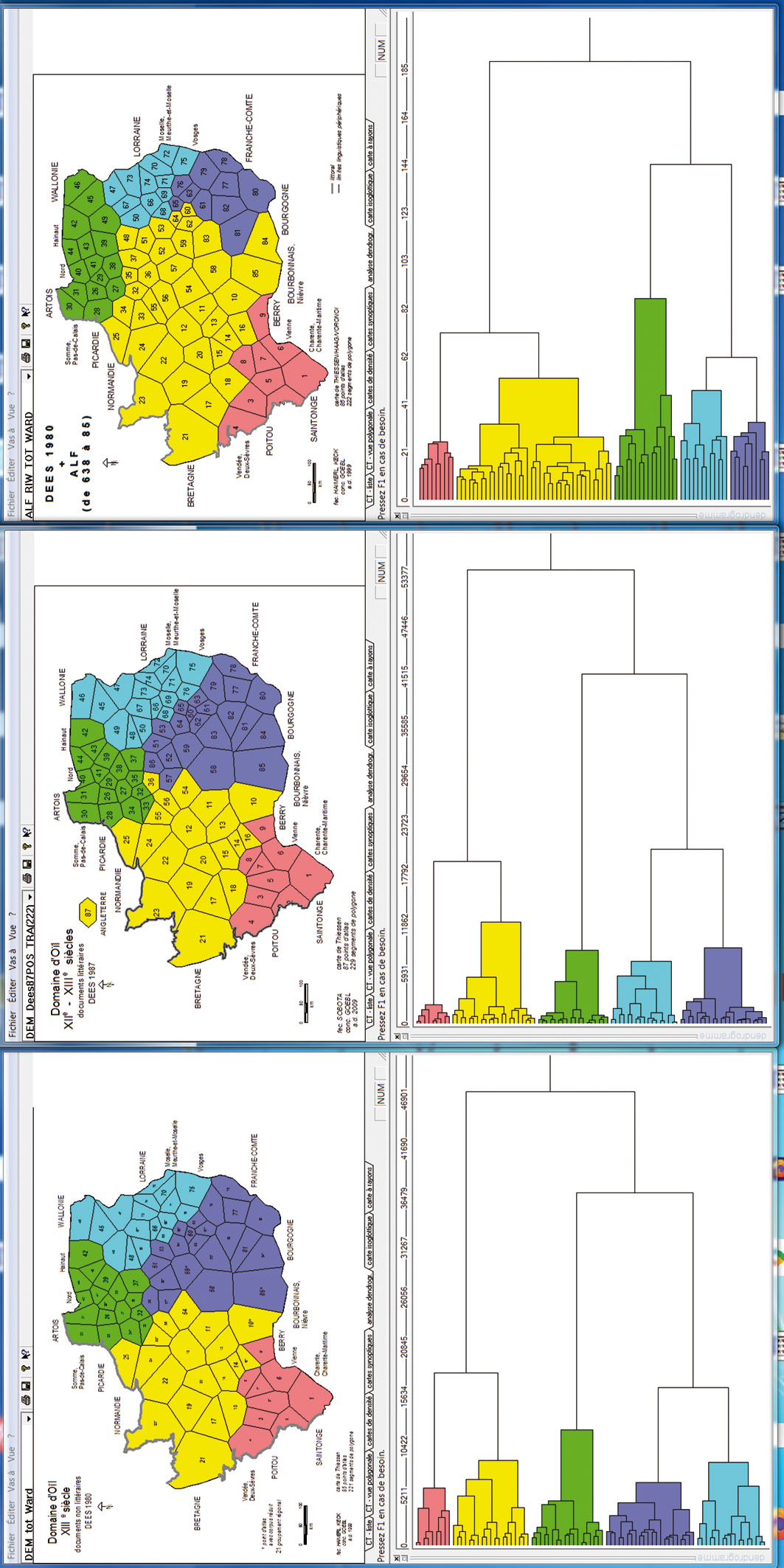
Trois classifications dendrographiques selon digiDees 1980, 1983 et le corpus-ALF réduit. Algorithme-CAH: méthode de J. A. Ward, Jr.; six chorèmes (en haut) et six dendrèmes (en bas), avec coloriage parallèle. Carte de gauche: corpus: 268 attributs scripturaires × 85 points d’atlas (selon digiDees 1980). Ids: DEMjk: = SEMjk. Carte du milieu: corpus: 222 vecteurs de localisation × 87 points d’atlas (selon digiDees 1983). Ids: PMKjk = r(BP)jk. Carte de droite: corpus: 1279 cartes de travail (de toutes les catégories linguistiques, tirées de 626 cartes-ALF originales) × 85 points d’atlas. Ids: RIWjk = IRIjk.
Remerciements
saisie électronique des résultats des calculs de corrélation effectués en 1983 par A. Dees : Pavel Smečka ; confection des figures 1 et 2 : Werner Goebl, Vienne ; tenue à jour et entretien régulier du programme VDM : Pavel Smečka. J’adresse ici l’expression de ma profonde reconnaissance à MM. P. Smečka et W. Goebl pour leur précieuse et patiente collaboration.
7 Références bibliographiques
AIS = Jaberg, Karl/Jud, Jakob, Sprach- und Sachatlas Italiens un der Südschweiz, Zofingen, Ringier, 8 vol., 1928–1940 (réimpression Nendeln, Kraus, 1973 ; en ligne : https://www3.pd.istc.cnr.it/navigais-web/?map=1 [= NavigAIS]).Search in Google Scholar
ALF = Gilliéron, Jules/Edmont, Edmond, Atlas linguistique de la France, 10 vol., Paris, Champion, 1902–1910 (réimpression Bologna, Forni, 1968 ; en ligne : Innsbruck : https://diglib.uibk.ac.at/urn:nbn:at:at-ubi:2–4568; Toulouse : http://symila.univ-tlse2.fr/alf).Search in Google Scholar
Bock, Hans Hermann, Automatische Klassifikation. Theoretische und praktische Methoden zur Gruppierung und Strukturierung von Daten (Cluster-Analyse), Göttingen, Vandenhoeck & Ruprecht, 1974.Search in Google Scholar
Chandon, Jean-Louis/Pinson, Suzanne, Analyse typologique. Théories et applications, Paris/New York/Barcelone/Milan, Masson, 1981.Search in Google Scholar
Dees, Anthonij, Étude sur l’évolution des démonstratifs en ancien et en moyen français, Groningen, Wolters-Nordhoff, 1971.Search in Google Scholar
Dees, Anthonij, Atlas des formes et des constructions des chartes françaises du 13 e siècle, Tübingen, Niemeyer, 1980.10.1515/9783111328980Search in Google Scholar
Dees, Anthonij, Regards quantitatifs sur les variations régionales en ancien français, in : Goebl, Hans (ed.), Dialectology, Bochum, Brockmeyer, 1984, 102–120.Search in Google Scholar
Dees, Anthonij, Dialectes et scriptae à l’époque de l’ancien français, Revue de linguistique romane 49 (1985), 87–117.Search in Google Scholar
Dees, Anthonij, Vers un atlas linguistique de l’ancien français écrit, in : Actes du XVIIème Congrès International de Linguistique et Philologie Romanes (Aix-en-Provence 1983), vol. 6, Aix-en-Provence, Université de Provence, Marseille, Jeanne Laffitte, 1986, 505–517.Search in Google Scholar
Dees, Anthonij, Atlas des formes linguistiques des textes littéraires de l’ancien français, Tübingen, Niemeyer, 1987.10.1515/9783110935493Search in Google Scholar
Ettmayer, Karl von, Über das Wesen der Dialektbildung erläutert an den Dialekten Frankreichs, Denkschriften der Akademie der Wissenschaften in Wien, phil.-hist. Klasse, vol. 66, Wien, Hölder-Pichler-Tempsky, 1924, 1–56. Search in Google Scholar
Goebl, Hans, compte rendu de Dees 1980, Zeitschrift für französische Sprache und Literatur 92 (1982), 280–283.Search in Google Scholar
Goebl, Hans, Parquet polygonal et treillis triangulaire : les deux versants de la dialectométrie interponctuelle, Revue de linguistique romane 47 (1983), 353–412.Search in Google Scholar
Goebl, Hans, Dialektometrische Studien. Anhand italoromanischer, rätoromanischer und galloromanischer Sprachmaterialien aus AIS und ALF, Tübingen, Niemeyer, 3 vol., 1984.Search in Google Scholar
Goebl, Hans, Points chauds de l’analyse dialectométrique : pondération et visualisation, Revue de linguistique romane 51 (1987), 63–118. Search in Google Scholar
Goebl, Hans, compte rendu de Dees 1987, Zeitschrift für französische Sprache und Literatur 103 (1993), 185–187.Search in Google Scholar
Goebl, Hans, Zu einer dialektometrischen Analyse der Daten des Dees-Atlasses von 1980, in : Werner, Edeltraud/Liver, Ricarda/Stork, Yvonne/Nicklaus, Martina (edd.), Et multum et multa. Festschrift für Peter Wunderli zum 60. Geburtstag, Tübingen, Narr, 1998, 293–309.Search in Google Scholar
Goebl, Hans, La strutturazione geolinguistica del dominio d’oïl nel 13 o secolo e alla fine dell’Ottocento: un raffronto dialettometrico, in : Zamboni, Alberto/Del Puente, Patrizia/Vigolo, Maria Teresa (edd.), La dialettologia oggi fra tradizione e nuove metodologie. Atti del Convegno Internazionale (Pisa 2000), Alessandria, Edizioni ETS, 2001, 11–43.Search in Google Scholar
Goebl, Hans, Regards dialectométriques sur les données de l’Atlas linguistique de la France (ALF) : relations quantitatives et structures de profondeur, Estudis romànics 25 (2003), 59–96 (avec 24 cartes en couleurs).Search in Google Scholar
Goebl, Hans, La dialectométrie corrélative. Un nouvel outil pour l’étude de l’aménagement dialectal de l’espace par l’homme, Revue de linguistique romane 69 (2005), 321–367.Search in Google Scholar
Goebl, Hans, Sur le changement macrolinguistique survenu entre 1300 et 1900 dans le domaine d’oïl. Une étude diachronique d’inspiration dialectométrique, Linguistica 46 (2006), 3–43.Search in Google Scholar
Goebl, Hans, Intervention in : Kunstmann, Pierre/Stein, Achim (edd.), Le Nouveau Corpus d’Amsterdam. Actes de l’atelier de Lauterbach, 23–26 février 2006, Stuttgart, Steiner, 2007, 186–188.Search in Google Scholar
Goebl, Hans,. La dialettometrizzazione integrale dell’AIS. Presentazione dei primi risultati, Revue de linguistique romane 72 (2008), 25–113 (avec 48 cartes en couleurs) (= 2008a).Search in Google Scholar
Goebl, Hans, Sur le changement macrolinguistique survenu entre 1300 et 1900 dans le domaine d’oïl. Une étude diachronique d’inspiration dialectométrique, Dialectologia (Barcelona) 1 (2008), 3–43 [version revue et corrigée de Goebl 2006] (= 2008b).10.4312/linguistica.46.1.3-43Search in Google Scholar
Goebl, Hans, Die beiden Skripta-Atlanten von Anthonij Dees (1980 und 1987) im dialektometrischen Vergleich: eine erste Bilanz, in : Overbeck, Anja/Schweickard, Wolfgang/Völker, Harald (edd.), Lexikon, Varietät, Philologie. Romanistische Studien. Günter Holtus zum 65. Geburtstag, Berlin/Boston, Walter de Gruyter, 2011, 665–677.10.1515/9783110262292.665Search in Google Scholar
Goebl, Hans, L’aménagement scripturaire du domaine d’oïl médiéval à la lumière des calculs de localisation d’Anthonij Dees effectués en 1983 : une étude d’inspiration scriptométrique, 11 p. (avec 24 cartes en couleurs) [2012]. Version écrite d’une conférence tenue à Venise en 2011 à l’occasion d’un congrès de la revue « Medioevo romanzo » dédié au sujet suivant : Il problema della scripta. Gli antichi testi romanzi tra filologia, dialettologia e storia della lingua ; disponible seulement en ligne : http://www.medioevoromanzo.it/uploads/H.Goebl_Amenagement_scripturaire_2012_article.pdfSearch in Google Scholar
Goebl, Hans, Un nouveau rejeton de l’« École dialectométrique de Salzbourg » : brève présentation du mode « béta » de la dialectométrie de Salzbourg, in : Aguilera, Vanderci de Andrade/Altino, Fabiane Cristina/Ramos, Conceição de Maria de Araújo (edd.): Estudos dialetais brasileiros e europeus: uma homenagem a João Saramago, Campo Grande, Editora UFMS, 2022, vol. 1, 101–140.Search in Google Scholar
Goebl, Hans/Schiltz, Guillaume, Der «Atlas des formes et des constructions des chartes françaises du 13 e siècle» von Anthonij Dees (1980) – dialektometrisch betrachtet, in : Gärtner, Kurt/Holtus, Günter/Rapp, Andrea/Völker, Harald (edd.), Skripta, Schreiblandschaften und Standardisierungstendenzen. Urkundensprachen im Grenzbereich von Germania und Romania im 13. und 14. Jahrhundert. Beiträge zum Kolloquium vom 16. bis 18. September 1998 in Trier, Trier, Kliomedia, 2001, 169–221.Search in Google Scholar
Goebl, Hans/Smečka, Pavel, L’interprétation dialectométrique des atlas « scripturaux » d’Anthonij Dees, Revue de linguistique romane 80 (2016), 321–368 (avec 50 cartes en couleurs).Search in Google Scholar
Goebl, Hans/Smečka, Pavel, Trois regards dialectométriques sur l’aménagement géolinguistique du domaine d’oïl, basés sur une synthèse des données médiévales réunies par Anthonij Dees en 1980 et 1983, et celles de l’ALF, in : Kristol, Andres M. (ed.), La mise à l’écrit et ses conséquences. Actes du troisième colloque « Repenser l’histoire du français », Université de Neuchâtel, 5–6 juin 2014, Tübingen, Francke, 2017, 15–49 (avec 12 planches en couleurs).Search in Google Scholar
Goebl, Hans/Sobota, Slawomir/Haimerl, Edgar, Analyse dialectométrique des structures de profondeur de l’ALF, Revue de linguistique romane 66 (2002), 5–63 (avec 24 cartes en couleurs).Search in Google Scholar
Lalanne, abbé Théobald, L’indépendance des aires linguistiques en Gascogne maritime, Saint-Vincent-de-Paul, chez l’auteur, 2 vol., 1949–1952 (réimpression Labatut, Atelier d’Histoire Trait d’Union, 2018).Search in Google Scholar
NCA: Kunstmann, Pierre/Stein, Achim (edd.), Le Nouveau Corpus d’Amsterdam. Actes de l’atelier de Lauterbad, 23–26 février 2006, Stuttgart, Steiner, 2007.Search in Google Scholar
Rosenqvist, Arvid, Limites administratives et division dialectale de la France, Neuphilologische Mitteilungen 20 (1919), 87–119.Search in Google Scholar
Schøsler, Lene, Nécrologie : Anthonij Dees (1928–2001), Revue de linguistique romane 66 (2002), 614–618. Search in Google Scholar
Sneath, Peter Henry Andrews/Sokal, Robert Reuven, The principles and practice of numerical classification, San Francesco, Freeman, 1973.Search in Google Scholar
van Reenen, Piet/van Reenen-Stein, Karin (edd.), Distributions spatiales et temporelles, constellations des manuscrits. Études de variation linguistique offertes à Anthonij Dees à l’occasion de son 60 e anniversaire, Amsterdam, Philadelphia, 1988.10.1075/z.37Search in Google Scholar
© 2023 Hans Goebl, published by Walter de Gruyter GmbH, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Frontmatter
- Thematischer Teil
- Scripta e spazio. Prefazione alla parte tematica
- Causeries scriptologiques posthumes avec Anthonij Dees : un rapide survol
- The visualization of dialect data with VDM
- (Re)cartographier la Galloromania médiévale : enjeux et perspectives quarante ans après l’Atlas de Dees
- Un esempio di mappatura dell’italiano antico: la carta «‑GN‑» del progetto MIRA
- El Atlas Histórico del Español: un nuevo recurso para el estudio de la dialectología histórica
- I sondaggi, i metodi e le analisi del progetto GeoDocuM. Alla ricerca delle tendenze locali e sovralocali del latino documentale dell’Italia meridionale
- Aufsätze
- Nigromancia ilusoria y ruptura del secreto en el Exemplo XI del Libro del Conde Lucanor
- Identifier et décrire l’hétérogénéité du français aux 17e et 18e siècles : le projet MACINTOSH (Missing hAlf the picture, ClassIcal NoT sO claSsical FrencH)
- The system of pronouns of address in the Azores
- Un computo astrologico in volgare del secolo XII
- Les ainsi nommées « reliques » lexicales d’origine latine des psautiers roumains du XVIe siècle
- Besprechungen
- Jörn Albrecht / Gunter Narr (edd.), Geschichte der romanischen Länder und ihrer Sprachen. Innerromanischer und deutsch-romanischer Sprachvergleich. Mit besonderer Berücksichtigung der Dacoromania. Festschrift für Rudolf Windisch, Tübingen, Narr Francke Attempto, 2021, 308 p.
- Besprechungen
- Gabriella Parussa / Andrea Valentini (edd.), Christine de Pizan en 2021, Studi francesi 195 (2021), pp. 431–572.
- Ricardo Muñoz Solla, Menéndez Pidal, Abraham Yahuda y la política de la Real Academia Española hacia el hispanismo judío y la lengua sefardí (Estudios Filológicos, 351), Salamanca, Ediciones Universidad de Salamanca, 2021, 406 p.
- Alastair Hamilton with Maurits van den Boogert (edd.), Johann Michael Wansleben’s travels in Turkey, 1673–1676. An annotated edition of his French report (The History of Oriental Studies, 13), Leiden/Boston, Brill, 2023, IX + 250 S.
- Kurzbesprechungen
- Gabriele Giannini (ed.), La vie de sainte Agnès en quatrains de décasyllabes (BNF, fr. 1553 (Collection des anciens auteurs belges 19), Bruxelles, Académie Royale de Belgique, 2022, lxxx + 72 p.
- Kurzbesprechungen
- Il ciclo di Guiron le Courtois. Romanzi in prosa del secolo XIII, edizione critica diretta da Lino Leonardi e Richard Trachsler, vol. III/1: I testi di raccordo, a cura di Véronique Winand, analisi letteraria di Nicola Morato (Archivio Romanzo 33), Firenze, Edizioni del Galluzzo per la Fondazione Ezio Franceschini, 2022, XVIII + 596 p.
Articles in the same Issue
- Frontmatter
- Frontmatter
- Thematischer Teil
- Scripta e spazio. Prefazione alla parte tematica
- Causeries scriptologiques posthumes avec Anthonij Dees : un rapide survol
- The visualization of dialect data with VDM
- (Re)cartographier la Galloromania médiévale : enjeux et perspectives quarante ans après l’Atlas de Dees
- Un esempio di mappatura dell’italiano antico: la carta «‑GN‑» del progetto MIRA
- El Atlas Histórico del Español: un nuevo recurso para el estudio de la dialectología histórica
- I sondaggi, i metodi e le analisi del progetto GeoDocuM. Alla ricerca delle tendenze locali e sovralocali del latino documentale dell’Italia meridionale
- Aufsätze
- Nigromancia ilusoria y ruptura del secreto en el Exemplo XI del Libro del Conde Lucanor
- Identifier et décrire l’hétérogénéité du français aux 17e et 18e siècles : le projet MACINTOSH (Missing hAlf the picture, ClassIcal NoT sO claSsical FrencH)
- The system of pronouns of address in the Azores
- Un computo astrologico in volgare del secolo XII
- Les ainsi nommées « reliques » lexicales d’origine latine des psautiers roumains du XVIe siècle
- Besprechungen
- Jörn Albrecht / Gunter Narr (edd.), Geschichte der romanischen Länder und ihrer Sprachen. Innerromanischer und deutsch-romanischer Sprachvergleich. Mit besonderer Berücksichtigung der Dacoromania. Festschrift für Rudolf Windisch, Tübingen, Narr Francke Attempto, 2021, 308 p.
- Besprechungen
- Gabriella Parussa / Andrea Valentini (edd.), Christine de Pizan en 2021, Studi francesi 195 (2021), pp. 431–572.
- Ricardo Muñoz Solla, Menéndez Pidal, Abraham Yahuda y la política de la Real Academia Española hacia el hispanismo judío y la lengua sefardí (Estudios Filológicos, 351), Salamanca, Ediciones Universidad de Salamanca, 2021, 406 p.
- Alastair Hamilton with Maurits van den Boogert (edd.), Johann Michael Wansleben’s travels in Turkey, 1673–1676. An annotated edition of his French report (The History of Oriental Studies, 13), Leiden/Boston, Brill, 2023, IX + 250 S.
- Kurzbesprechungen
- Gabriele Giannini (ed.), La vie de sainte Agnès en quatrains de décasyllabes (BNF, fr. 1553 (Collection des anciens auteurs belges 19), Bruxelles, Académie Royale de Belgique, 2022, lxxx + 72 p.
- Kurzbesprechungen
- Il ciclo di Guiron le Courtois. Romanzi in prosa del secolo XIII, edizione critica diretta da Lino Leonardi e Richard Trachsler, vol. III/1: I testi di raccordo, a cura di Véronique Winand, analisi letteraria di Nicola Morato (Archivio Romanzo 33), Firenze, Edizioni del Galluzzo per la Fondazione Ezio Franceschini, 2022, XVIII + 596 p.