Scheduling equal-length jobs with arbitrary sizes on uniform parallel batch machines
-
Xiao Xin


Abstract
We consider the problem of scheduling jobs with equal lengths and arbitrary sizes on uniform parallel batch machines with different capacities. Each machine can only process the jobs whose sizes are not larger than its capacity. Several jobs can be processed as a batch simultaneously on a machine, as long as their total size does not exceed the machine’s capacity. The objective is to minimize makespan. Under a divisibility constraint, we obtain two efficient exact algorithms. For the general problem, we obtain an efficient 2-approximation algorithm. Previous work has shown that the problem cannot be approximated to within an approximation ratio better than 2, unless P = NP, even when all machines have identical speeds and capacities.
1 Introduction
In today’s competitive environment, batch processing is a very common procedure in many manufacturing fields such as metalworking, and wafer fabrication for the avoidance of setups and/or facilitation of material handling [1,2]. A batch is defined as a group of jobs that have to be processed jointly and a batch scheduling problem consists of grouping jobs on each machine into batches that are scheduled either in serial (called serial batch) or in parallel (called parallel batch). For the serial batch, the processing time of a batch equals to the sum of the processing times of its jobs, while for the parallel batch, the processing time of a batch equals to the largest processing time of its jobs. In this article, we consider the parallel batch scheduling model.
There are numerous applications of parallel batch mentioned in the literature, such as aircraft manufacturing, automobile gear manufacturing and healthcare. However, the bulk of the literature on parallel batch scheduling deals with the semiconductor industry [2–4], which has already become one of the largest industries in the world. Nowadays microprocessors, memory chips and other semiconductor-related devices appear in electronics as a part of real daily life ranging from personal computers to cellular phones. Semiconductor manufactures need to utilize their resources effectively to confront the huge demand and severe competition in the marketplace. Consequently, efficient scheduling is of great concern to overall performance.
Real-world production systems usually require batch processing machines arranged in parallel in order to prevent the system from being blocked by the unavailability (e.g., breakdown) of a single machine. To make a scheduling problem closer to the real-world situation, the constraints of non-identical job sizes should be considered. Moreover, batch processing machines often have different capacities and may run at different speeds.
1.1 Problem formulation
In this article, we consider the following problem of scheduling
Note that
1.2 Literature review
In recent years, a body of research has started to address the parallel batch scheduling problems. For a detailed review of the existing results, please refer to [1–4].
This article is motivated by [10,11]. Wang and Leung [10] studied
Although the problem of scheduling parallel batch machines has been studied extensively in the last few decades, relatively little research has been done on the problem of scheduling uniform parallel batch machines with non-identical capacities [2,3]. Also, some research considered non-identical job sizes [13,14]. Li et al. [13] proposed several heuristics for the problem of scheduling uniform parallel batch machines with non-identical job sizes, unequal release times, identical capacities and makespan minimization. Zhou [14] proposed an effective discrete differential evolution (DDE) algorithm for the problem of scheduling uniform parallel batch machines with non-identical job sizes, unequal release times, non-identical capacities and makespan minimization. Both Li et al. [13] and Zhou et al. [14] assumed that largest job size fits in the machine with the smallest capacity, i.e.,
Several papers are concerned with the problem of scheduling parallel batch machines (all machines have identical speeds) with non-identical job sizes, non-identical capacities and makespan minimization [10,17–22]. Among them, [17,18] assumed that any job can fit in any machine, which is different from the problem we study in this article; while in [10,19–22] there is no such restriction.
Many recent research results contain complexity, mathematical models, as well as heuristic/meta-heuristic algorithms and are also related to different production areas. Some of them but not all, please see [23–28]. Note that in [28], Li discussed the problem of scheduling equal-length jobs with processing set restrictions on uniform parallel batch machines, where all jobs have the same size. However, in this article, we focus on the case of arbitrary job sizes.
1.3 Contribution and organization
For the case of equal release times, we can extend the results obtained in [10,11] to uniform parallel batch machines, allowing non-identical capacities. To the best of our knowledge,
The organization of the article is as follows. Section 2 provides preliminaries and notations. In Section 3, we consider the special case of
2 Preliminaries and notations
Before we proceed, we introduce some useful notations. Let
Throughout this article, let
3 Scheduling with divisible job sizes
In this section, we consider a special case where the job sizes form a divisible sequence, i.e., for any two jobs
Divisible job sizes are of interest because they arise naturally in certain applications and because some NP-hard problems produce substantially better solutions for such sets of jobs, see, e.g., [11,12,31–34].
Ozturk et al. [11] presented an exact algorithm running in
Lemma 1
[12] If
At the beginning, we do the following preprocessing in
We use a binary search to determine OPT in
Assignment A(
Let
While
Let
If
Let
Lemma 2
If
Proof
We need to prove that if
Let
Label the batches on
We will modify
For simplicity of notation, assume for the moment that batch
Repeat the aforementioned process to modify batches
It remains to offer an implementation of Assignment A, which gives the required time complexity. Clearly, the overall running time of the procedure is dominated by Step 2(ii). Note that we handle an empty batch on
Each iteration of Step 2(ii) can be executed by a naive quadratic time implementation. Also, there are easy implementations such that each iteration of Step 2(ii) can be executed in sub-quadratic time, leading to an overall running time
Precisely, in the
The tree is constructed incrementally, which is different from [35]. Let leaves denote the number of its current leaves. Initially,
In the first phase, we scan
Below, let us illustrate the implementation details.
In the first phase, we scan
Case 1. The label of the root is not less than the size of the job.
In this case, the job can be filled into a batch on
The path from the tree root to the destination leaf is an updating path. Update the labels of the nodes on the updating path as follows. First, let the label of the destination leaf be equal to its value minus the size of the job. Then, proceed back up the updating path and relabel the label of each internal node with the larger of the labels of its (at most) two sons. Keep
Case 2. The label of the root is less than the size of the job.
In this case, the job cannot be filled into a non-empty batch on
Subcase 2.1.
We fill this job into an empty batch which starts earliest on
Subcase 2.2.
It indicates that the first phase ends, and we have to enter the second phase.
Constructing the binary tree used in the
In the second phase, using a binary search in
Assigning each job to a batch in the second phase can be done in
Hence, the time complexity of Assignment A is
Example 1
Here is an example to illustrate how the binary tree grows. Fix a particular machine

Tree directory for the Implementation of Step 2(ii), after assigning the first three jobs of size 8.
The next three jobs of size 8 cannot fit in any non-empty batch and have to be left over (to be assigned in the next iterations). Among them, the first one tells us that the second phase begins. Then, the first three jobs of size 4 can be assigned, and we assign each of them to a different non-empty batch. The state of the binary tree after the first three jobs of size 4 are assigned is shown in Figure 2.

Tree directory for the Implementation of Step 2(ii), after assigning the first three jobs of size 4.
Now, the unused capacity of each existing batch is 1. Neither the next three jobs of size 4 nor the two jobs of size 2 can be filled in. These jobs have to be left over. Only the two jobs of size 1 can be assigned, and we assign them in the first two batches. The state of the binary tree after the two jobs of size 1 are assigned is shown in Figure 3. In final
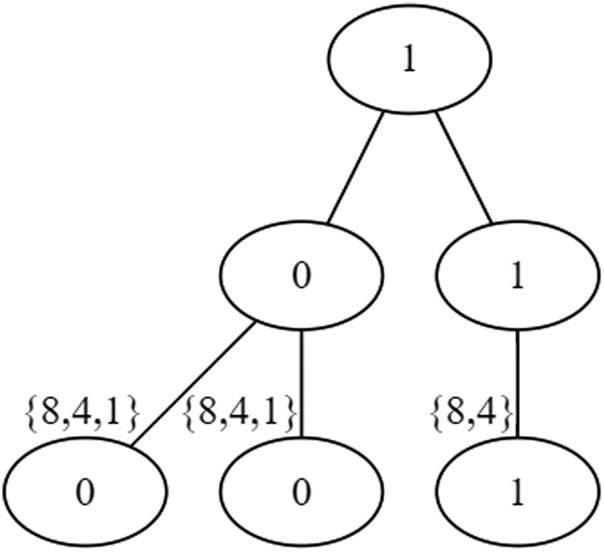
Tree directory for the Implementation of Step 2(ii), after assigning the two jobs of size 1.
We can use the following Assignment A1 procedure instead of Assignment A. It runs in
The procedure handles the machines in decreasing order of their indices. In the procedure,
Assignment A1 (
Let
For
Assign
Construct a binary tree of depth
If
We obtain the following theorem.
Theorem 1
There is an exact algorithm (the binary search together with Assignment A or Assignment A1) for
Proof
The correctness of the algorithm follows from the aforementioned analysis. Procedure Assignment A (or Assignment A1) runs in
4 An algorithm for the general case
We now turn to the general case of
Again, we restrict our attention on an optimal schedule where the
We can obtain all
We use a binary search to determine
Assignment B (
Let
While
Let
While
Open a batch of length
Let
Lemma 3
If
We obtain:
Theorem 2
There is a 2-approximation algorithm for
Proof
The binary search equipped with Assignment B will return a schedule allowing one-job-overfull batches for
Note that a bottleneck operation in the algorithm is the sorting procedure performed once at the beginning.
5 Conclusion
In this article, we investigated the problem of minimizing makespan for scheduling jobs with equal lengths and arbitrary sizes on uniform parallel batch machines with different capacities. Each machine can only process the jobs whose sizes are not larger than the machine’s capacity. We presented two exact algorithms under a divisibility constraint, and a 2-approximation algorithm for the general problem. These algorithms are of practical significance, since they are efficient and easy to implement. A future research topic is to investigate some other objective functions for parallel batch scheduling problems with equal job lengths and arbitrary job sizes.
Acknowledgments
The authors would like to thank the editor and the referees for their helpful comments in improving the quality of the article.
-
Funding information: This work was supported by Natural Science Foundation of Shandong Province China (No. ZR2020MA030).
-
Author contributions: All authors contributed equally to the writing of this article. All authors read and approved the final manuscript.
-
Conflict of interest: The authors state no conflict of interest.
-
Data availability statement: No data, models, or code are generated or used during the study.
References
[1] C. N. Potts and M. Y. Kovalyov, Scheduling with batching: a review, European J. Oper. Res. 120 (2000), 228–249. 10.1016/S0377-2217(99)00153-8Search in Google Scholar
[2] J. W. Fowler and L. Mönch, A survey of scheduling with parallel batch (p-batch) processing, European J. Oper. Res. 298 (2022), 1–24. 10.1016/j.ejor.2021.06.012Search in Google Scholar
[3] M. Mathirajan and A. Sivakumar, A literature review, classification and simple meta-analysis on scheduling of batch processors in semiconductor, Int. J. Adv. Manuf. Technol. 29 (2006), 990–1001. 10.1007/s00170-005-2585-1Search in Google Scholar
[4] L. Mönch, J. W. Fowler, S. Dauzère-Pérès, S. J. Mason, and O. Rose, A survey of problems, solution techniques, and future challenges in scheduling semiconductor manufacturing operations, J. Sched. 14 (2011), 583–599. 10.1007/s10951-010-0222-9Search in Google Scholar
[5] R. L. Graham, E. L. Lawler, J. K. Lenstra, and A. R. Kan, Optimization and approximation in deterministic sequencing and scheduling: a survey, Ann. Discr. Math. 5 (1979), 287–326. 10.1016/S0167-5060(08)70356-XSearch in Google Scholar
[6] P. Brucker, Scheduling Algorithms, 5th edition, Springer, Berlin, Heidelberg, New York, 2007. Search in Google Scholar
[7] E. G. Coffman, M. R. Garey, and D. S. Johnson, Approximation algorithms for bin packing: A survey, Approximation Algorithms for NP-hard Problems, PWS Publishing Co., Boston, MA, USA, 1996, pp. 46–93. 10.1007/978-3-7091-4338-4_3Search in Google Scholar
[8] M. R. Garey and D. S. Johnson, Computers and Intractability: A Guide to the Theory of NP-completeness, Freeman, New York, 1979. Search in Google Scholar
[9] G. Dosa, Z. Tan, Z. Tuza, Y. Yan, and C. S. Lanyi, Improved bounds for batch scheduling with nonidentical job sizes, Naval Res. Logist. 61 (2014), 351–358. 10.1002/nav.21587Search in Google Scholar
[10] J.-Q. Wang and J. Y.-T. Leung, Scheduling jobs with equal-processing-time on parallel machines with non-identical capacities to minimize makespan, Int. J. Prod. Econ. 156 (2014), 325–331. 10.1016/j.ijpe.2014.06.019Search in Google Scholar
[11] O. Ozturk, M.-L. Espinouse, M. D. Mascolo, and A. Gouin, Makespan minimisation on parallel batch processing machines with non-identical job sizes and release dates, Int. J. Prod. Res. 50 (2012), 6022–6035. 10.1080/00207543.2011.641358Search in Google Scholar
[12] E. G. Coffman, M. R. Garey, and D. S. Johnson, Bin packing with divisible item sizes, J. Complexity 3 (1987), 406–428. 10.1016/0885-064X(87)90009-4Search in Google Scholar
[13] X. Li, H. Chen, B. Du, and Q. Tan, Heuristics to schedule uniform parallel batch processing machines with dynamic job arrivals, Int. J. Comput. Integr. Manuf. 26 (2013), 474–486. 10.1080/0951192X.2012.731612Search in Google Scholar
[14] S. Zhou, M. Liu, H. Chen, and X. Li, An effective discrete differential evolution algorithm for scheduling uniform parallel batch processing machines with non-identical capacities and arbitrary job sizes, Int. J. Prod. Econ. 179 (2016), 1–11. 10.1016/j.ijpe.2016.05.014Search in Google Scholar
[15] X. Li, Y. Huang, Q. Tan, and H. Chen, Scheduling unrelated parallel batch processing machines with non-identical job sizes, Comput. Oper. Res. 40 (2013), 2983–2990. 10.1016/j.cor.2013.06.016Search in Google Scholar
[16] J. E. C. Arroyo and J. Y.-T. Leung, Scheduling unrelated parallel batch processing machines with non-identical job sizes and unequal ready times, Comput. Oper. Res. 78 (2017), 117–128. 10.1016/j.cor.2016.08.015Search in Google Scholar
[17] S. Xu and J. C. Bean, A genetic algorithm for scheduling parallel non-identical batch processing machines, IEEE Symposium on Computational Intelligence in Scheduling, Honolulu, HI, USA, 2007, pp. 143–150. 10.1109/SCIS.2007.367682Search in Google Scholar
[18] H.-M. Wang and F.-D. Chou, Solving the parallel batch-processing machines with different release times, job sizes, and capacity limits by metaheuristics, Expert Syst. Appl. 37 (2010), 1510–1521. 10.1016/j.eswa.2009.06.070Search in Google Scholar
[19] P. Damodaran, D. A. Diyadawagamage, O. Ghrayeb, and M. C. Velez-Gallego, A particle swarm optimization algorithm for minimizing makespan of nonidentical parallel batch processing machines, Int. J. Adv. Manuf. Technol. 58 (2012), 1131–1140. 10.1007/s00170-011-3442-zSearch in Google Scholar
[20] Z.-H. Jia, K. Li, and J. Y.-T. Leung, Effective heuristic for makespan minimization in parallel batch machines with non-identical capacities, Int. J. Prod. Econ. 169 (2015), 1–10. 10.1016/j.ijpe.2015.07.021Search in Google Scholar
[21] Z.-H. Jia, T. T. Wen, J. Y.-T. Leung, and K. Li, Effective heuristics for makespan minimization in parallel batch machines with non-identical capacities and job release times, J. Ind. Manag. Optim. 13 (2017), 977–993. 10.3934/jimo.2016057Search in Google Scholar
[22] S. Li, Approximation algorithms for scheduling jobs with release times and arbitrary sizes on batch machines with non-identical capacities, European J. Oper. Res. 263 (2017), 815–826. 10.1016/j.ejor.2017.06.021Search in Google Scholar
[23] A. Gürsoy, Optimization of product switching processes in assembly lines, Arab. J. Sci. Eng. 2022 (2022), 1–16. 10.1007/s13369-021-06430-9Search in Google Scholar
[24] F. Zheng, Y. Chen, M. Liu, and Y. Xu, Competitive analysis of online machine rental and online parallel machine scheduling problems with workload fence, J. Comb. Optim. 44 (2022), 1060–1076. 10.1007/s10878-022-00882-xSearch in Google Scholar
[25] A. Gürsoy and N. K. Gürsoy, On the flexibility constrained line balancing problem in lean manufacturing, Textile Apparel. 25 (2015), 345–351. Search in Google Scholar
[26] R. Zhang, P.-C. Chang, S. Song, and C. Wu, A multi-objective artificial bee colony algorithm for parallel batch-processing machine scheduling in fabric dyeing processes, Knowl. Based Syst. 116 (2017), 114–129. 10.1016/j.knosys.2016.10.026Search in Google Scholar
[27] A. Gürsoy, An integer model and a heuristic algorithm for the flexible line balancing problem, Textile Apparel. 22 (2012), 58–63. Search in Google Scholar
[28] S. Li, Efficient algorithms for scheduling equal-length jobs with processing set restrictions on uniform parallel batch machines, Math. Biosci. Eng. 19 (2022), 10731–10740. 10.3934/mbe.2022502Search in Google Scholar PubMed
[29] C. L. Li, Scheduling unit-length jobs with machine eligibility restrictions, European J. Oper. Res. 174 (2006), 1325–1328. 10.1016/j.ejor.2005.03.023Search in Google Scholar
[30] A. V. Aho, J. E. Hopcroft, and J. D. Ullman, The Design and Analysis of Computer Algorithms, Addison-Wesley Publ. Comp. London-Amsterdam-Don Mills-Sydney, 1974. Search in Google Scholar
[31] J. Kang and S. Park, Algorithms for the variable sized bin packing problem, European J. Oper. Res. 147 (2003), 365–372. 10.1016/S0377-2217(02)00247-3Search in Google Scholar
[32] A. Bar-Noy, R. E. Ladner, and T. Tamir, Windows scheduling as a restricted version of bin packing, ACM Trans. Algorithms 3 (2007), 28-es. 10.1145/1273340.1273344Search in Google Scholar
[33] P. Detti, A polynomial algorithm for the multiple knapsack problem with divisible item sizes, Inform. Process. Lett. 109 (2009), 582–584. 10.1016/j.ipl.2009.02.003Search in Google Scholar
[34] G. Wang and L. Lei, Polynomial-time solvable cases of the capacitated multi-echelon shipping network scheduling problem with delivery deadlines, Int. J. Prod. Econ. 137 (2012), 263–271. 10.1016/j.ijpe.2012.02.006Search in Google Scholar
[35] D. S. Johnson, Near-optimal Bin Packing Algorithms, Ph.D. thesis, Massachusetts Institute of Technology, Department of Mathematics, Cambridge, 1973. Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Special Issue on Future Directions of Further Developments in Mathematics
- What will the mathematics of tomorrow look like?
- On H 2-solutions for a Camassa-Holm type equation
- Classical solutions to Cauchy problems for parabolic–elliptic systems of Keller-Segel type
- Control of multi-agent systems: Results, open problems, and applications
- Logical perspectives on the foundations of probability
- Subharmonic solutions for a class of predator-prey models with degenerate weights in periodic environments
- A non-smooth Brezis-Oswald uniqueness result
- Luenberger compensator theory for heat-Kelvin-Voigt-damped-structure interaction models with interface/boundary feedback controls
- Special Issue on Fractional Problems with Variable-Order or Variable Exponents (Part II)
- Positive solution for a nonlocal problem with strong singular nonlinearity
- Analysis of solutions for the fractional differential equation with Hadamard-type
- Hilfer proportional nonlocal fractional integro-multipoint boundary value problems
- A comprehensive review on fractional-order optimal control problem and its solution
- The θ-derivative as unifying framework of a class of derivatives
- Review Articles
- On the use of L-functionals in regression models
- Minimal-time problems for linear control systems on homogeneous spaces of low-dimensional solvable nonnilpotent Lie groups
- Regular Articles
- Existence and multiplicity of solutions for a new p(x)-Kirchhoff problem with variable exponents
- An extension of the Hermite-Hadamard inequality for a power of a convex function
- Existence and multiplicity of solutions for a fourth-order differential system with instantaneous and non-instantaneous impulses
- Relay fusion frames in Banach spaces
- Refined ratio monotonicity of the coordinator polynomials of the root lattice of type Bn
- On the uniqueness of limit cycles for generalized Liénard systems
- A derivative-Hilbert operator acting on Dirichlet spaces
- Scheduling equal-length jobs with arbitrary sizes on uniform parallel batch machines
- Solutions to a modified gauged Schrödinger equation with Choquard type nonlinearity
- A symbolic approach to multiple Hurwitz zeta values at non-positive integers
- Some results on the value distribution of differential polynomials
- Lucas non-Wieferich primes in arithmetic progressions and the abc conjecture
- Scattering properties of Sturm-Liouville equations with sign-alternating weight and transmission condition at turning point
- Some results for a p(x)-Kirchhoff type variation-inequality problems in non-divergence form
- Homotopy cartesian squares in extriangulated categories
- A unified perspective on some autocorrelation measures in different fields: A note
- Total Roman domination on the digraphs
- Well-posedness for bilevel vector equilibrium problems with variable domination structures
- Binet's second formula, Hermite's generalization, and two related identities
- Non-solid cone b-metric spaces over Banach algebras and fixed point results of contractions with vector-valued coefficients
- Multidimensional sampling-Kantorovich operators in BV-spaces
- A self-adaptive inertial extragradient method for a class of split pseudomonotone variational inequality problems
- Convergence properties for coordinatewise asymptotically negatively associated random vectors in Hilbert space
- Relating the super domination and 2-domination numbers in cactus graphs
- Compatibility of the method of brackets with classical integration rules
- On the inverse Collatz-Sinogowitz irregularity problem
- Positive solutions for boundary value problems of a class of second-order differential equation system
- Global analysis and control for a vector-borne epidemic model with multi-edge infection on complex networks
- Nonexistence of global solutions to Klein-Gordon equations with variable coefficients power-type nonlinearities
- On 2r-ideals in commutative rings with zero-divisors
- A comparison of some confidence intervals for a binomial proportion based on a shrinkage estimator
- The construction of nuclei for normal constituents of Bπ-characters
- Weak solution of non-Newtonian polytropic variational inequality in fresh agricultural product supply chain problem
- Mean square exponential stability of stochastic function differential equations in the G-framework
- Commutators of Hardy-Littlewood operators on p-adic function spaces with variable exponents
- Solitons for the coupled matrix nonlinear Schrödinger-type equations and the related Schrödinger flow
- The dual index and dual core generalized inverse
- Study on Birkhoff orthogonality and symmetry of matrix operators
- Uniqueness theorems of the Hahn difference operator of entire function with a Picard exceptional value
- Estimates for certain class of rough generalized Marcinkiewicz functions along submanifolds
- On semigroups of transformations that preserve a double direction equivalence
- Positive solutions for discrete Minkowski curvature systems of the Lane-Emden type
- A multigrid discretization scheme based on the shifted inverse iteration for the Steklov eigenvalue problem in inverse scattering
- Existence and nonexistence of solutions for elliptic problems with multiple critical exponents
- Interpolation inequalities in generalized Orlicz-Sobolev spaces and applications
- General Randić indices of a graph and its line graph
- On functional reproducing kernels
- On the Waring-Goldbach problem for two squares and four cubes
- Singular moduli of rth Roots of modular functions
- Classification of self-adjoint domains of odd-order differential operators with matrix theory
- On the convergence, stability and data dependence results of the JK iteration process in Banach spaces
- Hardy spaces associated with some anisotropic mixed-norm Herz spaces and their applications
- Remarks on hyponormal Toeplitz operators with nonharmonic symbols
- Complete decomposition of the generalized quaternion groups
- Injective and coherent endomorphism rings relative to some matrices
- Finite spectrum of fourth-order boundary value problems with boundary and transmission conditions dependent on the spectral parameter
- Continued fractions related to a group of linear fractional transformations
- Multiplicity of solutions for a class of critical Schrödinger-Poisson systems on the Heisenberg group
- Approximate controllability for a stochastic elastic system with structural damping and infinite delay
- On extremal cacti with respect to the first degree-based entropy
- Compression with wildcards: All exact or all minimal hitting sets
- Existence and multiplicity of solutions for a class of p-Kirchhoff-type equation RN
- Geometric classifications of k-almost Ricci solitons admitting paracontact metrices
- Positive periodic solutions for discrete time-delay hematopoiesis model with impulses
- On Hermite-Hadamard-type inequalities for systems of partial differential inequalities in the plane
- Existence of solutions for semilinear retarded equations with non-instantaneous impulses, non-local conditions, and infinite delay
- On the quadratic residues and their distribution properties
- On average theta functions of certain quadratic forms as sums of Eisenstein series
- Connected component of positive solutions for one-dimensional p-Laplacian problem with a singular weight
- Some identities of degenerate harmonic and degenerate hyperharmonic numbers arising from umbral calculus
- Mean ergodic theorems for a sequence of nonexpansive mappings in complete CAT(0) spaces and its applications
- On some spaces via topological ideals
- Linear maps preserving equivalence or asymptotic equivalence on Banach space
- Well-posedness and stability analysis for Timoshenko beam system with Coleman-Gurtin's and Gurtin-Pipkin's thermal laws
- On a class of stochastic differential equations driven by the generalized stochastic mixed variational inequalities
- Entire solutions of two certain Fermat-type ordinary differential equations
- Generalized Lie n-derivations on arbitrary triangular algebras
- Markov decision processes approximation with coupled dynamics via Markov deterministic control systems
- Notes on pseudodifferential operators commutators and Lipschitz functions
- On Graham partitions twisted by the Legendre symbol
- Strong limit of processes constructed from a renewal process
- Construction of analytical solutions to systems of two stochastic differential equations
- Two-distance vertex-distinguishing index of sparse graphs
- Regularity and abundance on semigroups of partial transformations with invariant set
- Liouville theorems for Kirchhoff-type parabolic equations and system on the Heisenberg group
- Spin(8,C)-Higgs pairs over a compact Riemann surface
- Properties of locally semi-compact Ir-topological groups
- Transcendental entire solutions of several complex product-type nonlinear partial differential equations in ℂ2
- Ordering stability of Nash equilibria for a class of differential games
- A new reverse half-discrete Hilbert-type inequality with one partial sum involving one derivative function of higher order
- About a dubious proof of a correct result about closed Newton Cotes error formulas
- Ricci ϕ-invariance on almost cosymplectic three-manifolds
- Schur-power convexity of integral mean for convex functions on the coordinates
- A characterization of a ∼ admissible congruence on a weakly type B semigroup
- On Bohr's inequality for special subclasses of stable starlike harmonic mappings
- Properties of meromorphic solutions of first-order differential-difference equations
- A double-phase eigenvalue problem with large exponents
- On the number of perfect matchings in random polygonal chains
- Evolutoids and pedaloids of frontals on timelike surfaces
- A series expansion of a logarithmic expression and a decreasing property of the ratio of two logarithmic expressions containing cosine
- The 𝔪-WG° inverse in the Minkowski space
- Stability result for Lord Shulman swelling porous thermo-elastic soils with distributed delay term
- Approximate solvability method for nonlocal impulsive evolution equation
- Construction of a functional by a given second-order Ito stochastic equation
- Global well-posedness of initial-boundary value problem of fifth-order KdV equation posed on finite interval
- On pomonoid of partial transformations of a poset
- New fractional integral inequalities via Euler's beta function
- An efficient Legendre-Galerkin approximation for the fourth-order equation with singular potential and SSP boundary condition
- Eigenfunctions in Finsler Gaussian solitons
- On a blow-up criterion for solution of 3D fractional Navier-Stokes-Coriolis equations in Lei-Lin-Gevrey spaces
- Some estimates for commutators of sharp maximal function on the p-adic Lebesgue spaces
- A preconditioned iterative method for coupled fractional partial differential equation in European option pricing
- A digital Jordan surface theorem with respect to a graph connectedness
- A quasi-boundary value regularization method for the spherically symmetric backward heat conduction problem
- The structure fault tolerance of burnt pancake networks
- Average value of the divisor class numbers of real cubic function fields
- Uniqueness of exponential polynomials
- An application of Hayashi's inequality in numerical integration
Articles in the same Issue
- Special Issue on Future Directions of Further Developments in Mathematics
- What will the mathematics of tomorrow look like?
- On H 2-solutions for a Camassa-Holm type equation
- Classical solutions to Cauchy problems for parabolic–elliptic systems of Keller-Segel type
- Control of multi-agent systems: Results, open problems, and applications
- Logical perspectives on the foundations of probability
- Subharmonic solutions for a class of predator-prey models with degenerate weights in periodic environments
- A non-smooth Brezis-Oswald uniqueness result
- Luenberger compensator theory for heat-Kelvin-Voigt-damped-structure interaction models with interface/boundary feedback controls
- Special Issue on Fractional Problems with Variable-Order or Variable Exponents (Part II)
- Positive solution for a nonlocal problem with strong singular nonlinearity
- Analysis of solutions for the fractional differential equation with Hadamard-type
- Hilfer proportional nonlocal fractional integro-multipoint boundary value problems
- A comprehensive review on fractional-order optimal control problem and its solution
- The θ-derivative as unifying framework of a class of derivatives
- Review Articles
- On the use of L-functionals in regression models
- Minimal-time problems for linear control systems on homogeneous spaces of low-dimensional solvable nonnilpotent Lie groups
- Regular Articles
- Existence and multiplicity of solutions for a new p(x)-Kirchhoff problem with variable exponents
- An extension of the Hermite-Hadamard inequality for a power of a convex function
- Existence and multiplicity of solutions for a fourth-order differential system with instantaneous and non-instantaneous impulses
- Relay fusion frames in Banach spaces
- Refined ratio monotonicity of the coordinator polynomials of the root lattice of type Bn
- On the uniqueness of limit cycles for generalized Liénard systems
- A derivative-Hilbert operator acting on Dirichlet spaces
- Scheduling equal-length jobs with arbitrary sizes on uniform parallel batch machines
- Solutions to a modified gauged Schrödinger equation with Choquard type nonlinearity
- A symbolic approach to multiple Hurwitz zeta values at non-positive integers
- Some results on the value distribution of differential polynomials
- Lucas non-Wieferich primes in arithmetic progressions and the abc conjecture
- Scattering properties of Sturm-Liouville equations with sign-alternating weight and transmission condition at turning point
- Some results for a p(x)-Kirchhoff type variation-inequality problems in non-divergence form
- Homotopy cartesian squares in extriangulated categories
- A unified perspective on some autocorrelation measures in different fields: A note
- Total Roman domination on the digraphs
- Well-posedness for bilevel vector equilibrium problems with variable domination structures
- Binet's second formula, Hermite's generalization, and two related identities
- Non-solid cone b-metric spaces over Banach algebras and fixed point results of contractions with vector-valued coefficients
- Multidimensional sampling-Kantorovich operators in BV-spaces
- A self-adaptive inertial extragradient method for a class of split pseudomonotone variational inequality problems
- Convergence properties for coordinatewise asymptotically negatively associated random vectors in Hilbert space
- Relating the super domination and 2-domination numbers in cactus graphs
- Compatibility of the method of brackets with classical integration rules
- On the inverse Collatz-Sinogowitz irregularity problem
- Positive solutions for boundary value problems of a class of second-order differential equation system
- Global analysis and control for a vector-borne epidemic model with multi-edge infection on complex networks
- Nonexistence of global solutions to Klein-Gordon equations with variable coefficients power-type nonlinearities
- On 2r-ideals in commutative rings with zero-divisors
- A comparison of some confidence intervals for a binomial proportion based on a shrinkage estimator
- The construction of nuclei for normal constituents of Bπ-characters
- Weak solution of non-Newtonian polytropic variational inequality in fresh agricultural product supply chain problem
- Mean square exponential stability of stochastic function differential equations in the G-framework
- Commutators of Hardy-Littlewood operators on p-adic function spaces with variable exponents
- Solitons for the coupled matrix nonlinear Schrödinger-type equations and the related Schrödinger flow
- The dual index and dual core generalized inverse
- Study on Birkhoff orthogonality and symmetry of matrix operators
- Uniqueness theorems of the Hahn difference operator of entire function with a Picard exceptional value
- Estimates for certain class of rough generalized Marcinkiewicz functions along submanifolds
- On semigroups of transformations that preserve a double direction equivalence
- Positive solutions for discrete Minkowski curvature systems of the Lane-Emden type
- A multigrid discretization scheme based on the shifted inverse iteration for the Steklov eigenvalue problem in inverse scattering
- Existence and nonexistence of solutions for elliptic problems with multiple critical exponents
- Interpolation inequalities in generalized Orlicz-Sobolev spaces and applications
- General Randić indices of a graph and its line graph
- On functional reproducing kernels
- On the Waring-Goldbach problem for two squares and four cubes
- Singular moduli of rth Roots of modular functions
- Classification of self-adjoint domains of odd-order differential operators with matrix theory
- On the convergence, stability and data dependence results of the JK iteration process in Banach spaces
- Hardy spaces associated with some anisotropic mixed-norm Herz spaces and their applications
- Remarks on hyponormal Toeplitz operators with nonharmonic symbols
- Complete decomposition of the generalized quaternion groups
- Injective and coherent endomorphism rings relative to some matrices
- Finite spectrum of fourth-order boundary value problems with boundary and transmission conditions dependent on the spectral parameter
- Continued fractions related to a group of linear fractional transformations
- Multiplicity of solutions for a class of critical Schrödinger-Poisson systems on the Heisenberg group
- Approximate controllability for a stochastic elastic system with structural damping and infinite delay
- On extremal cacti with respect to the first degree-based entropy
- Compression with wildcards: All exact or all minimal hitting sets
- Existence and multiplicity of solutions for a class of p-Kirchhoff-type equation RN
- Geometric classifications of k-almost Ricci solitons admitting paracontact metrices
- Positive periodic solutions for discrete time-delay hematopoiesis model with impulses
- On Hermite-Hadamard-type inequalities for systems of partial differential inequalities in the plane
- Existence of solutions for semilinear retarded equations with non-instantaneous impulses, non-local conditions, and infinite delay
- On the quadratic residues and their distribution properties
- On average theta functions of certain quadratic forms as sums of Eisenstein series
- Connected component of positive solutions for one-dimensional p-Laplacian problem with a singular weight
- Some identities of degenerate harmonic and degenerate hyperharmonic numbers arising from umbral calculus
- Mean ergodic theorems for a sequence of nonexpansive mappings in complete CAT(0) spaces and its applications
- On some spaces via topological ideals
- Linear maps preserving equivalence or asymptotic equivalence on Banach space
- Well-posedness and stability analysis for Timoshenko beam system with Coleman-Gurtin's and Gurtin-Pipkin's thermal laws
- On a class of stochastic differential equations driven by the generalized stochastic mixed variational inequalities
- Entire solutions of two certain Fermat-type ordinary differential equations
- Generalized Lie n-derivations on arbitrary triangular algebras
- Markov decision processes approximation with coupled dynamics via Markov deterministic control systems
- Notes on pseudodifferential operators commutators and Lipschitz functions
- On Graham partitions twisted by the Legendre symbol
- Strong limit of processes constructed from a renewal process
- Construction of analytical solutions to systems of two stochastic differential equations
- Two-distance vertex-distinguishing index of sparse graphs
- Regularity and abundance on semigroups of partial transformations with invariant set
- Liouville theorems for Kirchhoff-type parabolic equations and system on the Heisenberg group
- Spin(8,C)-Higgs pairs over a compact Riemann surface
- Properties of locally semi-compact Ir-topological groups
- Transcendental entire solutions of several complex product-type nonlinear partial differential equations in ℂ2
- Ordering stability of Nash equilibria for a class of differential games
- A new reverse half-discrete Hilbert-type inequality with one partial sum involving one derivative function of higher order
- About a dubious proof of a correct result about closed Newton Cotes error formulas
- Ricci ϕ-invariance on almost cosymplectic three-manifolds
- Schur-power convexity of integral mean for convex functions on the coordinates
- A characterization of a ∼ admissible congruence on a weakly type B semigroup
- On Bohr's inequality for special subclasses of stable starlike harmonic mappings
- Properties of meromorphic solutions of first-order differential-difference equations
- A double-phase eigenvalue problem with large exponents
- On the number of perfect matchings in random polygonal chains
- Evolutoids and pedaloids of frontals on timelike surfaces
- A series expansion of a logarithmic expression and a decreasing property of the ratio of two logarithmic expressions containing cosine
- The 𝔪-WG° inverse in the Minkowski space
- Stability result for Lord Shulman swelling porous thermo-elastic soils with distributed delay term
- Approximate solvability method for nonlocal impulsive evolution equation
- Construction of a functional by a given second-order Ito stochastic equation
- Global well-posedness of initial-boundary value problem of fifth-order KdV equation posed on finite interval
- On pomonoid of partial transformations of a poset
- New fractional integral inequalities via Euler's beta function
- An efficient Legendre-Galerkin approximation for the fourth-order equation with singular potential and SSP boundary condition
- Eigenfunctions in Finsler Gaussian solitons
- On a blow-up criterion for solution of 3D fractional Navier-Stokes-Coriolis equations in Lei-Lin-Gevrey spaces
- Some estimates for commutators of sharp maximal function on the p-adic Lebesgue spaces
- A preconditioned iterative method for coupled fractional partial differential equation in European option pricing
- A digital Jordan surface theorem with respect to a graph connectedness
- A quasi-boundary value regularization method for the spherically symmetric backward heat conduction problem
- The structure fault tolerance of burnt pancake networks
- Average value of the divisor class numbers of real cubic function fields
- Uniqueness of exponential polynomials
- An application of Hayashi's inequality in numerical integration