Robust estimation for partial functional linear regression models based on FPCA and weighted composite quantile regression
-
Peng Cao
 and
Jun Sun
and
Jun Sun

Abstract
In this paper, we consider a novel estimation for partial functional linear regression models. The functional principal component analysis method is employed to estimate the slope function and the functional predictive variable, respectively. An efficient estimation based on principal component basis function approximation is used for minimizing the proposed weighted composite quantile regression (WCQR) objective function. Since the proposed WCQR involves a vector of weights, we develop a computational strategy for data-driven selection of the optimal weights. Under some mild conditions, the theoretical properties of the proposed WCQR method are obtained. The simulation study and a real data analysis are provided to illustrate the numerical performance of the resulting estimators.
1 Introduction
In the literature of functional data analysis, functional linear regression models (FLRMs) provide an efficient method to analyze the relationship between a functional predictor and a scalar response. Therefore, much effort has been devoted to studying its estimation and other relevant inference problems, see [1,2, 3,4,5, 6,7,8, 9,10,11, 12,13]. However, in practice, we often see that a scalar response is related not only to functional covariates but also to scalar covariates. Thus, Shin considered partial functional linear regression models (PFLRMs) to balance the flexibility of FLRMs and interpretation of classical linear regression models [14]. Generally, PFLRM has the following form:
where
The PFLRMs have been studied by many authors. For example, Shin [14] proposed the estimation method based on functional principal component analysis (FPCA) and investigated the asymptotic properties of the estimators for model (1). Zhou et al. [15] considered the polynomial spline method to estimate model (1) and established the asymptotic normality for the parameter vector and the global convergence rate for the slope function. Furthermore, Kong et al. [16] studied variable selection in model (1) with multiple functional and ultrahigh-dimensional scalar predictors. Ling et al. [17] developed the k-nearest-neighbors estimation for PFLRMs. Kong et al. [18] proposed the partial functional linear cox regression model for censored outcomes. Cao et al. [19] developed a two-step estimation procedure via maximizing the quasi likelihood function in the framework of generalized PFLRMs. Yuan and Zhang [20] investigated the hypothesis test of the parametric components in PFLRMs based on B-spline. Zhu et al. [21] considered estimation and testing problems for PFLRMs when the covariates of the non-functional linear component are measured with additive error. Li et al. [22] proposed two test statistics for series correlation in PFLRMs and derived their asymptotic distributions under the null hypothesis.
Quantile regression (QR) is an effective approach for functional data analysis. This is due to the fact that QR models compared to the mean regression models [23] offer more robust merits especially the observations contain some outliers. For relevant literature, see [24,25,26]. Hence, QR method may result in an arbitrarily small relative efficiency compared with the mean regression. To conquer this drawback of QR method, Zou and Yuan proposed the composite quantile regression (CQR) method for linear models and showed that the relative efficiency of the CQR estimator is greater than 70% regardless of the error distribution compared with the least square (LS) estimator [27]. In many cases, CQR provides more efficient estimation compared with a single QR or the LS estimator for non-normal error distributions. This method has been deeply investigated in the literature and widely applied in many statistical models. For further references about the CQR method on nonparametric/semi-parametric models see [28,29,30, 31,32]. Even though CQR has been well developed, theory and methodology of PFLRMs are rare. Du et al. [33] used the penalized CQR method to study variable selection for parametric part in the PFLRMs, Yu et al. [34] considered composite quantile estimation for the PFLRMs with errors from short-range dependent and strictly stationary linear processes. However, the aforementioned CQR method for PFLRMs is a sum of different QRs with equal weights. Intuitively, using equal weights is not optimal in general, though CQR enjoys great advantages in terms of estimation efficiency. Therefore, Jiang et al. [35] addressed the issue of statistical inference for nonlinear models with large-dimensional covariates by using the weighted composite quantile regression (WCQR) method. Moreover, they pointed out that their method was more robust than some existing methods. Guo et al. [36] investigated group SCAD penalized WCQR estimation for varying coefficient models with diverging number of parameters. Jiang et al. [37] developed a data-driven WCQR for heteroscedastic partially linear varying coefficient models. Similar conclusions of WCQR method have been further confirmed in [6,38,39]. Until now, the WCQR method has not been used in functional regression analysis. Consequently, motivated by this fact, we devote to extending the WCQR method to PFLRMs in this paper. We show that the resulting estimators for both parametric components and slope function are more efficient in the case of asymmetrical error distribution, and as asymptotically efficient as the corresponding LS estimators when the error distribution is normal.
It is well known that many smoothing methods have been proposed for functional regressions, and two popular approaches for estimating the slope function
This is the first attempt to provide robust estimate via WCQR and establish the asymptotic properties of the proposed estimators for model (1).
Theoretically, the proposed WCQR method generalizes the results of the composite quantile estimators in [8]. Particularly, our method reduces to that of Du et al. when the weights are all equal.
The rest of this paper is organized as follows. In Section 2, we describe the implementation details of the proposed algorithm and establish the theoretical properties of the estimators. In Section 3, we discuss the selection of weights and tuning parameters. Simulation study and a real data analysis are conducted in Sections 4 and 5 to evaluate the performance of our proposed approach, and then followed by a short conclusion in Section 6. All technical proofs are collected in the Appendix.
2 Method and main results
In partial functional linear QR model, for a given quantile level
where
Denote the covariance function of the process
The covariance function
where
where
where
Therefore, the regression model in (4) can be well approximated by
where
where
Note that the CQR method used the same weight for different QR models. Intuitively, it will be more effective if different weights are used. According to Jiang et al. [35], the WCQR procedure estimates
where
3 Assumptions and asymptotic results
To establish the asymptotic properties of the proposed estimators, first, we introduce some notations. Let
The random function
For each
The tuning parameter
The random vector
Remark 1
Assumptions A1–A3 are required in the classical functional linear regression (see [5,7,24]). Specifically, Assumption A1 ensures the consistency of
Theorem 3.1
Suppose that Assumptions A1–A7 are satisfied, then
Remark 2
The result of Theorem 3.1(i) indicates that the estimator
Remark 3
When
Under the assumptions of Theorem 3.1, then
Under the assumptions of Theorem 3.1, then
Under the assumptions of Theorem 3.1, then
4 Computational issues
From Theorem 3.1, we find that the asymptotic variance of
where
It can be seen from (8) that the optimal weight vector is rather complicated and involves the density of the errors
Step 1. We give the initial estimators
Step 2. Compute
Similar to Silverman [42], the bandwidth
Step 3. Estimate
The proposed estimators involve the tuning parameter
where
5 Simulation study
In this section, we conduct a Monte Carlo simulation example to assess the finite sample performance of the proposed procedures. Moreover, we include four competitors in our comparisons: (1) the LS method [14], (2) the QR method (QR) with
where both
In order to show the robustness of our estimators, the following six different error distributions are considered: standard normal distribution N(0, 1),
To assess the performance of the estimated parameters, the following criteria are considered:
(1) the average value of the corresponding coefficients (MEAN);
(2) the sample standard deviation (SD);
(3) the median of absolute bias (ABISE). To assess the performance of the slope function, we consider the following square root of average square errors (RASE):
where
Simulation results for
|
|
Method |
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 100 | LS | 0.8010 | 0.1003 | 0.0778 | 1.9969 | 0.0989 | 0.0784 | 0.4293 |
| QR | 0.5162 | 0.4613 | 0.5243 | 0.4427 | 0.5346 | 0.5016 | 0.5162 | |
| RR | 0.4331 | 0.4403 | 0.3859 | 0.3696 | 0.3931 | 0.4097 | 0.4331 | |
| CQR | 0.4371 | 0.4408 | 0.3882 | 0.3717 | 0.3942 | 0.4072 | 0.4371 | |
| WCQR | 0.4385 | 0.4445 | 0.3654 | 0.3492 | 0.3625 | 0.3721 | 0.4385 | |
| 200 | LS | 0.2894 | 0.3419 | 0.3935 | 0.3033 | 0.3840 | 0.3712 | 0.2894 |
| QR | 0.3405 | 0.3302 | 0.3791 | 0.2966 | 0.3807 | 0.3419 | 0.3405 | |
| RR | 0.2930 | 0.3141 | 0.2762 | 0.2504 | 0.2774 | 0.2909 | 0.2903 | |
| CQR | 0.2940 | 0.3138 | 0.2764 | 0.2500 | 0.2778 | 0.2908 | 0.2940 | |
| WCQR | 0.2941 | 0.3153 | 0.2587 | 0.2350 | 0.2602 | 0.2645 | 0.2941 | |
| 400 | LS | 0.2007 | 0.2316 | 0.2794 | 0.2133 | 0.2828 | 0.2483 | 0.2007 |
| QR | 0.2273 | 0.2275 | 0.2737 | 0.2078 | 0.2701 | 0.2336 | 0.2273 | |
| RR | 0.2025 | 0.2160 | 0.1987 | 0.1776 | 0.1899 | 0.1957 | 0.2025 | |
| CQR | 0.2037 | 0.2162 | 0.1990 | 0.1783 | 0.1910 | 0.1959 | 0.2037 | |
| WCQR | 0.2045 | 0.2160 | 0.1877 | 0.1676 | 0.1788 | 0.1800 | 0.2045 |
Simulation results for
|
|
Method |
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 100 | LS | 0.7997 | 0.1735 | 0.1323 | 2.0071 | 0.1671 | 0.1311 | 0.4742 |
| QR | 0.7993 | 0.1409 | 0.1119 | 2.0033 | 0.1457 | 0.1147 | 0.4613 | |
| RR | 0.7959 | 0.1256 | 0.1007 | 1.9999 | 0.1310 | 0.1017 | 0.4403 | |
| CQR | 0.7961 | 0.1268 | 0.1015 | 1.9994 | 0.1319 | 0.1022 | 0.4408 | |
| WCQR | 0.7957 | 0.1287 | 0.1015 | 1.9986 | 0.1352 | 0.1052 | 0.4445 | |
| 200 | LS | 0.8124 | 0.1229 | 0.0969 | 1.9922 | 0.1142 | 0.0911 | 0.3419 |
| QR | 0.8090 | 0.1019 | 0.0813 | 2.0029 | 0.0951 | 0.0757 | 0.3302 | |
| RR | 0.8102 | 0.0941 | 0.0749 | 1.9984 | 0.0862 | 0.0689 | 0.3141 | |
| CQR | 0.8096 | 0.0935 | 0.0743 | 1.9988 | 0.0860 | 0.0689 | 0.3138 | |
| WCQR | 0.8096 | 0.0937 | 0.0741 | 2.0004 | 0.0888 | 0.0713 | 0.3153 | |
| 400 | LS | 0.7984 | 0.0831 | 0.0660 | 1.9967 | 0.0836 | 0.0665 | 0.2316 |
| QR | 0.8029 | 0.0696 | 0.0561 | 2.0016 | 0.0696 | 0.0555 | 0.2275 | |
| RR | 0.8009 | 0.0623 | 0.0504 | 2.0006 | 0.0642 | 0.0505 | 0.2160 | |
| CQR | 0.8007 | 0.0623 | 0.0502 | 2.0002 | 0.0637 | 0.0501 | 0.2162 | |
| WCQR | 0.8012 | 0.0623 | 0.0498 | 2.0006 | 0.0634 | 0.0495 | 0.2160 |
Simulation results for
|
|
Method |
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 100 | LS | 0.7799 | 0.2804 | 0.2112 | 1.9781 | 0.2627 | 0.1940 | 0.5477 |
| QR | 0.7965 | 0.2059 | 0.1661 | 1.9935 | 0.1992 | 0.1591 | 0.5243 | |
| RR | 0.7970 | 0.0870 | 0.0684 | 1.9940 | 0.0921 | 0.0731 | 0.3859 | |
| CQR | 0.7956 | 0.0887 | 0.0693 | 1.9931 | 0.0929 | 0.0738 | 0.3882 | |
| WCQR | 0.7990 | 0.0552 | 0.0431 | 1.9979 | 0.0584 | 0.0459 | 0.3654 | |
| 200 | LS | 0.7998 | 0.1780 | 0.1379 | 1.9956 | 0.1754 | 0.1346 | 0.3935 |
| QR | 0.8030 | 0.1429 | 0.1161 | 1.9984 | 0.1391 | 0.1144 | 0.3791 | |
| RR | 0.7998 | 0.0570 | 0.0446 | 1.9966 | 0.0564 | 0.0452 | 0.2762 | |
| CQR | 0.7999 | 0.0567 | 0.0448 | 1.9972 | 0.0566 | 0.0455 | 0.2764 | |
| WCQR | 0.8007 | 0.0330 | 0.0254 | 1.9985 | 0.0343 | 0.0273 | 0.2587 | |
| 400 | LS | 0.8054 | 0.1368 | 0.1065 | 2.0018 | 0.1212 | 0.0966 | 0.2794 |
| QR | 0.8046 | 0.1078 | 0.0872 | 2.0088 | 0.1154 | 0.0948 | 0.2737 | |
| RR | 0.7999 | 0.0426 | 0.0332 | 2.0009 | 0.0371 | 0.0301 | 0.1987 | |
| CQR | 0.8004 | 0.0430 | 0.0337 | 2.0010 | 0.0379 | 0.0305 | 0.1990 | |
| WCQR | 0.8003 | 0.0213 | 0.0168 | 2.0012 | 0.0211 | 0.0166 | 0.1877 |
Simulation results for
|
|
Method |
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 100 | LS | 0.8006 | 0.1473 | 0.1171 | 2.0058 | 0.1478 | 0.1165 | 0.4633 |
| QR | 0.8001 | 0.1255 | 0.0956 | 2.0021 | 0.1279 | 0.0993 | 0.4427 | |
| RR | 0.7976 | 0.0721 | 0.0565 | 2.0019 | 0.0742 | 0.0578 | 0.3696 | |
| CQR | 0.7975 | 0.0717 | 0.0558 | 2.0017 | 0.0731 | 0.0567 | 0.3717 | |
| WCQR | 0.7970 | 0.0484 | 0.0371 | 2.0025 | 0.0478 | 0.0370 | 0.3492 | |
| 200 | LS | 0.8014 | 0.1012 | 0.0793 | 1.9995 | 0.1045 | 0.0819 | 0.3033 |
| QR | 0.8026 | 0.0780 | 0.0615 | 1.9981 | 0.0831 | 0.0651 | 0.2966 | |
| RR | 0.7983 | 0.0486 | 0.0388 | 2.0022 | 0.0461 | 0.0358 | 0.2504 | |
| CQR | 0.7984 | 0.0481 | 0.0384 | 2.0020 | 0.0460 | 0.0362 | 0.2500 | |
| WCQR | 0.7997 | 0.0270 | 0.0214 | 2.0012 | 0.0260 | 0.0201 | 0.2350 | |
| 400 | LS | 0.7996 | 0.0730 | 0.0581 | 1.9989 | 0.0671 | 0.0536 | 0.2133 |
| QR | 0.8010 | 0.0565 | 0.0445 | 2.0002 | 0.0512 | 0.0416 | 0.2078 | |
| RR | 0.8000 | 0.0308 | 0.0246 | 1.9991 | 0.0336 | 0.0267 | 0.1776 | |
| CQR | 0.7999 | 0.0307 | 0.0246 | 1.9992 | 0.0329 | 0.0264 | 0.1783 | |
| WCQR | 0.8005 | 0.0157 | 0.0123 | 2.0001 | 0.0157 | 0.0123 | 0.1676 |
Simulation results for
|
|
Method |
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 100 | LS | 0.8032 | 0.2684 | 0.2074 | 1.9916 | 0.2784 | 0.2112 | 0.5724 |
| QR | 0.8091 | 0.2067 | 0.1646 | 1.9828 | 0.2042 | 0.1671 | 0.5346 | |
| RR | 0.8015 | 0.0937 | 0.0725 | 1.9982 | 0.0906 | 0.0711 | 0.3931 | |
| CQR | 0.8017 | 0.0943 | 0.0736 | 1.9961 | 0.0910 | 0.0718 | 0.3942 | |
| WCQR | 0.8009 | 0.0597 | 0.0456 | 1.9991 | 0.0574 | 0.0445 | 0.3625 | |
| 200 | LS | 0.7921 | 0.1878 | 0.1469 | 1.9992 | 0.1898 | 0.1473 | 0.3840 |
| QR | 0.7934 | 0.1530 | 0.1265 | 1.9964 | 0.1561 | 0.1271 | 0.3807 | |
| RR | 0.7953 | 0.0581 | 0.0460 | 1.9998 | 0.0606 | 0.0481 | 0.2774 | |
| CQR | 0.7949 | 0.0589 | 0.0471 | 1.9998 | 0.0608 | 0.0484 | 0.2778 | |
| WCQR | 0.7989 | 0.0327 | 0.0261 | 2.0005 | 0.0332 | 0.0259 | 0.2602 | |
| 400 | LS | 0.8036 | 0.1418 | 0.1135 | 1.9964 | 0.1380 | 0.1076 | 0.2828 |
| QR | 0.8014 | 0.1186 | 0.0971 | 1.9953 | 0.1158 | 0.0928 | 0.2701 | |
| RR | 0.7992 | 0.0415 | 0.0328 | 1.9975 | 0.0422 | 0.0337 | 0.1899 | |
| CQR | 0.7994 | 0.0425 | 0.0337 | 1.9971 | 0.0430 | 0.0345 | 0.1910 | |
| WCQR | 0.7997 | 0.0222 | 0.0175 | 2.0003 | 0.0207 | 0.0162 | 0.1788 |
Simulation results for
|
|
Method |
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 100 | LS | 0.7913 | 0.2093 | 0.1658 | 2.0096 | 0.2212 | 0.1768 | 0.5117 |
| QR | 0.7972 | 0.1829 | 0.1423 | 2.0069 | 0.1928 | 0.1527 | 0.5016 | |
| RR | 0.7916 | 0.1024 | 0.0806 | 2.0000 | 0.1071 | 0.0843 | 0.4097 | |
| CQR | 0.7924 | 0.1011 | 0.0799 | 2.0014 | 0.1039 | 0.0821 | 0.4072 | |
| WCQR | 0.7958 | 0.0642 | 0.0500 | 2.0030 | 0.0667 | 0.0522 | 0.3721 | |
| 200 | LS | 0.7888 | 0.1497 | 0.1199 | 1.9919 | 0.1450 | 0.1155 | 0.3712 |
| QR | 0.7881 | 0.1246 | 0.0984 | 1.9944 | 0.1175 | 0.0912 | 0.3419 | |
| RR | 0.7991 | 0.0660 | 0.0515 | 1.9997 | 0.0718 | 0.0557 | 0.2909 | |
| CQR | 0.7983 | 0.0650 | 0.0508 | 1.9994 | 0.0706 | 0.0550 | 0.2908 | |
| WCQR | 0.7999 | 0.0381 | 0.0292 | 1.9992 | 0.0402 | 0.0306 | 0.2645 | |
| 400 | LS | 0.7932 | 0.1092 | 0.0878 | 1.9959 | 0.1113 | 0.0869 | 0.2483 |
| QR | 0.7988 | 0.0852 | 0.0661 | 1.9961 | 0.0829 | 0.0637 | 0.2336 | |
| RR | 0.7986 | 0.0473 | 0.0375 | 2.0016 | 0.0502 | 0.0403 | 0.1957 | |
| CQR | 0.7984 | 0.0471 | 0.0374 | 2.0012 | 0.0502 | 0.0402 | 0.1959 | |
| WCQR | 0.8007 | 0.0226 | 0.0177 | 1.9993 | 0.0233 | 0.0181 | 0.1800 |
6 Application to Tecator data
We illustrate the proposed approach by analyzing a real estate data set which is available at http://lib.stat.cmu.edu/datasets/tecator. The data have been widely used to predict fat content on samples of finely chopped meat [44,45,46]. For each food sample, the functional data consist of a 100-channel spectrum of absorbances recorded on a Tecator Infratec Food and Feed Analysis working in the wavelength range 850–1,050 nm by the near infrared transmission principle. More details on the data can be found in Ferraty and Vieu [47]. In this section, we construct the following PFLRM model:
We denote the scale of fat content as
To evaluate the performance of the method, the sample is randomly divided into two subsamples: the training sample,
where
MSEPs for different methods
| Method | MSEP |
|---|---|
| LS | 0.5684 |
| QR | 0.0522 |
| CQR | 0.0503 |
| WCQR | 0.0495 |
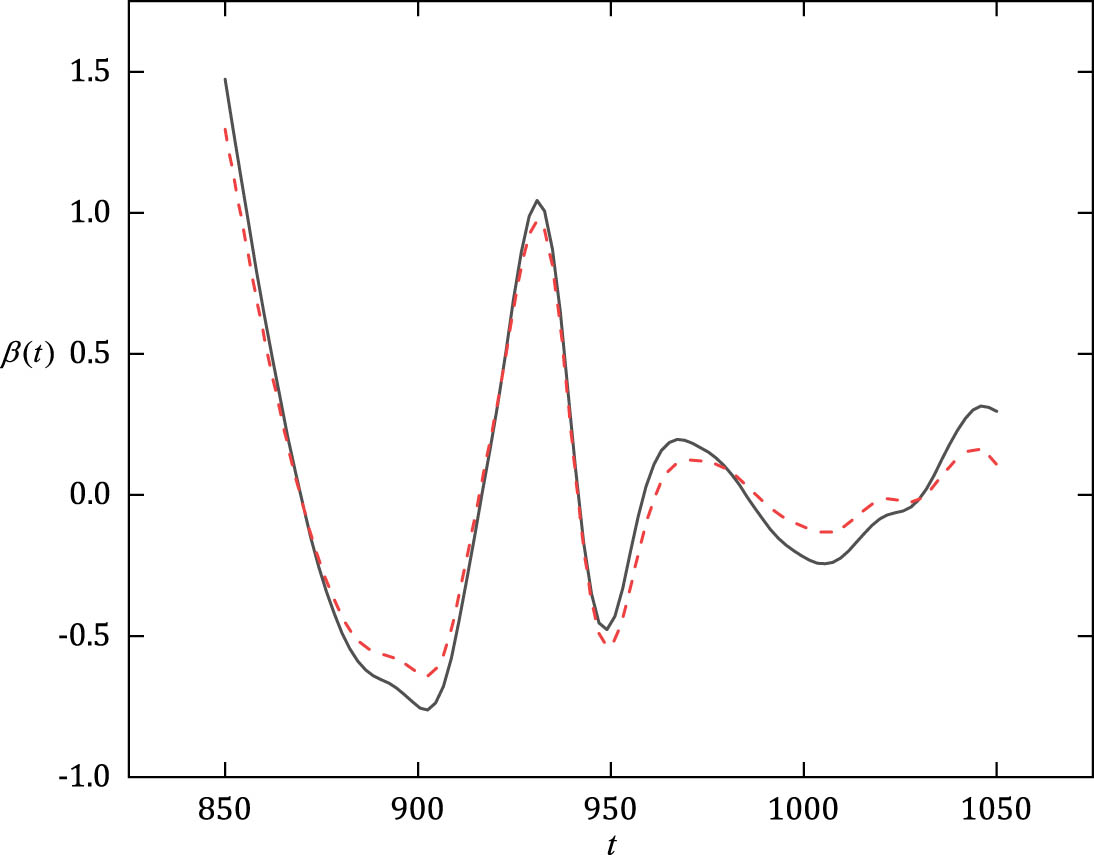
Curves of slope function
7 Conclusion
In this paper, a novel and robust procedure based on WCQR and principal component basis function approximations is developed for PFLRMs. Theoretical properties of the estimators of both slope function and linear parameters are derived under some mild assumptions. We show that the estimators do not require any specification for error distribution, and thus more robust than those based on the LS, QR and CQR in the case of asymmetric errors. Furthermore, we present an efficient algorithm for the selection of optimal weights and discuss the selection of tuning parameters. Numerical studies and the real data analysis illustrate that our proposed method performs very well for moderate sample size.
In addition, we could extend the proposed procedure to the functional regression models with diverse dimension of covariates. These deserve to be studied further.
-
Conflict of interest: Authors state no conflict of interest.
Appendix Proof of Theorem 3.1(i)
Let
This implies that, with probability tending to one, there is local minimum
First, by
For
As for
one has
By the study of Knight [49],
then
we can rewrite
where
Note that, by Assumptions A2 and A4, respectively, we have
Invoking Assumption A7, a simple calculation yields
Similarly,
Hence,
Then, we can obtain
It follows from (A.2) to (A.6), we can obtain that
Observe that
By Assumption A2, the orthogonality of
and
Then, combining (A.8)–(A.10), we can complete the proof of Theorem 3.1(i).
B Proof of Theorem 3.1(ii)
According to Theorem 3.1(i), we know that, as
where
Moreover, we can write equation (A.13) as
where
Invoking Taylor expansion, a simple calculation yields
By direct calculation of the mean and variance, we can show, as in the study by Jiang et al. (2012), that
Similarly, we have
Let
Substituting equation (A.17) into equation (A.15), we can obtain that
Note that
According to equation (A.18)–(A.20), it is easy to show that
where
Note
is normal with mean 0 and covariance matrix
We complete the proof of Theorem 3.1(ii).
References
[1] H. Cardot , F. Ferraty , and P. Sarda , Functional linear model, Statist. Probab. Lett. 45 (1999), no. 1, 11–22, https://doi.org/10.1016/S0167-7152(99)00036-X . 10.1016/S0167-7152(99)00036-XSearch in Google Scholar
[2] H. Cardot , F. Ferraty , and P. Sarda , Spline estimators for the functional linear model, Statist. Sinica 13 (2003), no. 3, 571–591, http://www.jstor.org/stable/24307112. Search in Google Scholar
[3] F. Yao , H. G. Müller , and J. L. Wang , Functional linear regression analysis for longitudinal data, Ann. Statist. 33 (2005), no. 6, 2873–2903, https://doi.org/10.1214/009053605000000660. Search in Google Scholar
[4] J. Ramsay and B. Silverman , Functional Data Analysis, 2nd edn., Springer, New York, 2005. 10.1007/b98888Search in Google Scholar
[5] T. Cai and P. Hall , Prediction in functional linear regression, Ann. Statist. 34 (2006), no. 5, 2159–2179, https://doi.org/10.1214/009053606000000830 . 10.1214/009053606000000830Search in Google Scholar
[6] H. Liu and H. Yang , Estimation and variable selection in single-index composite quantile regression, Comm. Statist. Simulation Comput. 46 (2016), no. 9, 7022–7039. 10.1080/03610918.2016.1222424Search in Google Scholar
[7] P. Hall and J. Horowitz , Methodology and convergence rates for functional linear regression, Ann. Statist. 35 (2007), no. 1, 70–91, https://doi.org/10.1214/009053606000000957. Search in Google Scholar
[8] C. Crambes , A. Kneip , and P. Sarda , Smoothing splines estimators for functional linear regression, Ann. Statist. 37 (2009), no. 1, 35–72, https://doi.org/10.1214/07-AOS563. Search in Google Scholar
[9] P. Hall and Y. Yang , Ordering and selecting components in multivariate or functional data linear prediction, J. R. Stat. Soc. Ser. B. Stat. Methodol. 72 (2010), no. 1, 93–110. 10.1111/j.1467-9868.2009.00727.xSearch in Google Scholar
[10] T. Cai and M. Yuan , Minimax and adaptive prediction for functional linear regression, J. Amer. Statist. Assoc. 107 (2012), no. 499, 1201–1216, https://www.jstor.org/stable/23427425. 10.1080/01621459.2012.716337Search in Google Scholar
[11] A. Delaigle and P. Hall , Methodology and theory for partial least squares applied to functional data, Ann. Statist. 40 (2012), no. 1, 322–352, https://doi.org/10.1214/11-AOS958. Search in Google Scholar
[12] E. R. Lee and B. U. Park , Sparse estimation in functional linear regression, J. Multivariate Anal. 105 (2012), no. 1, 1–17, https://doi.org/10.1016/j.jmva.2011.08.005. Search in Google Scholar
[13] L. Huang , H. Wang , and A. Zheng , The M-estimator for functional linear regression model, Statist. Probab. Lett. 88 (2014), no. C, 165–173, https://doi.org/10.1016/j.spl.2014.01.016. Search in Google Scholar
[14] H. J. Shin , Partial functional linear regression, J. Statist. Plann. Inference 139 (2009), no. 10, 3405–3418, https://doi.org/10.1016/j.jspi.2009.03.001 . 10.1016/j.jspi.2009.03.001Search in Google Scholar
[15] J. Zhou , Z. Chen , and Q. Peng , Polynomial spline estimation for partial functional linear regression models, Comput. Statist. 31 (2016), no. 3, 1107–1129, https://doi.org/10.1007/s00180-015-0636-0. Search in Google Scholar
[16] D. Kong , K. Xue , F. Yao , and H. Zhang , Partially functional linear regression in high dimensions, Biometrika 103 (2016), no. 1, 147–159, https://doi.org/10.1093/biomet/asv062. Search in Google Scholar
[17] N. Ling , G. Aneiros , and P. Vieu , kNN estimation in functional partial linear modeling, Statist. Papers 61 (2020), no. 1, 423–444, https://doi.org/10.1007/s00362-017-0946-0. Search in Google Scholar
[18] D. Kong , J. Ibrahim , E. Lee , and H. Zhu , FLCRM: functional linear cox regression model, Biometrics 74 (2018), no. 1, 109–117. 10.1111/biom.12748Search in Google Scholar PubMed PubMed Central
[19] R. Cao , J. Du , J. Zhou , and T. Xie , FPCA-based estimation for generalized functional partially linear models, Statist. Papers 61 (2020), no. 6, 2715–2735, https://doi.org/10.1007/s00362-018-01066-8. Search in Google Scholar
[20] M. Yuan and Y. Zhang , Test for the parametric part in partial functional linear regression based on B-spline, Comm. Statist. Simulation Comput. 50 (2021), no. 1, 1–15, https://doi.org/10.1080/03610918.2019.1667391. Search in Google Scholar
[21] H. Zhu , R. Zhang , Z. Yu , H. Lian , and Y. Liu , Estimation and testing for partially functional linear errors-in-variables models, J. Multivariate Anal. 170 (2019), 296–314, https://doi.org/10.1016/j.jmva.2018.11.005. Search in Google Scholar
[22] Q. Li , X. Tan , and L. Wang , Testing for error correlation in partially functional linear regression models, Comm. Statist. Theory Methods 50 (2021), no. 3, 747–761, https://doi.org/10.1080/03610926.2019.1642492 . 10.1080/03610926.2019.1642492Search in Google Scholar
[23] R. Koenker and G. Basset , Regression quantiles, Econometrica 46 (1978), no. 1, 33–50, https://doi.org/10.2307/1913643 . 10.2307/1913643Search in Google Scholar
[24] Y. Lu , J. Du , Z. Sun , Functional partially linear quantile regression model, Metrika 77 (2014), no. 2, 317–332, https://doi.org/10.1007/s00184-013-0439-7. Search in Google Scholar
[25] H. Ma , T. Li , H. Zhu , and Z. Zhu , Quantile regression for functional partially linear model in ultra-high dimensions, Comput. Statist. Data Anal. 129 (2019), no. 1, 135–147, https://doi.org/10.1016/j.csda.2018.06.005. Search in Google Scholar
[26] R. Koenker , Quantile Regression, Cambridge University Press, Cambridge, 2005. 10.1017/CBO9780511754098Search in Google Scholar
[27] H. Zou and M. Yuan , Composite quantile regression and the Oracle model selection theory, Ann. Statist. 36 (2008), no. 3, 1108–1126, https://www.jstor.org/stable/25464661. 10.1214/07-AOS507Search in Google Scholar
[28] B. Kai , R. Li , and H. Zou , Local composite quantile regression smoothing: an efficient and safe alternative to local polynomial regression, J. R. Stat. Soc. Ser. B Stat. Methodol. 72 (2010), no. 1, 49–69, https://doi.org/10.1111/j.1467-9868.2009.00725.x. Search in Google Scholar PubMed PubMed Central
[29] B. Kai , R. Li , and H. Zou , New efficient estimation and variable selection methods for semiparametric varying-coefficient partially linear models, Ann. Statist. 39 (2011), no. 1, 305–332, https://doi.org/10.1214/10-AOS842. Search in Google Scholar PubMed PubMed Central
[30] J. Guo , M. Tang , M. Tian , and K. Zhu , Variable selection in high-dimensional partially linear additive models for composite quantile regression, Comput. Statist. Data Anal. 65 (2013), 56–67, https://doi.org/10.1016/j.csda.2013.03.017. Search in Google Scholar
[31] R. Jiang , Z. Zhou , W. Qian , and Y. Chen , Two step composite quantile regression for single-index models, Comput. Statist. Data Anal. 64 (2013), 180–191, https://doi.org/10.1016/j.csda.2013.03.014. Search in Google Scholar
[32] R. Jiang , W. Qian , and Z. Zhou , Test for single-index composite quantile regression, Hacet. J. Math. Stat. 43 (2014), no. 5, 861–871. Search in Google Scholar
[33] J. Du , D. Xu , and R. Cao , Estimation and variable selection for partially functional linear models, J. Korean Statist. Soc. 47 (2018), no. 4, 436–449, https://doi.org/10.1016/j.jkss.2018.05.002. Search in Google Scholar
[34] P. Yu , T. Li , Z. Zhu , and Z. Zhang , Composite quantile estimation in partial functional linear regression model with dependent errors, Metrika 82 (2019), no. 6, 633–656, https://doi.org/10.1007/s00184-018-0699-3. Search in Google Scholar
[35] X. Jiang , J. Jiang , and X. Song , Oracle model selection for nonlinear models based on weighted composite quantile regression, Statist. Sinica 22 (2012), no. 4, 1479–1506, https://doi.org/10.5705/ss.2010.203. Search in Google Scholar
[36] C. Guo , H. Yang , and J. Lv , Robust variable selection in high-dimensional varying coefficient models based on weighted composite quantile regression, Statist. Papers 58 (2017), no. 4, 1009–1033, https://doi.org/10.1007/s00362-015-0736-5. Search in Google Scholar
[37] R. Jiang , W. Qian , and Z. Zhou , Weighted composite quantile regression for partially linear varying coefficient models, Comm. Statist. Theory Methods 47 (2018), no. 16, 3987–4005, https://doi.org/10.1080/03610926.2017.1366522. Search in Google Scholar
[38] J. Sun , Y. Gai , and L. Lin , Weighted local linear composite quantile estimation for the case of general error distributions, J. Statist. Plann. Inference 143 (2013), no. 6, 1049–1063, https://doi.org/10.1016/j.jspi.2013.01.002. Search in Google Scholar
[39] R. Jiang , W. Qian , and Z. Zhou , Weighted composite quantile regression for single-index models, J. Multivariate Anal. 148 (2016), 34–48, https://doi.org/10.1016/j.jmva.2016.02.015. Search in Google Scholar
[40] P. Yu , Z. Zhang , and J. Du , A test of linearity in partial functional linear regression, Metrika 79 (2016), no. 8, 953–969, https://doi.org/10.1007/s00184-016-0584-x. Search in Google Scholar
[41] L. Horváth and P. Kokoszka , Inference for Functional Data with Applications, Springer, New York, 2012. 10.1007/978-1-4614-3655-3Search in Google Scholar
[42] B. Silverman , Density Estimation, Chapman and Hall, London, 1986. Search in Google Scholar
[43] J. Sun and L. Lin , Local rank estimation and related test for varying-coefficient partially linear models, J. Nonparametr. Stat. 26 (2014), no. 1, 187–206, https://doi.org/10.1080/10485252.2013.841910. Search in Google Scholar
[44] G. Aneiros-Pérez and P. Vieu , Semi-functional partial linear regression, Statist. Probab. Lett. 76 (2006), no. 11, 1102–1110, https://doi.org/10.1016/j.spl.2005.12.007. Search in Google Scholar
[45] G. Aneiros-Pérez and P. Vieu , Partial linear modelling with multi-functional covariates, Comput. Statist. 30 (2015), no. 3, 647–671, https://doi.org/10.1007/s00180-015-0568-8. Search in Google Scholar
[46] P. Yu , J. Du , and Z. Zhan , Single-index partially functional linear regression model, Statist. Papers 61 (2020), no. 3, 1107–1123, https://doi.org/10.1007/s00362-018-0980-6. Search in Google Scholar
[47] F. Ferraty and P. Vieu , Nonparametric Functional Data Analysis: Theory and Practice, Springer, New York, 2006. Search in Google Scholar
[48] C. Crambes , A. Kneip , and P. Sarda , Smoothing splines estimators for functional linear regression, Ann. Statist. 37 (2009), no. 1, 35–72, https://doi.org/10.1214/07-AOS563. Search in Google Scholar
[49] K. Knight , Limiting distributions for L1 regression estimators under general conditions, Ann. Statist. 26 (1998), no. 2, 755–770, https://www.jstor.org/stable/120050.10.1214/aos/1028144858Search in Google Scholar
© 2021 Peng Cao and Jun Sun, published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Regular Articles
- Sharp conditions for the convergence of greedy expansions with prescribed coefficients
- Range-kernel weak orthogonality of some elementary operators
- Stability analysis for Selkov-Schnakenberg reaction-diffusion system
- On non-normal cyclic subgroups of prime order or order 4 of finite groups
- Some results on semigroups of transformations with restricted range
- Quasi-ideal Ehresmann transversals: The spined product structure
- On the regulator problem for linear systems over rings and algebras
- Solvability of the abstract evolution equations in Ls-spaces with critical temporal weights
- Resolving resolution dimensions in triangulated categories
- Entire functions that share two pairs of small functions
- On stochastic inverse problem of construction of stable program motion
- Pentagonal quasigroups, their translatability and parastrophes
- Counting certain quadratic partitions of zero modulo a prime number
- Global attractors for a class of semilinear degenerate parabolic equations
- A new implicit symmetric method of sixth algebraic order with vanished phase-lag and its first derivative for solving Schrödinger's equation
- On sub-class sizes of mutually permutable products
- Asymptotic solution of the Cauchy problem for the singularly perturbed partial integro-differential equation with rapidly oscillating coefficients and with rapidly oscillating heterogeneity
- Existence and asymptotical behavior of solutions for a quasilinear Choquard equation with singularity
- On kernels by rainbow paths in arc-coloured digraphs
- Fully degenerate Bell polynomials associated with degenerate Poisson random variables
- Multiple solutions and ground state solutions for a class of generalized Kadomtsev-Petviashvili equation
- A note on maximal operators related to Laplace-Bessel differential operators on variable exponent Lebesgue spaces
- Weak and strong estimates for linear and multilinear fractional Hausdorff operators on the Heisenberg group
- Partial sums and inclusion relations for analytic functions involving (p, q)-differential operator
- Hodge-Deligne polynomials of character varieties of free abelian groups
- Diophantine approximation with one prime, two squares of primes and one kth power of a prime
- The equivalent parameter conditions for constructing multiple integral half-discrete Hilbert-type inequalities with a class of nonhomogeneous kernels and their applications
- Boundedness of vector-valued sublinear operators on weighted Herz-Morrey spaces with variable exponents
- On some new quantum midpoint-type inequalities for twice quantum differentiable convex functions
- Quantum Ostrowski-type inequalities for twice quantum differentiable functions in quantum calculus
- Asymptotic measure-expansiveness for generic diffeomorphisms
- Infinitesimals via Cauchy sequences: Refining the classical equivalence
- The (1, 2)-step competition graph of a hypertournament
- Properties of multiplication operators on the space of functions of bounded φ-variation
- Disproving a conjecture of Thornton on Bohemian matrices
- Some estimates for the commutators of multilinear maximal function on Morrey-type space
- Inviscid, zero Froude number limit of the viscous shallow water system
- Inequalities between height and deviation of polynomials
- New criteria-based ℋ-tensors for identifying the positive definiteness of multivariate homogeneous forms
- Determinantal inequalities of Hua-Marcus-Zhang type for quaternion matrices
- On a new generalization of some Hilbert-type inequalities
- On split quaternion equivalents for Quaternaccis, shortly Split Quaternaccis
- On split regular BiHom-Poisson color algebras
- Asymptotic stability of the time-changed stochastic delay differential equations with Markovian switching
- The mixed metric dimension of flower snarks and wheels
- Oscillatory bifurcation problems for ODEs with logarithmic nonlinearity
- The B-topology on S∗-doubly quasicontinuous posets
- Hyers-Ulam stability of isometries on bounded domains
- Inhomogeneous conformable abstract Cauchy problem
- Path homology theory of edge-colored graphs
- Refinements of quantum Hermite-Hadamard-type inequalities
- Symmetric graphs of valency seven and their basic normal quotient graphs
- Mean oscillation and boundedness of multilinear operator related to multiplier operator
- Numerical methods for time-fractional convection-diffusion problems with high-order accuracy
- Several explicit formulas for (degenerate) Narumi and Cauchy polynomials and numbers
- Finite groups whose intersection power graphs are toroidal and projective-planar
- On primitive solutions of the Diophantine equation x2 + y2 = M
- A note on polyexponential and unipoly Bernoulli polynomials of the second kind
- On the type 2 poly-Bernoulli polynomials associated with umbral calculus
- Some estimates for commutators of Littlewood-Paley g-functions
- Construction of a family of non-stationary combined ternary subdivision schemes reproducing exponential polynomials
- On the evolutionary bifurcation curves for the one-dimensional prescribed mean curvature equation with logistic type
- On intersections of two non-incident subgroups of finite p-groups
- Global existence and boundedness in a two-species chemotaxis system with nonlinear diffusion
- Finite groups with 4p2q elements of maximal order
- Positive solutions of a discrete nonlinear third-order three-point eigenvalue problem with sign-changing Green's function
- Power moments of automorphic L-functions related to Maass forms for SL3(ℤ)
- Entire solutions for several general quadratic trinomial differential difference equations
- Strong consistency of regression function estimator with martingale difference errors
- Fractional Hermite-Hadamard-type inequalities for interval-valued co-ordinated convex functions
- Montgomery identity and Ostrowski-type inequalities via quantum calculus
- Universal inequalities of the poly-drifting Laplacian on smooth metric measure spaces
- On reducible non-Weierstrass semigroups
- so-metrizable spaces and images of metric spaces
- Some new parameterized inequalities for co-ordinated convex functions involving generalized fractional integrals
- The concept of cone b-Banach space and fixed point theorems
- Complete consistency for the estimator of nonparametric regression model based on m-END errors
- A posteriori error estimates based on superconvergence of FEM for fractional evolution equations
- Solution of integral equations via coupled fixed point theorems in 𝔉-complete metric spaces
- Symmetric pairs and pseudosymmetry of Θ-Yetter-Drinfeld categories for Hom-Hopf algebras
- A new characterization of the automorphism groups of Mathieu groups
- The role of w-tilting modules in relative Gorenstein (co)homology
- Primitive and decomposable elements in homology of ΩΣℂP∞
- The G-sequence shadowing property and G-equicontinuity of the inverse limit spaces under group action
- Classification of f-biharmonic submanifolds in Lorentz space forms
- Some new results on the weaving of K-g-frames in Hilbert spaces
- Matrix representation of a cross product and related curl-based differential operators in all space dimensions
- Global optimization and applications to a variational inequality problem
- Functional equations related to higher derivations in semiprime rings
- A partial order on transformation semigroups with restricted range that preserve double direction equivalence
- On multi-step methods for singular fractional q-integro-differential equations
- Compact perturbations of operators with property (t)
- Entire solutions for several complex partial differential-difference equations of Fermat type in ℂ2
- Random attractors for stochastic plate equations with memory in unbounded domains
- On the convergence of two-step modulus-based matrix splitting iteration method
- On the separation method in stochastic reconstruction problem
- Robust estimation for partial functional linear regression models based on FPCA and weighted composite quantile regression
- Structure of coincidence isometry groups
- Sharp function estimates and boundedness for Toeplitz-type operators associated with general fractional integral operators
- Oscillatory hyper-Hilbert transform on Wiener amalgam spaces
- Euler-type sums involving multiple harmonic sums and binomial coefficients
- Poly-falling factorial sequences and poly-rising factorial sequences
- Geometric approximations to transition densities of Jump-type Markov processes
- Multiple solutions for a quasilinear Choquard equation with critical nonlinearity
- Bifurcations and exact traveling wave solutions for the regularized Schamel equation
- Almost factorizable weakly type B semigroups
- The finite spectrum of Sturm-Liouville problems with n transmission conditions and quadratic eigenparameter-dependent boundary conditions
- Ground state sign-changing solutions for a class of quasilinear Schrödinger equations
- Epi-quasi normality
- Derivative and higher-order Cauchy integral formula of matrix functions
- Commutators of multilinear strongly singular integrals on nonhomogeneous metric measure spaces
- Solutions to a multi-phase model of sea ice growth
- Existence and simulation of positive solutions for m-point fractional differential equations with derivative terms
- Bernstein-Walsh type inequalities for derivatives of algebraic polynomials in quasidisks
- Review Article
- Semiprimeness of semigroup algebras
- Special Issue on Problems, Methods and Applications of Nonlinear Analysis (Part II)
- Third-order differential equations with three-point boundary conditions
- Fractional calculus, zeta functions and Shannon entropy
- Uniqueness of positive solutions for boundary value problems associated with indefinite ϕ-Laplacian-type equations
- Synchronization of Caputo fractional neural networks with bounded time variable delays
- On quasilinear elliptic problems with finite or infinite potential wells
- Deterministic and random approximation by the combination of algebraic polynomials and trigonometric polynomials
- On a fractional Schrödinger-Poisson system with strong singularity
- Parabolic inequalities in Orlicz spaces with data in L1
- Special Issue on Evolution Equations, Theory and Applications (Part II)
- Impulsive Caputo-Fabrizio fractional differential equations in b-metric spaces
- Existence of a solution of Hilfer fractional hybrid problems via new Krasnoselskii-type fixed point theorems
- On a nonlinear system of Riemann-Liouville fractional differential equations with semi-coupled integro-multipoint boundary conditions
- Blow-up results of the positive solution for a class of degenerate parabolic equations
- Long time decay for 3D Navier-Stokes equations in Fourier-Lei-Lin spaces
- On the extinction problem for a p-Laplacian equation with a nonlinear gradient source
- General decay rate for a viscoelastic wave equation with distributed delay and Balakrishnan-Taylor damping
- On hyponormality on a weighted annulus
- Exponential stability of Timoshenko system in thermoelasticity of second sound with a memory and distributed delay term
- Convergence results on Picard-Krasnoselskii hybrid iterative process in CAT(0) spaces
- Special Issue on Boundary Value Problems and their Applications on Biosciences and Engineering (Part I)
- Marangoni convection in layers of water-based nanofluids under the effect of rotation
- A transient analysis to the M(τ)/M(τ)/k queue with time-dependent parameters
- Existence of random attractors and the upper semicontinuity for small random perturbations of 2D Navier-Stokes equations with linear damping
- Degenerate binomial and Poisson random variables associated with degenerate Lah-Bell polynomials
- Special Issue on Fractional Problems with Variable-Order or Variable Exponents (Part I)
- On the mixed fractional quantum and Hadamard derivatives for impulsive boundary value problems
- The Lp dual Minkowski problem about 0 < p < 1 and q > 0
Articles in the same Issue
- Regular Articles
- Sharp conditions for the convergence of greedy expansions with prescribed coefficients
- Range-kernel weak orthogonality of some elementary operators
- Stability analysis for Selkov-Schnakenberg reaction-diffusion system
- On non-normal cyclic subgroups of prime order or order 4 of finite groups
- Some results on semigroups of transformations with restricted range
- Quasi-ideal Ehresmann transversals: The spined product structure
- On the regulator problem for linear systems over rings and algebras
- Solvability of the abstract evolution equations in Ls-spaces with critical temporal weights
- Resolving resolution dimensions in triangulated categories
- Entire functions that share two pairs of small functions
- On stochastic inverse problem of construction of stable program motion
- Pentagonal quasigroups, their translatability and parastrophes
- Counting certain quadratic partitions of zero modulo a prime number
- Global attractors for a class of semilinear degenerate parabolic equations
- A new implicit symmetric method of sixth algebraic order with vanished phase-lag and its first derivative for solving Schrödinger's equation
- On sub-class sizes of mutually permutable products
- Asymptotic solution of the Cauchy problem for the singularly perturbed partial integro-differential equation with rapidly oscillating coefficients and with rapidly oscillating heterogeneity
- Existence and asymptotical behavior of solutions for a quasilinear Choquard equation with singularity
- On kernels by rainbow paths in arc-coloured digraphs
- Fully degenerate Bell polynomials associated with degenerate Poisson random variables
- Multiple solutions and ground state solutions for a class of generalized Kadomtsev-Petviashvili equation
- A note on maximal operators related to Laplace-Bessel differential operators on variable exponent Lebesgue spaces
- Weak and strong estimates for linear and multilinear fractional Hausdorff operators on the Heisenberg group
- Partial sums and inclusion relations for analytic functions involving (p, q)-differential operator
- Hodge-Deligne polynomials of character varieties of free abelian groups
- Diophantine approximation with one prime, two squares of primes and one kth power of a prime
- The equivalent parameter conditions for constructing multiple integral half-discrete Hilbert-type inequalities with a class of nonhomogeneous kernels and their applications
- Boundedness of vector-valued sublinear operators on weighted Herz-Morrey spaces with variable exponents
- On some new quantum midpoint-type inequalities for twice quantum differentiable convex functions
- Quantum Ostrowski-type inequalities for twice quantum differentiable functions in quantum calculus
- Asymptotic measure-expansiveness for generic diffeomorphisms
- Infinitesimals via Cauchy sequences: Refining the classical equivalence
- The (1, 2)-step competition graph of a hypertournament
- Properties of multiplication operators on the space of functions of bounded φ-variation
- Disproving a conjecture of Thornton on Bohemian matrices
- Some estimates for the commutators of multilinear maximal function on Morrey-type space
- Inviscid, zero Froude number limit of the viscous shallow water system
- Inequalities between height and deviation of polynomials
- New criteria-based ℋ-tensors for identifying the positive definiteness of multivariate homogeneous forms
- Determinantal inequalities of Hua-Marcus-Zhang type for quaternion matrices
- On a new generalization of some Hilbert-type inequalities
- On split quaternion equivalents for Quaternaccis, shortly Split Quaternaccis
- On split regular BiHom-Poisson color algebras
- Asymptotic stability of the time-changed stochastic delay differential equations with Markovian switching
- The mixed metric dimension of flower snarks and wheels
- Oscillatory bifurcation problems for ODEs with logarithmic nonlinearity
- The B-topology on S∗-doubly quasicontinuous posets
- Hyers-Ulam stability of isometries on bounded domains
- Inhomogeneous conformable abstract Cauchy problem
- Path homology theory of edge-colored graphs
- Refinements of quantum Hermite-Hadamard-type inequalities
- Symmetric graphs of valency seven and their basic normal quotient graphs
- Mean oscillation and boundedness of multilinear operator related to multiplier operator
- Numerical methods for time-fractional convection-diffusion problems with high-order accuracy
- Several explicit formulas for (degenerate) Narumi and Cauchy polynomials and numbers
- Finite groups whose intersection power graphs are toroidal and projective-planar
- On primitive solutions of the Diophantine equation x2 + y2 = M
- A note on polyexponential and unipoly Bernoulli polynomials of the second kind
- On the type 2 poly-Bernoulli polynomials associated with umbral calculus
- Some estimates for commutators of Littlewood-Paley g-functions
- Construction of a family of non-stationary combined ternary subdivision schemes reproducing exponential polynomials
- On the evolutionary bifurcation curves for the one-dimensional prescribed mean curvature equation with logistic type
- On intersections of two non-incident subgroups of finite p-groups
- Global existence and boundedness in a two-species chemotaxis system with nonlinear diffusion
- Finite groups with 4p2q elements of maximal order
- Positive solutions of a discrete nonlinear third-order three-point eigenvalue problem with sign-changing Green's function
- Power moments of automorphic L-functions related to Maass forms for SL3(ℤ)
- Entire solutions for several general quadratic trinomial differential difference equations
- Strong consistency of regression function estimator with martingale difference errors
- Fractional Hermite-Hadamard-type inequalities for interval-valued co-ordinated convex functions
- Montgomery identity and Ostrowski-type inequalities via quantum calculus
- Universal inequalities of the poly-drifting Laplacian on smooth metric measure spaces
- On reducible non-Weierstrass semigroups
- so-metrizable spaces and images of metric spaces
- Some new parameterized inequalities for co-ordinated convex functions involving generalized fractional integrals
- The concept of cone b-Banach space and fixed point theorems
- Complete consistency for the estimator of nonparametric regression model based on m-END errors
- A posteriori error estimates based on superconvergence of FEM for fractional evolution equations
- Solution of integral equations via coupled fixed point theorems in 𝔉-complete metric spaces
- Symmetric pairs and pseudosymmetry of Θ-Yetter-Drinfeld categories for Hom-Hopf algebras
- A new characterization of the automorphism groups of Mathieu groups
- The role of w-tilting modules in relative Gorenstein (co)homology
- Primitive and decomposable elements in homology of ΩΣℂP∞
- The G-sequence shadowing property and G-equicontinuity of the inverse limit spaces under group action
- Classification of f-biharmonic submanifolds in Lorentz space forms
- Some new results on the weaving of K-g-frames in Hilbert spaces
- Matrix representation of a cross product and related curl-based differential operators in all space dimensions
- Global optimization and applications to a variational inequality problem
- Functional equations related to higher derivations in semiprime rings
- A partial order on transformation semigroups with restricted range that preserve double direction equivalence
- On multi-step methods for singular fractional q-integro-differential equations
- Compact perturbations of operators with property (t)
- Entire solutions for several complex partial differential-difference equations of Fermat type in ℂ2
- Random attractors for stochastic plate equations with memory in unbounded domains
- On the convergence of two-step modulus-based matrix splitting iteration method
- On the separation method in stochastic reconstruction problem
- Robust estimation for partial functional linear regression models based on FPCA and weighted composite quantile regression
- Structure of coincidence isometry groups
- Sharp function estimates and boundedness for Toeplitz-type operators associated with general fractional integral operators
- Oscillatory hyper-Hilbert transform on Wiener amalgam spaces
- Euler-type sums involving multiple harmonic sums and binomial coefficients
- Poly-falling factorial sequences and poly-rising factorial sequences
- Geometric approximations to transition densities of Jump-type Markov processes
- Multiple solutions for a quasilinear Choquard equation with critical nonlinearity
- Bifurcations and exact traveling wave solutions for the regularized Schamel equation
- Almost factorizable weakly type B semigroups
- The finite spectrum of Sturm-Liouville problems with n transmission conditions and quadratic eigenparameter-dependent boundary conditions
- Ground state sign-changing solutions for a class of quasilinear Schrödinger equations
- Epi-quasi normality
- Derivative and higher-order Cauchy integral formula of matrix functions
- Commutators of multilinear strongly singular integrals on nonhomogeneous metric measure spaces
- Solutions to a multi-phase model of sea ice growth
- Existence and simulation of positive solutions for m-point fractional differential equations with derivative terms
- Bernstein-Walsh type inequalities for derivatives of algebraic polynomials in quasidisks
- Review Article
- Semiprimeness of semigroup algebras
- Special Issue on Problems, Methods and Applications of Nonlinear Analysis (Part II)
- Third-order differential equations with three-point boundary conditions
- Fractional calculus, zeta functions and Shannon entropy
- Uniqueness of positive solutions for boundary value problems associated with indefinite ϕ-Laplacian-type equations
- Synchronization of Caputo fractional neural networks with bounded time variable delays
- On quasilinear elliptic problems with finite or infinite potential wells
- Deterministic and random approximation by the combination of algebraic polynomials and trigonometric polynomials
- On a fractional Schrödinger-Poisson system with strong singularity
- Parabolic inequalities in Orlicz spaces with data in L1
- Special Issue on Evolution Equations, Theory and Applications (Part II)
- Impulsive Caputo-Fabrizio fractional differential equations in b-metric spaces
- Existence of a solution of Hilfer fractional hybrid problems via new Krasnoselskii-type fixed point theorems
- On a nonlinear system of Riemann-Liouville fractional differential equations with semi-coupled integro-multipoint boundary conditions
- Blow-up results of the positive solution for a class of degenerate parabolic equations
- Long time decay for 3D Navier-Stokes equations in Fourier-Lei-Lin spaces
- On the extinction problem for a p-Laplacian equation with a nonlinear gradient source
- General decay rate for a viscoelastic wave equation with distributed delay and Balakrishnan-Taylor damping
- On hyponormality on a weighted annulus
- Exponential stability of Timoshenko system in thermoelasticity of second sound with a memory and distributed delay term
- Convergence results on Picard-Krasnoselskii hybrid iterative process in CAT(0) spaces
- Special Issue on Boundary Value Problems and their Applications on Biosciences and Engineering (Part I)
- Marangoni convection in layers of water-based nanofluids under the effect of rotation
- A transient analysis to the M(τ)/M(τ)/k queue with time-dependent parameters
- Existence of random attractors and the upper semicontinuity for small random perturbations of 2D Navier-Stokes equations with linear damping
- Degenerate binomial and Poisson random variables associated with degenerate Lah-Bell polynomials
- Special Issue on Fractional Problems with Variable-Order or Variable Exponents (Part I)
- On the mixed fractional quantum and Hadamard derivatives for impulsive boundary value problems
- The Lp dual Minkowski problem about 0 < p < 1 and q > 0