Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
-
Jose M. Peña


Abstract
We present two methods for bounding the probabilities of benefit (a.k.a. the probability of necessity and sufficiency, i.e., the desired effect occurs if and only if exposed) and harm (i.e., the undesired effect occurs if and only if exposed) under unmeasured confounding. The first method computes the upper or lower bound of either probability as a function of the observed data distribution and two intuitive sensitivity parameters, which can then be presented to the analyst as a 2-D plot to assist in decision-making. The second method assumes the existence of a measured nondifferential proxy for the unmeasured confounder. Using this proxy, tighter bounds than the existing ones can be derived from just the observed data distribution.
1 Introduction
Consider the causal graph in Figure 1, where
Note that the first term comprises both causal and immune types, while the second term comprises both preventive and immune types.[1]

Causal graph where
Formally, the probability of benefit [1] (a.k.a. the probability of necessity and sufficiency [2,3]) is the probability of survival if treated and death otherwise:
The probability of harm [1] is the probability of death if treated and survival otherwise:
In general, neither the ATE nor
Likewise,
Likewise,
The rest of the article is organized as follows. Section 2 describes our sensitivity analysis method, and illustrates it with an example. Section 3 presents our tighter bounds, illustrates it an example, and reports simulations showing that our bounds are useful in many cases. We close the article with Section 4, where we discuss our results and related works. The main difference between ours and the existing works is that we just make use of the observed data distribution to bound the quantities of interest, i.e., no counterfactual probability or experimental data is involved.
2 Sensitivity analysis of
p
(
benefit
)
and
p
(
harm
)
For simplicity, we assume that the unmeasured confounders
Note that
where the second equality follows from counterfactual consistency, i.e.,
where the second equality follows from
Now, let us define
and
Then,
and, likewise,
Therefore,
and
where
and likewise for
Our lower bound in equation (8) is informative if and only if[3]
or
Then, the informative regions for
and
On the other hand, our upper bound in equation (9) is more informative than the upper bound in equation (1) if and only if[4]
or
which occurs if and only if
2.1 Sensitivity analysis of the average treatment effect
The average treatment effect is the difference in survival of a patient when treated and not treated averaged over the entire population:
Like
This results in a method for sensitivity analysis of the ATE, where, as before,
The sensitivity analysis of the ATE can supplement the sensitivity analysis of
We illustrate this in the next section.
2.2 Example
We illustrate our method for sensitivity analysis of
Since this model does not specify the functional forms of the causal mechanisms, we cannot compute the true
using first the law of total probability, then
Figure 2 (top) shows our lower bound of

Lower and upper bounds of
A similar reasoning leads the epidemiologist to conclude from Figure 3 that

Lower and upper bounds of
Finally, the epidemiologist can combine
We now illustrate how the sensitivity analysis of the ATE described in Section 2.1 can supplement the previous sensitivity analysis of

Lower and upper bounds of the ATE in the example in Section 2.2 as functions of the sensitivity parameters
Recall that the epidemiologist previously concluded that
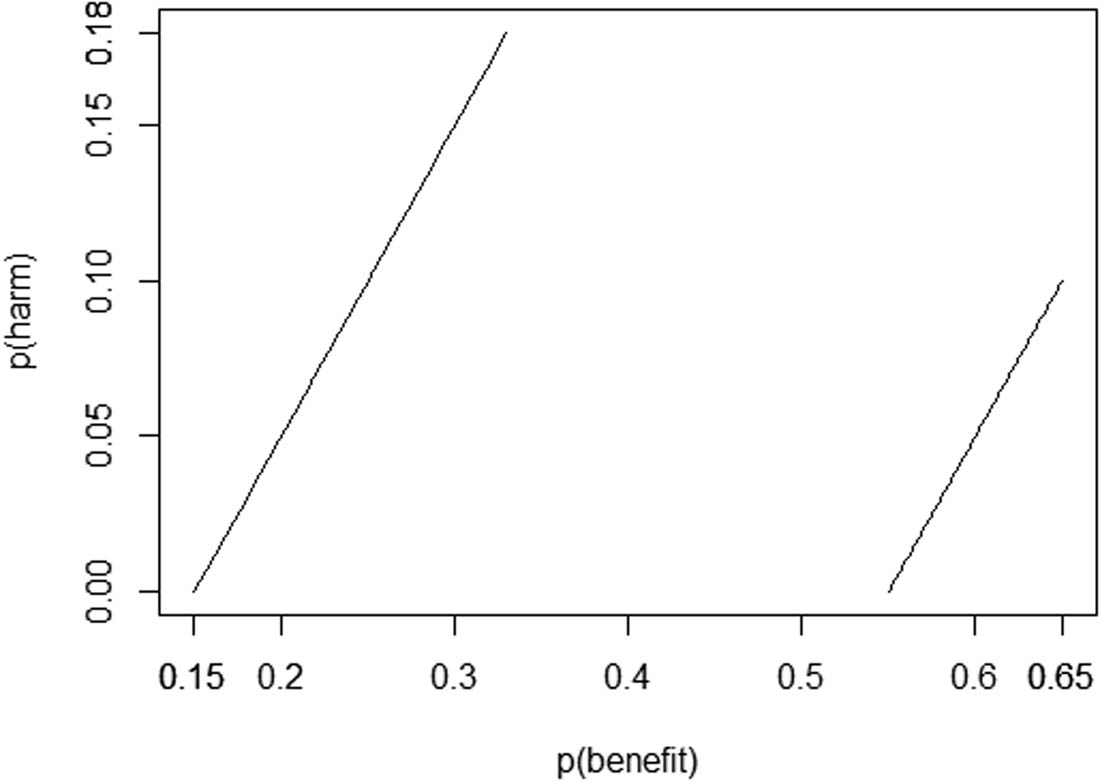
Only the values between the two lines comply with the ATE interval in the example in Section 2.2.
Recall that the epidemiologist previously concluded that the social good of the treatment lies in the interval
3 Tighter bounds of
p
(
benefit
)
and
p
(
harm
)
via proxies
Consider the causal graph in Figure 6, where

Causal graph where
From equation (11), we have that
Since
and by the observed or partially adjusted average treatment effect,
Ogburn and VanderWeele [4] prove that the
or
In words,
Provided that
by equation (2). On the other hand, if
by equation (2). Note that the conditions under which the new bounds hold (i.e.,
3.1 Bounds under nonincreasing and nondecreasing conditions
Let
Provided that
by equation (2). On the other hand, if
by equation (2). Note that the conditions under which the bounds above hold are testable from the observed data distribution.
3.2 Condition-free bounds
Peña [5] proved that some of the results in the previous section also hold under weaker conditions.[7] Specifically, if
The results above lead to tighter bounds than those in equation (1) from just the observed data distribution. Specifically, if
by equation (2); otherwise,
On the other hand, if
by equation (2); otherwise,
Note that unlike equations (12)–(15) that require
3.3 Example
To illustrate our tighter bounds of
Recall that
While the epidemiologist cannot test from the observed data distribution whether
and conclude that
The epidemiologist can also compute
from the observed data distribution and conclude that
Finally, we modify the running example so that now
from the observed data distribution and conclude that
and conclude that
3.4 Simulations
In this section, we show through simulations that our condition-free bounds in equations (16)–(19) are useful in many cases. Specifically, we randomly generate 100,000 probability distributions compatible with the causal graph in Figure 6. For the
Table 1 displays the results of our simulations. equations (16)–(19) are useful in 70% of the simulations, which is a substantial percentage. When they are useful, these equations return an interval that is 0.17 units on average narrower than the interval returned by equation (1). More concretely, they increase the lower bound by 0.08 units on average, and decrease the upper bound by 0.09 units on average. In some cases, the improvement exceeds the 0.8 units. The improvement in individual simulations can be better appreciated in Figure 7, which summarizes the first 100 simulations sorted by the upper bound returned by equation (1).
Results of the simulations in Section 3.4
| Usefulness | 70% |
| Average gap decrease | 0.17 |
| Maximum gap decrease | 0.88 |
| Average lower bound increase | 0.08 |
| Maximum lower bound increase | 0.88 |
| Average upper bound decrease | 0.09 |
| Maximum upper bound decrease | 0.86 |

4 Discussion
The contribution of this work is twofold. First, to present a sensitivity analysis method for
Our sensitivity analysis method has four sensitivity parameters (i.e.,
As mentioned above, our sensitivity parameters bound
In a study by Peña [7], a method for sensitivity analysis of the ATE under unmeasured confounding is presented. The method has two sensitivity parameters as follows:
These parameters are not useful for our purpose. Specifically, they produce a non-informative lower bound of
To the best of our knowledge, we are the first to use just a single binary proxy of the unmeasured confounder in order to tighten the bounds of
In this work, we were interested in assessing the true benefit and harm of an exposure and, consequently, were focused on bounding the probabilities of benefit and harm. However, our methods can be easily adapted to bound other probabilities of causality, such as the probability of necessity and the probability of sufficiency [2,3]. Specifically, the probability of necessity is defined as
The probability of necessity and sufficiency are not identifiable in general, but they can be bounded:
and
Note that the bounds are non-informative (i.e., they are 0 and 1) if, as we assume in this work, we only have access to the observed data distribution. Our methods can certainly be adapted to tighten the bounds, since they resemble those in equation (2). The adaptation is straightforward.
Finally, it would be worth studying the possibility of extending our bounds beyond binary random variables by making use of the results in [15–17]. It may also be worth extending our sensitivity analysis method to the case where there is a proxy
Acknowledgements
We thank the reviewers for their comments, which helped us improve our work. We also thank Manabu Kuroki and Haruka Yoshida for their comments on an earlier version of this manuscript.
-
Funding information: We gratefully acknowledge financial support from the Swedish Research Council (ref. 2019-00245).
-
Conflict of interest: Author states no conflict of interest.
Appendix A Derivations of equations (8) and (9)
From equations (6) and (7), we have that
and
which imply that
and
and
which together with equation (2) imply equation (8). Likewise, from equations (6) and (7), we have that
and
which imply that
and
References
[1] Mueller S, Pearl J. Personalized decision-making - a conceptual introduction. 2022. arXiv:220809558 [csAI]. 10.1515/jci-2022-0050Suche in Google Scholar
[2] Pearl J. Causality: models, reasoning, and inference. Cambridge, UK: Cambridge University Press; 2009. 10.1017/CBO9780511803161Suche in Google Scholar
[3] Tian J, Pearl J. Probabilities of causation: bounds and identification. Ann Math Artif Intell. 2000;28:287–313. 10.1023/A:1018912507879Suche in Google Scholar
[4] Ogburn EL, VanderWeele TJ. On the nondifferential misclassification of a binary confounder. Epidemiology. 2012;23:433–9. 10.1097/EDE.0b013e31824d1f63Suche in Google Scholar PubMed PubMed Central
[5] Peña JM. On the monotonicity of a nondifferentially mismeasured binary confounder. J Causal Inference. 2020;8:150–63. 10.1515/jci-2020-0014Suche in Google Scholar
[6] Li A, Mueller S, Pearl J. ε-identifiability of causal quantities. 2023. arXiv:230112022 [csAI]. Suche in Google Scholar
[7] Peña JM. Simple yet sharp sensitivity analysis for unmeasured confounding. J Causal Inference. 2022;10:1–17. 10.1515/jci-2021-0041Suche in Google Scholar
[8] Kawakami Y. Instrumental variable-based identification for causal effects using covariate information. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence; 2021. p. 12131–8. 10.1609/aaai.v35i13.17440Suche in Google Scholar
[9] Kuroki M, Cai Z. Statistical analysis of “probabilities of causation” using co-variate information. Scandinavian J Stat. 2011;38:564–77. 10.1111/j.1467-9469.2011.00730.xSuche in Google Scholar
[10] Shingaki R, Kuroki M. Identification and estimation of joint probabilities of potential outcomes in observational studies with covariate information. In: Advances in neural information processing systems. Vol. 34; 2021. p. 26475–86. Suche in Google Scholar
[11] Kuroki M, Pearl J. Measurement bias and effect restoration in causal inference. Biometrika. 2014;101:423–37. 10.1093/biomet/ast066Suche in Google Scholar
[12] Mueller S, Li A, Pearl J. Causes of effects: learning individual responses from population data. In: Proceedings of the 31st International Joint Conference on Artificial Intelligence; 2022. p. 2712–8. 10.24963/ijcai.2022/376Suche in Google Scholar
[13] Li A, Pearl J. Unit selection with causal diagram. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence; 2022. p. 5765–72. 10.1609/aaai.v36i5.20519Suche in Google Scholar
[14] Li A, Pearl J. Unit selection based on counterfactual logic. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence; 2019. p. 1793–9. 10.24963/ijcai.2019/248Suche in Google Scholar
[15] Li A, Pearl J. Probabilities of causation with nonbinary treatment and effect. 2022. arXiv:220809568 [csAI]. Suche in Google Scholar
[16] Peña JM, Balgi S, Sjölander A, Gabriel EE. On the bias of adjusting for a non-differentially mismeasured discrete confounder. J Causal Inference. 2021;9:229–49. 10.1515/jci-2021-0033Suche in Google Scholar
[17] Sjölander A, Peña JM, Gabriel EE. Bias results for nondifferential mismeasurement of a binary confounder. Stat Probability Letters. 2022;186:109474. 10.1016/j.spl.2022.109474Suche in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Research Articles
- Adaptive normalization for IPW estimation
- Matched design for marginal causal effect on restricted mean survival time in observational studies
- Robust inference for matching under rolling enrollment
- Attributable fraction and related measures: Conceptual relations in the counterfactual framework
- Causality and independence in perfectly adapted dynamical systems
- Sensitivity analysis for causal decomposition analysis: Assessing robustness toward omitted variable bias
- Instrumental variable regression via kernel maximum moment loss
- Randomization-based, Bayesian inference of causal effects
- On the pitfalls of Gaussian likelihood scoring for causal discovery
- Double machine learning and automated confounder selection: A cautionary tale
- Randomized graph cluster randomization
- Efficient and flexible mediation analysis with time-varying mediators, treatments, and confounders
- Minimally capturing heterogeneous complier effect of endogenous treatment for any outcome variable
- Quantitative probing: Validating causal models with quantitative domain knowledge
- On the dimensional indeterminacy of one-wave factor analysis under causal effects
- Heterogeneous interventional effects with multiple mediators: Semiparametric and nonparametric approaches
- Exploiting neighborhood interference with low-order interactions under unit randomized design
- Robust variance estimation and inference for causal effect estimation
- Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
- Potential outcome and decision theoretic foundations for statistical causality
- 2D score-based estimation of heterogeneous treatment effects
- Identification of in-sample positivity violations using regression trees: The PoRT algorithm
- Model-based regression adjustment with model-free covariates for network interference
- All models are wrong, but which are useful? Comparing parametric and nonparametric estimation of causal effects in finite samples
- Confidence in causal inference under structure uncertainty in linear causal models with equal variances
- Special Issue on Integration of observational studies with randomized trials - Part II
- Personalized decision making – A conceptual introduction
- Precise unbiased estimation in randomized experiments using auxiliary observational data
- Conditional average treatment effect estimation with marginally constrained models
- Testing for treatment effect twice using internal and external controls in clinical trials
Artikel in diesem Heft
- Research Articles
- Adaptive normalization for IPW estimation
- Matched design for marginal causal effect on restricted mean survival time in observational studies
- Robust inference for matching under rolling enrollment
- Attributable fraction and related measures: Conceptual relations in the counterfactual framework
- Causality and independence in perfectly adapted dynamical systems
- Sensitivity analysis for causal decomposition analysis: Assessing robustness toward omitted variable bias
- Instrumental variable regression via kernel maximum moment loss
- Randomization-based, Bayesian inference of causal effects
- On the pitfalls of Gaussian likelihood scoring for causal discovery
- Double machine learning and automated confounder selection: A cautionary tale
- Randomized graph cluster randomization
- Efficient and flexible mediation analysis with time-varying mediators, treatments, and confounders
- Minimally capturing heterogeneous complier effect of endogenous treatment for any outcome variable
- Quantitative probing: Validating causal models with quantitative domain knowledge
- On the dimensional indeterminacy of one-wave factor analysis under causal effects
- Heterogeneous interventional effects with multiple mediators: Semiparametric and nonparametric approaches
- Exploiting neighborhood interference with low-order interactions under unit randomized design
- Robust variance estimation and inference for causal effect estimation
- Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
- Potential outcome and decision theoretic foundations for statistical causality
- 2D score-based estimation of heterogeneous treatment effects
- Identification of in-sample positivity violations using regression trees: The PoRT algorithm
- Model-based regression adjustment with model-free covariates for network interference
- All models are wrong, but which are useful? Comparing parametric and nonparametric estimation of causal effects in finite samples
- Confidence in causal inference under structure uncertainty in linear causal models with equal variances
- Special Issue on Integration of observational studies with randomized trials - Part II
- Personalized decision making – A conceptual introduction
- Precise unbiased estimation in randomized experiments using auxiliary observational data
- Conditional average treatment effect estimation with marginally constrained models
- Testing for treatment effect twice using internal and external controls in clinical trials