Causality and independence in perfectly adapted dynamical systems
-
Tineke Blom


Abstract
Perfect adaptation in a dynamical system is the phenomenon that one or more variables have an initial transient response to a persistent change in an external stimulus but revert to their original value as the system converges to equilibrium. With the help of the causal ordering algorithm, one can construct graphical representations of dynamical systems that represent the causal relations between the variables and the conditional independences in the equilibrium distribution. We apply these tools to formulate sufficient graphical conditions for identifying perfect adaptation from a set of first-order differential equations. Furthermore, we give sufficient conditions to test for the presence of perfect adaptation in experimental equilibrium data. We apply this method to a simple model for a protein signalling pathway and test its predictions in both simulations and using real-world protein expression data. We demonstrate that perfect adaptation can lead to misleading orientation of edges in the output of causal discovery algorithms.
1 Introduction
Understanding causal relations is an objective that is central to many scientific endeavours. It is often said that the gold standard for causal discovery is a randomized controlled trial, but practical experiments can be too expensive, unethical, or otherwise infeasible. The promise of causal discovery is that we can, under certain assumptions, learn about causal relations by using a combination of data and background knowledge [1–10]. Roughly speaking, causal discovery algorithms construct a graphical representation that encodes certain aspects of the data, such as conditional independences, given some constraints that are imposed by background knowledge. Under additional assumptions on the underlying causal mechanisms, these graphical representations have a causal interpretation as well. In this work, we specifically consider the equilibrium distribution of perfectly adapted dynamical systems. We will show that such systems may have the property that the corresponding graphs that encode the conditional independences in the distribution do not have a straightforward causal interpretation in terms of the changes in distribution induced by interventions.
Perfect adaptation in a dynamical system is the phenomenon that one or more variables in the system temporarily respond to a persistent change of an external stimulus, but ultimately revert to their original values as the system reaches equilibrium again. We study the differences between the causal structure implied by the dynamic equations and the conditional dependence structure of the equilibrium distribution. To do so, we make use of the technique of causal ordering, introduced by Simon [11], which can be used to construct a causal ordering graph that represents causal relations and a Markov ordering graph that encodes conditional independences between variables [12]. We introduce the notion of a dynamic causal ordering graph to represent transient causal effects in a dynamical model. We use these graphs to provide a sufficient graphical condition for a dynamical system to achieve perfect adaptation, which does not require simulations or cumbersome calculations. Furthermore, we provide sufficient conditions to test for the presence of perfect adaptation in real-world data with the help of the equilibrium Markov ordering graph, and we explain why the usual interpretation of causal discovery algorithms, when applied to perfectly adapted dynamical systems at equilibrium, can be misleading.
We illustrate our ideas on three simple dynamical systems with feedback: a filling bathtub model [13,14], a viral infection model [15,16], and a chemical reaction network [17]. We point out how perfect adaptation may also manifest itself in protein signalling networks, and take a closer look at the consequences for causal discovery from a popular protein expression data set [18]. We adapt a model for the RAS-RAF-MEK-ERK signalling pathway from [19] and study its properties under certain saturation conditions. We test its predictions both in simulations and on real-world data. We propose that the phenomenon of perfect adaptation might explain why the presence and orientation of edges in the output of causal discovery algorithms does not always agree with the direction of edges in biological consensus networks that are based on a partial representation of the underlying dynamical mechanisms.
2 Background
In this section, we provide an overview of the relevant background material on which this work is based. We first consider the assumptions underpinning popular constraint-based causal discovery algorithms and give a brief description of a simple causal discovery algorithm in Section 2.1. In Section 2.2, we proceed with a concise introduction to the causal ordering algorithm of Simon [11] and demonstrate how it can be applied to a set of equations together with a pre-specified set of exogenous variables to deduce the implied causal relations and conditional independences. Finally, in Section 2.3, we discuss the relationship with existing work.
2.1 Causal discovery
The main objective of causal discovery is to infer causal relations from experimental and observational data. The most common causal discovery algorithms can be roughly divided into score-based and constraint-based approaches. In this work, we will focus on the latter approach (examples include PC, FCI, and variants thereof, and see [1,2,4,5,7,9,10]), which exploits conditional independences in data to infer causal relations. We will first discuss assumptions for constraint-based causal discovery. We then consider the application of causal discovery algorithms to models with feedback. We proceed with a brief but concrete introduction to a simple causal discovery algorithm. Finally, we discuss how the present work relates to the existing literature.
Learning a graphical structure from conditional independence constraints typically relies on Markov and faithfulness assumptions relating conditional independences to properties of a graph. In particular, a d-separation is a relation between three disjoint sets of vertices in a graph that indicates whether all paths between two sets of vertices are
However, many systems of interest in various scientific disciplines (e.g., biology, econometrics, physics) include feedback mechanisms. Cyclic structural causal models (SCMs) can be used to model causal features and conditional independence relations of systems that contain cyclic causal relationships [23]. For linear SCMs with causal cycles, several causal discovery algorithms have been developed that are based on
For the sake of simplicity, we will limit our attention in this article to one of the simplest causal discovery algorithms, local causal discovery (LCD) [1]. This algorithm is a straightforward and efficient search method to detect a specific causal structure from background knowledge and observational or experimental data. The algorithm looks for triples of variables

All ADMGs that form an LCD triple
In this article, we consider equilibrium distributions that are generated by dynamical models. The causal relations in an equilibrium model are defined through the effects of persistent interventions (i.e., interventions that are constant over time) on the equilibrium distribution, assuming that the system again converges to equilibrium. It has been shown that directed graphs encoding the conditional independences between endogenous variables in the equilibrium distribution of dynamical systems with feedback do not always have a straightforward and intuitive causal interpretation [12–14] (see also Appendix F). As a consequence, the output of causal discovery algorithms applied to equilibrium data of dynamical systems with feedback cannot always be interpreted causally in a naive way. In this work, we will show that this not only happens in isolated cases, but that this is actually a common phenomenon in a large class of models with perfectly adapting feedback mechanisms. In our opinion, a better understanding of how perfectly adapting feedback loops affect the causal interpretation of the conditional independence structure is a prerequisite for successful applications of causal discovery in fields like systems biology, where one often encounters perfect adaptivity. One way to arrive at such understanding is through the application of the causal ordering algorithm, the topic of the next section.
2.2 Causal ordering
The causal ordering algorithm of Simon [11] returns an ordering of endogenous variables that occur in a set of equations, given a specification of which variables are exogenous. The algorithm was recently reformulated so that the output is a causal ordering graph that encodes the generic effects of certain interventions and a Markov ordering graph that represents conditional independences (both under certain assumptions regarding the solvability of the equations) [12]. We refer readers who are not yet familiar with the causal ordering algorithm to ref. [12] for a more extensive introduction to this approach. Here, we will provide only a brief description of the algorithm and discuss how its output should be interpreted.
First, note that the structure of a set of equations and the variables that appear in them can be represented by a bipartite graph
Find a perfect matching
For each
Partition vertices
Exogenous variables appearing in the equations are added as singleton clusters to
Output the directed cluster graph
Example 1
Consider the following set of equations with index set
where

Several graphs occurring in Example 1. The bipartite graph
Throughout this work, we will assume that sets of equations are uniquely solvable with respect to the causal ordering graph, which means that for each cluster, the equations in that cluster can be solved uniquely for the endogenous variables in that cluster (see Definition 14 in ref. [12] for details). This implies amongst others that the endogenous variables in the model can be solved uniquely along a topological ordering of the causal ordering graph. Under this assumption, the causal ordering graph represents the effects of soft and certain perfect interventions [12]. Soft interventions target equations; they do not change which variables appear in the targeted equation and may only alter the parameters or functional form of the equation. Perfect interventions target clusters in the causal ordering graph and replace the equations in the targeted cluster with equations that set the variables in the cluster equal to constant values. A soft intervention on an equation or a perfect intervention on a cluster has no effect on a variable in the causal ordering graph whenever there is no directed path to that variable from the intervention target (i.e., the targeted equation or an arbitrary vertex in the targeted cluster, respectively), see Theorems 20 and 23 in ref. [12].[6] Since the equations in Example 1 are uniquely solvable with respect to the causal ordering graph in Figure 2(c),[7] we can, for example, read off from the causal ordering graph that a soft intervention targeting
Given the probability distribution of the exogenous random variables, one obtains a unique probability distribution on all the variables under the assumption of unique solvability with respect to the causal ordering graph. The Markov ordering graph is a DAG
Assuming that the probability distribution is
2.3 Related work
The causal ordering algorithm can be applied, for instance, to the equilibrium equations of a dynamical system to uncover its causal properties and conditional independence relations at equilibrium. The relationship between dynamical models and causal models has received much attention over the years. For instance, the works of [13,30–35] considered causal relations in dynamical systems that are not at equilibrium, while [6,13,14,16,21,34,36–39] considered graphical and causal models that arise from studying the stationary behaviour of dynamical models. In particular, extensions of the causal ordering algorithm for dynamical systems were proposed and discussed in ref. [13]. Also, the causal ordering algorithm was applied in ref. [16] to study the robustness of model predictions when combining two systems. The relationship between the causal semantics of a dynamical system before it reaches equilibrium and at equilibrium has also been studied [14,34,36].
In previous work, researchers have noted various problems when attempting to use a single graphical model to represent both conditional independence properties and causal properties of certain dynamical systems at equilibrium [14,21,37,39,40]. Often, restrictive assumptions on the underlying dynamical models are made to avoid these subtleties – the most common one being to exclude the possibility of cycles altogether. In this work, we will not make such restrictive assumptions and instead show that such problems are pervasive in the important class of perfectly adapted dynamical systems. We follow [12,16] in addressing the issues by using the causal ordering algorithm to construct separate graphical representations for the causal properties and conditional independence relations implied by these systems.
It has been shown that the popular SCM framework [3,23] is not flexible enough to fully capture the causal semantics (in terms of perfect interventions targeting variables) of the dynamics of a basic enzyme reaction at equilibrium, and for that purpose, [39] proposed to use causal constraints models (CCMs) instead. However, CCMs lack a graphical representation (and consequently, all the benefits that usually come with it, like a Markov property and a graphical approach to causal reasoning). The techniques in ref. [12] can also be used to construct graphical representations of causal relations and conditional independences of these models. In Appendix D, we demonstrate that the basic enzyme reaction is perfectly adapting and we show how the causal ordering technique can be used to obtain graphical presentations and a Markov property for this model. This approach offers several advantages over the CCMs approach to model this system.
An application area where obtaining a causal understanding of complex systems is often non-trivial due to feedback and perfect adaptation is that of systems biology. A research question that has seen considerable interest in that field is which reaction networks can achieve perfect adaptation [17,41–44]. The present work provides a method that facilitates the analysis of perfectly adapted dynamical systems by providing a principled and computationally efficient procedure to identify perfect adaptation either from model equations or from experimental data and background knowledge.
In Section 5, we apply our methodology in an attempt to arrive at a better understanding of the causal mechanisms present in protein signalling networks. For protein signalling networks, apparent “causal reversals” have been reported, that is, cases where causal discovery algorithms find the opposite causal relation of what is expected [9,45–48]. One explanation for these reversed edges in the output of causal discovery algorithm could be the unknown presence of measurement error [49]. As we demonstrate in this work, unknown feedback loops that result in perfect adaptation can be another reason why one might find reversed causal relations when applying causal discovery algorithms to biological data.
3 Perfect adaptation
In this section, we introduce the notion of perfect adaptation by taking a close look at several examples of dynamical systems that can achieve perfect adaptation. We then consider graphical representations of these systems both before and after they have reached equilibrium. This will set the stage for our main theoretical results regarding the identification of perfect adaptation in models or data, which will be presented in Section 4. The goals of this section are as follows: (i) building intuition about mechanisms that result in perfect adaptation, (ii) outlining the relevance of this phenomenon in application domains, and (iii) explaining how the causal ordering algorithm helps to understand perfect adaptation.
The ability of (part of) a system to converge to its original state when a constant and persistent external stimulus is added or changed is referred to as perfect adaptation. If the adaptive behaviour does not depend on the precise setting of the system’s parameters, then we say that the adaptation is robust. For our purposes, the most interesting of the two is robust perfect adaptation. As this is also often simply referred to as “perfect adaptation” in the literature, we will do so here as well.
3.1 Examples
We consider three different dynamical models corresponding to a filling bathtub, a viral infection with an immune response, and a chemical reaction network. We use simulations to demonstrate that all of these systems are capable of achieving perfect adaptation. The details of the simulations presented in this section are provided in Appendix B, and the code to reproduce these is provided under a free and open source license (see the Data availability statement at the end of this article).
3.1.1 Filling bathtub
We consider the example of a filling bathtub of Iwasaki and Simon [13] (see also [12,14]). Let
where
We call the labelling

Simulations of the outflow rate
3.1.2 Viral infection model
We consider the example of a simple dynamical model for a viral infection and immune response of De Boer [15] (also discussed in ref. [16]). The model describes target cells
Here,
assuming a constant value
3.1.3 Reaction networks with a negative feedback loop
The phenomenon of perfect adaptation is a common feature in biochemical reaction networks, and there exist many reaction networks that can achieve (near) perfect adaptation [41,43]. For networks consisting of only three nodes, Ma et al. [17] found by an exhaustive search that there exist two major classes of reaction networks that produce (robust) adaptive behaviour. The reaction diagrams for these networks are given in Figure 4. Here, we will only analyze the “Negative Feedback with a Buffer Node” (NFBN) network. An analysis of the other network, the “Incoherent Feed-Forward Loop with a Proportioner Node” (IFFLP), is provided in Appendix E. The NFBN system can be described by the following first-order differential equations:
where
Under the assumption that
![Figure 4
The two reaction networks that can achieve perfect adaptation [17]. (a) NFBN network, and (b) IFFLP network. Orange edges represent saturated reactions, blue edges represent linear reactions, and black edges are unconstrained reactions. Arrowheads represent positive influence and edges ending with a circle represent negative influence.](/document/doi/10.1515/jci-2021-0005/asset/graphic/j_jci-2021-0005_fig_004.jpg)
The two reaction networks that can achieve perfect adaptation [17]. (a) NFBN network, and (b) IFFLP network. Orange edges represent saturated reactions, blue edges represent linear reactions, and black edges are unconstrained reactions. Arrowheads represent positive influence and edges ending with a circle represent negative influence.
3.2 Graphical representations
We will now provide the different graphical representations of the perfectly adapted dynamical systems that were introduced in the previous section. These representations are based on the graphs that are used in refs [12,13] to encode the equilibrium structure of equations, causal relations, and conditional independences. The main difference with the previous work is that we also explicitly consider similar graphical representations for systems that have not yet reached equilibrium.
Bipartite graph: The equilibrium bipartite graphs associated with the equilibrium equations of the filling bathtub, the viral infection, and the reaction network with feedback are given in Figure 5(a), (b), and (c), respectively. We have added also a node representing the input signal. The dynamic bipartite graphs for the dynamics of these models are constructed from first-order differential equations in canonical form[14] in the following way. Both the derivative

Graphical representations of the bathtub model (left column), the viral infection model (center column), and the reaction network with negative feedback (right column). The input vertices
Comparing the equilibrium bipartite graphs with the dynamic bipartite graphs we note that there is no edge
Causal ordering graph: The application of the causal ordering algorithm to the equilibrium bipartite graphs of the filling bathtub, the viral infection, and the reaction network results in the equilibrium causal ordering graphs in Figure 5(g), (h), and (i), respectively. Henceforth, we will assume that the dynamic bipartite graph has a perfect matching that extends the natural labelling of the dynamic equations, i.e., such that all pairs
As shown in ref. [12], the absence (presence) of a directed path from an equation vertex to a variable vertex in the equilibrium causal ordering graph indicates that a soft intervention targeting a parameter in that equation has no (a generic) effect on the value of that variable once the system has reached equilibrium again. Furthermore, the absence (presence) of a directed path from a cluster to a variable vertex in the equilibrium causal ordering graph indicates that a perfect intervention targeting the cluster has no (a generic) effect on the value of that variable once the system has reached equilibrium again. Notice that the variables
Equilibrium Markov ordering graph: As explained in Section 2.2, the Markov ordering graph is constructed from the causal ordering graph and includes exogenous variables. For the bathtub model, we let vertices
3.3 Existence and uniqueness of solutions
The causal ordering algorithm is a graphical tool that can be useful when solving a system of equations. It decomposes the question of existence and uniqueness of a “global” solution into several “local” existence and uniqueness problems corresponding to a partitioning of the equations. When a unique global solution exists for all possible joint values of the (independent) exogenous variables, this leads to both a causal semantics and a Markov property [12]. We argue here that these ideas can also be extended to include differential equations. We will illustrate this with the filling bathtub model. We start with the (conceptually simpler) equilibrium model, which solely contains static equations, before discussing what to do when dynamic equations are present.
The equilibrium equations (7)–(10) can be solved in steps by following the topological ordering of the clusters in the equilibrium causal ordering graph in Figure 5(g). First, use
Since we obtain a unique solution of each equation for the target variable in terms of the other variables appearing in the equation, this procedure shows that there exists a unique global solution of the system of equations for any value of the exogenous variables
For the dynamic filling bathtub model, we can follow a similar procedure, but now the clusters may also contain differential equations. We can make use of the theory for the existence and uniqueness of solutions of ordinary differential equations. First, note that the dynamic bipartite graph reflects the structure of the static and dynamic equations once we rewrite the differential equations as integral equations. For example, for the time interval
Rewriting the differential equations as integral equations has two advantages: (i) there is no need to introduce the derivatives as if they were (variation) independent processes; (ii) it makes the dependence on the initial conditions
Important to note here is that this explicit solution procedure shows that at equilibrium, the value of the input signal
4 Identification of perfect adaptation
In Section 3.1, we identified perfect adaptation in three simple models through simulations. Here, we consider how to identify models that are capable of perfect adaptation without requiring simulations or explicit calculations. In Section 4.1, we will put the graphical representations of Section 3.2 to use for identifying perfect adaptation in dynamical models. We discuss possibilities for the identification of perfect adaptation from equilibrium data in Section 4.2.
4.1 Identification of perfect adaptation via causal ordering
The identification of perfect adaptation via causal ordering makes use of the causal semantics of the equilibrium causal ordering graph. The following lemma states that a change in the input signal has no effect on the value of a variable if there is no directed path from the input vertex to that variable in the equilibrium causal ordering graph.
Lemma 1
Consider a model consisting of static equations, a set of first-order differential equations in canonical form, and an input signal. Assume that the equilibrium bipartite graph has a perfect matching and that the static equations and equilibrium equations derived from the first-order differential equations are uniquely solvable with respect to the equilibrium causal ordering graph for all relevant values of the input signal. If there is no directed path from the input vertex to a variable vertex in the equilibrium causal ordering graph, then the value of the input signal does not influence the equilibrium distribution of that variable.
Proof
The statement follows directly from Theorem 20 in ref. [12].□
To establish perfect adaptation, we assume that the presence of a directed path in the dynamic causal ordering graph implies the presence of a transient causal effect.
Assumption 1
Consider a model consisting of static equations, a set of first-order differential equations in canonical form, and an input signal. Assume that the dynamic bipartite graph has a perfect matching that extends the natural labelling. If there is a directed path from the input vertex to a variable vertex in the dynamic causal ordering graph, then there will be a response of that variable to changes in the input signal some time later.
Intuitively, this assumption may seem plausible, as the presence of the directed path in the dynamic causal ordering graph implies that the input signal enters into the construction of the solution of the variable, as sketched in Section 3.3. Unless a perfect cancellation occurs, one then expects a generic effect on the solution some time after the change in the input signal. Assumption 1 can be seen as a consequence of a certain faithfulness assumption.[19] We conjecture that this assumption is generically satisfied for a large class of dynamical systems (e.g., it might hold for almost all parameter values with respect to the Lebesgue measure on a suitable parameter space).[20]
By combining Lemma 1 and Assumption 1, we immediately obtain the following result.
Theorem 1
Consider a model that satisfies the conditions of Lemma
1
and assume that the associated dynamic bipartite graph has a perfect matching that extends the natural labelling. Under Assumption
1, the presence of a directed path from the input signal I to a variable
Theorem 1 can be directly applied to the equilibrium and dynamic causal ordering graphs in Figure 5 to identify perfect adaptation. For example, we see that there is a directed path from the input signal
In Appendix D, we show that the sufficient conditions in Theorem 1 for the identification of perfect adaptation are not necessary. More specifically, we construct graphical representations for a dynamical model of a basic enzymatic reaction that achieves perfect adaptation but does not satisfy the conditions in Theorem 1. Interestingly, though, after rewriting the equations, the perfectly adaptive behaviour of these systems can be captured via Theorem 1. Further, in Appendix E, we show that the biochemical reaction network in Figure 4(b), which Ma et al. [17] identified as being capable of achieving perfect adaptation, does not satisfy the conditions in Theorem 1 either. We show that a change of variables enables one to still capture the perfectly adaptive behaviour of this system via Theorem 1.
4.2 Identification of perfect adaptation from data
So far we have only considered how perfect adaptation can be identified in mathematical models. In this section, we focus on methods for identifying perfect adaptation from data that are generated by perfectly adapted dynamical systems under experimental conditions. The most straightforward approach to detect perfect adaptation is to collect time-series data while experimentally changing the input signal to the system. One can then simply observe whether the variables in the system revert to their original values. However, this type of experimentation is not always feasible. Another way to identify feedback loops that achieve perfect adaptation uses a combination of observational equilibrium data, background knowledge, and experimental data. Our second main result, Theorem 2, gives sufficient conditions under which we can identify a system that is capable of perfect adaptation from experimental equilibrium data.
Theorem 2
Consider a set of first-order dynamical equations in canonical form for variables V, satisfying the conditions of Theorem
1, with equilibrium equations F under the natural labelling. Consider a soft intervention targeting an equation
The soft intervention does not change the equilibrium distribution of
the soft intervention alters the equilibrium distribution of a variable corresponding to a nondescendant of
Proof
The proof is given in Appendix A.□
Theorem 2 applies in particular to experiments on the filling bathtub, viral infection, and chemical reaction systems (for the corresponding graphs, see Figure 5). For example, a soft intervention targeting
We can devise the following scheme to detect perfectly adapted dynamical systems from data and background knowledge. The procedure relies on several assumptions, including
5 Perfect adaptation in protein signalling
In this section, we apply the ideas developed in the previous sections to a biological system that has been intensely studied during the past decades to emphasize the practical relevance of perfect adaptation. The so-called RAS-RAF-MEK-ERK signalling cascade is a textbook example of a protein signalling network, which forms an important ingredient of the “machinery” of cells in living organisms. The molecular pathways in such a network fulfil various important functions, for instance, the transmission and processing of information. Systems biologists make use of dynamical systems to model such networks both qualitatively and quantitatively. Because of the high complexity of protein signalling networks, which typically consist of many different interacting components, this has also been considered a promising application domain for causal discovery methods.
In an influential article, Sachs et al. [18] applied causal discovery to reconstruct a protein signalling network from experimental data. Over the years, the dataset of [18] has become an often used “benchmark” for assessing the accuracy of causal discovery algorithms, where the “consensus network” in ref. [18] is usually considered as the perfect ground truth. The apparent successes of causal discovery on this particular dataset may have led to the impression that causal discovery algorithms can in general successfully discover the causal semantics of complex protein signalling networks from real-world data. However, this success has hitherto not been repeated on other, similar datasets, to the best of our knowledge. Indeed, modelling and understanding such systems and inferring their behaviour and structure from data still pose many challenges, for instance, because of feedback loops and the inherent dynamical nature of such systems [52].
In this section, we focus on understanding the properties of the equilibrium distribution of a simple model of the RAS-RAF-MEK-ERK signalling pathway, and specifically we investigate the phenomenon of perfect adaptation. Like many other biological systems, protein signalling networks often show adaptive behaviour that helps to ensure a certain robustness of their functionality against various disturbances and perturbations [43]. By using the technique of causal ordering to analyze the conditional independences and causal relations that are implied by the model at equilibrium, we elucidate the causal interpretation of the output of constraint-based causal discovery algorithms when they are applied to equilibrium protein expression data if the parameters are such that the system shows perfect adaptation.
We test some of the model’s predictions on real-world data and compare with another model that has been proposed. We do not claim that the perfectly adaptive model that we analyze here is a realistic model of the protein signalling pathway. Although we will show in Section 5.4 that the model is able to explain certain observations in real-world data, this is not that surprising for a model with that many parameters.[21] Instead, our goal is to demonstrate that in systems with perfect adaptation, the standard interpretation of the output of causal discovery algorithms may not apply.[22] This could explain why the output of certain causal discovery algorithms applied to the data of [18] appears to be at odds with the biological consensus network presented in ref. [18], see, for example, [47] and [9].
This section is structured as follows. In Section 5.1 we introduce the perfectly adaptive model for the signalling pathway. We proceed with the associated graphical representations in Section 5.2. Then, in Section 5.3, we study the model’s predictions under a soft intervention and verify these in simulations. In Section 5.4 we take a closer look at some real-world data, more specifically, the data from [18], and compare the model’s predictions with the data. In Section 5.5, we explain how the phenomenon of perfect adaptation may lead to unexpected outcomes of causal discovery methods. In the end, we will have to conclude that the causal structure of the RAS-RAF-MEK-ERK cascade seems far from understood, and that it seems unlikely that the data in ref. [18] is sufficiently rich to be able to draw strong conclusions regarding the causal behaviour of the signalling network.
5.1 Dynamical model
We adapt the mathematical model of [19] for the RAS-RAF-MEK-ERK signalling cascade, as in ref. [16].[23] Let
where we assume that
We let
We simulated the model under these saturation conditions (picking values for
5.2 Graphical representations
We consider graphical representations of the protein signalling pathway. By using the natural labelling, we construct the dynamic bipartite graph in Figure 7(a) from the first-order differential equations, with the input signal
Under saturation conditions, the equilibrium equations
There is a directed path from the input vertex

Perfect adaptation in the model for the RAS-RAF-MEK-ERK signalling pathway. After an initial response to a change of the input signal from value
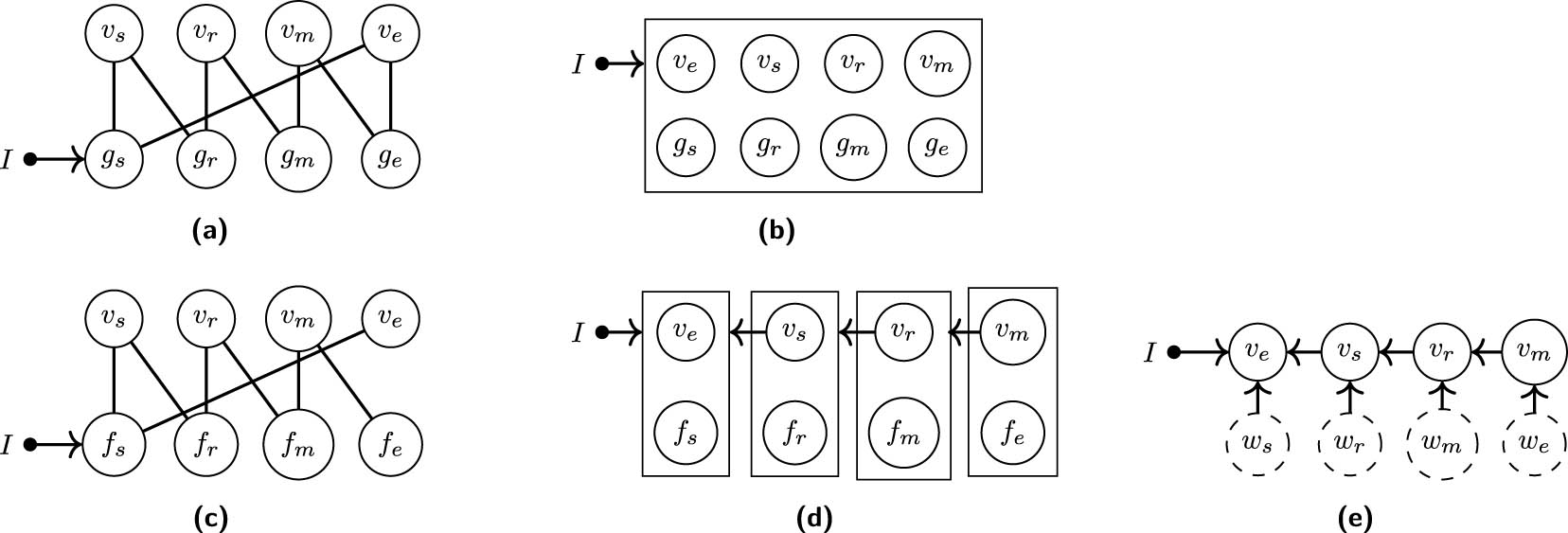
Five graphs associated with the protein signalling pathway model under saturation conditions where indices
The
We verified that these conditional independences indeed appear in the simulated equilibrium distribution of the model (see Appendix C for details).
5.3 Inhibiting the activity of MEK
A common biological experiment that is used to study protein signalling pathways is the use of an inhibitor that decreases the activity of a protein on the pathway. Such an inhibitor slows down the rate at which the active protein is able to activate another protein. Here, we consider inhibition of MEK activity. We can model this as a change of the parameters of the differential equations in which
We assessed the effect of decreasing the activity of MEK on the equilibrium concentrations of RAS, RAF, MEK, and ERK. To that end, we simulated the perfectly adapted model (with parameters as described in Appendix B, in particular,

Simulation of the response of the concentrations of active RAS, RAF, MEK, and ERK after inhibition of the activity of MEK. The system starts out in equilibrium with
Note that RAS, RAF, and MEK are non-descendants of ERK in the equilibrium Markov ordering graph in Figure 7(e), so that under the assumptions in Theorem 2, we could actually use this experiment to detect perfect adaptation in the protein pathway.
5.4 Testing model predictions on real-world data
In this subsection, we verify some of the predictions of the model we obtained in Sections 5.2 and 5.3 on real-world data. We will compare with predictions of the causal Bayesian network model proposed by ref. [18].
Figure 9 shows scatter plots for the (logarithms of) the expressions of active RAF, MEK, and ERK in the multivariate single-cell protein expression dataset that was used in ref. [18], for three (out of 14) different experimental conditions. The baseline condition (in blue) is the one where the cells were treated with anti-CD3 and anti-CD28, activators of the RAS-RAF-MEK-ERK signalling cascade. In another condition (in red), the cells were additionally exposed to U0126, a known inhibitor of MEK activity. By inspecting the scatter plots, we get a quick visual check of some of the predictions of the model. In particular, these plots clearly show that inhibition of MEK activity by administering U0126 results in an increase in the concentrations of active RAF and active MEK and a reduction in the concentration of active ERK. Furthermore, we clearly see a strong dependence between RAF and MEK (in both experimental conditions), but there is no discernible dependence between RAF and ERK or between MEK and ERK (in either experimental condition). In the light of the supposedly direct effect of MEK on ERK, it is surprising that the data show no significant dependence between the two.[24] This apparent “faithfulness violation” is problematic for constraint-based causal discovery methods, as they will typically not identify the causal relation between MEK and ERK.
![Figure 9
Scatter plots of the logarithms of active RAF, MEK, and ERK concentrations for the data in ref. [18]. The blue circles correspond to cells treated only with anti-CD3 and anti-CD28, which activate the signalling cascade. The red circles correspond to cells treated with anti-CD3, anti-CD28, and in addition, the MEK-activity inhibitor U0126. The inhibition of MEK results in an increase of MEK and RAF, whereas ERK is reduced. The black circles correspond to cells treated with
β
{\rm{\beta }}
2cAMP (but not anti-CD3 and anti-CD28), which seems to affect MEK, but leaves RAF and ERK invariant.](/document/doi/10.1515/jci-2021-0005/asset/graphic/j_jci-2021-0005_fig_009.jpg)
Scatter plots of the logarithms of active RAF, MEK, and ERK concentrations for the data in ref. [18]. The blue circles correspond to cells treated only with anti-CD3 and anti-CD28, which activate the signalling cascade. The red circles correspond to cells treated with anti-CD3, anti-CD28, and in addition, the MEK-activity inhibitor U0126. The inhibition of MEK results in an increase of MEK and RAF, whereas ERK is reduced. The black circles correspond to cells treated with
According to ref. [18], the biological consensus (at the time) was that there is a signalling pathway from RAF to MEK to ERK.[25] They propose to model this pathway as a causal Bayesian network
For various observations in the data of [18], we indicate whether they are predicted by the causal Bayesian network model
| Observation | Causal Bayesian network model | Perfectly adaptive model |
|---|---|---|
| RAF and MEK are dependent in both conditions |
|
|
| MEK and ERK are independent in both conditions |
|
|
| Inhibition of MEK activity affects active RAF |
|
|
| Inhibition of MEK activity affects active MEK |
|
|
| Inhibition of MEK activity affects active ERK |
|
|
Still, the perfectly adaptive model does not explain all aspects of the data. For example, the effects of the
Qualitative effects of reagents on the measured abundances of active RAF, MEK, and ERK, as read off from the data in ref. [18]
| Condition | Reagents | RAF | MEK | ERK |
|---|---|---|---|---|
| 1 | Anti-CD3 + anti-CD28 | ……Baseline …… | ||
| 3 | Anti-CD3 + anti-CD28 + AKT inhibitor | NA | NA | 0 |
| 4 | Anti-CD3 + anti-CD28 + G06976 |
|
|
|
| 5 | Anti-CD3 + anti-CD28 + Psitectorigenin | 0 | 0 |
|
| 6 | Anti-CD3 + anti-CD28 + U0126 |
|
|
(
|
| 7 | Anti-CD3 + anti-CD28 + LY294002 | NA | NA | 0 |
| 8 | PMA |
|
0 | 0 |
| 9 |
|
(
|
|
(
|
| 2 | Anti-CD3 + anti-CD28 + ICAM-2 | ……Baseline …… | ||
| 10 | Anti-CD3 + anti-CD28 + ICAM-2 + AKT inhibitor | 0 | 0 |
|
| 11 | Anti-CD3 + anti-CD28 + ICAM-2 + G06976 |
|
|
|
| 12 | Anti-CD3 + anti-CD28 + ICAM-2 + Psitectorigenin | 0 | 0 |
|
| 13 | Anti-CD3 + anti-CD28 + ICAM-2 + U0126 | 0 |
|
|
| 14 | Anti-CD3 + anti-CD28 + ICAM-2 + LY294002 | 0 | 0 |
|
Legend:
5.5 Caveats for causal discovery
Experiments in which the protein signalling network is perturbed in various ways are of crucial importance to obtaining a causal understanding of the system. While very sophisticated causal discovery algorithms are available, we will here illustrate the key concepts by means of applying one of the simplest causal discovery algorithms based on conditional independences to equilibrium data from the model. We simulate the system in two different conditions, a baseline and a condition where the activity of MEK has been inhibited.
Consider observational equilibrium data from the protein signalling pathway model and also experimental equilibrium data from a setting where the MEK activity is inhibited. We introduce a context variable
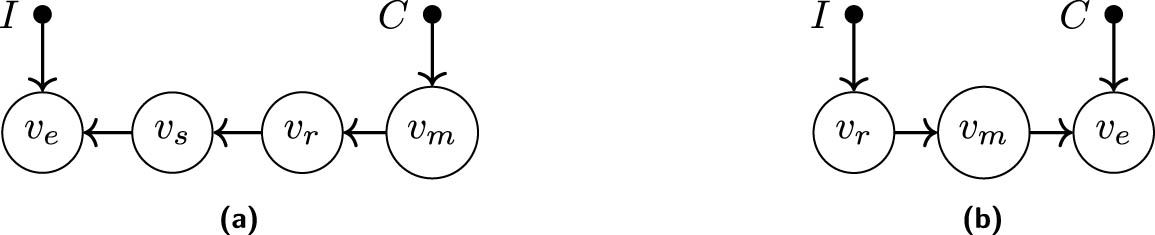
Equilibrium Markov ordering graphs of the protein signalling pathway with the context variable
In particular, one of the LCD triples we obtained is
Apparently, the causal relationship RAF
We investigated which of these LCD patterns can be found in the real-world data. In Table 3, we list the
Results of conditional independence tests on the (log-transformed) protein expression data of [18]
| (Conditional) independence tested |
|
|---|---|
|
|
|
|
|
0.79 |
|
|
0.35 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Specifically, we report the
6 Discussion and conclusion
Perfect adaptation is the phenomenon that a dynamical system initially responds to a change of input signal but reverts back to its original value as the system converges to equilibrium. We used the technique of causal ordering to obtain sufficient graphical conditions to identify perfect adaptation in a dynamical system described by a combination of equations and first-order differential equations. To represent the structure of the (non-equilibrium) dynamical system, we introduced the notions of the dynamic bipartite graph and the corresponding dynamic causal ordering graph obtained by the causal ordering algorithm. Moreover, we showed how perfect adaptation can be detected in equilibrium observational and experimental data for soft interventions with known targets. We illustrated our ideas on a variety of dynamical models and corresponding equilibrium equations. We believe that the methods presented in this work provide a useful tool for the characterization of a large class of dynamical systems that are able to achieve perfect adaptation and for the automated analysis of the behaviour of certain perfectly adapted dynamical systems.
In all examples that we discussed, the technique of causal ordering revealed the structure of a given set of equations. In some cases, more structure can be revealed by first rewriting the equations before applying the causal ordering algorithm. In Appendix D, we analyze a dynamical system describing a basic enzyme reaction, for which rewriting of the equilibrium equations reveals more structure (and hence yields a stronger Markov property). In Appendix E, we analyze the IFFLP network. We observe that a nonlinear transformation of the variables (and rewriting the equations correspondingly) reveals more structure and hence yields more conditional independences and less causal relations amongst the transformed variables. The further development of methods to analyze perfectly adapted dynamical systems that do not satisfy the conditions of Theorem 1 remains a challenge for future work. Also, the question of how one can more generally discover causal structure using nonlinear transformations of the variables is an interesting topic for future research that relates to what is nowadays known as “causal representation learning” in machine learning [55].
We also investigated the consequences of the phenomenon of perfect adaptation for causal discovery. We demonstrated that for perfectly adapted dynamical systems, the output of existing constraint-based causal discovery algorithms applied to equilibrium data may appear counterintuitive and at odds with our understanding of the mechanisms that drive the system. As we have illustrated in this work, careful application of the causal ordering algorithm enables a better theoretical understanding of these phenomena.
We applied our approach to a model for a well-known protein signalling pathway and tested the model’s predictions both in simulations and on real-world protein expression data. The challenges for causal discovery that are encountered in non-linear dynamical systems with feedback loops, possibly leading to context-specific perfectly adaptive behaviour, are substantial. If the behaviour of the model that we analyzed in Section 5 is representative of that of actual systems occurring in vitro and in vivo, then it seems unlikely that existing causal discovery methods based on causal Bayesian networks will lead to reasonable results. These observations further motivate the development of causal discovery algorithms based on bipartite graphical representations that would be more widely applicable than the existing ones based on causal Bayesian networks or simple SCMs.
Acknowledgements
We thank the reviewers and the editor for their constructive comments, which helped us improve our work.
-
Funding information: This work was supported by the ERC under the European Union’s Horizon 2020 research and innovation programme (grant agreement 639466).
-
Author contributions: The idea to use causal ordering to study perfectly adapted dynamical systems was due to TB, as well as the development of the theoretical results. The notions of the dynamic bipartite graph and the dynamic causal ordering graph were proposed by JMM. Simulations were conducted by TB. Analysis of the protein signalling data and preparation of the manuscript was done by both authors. The SDC approach was applied for the sequence of authors. All authors have accepted responsibility for the entire content of this article and approved its submission.
-
Conflict of interest: JMM is a member of the Editorial Board of Journal of Causal Inference and was not involved in the review process of this article.
-
Data availability statement: The simulated datasets can be reproduced with the R code provided at https://bitbucket.org/jorism/jci2023paper.git as free and open source software. The protein expression dataset of [18] analyzed in Section 5.4 is publicly available as Supplementary Material to ref. [18] at https://www.science.org/doi/suppl/10.1126/science.1105809/suppl_file/sachs.som.datasets.zip.
Appendix A Proof of Theorem 2
Theorem 2
Consider a set of first-order dynamical equations in canonical form for variables V, satisfying the conditions of Theorem
1, with equilibrium equations F under the natural labelling. Consider a soft intervention targeting an equation
the soft intervention does not change the equilibrium distribution of
the soft intervention alters the equilibrium distribution of a variable corresponding to a non-descendant of
Proof
If condition 1 holds there is no directed path from
Suppose that condition 1 does not hold while condition 2 does hold. By Theorem 4 in ref. [12] (which roughly states that the presence of a causal effect at equilibrium implies the presence of a corresponding directed path in the equilibrium causal ordering graph) we have that
B Simulation settings
For the simulations in Figures 3,6, and 8 of the model of a filling bathtub, the viral infection model, the reaction network with a feedback loop, and the protein pathway we used the settings outlined below. Since we only simulated a single response, we used constant values for the exogenous random variables as well.
Filling bathtub. First, we recorded the behaviour of the system for the parameters
Viral infection. For the parameter settings
Reaction network. We simulated the model until it reached equilibrium with parameters
Protein pathway. The parameter settings of the simulation were
The same qualitative behaviour as reported here can be observed for a range of parameter values. The behaviour of the protein pathway is rather complex; in particular,
C Conditional independences and causal discovery
The equilibrium Markov ordering graph in Figure 7(e) was derived from the equilibrium equations of the protein pathway model under saturation conditions. From this, we can read off the following
It is easy to check that the equilibrium equations and endogenous variables in this model are uniquely solvable with respect to the causal ordering graph. Therefore, the aforementioned
To test whether the predicted conditional independences hold when the system is at equilibrium, we ran the simulation
The conditional independences in the simulation of the protein pathway (described in Section 5.2 and Appendix C) were assessed using Spearman’s rank correlations. With a
| Independence test | Correlation |
|
|
|---|---|---|---|
|
|
|
0.82 | Yes |
|
|
|
0.94 | Yes |
|
|
|
0.80 | Yes |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
0.46 | Yes |
|
|
|
0.14 | Yes |
|
|
|
0.48 | Yes |
|
|
|
0.19 | Yes |
|
|
|
0.14 | Yes |
|
|
|
0.18 | Yes |
|
|
|
0.66 | Yes |
|
|
|
0.32 | Yes |
|
|
|
0.36 | Yes |
|
|
|
0.87 | Yes |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
|
|
|
|
No |
To verify the predicted LCD triples of Section 5.5, we ran the simulation
D Rewriting equations may reveal additional structure
Theorem 1 specifies sufficient but not necessary conditions for the presence of perfect adaptation. The equilibrium distribution of some systems is not faithful to the equilibrium Markov ordering graph associated with the equilibrium equations of the model. Here, we will discuss a dynamical model for a basic enzymatic reaction, and we will demonstrate that this model is capable of perfect adaptation. However, it does not satisfy the conditions in Theorem 1, and the presence of directed paths in the equilibrium causal ordering graph does not imply the presence of a causal effect at equilibrium. We will also show that this may be addressed by appropriately rewriting the equations.
The basic enzyme reaction models a substrate
where
Figure A1(a) shows the dynamic bipartite graph corresponding to the dynamic equations, and Figure A1(b) the corresponding dynamic causal ordering graph. Since there is a directed path from

The equilibrium equations of the model are given by:
where the last equation is derived from the constant of motion

Different graphical representations of the basic enzyme reaction at equilibrium. Panels (a) and (b) show the equilibrium bipartite graph and equilibrium causal ordering graph, respectively, for the equilibrium equations (A5), (A6), (A7), (A8), and (A9). Panels (c) and (d) show the equilibrium bipartite graph and the equilibrium causal ordering graph, respectively, for the rewritten equilibrium equations (A5), (A8), (A9), and (A10). Rewriting the equilibrium equations yields a sparser equilibrium bipartite graph, and therefore, more structure is revealed in the equilibrium causal ordering graph.
By rewriting the equilibrium equations, we can achieve stronger conclusions for this particular case. For instance, we can consider the equation
in combination with
The two equilibrium causal ordering graphs do not model the same set of perfect interventions. For example, the (non)effects of an intervention targeting the cluster
E Transforming variables may reveal structure
The IFFLP network in Ma et al. [17] that we briefly discussed in Section 3.1.3 could be a graphical representation of the following differential equations:
where
Therefore, an equilibrium solution
The equilibrium equations associated with equations (A11), the approximation (A14) to (A12), and (A13) are given by:
The associated equilibrium causal ordering graph in Figure A3(a) shows that there is a directed path from the input signal

Interestingly, though, if we first make a change of variables from
This yields a sparser equilibrium bipartite graph. As shown in Figure A3(b), we can now read off from the corresponding equilibrium causal ordering graph that the input signal
F Markov ordering graphs have no inherent causal interpretation
The causal interpretation of the equilibrium Markov ordering graph for the bathtub model is discussed at length in ref. [12]. The conclusion is that the Markov ordering graph alone does not contain enough information to read off the effects of interventions in an unambiguous way.[28] As a result, the Markov ordering graph does not have a straightforward causal interpretation in terms of interventions, contrary to what is sometimes claimed [13,14]. For the sake of completeness, we will summarize here the discussion of the causal interpretation of the equilibrium Markov ordering graph of the bathtub model.
Example 2
For the bathtub model (Section 3.1.1), consider an intervention targeting the dynamical equation
where
A correct interpretation of a directed edge
However, there is another obstacle to interpreting a directed edge
Therefore, if one cannot rule out the possibility of feedback, one should avoid reading the Markov ordering graph as if the directed edges represent direct causal effects (and as if directed paths represent causal effects).
References
[1] Cooper GF. A simple constraint-based algorithm for efficiently mining observational databases for causal relationships. Data Min Knowl Discov. 1997;1:203–24. 10.1023/A:1009787925236Search in Google Scholar
[2] Richardson TS, Spirtes P. Automated discovery of linear feedback models. In: Gregory F. Cooper, Clark Glymour. Computation, Causation and Discovery. London, England: MIT Press; 1999. p. 253–302.10.7551/mitpress/2006.003.0010Search in Google Scholar
[3] Pearl J. Causality: models, reasoning, and inference. Cambridge, UK: Cambridge University Press; 2000. Search in Google Scholar
[4] Spirtes P, Glymour C, Scheines R. Causation, prediction, and search. Cambridge, Massachusetts: MIT Press; 2000. 10.7551/mitpress/1754.001.0001Search in Google Scholar
[5] Zhang J. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias. Artif Intell. 2008;172:1873–96. 10.1016/j.artint.2008.08.001Search in Google Scholar
[6] Hyttinen A, Eberhardt F, Hoyer PO. Learning linear cyclic causal models with latent variables. J Mach Learn Res. 2012;13(1):3387–439. Search in Google Scholar
[7] Colombo D, Maathuis MH, Kalisch M, Richardson TS. Learning high-dimensional directed acyclic graphs with latent and selection variables. Ann Stat. 2012;40:294–321. 10.1214/11-AOS940Search in Google Scholar
[8] Forré P, Mooij JM. Constraint-based causal discovery for non-linear structural causal models with cycles and latent confounders. In: Proceedings of the 34th Annual Conference on Uncertainty in Artificial Intelligence (UAI-18); 2018. p. 269–78. Search in Google Scholar
[9] Mooij JM, Magliacane S, Claassen T. Joint causal inference from multiple contexts. J Mach Learn Res. 2020;21:1–108. Search in Google Scholar
[10] Mooij JM, Claassen T. Constraint-based causal discovery using partial ancestral graphs in the presence of cycles. In: Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI-20). vol. 124. Proceedings of Machine Learning Research (PMLR); 2020. p. 1159–68. Search in Google Scholar
[11] Simon HA. Causal ordering and identifiability. In: Studies in econometric methods. New York: John Wiley & Sons; 1953. p. 49–74. 10.1007/978-94-010-9521-1_5Search in Google Scholar
[12] Blom T, van Diepen MM, Mooij JM. Conditional independences and causal relations implied by sets of equations. J Mach Learn Res. 2021;22(178):1–62. Search in Google Scholar
[13] Iwasaki Y, Simon HA. Causality and model abstraction. Artif Intell. 1994;67:143–94. 10.1016/0004-3702(94)90014-0Search in Google Scholar
[14] Dash D. Restructuring dynamic causal systems in equilibrium. In: Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics (AIStats 2005); 2005. p. 81–8. Search in Google Scholar
[15] De Boer RJ. Which of our modeling predictions are robust? PLOS Comput Biol. 2012;8:e1002593. 10.1371/journal.pcbi.1002593Search in Google Scholar PubMed PubMed Central
[16] Blom T, Mooij JM. Robustness of model predictions under extension. In: Cussens J, Zhang K, editors. Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence (UAI-22). vol. 180 of Proceedings of Machine Learning Research. PMLR; 2022. p. 213–22. Search in Google Scholar
[17] Ma W, Trusina A, El-Samad H, Lim WA, Tang C. Defining network topologies that can achieve biochemical adaptation. Cell. 2009;138:760–73. 10.1016/j.cell.2009.06.013Search in Google Scholar PubMed PubMed Central
[18] Sachs K, Perez O, Pe’er D, Lauffenburger DA, Nolan GP. Causal protein-signaling networks derived from multiparameter single-cell data. Science. 2005;308:523–9. 10.1126/science.1105809Search in Google Scholar PubMed
[19] Shin SY, Rath O, Choo SM, Fee F, McFerran B, Kolch W, et al. Positive- and negative-feedback regulations coordinate the dynamic behavior of the Ras-Raf-Mek-Erk signal transduction pathway. J Cell Sci. 2009;122:425–35. 10.1242/jcs.036319Search in Google Scholar PubMed
[20] Lauritzen SL, Dawid AP, Larsen BN, Leimer HG. Independence properties of directed Markov fields. Networks. 1990;20:491–505. 10.1002/net.3230200503Search in Google Scholar
[21] Lacerda G, Spirtes P, Ramsey J, Hoyer PO. Discovering cyclic causal models by independent components analysis. In: Proceedings of the 24th Annual Conference on Uncertainty in Artificial Intelligence (UAI-08); 2008. p. 1159–68. Search in Google Scholar
[22] Strobl EV. A constraint-based algorithm for causal discovery with cycles, latent variables and selection bias. Int J Data Sci Anal. 2019;8:33–56. 10.1007/s41060-018-0158-2Search in Google Scholar
[23] Bongers S, Forré P, Peters J, Mooij JM. Foundations of structural causal models with cycles and latent variables. Ann Stat. 2021;49(5):2885–915. 10.1214/21-AOS2064Search in Google Scholar
[24] Spirtes P. Directed cyclic graphical representations of feedback models. In: Proceedings of the 11th Annual Conference on Uncertainty in Artificial Intelligence (UAI-1995); 1995. p. 491–8. Search in Google Scholar
[25] Forré P, Mooij JM. Markov properties for graphical models with cycles and latent variables. 2017. arXiv:1710.08775v1 [math.ST]. https://arxiv.org/abs/1710.08775v1. Search in Google Scholar
[26] Richardson TS. Models of feedback: interpretation and discovery. PhD dissertation. Carnegie-Mellon University, 1996. Search in Google Scholar
[27] Nayak P. Automated modeling of physical systems. Berlin: Springer-Verlag; 1995. 10.1007/3-540-60641-6Search in Google Scholar
[28] Pothen A, Fan CJ. Computing the block triangular form of a sparse matrix. ACM Trans Math Softw. 1990;16:303–24. 10.1145/98267.98287Search in Google Scholar
[29] Gonçalves B, Porto F. A note on the complexity of the causal ordering problem. Artif Intell. 2016;238:154–65. 10.1016/j.artint.2016.06.004Search in Google Scholar
[30] Fisher FM. A correspondence principle for simultaneous equation models. Econometrica. 1970;38(1):73–92. 10.2307/1909242Search in Google Scholar
[31] Voortman M, Dash D, Druzdzel MJ. Learning why things change: the difference-based causality learner. In: Proceedings of the Twenty-Sixth Annual Conference on Uncertainty in Artificial Intelligence (UAI-10); 2010. p. 641–50. Search in Google Scholar
[32] Sokol A, Hansen NR. Causal interpretation of stochastic differential equations. Electr J Probabil. 2014;19:1–24. 10.1214/EJP.v19-2891Search in Google Scholar
[33] Rubenstein PK, Bongers S, Schölkopf B, Mooij JM. From deterministic ODEs to dynamic structural causal models. In: Proceedings of the 34th Annual Conference on Uncertainty in Artificial Intelligence (UAI-18); 2018. p. 114–23. Search in Google Scholar
[34] Bongers S, Blom T, Mooij JM. Causal modeling of dynamical systems. 2022 Mar. Preprint. arXiv:1803.08784v4 [cs.AI]. https://arxiv.org/abs/1803.08784v4. Search in Google Scholar
[35] Mogensen SW, Malinsky D, Hansen NR. Causal learning for partially observed stochastic dynamical systems. In: Proceedings of the 34th Annual Conference on Uncertainty in Artificial Intelligence (UAI-18); 2018. p. 350–60. Search in Google Scholar
[36] Mooij JM, Janzing D, Schölkopf B. From ordinary differential equations to structural causal models: the deterministic case. In: Proceedings of the 29th Annual Conference on Uncertainty in Artificial Intelligence (UAI-13); 2013. p. 440–8. Search in Google Scholar
[37] Lauritzen SL, Richardson TS. Chain graph models and their causal interpretations. J R Stat Soc Ser B (Stat Methodol). 2002;64:321–61. 10.1111/1467-9868.00340Search in Google Scholar
[38] Mooij JM, Janzing D, Heskes T, Schölkopf B. On causal discovery with cyclic additive noise models. Adv Neural Inform Process Syst (NIPS 2011). 2011;24:639–47. Search in Google Scholar
[39] Blom T, Bongers S, Mooij JM. Beyond structural causal models: causal constraints models. In: Proceedings of the 35th Uncertainty in Artificial Intelligence Conference (UAI-19). vol. 115 of Proceedings of Machine Learning Research; 2020. p. 585–94.Search in Google Scholar
[40] Dawid AP. Beware of the DAG! In: Proceedings of Workshop on Causality: Objectives and Assessment at NIPS 2008. vol. 6 of Proceedings of Machine Learning Research; 2010. p. 59–86. Search in Google Scholar
[41] Araujo RP, Liotta LA. The topological requirements for robust perfect adaptation in networks of any size. Nature Commun. 2018;9:29717141. 10.1038/s41467-018-04151-6Search in Google Scholar PubMed PubMed Central
[42] Muzzey D, Gómez-Uribe CA, Mettetal JT, van Oudenaarden A. A systems-level analysis of perfect adaptation in yeast osmoregulation. Cell. 2009;138:160–71. 10.1016/j.cell.2009.04.047Search in Google Scholar PubMed PubMed Central
[43] Ferrell JE. Perfect and near-perfect adaptation in cell signaling. Cell Sys. 2016;2:62–67. 10.1016/j.cels.2016.02.006Search in Google Scholar PubMed
[44] Krishnan J, Floros I. Adaptive information processing of network modules to dynamic and spatial stimuli. BMC Syst Biol. 2019;13:30866946. 10.1186/s12918-019-0703-1Search in Google Scholar PubMed PubMed Central
[45] Triantafillou S, Lagani V, Heinze-Deml C, Schmidt A, Tegner J, Tsamardinos I. Predicting causal relationships from biological data: applying automated causal discovery on mass cytometry data of human immune cells. Sci Rep. 2017;7:12724. 10.1038/s41598-017-08582-xSearch in Google Scholar PubMed PubMed Central
[46] Mooij JM, Heskes T. Cyclic causal discovery from continuous equilibrium data. In: Proceedings of the 29th Annual Conference on Uncertainty in Artificial Intelligence (UAI-13). Arlington, Virgina: AUAI Press; 2013. p. 431–9. Search in Google Scholar
[47] Ramsey J, Andrews B. FASK with interventional knowledge recovers edges from the Sachs model. 2018; arXiv:1805.03108 [q-bio.MN]. https://arxiv.org/abs/1805.03108. Search in Google Scholar
[48] Boeken PA, Mooij JM. A Bayesian nonparametric conditional two-sample test with an application to local causal discovery. In: Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence (UAI-21). vol. 161 of Proceedings of Machine Learning Research; 2021. p. 1565–75. Search in Google Scholar
[49] Blom T, Klimovskaia A, Magliacane S, Mooij JM. An upper bound for random measurement error in causal discovery. In: Proceedings of the 34th Annual Conference on Uncertainty in Artificial Intelligence (UAI-18); 2018. p. 570–9. Search in Google Scholar
[50] Coddington EA, Levinson N. Theory of ordinary differential equations. New York: McGraw-Hill; 1955. Search in Google Scholar
[51] Meek C. Strong completeness and and faithfulness in Bayesian networks. In: Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence (UAI-95); 1995. p. 411–8. Search in Google Scholar
[52] Sachs K, Itani S, Fitzgerald J, Schoeberl B, Nolan GP, Tomlin CJ. Single timepoint models of dynamic systems. Interface Focus. 2013;3:24511382. 10.1098/rsfs.2013.0019Search in Google Scholar PubMed PubMed Central
[53] Filippi S, Barnes CP, Kirk PD, Kudo T, Kunida K, McMahon SS, et al. Robustness of MEK-ERK dynamics and origins of cell-to-cell variability in MAPK signaling. Cell Reports. 2016 Jun;15:2524–35. 10.1016/j.celrep.2016.05.024Search in Google Scholar PubMed PubMed Central
[54] Fritsche-Guenther R, Witzel F, Sieber A, Herr R, Schmidt N, Braun S, et al. Strong negative feedback from Erk to Raf confers robustness to MAPK signalling. Mol Syst Biol. 2011;7(1):489. 10.1038/msb.2011.27Search in Google Scholar PubMed PubMed Central
[55] Chalupka K, Eberhardt F, Perona P. Causal feature learning: an overview. Behaviormetrika. 2017;44:137–67. 10.1007/s41237-016-0008-2Search in Google Scholar
[56] Murray JD. Mathematical biology I: an introduction. 3rd edition. New York: Springer-Verlag; 2002. 10.1007/b98868Search in Google Scholar
[57] Dash D, Druzdzel MJ. A note on the correctness of the causal ordering algorithm. Artif Intell. 2008;172:1800–8. 10.1016/j.artint.2008.06.005Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Adaptive normalization for IPW estimation
- Matched design for marginal causal effect on restricted mean survival time in observational studies
- Robust inference for matching under rolling enrollment
- Attributable fraction and related measures: Conceptual relations in the counterfactual framework
- Causality and independence in perfectly adapted dynamical systems
- Sensitivity analysis for causal decomposition analysis: Assessing robustness toward omitted variable bias
- Instrumental variable regression via kernel maximum moment loss
- Randomization-based, Bayesian inference of causal effects
- On the pitfalls of Gaussian likelihood scoring for causal discovery
- Double machine learning and automated confounder selection: A cautionary tale
- Randomized graph cluster randomization
- Efficient and flexible mediation analysis with time-varying mediators, treatments, and confounders
- Minimally capturing heterogeneous complier effect of endogenous treatment for any outcome variable
- Quantitative probing: Validating causal models with quantitative domain knowledge
- On the dimensional indeterminacy of one-wave factor analysis under causal effects
- Heterogeneous interventional effects with multiple mediators: Semiparametric and nonparametric approaches
- Exploiting neighborhood interference with low-order interactions under unit randomized design
- Robust variance estimation and inference for causal effect estimation
- Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
- Potential outcome and decision theoretic foundations for statistical causality
- 2D score-based estimation of heterogeneous treatment effects
- Identification of in-sample positivity violations using regression trees: The PoRT algorithm
- Model-based regression adjustment with model-free covariates for network interference
- All models are wrong, but which are useful? Comparing parametric and nonparametric estimation of causal effects in finite samples
- Confidence in causal inference under structure uncertainty in linear causal models with equal variances
- Special Issue on Integration of observational studies with randomized trials - Part II
- Personalized decision making – A conceptual introduction
- Precise unbiased estimation in randomized experiments using auxiliary observational data
- Conditional average treatment effect estimation with marginally constrained models
- Testing for treatment effect twice using internal and external controls in clinical trials
Articles in the same Issue
- Research Articles
- Adaptive normalization for IPW estimation
- Matched design for marginal causal effect on restricted mean survival time in observational studies
- Robust inference for matching under rolling enrollment
- Attributable fraction and related measures: Conceptual relations in the counterfactual framework
- Causality and independence in perfectly adapted dynamical systems
- Sensitivity analysis for causal decomposition analysis: Assessing robustness toward omitted variable bias
- Instrumental variable regression via kernel maximum moment loss
- Randomization-based, Bayesian inference of causal effects
- On the pitfalls of Gaussian likelihood scoring for causal discovery
- Double machine learning and automated confounder selection: A cautionary tale
- Randomized graph cluster randomization
- Efficient and flexible mediation analysis with time-varying mediators, treatments, and confounders
- Minimally capturing heterogeneous complier effect of endogenous treatment for any outcome variable
- Quantitative probing: Validating causal models with quantitative domain knowledge
- On the dimensional indeterminacy of one-wave factor analysis under causal effects
- Heterogeneous interventional effects with multiple mediators: Semiparametric and nonparametric approaches
- Exploiting neighborhood interference with low-order interactions under unit randomized design
- Robust variance estimation and inference for causal effect estimation
- Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
- Potential outcome and decision theoretic foundations for statistical causality
- 2D score-based estimation of heterogeneous treatment effects
- Identification of in-sample positivity violations using regression trees: The PoRT algorithm
- Model-based regression adjustment with model-free covariates for network interference
- All models are wrong, but which are useful? Comparing parametric and nonparametric estimation of causal effects in finite samples
- Confidence in causal inference under structure uncertainty in linear causal models with equal variances
- Special Issue on Integration of observational studies with randomized trials - Part II
- Personalized decision making – A conceptual introduction
- Precise unbiased estimation in randomized experiments using auxiliary observational data
- Conditional average treatment effect estimation with marginally constrained models
- Testing for treatment effect twice using internal and external controls in clinical trials