Robust inference for matching under rolling enrollment
-
Amanda K. Glazer
 and
Samuel D. Pimentel
and
Samuel D. Pimentel

Abstract
Matching in observational studies faces complications when units enroll in treatment on a rolling basis. While each treated unit has a specific time of entry into the study, control units each have many possible comparison, or “pseudo-treatment,” times. Valid inference must account for correlations between repeated measures for a single unit, and researchers must decide how flexibly to match across time and units. We provide three important innovations. First, we introduce a new matched design, GroupMatch with instance replacement, allowing maximum flexibility in control selection. This new design searches over all possible comparison times for each treated-control pairing and is more amenable to analysis than past methods. Second, we propose a block bootstrap approach for inference in matched designs with rolling enrollment and demonstrate that it accounts properly for complex correlations across matched sets in our new design and several other contexts. Third, we develop a falsification test to detect violations of the timepoint agnosticism assumption, which is needed to permit flexible matching across time. We demonstrate the practical value of these tools via simulations and a case study of the impact of short-term injuries on batting performance in major league baseball.
1 Introduction
Matching methods attempt to estimate average causal effects by grouping each treated unit with one or more otherwise similar controls and using paired individuals to approximate the missing potential outcomes. Assuming that paired individuals are sufficiently similar on observed attributes and that no important unobserved attributes confound the comparison, the difference in outcomes approximates the impact of treatment for individuals in the pair [1]. Despite matching’s transparency and intuitive appeal, it faces complications in datasets containing repeated measures for the same individuals over time. When only a single time of treatment is present, the primary challenge is deciding how to construct matching distances from pre-treatment repeated measures and assess outcomes using post-treatment repeated measures [2]. The situation is more complex under rolling enrollment, or staggered adoption, when individuals opt into treatment at different times [3]. Several authors [4–7] proceed by matching each treated unit to the version of the control unit present in the data at the time of treatment. For example, in Imai et al. [7]’s reanalysis of data from Acemoglu et al. [8] on the impact of democratization on economic growth, countries undergoing democratizing political reforms are matched to similar control countries not undergoing such reforms in the same year.
Although this method is logical whenever strong time trends are present, in other cases, it may overemphasize similarity on time at the expense of other variables. Bohl et al. [9] study the impact of serious falls on subsequent healthcare expenditures for elderly adults using patient data from a large healthcare system. While patients who fall could be matched to patients who appear similar based on recent health history on the calendar date of the fall, the degree of similarity in health histories is likely much more important than the similarity of the exact date at which each patient is measured. Following this idea, the GroupMatch algorithm [10] constructs matches optimally across time, prioritizing matching on important covariates over ensuring that units are compared at the same point in time.
Another example where rolling enrollment arises is in major league baseball (MLB). Quantifying the impact of injury on player performance in professional sports is important for both managers and players themselves. Increasingly, players are valued and compensated in a manner driven by quantitative metrics of past performance, but injuries have potential to disrupt the continuity between past and future performance [11–14]. One way to quantify impact in this setting is by finding the difference between the value of a performance metric the player would have achieved in the absence of injury and the value of the same metric achieved after a given injury. This quantity can be estimated using matching. However, players do not all get injured at the same time, so GroupMatch is a natural fit here. It allows us to match injured and noninjured players flexibly across time, because we likely do not care whether a player injured on June 1 is matched to a noninjured player on exactly the same day or a couple weeks earlier, e.g., May 15, so long as those players are sufficiently similar on other covariates such as recent performance.
Several challenges remain outstanding for matching methods under rolling enrollment. GroupMatch’s flexible approach relies heavily on a strong assumption that time itself is not a confounder, and discussion of checking this assumption has been minimal so far. Even when flexible matching is warranted, the presence of multiple copies of the same control individual necessitates a constraint to ensure that a treated unit is not simply paired to multiple slightly different copies of the same control; several choices of this constraint exist permitting varying degrees of flexibility, and users must choose among them. Most importantly, for both GroupMatch and methods that match exactly in time, there is substantial ambiguity about how to conduct valid inference. When multiple copies of a control individual are forbidden from appearing in the matched design, randomization inference may be used [5,10], but no strong guarantees exist outside this special case.
In what follows, we present several innovations that greatly enhance the toolkit for matching and treatment effect evaluation under rolling enrollment. First, we introduce a new matched design called GroupMatch with instance replacement, which has computational, analytical, and statistical advantages over existing designs in many common settings. Second, we give a comprehensive characterization of a new block-bootstrap-based method for inference that applies broadly across existing methods for matching under rolling enrollment, including our new design. The block-bootstrap approach was originally suggested by Imai et al. [7] and is based on related work in the cross-sectional case by Otsu and Rai [15], but until now has not carried any formal guarantee. Finally, we introduce a falsification test to provide a partial check of the assumption of timepoint agnosticism underpinning GroupMatch’s validity, empowering investigators to extract evidence from the data about this key assumption before matching. We prove the validity of our bootstrap method under the most relevant set of constraints on reuse of controls, and we also demonstrate the effectiveness of both the falsification test and the bootstrap inference approach through simulations and an analysis of injury data in MLB. In particular, the bootstrap method shows improved performance over linear regression-based approaches to inference often applied in similar settings.
This article is organized as follows. Section 2 presents the basic statistical framework and reviews the GroupMatch framework, inference approaches for matching designs, and other related literature. In Section 3, we introduce a new constraint for use of controls in GroupMatch designs, leading to a new design called GroupMatch with instance replacement. Section 4 presents a block bootstrap inference approach for matching under rolling enrollment, and Section 5 evaluates it via simulation. In Section 6, we present a falsification test for the assumption that time is not a confounder. In Section 7, we apply our methods to evaluate whether minor injuries impact short-term MLB performance. Section 8 concludes this article.
2 Statistical framework
2.1 Setting and notation
We observe
For clarity, we focus on “instantaneous” effects of treatment, with outcomes measured immediately following treatment. Let
Here, the
Throughout, we relax notation slightly by writing
The potential outcomes framework adopted here represents one of many possible framings for studies with rolling enrollment. Pimentel et al. [10] define potential outcomes as functions of the length of time since treatment initiation, while both Ben-Michael et al. [3] and Athey and Imbens [16] define them as functions of the time of treatment initiation for the subject in question. In principle, these alternate constructions are much richer than ours, allowing for much more general and complicated patterns of effects, but in practice, all these authors use simplifying assumptions or focus on estimands that reduce attention to at most two potential outcomes of interest for each individual at each timepoint. For example, both Pimentel et al. [10] and Ben-Michael et al. [3] allow for treatment effects to be measured at some follow-up time postdating the time of treatment rather than focusing on instantaneous effects, but since the length of follow-up is fixed in advance, only two potential outcomes ever need to be considered for each unit. Similarly, the “no anticipation” assumption of both Ben-Michael et al. [3] and Athey and Imbens [16] ensures that there is exactly one potential outcome of interest associated with the control condition for each individual, and the “invariance to history” assumption of Athey and Imbens [16] collapses distinctions among potential outcomes under treatment. As such, the results we present in the following sections extend easily to all the potential outcomes frameworks just described, making the appropriate substitutions for our
2.2 Identification assumptions
Pimentel et al. [10] studied the following difference-in-means estimator in designs where each treated unit is matched to
Pimentel et al. [10] show that this estimator is unbiased for the population ATT under the following conditions:
Exact matching: matched units share identical values for covariates in the
Intuitively, this assumption prevents unobserved confounding that makes potential outcomes for treated subjects systematically different from those that remain controls even after accounting for information from a baseline period.
Timepoint agnosticism: mean potential outcomes under control do not differ for any instances with identical covariate histories at different timepoints. Formally, for any set of
This assumption ensures that matching across time is reasonable by ruling out time trends other than those captured by time-varying covariates. For clarity, we drop the
Covariate
Like time agnosticism, covariate
Overlap: given that a unit is not yet treated at time
While this assumption is not stated explicitly in the study by Pimentel et al. [10], we note that the authors rely on an overlap assumption of this type in the proof of their main result.
The exact matching assumption is no longer needed for asymptotic identification of the population ATT if we modify the estimator by adding in a bias correction term. As shown in the studies by Otsu and Rai [15] and Abadie and Imbens [19], we first estimate the conditional mean function
Datasets with many variables, especially continuous variables or variables with many categories, ensure that exact matching is rarely possible in practice, and in light of this, we focus primarily on estimator
As discussed by Imai et al. [7] for settings without rolling enrollment, identification is possible under weaker assumptions if a difference-in-differences estimator is used instead of the difference-in-means. While we focus primarily on the simpler bias-corrected difference-in-means estimator for clarity of exposition, the difference-in-differences approach also offers advantages for our setting, and the new matching and inference strategies we propose extend naturally to such estimators. We provide further discussion in Section 4.3.
3 GroupMatch with instance replacement
Before discussing our method for inference in general matched designs under rolling enrollment, we introduce a new type of GroupMatch design. Pimentel et al. [10] described two different designs produced by GroupMatch and denoted them Problems A and B. For increased clarity, we refer to Problem A as GroupMatch without replacement, and Problem B as GroupMatch with trajectory replacement.
GroupMatch without replacement: Each control unit can be matched to at most one treated unit. If a treated unit is matched to an instance of a control unit, no other treated unit can match to (any instance of) that control unit.
GroupMatch with trajectory replacement: Each control instance can be matched to at most one treated unit. Each treated unit can match to no more than one instance from the same control trajectory. However, different treated units can match to different instances of the same control trajectory, so a single control trajectory can contribute multiple distinct instances to the design.
As our chosen names for these designs suggest, their relative costs and benefits reflect the choice between matching without and with replacement in cross-sectional settings. As discussed by Hansen [22], matching without replacement (in which each control may appear in at most one matched set), leads to less similar matches compared to matching with replacement (in which controls can reappear in many matched sets) since in cases where two treated units share the same nearest control, only one can use it. On the other hand, matching without replacement frequently leads to estimators with lower variance than those from matching with replacement, where an individual control unit may appear in many matched sets, making the estimator more sensitive to random fluctuations in its response. Thus, one aspect of choosing between these designs is a choice about how to strike a bias-variance tradeoff. The other important aspect distinguishing these designs is that randomization inference, which is based on permuting treatment assignments in each matched set independently of others, generally requires matching without replacement. Specifically, when multiple controls may be matched to each treated unit and replacement is allowed, the resulting configuration of treated and control units no longer resembles the design of a blocked or matched experiment.
These same dynamics play out in comparing GroupMatch without replacement and GroupMatch with trajectory replacement. GroupMatch without replacement ensures that responses in distinct matched sets are statistically independent (under a model in which trajectories are sampled independently), allowing for randomization inference, and ensures that the total weight on observations from any one control trajectory can sum only to
We suggest a third GroupMatch design that leans even further towards expanding the potential control pool and reducing bias.
GroupMatch with instance replacement: Each treated unit can match to no more than one instance from the same control unit, but control instances can be matched to more than one treated unit.
GroupMatch with instance replacement is identical to GroupMatch without trajectory replacement except that it allows repetition of individual instances within the matched design as well as nonidentical instances from the same trajectory. As such, it is guaranteed to produce higher-quality matches than GroupMatch without trajectory replacement, but may lead to higher-variance estimators since individual instances may receive weights larger than

Toy example illustrating the three GroupMatch matching methods. Two injured baseball players (T1 and T2) are matched 1-1 to noninjured baseball players (C1a/b and C2a/b) based on player OBP. Each noninjured player has two pseudo-injury times or instances. Under GroupMatch without replacement, T2 must match to an instance in Trajectory 2 because at most one instance from Trajectory 1 can participate in the match. Under GroupMatch with trajectory replacement, T2 can match to C1b but not to C1a, since multiple control instances can be chosen from the same trajectory as long as they are distinct. Under GroupMatch with instance replacement, both T1 and T2 are able to match to C1a. However, if each treated instance were matched to two control instances instead of one, GroupMatch with instance replacement would still forbid either T1 or T2 to match to a second instance in Trajectory 1.
In practice, we view GroupMatch with instance replacement as a more attractive approach than GroupMatch with trajectory replacement almost without exception. One reason is that while the true variance of estimators from GroupMatch with instance replacement may often exceed that of estimators from GroupMatch with trajectory replacement by a small amount, our recommended approach for estimating the variance and conducting inference are not able to capture this difference. As we describe in Section 4, in the absence of a specific parametric model for correlations within a trajectory, inference proceeds in a conservative manner by assuming arbitrarily high correlations within a trajectory (much like the clustered standard error adjustment in linear regression). Since the variance advantage for GroupMatch with trajectory replacement arises only when correlations between instances within a trajectory are lower than one, the estimation strategy is not able to take advantage of them. This disconnect means that GroupMatch with trajectory replacement will not generally lead to narrower empirical confidence intervals, much as variance gains associated with paired randomized trials relative to less-finely stratified randomized trials may not translate into reduced variance estimates [24].
A second important advantage of GroupMatch with instance replacement is its computational and analytical tractability relative to the other GroupMatch designs. One way to implement GroupMatch with instance replacement as a network flow optimization problem is to remove a set of constraints in Pimentel et al. [10]’s Network B (specifically the upper capacity on the directed edges connected to the sink node), and in Sections 5 and 7, we use this implementation for its convenient leveraging of the existing groupmatch package in R. However, much more computationally efficient algorithms are also possible. Crucially, the removal of the constraint forbidding instance replacement means that matches can be calculated for each treated instance without reference to the choices made for other treated units; the
4 Block bootstrap inference
4.1 Inference methods for matched designs
Broadly speaking, there are two schools of thought in conducting inference for matched designs. One approach, spearheaded by Abadie and Imbens [19,25–27], views the raw data as samples from an infinite population and demonstrates that estimators based on matched designs (which in this framework are considered to be random variables, as functions of random data) are asymptotically normal. Inferences are based on the asymptotic distributions of matched estimators. A second approach, described in detail in Rosenbaum [28,29] and Fogarty [30], adopts the perspective of randomization inference in controlled experiments. Conditional on the structure of the match and the potential outcomes, the null distribution of a test statistic over all possible values of the treatment vector is obtained by permuting values of treatment within matched sets. When matches are exact and unobserved confounding is absent, strong finite sample guarantees hold for testing sharp null hypotheses without further assumptions on outcome variables. Asymptotic guarantees for weak null hypotheses may be obtained too, assuming a sequence of successively larger finite populations [31]. Well-developed methods of sensitivity analysis are also available.
As described in the study by Pimentel et al. [10], while standard methods of inference may be applied to GroupMatch without replacement, in which control individuals contribute at most one unit to any part of the match, none have been adequately developed for GroupMatch with trajectory replacement, in which distinct matched sets may contain different versions of the same control individual. For randomization inference, the barrier appears to be quite fundamental, because permutations of treatment within one matched set can no longer be considered independently for different matched sets. In GroupMatch with trajectory replacement, a treated unit receives treatment at one time and appears in a match only once; if treatment is permuted among members of a matched set so that a former control now attains treatment status, what is to be done about other versions of this control unit that are present in distinct matched sets? We note that similar issues arise when contemplating randomization inference for general cross-sectional matching designs with replacement, and we are aware of no solutions for randomization inference even in this simpler case.
In contrast, the primary issue in applying sampling-based inference to GroupMatch designs with trajectory replacement is the unknown correlation structure for repeated measures from a single control individual. The literature on matching with replacement provides estimators for pairs that are fully independent [27] and for cases in which a single observation appears identically in multiple pairs [25], but not for the intermediate case of GroupMatch with trajectory replacement where distinct but correlated observations appear in distinct matched sets. These issues extend beyond the GroupMatch family to any matched design under rolling enrollment in which control trajectories contribute to multiple matched sets, including those of Witman et al. [6] and Imai et al. [7].
In what follows, we give formal guarantees for a sampling-based inference method appropriate for general matching designs under rolling enrollment suggested by Imai et al. [7], which generalizes a recent proposal of Otsu and Rai [15] for valid sampling-based inference of cross-sectional matched studies using the bootstrap. Although the bootstrap often works well for matched designs without replacement [32], naive applications of the bootstrap in matched designs with replacement have been shown to produce incorrect inferences as a consequence of the failure of certain regularity conditions [26]. Intuitively, if matching is performed after bootstrapping the original data, multiple copies of a treated unit will necessarily all match to the same control unit, creating a clumping effect not present in the original data. However, Otsu and Rai [15] arrived at an asymptotically valid bootstrap inference method for matching by bootstrapping weighted and bias-corrected functions of the original observations after matching rather than repeatedly matching from scratch in new bootstrap samples. We show that a similar bootstrap approach, applied to entire trajectories of repeated measures in a form of the block bootstrap, provides valid inference for matched designs under rolling enrollment. Note that in our formal results, we focus on GroupMatch with instance replacement as the most difficult case, since the designs of Witman et al. [6] and Imai et al. [7] may be understood as restricted special cases in which matching on time is exact.
4.2 Block bootstrap
To conduct inference under GroupMatch with trajectory or instance replacement, we propose a weighted block bootstrap approach. We rearrange the GroupMatch ATT estimator from Section 2 as follows, letting
Because different instances of the same control unit are correlated, we resample the trajectory-level quantities
Fit an outcome regression
Match treated instances to control instances using GroupMatch with instance replacement. Calculate matching weights
Calculate the model-adjusted ATT estimator
Repeat
Randomly sample
Calculate the bootstrap bias-corrected ATT estimator
Construct a (
This method is essentially a block bootstrap, very similar to the method proposed in Imai et al. [7]. Note that while the recipe given earlier uses the nonparametric bootstrap, it may easily be generalized to other approaches such as the wild bootstrap and the Bayesian bootstrap. In particular, consider rewriting
To recover the nonparametric bootstrap, the bootstrap weights
Our main result given here shows the asymptotic validity of this approach. Several assumptions, in addition to Assumptions 2–5 in Section 2.2, are needed to prove this result. We summarize these assumptions verbally here, deferring formal mathematical statements to Section A.1 of the supplemental appendix. First, we require the covariates
Theorem 1
Under assumptions M, W, and R presented in Section A.1 of the supplemental appendix,
as
Our regularity assumptions on the data-generating process and the regression estimator
4.3 Difference-in-differences estimator
While we have focused so far on the difference-in-means estimator, Imai et al. [7] recommend a difference-in-differences estimator for matched designs with rolling enrollment in the context of designs that match exactly on time. This estimator can be used under rolling enrollment as well, taking the following form under bias correction:
This estimator requires
A key advantage of this bias-corrected differences-in-differences estimator is that it relies on different identification assumptions than the bias-corrected difference-in-means: essentially, any assumption previously made on the potential outcome
We can easily adapt the results of the previous section to show that the block bootstrap gives valid inference for the difference-in-difference estimator when these identification assumptions hold. The inference procedure simply requires bootstrapping the
5 Simulations
We now explore the performance of weighted block bootstrap inference via simulation. In particular, we investigate coverage and length of confidence intervals compared to those obtained by conducting parametric inference for weighted least squares (WLS) estimators with and without cluster-robust error adjustment for controls from the same trajectory.
5.1 Data generation
We generate eight covariates, four of them uniform across time for each individual
where
For treated units:
Four of the covariates are time-varying for control units. For each control unit, three instances are generated from a random walk process to correlate their values across time. Formally, for instance,
Fixing
The outcome for a unit is correlated across time as it is generated from some time-varying covariates. Each simulation consists of 400 treated and 600 control individuals. We consider 1:2 matching. The true treatment effect,
We consider two alternative ways of generating the continuous outcome variable besides model (2). First, we add correlation to the error terms within trajectories. Specifically, the
We compare the bias-corrected block bootstrap approach outlined in Section 4, using a linear outcome model and a nonparametric bootstrap, to the confidence intervals obtained from WLS regression and WLS with clustered standard errors. We focus on the nonparametric bootstrap, as opposed to alternatives such as the wild bootstrap, because of its more common prevalence in practice; however, for comparisons between the wild bootstrap and the nonparametric bootstrap showing almost equivalent performance in a generally similar setting, see Otsu and Rai [15]. We choose to compare to WLS because this is commonly recommended in matching literature [33,34]. However, Abadie and Spiess [35] pointed out that standard errors from regression may be incorrect due to dependencies among outcomes of matched units, and identified matching with replacement as a setting in which these dependencies are particularly difficult to correct for. Our simulation results suggest that are used these difficulties carry over into the case of repeated measures. It is worth noting that the standard functions in R are used to compute WLS with matching weights such as lm and Zelig (which calls lm), compute biased standard error estimates in most settings. See Section B of the supplemental appendix for details.
5.2 Results
Tables 1 and 2 show the coverage and average 95% confidence interval (CI) length, respectively, of WLS regression, WLS regression with clustered standard errors, and bootstrap inference using our model-adjusted ATT estimator, for each of our three simulation settings under 10,000 simulations. As misspecification of the estimated linear outcome model increases, the bootstrap method is substantially more robust (although under substantial misspecification the bias-corrected method also fails to achieve nominal coverage). While the bootstrap confidence intervals are generally slightly wider than the WLS and WLS cluster confidence intervals, this is to be expected as the wider confidence intervals lead to improved coverage. In settings where strong scientific knowledge about the exact form of the outcome model is absent, the bootstrap approach appears more reliable than its chief competitors.
Coverage of the WLS, WLS cluster and bootstrap bias corrected methods of inference for our three simulation set-ups
| Coverage | WLS (%) | WLS cluster (%) | Bootstrap bias corrected (%) |
|---|---|---|---|
| Linear DGP | 92.6 | 94.4 | 94.0 |
| Linear DGP, correlated errors | 89.4 | 91.7 | 94.4 |
| Nonlinear DGP, correlated errors | 83.3 | 86.2 | 89.8 |
Average 95% confidence interval length for the WLS, WLS cluster and bootstrap bias corrected methods of inference for our three simulation set-ups
| Average CI length | WLS | WLS cluster | Bootstrap bias corrected |
|---|---|---|---|
| Linear DGP | 0.25 | 0.27 | 0.27 |
| Linear DGP, correlated errors | 0.25 | 0.27 | 0.30 |
| Nonlinear DGP, correlated errors | 0.26 | 0.28 | 0.31 |
Results in Tables 1 and 2 are for GroupMatch with instance replacement, however matching with trajectory replacement performed very similarly in our simulations. Computation time was similar for GroupMatch with instance replacement and with trajectory replacement. In principle, GroupMatch with instance replacement should be substantially faster; however, in its current form GroupMatch does not implement the most computationally efficient algorithm for matching with instance replacement. Over 100 iterations, the average matching computation time was 4.63 seconds for matching with instance replacement and 4.71 seconds for matching with trajectory replacement. The average block bootstrap computation time was 2.51 seconds. Computation time was calculated on an Apple M1 Max 10-core CPU with 3.22 GHz processor and 64 GB RAM running on macOS Monterey.
6 Testing for timepoint agnosticism
The key advantage of GroupMatch relative to other matching techniques designed for rolling enrollment settings is its ability to consider and optimize over matches between units at different timepoints, which leads to higher quality matches on lagged covariates. This advantage comes with a price in additional assumptions, notably the assumption of timepoint agnosticism. Timepoint agnosticism means that mean potential outcomes under control for any two individual timepoints in the data should be identical; in particular, this rules out time trends of any kind in the outcome model that cannot be explained by covariates in the prior
While in many applications scientific intuition about the data generating process suggests this assumption may be reasonable, it is essential that we consider any information contained in the observed data about whether it holds in a particular case. Accordingly, we present a falsification test for timepoint agnosticism. Falsification tests are tests “for treatment effects in places where the analyst knows they should not exist” [36] and are useful in a variety of settings in observational studies [37]. In particular, our test is designed to detect violations of timepoint agnosticism, or “treatment effects of time” when they should be absent; rejections indicate settings in which GroupMatch is not advisable and other rolling enrollment matching techniques that do not rely on timepoint agnosticism are likely more suitable. While failure to reject may not constitute proof positive of timepoint agnosticism’s validity, it rules out gross violations, thereby limiting the potential for bias.
To test the timepoint agnosticism assumption we use control-control time matching: matching control units at different timepoints and testing if the average difference in outcomes between the two timepoint groups, conditional on relevant covariates, is significantly different from zero using a bootstrap test. Specifically, restricting attention to trajectories
The test statistic for the falsification test is motivated by the ATT estimator in Section 2.2. Let
We use a bootstrap test to test the following null hypothesis, where
In words, this null hypothesis says that, accounting for differences in the covariate distribution at times 0 and 1, the difference in the average outcomes of control instances at the two timepoints is zero.
The test constructs a bootstrap confidence interval as in Section 3 and checks whether the interval covers 0. If the interval covers 0, the test fails to reject. We present the following steps:
Label control instances from the first group of trajectories at timepoint
Fit a bias correction model on the new control units.
Match the new treated units to the new control units and calculate the test statistic.
Repeat
Randomly resample
Calculate
Construct a
If this confidence interval covers 0, fail to reject the null hypothesis.
We choose to use a bootstrap test here in line with our inference methods in previous sections. However, it is worth noting that a permutation test is also feasible here.
A key consideration for the falsification test is which timepoints to choose as
The falsification test is subject to several common criticisms levied at falsification tests, particularly their ineffectiveness in settings with low power. One possible approach is to reconfigure the test to assume violation of timepoint agnosticism as a null hypothesis and seek evidence in the data to reject it; Hartman and Hidalgo [38] recommend a similar change for falsification tests used to assess covariate balance, called equivalence tests.
The implementation of these modifications is fairly straightforward. First, we must define an equivalence range for our outcome variable: a set of values for which the difference is substantively inconsequential. Let
See Section D of the supplemental appendix for simulations illustrating this method.
7 Application: baseball injuries
We study the impact of short-term injury on hitting performance in observational data from MLB during 2013–2017. Quantitative studies of major league hitting performance [39] and of injury trends and impact in athletics [12] have been performed repeatedly, but only a few studies so far have evaluated the impact of injury on position players’ hitting performance. These have focused on specific injury types and have not found strong evidence that injury is associated with a decline in performance [11,13,14].
We use GroupMatch to match baseball players injured at certain times to similar players at other points in the season that were not injured. We evaluate whether players see a decline in offensive performance immediately after their return from injury. In contrast to other studies, we pool across injury types to see if there is a more general effect of short-term injury on hitter performance.
7.1 Data and methodology
We use publicly available MLB player data from Retrosheet.org and injury data scraped from ProSportsTransactions.com for the years 2013–2017. Our dataset is composed of player height, weight and age, quantities that remain constant over a single season of play, as well as OBP, plate appearances (PAs) at different points in the season, and dates of short-term injuries, in which the player’s team designated him for a 7–10 day stay on the team’s official injured list, for each year. OBP is a common measure of hitter performance and is approximately equal to the number of times a player reaches base divided by their number of plate appearances.[1]
For each noninjured player, we generate three pseudo-injury dates evenly spaced over their PAs. In each season, we match injured players to four noninjured players. Matches were formed using GroupMatch with instance replacement, matching on age, weight, height, number of times previously injured, recent performance measured by OBP over the previous 100 PAs, and performance over the entire previous year as measured by end-of-year OBP after James-Stein shrinkage.[2] We choose to shrink OBP using James-Stein to limit the impact of sampling variability for players with a relatively small number of PAs the previous season [40]. Table 3 shows the balance for each of the covariates before and after matching. For each covariate, matching shrinks the standardized difference between the treated and control means. The balance achieved is not perfect, especially for the number of previous injuries. This underlines the importance of combining matching with bias correction to clean up imbalances not removed by matching.
Balance table for MLB injury analysis before and after matching each injured player to four noninjured players
| Variable | Treated mean | Control mean | Standardized difference | ||
|---|---|---|---|---|---|
| Before | After | Before | After | ||
| Height | 73.7 | 73.1 | 73.4 | 0.26 | 0.14 |
| Weight | 213 | 209 | 212 | 0.24 | 0.07 |
| 2016 OBP (JS shrunk) | 0.324 | 0.328 | 0.323 |
|
0.02 |
| Lag OBP | 0.336 | 0.341 | 0.338 |
|
|
| Birth year | 1988 | 1988 | 1988 |
|
|
| Number previous injuries | 2.73 | 1.91 | 2.16 | 0.30 | 0.21 |
7.2 Results
We compare the results for bias-corrected block bootstrap inference, WLS, and WLS with clustered standard errors. The ATT estimates are positive (0.010), but the 95% confidence intervals cover zero for all methods, indicating that there is not strong evidence that short-term injury impacts hitter performance. We present the results for 2017 in Figure 2. Results from each of 2013–2016 were substantively the same, as were results obtained by pooling the matched data across years. The data pass the timepoint agnosticism test, comparing the first and last pseudo-injury dates. We chose to compare the first and last pseudo-injury dates, because we were most concerned about player performance degrading over the course of the entire season due to fatigue. We also perform equivalence tests using
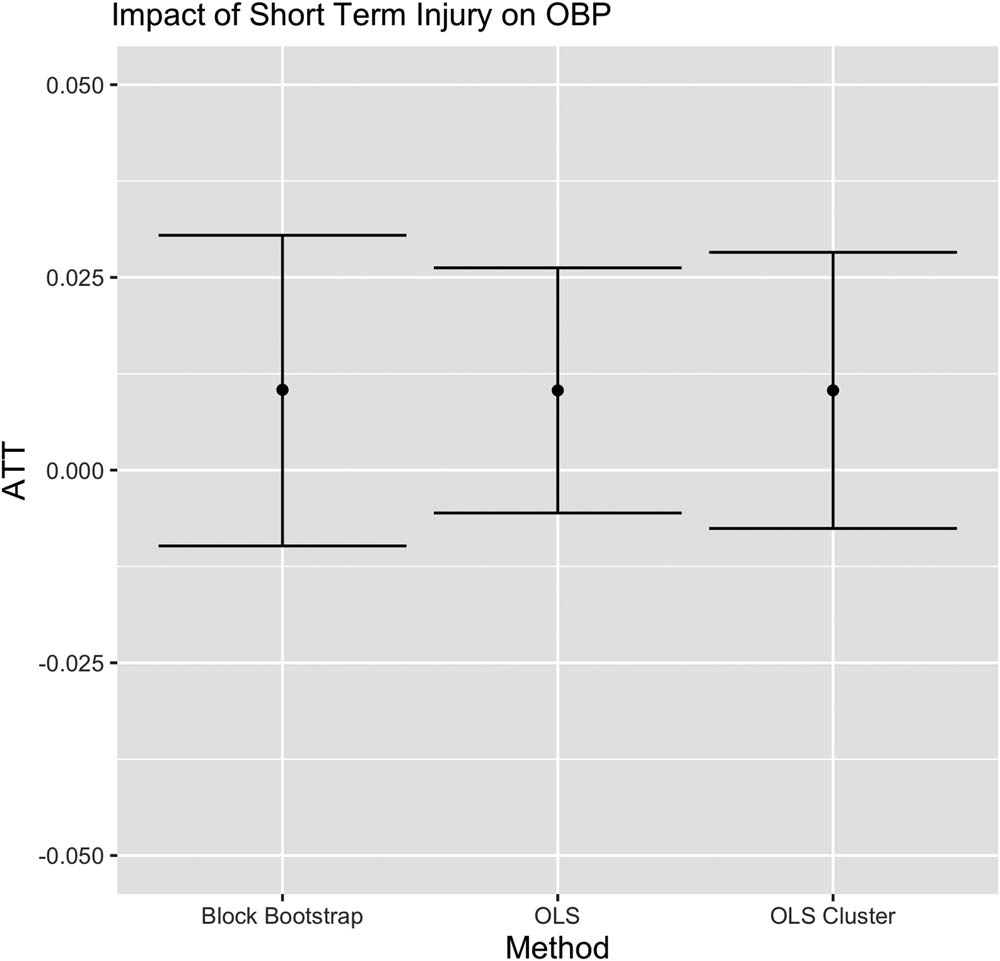
Estimates and 95% confidence intervals for block bootstrap, WLS and cluster WLS inference methods for the ATT in our 2017 baseball injury analysis.
We could have also chosen to use a difference-in-differences estimator here, using the difference in performance right before and after the injury, or pseudo-injury, date as our outcome. Results are substantively the same for both estimators. This similarity is due to the close lag OBP matches GroupMatch produces for this example.
8 Discussion
The introduction of GroupMatch with instance replacement, a method for block bootstrap inference, and a test for timepoint agnosticism provide substantial new capabilities for matching in settings with rolling enrollment. We now discuss a number of limitations and opportunities for improvement.
Our proof of the block bootstrap approach assumes the use of GroupMatch with instance replacement. The large-sample properties of matched-pair discrepancies are substantially easier to analyze mathematically in this setting than GroupMatch with trajectory replacement or GroupMatch without replacement, designs in which different treated units may compete for the same control units, and the technical argument must be altered to account for this complexity. However, Abadie and Imbens [27] successfully characterized similar large-sample properties in cross-sectional settings for matching without replacement. While beyond the scope of our work here, we believe it is likely that this approach could provide an avenue for extending Theorem 1 to cover the other two GroupMatch designs. Empirically, we have found that the block bootstrap performs well when matches are calculated using any of the three GroupMatch designs.
Setting aside the technical barriers associated with extending the theory to GroupMatch without replacement, our new approach provides a competitor method to the existing randomization inference framework described by Pimentel et al. [10] available for GroupMatch without replacement. The randomization inference framework offers the advantage of closely-related methods of sensitivity analysis and freedom from making assumptions about the sampling distribution of the response variables; on the other hand, the block bootstrap method avoids the need to assume a sharp null hypothesis. In general, these same considerations arise in choosing between sampling-based inference and randomization-based inference for a cross-sectional matched study, although such choices have received surprisingly little direct and practical attention in the literature thus far.
As described in Section 6, the falsification test faces several criticisms, such as ineffectiveness in lower power settings. The modifications to construct equivalence tests as in Hartman and Hildago [38] address these concerns. However, even in the absence of such a change, the falsification test may prove useful in concert with a sensitivity analysis. Sensitivity analysis, already widely studied in causal inference as a way to assess the role of ignorability assumptions, places a nonzero bound on the degree of violation of an assumption and reinterprets the study’s results under this bound, often repeating the process for larger and larger values of the bound to gain insight. Such a procedure, which focuses primarily on assessing the impact of small or bounded violations of an assumption, naturally complements our falsification test, which can successfully rule out large violations but is more equivocal about minor violations.
Unfortunately, no sensitivity analysis appropriate for block bootstrap inference has been developed yet, either for timepoint agnosticism or other strong assumptions such as ignorability. The many existing methods for sensitivity analysis (developed primarily with ignorability assumptions in mind) are unsatisfying in our framework for a variety of reasons: some rely on randomization inference [29], others focus on weighting methods rather than matching [41,42], and others are limited to specific outcome measures [43] or specific test statistics [44]. We view the development of compelling sensitivity analysis approaches to be an especially important methodological objective for matching under rolling enrollment.
Finally, we note that in cross-sectional settings, moderate imbalances like those observed after matching in the baseball study in Section 7 can often be removed by refining the match to include calipers [45,46] or balance constraints [47–49] on important variables. For computational reasons, these constraints are difficult to implement and use in full generality for GroupMatch designs. For example, some balance constraints rely on network flow representations of the matching problem that are not immediately compatible with the network flow representation underpinning GroupMatch. Further work to consider how calipers and balance constraints can be elegantly incorporated will enhance GroupMatch’s effectiveness in practice.
Acknowledgments
The MLB performance data was obtained from and is copyrighted by Retrosheet (www.retrosheet.org). We thank the author and maintainer of the GitHub repository https://github.com/robotallie/baseball-injuriesfor making the injury data easily available. We also thank Eli Ben-Michael, Peng Ding, Avi Feller, Lauren Forrow, Shirshendu Ganguly, and Jiaqi Li for helpful conversations and feedback.
-
Funding information: Amanda Glazer (DMS RTG #1745640) and Samuel D. Pimentel (#2142146) acknowledge support from the National Science Foundation.
-
Conflict of interest: Prof. Samuel D. Pimentel is a member of the Editorial Board of the Journal of Causal Inference but was not involved in the review process of this article.
References
[1] Stuart E. Matching methods for causal inference: a review and a look forward. Stat Sci Rev J Instit Math Stat. 2010;25:1. 10.1214/09-STS313Search in Google Scholar PubMed PubMed Central
[2] Haviland A, Nagin DS, Rosenbaum PR, Tremblay RE. Combining group-based trajectory modeling and propensity score matching for causal inferences in nonexperimental longitudinal data. Develop Psychol. 2008;44(2):422–36. 10.1037/0012-1649.44.2.422Search in Google Scholar PubMed
[3] Ben-Michael E, Feller A, Rothstein J. Synthetic controls and weighted event studies with staggered adoption. 2021. arXiv: http://arXiv.org/abs/arXiv:191203290. 10.3386/w28886Search in Google Scholar
[4] Li YP, Propert KJ, Rosenbaum PR. Balanced risk set matching. J Amer Stat Assoc. 2001;96(455):870–82. 10.1198/016214501753208573Search in Google Scholar
[5] Lu B. Propensity score matching with time-ÂŘdependent covariates. Biometrics. 2005;61:721–8. 10.1111/j.1541-0420.2005.00356.xSearch in Google Scholar PubMed
[6] Witman A, Beadles C, Liu Y, Larsen A, Kafali N, Gandhi S, et al. Comparison group selection in the presence of rolling entry for health services research: Rolling entry matching. Health Services Res. 2019;54:492–501. 10.1111/1475-6773.13086Search in Google Scholar PubMed PubMed Central
[7] Imai K, Kim IS, Wang E. Matching methods for causal inference with time-series cross-section data. Amer J Political Sci. 2020;1–19. 10.1111/ajps.12685Search in Google Scholar
[8] Acemoglu D, Naidu S, Restrepo P, Robinson JA. Democracy does cause growth. J Political Econ. 2019;127(1):47–100. 10.3386/w20004Search in Google Scholar
[9] Bohl AA, Fishman PA, Ciol MA, Williams B, LoGerfo J, Phelan EA. A longitudinal analysis of total 3-year healthcare costs for older adults who experience a fall requiring medical care. J Amer Geriatric Soc. 2010;58(5):853–60. 10.1111/j.1532-5415.2010.02816.xSearch in Google Scholar PubMed
[10] Pimentel SD, Forrow LV, Gellar J, Li J. Optimal matching approaches in health policy evaluations under rolling enrollment. J R Stat Soc Ser A (Stat Soc). 2020;183:1411–35. 10.1111/rssa.12521Search in Google Scholar
[11] Begly JP, Guss MS, Wolfson TS, Mahure SA, Rokito AS, Jazrawi LM. Performance outcomes after medial ulnar collateral ligament reconstruction in Major League Baseball positional players. J Shoulder Elbow Surgery. 2018;27:282–90. 10.1016/j.jse.2017.09.004Search in Google Scholar PubMed
[12] Conte S, Camp CL, Dines JS. Injury trends in Major League Baseball over 18 seasons: 1998–2015. Am J Orthop. 2016;45:116–23. Search in Google Scholar
[13] Frangiamore SJ, Mannava S, Briggs KK, McNamara S, Philippon MJ. Career length and performance among professional baseball players returning to play after hip arthroscopy. Amer J Sports Med. 2018;46:2588–93. 10.1177/0363546518775420Search in Google Scholar PubMed
[14] Wasserman EB, Abar B, Shah MN, Wasserman D, Bazarian JJ. Concussions are associated with decreased batting performance among major league baseball players. Amer J Sports Med. 2015;43:1127–33. 10.1177/0363546515576130Search in Google Scholar PubMed
[15] Otsu T, Rai Y. Bootstrap inference of matching estimators for average treatment effects. J Amer Statist Assoc. 2017;112:1720–32. 10.1080/01621459.2016.1231613Search in Google Scholar
[16] Athey S, Imbens GW. Design-based analysis in difference-in-differences settings with staggered adoption. J Econometric. 2022;226(1):62–79. 10.3386/w24963Search in Google Scholar
[17] Rosenbaum PR. The consequences of adjustment for a concomitant variable that has been affected by the treatment. J R Stat Soc Ser A (General). 1984;147(5):656–66. 10.2307/2981697Search in Google Scholar
[18] Hansen BB. The prognostic analogue of the propensity score. Biometrika. 2008;95(2):481–8. 10.1093/biomet/asn004Search in Google Scholar
[19] Abadie A, Imbens GW. Bias-corrected matching estimators for average treatment effects. J Business Economic Stat. 2011;29:1–11. 10.1198/jbes.2009.07333Search in Google Scholar
[20] Rubin DB. Using multivariate matched sampling and regression adjustment to control bias in observational studies. J Amer Stat Assoc. 1979:318–28. 10.1017/CBO9780511810725.013Search in Google Scholar
[21] Antonelli J, Cefalu M, Palmer N, Agniel D. Doubly robust matching estimators for high dimensional confounding adjustment. Biometrics. 2018;74(4):1171–9. 10.1111/biom.12887Search in Google Scholar PubMed PubMed Central
[22] Hansen BB. Full matching in an observational study of coaching for the SAT. J Amer Stat Assoc. 2004;99(467):609–18. 10.1198/016214504000000647Search in Google Scholar
[23] Kapelner A, Krieger A. Matching on-the-fly: sequential allocation with higher power and efficiency. Biometrics. 2014;70(2):378–88. 10.1111/biom.12148Search in Google Scholar PubMed
[24] Imbens GW. Experimental design for unit and cluster randomized trials. International Initiative for Impact Evaluation. Cuernavaca; 2011. Search in Google Scholar
[25] Abadie A, Imbens GW. Large sample properties of matching estimators for average treatment effects. Econometrica. 2006;74:235–67. 10.1111/j.1468-0262.2006.00655.xSearch in Google Scholar
[26] Abadie A, Imbens GW. On the failure of the bootstrap for matching estimators. Econometrica. 2008;76:1537–57. 10.3386/t0325Search in Google Scholar
[27] Abadie A, Imbens GW. A Martingale representation for matching estimators. J Amer Stat Assoc. 2012;107:833–43. 10.3386/w14756Search in Google Scholar
[28] Rosenbaum PR. Covariance adjustment in randomized experiments and observational studies. Stat Sci. 2002;17(3):286–327. 10.1214/ss/1042727942Search in Google Scholar
[29] Rosenbaum PR. Observational studies. New York, NY: Springer; 2002. 10.1007/978-1-4757-3692-2Search in Google Scholar
[30] Fogarty CB. Studentized sensitivity analysis for the sample average treatment effect in paired observational studies. J Amer Stat Assoc. 2020;115(531):1518–30. 10.1080/01621459.2019.1632072Search in Google Scholar
[31] Li X, Ding P. General forms of finite population central limit theorems with applications to causal inference. J Amer Stat Assoc. 2017;112(520):1759–69. 10.1080/01621459.2017.1295865Search in Google Scholar
[32] Austin PC, Small DS. The use of bootstrapping when using propensity-score matching without replacement: a simulation study. Stat Med. 2014;33(24):4306–19. 10.1002/sim.6276Search in Google Scholar PubMed PubMed Central
[33] Ho DE, Imai K, King G, Stuart EA. Matching as nonparametric preprocessing for reducing model dependence in parametric causal inference. Political Anal. 2007;15:199–236. 10.1093/pan/mpl013Search in Google Scholar
[34] Stuart EA, King G, Imai K, Ho D. MatchIt: nonparametric preprocessing for parametric causal inference. J Stat Software. 2011;42(8):1–28. 10.18637/jss.v042.i08Search in Google Scholar
[35] Abadie A, Spiess J. Robust post-matching inference. J Amer Stat Assoc. 2022;117(538):1–13.10.1080/01621459.2020.1840383Search in Google Scholar
[36] Keele L. The statistics of causal inference: A view from political methodology. Political Anal. 2015;23(3):313–35. 10.1093/pan/mpv007Search in Google Scholar
[37] Rosenbaum PR. Choice as an alternative to control in observational studies. Stat Sci. 1999;14(3):259–78. 10.1214/ss/1009212410Search in Google Scholar
[38] Hartman E, Hidalgo FD. An equivalence approach to balance and placebo tests. Amer J Political Sci. 2018;62(4):1000–13. https://onlinelibrary.wiley.com/doi/abs/10.1111/ajps.12387. 10.1111/ajps.12387Search in Google Scholar
[39] Baumer BS. Why on-base percentage is a better indicator of future performance than batting average: An algebraic proof. J Quantitat Anal Sports. 2008;4(2). https://doi.org/10.2202/1559-0410.1101. 10.2202/1559-0410.1101Search in Google Scholar
[40] Efron B, Morris C. Data analysis using Stein’s estimator and its generalizations. J Amer Stat Assoc. 1975;70:311–9. 10.1080/01621459.1975.10479864Search in Google Scholar
[41] Zhao Q, Small DS, Bhattacharya BB. Sensitivity analysis for inverse probability weighting estimators via the percentile bootstrap. J R Stat Soc Ser B (Stat Methodol). 2019;81(4):735–61. 10.1111/rssb.12327Search in Google Scholar
[42] Soriano D, Ben-Michael E, Bickel PJ, Feller A, Pimentel SD. Interpretable sensitivity analysis for balancing weights. 2021. arXiv: http://arXiv.org/abs/arXiv:210213218. Search in Google Scholar
[43] Ding P, VanderWeele TJ. Sensitivity analysis without assumptions. Epidemiology (Cambridge, Mass). 2016;27(3):368. 10.1097/EDE.0000000000000457Search in Google Scholar PubMed PubMed Central
[44] Cinelli C, Hazlett C. Making sense of sensitivity: Extending omitted variable bias. J R Stat Soc Ser B (Stat Methodol). 2020;82(1):39–67. 10.1111/rssb.12348Search in Google Scholar
[45] Rosenbaum PR, Rubin DB. Constructing a control group using multivariate matched sampling methods that incorporate the propensity score. Amer Stat. 1985;39(1):33–8. 10.1017/CBO9780511810725.019Search in Google Scholar
[46] Yu R, Silber JH, Rosenbaum PR. Matching methods for observational studies derived from large administrative databases. Stat Sci. 2020;35(3):338–55. 10.1214/19-STS699Search in Google Scholar
[47] Rosenbaum PR, Ross RN, Silber JH. Minimum distance matched sampling with fine balance in an observational study of treatment for ovarian cancer. J Amer Stat Assoc. 2007;102(477):75–83. 10.1198/016214506000001059Search in Google Scholar
[48] Zubizarreta JR. Using mixed integer programming for matching in an observational study of kidney failure after surgery. J Amer Stat Assoc. 2012;107(500):1360–71. 10.1080/01621459.2012.703874Search in Google Scholar
[49] Pimentel SD, Kelz RR, Silber JH, Rosenbaum PR. Large, sparse optimal matching with refined covariate balance in an observational study of the health outcomes produced by new surgeons. J Amer Stat Assoc. 2015;110(510):515–27. 10.1080/01621459.2014.997879Search in Google Scholar PubMed PubMed Central
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Adaptive normalization for IPW estimation
- Matched design for marginal causal effect on restricted mean survival time in observational studies
- Robust inference for matching under rolling enrollment
- Attributable fraction and related measures: Conceptual relations in the counterfactual framework
- Causality and independence in perfectly adapted dynamical systems
- Sensitivity analysis for causal decomposition analysis: Assessing robustness toward omitted variable bias
- Instrumental variable regression via kernel maximum moment loss
- Randomization-based, Bayesian inference of causal effects
- On the pitfalls of Gaussian likelihood scoring for causal discovery
- Double machine learning and automated confounder selection: A cautionary tale
- Randomized graph cluster randomization
- Efficient and flexible mediation analysis with time-varying mediators, treatments, and confounders
- Minimally capturing heterogeneous complier effect of endogenous treatment for any outcome variable
- Quantitative probing: Validating causal models with quantitative domain knowledge
- On the dimensional indeterminacy of one-wave factor analysis under causal effects
- Heterogeneous interventional effects with multiple mediators: Semiparametric and nonparametric approaches
- Exploiting neighborhood interference with low-order interactions under unit randomized design
- Robust variance estimation and inference for causal effect estimation
- Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
- Potential outcome and decision theoretic foundations for statistical causality
- 2D score-based estimation of heterogeneous treatment effects
- Identification of in-sample positivity violations using regression trees: The PoRT algorithm
- Model-based regression adjustment with model-free covariates for network interference
- All models are wrong, but which are useful? Comparing parametric and nonparametric estimation of causal effects in finite samples
- Confidence in causal inference under structure uncertainty in linear causal models with equal variances
- Special Issue on Integration of observational studies with randomized trials - Part II
- Personalized decision making – A conceptual introduction
- Precise unbiased estimation in randomized experiments using auxiliary observational data
- Conditional average treatment effect estimation with marginally constrained models
- Testing for treatment effect twice using internal and external controls in clinical trials
Articles in the same Issue
- Research Articles
- Adaptive normalization for IPW estimation
- Matched design for marginal causal effect on restricted mean survival time in observational studies
- Robust inference for matching under rolling enrollment
- Attributable fraction and related measures: Conceptual relations in the counterfactual framework
- Causality and independence in perfectly adapted dynamical systems
- Sensitivity analysis for causal decomposition analysis: Assessing robustness toward omitted variable bias
- Instrumental variable regression via kernel maximum moment loss
- Randomization-based, Bayesian inference of causal effects
- On the pitfalls of Gaussian likelihood scoring for causal discovery
- Double machine learning and automated confounder selection: A cautionary tale
- Randomized graph cluster randomization
- Efficient and flexible mediation analysis with time-varying mediators, treatments, and confounders
- Minimally capturing heterogeneous complier effect of endogenous treatment for any outcome variable
- Quantitative probing: Validating causal models with quantitative domain knowledge
- On the dimensional indeterminacy of one-wave factor analysis under causal effects
- Heterogeneous interventional effects with multiple mediators: Semiparametric and nonparametric approaches
- Exploiting neighborhood interference with low-order interactions under unit randomized design
- Robust variance estimation and inference for causal effect estimation
- Bounding the probabilities of benefit and harm through sensitivity parameters and proxies
- Potential outcome and decision theoretic foundations for statistical causality
- 2D score-based estimation of heterogeneous treatment effects
- Identification of in-sample positivity violations using regression trees: The PoRT algorithm
- Model-based regression adjustment with model-free covariates for network interference
- All models are wrong, but which are useful? Comparing parametric and nonparametric estimation of causal effects in finite samples
- Confidence in causal inference under structure uncertainty in linear causal models with equal variances
- Special Issue on Integration of observational studies with randomized trials - Part II
- Personalized decision making – A conceptual introduction
- Precise unbiased estimation in randomized experiments using auxiliary observational data
- Conditional average treatment effect estimation with marginally constrained models
- Testing for treatment effect twice using internal and external controls in clinical trials