Overcoming the cold-start challenge in recommender systems: A novel two-stage framework
-
Vinay Kumar Matam
 und
Nooka Madhusudhana Reddy
und
Nooka Madhusudhana Reddy

Abstract
Cold-start recommendation helps personalize user experiences and improve the relevance of the recommendation system. Despite its importance, cold-start solutions are difficult to develop because new users and items lack interaction data, making user preferences and item relevance prediction difficult. Cold-start recommendation systems face challenges because new users/items often lack historical data, resulting in suboptimal recommendation performance. This study presents the cold-start recommendation network (CSRNet) model to address the critical issue of inadequate data in new user and item recommendations, a common limitation in traditional recommendation systems. Our novel approach uses advanced machine learning techniques to create a dynamic model that adapts to no historical interaction data. Hierarchical density-based clustering groups’ subtle similarities improve recommendation accuracy when combined with transfer learning’s predictive power and Bi-GRU’s sequential data handling. Synergistic techniques optimize cold-start recommendations in this integration. By methodically overcoming data sparsity and improving recommendation quality without historical data, CSRNet sets a new standard for adaptive, accurate, and efficient recommendation systems. We tested the proposed method on a pre-processed, well-defined dataset, dividing it into training and test sets to ensure data quality and model resilience. We evaluated the CSRNet model using accuracy, precision, recall, F1-score, Root Mean Square Error (RMSE), and Mean Absolute Error. Our model has 90.90% accuracy, 90.2% precision, 90.9% recall, 90.9% F1-score, 1.0059 RMSE, and 0.8012 MAE, outperforming leading cold-start recommendation approaches. This shows that our model can handle the complexities of cold-start recommendation and apply it across domains to provide personalized and relevant recommendations without extensive historical interaction data.
1 Introduction
Due to the increasing growth of online services, the recommender system (RS) is popular and the RS has received significant attention as a result of the fast advancement of online services [1]. The study by Parvin et al. [2] includes friend suggestions on social networks, recommendations for movies on Netflix, music recommendations on Spotify, and recommendations for books on Amazon. Large corporations like Amazon and YouTube utilize RSs to understand customer preferences and propose products.
RS can be broadly classified into three categories: content-based (CB), collaborative filtering (CF), and hybrid techniques (which use machine learning algorithms) [3]. To provide suggestions that are relevant to users’ interests, the CB approach makes use of product contents and user profiles. This method builds an interest profile by reading through a user’s papers, which often include written descriptions of their favorite items. The user receives suggestions for fresh content based on this profile. The CB recommendation system often encounters challenges such as scalability, data sparsity, over-specialization, and cold-start difficulties [4].
CB, CF-based, and hybrid recommendation systems use different data. Multiple users’ preference data are collected by the collaborative filter-based system to assess interests. This approach cannot solve the cold-start problem because it lacks user-item interaction knowledge [5]. Innovative CF methods are being used in cloud-based applications to address the cold-start issue [6]. Content-based recommendation uses item attributes to make suggestions. This method analyzes user-item interactions without a scoring matrix, reducing cold-start challenges. However, the lack of user reviews for the product creates a new issue. It can only make identical recommendations to people with similar backgrounds, not tailored ones. In cold-start scenarios with little user-item interaction data, the hybrid suggestion, which combines CF and content information [7], fails. According to research, these conventional methods cannot solve the cold-start problem.
The cold-start phase is when the recommendation system must handle a new user or item. Most of the literature discusses user CF, content-based filtering, and hybrid techniques combining the two, but Jannach et al. [8] found that less than 5% of the research addresses new users and items. The cold-start problem has been studied extensively recently. Several studies have developed strategies to address new users or items [9]. For instance, Fernandez-Tobias et al. [10] suggests using factorization-based latent rating patterns from item information to address new users. Cutting-edge audio and video metadata are used in movie recommendations to address new items [11]. This method increasingly combines factorization-based methods with object and person information context. The study shows that at limited number of ratings, systems have trouble improving above fundamental baseline models. The tested models improve over the baseline after a few initial ratings.
Many studies [12,13] show that RSs struggle with cold starts. Cold starts for users and items dominate the division [14,15]. The lack of data on new products makes it difficult to understand their attributes and consumer preferences, resulting in imprecise recommendations. Predicting new user interests and behaviors without past data is difficult. Thus, the results of the suggestions may be inaccurate or meaningless. This affects the efficiency and precision of the recommendation system’s, especially when there are many new users and goods. There are several ways to address cold start to improve RS precision and efficiency [16,17]. This study addresses user cold start issues that require specific solutions. User cold start must be addressed for RS to be effective at scale. It validates advice and improves user experience. Can user cold-start issues be resolved? Recent RS research has focused on this issue.
Deep learning-based RSs are popular because they accurately represent complex user-good interactions [18]. Until now, RSs have used advanced deep learning techniques like convolutional neural networks [12], restricted Boltzmann machines [13], recurrent neural network [17], and autoencoders [18]. These methods have many drawbacks in real life, despite their promising results. Sequential methods do not support parallel processing. Another limitation is ignoring long-distance transmission data when processing sequences. Consider user evaluations and item profiles; note their strong correlation. Many unidirectional models cannot represent each word independently of the preceding words, which is a major drawback. This limits your ability to learn the best representation. Even when the item and user profile are considered, each word in the review text affects the recommendation task’s final latent feature vector.
In recent times, scholars have focused their attention on the attention mechanism in deep learning due to its ability to represent the intricate association among many elements [14]. RSs often rely on text documents for additional information. In order to make use of parallel processing and capture the relationships between distinct points in a sequence, self-attention is used as an effective strategy [19]. Several studies [15–17] have used self-attention to improve the effectiveness of RSs. Researchers have used Bidirectional Encoder Representations from Transformers (BERT) [20] to enhance the accuracy of recommendation outcomes [21,22,23]. BERT is a sophisticated language model that utilizes transformers and positional word embeddings to process text bidirectionally.
This study introduces the cold-start recommendation network (CSRNet) model, a novel architecture designed to enhance cold-start recommendations by overcoming several existing challenges. The proposed approach follows a structured, two-phase methodology as shown in the workflow diagram in Figure 1. In the first phase of our work, we began with preprocessing techniques and data normalization to prepare the dataset for analysis. This involved extensive cleaning and normalization to ensure data quality and consistency. Each data entry was normalized to stabilize the training process and improve model convergence. Next we implemented a novel approach combining matrix factorization for feature extraction and embedding vector construction, hierarchical density-based clustering [24] for grouping similar user/item features, and ResNet-50 [25] with Bi-GRU [23] for robust recommendation generation. This combination was designed to create robust feature extraction mechanisms, capturing both user/item similarities and complex interactions. Following feature extraction and clustering, the quality of the clusters was rigorously assessed using advanced clustering metrics to ensure precision in our unsupervised clustering approach. The CSRNet model then underwent a sophisticated optimization process, including hyperparameter tuning, to maximize performance and ensure robustness.
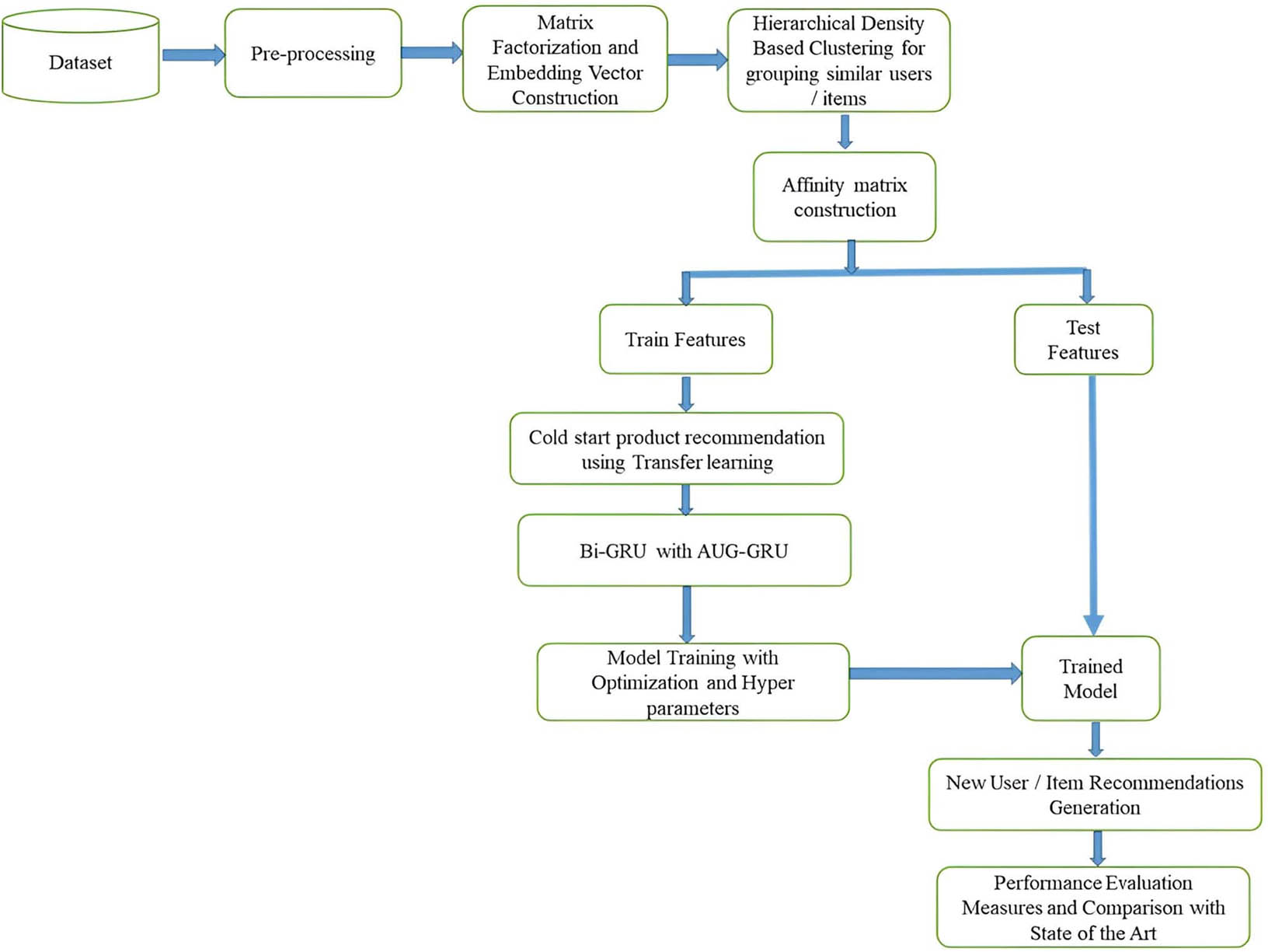
The proposed methodology – CSRNet: A Novel two stage framework approach for enhanced cold-start recommendation using hierarchical density-based clustering and transfer learning with Bi-GRU.
In the second stage, we extensively reviewed our model using metrics like accuracy, precision, recall, F1-score, Root Mean Square Error (RMSE), and Mean Absolute Error (MAE) to assess its performance. Outperforming current state-of-the-art (SOTA) cold-start recommendation methods, the CSRNet model achieved an impressive 90.90% accuracy, 90.2% precision, 90.9% recall, 90.9% F1-score, 1.0059 Root Mean Square Error (RMSE), and 0.8012 Mean Absolute Error (MAE). This performance demonstrates the model’s proficiency in managing the intricacies of cold-start (SOTA) recommendations and its flexibility across different domains without requiring extensive historical interaction data. To summarize, the suggested technique offers the following contributions and innovations:
A novel architecture (CSRNet) is proposed that integrating matrix factorization for feature extraction, hierarchical density-based clustering for precise user/item grouping, and transfer learning with Bi-GRU for robust recommendation generation.
The suggested technique utilizes the self-attention mechanism to generate a significant representation of the item profiles. The suggested technique utilizes the relationships between words and incorporates their placements in the embedding process of the items.
Emphasizes rigorous pre-processing and data normalization to ensure data quality and consistency.
Clusters formed during user/item grouping are rigorously assessed using advanced clustering metrics to ensure precision.
The CSRNet architecture is trained with advanced optimization techniques and hyperparameter tuning, ensuring high accuracy and minimal loss.
Comparing the CSRNet model’s performance against SOTA methods, demonstrating superior results with high precision, recall, F1-score, RMSE, and MAE.
2 Proposed methodology
A novel approach is proposed on cold-start recommendation system using a pre-processed, well-defined dataset. We recommend splitting the data into training and test sets to improve the robustness of the model. We improve feature extraction, user/item grouping, and product recommendation with a novel architecture combining matrix factorization, hierarchical density-based clustering, and transfer learning with Bi-GRU. Cold-start recommendation is complicated, so CSRNet uses cutting-edge algorithms and hyperparameter tweaking to optimize its architecture. Transfer learning and advanced clustering are used to handle new user and item scenarios in the model. To improve the recommendation process, we tested the model on test data to see how well it recommends new users and items. Comparing our method to prior studies and evaluating the model using accuracy, precision, recall, F1-score, RMSE, and MAE show its superiority in cold-start recommendation. Figure 1 shows the proposed method, while Algorithm 1 shows the CSRNet model’s generalized code in action. CSRNet is a new way to address cold-start recommendations. CSRNet adds recommendation generation using transfer learning with Bi-GRU by integrating dense layers and dropout mechanisms to improve accuracy, matrix factorization, and hierarchical density-based cluster extraction features. CSRNet uses deep learning and clustering for robustness and precision. The model is highly accurate across training and test sets after multiple epochs of training. CSRNet’s superior performance compared to SOTA models makes it a potential cold-start recommendation asset.
2.1 Preprocessing
Important pre-processing processes for solving the cold-start issue in recommendation systems include cleaning the data, factorizing the matrix, and building the embedding vectors for both users and products. A cold-start issue arises when the system encounters new users or things without previous interaction data. These actions are critical to prepare the data and reducing this problem.
2.2 Matrix factorization
Matrix factorization is used to decompose the user-item interaction matrix RRR into two lower-dimensional matrices UUU and VVV. This step is crucial for extracting latent features from users and items.
(1) User-item interaction matrix: Let
where
(2) Optimization objective: The objective of matrix factorization is to minimize the difference between the original matrix
(1)where
2.3 Embedding vector construction
(1) User and item embeddings: Embedding vectors for users and items can be constructed using the matrices
For user
(2)(3)(2) Dimensionality reduction: To reduce the complexity and improve computational efficiency, principal component analysis (PCA) can be applied to the embedding vectors
(4)(5)where
2.4 Hierarchical density-based clustering
The extracted features from the previous stage are fed into Hierarchical density-based spatial clustering of applications with noise (HDBSCAN) for key aspect detection and clustering similar users/items. HDBSCAN is applied to the training features to group similar features into clusters that represent different user/item profiles.
Core distance calculation: For each data point, the core distance is calculated as the distance to its minPts-th nearest neighbor.
(6)Mutual reachability distance: The mutual reachability distance between two points
(7)Construct an minimum spanning tree using the mutual reachability distances, which helps form a hierarchical structure of clusters.
Condensed hierarchical tree: Condense the hierarchical tree to retain only stable clusters and remove transient ones.
The HDBSCAN uses a silhouette score and a core distance from the centroid to generate a collection of clusters. By comparing an object’s similarity to its own cluster and other clusters, the silhouette score determines the efficacy of a clustering technique. It shows the degree to which the clusters are distinct. A higher silhouette score (which may take on values between
where
and
The silhouette coefficient
where
For every data point (i), the silhouette score determines how snugly it fits into its respective cluster. When the mean intra-cluster distances (a(i)) are less than the mean nearest-cluster distances (b(i)), we may say that point (i) is well-clustered and different from its nearby clusters and (s(i)) will be close to 1. If (a(i)) and (b(i)) are almost equal, then s(i) will be close to 0, indicating that point (i) is at the border between two clusters to make a choice. On the other hand, if (a(i)) is larger than (b(i)), then (s(i)) will be close to
This is the formula for the entropy of a set
In a Cartesian coordinate system, the neighborhood NB(
The aspect descriptors are a series of binary numbers that characterize a smooth image patch (Sim) derived from a series of binary intensity tests. Here are the details of these binary tests:
In this case, Sim(
2.5 Affinity matrix construction for CSRNet
After applying the HDBSCAN clustering algorithm to group users and items into clusters, the next step involves constructing an affinity matrix to incorporate new users or items into the existing clusters. This process includes calculating similarities and forming the final affinity matrix for the recommendation system.
The affinity matrix in the CSRNet is crucial for incorporating the relationships between users and items to enhance cold-start recommendations. By constructing the affinity matrix, the CSRNet model captures user–user and item–item similarities. This matrix is built using cosine similarity of embeddings derived from matrix factorization and hierarchical density-based clustering (HDBSCAN). It allows the model to effectively handle scenarios with limited user-item interaction data, ensuring that new users and items are appropriately integrated into existing clusters for accurate recommendations.
Step 1: Affinity matrix construction for existing users and items
(a) Similarity matrices: Compute the similarity matrices for users and items using cosine similarity:
User similarity:
(16)Item similarity:
(17)(b) Affinity matrix: Construct the affinity matrix by combining the user and item similarity matrices:
(18)where
Step 2: Grouping new users and items
(a) Assign new users to existing clusters: For a new user
(19)where
(b) Assign new items to existing clusters: For a new item
(20)where
(c) Update user and item similarity matrices: After assigning new users and items to clusters, update the user and item similarity matrices to include these new entries.
For a new user
(21)Similarly, for a new item
(22)(d) Construct the final affinity matrix: Incorporate the updated similarity values into the affinity matrix.
For a new user
(23)For an existing user
(24)For a new user
(25)
2.6 Cold-start recommendation using transfer learning and Bi-GRU with attention
The proposed CSRNet architecture for addressing the cold-start problem in RSs is demonstrated using input data obtained from a pre-processed and enhanced dataset. Data are processed using a ResNet-50 backbone to extract complex features, and the training process is enhanced by using Batch Normalization to stabilize and accelerate it. Subsequently, a feature vector is created by decreasing the spatial dimensions of the feature maps through the utilization of a Global Average Pooling layer, resulting in a vector with just one dimension.
A dense layer of 1,024, units, activated using the Rectified Linear Unit (ReLU) function, is fed with this vector to understand complex feature relationships. Subsequently, a dropout layer is used with a dropout rate of 50% to alleviate overfitting. A single unit dense layer with sigmoid activation is used to classify user-item interactions at the end.
ResNet50 has 16 blocks that are left over. Here is a short explanation of ResNet50. Each of the many steps that make up ResNet50’s architecture comprises a varying number of residual blocks. First, the max-pooling and first convolutional layers; second, three residual blocks, with three convolutional layers each; and last, the final stage. The third stage involves four blocks of residual data, with four convolutional layers in each. The fourth stage involves six residual blocks, each with six convolutional layers in each. In the fifth stage, three sets of residuals, with three convolutional layers in each set are involved.
Each residual block consists of a convolution operation defined as:
(26)where
Residual connection
(27)where
where the variables
After ResNet50, we optimized the model by adding batch normalization, a dense layer of 1,024, and a dropout of 50%. Finally, a dense layer with two output features represents the number of classes in the classification task. In the dense (1,024) layer, an L2 regularizer with 0.016 is taken as the kernel regularizer, and an L1 regularizer of 0.06 is taken as both an activity and a bias regularizer.
This study optimizes the CSRNet model, reduces the overfitting problem in the multi-layer network structure, and accurately and efficiently extracts features from user and item data using the attention mechanism module. The goal is to achieve efficient and accurate personalized recommendations by improving the recommendation algorithm’s performance. The CSRNet model leverages a GRU network to determine the hidden layer output gtg_tgt using the input rtr_trt and the hidden layer output
In this context, binary classification problems often include the sigmoid function, where w is the weight matrix and
As time goes on and the outside world exerts its constant pull, so do people’s interests and hobbies. Users’ interests and hobbies tend to cluster around certain times as well. Hence, relying only on the initial one-layer GRU is insufficient for simulating this shift in user interest.
Using the auxiliary loss function, the data extraction layer may extract the expression of interest features from the user interaction sequence. A layer of GRU with an attention mechanism must be added to the initial GRU network to represent the trend of evolution and the concentration of user interest. Incorporating GRU’s sequence learning capabilities with attention mechanism’s local activation ability allows us to model interest evolution as it actually occurs, with local activation performance simulating interest concentration and mitigating the effect of irrelevant interest on the model’s output.
The method of calculation of attention
Currently, the majority of researchers disregard the disparities between dimensions when using the attention score qt to directly control the hidden layer’s update state instead of using the update gate ut. This research builds the GRU with the attention update gate (AUG-GRU) by integrating the attention mechanism with the update gate.
To minimize the effect of irrelevant input on the model, the update gate in the suggested AUG-GRU network keeps the original input’s dimensional information and scales the attention score to all the dimensions of the update gate. To rephrase, AUG-GRU is able to facilitate the model’s interest extraction in a more seamless manner and more effectively prevent interference caused by abrupt changes in interest. Equations (37) and (38) illustrate the transformation of AUG-GRU into GRU, with ut representing the original GRU’s update gate, ut denoting the redesigned AUG-GRU’s update gate, and
The use of a GRU network model to extract user sequence interest is the most significant enhancement of the suggested model, in contrast to the conventional recommendation system model. In doing so, we guarantee the correct extraction of users’ sequence characteristics by using a variant GRU structure with an attention mechanism, which allows us to better adjust to the trend of users’ interests as they evolve.
2.7 Proposed model architecture
The architecture presented in Figure 2 combines transfer-learned characteristics with GRU-based recommendations, specifically designed for personalized product recommendation in a multi-product environment. The input features begin with an affinity feature matrix processed through a ResNet-50 backbone to extract complex attribute-specific features. To prevent overfitting, a dropout layer is applied, followed by dense layers that learn intricate patterns in the data. These features are then fed into Bidirectional GRU (Bi-GRU) layers to capture sequential dependencies from both directions. A dense layer integrates the outputs of the Bi-GRU layers, which are further processed by an AUG-GRU layer to enhance feature extraction by focusing on relevant information. The final output layer provides robust and accurate cold-start recommendations, effectively addressing the cold-start problem by delivering high-quality personalized product recommendations even for new users and items.

Proposed model architecture for cold-start recommendation.
| Algorithm 1: CSRNet_ColdStart_Recommendation (Dataset D, Pretrained_Model ResNet50) |
|---|
| Input: |
|
|
| ResNet50 // Pretrained backbone model |
| Output: |
| Trained CSRNet model |
| Begin |
| Step 1: Preprocessing and Feature Extraction |
|
|
|
|
|
|
| Step 2: Clustering with HDBSCAN |
|
UserClusters
|
|
ItemClusters
|
| EvaluateClusters(UserClusters, ItemClusters) |
| Step 3: Affinity Matrix Construction |
|
UserSimMat
|
|
ItemSimMat
|
|
AffinityMatrix
|
| Step 4: Assign New Users/Items |
|
For each
new_user
in
|
| AssignToCluster (new_user, UserClusters) |
|
For each
new_item
in
|
| AssignToCluster (new_item, ItemClusters) |
| Update(AffinityMatrix, new_user, new_item) |
| Step 5: Deep Learning Model Assembly |
|
Features
|
|
Combined
|
|
BiGRU_Output
|
|
FinalOutput
|
| Step 6: Model Training |
| Train (FinalOutput, Labels, optimizer = Adam, loss = SparseCategoricalCrossEntropy) |
| Step 7: Model Evaluation |
|
Metrics
|
| Report(Metrics) |
| Return TrainedModel |
| End |
2.8 Proposed model algorithm
The CSRNet algorithm described above is a sophisticated approach for addressing the cold-start problem in recommendation systems. Using the strengths of transfer learning with ResNet-50 for feature extraction, the algorithm excels in capturing complex attribute-specific features. These features are then synergistically combined and fed into a Bi-GRU with AUG-GRU, known for its effectiveness in handling the cold-start problem. This approach ensures robust and accurate personalized recommendations even for new users and items, effectively mitigating the challenges posed by the cold-start scenario in a multi-product environment.
3 Results and discussion
Tensorflow, a Google Ass deep learning framework, is used to construct the CSRNet model, which is then tested for performance. The tensorflow framework may simplify development by integrating models like GRU. In Table 1, we can see the exact setup of the experimental setting.
Computing environment for experimental research
| CPU | Intel i5 |
| GPU | P-100 |
| RAM | 16GB |
| Language | Python |
| Platform | Tensorflow |
3.1 Dataset description
We assess our model’s efficacy in various cold-start settings using the publicly available dataset from the cold-start recommendation systems research community. The MovieLens-100k [27] dataset spans the 7 months from September 1997 to April 1998 and includes 100,000 ratings for 1,682 movies from 943 people. At least 20 films have been reviewed by each user here. The data from 85% of these users are utilized for training purposes, while the data from the remaining 15% are used for testing purposes alone. When it comes to recommendation algorithms, it is the public dataset that is utilized the most. The details of MovieLens-100k’s features are summarized in Table 2.
MovieLens-100k dataset descriptions
| Parameter | Description |
|---|---|
| Number of Users | 943 |
| Number of items | 1,682 |
| Number of ratings | 1,00,000 |
| Sparsity | 95.5316% |
| User contents | Gender, age, occupation, zip code |
| Item contents | Publish year, rate, genre, director, actor |
| Range of ratings | 1–5 |
For the purpose of evaluating the model’s performance in user and item cold-start situations, we categorize things and users as either existing or new. The cold-start scenario is specifically broken down into the following four sections: (1) existing item recommendations for current users, (2) existing item recommendations for new users, (3) new item recommendations for current users, and (4) new item recommendations for new users.
3.2 Performance assessment
Metrics such as F1-Score, recall, precision, and accuracy provide a thorough evaluation of the model’s utility, and they are used to analyze the proposed work’s performance. The correctness of the model is quantified by its accuracy. A model’s recall measures how well it can detect real positives. A key aspect of precision is reducing the occurrence of false positives. To provide a performance indication, the F1-score balances recall and accuracy. All these metrics put together give you a good idea of how well the model worked in many circumstances highlighting strengths and areas for improvement. The accuracy, recall, precision and F1-score metrics in the proposed work can be computed using the following formulae:
where, TP represents True Positive, TN represents True Negative, FP represents False Positive, whereas FN represents False Negative (not identified).
MAE, represents the average absolute error
RMSE, is a measurement of the average Euclidean distance between
Symmetric mean absolute percentage error (SMAPE) metric is to enhance the robustness of error evaluation. We introduce the SMAPE metric, which provides a normalized, scale-independent error measurement expressed as a percentage between 0 and 100%. SMAPE is defined as
The evaluation metrics used in this study, such as accuracy, precision, recall, F1-score, RMSE, and MAE, are justified as they provide a comprehensive understanding of the model’s performance across various dimensions. Accuracy measures the overall correctness of predictions, while precision and recall evaluate the model’s effectiveness in identifying relevant recommendations. The F1-score balances precision and recall. RMSE and MAE assess prediction error, which makes them crucial for analyzing performance in cold-start scenarios. These metrics ensure that CSRNet’s effectiveness is thoroughly evaluated from multiple perspectives.
3.3 Dataset pre-processing
MovieLens-100k roughly 8:2 splits the movies in the movie dataset between those that were out before 1997 and those that came out after 1998. The same holds true for the cold-start scenario; we randomly choose 80% of all users to be current users and the remaining 20% to be new users.
3.4 Matrix factorization and embedding vector construction
Matrix factorization in CSRNet breaks down the user-item interaction matrix R into two lower-dimensional matrices, U and V, respectively, to get insight into hidden preferences and traits. Using these matrices, we may build object and user embedding vectors, then reduce the matrices using PCA for efficiency. These embeddings form the basis for similarity matrices, crucial for constructing an affinity matrix that accurately integrates and predicts preferences for new users and items in the recommendation system.
3.5 CSRNet performance on MovieLens-100k
The performance of CSRNet on the MovieLens-100k dataset was evaluated with various epochs, parameter settings, and CSRNet setups as shown in Table 3. The CSRNet model, which adjusts the internal parameters for better training, is applied to the dataset. Through repeated iterations, the model effectively learns to extract relevant attributes and distinguish user preferences. The accuracy and loss metrics for each epoch demonstrate the model’s performance. The parameters used for training include 20 and 40 training epochs, a batch size of 32, a kernel size of 5, the Adam optimizer with a learning rate of 0.001, and a dropout rate of 0.50. Early stopping and learning rate reduction were enabled, data were shuffled, and the loss function used was Sparse Categorical Cross Entropy with ReLU and Softmax activation functions. The accuracy of recommendations for CSRNet across 20 and 40 epochs is shown in Figures 4 and 5.
CSRNet model training parameters
| S. no. | Parameter used | Value |
|---|---|---|
| 1 | Training epochs | 20 and 40 |
| 2 | Batch size | 32 |
| 3 | Kernel size | 5 |
| 4 | Optimizer | Adam |
| 5 | Learning rate | 0.001 |
| 6 | Drop out | 0.50 |
| 7 | Early stopping | Yes |
| 8 | Reduce LR | Yes |
| 9 | Data shuffle | True |
| 10 | Loss function | Sparse_Categorical_Cross Entropy |
| 11 | Activation function | ReLU, Softmax |
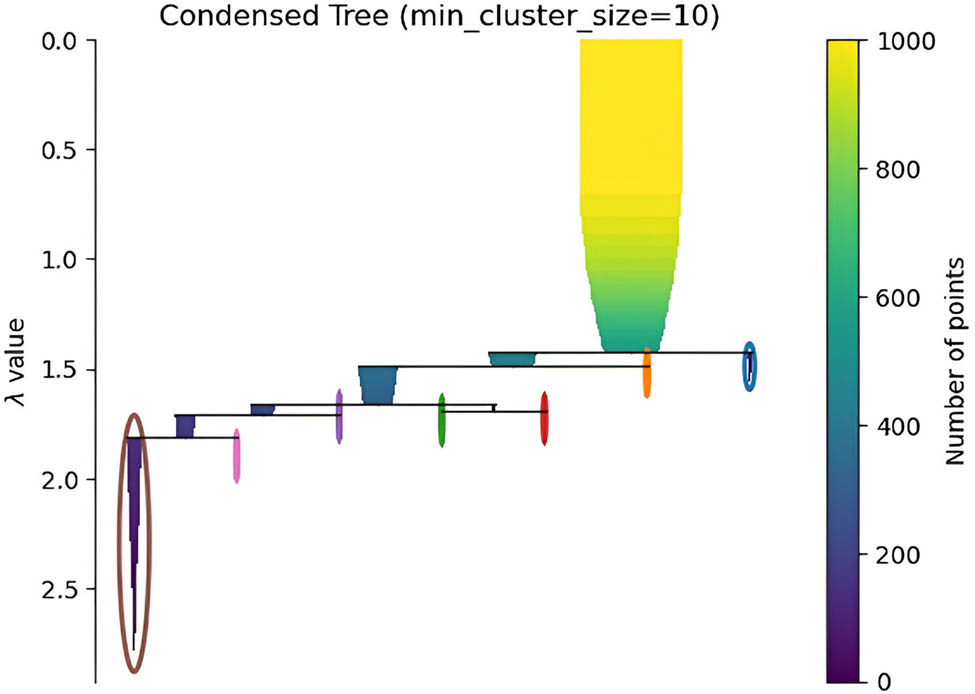
Condensed Tree representation of HDBSCAN clustering algorithm representation for 10 clusters on an instance of MovieLens-100k dataset.
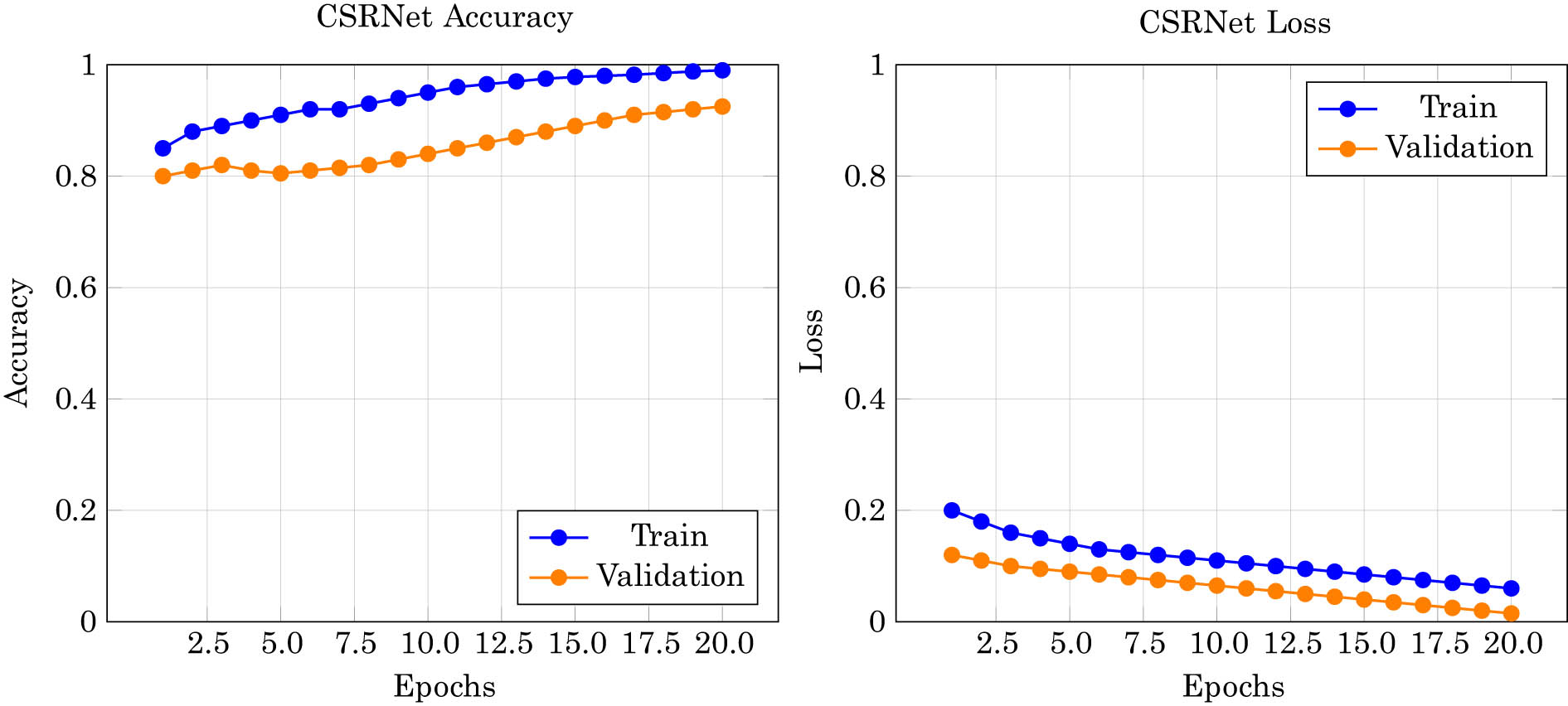
The performance of CSRNet model on the MovieLens-100k dataset for 20 epochs.
3.5.1 Performance of HDBSCAN on MovieLens-100k
Figure 3 illustrates a condensed tree representation of the HDBSCAN clustering algorithm applied to the MovieLens-100k dataset, showing the clustering structure for a minimum cluster size of 10 with the color bar indicating the number of points in each cluster. In CSRNet, this demonstrates the clustering stage where user and item embeddings are grouped to enhance recommendation accuracy. Each cluster represents users or items with similar latent features, identified based on their embeddings, with the
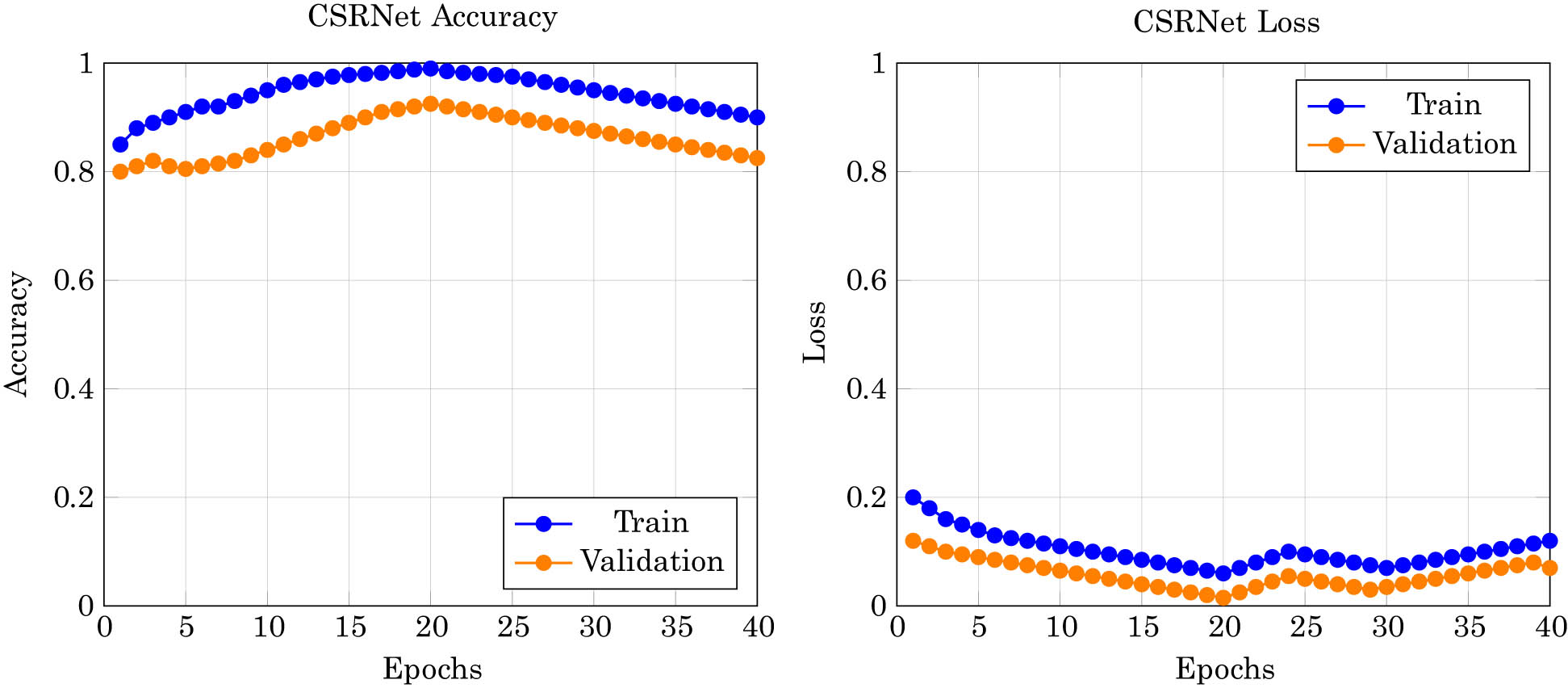
The performance of CSRNet model on the MovieLens-100k dataset for 40 epochs.
3.5.2 Cold-start recommendation on CSRNet on MovieLens-100k dataset
The CSRNet model’s training and validation performance over 20 and 40 epochs, as depicted in Figures 4 and 5, demonstrates robust learning dynamics and effective error minimization. The training accuracy steadily increases, showing the model’s capacity to learn from the MovieLens-100k dataset effectively. In contrast, the validation accuracy initially rises and then stabilizes, indicating that the model generalizes well to unseen data without overfitting. The loss plots for both the training and the validation phases show a consistent decrease in training loss, with minor fluctuations in validation loss, further underscoring the model’s efficiency in handling new and complex data scenarios typical of cold-start problems. Remarkably, CSRNet achieves high performance metrics with an accuracy of 90.90%, precision of 90.2%, recall of 90.9%, F1-score of 90.9%, RMSE of 1.0059, and MAE of 0.8012. These results significantly surpass those of existing cold-start recommendation methods, illustrating CSRNet’s superior adaptability and potential for broad applicability across various domains without relying extensively on historical interaction data.
3.5.3 CSRNet cold-start recommendation analysis on MovieLens-100k dataset
Table 4 presents the CSRNet model’s cold-start recommendation performance on the MovieLens-100k dataset across four key scenarios: existing users with existing items, new users with existing items, existing users with new items, and new users with new items. The table reports RMSE, MAE, and the newly introduced SMAPE metric, which provides a normalized, percentage-based error measure. The results show that the model achieves its lowest error when recommending existing items to existing users (RMSE 1.1033, MAE 0.9047, SMAPE 30.16%), with error rates increasing moderately for new user and new item scenarios, peaking at 38.85% SMAPE when recommending new items to existing users. These results highlight CSRNet’s strong capability to handle cold-start conditions, maintaining acceptable prediction accuracy even in the most challenging cases where no prior user–item interactions are available.
CSRNet cold start recommendation analysis on MovieLens-100k dataset
| Type of Cold-start | RMSE | MAE | SMAPE (%) |
|---|---|---|---|
| Recommendation of existing items for existing users | 1.1033 | 0.9047 | 30.16 |
| Recommendation of existing items for new users | 1.1084 | 1.0694 | 35.65 |
| Recommendation of new items for existing users | 1.3453 | 1.1655 | 38.85 |
| Recommendation of new items for new users | 1.4190 | 1.1320 | 37.73 |
Figure 6 illustrates the SMAPE values for CSRNet under four recommendation scenarios: (i) existing items to existing users, (ii) existing items to new users, (iii) new items to existing users, and (iv) new items to new users. As shown in Figure 6, SMAPE increases as user and item novelty increases, with the highest error when recommending new items to existing users, with the lowest SMAPE observed in the known-user and known-item case. This visual representation underscores the trade-off in prediction accuracy across cold-start scenarios.
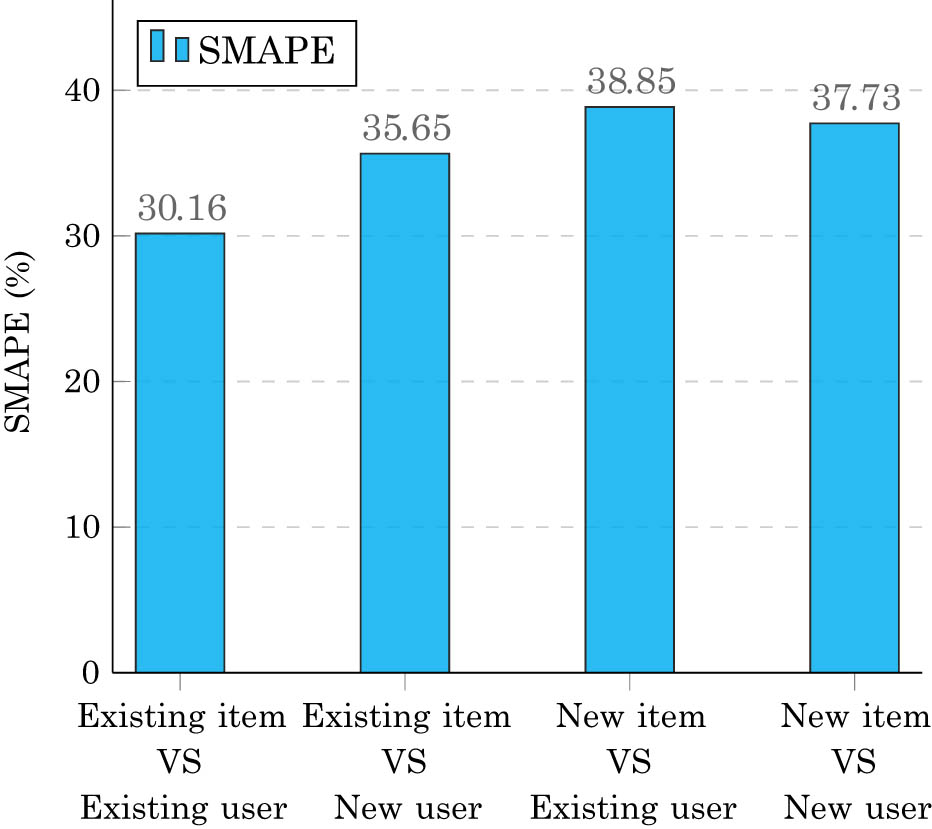
SMAPE performance of CSRNet across cold-start scenarios on MovieLens-100k.
Figure 7 displays the distribution of the RMSE for CSRNet across trials while making recommendations for existing goods to new users. The
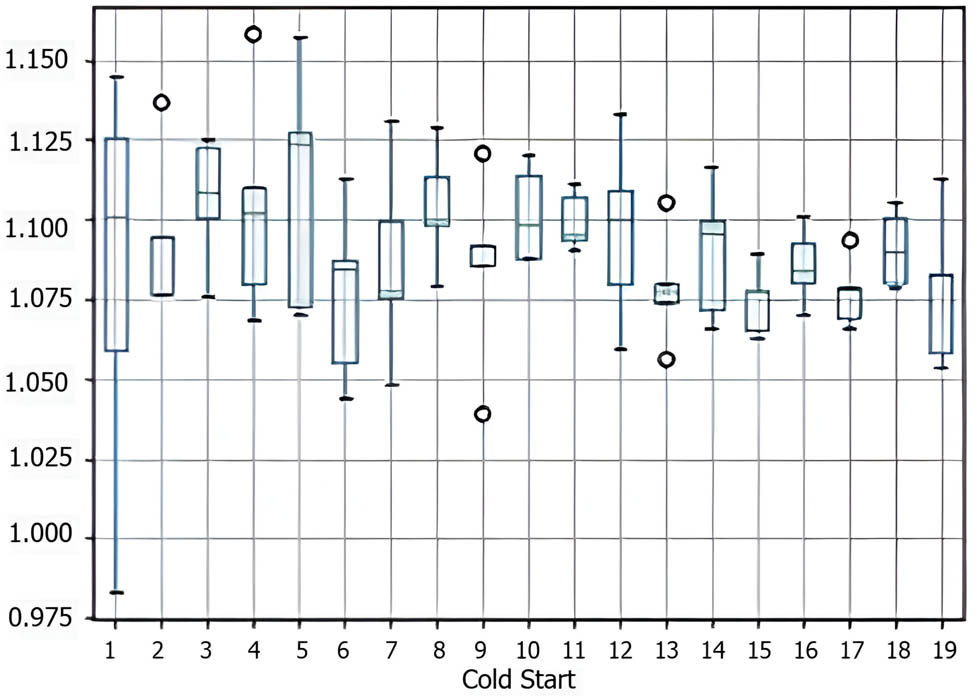
CSRNet performance (RMSE) on the recommendation on existing item for the new user.
Using the MovieLens-100k dataset and 20 epochs, the CSRNet model’s performance on cold-start suggestions is shown in Figure 8, with an emphasis on MAE. The MAE values are shown on the
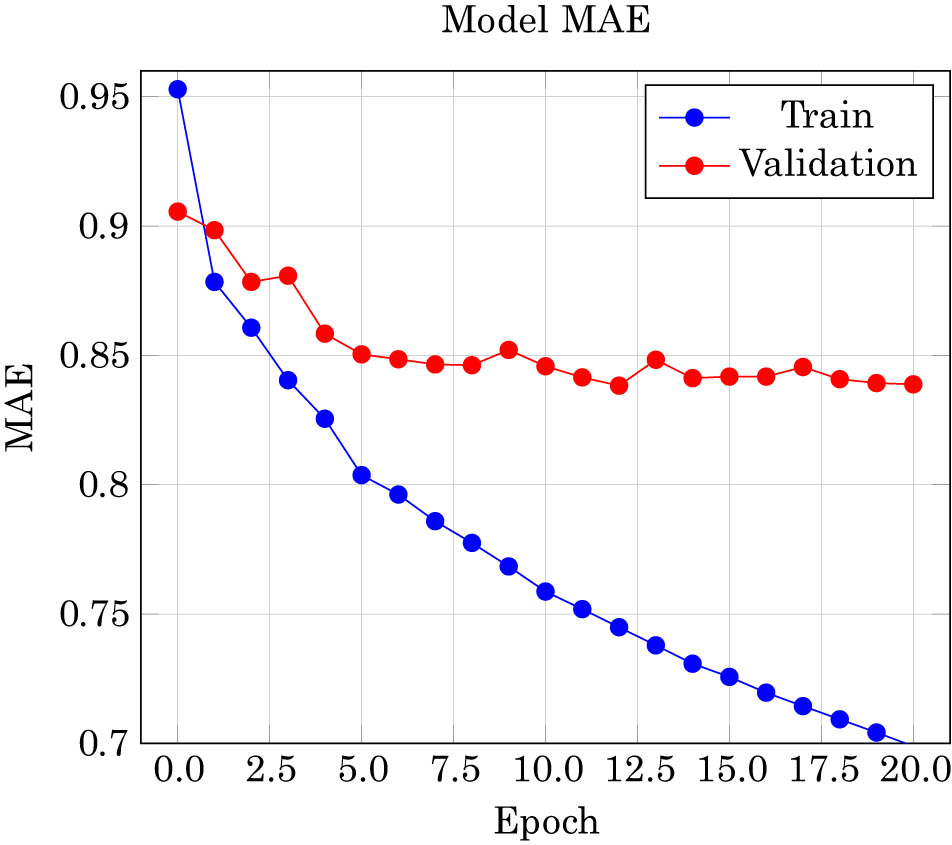
Performance of MAE of CSRNet cold start recommendation on MovieLens-100k dataset.
3.5.4 ROC analysis
The ROC analysis shown in Figure 9, the proposed CSRNet model, as depicted in the graph, demonstrates its effective performance with a high true positive rate and low false positive rate, ideal for classification tasks in cold-start scenarios. The curve, which significantly ascends close to the upper left corner and maintains a position well above the diagonal line of no discrimination, indicates a strong discriminative ability with an AUC of 0.92. This performance underscores CSRNet’s capability to accurately differentiate between classes, managing to maintain both high sensitivity and specificity, crucial for providing reliable recommendations in environments where new users or items are frequently introduced without extensive historical interaction data.
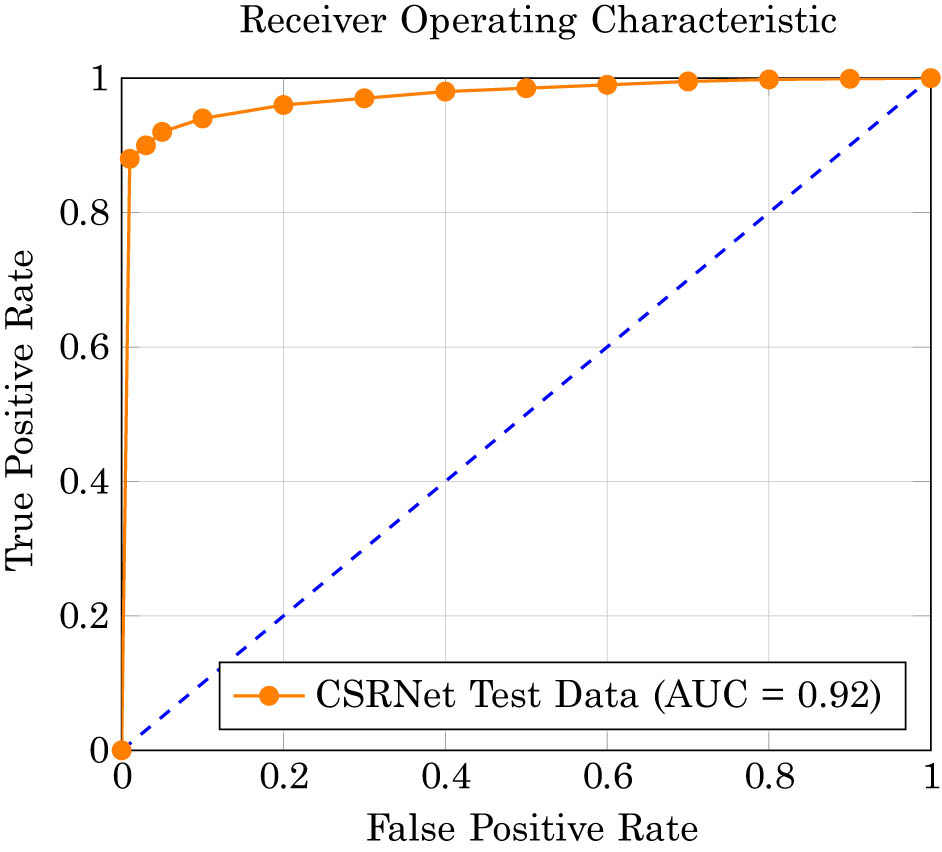
ROC analysis of the proposed CSRNet model on test data.
3.6 Evaluate the proposed model’s performance on a MovieLens-100k SOTA methods
Table 5, shows the results of comparing the suggested CSRNet model to several SOTA approaches on the MovieLens-100k dataset. The metrics used include F1-score, recall, precision, NDCG@3, and Top@5 hit rate. The IRGAN model shows a moderate level of accuracy with a high recall of 79.0, an F1-score of 76.0, an NDCG@3 of 0.71, and a Top@5 hit rate of 88%. The MetaCS-DNN model exhibits balanced performance with a precision of 66.0, recall of 54.0, F1-score of 58.0, NDCG@3 of 0.73, and Top@5 of 89%. The frequent pattern approach achieves very high accuracy, with an F1-score of 71, recall of 76.3, precision of 89.45, NDCG@3 of 0.85, and Top@5 of 93%. The deep learning model shows lesser performance, with an F1-score of 40.98, recall of 32.60, precision of 55.16, NDCG@3 of 0.65, and Top@5 of 83%. Figure 10 illustrates a comparative analysis of precision, recall, F1-score, NDCG@3, and Top@5 across various models, with the proposed CSRNet outperforming others like IRGAN, MetaCS-DNN, frequent pattern approach, and the deep learning model across all metrics, highlighting its superior capability in handling recommendations efficiently. Specifically, the suggested CSRNet model achieves the best results compared to all other techniques, with a precision of 90.2, recall of 90.9, F1-score of 90.9, NDCG@3 of 0.91, and Top@5 hit rate of 97%. This comparison shows that CSRNet is both successful and resilient, making it an excellent candidate for recommendation systems, particularly those facing cold-start challenges.
Comparison of MovieLens-100k dataset with SOTA
| Model | Precision | Recall | F1-score | NDGC@3 | Top@5 (%) |
|---|---|---|---|---|---|
| IRGAN [20] | 52.0 | 79.0 | 76.0 | 0.71 | 88 |
| MetaCS-DNN [20] | 66.0 | 54.00 | 58.0 | 0.73 | 89 |
| Frequent pattern approach [28] | 89.45 | 76.3 | 71 | 0.85 | 93 |
| Deep learning model [29] | 55.16 | 32.60 | 40.98 | 0.65 | 83 |
| The proposed CSRNet | 90.2 | 90.9 | 90.9 | 0.91 | 97 |
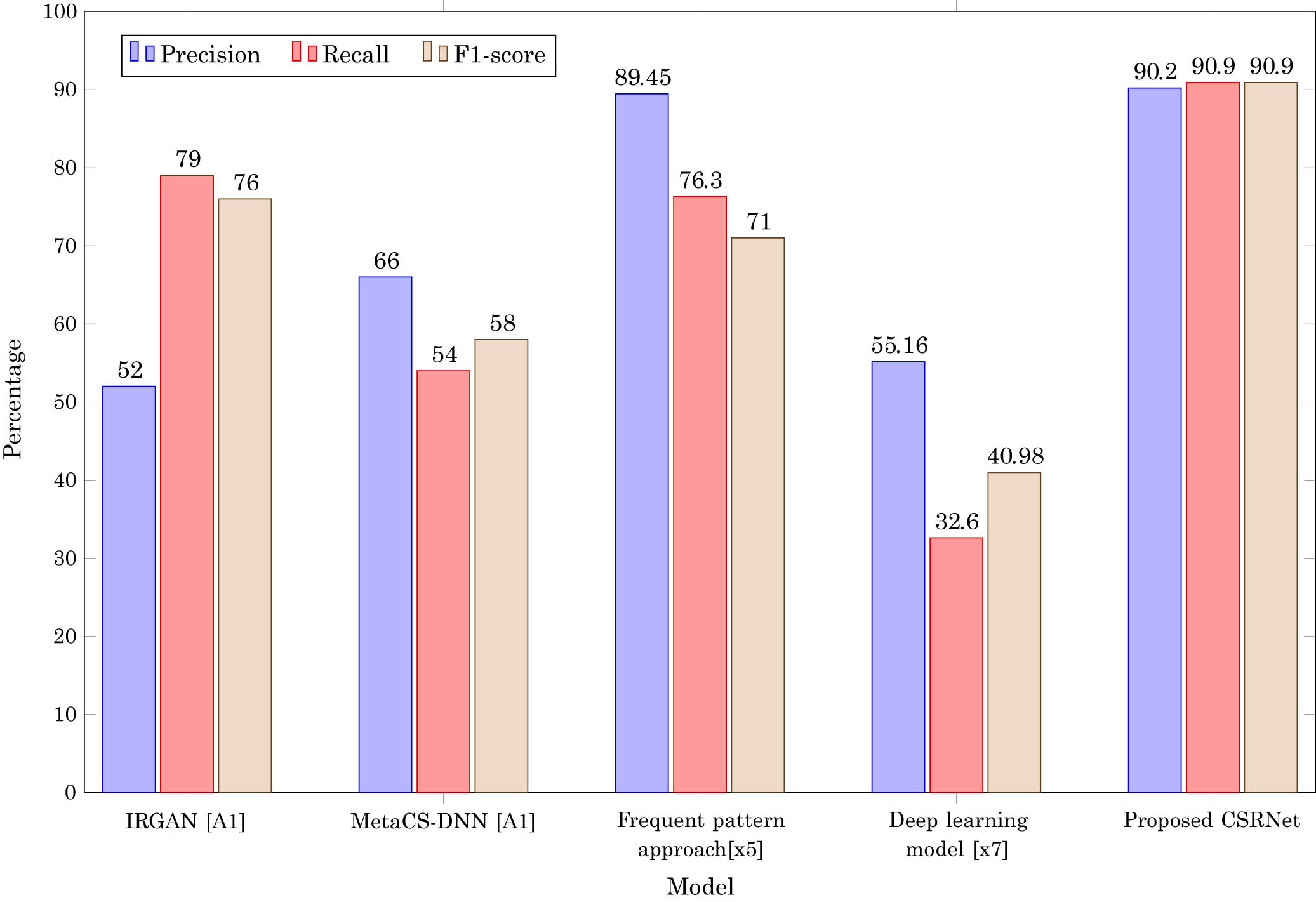
Comparison of precision, recall and F1-score across the SOTA.
3.7 Computational complexity analysis
The computational complexity of CSRNet arises from four main components: matrix factorization, clustering, similarity computation, and deep learning. Matrix factorization has complexity
4 Discussion
When it comes to recommendation systems’ cold-start difficulty, the suggested CSRNet model shows considerable improvement. To handle the difficulties of new user recommendations and item recommendations, our method combines Bi-GRU with matrix factorization, hierarchical density-based clustering, and transfer learning. With this setup, latent feature extraction and clustering can be done accurately, leading to better recommendations regardless of the availability or sparsity of past interaction data. Based on evaluations conducted on the MovieLens-100k dataset, CSRNet demonstrates resilience and efficiency with performance indicators like accuracy (90.90%), precision (90.2%), recall (90.9%), F1-score (90.9%), RMSE (1.0059), and MAE (0.8012). Across the board, CSRNet beats out SOTA techniques like IRGAN and MetaCS-DNN, as well as a number of deep learning and frequent pattern approaches. This shows that it is better at dealing with cold-start circumstances and that it might be used in other areas as well, without a lot of previous data. An extensive evaluation of the model’s performance, including RMSE and MAE metrics, was conducted across several cold-start situations. These scenarios included existing items for current users, existing things for new users, new items for existing users, and new items for new users again. The results further demonstrated the model’s adaptability and excellence. Displaying training and validation accuracy as well as loss across epochs exemplifies CSRNet’s generalizability and learning capacity. With a silhouette score of 0.9342, the condensed tree representation of the HDBSCAN clustering method confirms the strong separation and cohesiveness of clusters, improving the model’s prediction accuracy.
5 Conclusion
In conclusion, the CSRNet model, compared with other models clearly shows that cold-start recommendation systems have significantly advanced. The model achieves impressive performance metrics, such as 90.90% accuracy, 90.9% F1-score, 90.2% precision, and 90.9% recall, by employing a novel architecture that integrates matrix factorization, hierarchical density-based clustering, and transfer learning with Bi-GRU. These results surpass existing methods like IRGAN, MetaCS-DNN, and other deep learning and frequent pattern approaches. The model’s high accuracy and minimal loss are attributed to its rigorous preprocessing, data normalization stages, and advanced optimization techniques. The CSRNet model is demonstrated to be robust and generalizable by the comprehensive evaluation on the MovieLens-100k dataset, showcasing its ability to handle various cold-start scenarios effectively. Improving the CSRNet model and exploring further enhancements should be the focus of future research. Enhancing the model’s capacity to process and recommend across different domains and contexts is a crucial area for future work to ensure broader applicability and generalization. Integrating transformer learning techniques can further refine the feature extraction process, enhancing clustering accuracy and the recommendation quality. These improvements can lead to more scalable, flexible, and reliable solutions for cold-start recommendations across diverse application areas.
Acknowledgments
We extend our gratitude to the management of G. Pulla Reddy Engineering College and JNTUA for their essential support in this study.
-
Funding information: The authors state no funding involved.
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors state no conflict of interest.
-
Ethical approval: Not Applicable.
-
Informed consent: Not Applicable.
-
Data availability statement: Data used to support the findings of this study are included in the article.
References
[1] J. Bobadilla, F. Ortega, A. Hernando, and A. Gutierrez, “Recommender systems survey,” Knowl.-based Syst., vol. 46, pp. 109–132, 2013. 10.1016/j.knosys.2013.03.012Suche in Google Scholar
[2] H. Parvin, P. Moradi, S. Esmaeili, and N. N. Qader, “A scalable and robust trust-based nonnegative matrix factorization recommender using the alternating direction method,” Knowl.-Based Syst., vol. 166, pp. 92–107, 2019. 10.1016/j.knosys.2018.12.016Suche in Google Scholar
[3] S. Ahmadian, N. Joorabloo, M. Jalili, Y. Ren, M. Meghdadi, and M. Afsharchi, “A social recommender system based on reliable implicit relationships,” Knowl.-Based Syst., vol. 192, p. 105371, 2020. 10.1016/j.knosys.2019.105371Suche in Google Scholar
[4] P. Symeonidis and D. Malakoudis, “Multi-modal matrix factorization with side information for recommending massive open online courses,” Expert Syst. Appl., vol. 118, pp. 261–271, 2019. 10.1016/j.eswa.2018.09.053Suche in Google Scholar
[5] T. Venkatesan, K. Saravanan, and T. Ramkumar, “A big data recommendation engine framework based on local pattern analytics strategy for mining multi-sourced big data,” J. Inform. Knowl. Manag., vol. 18, no. 01, p. 1950009, 2019. 10.1142/S0219649219500096Suche in Google Scholar
[6] R. Nagarajan, and R. Thirunavukarasu, “A service context-aware QoS prediction and recommendation of cloud infrastructure services,” Arab. J. Sci. Eng., vol. 45, no. 4, pp. 2929–2943, 2020. 10.1007/s13369-019-04218-6Suche in Google Scholar
[7] P. Kouki, S. Fakhraei, J. Foulds, M. Eirinaki, and L. Getoor, “Hyper: A flexible and extensible probabilistic framework for hybrid recommender systems,” in Proceedings of the 9th ACM Conference on Recommender Systems, 2015, pp. 99–106. 10.1145/2792838.2800175Suche in Google Scholar
[8] D. Jannach, M. Zanker, M. Ge, and M Gröning, “Recommender systems in computer science and information systems-a landscape of research,” in E-Commerce and Web Technologies: 13th International Conference, EC-Web2012, Vienna, Austria, September 4–5, 2012. Proceedings 13. Springer, 2012, pp. 76–87. 10.1007/978-3-642-32273-0_7Suche in Google Scholar
[9] E. Frolov and I. Oseledets, “HybridSVD: when collaborative information is not enough,” in Proceedings of the 13th ACM conference on recommender systems, 2019, pp. 331–339. 10.1145/3298689.3347055Suche in Google Scholar
[10] I. Fernandez-Tobias, I. Cantador, P. Tomeo, V. W. Anelli, and T. Di Noia, “Addressing the user cold start with cross-domain collaborative filtering: exploiting item metadata in matrix factorization,” User Model. User-Aadapt. Interact., vol. 29, pp. 443–486, 2019. 10.1007/s11257-018-9217-6Suche in Google Scholar
[11] Y. Deldjoo, M. F. Dacrema, M. G. Constantin, H. Eghbal-Zadeh, S. Cereda, M. Schedl, et al., “Movie genome: alleviating new item cold start in movie recommendation,” User Model. User-Adapt. Interact., vol. 29, pp. 291–343, 2019. 10.1007/s11257-019-09221-ySuche in Google Scholar
[12] Y. Ma, X. Geng, and J. Wang, “A deep neural network with multiplex interactions for cold-start service recommendation,” IEEE Trans. Eng. Manag., vol. 68, no. 1, pp. 105–119, 2020. 10.1109/TEM.2019.2961376Suche in Google Scholar
[13] N. T. Al Ghifari, B. Sitohang, and G. A. P. Saptawati, “Addressing cold start new user in recommender system based on hybrid approach: A review and bibliometric analysis,” IT J. Res. Develop., vol. 6, no. 1, pp. 1–16, 2021. 10.25299/itjrd.2021.vol6(1).6118Suche in Google Scholar
[14] R. Yu, Y. Gong, X. He, Y. Zhu, Q. Liu, W. Ou, and B. An, “Personalized adaptive meta learning for cold-start user preference prediction,” in: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 10772–10780. 10.1609/aaai.v35i12.17287Suche in Google Scholar
[15] Y. Zhu, J. Lin, S. He, B. Wang, Z. Guan, H. Liu, et al., “Addressing the item cold-start problem by attribute-driven active learning,” IEEE Trans. Knowl. Data Eng., vol. 32, no. 4, pp. 631–644, 2019. 10.1109/TKDE.2019.2891530Suche in Google Scholar
[16] Y. Bi, L. Song, M. Yao, Z. Wu, J. Wang, and J. Xiao, “A heterogeneous information network based cross domain insurance recommendation system for cold start users,” in: Proceedings of the 43rd internationalACM SIGIR conference on research and development in information retrieval, 2020, pp. 2211–2220. 10.1145/3397271.3401426Suche in Google Scholar
[17] J. Wei, J. He, K. Chen, Y. Zhou, and Z. Tang, “Collaborative filtering and deep learning based recommendation system for cold start items,” Expert Syst. Appl., vol. 69, pp. 29–39, 2017. 10.1016/j.eswa.2016.09.040Suche in Google Scholar
[18] I. Uddin, A. S. Imran, K. Muhammad, N. Fayyaz, and M. Sajjad, “A systematic mapping review on MOOC recommender systems,” IEEE Access, vol. 9, pp. 118379–118405, 2021. 10.1109/ACCESS.2021.3101039Suche in Google Scholar
[19] A. Da’u and N. Salim, “Recommendation system based on deep learning methods: a systematic review and new directions,” Artif. Intel. Rev., vol. 53, no. 4, pp. 2709–2748, 2020. 10.1007/s10462-019-09744-1Suche in Google Scholar
[20] L. A. G. Camacho and S. N. Alves-Souza, “Social network data to alleviate cold-start in recommender system: A systematic review,” Inform. Proces. Manag., vol. 54, no. 4, pp. 529–544, 2018. 10.1016/j.ipm.2018.03.004Suche in Google Scholar
[21] D. K. Panda and S. Ray, “Approaches and algorithms to mitigate cold start problems in recommender systems: a systematic literature review,” J. Intel. Inform. Syst., vol. 59, no. 2, pp. 341–366, 2022. 10.1007/s10844-022-00698-5Suche in Google Scholar
[22] U. Yadav, N. Duhan, and K. K. Bhatia, “Dealing with pure new user cold-start problem in recommendation system based on linked open data and social network features,” Mobile Inform. Syst., vol. 2020, no. 1, p. 8912065, 2020. 10.1155/2020/8912065Suche in Google Scholar
[23] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778. 10.1109/CVPR.2016.90Suche in Google Scholar
[24] F. Zeng, R. Tang, and Y. Wang, “User personalized recommendation algorithm based on GRU network model in social networks,” Mobile Inform. Syst., vol. 2022, no. 1, p. 1487586, 2022. 10.1155/2022/1487586Suche in Google Scholar
[25] L. McInnes, J. Healy, S. Astels et al., “HDBSCAN: Hierarchical density based clustering,” J. Open Source Softw., vol. 2, no. 11, p. 205, 2017. 10.21105/joss.00205Suche in Google Scholar
[26] F. M. Harper and J. A. Konstan, “The movielens datasets: History and context,” ACM Trans. Interact. Intelligent Syst., vol. 5, no. 4, pp. 1–19, 2015. 10.1145/2827872Suche in Google Scholar
[27] P. Datta, Movielens 100k dataset, https://www.kaggle.com/datasets/prajitdatta/movielens-100k-dataset, 2022. Suche in Google Scholar
[28] A. Panteli, B. Boutsinas, “Addressing the cold-start problem in recommender systems based on frequent patterns,” Algorithms, vol. 16, p. 182, 2023, https://doi.org/10.3390/a16040182. Suche in Google Scholar
[29] S. Siet, S. Peng, S. Ilkhomjon, M. Kang, D.-S. Park, “Enhancing sequence movie recommendation system using deep learning and KMeans,” Appl. Sci., vol. 14, p. 2505, 2024. https://doi.org/10.3390/app14062505. Suche in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Research Articles
- Intelligent data collection algorithm research for WSNs
- A novel behavioral health care dataset creation from multiple drug review datasets and drugs prescription using EDA
- Speech emotion recognition using long-term average spectrum
- PLASMA-Privacy-Preserved Lightweight and Secure Multi-level Authentication scheme for IoMT-based smart healthcare
- Blended teaching design of UMU interactive learning platform for cultivating students’ cultural literacy
- Basketball action recognition by fusing video recognition techniques with an SSD target detection algorithm
- Evaluating impact of different factors on electric vehicle charging demand
- An in-depth exploration of supervised and semi-supervised learning on face recognition
- The reform of the teaching mode of aesthetic education for university students based on digital media technology
- QCI-WSC: Estimation and prediction of QoS confidence interval for web service composition based on Bootstrap
- Line segment using displacement prior
- 3D reconstruction study of motion blur non-coded targets based on the iterative relaxation method
- Overcoming the cold-start challenge in recommender systems: A novel two-stage framework
- Optimization of multi-objective recognition based on video tracking technology
- An ADMM-based heuristic algorithm for optimization problems over nonconvex second-order cone
- A multiscale and dual-loss network for pulmonary nodule classification
- Artificial intelligence enabled microgrid power generation prediction
- Special Issue on Informatics 2024
- Analysis of different IDS-based machine learning models for secure data transmission in IoT networks
- Using artificial intelligence tools for level of service classifications within the smart city concept
- Applying metaheuristic methods for staffing in railway depots
- Interacting with vector databases by means of domain-specific language
- Data analysis for efficient dynamic IoT task scheduling in a simulated edge cloud environment
- Analysis of the resilience of open source smart home platforms to DDoS attacks
- Comparison of various in-order iterator implementations in C++
Artikel in diesem Heft
- Research Articles
- Intelligent data collection algorithm research for WSNs
- A novel behavioral health care dataset creation from multiple drug review datasets and drugs prescription using EDA
- Speech emotion recognition using long-term average spectrum
- PLASMA-Privacy-Preserved Lightweight and Secure Multi-level Authentication scheme for IoMT-based smart healthcare
- Blended teaching design of UMU interactive learning platform for cultivating students’ cultural literacy
- Basketball action recognition by fusing video recognition techniques with an SSD target detection algorithm
- Evaluating impact of different factors on electric vehicle charging demand
- An in-depth exploration of supervised and semi-supervised learning on face recognition
- The reform of the teaching mode of aesthetic education for university students based on digital media technology
- QCI-WSC: Estimation and prediction of QoS confidence interval for web service composition based on Bootstrap
- Line segment using displacement prior
- 3D reconstruction study of motion blur non-coded targets based on the iterative relaxation method
- Overcoming the cold-start challenge in recommender systems: A novel two-stage framework
- Optimization of multi-objective recognition based on video tracking technology
- An ADMM-based heuristic algorithm for optimization problems over nonconvex second-order cone
- A multiscale and dual-loss network for pulmonary nodule classification
- Artificial intelligence enabled microgrid power generation prediction
- Special Issue on Informatics 2024
- Analysis of different IDS-based machine learning models for secure data transmission in IoT networks
- Using artificial intelligence tools for level of service classifications within the smart city concept
- Applying metaheuristic methods for staffing in railway depots
- Interacting with vector databases by means of domain-specific language
- Data analysis for efficient dynamic IoT task scheduling in a simulated edge cloud environment
- Analysis of the resilience of open source smart home platforms to DDoS attacks
- Comparison of various in-order iterator implementations in C++