Interacting with vector databases by means of domain-specific language
-
Elena Akik
 ,
Vladimir Dimitrieski
,
Vladimir Dimitrieski

Abstract
Vector database management systems have been recognized as a crucial innovation in the era dominated by artificial intelligence, where vast and high-dimensional datasets are generated at unprecedented scales. These systems are designed to efficiently handle, store, retrieve, and analyze high-dimensional vector data, while uncovering patterns within unstructured and heterogeneous datasets. The ability of vector database management systems to perform fast and accurate similarity searches allows contextual data retrieval. Access to vector databases is often facilitated through application code tailored to proprietary application programming interfaces and query languages, varying in syntax and terminology used among vector database management systems of different vendors. A state of tight coupling, interoperability challenges, and difficulties during transitions between vector database management systems that ultimately affect usability is thereby produced. To address these issues, we propose a model-driven software development solution that incorporates vecDSL – a domain-specific language serving as its central component – to provide a uniform approach to accessing vector databases. The goal of the proposed solution is to have vector database management simplified and its interactions streamlined, thereby ensuring that end-user efficiency is enhanced through the utilization of vecDSL. Concepts uniformly used in vecDSL are expected to ease learning and eliminate database-specific adjustments, while abstraction provided by the language aims to simplify testing and enable efficient performance assessments across different vector database management systems. In this article, we describe the syntax and usage of vecDSL, as well as the application of the MDSD-based solution in supporting the interaction with diverse vector databases. We also include the evaluation of the proposed vecDSL syntax, to examine its ability in addressing current issues and explore its potential for further development.
1 Introduction
Data have been recognized as a central element in contemporary technological and economic advancements, influencing industries and decision-making processes. Over the last two decades, as the amount of data being generated continues to grow, the need to process and analyze it has become increasingly urgent. Rapid advancements in computational intelligence, along with the proliferation of internet of things (IoT) devices, advancements in artificial intelligence (AI), and the widespread adoption of cloud computing have driven greater automation in data handling [1,2].
In today’s digital age, raw data are generated in structured, semi-structured, and unstructured formats. Rapid growth coupled with scalability challenges is catalyzing the emergence of Big Data – often described as the “intellectual petroleum” of sociotechnical sectors – characterized by its volume, velocity, and variety [3,4]. These challenges necessitate advanced methodologies for insight discovery, informed decision-making, and business process optimization. Furthermore, it has been noted that such dimensions introduce significant methodological and computational challenges, prompting the development of sophisticated tools and techniques for effective data management [2]. Ultimately, the objective is to leverage vast amounts of data to enable knowledge discovery and better decision-making, overcoming the hurdles associated with managing heterogeneous information.
Existing systems often fall short in handling unstructured data and addressing computational inefficiencies. In addition, the challenges posed by real-time data streams and data veracity issues, such as noise and uncertainty, require robust cleaning and validation techniques [5,6]. These challenges are effectively addressed by transformative innovations such as machine learning (ML). Recognized for its scalability and adaptability, ML enables patterns to be extracted and predictions to be generated from large datasets, thereby converting Big Data’s inherent complexity – which stems from its vast volume, diverse formats, and dynamic nature – into actionable knowledge [7,8].
Building on these advancements, attention is drawn to vector databases as a pivotal technological innovation. In response to the rising complexity and proliferation of high-dimensional data, vector database management systems (VDBMSs) are positioned as essential tools for managing and retrieving vast, heterogeneous datasets while facilitating pattern extraction from unstructured data. High-dimensional data points, known as vectors and ranging from tens to thousands of dimensions depending on data complexity, are efficiently stored, indexed, and searched by these VDBMSs [9]. Moreover, vector databases are identified as core components in AI-powered applications [4] and in the deployment of ML models across production environments, where enhancements in performance and decision-making have been achieved. Their employment as dynamic external memory systems enabled continuous updates and facilitated the retention and recall of information by ML models, thereby improving the capacity to handle complex, state-dependent tasks. Through this integration, the overall reliability and effectiveness of AI systems in managing complex data and generating accurate results across diverse applications are realized.
Although vector databases offer substantial benefits, it is observed that the mastery of various vector database systems is hindered by the diversity of underlying concepts and the terminology used to name the concepts [10]. In addition, to retrieve data stored in vector databases, users are required to write application code specific to different types of persistence backends. Relational database management systems provide standardized support for structured query language (SQL) and application programming interfaces (APIs) such as Java database connectivity (JDBC) or open database connectivity (ODBC) and are typically interchangeable. VDMSs, however, typically rely on proprietary APIs and vendor-specific query languages. Therefore, exposing users directly to the API of a particular VDBMS is seen to result in strong coupling between the application code and that system, thereby hindering future migration to alternative VDBMSs. In addition, difficult management of VDBMSs in database systems containing different VDBMSs is encountered, a challenge that is mirrored by those found in other NoSQL databases. The lack of unified standards, which is largely attributable to the difficulties of integrating disparate APIs and languages into established software development processes and frameworks, has long been accepted by practitioners.
In response to these challenges, approaches that can effectively manage the growing complexity – involving diverse underlying data models, vendor-specific APIs, and proprietary query languages – and simplify access to vector database systems are required. Within this context, we recognized the application of the model-driven software development (MDSD) paradigm within the vector databases domain as a promising solution for mitigating these complexities. MDSD practices leverage structured, machine-readable models as primary artifacts at all stages of software system development. In that way, the complexity is addressed through abstraction and MDSD facilitates automation, standardized communication, and improved software maintainability. Within MDSD, domain-specific languages (DSLs) facilitate model creation and form the foundation for code generators that transform these models into alternative models, text, or executable code. As shown by Rädler et al. [11], development processes are simplified and standardization and reusability are promoted by the application of MDSD principles to database systems, thereby rendering the methodology effective for the engineering of robust and adaptable solutions.
In the vector databases domain, the application of the MDSD paradigm is justified using models that are created by means of a DSL, designed for uniform access to diverse vector databases. To the best of our knowledge, the establishment of such a language is not achieved. To address this gap, we propose a novel MDSD solution that represents a software system incorporating DSL as its central component, thereby establishing a uniform method for interacting with these databases. Our proposed DSL, named vecDSL, is developed as a prototype declarative language, designed to standardize access to vector databases, by ensuring a uniform workflow and eliminating dependencies on specific VDBMS vendors. Our goal is to simplify data management, streamline database interactions, and enhance operational efficiency by using vecDSL. The learning curve for users unfamiliar with vector databases is anticipated to be reduced by the facilitated uniform application of concepts across systems, thereby obviating the need for database-specific adjustments. In addition, the abstraction of implementation details is expected to simplify the testing of different vector databases and enable performance assessments to be conducted more efficiently.
This article is an extended version of the conference paper [12]. In this extension: (i) an overview of DSLs for NoSQL database access has been provided; (ii) a deeper examination of vector databases access has been included; (í) the abstract and concrete syntaxes are extended; (iv) the use case of vecDSL models and generated code have been extended; and (v) the evaluation of vecDSL syntax is conducted to provide insights into the structural and syntactic characteristic of the language compared to existing ways of interacting with diverse vector databases.
Having established the foundation of our MDSD solution, we now examine the key research questions that guide its development and evaluation:
Research question 1 (RQ1): Which specific abstractions and language constructs, including their semantics, are necessary within a DSL to express vector database operations and ensure ease of use?
Research question 2 (RQ2): To what extent can the MDSD-based solution, using a DSL, provide uniform access and integration across diverse VDBMSs?
Research question 3 (RQ3): How does the adoption of the DSL impact on usability, portability, and operational efficiency of vector database management compared to traditional, vendor-specific approaches?
2 Background and related works
In this section, the methods and challenges associated with accessing data in vector databases – a subset of NoSQL systems – are examined, and a brief overview of the MDSD paradigm and DSLs is provided.
2.1 DSLs for NoSQL databases access
The rapid evolution of NoSQL systems has prompted the development of model-driven (MD) solutions that abstract vendor-specific intricacies and provide uniform access to heterogeneous data stores [13]. Initially, querying tasks were focused on by these solutions, and subsequently, operations such as data migration, transformation, and schema mapping were incorporated.
It is acknowledged that vector databases are classified as one type of NoSQL systems, and access to NoSQL databases in general, including vector databases, is thereby provided. The investigation is hereby aimed at determining whether DSLs for vector database access are available. In this section, we provide an overview of some prominent DSLs developed for NoSQL database access, where the complexity of interacting with diverse NoSQL backends is encapsulated by these languages through tailored abstractions and syntax.
To begin with, the save our systems interface [13] was introduced in 2014 to standardize data access across heterogeneous NoSQL systems. A mechanism was provided to translate queries between various database models, such as document-oriented stores, extensible record stores, and key value stores, which allowed uniform querying and data manipulation capabilities to be applied across platforms such as HBase [14], MongoDB [15], and Redis [16].
Expanding on this work, ATHENA [17] was developed, as an ontology-driven system for natural language querying over relational databases. In ATHENA, natural language queries were mapped to an intermediate ontology query language and then compiled into SQL. Through this process, the decoupling of query formulation from the underlying schema was achieved. Although ATHENA targeted relational databases, its MD methodology provided valuable insights into abstracting complex query formulations.
Following this, attention was directed toward addressing scalability challenges in model persistence with the development of NeoEMF [18]. It was designed to support multiple database backends, including key-value databases, graph databases, and column databases. Integration into the eclipse modeling framework (EMF) allowed for seamless use with the existing modeling tools, while an advanced API was provided for fine-grained database tuning. As a result, a flexible and scalable persistence solution for handling extensive model-based data was established.
Advancements continued with the model-based methodology presented in the study by Kolovos et al. [19], which addressed the design, deployment, and querying of hybrid NoSQL and relational data persistence architectures. In this work, three DSLs were developed; however, two are particularly relevant to this discussion: (i) TyphonDL was proposed to bridge the gap between high-level designs and concrete database configurations through automated deployment, thereby addressing aspects of data definition language (DDL) and system configuration; and (ii) TyphonQL was created to compile high-level queries into database-specific commands, thereby facilitating querying across heterogeneous systems that include document-oriented databases, key-value databases, and graph databases.
In a related advancement, an extension of the Cypher query language was detailed by Castellort and Martin [20]. The integration of the Fuzzy4S framework allowed fuzzy logic to be incorporated into the querying process, thereby supporting the formulation of approximate queries and enhancing data manipulation capabilities in graph environments such as Neo4J.
Concurrently, research was conducted on schema design in column-family and document-oriented databases, leading to the development of Mortadelo [21]. In this solution, agnostic generic data model (GDM) was employed to support DDL operations and data modeling for these types of databases. A three-stage transformation process was utilized to automatically generate physical implementations (e.g., Cassandra query language (CQL)), and a textual DSL was provided to define and validate GDM instances.
Further contributions have been made in the area of structured access to heterogeneous data sources through the development of a JavaScript object notation (JSON)-based DSL [22]. In this approach, the JSON grammar is leveraged to define and process domain-specific queries and transformations, thereby facilitating interoperability between different NoSQL databases. The DSL is primarily designed for document-oriented stores such as MongoDB [15], CouchDB [23], and Firebase Firestore [24], where JSON-based data are natively managed. Moreover, DSL is employed to standardize data exchange between client-side and server-side applications, thereby ensuring consistency in data representation. This JSON-based DSL provides an abstraction layer that facilitates schema management, querying, and integration, thereby enhancing the efficiency of web applications that rely on such storage solutions.
SkiQL [25], a unified schema query language, was proposed to facilitate uniform access to NoSQL database schemas. Designed as a platform-independent query language, it is utilized for logical schema querying across columnar, document-oriented, key-value, graph, and relational databases. SkiQL was designed to enable schema extraction, visualization, and querying. Although data manipulation is not supported, schema management tasks such as modeling and transformation are assisted. By offering a standardized method for querying NoSQL schemas, SkiQL contributed to multimodel database management, ensuring consistency across diverse NoSQL environments.
We can conclude that there is a number of DSLs aimed at supporting: data modeling, DDL and data manipulation language (DML) operations, and querying across a variety of NoSQL systems. However, based on the presented literature, no comprehensive DSL has been developed to provide uniform access to vector databases managed by different VDBMSs. The increasing relevance of vector databases in applications that involve similarity search and high-dimensional data analysis is noted, indicating the need for further research on MD solutions tailored to the management of vector databases. In the following section, we explore an overview of vector database access strategies.
2.2 Overview of vector databases accessing methods
Vector databases are used as storage systems for the outputs of embedding models, with vectors – referred to as vector embeddings [26] – being preserved within their domain. The speed of similarity searches is enhanced by these embeddings being stored, with user queries being vectorized and matched to relevant vector embeddings. ML algorithms are utilized to index these embeddings [27], with specialized data structures being mapped to optimize quick similarity or distance calculations, particularly in approximate nearest neighbor searches [7].
The searching process of nearest neighbors is executed by the calculation of distances between stored and query vectors using similarity metrics such as cosine similarity [27], performed by a VDBMS [9]. The most similar vectors are subsequently provided in response to specific queries, and these computed distances are applied in various ML applications, including semantic search, recommendation systems, image recognition, and natural language processing [8].
This section focuses on comprehension of accessing methods to vector databases, identifying which languages are supported by databases of various vendors and determining whether they offer their own DSL, query language or both. During the research, ten VDBMSs and eight multi-model database management systems (MMDBMSs) with the vector data model supported were analyzed. MMDBMSs support diverse data models, such as relational, document-oriented, vector, graph, and key-value, enabling the seamless integration and management of heterogeneous data, while reducing structural complexity. The analysis is carried out on widely used database management systems (DBMSs) in 2024 and 2025. Analyzed DBMSs are as follows:
Overview of supported programming languages and DSL/Query interface types for VDBMSs and MMDBMSs
| VDBMS/ MMDBMS | Native client libraries | Additional access | DSL/Query interface type |
|---|---|---|---|
| Milvus | Python, Java, Go, Node.js, C++ | ANY REST API | SQL-like (through Vanna) |
| Pinecone | Python, Java, Go, Node.js, .NET, Rust | ANY REST API | RESTful API DSL |
| Qdrant | Python, Go, Rust, TypeScript, JavaScript, .NET | ANY REST API | JSON-based DSL |
| Weaviate | Python, Go, Java, Node.js, JavaScript | ANY REST API | GraphQL-inspired query language |
| Chroma | Python, JavaScript, TypeScript | ANY REST API | JSON-like DSL |
| Actian Vector | Python, Java, C/C++ | ANY ODBC/JDBC | SQL |
| Vald | Go, Clojure | ANY REST API | Clojure DSL/gRPC |
| DeepLake | Python, JavaScript, TypeScript | ANY REST API | TQL |
| SvectorDB | Python | ANY REST API | RESTful API DSL |
| Transwarp Hippo | Python, Java | — | ExtSQL |
| OpenSearch | Python, Java, C#, Go, Node.js, JavaScript | ANY REST API | SQL-like and JSON DSL |
| Microsoft Azure AI Search | Python, Java, C#, JavaScript | ANY REST API | Odata-based query language |
| Apache Cassandra | Python, Java, C#, C/C++, Go, Node.js | ANY REST API | CQL (SQL-like) |
| MyScale | Python, Java | ANY JDBC/ODBC | SQL (vector extension) |
| Elasticsearch | Python, Java, JavaScript, C#, Go | ANY REST API | JSON-based DSL |
| Marqo | Python | ANY REST API | RESTful API DSL |
| JaguarDB | Python | ANY REST API | Custom DSL for key-value and vector search |
| Vespa | Python, Java, Go, Node.js | ANY REST API | YQL/JSON hybrid DSL |
VDBMS/MMDBMS – evaluated VDBMSs and MMDBMSs;
Native client libraries – languages supported by the DBMSs via native client libraries;
Additional access – alternative connectivity methods supported by the DBMSs, with “ANY” is used to denote that it can be accessed using any programming language via standard APIs such as representational state transfer (REST), JDBC or ODBC; and
DSL/query interface type – the available query interfaces or DSLs supported by the DBMSs.
Based on the analysis that has been conducted, it has been observed that access to vector databases is primarily achieved through programming code, which is facilitated by language-specific libraries and REST APIs that enable language-independent access. Support for dynamically typed, high-level programming languages that facilitate rapid development and ease of integration has been emphasized, as evidenced by Python being supported by 94.4% of the surveyed systems, while Java, Go, Node.js, and JavaScript have been supported by 55.6%, 44.4%, 27.8%, and 22.2% of the systems, respectively. Query interfaces have been implemented in either SQL-like or non-SQL forms, with only a few systems having been provided with a DSL that is typically limited to querying. Approximately 33.3% of the systems have been equipped with SQL-like or extended SQL interfaces – examples being those provided by Milvus (via Vanna), Actian Vector, Transwarp Hippo, Apache Cassandra (via CQL), MyScale, and OpenSearch – while the remaining 66.7% have been equipped with non-SQL query languages, including JSON-based, RESTful API, GraphQL-inspired, and proprietary query languages.
Challenges in interoperability and query migration have been found to be contributed by the predominance of non-SQL interfaces, owing to the steeper learning curve and syntactic heterogeneity that have been introduced. Confusion has been observed to arise when the SQL syntax, which closely resembles that of relational DBMSs, is employed to describe contextually different concepts.
Despite the availability of diverse programming languages and query methods, the mastery of vector database concepts is hindered by the inherent complexity and heterogeneity that is observed across current VDBMSs. Various query methods – including SQL-like, JSON-based, GraphQL-inspired languages, and DSLs custom-made for specific VDBMSs or MMDBSMs – have been noted, and difficulties have been introduced to integration, learning, and maintenance [10]. Furthermore, potential misunderstandings are introduced by the differing syntaxes used for accessing various vector databases and by the inconsistent application of terminology, where synonyms may represent the same concepts and homonyms may denote different concepts. This variability in terminology and syntax further complicates the learning process.
We determine that a novel language is required to provide straightforward access to vector databases and to unify heterogeneous concepts, thereby addressing the identified challenges of integration, learning, and maintenance. Here, we propose employing the MDSD paradigm to abstract vendor-specific intricacies and provide access to different VDBMSs through a single language. During the development of this language, careful consideration is to be given to the naming of concepts so that end-users may be allowed to focus on working with vector databases rather than on deciphering complex syntax. Finally, the syntax for database access is to be designed to be clear, concise, and easy to learn.
2.3 Foundation of MDSD paradigm and DSLs
Within the MD paradigm [46,47], the entire system development is regarded as being guided by models that are considered to be foundational artifacts for all phases of development. When the decision is made that complex systems are to be designed with guidance provided by models rather than with manually written program code, it is required that the multifaceted role played by these models be understood.
MDSD extends the MD paradigm by utilizing models to guide software system development. This paradigm is supported by documented observations, as it is recognized that software artifacts are rendered increasingly complex. Different levels of abstraction are employed to manage such complexity in a manner tailored to the profiles of the users involved, the stages of the development process, and the specific goals of the work. It is further observed that software is made to permeate various spheres of everyday life and that an increased demand is placed on both the development of new systems and the evolution of existing ones. Moreover, a shortage of skills in software development is periodically experienced in relation to prevailing job demands. The collaborative nature of development is acknowledged, and collaboration is frequently observed to be required with individuals who are not directly involved in software development, such as clients or managers. Their input is regarded as crucial for the description of the technical aspects of the system.
In this context, the organization of models across multiple layers of abstraction is carried out enabling automated or semi-automated model-to-model or model-to-text transformations. The generation of implementation artifacts from abstract models is thereby facilitated. The advantages of modeling over traditional methods – including direct manual coding and ad-hoc software development practices – have been documented, which include [46]: (i) enhancing the speed of software system development through automation and centralized knowledge representation; (ii) improving software quality through formalization; (í) increasing the reusability of models; and (iv) reducing system complexity through the use of abstraction levels.
In MDSD, DSLs are employed to create models and code generators are utilized to transform models into other models, text or executable code. DSLs are designed for specific domains or contexts, allowing users to define solutions using familiar concepts. In contrast, general purpose languages (GPLs) can be applied to any sector or domain but require additional time and expertise for domain-specific tasks [48].
A lack of uniform access to vector databases has been observed, and reliance on proprietary APIs and vendor-specific query languages is known to result in strong coupling between application code and individual systems, potentially hindering future migration between different VDBMSs. In addition, difficult management of VDBMSs in database systems containing different VDBMSs is encountered. It has been determined that the development of a novel language may be required to provide more straightforward access to vector databases and to unify heterogeneous concepts.
The employment of the MDSD paradigm is proposed to abstract vendor-specific intricacies and to facilitate access to different vector databases through a single language. Particular attention was devoted to the designation of the language’s concepts so as to ensure emphasis remains on interaction with vector databases rather than on interpretation of intricate syntax. It was demonstrated by Rädler et al. [11] that the adoption of MDSD principles may simplify development processes and foster standardization and reusability.
Within this context, we propose a novel DSL, named vecDSL, and offer an MDSD solution to establish a uniform method for interacting with vector databases. With vecDSL being developed as a prototype declarative language, it is anticipated that vendor-specific dependencies may be reduced, data management may be streamlined, and performance assessments may be facilitated for more efficient execution.
3 Architecture of MDSD solution for uniform access to vector databases
Several potential advantages are anticipated to be achieved through the adoption of a unified solution for vector database access via the MDSD paradigm. Traditional approaches are characterized by manual coding and adaptation to vendor-specific APIs, with developers being required to navigate distinct syntaxes across various VDBMSs. Abstraction models could be utilized to encapsulate these difficulties, which may contribute to improved consistency, a reduction in manual coding errors, and enhanced efficiency and maintainability. It is recognized that the development of both an MDSD solution and a dedicated DSL may offer a means to address these challenges. Accordingly, in this article, a novel MDSD solution comprising a software system and a DSL as its central component is presented, in which standardized access to vector databases is provided.
The architecture of the proposed MDSD software system, designed for uniform access to vector databases regardless of the vendor, is shown in Figure 1. The system takes vecDSL statements – comprising DDL, DML, and query statements – as input and produces executable scripts as output, which are compatible with various vector databases.

The architecture of the MDSD software system for uniform access to vector databases.
The system consists of two main parts: the vecDSL tool and the code generators. Users provide vecDSL statements as input to the vecDSL tool. Within this tool, the statements are first drafted and refined in the code editor. The output from the code editor is then passed to the compiler, which checks for syntactic correctness and compiles the statements. Compiled statements are subsequently validated by the code validator to ensure semantic accuracy and consistency. If validation errors are detected, a detailed report is generated to guide the necessary modifications. Once successfully validated, the output is transformed into vecDSL models. These models serve as input to the code generators, which consist of DDL, DML, and query language (QL) modules. The code generators convert the models into executable scripts that are tailored for the target vector databases. These executable scripts form the final output of the system, enabling standardized and efficient interactions with diverse VDBMS.
The development of vecDSL was initiated with the creation of an abstract syntax as a meta-model using the Ecore language within EMF [49]. Constraints not enforceable at the meta-model level were addressed using Object Constraint Language (OCL) [50] and implemented through eclipse OCL for model validation. A textual concrete syntax was chosen for vecDSL, to align with familiar programming languages, which serve as the primary tools for most users and to utilize robust modeling support through code-editing tools. The textual syntax was developed using Xtext [51], which facilitates the initialization of all necessary tools, including a compiler and a code editor, that can be customized further.
Separate modules for DDL, DML, and QL instructions generation have been incorporated into code generators. These generators, written in Xtend [51], a dialect of Java, were developed to produce executable scripts that support operations with the selected vector databases. Templates were employed to generate scripts from models created with vecDSL, in accordance with the defined transformation rules. Code generators generate programming code in the form of Python scripts to support work with one of the chosen vector databases. The currently supported programming language is Python, while new programming languages can be integrated by developing appropriate templates for generating executable scripts in the desired language. This allows for the creation of additional code generators, which can be tailored to specific languages, ensuring adaptability and scalability when interacting with various vector databases. When it comes to vector databases, in this work, the supported ones are Milvus, Pinecone, and Chroma.
The described MDSD solution is designed to enhance flexibility by enabling seamless integration with a variety of databases and programming ecosystems and is available on the online repository[1]. In the following section, the abstract and concrete syntaxes of vecDSL are outlined.
4 Abstract and concrete syntaxes of vecDSL
In our previous research [10], the domain analysis was conducted, and the terminology used by various vector databases was summarized using the feature-oriented domain analysis [52] method. The syntax of vecDSL is created based on that domain analysis, as described in the following sections.
4.1 Abstract syntax of vecDSL
The vecDSL meta-model is presented in Figures 2 and 3, and each class of the meta-model is referenced in the text with its name written in italics. Diagrams from these figures represent a single meta-model visually divided to enhance clarity and facilitate a better understanding of its content. Also, there is a notable duality in the meta-model, with two classes playing crucial roles while clearly distinguishing different aspects of the meta-model. One class (Script) models script at a high level of abstraction, while the other (Concept) defines the concepts of a vector database on which these scripts will be executed, thereby delineating distinct concerns within the meta-model. Therefore, the concept view of the vecDSL meta-model is presented in Figure 2 and discussed first in this section, while the script view of the vecDSL meta-model is presented in Figure 3 and discussed afterward. To facilitate a comprehensive understanding of vector database concepts, an overview of key concepts essential for users is provided in this section as well.

The concept view of the vecDSL abstract syntax.
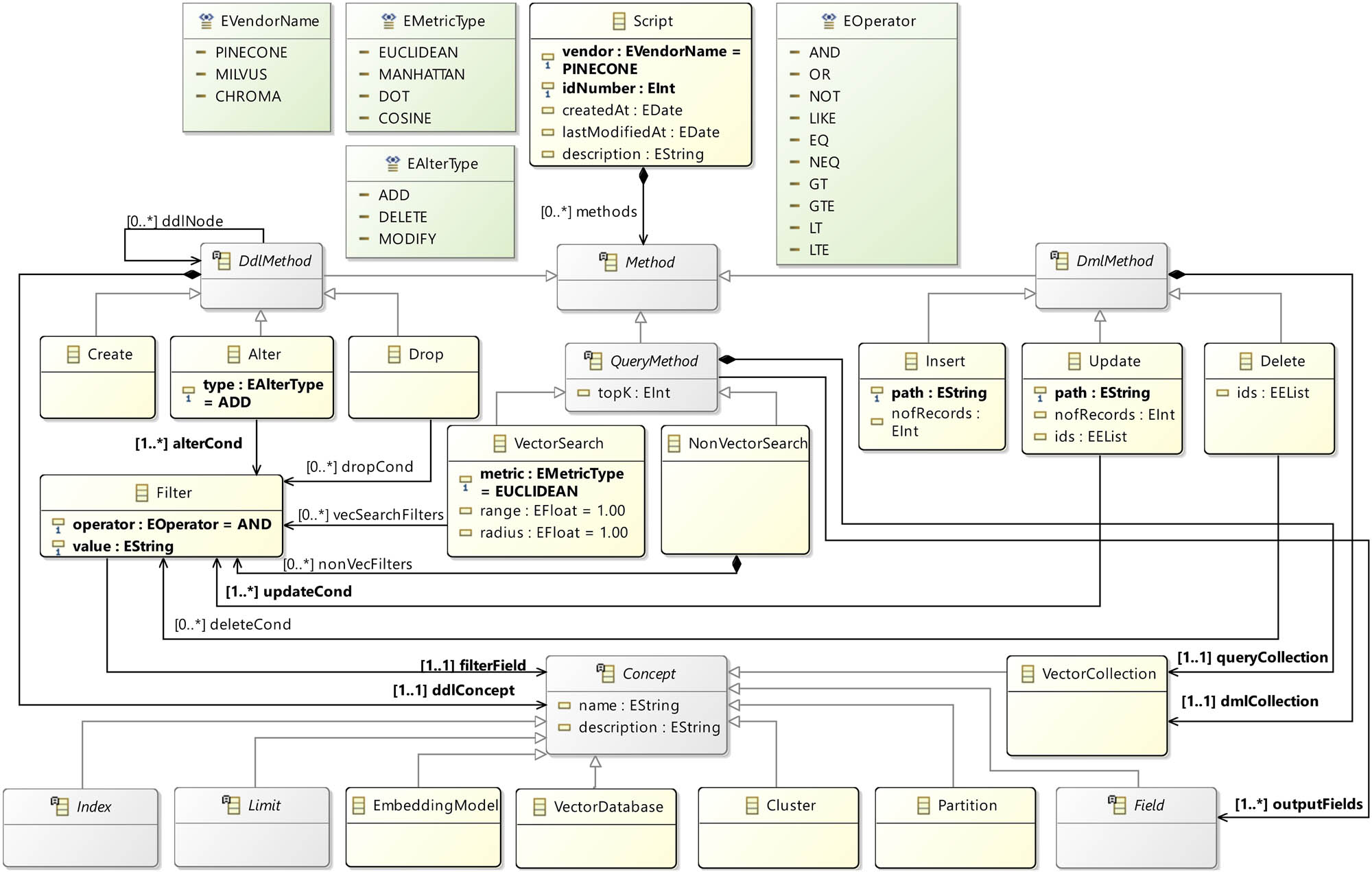
The script view of the vecDSL abstract syntax.
4.1.1 Concept view of vecDSL abstract syntax
A part of the meta-model representing vector database concepts needed to describe its structure and constraints is presented in Figure 2. The abstract class Concept generalizes concepts of different types within vector databases, and thus, various classes representing these concepts inherit the Concept class. Each concept, regardless of the type, is described by its name and description.
In the context of vector databases, various data structures are represented within the meta-model to ensure efficient organization, management, and retrieval of data. The Connection class is included, so that the details required for communication with the database can be stored (host, port, apiKey, username, password, region, userRole, userPrivillege, cloud and environment). The primary data structure is encapsulated within the VectorDatabase class. VectorDatabase is designed to contain clusters of data, where each Cluster is organized to group VectorCollection objects, which are analogous to tables in traditional relational databases. At the cluster level, it can also be stated how many collections will be through the attribute nofCollections. Each vector collection is characterized by the following attributes: dynamic – indicating whether vector collection schema can be updated after initial creation; and podtype, podSize, and podEnv – representing pod characteristics. A pod represents a unit of compute and storage used to host and operate an index and its attributes indicate the following: podtype – refers to the underlying hardware and performance characteristics of the pod; podSize – determines the amount of memory allocated to each pod, typically expressed in the terms of the number of replicas or scaling factor; and podEnv – specifies the deployment environment of the pod.
Within each VectorCollection, data are structured into Field objects, which are categorized as either VectorField – specifically utilized for similarity searches, or NonVectorField – employed to manage more conventional data types. Through Field’s attribute isPrimary, it is possible to indicate whether field is identifier for some instance inside vector collection. Inside VectorField and NonVectorField, the datatype can be specified through the attribute type, which is of enumeration type EScalarDType or EVectorDType, respectively. Furthermore, at the VectorField level, it is possible to define dimension of embedding, which will be generated for that field through the attribute dimension. The EmbeddingModel class is introduced to support the generation of vector embeddings for VectorField, which are critical for representing data in high-dimensional vector spaces, enabling effective similarity searches.
In addition, Partition objects are used to further subdivide collections to enhance query performance. Each Partition holds the partitionStrategy attribute of enumeration type EPartitionStrategy, which governs how data are subdivided.
To optimize query performance, Index objects are employed at the Field level, which are categorized as either ScalarIndex or VectorIndex, whether its index is defined for NonVectorField or VectorField. VectorIndex is significant for accelerating similarity searches, and it operates based on metrics defined in the EMetricType enumeration. These metrics include Euclidean and Manhattan distances, among others. Currently supported index types are shown through enumerations ENVIdxType and EVIdxType.
Constraints are enforced across various structures, such as clusters, collections, fields, and indexes, with Limit objects applied to ensure adherence to predefined rules, thereby maintaining data integrity. At the Cluster level, the limitation of the maximum number of collections is defined through the EClusterLimit enumeration type. When it comes to VectorCollection, the limitations of the maximum number of partitions, fields, and dimensions of VectorField are defined by the ECollectionLimit enumeration type. At the Field level, the limitations that can be expressed through the EFieldLimit enumeration type are the maximum dimension of VectorField, the length of an array for data of type ARRAY, and the maximum length for data of type VARCHAR. Limits can also be defined at the Index level, where they can be specified through the EIndexLimit enumeration type, in which it is possible to limit number of cluster units, which sets the data partitioning granularity; the number of product quantization factors, which controls the resolution of vector approximations; and the maximum node degree, which restricts the connectivity in the search graph, together balancing search precision with computational efficiency.
4.1.2 Script view of vecDSL abstract syntax
Another part of the meta-model related to a vecDSL script that contains instructions for accessing a vector database is presented in Figure 3. The script-related classes and their relations are showed in the figure above the Concept class. While the Concept abstract class and its inherited classes belong to the concept view of the meta-model discussed in Section 4.1.1, they are given in Figure 3 to outline relations between script-related and concept-related classes.
At the core of the meta-model, the Script class is identified as the root element. It is constructed to encapsulate various operations within a vector database. It is possible to state for which vector database executable scripts will be generated through the vendor attribute of enumeration type EVendorName, thereby accommodating the specific requirements of vendor-specific implementation. Beside that attribute, there are also the following attributes and their description: idNumber – identificatory which is used if structures written in this script are referenced within other scripts; createdAt – used to specify when the script is written in the form of date and time; lastModifiedAt – indicating date and time of the last update of a script; and description – used for short explanation of what is done within a script. This can be useful in cases where several co-workers are working on the same project, so they can just reference specific scripts and do the necessary work.
Script is designed to contain multiple instructions, each representing a distinct operation within a vector database. These instructions are built upon the Method abstract class, which serves as the foundation for both DDL and DML operations and queries.
The DdlMethod class is employed to handle operations such as Create, Alter, and Drop, which are fundamental to defining and modifying the structure of a database. With the reference ddlNode, it is ensured that the DDL operation is capable of encapsulating multiple nested suboperations through an internal structure that groups related changes. Within the Alter class, an attribute designated as type is provided. The intended purpose of an instance of this class is thereby determined by the value assigned to this attribute; possible values are employed to indicate whether the addition, deletion, or modification of concepts within the vector database is to be affected.
Conversely, the DmlMethod class is utilized to manage the manipulation of data through Insert, Update, and Delete operations, ensuring that data within a database is accurately and efficiently handled. Within the Insert and Update classes, it is necessary to specify the parameters related to: path – the path to the file which the data that is to be inserted or updated into the vector database is stored; and nofRecords – the number of instances from the dataset that are to be inserted or updated into the vector database. In addition, within the Update class, it is possible to define which specific instances will be changed by defining their identifiers through a series of ids; by default, all instances of dataset will be updated if no identifier is specified. Similarly, within the Delete class, it is possible to define which specific instances will be deleted by defining their identifiers through an array of ids; by default, all dataset instances will be deleted if no identifier is specified.
The QueryMethod class is introduced as another specialization of the Method class, facilitating the retrieval of data through VectorSearch and NonVectorSearch. Within the QueryMethod class, the topK attribute is employed to denote the retrieval of k most similar vectors to a given query vector based on a defined similarity metric. In the class VectorSearch, the attribute metric is used to denote the distance or similarity function that is employed to compare vectors. The attribute radius is defined as the maximum distance threshold that is specified in a radius search query; all vectors that are located at a distance less than or equal to this threshold are retrieved. The attribute range is employed to denote an interval of distances within which vectors are retrieved, and it may be used either interchangeably with radius or to specify both a lower and an upper bound on acceptable distances.
Classes inherited from Method class utilize Filter objects, defined by operators from the enumeration EOperator to specify conditions for specific operations. Filters are particularly important in vector databases, as they enable precise and contextually relevant data handling based on similarity metrics or exact value matches.
The concrete textual syntax has been defined atop the aforementioned abstract syntax, and illustrative examples of its application are presented in the subsequent section.
4.2 Example of using concrete syntax of vecDSL
In Listings 1 and 2, an example of DDL, DML and Query statements written by vecDSL are presented in the domain of faculty courses. Through the examples, a model was created to support operations within a VDBMS, demonstrating the process of creating data structures, inserting data into the database, and querying the stored data. The data structure of a university, a faculty, and its courses is created in a vector database, and after vectors representing courses are stored and changed, search through courses is performed.
Listing 1: An example of a vecDSL script model for defining the structure of a Milvus vector database.
| 1 | SCRIPT |
| 2 |
|
| 3 |
|
| 4 | |
| 5 | METHODS |
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 | |
| 11 |
|
| 12 |
|
| 13 | |
| 14 |
|
| 15 |
|
| 16 |
|
| 17 | |
| 18 |
|
| 19 |
|
| 20 |
|
| 21 | |
| 22 |
|
| 23 |
|
| 24 |
|
| 25 |
|
| 26 | |
| 27 |
|
| 28 |
|
| 29 | |
| 30 |
|
| 31 |
|
| 32 | |
| 33 |
|
| 34 |
|
| 35 | |
| 36 |
|
| 37 |
|
| 38 |
|
| 39 |
|
| 40 | |
| 41 |
|
| 42 |
|
| 43 |
|
| 44 | |
| 45 |
|
| 46 |
|
| 47 |
|
| 48 | |
| 49 |
|
| 50 |
|
Listing 2: An example of a vecDSL script model for data manipulation operations in Milvus vector database.
| 1 | SCRIPT |
| 2 |
|
| 3 |
|
| 4 | |
| 5 | METHODS |
| 6 |
|
| 7 |
|
| 8 |
|
| 9 | |
| 10 |
|
| 11 |
|
| 12 |
|
| 13 | |
| 14 |
|
| 15 |
|
| 16 | |
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|
| 24 | |
| 25 |
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 | |
| 30 |
|
| 31 |
|
| 32 |
|
| 33 | |
| 34 |
|
Scripts can be used for any VDBMS for which a code generator is provided. In this example, script models are designed for the Milvus VDBMS by having the vendor parameter set to “MILVUS” (Listings 1 and 2, lines 1 and 2). By defining idNumber inside of script (Listing 1, line 3), it is granted that all written statements inside that script can be referenced in another script (Listing 2, line 3), by citing that same idNumber. Also, this indicates that a user which is citing specific idNumber has all equivalent access rules and permissions within specific vector database instance as the user who created the script. The scripts are defined with a series of methods (Listing 1 and Listing 2, line 5) representing various DDL, DML and Query statements.
In Listing 1, statements for creating a vector database structure are presented. A vector database named “UniversityDb” (Listing 1, lines 6–9) is created via a connection whose host is set to “localhost” and port to “8081.” A cluster named “FacultyOfScience” is created within “UniversityDb” (Listing 1, lines 11 and 12) with its capacity defined as two collections. Thereafter, a collection named “ScienceCourses” is created within “FacultyOfScience” (Listing 1, lines 14–16), is marked as dynamic, and is provided with a description. A limit called “CourseLimit” is created for “ScienceCourses” (Listing 1, lines 18–20), with its type set to “NOFFIELDS” and its value set to “4,” so that the number of fields is restricted.
Subsequently, a nonvector field named “courseId” is created in “ScienceCourses” (Listing 1, lines 22–25) is designated as primary, typed as “INT,” and provided with a description, while a nonvector index named “CourseIdIndex” is created for “courseId” (Listing 1, lines 27 and 28) with its type set to “INTEGER,” so that efficient lookup is enabled. A partition named “UndergradPartition” is created in “ScienceCourses” for the field “courseId” (Listing 1, lines 30 and 31), with its partition strategy set to “HASH,” thereby ensuring that data segmentation is defined. Another non-vector field, “courseName,” is created in “ScienceCourses” (Listing 1, lines 33 and 34) with its type set to “VARCHAR.” In addition, a vector field named “courseDescription” is created in “ScienceCourses” (Listing 1, lines 36–39) with its type set to “FLOAT_VECTOR,” its dimension defined as “768,” and embedding model specified as “SentenceTransformer(BAAI/bge-m3),” thereby ensuring that vector embeddings are generated for similarity search. A limit called “DescLimit” is created for “courseDescription” (Listing 1, lines 41–43) with its type set to “VECTORDIM” and its value set to “768,” so that the vector dimensionality is enforced. Also, a vector index named “CourseVecIndex” is created for the referenced vector field (Listing 1, lines 45–47) with its type set to “HNSW” and its metric set to “COSINE” so that similarity searches are accelerated. Furthermore, a non vector field named “creditHours” is created in “ScienceCourses” (Listing 1, lines 49 and 50) with its type set to “INT.”
In Listing 2, a script model is presented that specifies a series of data manipulation operations for managing university-related data. Access to structures created in the previously provided script is granted by citing idNumber of the provided script (Listing 2, line 3).
The script begins with an insertion operation for “ScienceCourses” (Listing 2, lines 6–8), where data are loaded from the file located at “/data/science/courses.csv” and included first “1000” rows. Thereafter, an update operation is executed in “ScienceCourses” (Listing 2, lines 10–12) to load data from “/data/science/courses_update.csv” under conditions where “courseId” is matched with the pattern “CS%,” and a delete operation is executed in “ScienceCourses” (Listing 2, lines 14 and 15) for dataset instances under conditions where “creditHours” is determined to be greater than “5.”
A vector search is executed on “ScienceCourses” (Listing 2, lines 17–23) with parameters specifying a top k value of “10,” a metric of “COSINE,” a range of “0.8,” and a radius of “0.9,” while output fields “courseName” and “courseDescription” are selected and filters are applied so that only records with “creditHours” greater than or equal to “3” are returned. A non-vector search is executed on “ScienceCourses” (Listing 2, lines 25–28) with a top k value of “5,” output fields set to “courseId” and “courseName,” and filters applied so that records with “courseId” matching the pattern “CS%” are returned.
An alteration is executed on the cluster “FacultyOfScience” within “UniversityDb” (Listing 2, lines 30–32) to delete field “creditHours.” Finally, a drop operation is executed on the instances of the collection “ScienceCourses” (Listing 2, line 34).
4.3 Example of generated executable python script
The scripts presented in Listing 1 and Listing 2 are being converted into Python code, by a code generator made for such a purpose. As noted in Section 2, Python is most widely supported across vector databases, so transformations will be predominantly carried out into Python code, although adjustments can be made for other languages if required.
Listing 3: An example of a script model for DML and DDL operations in Milvus vector database.
| 1 | import pandas as pd |
| 2 | from pymilvus import connections, FieldSchema, CollectionSchema, Collection, DataType |
| 3 | from sentence_transformers import SentenceTransformer |
| 4 | |
| 5 | connections.connect( |
| 6 |
|
| 7 |
|
| 8 | |
| 9 | embedding_model = SentenceTransformer("BAAI/bge-m3") |
| 10 | |
| 11 | course_id_field = FieldSchema( |
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 | |
| 17 | course_name_field = FieldSchema( |
| 18 |
|
| 19 |
|
| 20 |
|
| 21 | |
| 22 | course_desc_field = FieldSchema( |
| 23 |
|
| 24 |
|
| 25 |
|
| 26 | |
| 27 | credit_hours_field = FieldSchema( |
| 28 |
|
| 29 |
|
| 30 | |
| 31 | schema = CollectionSchema( |
| 32 |
|
| 33 | |
| 34 | collection = Collection( |
| 35 |
|
| 36 |
|
| 37 | |
| 38 | collection.create_partition("UndergradPartition") |
| 39 | |
| 40 | index_params = { |
| 41 |
|
| 42 |
|
| 43 |
|
| 44 | |
| 45 | collection.create_index( |
| 46 |
|
| 47 |
|
| 48 | |
| 49 | df = pd.read_csv( |
| 50 |
|
| 51 |
|
| 52 | |
| 53 | embeddings = embedding_model.encode(df["courseDescription"].tolist()) |
| 54 | df["courseDescription"] = list(embeddings) |
| 55 | |
| 56 | data_to_insert = [ |
| 57 |
|
| 58 |
|
| 59 |
|
| 60 |
|
| 61 | |
| 62 | collection.insert(data_to_insert) |
| 63 | collection.flush() |
When code generation templates are utilized, and after specific syntax concepts have been instantiated through a use case, code is generated based on a specific part of the template for that concept. Within Listing 3, an insight into the executable generated Python code for the Milvus VDBMS is given, where the example of the model from Section 4.2 provided in Listing 1 is taken, as well as part of the Listing 2, related to the INSERT method, to provide embedding generation source data path. Executable scripts for Pinecone and Chroma would be generated analogously to this example, if a parameter for those VDBMS is specified in the vecDSL script model, within the attribute vendor.
It has been demonstrated that the vecDSL script model encapsulates a comprehensive abstraction of vector database configuration – encompassing connection setup, database and cluster definition, collection creation with detailed field specifications, partitioning, and index configuration – in a concise and vendor-neutral format. In contrast, the generated Python code for Milvus, Pinecone, and Chroma exhibits substantial variations in syntax and structure due to the heterogeneous nature of their underlying APIs, which will be explained further in the next section. A uniform specification is provided that can be automatically transformed into target-specific code. The benefits of this approach include reduced development effort, minimized potential for human error, and enhanced maintainability when supporting multiple VDBMSs.
In the next section, the evaluation of vecDSL is outlined through a detailed analysis of its complexity, where various metrics are examined, comparisons with other database query languages are conducted, and insights into its structural efficiency and expressiveness are provided.
5 Evaluation of vecDSL syntax
In this section, a comprehensive evaluation of vecDSL for uniform access to vector databases is presented, with a primary focus on analyzing its complexity through various metrics. To achieve this, we manually developed a series of scripts for the analyzed VDBMSs and MMDBMSs that integrate the vector search capabilities detailed in Section 2. These scripts were constructed based on the content presented in Listing 1 and Listing 2 from Section 4.2, with the vecDSL model script included. The evaluation is conducted by measuring multiple complexity-related factors (presented and discussed in Section 5.2), providing insights into the structural and syntactic characteristics of vecDSL compared to existing database query languages.
5.1 Diversity of languages’ syntaxes
In addition to the metric-based analysis, a brief example of a query has been provided in Table 2 to illustrate the diversity of syntax used across different VDBMSs. The following task has been designed to demonstrate a vector search query within a collection of “ScienceCourses”: “A vector search query must be constructed to retrieve university course data from a collection named ‘ScienceCourses.’ The query should return information on course names, descriptions, and credit hours. A vector similarity search should be performed using the cosine metric, retrieving the top 10 closest results within a similarity range of 0.8 and a radius of 0.9. In addition, filtering conditions must be applied to select only courses that begin with ‘Intro’ in their name, have a course ID greater than 101, and do not exceed 4 credit hours.”
An overview of query language syntaxes
| VDBMS/MMDBMS (DSL/query interface type) | Query representation | |
|---|---|---|
| Pinecone (RESTful API DSL) | 1 | {"collection": "ScienceCourses", |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
| 8 |
|
|
| 9 |
|
|
| 10 |
|
|
| 11 |
|
|
| 12 |
|
|
| 13 |
|
|
| Chroma (JSON-like DSL) | 1 | {"db": "ScienceCourses", |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
| 8 |
|
|
| 9 |
|
|
| 10 |
|
|
| 11 |
|
|
| 12 |
|
|
| DeepLake (TQL) | 1 | data = deeplake.load("ScienceCourses") |
| 2 | result = data.query( | |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
| 8 |
|
|
| OpenSearch (SQL-like and JSON DSL) | 1 | POST /_opendistro/_sql |
| 2 | {"query": | |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
| Elasticsearch (JSON-based DSL) | 1 | {"query": { |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
| 8 |
|
|
| 9 |
|
|
| 10 |
|
|
| 11 |
|
|
| 12 |
|
|
| 13 |
|
|
| 14 |
|
|
| 15 |
|
|
| vecDSL | 1 | VECTOR SEARCH ON ScienceCourses |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
Through the examination of access methods, distinct categories of DSLs have been identified, each reflecting a specific paradigm of interaction with vector databases. Representative VDBMSs or MMDBMSs have been selected for each category, allowing a comparison of their syntax and query structures. Consequently, vendor-specific examples have been developed for Pinecone, Chroma, and DeepLake, as well as for the MMDBMSs OpenSearch and Elasticsearch, ensuring comprehensive coverage of different DSL families.
We observe that JSON-based DSLs, such as those used by Pinecone, Chroma, and Elasticsearch, are constructed with a high degree of verbosity, where nested objects and arrays are explicitly defined (Table 2, Pinecone; Chroma; Elasticsearch). This explicit nesting has been seen to provide fine-grained control over filtering and selection operations, yet it has also been noted that the resulting syntaxes are more complex and less concise compared to those of SQL-like or GraphQL-inspired languages.
In addition, we determine that keywords make cross-system query translation difficult, such as:
Further, the handling of nested conditions has been implemented in different ways: JSON-based DSLs have been seen to employ operators like “$elemMatch” to address array filtering, while DSLs as those used in Chroma have been observed to utilize simpler operators such as “contains” to achieve similar objectives. The DSL of DeepLake has been designed to incorporate Python lambda functions, which have been noted to provide dynamic flexibility in constructing queries, although the potential for runtime errors has been highlighted as a drawback. In contrast, SQL-like DSLs, employed by OpenSearch and Vespa, have been designed to leverage the familiarity of SQL syntax, thereby reducing learning curves and simplifying query structures at the cost of expressiveness and granular control.
To build upon this foundational analysis of DSL diversity, a detailed evaluation of vecDSL’s complexity and structural efficiency is presented in the following section. By systematically measuring various syntactic and operational metrics, a comparative assessment is conducted to determine how vecDSL aligns with existing query languages in terms of verbosity, readability, and functionality. Through this quantitative examination, deeper insights into its usability and potential areas for improvement are gained, further complementing the qualitative observations made in the previous discussion.
5.2 Evaluation of syntactic and operational metrics of vecDSL
The evaluation in this study is conducted to assess the complexity and practicality of vecDSL in relation to various VDBMSs and MMDBMSs. The primary objective of the evaluation is to determine whether vecDSL provides a more streamlined method to interact with vector databases while identifying areas where improvements could be introduced. To achieve this, an analysis is carried out by measuring multiple syntactic complexity indicators across different query languages.
For evaluation purposes, scripts for all VDBMSs and MMDBMSs presented in Section 2 are created analogously scripts from Listing 1 and Listing 2. The evaluation of vecDSL script was performed using the original scripts from Listing 1 and Listing 2 without any modifications. By examining its structure, conciseness, and efficiency, valuable insights into vecDSL’s effectiveness are gained. A set of metrics was adopted from the established study [53] and complemented by additional measures developed during this research. The additional metrics were chosen to capture aspects of syntactic complexity specific to vecDSL, such as verbosity, structural depth, and cognitive load. They were selected to provide a more nuanced comparison with other query languages, particularly given the declarative nature of vecDSL. The resulting syntactic complexity indicators are described as follows.
5.2.1 Script comparison metrics
The number of code lines (LOC) has been considered as a fundamental measure of verbosity since a greater quantity of lines typically suggests a more detailed or intricate syntax. The token count (TOC) has been recorded to evaluate the density of syntactic components, offering insight into the number of elements that must be processed when composing queries. The frequency of non-alphabetic characters (NWCC) has been measured, as symbols and special characters tend to increase syntactic intricacy, making a language more challenging to interpret. The number of keywords (NKW) and different used keywords (NDKW) have been analyzed to understand the dependency on reserved terms, which impacts consistency and ease of comprehension. The deepest level of nesting (MXN) has been determined to assess the extent to which hierarchical structures are utilized, as greater depth often corresponds to the increased cognitive load. In addition, the number of function invocations (NFC) and their associated parameters – number of parameters (NPR) and average number of parameters per function call (APPC) – have been examined, as these factors contribute to the procedural complexity of a query language. A higher parameter count suggests greater configurability but may also result in a more demanding learning process. The total number of supported operations (NOP) and the variety of distinct operations (NDOP) in evaluated scripts have been measured to assess how extensive and diverse the language’s functionality is. Finally, the Halstead Volume (HV) is calculated by accounting for both the operators (e.g., keywords, symbols, or function calls that perform actions) and operands (e.g., identifiers, values, or variables) present in the code. This metric provides an overall “size” or cognitive footprint of the language’s syntax. Essentially, a higher HV indicates that more information must be processed to understand and maintain the code, thereby implying greater cognitive difficulty. Conversely, a lower HV suggests that the language is simpler and easier to grasp.
These indicators collectively provide a structured evaluation of the usability and complexity of vecDSL compared to alternative solutions. The resulting complexity indicators, as detailed in Table 3, are based on scripts from Listing 1 and 2, thereby providing a thorough understanding of the difficulty associated with each query language.
Syntax complexity qualitative comparison
| VDBMS/MMDBMS | LOC | TOC | NWCC | NKW | NDKW | MXN | NFC | NPR | APPC | NOP | NDOP | HV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Milvus | 41 | 413 | 294 | 14 | 8 | 2 | 30 | 40 | 1.33 | 212 | 19 | 2403.51 |
| Pinecone | 25 | 308 | 222 | 16 | 6 | 0 | 21 | 26 | 1.23 | 170 | 17 | 1740.38 |
| Qdrant | 25 | 383 | 270 | 14 | 6 | 0 | 29 | 40 | 1.38 | 206 | 17 | 2312.48 |
| Weaviate | 36 | 416 | 363 | 17 | 6 | 2 | 25 | 26 | 1.04 | 230 | 17 | 2384.26 |
| Chroma | 93 | 628 | 397 | 23 | 7 | 3 | 37 | 46 | 1.24 | 311 | 18 | 3472.72 |
| Actian Vector | 79 | 385 | 340 | 13 | 5 | 2 | 42 | 33 | 0.78 | 185 | 17 | 1998.15 |
| Vald | 71 | 576 | 352 | 24 | 7 | 3 | 32 | 53 | 1.65 | 275 | 18 | 3182.31 |
| DeepLake | 56 | 448 | 318 | 18 | 6 | 3 | 28 | 45 | 1.61 | 213 | 17 | 2490.74 |
| SvectorDB | 61 | 464 | 338 | 14 | 8 | 2 | 32 | 45 | 1.41 | 225 | 19 | 2634.48 |
| Transwarp Hippo | 59 | 461 | 316 | 14 | 8 | 2 | 33 | 45 | 1.36 | 225 | 19 | 2641.17 |
| OpenSearch | 133 | 771 | 566 | 21 | 8 | 2 | 29 | 39 | 1.34 | 376 | 19 | 4353.33 |
| Microsoft Azure AI Search | 123 | 801 | 558 | 44 | 11 | 2 | 43 | 66 | 1.54 | 366 | 22 | 4465.07 |
| Apache Cassandra | 74 | 541 | 370 | 38 | 12 | 2 | 43 | 46 | 1.07 | 267 | 22 | 3109.32 |
| MyScale | 100 | 754 | 601 | 42 | 11 | 4 | 46 | 46 | 1.00 | 354 | 23 | 4316.86 |
| Elasticsearch | 108 | 701 | 588 | 21 | 8 | 2 | 29 | 39 | 1.34 | 342 | 19 | 3849.37 |
| Marqo | 69 | 514 | 321 | 26 | 10 | 2 | 42 | 48 | 1.14 | 248 | 20 | 2683.87 |
| JaguarDB | 60 | 460 | 315 | 14 | 8 | 2 | 33 | 45 | 1.36 | 224 | 19 | 2622.26 |
| Vespa | 80 | 622 | 463 | 45 | 13 | 3 | 38 | 42 | 1.11 | 291 | 27 | 3587.04 |
| vecDSL | 80 | 301 | 92 | 49 | 17 | 0 | 0 | 0 | 0 | 66 | 10 | 1681.45 |
The assessment has been performed using a manually developed Python script, designed to analyze and quantify the complexity of different query languages. This process has involved tokenization and parsing, allowing key characteristics of each language to be extracted and examined. These characteristics have been carefully selected because they reflect crucial aspects of a query language, such as verbosity, structural depth, and the mental effort required for its use. The collected data have been systematically compared across various database interfaces to determine vecDSL’s position relative to other approaches.
5.2.2 Results and discussion
Upon analyzing the results, we observe that SQL-inspired query languages, such as those found in Milvus, OpenSearch, and Apache Cassandra, maintain a moderate number of code lines while supporting a broad range of operations. This suggests that SQL-like languages offer extensive capabilities, albeit with a slightly increased level of complexity. JSON-based interfaces, including those used by Chroma, Weaviate, and Qdrant, exhibit significantly higher token counts and nesting depths, implying a more structured and hierarchical syntax. Although this facilitates powerful querying mechanisms, it also introduces additional complexity when composing and interpreting queries. More specialized query languages, such as those implemented in Pinecone, DeepLake, and SvectorDB, demonstrate varying degrees of difficulty, with some prioritizing simplicity, while others emphasize advanced functionality. The most intricate syntaxes are observed in MMDBMS solutions, including Microsoft Azure AI Search and Elasticsearch, where a higher Halstead Volume and increased function invocations indicate an extensive yet complex system of operations.
The recorded metrics for vecDSL highlight its simplicity. Specifically, vecDSL spans 80 lines of code, although this figure can vary depending on whether queries are written on a single line or split across multiple lines. The token count stands at 301, with 92 of these being non-alphabetic characters. The language uses 49 total keywords, 17 of which are distinct, and exhibits a maximum nesting depth of 0, indicating that queries do not employ nested structures. In terms of function usage, no function calls or parameters were detected in the analyzed queries. Moreover, while looking at a script-level, vecDSL supports 66 total operations in evaluated script model, with 10 distinct ones identified – substantially fewer than those observed in some other systems. Lastly, the Halstead Volume for vecDSL was measured at 1681.45, suggesting a moderate level of syntactic complexity when considering the variety of tokens and operations present.
Several advantages of vecDSL have been identified through this evaluation. The minimal syntactic complexity allows queries to be written and understood with ease, making it a highly accessible solution for interacting with vector databases. Its concise structure ensures that users are not burdened with excessive verbosity, facilitating rapid query composition. The restricted set of operations and keywords contributes to a lower cognitive load, which makes vecDSL particularly suitable for straightforward use cases that do not require highly intricate queries. Furthermore, the reduced presence of non alphabetic characters suggests that unnecessary syntactic elements have been avoided, further improving clarity.
While its strengths lie in its simplicity, portability, and improved usability, some areas for improvement have been identified. Specifically, the number of keywords is notably high, suggesting that a reduction in keyword usage could further enhance the language’s minimalism. A more concise set of keywords would streamline the syntax and reduce the cognitive load required to compose queries. One approach to achieving this could be to consolidate semantically similar keywords or introduce contextual keyword behavior to minimize redundancy. The absence of nesting structures (MXN = 0) and the lack of function calls indicate a declarative style that, while simple, may limit the language’s expressiveness and flexibility. Developers are generally accustomed to hierarchical and functional paradigms, and the absence of these features may hinder the representation of more complex query scenarios. To address this, introducing controlled nesting and basic function support is recommended. Allowing a limited level of hierarchical composition could enhance the language’s expressiveness without significantly increasing its syntactic complexity. Similarly, incorporating fundamental function definitions and calls would enable modularization and reuse of query logic, catering to developers familiar with functional programming constructs.
To further enhance usability and adoption, it is recommended that vecDSL be integrated into existing libraries of popular programming languages such as Python, JavaScript, and Go. By embedding vecDSL within familiar development environments, the learning curve could be minimized, and developer productivity enhanced. This approach would allow developers to leverage vecDSL’s simplicity, while maintaining consistency with their preferred programming paradigms. In addition, providing robust documentation, usage examples, and community support would facilitate adoption and reduce onboarding friction. Introducing vecDSL as a module or extension within established database management libraries (e.g., SQLAlchemy [54] for Python or TypeORM [55] for JavaScript) could provide seamless integration with existing data pipelines. Such an approach would not only increase accessibility but would also promote vecDSL as a lightweight yet powerful alternative to more complex query languages.
Quantitative performance benchmarks could be established to determine whether translation overhead remains negligible in practice or whether fall-through to hand-tuned code is necessary in latency-sensitive scenarios. Such benchmarks would ensure that the benefits of vecDSL’s simplicity do not incur unacceptable runtime costs.
Empirical evaluation of integration modalities could be conducted to compare embedding as a language-specific module versus exposure via a language-agnostic API. Understanding the trade-offs in required system modifications, development ergonomics, and runtime efficiency would guide effective adoption strategies.
In conclusion, vecDSL emerges as a practical solution for basic vector database interactions due to its uniform syntax, reduced verbosity, and ease of use. However, refinements will be necessary to fully support advanced use cases. Enhancements should focus on increasing the language’s expressiveness while preserving its core advantage of minimalism. By reducing keyword usage, introducing controlled nesting and basic function support, and integrating vecDSL into established programming libraries, the language could maintain its simplicity, while providing developers with the necessary tools to handle more complex scenarios. The results indicate that vecDSL serves as an effective tool for basic vector database interactions but may require enhancements to support more sophisticated use cases.
5.2.3 Threats to validity
In the first place, a threat to validity is posed by the limited scope of the evaluation, as it was conducted on relatively small scripts that may not capture the complexities of larger, real-world applications. Consequently, the results are not considered fully representative of broader use cases or the range of scenarios encountered in production environments. Moreover, the linguistic metrics were intentionally measured on basic query fragments to isolate syntactic differences, but this choice further limits external validity since it omits interaction patterns and code reuse present in medium- and large-scale scripts.
Furthermore, a threat is posed by the language-specific differences inherent in the evaluation. It has been acknowledged that the metrics – including lines of code, token count, keyword frequency, and Halstead Volume – were derived solely from Python scripts, and variations in these metrics are likely to be encountered when other programming languages are employed due to differences in syntax, verbosity, and inherent language constructs.
The number of code lines (LOC) is employed as a measure of verbosity, with a greater quantity of lines being suggestive of a more detailed or intricate syntax; however, this measure may have been influenced by the procedural nature of Python, which tends to favor explicitness over conciseness when compared to declarative languages. Similarly, the token count (TOC) is employed to evaluate the density of syntactic components, and it is noted that the density may be artificially inflated or deflated by the intrinsic design of Python as opposed to that of a declarative language such as vecDSL. The frequency of non-alphabetic characters (NWCC) has been measured to assess syntactic intricacy, although the prevalence of such characters in Python may not have been directly correlated with cognitive complexity when compared to a declarative approach. In addition, the number of keywords (NKW) and the count of distinct keywords (NDKW) have been analyzed to understand the dependency on reserved terms, and the evaluation may have been skewed by Python’s reliance on explicit syntax rules that differ significantly from the design principles of vecDSL. The deepest level of nesting (MXN) and the number of function invocations (NFC), and with their associated parameters (NPR and APPC), have been determined to assess hierarchical and procedural complexity; however, these measures may have been impacted by Python’s procedural style, which inherently encourages a different structural organization than found in declarative query languages. Finally, the Halstead volume (HV) has been calculated to provide an overall indication of cognitive load, although the interpretation of HV may have been distorted by the configuration of Python’s operators and operands in a manner that does not directly correspond to the conceptual elements of a declarative language such as vecDSL.
Although the current evaluation provided valuable insights into the syntactic structure of vecDSL, its focus on language syntax has left an incomplete picture of the DSL’s overall usability and real-world performance, particularly given the scarcity of empirical studies involving end users [56].
Unquantified translation overhead poses an internal-validity threat, as parsing, code-emission, and runtime scheduling costs inherent to the vecDSL pipeline were not measured. These costs may bias performance comparisons against native-API implementations, especially in low-latency scenarios.
Integration modality effects constitute a further validity concern. Embedding vecDSL as a module versus exposing it via an API may introduce differing overheads (dependency management, serialization, or network latency) and compatibility challenges, potentially influencing both developer productivity and runtime performance.
The absence of user-based evaluations limits construct validity since learnability, error rates, and satisfaction when authoring vecDSL scripts have not been assessed.
In conclusion, limitations have been imposed on the evaluation by the narrow scope of the test script, by language-specific factors, by the inherent difficulties encountered in conducting comprehensive empirical studies, by unvalidated integration requirements. Future research will therefore expand the evaluation to encompass medium- and large-scale use cases from diverse codebases, include a wider range of programming languages, incorporate empirical user testing, systematically compare integration modalities and system-change requirements.
6 Conclusion and future work
The MDSD solution described in this article offers uniform interaction with diverse vector databases. Compared to contemporary approaches where users must learn the query syntax, concepts, and access methods specific to each vector database, this solution reduces complexity by introducing a single, standardized interface.
Through vecDSL, the central component of the proposed solution, various concepts in the vector database domain are unified, allowing users to master the context of vector databases. VecDSL is intended to shorten the time required for interpreting operations on target vector databases and reduce the learning curve associated with vector database concepts. In addition, the solution aims to minimize the time required for testing various vector databases by using the same vecDSL models. The selection of the vector database for which executable code is generated is enabled for users, thereby facilitating the development of complex software systems that depend on various vector databases for optimal performance. The evaluation results may indicate that vecDSL effectively abstracts vendor-specific APIs by providing a consistent syntax and query structure, eliminating the need for users to adapt to multiple database-specific languages. This standardization simplifies the learning process, allowing queries to be written without concern for vendor-specific variations, thereby addressing RQ2.
A reduction in syntactic complexity was demonstrated by the evaluation, with vecDSL exhibiting lower token counts, reduced nesting depths, fewer function invocations, and diminished Halstead volume compared to traditional query languages. Readability and ease of use were enhanced by the avoidance of deep nesting, while essential functionality was maintained. Usability was improved and portability was ensured by allowing queries to be executed across various systems without modification, and operational efficiency was increased through a more concise syntax, thereby meeting RQ3. It was also noted that the limited number of operations may restrict expressiveness for advanced query formulations.
In light of these observations, it is suggested that further refinements may be considered to balance minimalism with enhanced expressiveness. Although the low syntactic complexity improves readability, the relatively high number of keywords may be streamlined by consolidating semantically similar terms or introducing contextual keyword behavior, which could reduce cognitive load. Moreover, while the absence of nested structures and function calls contributes to simplicity, it may also limit the language’s flexibility in representing complex queries. To address this, controlled nesting and basic function support may be introduced to enable modularization and greater expressiveness, thereby aligning with common programming practices. These enhancements may provide a balanced solution that preserves vecDSL’s core advantages while extending its applicability to more sophisticated query scenarios, thereby covering RQ1.
Evaluating a DSL without defined criteria or methods undermines validity, reliability, and reproducibility, risking subjective, inconsistent assessments that overlook key features [57]. Since our initial evaluation focused solely on the syntax, future research must include a user-based study – applying a structured framework such as the Framework for Qualitative Assessment of Domain-Specific Languages (FQAD) [58] – to involve both academic researchers and industry developers. By using clear criteria, standardized metrics, and user feedback, this process will determine whether vecDSL truly facilitates efficient access to vector databases, lowers the learning curve, accelerates coding, and shortens testing and migration times.
Furthermore, comprehensive performance benchmarks – measuring script generation latency, scheduler overhead, and end-to-end query throughput against native Python APIs and other high-level query languages – are scheduled to be completed. These benchmarks will report both average and worst-case performance, resource utilization profiles, and comparative cost analyzes to elucidate expressivity versus efficiency trade-offs in realistic deployment scenarios.
Initially, vecDSL was developed to facilitate interaction with vector databases through its dedicated code editor. However, a more integrated approach might be favored by developers, in which vecDSL is embedded directly into their existing programming environments. Therefore, the future stage of development will involve the integration of vecDSL within code written in a programming language chosen by developers. The primary objective will be to streamline the developers’ workflow by eliminating the necessity for environment switching during programming and database access. The proposed integration strategy will involve the creation of a built-in module or library or the implementation of integration through a parser.
-
Funding information: This research was supported by the Ministry of Science, Technological Development and Innovation (Contract No. 451-03-137/2025-03/200156) and the Faculty of Technical Sciences, University of Novi Sad through project “Scientific and Artistic Research Work of Researchers in Teaching and Associate Positions at the Faculty of Technical Sciences, University of Novi Sad 2025” (No. 01-50/295).
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors state no conflict of interest.
-
Data availability statement: Data used to support the findings of this study are included in the article.
References
[1] X. Han, O. J. Gstrein, and V. Andrikopoulos, “When we talk about big data, what do we really mean? toward a more precise definition of big data,” vol. 7, Frontiers, 2024. https://www.frontiersin.org/journals/big-data/articles/10.3389/fdata.2024.1441869/full. 10.3389/fdata.2024.1441869Search in Google Scholar PubMed PubMed Central
[2] S. Sarker, M. S. Arefin, M. Kowsher, T. Bhuiyan, P. K. Dhar, and O.-J. Kwon, “A comprehensive review on big data for industries: Challenges and opportunities,” IEEE Access, vol. 11, pp. 744–769, 2023. https://ieeexplore.ieee.org/document/9999445/. 10.1109/ACCESS.2022.3232526Search in Google Scholar
[3] J. Powell, A. McCafferty-Leroux, W. Hilal, and S. A. Gadsden, “Smart grids: A comprehensive survey of challenges, industry applications, and future trends,” Energy Reports, vol. 11, pp. 5760–5785, 2024. https://www.sciencedirect.com/science/article/pii/S2352484724003299. 10.1016/j.egyr.2024.05.051Search in Google Scholar
[4] M. Shahnawaz and M. Kumar, “A comprehensive survey on big data analytics: Characteristics, tools and techniques,” ACM Comput. Surv., vol. 57, no. 8, pp. 1–33. https://dl.acm.org/doi/10.1145/3718364. 10.1145/3718364Search in Google Scholar
[5] A. Ali, S. Naeem, S. Anam, and M. Ahmed, “A state of art survey for big data processing and NoSQL database architecture,” Int. J. Comput. Digital Syst., vol. 14, no. 1, pp. 297–309, 2023. https://journal.uob.edu.bh:443/handle/123456789/4905. 10.12785/ijcds/140124Search in Google Scholar
[6] W. Khan, T. Kumar, C. Zhang, K. Raj, A. M. Roy, and B. Luo, “SQL and NoSQL database software architecture performance analysis and assessmentsaa systematic literature review,” Big Data and Cognitive Computing, vol. 7, no. 2, p. 97, 2023, https://www.mdpi.com/2504-2289/7/2/97. 10.3390/bdcc7020097Search in Google Scholar
[7] J. Gao and C. Long, “High-dimensional approximate nearest neighbor search: with reliable and efficient distance comparison operations,” Proc. ACM Manag. Data, vol. 1, no. 2, pp. 1–27, 2023. https://dl.acm.org/doi/10.1145/3589282. 10.1145/3589282Search in Google Scholar
[8] R. Egger and E. Gokce, “Natural language processing (NLP): An introduction: Making sense of textual data,” in: Applied Data Science in Tourism, R. Egger, Ed. Springer International Publishing, Cham, pp. 307–334, 2022, series Title: Tourism on the Verge. https://link.springer.com/10.1007/978-3-030-88389-8_15. 10.1007/978-3-030-88389-8_15Search in Google Scholar
[9] T. Taipalus, “Vector database management systems: Fundamental concepts, use-cases, and current challenges,” Cognitive Systems Research, vol. 85, p. 101216, 2024, https://www.sciencedirect.com/science/article/pii/S1389041724000093. 10.1016/j.cogsys.2024.101216Search in Google Scholar
[10] E. Akik, M. Vještica, V. Dimitrieski, S. Kordić, and S. Ristić, “Towards a model-driven approach to enable uniform access to vector databases,” in: New Trends in Database and Information Systems, J. Tekli, J. Gamper, R. Chbeir, Y. Manolopoulos, S. Sassi, M. Ivanovic, G. Vargas-Solar, and E. Zumpano, Eds., Springer Nature, Switzerland, 2024, pp. 225–237. 10.1007/978-3-031-70421-5_19Search in Google Scholar
[11] S. Rädler, L. Berardinelli, K. Winter, A. Rahimi, and S. Rinderle-Ma, “Bridging MDE and A: a systematic review of domain-specific languages and model-driven practices in AI software systems engineering,” in: Softw Syst Model, (Sept. 28, 2024), ISSN: 1619-1374. https://doi.org/10.1007/s10270-024-01211-y. Search in Google Scholar
[12] E. Akik, M. Vještica, V. Dimitrieski, M. Ćeliković, and S. Ristić, “Prototype of domain-specific language for uniform access to vector databases,” in: 2024 IEEE 17th International Scientific Conference on Informatics (Informatics). IEEE, pp. 11–16, 2024. https://ieeexplore.ieee.org/document/10900871/. 10.1109/Informatics62280.2024.10900871Search in Google Scholar
[13] P. Atzeni, F. Bugiotti, and L. Rossi, “Uniform access to NoSQL systems,” Inform. Syst., vol. 43, pp. 117–133, 2014. https://linkinghub.elsevier.com/retrieve/pii/S0306437913000719. 10.1016/j.is.2013.05.002Search in Google Scholar
[14] Apache HBase. https://hbase.apache.org/ (Accessed: 05/02/2025). Search in Google Scholar
[15] MongoDB. https://www.mongodb.com/ (Accessed: 05/02/2025). Search in Google Scholar
[16] Redis. https://redis.io/ (Accessed: 05/02/2025). Search in Google Scholar
[17] D. Saha, A. Floratou, K. Sankaranarayanan, U. F. Minhas, A. R. Mittal, and F. Özcan, “ATHENA: An ontology-driven system for natural language querying over relational data stores,” Proc. VLDB Endow. vol. 9, no. 12, pp. 1209–1220, 2016. https://doi.org/10.14778/2994509.2994536. Search in Google Scholar
[18] G. Daniel, G. Sunyé, A. Benelallam, M. Tisi, Y. Vernageau, A. Gómez, et al., “NeoEMF: A multi-database model persistence framework for very large models,” Science of Computer Programming, vol. 149, pp. 9–14, 2017. https://www.sciencedirect.com/science/article/pii/S0167642317301600. 10.1016/j.scico.2017.08.002Search in Google Scholar
[19] D. Kolovos, F. Medhat, R. Paige, D. Di Ruscio, T. Van Der Storm, S. Scholze, et al., “Domain-specific languages for the design, deployment and manipulation of heterogeneous databases,” in: 2019 IEEE/ACM 11th International Workshop on Modelling in Software Engineering (MiSE). IEEE, pp. 89–92. https://ieeexplore.ieee.org/document/8876980/. 10.1109/MiSE.2019.00021Search in Google Scholar
[20] A. Castelltort and T. Martin, “Handling scalable approximate queries over NoSQL graph databases: Cypherf and the fuzzy’s framework,” Fuzzy Sets Syst., vol. 348, pp. 21–49, 2018. https://www.sciencedirect.com/science/article/pii/S0165011417303093. 10.1016/j.fss.2017.08.002Search in Google Scholar
[21] A. De La Vega, D. García-Saiz, C. Blanco, M. Zorrilla, and P. Saaanchez, “Mortadelo: Automatic generation of NoSQL stores from platform-independent data models,” Future Generat. Comput. Syst., vol. 105, pp. 455–474, 2020. https://linkinghub.elsevier.com/retrieve/pii/S0167739X19312063. 10.1016/j.future.2019.11.032Search in Google Scholar
[22] E. Chavarriaga, F. Jurado, and F. D. Rodríguez, “An approach to build JSON-based domain specific languages solutions for web applications,” Journal of Computer Languages, vol. 75, p. 101203, 2023. https://www.sciencedirect.com/science/article/pii/S2590118423000138. 10.1016/j.cola.2023.101203Search in Google Scholar
[23] Apache CouchDB. https://couchdb.apache.org/ (Accessed: 05/02/2025). Search in Google Scholar
[24] Firebase. https://firebase.google.com/ (Accessed: 05/02/2025). Search in Google Scholar
[25] C. J. Fernández Candel, J. J. Garcá-Molina, and D. Sevilla Ruiz, “SkiQL: A unified schema query language,” Data Knowl. Eng., vol. 148, p. 102234, 2022. https://www.sciencedirect.com/science/article/pii/S0169023X23000940. 10.1016/j.datak.2023.102234Search in Google Scholar
[26] J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, et al., “Milvus: A purpose-built vector data management system,” in: Proceedings of the 2021 International Conference on Management of Data. ACM, 2021, pp. 2614–2627. ISBN: 978-1-4503-8343-1, https://dl.acm.org/doi/10.1145/3448016.3457550. Search in Google Scholar
[27] J. J. Pan, J. Wang, and G. Li, “Vector database management techniques and systems,” in: Companion of the 2024 International Conference on Management of Data, ser. SIGMOD/PODS ’24. ACM, pp. 597–604, 2024, https://dl.acm.org/doi/10.1145/3626246.3654691. Search in Google Scholar
[28] Milvus. https://milvus.io/ (Accessed: 05/02/2025). Search in Google Scholar
[29] Pinecone. https://www.pinecone.io/ (Accessed: 05/02/2025). Search in Google Scholar
[30] Qdrant. https://qdrant.tech/ (Accessed: 05/02/2025). Search in Google Scholar
[31] Weaviate. https://weaviate.io/ (Accessed: 05/02/2025). Search in Google Scholar
[32] Chroma. https://trychroma.com (Accessed: 05/02/2025). Search in Google Scholar
[33] Actian Vector. https://www.actian.com/databases/vector/ (Accessed: 05/02/2025). Search in Google Scholar
[34] Vald. https://vald.vdaas.org/ (Accessed: 05/02/2025). Search in Google Scholar
[35] DeepLake. May 2, 2025. Search in Google Scholar
[36] SvectorDB. https://svectordb.com/ (Accessed: 05/02/2025). Search in Google Scholar
[37] Transwarp Hippo. https://www.transwarp.cn/en/subproduct/hippo(Accessed:05/02/2025). Search in Google Scholar
[38] OpenSearch. https://opensearch.org/ (Accessed: 05/02/2025). Search in Google Scholar
[39] Microsoft Azure AI Search. https://azure.microsoft.com/en-us/products/aiservices/ai-search, (Accessed: 05/02/2025). Search in Google Scholar
[40] Apache Cassandra. https://cassandra.apache.org/ (Accessed: 05/02/2025). Search in Google Scholar
[41] MyScale. https://myscale.com (Accessed: 05/02/2025). Search in Google Scholar
[42] Elasticsearch. https://www.elastic.co/elasticsearch (Accessed: 05/02/2025). Search in Google Scholar
[43] Marqo. https://www.marqo.ai/ (Accessed: 05/02/2025). Search in Google Scholar
[44] JaguarDB. http://www.jaguardb.com/windex.html. (Accessed: 05/02/2025). Search in Google Scholar
[45] Vespa. https://vespa.ai/ (Accessed: 05/02/2025). Search in Google Scholar
[46] M. Brambilla, J. Cabot, and M. Wimmer, Model-Driven Software Engineering in Practice, 2nd ed. Morgan & Claypool Publishers, San Rafael, CA, USA, 2017. 10.1007/978-3-031-02549-5Search in Google Scholar
[47] J. Michael, L. Cleophas, S. Zschaler, T. Clark, B. Combemale, T. Godfrey, et al., “Model-driven engineering for digital twins: Opportunities and challenges,” Syst. Eng., p. sys.21815, 2025. https://incose.onlinelibrary.wiley.com/doi/10.1002/sys.21815. Search in Google Scholar
[48] M. Mernik, J. Heering, and A. M. Sloane, “When and how to develop domain-specific languages,” ACM Comput. Surv., vol. 37, no. 4, pp. 316–344. https://doi.org/10.1145/1118890.1118892. Search in Google Scholar
[49] D. Steinberg, F. Budinsky, M. Paternostro, and E. Merks, EMF: Eclipse Modeling Framework, 2nd ed., Addison-Wesley Professional, Upper Saddle River, NJ, 2008. Search in Google Scholar
[50] J. Warmer and A. Kleppe, The object constraint language: Getting your models ready for MDA, 2nd ed. Addison-Wesley, Boston, MA, USA, 2003. Search in Google Scholar
[51] L. Bettini and S. Efftinge, Implementing domain-specific languages with Xtext and Xtend, 2nd ed. Packt Publishing, Birmingham Mumbai, 2016. Search in Google Scholar
[52] K. C. Kang, S. G. Cohen, J. A. Hess, W. E. Novak, and A. S. Peterson, Feature-Oriented Domain Analysis (FODA) Feasibility Study, Software Engineering Institute, Carnegie Mellon University, Technical Report CMU/SEI-90-TR-021, Pittsburgh, PA, Nov. 1, 1990. 10.21236/ADA235785Search in Google Scholar
[53] A. De La Vega, D. García-Saiz, M. Zorrilla, and P. Saaanchez, “Lavoisier: A DSL for increasing the level of abstraction of data selection and formatting in data mining,” Journal of Computer Languages, vol. 60, p. 100987, 2020. https://linkinghub.elsevier.com/retrieve/pii/S2590118420300472. 10.1016/j.cola.2020.100987Search in Google Scholar
[54] SQLAlchemy. https://www.sqlalchemy.org (Accessed: 05/02/2025). Search in Google Scholar
[55] TypeORM. https://typeorm.io/ (Accessed: 05/02/2025). Search in Google Scholar
[56] R. Deckers and P. Lago, “Systematic literature review of domain-oriented specification techniques,” Journal of Systems and Software, vol. 192, p. 111415, 2022. https://www.sciencedirect.com/science/article/pii/S0164121222001261. 10.1016/j.jss.2022.111415Search in Google Scholar
[57] Ildevana Poltronieri, Avelino Francisco Zorzo, Maicon Bernardino, and Edson Oliveira Jr. “USA-DSL: A process for usability evaluation of domain-specific languages,” In: JUCS – 30.8 (Aug. 28, 2024). Number: 8, Publisher: Journal of Universal Computer Science, pp. 1023–1047. ISSN: 0948-6968. https://doi.org/10.3897/jucs.103264. Search in Google Scholar
[58] G. Kahraman and S. Bilgen, “A framework for qualitative assessment of domain-specific languages,” Softw. Syst. Model, vol. 14, no. 4, pp. 1505–1526. https://doi.org/10.1007/s10270-013-0387-8. Search in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Intelligent data collection algorithm research for WSNs
- A novel behavioral health care dataset creation from multiple drug review datasets and drugs prescription using EDA
- Speech emotion recognition using long-term average spectrum
- PLASMA-Privacy-Preserved Lightweight and Secure Multi-level Authentication scheme for IoMT-based smart healthcare
- Basketball action recognition by fusing video recognition techniques with an SSD target detection algorithm
- Evaluating impact of different factors on electric vehicle charging demand
- An in-depth exploration of supervised and semi-supervised learning on face recognition
- The reform of the teaching mode of aesthetic education for university students based on digital media technology
- QCI-WSC: Estimation and prediction of QoS confidence interval for web service composition based on Bootstrap
- Line segment using displacement prior
- 3D reconstruction study of motion blur non-coded targets based on the iterative relaxation method
- Overcoming the cold-start challenge in recommender systems: A novel two-stage framework
- Optimization of multi-objective recognition based on video tracking technology
- Special Issue on AI based Techniques in Wireless Sensor Networks
- Blended teaching design of UMU interactive learning platform for cultivating students’ cultural literacy
- Special Issue on Informatics 2024
- Analysis of different IDS-based machine learning models for secure data transmission in IoT networks
- Using artificial intelligence tools for level of service classifications within the smart city concept
- Applying metaheuristic methods for staffing in railway depots
- Interacting with vector databases by means of domain-specific language
- Data analysis for efficient dynamic IoT task scheduling in a simulated edge cloud environment
Articles in the same Issue
- Research Articles
- Intelligent data collection algorithm research for WSNs
- A novel behavioral health care dataset creation from multiple drug review datasets and drugs prescription using EDA
- Speech emotion recognition using long-term average spectrum
- PLASMA-Privacy-Preserved Lightweight and Secure Multi-level Authentication scheme for IoMT-based smart healthcare
- Basketball action recognition by fusing video recognition techniques with an SSD target detection algorithm
- Evaluating impact of different factors on electric vehicle charging demand
- An in-depth exploration of supervised and semi-supervised learning on face recognition
- The reform of the teaching mode of aesthetic education for university students based on digital media technology
- QCI-WSC: Estimation and prediction of QoS confidence interval for web service composition based on Bootstrap
- Line segment using displacement prior
- 3D reconstruction study of motion blur non-coded targets based on the iterative relaxation method
- Overcoming the cold-start challenge in recommender systems: A novel two-stage framework
- Optimization of multi-objective recognition based on video tracking technology
- Special Issue on AI based Techniques in Wireless Sensor Networks
- Blended teaching design of UMU interactive learning platform for cultivating students’ cultural literacy
- Special Issue on Informatics 2024
- Analysis of different IDS-based machine learning models for secure data transmission in IoT networks
- Using artificial intelligence tools for level of service classifications within the smart city concept
- Applying metaheuristic methods for staffing in railway depots
- Interacting with vector databases by means of domain-specific language
- Data analysis for efficient dynamic IoT task scheduling in a simulated edge cloud environment