Optimization of shared bike paths considering faulty vehicle recovery during dispatch
-
Donghao Shi


Abstract
With the rapid development of China’s social economy and the improvement of the level of urbanization, urban transportation has also been greatly developed. With the booming development of the internet and the sharing economy industry, shared bicycles have emerged as the times requirement. Shared bicycles are a new type of urban transportation without piles. As a green way of travel, shared bicycles have the advantages of convenience, fashion, green, and environmental protection. However, many problems have also arisen in the use of shared bicycles, such as man-made damage to the vehicle, the expiration of the service life of the vehicle, etc. These problems are unavoidable, and the occurrence of these failure problems will also cause serious harm to the use of shared bicycles. This article aims to study the path optimization of shared bicycles considering the recovery of faulty vehicles during dispatching. Based on the K-means spatial data clustering algorithm, a path optimization experiment of shared bicycle recycling scheduling considering the recycling of faulty vehicles is carried out. The experiment concluded that the shared bicycle recycling scheduling path based on K-means clustering planning significantly reduces the total time spent and the total cost of performing recycling scheduling tasks. Among them, the unit price of recycling and dispatching of each faulty shared bicycle has dropped by 4.1 yuan compared with the market unit price. The conclusion shows that the shared bicycle recycling scheduling path considering faulty vehicle recycling based on K-means clustering algorithm has been greatly optimized.
1 Introduction
In recent years, with the development of the global economy, the world’s energy consumption has increased substantially, and the greenhouse effect has become increasingly intensified. Environmental pollution and energy issues have become more and more important issues of concern in today’s world. The energy consumption and exhaust emissions of various vehicles such as private vehicles are the cause of energy consumption in today’s world, and one of the important factors for the increasing environmental pollution and greenhouse effect. Therefore, countries have begun to actively explore low-carbon and environmentally friendly green travel methods. With the rapid development of China’s internet and sharing economy industries, a new type of low-carbon and environmentally friendly green travel mode, shared bicycles, was born. Shared bicycles are a new type of dockless urban transportation. The characteristics of shared bicycles without piles make them have three advantages. One is that the shared bicycle traveler can save the distance to the bicycle pile, thereby saving travel time. Second, the flexible and extensive distribution mode of shared bicycles makes it very convenient for users to travel by shared bicycles. Third, the parking of shared bicycles is also more convenient, because the density of shared bicycle parking spots is constantly increasing. These three advantages of shared bicycles make it an effective solution to the “last mile” problem in urban commuting traffic, so shared bicycles are more and more popular. The shared bicycle system integrates the mobile network and GPS positioning technology, and services such as positioning and query of shared bicycles can be performed through the user’s mobile phone positioning. This also enables cyclists to predict the real-time locations where shared bicycles can be used before traveling, which is convenient for users to plan specific travel routes, thereby improving the travel efficiency of users. After the shared bicycle ride is over, the user can park the vehicle in a nearby planned bicycle parking area according to the specifications. And due to the increasing density of shared bicycle parking areas today, it is becoming more and more convenient for users to park when using shared bicycles to travel. It has basically realized that shared bicycles can be parked anytime, anywhere. But even if shared bicycles have such significant travel advantages, there will be various problems in the actual use of shared bicycles. For example, the vehicle is vandalized, the vehicle is faulty or worn, the bicycle needs to be scrapped when its service life expires, the user rides and parks illegally, etc. All these problems have caused the number of broken bicycles in the city to continue to increase. If the faulty vehicle is not dealt with in time, it will pose a major threat to the user’s riding safety. It will also have a negative impact on the management of social traffic order, and will seriously hinder the healthy development of green travel methods such as shared bicycles. Therefore, it is of great practical significance to study the route optimization of shared bicycle dispatching considering the recovery of faulty vehicles during dispatching.
The innovation of this study is that: (1) during the scheduling of shared bicycles, the method of recycling faulty vehicles is considered to optimize the path of shared bicycle recycling; (2) based on the K-means clustering algorithm, the optimization experiment of the shared bicycle recycling scheduling path considering the recycling of faulty vehicles is carried out. It also draws an effective conclusion that the scheduling path optimization of shared bicycles is realized.
2 Related work
In view of the fact that the research on the scheduling path optimization of shared bicycles has certain practical significance, in recent years, there have been many studies related to the optimization of shared bicycle dispatching routes in the academic circle. Among them, Shen, in order to alleviate the confusion in the use of shared bicycles, in his research and experimental analysis, proposed a hybrid dispatch path optimization algorithm based on shared bicycle demand data [1]. Li et al., based on his research, designed a shared bicycle path optimization model that can minimize the scheduling problem for the scheduling and travel of shared bicycles in small areas [2]. The research by Gu proposed a heuristic shared bicycle dispatching route optimization algorithm to determine the optimal dispatching route considering the riding effect of shared bicycles. He also took Shenzhen as an example to test the effect of this algorithm on the optimization of shared bicycle dispatch paths [3]. Mo’s study, on the other hand, aimed to investigate some of the key factors that affect the scheduling performance of shared bikes over the long term. He also proposed a Markov-based queuing theory based on the basic principles of the shared bicycle system. He considers the model simplification method of high and low demand nodes to reduce the complexity of the theoretical network model of shared bicycle dispatching [4]. The study by Fan calculates data such as the usage flow of shared bicycles by using an analysis of K-means algorithm. He also proposed two ways to determine the optimal number of shared bicycles and the optimal dispatch path [5]. The research by Lin proposed an improved multi-objective optimization-based scheduling path optimization algorithm for shared bicycles. Their experimental results show that the algorithm can shorten the predicted shared bicycle dispatch distance by 20–50%. It can effectively balance the scheduling workload of shared bicycles in various regions [6]. Although the above studies are all closely related to the optimization of shared bicycle paths, these studies also have some deficiencies, such as single research perspective, complicated process, and weak practicability.
3 Optimization method of shared bicycle dispatching path
3.1 Recovery of faulty vehicles
The faulty vehicle of shared bicycle refers to the shared bicycle vehicle that has been damaged and cannot be used normally and safely. Among them, the bicycles that cannot be used normally include damaged vehicles and accessories. Damaged accessories such as handlebars, brakes, pedals, seat cushions, and frame. It also includes shared bicycles where GPS accessories have failed to locate them. The vehicle configuration of the shared bicycle is shown in Figure 1.

Shared bike configuration.
Generally, a shared bicycle will be identified as a faulty vehicle in the following three cases:
When a user rides a shared bicycle and when it is determined that the bicycle cannot be used normally, he can apply for repair through the mobile internet device. The bicycle-sharing company can receive the number and location information of the bicycle in question. Damage to handlebars, brakes, tires, pedals, seat cushions, chain damage, locks, etc., are all of this type. The user can select the corresponding fault type according to the damage situation.
Each shared bicycle has a certain service life. When the bicycle reaches the minimum lifespan or the government-mandated minimum lifespan of shared bicycles, the system automatically identifies the bicycle as a faulty vehicle. Thereby, its use is stopped and the bicycle is forcibly scrapped.
When the shared bicycle cannot provide positioning service due to the failure of the intelligent positioning system, the system will also identify it as a faulty vehicle and prevent the user from using the vehicle. This does not include vehicles with damaged GPS devices while riding. In the event of GPS damage while riding, the system records the status and location of the bike’s most recent appearance.
In order to ensure the riding safety of shared bicycle users, shared bicycle operating companies choose to set up maintenance depots in each area according to the placement density of shared bicycles. After classifying the three types of faulty vehicles, a unified recovery method is adopted, and the maintenance personnel of the maintenance station will repair the faulty vehicles in time. This is the faulty car recycling of shared bicycles. The shared bicycle fault vehicle recovery network is shown in Figure 2.

Shared bicycle breakdown vehicle recovery network.
The recovery of faulty shared bicycles is a rational design under the theoretical system and requirements of the sharing economy and circular economy. The recovery of faulty bicycles for shared bicycles can change the pollution phenomenon under the linear economic model of “large-scale production, large-scale delivery, and large-scale disposal” of shared bicycles. This makes shared bicycles not only promote economic development, but also take into account environmental benefits [7]. The recovery process of faulty shared bicycles is shown in Figure 3.

The recovery process of shared bicycles with faulty vehicles.
3.2 K-means spatial data clustering algorithm
The K-means algorithm is a classical spatial data clustering algorithm that realizes the clustering of similar data by iterative solution. The basic idea of the algorithm is to divide n data objects into b clusters according to the input parameter a. The error of the sum of squares from the data points in each cluster to that cluster center is then minimized. The basic flow of the algorithm is as follows. It first determines the value of the number b of clustering service points to be divided. Then, it randomly selects initial data object points as the initial aggregation service points. The third step is to calculate the distances from the remaining data objects to an initial clustering service point. It plans the data object to the clustering service center where the center is located closest to it. The final step is to adjust the new cluster and recalculate the new cluster service point. If the cluster center has changed, the go back to the third step. If the position of the clustering service point calculated twice has not changed, then it can be shown that the input data have satisfied the convergence condition after clustering processing. Then, the final clustering result is output, and the algorithm operation ends [8]. The entire algorithm flow can be shown in Figure 4.

K-means spatial data clustering algorithm flow.
The specific operation flow of this algorithm is as follows:
First, the criterion function of the K-means clustering algorithm is as follows:
It can also be simplified to:
where E is the sum of the mean square errors of all objects in the dataset. x is the data object and 1 is the mean of cluster c.
Step 1: It first randomly selects n data objects from the dataset as the initial cluster center points.
Step 2: It performs a preliminary division of the dataset C. The division rule is to calculate the distance from each object to each cluster center. The cluster center points are: 1, and they are divided into the nearest cluster centers.
Step 3: It calculates the center point of each cluster:
where a and n are the number of C-type data objects, and x is the preset cluster center point value.
Step 4: If it can be established for any C, that is, the sum of the mean squares E reaches the convergence condition, the algorithm ends, otherwise it returns to the second step to continue execution.
Step 5: It outputs the final clustering result of the algorithm.
In the operation process of the K-means algorithm, there are two key implicit steps. That is, the determination of feature weights and the determination of initial cluster centers. The first is feature weight determination. Through the above steps, the attribute feature weight value assigned to the ith dimension of the data is as follows:
which is:
The sum of the intra-class distances of all C clusters on the ith dimension attribute is:
which is:
where
The size of the feature weights assigned to the data is determined by the importance of the attributes of each data in the dataset to the clustering. If the attributes of the data are not important for the overall clustering effect, then the feature weight value assigned to this data will be relatively small. This makes the axes of the data’s properties less stretched in Euclidean space. Otherwise, the feature weight value given to this data will be relatively large. It makes the attributes of the data have a greater stretching effect in the coordinate axis of Euclidean space [9]. The function of the feature weight value is to adjust the Euclidean space and then perform clustering. At this time, the distribution of data in the Euclidean space can be more intuitively reflected, thereby making data clustering more accurate [10].
Next is the determination of the initial cluster centers. Because the K-means algorithm is highly dependent on the cluster center points, it is easy to cause locally optimal clustering results. Usually the best case is to choose a point with a wider distribution in the dataset as the center point. Therefore, two factors, distance and density, are always considered when selecting the initial point [11].
Criterion function:
One way to compare the quality of clusters is to calculate the size of the criterion function. The smaller the value of the criterion function G(n), the better the clustering effect, and the clustering result with the smallest criterion function value is the optimal result [12].
The intra-class distance within (a) of a dataset is the minimum average distance between each object in a cluster and all other objects in the same cluster. The intra-class distance of the entire sample data is the maximum value of the intra-class distance in all clusters [13], then:
which is:
It can be seen from the criterion function that the smaller the intra-class distance, the smaller the within (a), and the smaller the i value. If the minimum distance between any two classes satisfies the requirement of evacuation, other classes must also satisfy the requirement [14]. The high-density collection is as follows:
where Density(x) represents the density at the sample point x. Dist represents the weighted Euclidean distance. That is to say, the density at the sample point x represents the number of sample points whose weighted Euclidean distance from the entire dataset to the point x is less than or equal to the specified radius r. The number of sample points whose weighted Euclidean distance between the value of r and the data point x is less than or equal to the specified radius r. The value of r is related to the average distance between the two data objects in the dataset [15].
It assumes that the number of objects in the high-density set is n. The s points with the farthest distance in the high-density area are selected as the initial center points. The data point with the highest density in the set is used as the first cluster center [16]:
After selecting the first initial cluster center, the second cluster center is the data object farthest from the first cluster center in the high-density point set [17], namely:
which is:
The criterion chosen when selecting the initial cluster center points is the farthest Euclidean distance between the two. This selection method not only randomly selects the initial cluster center point, but also ensures the stability of the data clustering results [18].
4 Optimization experiment of shared bicycle dispatch path considering faulty vehicle recovery
4.1 Experimental method
The methods and main experimental steps adopted in this optimization experiment of shared bicycle dispatching route considering the recovery of faulty vehicles are as follows. First, this experiment selects a district L in Beijing as the experimental object. Because there are universities and enterprises in the L area, office workers and students use shared bicycles most frequently. The number of faulty cars is also the largest, which meets the needs of the experimental conditions. There are 1,800 shared bicycles in the area, and 210 of them were randomly selected for recycling. It also set up 3 recycling vehicles, each recycling vehicle can transport 70 faulty vehicles. Then, the K-means clustering algorithm is used to cluster the related data of all faulty vehicles. It determines the service point of the cluster center, and selects the repair station closest to the service point of the cluster center as the repair station for this experiment. Then, based on the clustering of the shared bicycle faulty vehicle spatial data, the faulty vehicle recovery and dispatching path planning is carried out. And with the goal of reducing the overall cost of vehicle recovery and dispatch work. The constraints such as vehicle scheduling path, vehicle loading rate and recovery time are used as constraints. Finally, the optimization of the recovery scheduling path is judged by evaluating the total cost of returning the faulty vehicle to the task [19]. The raw data of the comprehensive 5 categories of 210 faulty vehicles selected in this experiment are shown in Table 1.
Raw data of faulty car
| Bike id | Bike type | Ln | Lat | |
|---|---|---|---|---|
| 1 | 10,041 | Lite | 116.3286 | 39.974 |
| 2 | 10,042 | Lite | 116.3271 | 39.980 |
| 3 | 10,043 | Classical | 116.3174 | 39.979 |
| 4 | 10,046 | Lite | 116.8571 | 39.761 |
| 5 | 10,048 | Classical | 116.8629 | 39.972 |
The data in Table 1 includes the bicycle number, vehicle type, and latitude and longitude coordinates of the faulty vehicle selected in this experiment.
4.2 Clustering of faulty vehicles
After collecting the relevant raw data of the selected faulty vehicles, the second step of this experiment is to use the K-means algorithm to cluster the selected faulty vehicles. It thus determines the service point of the cluster center, and selects the repair station closest to the service point of the cluster center as the repair station for this experiment. It first enters the latitude and longitude coordinate data of the faulty vehicle and other related data, and sets the algorithm parameters. Then, the location of the service point of the cluster center is obtained through the clustering operation. Since the K-means data space clustering algorithm requires human intervention in the number of clusters, this article designs four clustering experiments with four groups in total. The experimental results are shown in Figures 5 and 6.

Results of the 1st and 2nd clustering experiments: (a) the first clustering data and (b) the second clustering data.

Results of the 3rd and 4th clustering experiments: (a) the 3rd clustering data and (b) the 4th clustering data.
As can be seen in Figure 5, in the first and second clustering experiments, the number of clustering points in the first group is the largest and the most stable. And the number of clustering points is not much different between the two groups. The highest number of clustering points was 20 for the first clustering experiment and 22 for the second.
It can be seen from Figure 6 that in the third clustering experiment, the third group has the largest number of clustering points, which is 26. In the 4th group, the largest number of clustering points is the first group, which is also 26, and then decreases in turn.
In summary, after the four clustering experiments are completed, the number of determined clustering points is 24. Among these 24 cluster points, the most central one is selected as the final cluster center service point. The latitude and longitude position outputs after the clustering operation are used to locate it, and after the positioning is completed, the position of the maintenance depot closest to the service point of the clustering center is determined. Its recovery vehicle transports all faulty vehicles to the maintenance depot. After the positioning is completed, the position closest to the service point of the cluster center is determined as the position of the maintenance depot. Recycling vehicles transports all faulty vehicles to the repair yard. This way, path detours are avoided as much as possible.
4.3 Path planning for recovery and dispatching of faulty vehicles
After the location of the maintenance depot is determined through the service point of the clustering center, the path planning for the recovery and dispatching of the faulty shared bicycles begins. A total of 3 recycling vehicles were set up in this experiment, and each recycling vehicle can reload 70 faulty vehicles. Based on the service point of the cluster center, the recovery and scheduling path of the faulty vehicle is planned, so that the path can be expanded around the service point of the cluster center of the faulty vehicle and along other cluster points as much as possible. This, thereby, reduces the path detour rate as much as possible. This keeps the route as close as possible to the service point of the cluster center of the faulty vehicle, thereby reducing the detour rate of the route as much as possible. Analysis of the route results of each recycling vehicle can obtain the results of each recycling vehicle’s travel path, handling time, loading rate, travel time, total time spent, and total cost [20]. First, the obtained driving path and handling time of the recycling vehicle are shown in Table 2.
Travel path and handling time
| Recycling path (cluster center service points that pass in sequence) | Handling time/min | |
|---|---|---|
| Recycling car 1 | 0-12-8-20 | 441 |
| Recycling car 2 | 0-6-16-24 | 466 |
| Recycling car 3 | 0-18-9-22 | 450 |
It can be seen from Table 2 that the driving path of each recovered vehicle passes through 4 service points of the faulty vehicle clustering center. There is also a certain span between each clustering point that passes through, and the positions of the passing clustering points are inconsistent, which avoids the path repetition. The handling time of each recycling vehicle is also about 7 min, and the handling time is not too long.
The resulting loading rate and travel time for each recycling vehicle are shown in Figure 7.
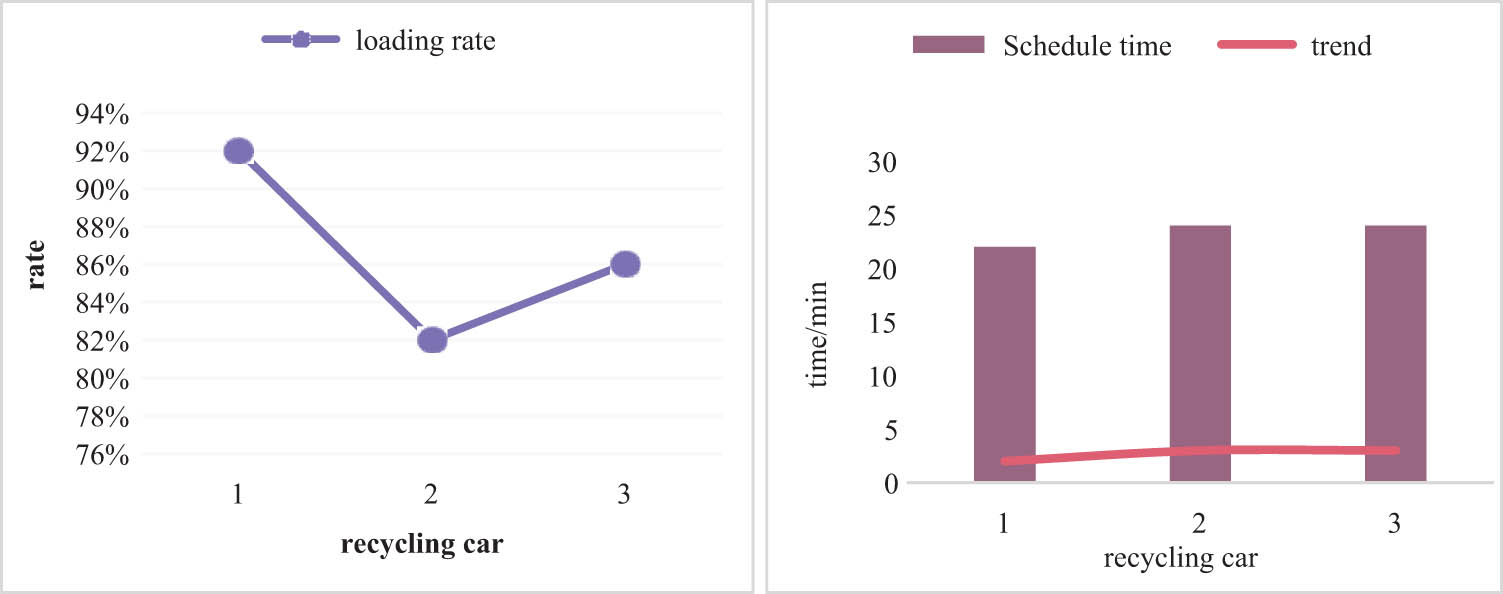
Recycling vehicle loading rate and travel time data: (a) loading rate and (b) travel time.
It can be seen from Figure 7 that the loading rate of the three recycling vehicles is above 80%. Among them, the first recycling vehicle had the highest loading rate of 92%. The recycling time for each recycling vehicle is also around 24 min. Compared with the previous conventional recovery path travel time is shortened.
The resulting total time spent and total cost results are shown in Figure 8.

Total time spent and total cost of car recovery: (a) total time spent and (d) total cost.
It can be obtained from Figure 8 that the total time spent by each recycling vehicle in this experiment is about 470 min, which does not exceed the maximum time limit for executing the recycle scheduling task. And the total cost of all the faulty vehicle scheduling and recovery tasks is 1,662 yuan. After conversion, the cost of recycling and dispatching of each faulty shared bicycle is only 7.9 yuan. This unit price is significantly lower than the average market price of 12 yuan.
The whole experiment ends here. In conclusion, the total time spent on the planned recovery path of shared bicycles after the clustering based on the K-means spatial data clustering algorithm is shortened. The total cost also decreased by 4.1 yuan compared with the market average price. Such experimental conclusions show that the efficiency and cost of the shared bicycle recovery scheduling path based on K-means clustering planning have been optimized.
5 Discussion
In recent years, shared bicycles have become a new mode of travel respected by urbanites due to their green, low-carbon, environmentally friendly, and convenient travel advantages. In the process of using shared bicycles, there are also some problems, such as the harm of faulty bicycles to people’s travel safety. Therefore, in the recycling scheduling of shared bicycles, it is of high practical significance to consider the scheduling path optimization of faulty vehicle recycling [21]. In this article, based on the K-means spatial data clustering algorithm, research on the route optimization of shared bicycle dispatching considering the recovery of faulty vehicles is carried out.
K-means spatial data clustering algorithm is a relatively classic data clustering algorithm. It makes the input data reach the convergence condition by clustering the input data, and finally outputs the ideal result. With the advantages of clustering, the algorithm is more and more widely used in various path planning. It also has certain application value for the route optimization of shared bicycle dispatching considering the recovery of faulty vehicles [22].
Based on the research topic, this article designs a shared bicycle dispatching route optimization experiment with K-means spatial data clustering algorithm considering faulty vehicle recovery. After clustering the faulty shared bicycle data and determining the cluster center service point, the shared bicycle recycling and dispatching path planning around the cluster center service point is carried out. Finally, the optimization of the path is judged by analyzing the loading rate of the planned path, the total time spent, and the total cost. The experimental conclusion shows that the planned recovery path of shared bicycles after the clustering based on the K-means spatial data clustering algorithm has been optimized to a certain extent.
6 Conclusion
The main purpose of this article is to design an optimization experiment of shared bicycle dispatching path considering faulty vehicle recovery based on K-means spatial data clustering algorithm. The experimental conclusion shows that the shared bicycle dispatching route considering the recovery of faulty vehicles based on the K-means spatial data clustering algorithm has been optimized to a certain extent. It is hoped that the research in this article can provide some reference for the optimization of the recycling and dispatching paths of shared bicycles. However, due to the limited research conditions and level, the research in this article also has some shortcomings. If the research angle still needs to be expanded, the research method still needs to be innovated. It is believed that there will be more excellent researches related to the optimization of shared bicycle scheduling paths in the academic community in the future. In this way, the optimization and development of shared bicycle dispatching paths will be continuously promoted.
-
Conflict of interest: The authors state no conflict of interest.
References
[1] Shen S, Wei Z, Sun L, Rao KS, Wang R. A hybrid dispatch strategy based on the demand prediction of shared bicycles. Appl Sci. 2020;10(8):27–78.10.3390/app10082778Search in Google Scholar
[2] Li M, Wang X, Zhang X, Yun L, Yuan Y. A multiperiodic optimization formulation for the operation planning of free-floating shared bike in China. Math Probl Eng. 2018;2(18):1–11.10.1155/2018/2639542Search in Google Scholar
[3] Gu Z, Zhu Y, Zhang Y, Zhou W, Chen Y. Heuristic bike optimization algorithm to improve usage efficiency of the station-free bike sharing system in Shenzhen, China. Int J Geo-Information. 2019;8(5):2–39.10.3390/ijgi8050239Search in Google Scholar
[4] Mo X, Liu X, Chan W. Modeling and optimization in resource sharing systems: application to bike-sharing with unequal demands. Algorithms. 2021;14(2):47.10.3390/a14020047Search in Google Scholar
[5] Fan RN, Ma FQ, Li QL. Optimization strategies for dockless bike sharing systems via two algorithms of closed queuing networks. Processes. 2020;8(3):3–45.10.3390/pr8030345Search in Google Scholar
[6] Lin F, Yang Y, Wang S, Xu Y, Ma H, Yu R. Urban public bicycle dispatching optimization method. PeerJ Computer Sci. 2019;5(3):2–24.10.7717/peerj-cs.224Search in Google Scholar PubMed PubMed Central
[7] Chen K, Tan G. Bike GPS: localizing shared bikes in street canyons with low-level GPS cooperation. ACM Trans Sens Netw. 2019;15(4):1–28.10.1145/3343857Search in Google Scholar
[8] Conrow L, Murray AT, Fischer. HA. An optimization approach for equitable bicycle share station siting. J Transp Geogr. 2018;6(9):163–70.10.1016/j.jtrangeo.2018.04.023Search in Google Scholar
[9] Xuan D, Ma X, Li C, Yan Z. Structural design and optimization of comb-type electric bicycle three-dimensional parking garage. Int J Plant Eng Manag. 2019;24:40–5.Search in Google Scholar
[10] Yu C. Design and optimization of multi-functional shared bicycle mechanical structure. Mech Eng Technol. 2019;08(2):147–57.10.12677/MET.2019.82019Search in Google Scholar
[11] Hong J, Han E, Choi C, Lee M, Park D. Estimation of Shared bicycle demand using the SARIMAX model: focusing on the COVID-19 impact of Seoul. J Korea Inst Intell Transp Syst. 2021;20(1):10–21.10.12815/kits.2021.20.1.10Search in Google Scholar
[12] Swart J, Holliday W. Cycling biomechanics optimization—the (R) evolution of bicycle fitting. Curr Sports Med Rep. 2019;18(12):490–6.10.1249/JSR.0000000000000665Search in Google Scholar PubMed
[13] Roa SD, Muoz LE. Bicycle change strategy for uphill time-trial races. Proc Inst Mech Eng Part P J Sports Eng Technol. 2017;231(3):207–19.10.1177/1754337117724310Search in Google Scholar
[14] Lee TY, Jeong MH, Jeon SB, Cho JM. Location optimization of bicycle-sharing stations using multiple-criteria decision making. Sens Mater. 2020;32(12):44–63.10.18494/SAM.2020.3125Search in Google Scholar
[15] Park C, Sohn SY. An optimization approach for the placement of bicycle-sharing stations to reduce short car trips: an application to the city of seoul. Transportation Res Part a Policy Pract. 2017;5(11):154–66.10.1016/j.tra.2017.08.019Search in Google Scholar
[16] Erdinç O, Yetilmezsoy K, Erenoğlu AK, Erdinç O. Route optimization of an electric garbage truck fleet for sustainable environmental and energy management. J Clean Prod. 2019;2(3):75–86.10.1016/j.jclepro.2019.06.295Search in Google Scholar
[17] Ma S, Sun J, Lu G. Optimization and adjustment of train route allocation scheme for high speed railway station, Zhongguo Tiedao Kexue/China Railway. Science. 2018;39(1):122–30.Search in Google Scholar
[18] Chindamo D, Gadola M, Armellin D, Marchesin FP. BikeShake: the design of an indoor simulator dedicated to motorcycle ride testing as an interactive project. Int J Interact Des Manuf (IJIDeM). 2018;12(4):371–83.10.1007/s12008-017-0435-7Search in Google Scholar
[19] Chen H, Zhang Y. Dynamic path optimization in sharing mode to relieve urban traffic congestion. Discret Dyn Nat Soc. 2021;2(7):1–16.10.1155/2021/8874957Search in Google Scholar
[20] Huang F, Qiao S, Peng J, Guo B. A bimodal Gaussian inhomogeneous Poisson algorithm for bike number prediction in a bike-sharing system. IEEE Trans Intell TransportatiSyst. 2019;20(8):848–57.10.1109/TITS.2018.2868483Search in Google Scholar
[21] Zhang H, Song X, Long Y, Xia T, Fang K, Zheng J, et al. Mobile phone GPS data in urban bicycle-sharing: Layout optimization and emissions reduction analysis. Appl Energy. 2019;242(84):138–47.10.1016/j.apenergy.2019.03.119Search in Google Scholar
[22] Pal A, Zhang Y. Free-floating bike sharing: Solving real-life large-scale static rebalancing problems. Transportation Res Part C Emerg Technol. 2017;80(7):92–116.10.1016/j.trc.2017.03.016Search in Google Scholar
© 2022 Donghao Shi, published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Construction of 3D model of knee joint motion based on MRI image registration
- Evaluation of several initialization methods on arithmetic optimization algorithm performance
- Application of visual elements in product paper packaging design: An example of the “squirrel” pattern
- Deep learning approach to text analysis for human emotion detection from big data
- Cognitive prediction of obstacle's movement for reinforcement learning pedestrian interacting model
- The application of neural network algorithm and embedded system in computer distance teach system
- Machine translation of English speech: Comparison of multiple algorithms
- Automatic control of computer application data processing system based on artificial intelligence
- A secure framework for IoT-based smart climate agriculture system: Toward blockchain and edge computing
- Application of mining algorithm in personalized Internet marketing strategy in massive data environment
- On the correction of errors in English grammar by deep learning
- Research on intelligent interactive music information based on visualization technology
- Extractive summarization of Malayalam documents using latent Dirichlet allocation: An experience
- Conception and realization of an IoT-enabled deep CNN decision support system for automated arrhythmia classification
- Masking and noise reduction processing of music signals in reverberant music
- Cat swarm optimization algorithm based on the information interaction of subgroup and the top-N learning strategy
- State feedback based on grey wolf optimizer controller for two-wheeled self-balancing robot
- Research on an English translation method based on an improved transformer model
- Short-term prediction of parking availability in an open parking lot
- PUC: parallel mining of high-utility itemsets with load balancing on spark
- Image retrieval based on weighted nearest neighbor tag prediction
- A comparative study of different neural networks in predicting gross domestic product
- A study of an intelligent algorithm combining semantic environments for the translation of complex English sentences
- IoT-enabled edge computing model for smart irrigation system
- A study on automatic correction of English grammar errors based on deep learning
- A novel fingerprint recognition method based on a Siamese neural network
- A hidden Markov optimization model for processing and recognition of English speech feature signals
- Crime reporting and police controlling: Mobile and web-based approach for information-sharing in Iraq
- Convex optimization for additive noise reduction in quantitative complex object wave retrieval using compressive off-axis digital holographic imaging
- CRNet: Context feature and refined network for multi-person pose estimation
- Improving the efficiency of intrusion detection in information systems
- Research on reform and breakthrough of news, film, and television media based on artificial intelligence
- An optimized solution to the course scheduling problem in universities under an improved genetic algorithm
- An adaptive RNN algorithm to detect shilling attacks for online products in hybrid recommender system
- Computing the inverse of cardinal direction relations between regions
- Human-centered artificial intelligence-based ice hockey sports classification system with web 4.0
- Construction of an IoT customer operation analysis system based on big data analysis and human-centered artificial intelligence for web 4.0
- An improved Jaya optimization algorithm with ring topology and population size reduction
- Review Articles
- A review on voice pathology: Taxonomy, diagnosis, medical procedures and detection techniques, open challenges, limitations, and recommendations for future directions
- An extensive review of state-of-the-art transfer learning techniques used in medical imaging: Open issues and challenges
- Special Issue: Explainable Artificial Intelligence and Intelligent Systems in Analysis For Complex Problems and Systems
- Tree-based machine learning algorithms in the Internet of Things environment for multivariate flood status prediction
- Evaluating OADM network simulation and an overview based metropolitan application
- Radiography image analysis using cat swarm optimized deep belief networks
- Comparative analysis of blockchain technology to support digital transformation in ports and shipping
- IoT network security using autoencoder deep neural network and channel access algorithm
- Large-scale timetabling problems with adaptive tabu search
- Eurasian oystercatcher optimiser: New meta-heuristic algorithm
- Trip generation modeling for a selected sector in Baghdad city using the artificial neural network
- Trainable watershed-based model for cornea endothelial cell segmentation
- Hessenberg factorization and firework algorithms for optimized data hiding in digital images
- The application of an artificial neural network for 2D coordinate transformation
- A novel method to find the best path in SDN using firefly algorithm
- Systematic review for lung cancer detection and lung nodule classification: Taxonomy, challenges, and recommendation future works
- Special Issue on International Conference on Computing Communication & Informatics
- Edge detail enhancement algorithm for high-dynamic range images
- Suitability evaluation method of urban and rural spatial planning based on artificial intelligence
- Writing assistant scoring system for English second language learners based on machine learning
- Dynamic evaluation of college English writing ability based on AI technology
- Image denoising algorithm of social network based on multifeature fusion
- Automatic recognition method of installation errors of metallurgical machinery parts based on neural network
- An FCM clustering algorithm based on the identification of accounting statement whitewashing behavior in universities
- Emotional information transmission of color in image oil painting
- College music teaching and ideological and political education integration mode based on deep learning
- Behavior feature extraction method of college students’ social network in sports field based on clustering algorithm
- Evaluation model of multimedia-aided teaching effect of physical education course based on random forest algorithm
- Venture financing risk assessment and risk control algorithm for small and medium-sized enterprises in the era of big data
- Interactive 3D reconstruction method of fuzzy static images in social media
- The impact of public health emergency governance based on artificial intelligence
- Optimal loading method of multi type railway flatcars based on improved genetic algorithm
- Special Issue: Evolution of Smart Cities and Societies using Emerging Technologies
- Data mining applications in university information management system development
- Implementation of network information security monitoring system based on adaptive deep detection
- Face recognition algorithm based on stack denoising and self-encoding LBP
- Research on data mining method of network security situation awareness based on cloud computing
- Topology optimization of computer communication network based on improved genetic algorithm
- Implementation of the Spark technique in a matrix distributed computing algorithm
- Construction of a financial default risk prediction model based on the LightGBM algorithm
- Application of embedded Linux in the design of Internet of Things gateway
- Research on computer static software defect detection system based on big data technology
- Study on data mining method of network security situation perception based on cloud computing
- Modeling and PID control of quadrotor UAV based on machine learning
- Simulation design of automobile automatic clutch based on mechatronics
- Research on the application of search algorithm in computer communication network
- Special Issue: Artificial Intelligence based Techniques and Applications for Intelligent IoT Systems
- Personalized recommendation system based on social tags in the era of Internet of Things
- Supervision method of indoor construction engineering quality acceptance based on cloud computing
- Intelligent terminal security technology of power grid sensing layer based upon information entropy data mining
- Deep learning technology of Internet of Things Blockchain in distribution network faults
- Optimization of shared bike paths considering faulty vehicle recovery during dispatch
- The application of graphic language in animation visual guidance system under intelligent environment
- Iot-based power detection equipment management and control system
- Estimation and application of matrix eigenvalues based on deep neural network
- Brand image innovation design based on the era of 5G internet of things
- Special Issue: Cognitive Cyber-Physical System with Artificial Intelligence for Healthcare 4.0.
- Auxiliary diagnosis study of integrated electronic medical record text and CT images
- A hybrid particle swarm optimization with multi-objective clustering for dermatologic diseases diagnosis
- An efficient recurrent neural network with ensemble classifier-based weighted model for disease prediction
- Design of metaheuristic rough set-based feature selection and rule-based medical data classification model on MapReduce framework
Articles in the same Issue
- Research Articles
- Construction of 3D model of knee joint motion based on MRI image registration
- Evaluation of several initialization methods on arithmetic optimization algorithm performance
- Application of visual elements in product paper packaging design: An example of the “squirrel” pattern
- Deep learning approach to text analysis for human emotion detection from big data
- Cognitive prediction of obstacle's movement for reinforcement learning pedestrian interacting model
- The application of neural network algorithm and embedded system in computer distance teach system
- Machine translation of English speech: Comparison of multiple algorithms
- Automatic control of computer application data processing system based on artificial intelligence
- A secure framework for IoT-based smart climate agriculture system: Toward blockchain and edge computing
- Application of mining algorithm in personalized Internet marketing strategy in massive data environment
- On the correction of errors in English grammar by deep learning
- Research on intelligent interactive music information based on visualization technology
- Extractive summarization of Malayalam documents using latent Dirichlet allocation: An experience
- Conception and realization of an IoT-enabled deep CNN decision support system for automated arrhythmia classification
- Masking and noise reduction processing of music signals in reverberant music
- Cat swarm optimization algorithm based on the information interaction of subgroup and the top-N learning strategy
- State feedback based on grey wolf optimizer controller for two-wheeled self-balancing robot
- Research on an English translation method based on an improved transformer model
- Short-term prediction of parking availability in an open parking lot
- PUC: parallel mining of high-utility itemsets with load balancing on spark
- Image retrieval based on weighted nearest neighbor tag prediction
- A comparative study of different neural networks in predicting gross domestic product
- A study of an intelligent algorithm combining semantic environments for the translation of complex English sentences
- IoT-enabled edge computing model for smart irrigation system
- A study on automatic correction of English grammar errors based on deep learning
- A novel fingerprint recognition method based on a Siamese neural network
- A hidden Markov optimization model for processing and recognition of English speech feature signals
- Crime reporting and police controlling: Mobile and web-based approach for information-sharing in Iraq
- Convex optimization for additive noise reduction in quantitative complex object wave retrieval using compressive off-axis digital holographic imaging
- CRNet: Context feature and refined network for multi-person pose estimation
- Improving the efficiency of intrusion detection in information systems
- Research on reform and breakthrough of news, film, and television media based on artificial intelligence
- An optimized solution to the course scheduling problem in universities under an improved genetic algorithm
- An adaptive RNN algorithm to detect shilling attacks for online products in hybrid recommender system
- Computing the inverse of cardinal direction relations between regions
- Human-centered artificial intelligence-based ice hockey sports classification system with web 4.0
- Construction of an IoT customer operation analysis system based on big data analysis and human-centered artificial intelligence for web 4.0
- An improved Jaya optimization algorithm with ring topology and population size reduction
- Review Articles
- A review on voice pathology: Taxonomy, diagnosis, medical procedures and detection techniques, open challenges, limitations, and recommendations for future directions
- An extensive review of state-of-the-art transfer learning techniques used in medical imaging: Open issues and challenges
- Special Issue: Explainable Artificial Intelligence and Intelligent Systems in Analysis For Complex Problems and Systems
- Tree-based machine learning algorithms in the Internet of Things environment for multivariate flood status prediction
- Evaluating OADM network simulation and an overview based metropolitan application
- Radiography image analysis using cat swarm optimized deep belief networks
- Comparative analysis of blockchain technology to support digital transformation in ports and shipping
- IoT network security using autoencoder deep neural network and channel access algorithm
- Large-scale timetabling problems with adaptive tabu search
- Eurasian oystercatcher optimiser: New meta-heuristic algorithm
- Trip generation modeling for a selected sector in Baghdad city using the artificial neural network
- Trainable watershed-based model for cornea endothelial cell segmentation
- Hessenberg factorization and firework algorithms for optimized data hiding in digital images
- The application of an artificial neural network for 2D coordinate transformation
- A novel method to find the best path in SDN using firefly algorithm
- Systematic review for lung cancer detection and lung nodule classification: Taxonomy, challenges, and recommendation future works
- Special Issue on International Conference on Computing Communication & Informatics
- Edge detail enhancement algorithm for high-dynamic range images
- Suitability evaluation method of urban and rural spatial planning based on artificial intelligence
- Writing assistant scoring system for English second language learners based on machine learning
- Dynamic evaluation of college English writing ability based on AI technology
- Image denoising algorithm of social network based on multifeature fusion
- Automatic recognition method of installation errors of metallurgical machinery parts based on neural network
- An FCM clustering algorithm based on the identification of accounting statement whitewashing behavior in universities
- Emotional information transmission of color in image oil painting
- College music teaching and ideological and political education integration mode based on deep learning
- Behavior feature extraction method of college students’ social network in sports field based on clustering algorithm
- Evaluation model of multimedia-aided teaching effect of physical education course based on random forest algorithm
- Venture financing risk assessment and risk control algorithm for small and medium-sized enterprises in the era of big data
- Interactive 3D reconstruction method of fuzzy static images in social media
- The impact of public health emergency governance based on artificial intelligence
- Optimal loading method of multi type railway flatcars based on improved genetic algorithm
- Special Issue: Evolution of Smart Cities and Societies using Emerging Technologies
- Data mining applications in university information management system development
- Implementation of network information security monitoring system based on adaptive deep detection
- Face recognition algorithm based on stack denoising and self-encoding LBP
- Research on data mining method of network security situation awareness based on cloud computing
- Topology optimization of computer communication network based on improved genetic algorithm
- Implementation of the Spark technique in a matrix distributed computing algorithm
- Construction of a financial default risk prediction model based on the LightGBM algorithm
- Application of embedded Linux in the design of Internet of Things gateway
- Research on computer static software defect detection system based on big data technology
- Study on data mining method of network security situation perception based on cloud computing
- Modeling and PID control of quadrotor UAV based on machine learning
- Simulation design of automobile automatic clutch based on mechatronics
- Research on the application of search algorithm in computer communication network
- Special Issue: Artificial Intelligence based Techniques and Applications for Intelligent IoT Systems
- Personalized recommendation system based on social tags in the era of Internet of Things
- Supervision method of indoor construction engineering quality acceptance based on cloud computing
- Intelligent terminal security technology of power grid sensing layer based upon information entropy data mining
- Deep learning technology of Internet of Things Blockchain in distribution network faults
- Optimization of shared bike paths considering faulty vehicle recovery during dispatch
- The application of graphic language in animation visual guidance system under intelligent environment
- Iot-based power detection equipment management and control system
- Estimation and application of matrix eigenvalues based on deep neural network
- Brand image innovation design based on the era of 5G internet of things
- Special Issue: Cognitive Cyber-Physical System with Artificial Intelligence for Healthcare 4.0.
- Auxiliary diagnosis study of integrated electronic medical record text and CT images
- A hybrid particle swarm optimization with multi-objective clustering for dermatologic diseases diagnosis
- An efficient recurrent neural network with ensemble classifier-based weighted model for disease prediction
- Design of metaheuristic rough set-based feature selection and rule-based medical data classification model on MapReduce framework