A Bi-GRU-DSA-based social network rumor detection approach
-
Xiang Huang
 and
Yan Liu
and
Yan Liu

Abstract
In the rumor detection based on crowd intelligence, the crowd behavior is constructed as a graph model or probability mode. The detection of rumors is achieved through the collaborative utilization of data and knowledge. Aiming at the problems of insufficient feature extraction ability and data redundancy of current rumor detection methods based on deep learning model, a social network rumor detection method based on bidirectional gated recurrent unit (Bi-GRU) and double self-attention (DSA) mechanism is suggested. First, a combination of application program interface and third-party crawler approach is used to obtain microblogging data from publicly available fake microblogging information pages, including both rumor and non-rumor information. Second, Bi-GRU is used to capture the tendency of medium- and long-term dependence of data and is flexible enough to deal with variable length input. Finally, the DSA mechanism is introduced to help reduce the redundant information in the dataset, thereby enhancing the model’s efficacy. The results of the experiments indicate that the proposed method outperforms existing advanced methods by at least 0.114, 0.108, 0.064, and 0.085 in terms of accuracy, precision, recall, and F1-scores, respectively. Therefore, the proposed method can significantly enhance the ability of social network rumor detection.
1 Introduction
In the Internet, every user is a producer and consumer of information. Through social media, users can understand hot news at the first time [1]. Social media has played a great role in promoting information dissemination [2,3]. WeChat, Weibo, and other social networking sites have emerged as the primary daily information outlets for individuals [4]. In particular, the volume of information generated has doubled due to the continuous expansion of network news users and users engaged in the dissemination of network information [5,6]. These data show that contemporary social networks have amassed an enormous user base and database and have emerged as the predominant medium through which individuals exchange and disseminate information [7,8,9].
A common use of social media sites is access to news, with nearly two-thirds of adults accessing news through social networks [10,11,12,13]. Unlike news media in the past, social media sites such as Sina Weibo allow users to create and share content and require little to no censorship or accountability from a third party; anyone can create and share information on the Internet [14,15,16]. The absence of limitations on platforms such as Sina Weibo frequently facilitates the emergence and dissemination of rumors. Unconfirmed information or rumors can propagate more rapidly and extensively on such platforms, making it more challenging for users to locate accurate and dependable data. As a result, platforms such as Sina Weibo present unprecedented challenges for the detection of rumor information. Because Sina Weibo has such a large user base, rumors that circulate on the platform can be extremely damaging – for instance, a sequence of misinformation pertaining to the population and geographical areas affected by the “new coronavirus” proliferated on Sina Weibo in 2020, engendering widespread public indignation and societal turmoil. The occurrence of this rumor showcased the significant practical utility of employing automated methods to verify the veracity of information on Sina Weibo [17,18,19].
Many current methods of automated rumor identification ignore the dynamic dissemination mode of rich structure of social media data. It makes too simple use of information features and ignores the impact of changes in content views on the dissemination mode in the process of information dissemination. A deep learning-based approach to rumor identification in a social network environment is proposed to address the limited feature extraction capability and data redundancy of existing deep learning-based rumor detection systems. The contributions are as follows:
A combination of application program interface (API) and third-party crawler approach is employed to acquire microblogging data from publicly available fake microblogging information pages, including both rumor and non-rumor information.
A bidirectional gated recurrent unit (Bi-GRU) is used to capture the tendency of medium- and long-term dependence of data and has the flexibility to deal with variable length input.
The double self-attention (DSA) mechanism is introduced to help reduce the redundant information in the dataset, thereby increasing the model’s efficacy.
The subsequent sections of this article are structured as follows: initially, the second section examines the pertinent research on deep learning as it relates to rumor detection Then, the process of constructing the Sina Weibo dataset is introduced in Part 3. The fourth chapter gives a specific description of the proposed deep learning-based microblog rumor detection technique; the fifth chapter is the experimental part. Part 6 concludes with a summary of the article and a discussion of potential future research.
2 Related works
At present, automated rumor identification methods still face many challenges. First, it is impossible to simply identify rumor in terms of the text content of information alone, because most false rumors are deliberately forged reports. The contents of these forged reports are usually mixed with false information and real information, which is true in false and false in true. It is difficult to determine their authenticity only based on the content; second, due to the personalization of social media, rumor information is also different in topics and styles. This leads to the inflexibility and poor effect of the text analysis algorithm carefully constructed by experts for specific data. Hence, in order to enhance the precision of rumor detection, supplementary data of various types must be incorporated, including Weibo tag data, interactive communication information, and multimedia data.
Text classification is the foundation of rumor authenticity evaluation. The research on judging the veracity of rumors is currently split into two categories: methods based on deep learning and traditional machine learning. The machine learning-based approaches typically make use of decision trees, support vector machines, and naive Bayesian classification among others.
To solve the drawbacks of current machine learning in rumor detection tasks, rumor detection tasks in deep learning are gradually coming into public view. Using linguistic and social contextual characteristics of news material, Shu et al. [20] suggested a social article fusion model to categorize fake news, but it was unable to successfully access textual semantic data. A framework for the detection of bogus news that uses dual sentiment representations was suggested by Guo et al. [21]. An attention-based approach for misinformation recognition was put up by Yu et al. [22]. The technique can mine significant posts and provide better event representations by incorporating the attention mechanism into the unsupervised Event2vec module, which learns distributed representations of events in microblogs. A deep learning model that can recognize rumors by learning continuous representations of microblog events was suggested by Ma et al. [23]. In order to collect contextual data on pertinent posts over time for classification, this model employs two hidden layers. A convolutional error information recognition model was put forth by Yu et al. [24]. The model divides each event into segments and learns the representation of each group by vectors based on the observation of the long-tail distribution of error and truth information. The model can therefore be easily adjusted to automatically extract locally significant features from the input cases. A deep learning-based rumor detection technique was proposed by Bhuvaneswari Amma et al. [25] by utilizing fully connected deep networks for learning and convolutional neural networks to minimize the dimensionality of tweet features. Bing et al. [26] explored the detection capabilities of the technique in an early rumor detection job and provided an attention mechanism for rumor detection with multi-feature fusion; however, they were unable to effectively extract contextual semantic features.
In summary, although the aforementioned literature has achieved some improvements in some tasks, there are still some limitations, such as low prediction accuracy, insufficient semantic information extraction, and data redundancy. In order to do this, the Bi-GRU modeling method for spatiotemporal rumor identification is proposed in this study. The method fully learns the contextual semantic information of the text using the Bi-GRU network and then highlights the important text features using the self-attention mechanism of the double layer. In the results, it is shown that the model can effectively improve the detection of rumors in social networks, and more details are given in Section III.
3 Weibo dataset construction
3.1 Data source of Weibo
Weibo provides extensive global connectivity, and the existence of unprecedented massive data is like a double-edged sword. It is easy for people to obtain unreliable information from these sources, and the speed of error information dissemination is greatly improved. How to control malicious or unintentional rumor information is a challenge. In view of the large amount of rumor information spread on Weibo, Weibo has set up rumor refutation accounts such as “catch rumor” and the official platform “Weibo community management center.” The reporting hall of the Weibo community management center contains various types of reporting information, such as reporting of false information and impersonating others. For each type of report, there are four states: default, proof stage, judgment stage, and result publicity. Among them, the result publicity is the confirmed rumor information. Therefore, a large number of links to rumor information can be obtained from the result publicity of untrue information.
In addition, the data of Weibo headlines are released by some relatively reliable official media, which are real and credible non-rumor data. Therefore, the rumor data in this article mainly use the existing large-scale official rumor data source of Weibo, and non-rumor data mainly use the data source of the headline section of the Weibo home page.
3.2 Weibo data collection
There are now two ways to gather Weibo data: one relies on a web crawler, and the other is the API made available through the Weibo platform. A web crawler is a program or script. It refers to the collection of web pages through hyperlinks starting from a small number of seed pages. The web crawler is used to download the web pages connected with one or more given seed Uniform Resource Locators (URLs). The web crawler extracts the hyperlinks existing therein and constantly downloads the web pages recursively identified by the extracted links for further processing until a sufficient number of pages are found. The web crawler’s flowchart is displayed in Figure 1.
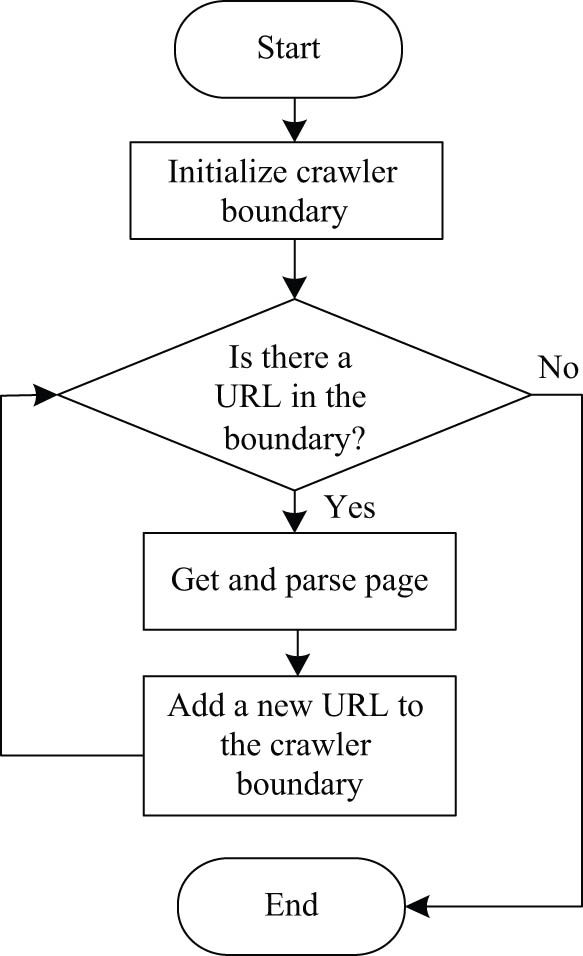
Flow chart of web crawler.
The work of a web crawler starts with a list of starting URLs provided by the user, and the crawler accesses the web page through an HTTP request and then passes the content of the page to a parser, which extracts the required information and also discovers new links. The new links pass through a page filter, uninteresting links are excluded, and then the storage processor interacts with the database and stores the new links. This cycle continues until all accessible links have been processed. Web crawlers are tools used for information gathering, but they need to be used with caution to comply with legal and ethical codes.
Ma et al. [27] released a dataset on rumors and non-rumors on Sina Weibo in 2016. Although the publicly available dataset by Ma et al. is very large and widely used, their dataset is too outdated for now. Therefore, in addition to using the microblog rumor dataset published by Ma et al. in 2016, this article also uses web crawler technology to crawl rumor and non-rumor event data from Sina Weibo for nearly 2 years from 2019 to the end of February 2021. The link information of the rumor data that needs to be crawled comes from the result publicity of false information in the Weibo community management center. For non-rumor data, this article crawls from the headline section of the Weibo homepage. This section covers a wide range of topics, including various information in people’s lives. Similarly, after crawling the data, delete text files with too few comments. Finally, 1,000 rumor events and 1,000 non-rumor events were obtained. And the dataset of Ma et al. was processed into a file with the same format as the dataset crawled in this article and then merged with the dataset in this article to form a new dataset for experimentation. Table 1 provides a detailed information on the final dataset.
Experimental dataset details
| Event | Statistics |
|---|---|
| Total number of Weibo events | 6,664 |
| Total number of rumor events | 3,313 |
| Total number of non-rumor events | 3,351 |
3.3 Dataset preprocessing
Due to the openness of the Weibo platform, users generally release information freely and informally, and the credibility of the information cannot be guaranteed. At the same time, in order to increase the interaction of the Weibo platform, users can freely publish their views and comments on the information without strict review. Certain users will purchase a substantial quantity of followers with the intention of bolstering their influence and notoriety. An extensive quantity of spam comments can be found within the Weibo comment corpus as a consequence. The presence of such “noise” data frequently significantly affects the accuracy of the experimental findings.
Whether a comment is a spam comment is related to the similarity between the comment text and the original Weibo text, the number of URLs contained in the comment, the repeated comments’ number, the replies’ number, the comments’ length, and the nouns’ proportion. Therefore, these are studied as the features of judging whether a comment is a spam comment.
3.4 Similarity with the original Weibo
Similarity with the original text of Weibo is an important standard to judge whether the comment is a spam comment. Map the original Weibo and comment to two vector spaces, and calculate their vector cosine similarity. The lower the similarity, the greater the irrelevance between the comment and the original text, and the greater the possibility of being a spam comment. Supposing that
3.5 Noun proportion
By studying the text characteristics of normal comments and spam comments, it can be found that normal comments are mostly the expression of users’ happy and angry emotions or likes and dislikes toward Weibo information [28]. However, spam comments are mostly declarative expressions, and the proportion of nouns is higher than that of normal comments. Therefore, calculating the proportion of nouns in the comment information can effectively judge whether the comment is spam. Set
3.6 Other features
The number of URLs included in comments, the repeated comments’ number, the replies’ number to comments, and the length of comment text can be calculated statistically. If the number of URLs included in the comment is more, the number of repeated comments is more, and the comment text is longer, the more likely it is to prove that the comment contains other information such as marketing and “flooded comment,” and the more likely it is that the comment is a spam comment [29]. On the contrary, the higher the number of comment responses, it proves that the comments have aroused extensive discussion and communication, and the probability of such comments being normal comments is greater.
The logistic regression approach is used in this study to forecast the likelihood that a comment will be spam and the labeled data are employed to train the model, so as to build a classifier to classify and filter spam comments.
Set
where
The probability that
Without loss of generality, the threshold of probability is set to 0.5. The predicted probability
4 Weibo rumor detection technology based on deep learning
4.1 Proposed model
The proposed model architecture comprises four network layers in its primary form, as illustrated in Figure 2. The input of the embedded fusion layer consists of heterogeneous temporal feature data, which is utilized to assemble these features through structured splicing. After extracting and obtaining the implicit data of the ternary features: text content of the information, the propagation track of the event, and the user’s feedback signal. These three types of feature aggregation data are used to capture the timing information of the event through the encoder layer. Then, the attention layer is used to learn the hidden-layer expression of the event period sequence from the time level and obtain its weight in different periods of the event propagation cycle. In this way, when learning the representation of the event information sequence, the model can focus on using all kinds of potential propagation mode information in the event period. Finally, the input of the fully connected layer is the implicit expression of the event output from the attention layer, which is utilized to predict and evaluate the event’s category.

Framework of depth attention model based on ternary elements.
The feature aggregation model of hierarchical attention not only captures the change trend of the ternary features of information text content, event propagation trace, and user feedback signal in the whole propagation cycle through the attention mechanism, but also learns the three heterogeneous features, respectively. This aggregation model makes full use of the feature perturbation, so that the ternary heterogeneous features can fully integrate the knowledge of learning on the basis of their original time series data. Moreover, the feature aggregation model combines unsupervised learning and external knowledge acquisition of user opinion signals to fully obtain the surface information of event propagation mode. Its generated implicit state has strong directivity and expression ability.
In essence, the objective of the rumor identification task on social networks is to classify event information that is disseminated on these platforms as rumor information or not. The provided mission is defined formally as follows:
Given an event set
4.2 Model method
4.2.1 Original input data
In order to mitigate the substantial long tail effect observed in event time series, this article obtains logarithmic interval intervals by non-linear partitioning of event periods, making the span of time intervals in the later stages of the event cycle larger, thus ensuring good consistency in the data distribution of various time periods within the complete propagation cycle. Let the earliest information timestamp of all the information in the event
where
According to the nonlinear time sequence segmentation method, the information text sequence
In this study, the ternary characteristics of information text content, event propagation trace, and user feedback signal in different periods of the event are proposed to represent the overall propagation mode of the event. Therefore, the ternary characteristic original data of the event
4.2.1.1 Event propagation trace
The user sequence
4.2.1.2 User feedback signal
The text content sequence
4.2.1.3 Text content of information
To learn the potential information of the related text of the event in different periods and avoid the cumbersome feature engineering process, the text content sequence
4.2.2 Embedded layer
As the research on recurrent neural networks (RNNs) continues to progress, recurrent neural is widely referenced in various fields. For example, Bi-GRU is a RNN architecture that combines bi-directional (forward and backward) GRU units to process sequential data. RNN RRN is a type of data with a neural network architecture. It receives inputs at each time step and hidden states from previous time steps and uses this information to capture temporal dependencies in sequence data. Traditional RNNs have difficulty in processing long sequence data due to their susceptibility to the gradient vanishing or gradient explosion problem, making it difficult to capture long-term dependencies. LSTM (Long Short-Term Memory): LSTM is an RNN variant designed to solve the long dependency problem of traditional RNNs. It includes three gates (input gate, forget gate, and output gate) to better handle long sequences. BiLSTM (bidirectional LSTM): BiLSTM is an RNN architecture that combines forward and backward LSTMs to capture both past and future information in a sequence. This helps to better understand and model the context in sequence data. The advantages of Bi-GRU are as follows:
Relative simplicity: compared to BiLSTM, Bi-GRU is simpler in terms of model structure as it uses GRUs instead of LSTM units. This may lead to faster training and fewer parameters. Compared to standard RNNs, GRUs have better gradient flow and can better handle long-term dependencies.
Better performance: despite its relative simplicity, Bi-GRU exhibits similar performance to BiLSTM in many sequence modeling tasks. It can effectively capture bi-directional information of sequence data and improve the understanding of context.
Because the text content of the event information, the propagation trace of the event and the user’s feedback signal come from different feature domains. They are not suitable to be directly used as the original input of the Bi-GRU network model. As a result, the main function of the first embedded layer in the model network architecture is to provide standardized aggregate feature data input for each time period of the subsequent Bi-GRU network model events [30]. The input of the embedded layer is the original input feature data
where
4.2.3 Encoding layer
In order to represent the temporal correlation between the mode of propagation and the rumor discrimination category of events, the Bi-GRU network model is utilized. For capturing the hidden-layer representation of event propagation mode under temporal relationship, the Bi-GRU network model is well suited due to its ability to capture the tendency of medium- and long-term dependence of data and its flexibility in handling variable length input. This layer will get the aggregate feature data
where
4.2.4 Attention layer
The DSA mechanism is suggested in an effort to address the issue that the present approaches struggle to handle redundant data effectively. To address the issue of data redundancy from the two dimensions of sentence and word, the self-attention mechanisms at the sentence and word levels are applied in the model.
4.2.4.1 Self-attention mechanism at sentence level
Weighting of the self-attention mechanism subsequent to feature extraction of all reply information in order to enable the model to identify valuable reply information is referred to as the self-attention mechanism at the sentence level. The precise computation procedure is illustrated in the subsequent formulas:
where
where
4.2.4.2 Self-attention mechanism at word level
The weighting of the self-attention mechanism based on the GRU processing outcomes is referred to as the self-attention mechanism at the word level; this permits more significant words to be assigned a greater weight. Due to the typically concise nature of reply to information, the word-level self-attention mechanism is not implemented in the output of GRU processing reply information. By integrating TextCNN and the GRU processing algorithm, the demand can be satisfied.
The input portion distinguishes the word-level self-attention mechanism from the sentence-level self-attention mechanism; the calculation process for the two is essentially identical. The input to the self-attention mechanism at the word level is as follows:
where
4.2.5 Output layer
The output of the attention layer is fed into the fully connected layer in order to perform the final rumor discrimination. As a low-dimensional representation of the event’s overall propagation mode, the result vector of the attention layer can capture the prospective information of ternary characteristics at various times during the event. As an independent analysis of events or as the input to the final output layer for rumor discrimination, it can be utilized in either capacity.
The final output discrimination of the output layer is expressed in formula (21), where
Use the Adam optimization algorithm for training iteration, as shown in the following formula, where
5 Example verification and result discussion
Implementation of the proposed model occurs through the open-source TensorFlow deep learning framework developed by Google. Python 3.10 is the programming language utilized. TensorFlow facilitates the integration of numerous prevalent deep learning models, offering developers a set of fundamental operations that are comparatively uncomplicated to comprehend and incorporate into the model (Table 2).
Model parameter settings
| Environment configuration | Parameters |
|---|---|
| IDE parameters | Anaconda3-Windows-x86_64 |
| GPU | NVIDIA GeForce RTX 3090 Ti 24GB。 |
| Hard disk | 1T |
| CPU | InterI CoreI i7-8750H@2.20GHz |
| Programming language | Python 3.10 |
| Development framework | Tensorflow 1.14.0 |
5.1 Evaluation index
Confusion matrix type of evaluation metric used to measure the accuracy of the classifier is a matrix of NXN, where N represents the number of classes in the data. The confusion matrix provides a comparison of the number of correctly categorized samples with the number of incorrectly categorized samples.
Each element in the confusion matrix is defined as:
True positive (TP): samples whose data are predicted to be “true” by the model and whose deeds are labeled as “true.”
False positive (FP): samples whose data are predicted to be true by the model and whose deeds are labeled as “false.”
False negatives (FN): samples whose data are predicted to be false by the model and whose events are labeled as “true.”
True negatives (TN): samples whose data are predicted to be false by the model and whose events are labeled as “false.”
Tables 3 and 4 show the description and data for the confusion matrix.
Confusion matrix
| Actual | |||
|---|---|---|---|
| Positive | Negative | ||
| Prediction | Positive | TP | FP |
| Negative | FN | TN | |
Data of confusion matrix
| Actual | |||
|---|---|---|---|
| 1/P | 0/N | ||
| Prediction | 1/P | 6,135 | 261 |
| 0/N | 629 | 6,410 | |
A number of assessment metrics can be derived from the confusion matrix, for instance, accuracy, precision, recall, and F1 value. The performance indexes of the method are evaluated by accuracy, precision, recall, and F1 value. The calculation methods of these four indexes are depicted in the following formulas:
5.2 Adjustment of experimental parameters
Model training is a critical component of deep learning in particular. Numerous parameters must be specified for a neural network. Critical to the process of model training is the modification of the super parameters. The grade of the parameter adjustment will have a direct impact on the model’s classification performance. Several parameters are briefly introduced below. (1) Sentence vector dimension: the dimension of sentence vector is obtained by doc2vec. (2) The learning rate is a determining factor in the pace at which the model converges. A significant increase in the learning rate will result in a highly unstable learning curve. The training process will be significantly slowed down if the learning rate is inadequate. (3) Batch size: the data in a batch jointly determine the direction of gradient update. When the batch size is too large, the calculation cost is high. When the batch size is too small, it is difficult to converge or obtain the local optimal solution. (4) Number of iterations: the more iterations, the more stable the model is, but it is easy to lead to over-fitting. (5) Optimizer: the optimizer significantly impacts the efficacy of the model. The settings information for experimental parameters is presented in Table 5.
Experimental dataset details
| Parameter name | Parameter value setting |
|---|---|
| Sentence vector dimension | 50, 100, 150, 200, 250, 300, 350 |
| Learning rate | 0.0001, 0.001, 0.01, 0.1 |
| Batch size | 64 |
| Number of comment categories | 20 |
| Optimizer | Adam |
Figure 3 shows the different sentence vector dimensions’ effect on the accuracy and F1. It can be seen that when the dimension of sentence vector is 200, the accuracy and F1 are the highest. Figure 4 shows the different learning rates’ effect on accuracy and F1. Figure 5 depicts the effect of different number of epochs on model’s loss function. It can be seen that when the initial learning rate is about 0.001, the accuracy is the highest. In the model training’s process, Adam optimization algorithm can automatically adjust the learning rate to make the model better. In addition, the number of epochs is set to 30 to lead model’s loss function become minimum.

Effect of sentence vector dimensions on accuracy.

Effect of learning rate on accuracy.

Effect of different number of epochs on model’s loss function.
5.3 Comparison with other methods
Patel et al. [22] proposed that Event2vec module combined with co-attentiion helps to learn a good representation of events, after which a convolutional neural network can extract the key features of the input sequence, thus effectively capturing the error messages to achieve excellent detection capability. Amma and Selvakumar [25] used a convolutional neural network to reduce tweet features and learning using fully connected neural network to achieve faster and more promising detection results. Reference [26] method based on deep learning has shown excellent detection ability in early rumor detection tasks. To validate the efficacy of the proposed method, it is compared to the methods referenced in previous studies ([22,25] and [26]) under identical experimental conditions. The results of the comparison are presented in Table 6. Through observation of the experimental outcomes, it is possible to ascertain that the proposed method yields the highest index. The accuracy, precision, recall, and F1 value of the proposed method are 0.962, 0.960, 0.904, and 0.931, respectively. By comparison, the accuracy, precision, recall, and F1 value of the method proposed in Yu et al. [22] are only 0.848, 0.852, 0.840, and 0.846, respectively. The proposed method improves at least 0.114, 0.108, 0.064, and 0.085 in accuracy, precision, recall and F1-scores over the existing methods.
Comparison of evaluation indexes of different rumor detection methods
| Methods | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|
| Proposed method | 0.962 | 0.960 | 0.904 | 0.931 |
| Ref. [22] | 0.848 | 0.852 | 0.840 | 0.846 |
| Ref. [26] | 0.861 | 0.843 | 0.887 | 0.864 |
| Ref. [25] | 0.924 | 0.901 | 0.835 | 0.867 |
The proposed method aggregates the text content of the information in the event cycle, the propagation trace of the event, and the feedback signal of the user and uses the temporal rumor identification modeling method based on deep learning to detect the Weibo data. The DSA mechanism is implemented in the model through the utilization of sentence-level and word-level self-attention mechanisms. Consequently, the proposed method effectively addresses the issue of redundant data in both the sentence and word dimensions. The comparison methodologies fail to address the issue of redundant data. Hence, in contrast to the comparison method, the proposed method yields considerably superior indexes. It demonstrates that the DSA mechanism has significantly enhanced the capability of determining the veracity of rumors.
The variations in the accuracy of the proposed method, as referenced in previous studies [22,25,26], in the validation set throughout the training process are illustrated in Figure 6. The learning capability of the Bi-GRU method with DSA is evidently the quickest. Following 200 iterations of training, the model has achieved a stable accuracy of approximately 0.96. While the reference models in previous studies [22,25,26] exhibit considerable initial learning capability even in the absence of word-level attention, their final learning outcome does not surpass that of the proposed model. As a result, the incorporation of the DSA mechanism may enhance the model’s capacity for learning.

Comparison of accuracy change.
5.4 Validity of unbalanced datasets
To demonstrate the efficacy of the model on an unbalanced dataset, this study takes the dataset with different ratios to assign rumor event and non-rumor event, and Figure 7 represents the detection results under different ratios between rumor and non-rumor.

Detection results under different ratios between rumors and non-rumors.
The results in Figure 7 demonstrate that the model works best at a 1:1 ratio. At 1:4 and 4:1 ratio, the model results are the worst, but it is still within an acceptable range. Analyzing the reasons, it becomes evident that the proposed model did not explicitly implement pertinent technologies to address the issue of data imbalance. Rather, its emphasis was placed on the extraction of deep-level features and contextual semantic information. Consequently, the proposed model is capable of producing more accurate detection outcomes when data are balanced.
6 Conclusion
In an effort to address the issues of inadequate feature extraction capability and redundant data that plague existing deep learning-based rumor detection methods, a social network rumor detection method based on deep learning is proposed. The proposed deep learning rumor detection methods include data acquisition, Bi-GRU, and DSA mechanism. Bi-GRU is used to capture the tendency of medium- and long-term dependence of data and has the flexibility to deal with variable length input. DSA mechanism is implemented to assist in the reduction of redundant information within the dataset, thereby enhancing the model’s efficacy. The experimental outcomes show that the accuracy, precision, recall rate, and F1 score of the suggested method are improved by 0.114, 0.108, 0.064, and 0.085 in comparison with existing methods. This indicates that the effectiveness of rumor detection in social networks could be enhanced by employing this method.
There are still certain areas where the research presented in this study could be improved. For example, the existing research has made less use of video and pictures that contain text information, so future research in the field of rumor detection can consider making full use of video information and text in pictures. Currently, the labeled datasets are very limited, and larger datasets can be utilized in the future to enhance the performance of the model proposed in this study.
-
Funding information: This work is not supported by any fund projects.
-
Author contributions: Xiang Huang: Conceptualization, Methodology, Data curation, Writing - Original draft preparation, Writing - Reviewing and Editing. Yan Liu: Investigation, Supervision, Validation, Writing - Reviewing and Editing.
-
Conflict of interest: The authors declare that there is no conflict of interest regarding the publication of this article.
-
Data availability statement: The data used to support the findings of this study are included within the article.
References
[1] M. Ahsan, M. Kumari, and T. P. Sharma, “Rumors detection, verification and controlling mechanisms in online social networks: A survey,” Online Soc. Netw. Media, vol. 14, pp. 100–107, 2019.10.1016/j.osnem.2019.100050Search in Google Scholar
[2] A. W. Wang, J. Y. Lan, M. H. Wang, and C. Yu, “The evolution of rumors on a closed social networking platform during COVID-19: Algorithm development and content study,” JMIR Med. Inform., vol. 9, pp. 2001–2012, 2021.10.2196/preprints.30467Search in Google Scholar
[3] R. M. Tripathy, A. Bagchi, and S. Mehta, “Towards combating rumors in social networks: Models and metrics,” Intell. Data Anal., vol. 17, pp. 149–175, 2013.10.3233/IDA-120571Search in Google Scholar
[4] A. Wang, W. Wu, and J. Chen, “Social network rumors spread model based on cellular automata,” 2014 10th International Conference on Mobile Ad-hoc and Sensor Networks, IEEE, 2014, pp. 236–242.10.1109/MSN.2014.39Search in Google Scholar
[5] W. Wang, Y. C. Qiu, S. C. Xuan, and W. Yang, “Early rumor detection based on deep recurrent Q-learning,” Secur. Commun. Netw., vol. 2021, pp. 13–13, 2021, 10.1155/2021/5569064.Search in Google Scholar
[6] S. Shelke and V. Attar, “Source detection of rumor in social network–a review,” Online Soc. Netw. Media, vol. 9, pp. 30–42, 2019.10.1016/j.osnem.2018.12.001Search in Google Scholar
[7] P. K. Roy and S. Chahar, “Fake profile detection on social networking websites: a comprehensive review,” IEEE Trans. Artif. Intell., vol. 1, pp. 271–285, 2020.10.1109/TAI.2021.3064901Search in Google Scholar
[8] N. N. Al-Enezi, “Employment of social networking sites in response to rumors,” J. Media Stud. Res., vol. 3, pp. 101–123, 2020Search in Google Scholar
[9] Q. Li, Q. Zhang, L. Si, and Y. Liu, “Rumor detection on social media: Datasets, methods and opportunities,” arXiv preprint arXiv, vol. 4, pp. 569–578, 2019.10.18653/v1/D19-5008Search in Google Scholar
[10] H. K. Thakur, A. Gupta, A Bhardwaj, and D. Verma, “Rumor detection on Twitter using a supervised machine learning framework,” Int. J. Inf. Retr. Res., vol. 8, pp. 1–13, 2018.10.4018/IJIRR.2018070101Search in Google Scholar
[11] Y. K. Yang, K. Niu, and Z. Q. He, “Exploiting the topology property of social network for rumor detection,” 2015 12th International Joint Conference on Computer Science and Software Engineering (JCSSE), IEEE, 2015, pp. 41–46.10.1109/JCSSE.2015.7219767Search in Google Scholar
[12] S. Tschiatschek, A. Singla, M. Gomez Rodriguez, A. Merchant, and A. Krause, “Fake news detection in social networks via crowd signals,” Companion Proceedings of the Web Conference, 2018, pp. 517–524.10.1145/3184558.3188722Search in Google Scholar
[13] R. M. Tripathy, A. Bagchi, and S. Mehta, “A study of rumor control strategies on social networks,” Proceedings of the 19th ACM international conference on Information and knowledge management, 2010, pp. 1817–1820.10.1145/1871437.1871737Search in Google Scholar
[14] A. P. B. Veyseh, M. T. Thai, T. H. Nguyen, and D. Dou, “Rumor detection in social networks via deep contextual modeling,” Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 2019, pp. 113–120.10.1145/3341161.3342896Search in Google Scholar
[15] M. Al-Sarem, W. Boulila, M. Al-Harby, J. Qadir, and A. Alsaeedi, “Deep learning-based rumor detection on Weiboging platforms: a systematic review,” IEEE Access, vol. 7, pp. 152788–152812, 2019.10.1109/ACCESS.2019.2947855Search in Google Scholar
[16] A. I. E. Hosni, K. Li, and S. Ahmad, “Minimizing rumor influence in multiplex online social networks based on human individual and social behaviors,” Inf. Sci., vol. 512, pp. 1458–1480, 2020.10.1016/j.ins.2019.10.063Search in Google Scholar
[17] W. Xu, and H. Chen, “Scalable rumor source detection under independent cascade model in online social networks,” 2015 11th International Conference on Mobile Ad-hoc and Sensor Networks (MSN), IEEE, 2015, pp. 236–242.10.1109/MSN.2015.36Search in Google Scholar
[18] S. Srinivasan and D. B. LD, “A parallel neural network approach for faster rumor identification in online social networks,” Int. J. Semantic Web Inf. Syst., vol. 15, pp. 69–89, 2019.10.4018/IJSWIS.2019100105Search in Google Scholar
[19] S. Shelke and V. Attar, “Rumor detection in social network based on user, content and lexical features,” Multimed. Tools Appl., vol. 81, pp. 17347–17368, 2022.10.1007/s11042-022-12761-ySearch in Google Scholar PubMed PubMed Central
[20] K. Shu, D. Mahudeswaran, and H. Liu, “FakeNewsTracker: A tool for fake news collection, detection, and visualization,” Comput Math. Organ. Theory, vol. 25, pp. 60–71, 2019.10.1007/s10588-018-09280-3Search in Google Scholar
[21] C. Guo, J. Cao, X. Zhang, K. Shu, and H. Liu, “Dean: Learning dual emotion for fake news detection on social media,” arXiv e-prints, vol. 9, pp. 1–11, 2019.Search in Google Scholar
[22] T.P. Patel, T.N. Kim, G. Yu, V.S. Dedania, P. Lieu, C.X. Qian, et al., “Attention-based convolutional approach for misinformation identification from massive and noisy Weibo posts,” Computers Secur, vol. 8, pp. 106–121, 2019.10.1016/j.cose.2019.02.003Search in Google Scholar
[23] J. Ma, W. Gao, P. Mitra, S. Kwon, B. J. Jansen, K. F. Wong, et al., “Detecting rumors from Weibos with recurrent neural networks,” International Joint Conference on Artificial Intelligence, 2016, pp. 1–11.Search in Google Scholar
[24] F. Yu, Q. Liu, S Wu, L. Wang, and T. Tan, “A convolutional approach for misinformation identification,” IJCAI, pp. 3901–3907, 2017.10.24963/ijcai.2017/545Search in Google Scholar
[25] N. G. Bhuvaneswari Amma and S. Selvakumar, “RumorDetect: Detection of rumors in twitter using convolutional deep tweet learning approach,” International Conference On Computational Vision and Bio Inspired Computing, Cham, Springer, 2019, 422–430.10.1007/978-3-030-37218-7_48Search in Google Scholar
[26] C. Bing, Y. Wu, F. Dong, S. Xu, X. Liu, and S. Sun, “Dual Co-attention-based multi-feature fusion method for rumor detection,” Information, vol. 13, pp. 25–32, 2022.10.3390/info13010025Search in Google Scholar
[27] J. Ma, W. Gao, P. Mitra, S. Kwon, B. J. Jansen, K. F. Wong, et al., “Detecting rumors from microblogs with recurrent neural networks,” Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI), 2016, pp. 3818–3824.Search in Google Scholar
[28] J. Choudrie, S. Patil, K. Kotecha, N. Matta, and I. Pappas, “Applying and understanding an advanced, novel deep learning approach: A Covid 19, text based, emotions analysis study,” Inf. Syst. Front., vol. 23, pp. 1431–1465, 2021.10.1007/s10796-021-10152-6Search in Google Scholar PubMed PubMed Central
[29] B. Kratzwald, S. Ilić, M. Kraus, S. Feuerriegel and H. Prendinger, “Deep learning for affective computing: Text-based emotion recognition in decision support,” Decis. Support. Syst., vol. 115, pp. 24–35, 2018.10.1016/j.dss.2018.09.002Search in Google Scholar
[30] S. Ahmad, M. Z. Asghar, F. M Alotaibi, and S. Khan, “Classification of poetry text into the emotional states using deep learning technique,” IEEE Access, vol. 8, pp. 73865–73878, 2020.10.1109/ACCESS.2020.2987842Search in Google Scholar
[31] E. A. H. Khalil, E. M. F. Houby, and H. K. Mohamed. “Deep learning for emotion analysis in Arabic tweets,” J. Big Data, vol. 8, pp. 1–15, 2021.10.1186/s40537-021-00523-wSearch in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Regular Articles
- AFOD: Two-stage object detection based on anchor-free remote sensing photos
- A Bi-GRU-DSA-based social network rumor detection approach
- Task offloading in mobile edge computing using cost-based discounted optimal stopping
- Communication network security situation analysis based on time series data mining technology
- The establishment of a performance evaluation model using education informatization to evaluate teacher morality construction in colleges and universities
- The construction of sports tourism projects under the strategy of national fitness by wireless sensor network
- Resilient edge predictive analytics by enhancing local models
- The implementation of a proposed deep-learning algorithm to classify music genres
- Moving object detection via feature extraction and classification
- Listing all delta partitions of a given set: Algorithm design and results
- Application of big data technology in emergency management platform informatization construction
- Evaluation of Internet of Things computer network security and remote control technology
- Solving linear and nonlinear problems using Taylor series method
- Chinese and English text classification techniques incorporating CHI feature selection for ELT cloud classroom
- Software compliance in various industries using CI/CD, dynamic microservices, and containers
- The extraction method used for English–Chinese machine translation corpus based on bilingual sentence pair coverage
- Material selection system of literature and art multimedia courseware based on data analysis algorithm
- Spatial relationship description model and algorithm of urban and rural planning in the smart city
- Hardware automatic test scheme and intelligent analyze application based on machine learning model
- Integration path of digital media art and environmental design based on virtual reality technology
- Comparing the influence of cybersecurity knowledge on attack detection: insights from experts and novice cybersecurity professionals
- Simulation-based optimization of decision-making process in railway nodes
- Mine underground object detection algorithm based on TTFNet and anchor-free
- Detection and tracking of safety helmet wearing based on deep learning
- WSN intrusion detection method using improved spatiotemporal ResNet and GAN
- Review Article
- The use of artificial neural networks and decision trees: Implications for health-care research
Articles in the same Issue
- Regular Articles
- AFOD: Two-stage object detection based on anchor-free remote sensing photos
- A Bi-GRU-DSA-based social network rumor detection approach
- Task offloading in mobile edge computing using cost-based discounted optimal stopping
- Communication network security situation analysis based on time series data mining technology
- The establishment of a performance evaluation model using education informatization to evaluate teacher morality construction in colleges and universities
- The construction of sports tourism projects under the strategy of national fitness by wireless sensor network
- Resilient edge predictive analytics by enhancing local models
- The implementation of a proposed deep-learning algorithm to classify music genres
- Moving object detection via feature extraction and classification
- Listing all delta partitions of a given set: Algorithm design and results
- Application of big data technology in emergency management platform informatization construction
- Evaluation of Internet of Things computer network security and remote control technology
- Solving linear and nonlinear problems using Taylor series method
- Chinese and English text classification techniques incorporating CHI feature selection for ELT cloud classroom
- Software compliance in various industries using CI/CD, dynamic microservices, and containers
- The extraction method used for English–Chinese machine translation corpus based on bilingual sentence pair coverage
- Material selection system of literature and art multimedia courseware based on data analysis algorithm
- Spatial relationship description model and algorithm of urban and rural planning in the smart city
- Hardware automatic test scheme and intelligent analyze application based on machine learning model
- Integration path of digital media art and environmental design based on virtual reality technology
- Comparing the influence of cybersecurity knowledge on attack detection: insights from experts and novice cybersecurity professionals
- Simulation-based optimization of decision-making process in railway nodes
- Mine underground object detection algorithm based on TTFNet and anchor-free
- Detection and tracking of safety helmet wearing based on deep learning
- WSN intrusion detection method using improved spatiotemporal ResNet and GAN
- Review Article
- The use of artificial neural networks and decision trees: Implications for health-care research