The use of artificial neural networks and decision trees: Implications for health-care research
-
Shaina Smith


Abstract
The use of decision trees and artificial neural networks (ANNs) in health-care research is widespread, as they enable health-care providers with the tools they need to make better medical decisions with their patients. ANNs specifically are extremely helpful in predictive research as they can provide investigators with knowledge about future trends and patterns. However, a major downside to ANNs is their lack of interpretability. Understandability of the model is important as it ensures the outcomes are true to the dataset’s original labels and are not impacted by algorithmic bias. In comparison, decision trees map out their entire process before providing the results, which leads to a higher level of trust in the model and the conclusions it supplies the investigators with. This is essential as many historical datasets lack equal and fair representation of all races and sexes, which might directly correlate to a lesser treatment given to females and individuals in minority groups. Here, we review existing work around the differences and connections between ANNs and decision trees with implications for research in health care.
1 Introduction
In recent decades, research has seen a rise in the use of algorithms and machine learning due to the exponential increase of rich data. Datasets that are rich in information are rampant in research systems; however, often these datasets are poor in knowledge [1]. To analyze this data researchers must use data mining techniques, however, there is a long list of boxes the chosen method must check-off before it can be used. A popular set of algorithms used in a wide range of application areas are artificial neural networks (ANNs), as they are useful in recognizing patterns and have powerful predictive abilities [2]. This makes them a popular, and logical, choice for research that is focused on future results and possibilities.
There is, however, a major drawback to ANNs: the models they construct are extremely difficult to explain and understand. Unlike other data mining models that are used in scientific studies, ANNs do not provide information on the process behind achieving their output, nor is the produced model intuitive to understand; little to no information is provided about what the model did, why those conclusions were made, or what the output means. This leaves much to be desired and can often lead to misinterpretation or varying interpretations of the results, and mistakes that go unseen due to a lack of understanding of the machine’s output [3].
This is why ANNs are known as “black box machine,” which are models or machines that do not let the user see what is going on inside, specifically regarding the process that is ongoing to reach the output. Black box machines make it challenging to improve the results obtained from a specific dataset because it is difficult to determine which features had the greatest impact on the neural network weights. Since these choices are not mapped out, it leads many researchers to turn away from using ANNs for their scientific investigation unless absolutely necessary [4].
To avoid dealing with this issue, many researchers choose to use a decision tree model to analyze their data. Decision trees are composed of linkages and nodes that visualize the predetermined rules through directed graphs [2].
Decision trees are easy to use; their decision-making process is constructed and driven by the inputted data and is visually outputted in a tree-like structure via interpretations that are consistent and simple to comprehend and explain. This is vital in fields where researchers lack data mining and computer science backgrounds, and where information and conclusions need to be presented in layman’s terms to be relayed to other investigators and reproduced in other studies [2]. This leaves little to no room for mistakes in the interpretation of models and what features were used in their construction. It also makes it simple for other researchers to recreate the study and obtain the same results, as the conclusions they come to are based on the map that is provided to them and not an interpretation of an ambiguous, nondeterministic output. However, the main disadvantage of decision trees is that they do not possess the same prediction abilities as ANNs [2].
Figure 1 shows a decision tree that represents the solution to the XOR problem. The input data are presented to the root, and samples travel down different branches of the tree to the leaf nodes representing classes, depending on the decisions related to input values made at the nodes. Using an ANN’s predetermined weights to map out a decision tree has been proposed as a possible answer to this predicament by combining these two powerful algorithms so that the outcome is understandable, has strong predictive qualities, and possibly restores trust in the model’s predictions for related investigators, doctors, and patients.

A decision tree capable of solving the XOR problem.
Here, we provide a literature discussion to relate the concepts of model understandability to decision trees and neural networks applications in health care. We first discuss the background and demonstrate the structure of decision trees and neural networks with a small example, followed by a discussion on model understandability. Example applications in the field are reviewed subsequently, followed by a discussion of the connection to explainable artificial intelligence (XAI). Finally, we discuss the concepts of replicability and bias as applicable to this article.
2 Background
Originally, ANNs were used mainly for classification purposes but fell out of favor for larger datasets because of their resource requirements. Figure 2 shows a schematic of an ANN that can be used to learn the XOR problem. Smaller processing units based on the “perceptron” proposed initially by McCulloch and Pitts [5] can be combined and trained by various algorithms, including “Backpropagation,” which was originally proposed by Rosenblatt [6]. The input data are presented to the input layer, and processed in the hidden layer to produce output values in the output layer. The correct output is then compared to the achieved output to propagate the error backward toward the input layer, which adjusts the weights (associated with connections between the nodes) to better represent the function to be learned.
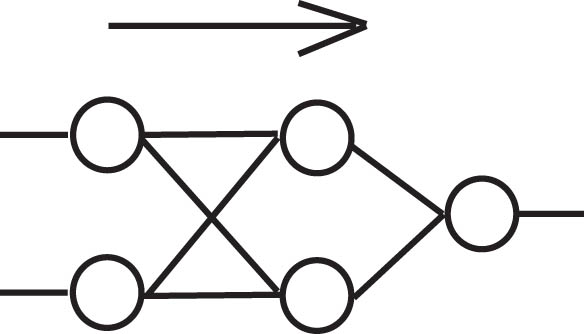
An ANN with two nodes in a single hidden layer, capable of solving the XOR problem.
Using an ANN is extremely time-consuming because the model reads through the dataset multiple times to fully understand the training data and weigh its linkages accordingly. The total runtime can also vary based on the number of hidden layers the model has, and when there are more layers, the complexity of the model increases. This leads to something known as “deep” neural networks, which is in contrast to neural networks that have very few hidden layers and are otherwise referred to as “shallow.”
This is another drawback to ANNs: smaller datasets do not work well with a greater number of hidden layers, which is what deep learning models and most ANNs consist of. This is because, as more hidden layers are added, the complexity of the model increases; if the dataset is too small, the model is more prone to overfitting of the data [7]. This occurs because the inputted features are going through many layers, but there is not enough information for the model to process, so it stretches the features and makes them fit the model. This is a problem because the dataset has only provided the model with a limited view of the relationships within it, deriving conclusions that do not accurately represent the patterns and correlations within the data [8]. This can be avoided in ANNs through the use of regularization techniques, a popular choice being the dropout method [9].
3 Model understandability
Black box machines are models or algorithms that process the data internally and output a result without showing how it was achieved. An ANN is a prime example of a black box machine. It leads researchers to have to interpret the results, ultimately coming up with interpretations that may be incorrect [3]. For this reason, black box machines also make it difficult to obtain cohesive results between researchers as the output they obtain tend to be based on interpretation. This means that two researchers could interpret the exact same results in various ways, leading to completely different conclusions for their studies. The dependency on personal interpretation of the results also makes peer-reviewing studies challenging, as different researchers may reach different conclusions based on their own interpretations of the data. It was also found that a lack of understanding as to how results are reached by these artificially-intelligent machines can lead to mistrust in the system [4]. Without understanding how specific results were achieved, there is no guarantee that the machine made the correct choices or predictions. Since the researchers cannot manually check how each of the weights was calculated or which feature led to specific outcomes, it might be difficult to establish trust in an ANN’s model.
In comparison, a decision tree model is significantly less complex and is considered a “glass box machine,” making it the preferable choice in many situations. Decision tree implementations, such as ID3 proposed by Quinlan in 1986 [10], are constructed with three different node types: a root node, one or more internal nodes, and leaf nodes, which are also sometimes known as terminal nodes. A decision tree takes a set of rules and applies them to each of the features that it receives. Based on those rules, it classifies each of the features to be in a specific place in the tree surrounded by and linked to other nodes that are of a similar value.
The main rules of decision tree construction decide which of the features should be used to split into different classes and when the algorithm should stop. Decision trees tend to be a more popular choice among researchers because they output where each of the features is mapped, meaning outputs can be easily traced back and explained without the need for interpretation.
4 Decision trees and ANNs in health care
Within the field of health care, both decision tree and ANN models are frequently used. ANNs are used very often with diagnosis and, more recently, with making decisions when it comes to managing a patient’s health care [11]. Shahid et al. found that most researchers use ANNs, feed-forward networks, and hybrid models, all with varying reported levels of accuracy [11].
Another popular approach in the field of health care is the use of decision trees. This is not because they are a superior model, but because they are reliable, easy to explain, and map out their results in a way that researchers are able to quickly spot mistakes in the logic. An early example of the use of decision trees is described by Montbriand [12], focusing on patient decision strategies in oncology. More recently, decision trees were used to predict the outcome of non-intensive care patients hospitalized for COVID-19 [13]. Decision tree models have been used to make decisions regarding various telehealth services and their integration with health insurance and welfare [14], along with choosing the best course of action when making clinical decisions with patients [15].
Several different algorithms were proposed in the 1980s, 1990s, and early 2000s to map the weights of ANN’s to decision trees. These include, for example, DecText [16], and various adaptations of algorithms that were already available, along with different proposed methods to analyze the results. For those adaptations, instead of the weights being mapped from one model to another, the results of the ANNs were either analyzed separately or they were mapped out using a decision tree-like structure. The latter method took the results and used them as input to be mapped in a decision tree to attempt to understand how they might correlate to each other. This was done in the hopes of exposing the decision-making process of the ANN so that the mystery would be removed, and less interpretation of the results would have to take place. If results needed to be interpreted, the hope was that these modifications and further analysis would aid in the interpretation portion of obtaining the results after.
5 Explainable AI
Predictive algorithms are ubiquitous. They are present in the autonomous AI-driven cars on the road, the choices presented to a viewer on streaming platforms, and the autocomplete in texts and emails. They help in completing our thoughts and predicting what we are going to do based on the information given to them. Predictive algorithms in research perform a similar task: they take inputted data from the researcher, process the data from the past, make predictions for the future, and then output the results. This can be helpful in many fields of research as it allows us to see what the future of a certain possibility might look like without having to go through the work of performing time-consuming experiments and waiting years for the results. The use of data mining models is now a requirement for most research as our datasets have grown to a point where machines are needed to analyze them. In contrast, while many of these datasets have proven to be extensive in their information, much of it is neither useful nor knowledgeable based on the information we need [1]. Therefore, using predictive algorithms have become an essential part of scientific research that has made it easier to obtain results faster so other researchers can build on the work while it is still new.
In particular, two studies, by Ghassemi et al. [3] and Rai [4], stand out prominently in this context. These two studies discuss many limitations currently faced in using artificial intelligence (AI) in health-care research. It is not always understood why AI machines make the choices they do, and the mistrust in the system and the results can lead to the rejection of the systems used [4]. This aversion can be exacerbated in situations where algorithmic bias is highly possible [4].
Along similar lines, Ghassemi et al. [3] discuss the importance of rigorous testing and validation when using AI systems to ensure that they are working safely and are reporting reliable results. Furthermore, they discuss the limitations of easily comprehensible AI, specifically regarding policies, uses, and reporting [3]. In addition, they discuss two types of algorithms: inherently explainable and post-hoc explainable, and provide an example of a form of post-hoc explainable visualization in the form of heat maps, which is a model that does not make clear why the model was built as is to begin with [3]. This gap in interpretability requires researchers to guess the reason and meaning behind the difference in heat signatures observed in the outputted heat map visualization, which can often lead to confirmation bias [3].
6 Replicability
Replicability is often described as the ability to repeat results of an experiment by a subsequent experiment of the same or similar design [17]. Bretz et al. also discuss the impact of replicability on public health and the cost of non-replicable research. Research that is replicable, not only for peer review but also for other researchers to build on and expand, is extremely important. Developments that work toward a brighter future depend on the discoveries of today. Interpretation-based research becomes a hindrance to society’s progress because it depends too heavily on the individual or team conducting the study and their ideas about what the results mean. This a critical problem that has been recorded across various fields and disciplines of research. Machine learning and predictive models used to map big datasets or provide researchers with trends and patterns need to show how they obtained those results to ensure they are correct and reliable. Models that do not portray how their results were achieved can be detrimental as researchers are no longer privy to the machine’s “thought process,” and are therefore unable to spot flaws in the logic unless they are blatantly obvious. Since the ANN processes the input inside its neural networks, a process that researchers are unable to see, it is possible that the model could have wrongly weighted a feature as more important than it should be. It is also possible that a feature that was not supposed to be included found its way into the inputted set of data and completely changed the acquired output. This could skew the results and lead to mistakes and wrongful interpretations, which can be detrimental to the research and everything it impacts.
Within the field of health-care research, a small mistake in the weighting done by the machine learning model can translate into bias and results that impact life-or-death decisions. For example, if a researcher is investigating certain biomarkers pointing toward a specific disease and they interpret the results incorrectly or are unaware of a mistake in them, patients could go on to get prematurely misdiagnosed. The same thing could occur within the industry of pharmaceuticals if a specific drug is being tested for a certain outcome and the results are incorrect or misinterpreted. Despite the risk, predictive algorithms are essential for health-care research, as they are for many other fields. In many situations, researchers are unable to wait years to see results for a specific biomarker or treatment. These models help scientists test theories and obtain conclusions based on past data without performing preliminary experiments on humans and without the extensive time commitments. Through machine learning, researchers can understand the data to a new level and are able to use it to build on possible future breakthroughs. Researchers are also able to use larger datasets for their studies, which can provide them with better, well-rounded results that better portray the desired population. These historical datasets often come from decades of collecting data from thousands of patients and can provide a broad view of the population that was tested. This is why, to ensure they are adhering to good research practices, when scientific investigators are performing a study and form their own dataset through study recruitment, it is better to have a large group of volunteers as it helps to minimize any possible bias and coincidences from within the results.
7 Bias
In addition, to further increase this problem, bias is already present in many of the health-care datasets we have dating back a few decades, leading to a further mistrust of models that do not allow the researcher to understand the process. These historically biased datasets make it easy that many of the machine learning algorithms become biased as well due to the previously biased training data that are unknowingly used.
This biased data comes from centuries of no data on females and people of color, who were not prioritized within the health-care system, and as such were left out of the datasets. In fact, in 2019, it was found that six different algorithms that had been used on approximately 60–100 million patients around the world and had been prioritizing the coordination of care for White people over Black people when they both had the same severity of illness [18]. This happened because the training data used for the algorithm were from insurance claims and their respective costs [18]. Since the dataset was making predictions based on who would be more expensive to take care of in the future, and historically more money is directed toward White patients than Black because of the years of the care of Black people being underprioritized, the algorithm ended up further exacerbating the bias [18]. Years of residential discrimination based on an individual’s race led to research being conducted and samples being taken solely from White males in rich societies that had access to and could afford decent health care and a healthier lifestyle [19]. In addition, for decades, females were frequently left out of the narrative [20]. As such, there is now a huge portion of the population consisting of females and people of color, that is severely underrepresented in the datasets [20] that are used to train many of these models. When this occurs, the output can become skewed or underrepresent the populations it directly impacts.
This is important in the field of health-care research because females and males exhibit different immune responses within diseases [21], which impacts incidence rates and disease progression [22]. It also impacts diagnosis as often diseases that present differently in females, like attention-deficit/hyperactive disorder (ADHD), get overlooked as the symptoms are different and not as pronounced in comparison to males with ADHD, leading to lower rates of diagnosis in women [23]. Furthermore, males and females can respond differently to the same medication, which is important for dosages and recommended treatments [24]. Within racialized communities, it has been discovered that people of color can often be predisposed to increased chances of developing certain diseases, leaving them with a lower health status [25]. This is data that is often not displayed in historic datasets due to the decades of health care for people of color being underprioritized. While these differences may seem minute to some, they are critical to account for in research that will impact males and females, White people and people of color, as well as people with varying backgrounds living in different environments. If the dataset that is being used has 90% of the data collected from White males, and the other 10% being a mix of everyone else, the weights derived from the inputted features for the model are going to be skewed. This unseen bias within the data can lead to incorrect results that may only be applicable to one group of people instead of the majority, which, in a field like health care, is problematic. For a systematic review of bias in health-care professionals, please see the work by FitzGerald and Hurst [26]. More recently, Jessica [27] has addressed structural racism and implicit bias in nursing education.
One main idea to solve this issue is for researchers to manually recruit their own study participants. This way they have full control over the diversity of the participants and can ensure that each individual has the exact characteristics that their study is looking for. This is done in the hopes that it will eliminate any bias toward a specific group of people and provide results that are far more accurate for the general public. However, these datasets continue to exclude women as a study in 2020 proved [28]. It followed up on a 2011 publication of a study conducted in 2009 that originally found that females were routinely excluded from neuroscience studies based on the idea that their different hormones would complicate the results [29]. The 2020 study found that in some fields, the number of studies that included females increased quite a bit in comparison to the 2009 results after the US National Institutes of Health declared that researchers must see sex as a biological feature in 2016 [28]. However, in some other fields, the percentage of studies that included females stayed the same or decreased [28]. A better way to approach this problem is to address the disparities by improving the algorithms, regulating the datasets more closely, and training and hiring more people who are from minority backgrounds [30]. By doing this, it would improve the distribution of people from various sexes and backgrounds, along with the algorithm and the model, while ensuring the study’s results are applicable to a wide range of people. Furthermore, approaches such as “semi-supervised learning,” in which smaller datasets are used to label additional data could be explored.
Since health-care research is going toward using machine learning models that use large datasets to better prepare and conceptualize possible new treatments and prevention plans, the lack of predictive capabilities shortchanges this research. However, this is a trade-off many researchers are forced to make, lest their research potentially hinge on interpretations and potential bias. Predictive machine learning models, specifically ANNs, do not show or explain their processes in obtaining the results, leaving researchers with only the output and no explanation as to what it means. This can lead to conformation bias or the researchers’ own personal bias playing a role in the interpretation, which can lead to inaccurate results being published. When researchers see the output that an ANN gives them, they are required to use those results to determine their conclusion. However, since they are not privy to the process that was undertaken to obtain those results, they have to interpret them based on the data that were inputted into the model. This leaves a lot of room for misinterpretations, and, while sometimes other researchers who are a part of the team are consulted, it can be difficult to stay unbiased if the results could be interpreted to support the original hypothesis.
8 Discussion
In this section, we highlight and summarize the main issues around trustworthiness of the models, and connect them to decision trees and neural networks. Work in this field attempts to expose the processes behind the choices that are made by the ANN models to make them more trustworthy and easier to use and explain. Since decision trees already have this capability, combining both of them through mapping the predetermined weights (as discussed in the research mentioned above) of the ANNs onto the decision tree would enable the researchers to have the best of both worlds. By training the ANN on the dataset and having it determine the weights of the input, and then taking those weights and using them with a decision tree, the decision tree could then visually map out the choices that are made and determine the output. This would give researchers a chance to see how the weights impact the data and why each choice is made, which minimizes the number of errors that go unseen. While it would not necessarily end in the decision tree having the same predictive powers as the ANN, because the same weights are used, it is highly possible that the results would be close. This is important because it gives researchers a chance to use a model that they feel comfortable with and that provides them with the process of determining the output in a way that can be easily explained and defended.
This is why work in the field of explainable AI is becoming more important. Explainable artificial intelligence, which is also known as XAI, is the specific class of systems that provide user with an insight as to how the system is making its decisions and why it is outputting certain results [4]. It would be ideal to have simple models that can provide us with the same capabilities as the more complex models in a way that can be easily explained and understood [4]. They would allow the enjoyment of all the predictive possibilities and benefits of using a model like an ANN, without having to worry about interpreting the results. It would also help us to better understand the model’s strengths and weaknesses, which would be indicative of how it is going to perform in the future [4].
The lack of trust in the ANN model also speaks to a larger ethical issue. These machines have been made to be inherently difficult to trust, and researchers are not privy to those choices. This brings to light the futuristic fear many people have that eventually AI and deep learning systems will make choices for mankind and not with them, as AI systems will no longer require human input to make decisions. This is another reason why this work is so important, because historical algorithms are inherently biased, and by leaving the weights and predictions to an ANN to make, there is a high potential that the choices it makes will be incorrect. Since there is no human presence double checking the processes, there is no guarantee that the results are not inherently biased. There are studies that do not use historical datasets (which may remove the problem of bias) but still do not provide the logic behind the choices, making the ANN slightly untrustworthy as the process that was used by the machine to derive them is unavailable to the user. It will be important to overcome these issues, for example, with regulatory frameworks such as the efforts in Europe aiming to create an ecosystem of trust [31].
These ANN models will not tell a user if they are biased or not, and it is unrealistic to expect researchers to peruse through their datasets before using them to ensure they are unbiased. What is needed are better models, and since creating an entirely new model is time-consuming, creating a hybrid where the best part of one model is taken and combined it with another, is more achievable and would accomplish extremely similar results. This would be beneficial to health-care research as it would build on what is currently available. ANNs and decision trees are indispensable in health-care research and are used for a variety of purposes, including making decisions for patient care, predictive modeling for diseases and pharmaceuticals, and testing how new treatment and administration options might play out. Improving the models would in turn improve the assistance health-care providers are able to provide their patients with by removing both the guesswork and interpretations that are required for current computationally-based research methods.
9 Summary
We highlighted relevant issues around the use of ANNs and decision trees in health-care research with respect to understandability of and trust in the models that are produced, along with bias and replicability. While there is still quite a bit of work that needs to be done in this field to raise AI models and algorithms to a level where they do not require a researcher to make interpretations about the output, hopefully, we will reach a point in the near future where we are able to fully trust our machines as they will all be based on explainable AI models. With our society’s technology improving so rapidly, making this major adjustment would be important for so much more than the health-care sector. It would improve the trust and reliability we have in all AI-driven technology, which is something that has slowly become a major part of our lives. Future work should address how these trust issues could potentially be overcome, especially in view of the regulatory framework for AI in Europe.
-
Conflict of interest: Authors state no conflict of interest.
-
Data availability statement: Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
References
[1] M. Gandhi and S. N. Singh, “Predictions in heart disease using techniques of data mining,” in: 2015 International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), 2015, pp. 520–525. 10.1109/ABLAZE.2015.7154917Search in Google Scholar
[2] D. Dancey, D. A. McLean, and Z. A. Bandar, Decision tree extraction from trained neural networks, American Association for Artificial Intelligence, 2004. Search in Google Scholar
[3] M. Ghassemi, L. Oakden-Rayner, and A. L. Beam, “The false hope of current approaches to explainable artificial intelligence in health care,” The Lancet, vol. 3, pp. 745–750, 2021. 10.1016/S2589-7500(21)00208-9Search in Google Scholar PubMed
[4] A. Rai, “Explainable AI: From black box to glass box,” J. Acad. Marketing Sci., vol. 48, no. 1, pp. 137–141, 2020. 10.1007/s11747-019-00710-5Search in Google Scholar
[5] W. S. McCulloch and W. H. Pitts, “A logical calculus of the ideas immanent in nervous activity,” Bulletin of Mathematical Biophysics, vol. 5, pp. 115–133, 1943. 10.1007/BF02478259Search in Google Scholar
[6] F. Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain,” Psychological Review, vol. 65, no. 6, pp. 386–408, 1958. 10.1037/h0042519. Search in Google Scholar PubMed
[7] P. Charilaou and R. Battat, “Machine learning models and over-fitting considerations,” World J. Gastroenterol., vol. 28, no. 5, pp. 605–607, 2022. 10.3748/wjg.v28.i5.605. PMID: 35316964; PMCID: PMC8905023. Search in Google Scholar PubMed PubMed Central
[8] P. Tan, M. Steinbach, V. Kumar, and A. Karpatne, Introduction to data mining. Pearson Education, New York, NY, 2019. Search in Google Scholar
[9] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” J. Machine Learn. Res., vol. 15, pp. 1929–1958, 2014. Search in Google Scholar
[10] J. R. Quinlan, “Induction of decision trees,” Machine Learning, vol. 1, no. 1, pp. 81–106, 1986. 10.1007/BF00116251Search in Google Scholar
[11] N. Shahid, T. Rappon, and W. Berta, “Applications of artificial neural networks in health care organizational decision-making: A scoping review,” PLoS ONE, vol. 14, no. 2, e0212356, 2019. 10.1371/journal.pone.0212356Search in Google Scholar PubMed PubMed Central
[12] M. J. Montbriand, “Decision tree model describing alternate health care choices made by oncology patients,” Cancer Nursing, vol. 18, no. 2, p. 117, 1995. 10.1097/00002820-199504000-00004Search in Google Scholar
[13] M. Giotta, P. Trerotoli, V. O. Palmieri, F. Passerini, P. Portincasa, I. Dargenio, et al., “Application of a decision tree model to predict the outcome of non-intensive inpatients hospitalized for COVID-19,” Int. J. Environ. Res. Public Health, vol. 19, no. 20, p. 13016, 2022. 10.3390/ijerph192013016. PMID: 36293594; PMCID: PMC9602523. Search in Google Scholar PubMed PubMed Central
[14] C. Chern, Y. Chen, and B. Hsiao, “Decision tree-based classifier in providing telehealth service,” BMC Medical Inform. Decision Making, vol. 19, no. 104, 2019. 10.1186/s12911-019-0825-9Search in Google Scholar PubMed PubMed Central
[15] J. Bae, “The clinical decision analysis using decision tree,” Epidemiol. Health, vol. 36, e2014025, 2014. 10.4178/epih/e2014025Search in Google Scholar PubMed PubMed Central
[16] O. Boz, Converting a trained neural network to a decision tree dectext - decision tree extractor. Ph.D. Dissertation. Lehigh University, USA. Advisor(s) Donald Hillman. Order Number: AAI9982861, 2000. Search in Google Scholar
[17] F. Bretz, W. Maurer, and D. Xi, “Replicability, reproducibility, and multiplicity in drug development,” Chance, vol. 32, no. 4, pp. 4–11, 2019. 10.1080/09332480.2019.1695432Search in Google Scholar
[18] Z. Obermeyer, B. Powers, C. Vogeli, and S. Mullainathan, “Dissecting racial bias in an algorithm used to manage the health of populations,” Science, vol. 366, no. 6464, pp. 447–452, 2019. 10.1126/science.aax2342Search in Google Scholar PubMed
[19] D. R. Williams and C. Collings, “Racial residential segregation: A fundamental cause of racial disparities in health,” Public Health Reports, vol. 116, no. 5, pp. 414–41, 2001. 10.1093/phr/116.5.404Search in Google Scholar PubMed PubMed Central
[20] R. Dresser, “Wanted single, white male for medical research,” The Hastings Center Report, vol. 22, no. 1, pp. 24–29, 1992. 10.2307/3562720Search in Google Scholar
[21] S. L. Klein and K. L. Flanagan, “Sex differences in immune responses,” Nature Reviews Immunology, vol. 16, pp. 626–638, 2016. 10.1038/nri.2016.90Search in Google Scholar PubMed
[22] D. Westergaard, P. Moseley, F. K. H. Sørup, P. Baldi, and S. Brunak, “Population-wide analysis of differences in disease progression patterns in men and women,” Nature Commun., vol. 10, no. 666, pp. 1143–1148, 2019. 10.1038/s41467-019-08475-9Search in Google Scholar PubMed PubMed Central
[23] P. O. Quinn and M. Madhoo, “A review of attention-deficit/hyperactivity disorder in women and girls: Uncovering this hidden diagnosis,” The Primary Care Companion for CNS Disorders, vol. 16, no. 3, PCC.13r01596, 2014. 10.4088/PCC.13r01596Search in Google Scholar PubMed PubMed Central
[24] O. P. Soldin and D. R. Mattison, “Sex differences in pharmacokinetics and pharmacodynamics,” Clin. Pharmacokinetics, vol. 48, no. 3, pp. 143–157, 2009. 10.2165/00003088-200948030-00001Search in Google Scholar PubMed PubMed Central
[25] H. J. Geiger, “Racial and ethnic disparities in diagnosis and treatment: A review of the evidence and a consideration of causes,” Washington (DC): National Academies Press (US), 2003. Search in Google Scholar
[26] C FitzGerald and S. Hurst, “Implicit bias in healthcare professionals: a systematic review,” BMC Med. Ethics, vol. 18, pp. 19–19, 2017. 10.1186/s12910-017-0179-8Search in Google Scholar PubMed PubMed Central
[27] J. H. Jessica, “Addressing health disparities by addressing structural racism and implicit bias in nursing education,” Nurse Education Today, 121, p. 105670, 2023. 10.1016/j.nedt.2022.105670Search in Google Scholar PubMed
[28] N. C. Woitowich, A. Beery, and T. Woodruff, “A 10-year follow-up study of sex inclusion in the biological sciences,” eLife, vol. 9, p. e56344, 2020. 10.7554/eLife.56344Search in Google Scholar PubMed PubMed Central
[29] A. K. Beery and I. Zucker, “Sex bias in neuroscience and biomedical research,” Neurosci. Biobehav. Rev., vol. 35, no. 3, pp. 565–572, 2011. 10.1016/j.neubiorev.2010.07.002Search in Google Scholar PubMed PubMed Central
[30] D. R. Williams and T. D. Rucker, “Understanding and addressing racial disparities in health care,” Health Care Financing Review, vol. 21, no. 4, pp. 75–90, 2000. Search in Google Scholar
[31] European Commission. White Paper on Artificial Intelligence: A European Approach to Excellence and Trust, 2020. Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Regular Articles
- AFOD: Two-stage object detection based on anchor-free remote sensing photos
- A Bi-GRU-DSA-based social network rumor detection approach
- Task offloading in mobile edge computing using cost-based discounted optimal stopping
- Communication network security situation analysis based on time series data mining technology
- The establishment of a performance evaluation model using education informatization to evaluate teacher morality construction in colleges and universities
- The construction of sports tourism projects under the strategy of national fitness by wireless sensor network
- Resilient edge predictive analytics by enhancing local models
- The implementation of a proposed deep-learning algorithm to classify music genres
- Moving object detection via feature extraction and classification
- Listing all delta partitions of a given set: Algorithm design and results
- Application of big data technology in emergency management platform informatization construction
- Evaluation of Internet of Things computer network security and remote control technology
- Solving linear and nonlinear problems using Taylor series method
- Chinese and English text classification techniques incorporating CHI feature selection for ELT cloud classroom
- Software compliance in various industries using CI/CD, dynamic microservices, and containers
- The extraction method used for English–Chinese machine translation corpus based on bilingual sentence pair coverage
- Material selection system of literature and art multimedia courseware based on data analysis algorithm
- Spatial relationship description model and algorithm of urban and rural planning in the smart city
- Hardware automatic test scheme and intelligent analyze application based on machine learning model
- Integration path of digital media art and environmental design based on virtual reality technology
- Comparing the influence of cybersecurity knowledge on attack detection: insights from experts and novice cybersecurity professionals
- Simulation-based optimization of decision-making process in railway nodes
- Mine underground object detection algorithm based on TTFNet and anchor-free
- Detection and tracking of safety helmet wearing based on deep learning
- WSN intrusion detection method using improved spatiotemporal ResNet and GAN
- Review Article
- The use of artificial neural networks and decision trees: Implications for health-care research
Articles in the same Issue
- Regular Articles
- AFOD: Two-stage object detection based on anchor-free remote sensing photos
- A Bi-GRU-DSA-based social network rumor detection approach
- Task offloading in mobile edge computing using cost-based discounted optimal stopping
- Communication network security situation analysis based on time series data mining technology
- The establishment of a performance evaluation model using education informatization to evaluate teacher morality construction in colleges and universities
- The construction of sports tourism projects under the strategy of national fitness by wireless sensor network
- Resilient edge predictive analytics by enhancing local models
- The implementation of a proposed deep-learning algorithm to classify music genres
- Moving object detection via feature extraction and classification
- Listing all delta partitions of a given set: Algorithm design and results
- Application of big data technology in emergency management platform informatization construction
- Evaluation of Internet of Things computer network security and remote control technology
- Solving linear and nonlinear problems using Taylor series method
- Chinese and English text classification techniques incorporating CHI feature selection for ELT cloud classroom
- Software compliance in various industries using CI/CD, dynamic microservices, and containers
- The extraction method used for English–Chinese machine translation corpus based on bilingual sentence pair coverage
- Material selection system of literature and art multimedia courseware based on data analysis algorithm
- Spatial relationship description model and algorithm of urban and rural planning in the smart city
- Hardware automatic test scheme and intelligent analyze application based on machine learning model
- Integration path of digital media art and environmental design based on virtual reality technology
- Comparing the influence of cybersecurity knowledge on attack detection: insights from experts and novice cybersecurity professionals
- Simulation-based optimization of decision-making process in railway nodes
- Mine underground object detection algorithm based on TTFNet and anchor-free
- Detection and tracking of safety helmet wearing based on deep learning
- WSN intrusion detection method using improved spatiotemporal ResNet and GAN
- Review Article
- The use of artificial neural networks and decision trees: Implications for health-care research