AFOD: Two-stage object detection based on anchor-free remote sensing photos
-
Liangrui Fu
 ,
Jinqiu Deng
,
Jinqiu Deng

Abstract
Aerial photo target detection in remote sensing utilizes high-resolution aerial images, along with computer vision techniques, to identify and pinpoint specific objects. To tackle imprecise detection caused by the random arrangement of objects, a two-stage model named anchor-free orientation detection, based on an anchor-free rotating frame, has been introduced. This model aims to deliver encouraging outcomes in the analysis of high-resolution aerial photos. Initially, the model adopts faster Region with CNN feature (faster R-CNN) as a foundational framework. Eliminating the anchor configuration and introducing supplementary angle parameters accommodates the identification of rotating frame objects. Subsequently, it integrates the spatial attention module to seize global semantic information and establish an approximate detection frame with certainty. Additionally, the channel attention module extracts critical features from the semantic data within the predicted frame. Ultimately, the faster R-CNN detection head is employed to refine, leading to enhanced model outcomes and further bolstered regression and classification precision. After validation, the accuracy of the model detection reaches 88.15 and 77.18% on the publicly accessible aerial remote sensing datasets HRSC2016 and DOTA, respectively, which is better than other advanced rotating frame object detection methods.
1 Introduction
In light of the swift advancements in remote sensing photography, the focus on detecting targets within remote sensing images has significantly heightened. Object detection can find the desired object on the image at a distance and can identify the category to which they belong and has universal and far-reaching industry values and prospects in military and civil aviation fields. Among them, the directional object detection model uses a directional frame to detect objects, which can more accurately represent the rotation angle of rectangular objects. Thanks to the swift progress in deep learning, the rotating target detection algorithm has significantly improved its precision in detecting targets, as demonstrated in the literature [1,2,3,4].
Currently, a lot of researchers have done relatively good work in the direction of directional object detection. One instance of this is using the RoI transformer [1], which transforms horizontal detection frames into directional detection frames using the RoI learner module. This module can be integrated into other two-stage target detection models to minimize detection losses. The S2ANet [4] model first generates rotational detection frames using horizontal detection frames, and then the second stage refines them based on the predicted values from the first stage, further improving the accuracy. However, although these object detection models achieve good detection results, they still generate detection frames based on horizontal anchors as a benchmark. Low IOU values due to horizontal frames still seriously affect these models. The rotated region proposal network (RPN) [5] model generates 54 oriented anchors (3 sizes, 3 scales, and 6 angles) on each pixel of the feature map, and these anchors can cover basically all the real boxes. Too many anchor points make the computational workload of the model much higher. Also, all the oriented anchors still cannot cover all the real boxes.
To tackle these challenges, this article introduces a target detection model, AFOD (anchor-free orientation detection), which is based on an anchor-free approach. Figure 1 shows the network structure of AFOD. Instead of using anchor points, the method in this article uses boundary-aware vectors and rotation angles to predict the coarse orientation detection frame of each object. Then, the RoIAlign technique is used to generate two proposed regions of size 7 × 7 and 3 × 11 using a bilinear interpolation method for the input features to generate a more accurate region of interest. The subsequent step involves employing the classification and localization segments of faster R-CNN for projecting the ultimate classification outcomes and bounding boxes oriented toward regression.

Algorithm structure diagram.
In summary, this article makes the following two main contributions:
Examining the limitations associated with horizontal detection frames and anchors in directional object detection, a novel approach is introduced to overcome these challenges. This newly proposed method focuses on anchor-free oriented directional object detection, facilitating the generation of superior proposed regions and leading to a substantial enhancement in the model’s detection capabilities.
After integrating the feature pyramid layer, a spatial attention module (SAM) is incorporated to emphasize the features of the target-containing image. Following the RoIAlign process, a channel attention module (CAM) is included to enhance the features of the object within the specific detection box.
The article is organized as follows: Section 1 presents an overview of the related studies and highlights their constraints. Section 2 offers a comprehensive elucidation of the suggested methodology. Section 3 assesses the practicality of this approach using the DOTA and HRSC2016 datasets and conducts a comparative analysis with current methodologies. Finally, Section 4 outlines the research goals and accomplishments.
2 Related work
With the rapid advancement of deep learning, computer vision has undergone substantial development [6,7,8,9,10,11,12]. Target detection has become a pivotal focus in machine vision research, experiencing notable advancements in recent times. Algorithms for detecting objects are generally categorized into two architectural types, namely, single-stage detectors and two-stage detectors, based on their design principles. Among them, two-stage detectors, including models like faster R-CNN [13,14,15], use a RPN for generating proposal regions and a fully connected network for fusing features and performing accurate classification and localization. Despite achieving higher detection accuracy, the two-stage detectors suffer from high computational complexity and intricate structures [16,17,18,19,20,21,22,23,24,25]. On the other hand, single-stage detectors perform classification and localization directly through a fully convolutional network, exhibiting higher efficiency and a simpler network structure. Nevertheless, the lack of a region of interest operation in single-stage detectors results in an excessive quantity of negative samples, thereby diminishing accuracy. Achieving a balance between positive and negative samples, focal loss [26] assigns a larger coefficient to positive samples, enabling single-stage detection models [26,27,28,29] to achieve comparable accuracy to two-stage detection models.
While directional object detection technology has made significant progress [1,2,3,30,31,32,33,34,35,36,37,38], these methods still have some drawbacks. For instance, although the SCRDet [3] model introduces the IoU-smooth L1 loss function to mitigate the impact of angular periodicity, its performance may be limited when dealing with highly inclined targets. Similarly, while the R3Det [32] model incorporates an encoding function containing center and corner information, its complex design might lead to more intricate training and inference processes. Additionally, although the gliding vertex [2] model can predict the coordinates of the quadrilateral vertices of the target to be detected in the image, it may encounter difficulties when handling blurred or indistinct target boundaries.
Despite these advancements, most directional target detection models still rely on horizontal anchors as references, leading to issues with the accuracy of the detection frame. To address this, several methods have been explored. For instance, RoI transformer [1] transforms the region of interest from a horizontal to a directed box scheme, effectively improving detection accuracy. S2ANet [4] aligns directed object features during the refinement phase to produce more precise predictions. While these methods have shown some success, they still rely on horizontal anchors for generating recommended regions, which results in a significant IoU problem associated with horizontal boxes. Several studies [6,39] employ directed anchors directly on images to generate specific regions of interest (RoI) or predicted targets. However, this technique involves creating multiple rotation anchors on the image, resulting in decreased efficiency and a notable disparity between the number of target objects and the background. Moreover, even with specialized designs, anchors often fail to match all target objects, as highlighted in the study of Tian et al. [40].
As a result, scholars have proposed anchor-free-based target detection models. These models [19] obtain anchor points from the feature map and extract overall object features centered on those anchor points. The cascade RPN [18] model employs a cascade structure to generate adaptive anchors step by step. Models such as FCOS [40] and FoveaBox [41] directly obtain detection boxes from point regression, predicting the distance of an object from points without predefined anchors. In a departure from the conventional approach, the CornerNet [42] and CenterNet [43] models treat target detection as point detection [44]. While CornerNet [42] predicts the top left and bottom right points of the object’s bounding box, CenterNet [43] focuses on detecting the center point of the object. For directional target detection, the DRN [31] adopts a point detection strategy, introducing a novel concept to directional target detection. Similarly, the BBAVector [45] model extends the object centroid generated by CenterNet [43] to a directional detection frame by generating a boundary-aware vector.
In summary, it can be seen that the existing methods usually have some limitations as follows: (1) Because of the mismatch between the detection frame orientation and the actual shape of the target, horizontal detection frames frequently encompass numerous background areas or other unintended objects. Consequently, during the training phase, the object’s features might incorporate a plethora of irrelevant elements, thereby impacting the model’s accuracy; (2) the model that relies on anchors necessitates a significant number of anchor operations, leading to a substantial increase in computational load and consequently, hampering the overall speed of the model. To address these limitations, a new anchor-free-based orientation object detection model (AFOD) is proposed. Instead of sliding on the input image to generate anchors of different sizes, the method is expanded by pixel points of the feature map into a detection frame of a specific orientation, thus avoiding the undesirable effects generated by horizontal anchors.
3 Algorithm design
3.1 Algorithm framework structure
In this article, the algorithm’s backbone network utilizes ResNet-50 and incorporates augment feature pyramid networks (AugFPNs) to merge the characteristics from each feature map. Given the prevalence of small objects in remote sensing photos and the complexity of the images, the algorithm in question employs AugFPN to enhance the precision of detecting small-sized targets. Meanwhile, in order to better detect the tilted and relatively large objects in length and width, this article adds an additional parameter θ ∈ [0, π/2], which refers to the angle between the short edge of the enclosing frame and the horizontal direction, in addition to the anchor-free approach. The initial feature map identifies the object’s location in the image by applying the SAM. Subsequently, the anchor-free rotating frame object detection module determines the confidence level and the bounding frame. Utilizing the coordinates of the bounding frame, the relevant segment of the feature map is chosen, and the RoIAlign module produces two feature maps of the region of interest, sized 7 × 7 and 3 × 11. These maps are further enriched by the CAM. The accurate detection results are ultimately derived using the R-CNN detection head module. The algorithm’s structure is illustrated in Figure 1.
3.2 Augment feature pyramid
The AugFPN proposes consistent supervision, which applies the same supervisory signal to features at different scales before feature integration to attenuate the differences between their semantic information. First, a feature pyramid is constructed based on multiple feature layers {C2, C3, C4, C5} of the backbone network, and then multiple RoI are generated at the feature pyramid layers {P2, P3, P4, P5} using the RPN, and map all the RoI to each feature layer, and get the features of the {M2, M3, M4, M5} RoI in each layer by RoIAlign, and finally add the branches used for prediction to get the auxiliary loss, as shown in Figure 2.

AugFPN structure diagram.
The network structure allows sharing the parameters on all layers into the output and fusing features from different layers to obtain more semantic information. Since the auxiliary loss and the predicted loss have different effects on the model, an additional weight is needed to balance them, as follows:
where L cls,M and L loc,M denote the losses on the feature map {M2, M3, M4, M5}, L cls,P and L loc,P represent the losses on the feature pyramid {P2, P3, P4, P5}. The variables n M and n P , respectively, refer to the total number of predictions at the Mth level of the feature map at the Pth level of the feature pyramid. Furthermore, p M and d M are the prediction results of the feature map, while p and d represent the feature prediction results of the pyramid. The terms t * and b * indicate the confidence and regression values of the true box, respectively. λ serves as the parameter for adjusting the proportion of auxiliary and original losses, whereas β is the parameter used for regulating the proportion of categorical and regression losses. Additionally, [t * ] is defined as follows:
3.3 AFOD box
The method in this article uses anchor-free object detection to produce rough orientation detection frames and confidence levels. The rough orientation detection box includes distance and angle, which are denoted by l, r, t, b, and θ, respectively, and the confidence level is denoted by c. Let B g = (x g,y g,w g,h g,θ g) be the ground truth box of an object, where B g ∈ ℜ 5 × C, (x g, y g) denotes the center coordinates of the object, w g and h g represent the object’s width and height, correspondingly. θ g represents the counterclockwise rotation angle of the actual bounding box, while C stands for the category number. In the classification branch, for each position (x, y), if it lies in the central region B δ = (x g, y g, δw g, δh g, θ g) of the real frame, and δ denotes the centrality, the position is labeled with a positive sample. The disparity between each site and the actual position is
If both |∆x| < δw g/2 and |∆y| < δh g/2 are satisfied, the position is a positive sample, as shown in Figure 3.

AFOD box.
In the regression branch, each positive sample is represented by d = (l,r,t,b,θ), indicating the distances from (x, y) to the left, right, upper, and lower bounding boxes, alongside the angle between the lower edge and the positive X-axis, where the values of l, r, t, b are calculated as follows:
3.4 RoIAlign
The implementation of RoIAlign in this article is shown in Figure 4. RoIAlign is based on the bilinear interpolation method, which uses the four nearest pixels on the feature map to obtain the pixel values, which are usually floating-point coordinates, so the interpolation method is used to obtain the pixel values. The output is the maximum of the four sampling points. In order to adapt to objects with large length and width, the regions of interest of 7 × 7 and 3 × 11 sizes are selected as the output. Ultimately, the CAM is leveraged to accentuate the distinctive foreground attributes while subduing the background elements.
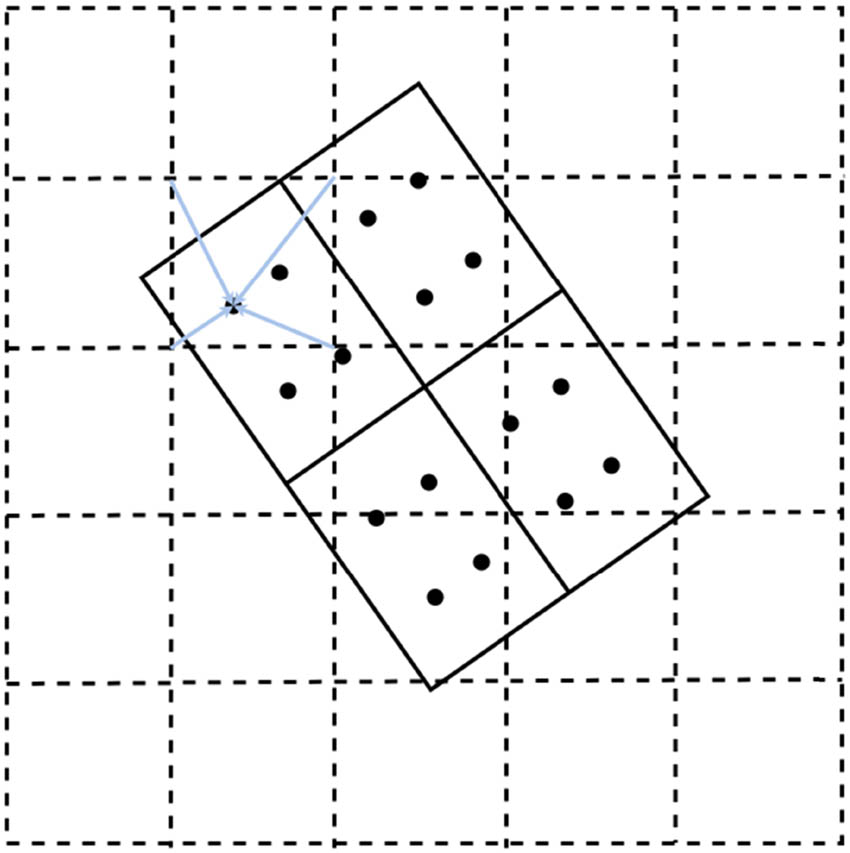
RoIAlign.
3.5 Faster R-CNN head
Utilizing the faster R-CNN detection head, we derive the ultimate classification outcomes and the localization frame coordinates. Within this component, the input feature map is transformed into a feature vector through two fully connected (FC) layers, later divided into a classification segment and a regression segment. The classification segment employs a single fully connected layer to forecast the classification score; in the regression segment, another parameter θ is added for the regression of the angle, i.e., the bounding box of the regression is denoted as (l, r, t, b, θ), where θ ∈ [0, π/2], in order to obtain the rotated detection frame, the final regression result is obtained by one fully connected layer. More accurate classification scores and directed detection boxes can be predicted using this module.
3.6 Loss function
The loss function in this article contains two components, the function L R-CNN of the augmented feature pyramid and the function L head of the detection head, where L R-CNN is shown in equation (1) and L head is as follows:
where L cls and L loc denote score loss and coordinate loss, respectively, used in this article are softmax and smooth-L1, respectively. The score value and coordinate value of the authentic frame are denoted as z* and d*, respectively. n denotes the t total sample count across the feature pyramid, and [z*] is defined as follows:
The total loss function of the algorithm in this article is
4 Experiment
The experiments in this article are initialized using the pre-trained ResNet-50 model. For each layer in AugFPN (P2∼P6), the corresponding normalization factors are set to {16, 32, 64, 128, 256}. The centrality δ in the anchor-free frame object detection module is set to 0.3. The experiments are trained and tested using NVIDIA RTX3060Ti. Multi-scale experiments are conducted on the datasets DOTA. First, the input picture is scaled to 3 sizes, 0.5, 1.0, and 2.0, and then all three scales are cropped to 1,024 × 1,024 size with a step size of 200 and trained for 24 epochs. SGD (stochastic gradient descent) serves as the model’s optimizer, with an initial learning rate of 0.005 and a decay rate of 0.1. The weight decay stands at 0.0001, while the momentum parameter is set to 0.9. The NMS (non-maximum suppression) threshold is fixed at 0.8.
4.1 Evaluation metrics
The model presented in this article utilizes the mean average precision (mAP) as its evaluation metric. In target detection, there are usually three types of detection results: correct detection boxes (TP), false detection boxes (FP), and missed detection boxes (FN). For these three cases, the accuracy (precision) and recall (recall) test criteria are used to verify the capability of the target detection algorithm. They are calculated as follows:
The mAP is the result obtained by detecting the average accuracy of all categories and then taking the average. In the detection process, the accuracy and recall of each prediction frame are calculated, and the point (P, R) is obtained. Each time an R value is acquired, it serves as the threshold for the subsequent calculations. When the R value surpasses this threshold, the maximum accuracy for the corresponding scenario is determined. By computing the average of these accuracies, the AP is derived, and subsequently, the mAP is computed from the collective average of all classified APs.
4.2 Datasets
The experimental data presented in this study primarily rely on two publicly accessible datasets for aerial remote sensing images: the DOTA datasets [34] and the HRSC2016 datasets [39]. The DOTA datasets consist of 2,806 aerial images with varying scene sizes, ranging from 800 × 800 to 4,000 × 4,000. These images encompass 188,282 instances distributed across 15 categories. The labeling technique involves a quadrilateral delineated by four points, allowing horizontal bracketing box and oriented bracketing box (OBB) detection tasks. Among the images, 1,411 are assigned to the training set, 458 to the validation set, and 937 to the test set. The classes within the DOTA datasets include plane (PL), bridge (BR), port (HA), athletic field (GTF), small vehicle (SV), large vehicle (LV), roundabout (RA), swimming pool (SP), ship (SH), soccer field (SBF), tennis court (TC), basketball court (BC), oil storage tank (ST), baseball field (BD), and helicopter (HC). On the other hand, the HRSC2016 datasets comprise 1,061 images and 2,976 instances captured from Google Earth, annotated in an oriented bracketing box (OBB) format. The dataset includes 436 images and 1,207 instances in the training set, 181 images and 541 instances in the validation set, and 444 images and 1,228 instances in the test set, constituting a comprehensive high-resolution detection dataset. Notably, for the purposes of this study, all ships within the datasets are grouped under a singular “ship” category during the training and testing phases.
4.3 Experimental results
The validation results for our approach to the DOTA datasets are depicted in Figure 5. Table 1 displays a comparison between the accuracy of our method and other models on the same datasets, where bold numbers indicate the currently optimal performance. To ensure the impact of the backbone network does not affect the results, all the compared models in this study utilize Resnet-50 or Resnet-101 and FPN as the feature extraction network, thus demonstrating the efficacy of the model structure. As can be seen from Table 1, the mAP of the method in this article reaches 77.18%, and the AP of this article is improved by about 2% compared with other methods in the categories of aircraft, large vehicles, and swimming pools, and about 3% in the categories of athletic fields and small vehicles, and even about 4% in the category of roundabout intersection. Compared to the top-performing one-stage model, AFOD further improves the mAP by 3.06%. First, the AFOD model utilizes an anchor-free approach, which, in contrast to traditional anchor-based methods, may suffer from limitations imposed by anchor settings in certain scenarios, leading to a certain degree of precision loss. Second, the AFOD model incorporates SAMs and CAMs, which help the model focus more on crucial features, extract and strengthen useful information, thereby contributing to improved accuracy in target detection. Finally, the AFOD model is based on a rotation framework specifically designed for directional targets. This enables the model to better adapt to the presence of rotating targets in the DOTA dataset, accurately capturing the orientation information of the targets. In contrast to the two-stage method, the gliding vertex technique aims to minimize the sequential label point confusion by smoothly moving vertices along the sides of the horizontal bounding box to depict objects with multiple orientations. Additionally, it incorporates an obliquity factor dependent on the area ratio to determine whether to opt for horizontal or oriented detection. However, the gliding vertex approach could face constraints when handling rotated objects. In contrast, the AFOD model, by removing the anchor setting and introducing additional angle parameters, can more accurately capture targets in the rotating frame, effectively addressing the limitations of traditional horizontal detection frameworks in multi-oriented object detection.

DOTA dataset visualization results.
Results of different models on the datasets DOTA
| Method | Backbone | Plane | BD | Bridge | GTF | SV | LV | Ship | TC |
|---|---|---|---|---|---|---|---|---|---|
| One-stage | |||||||||
| DAL [46] | R-50-FPN | 88.68 | 76.55 | 45.08 | 66.80 | 67.00 | 76.76 | 79.74 | 90.84 |
| R3Det [32] | R-101-FPN | 88.76 | 83.09 | 50.91 | 67.27 | 76.23 | 80.39 | 86.72 | 90.78 |
| S3ANet [4] | R-50-FPN | 89.11 | 82.84 | 48.37 | 71.11 | 78.11 | 78.39 | 87.25 | 90.83 |
| Two-stage | |||||||||
| Faster R-CNN-O* [13] | R-50-FPN | 88.44 | 73.06 | 44.86 | 59.09 | 73.25 | 71.49 | 77.11 | 90.84 |
| ROI transformer* [1] | R-50-FPN | 88.65 | 82.60 | 52.53 | 70.87 | 77.93 | 76.67 | 86.87 | 90.71 |
| Gliding vertex [2] | R-101-FPN | 89.64 | 85.00 | 52.26 | 77.34 | 73.01 | 73.14 | 86.82 | 90.74 |
| Ours | |||||||||
| AFOD | R-50-FPN | 89.42 | 86.02 | 51.62 | 77.56 | 78.36 | 76.91 | 79.77 | 91.79 |
| AFOD | R-101-FPN | 90.17 | 87.14 | 52.18 | 78.18 | 79.33 | 81.41 | 84.31 | 91.12 |
| Method | Backbone | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|
| One-stage | |||||||||
| DAL [46] | R-50-FPN | 79.54 | 78.45 | 57.71 | 62.27 | 69.05 | 73.14 | 60.11 | 71.44 |
| R3Det [32] | R-101-FPN | 84.68 | 83.24 | 61.98 | 61.35 | 66.91 | 70.63 | 53.94 | 73.79 |
| S3ANet [4] | R-50-FPN | 84.90 | 85.64 | 60.36 | 62.60 | 65.26 | 69.13 | 57.64 | 74.12 |
| Two-stage | |||||||||
| Faster R-CNN-O* [13] | R-50-FPN | 78.94 | 83.90 | 48.59 | 62.95 | 62.18 | 64.91 | 56.18 | 69.05 |
| ROI transformer* [1] | R-50-FPN | 83.83 | 82.51 | 53.95 | 67.61 | 74.67 | 68.75 | 61.03 | 74.61 |
| Gliding vertex [2] | R-101-FPN | 79.02 | 86.81 | 59.55 | 70.91 | 72.94 | 70.86 | 57.32 | 75.02 |
| Ours | |||||||||
| AFOD | R-50-FPN | 84.51 | 85.62 | 59.61 | 70.15 | 71.36 | 70.92 | 59.72 | 76.79 |
| AFOD | R-101-FPN | 86.12 | 87.44 | 62.15 | 71.82 | 72.15 | 73.22 | 61.31 | 77.18 |
The validation results of our method on the HRSC2016 datasets are depicted in Figure 6. Table 2 presents a comparison between the accuracy of our approach in this article and that of alternative models on the same datasets, where bold numbers indicate the currently optimal performance. On the HRSC2016 dataset, although the RoI transformer has introduced a novel RoI transformation module that can optimize localization and feature extraction, it may not comprehensively address the challenges of object detection in a rotating framework. In contrast, the AFOD model employs an anchor-free approach based on the rotating frame in its proposed algorithm, combined with spatial attention and CAMs. Consequently, it can more accurately locate and identify targets in high-resolution aerial photographs, achieving an mAP of 88.15%.

HRSC2016 datasets visualization results.
Results of different models on the datasets HRSC2016
| Method | Backbone | Image size | FPS | AP |
|---|---|---|---|---|
| R2PN [47] | VGG16 | 384 × 384 | — | 79.60 |
| RRD [48] | VGG16 | 512 × 800 | — | 84.30 |
| ROI transformer [1] | R-101-FPN | 608 × 608 | 5.9 | 86.20 |
| DAL [46] | R-101-FPN | 608 × 608 | — | 87.52 |
| S3ANet [4] | R-101-FPN | 608 × 608 | — | 87.90 |
| AFOD | R-101-FPN | 608 × 608 | 11.2 | 88.15 |
5 Conclusion
Based on the analysis of the limitations associated with anchor-based and horizontal detection box target detection models, this research introduces an innovative anchor-free rotating target detection model, AFOD, which not only overcomes these limitations but also significantly enhances feature extraction through the integration of an SAM and a CAM. The experimental results showcase the superiority of the AFOD over other target detection models, both in terms of detection accuracy on the DOTA datasets and the HRSC2016 datasets and in achieving a detection efficiency that surpasses that of other two-stage models.
Despite the substantial progress demonstrated by the AFOD model in aerial remote sensing photo target detection, it is crucial to recognize certain limitations. Primarily, the intricate architecture of the model could potentially hinder computational efficiency, especially when processing extensive aerial images. Additionally, although the AFOD aims to tackle imprecise detection resulting from arbitrary object arrangements, its efficacy might be compromised in instances involving densely cluttered and overlapping objects.
Going forward, it will be essential to investigate how the AFOD model can complement other established methods tailored for detecting rotating targets. This exploration aims to foster the creation of more resilient and adaptable detection systems. Additionally, investigating the feasibility of applying the principles of the AFOD to single-stage multidirectional target detection represents a promising avenue for further research and development in the field. Moreover, there is a need to optimize the model’s adaptability to various environmental conditions and to ensure its scalability for real-time applications, especially in scenarios where timely and accurate target detection is critical.
-
Funding information: This research received no external funding.
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors declare that there is no conflict of interest regarding the publication of this article.
-
Data availability statement: The data used to support the findings of this study are included within the article.
References
[1] J. Ding, N. Xue, Y. Long, G. S. Xia, and Q. Lu, “Learning roi transformer for oriented object detection in aerial images,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2849–2858.10.1109/CVPR.2019.00296Search in Google Scholar
[2] Y. Xu, M. Fu, Q. Wang, Y. Wang, K. Chen, G. S. Xia, et al., “Gliding vertex on the horizontal bounding box for multi-oriented object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 4, 2020, pp. 1452–1459.10.1109/TPAMI.2020.2974745Search in Google Scholar PubMed
[3] X. Yang, J. Yang, J. Yan, Y. Zhang, T. Zhang, Z. Guo, et al., “Scrdet: Towards more robust detection for small, cluttered and rotated objects,” In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8232–8241.10.1109/ICCV.2019.00832Search in Google Scholar
[4] J. Han, J. Ding, J. Li, and G. S. Xia, “Align deep features for oriented object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2021.10.1109/TGRS.2021.3062048Search in Google Scholar
[5] J. Ma, W. Shao, H. Ye, L. Wang, H. Wang, Y. Zheng, et al., “Arbitrary-oriented scene text detection via rotation proposals,” IEEE Trans. Multimedia, vol. 20, no. 11. pp. 3111–3122, 2018.10.1109/TMM.2018.2818020Search in Google Scholar
[6] K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,” ISPRS J. Photogramm. Remote Sens., vol. 159, pp. 296–307, 2020.10.1016/j.isprsjprs.2019.11.023Search in Google Scholar
[7] X. Sun, B. Wang, Z. Wang, H. Li, H. Li, and K. Fu, “Research progress on few-shot learning for remote sensing image interpretation,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 2387–2402, 2021.10.1109/JSTARS.2021.3052869Search in Google Scholar
[8] Q. He, X. Sun, Z. Yan, and K. Fu, “Dabnet: Deformable contextual and boundary-weighted network for cloud detection in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–16, 2022.10.1109/TGRS.2020.3045474Search in Google Scholar
[9] G. Cheng, C. Yang, X. Yao, L. Guo, and J. Han, “When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNS,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 5. pp. 2811–2821, 2018.10.1109/TGRS.2017.2783902Search in Google Scholar
[10] G. Cheng, B. Yan, P. Shi, K. Li, X. Yao, L. Guo, et al., “Prototypecnn for few-shot object detection in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–10, 2022.10.1109/TGRS.2021.3078507Search in Google Scholar
[11] X. Feng, J. Han, X. Yao, and G. Cheng, “Tcanet: Triple contextaware network for weakly supervised object detection in remote sensing images,” IEEE Trans. Geosci. Remote Sens.,” vol. 59, no. 8. pp. 6946–6955.10.1109/TGRS.2020.3030990Search in Google Scholar
[12] G. Cheng, X. Sun, K. Li, L. Guo, and J. Han, “Perturbation-seeking generative adversarial networks: A defense framework for remote sensing image scene classification,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.10.1109/TGRS.2021.3081421Search in Google Scholar
[13] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: towards real-time object detection with region proposal networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6. pp. 1137–1149, 2016.10.1109/TPAMI.2016.2577031Search in Google Scholar PubMed
[14] R. Girshick, “Fast R-CNN,” In Proceedings of IEEE International Conference on Computer Vision, 2015, pp. 1440–1448.10.1109/ICCV.2015.169Search in Google Scholar
[15] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask R-CNN,” In Proceedings of IEEE International Conference on Computer Vision, 2017, pp. 2961–2969.10.1109/ICCV.2017.322Search in Google Scholar
[16] L. Liu, W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu, et al., “Deep learning for generic object detection: A survey,” Int. J. Comput. Vis., vol. 128, no. 2. pp. 261–318, 2020.10.1007/s11263-019-01247-4Search in Google Scholar
[17] Z. Cai and N. Vasconcelos, “Cascade R-CNN: Delving into high quality object detection,” In Proc. IEEE Int. Conf. Comput. Vision Pattern Recognit, 2018, p. 6154–6162.10.1109/CVPR.2018.00644Search in Google Scholar
[18] T. Vu, H. Jang, T. X. Pham, and C. D. Yoo, “Cascade rpn: Delving into high-quality region proposal network with adaptive convolution,” In Proc. Conf. Adv. Neural Inform. Process. Syst., 2019, pp. 1–11.Search in Google Scholar
[19] J. Wang, K. Chen, S. Yang, C. C. Loy, and D. Lin, “Region proposal by guided anchoring,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2965–2974.10.1109/CVPR.2019.00308Search in Google Scholar
[20] J. Pang, K. Chen, J. Shi, H. Feng, W. Ouyang, and D. Lin, “Libra RCNN: Towards balanced learning for object detection,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 821–830.10.1109/CVPR.2019.00091Search in Google Scholar
[21] T. -Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 2117–2125.10.1109/CVPR.2017.106Search in Google Scholar
[22] G. Cheng, C. Lang, M. Wu, X. Xie, X. Yao, and J. Han, “Feature enhancement network for object detection in optical remote sensing images,” J. Remote Sens., vol. 2021, pp. 101–114, 2021.10.34133/2021/9805389Search in Google Scholar
[23] G. Cheng, Y. Yao, S. Li, K. Li, X. Xie, J. Wang, et al., “Dual-aligned oriented detector,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.10.1109/TGRS.2022.3149780Search in Google Scholar
[24] K. Li, G. Cheng, S. Bu, and X. You, “Rotation-insensitive and context augmented object detection in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 4. pp. 2337–2348, 2018.10.1109/TGRS.2017.2778300Search in Google Scholar
[25] G. Cheng, J. Han, P. Zhou, and D. Xu, “Learning rotation-invariant and fifisher discriminative convolutional neural networks for object detection,” IEEE Trans. Image Process, vol. 28, no. 1. pp. 265–278, 2019.10.1109/TIP.2018.2867198Search in Google Scholar PubMed
[26] T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for dense object detection,” In Proceedings of IEEE International Conference on Computer Vision, 2017, pp. 2980–2988.10.1109/ICCV.2017.324Search in Google Scholar
[27] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unifified, real-time object detection,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 779–788.10.1109/CVPR.2016.91Search in Google Scholar
[28] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, et al., “Ssd: Single shot multibox detector,” In Proc. Eur. Conf. Comput. Vis., 2016, pp. 21–37.10.1007/978-3-319-46448-0_2Search in Google Scholar
[29] S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9759–9768.10.1109/CVPR42600.2020.00978Search in Google Scholar
[30] X. Xie, G. Cheng, J. Wang, X. Yao, and J. Han, “Oriented R-CNN for object detection,” In Proceedings of IEEE International Conference on Computer Vision, 2021, pp. 3520–3529.10.1109/ICCV48922.2021.00350Search in Google Scholar
[31] X. Pan, Y. Ren, K. Sheng, W. Dong, H. Yuan, X. Guo, et al., “Dynamic refinement network for oriented and densely packed object detection,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11207–11216.10.1109/CVPR42600.2020.01122Search in Google Scholar
[32] X. Yang, Q. Liu, J. Yan, A. Li, Z. Zhang, and G. Yu, “R3det: Refined single-stage detector with feature refinement for rotating object,” arXiv preprint arXiv:1908.05612, 2019.Search in Google Scholar
[33] G. Cheng, P. Zhou, and J. Han, “Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 12. pp. 7405–7415, 2016.10.1109/TGRS.2016.2601622Search in Google Scholar
[34] G. -S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, et al., “Dota: A large-scale dataset for object detection in aerial images,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 3974–3983.10.1109/CVPR.2018.00418Search in Google Scholar
[35] J. Wang, J. Ding, H. Guo, W. Cheng, T. Pan, and W. Yang, “Mask OBB: A semantic attention-based mask oriented bounding box representation for multi-category object detection in aerial images,” Remote Sens., vol. 11, no. 24. p. 2930, 2019.10.3390/rs11242930Search in Google Scholar
[36] K. Fu, Z. Chang, Y. Zhang, and X. Sun, “Point-based estimator for arbitrary-oriented object detection in aerial images,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 5, pp. 4370–4387, 2020.10.1109/TGRS.2020.3020165Search in Google Scholar
[37] J. Wang, W. Yang, H. C. Li, H. Zhang, and G. S. Xia, “Learning center probability map for detecting objects in aerial images,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 5, pp. 4307–4323, 2020.10.1109/TGRS.2020.3010051Search in Google Scholar
[38] C. Li, C. Xu, Z. Cui, D. Wang, T. Zhang, and J. Yang, “Featureattentioned object detection in remote sensing imagery,” In IEEE International Conference on Image Processing, 2019, pp. 3886–3890.10.1109/ICIP.2019.8803521Search in Google Scholar
[39] Z. Liu, H. Wang, L. Weng, and Y. Yang, “Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds,” IEEE Geosci. Remote Sens. Lett., vol. 13, no. 8. pp. 1074–1078, 2016.10.1109/LGRS.2016.2565705Search in Google Scholar
[40] Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional one stage object detection,” In Proc. IEEE Int. Conf. Comput. Vision, 2019, pp. 9627–9636.10.1109/ICCV.2019.00972Search in Google Scholar
[41] T. Kong, F. Sun, H. Liu, Y. Jiang, L. Li, and J. Shi, “Foveabox: Beyond anchor-based object detection,” IEEE Trans Image Process, vol. 29, pp. 7389–7398, 2020.10.1109/TIP.2020.3002345Search in Google Scholar
[42] H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” In Proc. Eur. Conf. Comput. Vis., 2018, pp. 734–750.10.1007/978-3-030-01264-9_45Search in Google Scholar
[43] X. Zhou, D. Wang, and P. Krahenbuhl, “Objects as points,” arXiv preprint arXiv:1904.07850, 2019.Search in Google Scholar
[44] J. Yang, Q. Liu, and K. Zhang, “Stacked hourglass network for robust facial landmark localisation,” In Proc. IEEE Int. Conf. Comput. Vision Pattern Recognit. Workshops, 2017, pp. 79–87.10.1109/CVPRW.2017.253Search in Google Scholar
[45] J. Yi, P. Wu, B. Liu, Q. Huang, H. Qu, and D. Metaxas, “Oriented object detection in aerial images with box boundary-aware vectors,” In Proc. IEEE Winter Conf. Appl. Comput. Vis, 2021, pp. 2150–2159.10.1109/WACV48630.2021.00220Search in Google Scholar
[46] Q. Ming, Z. Zhou, L. Miao, H. Zhang, and L. Li, “Dynamic anchor learning for arbitrary-oriented object detection,” arXiv preprint arXiv:2012.04150, 2020.Search in Google Scholar
[47] Z. H. Zhang, W. W. Guo, S. G. Zhu, and W. X. Yu, “Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks,” IEEE Geosci. Remote Sens. Lett., vol. 15, no. 11. pp. 1745–1749, 2018.10.1109/LGRS.2018.2856921Search in Google Scholar
[48] M. H. Liao, Z. Zhu, B. G. Shi, G. S. Xia, and X. Bai. “Rotation-sensitive regression for oriented scene text detection,” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5909–5918.10.1109/CVPR.2018.00619Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Regular Articles
- AFOD: Two-stage object detection based on anchor-free remote sensing photos
- A Bi-GRU-DSA-based social network rumor detection approach
- Task offloading in mobile edge computing using cost-based discounted optimal stopping
- Communication network security situation analysis based on time series data mining technology
- The establishment of a performance evaluation model using education informatization to evaluate teacher morality construction in colleges and universities
- The construction of sports tourism projects under the strategy of national fitness by wireless sensor network
- Resilient edge predictive analytics by enhancing local models
- The implementation of a proposed deep-learning algorithm to classify music genres
- Moving object detection via feature extraction and classification
- Listing all delta partitions of a given set: Algorithm design and results
- Application of big data technology in emergency management platform informatization construction
- Evaluation of Internet of Things computer network security and remote control technology
- Solving linear and nonlinear problems using Taylor series method
- Chinese and English text classification techniques incorporating CHI feature selection for ELT cloud classroom
- Software compliance in various industries using CI/CD, dynamic microservices, and containers
- The extraction method used for English–Chinese machine translation corpus based on bilingual sentence pair coverage
- Material selection system of literature and art multimedia courseware based on data analysis algorithm
- Spatial relationship description model and algorithm of urban and rural planning in the smart city
- Hardware automatic test scheme and intelligent analyze application based on machine learning model
- Integration path of digital media art and environmental design based on virtual reality technology
- Comparing the influence of cybersecurity knowledge on attack detection: insights from experts and novice cybersecurity professionals
- Simulation-based optimization of decision-making process in railway nodes
- Mine underground object detection algorithm based on TTFNet and anchor-free
- Detection and tracking of safety helmet wearing based on deep learning
- WSN intrusion detection method using improved spatiotemporal ResNet and GAN
- Review Article
- The use of artificial neural networks and decision trees: Implications for health-care research
Articles in the same Issue
- Regular Articles
- AFOD: Two-stage object detection based on anchor-free remote sensing photos
- A Bi-GRU-DSA-based social network rumor detection approach
- Task offloading in mobile edge computing using cost-based discounted optimal stopping
- Communication network security situation analysis based on time series data mining technology
- The establishment of a performance evaluation model using education informatization to evaluate teacher morality construction in colleges and universities
- The construction of sports tourism projects under the strategy of national fitness by wireless sensor network
- Resilient edge predictive analytics by enhancing local models
- The implementation of a proposed deep-learning algorithm to classify music genres
- Moving object detection via feature extraction and classification
- Listing all delta partitions of a given set: Algorithm design and results
- Application of big data technology in emergency management platform informatization construction
- Evaluation of Internet of Things computer network security and remote control technology
- Solving linear and nonlinear problems using Taylor series method
- Chinese and English text classification techniques incorporating CHI feature selection for ELT cloud classroom
- Software compliance in various industries using CI/CD, dynamic microservices, and containers
- The extraction method used for English–Chinese machine translation corpus based on bilingual sentence pair coverage
- Material selection system of literature and art multimedia courseware based on data analysis algorithm
- Spatial relationship description model and algorithm of urban and rural planning in the smart city
- Hardware automatic test scheme and intelligent analyze application based on machine learning model
- Integration path of digital media art and environmental design based on virtual reality technology
- Comparing the influence of cybersecurity knowledge on attack detection: insights from experts and novice cybersecurity professionals
- Simulation-based optimization of decision-making process in railway nodes
- Mine underground object detection algorithm based on TTFNet and anchor-free
- Detection and tracking of safety helmet wearing based on deep learning
- WSN intrusion detection method using improved spatiotemporal ResNet and GAN
- Review Article
- The use of artificial neural networks and decision trees: Implications for health-care research