Augmenting heart disease prediction with explainable AI: A study of classification models
-
Raja Rani Titti
 ,
Shalini Pukkella
,
Shalini Pukkella

Abstract
Although heart disease stands as a prominent contributor to worldwide deaths, not all individuals affected by it ultimately fall prey to its effects. Timely diagnosis and effective treatment can offer those with heart conditions a high-quality life in their later years. Consequently, early disease detection using accessible medical data has been a central goal for researchers in recent decades. Traditionally, researchers relied on statistical tools for this purpose. However, machine learning algorithms, especially classification models, have gained prominence with the growing accumulated data. These algorithms have shown promise in predicting heart disease based on individual data. Our study employed various classification algorithms to predict heart disease incidence using the available dataset. We prioritized model reliability by incorporating the conformal classifier. Our results have shown that boosting algorithms, such as XGBoost and CatBoost, demonstrated exceptional performance with promising metrics. These models identified chest pain type and ST segment slope as crucial indicators of heart disease. Boosting algorithms exhibited a compelling combination of broad coverage and a small prediction set size, making them well-suited for heart disease prediction. Furthermore, we employed explainable artificial intelligence-boosting algorithms to enhance the interpretability of our predictions.
1 Introduction
Heart disease significantly contributes to mortality, but it is crucial to emphasize that not all individuals diagnosed with heart disease face fatal outcomes. Timely and precise diagnosis and appropriate treatment can empower those dealing with heart diseases to lead fulfilling lives well into their later years, substantially enhancing their overall quality of life. Recent advancements have introduced potent tools like machine learning (ML) classification models, which have become instrumental in delivering accurate heart disease diagnoses. These models harness patient data to provide promising predictions about heart disease outcomes. In our ongoing research, we have harnessed these classification models using a comprehensive heart disease dataset. A central focus of our work revolves around ensuring the fairness and reliability of the models we develop. To achieve this, we have integrated explainable artificial intelligence (XAI) techniques, focusing on the conformal classifier, designed to identify the most dependable model. Our study extensively analyzes diverse classification models, including logistic regression, K-nearest neighbors (KNNs), decision trees (DTs), XGBoost, and CatBoost classifiers. The results explicitly highlight the outstanding performance of boosting algorithms, both XGBoost and CatBoost, displaying highly promising metrics. Furthermore, these models have successfully pinpointed the type of chest pain (e.g., TA, typical angina, ATA, atypical angina, NAP, non-anginal pain, or ASY, asymptomatic) and the slopes of the ST segment of the PQRST ECG wave as vital indicators of heart disease onset. Our findings provide evidence that the XGBoost and CatBoost classifier models, in particular, exhibit significantly higher coverage and lower set size, affirming their fairness and suitability for deployment in heart disease prediction.
2 Literature review
The results of the work by Bhatt et al. [8] underscore the promising capabilities of k-mode clustering in precisely predicting heart disease, indicating its potential as a valuable asset in shaping tailored diagnostic and treatment approaches for this ailment. Nagavelli et al. [14] adopted naive Bayes with weighted approach-based prediction, support vector machine (SVM) with XGBoost-based prediction, an improved SVM based on duality optimization technique-based prediction, and an XGBoost-based prediction for heart disease detection. Their analysis showed that the XGBoost algorithm has high-performance metrics, indicating its suitability. Tao et al. developed an automated system for detecting and pinpointing ischemic heart disease (IHD). The findings of Tao et al. [19] showed that the synchronicity of T-wave repolarization is a crucial factor in distinguishing IHD from normal subjects. Further, magnetic field patterns are closely linked to the location of stenosis in the heart. Mohan et al. [13] introduced an innovative approach that leveraged ML to identify crucial features, thereby enhancing the accuracy of cardiovascular disease prediction. Their model, hybrid random forest (RF) with a linear model, achieved an impressive 88.7% accuracy, surpassing other feature combinations and classification methods. Fitriyani et al. [9] introduced an advanced heart disease prediction model (HDPM) combining density-based spatial clustering of applications with noise, synthetic minority oversampling technique and edited nearest neighbor, and XGBoost-based ML techniques to enhance prediction accuracy. When validated on two publicly available heart disease datasets, their model outperformed existing models with an accuracy of up to 95.90 and 98.40%. In addition, they integrated HDPM into a heart disease clinical decision support system for efficient diagnosis and data management, offering potential benefits for clinicians and healthcare practitioners.
Baviskar et al. [7] integrated ensemble learning techniques with feature variance maximization that excelled in binary and multiple disease classification, surpassing existing models by 3.4% in the latter. These enhancements enabled efficient classification across various datasets and clinical applications. Shorewala [18] assessed ML’s efficacy in coronary heart disease prediction, wherein initial models were found to give an accuracy plateau of 75%. Base models averaged 71.92% accuracy, with neural networks reaching 73.97%. Ensemble methods such as bagging, boosting (notably gradient boosting with optimized parameters at 73.89%), and stacking effectively enhanced accuracy. Stacking, combining diverse models like KNN, RF classifier, and SVM with logistic regression as the meta-classifier, achieved the highest accuracy at 75.1%. Mamun et al. [12] employed a heart disease dataset to assess the effectiveness of ML methods in predicting heart disease. Notably, three classification algorithms – KNN, RF, and DT – demonstrated exceptional performance, achieving a flawless 100% accuracy rate. Furthermore, they computed feature importance scores for each attribute using all applied algorithms except multilayer perceptron and KNN. Guleria et al. [10] studied artificial intelligence (AI) and ML’s role in healthcare, highlighting their benefits and challenges. They explored an experimental method for heart disease prediction using ML techniques, with SVM standing out, achieving an 82.5% accuracy, surpassing other classifiers. Aghamohammadi et al. [1] devised an innovative method, merging the adaptive neural fuzzy inference system with genetic algorithm (GA) for heart attack prediction, capitalizing on fuzzy rule interpretability, neural network training, and GA optimization. Applied to the Cleveland dataset, the root-mean-square error improved from 0.82754 to 0.75372. For clinical benefit, their algorithm categorized patients by heart attack risk. In addition, they introduced an importance evaluation function to gauge feature significance in prediction, systematically assessing feature removal’s impact on model performance. Alsaleh et al. [2] presented a systematic review of the application of explainable AI for predicting comorbidities. They suggested that integrating additional variables, such as social determinants of health and genetic characteristics, could lead to even more accurate and personalized predictions. Rajjliwal and Chetty [16] demonstrated that shallow ML models, such as DT, exhibit exceptional interpretability and explainability, even if their predictive performance may be relatively modest. They suggested that when detection and prediction accuracy reach acceptable levels, post hoc processing can enhance interpretability, explanations, and trustworthiness for integration into clinical decision workflows. Anand et al. [4] applied deep neural networks to the PTB-XL ECG dataset for cardiac disorder detection. Their proposed model outperformed existing results with a 93.41% area under the receiver operating characteristic curve (AUC). They also tested this architecture on another arrhythmia ECG dataset, achieving 95.8% accuracy and a 99.46% AUC, competitive with state-of-the-art models. They assessed the model’s interpretability using Shapley additive explanations and established its ability to highlight relevant ECG wave alterations for diagnostic purposes. Pawar et al. [15] recommended integrating XAI techniques in healthcare to harness benefits such as improved transparency, traceable outcomes, and model refinement. The proposal suggests harnessing well-established XAI models with clinical expertise to optimize the advantages within AI-driven healthcare systems. Sheu and Pardeshi’s [17] XAI survey article provided a comprehensive approach to advancing research in XAI. Their work addressed legal and ethical concerns, focusing on vital aspects of medicine, all aimed at bolstering user trust through enhanced transparency. In their study, Amann et al. [3] utilized AI-powered clinical decision support systems as a case study, adopting a multidisciplinary approach to evaluate the significance of explainability in the context of medical AI. Their research demonstrated that various perspectives, including technological, legal, medical, and patient viewpoints, required distinct fundamental considerations and values to grasp explainability’s role in clinical practice fully. Band et al. [6] investigated the potential of AI and ML in reshaping healthcare, highlighting their applicability and dependability in various applications, such as using XGBoost for mediastinal cysts and tumor detection, 3D brain tumor segmentation, and the trace method for medical image analysis. Their research contributed to the growing domain of XAI, providing valuable insights for healthcare professionals. In addition, the article delved into the performance of XAI techniques in medical systems and elucidated their implementation.
3 Problem identification and research objectives
Building upon the ongoing endeavors to merge XAI with ML classification models, our research aims to construct ML models utilizing a labeled dataset related to heart disease sourced from Kaggle [11]. The description of the dataset is in the Appendix.
Given the availability of labeled data, we focused on supervised ML techniques. Since the target variable is categorical, we naturally gravitated toward employing classification algorithms to gain deeper insights into the dataset. In the realm of classification algorithms, we can classify them into two broad categories: eager learners and lazy learners. In our study, we decided to explore both categories: specifically, we selected logistic regression and decision tree algorithms within the eager-learner category, which are known for their proactive approach to building a model based on the entire dataset. On the other hand, in the lazy-learner category, we chose the KNN algorithm, characterized by its more adaptive, instance-based approach, relying on local patterns in the data. We intend to assess and compare the performance of these selected algorithms on the heart disease dataset. By doing so, we aim to comprehensively understand their effectiveness in predicting heart disease, ultimately contributing to our knowledge of this critical medical condition.
The following research question is put forth as the primary goal of the analysis: to construct ML models using the dataset.
3.1 Research question
Can conformal prediction enhance the deployment of ML models for predictive tasks?
3.2 Research objectives
Thus, the objectives are as follows:
To identify an accurate ML classification model to predict the prevalence of heart disease.
To fit ML models suitable for the considered dataset.
To compute the performance metrics for these models and identify the most appropriate model for the data.
To determine the most suitable model for the data by calculating performance metrics for these models.
To utilize Mapie conformal classification algorithm to find the reliable ML model.
To interpret the results obtained from the established reliable model.
To implement XAI algorithms
The forthcoming sections of this article are organized as follows: We initiate the presentation of our proposed approach in Section 4. Subsequently, we delve into the results and discussion in Section 5, and finally, we conclude with our final remarks and recommendations in Section 6.
3.3 Feature set and target variables
This dataset encompasses various features, including (#0) age, (#1) sex, (#2) chest pain type, (#3) resting blood pressure, (#4) cholesterol levels, (#5) fasting blood sugar, (#6) resting electrocardiographic results, (#7) maximum heart rate, (#8) exercise-induced angina, (#9) ST depression induced by exercise relative to rest, (#10) ST segment slope, and the target variable, which is categorical and is denoted as “Yes (1)” for individuals with heart disease and “No (0).”
4 Proposed approach
To begin with, we obtained a dataset on heart disease from Kaggle [11]. We employed it to train several ML classification models, including logistic regression, KNN, DTs, XGBoost, and CatBoost. Subsequently, we utilized accuracy, precision, and F1-score as performance metrics to identify the most suitable model to make predictions. Subsequently, we utilized the Mapie conformal classification algorithm to evaluate the reliability of the developed ML models. Ultimately, we turned to XAI algorithms to extract meaningful interpretations from the results.
We present the following flowchart (Figure 1) outlining the key elements of the current workflow. This diagram shows the “DATA” component, representing the heart disease dataset from Kaggle [11]. This dataset serves as the input for the subsequent component, the ML classification models. As mentioned in Section 3, our approach involves investigating eager and lazy learning models to assess their suitability for the current dataset. These models encompass logistic regression, KNN, DT, XGBoost, and CatBoost. Following an evaluation of performance metrics, the most appropriate model is advanced to the next prediction stage. At this point, we forecast the target variables based on the selected model and determine the feature importance. This information is transferred to the subsequent component, XAI. We employ the conformalized quantile classification model. It is worth noting that standard learning algorithms typically offer binary YES/NO classifications without any measure of uncertainty. On the other hand, the conformalized quantile classification model regulates prediction certainty through two primary measures: coverage score and prediction set size. Subsequently, we employed an explainable classifier that aligns with the most reliable model pinpointed by the conformalized quantile classifier to render the obtained outcomes interpretable. The ultimate stage of this study involves presenting definitive findings and offering valuable recommendations.
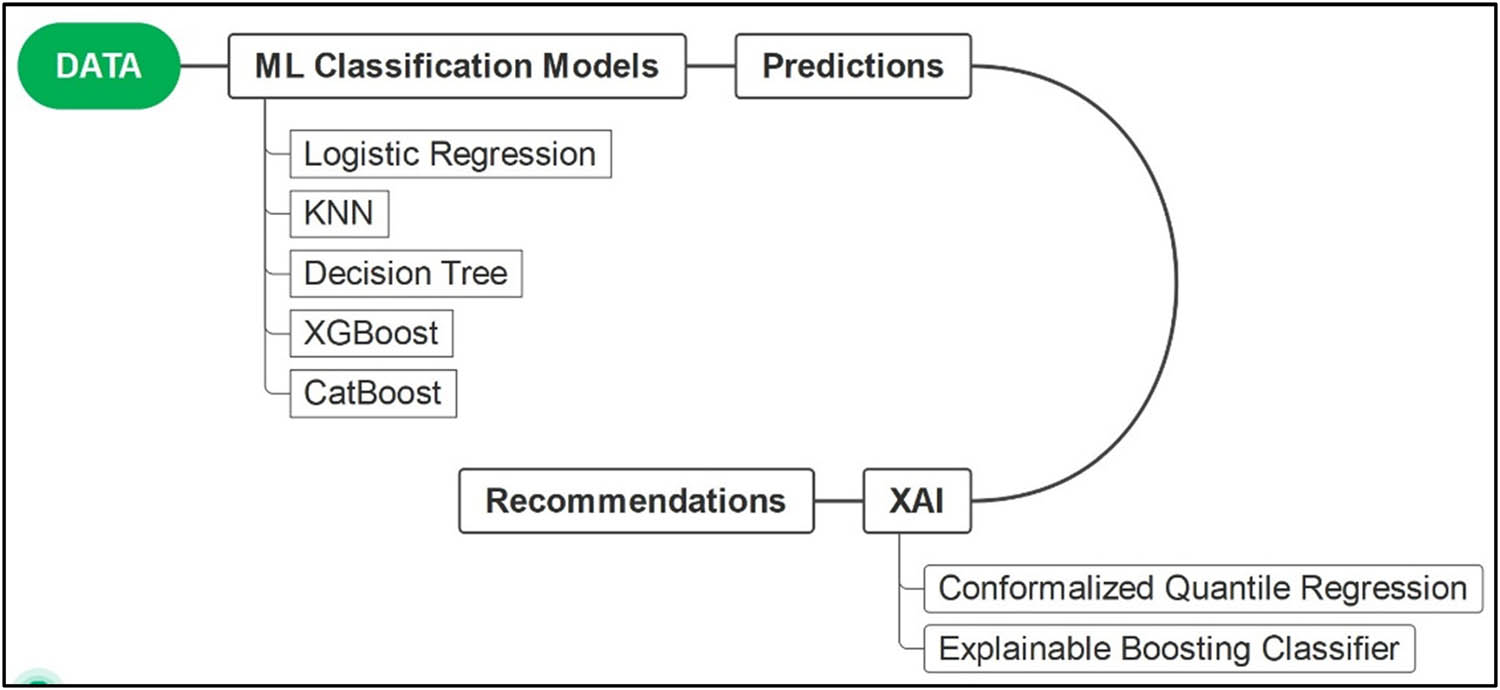
Workflow diagram.
5 Results and discussion
The performance metrics generated through the Python code we developed for the classification models are illustrated in Figure 2. Notably, the KNN classifier appears less suitable for the current dataset, with accuracy, precision, and F1-score for both the train and test sets falling within the 70–78% range. Conversely, the other models exhibit greater reliability regarding these metrics than the KNN model. However, when examining the statistics on false positives (FPs) and false negatives (FNs), as presented in Table 1, it becomes evident that KNN and DT struggled to accurately identify the presence or absence of heart disease. It is worth noting that a higher number of cases identified as FN can be detrimental to the recommendation system, constituting a critical failure.

Performance metrics.
Statistics on FP and FN for M models for the test dataset of 184 cases
| Model | FP | FN |
|---|---|---|
| Logistic regression | 05 | 02 |
| KNN | 09 | 28 |
| Decision tree | 12 | 35 |
| XGBoost | 03 | 09 |
| CatBoost | 02 | 07 |
In Figure 3, we display a bar chart that visually represents the degree of importance of each feature on the target variable. Analyzing this chart in the context of our dataset, we can recognize that the features “(#2) Chest Pain Type” and “(#10) ST Slope” emerge as the most influential factors contributing to the occurrence of heart disease. It suggests that, within the dataset, these two particular features play a substantial role in determining the presence or absence of heart disease.

Feature importance chart.
The subsequent step in the workflow diagram involves the incorporation of conformality quantile classification model. This approach yields a binary prediction and furnishes an estimate of the prediction’s confidence or probability level. Two pivotal metrics are linked to this approach: the coverage score and set size. The coverage score quantifies the ratio of correctly classified cases, and a model characterized by a good coverage score and a minimal prediction set size is deemed reliable and trustworthy.
This article employed the Mapie conformal quantile classification across all the ML models considered for traditional classification tasks. The schematic representation of this technique is depicted in Figure 4. As depicted in the framework, the first stage entails splitting the dataset into training and testing subsets, using a chosen division ratio of 90% for training and 10% for testing. A further division is made into calibration and primary training sets within the training set, distributed in an 80–10% ratio. The ML models, including logistic regression, KNN, DT, Catboost, and XGboost, are trained using the 80% dataset. The calibration dataset is utilized to fine-tune the model parameters, and the resulting calibrated models are subsequently evaluated for final predictions across different significance or quantile levels (

Conformal quantile classification framework.
Figures 5, 6, 7, 8, 9 display the model predictions. In these figures, the top-left plot represents the prediction generated by the base estimator, while the remaining three subplots each illustrate a distinct

Predictions from the logistic regression model.
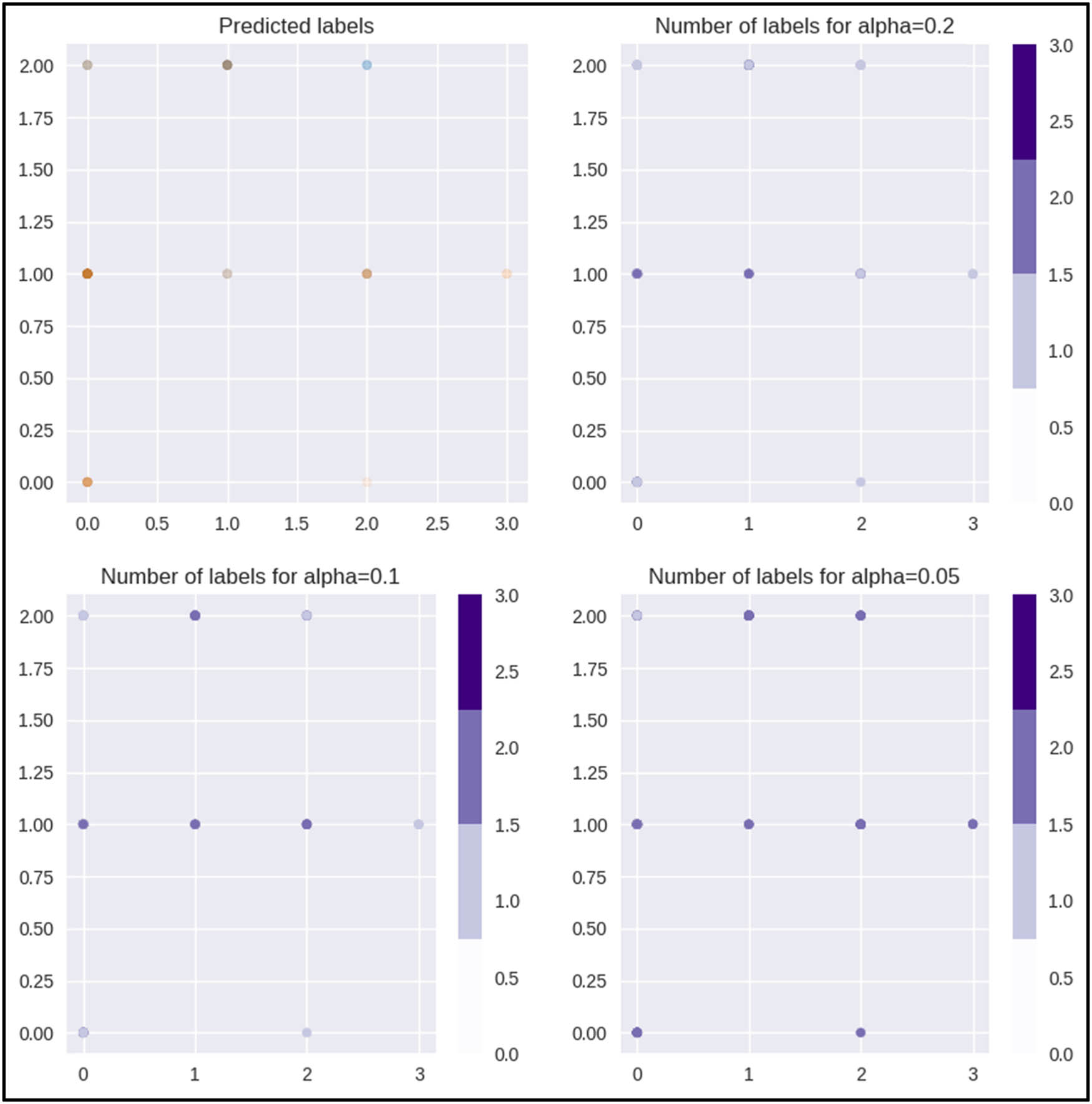
Predictions from the KNN model.

Predictions from the decision tree model.

Predictions from the XGBoost model.

Predictions from the CatBoost model.
Further, we used the explainable boosting classifier to enhance result interpretability, driven by its high predictive accuracy. It unveils critical factors, making our findings more explicit and essential for real-world applications and medical communication.
Figures 10, 11, 12, 13 present predictions based on patient-specific data from the dataset, offering an insight into how the model’s predictions relate to individual features. For example, Figure 10 highlights the prominent influence of a flat ST_Slope (encoded as 1), followed by a high level of fasting blood sugar (120 mg/dl). Interestingly, despite the absence of chest pain symptoms related to heart disease, the predictions favor the presence of heart disease. The other contributing features are represented by bars in the color orange. The prediction in Figure 11 shows that a higher heart rate does not indicate heart disease.

Predictions for a patient’s data falling into class 1.

Predictions for a patient’s data falling into class 0.

Predictions for a patient’s data falling into class 0.

Predictions for a patient’s data falling into class 0.

Feature importance from XAI boosting algorithms.
Figure 12 demonstrates an instance of misclassification, potentially linked to the significance of particular symptoms (such as Flat ST_Slope, asymptomatic chest pain, and moderate ST_Depression or old peak) highlighted as crucial features by the boosting algorithms (refer to Figures 3 and 14). Figure 13 depicts another misclassification scenario where a patient diagnosed with heart disease is erroneously categorized as being healthy. This discrepancy may be attributed to the upsloping of the ST curve (designated as “2”), a notable feature associated with a healthy individual. This highlights that although boosting algorithms have been deemed the most reliable by the conformality quantile classification model, this predictive tool is not entirely foolproof [5], thus necessitating expert intervention in decision-making.

Interaction of age and max heart rate.
6 Conclusions and recommendations
Based on the available dataset, this study combines conventional classification models with XAI to draw insights regarding an individual’s health status. The analysis leveraged the conformalized quantile regression model to interpret outcomes generated by the logistic regression, KNN, DT, Xgboost, and Catboost algorithms. Notably, the boosting algorithms demonstrated a remarkable ability to offer binary classifications with 97% confidence for the specific dataset. A detailed analysis of the patient-specific dataset is carried out using explainable boosting algorithms, and the results are presented and discussed. After conducting a comprehensive global term analysis of the provided dataset, we suggest the following recommendations based on Figures 15 and 16. For individuals aged 60 years and above, a heart rate of more than 150 bpm is a high-risk factor. It is recommended for those individuals to maintain a heart rate in the range of 120–150 bpm (Figure 16). Furthermore, individuals in the age group 30–35 years who have a heart rate in the range of 110–150 bpm need to be cautious, and it is recommended to maintain a heart rate below 110 bpm. For individuals who are 63 years and older, having a cholesterol level exceeding 350 mg/dl indicates a significant risk. In addition, middle-aged individuals between 30 and 55 years with lower cholesterol levels (0–40 mg/dl) are also at risk of developing heart disease. It is advisable to maintain cholesterol levels within the normal range to prevent potential complications (Figure 16). In conclusion, our approach will sustain trust and facilitate decision-making within the healthcare domain, where precision, reliability, and transparency hold utmost significance. In the future, the research emphasizes collaborative efforts between researchers, clinicians, and data scientists, aligning with the evolving landscape of healthcare research. Moreover, considering the dynamic health data over time with emerging technologies, federated learning comes into play to address privacy issues.

Interaction of age and cholesterol.
Limitations: It is crucial to emphasize that the findings presented in this study are founded upon ML models trained with the currently available dataset. Over time, a balanced and dynamic health dataset is essential to enhance the reliability of these results. Otherwise, the implications of misclassifications in real-world clinical settings underscore the importance of robust diagnostic processes, evidence-based decision-making, and continuous quality improvement initiatives in the healthcare sector.
Acknowledgement
The authors are grateful for the reviewer s valuable comments that improved the manuscript.
-
Funding information: Authors state no funding involved.
-
Author contributions: T. Raja Rani: Methodology, Supervision, Writing – review & editing; Shalini Pukkella: Data Analysis, Investigation, Validation, Visualization, Writing – original draft; T. S. L. Radhika: Conceptualization, Writing – review & editing.
-
Conflict of interest: Authors state no conflict of interest.
-
Informed consent: Informed consent has been obtained from all individuals included in this study.
-
Ethical approval: The research related to human use has been complied with all the relevant national regulations, institutional policies and has been approved by the authors’ institutional review board.
-
Data availability statement: The datasets generated during and/or analysed during the current study are available in https://www.kaggle.com/code/akhiljethwa/heart-failure-classification-knn-decision-tree (Available resource on 1 October 2023).
Appendix
Appendix
| Attribute information | Description | Range |
|---|---|---|
| Age | Age of the patient [years] | 0–99 |
| Sex | Sex of the patient | M: male, F: female |
| ChestPainType | Different types of chest pain | TA, typical angina, |
| ATA, atypical angina, | ||
| NAP, non-anginal pain, | ||
| ASY, asymptomatic | ||
| RestingBP | Resting blood pressure [mm Hg] | Normal: 120/80 |
| Elevated: 120–129/80 | ||
| Hypertension stage 1: 130–139/80–89 | ||
| Hypertension stage 2: 140/90–120 | ||
| Hypertensive crisis: 180/
|
||
| Cholesterol | Serum cholesterol [mg/dl] | Desirable: less than 200 |
| Borderline high: 200–239 | ||
| High: 240 and above | ||
| FastingBS | Fasting blood sugar [mg/dl] | 1: if fasting BS
|
| 0: otherwise | ||
| RestingECG | Resting electrocardiogram results | Normal: normal, |
| ST: having ST-T wave abnormality, | ||
| LVH: showing probable or definite left | ||
| ventricular hypertrophy by Estes’ criteria | ||
| MaxHR | Maximum heart rate achieved [bpm] | 20 years around 200 bpm |
| 30 years around 190–195 bpm | ||
| 40 years around 180–185 bpm | ||
| 50 years around 170–175 bpm | ||
| 60 years around 160–165 bpm | ||
| 70 years around 150–155 bpm | ||
| Exercise Angina | Exercise-induced angina | Y: yes, N: no |
| Oldpeak [ST depression] | ST depression is a significant parameter | Normal: less than 0.5 mm |
| in the prediction and diagnosis of various | Mild ST: 0.5–1 mm | |
| cardiovascular conditions and is considered | Moderate ST: 1–2 mm | |
| in the context of an exercise stress test | Severe ST: above 2 mm | |
| ST _ Slope | The slope of the peak exercise ST | Upsloping: positive slope, |
| segment of PQRST wave in ECG. | upwards from the baseline | |
| The ST segment encompasses the | Horizontal (flat): segment is | |
| region between the end of | approximately parallel to the baseline | |
| ventricular depolarization | Downsloping: negative slope, | |
| and the beginning of ventricular | downwards from the baseline. | |
| repolarization on the ECG. | ||
| Heartdisease | Output class | 1: heart disease, 0: normal |
References
[1] Aghamohammadi, M., Madan, M., Hong, J. K., & Watson, I. (2019). Predicting heart attack through explainable artificial intelligence. In: Rodrigues, J., et al. Computational Science - ICCS. Lecture Notes in Computer Science (vol. 11537), Springer, Cham. 10.1007/978-3-030-22741-8_45Search in Google Scholar
[2] Alsaleh, M. M., Allery, F., Choi, J. W., Hama, T., McQuillin, A., Wu, H., & Thygesen, J. H. (2023). Prediction of disease comorbidity using explainable artificial intelligence and machine learning techniques: A systematic review. International Journal of Medical Informatics, 175, 105088. 10.1016/j.ijmedinf.2023.105088Search in Google Scholar PubMed
[3] Amann, J., Blasimme, A., Vayena, E., Frey, D., & Madai, VI. (2020). Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Medical Informatics and Decision Making, 20, 310. 10.1186/s12911-020-01332-6Search in Google Scholar PubMed PubMed Central
[4] Anand, A., Kadian, T., Kumar Shetty, M., & Gupta, A. (2022). Explainable AI decision model for ECG data of cardiac disorders. Biomedical Signal Processing and Control, 75, 103584. 10.1016/j.bspc.2022.103584Search in Google Scholar
[5] Attia, Z. I., & Friedman, P. A. (2023). Explainable AI for ECG-based prediction of cardiac resynchronization therapy outcomes: Learning from machine learning. European Heart Journal, 44(8), 693–695. 10.1093/eurheartj/ehac733Search in Google Scholar PubMed
[6] Band, S. S., Yarahmadi, A., Hsu, C. C., Biyari, M., Sookhak, M., Ameri, R., …, Liang, H. W. (2023). Application of explainable artificial intelligence in medical health: A systematic review of interpretability methods. Informatics in Medicine Unlocked, 40, 101286. 10.1016/j.imu.2023.101286Search in Google Scholar
[7] Baviskar, V., Ojha, A., Verma, I., Mahla, S., Verma, M., Chatterjee, P., & Kumar, S. (2023). H2EMDCO: Design of a hyper ensemble model for evaluation of heart diseases from clinical observations. Procedia Computer Science, 218, 1288–1294. 10.1016/j.procs.2023.01.107Search in Google Scholar
[8] Bhatt, C. M., Patel, P., Ghetia, T., & Mazzeo, P. L. (2023). Effective heart disease prediction using machine learning techniques. Algorithms, 16(2), 88. 10.3390/a16020088Search in Google Scholar
[9] Fitriyani, N. L., Syafrudin, M., Alfian, G., & Rhee, J. (2020). HDPM: Aan effective heart disease prediction model for a clinical decision support system. IEEE Access, 8, 133034. 10.1109/ACCESS.2020.3010511Search in Google Scholar
[10] Guleria, P., Naga Srinivasu, P., Ahmed, S., Almusallam, N., & Alarfaj, F. K. (2022). XAI framework for cardiovascular disease prediction using classification techniques. Electronics, 11(24), 4086. 10.3390/electronics11244086Search in Google Scholar
[11] https://www.kaggle.com/code/akhiljethwa/heart-failure-classification-knn-decision-tree (Available resource on 1 October 2023). Search in Google Scholar
[12] Mamun Ali, M., Paul, B. K., Ahmed, K., Bui F. M., Quinn, J. M. W., & Moni, M. A. (2021). Heart disease prediction using supervised machine learning algorithms: Performance analysis and comparison. Computers in Biology and Medicine, vol. 136, 104672. 10.1016/j.compbiomed.2021.104672Search in Google Scholar PubMed
[13] Mohan, S., Thirumalai, C., & Srivastava, G. (2019). Effective heart disease prediction using hybrid machine learning techniques. IEEE Access, 7, 81542–81554. 10.1109/ACCESS.2019.2923707Search in Google Scholar
[14] Nagavelli, U., Samanta, D., & Chakraborty, P. (2022). Machine learning technology-based heart disease detection models. Journal of Healthcare Engineering, Article ID 7351061, 9 pages. 10.1155/2022/7351061Search in Google Scholar PubMed PubMed Central
[15] Pawar, U, OShea, D, Rea, S, & O’Reilly, R. (2020). Explainable AI in healthcare. in: International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA) (pp. 1–2), Dublin, Ireland. 10.1109/CyberSA49311.2020.9139655Search in Google Scholar
[16] Rajjliwal, N. S., & Chetty, G. (2022). Cardiovascular disease detection based on interpretable and explainable AI. in: IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE) (pp. 1–7), Gold Coast, Australia. 10.1109/CSDE56538.2022.10089349Search in Google Scholar
[17] Sheu, R-.K., & Pardeshi M. S. (2022). A survey on medical explainable AI (XAI): Recent progress, explainability approach, human interaction and scoring system. Sensors, 22(20), 8068. 10.3390/s22208068Search in Google Scholar PubMed PubMed Central
[18] Shorewala, V. (2021). Early detection of coronary heart disease using ensemble techniques. Informatics in Medicine Unlocked, 26, 100655, ISSN 2352–9148. 10.1016/j.imu.2021.100655Search in Google Scholar
[19] Tao, R., Zhang, S., Huang, X., Tao, M., Ma, J., Ma, S., …, Xie, X. (2019). Magnetocardiography-based Ischemic heart disease detection and localization using machine learning methods. IEEE Transactions on Biomedical Engineering, 66, 1658–1667. 10.1109/TBME.2018.2877649Search in Google Scholar PubMed
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Special Issue: Recent Trends in Mathematical Biology – Theory, Methods, and Applications
- Editorial for the Special Issue: Recent trends in mathematical Biology – Theory, methods, and applications
- Behavior of solutions of a discrete population model with mutualistic interaction
- Influence of media campaigns efforts to control spread of COVID-19 pandemic with vaccination: A modeling study
- Optimal control and bifurcation analysis of SEIHR model for COVID-19 with vaccination strategies and mask efficiency
- A mathematical study of the adrenocorticotropic hormone as a regulator of human gene expression in adrenal glands
- On building machine learning models for medical dataset with correlated features
- Analysis and numerical simulation of fractional-order blood alcohol model with singular and non-singular kernels
- Stability and bifurcation analysis of a nested multi-scale model for COVID-19 viral infection
- Augmenting heart disease prediction with explainable AI: A study of classification models
- Plankton interaction model: Effect of prey refuge and harvesting
- Modelling the leadership role of police in controlling COVID-19
- Robust H∞ filter-based functional observer design for descriptor systems: An application to cardiovascular system monitoring
- Regular Articles
- Mathematical modelling of COVID-19 dynamics using SVEAIQHR model
- Optimal control of susceptible mature pest concerning disease-induced pest-natural enemy system with cost-effectiveness
- Correlated dynamics of immune network and sl(3, R) symmetry algebra
- Variational multiscale stabilized FEM for cardiovascular flows in complex arterial vessels under magnetic forces
- Assessing the impact of information-induced self-protection on Zika transmission: A mathematical modeling approach
- An analysis of hybrid impulsive prey-predator-mutualist system on nonuniform time domains
- Modelling the adverse impacts of urbanization on human health
- Markov modeling on dynamic state space for genetic disorders and infectious diseases with mutations: Probabilistic framework, parameter estimation, and applications
- In silico analysis: Fulleropyrrolidine derivatives against HIV-PR mutants and SARS-CoV-2 Mpro
- Tangleoids with quantum field theories in biosystems
- Analytic solution of a fractional-order hepatitis model using Laplace Adomian decomposition method and optimal control analysis
- Effect of awareness and saturated treatment on the transmission of infectious diseases
- Development of Aβ and anti-Aβ dynamics models for Alzheimer’s disease
- Compartmental modeling approach for prediction of unreported cases of COVID-19 with awareness through effective testing program
- COVID-19 transmission dynamics in close-contacts facilities: Optimizing control strategies
- Modeling and analysis of ensemble average solvation energy and solute–solvent interfacial fluctuations
- Application of fluid dynamics in modeling the spatial spread of infectious diseases with low mortality rate: A study using MUSCL scheme
Articles in the same Issue
- Special Issue: Recent Trends in Mathematical Biology – Theory, Methods, and Applications
- Editorial for the Special Issue: Recent trends in mathematical Biology – Theory, methods, and applications
- Behavior of solutions of a discrete population model with mutualistic interaction
- Influence of media campaigns efforts to control spread of COVID-19 pandemic with vaccination: A modeling study
- Optimal control and bifurcation analysis of SEIHR model for COVID-19 with vaccination strategies and mask efficiency
- A mathematical study of the adrenocorticotropic hormone as a regulator of human gene expression in adrenal glands
- On building machine learning models for medical dataset with correlated features
- Analysis and numerical simulation of fractional-order blood alcohol model with singular and non-singular kernels
- Stability and bifurcation analysis of a nested multi-scale model for COVID-19 viral infection
- Augmenting heart disease prediction with explainable AI: A study of classification models
- Plankton interaction model: Effect of prey refuge and harvesting
- Modelling the leadership role of police in controlling COVID-19
- Robust H∞ filter-based functional observer design for descriptor systems: An application to cardiovascular system monitoring
- Regular Articles
- Mathematical modelling of COVID-19 dynamics using SVEAIQHR model
- Optimal control of susceptible mature pest concerning disease-induced pest-natural enemy system with cost-effectiveness
- Correlated dynamics of immune network and sl(3, R) symmetry algebra
- Variational multiscale stabilized FEM for cardiovascular flows in complex arterial vessels under magnetic forces
- Assessing the impact of information-induced self-protection on Zika transmission: A mathematical modeling approach
- An analysis of hybrid impulsive prey-predator-mutualist system on nonuniform time domains
- Modelling the adverse impacts of urbanization on human health
- Markov modeling on dynamic state space for genetic disorders and infectious diseases with mutations: Probabilistic framework, parameter estimation, and applications
- In silico analysis: Fulleropyrrolidine derivatives against HIV-PR mutants and SARS-CoV-2 Mpro
- Tangleoids with quantum field theories in biosystems
- Analytic solution of a fractional-order hepatitis model using Laplace Adomian decomposition method and optimal control analysis
- Effect of awareness and saturated treatment on the transmission of infectious diseases
- Development of Aβ and anti-Aβ dynamics models for Alzheimer’s disease
- Compartmental modeling approach for prediction of unreported cases of COVID-19 with awareness through effective testing program
- COVID-19 transmission dynamics in close-contacts facilities: Optimizing control strategies
- Modeling and analysis of ensemble average solvation energy and solute–solvent interfacial fluctuations
- Application of fluid dynamics in modeling the spatial spread of infectious diseases with low mortality rate: A study using MUSCL scheme