Application of dynamic mode decomposition and compatible window-wise dynamic mode decomposition in deciphering COVID-19 dynamics of India
-
Kanav Singh Rana


Abstract
The COVID-19 pandemic recently caused a huge impact on India, not only in terms of health but also in terms of economy. Understanding the spatio-temporal patterns of the disease spread is crucial for controlling the outbreak. In this study, we apply the compatible window-wise dynamic mode decomposition (CwDMD) and dynamic mode decomposition (DMD) techniques to the COVID-19 data of India to model the spatial-temporal patterns of the epidemic. We preprocess the COVID-19 data into weekly time-series at the state-level and apply both the CwDMD and DMD methods to decompose the data into a set of spatial-temporal modes. We identify the key modes that capture the dominant features of the COVID-19 spread in India and analyze their phase, magnitude, and frequency relationships to extract the temporal and spatial patterns. By incorporating rank truncation in each window, we have achieved greater control over the system’s output, leading to better results. Our results reveal that the COVID-19 outbreak in India is driven by a complex interplay of regional, demographic, and environmental factors. We identify several key modes that capture the patterns of disease spread in different regions and over time, including seasonal fluctuations, demographic trends, and localized outbreaks. Overall, our study provides valuable insights into the patterns of the COVID-19 outbreak in India using both CwDMD and DMD methods. These findings can help public health organizations to develop more effective strategies for controlling the spread of the pandemic. The CwDMD and DMD methods can be applied to other countries to identify the unique drivers of the outbreak and develop effective control strategies.
1 Introduction
The novel coronavirus struck India in January 2020, which caused a health emergency throughout the nation. The coronavirus (COVID-19) originated in Wuhan city in China and rapidly spread across the world. China reported to the World Health Organisation (WHO) about a cluster of cases of pneumonia in Wuhan city on December 31, 2021, which was later identified as a severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Thereby the disease has been named COVID-19. In no time, India reported its first case of COVID-19 on January 27, 2020, in Thrissur, Kerala [1] (Figure 1). After that COVID-19 spread to all other states, and situations got worse with international migration. A total of 44,676,470 cases have been reported with 530,658 deaths, in India, as of December 15, 2022 [16]. Many steps have been taken to control COVID-19, including vaccination [12], social distancing, lockdowns, etc. Reducing the speed of transmission and aid planning becomes a difficult task without knowing the disease’s future trend. But, modeling such an infectious disease becomes testing given the complexity of the unknown underlying system (Table 1).

India map showing COVID-19 cumulative confirmed cases.
| States & union territories | Population
|
Area (
|
Confirmed cases |
|---|---|---|---|
| Andaman & Nicobar Islands | 400 | 8,249 | 7,651 |
| Andhra Pradesh | 52,787 | 162,970 | 2,063,555 |
| Arunachal Pradesh | 1,533 | 83,743 | 54,340 |
| Assam | 35,043 | 78,438 | 610,645 |
| Bihar | 123,083 | 94,163 | 726,153 |
| Chandigarh | 1,208 | 114 | 65,351 |
| Chhattisgarh | 29,493 | 135,192 | 1,008,776 |
| Dadra & Nagar Haveli and Daman & Diu | 1,078 | 603 | 10,682 |
| Delhi | 20,571 | 1,483 | 1,439,870 |
| Goa | 1,559 | 3,702 | 178,108 |
| Gujarat | 69,788 | 196,244 | 826,689 |
| Haryana | 29,483 | 44,212 | 771,254 |
| Himachal Pradesh | 7,394 | 55,673 | 2,20,606 |
| Jammu & Kashmir | 13,408 | 55,538 | 333,051 |
| Jharkhand | 38,471 | 79,716 | 348,807 |
| Karnataka | 66,845 | 191,791 | 2,988,300 |
| Kerala | 35,489 | 38,852 | 4,968,657 |
| Ladakh | 297 | 166,698 | 20,962 |
| Lakshadweep | 68 | 32 | 10,365 |
| Madhya Pradesh | 84,516 | 308,252 | 791,493 |
| Maharashtra | 124,437 | 307,713 | 6,662,984 |
| Manipur | 3,165 | 22,327 | 123,731 |
| Meghalaya | 3,288 | 22,429 | 84,041 |
| Mizoram | 1,216 | 21,081 | 121,417 |
| Nagaland | 2,192 | 16,579 | 32,068 |
| Odisha | 45,696 | 155,707 | 1,009,420 |
| Puducherry | 1,572 | 490 | 128,028 |
| Punjab | 30,339 | 50,362 | 602,812 |
| Rajasthan | 79,281 | 342,239 | 954,182 |
| Sikkim | 677 | 7,096 | 31,992 |
| Tamil Nadu | 76,402 | 130,060 | 2,697,859 |
| Telangana | 37,725 | 112,077 | 671,463 |
| Tripura | 4,071 | 10,486 | 110,478 |
| Uttar Pradesh | 230,907 | 240,928 | 1,689,078 |
| Uttarakhand | 11,399 | 53,483 | 344,715 |
| West Bengal | 98,125 | 88,752 | 1,592,848 |
Several well-established methods are used to predict the likelihood of a pandemic outbreak. One of the most common ways to model infectious diseases is by using compartmental models, like the susceptible-infectious-recovered (SIR) and susceptible-exposed-infectious-recovered (SEIR) models. Kumar et al. [11] performed an SEIR model-based analysis of COVID-19 outbreak in Italy. Malavika et al. [15] forecasted the epidemic in India using the SIR model. These models have been used at great length and are proved to be good in terms of fitting the data. But this type of modeling requires solving numerously burdensome equations and also requires a lot of assumptions in order to fit the data, which might affect the results. Machine learning techniques have also been used, including neural networks [7], and support vector machines [9] have been used to predict the disease’s spread. Other studies have used statistical methods, such as the autoregressive integrated moving average (ARIMA) model [6,22], to analyze the time-series data of COVID-19 cases. While these methods have provided valuable insights, they are limited in their ability to capture the underlying dynamics of the disease. To get rid of this problem, in our work, to model the spread of the disease, we used an equation-free data-driven method known as the dynamic mode decomposition (DMD) [23]. The choice of DMD is made because of its ability to analyze complex spatio-temporal patterns which becomes utterly important in the sense that preventive measures can be provided.
DMD is much more prevalent in the fluid mechanics community. DMD had been extended by Proctor and Eckhoff [19] to be used for the analysis of infectious disease data. It decomposes the data into a set of dynamic modes that capture the underlying spatio-temporal patterns of the system. There are many variants of DMD that have been utilized in disease modeling [4,5,26]. In this article, we have used DMD for the reconstruction of the districtwise COVID-19 data to show the efficiency of DMD, which was then validated by the error analysis done in Section 2.4. We have also used compatible-window dynamic mode decomposition (CwDMD) [10], which is a recent extension of DMD, for the statewise spatio-temporal analysis. CwDMD overcomes the limitation of DMD, and hence, it is incompatible for the inconsistent data according to Tu [25], and CwDMD enables more accurate and efficient analysis of spatio-temporal data.
The study explores various spatial-temporal patterns of the novel coronavirus across India using the DMD and CwDMD, based on confirmed cases data, obtained from The Ministry of Health and Family Welfare. We have selected three windows from the COVID-19 time series data. We employ the use of rank
The exposition includes insightful phase analysis along with extensive computations. Our investigation demonstrates that high transmissibility can be attributed to various factors, including crowded political and religious events, demographic patterns, lax adherence to protocols, festive celebrations, and migration within the country. In addition, we reconstructed datatsets for districts vs dates and states vs weeks, and we evaluated the performance of algorithms used by comparing the errors of CwDMD and DMD when applied to an incompatible dataset. These measures enabled us to assess the accuracy of the algorithms used.
In Section 2, we present the methodology used. Section 3 discusses the results obtained, and Section 4 concludes this article.
2 Methods
2.1 Data
The dataset, which is used for the analysis of the novel COVID-19 virus, has been retrieved from https://data.covid19india.org/ [2]. This dataset consists of confirmed cases of 640 Indian districts from April 26, 2020, to October 31, 2021. The columns of this data matrix comprise dates (in increasing order) and the rows comprise the districts, i.e., the rows represent spatial locations and the columns represent temporal locations. Mathematically, the matrix is given by:
In this study, we used two datasets, one of which comprise Indian district’s datewise cumulative data (Dataset A), and the other dataset (which is converted from previous dataset), contains state’s weekwise cumulative data (Dataset B). Both the datasets have been arranged as shown in Figure 2.

Dataset A represents districts vs dates matrix of order
2.2 DMD
DMD is a spatial dimensionality reduction algorithm that analyzes the relationship between the future data measurement
for all pairs of data. Depending on the data, it can already be assumed that operator
where
where
An approximation of the operator
where
where
where
2.3 CwDMD
CwDMD is an extension of DMD that takes into account the spatial structure of the data. It is based upon a key idea that the compatibility condition is satisfied as defined by Kim et al. [10]. Compatibility condition is the balance between spatial and temporal resolutions, i.e., the dataset
where
2.4 Magnitude, phase, and error analysis
We now discuss the choice of mode for the magnitude and phase analysis. To choose the important DMD modes, we need to find which DMD mode contributes significantly to the data both spatially and temporally. There are many ways to choose relevant DMD mode as mentioned by Proctor et al. In our work, we use:
where
These data obtained are generally complex valued, which are then used for interpreting phases and magnitudes. The phase difference between two variables can be computed, which upon comparing with the frequency of the mode, the time lag will be obtained by the relation:
To measure the discrepancy between the original data and the reconstructed data, we have used the relative error [8], and the relative error for vector
3 Results
Now that we have some essential ideas of the framework, we begin to discuss facts and figures of COVID-19 gathered during data collection to investigate spatio-temporal transmission mechanisms.
In this section, we apply DMD on the data collected to analyze spatio-temporal patterns of COVID-19 in India. We choose three windows, each of which consists of 26 weeks. Now we apply CwDMD (with rank 10 truncation), which in return, provides us discrete eigenvalues and DMD modes. Some of these complex DMD modes are of vital importance and thus are classified into three categories: growing, oscillatory, and decaying. We can carry out the magnitude and phase analysis of each window with the help of these modes. While selecting the windows, we kept into consideration the following two factors: (1) No overlapping of windows. (2) Results are not influenced by the choice of data.
3.1 The first window: April 2020 to October 2020
Since, the first window is of 26 weeks, which implies the compatible spatial vs temporal resolution must be of order

The first window at rank 10 truncation. (a) Left panel shows the discrete eigenspectrum plotted against a unit circle. Right panel shows the power vs frequency plot of the corresponding DMD modes. Both
We select two DMD modes that have the largest power for which we represent as
Andhra Pradesh, with highly dense population, had large number of migrant workers coming back to their hometown. In addition, around 9,000 to 10,000 pilgrims were visiting the well-known Tirumala Temple everyday since its reopening in June 2020. Maharashtra, the second most populous and the worst-hit state during the outbreak, witnessed large number of cases in the first wave. Its capital, Mumbai, which is home to around 20 million people, almost 40% of it living in overcrowded slums [3], where diseases spread like wildfire. A lax attitude toward proper-masking and social distancing protocols during national lockdown from March to June 2020 likely contributed in the surge. Tamil Nadu has attributed its spike in cases to mostly to returnees from abroad and migrant workers within the country. Many of the people were traced to be attendees in the religious event held in Kerala (Onam celebrations).
For phase analysis, we chose DMD modes having largest power corresponding to these complex eigenvalues represented by
3.2 The second window: November 2020 to April 2021
Again, the second window is of 26 weeks, which yields that the compatible spatial vs temporal resolution must be of order
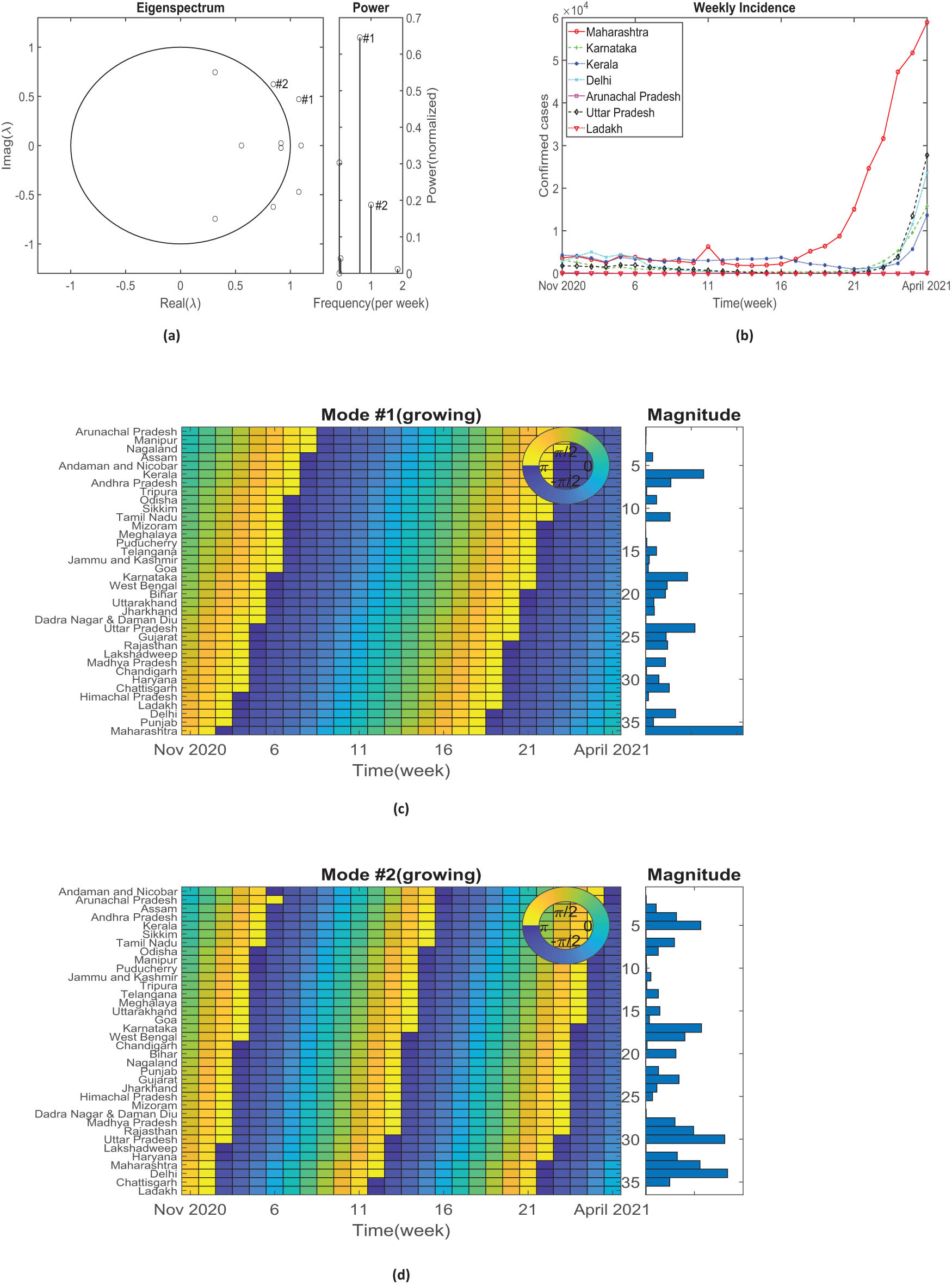
The second window at rank 10 truncation. (a) Left panel shows the discrete eigenspectrum plotted against a unit circle. Right panel shows the power vs frequency plot of the corresponding DMD modes. (b) Weekly incidence of COVID-19 cases from November 2020 to April 2021 for some selected states. Both
For phase analysis, we are primarily interested in the complex eigenvalues since real ones do not have a phase. We chose DMD modes having the largest power corresponding to these complex eigenvalues represented by
The magnitude analysis demonstrates that Maharashtra, Delhi, Uttar Pradesh, Kerala, and Karnataka’s cumulative confirmed cases have a substantially large magnitude, which in fact complies with the data shown in Figure 4(c) and (d). The government critiqued the lax safety protocols and negligence by people during Diwali, Christmas, and New Year celebrations for the surge in cases. The spike in cases in Kerala has been attributed to violating protocols in political campaigns and house visits during local body elections in December 2020. Delhi, the capital city, witnessed a large-scale farmers’ protest, a nationwide strike by thousands of farmers at Delhi borders during the second wave, which caused an alarming rise in the number of COVID-19 cases. Uttar Pradesh, India’s most populated state, eased out restrictions during the village council elections [14] (Gram Panchayat Election 2021) held in April 2021. More than 1,600 teachers died of COVID who supervised those elections in the same month, as stated by a well-known teachers union. The second most populous state, Maharashtra, and the worst-hit state during the outbreak blamed complacency, poor masking, overcrowding, and scant guidelines about what should be open and what should be closed. Considering its high transmissibility, it is impossible to implement social-distancing rules without a complete lockdown in such crowded places as marine drive. Bengaluru, the epicenter of Karnataka, faced crowds at airports that were often seen without masks and violating other protocols like maintaining social distance in marriage halls, marketplaces, and malls.
Next, we discuss phase analysis from the two selected DMD modes. We state two observations:
In the DMD mode
In the DMD mode
3.3 The third window: April 2021 to October 2021
The third window also consists of 26 weeks, so the compatible spatial vs temporal resolution will be of order

The third window at rank 10 truncation. (a) Left panel shows the discrete eigenspectrum plotted against a unit circle. Right panel shows the power vs frequency plot of the corresponding DMD modes. Both
The phase analysis of mode
3.4 Reconstruction of district and statewise data
In this subsection, we have used Dataset A for the reconstruction of district vs date data (cumulative cases). The reconstructed data of top 20 districts with most COVID cases have been visualized in Figure 6. DMD has been applied to this dataset and the truncation of rank 530 has been chosen in order to construct the new data. We have plotted the reconstructed data obtained from equation (8) with black bold line, and the red dots indicate the original data points spaced equidistantly. DMD has performed extremely well in the reconstruction, which can also be verified by the error analysis done in Section 3.5. In addition to this, we have reconstructed state vs week (cumulative cases) data using CwDMD. Rank 34, 10, and 8 truncation have been chosen for window first, second, and third, respectively.

(a) In each panel, red dots show the daily cases data and bold line indicates the reconstructed data for each district. (b) In each panel, red dots show the weekly cases data and bold line indicates the reconstructed data for each state.
3.5 Error analysis
To ensure the accuracy and reliability of the results, it is important to perform proper error analysis. Error analysis in DMD involves assessing the quality of the reconstructed data and comparing it to the original data. One common approach to error analysis in CwDMD and DMD is to use a measure of the discrepancy between the original data and the reconstructed data, for which we use the relative error. Relative error is the ratio of the normed error to the norm of the original data.
The top panel in Figure 7 shows the error comparison of CwDMD and DMD in the reconstruction of dataset B. Note that this dataset is incompatible for DMD architecture, as spatial resolution is less than temporal resolution, which can be verified in the figure. We performed SVD with rank 34 truncation, resulting in huge errors because of the inconsistent data. Using CwDMD on same dataset, the reduction in error is significant, showing the importance of CwDMD. The dataset has been divided into three compatible windows with each window having resolution

Top panel shows the relative error in the reconstruction of dataset B using DMD and CwDMD. Bottom panel shows the relative error in the reconstruction of dataset A using DMD.
In the below panel we have applied DMD on dataset A, with rank 530 truncation. It can be noted that DMD works remarkably well when the data is consistent. The reconstructed data in this panel have produced very less error.
4 Discussion and conclusion
In this study, by using the DMD and CwDMD, we have identified the spatio-temporal transmission mechanisms of COVID-19 in India from April 26, 2020, to October 31, 2021. Despite being difficult to unveil the transmission dynamics of the disease because of the external factors such as migration, unpredictability of the virus, our analysis show how the states evolve spatially even with the presence of complex dynamics of the system. While prior research in India has not utilized DMD and CwDMD methods for the analysis of COVID-19 spread patterns, our study marks a significant step toward understanding the spatio-temporal dynamics of the pandemic. By preserving the coherent structures of the system and identifying dynamics of the transmission mechanism, our approach provides unique insights into the patterns of COVID-19 spread in India. Furthermore, it is noteworthy that the architecture of the CwDMD method in the literature does not mention the incorporation of rank
We compared the performance of DMD and CwDMD on two datasets. The first dataset is incompatible with DMD architecture, resulting in large errors when SVD is performed with rank 34 truncation. Using CwDMD on the same dataset reduces the error significantly because of the ability to control the system by choosing window resolution and rank truncation. The second dataset, which is consistent, is reconstructed using DMD with rank 530 truncation, resulting in very low error. Overall, error analysis emphasizes the superiority (in terms of better results) of CwDMD over DMD in cases of inconsistent data.
In the first window, we observed that COVID-19 was more prevalent in the states, which were densely populated and the states, which provided employment to people throughout the India. The negligence of people and the laxity in COVID-19 protocols fueled rise in cases in these states. The migration of people from these states was also one of the reasons of corona spread throughout the country. International returnees and events like Tablighi Jamaat were also considered as the rise of cases in the first wave of COVID. Our phase analysis showed that there were huge time lags between states during the first window. Lakshadweep was by far the most behind union territory as it did not encounter its first COVID case until January 18, 2021.
Analysis in second window shows us the phase difference between all the states of the country is not as large as it was in the first window showing a significantly small time lag between states. This windows suggests that there was a nationwide spread and even the small states took a toll. During second wave, Kerala, Delhi, Uttar Pradesh, Mumbai, and Bengaluru came out to be significant hotspots, with a high number of cases and deaths, an overwhelmed healthcare system, and significant economic and social disruption attributed to post-Diwali, Christmas, and New Year celebrations including the emergence of new variants of the virus for the surge in cases. In addition to being the heavily populated regions of the country, their airports are also connected internationally, which led to increase in mobility and travel. The causes of the second wave of COVID-19 in India were complex and multifactorial. The spike in cases in Kerala have been attributed to violating protocols in political campaigns and house visits during local body elections in December 2020. The events like farmers’ protest, which began in November 2020 and continued through early 2021, in particular a historic parade by lakhs of farmers with over 2 lakh tractors on 26th January in Delhi, proved to be a super-spreader event. Easing out restrictions on preparations of Kumbh Mela [20,21] (gathering of millions of pilgrims on the banks of the Ganges river in India) and local body elections in Uttar Pradesh contributed to the surge.
Analysis in the third window shows us that both the corresponding modes are decaying modes. Magnitude analysis is performed on the selected dominant modes, and it is observed that Kerala has the highest magnitude, followed by Maharashtra, Tamil Nadu, and Karnataka. The rise in cases may be attributed to the Kumbh Mela event and lack of active surveillance during Bakrid and Onam celebrations. Phase analysis is also performed on mode
The DMD and CwDMD has shown effectiveness in identifying spatio-temporal coherent patterns, but there are some limitations associated with these techniques. One limitation is that both techniques rely on the assumption of linearity of the data, which may not hold true for the underlying dynamics of the pandemic and hence requires data preprocessing. Moreover, these techniques require large datasets to identify dominant modes accurately, which may not be available for smaller regions within India. Both DMD and CwDMD are data-driven methods and may not take into account external factors such as change in public health policies, new variants of the virus, or patterns in the data that exhibit irregular fluctuations. Therefore, the effectiveness of these techniques may vary depending on the quality and quantity of the data available for analysis.
In the future, DMD and CwDMD may be combined with other methods such as deep learning and machine learning algorithms that understand the complex interactions between external factors that influence the spread of the disease. This will help us to develop a mathematical model that considers data related to external controls, for forecasting and early detection of outbreaks. Therefore, the future scope of DMD and CwDMD in the field of epidemiology and public health is promising and can potentially contribute significantly to the prevention and control of infectious diseases.
In conclusion, DMD and CwDMD has proven to be a powerful tool for analyzing COVID-19 India data, enabling researchers to identify patterns, and trends of variation in the spread of the virus. Therefore, the combined use of DMD and CwDMD is a promising approach to analyze and understand the disease data, and it is expected to provide valuable insights into the dynamics of disease as it continues to evolve.
Acknowledgements
We thank anonymous reviewers for their constructive suggestions that have helped to improve the quality of the article.
-
Funding information: The research of the corresponding author is supported by the Council of Scientific & Industrial Research (CSIR, India), under the research grant #25[22832]∕2022.
-
Conflict of interest: The authors declare that there is no conflict of interest in this article.
-
Ethical approval: This research did not require ethical approval.
References
[1] Andrews, M., Areekal, B., Rajesh, K., Krishnan, J., Suryakala, R., Krishnan, B., … Santhosh, P. (2020). First confirmed case of COVID-19 infection in India: A case report. The Indian Journal of Medical Research, 151(5), 490. 10.4103/ijmr.IJMR_2131_20Suche in Google Scholar PubMed PubMed Central
[2] Babu, J., Shukla, A., & Bharath. India’s COVID-19 districtwise data. https://github.com/covid19india/data/tree/gh-pages. Accessed: November 2022. Suche in Google Scholar
[3] Banaji, M. (2021). Estimating COVID-19 infection fatality rate in Mumbai during 2020. medRxiv, (p. 2021–04). 10.1101/2021.04.08.21255101Suche in Google Scholar
[4] Bistrian, D., Dimitriu, G., & Navon, I. (2019). Processing epidemiological data using dynamic mode decomposition method. AIP Conference Proceedings, 2164, 080002, AIP Publishing LLC. 10.1063/1.5130825Suche in Google Scholar
[5] Bistrian, D. A., Dimitriu, G., & Navon, I. M. (2020). Application of deterministic and randomized dynamic mode decomposition in epidemiology and fluid dynamics. Annals of the Alexandru Ioan Cuza University-Mathematics, 66(2), 251–287. Suche in Google Scholar
[6] Bistrian, D. A., Dimitriu, G., & Navon, I. M. (2020). Modeling dynamic patterns from COVID-19 data using randomized dynamic mode decomposition in predictive mode and ARIMA. AIP Conference Proceedings, 2302(1), 080002. 10.1063/5.0033963Suche in Google Scholar
[7] Dhamodharavadhani, S., Rathipriya, R., & Chatterjee, J. M. (2020). COVID-19 mortality rate prediction for India using statistical neural network models. Frontiers in Public Health, 8, p. 44110.3389/fpubh.2020.00441Suche in Google Scholar PubMed PubMed Central
[8] Duke, D., Soria, J., & Honnery, D. (2012). An error analysis of the dynamic mode decomposition. Experiments in Fluids, 52, 529–542. 10.1007/s00348-011-1235-7Suche in Google Scholar
[9] Gupta, A. K., Singh, V., Mathur, P., & Travieso-Gonzalez, C. M. (2021). Prediction of COVID-19 pandemic measuring criteria using support vector machine, prophet and linear regression models in Indian scenario. Journal of Interdisciplinary Mathematics, 24(1), 89–108. 10.1080/09720502.2020.1833458Suche in Google Scholar
[10] Kim, S., Kim, M., Lee, S., & Lee, Y. J. (2021). Discovering spatiotemporal patterns of COVID-19 pandemic in South Korea. Scientific Reports, 11(1), 24470. 10.1038/s41598-021-03487-2Suche in Google Scholar PubMed PubMed Central
[11] Kumar, S., Sharma, S., Singh, F., Bhatnagar, P., & Kumari, N. (2021). A mathematical model for COVID-19 in Italy with possible control strategies. In N. H. Shah & M. Mittal, (Eds.), Mathematical Analysis for Transmission of COVID-19, (pp. 101–124), Singapore: Springer. 10.1007/978-981-33-6264-2_6Suche in Google Scholar
[12] Kumar, V. M., Pandi-Perumal, S. R., Trakht, I., & Thyagarajan, S. P. (2021). Strategy for COVID-19 vaccination in India: The country with the second highest population and number of cases. NPJ Vaccines, 6(1), 60. 10.1038/s41541-021-00327-2Suche in Google Scholar PubMed PubMed Central
[13] Kutz, J. N., Brunton, S. L., Brunton, B. W., & Proctor, J. L. (2016). Dynamic mode decomposition: Data-driven modeling of complex systems. SIAM. 10.1137/1.9781611974508Suche in Google Scholar
[14] Mahmood, Z. (2022). Elections During Covid-19: The Indian Experience in 2020–2021. Case Study, Stockholm: International Institute for Democracy and Electoral Assistance. Suche in Google Scholar
[15] Malavika, B., Marimuthu, S., Joy, M., Nadaraj, A., Asirvatham, E. S., & Jeyaseelan, L. (2021). Forecasting COVID-19 epidemic in India and high incidence states using SIR and logistic growth models. Clinical Epidemiology and Global Health, 9, 26–33. 10.1016/j.cegh.2020.06.006Suche in Google Scholar PubMed PubMed Central
[16] Mathieu, E., Ritchie, H., Rodés-Guirao, L., Appel, C., Giattino, C., Hasell, J., … Roser, M. (2020). Coronavirus Pandemic (COVID-19). Our World in Data. https://ourworldindata.org/coronavirus. Suche in Google Scholar
[17] Ministry of Health and Family Welfare. Population projection report. https://main.mohfw.gov.in/reports-0, Accessed: February 2023. Suche in Google Scholar
[18] National Portal of India. India at a glance. https://www.india.gov.in/india-glance/states-india. Accessed: February 2023. Suche in Google Scholar
[19] Proctor, J. L., & Eckhoff, P. A. (2015). Discovering dynamic patterns from infectious disease data using dynamic mode decomposition. International Health, 7(2), 139–145. 10.1093/inthealth/ihv009Suche in Google Scholar PubMed PubMed Central
[20] Quadri, S. A., & Padala, P. R. (2021). An aspect of Kumbh Mela massive gathering and COVID-19. Current Tropical Medicine Reports, 8, 225–230. 10.1007/s40475-021-00238-1Suche in Google Scholar PubMed PubMed Central
[21] Rocha, I. C. N., Pelayo, M. G. A., & Rackimuthu, S. (2021). Kumbh Mela religious gathering as a massive superspreading event: Potential culprit for the exponential surge of COVID-19 cases in India. The American Journal of Tropical Medicine and Hygiene, 105(4), 868. 10.4269/ajtmh.21-0601Suche in Google Scholar PubMed PubMed Central
[22] Roy, S., Bhunia, G. S., & Shit, P. K. (2021). Spatial prediction of COVID-19 epidemic using ARIMA techniques in India. Modeling Earth Systems and Environment, 7, 1385–1391. 10.1007/s40808-020-00890-ySuche in Google Scholar PubMed PubMed Central
[23] Schmid, P. J. (2010). Dynamic mode decomposition of numerical and experimental data. Journal of Fluid Mechanics, 656, 5–28. 10.1017/S0022112010001217Suche in Google Scholar
[24] The Lancet. (2020). India under COVID-19 lockdown. The Lancet, 395(10233), 1315. 10.1016/S0140-6736(20)30938-7Suche in Google Scholar PubMed PubMed Central
[25] Tu, J. H. (2013). Dynamic mode decomposition: Theory and applications. (PhD thesis). Princeton, NJ, USA: Princeton University. Suche in Google Scholar
[26] Viguerie, A., Barros, G. F., Grave, M., Reali, A., & Coutinho, A. L. (2022). Coupled and uncoupled dynamic mode decomposition in multi-compartmental systems with applications to epidemiological and additive manufacturing problems. Computer Methods in Applied Mechanics and Engineering, 391, 114600. 10.1016/j.cma.2022.114600Suche in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Special Issue: Infectious Disease Modeling In the Era of Post COVID-19
- A comprehensive and detailed within-host modeling study involving crucial biomarkers and optimal drug regimen for type I Lepra reaction: A deterministic approach
- Application of dynamic mode decomposition and compatible window-wise dynamic mode decomposition in deciphering COVID-19 dynamics of India
- Role of ecotourism in conserving forest biomass: A mathematical model
- Impact of cross border reverse migration in Delhi–UP region of India during COVID-19 lockdown
- Cost-effective optimal control analysis of a COVID-19 transmission model incorporating community awareness and waning immunity
- Evaluating early pandemic response through length-of-stay analysis of case logs and epidemiological modeling: A case study of Singapore in early 2020
- Special Issue: Application of differential equations to the biological systems
- An eco-epidemiological model with predator switching behavior
- A numerical method for MHD Stokes model with applications in blood flow
- Dynamics of an eco-epidemic model with Allee effect in prey and disease in predator
- Optimal lock-down intensity: A stochastic pandemic control approach of path integral
- Bifurcation analysis of HIV infection model with cell-to-cell transmission and non-cytolytic cure
- Special Issue: Differential Equations and Control Problems - Part I
- Study of nanolayer on red blood cells as drug carrier in an artery with stenosis
- Influence of incubation delays on COVID-19 transmission in diabetic and non-diabetic populations – an endemic prevalence case
- Complex dynamics of a four-species food-web model: An analysis through Beddington-DeAngelis functional response in the presence of additional food
- A study of qualitative correlations between crucial bio-markers and the optimal drug regimen of Type I lepra reaction: A deterministic approach
- Regular Articles
- Stochastic optimal and time-optimal control studies for additional food provided prey–predator systems involving Holling type III functional response
- Stability analysis of an SIR model with alert class modified saturated incidence rate and Holling functional type-II treatment
- An SEIR model with modified saturated incidence rate and Holling type II treatment function
- Dynamic analysis of delayed vaccination process along with impact of retrial queues
- A mathematical model to study the spread of COVID-19 and its control in India
- Within-host models of dengue virus transmission with immune response
- A mathematical analysis of the impact of maternally derived immunity and double-dose vaccination on the spread and control of measles
- Influence of distinct social contexts of long-term care facilities on the dynamics of spread of COVID-19 under predefine epidemiological scenarios
Artikel in diesem Heft
- Special Issue: Infectious Disease Modeling In the Era of Post COVID-19
- A comprehensive and detailed within-host modeling study involving crucial biomarkers and optimal drug regimen for type I Lepra reaction: A deterministic approach
- Application of dynamic mode decomposition and compatible window-wise dynamic mode decomposition in deciphering COVID-19 dynamics of India
- Role of ecotourism in conserving forest biomass: A mathematical model
- Impact of cross border reverse migration in Delhi–UP region of India during COVID-19 lockdown
- Cost-effective optimal control analysis of a COVID-19 transmission model incorporating community awareness and waning immunity
- Evaluating early pandemic response through length-of-stay analysis of case logs and epidemiological modeling: A case study of Singapore in early 2020
- Special Issue: Application of differential equations to the biological systems
- An eco-epidemiological model with predator switching behavior
- A numerical method for MHD Stokes model with applications in blood flow
- Dynamics of an eco-epidemic model with Allee effect in prey and disease in predator
- Optimal lock-down intensity: A stochastic pandemic control approach of path integral
- Bifurcation analysis of HIV infection model with cell-to-cell transmission and non-cytolytic cure
- Special Issue: Differential Equations and Control Problems - Part I
- Study of nanolayer on red blood cells as drug carrier in an artery with stenosis
- Influence of incubation delays on COVID-19 transmission in diabetic and non-diabetic populations – an endemic prevalence case
- Complex dynamics of a four-species food-web model: An analysis through Beddington-DeAngelis functional response in the presence of additional food
- A study of qualitative correlations between crucial bio-markers and the optimal drug regimen of Type I lepra reaction: A deterministic approach
- Regular Articles
- Stochastic optimal and time-optimal control studies for additional food provided prey–predator systems involving Holling type III functional response
- Stability analysis of an SIR model with alert class modified saturated incidence rate and Holling functional type-II treatment
- An SEIR model with modified saturated incidence rate and Holling type II treatment function
- Dynamic analysis of delayed vaccination process along with impact of retrial queues
- A mathematical model to study the spread of COVID-19 and its control in India
- Within-host models of dengue virus transmission with immune response
- A mathematical analysis of the impact of maternally derived immunity and double-dose vaccination on the spread and control of measles
- Influence of distinct social contexts of long-term care facilities on the dynamics of spread of COVID-19 under predefine epidemiological scenarios