Das Internationale Quellenlexikon der Musik, RISM
-
Klaus Keil
 and
Laurent Pugin
and
Laurent Pugin

Zusammenfassung
Das Internationale Quellenlexikon der Musik (RISM) ist ein internationales Gemeinschaftsprojekt mit dem Ziel, die weltweit überlieferten Quellen zur Musik umfassend zu dokumentieren. Es bietet einen Online-Katalog, der Bibliothekaren, Musikern, Wissenschaftlern und allen interessierten Personen kostenlos zur Verfügung steht. Zunehmend gerät aber der Austausch von Daten in den Vordergrund, sei es von lokalen Online- Bibliothekskatalogen zu RISM oder umgekehrt. Für die Wissenschaft dürfte die Nachnutzung der Daten, die sowohl als Open Data als auch Linked Open Data bereitstehen, in Spezialprojekten von Interesse sein.
Abstract
The International Inventory of musical Sources (RISM) is an international joint project with the aim of comprehensively documenting the sources of music worldwide. It offers an online catalogue that is available free of charge to librarians, musicians, scientists and all interested people. Increasingly, however, the exchange of data comes to the fore, be it from local online library catalogues to RISM or vice versa. For the science, the reuse of the data, which are available as open data as well as linked open data, may be of interest in special projects.
1 Das Internationale Quellenlexikon der Musik – Répertoire International des Sources Musicales (RISM)
Das Internationale Quellenlexikon der Musik – Répertoire International des Sources Musicales (RISM) – ist ein länderübergreifendes Gemeinschaftsprojekt mit dem Ziel, die weltweit überlieferten Quellen zur Musik umfassend zu dokumentieren. Die erfassten musikalischen Materialien sind handschriftliche oder gedruckte Noten, Schriften über Musik und Textbücher. Sie liegen in Bibliotheken, Archiven, Klöstern, Schulen und Privatsammlungen. RISM weist nach, was vorhanden ist und wo es aufbewahrt wird!
Das ehrgeizige Unternehmen begann 1952 in Paris als die International Musicological Society und die International Association of Music Libraries, Archives and Documentation Centers erstmals eine Commission mixte einberiefen, um den Masterplan des Projekts zu erarbeiten. Bis heute wird RISM von den beiden Vereinigungen begleitet.[1] Das Projekt wird wesentlich von der in Frankfurt am Main ansässigen Zentralredaktion koordiniert und vorangetrieben, die seit 1980 von der Mainzer Akademie der Wissenschaften finanziert wird. Durch eine Kooperation mit der Bayerischen Staatsbibliothek München und der Staatsbibliothek zu Berlin können seit dem Jahr 2010 die RISM-Daten frei zur Verfügung gestellt werden.[2]
RISM wurde von Anfang an als internationales Gemeinschaftsunternehmen konzipiert, das spätestens seit Beginn des Projekts A/I (Einzeldrucke bis 1800)[3] ein Arbeitsmodell nutzte, das der traditionellen wissenschaftlichen Einzelleistung entgegengesetzt ist. Hier hebt sich RISM vom großen Musikbibliografen Robert Eitner ab, der für sein um 1900 erschienenes Bio-bibliographisches Quellenlexikon[4] noch selbst von Bibliothek zu Bibliothek gereist war. In heute 36 Ländern beteiligen sich je eine oder mehrere nationale RISM-Arbeitsgruppen an der Arbeit für das Quellenlexikon. Rund 100 Mitarbeiter beschreiben die musikalischen Quellen, die in ihren Ländern aufbewahrt werden. Das sternförmig initiierte Arbeitsmodell mit der Zentralredaktion in der Mitte wird auf nationaler Ebene sternförmig ergänzt um die Bibliotheken, die sich an der Arbeit beteiligen oder doch wenigstens die Bestände zur Aufnahme zur Verfügung stellen.

Bände des RISM, Reihen A/I und B (Auswahl)
2 Die Daten
Als RISM in den 1980er-Jahren sein großes, damals neues Projekt A/II (Musikhandschriften nach 1600) gleich als Computerprojekt auslegte,[5] war das keine Selbstverständlichkeit, sondern wurde mit großem Argwohn betrachtet. Musikwissenschaft habe doch neben den historischen Hintergründen die künstlerische Idee eines Werkes und deren konsequente Durchführung nachzuvollziehen, woraus letztlich ein Urteil über die Qualität zu begründen sei. Digital musicology – wenn der Begriff damals schon gebräuchlich gewesen wäre – wäre unseren Altvorderen wie ein hölzernes Eisen vorgekommen. Wie sich heute zeigt, entfaltet RISM gerade im Kontext der digitalisierten Wissenschaft eine neue Dynamik und neue Potentiale.
Ein kurzer Blick zurück: Die Arbeitsergebnisse kamen anfangs meist als Bibliothekskarten in die damals noch in Kassel ansässige RISM-Zentralredaktion und stellten oft Kopien der Katalogkarten einer Bibliothek dar, auf denen für die Tiefenerschließung bei RISM benötigte Musikincipits meist von Hand dazugeschrieben waren. Die Aufgabe der Zentralredaktionbestand nun darin, diese Karten nach einem Feldschema zu redigieren, dabei das Musikincipit zu codieren[6] und eine Maske mit eben diesem Feldschema im Computer auszufüllen. Um dieses zeitaufwendige Verfahren zu vereinfachen, wurde schon Anfang der 1990er-Jahre ein PC-Programm entwickelt und an die Arbeitsgruppen übergeben. Auch die redaktionelle Arbeit wurde von nun an ausschließlich am PC durchgeführt und das Programm unterstützte sie in vielfältiger Weise.
Dabei ist einiges erreicht: Der RISM Online-Katalog enthält heute (September 2017) knapp 1 084 000 Einträge.[7] Davon sind 971 000 im Rahmen der Serie A/II (Musikhandschriften nach 1600) entstanden, der Rest verteilt sich auf die ursprünglich in Buchform publizierten Serien A/I (Einzeldrucke bis 1800)[8] und einem Teil des Bandes Serie B/I (Sammeldrucke),[9] deren Ergebnisse konvertiert und als Kurzaufnahmen in die Datenbank gespielt wurden.
Die Handschriftenkatalogisierung, die von Anfang an als Tiefenerschließung angelegt war, bei der jede Quelle am Original so genau wie möglich beschrieben wird, wozu eine genaue Auflistung der enthaltenen Werke mit Musikincipit gehört, hat in den letzten Jahren ein beachtliches wissenschaftliches Niveau erreicht. Bereits in den 1990er-Jahren gingen von den von der Deutschen Forschungsgemeinschaft (DFG) geförderten und an der Sächsischen Landesbibliothek – Staats- und Universitätsbibliothek Dresden (SLUB) angesiedelten Projekten zur Erschließung der Werke Johann Adolf Hasses[10] und zur Erschließung der Dresdner Opernsammlung[11] wesentliche Impulse zur Schreiberforschung aus. Die intensive Beschäftigung mit geschlossenen Bestandssegmenten legte Zusammenhänge offen, die in Einzelbetrachtungen nicht zu erfassen sind. Ein wirklich außerordentlicher Fortschritt ließ sich dann beim institutionenübergreifenden Blick erreichen, wie ihn Ortrun Landmann außerhalb der Projektförderung mit ihren Recherchen im Sächsischen Hauptstaatsarchiv Dresden vollzog. Durch Archivmaterial wie Eingaben, Abrechnungen etc. konnten zahlreiche Kopisten überhaupt erst identifiziert werden, wodurch die Dresdner Schreiberforschung wesentliche Impulse erhielt. Diese Vernetzung verschiedener Quellenarten in verschiedenen Einrichtungen ist in der Projektförderung und in der digitalen Darstellung der Forschungsergebnisse zukünftig konsequenter zu verfolgen. Das Dresdner Opernprojekt nahm zudem für jede Nummer einer Oper, die Rezitative ausgenommen, ein Musikincipit auf, wodurch ein umfassender Datenkorpus entstand, der weit über Dresden hinaus für die Identifizierung anonym überlieferter Arien eine wertvolle Vergleichsbasis bietet. Die damals entwickelten Standards wurden in zahlreichen Folgeprojekten der SLUB Dresden und anderer Bibliotheken übernommen und weiter ausgebaut. So verzichtet das KoFIM-Projekt[12] der Staatsbibliothek zu Berlin zwar bei bekannteren Komponisten und Werken auf Musikincipits, betreibt aber ebenfalls umfangreiche Erhebungen zu Schreibern, früheren Besitzern und anderen Sammlungszusammenhängen. Als neuer Schritt wurden in diesem Kontext die Personennormsätze zu Schreibern mit Schriftproben angereichert.[13]
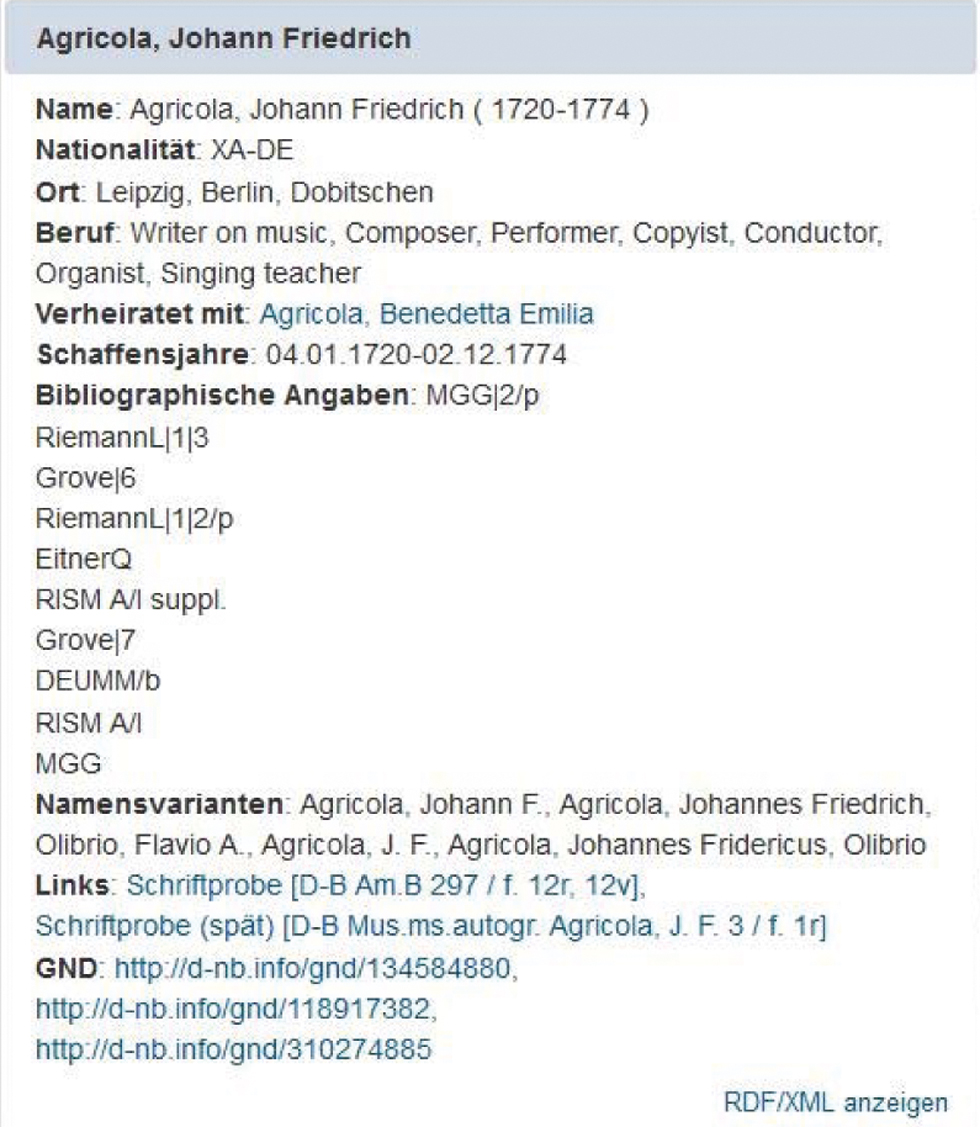
Normdatensatz zu Johann Friedrich Agricola mit Link zu digitalisierten Schriftproben
In den Anfangsjahren setzte RISM im Hinblick auf Datenstruktur, Vokabular und Standards zunächst auf eigenständige Entwicklungen, die sich zum Teil an die Arbeit der Library of Congress anlehnten. Im Jahr 2017 führte RISM die Open-Source-Erfassungssoftware Muscat ein,[14] die browserbasiert und plattformunabhängig genutzt werden kann. Als Datenformat kommt nun MARC zur Anwendung, was den Datenaustausch erheblich erleichtert. RISM pflegt weiter eigene Normdateien für Namen und Körperschaften, wobei die Namendatei, wenn vorhanden, Identnummer der Virtual authority files (VIAF) und der Gemeinsamen Normdatei (GND) enthalten und die Institutionendatei, soweit es sich um Bibliotheken handelt, ISIL-Nummern mitführt. Die Einführung einer Werknormdatei und ihre Verknüpfung mit VIAF und GND ist in Planung. Sie verspricht ein enormes Potential für die Verbindung von Quellen innerhalb der Datenbank wie für die Anschlussfähigkeit zu anderen digitalen Angeboten.
Im Zusammenhang mit der systematischen Digitalisierung musikalischer Quellen werden die Quellenbeschreibungen immer häufiger durch persistente Links auf Digitalisate ergänzt. In größeren Umfang hat erstmals das zwischen 2008 und 2011 von der DFG geförderte Schrank II-Projekt[15] der SLUB Dresden die Tiefenerschließung mit der Digitalisierung verknüpft und ca. 1 700 Links zu Quellendigitalisaten (incl. Wasserzeichenabbildungen) in RISM eingebracht. Heute haben fast 40 000 RISM-Titel solche Links, durch die Benutzer von der bibliografischen Beschreibung meist direkt auf eine Reproduktion der Quelle zugreifen können. RISM selbst bietet keine Digitalisate an, sondern verweist nur auf öffentlich zugängliche Ressourcen. Neben den Verweis auf bibliothekseigene Sammlungen treten Links zu Spezialsystemen wie den beiden Wasserzeichenportalen Bernstein[16] oder WZIS,[17] die von verschiedenen Projektgruppen zur Beschreibung und zum Nachweis von Wasserzeichen genutzt werden.
3 Bereitstellung der Daten
Nachdem die Daten zur Serie A/II (Handschriften) in den 1980er-Jahren als Mikrofiche und ab 1994 jährlich als CD-ROM kommerziell veröffentlicht wurden, stehen sie seit Juli 2010 in einem Online-Katalog kostenlos im Internet zur Verfügung. Dies konnte nur erreicht werden, weil sich die beiden großen Bibliotheken, die Bayerische Staatsbibliothek, München und die Staatsbibliothek zu Berlin zu umfangreichen unterstützenden Leistungen bei Datenspeicherung und Softwareentwicklung bereitfanden. So wurde die Entwicklung der Suchoberfläche durch eine Zusammenarbeit des RISM mit der Bayerischen Staatsbibliothek möglich, die die Weiterentwicklungen regelmäßig im Rahmen des Fachinformationsdienstes Musikwissenschaft realisiert. Ein neues Release ist für Anfang 2018 geplant.
Die oben genannte neue Erfassungssoftware Muscat verfügt über eine eigene Suchoberfläche, die zurzeit aber nur von der schweizerischen und der UK-Arbeitsgruppe für die Darstellung ihrer Daten öffentlich genutzt wird.[18] Nur von den Muscat verwendenden Arbeitsgruppen kann damit auch im Gesamtbestand gesucht werden. Derzeit wird untersucht, ob und wie die beiden Online-Kataloge zusammenwirken können. Im zweiten Teil des vorliegenden Aufsatzes werden von Laurent Pugin die Vorzüge von Muscat beschrieben.
Seit Juli 2013 werden die Daten des Online-Katalogs als Open Data und seit 2014 als Linked Open Data zur Verfügung gestellt. Dieses Angebot richtet sich an Bibliotheken, die ihre Titel in den eigenen lokalen Online-Katalog übertragen möchten, genauso wie an musikwissenschaftliche Projekte, die einen Datenkorpus zu nach bestimmten Kriterien ausgewählten Quellen als Basis für ihre Forschung benötigen. Zur Abholung und Weiterverwendung der Daten stehen verschiedene Wege zur Verfügung: eine SRU-Schnittstelle, eine GND-Beacon-Datei sowie ein SPARQL-Endpoint, über den die gesamten Daten im MARCXML-Format heruntergeladen werden können.[19] Hoffnung besteht, dass über einen noch zu organisierenden Rückfluss auch die RISM-Datenbank erweitert und die Einträge – wo nötig – korrigiert werden.
Alle, die einen konventionellen Buchkatalog aus ihren Daten herstellen möchten, finden in Muscat die Möglichkeit, nach bestimmten Auswahlkriterien – üblicherweise ist es das Bibliothekssigel – eine pdf-Datei herzustellen, die als Druckvorlage verwendet werden kann. Die Quellenbeschreibungen werden alphabetisch nach Komponistennamen aufgeführt, es folgen die Anonyma und die Sammlungen. Automatisch werden Register hergestellt und an den Schluss platziert. Am Ende befinden sich noch Literaturangaben, sofern in den Daten mit der im System integrierten Literatur-Datei verlinkte Angaben vorliegen.
4 Weitere Entwicklungen
Nachdem 1999 der letzte Addenda-Band und 2003 schließlich der Registerband zur bibliografischen Dokumentation von Einzeldrucken erschienen war, bot es sich an die hier zusammengetragenen Daten auch online zur Verfügung zu stellen.[20] Dies geschah in einem ersten Schritt durch die Konvertierung der Daten der Reihe A/I (Einzeldrucke bis 1800) und ihre in Kooperation mit dem Bärenreiter-Verlag erstellte Publikation auf CD-ROM. 2015 wurden dieselben Daten in die RISM-Datenbank eingespielt, die von nun an Handschriften und Drucke nachweist. Im gleichen Jahr ist noch eine Teilmenge konvertierter Daten der Reihe B/I (Sammeldrucke aus dem Zeitraum 1500-1550) hinzugekommen. Seit 2017 wird im Rahmen des Fachinformationsdiensts Musikwissenschaft in Kooperation zwischen der RISM-Zentralredaktion und der SLUB Dresden in der Erfassungssoftware Muscat ein erweitertes Template geschaffen, mit dem Drucke über die bereits vorhandenen Kurzaufnahmen hinaus wissenschaftlich beschrieben werden können. Durch die Differenzierung von bibliographic records und holding records wird es möglich sein, auch exemplarspezifische Angaben aufzunehmen. Im Rahmen des FID-Arbeitspakets wird zudem eine Pilotmenge von 1 300 Titeln erfasst, anhand derer das Template getestet und eine Handreichung für die RISM-Anwender erstellt wird. Die international immer wieder geforderte Möglichkeit der Tiefenerschließung von Drucken erlaubt es zukünftig, Zusammenhänge zwischen den verschiedenen Quellentypen (Handschrift/Druck) offenzulegen und darzustellen, und eröffnet die Perspektive einer nachhaltigen Datenbasis, mit der Fragen der Überlieferung von Musik aus zahlreichen Blickwinkeln mit analogen und digitalen Methoden umfänglich beantwortet werden können.
5 Arbeit mit Muscat – Big Data und Visualisierung
In der Literaturwissenschaft führte Franco Moretti mit seiner so genannten „Fernlektüre“ den Big-Data-Ansatz ein, im Gegensatz zu dem bis dato typischen Ansatz der „Nahlektüre“, bei der man sich auf eine begrenzte Anzahl von Quellen konzentrierte. Seine Forschungen über das 18. und 19. Jahrhundert öffneten den Blick für das „große Ungelesene“, in dem er auf Tausende von Titeln aufmerksam machte, die von Studien gewöhnlich ignoriert werden. Für Musik können die RISM-Daten den gleichen Zweck erfüllen. Das heißt, RISM liefert die Metadaten für die „Fernlektüre“, woraus sich hier das „große Ungehörte“ ergibt. Ein erstes Beispiel liefert das Projekt Big Data History of Music der Royal Holloway, University of London, und der British Library, das mit den RISM-Daten der Serie A/I (Einzeldrucke bis 1800) kombiniert mit Daten aus anderen Projekten durchgeführt wurde.[21] Die quantitative Analyse des RISM-Datenkorpus legte verschiedene Tendenzen im Aufstieg und Fall des Musikdrucks zwischen dem 16. und 17. Jahrhundert offen. Einen methodischen Vorteil bietet der leichte Wechsel von der Makroskalenanalyse (z. B. zwei Jahrhunderte Musikdruck) auf kleinere oder gar mikroskalige Analysen (z. B. nach Dekade oder Jahr für Jahr). Ebenso kann der Analyseumfang geografisch verändert werden, z. B. um genauer zu hinterfragen, wie der bekannte Verfall der Vorherrschaft Venedigs im Musikdruck zu Beginn des 17. Jahrhunderts sich im Einzelnen vollzog.
Die Big-Data-Analyse wirft eine Vielzahl neuer Herausforderungen einschließlich der Frage auf, wie die Ergebnisse zu verwalten und zu verstehen sind. Eine lange Liste mit passenden Treffern oder Zahlen kann schwer interpretierbar sein. Die Methode kann sich schnell in ein labyrinthartiges Fluchtspiel verwandeln, womit das Ergebnis des Prozesses sinnlos bliebe. Hilfe bieten immer wieder neu zu entwickelnde Werkzeuge, zu denen auch Visualisierungstechniken gehören. Bei großen Datenmengen unterstützen sie eine sachgerechte Auswertung und Interpretation der Ergebnisdaten. Im Jahr 2015 präsentierte RISM Schweiz auf dem internationalen Jahreskongress der International Association of Music Libraries and Archives (IAML) Visualisierungsexperimente mit den konvertierten Daten der Serie A/I (Musikdrucke vor 1800).[22] Diese Experimente konzentrierten sich auf die räumlich-zeitliche Visualisierung. Da das Ergebnis der Kombination dreidimensional ist, kann es nicht direkt in einem Bild dargestellt werden. Es erfordert eine ausgefeiltere Lösung mit Interaktionsmöglichkeiten, welche es dem Leser ermöglichen, durch Phasenfolgen zu navigieren. Zu diesem Zweck wurde der DARIAH-GeoBrowser für diese Experimente verwendet.[23] Er ermöglicht die Darstellung von Datensätzen mit Datums- und Ortsangaben auf einer Karte und einer darunterliegenden Zeitleiste. Damit sind verschiedene interaktive Aktionen möglich, nicht nur mit Datums- und Ortsangaben, sondern auch mit dem Datensatz selbst. Dies greift die drei typischen Fragestellungen auf, die mit solchen Datenkonfigurationen formuliert werden können: 1. Welchen Subdatensatz haben wir für eine bestimmte Zeit an einem bestimmten Ort? 2. Wo ist ein gegebener Subdatensatz zu einer bestimmten Zeit? oder 3. Wann erhält man den Subdatensatz an einem bestimmten Ort?[24] Im GeoBrowser können die drei Fragen über Filterung im Dataset (z. B. durch die Suche nach Madrigaldrucken), durch Auswahl eines beliebigen Punktes (oder Bereichs) auf der Zeitleiste oder durch die Auswahl einer beliebigen Region auf der Karte inkrementell eingestellt werden. Letzteres ist besonders interessant, da der GeoBrowser hier verschiedene Auswahlmöglichkeiten zulässt. Dazu gehören z. B. das Zeichnen von polygonalen Flächen zur Auswahl der Objekte, aber auch die Auswahl nach Regionen mithilfe von integrierten oder benutzerdefinierten historischen Karten. [25]

Der DARIAH-GeoBrowser mit den Daten der RISM-Serie A/I[25]
Das Ergebnis der Auswahl kann visualisiert, aber auch zur Weiterverarbeitung einer Analyse heruntergeladen werden. Damit wird ein wesentliches Merkmal solcher Visualisierungstools sichtbar, nämlich dass sie nicht nur einfach visualisieren, sondern auch ein Werkzeug zur Datenmanipulation sind, mit denen Aufgaben ausführbar sind, die über traditionelle textbasierte Suchfunktionen nur schwer umsetzbar wären. Dieser Aspekt ist nicht zu unterschätzen, ganz im Gegenteil, die Möglichkeit der Datenmanipulation sollte zu einem Schlüsselmerkmal gemacht werden, das in gängige Suchschnittstellen generell integriert wird. RISM nähert sich diesen Anforderungen als work-in-progress: Eine ähnliche Visualisierung, wie sie der GeoBrowser bietet, wird in die kommende Version (4.0) von Muscat integriert sein.[26] Die räumlich-zeitliche Visualisierung berücksichtigt in einem ersten Schritt die Orte von Institutionen, während die Produktionsorte (z. B. Druckerei) erst später hinzugefügt werden. Diese Visualisierungs- und Datenselektionsfunktionen werden für jede Abfrage in der Facettensuche in Muscat zur Verfügung stehen und den Benutzern bisher verborgene Perspektiven auf den RISM-Datenkorpus bieten, was durch neue, extrem flexible und leistungsfähige Datenextraktionsmechanismen ermöglicht wird.
6 Metadatenformate: Von MarcXML zu MEI
Vor dem Hintergrund, wie zeitaufwändig das intellektuelle Erfassen von Metadaten ist, sollte ein besonderes Augenmerk darauf gerichtet werden, Datenstandards als Schlüsselelemente zur Herstellung interoperabler, großer Metadaten-Sets zu nutzen. Dies gilt aus mehreren Gründen insbesondere für ein Projekt wie RISM: Wegen seines internationalen Charakters war RISM gezwungen, sich an internationale Standards anzupassen, um den Datenaustausch mit Institutionen auf der ganzen Welt zu ermöglichen, und zwar sowohl für die Datenübernahme als auch für deren Veröffentlichung. Durch die Entscheidung für MarcXML wurde der Datenaustausch erheblich erleichtert. Die Beschäftigung mit Standards ist ferner von besonderer Bedeutung, da RISM sich mit ungewöhnlichem Material auseinandersetzt, das nicht nur aus verbalen Texten, sondern auch aus Notation von Musik besteht. Bei der Wahl der Standards für die Erfassung sowohl der Text- als auch der Notenbestandteile ist ein Ausgleich zu finden zwischen den Vorteilen von allgemein verbreiteten und von musikspezifischen Ansätzen. Allgemein für Textressourcen genutzte Standards eröffnen die Möglichkeit, zahlreiche in unterschiedlichen Kontexten genutzte Tools nutzen zu können und eröffnen die Möglichkeit des Austauschs mit großen Institutionen und Projekten – zwar ohne musikalische Expertise, aber mit unschätzbaren Fachkenntnissen in der Verwaltung von Textressourcen. Musikspezifische Ansätze ermöglichen gut durchdachte und passgenaue musikspezifischen Features, die z. B. Besonderheiten musikalischer Werke und Titel berücksichtigen oder mit der Codierung von Musiknotation umgehen können.
Im Bereich musikspezifischer Standards hat sich die Music Encoding Initiative (MEI) in den letzten zehn Jahren zum prominentesten Projekt entwickelt.[27] MEI bietet eine breite Palette an Einsatzmöglichkeiten, von der digitalen kritischen Musikedition bis hin zur Musikanalyse. MEI fungiert als Kodierungssystem für Musikdokumente, das auf ganz spezielle Bedürfnisse zugeschnitten werden kann. Entsprechend der Praxis der Text Encoding Initiative (TEI), von der sie abgeleitet wurde, hat MEI eine modulare Struktur, bei der jedes Modul die Kodierungsfunktionen neu gruppiert, z. B. spezifisch für eine Anwendungsnutzung (z. B. Analyse) oder für einen Musiknotationstyp (z. B. Mensuralnotation). Es gibt eine Reihe von Modulen, die in den meisten MEI-Anwendungen zu finden sind, auch wenn dies technisch gesehen keine Voraussetzung ist. Die beiden wichtigsten Module sind das sogenannte Shared-Modul und das Header-Modul, in denen alle Metadaten für MEI definiert und gruppiert sind. Der Metadaten-Header in MEI ist extrem reichhaltig und bietet neben der Möglichkeit, präzise Quellbeschreibungen zu kodieren, auch Features zur Implementierung des FRBR-Modells. Eine weitere Stärke des Metadaten-Frameworks, das der MEI-Header bietet, ist die Möglichkeit, Musikincipits in verschiedenen Formaten zu kapseln, unter anderem im Plaine und Easie Code, der für die Musikincipits bei RISM verwendet wird, aber natürlich auch direkt in MEI, so dass es damit möglich ist, die Incipits deutlich zu erweitern, sollte dies von einem Projekt gewünscht werden.
Auch wenn die Ziele von RISM und der MEI-Gemeinschaft recht unterschiedlich sind, besteht eine Schnittmenge der Interessen und werden Abstimmung und Zusammenarbeit gesucht. Die meisten Projekte, die MEI in den letzten Jahren eingeführt haben, zielen im Wesentlichen darauf ab, einen extrem reichen Datensatz mit einer begrenzten Anzahl von Quellen zu produzieren. Dies unterscheidet sie von RISM, bei dessen Projekten sinnvoller Weise nur ein begrenzter Detaillierungsgrad in Betracht gezogen werden kann, um das Projekt skalierbar zu halten. Dennoch gibt es eine natürliche Anziehungskraft beider Initiativen, und mehrere Projekte haben bereits eine Brücke zwischen RISM-Datenkorpus und der MEI-Codierung geschlagen. Eines davon ist das Detmolder Hoftheaterprojekt, das seine Arbeit auf der Grundlage von vorläufig aus RISM MarcXML in MEI konvertierten Daten mithilfe eines XSLT-Stylesheets der MEI-Community aufbaute.[28] Dieses Stylesheet wurde von RISM Schweiz weiterentwickelt und wird zurzeit in Muscat integriert. Eine erste Version dieser Integration wurde bereits 2015 auf der Music Encoding Conference in Florenz vorgestellt, arbeitete damals aber nur an Schweizer Daten. Da die gesamten RISM-Daten nun nach Muscat migriert sind, werden wir ab der kommenden Version von Muscat alle RISM-Daten als MEI zur Verfügung stellen, was einen bedeutenden Durchbruch für die Forschung darstellen wird.
Bei der bereits geleisteten Arbeit zur Bereitstellung von RISM-Daten in MEI blieben einige zentrale Desiderate offen. Eines der wichtigsten ist die Überführung der quellenbezogenen Daten, die in RISM erstellt werden und in der Konvertierung angeboten werden, in die oft (aber nicht ausschließlich) von MEI-basierten Projekten gewünschte werkzentrierte Datenstruktur, wie sie das FRBR-Modell vorgibt: Eine MEI-Datei konzentriert sich auf ein Werk, wobei die einzelnen Quellen als Instanzen des Werkes erscheinen. An dieser Stelle wird eine gewisse Flexibilität erforderlich sein, wobei für die Integration der Konvertierung nach MEI in Muscat die Verwendung eines benutzerdefinierten oder angepassten Stylesheets vorgesehen ist. Zukünftig lässt sich auch eine Erweiterung um Möglichkeiten zur Aggregation von Datensätzen mit RISM-Quellbeschreibungen direkt während des Konvertierungsprozesses vorstellen, um MEI-Dateien auf Werkebene zu erzeugen, die in bestimmten Forschungsprojekten weiterverwendet werden können, wie es sich im Detmolder Hoftheaterprojekten bewährt hat.
7 Musikincipits
Ein weiterer Bereich der Forschung und Entwicklung mit RISM-Daten befasst sich mit den Musikincipits. Die Erfassung der Incipits im Plaine und Easie Code wurde in den achtziger Jahren hauptsächlich mit dem Ziel eingeführt, anonyme oder unsicher zugeschriebene Quellen zu identifizieren.[29] Die Idee, diese Daten für andere Forschungszwecke zu nutzen, war aber schon damals vorhanden. So überrascht es nicht, dass RISM-Incipits für die Music Information Retrieval (MIR)-Forschung von Anfang an eingesetzt wurden. Dabei wurden zahlreiche Methoden vorgeschlagen, darunter die Editierdistanz-Methode, n-Gramm-Methoden oder Vergleiche geometrischer Darstellungen.[30] In den Jahren 2005 und 2006 wurden RISM-Incipits für die symbolische Ähnlichkeitssuche in MIREX, einer Community-basierten Plattform zur Evaluierung und zum Vergleich von Musiksuchalgorithmen und -techniken, eingesetzt.[31]
Trotz der Vielzahl der vorgeschlagenen Incipit-Suchtechniken und aller möglichen Verbesserungen wurde im Laufe der Zeit immer deutlicher, dass es aus Perspektive des RISM-Anwenders nicht die eine, one-size-fits-all Incipit-Suchlösung geben wird. Die Erwartungen der Nutzer variieren sehr stark, z. B. je nach Repertoire, das durchsucht werden soll, oder nach Suchinteresse, das z. B. eher auf rhythmische oder auf Intervallähnlichkeiten ausgerichtet sein kann.[32] Aus diesem Grund sollte die Integration von Incipit-Suchtechniken in RISM-Ressourcen nicht nur auf die Auswahl effizienter und zuverlässiger Suchalgorithmen, sondern auch auf die Bereitstellung einer geeigneten und flexiblen Oberfläche für die Benutzer ausgerichtet sein. Die nächste Version von Muscat wird eine angepasste Version der Themefinder-Suchmaschine enthalten, die an der Stanford University entwickelt wurde. Ihre Besonderheit liegt in der Fuzzy-Melodic-Kontur-Suche mit zwei Ebenen der Unschärfe (verfeinerte und grobe Kontur).[33] Wie im von der Bayerischen Staatsbibliothek betriebenen RISM-OPAC wird auch in Muscat die Incipit-Suche über eine Tastaturschnittstelle mit Metadatenfilterung durchgeführt, hier jedoch mit den zusätzlichen Unschärfe-Suchebenen, die der Suchalgorithmus des Themefinders bietet. Die Besonderheit der Themefinder-Suchmaschine in seiner Muscat-Integration ist, dass der Benutzer die interne Themefinder-Kontursyntax nicht zu kennen braucht, um eine Abfrage zu machen, sondern durch einfaches Auswählen von expliziten Dropdown-Suchoptionen geführt wird.
Die nächsten Schritte für die Incipit-Suche werden die Integration anderer bereits vorhandener Suchmaschinen sein. Derzeit laufen Vorarbeiten für die Einbindung eines an der Universität Utrecht entwickelten Indexierwerkzeugs,[34] das nicht nur auf eine Verbesserung der Incipit-Suche zielt, sondern auch Vorschläge für die Zuschreibung von anonym überlieferten oder falsch zugeschriebenen Quellen macht.
Bei der Darstellung von Musikincipits wurde mit der Entwicklung der Software Verovio, die seit Version 2.0 in Muscat integriert ist, ein wichtiger Meilenstein gesetzt.[35] Incipit-Rendering geschieht nun dynamisch in den Browsern und vermeidet so zahlreiche Probleme, die bisher bei der Erzeugung und Zwischenspeicherung von Bildern aufgetreten sind. Mit der Verovio-Inhouse-Lösung kann das Rendering zudem wesentlich einfacher als bisher verbessert werden. Ferner sollen zukünftig durch die Interaktionsfunktionen von Verovio Ergebnisse der Incipit-Suche hervorgehoben werden. Ein wesentlicher Gewinn liegt zudem darin, dass Verovio MEI nativ implementiert. Das bedeutet, dass alle RISM-Incipits de facto als MEI verfügbar sind, was für die bereits erwähnte Konvertierung von RISM-MarcXML-Datensätzen in MEI sehr nützlich ist. Bei der Konvertierung der Daten gibt es die Möglichkeit, die Incipits entweder als Plaine und Easie Code zu konservieren, was in MEI unterstützt wird, oder sie aber in MEI-kodierte Musik mit zu konvertieren werden, so dass alle von der MEI-Community entwickelten Tools nutzbar sind.
8 Weitere Entwicklungen
Ein zentrales Thema für die Muscat-Weiterentwicklung wird die Einrichtung einer Werkebene sein, die unter Verwendung vorhandener Normdatenbanken für Werke (z. B. GND oder VIAF) sowie durch andere Datenaggregations- und Verknüpfungsmechanismen realisiert werden soll. Dies erfordert grundlegende Überlegungen wird dann aber eine völlig neue Sichtweise auf den RISM-Datenkorpus ergeben. Die Werkebene wird nicht nur für traditionelle RISM-Benutzer von großem Nutzen sein, sondern auch für andere maschinelle Auswertung von RISM-Daten neue Perspektiven eröffnen.
Die Entwicklung des International Image Interoperability Framework (IIIF) stellt einen bedeutenden Durchbruch beim Zugang zu hochauflösenden Bildern dar, der perfekt zum RISM-Projekt passt. Auch wenn RISM keine Holdinginstitution und auch nicht dazu bestimmt ist, selbst eine große Sammlung von Bildern aufzunehmen, profitiert RISM als übergreifendes Referenz-Projekt davon, dass Bildressourcen über IIIF zur Verfügung gestellt werden, indem einfach ein Link zum IIIF-Manifest in den RISM-Datensatz integriert wird. Muscat hat bereits die Fähigkeit, Inline-Bilder, die durch IIIF zur Verfügung gestellt werden, mit dem Diva.js Image Viewer anzuzeigen.[36] Zu diesem Zeitpunkt haben nur wenige Hunderte von Datensätzen IIIF-Links, aber wir hoffen, dass sie in naher Zukunft stärker genutzt werden, auch durch den Import großer Mengen vorhandener IIIF-Manifest-Links.
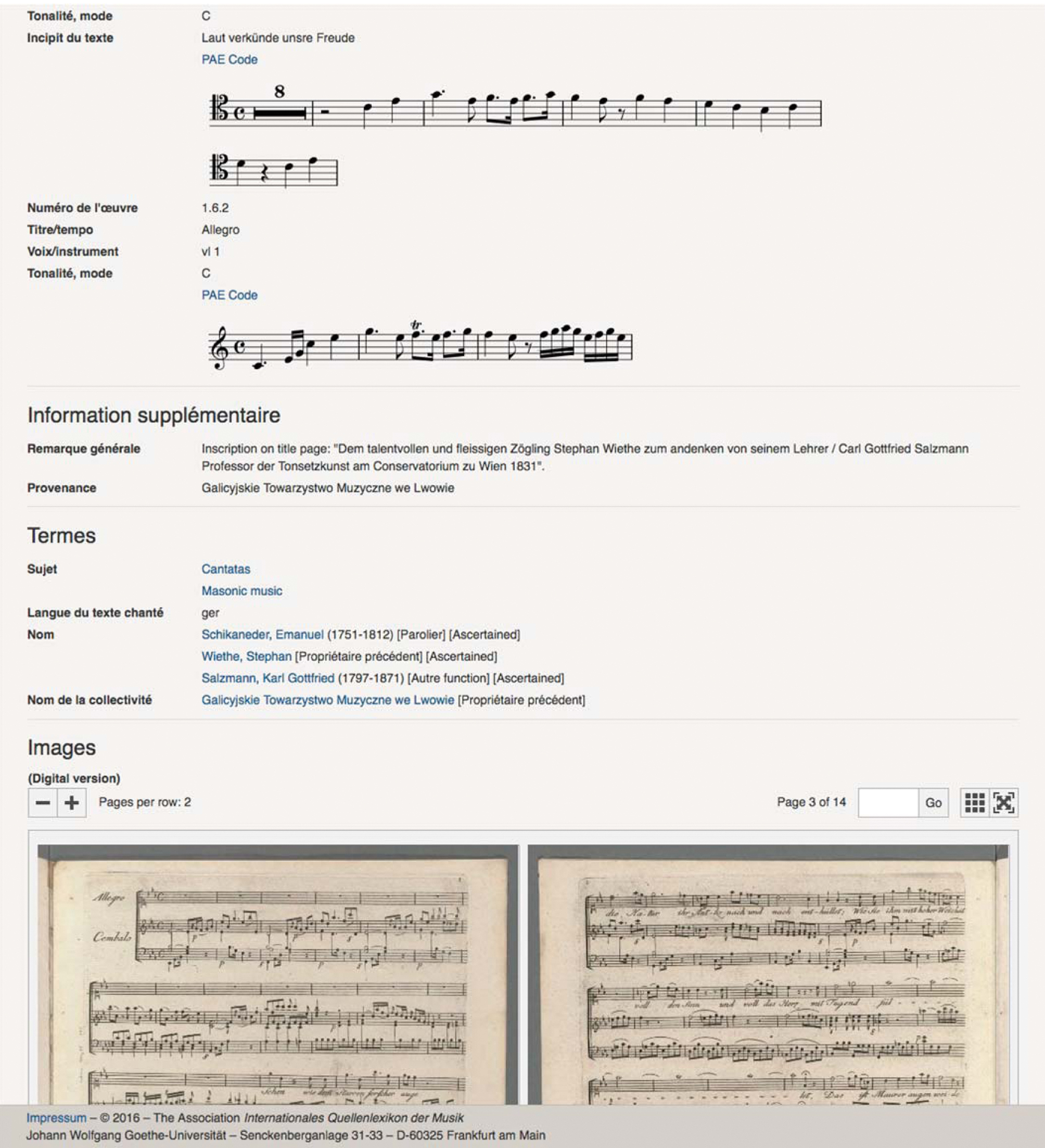
Eine Quellenbeschreibung in Muscat mit Incipit-Rendering und Inline-Bilddarstellung durch Diva.js und IIIF
Die skizzierten Entwicklungen zeigen deutlich, wie traditionell gewachsene, verlässliche Referenz-Ressourcen heute stetig mit gut konzipierter Verbindungstechnologie zusammengeführt werden müssen, um analoges und digitales wissenschaftliches Arbeiten nachhaltig und zeitgemäß zu unterstützen und musikwissenschaftliche Forschungsarbeit zu erleichtern und zu beschleunigen.
Über die Autoren


© 2018 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Titelseiten
- Inhaltsfahne
- Digitale Forschungsinfrastruktur für die Musikwissenschaft
- Editorial
- Ontologien als semantische Zündstufe für die digitale Musikwissenschaft?
- Improving (Re-) Usability of Musical Datasets: An Overview of the DOREMUS Project
- Building Prototypes Aggregating Musicological Datasets on the Semantic Web
- Normdaten zu „Werken der Musik“ und ihr Potenzial für die digitale Musikwissenschaft
- Lesen und Schreiben im digitalen Dickicht
- Bach digital: Ein „work in progress“ der digitalen Musikwissenschaft
- The letters of Casa Ricordi
- Digitizing Sound Archives at Royal Library of Belgium
- Open Cultural Heritage – zum Hören!
- Zur Edition historischer Tonaufnahmen – ein Praxisbericht
- Stand und Perspektiven der Nutzung von MEI in der Musikwissenschaft und in Bibliotheken
- Langzeitverfügbarkeit von wissenschaftlicher Software im Bereich historisch-kritischer Musikedition
- Das Internationale Quellenlexikon der Musik, RISM
- Optical Music Recognition in der Bayerischen Staatsbibliothek
- Digital Humanities in der Musikwissenschaft – Computergestützte Erschließungsstrategien und Analyseansätze für handschriftliche Liedblätter
- New Library Science
- Warum brauchen wir eine (neue) Bibliothekswissenschaft?
- Why Do We Need a New Library Science
- How to Qualify the Debate on the Public Library by the Use of Research-Developed Tools
- Die drei Dimensionen des Dokuments und ihre Auswirkungen auf die Bibliotheks- und Informationswissenschaft
- Do We Need a New Approach to Library and Information Science?
- Bibliotheken mit Vorstellungskraft – Bausteine für einen Lehrplan für zukünftige Bibliotheksarbeit
- Im Labyrinth
- Die Unwahrscheinlichkeit von Wissenstradition und die Beharrlichkeit der Bibliothek
- Rezensionen
- Petra Hauke, Andrea Kaufmann und Vivien Petras (Hrsg.): Festschrift für Konrad Umlauf zum 65. Geburtstag. Berlin; Boston: de Gruyter Saur, 2017. XVI, 726 S., 119,00 €, ISBN 978-3-11-051971-6, e-ISBN (PDF) 978-3-11-052233-4, e-ISBN (EPUB) 978-3-11-051993-8
- Ulrich Hohoff: Wissenschaftliche Bibliothekare als Opfer der NS-Diktatur. Ein Personenlexikon. Beiträge zum Buch- und Bibliothekswesen Band 62. Wiesbaden: Harrassowitz, 2017. XIII, 415 Seiten. Fest geb. € 72.-, ISSN 0408-8107, ISBN 9078-3-447-10842-3, E-Book ISBN 978-3-447-19613-0; 1980–83 erschien das „Biographische Handbuch der deutschsprachigen Emigration“.
Articles in the same Issue
- Titelseiten
- Inhaltsfahne
- Digitale Forschungsinfrastruktur für die Musikwissenschaft
- Editorial
- Ontologien als semantische Zündstufe für die digitale Musikwissenschaft?
- Improving (Re-) Usability of Musical Datasets: An Overview of the DOREMUS Project
- Building Prototypes Aggregating Musicological Datasets on the Semantic Web
- Normdaten zu „Werken der Musik“ und ihr Potenzial für die digitale Musikwissenschaft
- Lesen und Schreiben im digitalen Dickicht
- Bach digital: Ein „work in progress“ der digitalen Musikwissenschaft
- The letters of Casa Ricordi
- Digitizing Sound Archives at Royal Library of Belgium
- Open Cultural Heritage – zum Hören!
- Zur Edition historischer Tonaufnahmen – ein Praxisbericht
- Stand und Perspektiven der Nutzung von MEI in der Musikwissenschaft und in Bibliotheken
- Langzeitverfügbarkeit von wissenschaftlicher Software im Bereich historisch-kritischer Musikedition
- Das Internationale Quellenlexikon der Musik, RISM
- Optical Music Recognition in der Bayerischen Staatsbibliothek
- Digital Humanities in der Musikwissenschaft – Computergestützte Erschließungsstrategien und Analyseansätze für handschriftliche Liedblätter
- New Library Science
- Warum brauchen wir eine (neue) Bibliothekswissenschaft?
- Why Do We Need a New Library Science
- How to Qualify the Debate on the Public Library by the Use of Research-Developed Tools
- Die drei Dimensionen des Dokuments und ihre Auswirkungen auf die Bibliotheks- und Informationswissenschaft
- Do We Need a New Approach to Library and Information Science?
- Bibliotheken mit Vorstellungskraft – Bausteine für einen Lehrplan für zukünftige Bibliotheksarbeit
- Im Labyrinth
- Die Unwahrscheinlichkeit von Wissenstradition und die Beharrlichkeit der Bibliothek
- Rezensionen
- Petra Hauke, Andrea Kaufmann und Vivien Petras (Hrsg.): Festschrift für Konrad Umlauf zum 65. Geburtstag. Berlin; Boston: de Gruyter Saur, 2017. XVI, 726 S., 119,00 €, ISBN 978-3-11-051971-6, e-ISBN (PDF) 978-3-11-052233-4, e-ISBN (EPUB) 978-3-11-051993-8
- Ulrich Hohoff: Wissenschaftliche Bibliothekare als Opfer der NS-Diktatur. Ein Personenlexikon. Beiträge zum Buch- und Bibliothekswesen Band 62. Wiesbaden: Harrassowitz, 2017. XIII, 415 Seiten. Fest geb. € 72.-, ISSN 0408-8107, ISBN 9078-3-447-10842-3, E-Book ISBN 978-3-447-19613-0; 1980–83 erschien das „Biographische Handbuch der deutschsprachigen Emigration“.