Quantifying the quality of configurational causal models
-
Michael Baumgartner
 and
Christoph Falk
and
Christoph Falk

Abstract
There is a growing number of studies benchmarking the performance of configurational comparative methods (CCMs) of causal data analysis. A core benchmark criterion used in these studies is a dichotomous (i.e., non-quantitative) correctness criterion, which measures whether all causal claims entailed by a model are true of the data-generating causal structure or not. To date, Arel-Bundock [The double bind of Qualitative Comparative Analysis] is the only one who has proposed a measure quantifying correctness. That measure, however, as this study argues, is problematic because it tends to overcount errors in models. Moreover, we show that all available correctness measures are unsuited to assess relations of indirect causation. We therefore introduce a new correctness measure that adequately quantifies errors and does justice to indirect causation. We also offer a new completeness measure quantifying the informativeness of CCM models. Together, these new measures broaden and sharpen the resources for CCM benchmarking.
1 Introduction
Configurational comparative methods (CCMs) constitute a family of methods of causal learning that track causal complexity by grouping multiple causes into bundles (conjunctions) that only become operative when all of their components are properly co-instantiated and by placing these bundles on alternative (disjunctive) causal paths that can bring about corresponding outcomes independently of one another. CCMs are custom-built to deal with causal structures featuring complex interactions, threshold effects, equifinality, or component causation, which tend to pose challenges for standard methods (e.g., Bayes nets methods or regression methods) because these structures often violate linearity and feature causes and effects that are not correlated in the data, giving rise to violations of causal faithfulness [1]. To this end, CCMs trace causation as defined by modern regularity theories of causation – which define causation in terms of Boolean difference-making and, unlike most other theories, do not entail that pairwise correlation is necessary for causation (cf. [2,3]).
The two main members of the CCM family are Qualitative Comparative Analysis (QCA; [4,5]) and Coincidence Analysis (CNA; [6,7]). They differ in various aspects, e.g., in search targets and implemented algorithms, or in domains of applicability [8]. While QCA has been widely used in the social and political sciences, in business administration, or in management, CNA has seen a significant uptick in applications in public health in recent years.
Accompanying the increasing dispersion of CCMs, there is a growing body of literature benchmarking the performance of QCA and CNA (e.g., [8–16]). These benchmarking studies conduct inverse searches by, first, (randomly) building data-generating structures – ground truths – second, simulating data from those structures featuring various deficiencies such as noise or fragmentation, and third, processing the data with CCMs to measure the degree to which the produced outputs comply with different quality criteria. One such criterion used in many studies (but not all, cf. [12]) is a dichotomous correctness criterion, which classifies a model as correct if all of its causal implications correspond to causal properties of the ground truth, meaning if it is a submodel of the ground truth, and as incorrect otherwise [11]. That is, a correct model is a model that does not commit a false positive error. But CCM models may have numerous causal implications: they can identify an array of causes, group these causes conjunctively and disjunctively, and they may feature multiple outcomes, for each of which they exhibit disjunctions of conjunctions of causes. Accordingly, only checking whether a model is a submodel of the ground truth amounts to a coarse-grained benchmark. Models that are not submodels of the ground truth can be further compared with respect to how many false implications they have. After all, a model with many true implications and one false positive error is still preferable over a model with many such errors. Hence, measuring correctness not just dichotomously but quantitatively is a natural further development of CCM benchmarking.
However, as this study will show, adequately quantifying errors in CCM models is an intricate problem. The only solution proposed so far is Arel-Bundock’s [9] wrongness measure, which counts implications of a model in terms of the number of its submodels and then quantifies wrongness as the proportion of its submodels that are not also submodels of the ground truth. In the first part of this study, we will argue that this approach is inadequate because it tends to disproportionally overcount errors. In addition, it will be shown that the notion of a submodel, which is at the heart of much of CCM benchmarking to date, is only suited to assess the correctness of models exclusively making claims about relations of direct causation, but it cannot handle models expressing indirect causation. In consequence, both the standard dichotomous correctness measure and Arel-Bundock’s wrongness measure are prone to misjudge the quality of CCM models when the ground truth is a causal chain.
The second part of the study sets out to rectify these shortcomings. In general terms, correctness of a model relative to a ground truth is the ratio of causal information contained in the model that is true of the ground truth. The problems of overcounting errors and of indirect causation show that the sets of submodels do not adequately measure that information content. As an alternative, we introduce the notion of a causal exposition, which, in a nutshell, refers to a list of all types of all causal ascriptions, including ascriptions of direct and indirect relevance, made by models and ground truths. These causal expositions can then be intersected and the correctness of the model quantified in terms of the ratio of the complexity of these intersections to the complexity of the model’s causal exposition.
Correctness is not the only quality measure, as it exclusively rewards error avoidance and is insensitive to a model’s informativeness. Benchmarking studies – in many methodological traditions – therefore, complement correctness (a.k.a. precision) by a completeness (a.k.a. recall) criterion measuring how much of the ground truth is revealed by a model, i.e., how informative a model is [17–20]. In CCM benchmarking, different completeness criteria are in use, some dichotomous, and some quantitative [9–11,15]. But they typically rely on the notion of a submodel that gives rise to problems when the ground truth is a causal chain. For that reason, we complement our new correctness criterion by an analogous new completeness criterion, which quantifies completeness with exclusive recourse to the tools developed in this study. To quantify a model’s overall quality, we then aggregate its correctness and completeness using the
2 Basics of CCMs
To learn structures featuring causal complexity from data, CCMs draw on the so-called (M)INUS theory of causation [2,3,21], which is especially suited for the analysis of complexity dimensions that give rise to linearity and faithfulness violations.[1] Contrary to most other theories of causation, the (M)INUS theory does not define causation with recourse to a pairwise dependence between causes and effects. Rather, it defines the relation of causal relevance (i.e., type-level causation) between a factor A taking some value
Factors in such Boolean functions can either be crisp-set (binary), taking two possible values 0 and 1, fuzzy-set, taking real values from the unit interval
Most sufficiency and necessity relations do not reflect causation, but some of them do, namely, the ones that are rigorously freed of redundancies. As shown by Baumgartner and Falk [2], there exists a tight connection between difference-making and redundancy-freeness:
When causally interpreted, (1) entails that
Of course, as deterministic dependencies are rare in (messy) real-life data, strictly sufficient and necessary conditions for an outcome often do not exist. In order to nonetheless distill causal information from such data, CCMs approximate deterministic dependency structures by suitably fitting their models to the data. The two core fit measures used for that purpose are consistency and coverage (for formal definitions, see [24]).[6] Consistency measures the degree to which the behavior of an outcome obeys a corresponding sufficiency or necessity relationship or a whole model; coverage measures the degree to which a sufficiency or necessity relationship or a whole model accounts for the behavior of the corresponding outcome. What counts as acceptable scores on these fit parameters (with values in the unit interval) is defined in thresholds that can either be set by the analyst prior to the analysis or chosen through the robustness protocol recently introduced by Parkkinen and Baumgartner [15]. They determine how closely a dependence in the data must approximate the deterministic ideal in order to pass as one of sufficiency or necessity.
Given their embedding in the (M)INUS theory, CCMs – unlike standard methods – do not infer their outputs from associations (e.g., effect sizes) observed in the data as a whole, rather they exploit difference-making evidence at the level of individual cases (units of observations) in the data. For example, if two cases
In order to establish, along these lines, that
This has ramifications for the interpretation of CCM models. First, if multiple models
Second, a model as (1), inferred from data, must be interpreted to be open for later expansions, i.e., it must be read with implicit placeholders for additional conjuncts
So the fact that, say,
Submodel. A CCM model
if
if
If
3 Assessing model quality by submodel criteria
3.1 State-of-the-art in CCM benchmarking
Even though the output of a CCM inferred from limitedly diverse data often contains more than one model and even though these models cannot be expected to reflect the complete ground truth, the output as a whole can and should be expected to truthfully reflect the data-generating structure. This is satisfied if at least one output model
Qualitative correctness (LCR). A model
While being important in current CCM benchmarking, (LCR) is clearly insufficient to assess the overall quality of models. For one, (LCR) does not take model complexity or informativeness into account. Models can be very sparse or very complex submodels of the ground truth, yet equally satisfy (LCR). Hence, correctness needs to be complemented by a completeness criterion suitably rewarding informativeness.[8] There are various completeness criteria on offer, some qualitative [7], some quantitative [9,10,15,16], but they all measure completeness by drawing on the submodel relation.
Another reason why (LCR) does not suffice for assessing model quality is that it is merely qualitative, meaning it can only be passed or not. As a result, (LCR) cannot capture important differences. To illustrate, let
As neither (4) nor (5) are submodels of
To date, Arel-Bundock [9] is the only one who has proposed a measure that is sensitive to such differences by expressing correctness quantitatively. Strictly speaking, Arel-Bundock does not define a measure for model correctness but for model wrongness: “I measure the level of wrongness by counting the proportion of solution submodels that are not submodels of the truth” [9, p. 7]. But to adjust this proposal to our preferred terminology (which is also standard in the benchmarking literature), we transform Arel-Bundock’s wrongness measure into a quantitative correctness measure (by negating it):
Quantitative correctness (NCR). The correctness of a model
To illustrate, we apply (NCR) to models (4) and (5). Table 1 lists all submodels of (4) and (5), respectively, and indicates whether they are submodels of the ground truth
All submodels of models (4) and (5), respectively, with marks indicating whether a submodel is also a submodel of the ground truth
|
|
sub
|
|
sub
|
|---|---|---|---|
|
|
|
|
|
|
|
✗ |
|
✗ |
|
|
|
|
|
|
|
✗ |
|
✗ |
|
|
|
|
✗ |
|
|
✗ |
|
✗ |
|
|
✗ |
|
✗ |
|
|
|
3.2 Problem of overcounting errors
The first problem of (NCR) is best introduced with another concrete example. Thus, let
The important feature of candidate models (6)–(8) is that they all contain the same error: instead of adding
Clearly, an adequate correctness measure must not punish models (7) and (8) for containing more true elements than (6) while committing the same error as (6). More generally, an adequate correctness measure should respect the following model expansion principle (MEP):
Model Expansion Principle (MEP). Expanding a model by truthfully located elements from the ground truth cannot reduce correctness.
(NCR), however, does not respect (MEP). It assigns the highest correctness score to (6) and the lowest to (8). Model (6) has a total of seven submodels, six of which are also submodels of
To bring this out more clearly, we take a closer look at (7). Table 2 lists all of (7)’s 15 submodels. The truthful submodels, i.e., the ones that are submodels of
| # |
|
sub(6) | sub
|
# |
|
sub(6) | sub
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
✗ |
|
|
|
|
|
|
|
✗ | ✗ |
|
|
|
|
|
|
|
✗ | ✗ |
|
|
|
|
|
||||
|
|
|
|
|
||||
|
|
|
|
|
||||
|
|
|
✗ |
|
||||
|
|
|
✗ |
|
||||
|
|
|
✗ |
|
||||
|
|
|
✗ |
|
||||
|
|
|
✗ |
|
||||
|
|
|
✗ |
|
Now, observe what proportions of true and false submodels are added when model (6) is expanded to (7). Model (6) has seven submodels, which are also marked in Table 2. Six of these submodels are true, one is false. When
We take this to show that not only (NCR) does not adequately quantify model correctness but any attempt to quantify correctness based on proportions of true or false submodels faces a risk of miscounting errors, because those proportions can be twisted under model expansion and thus are not guaranteed to respect (MEP).
3.3 Problem of indirect causation
To date, CCM benchmarking has predominantly focused on QCA’s or CNA’s success in recovering single-outcome models, i.e., atomic MINUS-formulas. Correspondingly, both (LCR) and (NCR) are custom-built for correctness assessment in single-outcome recovery. This section argues that (LCR) and (NCR) are in fact inadequate when the data are generated by multi-outcome structures with causally related outcomes, i.e., by causal chains. In a nutshell, the reason is that models leaving out intermediate links on causal paths to an ultimate outcome may be perfectly correct without being a submodel of the ground truth or even containing such a submodel.
To see this, consider the causal chains in the hypergraph of Figure 1. This graph has two non-standard elements that require introduction: arrows merged by “•” symbolize conjunctive relevance, and “◇” expresses that the negation of the factor at the tail of the arrow is relevant. Another notable feature of that structure, which will become important in Section 4.1, is the switching factor F: its positive value
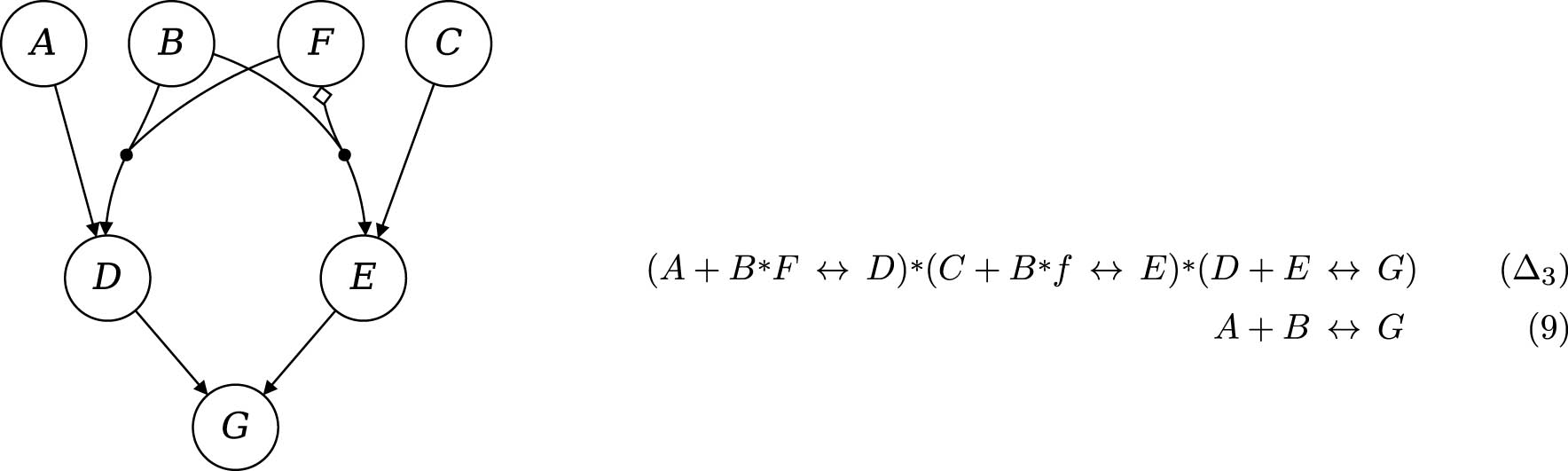
A causal chain with switching factor F, the corresponding complex MINUS-formula
One might be inclined to respond that, despite making numerous true claims about
To avoid that consequence, it is standard to view the distinction between direct and indirect causation as inherently relative to the factors contained in a given model [26,27]. That means that a causal relation can be truthfully represented as a direct one in a first model and as an indirect one in a second. Relative to the factors in model (9),
Against that backdrop, model (9) is incomplete but does not commit an error. An adequate correctness measure should thus reward it with a maximal score. However, both (LCR) and (NCR) fail to do so. The only atomic MINUS-formula for outcome
But (9) is neither itself a submodel of (10), and thereby of
4 A new approach to correctness assessment
In the most general terms, correctness of a model
4.1 Building causal expositions
MINUS-formulas contain four types of causal information: ascriptions of causal relevance (i) to individual factor values (or literals), (ii) to conjunctions, (iii) to disjunctions, and (iv) sequential orderings of causal relations in causal paths. For brevity, we refer to these types as literal, conjunctive, disjunctive, and sequential ascriptions, respectively. To illustrate, reconsider
Among many others,
Causal exposition. The causal exposition of a MINUS-formula
One lesson to learn from the problem of indirect causation is that causal expositions cannot simply be read off the syntax of a MINUS-formula (or of its submodels), because MINUS-formulas only represent direct causation (relative to the factors in the formula) and lack a syntactic expression of indirect causation. But information about indirect causation, and thus causal expositions, can be recovered from MINUS-formulas by syntactic transformations standard in Boolean algebra.
Viewed as a mere Boolean expression, the first atomic MINUS-formula in
(11) is automatically in DNF. In other examples, additional transformations – for instance, factoring out – may be required to bring expressions resulting from such substitutions into DNF; but any Boolean expression can easily be brought into DNF. The substitutability principle ensures that if
If we additionally minimize sufficient and necessary conditions in (11) relative to ideal data on
(12) has the form of an atomic MINUS-formula. As it results from syntactic transformations of
Two further indirect MINUS-formulas can be recovered from
(12), (13), and (14) are all the indirect MINUS-formulas recoverable from
Hence, suppose that the following multi-outcome model is inferred from data simulated from ground truth
If we substitute
Chain-expansion. The chain-expansion of a MINUS-formula
The important feature of chain-expansions for quantifying model quality is that they syntactically represent all types of causal ascriptions entailed by a MINUS-formula
Table 3 lists the chain-expansion of
Chain-expansion and causal exposition of ground truth
| Chain-expansion | Causal exposition | ||||
|---|---|---|---|---|---|
| Literals | Conjunctions | Disjunctions | Sequences | ||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|||
|
|
|
|
|||
4.2 Intersecting causal expositions
To quantify the correctness of a model
To make that concrete, assume that the following model is inferred from data generated by ground truth
Model (16), which contains no information about outcome
Chain-expansion and causal exposition of model (16)
| Chain-expansion | Causal exposition | ||||
|---|---|---|---|---|---|
| Literals | Conjunctions | Disjunctions | Sequences | ||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Intersecting the literal, conjunctive, and disjunctive ascriptions of (16) and
Intersections and correctness scoring for model (16) relative to ground truth
| Out. | Model (16) | Ground truth
|
Intersection | Ratio | Weight | Correctness | |
|---|---|---|---|---|---|---|---|
| lit. |
|
|
|
|
|
|
|
|
|
|
1 | |||||
|
|
|
|
|
|
|
||
| conj. |
|
|
|
|
|
|
|
|
|
|
0.57 | |||||
|
|
|
|
|
|
|
||
| dis. |
|
|
|
|
|
|
|
|
|
|
0.56 | |||||
|
|
|
|
|
|
|
||
| seq. |
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
1 | |
|
Overall correctness (Corr):
|
|||||||
Factor values in bold indicate the expressions used for calculating the correctness ratios. “
As the difference between direct and indirect causal relevance is relative to a set of modeled factors, the correctness of the sequential ascriptions of a model must be assessed relative to its set of factors. This, in turn, requires that the sequential ascriptions of the corresponding ground truth be pruned to the model’s factor set before intersecting. More concretely, model (16) is correct to entail that
4.3 Quantifying correctness
An intersection expresses the amount of causal information of a particular type shared by the model and ground truth, in other words, it expresses the causal claims made by the model that are true of the ground truth, i.e., the model’s true positives. As correctness is a measure for the ratio of true information in a model, the next step toward putting a number on the correctness of (16), is to quantify the complexities of intersections and corresponding ascriptions. For literals, conjunctions, and disjunctions we quantify complexities in terms of numbers of factor values. For instance, the set
For sequences, we aim to avoid unnecessary double-counting by quantifying complexities not in terms of the number of factor values but in terms of the number of paths. That is, correctness ratios for the sequential ascriptions of a model are ratios of the model’s paths that are contained in the sequential intersection with the ground truth. For example, as both paths in the set of sequential ascriptions
The next step to a correctness quantification of (16) consists in aggregating these correctness ratios of the component ascriptions. We choose a weighted mean for that purpose, where weights are the complexity shares of component ascriptions. For literal, conjunctive, and disjunctive correctness, weights are calculated based on the number of factor values in a corresponding ascription. In the case of sequential correctness, they are based on the number of paths. For instance, for both outcomes combined, the conjunctive ascriptions of (16) have a total complexity of seven factor values, with two pertaining to outcome
Finally, the four correctness scores must be aggregated into one overall score, which we again do with a weighted mean. The weights are based on the complexity shares of a model’s whole causal exposition covered by a corresponding correctness score. The total complexity of the causal exposition is the sum of the complexities of the four types of causal ascriptions. For model (16), it is
Here, then, is our quantitative correctness measure in condensed form. Let
Aggregating these measures yields the following measure for overall correctness:
Correctness (Corr). The overall correctness of
An isolated (Corr)-score as 0.75 for (16) is not very informative; it merely says that (16) is neither entirely correct nor entirely incorrect. How (in)correct it is becomes clear only if its correctness score is compared with the scores of other models inferred from the same data. Table 6a thus lists the (Corr)-scores of further model candidates assumed to be inferred from the same data simulated from
(a) contains additional CCM models and their (Corr)-scores relative to
| (a) | (b) | ||||
|---|---|---|---|---|---|
| # | Model | (Corr)-score | # | Model | (Corr)-score |
|
|
|
0.75 |
|
|
|
|
|
|
0.88 | (6) |
|
0.92 |
|
|
|
1 | (7) |
|
0.94 |
|
|
|
1 | (8) |
|
0.95 |
|
|
|
1 | |||
|
|
|
0.81 | |||
|
|
|
0.65 | |||
Finally, Table 6b exhibits the (Corr)-scores of the examples demonstrating the shortcomings of (NCR) in Section 3.2. Model (8) has the highest and (6) the lowest score. That is, contrary to (NCR), (Corr) does not punish (8) for containing more true information than (6), while committing the same mistake as (6). This result generalizes. Adding truthfully located elements from the ground truth to a model increases the complexities of the literal, conjunctive, disjunctive, and sequential intersections and of the model’s corresponding causal ascriptions by the same amount, meaning that numerators and denominators of (
5 Completeness
Table 6a also shows that correctness cannot be the only measure of model quality. Models
In the most general terms, completeness of a model
(
Completeness (Comp). The overall completeness of
To illustrate, we reconsider model (16) from Section 6 and calculate its (Comp)-score relative to ground truth
Intersections and completeness scoring for model (16) relative to ground truth
| Out | Ground truth
|
Model (16) | Intersection | Ratio | Weight | Completeness | |
|---|---|---|---|---|---|---|---|
| lit. |
|
|
|
|
|
|
|
|
|
|
|
|
0.55 | |||
|
|
|
|
|
|
|
||
| conj. |
|
|
|
|
|
|
|
|
|
|
|
|
0.55 | |||
|
|
|
|
|
|
|
||
| dis. |
|
|
|
|
|
|
|
|
|
|
|
|
0.47 | |||
|
|
|
|
|
|
|
||
| seq. |
|
|
|
|
|
|
0.4 |
|
|
|
|
|
||||
|
|
|
|
|
|
|
||
| Overall completeness (Comp):
|
|||||||
Bold indicates the expressions used for calculating the completeness ratios.
Like correctness scores, completeness scores are easiest to interpret when contrasting multiple models inferred from the same data. For that reason, let us compare the (Comp)-score of (16) with the scores of the models in Table 8, all of which are assumed to be inferred from the same data simulated from
Additional CCM models and their (Comp)-scores relative to
| # | Model | (Comp)-score |
|---|---|---|
|
|
|
0.29 |
|
|
|
0.31 |
|
|
|
0.43 |
|
|
|
0.18 |
|
|
|
0.29 |
|
|
|
0.40 |
|
|
|
0.40 |
|
|
|
1 |
|
|
|
1 |
6 Aggregating correctness and completeness
In order to assess the overall quality of models in CCM benchmarking, correctness and completeness scores need to be suitably aggregated. Ideally, both scores are 1. In that case, the ground truth is correctly and completely recovered, meaning that the inferred model is identical to the ground truth. It is uncontroversial that this is the optimal result of a benchmark test. It means that the tested method successfully recovers the very structure used to simulate the data. Unfortunately, this ideal scenario often does not occur when the data are non-ideal, i.e., when they feature fragmentation or noise. We cannot expect a method to find the complete ground truth if the evidence in the data is incomplete, and we cannot expect a method to avoid mistakes entirely if some of the evidence is not faithful to the ground truth. But of course, even in non-ideal data scenarios we want the quality of the models to be as high as possible. Methods outputting models of higher quality, on average, are preferable to methods with lower quality outputs. Hence, we need an account of overall model quality that suitably aggregates (Corr)- and (Comp)-scores.
Unfortunately, it is not uncontroversial among CCM methodologists how correctness and completeness should be aggregated. Hasebrouck and Thomann [29] distinguish between two approaches for evaluating models: the SI-approach prioritizes the substantive interpretability of models and the RF-approach prioritizes the redundancy-freeness of the models. According to the SI-approach, the consistency (footnote 6) of each disjunct in a model should be as high as possible, even if a disjunct contains conjuncts that are not causes of the outcome. The idea is that each disjunct should constitute a complete recipe – possibly with redundant ingredients – to actualize the outcome. By contrast, the RF-approach demands that each disjunct in a model be exclusively composed of true causes of the outcome, even if the disjunct as a whole does not reach optimal consistency and is only an incomplete recipe for the outcome. It follows that the SI-approach puts more weight on completeness, whereas the RF-approach takes correctness to be more important. A majority of representatives of the QCA method adhere to the SI-approach, while a minority (i.e., those that advocate so-called parsimonious QCA solutions) and all representatives of the CNA method adhere to the RF-approach.
We do not want to take a stance, here, on whether correctness or completeness should be preferred when measuring overall model quality. An aggregation that is standard in binary classification and that can easily accommodate either preference is a weighted harmonic mean with a positive real weight
Overall quality. Let
By assigning a value to
The harmonic mean is preferred over the arithmetic mean because, contrary to the latter, it requires that a high-quality model strike a balance between correctness and completeness. More specifically, if correctness and completeness scores are balanced at moderate values, the harmonic mean is higher than if the two scores are at opposite extremes, whereas the arithmetic mean is insensitive to such imbalances.
To illustrate
Comparing the overall quality of model (16) relative to ground truth
| # | Model | Corr | Comp |
|
|
|---|---|---|---|---|---|
| (16) |
|
0.75 | 0.49 | 0.68 | 0.53 |
|
|
|
0.75 | 0.29 | 0.57 | 0.33 |
|
|
|
0.88 | 0.31 | 0.64 | 0.35 |
|
|
|
1 | 0.43 | 0.79 | 0.48 |
|
|
|
1 | 0.18 | 0.53 | 0.22 |
|
|
|
1 | 0.29 | 0.67 | 0.34 |
|
|
|
0.81 | 0.40 | 0.67 | 0.45 |
|
|
|
0.65 | 0.40 | 0.58 | 0.43 |
|
|
|
1 | 1 | 1 | 1 |
|
|
|
0.73 | 1 | 0.77 | 0.93 |
This demonstrates that the relative importance assigned to (Corr) and (Comp) in a CCM benchmark test may have a great influence on the results. Any such test must hence be accompanied by an argument justifying the chosen
7 Conclusion
This study developed quantitative correctness (precision) and completeness (recall) measures, (Corr) and (Comp), to be used in benchmarking of CCMs as QCA or CNA. Contrary to the benchmarking criteria currently employed, these new measures do not rely on comparing sets of submodels of candidate models and ground truths. Instead, (Corr) and (Comp), first, unpack the different types of causal ascriptions implied by models and ground truths in causal expositions, second, intersect those expositions, and third, quantify correctness and completeness in terms of the complexities of these intersections. In this manner, (Corr) and (Comp) avoid the problems of overcounting errors and of indirect causation, which affect current benchmarking criteria. The study concludes by accounting for overall model quality in terms of a weighted harmonic mean of (Corr) and (Comp). That account is easily fine-tuned to accommodate any preference ordering of correctness and completeness that may be relevant in a given benchmarking context. Taken jointly, these new measures not only avoid problems of current benchmarking criteria, but they broaden and sharpen the resources for CCM benchmarking more generally.
Acknowledgement
We are grateful to Luna de Souter and Veli-Pekka Parkkinen for extended discussions and their helpful comments on an earlier draft. Moreover, we thank Roel Rutten, Adrian Dusa, the audience at 9th International QCA Expert Workshop, and three anonymous referees.
-
Funding information: The research behind this study was supported by the Toppforsk program of the University of Bergen and the Trond Mohn Foundation (Grant number 811866) and by the Norwegian Research Council (Project number 326215).
-
Author contributions: Both authors contributed equally.
-
Conflict of interest: The authors have no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
-
Data availability statement: The datasets generated and analyzed during the current study can be reproduced with the R scripts available at https://github.com/m-baum/quantifyQuality.
References
[1] Spirtes P, Glymour C, Scheines R. Causation, prediction, and search (second edition). Cambridge: MIT Press; 2000. 10.7551/mitpress/1754.001.0001Search in Google Scholar
[2] Baumgartner M, Falk C. Boolean difference-making: a modern regularity theory of causation. British J Philos Sci. 2023;74(1):171–97. 10.1093/bjps/axz047Search in Google Scholar
[3] Mackie JL. The cement of the universe: a study of causation. Oxford: Clarendon Press; 1974. Search in Google Scholar
[4] Ragin CC. The comparative method. Berkeley: University of California Press; 1987. Search in Google Scholar
[5] Rihoux B, Ragin CC (Ed.). Configurational comparative methods: Qualitative Comparative Analysis (QCA) and related techniques. Thousand Oaks: Sage; 2009. 10.4135/9781452226569Search in Google Scholar
[6] Baumgartner M. Uncovering deterministic causal structures: a Boolean approach. Synthese. 2009;170:71–96. 10.1007/s11229-008-9348-0Search in Google Scholar
[7] Baumgartner M, Ambühl M. Causal modeling with multi-value and fuzzy-set Coincidence Analysis. Politic Sci Res Methods. 2020;8(3):526–42. 10.1017/psrm.2018.45Search in Google Scholar
[8] Swiatczak MD. Different algorithms, different models. Quality Quantity. 2022;56:1913–37. 10.1007/s11135-021-01193-9Search in Google Scholar
[9] Arel-Bundock V. The double bind of Qualitative Comparative Analysis. Sociol Methods Res. 2022;51(3):963–82. 10.1177/0049124119882460Search in Google Scholar
[10] Baumgartner M, Falk C. Configurational causal modeling and logic regression. Multivariate Behav Res. 2023;58(2):292–310. 10.1080/00273171.2021.1971510Search in Google Scholar PubMed
[11] Baumgartner M, Thiem A. Often trusted but never (properly) tested: evaluating Qualitative Comparative Analysis. Sociol Methods Res. 2020;49(2):279–311. 10.1177/0049124117701487Search in Google Scholar
[12] Dusa A. Critical tension: sufficiency and parsimony in QCA. Sociol Methods Res. 2022 Nov;51(2):541–65. 10.1177/0049124119882456Search in Google Scholar
[13] Krogslund C, Choi DD, Poertner M. Fuzzy sets on shaky ground: parameter sensitivity and confirmation bias in fsQCA. Politic Anal. 2015;23(1):21–41. 10.1093/pan/mpu016Search in Google Scholar
[14] Lucas SR, Szatrowski A. Qualitative Comparative Analysis in critical perspective. Sociol Methodol. 2014;44(1):1–79. 10.1177/0081175014532763Search in Google Scholar
[15] Parkkinen VP, Baumgartner M. Robustness and model selection in configurational causal modeling. Sociol Methods Res. 2023;52(1):176–208. 10.1177/0049124120986200Search in Google Scholar
[16] Swiatczak MD, Baumgartner M. Data imbalances in Coincidence Analysis: a simulation study. Sociol Methods Res. 2024 March. DOI: https://doi.org/10.1177/00491241241227039. 10.1177/00491241241227039Search in Google Scholar
[17] Cheng L, Guo R, Moraffah R, Sheth P, Candan KS, Liu H. Evaluation methods and measures for causal learning algorithms. IEEE Trans Artif Intel. 2022;3(6):924–43. 10.1109/TAI.2022.3150264Search in Google Scholar
[18] Maier M, Taylor B, Oktay H, Jensen D. Learning causal models of relational domains. Proc AAAI Confer Artif Intell. 2010;24:531–8. DOI: https://doi.org/10.1609/aaai.v24i1.7695.10.1609/aaai.v24i1.7695Search in Google Scholar
[19] Meek C. Causal inference and causal explanation with background knowledge. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence. 1995. p. 403–10. https://arxiv.org/ftp/arxiv/papers/1302/1302.4972.pdf. Search in Google Scholar
[20] Tabib Mahmoudi F, Samadzadegan F, Reinartz P. Object recognition based on the context aware decision level fusion in multi views imagery. IEEE J Selected Topics Appl Earth Observations Remote Sensing. 2015 Jan;8(1):12–22. 10.1109/JSTARS.2014.2362103Search in Google Scholar
[21] Beirlaen M, Leuridan B, Van De Putte F. A logic for the discovery of deterministic causal regularities. Synthese. 2018;195(1):367–99. 10.1007/s11229-016-1222-xSearch in Google Scholar
[22] Bowran AP. A Boolean algebra: abstract and concrete. London: Macmillan; 1965. 10.1007/978-1-349-00216-0Search in Google Scholar
[23] Lemmon EJ. Beginning logic. London: Chapman & Hall; 1965. Search in Google Scholar
[24] Ragin CC. Set relations in social research: evaluating their consistency and coverage. Political Analysis. 2006;14(3):291–310. 10.1093/pan/mpj019Search in Google Scholar
[25] Baumgartner M. Qualitative Comparative Analysis and robust sufficiency. Quality Quantity. 2022;56:1939–63. 10.1007/s11135-021-01157-zSearch in Google Scholar PubMed PubMed Central
[26] Parkkinen VP. Variable relativity of causation is good. Synthese. 2022;200:194. DOI: https://doi.org/10.1007/s11229-022-03676-0.10.1007/s11229-022-03676-0Search in Google Scholar
[27] Woodward J. Response to Strevens. Philosophy Phenomenol Res. 2008;LXXVII:193–212, 10.1111/j.1933-1592.2008.00181.xSearch in Google Scholar
[28] McCluskey EJ. Minimization of Boolean functions. Bell Syst Tech J. 1956;35:1417–44. 10.1002/j.1538-7305.1956.tb03835.xSearch in Google Scholar
[29] Haesebrouck T, Thomann E. Introduction: causation, inferences, and solution types in configurational comparative methods. Quality Quantity. 2022;56(4):1867–88. 10.1007/s11135-021-01209-4Search in Google Scholar
[30] Chinchor N. Muc-4 evaluation metrics. In Proceedings of the 4th Conference on Message Understanding. 1992 June. p. 22–29. https://aclanthology.org/M92-1002.pdf. 10.3115/1072064.1072067Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Evaluating Boolean relationships in Configurational Comparative Methods
- Doubly weighted M-estimation for nonrandom assignment and missing outcomes
- Regression(s) discontinuity: Using bootstrap aggregation to yield estimates of RD treatment effects
- Energy balancing of covariate distributions
- A phenomenological account for causality in terms of elementary actions
- Nonparametric estimation of conditional incremental effects
- Conditional generative adversarial networks for individualized causal mediation analysis
- Mediation analyses for the effect of antibodies in vaccination
- Sharp bounds for causal effects based on Ding and VanderWeele's sensitivity parameters
- Detecting treatment interference under K-nearest-neighbors interference
- Bias formulas for violations of proximal identification assumptions in a linear structural equation model
- Current philosophical perspectives on drug approval in the real world
- Foundations of causal discovery on groups of variables
- Improved sensitivity bounds for mediation under unmeasured mediator–outcome confounding
- Potential outcomes and decision-theoretic foundations for statistical causality: Response to Richardson and Robins
- Quantifying the quality of configurational causal models
- Design-based RCT estimators and central limit theorems for baseline subgroup and related analyses
- An optimal transport approach to estimating causal effects via nonlinear difference-in-differences
- Estimation of network treatment effects with non-ignorable missing confounders
- Double machine learning and design in batch adaptive experiments
- The functional average treatment effect
- An approach to nonparametric inference on the causal dose–response function
- Review Article
- Comparison of open-source software for producing directed acyclic graphs
- Special Issue on Neyman (1923) and its influences on causal inference
- Optimal allocation of sample size for randomization-based inference from 2K factorial designs
- Direct, indirect, and interaction effects based on principal stratification with a binary mediator
- Interactive identification of individuals with positive treatment effect while controlling false discoveries
- Neyman meets causal machine learning: Experimental evaluation of individualized treatment rules
- From urn models to box models: Making Neyman's (1923) insights accessible
- Prospective and retrospective causal inferences based on the potential outcome framework
- Causal inference with textual data: A quasi-experimental design assessing the association between author metadata and acceptance among ICLR submissions from 2017 to 2022
- Some theoretical foundations for the design and analysis of randomized experiments
Articles in the same Issue
- Research Articles
- Evaluating Boolean relationships in Configurational Comparative Methods
- Doubly weighted M-estimation for nonrandom assignment and missing outcomes
- Regression(s) discontinuity: Using bootstrap aggregation to yield estimates of RD treatment effects
- Energy balancing of covariate distributions
- A phenomenological account for causality in terms of elementary actions
- Nonparametric estimation of conditional incremental effects
- Conditional generative adversarial networks for individualized causal mediation analysis
- Mediation analyses for the effect of antibodies in vaccination
- Sharp bounds for causal effects based on Ding and VanderWeele's sensitivity parameters
- Detecting treatment interference under K-nearest-neighbors interference
- Bias formulas for violations of proximal identification assumptions in a linear structural equation model
- Current philosophical perspectives on drug approval in the real world
- Foundations of causal discovery on groups of variables
- Improved sensitivity bounds for mediation under unmeasured mediator–outcome confounding
- Potential outcomes and decision-theoretic foundations for statistical causality: Response to Richardson and Robins
- Quantifying the quality of configurational causal models
- Design-based RCT estimators and central limit theorems for baseline subgroup and related analyses
- An optimal transport approach to estimating causal effects via nonlinear difference-in-differences
- Estimation of network treatment effects with non-ignorable missing confounders
- Double machine learning and design in batch adaptive experiments
- The functional average treatment effect
- An approach to nonparametric inference on the causal dose–response function
- Review Article
- Comparison of open-source software for producing directed acyclic graphs
- Special Issue on Neyman (1923) and its influences on causal inference
- Optimal allocation of sample size for randomization-based inference from 2K factorial designs
- Direct, indirect, and interaction effects based on principal stratification with a binary mediator
- Interactive identification of individuals with positive treatment effect while controlling false discoveries
- Neyman meets causal machine learning: Experimental evaluation of individualized treatment rules
- From urn models to box models: Making Neyman's (1923) insights accessible
- Prospective and retrospective causal inferences based on the potential outcome framework
- Causal inference with textual data: A quasi-experimental design assessing the association between author metadata and acceptance among ICLR submissions from 2017 to 2022
- Some theoretical foundations for the design and analysis of randomized experiments