An optimal transport approach to estimating causal effects via nonlinear difference-in-differences
-
William Torous
 ,
Florian Gunsilius
,
Florian Gunsilius

Abstract
We propose a nonlinear difference-in-differences (DiD) method to estimate multivariate counterfactual distributions in classical treatment and control study designs with observational data. Our approach sheds a new light on existing approaches like the changes-in-changes estimator and the classical semiparametric DiD estimator, and it also generalizes them to settings with multivariate heterogeneity in the outcomes. The main benefit of this extension is that it allows for arbitrary dependence between the coordinates of vector potential outcomes and includes higher-dimensional unobservables, something that existing methods cannot provide in general. We demonstrate its utility on both synthetic and real data. In particular, we revisit the classical Card & Krueger dataset, which reports fast food restaurant employment before and after a minimum wage increase. A reanalysis with our methodology suggests that these restaurants substitute full-time labor with part-time labor on aggregate in response to a minimum wage increase. This treatment effect requires estimation of the multivariate counterfactual distribution, an object beyond the scope of classical causal estimators previously applied to this data.
1 Introduction
Difference-in-differences (DiD) estimators are among the most widely used approaches to estimate causal effects of discrete treatment interventions in observational data [1–4]. The classical setting we considered in this article is one in which the researcher observes the outcomes of interest in a group of treated units and a corresponding control group of untreated units over time, i.e., a binary treatment setting.[1] At one fixed point in time, the treatment group undergoes an intervention and stays treated thereafter. The fundamental problem consists of isolating the causal effect of this intervention from the existing natural trend that the treatment group undergoes irrespectively. The method of DiD achieves this under the assumption that the units in the control group have the same fundamental trend as the treated units would have without intervention. Under this assumption, the difference of the average outcome of the treated group between preintervention and postintervention periods net the difference of the control groups average outcomes preintervention and postintervention manages to isolate the true average causal effect of the intervention.
The arguably two most fundamental methods for estimating causal effects in this setting are the classical method of DiD [1,2,5] as described earlier and its generalization beyond average and aggregate effects, the changes-in-changes (CiC) estimator [6].
DiD is a linear approach designed to estimate average (or aggregate) causal effects [1,7] over all units within a group. This method can be proved to correctly identify counterfactuals under the “parallel trends” assumption [1,8,9] under which the average natural trend is assumed to be the same across both the control and treatment groups. This idea has been used in many areas of science where capturing the average treatment effect is sufficient to formulate informative causal conclusions. Recent applications include quantifying the effect of public health measures in response to COVID-19 [10] and estimating how irrigation farmers adapt their watering to fixed usage limits [11].
The classical linear DiD estimator only provides estimates of average and aggregate treatment effects. This can be limiting in many settings where treatment heterogeneity is important, i.e., where different units can react differently to the same level of intervention. The CiC estimator [6] addresses this issue for univariate outcomes. It extends the fundamental idea of the DiD estimator by estimating changes in the entire probability distribution of the respective units within a group. This permits the estimation of the entire counterfactual law of the treated units had they not received the treatment, hence allowing for a general form of heterogeneity in their response to treatment. The cost is a slightly stricter assumption on the evolution of the unobservable distribution as we specify below.
In its current form, the CiC estimator is only applicable in settings with univariate outcomes, as it relies heavily on the definition of quantile functions. This can be restrictive for modern applications where the outcomes of interest are often multivariate. Examples range from A/B testing in digital marketing campaigns where outcomes are a combination of features such as click-through rate, time-per-page, and so on, to measuring intervention effects such as gene knock down on a population of cells measured in high-dimensional gene space. In principle, the CiC estimator may be extended to higher dimensions through tensorization, which estimates treatment effects independently for each coordinate, but this solution fails to capture correlations that are often important in causal discovery. We demonstrate a simple linear setting with synthetic data where this is the case in Section 4.1.
Our contribution. We recast the CiC estimator using tools from the theory of optimal transportation. This perspective allows us to extend this methodology to handle multivariate observables after introducing novel structural assumptions on the natural trend underlying both treatment and control groups. In particular, we note that the causal model proposed in Athey and Imbens [6] readily implies that both populations, treatment and control, evolve between pretreatment and posttreatment periods via optimal transport maps (Theorem 2); our methodology relies on a natural higher-dimensional extension of this via optimal transport theory. In fact, we show that if the corresponding functions mapping the unobservables to the potential outcomes are cyclically comonotone, then the counterfactual distributions and causal effects can be estimated from data. In particular, this allows for the unobservable variables to be of the same dimension as the dimension of the outcome variables and not just univariate.
The counterfactual distributions can be estimated consistently from data using recent results from statistical optimal transport and implemented efficiently using recent advances in computational optimal transport [12]. We demonstrate the benefits of this extension by comparing it to the simple multivariate extension of the CiC estimator on both artificial and real data. As illustrated in Section 4.1, a tensorized version of CiC can be inconsistent and even estimate opposite correlation structures in the multivariate distribution of counterfactual outcomes. We also revisit the classical dataset of Card and Krueger [13], which has sparked an intense debate about the effects of raising the minimum wage on employment. Our ability to jointly handle the number of part-time and full-time workers as a bivariate outcome reveals an interesting substitution effect from the perspective of labor economics: When the minimum wage is raised, restaurants increase full-time labor and decrease part-time labor, suggesting a substitution effect.
2 The causal model behind the CiC estimator
2.1 The CiC model
We recall in this section the general causal model on which the classical DiD and CiC estimators are built, and which our model extends. See Figure 1 for illustration.

Illustration of various maps in the space of measures. An arrow indicates a pushforward map between two measures; for example
We first formalize a stochastic model for an experimental design in which two groups are measured before and after some intervention. Sampled from a larger population, each unit
We assume that each potential outcome vector is generated by a deterministic function of a latent random vector also in
As Figure 1 illustrates, three global production functions
As units in the same treatment arm share a latent variable distribution, we define random vectors with the population distribution such that
In addition, assuming that
In the sequel, we will propose a class of production functions such that the multivariate counterfactual distribution for the treated, distributed as a random variable
A consistent estimator for
2.2 Modeling the control group time trend
Given two measures
Recall that the source of randomness in the proposed causal model are latent random vectors
In a setting with uncoupled scalar data, the map
Recently, in the univariate setting, other approaches for modeling the control group time trend have been proposed, which generalize the “parallel trends” assumption to allow for general heterogeneity. These models in general make stronger or less interpretable assumptions than the monotone production functions of Athey and Imbens [6]. Callaway and Li [19] directly assume that the copulas between
In the following section, we show that under the CiC model, the univariate natural trend map
3 Higher dimensional CiC
3.1 An optimal transport extension of the CiC estimator
Identifiability of the causal model presented in the previous section hinges on the uniqueness of the monotone increasing map
Theorem 1
[Brenier, 21] Let P and Q be two probability measures defined over
Let
admits a unique solution
For
Theorem 1 demonstrates that the structural properties of the univariate CiC model can be extended to higher dimensions by leveraging the theory of optimal transportation. In particular, the Brenier map is unique and hence identifiable between pairs of sufficiently regular measures in
For our main result, we assume that all four the potential outcome measures
Assumption 1
The observable measures
When
Therefore, the natural trend map is identifiable when it is cyclically monotone. For
Furthermore, in the univariate case, these two definitions are equivalent; in the CiC model, this implies that the monotone map
In the context of our latent model, the monotonicity assumption on the production functions for the CiC estimator implies that larger values of the unobservable latent variable correspond to strictly larger potential outcomes. This is a common assumption in economic models [24–26], but can be restrictive in some settings. For instance, consider a classroom experiment where the treatment variable is class size and the outcomes of interest are standardized test scores before the intervention and 5 years after. Monotone production functions imply that individuals with higher unobserved ability
A careful inspection of the data generating process reveals that monotone assumptions on the production functions allow the latent variable to be entirely abstracted away. This actually follows from the weaker notion of comonotonicity such that
We have now seen that that the monotone production functions assumption in Athey and Imbens [6] implies that the natural trend is cyclically monotone, which enables identification of the counterfactual. Furthermore, the production functions are comonotone, which allows the model to include general latent space distributions. However, these two functional assumptions only collapse to monotonicity in the scalar case. To extend their model to higher dimensions, we propose an assumption of cyclically comonotone production functions, which achieves both these desired properties.
Definition 1
Two production functions
Just as cyclical monotonicity collapses to monotonicity when
Cyclical comonotonicity is one of the several concepts to extend comonotonicity to higher dimensions. One set of extensions imposes a total ordering on the outcome space; however, these imply that the copula of outcomes preintervention and postintervention are identical, a strong assumption on the causal model. Note that the tensorized CiC assumes this shared copula structure. More recently, optimal transportation theory has been used to propose other multivariate notions of comonotonicity. A particular contribution is
Cyclical monotonicity is a natural extension of monotonicity to multivariate settings with many uses in economic theory and mechanism design [30,31], econometrics [32,33], and statistics [34]. Cyclical comonotonicity is even weaker than this, as it does not imply that each production function itself is cyclically monotone, which makes it a natural and weak extension of the monotonicity assumption in the univariate setting. In particular, it is weaker than the assumption that individuals can be ranked in terms of a univariate unobservable variable (ability in the classroom example) and that this ranking persists in the observed outcome distribution. We argue that this makes it a more natural assumption than the monotonicity assumption of the CiC estimator in practical settings. Examples of cyclic monotonicity in causal inference have been highlighted by Chernozhukov et al. [33], Shi et al. [32], and Gunsilius [35], among many others. More fundamentally, Rochet [31] shows that the maximizer of quasi-linear utility functions is cyclically monotone. For a concise survey, we refer to the study by Galichon [36].
From a practical perspective, cyclical comonotonicity is an important weakening of cyclic monotonicity in that it allows for unobservables of general dimension in practice. Allowing for multivariate unobserved heterogeneity in general causal models has been a long-standing challenge: in most models, the unobservable
3.1.1 Discrete outcome distributions
Mirroring the univariate setting [6], our methodology does not guarantee a point identified-counterfactual distribution when outcomes are discrete valued. Theorem 1 guarantees a unique control group natural trend with optimal transport structure when the measure of preintervention outcomes is absolutely continuous with respect to the Lebesgue measure. Indeed, unique optimal transport maps between discrete measures need not exist. For illustration, consider transporting a measure distributed on vertices of the unit square with equiprobability at each main diagonal vertex to a one with equiprobability at the antidiagonal vertices. With respect to squared distance, it is equivalent to transport the mass between vertical and horizontal pairs of vertices. Furthermore, it is admissible to split mass and transport 0.25 probability mass from each main diagonal vertex to each antidiagonal vertex. This solution with fractional structure is an example of a nondeterministic optimal transport plan (cf. deterministic optimal transport maps), which can be interpreted as a probabilistic assignment rule. Discrete-valued optimal transport problems often have a minimum cost achieved by multiple probabilistic plans but no deterministic maps. This reality implies that point-identification in the discrete case need not be possible in general without restrictive further assumptions.
This optimal transport view hence also explains the lack of point-identification in the univariate setting, matching the conclusions of Athey and Imbens [6]. The extension of CiC to discrete outcomes in that setting provides bounds on the counterfactual outcome distribution due to the same challenges described earlier. Their estimator for that case is heavily dependent on notions of quantile functions without a direct multivariate extension. Identification only becomes possible with additional assumptions about conditional independence and exogenous covariates, which the authors admit are restrictive. In the discrete multivariate setting, similar partial identification results are possible through carefully application of recent developments in optimal transport theory. For example, Auricchio and Veneroni [38] bound the supremum cost of moving any single point mass in
3.2 Identification of causal effects in the multivariate setting
On the basis of the extensions of the causal model introduced in the previous sections, we can formally state the identification result for the counterfactual distribution of the treated units had they not received treatment.
Theorem 2
Consider the causal model depicted in
Figure 1. Let Assumption
1
hold. Moreover, assume that the production function
The proof of Theorem 2 is presented in Appendix A.1. Another potential quantity of interest is the actual counterfactual random variable
Corollary 1
Consider the setting and assumptions from Theorem
2. If the production function
The assumption that
In general, the assumptions of our model match those in Athey and Imbens [6] when outcomes are scalar and extend their structure in higher dimensional cases. Our production function setup illustrated in Figure 1 exactly matches that of CiC. In the scalar case, our assumption of comonotone production functions reduces to monotone production functions; although this is weaker than CiC’s requirement that
For the latent distributions, our extension retains the time invariance within groups assumption of CiC. While we do not make the same assumption of nested latent supports
3.2.1 Examples of functionals that can be analyzed with the proposed method
One of the advantages of the method is to deal with multivariate outcome distributions. Many functionals of interest in different areas of the (social) sciences are based on the information of the joint distribution of several outcomes of interest, from social inequality [39–41] to risk management [42,43] to decision theory [44], to name a few.
More generally, the proposed estimator provides consistent estimates of functionals that fundamentally rely on the copula structure of the outcome distributions. Examples of this are multivariate stochastic dominance [45], multivariate risk [46], and functionals that encompass interrelation between random variables such as mutual information or correlation. We say that a distribution
with
where
where
The aforementioned examples are only a short list of potentially interesting functionals one can analyze using the proposed method. All of these functionals rely on the information of the corresponding copula structure, which cannot be identified with a tensorized version of the CiC estimator unless in the limited setting of completely independent coordinates described previously.
3.3 Estimation from observed data
In practice, we only observe observations from each of the four distributions
The observations form empirical measures
Under the assumptions on population measures stated in Assumption 1, the Wasserstein distance between the estimated and population counterfactual distribution converges uniformly to zero. This enables a consistency statement about that distance converging to probability to zero, as well as a stronger statement about the Wasserstein distance of the estimated and population natural trend maps.
Proposition 1
Under the conditions of Assumption 1,
Furthermore, the squared 2-Wasserstein distance of the empirical natural trend map,
Under mild further assumptions, we show that the expected 2-Wasserstein distance between the population and estimated counterfactual measures converges to 0 at a
Assumption 2
The convex support
Combining these assumptions with those previously stated for consistency under Assumption 1 yields the following claim.
Proposition 2
The expected 2-Wasserstein distance between
Obtaining the large sample distribution of optimal transport maps is largely an open problem. However, rates of convergence are known [50,57], which enables inference on these functionals through subsampling methods. Under mild assumptions (e.g., those in [58–60]), subsampling theory provides confidence regions and hypothesis tests with strong asymptotic guarantees. Even if the rate of convergence for the functional is unknown, that rate may still be estimated.
4 Numerical experiment and application to the Card and Krueger dataset
In this section, we demonstrate the performance of the optimal transport-based estimator with two numerical experiments and apply it to a classical causal inference dataset.
4.1 A stylized example
We first present a simple simulation experiment, which demonstrates that improper modeling of dependency between coordinates of multivariate outcomes can lead to highly biased estimates. In particular, our proposed method manages to estimate the correct bivariate counterfactual distributions, while the multivariate extension of the CiC estimator through tensorization does not. Consider the following set of linear production functions in which map latent vectors in
These production functions are a cyclically comonotone but not element-wise monotone as required for the CiC estimator. Choosing beta distributions as the laws of the latent variables, we generate n = 3,000 independent outcomes from the control population before and after the intervention, as well as from the treatment group before the intervention and its unobserved counterfactual. Further details about the implementation can be found in Appendix C.1.
The recovered marginals in Figure 2 and the kernel density estimator (KDE) of the counterfactual joint distribution in Figure 3 demonstrate that our methodology estimates the true counterfactual distribution almost exactly, while the CiC estimator cannot. Notably, the CiC estimator recovers a joint distribution with a mirrored dependence structure.

Recovery of counterfactual marginals by OT and CiC. (a) First marginal and (b) second marginal.

KDE plots of the distribution of counterfactual outcomes for the treatment group. The first covariate increases along the horizontal axis and the second along the vertical. KDE bandwidth = 0.5. (a) True CF, (b) OT estimate, and (c) CiC estimate.
As previously noted, the tensorized CiC estimates counterfactuals under the strong assumption that the copula of outcomes preintervention and postintervention are identical. Each coordinate of the potential outcomes vectors is assumed to be a monotone increasing function of the latent random vector’s corresponding coordinate. When there are interactions between latent coordinates during potential outcome generation, the multivariate CiC will not identify counterfactual distributions. We believe that proper accounting for correlation structures contributes to our seemingly novel substitution result when reanalyzing the classical minimum wage data from Card and Krueger [13] in Section 4.3.
4.2 Numerical experiment in higher dimensions
In the following numerical experiment, we consider the performance of our estimator against the multivariate tensorized CiC estimator as the dimensionality of the observations grows. Optimal transport’s strong recovery of higher-dimensional joint distributions, illustrated by Figure 4, distinguishes it.

True and estimated eCDF quantiles for counterfactual treatment individuals,
Recall from Theorem 1 that optimal transport maps can be characterized as the gradients of convex functions. Consider the function
Our experiment is designed to quantify how well the two methods estimate a joint counterfactual distribution. For computational reasons, we focus on randomly selected pair-wise coordinate interactions. To this end, we construct the eCDF of the true counterfactual, its optimal transport estimate, and its CiC estimate over a uniform mesh of 10,000 points. We compute the mean absolute difference between the true and estimated eCDFs over each point in the mesh and have 20 runs per trial. As demonstrated in Figure 4, our proposed method better estimates the quantiles of a plane in the outcome space. Table 1 shows that optimal transport has a mean absolute difference consistently smaller than CiC with a smaller standard deviation as well. Our method’s monotone increasing loss likely occurs due to the curse of dimensionality and the difficulty of matching vectors in very high dimensions with only 3,000 samples. Regardless, optimal transport still has substantially smaller MAD and standard deviation than CiC when
Mean absolute deviation of the estimated counterfactual CDF to the true one. eCDFs are evaluated over one randomly selected plane per run
| Dimension | 2 | 10 | 20 | 50 | 100 |
|---|---|---|---|---|---|
| OT MAD | 0.0006 | 0.0017 | 0.0019 | 0.0033 | 0.0037 |
| st. dev. | 0.0003 | 0.0011 | 0.0016 | 0.0027 | 0.0055 |
| CiC MAD | 0.0083 | 0.0104 | 0.0092 | 0.0088 | 0.0090 |
| st. dev. | 0.0055 | 0.0078 | 0.0074 | 0.0073 | 0.0125 |
4.3 Revisiting the Card and Krueger dataset
On April 1, 1992, New Jersey raised its minimum wage from the Federal level of $4.25 per hour to $5.05 per hour. Card and Krueger [13] (CK henceforth) investigated the effect this increase had on employment in fast food restaurants with a case–control experimental design, taking the bordering region of eastern Pennsylvania, where the minimum wage remained at $4.25, as a control group. The original study employs the standard DiD estimator to conclude that the higher minimum wage led to increased employment in New Jersey restaurants. This result spawned much debate within the economics community about the effect of minimum wage policies on employment (e.g., Neumark and Wascher [61], Dube et al. [62], Meer and West [63], Neumark et al. [64], and the references therein).
The treatment effect of interest in CK and many subsequent reevaluations is the change in full-time equivalent employees (FTE), which is defined via
We analyze the number of full- and part-time employees as drawn from an underlying continuous distribution. In the original CK data, “there are 28 records that report fractional full-time employees (the fraction is always one-half), 29 records that report fractional numbers of part-time employees, and one record that reports a fractional number of managers” [66]. These partial observations could represent ambiguity in the classification of a worker as full- or part-time (Alan Krueger via interview reported in by Ehrenberg et al. [66]). As the restaurant employee responding to the phone interview was not necessarily the same at both measurements, Neumark and Wascher [61] argue, “there is no reason to believe that the responses in the first and second waves are based on the same ‘definition’ of employment.” Therefore, these fractional observations can also be considered a degree of belief statement. As discussed earlier, deterministic optimal transport maps are the unique solution in the continuous case while the discrete case also admits probabilistic optimal transport plans as solutions. In practice, we use a linear program implemented in the Python package POT which finds a deterministic plan, matching the structure of our theoretical results.
The original CK study finds a positive average treatment effect of 2.76 FTE jobs added in the treatment group compared to the control group, a result reproduced by Neumark and Wascher [61] using different methodology. Neumark and Wascher [61] also compute an average treatment effect in full- and part-time jobs with separate regressions and find treatment effects of 3.16 gained full-time jobs and 0.60 lost part-time jobs. These classical contributions only focus on aggregate outcomes over all restaurants, irrespective of the size of the respective restaurant. An exception is Ropponen [67] who reanalyzes the data with the CiC estimator, taking into account the heterogeneity in the size of the fast-food restaurants. He finds the average treatment effect bounded in [0.90, 1.70]. Ropponen also notes in New Jersey that large restaurants preintervention (measured in FTE employees) have a negative treatment effect, while small restaurants preintervention have a positive treatment effect. Our analysis recovers this trend for both FT and PT employees in New Jersey. As we also generate counterfactual controls, we find an opposite trend for Pennsylvania restaurants. This opposite trend is intriguing and worth exploring further as it does not seem to be explained by substitution effects of employees moving across the state line to find jobs (Table 2).
Estimated average treatment effect on full- and part-time employment by method with subsampled 95% confidence intervals
| OT | CiC | DiD | |
|---|---|---|---|
| ATE FT | 3.07 (2.00, 4.67) | 2.61 (0.40,3.45) | 3.45 (3.05,5.46) |
| ATE PT |
|
|
|
The previously discussed subsampling approach to inference was applied to generate symmetric 95 % confidence intervals around each point estimate. The only interval to contain zero is for the DiD treatment effect on part-time employment. Furthermore, we run subsampled hypothesis tests to check whether the point estimates are significantly different across estimators. Of the four tests between optimal transport to an alternative, only the difference in treatment effect on part-time employment estimated with CiC was not significantly different from zero at the
The average treatment effects estimated using the OT and CiC counterfactual distributions depend only on the marginals, not the full joint structure. However, as illustrated in Figure A3 in Appendix, the strong copula assumptions between preintervention and postintervention periods for CiC can lead to markedly different estimated marginals. That structure implies restaurants with the largest preintervention full/part-time employment will also have the largest counterfactual full/part-time employment. The wider tails of the CiC treatment effect marginals compared to OT suggest that additional joint structure in this setting leads to counterfactuals with less variance from the observed potential outcome.
The proposed multivariate extension of the CiC estimator allows us to jointly estimate the effects on full- and part-time employment while accounting for the heterogeneity in restaurant size. For the results in this section, restaurants are represented in
Our optimal transport analysis suggests that fast food restaurants responded to an increased minimum wage by substituting full-time employees for part-time ones with a net gain of FTEs. Our results seem to indicate that the negative effect on part-time employees is more pronounced than previously estimated. The quantile plot in Figure 5 suggests this effect applies throughout the distribution of restaurants, not just the mean: fixing the number of full-time employees, counterfactual quantiles tend to have more part-time employees than treatment group quantiles at the same level; likewise fixing the number of part-time employees, treatment group quantiles tend to have more full-time employees. In their original paper, CK suggest that restaurants may respond to higher labor costs with more full-time employees because they tend to be older, more skilled, and more productive, thus a better investment of capital. Furthermore, the univariate methods may underestimate the number of part-time employees lost, a conclusion supported by the higher dimensional analysis in Table A3 in Appendix.
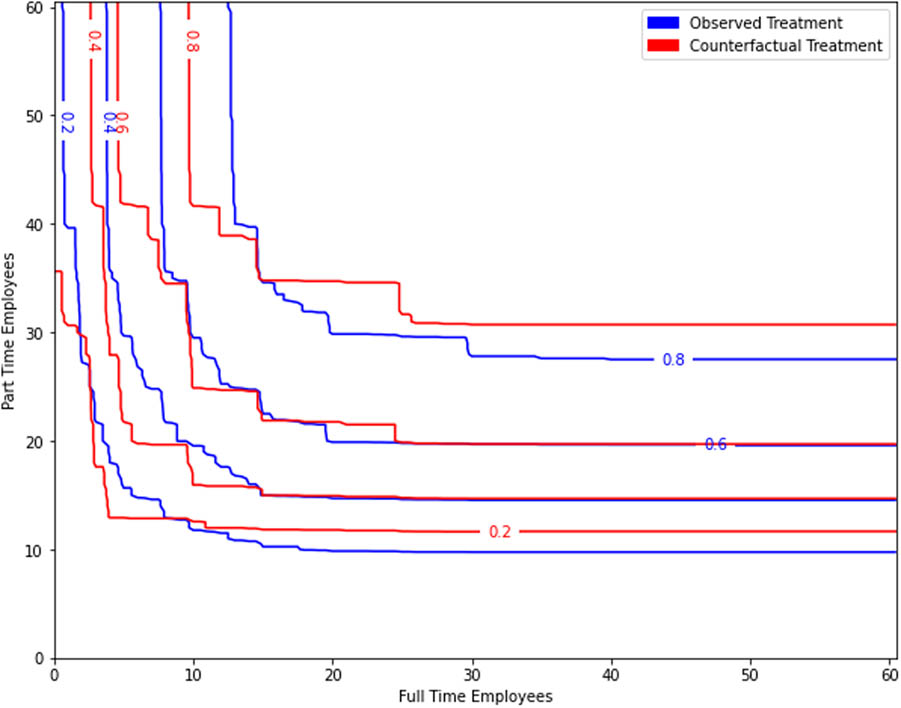
Postintervention quantile curves for observed treatment group units and their counterfactuals.
5 Discussion
We have introduced a general method based on optimal transport theory for causal inference in observational treatment and control study designs. It combines two desirable properties: it is designed for multivariate settings while at the same time capturing the heterogeneity in treatment response of individuals. In particular, it complements both the classical DiD estimator, which is applicable in multivariate settings but only captures average effects, and the CiC estimator [6], which allows for general treatment heterogeneity but is only applicable in univariate settings.
Showcasing the utility of the proposed method, we revisit the classical Card and Krueger dataset by decomposing the treatment effects for full-and part-time employees. We find that fast-food restaurants responded to an increased minimum wage by substituting full-time employees for part-time employees, even when accounting for restaurant size. This provides a novel insight by dissecting the relationship between full- and part-time employees while accounting for the heterogeneity in restaurant size. More generally, since our proposed method is able to consider multivariate outcomes, it can help uncover interesting causal effects and nonlinear relations in a wide array of applications.
-
Funding information: William Torous was supported as an undergraduate through MIT’s UROP program with funding from the Lord Foundation and the Paul E. Gray UROP Fund. Florian Gunsilius was supported by a MITRE faculty research award. Philippe Rigollet was supported by NSF grants IIS-1838071, DMS-2022448, and CCF-2106377.
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: The authors state no conflict of interest.
-
Data availability statement: The datasets analyzed during the current study are available at David Card’s public website, https://davidcard.berkeley.edu/data_sets.html.
-
Code availability statement: Code to reproduce the results of this paper and software implementations of our methodology in Python, R, and STATA are available at otcic.com.
Appendix A Proofs of stated results
For compactness and clarity, we use a different notation for measures in these proofs than in the main text. For control group outcomes,
A.1 Proof of Theorem 2
Proof
The cyclically comonotonicity assumption reads as follows:
for all
for all
A.2 Proof of Proposition 1
Proof
The main result to enable a consistency statement for
In other words, the pushforward of singletons under
For finite
The exchange of
This implies for sufficiently large
We now consider
The first integral must converge to 0 in the limit supremum because of the uniform convergence for optimal maps stated earlier. The second integral involves a Brenier map
This integral also upper bounds
Hölder’s inequality and the triangle inequality gives
so we have convergence in probability of
A.3 Proof of Proposition 2
Proof
We wish to bound the risk between the true and estimated counterfactual outcome distributions with respect to the 2-Wasserstein metric:
By applying the triangle inequality, we have
Consider first
We have
The distributions of these empirical measures for a fixed sample size are denoted
Lemma 3.1 from Canas and Rosasco [74] states
Now we turn our attention to the rate of convergence for
To show the first and third terms are
Let
It remains to show
We have shown each term of equation (A2) converges at a rate of
B Calculating optimal transport couplings from data
This section outlines how to estimate optimal transport couplings from sampled data and provides references to supporting theory. Given
In practice, the measures
Here,
Our methodology involves first estimating
To compute optimal transport maps in this article, we use a linear programming method ot.lp.emd from the Python package Python Optimal Transport[82]. These maps are then extrapolated into optimal transport plans with Euclidean nearest neighbor matching. In our simulations, the control and treatment groups preintervention have almost complete overlap of sampled support, justifying this technique. All numerical experiments in this article are written and run in Python 3. Replication code is available in Appendix of this article.
C Numerical experiments
In this section, we provide implementation details for results computed in Sections 4.1 and 4.2.
C.1 Implementation details for numerical experiment in Section 4.1
We consider n = 3,000 units in
Recall that we consider the following set of production functions that are cyclically comonotone:
In our simulations, the
Proof
We begin by simplifying the inner product terms contained in the definition of cyclical comonotonicity (6). We have
After expansion and simplification, this reduces to
By using these production functions, we generate
To estimate the transport map
We also compute the eCDF for our 3,000 true counterfactual observations and the counterfactuals generated by the two methods over a uniform mesh of 10,000 points. Figure A1 visually demonstrates that OT almost perfectly recovers the eCDF, and Table A1 quantifies this result. The mean absolute difference over each mesh point is an order of magnitude smaller for OT and has a smaller standard deviation.

Quantiles of the eCDF for the bivaraite experiment over a uniform mesh with 10,000 points.
Recovery of eCDF by method over 20 runs
| MAD OT | MAD CiC | |
|---|---|---|
| Mean | 0.008 | 0.089 |
| st. dev. | 0.002 | 0.003 |
C.2 Implementation details for numerical experiment in Section 4.2
Recall that we consider a class convex functions indexed by
It is well known the that function
In our experiment, we define
The
The implementation of our experiment is otherwise identical to that described in Appendix C.1; we generate data for the four relevant distributions and compute transport plans with nearest neighbor extrapolation. The eCDF and MAD computation is also the same.
D Additional CK experiment
We begin by presenting an additional figure from our bivariate CK analysis in Section 4.3. Figure A2 demonstrates a negative correlation between the change in full-time employees after the intervention and the change in part-time employees. This suggests that fast food restaurants substituted full-time employees for part-time ones.

Distribution of unit-level treatment effect estimates, demonstrating a negative correlation between change in full-time and part-time employees.

Recovery of counterfactual marginals by OT and CiC. (a) Full-time employment and (b) part-time employment.
For our reanalysis of the CK data on the minimum wage and fast food employment, we use the original dataset provided by David Card on his website. It contains survey information, collected via telephone, for 410 fast food restaurants across four fast-food chains. We remove 19 restaurants with missing outcome observations. Of the remaining, 76 are in the control region of northeastern Pennsylvania and 315 are in New Jersey. In addition to the two employment outcomes of interest, a number of other observations about a restaurant’s wages, prices, and operations were collected. Our optimal transport methodology allows us to estimate treatment effects more richly with potential outcomes including nonemployment time varying restaurant characteristics. We emphasize that this experiment is presented to illustrate the applicability of our method in higher dimensions. Our variable selection is not data driven and the ratio of covariate to units is low.
We select a representative subset of 10 numerical covariates, listed in Table A2, and remove any restaurant with a missing entry for any of these covariates. This leaves a final sample of 52 controls and 200 treatments. The full dataset has 15 numerical covariates but including all 15 leads to a small sample size due to missing data. The covariates we do not include add little additional information, such as the price of fries (we include the price of entrees and sodas), have high rates of missingness, or have a different distribution in the subsample with complete data than the entire survey population. Unlike the outcome-only analysis presented in Section 4.3, the included covariates have different scales. Thus, we standardize each to zero mean and unit standard deviation. The dataset also includes categorical data such as the fast-food chain, which we do not include because the Euclidean distance between restaurants would depend on how these are encoded.
Outcomes and covariates included in our analysis
| Covariate name | Description |
|---|---|
| EMPFT | Number of full-time employees |
| EMPPT | Number of part-time employees |
| PCTAFF | Percent of employees affected by new minimum wage |
| NMGRS | Number of managers |
| INCTIME | Months until usual first raise |
| PENTREE | Price of an entrÃľe with tax |
| PSODA | Price of a soda with tax |
| NREGS | Number of cash registers in the restaurant |
| OPEN | Hour of opening |
| HRSOPEN | Number of hours open per day |
Instead of presenting results conditional on some set of covariates, we present aggregate results over subsets of all subsets of potential outcome vectors including both employment outcomes and 2, 3, or 4 other covariates. The positive results of this experiment are included in Table A3. The sign of our two estimates never change in this experiment. Furthermore, addings covariates leads to optimal transport estimators with smaller estimated full-time ATE and larger part-time ATE on aggregate. In future work with more tests for covariate selection and further sensitivity analysis, we hope stronger claims about the estimates’ magnitude can be made.
Summary statistics of higher dimensional subsets for the CK ATE
| TE FT | TE PT | |
|---|---|---|
| Mean | 1.56 |
|
| st. dev. | 0.38 | 0.56 |
| Min | 0.69 |
|
| Max | 2.63 |
|
References
[1] Abadie A. Semiparametric difference-in-differences estimators. Rev Econ Stud. 2005;72(1):1–19. 10.1111/0034-6527.00321Search in Google Scholar
[2] Lechner M. The estimation of causal effects by difference-in-difference methods. Foundations and Trends® in Econometrics. 2011;4(3):165–224. 10.1561/0800000014Search in Google Scholar
[3] Imbens GW, Rubin DB. Causal inference in statistics, social, and biomedical sciences. New York, NY: Cambridge University Press; 2015. 10.1017/CBO9781139025751Search in Google Scholar
[4] Roth J, Sant’Anna PH, Bilinski A, Poe J. What’s trending in difference-in-differences? A synthesis of the recent econometrics literature. 2022. arXiv: http://arXiv.org/abs/arXiv:220101194. Search in Google Scholar
[5] Wing C, Simon K, Bello-Gomez RA. Designing difference in difference studies: best practices for public health policy research. Annual Review Public Health. 2018;39:453–69.10.1146/annurev-publhealth-040617-013507Search in Google Scholar PubMed
[6] Athey S, Imbens GW. Identification and inference in nonlinear difference-in-differences models. Econometrica. 2006;74(2):431–97. 10.1111/j.1468-0262.2006.00668.xSearch in Google Scholar
[7] Heckman J. Varieties of selection bias. Amer Econ Rev. 1990;80(2):313–8. Search in Google Scholar
[8] Roth J, Sant’Anna PH. When is parallel trends sensitive to functional form? 2020. arXiv: http://arXiv.org/abs/201004814. Search in Google Scholar
[9] Ryan AM, Kontopantelis E, Linden A, Burgess Jr JF. Now trending: Coping with non-parallel trends in difference-in-differences analysis. Stat Methods Med Res. 2019;28(12):3697–711. 10.1177/0962280218814570Search in Google Scholar PubMed
[10] Goodman-Bacon A, Marcus J. Using difference-in-differences to identify causal effects of COVID-19 policies. Survey Res Methods. 2020;14(2):153–8. 10.2139/ssrn.3603970Search in Google Scholar
[11] Drysdale KM, Hendricks NP. Adaptation to an irrigation water restriction imposed through local governance. J Environ Econ Management. 2018;91:150–65. 10.1016/j.jeem.2018.08.002Search in Google Scholar
[12] Peyré G, Cuturi M. Computational optimal transport. Foundations and Trends® in Machine Learning. 2019;11(5–6):355–607. 10.1561/2200000073Search in Google Scholar
[13] Card D, Krueger AB. Minimum wages and employment: a case study of the fast-food industry in New Jersey and Pennsylvania. Amer Econ Rev. 1994;84(4):772–93. 10.3386/w4509Search in Google Scholar
[14] Ghanem D, Sant’Anna PHC, Wüthrich K. Selection and parallel trends. 2022. arXiv: http://arXiv.org/abs/220309001. Search in Google Scholar
[15] Marx P, Tamer E, Tang X. Parallel trends and dynamic choices. 2022. arXiv: http://arXiv.org/abs/220706564. Search in Google Scholar
[16] Rigollet P, Weed J. Uncoupled isotonic regression via minimum Wasserstein deconvolution. Inform Inference A J IMA. 2019;8(4):691–717. 10.1093/imaiai/iaz006Search in Google Scholar
[17] Balabdaoui F, Doss CR, Durot C. Unlinked monotone regression. 2021. arXiv: http://arXiv.org/abs/arXiv:200700830. Search in Google Scholar
[18] Slawski M, Sen B. Permuted and unlinked monotone regression in Rd: an approach based on mixture modeling and optimal transport. 2022. arXiv: http://arXiv.org/abs/arXiv:220103528. Search in Google Scholar
[19] Callaway B, Li T. Quantile treatment effects in difference in differences models with panel data. Quantitative Econom. 2019;10(4):1579–618. 10.3982/QE935Search in Google Scholar
[20] Bonhomme S, Sauder U. Recovering distributions in difference-in-differences models: A comparison of selective and comprehensive schooling. Review Econom Stat. 2011;93(2):479–94. 10.1162/REST_a_00164Search in Google Scholar
[21] Brenier Y. Polar factorization and monotone rearrangement of vector-valued functions. Commun Pure Appl Math. 1991;44(4):375–417. 10.1002/cpa.3160440402Search in Google Scholar
[22] Caffarelli LA. Monotonicity properties of optimal transportation and the FKG and related inequalities. Comm Math Phys. 2000;214(3):547–63. 10.1007/s002200000257Search in Google Scholar
[23] Rockafellar RT. Convex analysis. Princeton, NJ: Princeton University Press; 1997. Search in Google Scholar
[24] Matzkin RL. Nonparametric estimation of nonadditive random functions. Econometrica. 2003;71(5):1339–75. 10.1111/1468-0262.00452Search in Google Scholar
[25] Chernozhukov V, Hansen C. An IV model of quantile treatment effects. Econometrica. 2005;73(1):245–61. 10.1111/j.1468-0262.2005.00570.xSearch in Google Scholar
[26] Imbens GW. Nonadditive models with endogenous regressors. Econometric Soc Monographs. 2007;43:17. 10.1017/CCOL0521871549.002Search in Google Scholar
[27] Ekeland I, Galichon A, Henry M. Comonotonic measures of multivariate risks. Math Finance. 2010 Oct;22(1):109–32. Search in Google Scholar
[28] Boissard E, Le Gouic T, Loubes JM. Distributionas template estimate with Wasserstein metrics. Bernoulli. 2015;21(2):740–59. 10.3150/13-BEJ585Search in Google Scholar
[29] Puccetti G, Scarsini M. Multivariate comonotonicity. J Multivariate Anal. 2010;101(1):291–304. 10.1016/j.jmva.2009.08.003Search in Google Scholar
[30] Ashlagi I, Braverman M, Hassidim A, Monderer D. Monotonicity and implementability. Econometrica. 2010;78(5):1749–72. 10.3982/ECTA8882Search in Google Scholar
[31] Rochet JC. A necessary and sufficient condition for rationalizability in a quasi-linear context. J Math Econom. 1987;16(2):191–200. 10.1016/0304-4068(87)90007-3Search in Google Scholar
[32] Shi X, Shum M, Song W. Estimating semi-parametric panel multinomial choice models using cyclic monotonicity. Econometrica. 2018;86(2):737–61. 10.3982/ECTA14115Search in Google Scholar
[33] Chernozhukov V, Galichon A, Henry M, Pass B. Identification of Hedonic equilibrium and nonseparable simultaneous equations. Journal of Political Economy. 2021;129(3):842–70. 10.1086/712447Search in Google Scholar
[34] Rüschendorf L. On c-optimal random variables. Stat Probability Lett. 1996;27(3):267–70. 10.1016/0167-7152(95)00078-XSearch in Google Scholar
[35] Gunsilius FF. A condition for the identification of multivariate models with binary instruments. J Econometrics. 2022;235:220–38. 10.1016/j.jeconom.2022.04.003Search in Google Scholar
[36] Galichon A. A survey of some recent applications of optimal transport methods to econometrics. Econometrics J. 2017;20(2):C1–11. 10.1111/ectj.12083Search in Google Scholar
[37] McCann RJ, Pass B. Optimal transportation between unequal dimensions. Archive Rational Mechanics Anal. 2020;238(3):1475–520. 10.1007/s00205-020-01569-5Search in Google Scholar
[38] Auricchio G, Veneroni M. On the structure of optimal transportation plans between discrete measures. Appl Math Optimiz. 2022;85(3):42. 10.1007/s00245-022-09861-4Search in Google Scholar
[39] Decancq K, Lugo MA. Weights in multidimensional indices of wellbeing: an overview. Econometric Rev. 2013;32(1):7–34. 10.1080/07474938.2012.690641Search in Google Scholar
[40] Duclos JY, Sahn DE, Younger SD. Robust multidimensional poverty comparisons. The Economic J. 2006;116(514):943–68. 10.1111/j.1468-0297.2006.01118.xSearch in Google Scholar
[41] Bourguignon F, Chakravarty SR. The measurement of multidimensional poverty. J Economic Inequality. 2003;1:25–49. 10.1023/A:1023913831342Search in Google Scholar
[42] Ekeland I, Galichon A, Henry M. Comonotonic measures of multivariate risks. Math Finance Int J Math Stat Financial Econom. 2012;22(1):109–32. 10.1111/j.1467-9965.2010.00453.xSearch in Google Scholar
[43] Embrechts P, McNeil A, Straumann D. Correlation and dependence in risk management: properties and pitfalls. Risk Management Value Risk Beyond. 2002;1:176–223. 10.1017/CBO9780511615337.008Search in Google Scholar
[44] Hallin M. Measure transportation and statistical decision theory. Ann Rev Stat Appl. 2022;9:401–24. 10.1146/annurev-statistics-040220-105948Search in Google Scholar
[45] García-Gómez C, Perez A, Prieto-Alaiz M. A review of stochastic dominance methods for poverty analysis. J Economic Surveys. 2019;33(5):1437–62. 10.1111/joes.12334Search in Google Scholar
[46] Embrechts P, Puccetti G. Bounds for functions of multivariate risks. J Multivariate Anal. 2006;97(2):526–47. 10.1016/j.jmva.2005.04.001Search in Google Scholar
[47] Shannon CE. A mathematical theory of communication. Bell Syst Technical J. 1948;27(3):379–423. 10.1002/j.1538-7305.1948.tb01338.xSearch in Google Scholar
[48] Forrow A, Hütter JC, Nitzan M, Rigollet P, Schiebinger G, Weed J. Statistical optimal transport via factored couplings. In: The 22nd International Conference on Artificial Intelligence and Statistics. PMLR; 2019. p. 2454–65. Search in Google Scholar
[49] Gunsilius FF. On the convergence rate of potentials of Brenier maps. Econometric Theory. Cambridge, England: Cambridge University Press; 2021. 10.1017/S0266466621000037Search in Google Scholar
[50] Hütter JC, Rigollet P. Minimax estimation of smooth optimal transport maps. Ann Stat. 2021;49(2):1166–94. 10.1214/20-AOS1997Search in Google Scholar
[51] de Lara L, González-Sanz A, Loubes JM. A consistent extension of discrete optimal transport maps for machine learning applications. 2021. arXiv: http://arXiv.org/abs/210208644. Search in Google Scholar
[52] Manole T, Balakrishnan S, Niles-Weed J, Wasserman L. Plugin estimation of smooth optimal transport maps. 2021. arXiv: http://arXiv.org/abs/arXiv:210712364. Search in Google Scholar
[53] Manole T, Niles-Weed J. Sharp convergence rates for empirical optimal transport with smooth costs. 2021. arXiv: http://arXiv.org/abs/arXiv:210613181. Search in Google Scholar
[54] Pooladian AA, Niles-Weed J. Entropic estimation of optimal transport maps. 2021. arXiv: http://arXiv.org/abs/arXiv:210912004. Search in Google Scholar
[55] Vacher A, Muzellec B, Rudi A, Bach F, Vialard FX. A dimension-free computational upper-bound for smooth optimal transport estimation. In: Proceedings of Thirty Fourth Conference on Learning Theory. PMLR; 2021. p. 4143–73. Search in Google Scholar
[56] Muzellec B, Vacher A, Bach F, Vialard FX, Rudi A. Near-optimal estimation of smooth transport maps with kernel sums-of-squares. 2021. arXiv: http://arXiv.org/abs/arXiv:211201907. Search in Google Scholar
[57] Deb N, Ghosal P, Sen B. Rates of estimation of optimal transport maps using plug-in estimators via barycentric projections. 2021. arXiv: http://arXiv.org/abs/arXiv:210701718. Search in Google Scholar
[58] Politis DN, Romano JP, Wolf M. On the asymptotic theory of subsampling. Stat Sinica. 2001;11:1105–24. Search in Google Scholar
[59] Romano JP, Shaikh AM. On the uniform asymptotic validity of subsampling and the bootstrap. Ann Stat. 2012;40(6):2798–822. 10.1214/12-AOS1051Search in Google Scholar
[60] Shao X, Politis DN. Fixed b subsampling and the block bootstrap: improved confidence sets based on p-value calibration. J R Stat Soc Ser B (Stat Methodol). 2013;75(1):161–84. 10.1111/j.1467-9868.2012.01037.xSearch in Google Scholar
[61] Neumark D, Wascher W. Minimum wages and employment: a case study of the fast-food industry in new jersey and pennsylvania: comment. Amer Econ Rev. 2000;90(5):1362–96. 10.1257/aer.90.5.1362Search in Google Scholar
[62] Dube A, Lester TW, Reich M. Minimum wage effects across state borders: Estimates using contiguous counties. Review Econom Stat. 2010;92(4):945–64. 10.1162/REST_a_00039Search in Google Scholar
[63] Meer J, West J. Effects of the minimum wage on employment dynamics. J Human Resources. 2016;51(2):500–22. 10.3368/jhr.51.2.0414-6298R1Search in Google Scholar
[64] Neumark D, Salas JI, Wascher W. Revisiting the minimum wage-Employment debate: Throwing out the baby with the bathwater? ILR Review. 2014;67(3 suppl):608–48. 10.1177/00197939140670S307Search in Google Scholar
[65] Lu B, Rosenbaum PR. Optimal pair matching with two control groups. J Comput Graph Stat. 2004;13(2):422–34. 10.1198/1061860043470Search in Google Scholar
[66] Ehrenberg RG, Brown C, Freeman RB, Hamermesh DS, Osterman P, Welch F. Myth and measurement: the new economics of the minimum wage. Industrial Labor Relations Review. 1995;48(4):827. 10.2307/2524359Search in Google Scholar
[67] Ropponen O. Reconciling the evidence of Card and Krueger (1994) and Neumark and Wascher (2000). J Appl Econometrics. 2011;26(6):1051–7. 10.1002/jae.1258Search in Google Scholar
[68] Segers J. Graphical and uniform consistency of estimated optimal transport plans. 2022. arXiv: http://arXiv.org/abs/arXiv:220802508. Search in Google Scholar
[69] Varadarajan VS. Weak convergence of measures on separable metric spaces. Sankhy Indian J Stat. 1958;19:15–22. Search in Google Scholar
[70] Rockafellar R. Characterization of the subdifferentials of convex functions. Pacific J Math. 1966;17(3):497–510. 10.2140/pjm.1966.17.497Search in Google Scholar
[71] Shorack GR, Wellner JA. Empirical processes with applications to statistics. Classics in Applied Mathematics. Philadelphia, PA: Society for Industrial and Applied Mathematics; 2009. 10.1137/1.9780898719017Search in Google Scholar
[72] Vapnik VN, Chervonenkis AY. On the uniform convergence of relative frequencies of events to their probabilities. Theory Probability Appl. 1971;16(2):264–80. 10.1137/1116025Search in Google Scholar
[73] Fournier N, Guillin A. On the rate of convergence in Wasserstein distance of the empirical measure. Probability Theory Related Fields. 2015;162(3):707–38. 10.1007/s00440-014-0583-7Search in Google Scholar
[74] Canas G, Rosasco L. Learning probability measures with respect to optimal transport metrics. In: Pereira F, Burges CJ, Bottou L, Weinberger KQ, editors. Advances in Neural Information Processing Systems. vol. 25. Boston, MA: Curran Associates, Inc.; 2012. https://proceedings.neurips.cc/paper/2012/file/c54e7837e0cd0ced286cb5995327d1ab-Paper.pdf. Search in Google Scholar
[75] Abadie A, Imbens GW. Large sample properties of matching estimators for average treatment effects. Econometrica. 2006 Jan;74(1):235–67. 10.1111/j.1468-0262.2006.00655.xSearch in Google Scholar
[76] Cuturi M. Sinkhorn distances: lightspeed computation of optimal transport. In: Advances in neural information processing systems. vol. 26. Boston, MA: Curran Associates, Inc.; 2013. Search in Google Scholar
[77] Altschuler J, Weed J, Rigollet P. Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. 2017. arXiv: http://arXiv.org/abs/170509634. Search in Google Scholar
[78] Papadakis N. Optimal transport for image processing [Habilitation à diriger des recherches]. Université de Bordeaux; Habilitation thesis; 2015. https://hal.science/tel-01246096. Search in Google Scholar
[79] Seguy V, Damodaran BB, Flamary R, Courty N, Rolet A, Blondel M. Large-scale optimal transport and mapping estimation. 2018. arXiv: http://arXiv.org/abs/171102283. Search in Google Scholar
[80] Makkuva AV, Taghvaei A, Oh S, Lee JD. Optimal transport mapping via input convex neural networks. 2020. arXiv: http://arXiv.org/abs/190810962. Search in Google Scholar
[81] Lu Y, Lu J. A Universal Approximation theorem of deep neural networks for expressing probability distributions. 2020. arXiv: http://arXiv.org/abs/200408867. Search in Google Scholar
[82] Flamary R, Courty N, Gramfort A, Alaya MZ, Boisbunon A, Chambon S, et al. POT: python optimal transport. J Machine Learn Res. 2021;22(78):1–8. Search in Google Scholar
© 2024 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Evaluating Boolean relationships in Configurational Comparative Methods
- Doubly weighted M-estimation for nonrandom assignment and missing outcomes
- Regression(s) discontinuity: Using bootstrap aggregation to yield estimates of RD treatment effects
- Energy balancing of covariate distributions
- A phenomenological account for causality in terms of elementary actions
- Nonparametric estimation of conditional incremental effects
- Conditional generative adversarial networks for individualized causal mediation analysis
- Mediation analyses for the effect of antibodies in vaccination
- Sharp bounds for causal effects based on Ding and VanderWeele's sensitivity parameters
- Detecting treatment interference under K-nearest-neighbors interference
- Bias formulas for violations of proximal identification assumptions in a linear structural equation model
- Current philosophical perspectives on drug approval in the real world
- Foundations of causal discovery on groups of variables
- Improved sensitivity bounds for mediation under unmeasured mediator–outcome confounding
- Potential outcomes and decision-theoretic foundations for statistical causality: Response to Richardson and Robins
- Quantifying the quality of configurational causal models
- Design-based RCT estimators and central limit theorems for baseline subgroup and related analyses
- An optimal transport approach to estimating causal effects via nonlinear difference-in-differences
- Estimation of network treatment effects with non-ignorable missing confounders
- Double machine learning and design in batch adaptive experiments
- The functional average treatment effect
- An approach to nonparametric inference on the causal dose–response function
- Review Article
- Comparison of open-source software for producing directed acyclic graphs
- Special Issue on Neyman (1923) and its influences on causal inference
- Optimal allocation of sample size for randomization-based inference from 2K factorial designs
- Direct, indirect, and interaction effects based on principal stratification with a binary mediator
- Interactive identification of individuals with positive treatment effect while controlling false discoveries
- Neyman meets causal machine learning: Experimental evaluation of individualized treatment rules
- From urn models to box models: Making Neyman's (1923) insights accessible
- Prospective and retrospective causal inferences based on the potential outcome framework
- Causal inference with textual data: A quasi-experimental design assessing the association between author metadata and acceptance among ICLR submissions from 2017 to 2022
- Some theoretical foundations for the design and analysis of randomized experiments
Articles in the same Issue
- Research Articles
- Evaluating Boolean relationships in Configurational Comparative Methods
- Doubly weighted M-estimation for nonrandom assignment and missing outcomes
- Regression(s) discontinuity: Using bootstrap aggregation to yield estimates of RD treatment effects
- Energy balancing of covariate distributions
- A phenomenological account for causality in terms of elementary actions
- Nonparametric estimation of conditional incremental effects
- Conditional generative adversarial networks for individualized causal mediation analysis
- Mediation analyses for the effect of antibodies in vaccination
- Sharp bounds for causal effects based on Ding and VanderWeele's sensitivity parameters
- Detecting treatment interference under K-nearest-neighbors interference
- Bias formulas for violations of proximal identification assumptions in a linear structural equation model
- Current philosophical perspectives on drug approval in the real world
- Foundations of causal discovery on groups of variables
- Improved sensitivity bounds for mediation under unmeasured mediator–outcome confounding
- Potential outcomes and decision-theoretic foundations for statistical causality: Response to Richardson and Robins
- Quantifying the quality of configurational causal models
- Design-based RCT estimators and central limit theorems for baseline subgroup and related analyses
- An optimal transport approach to estimating causal effects via nonlinear difference-in-differences
- Estimation of network treatment effects with non-ignorable missing confounders
- Double machine learning and design in batch adaptive experiments
- The functional average treatment effect
- An approach to nonparametric inference on the causal dose–response function
- Review Article
- Comparison of open-source software for producing directed acyclic graphs
- Special Issue on Neyman (1923) and its influences on causal inference
- Optimal allocation of sample size for randomization-based inference from 2K factorial designs
- Direct, indirect, and interaction effects based on principal stratification with a binary mediator
- Interactive identification of individuals with positive treatment effect while controlling false discoveries
- Neyman meets causal machine learning: Experimental evaluation of individualized treatment rules
- From urn models to box models: Making Neyman's (1923) insights accessible
- Prospective and retrospective causal inferences based on the potential outcome framework
- Causal inference with textual data: A quasi-experimental design assessing the association between author metadata and acceptance among ICLR submissions from 2017 to 2022
- Some theoretical foundations for the design and analysis of randomized experiments