#EveryNameCounts – Die Crowdsourcing-Initiative der Arolsen Archives
-
Ramona Bräu ist Manager Digital Business Development bei den Arolsen Archives – International Center on Nazi Persecution. Sie studierte Geschichte und Politikwissenschaft an den Universitäten Jena und Wrocław. Nach ihrer Tätigkeit als wissenschaftliche Volontärin bei der Gedenkstätten Stiftung Buchenwald und Mittelbau-Dora war sie als Mitarbeiterin im Rahmen des Bundesforschungsprojekts zur Geschichte des Reichsministeriums der Finanzen tätig.
 ,
,
Dr. Kerstin Hofmann ist wissenschaftliche Mitarbeiterin in der Abteilung Forschung und Bildung der Arolsen Archives – International Center on Nazi Persecution. Sie studierte Geschichte und Politikwissenschaft an der Universität Mannheim und wurde dort 2017 über die strafrechtliche Aufarbeitung von NS-Verbrechen in der Bundesrepublik promoviert. Das Projekt #EveryNameCounts begleitet sie seit Sommer 2020 als Moderatorin und Ansprechpartnerin für wissenschaftliche Fragen.
Sonja Nilson ist wissenschaftliche Mitarbeiterin der Abteilung Archiv der Arolsen Archives – International Center on Nazi Persecution. Sie studierte Geschichte und Politikwissenschaft an der Universität Düsseldorf. Sie befasst sich bei den Arolsen Archives mit Datenbanken und Datenmanagement und begleitet das Projekt #EveryNameCounts als Datenkuratorin.
Christa Zwilling-Seidenstücker ist wissenschaftliche Mitarbeiterin in der Abteilung Forschung und Bildung der Arolsen Archives – International Center on Nazi Persecution. Sie studierte Politikwissenschaften in Heidelberg und Jerusalem. Bei den Arolsen Archives ist sie Mitarbeiterin im Projektteam von #EveryNameCounts und bereitet aktuell die Schulkampagne zum Projekt vor, die im Herbst 2021 starten wird.

Zusammenfassung
Das Crowdsourcing-Projekt #EveryNameCounts der Arolsen Archives begann 2020 als Schulkampagne und wuchs binnen weniger Monate zu einer weltweiten Initiative. Durch die Arbeit der Freiwilligen werden Millionen von Datensätzen zu Konzentrationslagerdokumenten erfasst. Diese Datengrundlage optimiert einerseits die Suche im Online-Archiv der Arolsen Archives und macht anderseits eine auf Massendaten gestützte Forschung erst möglich. Die Arbeit der Freiwilligen geht dabei über reine Datenerhebung weit hinaus. Es entsteht ein digitales Denkmal.
Abstract
The Arolsen Archives’ crowdsourcing project #EveryNameCounts began in 2020 as a school campaign and within a few months grew into a worldwide initiative. Through the work of volunteers, millions of records of concentration camp documents are captured. On the one hand, this data basis optimizes the search in the online archive of the Arolsen Archives and, on the other hand, makes research based on mass data possible in the first place. The work of the volunteers goes far beyond mere data collection. A digital monument is being created.
Résumé
Le projet de crowdsourcing des Arolsen Archives, #EveryNameCounts, a commencé comme une campagne scolaire en 2020 et s’est transformé en une initiative mondiale en quelques mois. Grâce au travail bénévoles, des millions des données de documents de camps de concentration sont saisies. D’une part, cette base de données optimise la recherche dans les archives en ligne des Arolsen Archives et, d'autre part, rend possible en premier lieu la recherche basée sur des données de masse. Le travail des volontaires va bien au-delà de la simple collecte de données. Un monument numérique est en cours de création.
„As I type each card into the database I think of each name and the person it belonged to – and I honor them as a human being.“
Die Indexierung von Massendaten, die Anreicherung von vorhandenen Metadaten und die Aufbereitung und Verknüpfung von Datensätzen gehören zu den umfangreichsten wie aufwendigsten Herausforderungen der modernen Archivarbeit. Die Anforderungen an die Benutzbarkeit von Archiven steigt entsprechend den Gewohnheiten derjenigen, die sie in einer zunehmend digitalisierten Alltagswelt nutzen. Digitalisierung endet aber – entgegen einer weitverbreiteten Vorstellung – nicht mit dem Scannen von Dokumenten, sondern beginnt eigentlich erst mit der Erstellung des Digitalisats. Crowdsourcing-Projekte werden in diesem Zusammenhang häufig als reines Mittel zum Zweck gesehen, um die Datengrundlage für diverse Such- und Filterfunktionen zu erheben, die nicht einfach durch die Integration von Normdaten optimiert werden können. Sie versprechen geringe Kosten, schnelle Bearbeitung und Ergebnisse, die nicht auf die Fähigkeiten eines Algorithmus begrenzt sind. Allerdings verkennt dieser doch sehr pragmatische, ja rationale Ansatz die eigentlichen Optionen und Chancen des Crowdsourcings sowie die Anforderungen an die Projektbeteiligten. Die Teilhabe an und das Engagement für ein solches Projekt hängen für die Freiwilligen der Crowd zu einem großen Teil von der Sinnhaftigkeit und von einem erkennbaren individuellen oder gesellschaftlichen bzw. wissenschaftlichen Mehrwert ab. Freiwillige ermüden in der Praxis schnell, wenn die Usability zu wünschen lässt. Dieser emotionale Charakter eröffnet aber zugleich einen Raum der Interaktion und macht ein solches Projekt über die reine Datenerfassung hinaus zu einem Seismometer der Relevanz.
Durch die historisch bedingte, institutionelle Verfasstheit der Arolsen Archives und die Tatsache, dass bereits ein Großteil der Dokumente in digitalisierter Form vorliegen, waren die Grundvoraussetzungen für ein solches Crowdsourcing-Projekt von vornherein günstig. Die Arolsen Archives, vormals International Tracing Service (ITS), sind ein internationales Zentrum über NS-Verfolgung mit dem weltweit umfassendsten Archiv zu den Opfern und Überlebenden des Nationalsozialismus. Neben den 30 Millionen Originaldokumenten und weiteren Millionen von Dokumentenkopien umfasst die stetig wachsende Datenbank insgesamt 110 Millionen Objekte. Die Sammlung mit Hinweisen zu rund 17,5 Millionen Menschen gehört zum UNESCO-Weltdokumentenerbe. Sie beinhaltet Dokumente zu den verschiedenen Verfolgtengruppen des NS-Regimes, zur Zwangsarbeit sowie zu Displaced Persons (DPs) und Migration nach 1945. Die Arolsen Archives haben eine digitale Strategie 2021 bis 2025 entwickelt, um den weltweiten barrierefreien Zugriff auf den gesamten Dokumentenbestand zu ermöglichen. Derzeitig sind im Online-Archiv bereits über 26 Millionen Dokumente einsehbar.[2]
Die Arolsen Archives begreifen sich zudem als Informations-Hub und möchten gemeinsam in einem Netzwerk, das sowohl die Copyholder[3] als auch Gedenkstätten, Erinnerungsorte und Museen, aber explizit auch die universitäre Forschung sowie das Engagement kleinerer Einrichtungen (Vereine, Initiativen und individuelle Multiplikatoren) einbezieht, die Möglichkeit schaffen, Sammlungen und Mikroarchive zu digitalisieren und online zugänglich zu machen. Neben der digitalen Sicherung von Informationen und Dokumenten für die Zukunft stehen die archivische Indexierung, Erschließung und Kontextualisierung solcher Überlieferungen im Vordergrund, die wiederum Teil sowie notwendige Basis für Projekte im Bereich der Data Science, der Digital Humanities bzw. der Public Science und Citizen Science sind.
Die Erfassung der Daten im Rahmen der Initiative #EveryNameCounts erfolgt über die international größte nichtkommerzielle Citizen Science-Plattform Zooniverse (mit Sitz an der Oxford University und dem Adler-Planetarium in Chicago, Illinois). Die Plattform ist frei zugänglich und hunderttausende Freiwillige aus der ganzen Welt helfen mit, große Datenbestände für Wissenschafts- und Kultureinrichtungen zu erschließen. Bei einem Vorhaben wie #EveryNameCounts auf einer solchen reichweitenstarken Plattform ist die Frage nach den Veränderungen und Entwicklungen in der Gedenk- und Erinnerungskultur am Ende der Zeitzeugenschaft ebenso evident, wie auch das Hinterfragen der Möglichkeiten und Grenzen eines Gedenkens mit digitalen Mitteln. Für die Überlebenden und Angehörigen der Opfer hat sich die Bedeutung der Sammlungen der Arolsen Archives über die Jahre hin zu einem „Denkmal aus Papier“[4] entwickelt. Die Arbeit der Freiwilligen mit den Dokumenten auf Zooniverse ergänzt diese Wahrnehmung um eine weitere bedeutsame Facette: das Digitale.
„I have done a lot of genealogical transcription in the past and somehow didn’t realize there are other ways to do this kind of work to help connect people with their history and their ancestors. I’m very excited to have found this platform to participate in new ways. I have always loved history and feel strongly about the need to preserve and make available this kind of information. I’m looking forward to contributing to this project and many others. Thanks for having me!“[4]
Im Folgenden werden die Entwicklungsstufen und Erfahrungen des Projektes chronologisch nachgezeichnet und besondere Herausforderungen an den Projektinhaber Arolsen Archives beschrieben.
Von der Schulkampagne zur weltweiten Initiative
#EveryNameCounts startete am 27. Januar 2020 als lokales Bildungsprojekt. Unter dem Motto „jeder Name zählt...!“ erfassten rund 1.000 Schülerinnen und Schüler aus Hessen einen Tag lang Namen und Geburtsdaten von Deportations- und Transportlisten. Um die Arbeit mit den Dokumenten aus der NS-Zeit vor- und nachzubereiten, erhielten die teilnehmenden Schulen umfassendes Unterrichtsmaterial. Das Feedback war durchweg positiv: Die Konfrontation mit den Originalquellen mit Namen, Alter und Wohnorten der Opfer war für die Schülerinnen und Schüler ein ungewohnt direkter Zugang zu den Verbrechen des NS-Regimes. Sie setzten sich durch das Projekt intensiv mit einzelnen Schicksalen auseinander und leisteten zugleich einen greifbaren Beitrag gegen das Vergessen. Die Menge und Qualität der Metadaten, die so an nur einem Tag erfasst worden waren, machte außerdem deutlich, dass das Projekt nicht nur pädagogischen Wert hat. Crowdsourcing zeigte das Potential, in Zukunft ein entscheidender Faktor bei der Indexierung der Dokumente der Arolsen Archives zu sein.
Als die Corona-Pandemie ab dem Frühjahr 2020 weite Teile des Lebens in den digitalen Raum verlegte, wurde dieser Prozess beschleunigt: Viele Gedenkveranstaltungen zum 75. Jahrestag der Befreiung ehemaliger Konzentrationslager konnten nicht vor Ort stattfinden. Dies gab den Anstoß, das Projekt kurzfristig auszubauen und so weltweit als einen digitalen Ort des Gedenkens zugänglich zu machen. Aus „jeder Name zählt“ wurde #EveryNameCounts. Die positiven Reaktionen waren sowohl in den klassischen Medien als auch in den Social Networks bemerkenswert. Die Bereitschaft zur Beteiligung war enorm:
“Hello, I am Mia from the US. I have only begun working on this project a few days ago, after having read about it in the New York Times.”[5]
Heute ist #EveryNameCounts eine internationale Initiative, die aktives Gedenken an die Opfer der nationalsozialistischen Verfolgung mit historischem Lernen verbindet. Über 19.000 registrierte Freiwillige arbeiten am Bau des „digitalen Denkmals“ mit.
“As I document each card, at first I merely transcribed the data needed for the archives. Then as days have passed, I started researching the camp admittance form. The cards reveal so much more than just the names, date of birth and prisoner number. Often prisoners were transferred to other camps and that is noted or sadly their date of death appears. [...] Categories of nationalities can also be found. As each name appears on my screen, a snapshot of who they were becomes apparent – making them even more precious and missed.”[6]
Die Arbeit mit der „Crowd“ bringt allerdings auch Herausforderungen mit sich: Bei den Freiwilligen kann kein Hintergrundwissen vorausgesetzt werden und nur ein Teil verfügt über Kenntnisse der deutschen Sprache, in der die Dokumente verfasst sind. Aus diesem Grund eignen sich besonders gleichförmige Dokumente für #EveryNameCounts. Die Freiwilligen können aus unterschiedlichen „Workflows“ auswählen. Diese unterscheiden sich in der Art der Daten, die erfasst werden und der Herkunft der Dokumente. Aktuell werden vor allem individuelle Unterlagen, wie Häftlings-Personal-Karten und Häftlingspersonalbögen aus verschiedenen Konzentrationslagern, bearbeitet. Konkret werden Daten wie Name, Geburtsdatum, Geburtsort, Beruf, Staatsangehörigkeit, Familienstand, Religion, letzter Wohnort, Häftlingsnummer oder Haftkategorie erfasst. Aber auch Angaben zu Angehörigen, die oft ebenfalls Verfolgte waren, werden eingetragen oder Informationen zu Überstellungen, mit deren Hilfe Verfolgungswege rekonstruiert werden können.
Die Dokumente werden einzeln angezeigt und die zugehörigen Daten in eine Maske eingegeben. In die Felder kann entweder Freitext eingetragen oder die zutreffenden Angaben aus einem Dropdown-Menü ausgewählt werden. Zu jedem Feld gibt es eine ausführliche bebilderte Anleitung, wo die jeweilige Information im Dokument zu finden ist und wie sie korrekt erfasst werden soll. Außerdem steht Freiwilligen seit dem 27. Januar 2021 eine digitale Einführung zur Arbeit im Projekt zur Verfügung.[7] Um Fehler möglichst ausschließen zu können, werden die Daten zu jedem Dokument mindestens dreimal erfasst. Anschließend werden die Daten ausgewertet und einer Qualitätssicherung unterzogen.
Im Forum haben Freiwillige die Möglichkeit, Fragen zu stellen und Rückmeldungen zum Projekt zu geben. Dieses Feedback fließt wieder in die Konstruktion der neuen Workflows ein. Da wir im Forum beispielsweise immer wieder Korrekturen von fehlerhaften Ortsangaben in den Dokumenten erhielten, entschlossen wir uns, einen speziellen Workflow zur Erfassung von GEO-Daten anzubieten. Darin haben Freiwillige die Möglichkeit, die Daten auf eine Weise mit uns zu teilen, die uns eine gezielte Weiterverarbeitung ermöglicht.
Zum 27. Januar 2021 wurden weitere 600.000 individuelle KZ-Dokumente über #EveryNameCounts bereitgestellt. Damit beläuft sich die Gesamtzahl auf etwa 1,6 Millionen Dokumente aus 15 Beständen, die in 31 Workflows bearbeitet wurden bzw. werden. Mit der Indexierung per Crowdsourcing in dieser Größenordnung haben die Arolsen Archives Neuland betreten. Seit dem Projektstart vor über einem Jahr haben wir viel dazu gelernt und das Projekt hat sich beständig weiterentwickelt.
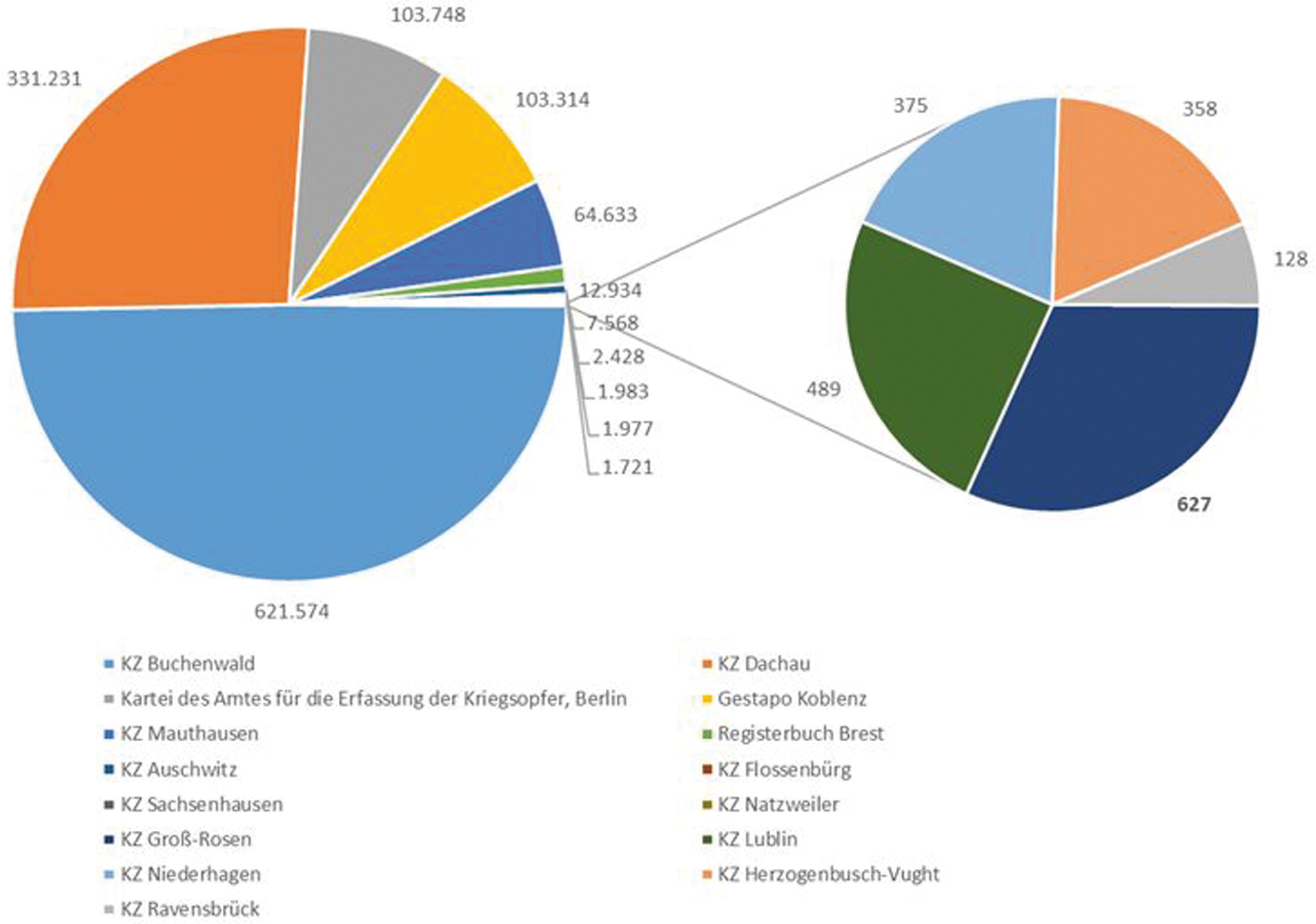
Anzahl der Dokumente nach Beständen.
Bereitstellung der Daten
Um die Arbeit in den verschiedenen Workflows überhaupt zu ermöglichen, ist zunächst die Art und Weise der Bereitstellung von Daten auf der Plattform ausschlaggebend. Begonnen haben wir mit den Mitteln, die Zooniverse bereitstellt: Der Zooniverse Project Builder ist eine graphische Oberfläche zur Gestaltung der Projektseite. Darüber werden u. a. auch die zu bearbeitenden Bilder hochgeladen.
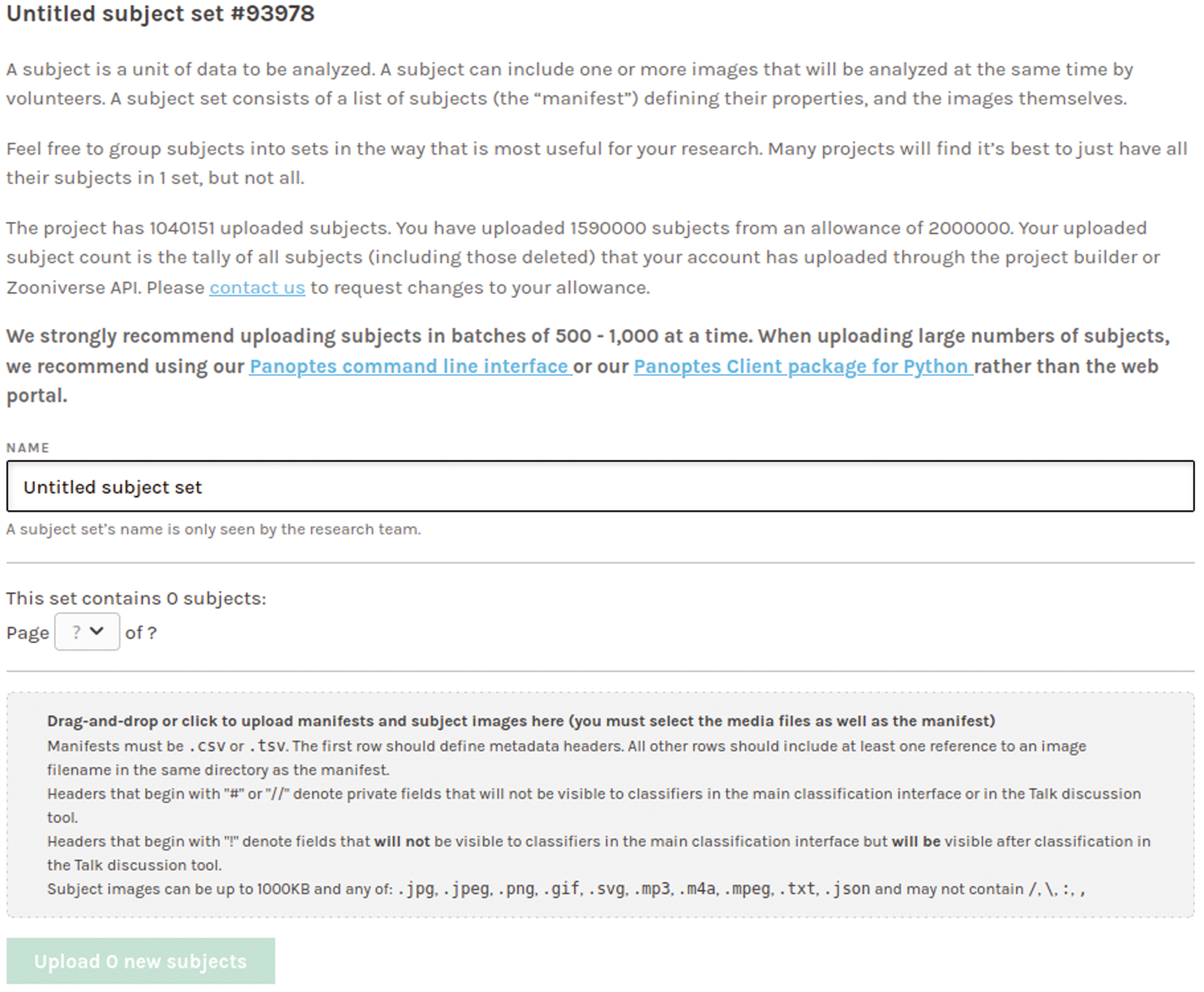
Uploadfunktion des Zooniverse Project Builders.
In den ersten Monaten wurden die Bilddateien direkt vom Server hochgeladen, was durch den Erfolg des Projektes bald an Grenzen stieß. Zooniverse empfiehlt für den Upload, Bilddateien in Gruppen von 500 bis 1.000 Stück zu bündeln. Bei Zehntausenden von Bildern oder mehr ist diese Vorgehensweise nicht nur zeitaufwändig, sondern auch fehleranfällig. Deshalb war es folgerichtig, dass wir uns technisch neu aufgestellt haben. Seit November 2020 werden die Bilddateien nicht mehr vom Server, sondern direkt aus der institutionseigenen Cloud nach Zooniverse hochgeladen.
Ein Nebeneffekt dieses Verfahrens kam ebenfalls zum Tragen: Die heimischen DSL-Anschlüsse konnten entlastet werden, denn alle Beschäftigten der Arolsen Archives arbeiten seit März 2020 im Homeoffice. Diese Umstellung führte allerdings dazu, dass der Project Builder nicht mehr genutzt werden konnte. Zooniverse bietet als Lösung zwei andere Wege an, um große Mengen von Dateien hochzuladen: Über das Kommandozeilenprogramm „Panoptes CLI“[8] oder den auf Python beruhenden „Panoptes Client“[9], wobei wir uns für die Nutzung der Kommandozeile entschieden haben. Seitdem können Massenuploads einer theoretisch unbegrenzten Menge von Bilddateien durchgeführt werden.
In der Praxis hat es sich als sinnvoll erwiesen, nicht mehr als 40.000 Dokumente in einem Paket hochzuladen. Neben der Entscheidung, jedem Digitalisat Metadaten beizufügen, wurde auch der Workflow bezüglich der Bilder angepasst. Denn die Erfahrung der ersten Monate hat gezeigt, dass eine Menge homogener und gut lesbarer Bilder in einem Subject Set, d. h. einer definierten Gruppe von Bildern, die Arbeit der Freiwilligen erleichtert, weniger Kommentare im Forum hervorruft und die Qualität der eingegebenen Daten deutlich verbessert. Deshalb wurden fortan anstatt ganzer Bestände mehrheitlich zuvor per Clustering gebildete Gruppen von Dokumenten für den Upload gebündelt. So haben wir beispielweise aus dem Bestand „Konzentrationslager Buchenwald“ den Teilbestand mit individuellen Unterlagen[10] ausgewählt und darin alle Häftlings-Personal-Karten sowie Häftlingspersonalbögen geclustert, exportiert und für diese zwei Arten von Dokumenten jeweils einen Workflow angelegt. Da aus früheren Projekten gute Erfahrungen mit der Layout-Erkennung von Dokumenten vorlagen und die notwendigen Prozesse bereits aufgesetzt waren, erfolgte die Filterung passender Dokumente ohne Zeitverzug.
Ein weiterer wichtiger Schritt war die Einbindung der auf dem Server liegenden Digitalisate in eine Qualitätssicherung noch vor dem Upload. Es hatte sich nämlich als durchaus störend erwiesen, wenn den Freiwilligen immer wieder Bilder zur Indexierung angezeigt wurden, die aus unterschiedlichen Gründen nicht passten[11]: Teilweise waren Seiten leer oder schwarz. Ebenso konnten die Deck- oder Zwischenblätter, deren Erfassung im Rahmen der bestehenden Workflows nicht zielführend war, herausgefiltert werden. Bei den Dokumenten, die mit Vorder- und Rückseite als ein Zooniverse-Subject hochgeladen worden waren, kam es außerdem vor, dass es in Folge einer Seitenverschiebung, bei der die Vorderseite fehlte, die Rückseite vorrückte und eine weitere Leerseite als Rückseite erschien.
Dieses durchaus häufige Problem geht allerdings auf einen fehlerhaften Import innerhalb unseres Archivinformationssystems zurück. Bei einem Umfang von über 100 Millionen digitalen Objekten können bei automatisierten Prozessen nicht alle Fehler aufgefangen werden. Ein weiterer Vorteil, den das Zooniverse-Projekt mit sich bringt, ist also die Möglichkeit, solche Auffälligkeiten gezielt nachzuarbeiten.
Neben der Optimierung der Qualität der bereitgestellten Digitalisate wurde außerdem die Verfahrensweise bzgl. des Umfangs der beigestellten Metadaten weiterentwickelt. Zooniverse bietet die Möglichkeit, beim Upload von Bilddateien diesen in Form eines Manifests auch Metadaten beizufügen. Eine CSV-Datei ist alles, was dafür nötig ist. Im Herbst 2020 sind wir dazu übergegangen, die Dokumente durchgängig mit Metadaten zu versehen. Da der Upload über „Panoptes CLI“ in jeden Fall ein Manifest erfordert, war die Bereitstellung spätestens ab November 2020 auch technisch zwingend. Darüber hinaus ergab sich im Besonderen mit Blick auf die Nutzungserfahrungen aus der historischen Kontextualisierung und der Verortung der Dokumente innerhalb der Archivtektonik ein klarer Mehrwert. Folglich werden seither jedem Dokument die Dokumenten-ID[12] sowie Nummer und Name des Bestandes als weiterführende Informationen beigefügt. Wo vorhanden, werden ebenfalls Personendaten aus der institutionseigenen Datenbank hinzugefügt. Hierfür wird per SQL-Abfrage des Archivinformationssystems für den in Bearbeitung befindlichen Bestand eine Werteliste der Felder Vorname, Nachname und Geburtsdatum sowie gegebenenfalls Häftlingsnummer ausgegeben.
Wenn die Dokumente bereits in unserem Onlinearchiv[13] veröffentlicht wurden und es möglich ist, eine direkt auf das Dokument verweisende URL zu erzeugen[14], wird dem Manifest zusätzlich ein Hyperlink hinzugefügt. Die Liste der Dateinamen wird mit Hilfe der Software „Total Commander“ vom Server ausgelesen. Beide Dateien werden als Projekte im Tool „OpenRefine“ angelegt und die Daten über ein Matching der Dokumenten-ID zusammengeführt.

Anzeige „Subject Metadata“ als Resultat eines Manifestes.
Community-Management
„It feels good to be helpful in a concrete way and work as part of a team, in a way giving voice to, and standing up for those who suffered under the National Socialist regime, and perhaps making it easier for a family member, or friend even, to find them.“[15]
Eine nicht zu unterschätzende Kernaufgabe der Projektleitung eines Crowdsourcing-Vorhabens ist es, die wachsende Community zu betreuen und die Ressourcen vorab bei der Projektplanung zu bedenken. Die Erwartungshaltung der Freiwilligen an den Support – sowohl den technischen als auch den inhaltlichen – ist ebenso zentral für das Gelingen des Projekts wie eine durchdachte Nutzerführung mit einem getesteten Usability-Konzept in den Workflows. Anfänglich genügte eine Kollegin, die sich vollumfänglich mit #EveryNameCounts beschäftigte. Es zeigte sich jedoch bereits nach wenigen Monaten, dass das Projekt und vor allem die Betreuung der Freiwilligen und ihrer Rückfragen nicht mehr allein von einer Person zu leisten war.
Während es im April 2020 noch 38.624 Klassifikationen und 4.445 Forumsbeiträge waren, stieg die Anzahl der eingegebenen Klassifikationen im Juni 2020 auf 746.548 und 12.765 Beiträge im Forum.[16] Im Juli 2020 wurde deshalb ein Moderationsteam aus sechs Personen gegründet. Die internen Arbeitsabläufe mussten sich erst einpendeln, doch schnell zeigte es sich, dass dies am besten mit einem Schichtplan mit fest zugeteilten Tagen und somit Zuständigkeiten funktionierte. Die engmaschige Kommunikation aller am Projekt beteiligter Moderatorinnen und Moderatoren mit den Workflowingenieurinnen und -ingenieuren stellte sich hierbei als Schlüssel für das Gelingen des Projekts und die rasche Beantwortung der Fragen und Anregungen der Freiwilligen heraus.
Zentrale Anlaufstelle hierfür ist der Diskussionsbereich des Projekts.[17] Die Gestaltung von Struktur und Umfang dieses Bereichs sollte also bestenfalls bereits bei Projektbeginn überlegt und entsprechend eingerichtet werden. Zooniverse macht hierbei nur minimale Anforderungen. Die Erfahrung hat gezeigt, dass eine Unterteilung der diversen Kommunikationsbedürfnisse sehr sinnvoll ist. Um die Beiträge übersichtlich zu halten und die Anliegen voneinander zu trennen, hat sich die Aufteilung in Notes (allgemeine Kommentare zu den jeweils indexierten Dokumenten), Troubleshooting (allgemeine Fragen und Probleme) sowie Introduce yourself (hier können sich die Freiwilligen vorstellen und untereinander vernetzen) bewährt.
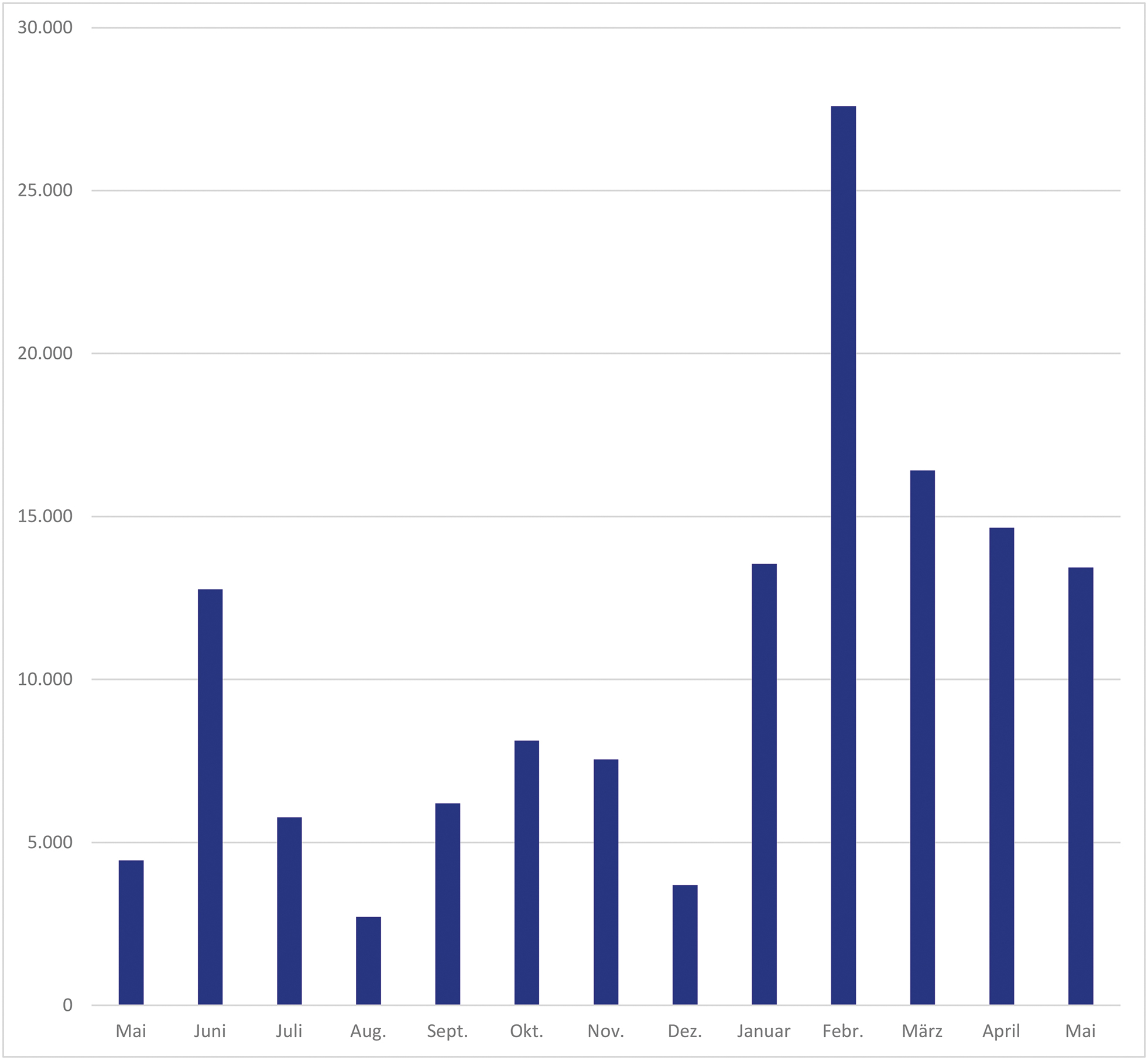
Anzahl der Kommentare von Mai 2020 bis März 2021.
Seit dem Start des Projekts wurde und wird der Betreuungsbedarf der Freiwilligen immer größer. Neben denjenigen, die nur hin und wieder ein Dokument indexierten und sich im Forum kaum beteiligten, bildete sich rasch ein Kern sogenannter „Superuser“ heraus. Diese besonders engagierten Freiwilligen mit den unterschiedlichsten Hintergründen und Muttersprachen, eigneten sich innerhalb weniger Monate ein so großes Fachwissen an, dass sie die Moderatorinnen und Moderatoren der Arolsen Archives seither im Forum unterstützen und auf Fehler in den Workflows hinweisen.
„For some cards I check the address on Google maps to make sure I got the correct city and typed correctly. Seeing the building from which someone got taken makes me so aware this was just few years ago and we have to raise our voice against similar sentiments.“[18]
Überraschend war für uns die Menge an Daten, die wir durch #EveryNameCounts nicht nur durch die Workflows, sondern auch durch das Diskussionsforum erhielten. Die Freiwilligen begannen, ausgehend von den individuellen Dokumenten aus den Workflows, zusätzliche Informationen zu den jeweiligen NS-Verfolgten zusammenzutragen und im Notes-Thread zu verlinken. Wir erhielten somit nicht nur die abgefragten Metadaten, sondern auch unzählige Weblinks, Fotos und Geo-IDs, die für unsere Datennachbereitung eine zusätzliche Herausforderung darstellen. Bis wir eine Lösung für die Nutzbarmachung dieser Daten gefunden haben, speichern wir die mühevolle und für unsere Forschungs- und Erinnerungsarbeit äußerst wertvollen Rechercheergebnisse ab. Nicht nur jeder Name, sondern auch jeder Kommentar/Beitrag zählt.
Datenaufbereitung. Ein Ausblick
Der Umfang der erfassten Daten ist einerseits durch die dreifache Eingabe und die Anzahl der indexierten Dokumente beträchtlich, und wird andererseits durch die beschriebenen zusätzlichen Daten um eine nicht strukturierte und auch nur schwerlich strukturierbare Datenmenge erhöht. Die Aufbereitung der Daten nach Abschluss der Workflows und erfolgreichem Download stellt einen mehrstufigen Prozess dar, der für die Institution ebenfalls völlig neu entwickelt werden musste. Hierzu ist der Aufbau gänzlich neuer Prozessabläufe notwendig, um die Daten in das Archivinformationssystem zu importieren und letztlich im Online-Archiv bereitzustellen. Der Aufwand an personellen und technischen Ressourcen darf hierbei nicht unterschätzt werden. Auch die Unterstützung durch externe Dienstleister, denen die Besonderheiten bzgl. der Anforderung an Archivdaten zumeist nicht geläufig sind, kann den erforderlichen Zeitbedarf nur bedingt minimieren. Die Arolsen Archives befinden sich inmitten dieses Weiterentwicklungsprozesses der archivischen Datenverarbeitung.
Über die Autoren

Ramona Bräu ist Manager Digital Business Development bei den Arolsen Archives – International Center on Nazi Persecution. Sie studierte Geschichte und Politikwissenschaft an den Universitäten Jena und Wrocław. Nach ihrer Tätigkeit als wissenschaftliche Volontärin bei der Gedenkstätten Stiftung Buchenwald und Mittelbau-Dora war sie als Mitarbeiterin im Rahmen des Bundesforschungsprojekts zur Geschichte des Reichsministeriums der Finanzen tätig.

Dr. Kerstin Hofmann ist wissenschaftliche Mitarbeiterin in der Abteilung Forschung und Bildung der Arolsen Archives – International Center on Nazi Persecution. Sie studierte Geschichte und Politikwissenschaft an der Universität Mannheim und wurde dort 2017 über die strafrechtliche Aufarbeitung von NS-Verbrechen in der Bundesrepublik promoviert. Das Projekt #EveryNameCounts begleitet sie seit Sommer 2020 als Moderatorin und Ansprechpartnerin für wissenschaftliche Fragen.

Sonja Nilson ist wissenschaftliche Mitarbeiterin der Abteilung Archiv der Arolsen Archives – International Center on Nazi Persecution. Sie studierte Geschichte und Politikwissenschaft an der Universität Düsseldorf. Sie befasst sich bei den Arolsen Archives mit Datenbanken und Datenmanagement und begleitet das Projekt #EveryNameCounts als Datenkuratorin.

Christa Zwilling-Seidenstücker ist wissenschaftliche Mitarbeiterin in der Abteilung Forschung und Bildung der Arolsen Archives – International Center on Nazi Persecution. Sie studierte Politikwissenschaften in Heidelberg und Jerusalem. Bei den Arolsen Archives ist sie Mitarbeiterin im Projektteam von #EveryNameCounts und bereitet aktuell die Schulkampagne zum Projekt vor, die im Herbst 2021 starten wird.
© 2021 Walter de Gruyter GmbH, Berlin/Boston
Artikel in diesem Heft
- Frontmatter
- Frontmatter
- Informationswissenschaft
- Was aus der Informationswissenschaft geworden ist
- Inhaltliche Erschließung
- #EveryNameCounts – Die Crowdsourcing-Initiative der Arolsen Archives
- Terminologie
- Terminologiemanagement: erfolgreicher Wissenstransfer durch Concept-Maps und die Überlegungen in DGI-AKTS
- Forschungsdatenmanagement
- Roadmap zur Servicestelle für Forschungsdatenmanagement am Beispiel der Universitätsbibliothek Duisburg-Essen
- Datendokumentation
- Datenqualität und -kuratierung als Voraussetzung für Open Research Data
- Scientometrie
- Möglichkeiten zur Steuerung der Ergebnisse einer Forschungsevaluation
- Tagungsberichte
- Interdisziplinäre Perspektiven auf Hate Speech und ihre Erkennung (IPHSE)
- Zwischen Sollen, Wollen und Dürfen
- Von Notizzetteln bis zu Emojis
- Informationen
- Informationen
- Buchbesprechungen
- Klar-text in Organisationen. Ein Ratgeber zur Optimierung administrativer Informationen Matthias Ballod. – Heidelberg: Springer Verlag für Sozialwissenschaften, 2020. XI, 154 S., 25 Abb. 978-3-658-31763-8 (Softcover), 49,99 Euro; 978-3-658-31764-5 (PDF), 39,99 Euro. DOI 10.1007/978-3-658-31764-5
- Publikationsberatung an Bibliotheken. Ein Praxisleit-faden zum Aufbau publikationsuntersützender Services. Karin Lackner, Lisa Schilhan, und Christian Kaier (Hrsg.). Bielefeld: transcript, 2020. 396 Seiten. Print-ISBN 978-3-8376-5072-3, 39 € PDF-ISBN 978-3-8394-5072-7, Open Access EPUB-ISBN 978-3-7328-5072-3, Open Access https://doi.org/10.14361/9783839450727
- Aus der DGI
- Aus der DGI
- Nachrichten
- Nachrichten
- Terminkalender 2021/2022
Artikel in diesem Heft
- Frontmatter
- Frontmatter
- Informationswissenschaft
- Was aus der Informationswissenschaft geworden ist
- Inhaltliche Erschließung
- #EveryNameCounts – Die Crowdsourcing-Initiative der Arolsen Archives
- Terminologie
- Terminologiemanagement: erfolgreicher Wissenstransfer durch Concept-Maps und die Überlegungen in DGI-AKTS
- Forschungsdatenmanagement
- Roadmap zur Servicestelle für Forschungsdatenmanagement am Beispiel der Universitätsbibliothek Duisburg-Essen
- Datendokumentation
- Datenqualität und -kuratierung als Voraussetzung für Open Research Data
- Scientometrie
- Möglichkeiten zur Steuerung der Ergebnisse einer Forschungsevaluation
- Tagungsberichte
- Interdisziplinäre Perspektiven auf Hate Speech und ihre Erkennung (IPHSE)
- Zwischen Sollen, Wollen und Dürfen
- Von Notizzetteln bis zu Emojis
- Informationen
- Informationen
- Buchbesprechungen
- Klar-text in Organisationen. Ein Ratgeber zur Optimierung administrativer Informationen Matthias Ballod. – Heidelberg: Springer Verlag für Sozialwissenschaften, 2020. XI, 154 S., 25 Abb. 978-3-658-31763-8 (Softcover), 49,99 Euro; 978-3-658-31764-5 (PDF), 39,99 Euro. DOI 10.1007/978-3-658-31764-5
- Publikationsberatung an Bibliotheken. Ein Praxisleit-faden zum Aufbau publikationsuntersützender Services. Karin Lackner, Lisa Schilhan, und Christian Kaier (Hrsg.). Bielefeld: transcript, 2020. 396 Seiten. Print-ISBN 978-3-8376-5072-3, 39 € PDF-ISBN 978-3-8394-5072-7, Open Access EPUB-ISBN 978-3-7328-5072-3, Open Access https://doi.org/10.14361/9783839450727
- Aus der DGI
- Aus der DGI
- Nachrichten
- Nachrichten
- Terminkalender 2021/2022