The interaction of affix size, type and shape: a cross-linguistic study
-
Tim Zingler

 and
Phillip Rogers
and
Phillip Rogers

Abstract
This study explores the phonological structure of affixes based on different parameters. We begin by investigating the common but insufficiently supported claim that affixes tend to be monosyllabic, and we then take up the ideas that prefixes and suffixes differ in terms of size and in their proclivity for allomorphy. Our database consists of affix lists of 25 unrelated languages, which come from all six geographical macro-areas and yield a total of 1,454 affixes (403 prefixes, 1,051 suffixes). The results show that both prefixes and suffixes are most often monosyllabic, but prefixes are still significantly shorter than suffixes in terms of segments and syllables. There is no significant difference in terms of allomorphy. We argue that the monosyllabic tendency emerges as an artifact, given that a monosyllabic affix is long enough to be perceived, short enough to be economical, and compatible even with simple syllable structures. Meanwhile, prefixes are shorter than suffixes because they pose a challenge for comprehension and because syllable onsets in many languages allow more complexity than codas. The overall insight is that syllables are a prominent domain in morphology as well as phonology, even though various factors may undermine the overlap of affixes and syllables.
1 Introduction
The intersection of phonology and morphology has been a long-standing area of interest. In fact, the two levels are so closely intertwined that it is often difficult to tease them apart (e.g., reduplication, external sandhi, vowel harmony). While research on this interface has led to different proposals concerning the grammatical “architecture,” it has also identified a large number of areas that call for empirical investigation. For instance, one prominent idea holds that affixes are characterized by less weight and make use of fewer types of segments than roots (Inkelas 2014: 21). However, a closer inspection of this idea (Bybee 2005) showed that it is not convincingly supported: there are no major differences between the types of segments found in affixes and those found in roots. In this work, we will dedicate ourselves to the other dimension referred to above, i.e., to the syntagmatic dimension of affix phonology. Specifically, this project proceeds from the fact that claims concerning the low weight and/or short length of affixes have been made in different places and guises, but empirical support for such claims is typically not provided. We therefore consider it a desideratum to clarify if this idea has any merit, and as such our goal is primarily an empirical one. Having said that, theoretical accounts based on specific ideas about affix phonology may of course be impacted by our findings.
It should be stated at the outset that this work is not concerned with phonological differences between roots/words and affixes. As suggested by Inkelas (2014: 22), there are good reasons to assume that some probabilistic differences of this sort emerge due to a combination of well-established synchronic and diachronic principles. First, Gordon (2016: 264) shows that phonological words in about a third of all languages in his sample have to be minimally disyllabic or bimoraic. Second, grammatical morphs, which largely develop from words, show a strong tendency to be reduced and thus shorter than their lexical origins (e.g., Asao 2015: 6; Givón 2001: 45). Incidentally, these two facts suggest that affixes might show a preference for monosyllabic size, which would be plausible in that the syllable is a psychologically salient unit for language users (Easterday 2019: 3–4; Hayes 2009: 250) that might be an ideal “anchor” for affixes.[1] In fact, Dressler (1977: 44, 1987: 117) suggests that morph boundaries are difficult to perceive if they do not align with syllable boundaries, and Mayerthaler (1987: 49) holds that the coincidence of syllable and morph boundaries is maximally transparent (i.e., advantageous in communication). In addition, a link between affixes and syllables would seem likely because a preference for sub-syllabic size, a conceivable alternative on paper, would clash with the syllable structure constraints found in many languages (cf. Section 4.1 for elaboration). The hypothesis sketched so far has been explicitly adopted by McCarthy and Prince (1994: A10), who state that “[s]ize requirements on affixes prefer monosyllabism.” However, they do not offer the kind of carefully sampled cross-linguistic data needed to prove such a comprehensive assertion. It is this more specific assumption about affix size (which we will interchangeably refer to as “affix length”) that will constitute the starting point of our study. That is, while factors such as those above lead to the prediction that affixes will cluster around a monosyllabic mean, this idea still needs to be tested. As is well-known, commonly held typological assumptions may turn out to be false once actually investigated (e.g., Klein 2011 on creole phonology).
There are additional claims in the literature that lead us to think that a cross-linguistic investigation of affix phonology will fill a research gap (cf. also Best 2005; Plank 1998: 223). For instance, Lehmann (2015: 171) states that “[grammatical formatives] very seldom comprise more than two syllables, very often no more than one or two segments, and occasionally even less than that, namely merely a feature on another morpheme.” While the class of grammatical formatives is larger than the class of affixes, the latter are a proper subset of the former, and so the structural conditions outlined by Lehmann (2015) should also hold for affixes. Yet, formulations like “very seldom” and “occasionally” are unfalsifiable, and Lehmann’s (2015) claim, much like the impressionistic statement by McCarthy and Prince (1994) cited above, does not come with (references to) relevant empirical evidence.[2] By contrast, Bybee et al. (1990) do work with a cross-linguistic database, but they limit themselves to the statement that “the majority” of bound and free verbal markers they investigate are of the types CV and CVCV (Bybee et al. 1990: 37, n. 12). As such, their claim is essentially identical to Lehmann’s (2015) and therefore also in need of closer scrutiny.
In his historical overview of claims about the typological interaction of phonology and morphology/syntax, Plank (1998: 198, 204, 205, 207) shows that different research traditions across different centuries have argued for correlations between affixes and certain syllable sizes. Yet, these claims were usually tied to the alleged difference between “agglutinating” and “fusional” languages, which is empirically ill-founded (Haspelmath 2009). Furthermore, they were speculative or, at best, based on insufficiently balanced samples (cf. Plank 1998: 207, 221). Hence, arguments for a thorough exploration of whether and how affixes and syllables align also come from the history of the field. Based on the statements known to us, then, the intuition among linguists appears to be that affixes show close links to certain syllable counts, and especially to monosyllables. Our first hypothesis will serve to subject this idea to proper empirical testing. Since the claim by McCarthy and Prince (1994) is more specific and thus more interesting than that by Lehmann (2015), this hypothesis is based on the former work.
Hypothesis 1:
Affixes show a statistically significant tendency to be monosyllabic (as opposed to sub-syllabic, disyllabic, etc.).
One aspect that Hypothesis 1 fails to capture is whether or not all affixes are alike in terms of length. It is therefore of interest that affix size has been discussed in the context of “affix asymmetries” (cf. Bybee et al. 1990). The most famous manifestation of this effect is commonly called the “suffixing preference” and can be understood in different ways. While Greenberg (1966: 92) approaches the issue by stating that there are more exclusively suffixing than exclusively prefixing languages, Sapir (1921: 70) makes the more general claim that of all affixation types in the languages of the world, suffixation is “much the commonest.” Unless indicated otherwise, the sense of the suffixing preference intended here corresponds to the latter. Simply put, the idea is that the set of all suffixes is considerably larger than the set of all other affixes combined. Relevant contemporary work on this phenomenon will be cited throughout.
One particular claim regarding asymmetries of affix size comes from Bybee et al. (1990: 24), who report that prefixes are shorter than suffixes. On the face of it, this is diametrically opposed to Berg (2015: 163), who finds that prefixes are significantly longer than suffixes. The contradiction potentially resolves since the two works deal with non-overlapping subsets of affixes. Bybee et al. (1990) generalize over a cross-linguistic database of verbal inflection, whereas Berg (2015) refers to English derivation. Crucially, though, their findings suggest that there may be length differences between prefixes and suffixes in the first place and that these should be investigated in more detail. Note that an investigation of this issue is logically independent of the alleged monosyllabic tendency. Berg (2015: 163) finds that the average length of both prefixes and suffixes exceeds one syllable, whereas Bybee et al. (1990) do not report exact lengths, but the fact that they attribute a preference for CV and CVCV shapes to their data suggests a similar average.
That there may be differences between the lengths of prefixes and suffixes follows from a broad range of research. However, different approaches yield conflicting hypotheses concerning the nature of those differences, falling in line with either Berg (2015) or Bybee et al. (1990). For instance, there is widespread agreement that prefixes are less phonologically integrated with their stems, and therefore more phonologically independent, than suffixes (e.g., Asao 2015: 166–174; Elkins 2020; Hyman 2008: 323–324; Nespor and Vogel 2007: 134–135, 139; Olsson 2021: 173–175; Wennerstrom 1993: 316; White et al. 2018). One major parameter of phonological independence is length/size, as discussed by Gordon (2016) for minimal words (cf. above). The same basic idea is also reflected in Hall’s (1992: 103) claim that initial syllables (i.e., the location of prefixes) are less reduced than final ones cross-linguistically, which in turn seems to correlate with the fact that word-initial stress is common (Goedemans and van der Hulst 2013). Specifically, the idea is that stressed syllables tend to retain full vowels, whereas unstressed vowels may reduce (Bybee et al. 1998). Meanwhile, the claim that prefixes are closer to word status than are suffixes also emerges from semantic considerations (Berg 2022a: 57–58) and from psycholinguistics (e.g., Beyersmann et al. 2015: 367). Experiments on the processing of affixes have shown that words with the same prefix prime each other, whereas words with the same suffix do not (e.g., Giraudo and Grainger 2003: 216–217 for French; Marslen-Wilson et al. 1994: 26–27 for English). This effect suggests that prefixes are cognitively more salient than suffixes, which in turn might be due to a greater structural (i.e., semantic and/or phonological) weight, as suggested by Giraudo and Grainger (2003: 225). Overall, these typological and experimental insights predict that, on average, prefixes should be longer than suffixes, as is found for English by Berg (2015).
Crucially, though, the study by Goedemans and van der Hulst (2013) shows that the one fixed stress pattern even more common than initial stress is penultimate stress, and other studies suggest that final stress is just as frequent (Gordon 2016: 177). These results point to the possibility that it is often elements occurring toward the end of word forms, and thus potentially suffixes, that are stressed and subsequently protected from reduction. There are also psycholinguistic reasons to assume that prefixes are more likely to be reduced than suffixes. Cutler et al. (1985) characterize prefixes as an obstacle to comprehension since listeners primarily depend on the identification of the stem when decoding words (cf. also Asao 2015; Hyman 2008: 343). Hence, as long as the stem is word-initial, efficient comprehension is largely secured, and semantic modifications of the stem via suffixes would largely mirror the path of language comprehension. Naturally, Cutler et al. (1985) do not deny that prefixes exist, despite the cognitive disadvantage they bring about. It therefore seems to be a valid inference from their argument that prefixes will generally be short so as to at least minimize the processing difficulties they incur (cf. also Berg 2022b on this general issue). Finally, Asao (2015: Ch. 6) uses several case studies to argue that prefixes show less allomorphy than suffixes and seem to depend on specific structural templates such as a monosegmental or monosyllabic size more often than do suffixes. To the extent that it is those sizes in particular, it would be difficult for suffixes to be significantly shorter than prefixes. In sum, the stress patterns, processing considerations, and analogical effects discussed suggest that prefixes should be shorter than suffixes, as found by Bybee et al. (1990).
The claims and findings contrasted above do not permit a straightforward prediction regarding the length differences between prefixes and suffixes.[3] Yet, given that the present study is exploratory, it can simply incorporate the current lack of knowledge by formulating a hypothesis that posits a difference between the two types without specifying the direction of that difference. This idea is encapsulated in Hypothesis 2. The operationalization of affix length will be discussed in Section 3.2.
Hypothesis 2:
There is a statistically significant difference in length between prefixes and suffixes.
Another aspect speaking to the syntagmatic dimension of affix phonology is the behavior of affixes with regard to neighboring elements, i.e., their allomorphic patterns. As stated above, Asao (2015) posits that prefixes show less allomorphy than suffixes. This would be compatible with both Berg’s (2020) and Himmelmann’s (2014) approaches to the suffixing preference. The former argues that more “grammatical” markers (roughly, those with more abstract or context-dependent semantics) are more likely to be co-activated and co-articulated with the lexical words/roots that they modify. Since Berg’s large sample shows that more grammatical markers tend to be postposed more often than less grammatical ones, it would stand to reason that there is more co-articulation with postposed markers, which should translate into more allomorphy with suffixes. Himmelmann’s (2014) arguments are also drawn from processing and language production. On his account, unintended speech pauses are more likely to occur before the production of content words than after them, which ultimately limits the amount of preposed grammatical material that fuses with lexical stems.[4] Since a production without pauses is a necessary prerequisite to fusion, the flip side of this argument is that postposed elements are more likely to develop the tight formal bond with their stems on which the development of allomorphy relies. This, too, argues for a higher degree of allomorphy among suffixes. On the whole, these aspects lead to Hypothesis 3.
Hypothesis 3:
There is a statistically significant difference in the prevalence of allomorphy between prefixes and suffixes.
The main reason for including allomorphy in our investigation is that one would assume a high degree of allomorphy to indicate a development toward a smaller size in the long run (cf. Bybee et al. 1994: 110 for this connection).[5] Simply put, the co-articulation of an item can be seen as the first step toward its eventual disappearance (which, naturally, may never manifest itself). As such, the degree of allomorphy is an independent means to establish whether the more straightforwardly size-based hypotheses are on the right track. For example, if Hypothesis 2 were to find that suffixes are shorter than prefixes, one would also expect Hypothesis 3 to find that suffixes show more allomorphy than prefixes. Conversely, if these hypotheses produce contrasting outcomes, they would have major repercussions for a number of concerns. This issue will be taken up in Sections 4 and 5.
Thanks to the inclusion of allomorphy, our hypotheses tackle the notion of affix length from different vantage points. While Hypothesis 1 looks at affixes in general, Hypothesis 2 splits the affixes into two groups, and Hypothesis 3 explores the variation found within subsets of these two groups. In conjunction with our inclusive approach toward the kinds of affixes considered (cf. the next section), we will thus be able to arrive at a more comprehensive view of affix size than previous accounts dealing with this or related issues.
The three hypotheses above circumscribe the focus of this paper. As such, this project falls within the research paradigm of traditional Greenbergian typology in that it attempts to establish whether there are cross-linguistic connections between logically independent phenomena. Section 2 will describe the database used to test the above hypotheses. Section 3 will present the empirical findings, while Section 4 will address the main implications. In that section, we will primarily focus on empirical issues, though we are aware that Greenbergian approaches ultimately call for theoretical explanations as well. The conclusion in Section 5 will suggest avenues for further research.
2 Methods
Since the object of interest in our hypotheses is affixes, the primary empirical task was to gather a relevant database of affixes. A considerable number of decisions went into the compilation of this database, and these will be outlined in the first part of this section. The second part will describe the sample resulting from those principles.
2.1 Data
Since our hypotheses refer to affixes in general rather than to those of specific word classes or functions (i.e., verbal, inflectional, etc.), the best data for the current project come in the form of “affix lists”. These are found in many reference grammars, typically as an appendix or as part of the frontmatter. Affix lists have the major advantage that they are concise and (usually) exhaustive. That is, their aim is to list all affixes found in the language (or rather: known to the grammarians), and using this resource is thus more economical than attempting to manually collect all affixes from the prose parts of the grammar. The latter method not only increases the risk of missing many affixes, but there is the additional problem that the grammar simply might not describe or mention all the known affixes. Rather commonly, for instance, only the inflectional or only the verbal affixes are listed. Furthermore, one cannot infer that a language has exactly two causative affixes simply because the grammar happens to describe two causative affixes, etc.
Given the above, all the data in this work are taken from dedicated affix lists, with one exception. That exception concerns Yele (yle; isolate), for which Levinson’s (2022: 80) prose description explicitly gives -ni and -pi as the only two affixes in the language. Note also that what we call “affix lists” often contains all bound and/or grammatical morphs, with affixes listed alongside clitics and/or function words. To the extent that the affixes in those lists were clearly distinguished from the other types of formatives, those lists were eligible for inclusion as well. However, an analysis of whether all elements listed as affixes actually behave like affixes was beyond the scope of this work. Therefore, all classifications of affixes were taken at face value (cf. Berg 2020: 359 on this methodological decision). Our empirical starting point was the collection of grammars at our disposal, which covered roughly 600 languages from about 180 families according to Glottolog (Hammarström et al. 2024). Most of those grammars do not contain affix lists, and so the majority of languages were discarded because of insufficient information. The criteria described below focus on our treatment of the available affix lists and the corresponding grammars, languages, and data.
In addition to an affix list, we required that the spelling conventions employed in the grammar be described in sufficient detail (cf. Maddieson 2023: 248–250). This served to make sure that the segment count (cf. below) for the affixes was correct. For instance, the grammar for Gooniyandi (gni; Bunaban) renders the velar nasal as ng (McGregor 1990: 37), and so the suffix -jinga was assigned four segments despite its orthographic appearance. Similar requirements pertained to the description of the syllable structure and the phonological status of diphthongs, both of which are crucial to the syllable count (cf. below). With regard to syllable structure, we primarily needed to know whether a language permits syllabic consonants. In Ikpana (lgq; Atlantic-Congo), where nasals can constitute nuclei (Dorvlo 2008: 12), the prefix n- was thus classified as monosyllabic (rather than as sub-syllabic). Meanwhile, orthographic diphthongs do not necessarily correspond to phonological singletons, and we only analyzed diphthongs where the relevant combination was explicitly described as one. Hence, in Vaeakau-Taumako (piv; Austronesian), for which Næss and Hovdhaugen (2011: 28) reject the presence of diphthongs, the prefix hie- was analyzed as disyllabic. Only when there was enough information on all these aspects was the relevant grammar/affix list considered for inclusion in the sample. This requirement had the expected reductive effect.
A similar set of issues concerns the identification of morphemes and determination of allomorphs. The general principle was the same as for the other empirical domains in that we followed the analysis of the grammarians whose work we used. That is to say, we only recorded allomorphy where it was explicitly indicated, and we limited ourselves to the information provided in the affix lists rather than attempting to gather information on allomorphy from the prose.[6] Therefore, when several forms were listed as variants, we classified those forms accordingly, even where they approximate suppletive allomorphy. For instance, Miller (2001: 373, 375) explicitly describes the form t- in Tipai (dih; Cochimi-Yuman) as an allomorph of ch-, and that is the way these forms were entered into the database. At no point did we set out to derive variants from a single “underlying” form, and instead we accept that such cases might not be phonologically conditioned allomorphy at all (cf. footnote 5). Tipai is further instructive in that it shows considerable homophony across its affixes. While the two allomorphs above express ‘plural’, the affix list also gives prefixes of the form ch- for causative and nominalizing functions. Hence, we recorded multiple entries of the form ch- for Tipai and proceeded analogously for other relevant forms in the other languages.
A further restriction imposed on our sample was the stipulation that we included no more than one language per family (as classified by Glottolog). This follows Bybee (2005: 168–171), who limits her sample in the same way. The reasoning is that affixes are typically old, and so the inclusion of related languages increases the risk that some of the entries in the database are not independent. This strategy also led to a reduction of the sample, mostly with respect to Pama-Nyungan languages, for which rather many affix lists exist. When lists from multiple languages of the same family were available, the eventual language was chosen based on different criteria. More often than not, we selected a language because the corresponding affix list was more readily interpretable than those of the other candidates. Ideally, though, the language with the longest list was selected, though in several cases we prioritized a language based on its location (cf. below). In some cases, none of these factors made a major difference, and the language was basically chosen at random.
A related consideration concerns (potential) language contact. The avoidance of languages spoken in geographical proximity is generally desirable in sampling, and it would also be appropriate in the present study given the borrowability of affixes (Seifart 2017). Yet, this criterion was more difficult to implement. Specifically, there are relatively many Papuan languages for which affix lists exist, and excluding most of them due to possible areal effects would have greatly undermined the goal of this study. Hence, the Papuan languages were all included, and it so happens that they are well distributed given the relatively small size of the Papunesian macro-area. A similar problem was encountered in North America, where the small number of appropriate affix lists forced the inclusion of two geographically close languages. A table and a map of all the languages in the sample are provided in Section 2.2.
The final substantive restriction on the sample was aimed at avoiding lists of more than 100 affixes. This cutoff point was arbitrarily chosen, but it only led to the exclusion of a few languages that we could have used otherwise. At the same time, it served as a simple measure to ensure that a small number of languages with large affix inventories, whose affixes might have a cross-linguistically unusual structure, does not dominate the database and distort the results. For instance, there is an affix list for Central Alaskan Yupik (esu; Eskimo-Aleut) in Miyaoka (2012: 1565–1575). It contains several hundred entries (which, however, seem to be limited to derivational markers) and would thus have accounted for a disproportionate share of the data and would have further amplified the suffixing bias in our database. In response to the latter issue, one exception to the 100-affix rule was made in that prefix-heavy Filomeno Mata Totonac (tlp; Totonacan) was included in the sample even though the corresponding affix list contains 129 affixes. Note that our goal is not to disprove the suffixing preference. Tilting the database in favor of more prefixes simply gives us an empirical foundation on which our hypotheses can be evaluated. In sum, the suffix-to-prefix ratio in our final database is 2.6 (1,051/403), which is more balanced than the one in the comparable study by Bybee et al. (1990: 4), at 2.9 (1,236/426).
The inclusion of Filomeno Mata Totonac has the further advantage that the language is spoken in the North American macro-area, for which we otherwise would have had very few affix lists. A geographical motivation also underlies the only other exception we made to the 100-affix principle. That is, Lezgian (lez; Nakh-Daghestanian), for which 133 affixes are listed, was included because without it Eurasia would have been the macro-area with the fewest languages in our sample, even though it is the largest in terms of territory in the traditional classification (Dryer 1992; Hammarström et al. 2024).
Due to the 100-affix restriction, the present study can technically only generalize about the phonological structure of affixes in languages with small to mid-sized inventories (i.e., those containing up to 100 affixes). Yet, even in this regard, our study goes beyond the most relevant previous work on the topic. Bybee et al. (1990: 3–4) investigate a total of 1,662 affixes from 71 languages, which gives an average of 23 affixes per language. Meanwhile, our database contains 1,454 affixes from 25 languages, for an average of 58 affixes per language.[7] The ramifications of the 100-affix principle for our results will be taken up in Section 4.4. Meanwhile, Section 3 will describe how the statistical methods we employ manage to further mitigate the quantitative asymmetries discussed above.
It follows from the interests and hypotheses of this work that only segmental affixes are relevant to this study. In other words, zero morphs, floating tones, ablaut patterns, etc., were not incorporated into the database, and where segmental affixes had such non-segmental allomorphs, the latter were not recorded. In the very few cases where an affix consisted of both segmental material and a floating tone, the former was entered and classified as described below, while the suprasegmental feature was ignored. Another minor restriction has to do with morphs that are argued to have affixal as well as syntactically free allomorphs. These were not classified as affixes, based on the understanding that an affix can only have bound allomorphs by definition (Julien 2002: 212). Note that no affix in any of our lists had both prefixal and suffixal allomorphs.[8] This both facilitated the classification and illustrates how rare this type of “mobile affixation”/“ambifixation” is (cf. Kim 2010).
It should also be emphasized that the function of the affixes we collected, including possible differences between inflection and derivation, played no role in the compilation of the database and will not be discussed here. On the one hand, this follows from the interests and hypotheses of this work, which are exclusively about the interplay of phonological and morphological form. On the other hand, providing a systematic, categorical account of whether the functions of the affixes in the sample are inflectional or derivational, etc., would have been highly problematic at best (cf. Haspelmath 2024).[9] One consequence of this approach is that we cannot investigate another claim regarding affix length, which emerges from an overview table in Aikhenvald (2007: 36) that juxtaposes prototypical derivational and inflectional properties. The relevant difference in that table concerns the idea that inflection “tends to be monosyllabic,” whereas derivation “may be monosyllabic or longer.” However, these claims are arguably even weaker and hence more difficult to falsify than the one in Lehmann (2015) discussed above.
A further complication regarding a classification of the affixes along functional lines would be that some items in affix lists are not assigned a function at all. Note that those items were included in the present database because they were classified as affixes by the grammarians and thus satisfy the formal criterion at issue here. In the case of Ik (ikx; Kuliak), however, there was a separate list of “archaic affixes,” which were excluded because this categorization calls into question the very status of those units as morphological items. Apart from that exception, a lack of productivity, which was noted in a small number of cases, did not prevent an affix from being included. This follows from the fact that unproductive elements may still be straightforward affixes (cf. the suffix in warmth, which is perfectly transparent in both form and function). In sum, then, our database might contain a trivial number of elements whose morphological status is questionable (e.g., epenthetic segments or “linkers”). Yet, this database has the benefit of not being limited to verbal (and nominal) affixes. As such, our project comes much closer than previous works to accounting for affixes as a whole.
The following information was recorded for each affix in the database: its form (including all listed variants), its type (P[refix], S[uffix], O[ther]), its length in terms of syllables, and its length in terms of segments. The next section will outline why both a segment and a syllable count were needed for the present project. We focused on segments and syllables because other phonological domains, like feet and mora, are less often and/or thoroughly described in reference grammars. By contrast, all the grammars that made it into our sample assume that the syllable is a relevant structural unit in the respective language, so this potential descriptive problem did not affect the data collection.
The procedure underlying our length counts can be illustrated with the example of the Kalamang (kgv; West Bomberai) prefix nak- and its allomorph na-, which in the present database were assigned the type P, the syllable length 1, and the segment length 2.5. The length counts derive from the sum of the counts of the individual forms, which is then divided by the number of forms. So, one syllable (for /na/) plus one syllable (for /nak/) equals two syllables, which is then divided by two (the number of forms) to give 1. This was the method used for both the syllable and segment counts of all affixes, many of which were listed with only a single form or only with forms of the same length. Note that the syllable count recorded for each affix refers to the size of the affix in isolation. Of course, affixes will be syllabified within the phonological words that they occur in, even where the present classification categorizes them as sub-syllabic.
Finally, we are aware that certain allomorphs of an affix X might have considerably more restricted contexts than other allomorphs of affix X, which might be reflected in widely different token frequencies and perhaps even in different degrees of psychological reality. Yet, since there is no reliable way to infer the exact contexts for each allomorph of each affix in each language, let alone the token frequencies resulting from those contexts or the mental representation of the different allomorphs, we did not factor this into our counts. Hence, all variants contributed equally to the counts of their respective affix morpheme.
2.2 Sample
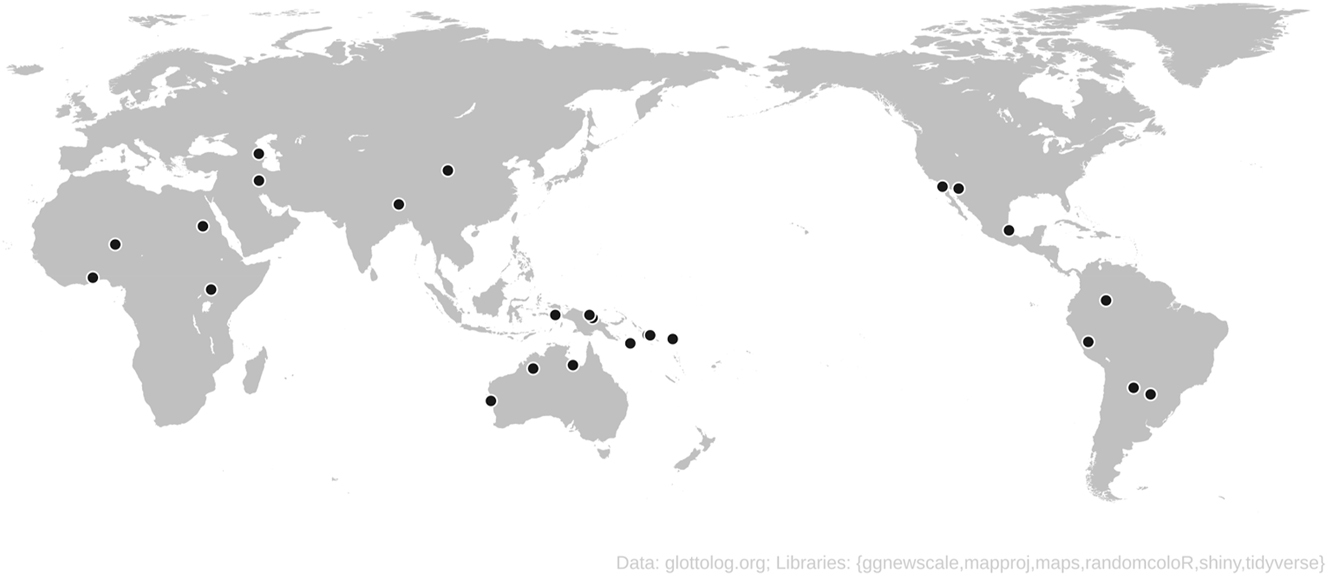
Table 1 lists the 25 languages whose affix lists met the above criteria and which were therefore included in the sample. The languages are listed alphabetically by family name, except that we listed the three isolates under the name “isolate.” This is to clearly set them apart from languages whose names are (largely) identical to those of their families but which are not isolates (e.g., Garrwa/Garrwan). Apart from that, family classifications as well as language and family names are based on Glottolog, even where that information diverges from the classifications and/or glossonyms in the corresponding source. Meanwhile, Map 1, created with the GlottoshinyR tool provided by Börstell (2021), illustrates the geographical distribution of the sample languages.
Languages in the sample.
| Language | Family | ISO 639-3 | Reference (= affix list) |
|---|---|---|---|
| Ashéninka Perené | Arawakan | prq | Mihas and Pérez (2015: 657–659) |
| Ikpana | Atlantic-Congo | lgq | Dorvlo (2008: xv) |
| Vaeakau-Taumako | Austronesian | piv | Næss and Hovdhaugen (2011: 500–502) |
| Gooniyandi | Bunaban | gni | McGregor (1990: 603–606) |
| Tipai | Cochimi-Yuman | dih | Miller (2001: 373–376) |
| Garrwa | Garrwan | wrk | Mushin (2012: 469–470) |
| Toba | Guaicuruan | tob | Klein (1973: 271–276) |
| Laki | Indo-European | lki | Belelli (2021: 459–465) |
| Yele | Isolate | yle | Levinson (2022: 80) |
| Lavukaleve | Isolate | lvk | Terrill (2003: 533–535) |
| Savosavo | Isolate | svs | Wegener (2012: 359–386) |
| Ik | Kuliak | ikx | Schrock (2014: xxv–xxvi) |
| Mangghuer | Mongolic-Khitan | mjga | Slater (2003: 367–372) |
| Hup | Naduhup | jup | Epps (2008: 928–934) |
| Lezgian | Nakh-Daghestanian | lez | Haspelmath (1993: 557–559) |
| Iatmul | Ndu | ian | Jendraschek (2012: 552–556) |
| Kenuzi-Dongola | Nubian | kzh | Abdel-Hafiz (1988: 316–317) |
| Yeri | Nuclear Torricelli | yev | Wilson (2017: 667–674) |
| Nhanda | Pama-Nyungan | nha | Blevins (2001: 152–153) |
| Yakkha | Sino-Tibetan | ybh | Schackow (2015: 565–568) |
| Tagdal | Songhay | tda | Benítez-Torres (2021: xiv–xvi) |
| Filomeno Mata Totonac | Totonacan | tlp | McFarland (2009: 240–244) |
| Paraguayan Guaraní | Tupian | gug | Estigarribia (2020: 309–311) |
| Tohono O’odham | Uto-Aztecan | ood | Zepeda (1983: 158–160) |
| Kalamang | West Bomberai | kgv | Visser (2022: 443–444) |
-
aThe ISO 639-3 code “mjg” refers to Mongghul, the closest relative of Mangghuer, according to Glottolog, which does not give an ISO 639-3 code for Mangghuer itself. By contrast, the World atlas of language structures (WALS; Dryer and Haspelmath 2013) links “mjg” to Mangghuer.
Geographical distribution of the sample languages.
The sample includes multiple languages from each of the six geographical macro-areas commonly employed in linguistic typology (Dryer 1992). Hence, it is decently balanced relative to its small overall size. Yet, given that 43 % of all families (184/430) are isolates according to Glottolog, the three isolates in the sample (=12 %) recall Miestamo et al.’s (2016: 243) criticism that isolates have traditionally been underrepresented in samples. A similar critique might be leveled at the representation of Eurasia and North America. The latter is equally due to a lack of relevant affix lists and to our preference for languages with fewer than 100 affixes. As is well known, both Eurasia and North America are home to a large number of language families with rich morphology, and the few relevant affix lists in our sources subsequently tend to exceed 100 items.[10] Recall also that the two exceptions we made to the 100-affix principle concern one language each from Eurasia (Lezgian) and North America (Filomeno Mata Totonac). In other instances, though, blank spots on the map are exclusively due to a lack of relevant affix lists available to us. This is the case for the languages of southern Africa, for example.
At the same time, the sample includes most of the very large language families of the world, especially Austronesian, Atlantic-Congo, Indo-European and Sino-Tibetan. In addition, it includes families that are rather dominant at the continental level, such as Arawakan and Tupian in South America, Pama-Nyungan in Australia and Uto-Aztecan in North America. This is important if the above reasoning that affixes are typically old is indeed valid. Simply put, by incorporating many large families, the probability increases that a major portion of the world’s affixes is included in the database, if only at an etymological level.[11] Note also that Indo-European is represented by a relatively little-known Indo-Iranian language, Laki. Hence, our findings are safe from the common criticism that major Western European languages are overrepresented in samples.
3 Results
In this section, we present the statistical evaluation of our findings. The broader implications will be the topic of Section 4. Unless stated otherwise, all the results reported below refer to our final database, which totals 1,454 affixes, consisting of 403 prefixes and 1,051 suffixes. An exact breakdown of how these affixes are distributed across the 25 sample languages is given in Table 5 in the Appendix.
3.1 Hypothesis 1: relationship between affixes and syllables
Our first hypothesis predicts that affixes show a significant tendency to be monosyllabic, and our data indeed exhibit this general pattern. The most common length of affixes in our data is exactly one syllable, and in fact, monosyllabic affixes outnumber all other affix lengths combined (877 vs. 577). The same prevalence of monosyllabic affixes can be found in most of the individual languages in our sample. Figure 1 above shows the number of affixes at each syllable length for each language. (Recall that affix length was averaged across allomorphs, so while most affix lengths are integers, some values involve decimals.) For 22 of the 25 languages in the sample, the most frequent affix length is one syllable. By contrast, monosyllabic affixes are slightly less frequent than affixes of another length in two of the three exceptional languages. In Ik, it is disyllabic affixes that edge out monosyllabic affixes, while in Yeri it is sub-syllabic affixes (i.e., length of 0). Tipai is the only language that strongly bucks the trend of monosyllabicity, with the number of sub-syllabic affixes approximately double that of monosyllabic affixes.
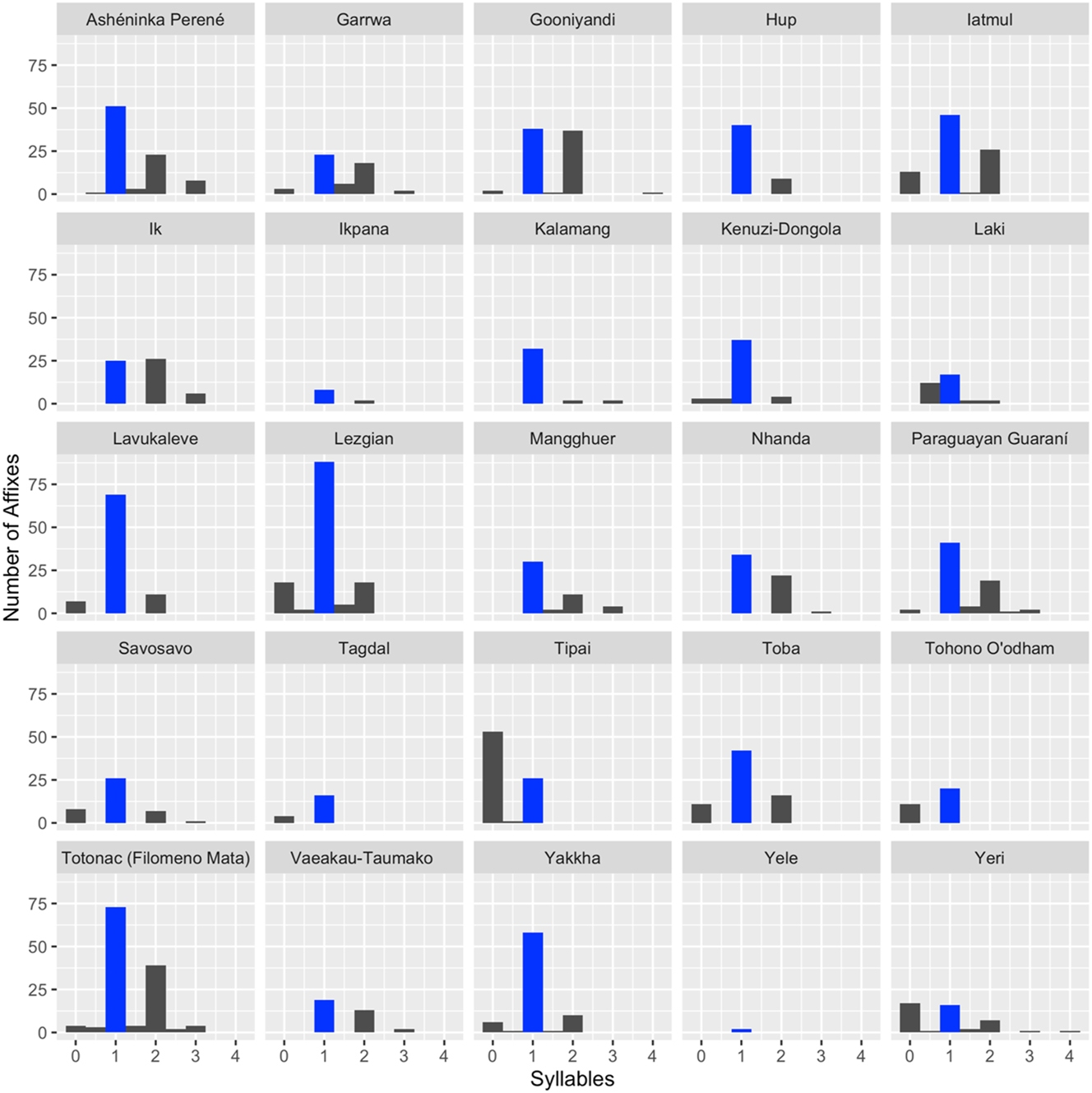
Histogram showing the number of affixes at different syllable lengths in the 25 sample languages. The bar representing monosyllabic affixes is shown in blue.
While informative, this cursory analysis must be supported by a statistical test of the hypothesis. Our prediction – that affixes tend to consist of one syllable – is somewhat unique in statistical terms in that it makes reference to a particular numerical value (one) in the midst of various other possible values. This hypothesis could be broken down into various sub-hypotheses, each of which could be tested independently: affixes are more likely to be monosyllabic than sub-syllabic, affixes are more likely to be monosyllabic than disyllabic, etc. The possibility of decimal values only exacerbates this “problem.” To simplify the analysis, we combine all these “other” lengths into one category and ask the question: are affixes more likely to be monosyllabic than non-monosyllabic? This consolidates our hypothesis into a single statistical question, which represents a more challenging bar to clear, so to speak. If we can show that affixes are more likely to be monosyllabic than anything else (including all values less than or greater than one syllable), it follows that the same holds for monosyllables compared to any of those specific subsets of non-monosyllabic lengths.
To test the primary hypotheses of this paper, we use mixed-effects regression models, which have increasingly been used as a state-of-the-art statistical tool within linguistic typology (e.g., Jaeger et al. 2011). These models can attribute some variance to language-specific trends (via random effects) while also identifying any overarching effect present in the entire sample (fixed effects). To test our first hypothesis, we fit a mixed-effects poisson regression model predicting the number of affixes in a language as a function of monosyllabicity (monosyllabic vs. non-monosyllabic). This model includes random intercepts for Language, which allows languages to vary with regard to the overall number of affixes.
The model reveals a substantial difference between the number of monosyllabic and non-monosyllabic affixes, supporting the hypothesis that affixes have a tendency toward monosyllabic length. Coefficients of this model can be found in Table 2, and the effect is illustrated in Figure 2. This plot shows that the model predicts more monosyllabic affixes than non-monosyllabic affixes. (The exact number on the y-axis is not important, as languages vary widely in the overall number of affixes they have.) We also performed a likelihood ratio test comparing our model to one without monosyllabicity as a predictor (but no change to random effects), and this test indicated that our model explains the data better than the null model (χ2(1) = 62.35, p < 0.001 ***).
Coefficients of the mixed-effects poisson regression model predicting number of affixes (count) from monosyllabicity (monosyllabic vs. non-monosyllabic) in 25 languages (CI = confidence interval; SD = standard deviation).
| β | 95 % CI (Lower) | 95 % CI (Upper) | SD (Language) | |
|---|---|---|---|---|
| Non-monosyllabic (Intercept) | 2.957 | 2.654 | 3.247 | 0.685 |
| Monosyllabic | 0.419 | 0.314 | 0.524 | — |
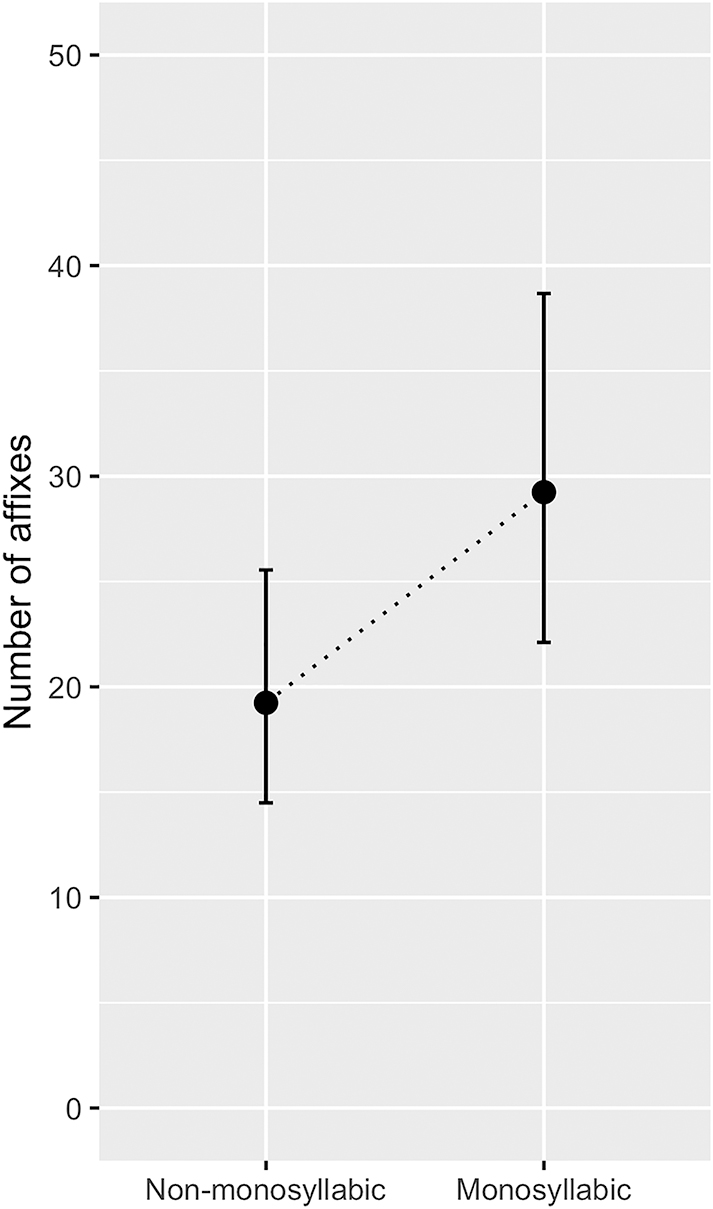
Fixed-effect plot showing the effect of monosyllabicity (monosyllabic vs. non-monosyllabic) on the number (count) of affixes for 25 languages.
3.2 Hypothesis 2: relationship between affix type and affix length
Hypothesis 2 predicts a significant difference in length between prefixes and suffixes. To investigate this hypothesis, we fit a linear mixed-effects regression model predicting affix length (measured in number of segments) from affix type (prefix vs. suffix). The dependent variable, affix length, was Box-Cox normalized in order to meet the assumptions of the statistical model (Fox and Weisberg 2019). The model includes random intercepts and slopes for Language. Coefficients of this model can be seen in Table 3.
Coefficients of the mixed-effects linear regression model predicting affix length from affix type in 25 languages. (The dependent variable has been Box-Cox normalized, so the coefficients cannot be interpreted as segment units.)
| β | 95 % CI (Lower) | 95 % CI (Upper) | SD (Language) | |
|---|---|---|---|---|
| Intercept (Prefix) | 0.637 | 0.484 | 0.792 | 0.317 |
| Suffix | 0.231 | 0.096 | 0.375 | 0.255 |
The model coefficients in Table 3 reveal a substantial effect of affix type on segment length. Prefixes are predicted to be shorter than suffixes by almost half a segment, lending support to Hypothesis 2. This effect is illustrated in Figure 3. Inspection of the random effects indicates some variation across languages in both overall segment lengths and the magnitude of the effect of affix type. However, the overall direction of the effect is fairly consistent across the sample. We also performed a likelihood ratio test comparing our model to one without affix type as a predictor (but no change to random effects), and this test indicated that our model explains the data better than the null model (χ2(1) = 9.89, p < 0.01 **).

Fixed-effect plot showing the effect of affix type (prefix vs. suffix) on affix length for 25 languages. The rugs on the left and right edges of the plot represent actual prefixes and suffixes in the data, respectively (they are “jittered” vertically so as not to hide the number of data points, but most actually represent whole number values).
The results above are based on segments as the unit of affix length because they are more fine-grained than syllables. Yet, we also fit a model predicting syllable length, and the results were qualitatively no different. At this point, it should be explained how prefixes can differ significantly from suffixes in length (even in length as measured in syllables), and yet both types exhibit a tendency toward monosyllabicity. The answer lies in the way our first hypothesis was operationalized. For both prefixes and suffixes, the most common affix length across our dataset is one syllable. However, the next most likely length for prefixes is less than one syllable, while the next most likely length for suffixes is two syllables. These secondary tendencies are masked in the way we tested Hypothesis 1 because all affixes are treated as either monosyllabic or non-monosyllabic. When sub-syllabic and disyllabic affixes are conflated (along with everything else that is not monosyllabic), prefixes and suffixes look very similar. In fact, a simple chi-square test comparing the ratio of monosyllabic (232) to non-monosyllabic (171) prefixes to the same ratio in suffixes (645–406, respectively) is not significant (χ2(1) = 1.60, p = 0.21), which means that prefixes and suffixes do not differ significantly in their preference for monosyllabic length. To summarize, both prefixes and suffixes tend toward a length of one syllable, but prefixes average a little less than one syllable while suffixes average a little more. These general statistics of length can be seen in Figure 4 along with similar information about segment lengths.
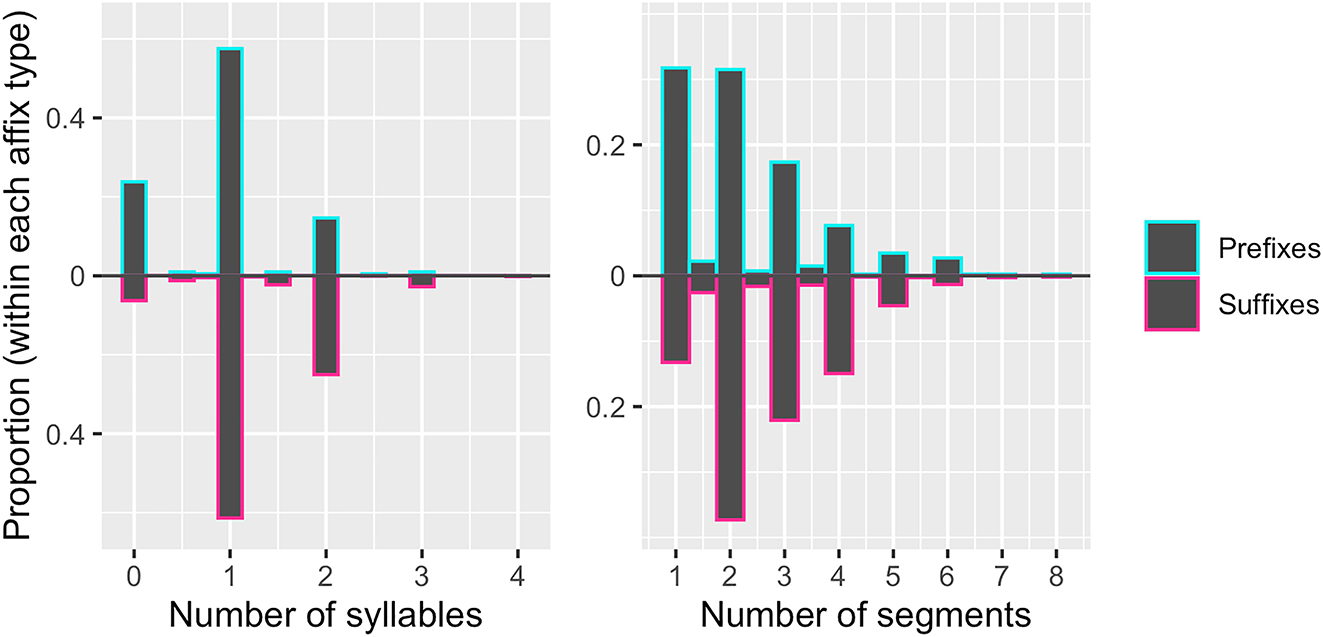
The proportion of affixes of different syllable (left) and segment (right) lengths for both prefixes (above) and suffixes (below). One syllable is easily the most frequent length for both prefixes and suffixes, yet prefixes are observed to be shorter on average in terms of both syllables and segments.
3.3 Hypothesis 3: relationship between affix type and allomorphy
Our third hypothesis is that prefixes and suffixes differ significantly in their proclivity for allomorphy, and we test this in two ways. First, we fit a logistic mixed-effects regression model predicting the presence of allomorphy (yes or no) from affix type, with random intercepts and slopes for each language. Coefficients for this model can be found in Table 4, and they suggest only a small effect of affix type on the odds of allomorphy. This effect is also shown in Figure 5. The plot illustrates how suffixes are slightly more likely to exhibit allomorphy, but the complete overlap in confidence intervals indicates that the difference is not significant. We also used a likelihood ratio test to compare this model to one without affix type as a predictor (but no change to random effects), and this test indicated that our model fails to explain the data better than the null model (χ2(1) = 0.84, p = 0.36).
Coefficients of the mixed-effects logistic regression model predicting presence of allomorphy from affix type in 25 languages.
| β | 95 % CI (Lower) | 95 % CI (Upper) | SD (Language) | |
|---|---|---|---|---|
| Intercept (Prefix) | -2.925 | -4.156 | -1.694 | 2.211 |
| Suffix | 0.519 | -0.576 | 1.615 | 1.344 |
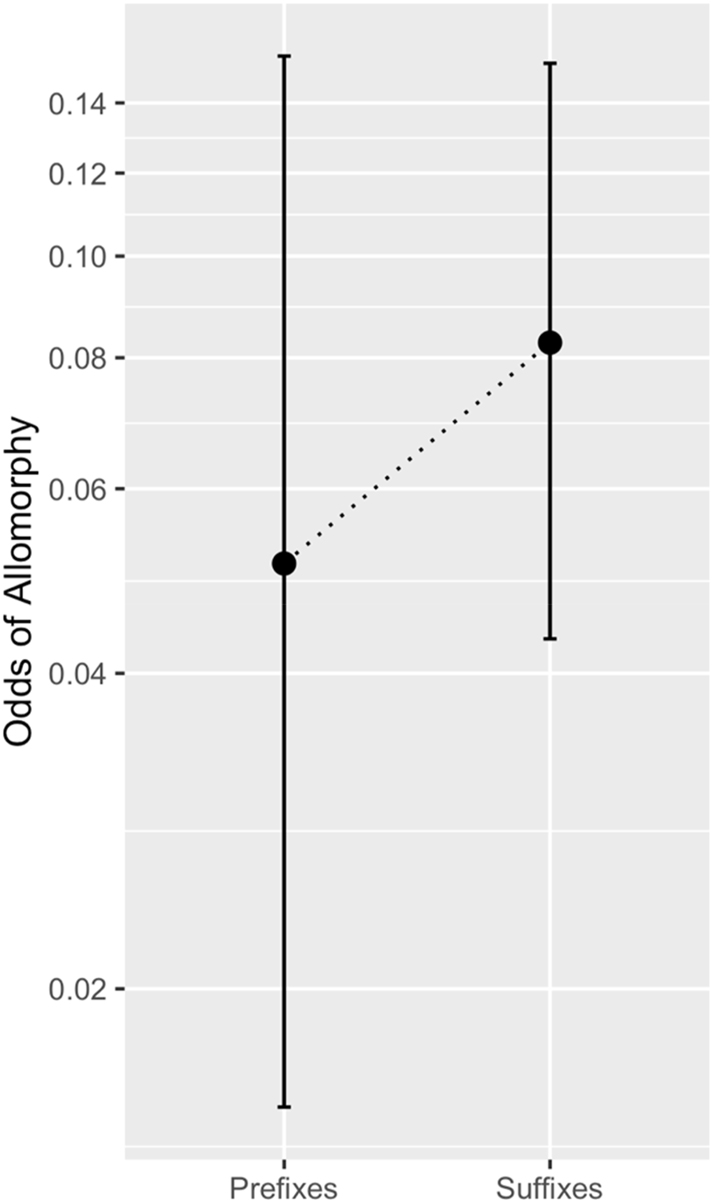
Fixed-effect plot showing the effect of affix type (prefix vs. suffix) on the odds of allomorphy. While the plot shows that suffixes are a little more likely to have allomorphy, the difference is not significant.
Second, while the analysis above concerns the presence/absence of allomorphy, we can also explore any potential difference in the number of allomorphs when allomorphy is present. For example, it could be that suffixes tend to have three or four allomorphs, while prefixes tend to have just two allomorphs. We checked for such a pattern among the 203 affixes with allomorphy in our database (out of 1,454 total).[12] As Figure 6 illustrates, prefixes and suffixes exhibit very similar distributions in the number of allomorphs, with two allomorphs being the strongly preferred option of both types. A Wilcoxon rank-sum test (p = 0.931) confirms that there is no significant difference in the number of allomorphs, while a Kolmogorov-Smirnov test (p = 0.965) confirms that there is no significant difference in the shape of the distributions.
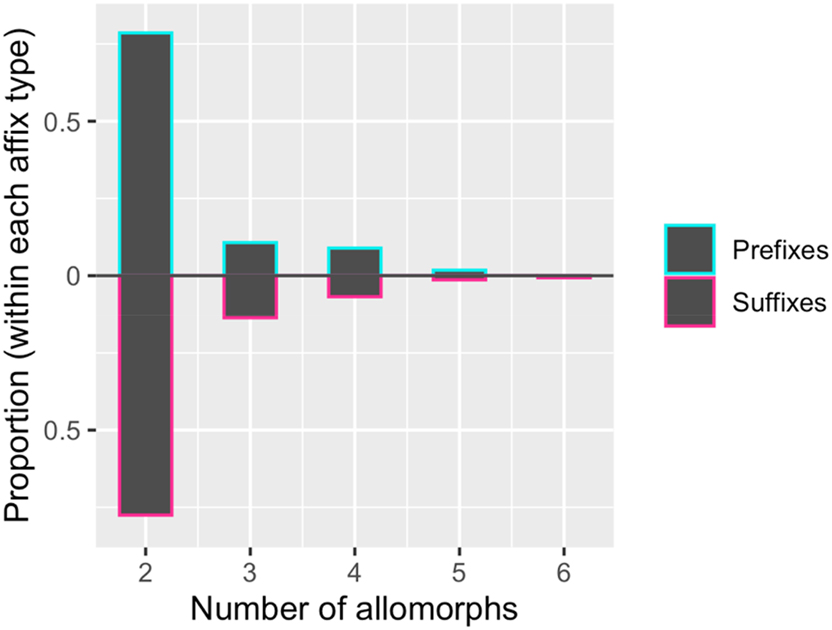
Among affixes that exhibit allomorphy, this plot shows the distribution of number of allomorphs for both prefixes (above) and suffixes (below). The distributions are very similar, with neither type showing a proclivity for more allomorphs than the other.
4 Discussion
Our results bear on previous claims and findings in interesting ways. On the one hand, we find considerable support for the popular idea that affixes show a tendency to be monosyllabic. To the best of our knowledge, this has not previously been investigated for the kind or size of sample employed here. In addition, our results are consonant with accounts that suggest that prefixes are (or should be) shorter than suffixes. On the other hand, our findings run counter to the similarly substantial literature that found/predicted suffixes to be shorter than prefixes and according to which suffixes (should) show significantly more allomorphy than prefixes. In the remainder of this section, we will embed this new set of findings within the larger picture of how phonology and morphology interact.
4.1 Hypothesis 1
The results for our first hypothesis suggest to us that one of the reasons the syllable is such a prominent and important concept in phonology (and morphology) is that it is targeted by different phenomena, which in turn are brought about by a combination of factors. We will outline here what we consider to be the main causes for the link between syllables and affixes.
As meaning-bearing elements, affixes should have some formal expression,[13] which essentially means that there is a lower bound to the amount of structure by which affixes may be expressed. At the same time, affixes are largely predictable in their occurrence because they are often triggered by the syntactic and/or pragmatic context, limited to stems of a specific word class, and do not typically vary in their position relative to their stem, etc. It follows that their expression can be greatly reduced compared to less predictable items such as content words (cf. Haspelmath 2021: 624; Mollica et al. 2021). These opposing trends of a minimum size and a drive for reduction correspond to the preferences of listeners and speakers, respectively. Yet, the reason that the resulting compromise tends to be exactly a syllable rather than something slightly longer or shorter arguably has structural reasons. As suggested in Section 1, chief among them seems to be the factor of syllable structure, which puts special constraints on suffixes in word-final position. Almost 69 % of the languages in Maddieson’s (2013) sample either do not permit codas at all or do not permit complex codas.[14] For the former languages, this means that sub-syllabic suffixes are impossible word-finally; for the latter, the same holds when the preceding morph (either the root or another suffix) is consonant-final. Put differently, phonotactic constraints require word-final suffixes to be minimally monosyllabic in many languages, as it seems reasonable to assume that most suffixes can generally occur in word-final position. By contrast, no syllable structure known to us requires that an affix be at least disyllabic, let alone larger than that. If this argument has merit, it would be rather powerful given that suffixes account for the majority of affixes worldwide and in our database.
Based on the above, a monosyllabic affix seems to strike the perfect balance between parsimony, perceptibility, and compatibility. More broadly, then, there is no reason to assume an overarching force that inherently privileges the level of the syllable. Rather, monosyllabic length may be epiphenomenal in affixes, the result of various principles that speakers and listeners rely on for independent reasons. As such, the syllable might be an “attractor” (e.g., Nichols 2018), and the phenomenon of monosyllabic affixes might have to be explained by something like the “invisible hand” (Keller 2014). There are a few languages in our sample that appear to defy the trend toward monosyllabicity (cf. Section 3.1), but this is not surprising given the complex set of factors – morphosyntactic, phonological, historical, psycholinguistic, etc. – that interact to produce affixes. Unique circumstances can lead to outliers, but an investigation of these specific languages is beyond the scope of this paper.
Given our data, we can assess Lehmann’s (2015: 171) claim that grammatical formatives, including affixes, are rarely more than two syllables and often no more than two segments in length. Among our 1,454 affixes, there are 38 that exceed two syllables (2.6 %) and 632 that exceed two segments (43.5 %). As such, the suprasegmental claim seems valid, while the segmental one appears untenable. Our findings also speak to the debate about whether affixes are subject to a monosyllabic maximum (cf. Gouskova 2023 for discussion). If such a maximum existed, it would more clearly distinguish affixes from roots, which often show a minimum size (cf. Section 1). Yet, as can be seen in Figure 1, only four of the 25 sample languages lack affixes exceeding one syllable. So, regardless of what motivated the affix maximality hypothesis, our results clearly refute the idea that this is a cross-linguistic tendency, and definitional differences between roots and affixes will thus have to be sought elsewhere.
4.2 Hypothesis 2
The above account leaves open why prefixes should be subject to the monosyllabic constraint. Specifically, prefixes can only appear in the highly restricted coda positions when they are part of a prefix chain, the latter of which can be assumed to be relatively rare given the suffixing preference (cf. Section 1). Generally speaking, our results again accommodate an explanation based on syllable structure. Recall that prefixes were shown in Section 3.2 to be significantly shorter than suffixes. This roughly ties in with the fact that syllable onsets permit complexity (i.e., clusters) more often than do codas (Maddieson 2013), and so onsets provide the opportunity for sub-syllabic prefixes more often than codas do for sub-syllabic suffixes. This seems to mean that language users reduce affixes to the extent that the syllable structure allows, and where degrees of tolerance with regard to syllable complexity differ, so do the corresponding affix sizes. This is in line with our findings, which show that monosyllabic size is the preferred choice for both prefixes and suffixes, but the next-highest preference for prefixes is sub-syllabic size while for suffixes it is disyllabic size.
There is additional evidence for this line of argument in Easterday (2019: 280–282) and Easterday et al. (2021: 12, 14). They find that sub-syllabic affixes are particularly common in onsets of word forms characterized by a high degree of synthesis, and their argument is that these contexts aid the primary factor of vowel reduction in the creation of complex syllable margins (but cf. below). As such, their results argue for the idea that prefixes (and especially prefix vowels) are reduced more easily/commonly than (vowels in) suffixes. Those studies are particularly relevant to the present project because they were seemingly not limited to particular affix types and apparently included at least verbs and nouns. Clearly, though, their results challenge the idea cited in Section 1, according to which initial syllables are subject to reduction less frequently than final syllables.
Another factor that probably leads to shorter prefixes overall is the argument made by Cutler et al. (1985) and mentioned in Section 1. To the extent that language comprehension is stem-based, prefixes create an obstacle, and the drive to minimize this obstacle should be correspondingly strong. While Cutler et al. (1985) use this argument to explain the relative rarity of prefixes, we think that it works equally well to explain their relative shortness in cases where they do exist. In fact, the latter explanation seems particularly apt for the above-mentioned tendency of short prefixes to appear in highly synthetic contexts. If prefixes constitute a processing problem on their own, their concatenation should be an even larger one. Thus, the tendency to condense prefixes as much as possible would be even more likely to manifest itself in synthetic forms. Overall, then, our results are adequately covered by – and might even be said to support – the approach in Cutler et al. (1985), even though the latter has been called into question (Harris and Samuel 2024; Martin and Culbertson 2020).
Technically, the question of cause and effect looms large here. That is, syllable structures might also change as a result of affix vowel reduction, as suggested by Easterday and colleagues. However, we think that our results furnish evidence for the idea that syllable structure is the yardstick for affixes rather than the other way around. That is, the constant reduction of prefixes introduces the possibility that they eventually fall below the monosyllabic threshold. That they do not do this more frequently (as per the findings for Hypothesis 1) suggests that the option to reduce is not made use of indiscriminately, perhaps because the convenient anchor (or “attractor”) of the monosyllable counteracts the general reductive tendency. In any case, the overlap between affixes and syllables is imperfect and always subject to change; as such, our findings are not generally incompatible with the arguments in Easterday et al. (2021).
Note that our findings regarding the prefix/suffix asymmetry corroborate Bybee et al. (1990), the only work that we know to have previously investigated this question in comparable fashion. This convergence is interesting in that Bybee et al. (1990) limited themselves to verbal inflection, whereas we did not discriminate based on word class or function. The most economical explanation for why we replicated their findings is that verbal markers account for a large share of affixation in general and that the structure of our database might thus be similar to theirs. Conversely, the difference between our results and those in Berg (2015) suggest that English derivation is typologically unusual. This would be compatible with the fact that English phonology and morphology feature many other traits that are not representative of the world’s languages (e.g., dental fricatives, complex syllable structure, a large portion of borrowed affixes, an almost total lack of inflection). Hence, the phonological structure of its derivational affixes might simply be another facet of what appears to be a cluster of cross-linguistically infrequent properties (cf. also Zingler 2024).
4.3 Hypothesis 3
Our third hypothesis was dedicated to potential differences in terms of allomorphy between prefixes and suffixes. It was derived from independent findings and predictions that suffixes show more allomorphy than prefixes, which in turn finds an explanation in contemporary accounts of the suffixing preference. In light of this, our result that prefixes and suffixes have virtually identical allomorphy profiles is unexpected, and we are thus forced to find factors that might explain why prefixes show more allomorphy than assumed. There is at least one major factor that is likely to be relevant here. Gordon (2016: 123–133) shows on the strength of cross-linguistic data that processes of anticipatory assimilation clearly outnumber those of perseverative assimilation.[15] While prefixes, by definition, always have following segments to assimilate to, they very often will not have any preceding segments to assimilate to, at least within the same phonological word. The opposite holds for suffixes (even though suffix chains should be found in more languages than prefix chains, given the suffixing preference; cf. Section 1). It is this set of facts that provides the necessary condition for the considerable allomorphy of prefixes: they occur in exactly those positions where natural co-articulatory tendencies render highly likely the kinds of assimilation that ultimately regularize to become allomorphy (cf. Hyman 2008: 317–323 for typological claims).
Our results for Hypothesis 3 diverge slightly from what Bybee et al. (1990: 20–23) found. In their data, prefix shapes and suffix shapes adapt to the stem in roughly equal measure, showing anticipatory and perseverative assimilation, respectively. While their binary investigation of whether prefixes or suffixes are more prone to allomorphy also produces a non-significant outcome, they found that prefixes show more allomorphy than suffixes, contrary to our results. Furthermore, they found that suffixes showing allomorphy at all have more allomorphs than prefixes that show allomorphy, whereas our data showed essentially no difference between the two types. The major takeaway from the allomorphy study, then, is that despite the “positional advantage” of prefixes in the domain of allomorphy, suffixes can keep up with them. The main reason for this is likely some version of the co-activation account proposed by Berg (2020) and sketched in Section 1. After all, a rather strong factor would be required to explain why suffixes might show the otherwise unusual process of perseverative assimilation to the extent that they do.
We also need to consider the connection between affix size and degree of allomorphy. As we argued in Section 1, these should be expected to correlate given that (phonologically conditioned) allomorphy is typically seen as a precursor to, or a manifestation of, diachronically decreasing length. However, our results do not bear this out because we do find a significant difference in affix size but not in degree of allomorphy. This would seem to mean that the equation of synchronic allomorphy with diachronic reduction is too simplistic in that formal variation might be historically stable and not necessarily cause reduction. Among other issues, this suggests that claims regarding grammaticalization that are primarily based on synchronic data would have to be treated with caution.
There is another link between length and allomorphy that deserves mention. That is, it might be thought that consistency in form (i.e., a low degree of allomorphy) is more important for shorter items than for longer ones lest the former become suppletive and an obstacle to comprehension (cf. also Järvikivi et al. 2006). Yet, our results refute that idea. Prefixes are almost as likely to be variable as suffixes despite their shorter overall length. This should make prefixes more difficult to parse than suffixes, and given that prefixes have generally been argued to constitute a parsing problem, this additional complication is unexpected. However, this apparent stalemate resolves when assimilation is understood as yet another happy medium. While it is an obvious benefit to speakers, its effects also provide relevant clues for listeners in terms of lexical access, which are more important word-initially than word-finally.[16]
4.4 Caveats
At this stage, we should acknowledge the potential impact that our restriction to affix inventories of 100 or fewer items (with two exceptions) might have on the results reported above. Generally speaking, we have no reason to assume that affixes in languages with small inventories are subject to different principles and patterns than those in languages with many affixes. While Stave et al. (2021: 6) find that synthetic word forms include shorter morphs than more analytic ones, synthetic word forms are not necessarily restricted to languages with large inventories. That is, a given language might have a few obligatory and thus highly frequent affixes, thereby potentially combining a moderate inventory with an above-average degree of synthesis. Crucially, Stave et al. (2021) consider morphs of all types for their counts, including stems and clitics. Hence, their study does not address the specific question that we pursue here.
That said, a correlation between affix inventory size and affix size/shape is conceivable. Many of the languages with large affix inventories are strongly suffixing (e.g., Eskimo-Aleut, Uralic, Turkic), while others appear to be more balanced between prefixes and suffixes (e.g., Siouan, Iroquoian, Bantu). These languages may exhibit atypical patterns in affix length and allomorphy because of the (apparently special) historical circumstances that led to their rich morphology and/or because of the processing pressures that rich (suffixing) morphology places on speakers and listeners. We leave this possibility as a question for future research.
4.5 Additional approaches
Apart from the research mentioned above, there are various other works that might inform certain aspects of our findings. We will briefly discuss some of them here, with the proviso that all these ideas deserve further consideration, both with regard to our database and in general.
The work by Easterday and colleagues cited above raises the issue of how affix sequences impact affix shapes. One aspect of this issue concerns affix order. Since we did not consider how distant the affixes in our database (usually) are from their roots or other affixes, we cannot presently say anything definitive about this. However, previous research permits certain ideas about how our database might be explored further. Specifically, Rice (2011: 182–184) outlines that in Athabaskan languages the prefixes closer to the root are shorter than those further away. While Athabaskan languages are heavily prefixing, it stands to reason that this general pattern can also be tested for suffixes and thus for much larger samples.
The pattern established by Rice (2011) supports the idea that affixes emerge at different times and that older affixes have undergone more reduction than the more recent ones that subsequently join the morphological template at a greater remove (but cf. Rice 2000, who generally argues against a templatic approach to Athabaskan verb morphology). Such an organization differs from the iconically motivated ordering discussed in Bybee (1985). On her account, functions more semantically relevant to the root (roughly, derivational) are expressed by affixes closer to the root than those less relevant to the root (roughly, inflectional). A major aspect of iconically motivated ordering is that the more relevant affixes also show a closer formal bond with the root, i.e., a greater degree of fusion. To the extent that fusion entails reduction, however, the prediction based on Bybee (1985) happens to be identical to that based on Rice (2011): inner affixes should be shorter than outer ones (cf. also Hay 2002 for English). Hence, both approaches suggest that it might be profitable to divide affixes into further categories, whether this be age, position, function, or several parameters at once.
Investigations such as those sketched above promise to reveal more nuanced correlations between affix types and affix sizes than our hypotheses permitted, and we consider them a desideratum for future research. Nevertheless, we need to reiterate that devising a cross-linguistically workable classification of affix functions, to say nothing of a substantive division between inflection and derivation, is a most ambitious goal. In addition, determining the age of affixes is virtually impossible in any language. So, while sufficient data for approaches like those above are available by now, operationalizations of possible explanatory factors remain a major challenge.
Another pertinent factor concerning affix size would seem to be token frequency. The general assumption since at least Zipf (1935/1965) has been that token frequency correlates with formal shortness (cf. also Haspelmath 2021). Crucially, this has been established as a cross-linguistically relevant factor in the domain of nominal inflection (Guzmán Naranjo and Becker 2021). Put differently, usage patterns appear to be an important complement to the predominantly structural explanations that we offered here. For instance, it might be relevant whether and which affixes are obligatory in a given language. That is, in a language in which the only obligatory category expressed on verbs is person indexation, one would expect the relevant markers to be highly frequent and thus short, other things being equal. Crucially, this prediction follows regardless of where the relevant affixes appear relative to the verb. Yet, such an approach might explain the shorter length of prefixes particularly well given that frequent units are available more quickly during production and are thus more likely to precede less frequent units (Berg 2020: 385).
5 Conclusions
This work has explored affix phonology cross-linguistically. In particular, we investigated for a sample of 25 unrelated languages from across the world whether affixes (n = 1,454) show a tendency to be monosyllabic, differ in length based on type (prefix vs. suffix), and differ in amount of allomorphy based on type. The first two predictions were confirmed, but the latter was not. While some of these issues had previously been investigated with different databases, our project permits a comprehensive view of these phenomena and their interdependencies, which in turn forces us to question some of the previous results. Overall, we suggest that the two positive findings owe to a combination of processing and structural factors, while the parity between prefixes and suffixes in terms of allomorphy is due to the interplay of co-articulation and co-activation.
We argued that affixes tend to adopt a monosyllabic shape due to a number of (onto)logically independent factors. One consequence of this claim is that syllables and affixes need not align and might even compete with one another. This view gains support from a language like Hinuq (gin; Nakh-Daghestanian), which strongly rejects tautosyllabic consonant clusters, even across morphological boundaries (Forker 2013: 35). This becomes an interesting problem with the gender agreement prefixes on verbs since these prefixes all consist of a single consonant (lending credence to the shortness of prefixes once again). As Forker (2013: 188–190) reports, the result of this conflict is that most vowel-initial verbs bear an agreement prefix, whereas most consonant-initial ones do not. Hence, the demands of the syllable are the stronger force in this context, and where these demands clash with those of the affixes, the latter are typically ignored. Cases like these, especially against the background of our findings, suggest that much can be learned by investigating if, where, and to what extent different structural phenomena find common ground.
An obvious idea to pursue along the lines of our Hypotheses 2 and 3 would be to juxtapose the phonological properties of proclitics and enclitics. Many of the affix lists we used also present the clitics of the respective language. So, the empirical situation should be roughly comparable to what was described here, even though the items called clitics are traditionally a less homogeneous set than the elements called affixes. Furthermore, such an investigation would be highly relevant to grammaticalization theory. Since clitics are considered to be less grammaticalized than affixes (e.g., Hopper and Traugott 2003: 6–7), they should also be longer (but cf. Spencer and Luís 2013: 127). A comparison of our affix data and a cross-linguistically balanced set of clitics might thus help to establish whether one of the core assumptions of grammaticalization theory is actually justified.
Finally, our results also produce a major discrepancy that we cannot currently account for. As found by the relevant sources cited in Section 1, and especially by Elkins (2020), prefixes are less phonologically integrated with their stems in terms of stress and harmony domains, etc., than are suffixes. On the reasonable assumption that less integration signals a greater degree of wordhood, the prediction is that prefixes should be longer than suffixes, given that more word-like units are longer than less word-like ones. However, our results (as well as those of Bybee et al. 1990) show that prefixes are shorter than suffixes. Rather than a convergence of parameters, our data thus identify a mismatch between integration and size. That is an interesting result in and of itself (tentative though it may be), but it also suggests that future investigations of affix behavior should synthesize the two dimensions of integration and size so as to better understand the roots of this conflict. This will be a task for phonology and morphology as well as for historical linguistics and psycholinguistics.
Acknowledgments
We are very grateful to Thomas Berg for his detailed feedback on an earlier draft of this paper and to the three anonymous reviewers for their many helpful suggestions. We are also indebted to the audience at the 21st International Morphology Meeting in Vienna for valuable comments on this work. All remaining errors are solely our responsibility.
Prefix and suffix counts for the 25 sample languages.
| Language | Prefixes | Suffixes |
|---|---|---|
| Ashéninka Perené | 5 | 81 |
| Garrwa | 0 | 52 |
| Gooniyandi | 24 | 55 |
| Hup | 3 | 46 |
| Iatmul | 5 | 81 |
| Ik | 0 | 57 |
| Ikpana | 9 | 1 |
| Kalamang | 16 | 20 |
| Kenuzi-Dongola | 2 | 45 |
| Laki | 5 | 28 |
| Lavukaleve | 22 | 65 |
| Lezgian | 19 | 112 |
| Mangghuer | 0 | 47 |
| Nhanda | 0 | 57 |
| Paraguayan Guaraní | 19 | 50 |
| Savosavo | 8 | 34 |
| Tagdal | 12 | 8 |
| Tipai | 62 | 18 |
| Toba | 31 | 38 |
| Tohono O’odham | 22 | 9 |
| Totonac (Filomeno Mata) | 94 | 35 |
| Vaeakau-Taumako | 20 | 14 |
| Yakkha | 13 | 63 |
| Yele | 0 | 2 |
| Yeri | 12 | 33 |
| TOTAL | 403 | 1,051 |
References
Abdel-Hafiz, Ahmed. 1988. A reference grammar of Kunuz Nubian. PhD dissertation, State University of New York.Search in Google Scholar
Aikhenvald, Alexandra. 2007. Typological distinctions in word-formation. In Timothy Shopen (ed.), Language typology and syntactic description, vol. III: Grammatical categories and the lexicon, 2nd edn., 1–65. Cambridge: Cambridge University Press.10.1017/CBO9780511618437.001Search in Google Scholar
Asao, Yoshihiko. 2015. Left-right asymmetries in words: A processing-based account. PhD dissertation, State University of New York.Search in Google Scholar
Bauer, Laurie. 2019. Rethinking morphology. Edinburgh: Edinburgh University Press.Search in Google Scholar
Belelli, Sara. 2021. The Laki variety of Harsin. Bamberg: University of Bamberg Press.Search in Google Scholar
Benítez-Torres, Carlos Miguel. 2021. A grammar of Tagdal, a Northern Songhay language. Amsterdam: LOT.Search in Google Scholar
Berg, Thomas. 2015. Locating affixes on the lexicon-grammar continuum. Cognitive Linguistic Studies 2. 150–180. https://doi.org/10.1075/cogls.2.1.08ber.Search in Google Scholar
Berg, Thomas. 2020. Ordering biases in cross-linguistic perspective. The interaction of serial order and structural level. Linguistic Typology 24. 353–397. https://doi.org/10.1515/lingty-2019-2031.Search in Google Scholar
Berg, Thomas. 2022a. The iconicity of possessive-affix position in Malayo-Polynesian. Cognitive Linguistic Studies 9. 31–63. https://doi.org/10.1075/cogls.00089.Search in Google Scholar
Berg, Thomas. 2022b. Paradigmatic consequences of the suffixing preference. Studies in Language 46. 376–401. https://doi.org/10.1075/sl.20019.ber.Search in Google Scholar
Best, Karl-Heinz. 2005. Morphlänge [Morpheme length]. In Reinhard Köhler, Gabriel Altmann & Rajmund Piotrowski (eds.), Quantitative Linguistik: Ein internationales Handbuch/Quantitative linguistics: An international handbook, 255–260. Berlin: De Gruyter.Search in Google Scholar
Beyersmann, Elisabeth, Johannes Ziegler & Jonathan Grainger. 2015. Differences in the processing of prefixes and suffixes revealed by a letter-search task. Scientific Studies of Reading 19. 360–373. https://doi.org/10.1080/10888438.2015.1057824.Search in Google Scholar
Blevins, James. 2016. Word and paradigm morphology. Oxford: Oxford University Press.10.1093/acprof:oso/9780199593545.001.0001Search in Google Scholar
Blevins, Juliette. 2001. Nhanda. Honolulu: University of Hawai’i Press.Search in Google Scholar
Börstell, Carl. 2021. GlottoshinyR. https://linguistr.shinyapps.io/glottoshinyr/ (accessed 19 January 2024).Search in Google Scholar
Bybee, Joan. 1985. Morphology: A study of the relation between meaning and form. Amsterdam: John Benjamins.10.1075/tsl.9Search in Google Scholar
Bybee, Joan. 2005. Restrictions on phonemes in affixes: A crosslinguistic test of a popular hypothesis. Linguistic Typology 9. 165–222. https://doi.org/10.1515/lity.2005.9.2.165.Search in Google Scholar
Bybee, Joan, William Pagliuca & Revere Perkins. 1990. On the asymmetries in the affixation of grammatical material. In William Croft, Keith Denning & Suzanne Kemmer (eds.), Studies in typology and diachrony, 1–42. Amsterdam: John Benjamins.10.1075/tsl.20.04bybSearch in Google Scholar
Bybee, Joan, Revere Perkins & William Pagliuca. 1994. The evolution of grammar: Tense, aspect, and modality in the languages of the world. Chicago: The University of Chicago Press.Search in Google Scholar
Bybee, Joan, Paromita Chakraborti, Dagmar Jung & Joanne Scheibman. 1998. Prosody and segmental effect: Some paths of evolution for word stress. Studies in Language 22. 267–314. https://doi.org/10.1075/sl.22.2.02byb.Search in Google Scholar
Cutler, Anne, John Hawkins & Gary Gilligan. 1985. The suffixing preference: A processing explanation. Linguistics 23. 723–758. https://doi.org/10.1515/ling.1985.23.5.723.Search in Google Scholar
Dorvlo, Kofi. 2008. A grammar of Logba (Ikpana). Utrecht: LOT.Search in Google Scholar
Dressler, Wolfgang. 1977. Phono-morphological dissimilation. In Wolfgang Dressler, Oskar Pfeiffer & Thomas Herok (eds.), Phonologica 1976, 41–48. Innsbruck: Innsbrucker Beiträge zur Sprachwissenschaft.Search in Google Scholar
Dressler, Wolfgang. 1987. Word formation (WF) as part of natural morphology. In Wolfgang Dressler (ed.), Leitmotifs in natural morphology, 99–126. Amsterdam: John Benjamins.10.1075/slcs.10.30dreSearch in Google Scholar
Dryer, Matthew. 1992. The Greenbergian word order correlations. Language 68. 81–138. https://doi.org/10.1353/lan.1992.0028.Search in Google Scholar
Dryer, Matthew & Martin Haspelmath (eds.). 2013. World atlas of language structures online. Available at: http://wals.info.Search in Google Scholar
Easterday, Shelece. 2019. Highly complex syllable structure: A typological and diachronic study. Berlin: Language Science Press.Search in Google Scholar
Easterday, Shelece, Matthew Stave, Marc Allassonnière-Tang & Frank Seifart. 2021. Syllable complexity and morphological synthesis: A well-motivated positive complexity correlation across sub-domains. Frontiers in Psychology 12. 638659. https://doi.org/10.3389/fpsyg.2021.638659.Search in Google Scholar
Elkins, Noah. 2020. Prefix independence: Typology and theory. MA thesis, University of California, Los Angeles.Search in Google Scholar
Epps, Patience. 2008. A grammar of Hup. Berlin: De Gruyter Mouton.10.1515/9783110199079Search in Google Scholar
Estigarribia, Bruno. 2020. A grammar of Paraguayan Guarani. London: UCL Press.10.2307/j.ctv13xpscnSearch in Google Scholar
Forker, Diana. 2013. A grammar of Hinuq. Berlin: De Gruyter Mouton.10.1515/9783110303971Search in Google Scholar
Fox, John & Sanford Weisberg. 2019. An R companion to applied regression, 3rd edn. Thousand Oaks: Sage.Search in Google Scholar
Giraudo, Hélène & Jonathan Grainger. 2003. On the role of derivational affixes in recognizing complex words: Evidence from masked priming. In Harald Baayen & Robert Schreuder (eds.), Morphological structure in language processing, 209–232. Berlin: De Gruyter Mouton.10.1515/9783110910186.209Search in Google Scholar
Givón, Talmy. 2001. Syntax: An introduction, vol. 1. Amsterdam: John Benjamins.10.1075/z.syn1Search in Google Scholar
Goedemans, Rob & Harry van der Hulst. 2013. Fixed stress locations. In Matthew Dryer & Martin Haspelmath (eds.), World atlas of language structures online. Available at: http://wals.info/chapter/14.Search in Google Scholar
Gordon, Matthew. 2016. Phonological typology. Oxford: Oxford University Press.10.1093/acprof:oso/9780199669004.001.0001Search in Google Scholar
Gouskova, Maria. 2023. Phonological asymmetries between roots and affixes. In Peter Ackema, Sabrina Bendjaballah, Eulàlia Bonet & Antonio Fábregas (eds.), The Wiley Blackwell companion to morphology, vol. 4, 1901–1944. Oxford: Wiley-Blackwell.10.1002/9781119693604.morphcom007Search in Google Scholar
Greenberg, Joseph. 1966. Some universals of grammar with particular reference to the order of meaningful elements. In Joseph Greenberg (ed.), Universals of language, 2nd edn., 73–113. Cambridge, MA: The MIT Press.Search in Google Scholar
Guzmán Naranjo, Matías & Laura Becker. 2021. Coding efficiency in nominal inflection: Expectedness and type frequency effects. Linguistics Vanguard 7. 1–16. https://doi.org/10.1515/lingvan-2019-0075.Search in Google Scholar
Hall, Christopher. 1992. Morphology and mind: A unified approach to explanation in linguistics. London: Routledge.Search in Google Scholar
Hall, T. Alan. 2011. Phonologie: Eine Einführung [Phonology: An introduction], 2nd edn. Berlin: Mouton de Gruyter.10.1515/9783110215885Search in Google Scholar
Hammarström, Harald, Robert Forkel, Martin Haspelmath & Sebastian Bank. 2024. Glottolog 5.0. Leipzig: Max Planck Institute for the science of human history. Available at: http://glottolog.org (accessed 29 April 2024).Search in Google Scholar
Harris, Alice & Arthur Samuel. 2024. Processing and production of affixes in Georgian and English: Testing a processing account of the suffixing preference. Journal of Linguistics 60. 791–824. https://doi.org/10.1017/S0022226724000033.Search in Google Scholar
Haspelmath, Martin. 1993. A grammar of Lezgian. Berlin: Mouton de Gruyter.10.1515/9783110884210Search in Google Scholar
Haspelmath, Martin. 2002. Understanding morphology. London: Arnold.Search in Google Scholar
Haspelmath, Martin. 2009. An empirical test of the agglutination hypothesis. In Sergio Scalise, Elisabetta Magni & Antonietta Bisetto (eds.), Universals of language today, 13–29. Dordrecht: Springer.10.1007/978-1-4020-8825-4_2Search in Google Scholar
Haspelmath, Martin. 2021. Explaining grammatical coding asymmetries: Form-frequency correspondences and predictability. Journal of Linguistics 57. 605–633. https://doi.org/10.1017/S0022226720000535.Search in Google Scholar
Haspelmath, Martin. 2024. Inflection and derivation as traditional comparative concepts. Linguistics 62. 43–77. https://doi.org/10.1515/ling-2022-0086.Search in Google Scholar
Hay, Jennifer. 2002. From speech perception to morphology: Affix ordering revisited. Language 78. 527–555. https://doi.org/10.1353/lan.2002.0159.Search in Google Scholar
Hayes, Bruce. 2009. Introductory phonology. Chichester: Wiley-Blackwell.Search in Google Scholar
Himmelmann, Nikolaus. 2014. Asymmetries in the prosodic phrasing of function words: Another look at the suffixing preference. Language 90. 927–960. https://doi.org/10.1353/lan.2014.0105.Search in Google Scholar
Hopper, Paul & Elizabeth Traugott. 2003. Grammaticalization, 2nd edn. Cambridge: Cambridge University Press.10.1017/CBO9781139165525Search in Google Scholar
Hyman, Larry. 2008. Directional asymmetries in the morphology and phonology of words, with special reference to Bantu. Linguistics 46. 309–350. https://doi.org/10.1515/LING.2008.012.Search in Google Scholar
Inkelas, Sharon. 2014. The interplay of morphology and phonology. Oxford: Oxford University Press.10.1093/acprof:oso/9780199280476.001.0001Search in Google Scholar
Jaeger, T. Florian, Peter Graff, William Croft & Daniel Pontillo. 2011. Mixed effect models for genetic and areal dependencies in linguistic typology. Linguistic Typology 15. 281–320. https://doi.org/10.1515/lity.2011.021.Search in Google Scholar
Järvikivi, Juhani, Raymond Bertram & Jussi Niemi. 2006. Affixal salience and the processing of derivational morphology: The role of suffix allomorphy. Language and Cognitive Processes 21. 394–431. https://doi.org/10.1080/01690960400013213.Search in Google Scholar
Jendraschek, Gerd. 2012. A grammar of Iatmul. Habilitation thesis, University of Regensburg.Search in Google Scholar
Julien, Marit. 2002. Syntactic heads and word formation. Oxford: Oxford University Press.10.1093/oso/9780195149500.001.0001Search in Google Scholar
Kalin, Laura. 2022. Infixes really are (underlyingly) prefixes/suffixes: Evidence from allomorphy on the fine timing of infixation. Language 98. 641–682. https://doi.org/10.1353/lan.2022.0017.Search in Google Scholar
Keller, Rudi. 2014. Sprachwandel: Von der unsichtbaren Hand in der Sprache [On language change: The invisible hand in language], 4th edn. Tübingen: Francke.10.36198/9783838542539Search in Google Scholar
Kim, Yuni. 2010. Phonological and morphological conditions on affix ordering in Huave. Morphology 20. 133–163. https://doi.org/10.1007/s11525-010-9149-2.Search in Google Scholar
Klein, Esther. 1973. A grammar of Argentine Toba. PhD dissertation, Columbia University.Search in Google Scholar
Klein, Thomas. 2011. Typology of creole phonology: Phoneme inventories and syllable structures. Journal of Pidgin and Creole Studies 26. 155–193. https://doi.org/10.1075/jpcl.26.1.06kle.Search in Google Scholar
Kürschner, Wilfried. 2017. Grammatisches Kompendium [Grammatical compendium], 7th edn. Tübingen: Francke.10.36198/9783838546933Search in Google Scholar
Lehmann, Christian. 2015. Thoughts on grammaticalization, 3rd edn. Berlin: Language Science Press.10.26530/OAPEN_603353Search in Google Scholar
Levinson, Stephen. 2022. A grammar of Yélî Dnye. Berlin: De Gruyter Mouton.10.1515/9783110733853Search in Google Scholar
Maddieson, Ian. 2013. Syllable structure. In Matthew Dryer & Martin Haspelmath (eds.), World atlas of language structures online. Available at: http://wals.info/chapter/12.Search in Google Scholar
Maddieson, Ian. 2023. Investigating the ‘what’, ‘where’ and ‘why’ of global phonological typology. Linguistic Typology 27. 245–266. https://doi.org/10.1515/lingty-2022-0076.Search in Google Scholar
Marslen-Wilson, William, Lorraine Komisarjevsky Tyler, Rachelle Waksler & Lianne Older. 1994. Morphology and meaning in the English mental lexicon. Psychological Review 101. 1–33. https://doi.org/10.1037/0033-295X.101.1.3.Search in Google Scholar
Martin, Alexander & Jennifer Culbertson. 2020. Revisiting the suffixing preference: Native-language affixation patterns influence perception of sequences. Psychological Science 31. 1107–1116. https://doi.org/10.1177/09567976209311.Search in Google Scholar
Mayerthaler, Willi. 1987. System-independent morphological naturalness. In Wolfgang Dressler (ed.), Leitmotifs in natural morphology, 25–58. Amsterdam: John Benjamins.10.1075/slcs.10.13maySearch in Google Scholar
McCarthy, John & Alan Prince. 1994. Two lectures on prosodic morphology. OTS/HIL Workshop on Prosodic Morphology 19. Available at: https://scholarworks.umass.edu/linguist_faculty_pubs/19/.Search in Google Scholar
McFarland, Teresa. 2009. The phonology and morphology of Filomeno Mata Totonac. PhD dissertation, University of California Berkeley.Search in Google Scholar
McGregor, William. 1990. A functional grammar of Gooniyandi. Amsterdam: John Benjamins.10.1075/slcs.22Search in Google Scholar
Miestamo, Matti, Dik Bakker & Antti Arppe. 2016. Sampling for variety. Linguistic Typology 20. 233–296. https://doi.org/10.1515/lingty-2016-0006.Search in Google Scholar
Mihas, Elena & Gregorio Santos Pérez. 2015. A grammar of Alto Perené (Arawak). Berlin: De Gruyter Mouton.Search in Google Scholar
Miller, Amy. 2001. A grammar of Jamul Tiipay. Berlin: De Gruyter Mouton.10.1515/9783110864823Search in Google Scholar
Miyaoka, Osahito. 2012. A grammar of Central Alaskan Yupik (CAY). Berlin: De Gruyter Mouton.10.1515/9783110278576Search in Google Scholar
Mollica, Francis, Geoff Bacon, Noga Zaslavsky, Yang Xu, Terry Regier & Charles Kemp. 2021. The forms and meanings of grammatical markers support efficient communication. Proceedings of the National Academy of Sciences 118(49). 1–10. https://doi.org/10.1073/pnas.2025993118.Search in Google Scholar
Mushin, Ilana. 2012. A grammar of (Western) Garrwa. Berlin: De Gruyter Mouton.10.1515/9781614512417Search in Google Scholar
Næss, Åshild & Even Hovdhaugen. 2011. A grammar of Vaeakau-Taumako. Berlin: De Gruyter Mouton.10.1515/9783110238273Search in Google Scholar
Nespor, Marina & Irene Vogel. 2007. Prosodic phonology, Rev. edn. Berlin: De Gruyter Mouton.10.1515/9783110977790Search in Google Scholar
Nichols, Johanna. 2018. Non-linguistic conditions for causativization as a linguistic attractor. Frontiers in Psychology 8. 2356. https://doi.org/10.3389/fpsyg.2017.02356.Search in Google Scholar
Olsson, Bruno. 2021. A grammar of Coastal Marind. Berlin: De Gruyter Mouton.10.1515/9783110747065Search in Google Scholar
Plank, Frans. 1998. The co-variation of phonology with morphology and syntax: A hopeful history. Linguistic Typology 2. 195–230. https://doi.org/10.1515/lingty-2017-1007.Search in Google Scholar
Rice, Keren. 2000. Morpheme order and semantic scope: Word formation in the Athapaskan verb. Cambridge: Cambridge University Press.10.1017/CBO9780511663659Search in Google Scholar
Rice, Keren. 2011. Principles of affix ordering: An overview. Word Structure 4. 169–200. https://doi.org/10.3366/word.2011.0009.Search in Google Scholar
Sapir, Edward. 1921. Language: An introduction to the study of speech. New York: Harcourt, Brace and Company.Search in Google Scholar
Schackow, Diana. 2015. A grammar of Yakkha. Berlin: Language Science Press.10.26530/OAPEN_603340Search in Google Scholar
Schrock, Terrill. 2014. A grammar of Ik (Icé-tód). Utrecht: LOT.Search in Google Scholar
Schümann, Michael. 2010. Affix. In Elke Hentschel (ed.), Deutsche Grammatik, 20. Berlin: De Gruyter Mouton.Search in Google Scholar
Seifart, Frank. 2017. Patterns of affix borrowing in a sample of 100 languages. Journal of Historical Linguistics 7. 389–431. https://doi.org/10.1075/jhl.16002.sei.Search in Google Scholar
Seifart, Frank, Jan Strunk, Swintha Danielsen, Iren Hartmann, Brigitte Pakendorf, Søren Wichmann, Alena Witzlack-Makarevich, Nivja de Jong & Balthasar Bickel. 2018. Nouns slow down speech across structurally and culturally diverse languages. Proceedings of the National Academy of Sciences 115(22). 5720–5725. https://doi.org/10.1073/pnas.1800708115.Search in Google Scholar
Seržant, Ilja & George Moroz. 2022. Universal attractors in language evolution provide evidence for the kinds of efficiency pressures involved. Humanities and Social Sciences 9. article number 58. https://doi.org/10.1057/s41599-022-01072-0.Search in Google Scholar
Slater, Keith. 2003. A grammar of Mangghuer. London: RoutledgeCurzon.Search in Google Scholar
Spencer, Andrew & Ana Luís. 2013. The canonical clitic. In Dunstan Brown, Marina Chumakina & Greville Corbett (eds.), Canonical morphology and syntax, 123–150. Oxford: Oxford University Press.10.1093/acprof:oso/9780199604326.003.0006Search in Google Scholar
Stave, Matthew, Ludger Paschen, François Pellegrino & Seifart Frank. 2021. Optimization of morpheme length: A cross-linguistic assessment of Zipf’s and Menzerath’s laws. Linguistics Vanguard 7. 1–11. https://doi.org/10.1515/lingvan-2019-0076.Search in Google Scholar
Terrill, Angela. 2003. A grammar of Lavukaleve. Berlin: De Gruyter Mouton.10.1515/9783110923964Search in Google Scholar
Visser, Eline. 2022. A grammar of Kalamang. Berlin: Language Science Press.Search in Google Scholar
Voegelin, Carl & Florence Voegelin. 1978. Classification and index of the world’s languages. New York: Elsevier.Search in Google Scholar
Wegener, Claudia. 2012. A grammar of Savosavo. Berlin: De Gruyter Mouton.10.1515/9783110289657Search in Google Scholar
Wennerstrom, Ann. 1993. Focus on the prefix: Evidence for word-internal prosodic words. Phonology 10. 309–324. https://doi.org/10.1017/S0952675700000075.Search in Google Scholar
White, James, René Kager, Tal Linzen, Giorgos Markopoulos, Alexander Martin, Andrew Nevins, Sharon Peperkamp, Krisztina, Polgárdi, Nina, Topintzi & Ruben van, de Vijver. 2018. Preference for locality is affected by the prefix/suffix asymmetry: Evidence from artificial language learning. In Sherry Hucklebridge & Max Nelson (eds.), NELS 48: Proceedings of the Forty-Eighth Annual Meeting of the North East Linguistic Society, vol. 3, 207–220. Amherst, MA: GLSA.Search in Google Scholar
Wilson, Jennifer. 2017. A grammar of Yeri. PhD dissertation, State University of New York.Search in Google Scholar
Zepeda, Ofelia. 1983. A Papago grammar. Tucson: University of Arizona Press.Search in Google Scholar
Zingler, Tim. 2024. Expletive insertion: A morphological approach. English Language and Linguistics 28. 23–42. https://doi.org/10.1017/S1360674323000254.Search in Google Scholar
Zipf, George. 1935/1965. The psycho-biology of language: An introduction to dynamic philology. Cambridge, MA: The MIT Press.Search in Google Scholar
Supplementary Material
This article contains supplementary material (https://doi.org/10.1515/lingty-2024-0004).
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Research Articles
- The interaction of affix size, type and shape: a cross-linguistic study
- Echo answers
- The rise of ternary quantity and its alignment with laryngeal articulations
- The interaction of irrealis markers and blocking effects in counterfactual conditionals: theoretical implications
- Methodological Contribution
- Phonotacticon: a cross-linguistic phonotactic database
- Book Reviews
- Lee, Nala H: A Grammar of Modern Baba Malay
- Roberto Zariquiey and Pilar M. Valenzuela: The Grammar of Body-Part Expressions. A View from the Americas
Articles in the same Issue
- Frontmatter
- Research Articles
- The interaction of affix size, type and shape: a cross-linguistic study
- Echo answers
- The rise of ternary quantity and its alignment with laryngeal articulations
- The interaction of irrealis markers and blocking effects in counterfactual conditionals: theoretical implications
- Methodological Contribution
- Phonotacticon: a cross-linguistic phonotactic database
- Book Reviews
- Lee, Nala H: A Grammar of Modern Baba Malay
- Roberto Zariquiey and Pilar M. Valenzuela: The Grammar of Body-Part Expressions. A View from the Americas