An efficient ‘P1’ algorithm for dual mixed-integer least-squares problems with scalar real-valued parameters
-
Lotfi Massarweh

 and
Peter J. G. Teunissen
and
Peter J. G. Teunissen

Abstract
In this contribution we consider mixed-integer least-squares problems, where the integer ambiguities
1 Introduction
The Integer Ambiguity Resolution (IAR) process concerns the successful resolution of the unknown integer ambiguities present in mixed-integer models. For instance, in the context of Global Navigation Satellite Systems (GNSS), carrier-phase IAR is the key to fast and high-precision baseline estimation [1]. Once these ambiguities have been correctly resolved, the carrier-phase data starts acting as very precise pseudo-range data, so enabling users’ precise positioning and navigation, see [2], 3].
When considering mixed-integer least-squares problems, two equivalent formulations are possible, denoted as primal and dual, respectively introduced by Teunissen [4] and by Teunissen and Massarweh [5]. In the primal formulation, integer ambiguities are firstly resolved followed by a conditional least-squares baseline estimator, so computing ambiguity-fixed baseline solutions. Efficient algorithms exist for tackling such IAR problems within the ambiguity domain, for instance with the Least-Squares AMBiguity Decorrelation Adjustment (LAMBDA) method, see [6]. On the other hand, in the dual formulation, the IAR process takes place directly in the parameters’ domain and globally convergent solutions could be defined, as presented by Teunissen and Massarweh [5].
In this contribution we further study dual mixed-ILS problems, focusing on the case p = 1, i.e. scalar real-valued parameter
In Section 2, a brief review of dual mixed-integer least-squares models is given, then focusing on the case n ≥ p = 1. In Section 3, the P1 algorithm is presented, along with some geometrical insights, and the linear growth of complexity with respect to the dimensionality n is demonstrated. The performance is numerically investigated in Section 4, i.e. considering GNSS models, while the main conclusions are summarized in Section 5.
2 Review of dual mixed ILS models
The dual formulation for mixed-integer least-squares models was introduced by Teunissen and Massarweh [5]. We start here with the observables’ vector
where ∼ refers to distributed as, given an m-dimensional normal distribution with expectation
The dual formulation considers a dual objective function
where the (dual) mixed ILS solution for the real-valued parameters follows as
given the (conditioned) ambiguity vectors
with
Two approximations of Eq. (2) are discussed in (ibid), such as
Approximate weighting, where we replace the conditional variance matrix
(5)for
Approximate mapping, where we replace the integer minimizer of Eq. (4) by an arbitrary admissible estimator
(6)and the two approximations differ since in the ‘approximate weighting’ case we neglect off-diagonal terms in
2.1 Particular case for n ≥ p = 1
We focus on the case p = 1, thus defining
for
For integer estimators, the pull-in regions are translational invariant over the integers and cover the entire space
such that
with two pull-in regions represented in red and blue respectively when using
![Figure 1:
The conditioned line
a
̂
β
$\hat{a}\left(\beta \right)$
is shown in magenta given
β
∈
β
MIN
,
β
MAX
$\beta \in \left[{\beta }_{\text{MIN}},{\beta }_{\text{MAX}}\right]$
, i.e. defined between the extreme points
a
̂
β
MIN
$\hat{a}\left({\beta }_{\text{MIN}}\right)$
and
a
̂
β
MAX
$\hat{a}\left({\beta }_{\text{MAX}}\right)$
. The magenta circle refers to
a
̂
b
$\hat{a}\left(b\right)$
for the true
b
∈
R
$b\in \mathbb{R}$
, while the asterisk refers to
a
̂
(
b
̂
)
≡
a
̂
$\hat{a}\left(\hat{b}\right)\equiv \hat{a}$
, i.e. the float ambiguity solution. Moreover, two pull-in regions are defined as hexagons (in red) or unit squares (in blue) when making use of
Q
a
̂
b
${Q}_{\hat{a}\left(b\right)}$
or
Q
a
̂
b
◦
${Q}_{\hat{a}\left(b\right)}^{{\circ}}$
as inverse-weighting matrix, respectively.](/document/doi/10.1515/jag-2024-0076/asset/graphic/j_jag-2024-0076_fig_001.jpg)
The conditioned line
The weighting approximation leads to an approximate dual objective function
so using

The dual objective function
The required interval
and therefore
where the first inequality follows from the definition of
3 The P1 algorithm
In the earlier Figure 1 we notice how several β values might belong to the same pull-in regions, implying that a grid search might be inefficient. At the same time, pull-in regions are convex regions for any n > 0, and the conditioning line
The intersection between
![Figure 3:
Illustration of the example p = 1, n = 2, from Figure 1, with the conditioning line
a
̂
β
$\hat{a}\left(\beta \right)$
in magenta color given
β
∈
β
MIN
,
β
MAX
$\beta \in \left[{\beta }_{\text{MIN}},{\beta }_{\text{MAX}}\right]$
. The intersections with all interfaces are shown as magenta squares, while the middle points
β
j
MP
${\beta }_{j}^{\text{MP}}$
are given as (filled) blue hexagrams.](/document/doi/10.1515/jag-2024-0076/asset/graphic/j_jag-2024-0076_fig_003.jpg)
Illustration of the example p = 1, n = 2, from Figure 1, with the conditioning line
3.1 Algorithm description
The P1 algorithm starts with an initial search radius R0 and we consider individually each i-th component of the conditioned ambiguity vector. By making use of the expression of the conditioned line
where
The middle point can be found by
This search-and-shrink strategy is similar to the primal counterpart already adopted in LAMBDA, but now we ‘shrink’ the real-valued parameters’ domain (i.e. on the conditioning line) where the enumeration process takes place. Once all potential candidates in the current interval are evaluated, the process stops and the global minimum β* is obtained. A summary of ‘P1’ algorithm is given in Algorithm 1, which consists of three parts: INITIALIZATION where an initial guess allows computing the initial search radius R0, ENUMERATION of the integer candidates that are found inside the initial interval, and MAIN SEARCH, where such potential solutions are evaluated, including the aforementioned ‘shrinking’ strategy.
Algorithm 1:
Summary of the ‘P1’ algorithm described in Section 3.1
| INPUTS: |
|
|
| INITIALIZATION: |
| Given
|
| ENUMERATION: % Find all potential integer candidates |
| For each i-th ambiguity component
|
| Collect all β-values in one sorted list:
|
| Compute the middle points
|
| MAIN SEARCH: % Evaluate each potential integer candidate |
| Set
|
| % Iterate over each j-th potential solution, sorted by
|
| for j = 1, …, N |
| % Outside the interval, search is over. |
| if
|
| Break loop; |
| end |
| % Evaluation of the current integer candidate. |
| Compute the integer vector
|
| % Update the current best solution |
| if
|
| Save
|
| % Shrinking step, see Eq. (12) |
| Update current R0 (search radius); |
| end |
| end |
| OUTPUTS: |
|
|
-
NOTE: the symbol ⌈·⌋ defines the integer rounding operator.
In Algorithm 1, the main search takes place starting with smaller values
given the approximate primal objective function
On the other hand, the candidates’ evaluation could also be performed directly in the dual formulation, starting from a selected integer value
so now evaluating
3.2 Algorithm complexity
Before presenting a numerical analysis of the performance, we can briefly discuss the linear growth of complexity, here defined by the number of potential candidates that are evaluated during the enumeration process. In fact, in the dual formulation with
Starting with Eq. (13), we can approximate a maximum number of candidates of each i-th component directly using
where the approximation ≅ gets more accurate for larger values of
Given that
and we further reformulate the approximation in Eq. (16) as
where
and the complexity is indeed dependent upon three elements: the problem dimensionality, the initial guess β0 and the variance/covariance terms. Note that given
4 Numerical assessments
We start by a simple numerical example for a multi-frequency geometry-free model, where the conditional variance matrix
The mixed-integer model of Eq. (1), given J frequencies, is based on
where
We consider four scenarios based on Galileo signal, i.e. E1 + E6 (n = 2), E1 + E6 + E5a (n = 3) E1 + E6 + E5a + E5b (n = 4) and E1 + E6 + E5a + E5b + E5 (n = 5), where computational time over 2,000 different samples has been presented in Figure 4. In all these simulations, the results for p = 1 using the P1 algorithm perfectly match with the ILS solutions computed by LAMBDA 4.0 toolbox [10], since
therefore no approximation takes place in our dual formulation, and
for the ambiguity residuals’ defined by

The computational times for primal (ILS) and dual (P1) solutions are shown given four different Galileo scenarios, i.e. E1 + E6 (n = 2, top left), E1 + E6 + E5a (n = 3, top right) E1 + E6 + E5a + E5b (n = 4, bottom left) and E1 + E6 + E5a + E5b + E5 (n = 5, bottom right). For each scenario, we use 2,000 different float samples, see text for more information.
Based on 2,000 samples (n = 3), we show in Figure 5 the maximum number of integer candidates (in blue) as defined by Eq. (16), which seems to well approximate the potential number of candidates (in orange) iterated in the MAIN SEARCH step (see Algorithm 1), i.e. number of middle points previously found in ENUMERATION. However, by means of the search-and-shrink approach, we note that the actual number of integer candidates evaluated (in yellow) is substantially reduced. This demonstrates substantial improvements in terms of efficiency once accounting for a search-and-shrink strategy in the ‘P1’ algorithm, as adopted in the numerical results of Figure 4.
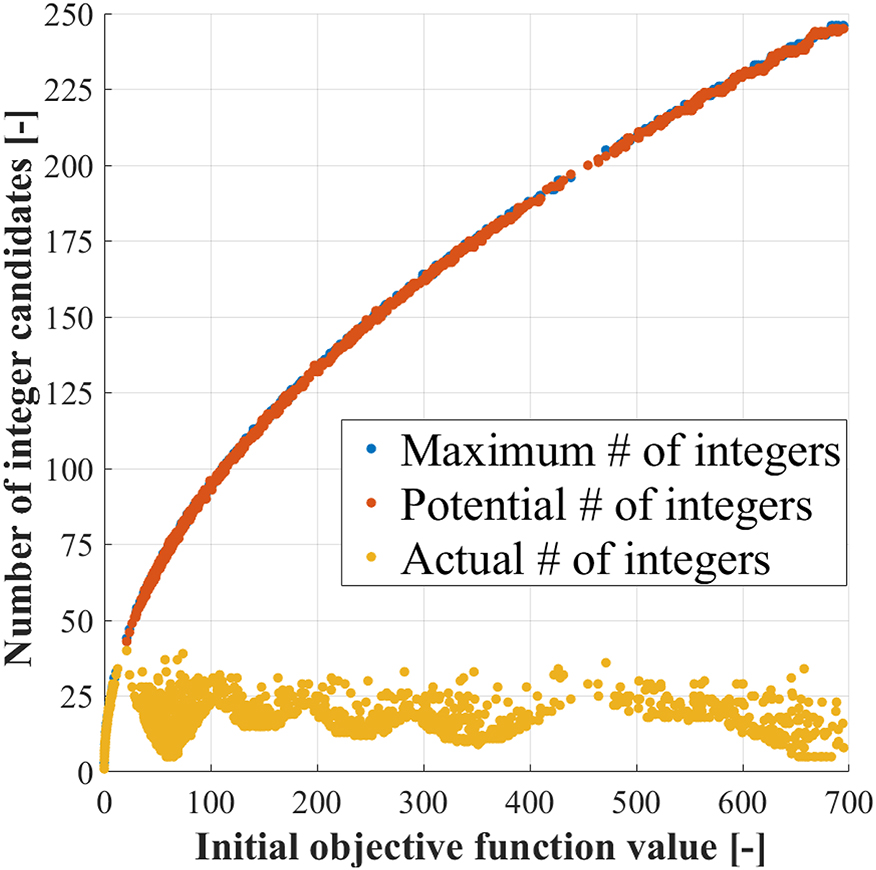
The maximum number of expected integer candidates is shown (in blue) based on the Eq. (16), while the potential number of integers refers to middle points (in orange) actually computed in this analysis over 2,000 different samples for n = 3. Lastly, we also provide the actual total number of integers being evaluated (in yellow), largely reduced thanks to the search-and-shrink strategy adopted by the ‘P1’ algorithm.
At this point, we continue with a different numerical example, where the matrix
4.1 Statistical performance for
Q
a
̂
b
not diagonal
We consider a single-epoch single-baseline geometry-based ionosphere-fixed model, with m satellites tracked on GPS L1 frequency. We assume the horizontal position known, leading to p = 1 estimation of the vertical (UP) coordinate
with
The stochastic model follows by a covariance propagation law for the undifferenced code and phase standard deviation (at zenith), respectively given as 30 cm and 3 mm, while an elevation weighting
At this point, given
Case #1: We use
Case #2: We use
Case #3: We use
In Figure 6, the errors for the ‘UP’ component are shown using 6,000 samples, where a total of 8 satellites has been tracked, i.e. n = 7. In grey color, the float solution is illustrated, having a standard deviation
![Figure 6:
The ‘UP’ error component [m] is shown for different samples generated based on a single-epoch single-baseline geometry-based ionosphere-fixed model for L1 signal tracked by 8 GPS satellites. In grey color, we show the float solution, along with fixed solutions in red or green respectively for incorrectly resolved or correctly resolved ambiguities. See text for more details on the three cases considered for this example.](/document/doi/10.1515/jag-2024-0076/asset/graphic/j_jag-2024-0076_fig_006.jpg)
The ‘UP’ error component [m] is shown for different samples generated based on a single-epoch single-baseline geometry-based ionosphere-fixed model for L1 signal tracked by 8 GPS satellites. In grey color, we show the float solution, along with fixed solutions in red or green respectively for incorrectly resolved or correctly resolved ambiguities. See text for more details on the three cases considered for this example.
We can further investigate the good performance of the dual formulation by looking at the two individual terms of
with
where the (conditioned) L1 ambiguities are correlated through the between-satellite single-differencing operator. In several GNSS models, like the one adopted for our last numerical example, most of the correlation in the unconditional variance matrix
For sake of completeness, in Figure 7 we can show the numerical values of

The entries of matrix
4.2 Additional remarks
The proposed P1 algorithm is limited to the rounding pull-in regions (i.e. unit hyper-cubes in
5 Conclusions
In this contribution we have considered mixed-integer models, and the dual mixed-Integer Least-Squares (ILS) formulation introduced by Teunissen and Massarweh [5]. In the dual problems, the resolution of integer ambiguities takes place in the domain of real-valued parameters, which are freely defined in
As an alternative to a grid search approach, we present the ‘P1’ algorithm, i.e. a deterministic global solution for the minimization of dual problems (p = 1). This algorithm is based on the intuition that potential integer candidates are the ones whose pull-in region is crossed by the conditioning line
Given that the algorithm assumes an approximate conditional matrix
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: LM devised and implemented the algorithms, performed the tests and wrote the manuscript. PT checked and revised the manuscript. All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: None declared.
-
Conflict of interest: The authors state no conflict of interest.
-
Research funding: None declared.
-
Data availability: All data used in this study is available within the article.
References
1. Teunissen, PJG. Carrier phase integer ambiguity resolution. In: Teunissen, PJ, Montenbruck, O, editors. Springer handbook of global navigation satellite systems. Cham: Springer Handbooks. Springer; 2017.10.1007/978-3-319-42928-1Search in Google Scholar
2. Blewitt, G. Carrier phase ambiguity resolution for the Global Positioning System applied to geodetic baselines up to 2000 km. J Geophys Res 1989;94:10187–203. https://doi.org/10.1029/JB094iB08p10187.Search in Google Scholar
3. Leick, A, Rapoport, L, Tatarnikov, D. GPS satellite surveying, 4th ed. Hoboken, New Jersey: John Wiley & Sons; 2015.10.1002/9781119018612Search in Google Scholar
4. Teunissen, PJG. Least-squares estimation of the integer GPS ambiguities. In: IAG general meeting. Invited lecture. Section IV theory and methodology; 1993.Search in Google Scholar
5. Teunissen, PJG, Massarweh, L. Primal and dual mixed-integer least-squares: distributional statistics and global algorithm. J Geodesy 2024;98:63. https://doi.org/10.1007/s00190-024-01862-1.Search in Google Scholar
6. Teunissen, PJG. The least-squares ambiguity decorrelation adjustment: a method for fast GPS integer ambiguity estimation. J Geodesy 1995;70:65–82. https://doi.org/10.1007/BF00863419.Search in Google Scholar
7. Jazaeri, S, Amiri-Simkooei, AR, Sharifi, MA. Fast integer least-squares estimation for GNSS high-dimensional ambiguity resolution using lattice theory. J Geodesy 2012;86:123–36. https://doi.org/10.1007/s00190-011-0501-z.Search in Google Scholar
8. Teunissen, PJG. On the integer normal distribution of the GPS ambiguities. Artif Satell 1998;33:49–64.Search in Google Scholar
9. Verhagen, S. GNSS ambiguity resolution and validation. In: Grafarend, E, editor. Encyclopedia of geodesy. Cham: Springer; 2015. https://doi.org/10.1007/978-3-319-02370-0_6-1.Search in Google Scholar
10. Massarweh, L, Verhagen, S and Teunissen, P.J.G. New LAMBDA toolbox for mixed-integer models: estimation and evaluation. GPS Solut 2025;29:14. https://doi.org/10.1007/s10291-024-01738-z.Search in Google Scholar
11. Odijk, D, Teunissen, PJG. ADOP in closed form for a hierarchy of multi-frequency single-baseline GNSS models. J Geodesy 2008;82:473–92. https://doi.org/10.1007/s00190-007-0197-2.Search in Google Scholar
12. Fincke, U, Pohst, M. Improved methods for calculating vectors of short length in a lattice, including a complexity analysis. Math Comput 1985;44:463–71. https://doi.org/10.2307/2007966.Search in Google Scholar
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Original Research Articles
- Locally robust Msplit estimation
- Extending geodetic networks for geo-monitoring by supervised point cloud matching
- Evaluation and homogenization of a marine gravity database from shipborne and satellite altimetry-derived gravity data over the coastal region of Nigeria
- Modelling geoid height errors for local areas based on data of global models
- Unmanned aerial vehicle-based aerial survey of mines in Shanxi Province based on image data
- Ionospheric TEC and its irregularities over Egypt: a comprehensive study of spatial and temporal variations using GOCE satellite data
- Monitoring of volcanic precursors using satellite data: the case of Taftan volcano in Iran
- Modeling of temperature deformations on the Dnister HPP dam (Ukraine)
- Impact of temporal resolution in global ionospheric models on satellite positioning during low and high solar activity years of solar cycle 24
- Comparative performance of PPP software packages in atmospheric delay estimation using GNSS data
- Assessment and fitting of high/ultra resolution global geopotential models using GNSS/levelling over Egypt
- An efficient ‘P1’ algorithm for dual mixed-integer least-squares problems with scalar real-valued parameters
- Spatio-temporal trajectory alignment for trajectory evaluation
- Monitoring of networked RTK reference stations for coordinate reference system realization and maintenance – case study of the Czech Republic
- Crustal deformation in East of Cairo, Egypt, induced by rapid urbanization, as seen from remote sensing and GNSS data
Articles in the same Issue
- Frontmatter
- Original Research Articles
- Locally robust Msplit estimation
- Extending geodetic networks for geo-monitoring by supervised point cloud matching
- Evaluation and homogenization of a marine gravity database from shipborne and satellite altimetry-derived gravity data over the coastal region of Nigeria
- Modelling geoid height errors for local areas based on data of global models
- Unmanned aerial vehicle-based aerial survey of mines in Shanxi Province based on image data
- Ionospheric TEC and its irregularities over Egypt: a comprehensive study of spatial and temporal variations using GOCE satellite data
- Monitoring of volcanic precursors using satellite data: the case of Taftan volcano in Iran
- Modeling of temperature deformations on the Dnister HPP dam (Ukraine)
- Impact of temporal resolution in global ionospheric models on satellite positioning during low and high solar activity years of solar cycle 24
- Comparative performance of PPP software packages in atmospheric delay estimation using GNSS data
- Assessment and fitting of high/ultra resolution global geopotential models using GNSS/levelling over Egypt
- An efficient ‘P1’ algorithm for dual mixed-integer least-squares problems with scalar real-valued parameters
- Spatio-temporal trajectory alignment for trajectory evaluation
- Monitoring of networked RTK reference stations for coordinate reference system realization and maintenance – case study of the Czech Republic
- Crustal deformation in East of Cairo, Egypt, induced by rapid urbanization, as seen from remote sensing and GNSS data