Mündlichkeitsphänomene in der gesprochenen Wissenschaftssprache: Korpuslinguistische Befunde und didaktische Perspektiven
-
Matthias Schwendemann
ist wissenschaftlicher Mitarbeiter im Bereich Linguistik am Herder-Institut der Universität Leipzig. Seine Arbeitsschwerpunkte in Forschung und Lehre liegen in den Bereichen Lexikologie, Wissenschaftssprache und Erwerb und Entwicklung des Deutschen als Fremd- und Zweitsprache sowie der Analyse von Lernersprache.
 and
Franziska Wallner
and
Franziska Wallner
ist wissenschaftliche Mitarbeiterin am Herder-Institut der Universität Leipzig. Ihre Forschungsschwerpunkte sind unter anderen das Deutsche als fremde Bildungs- und Wissenschaftssprache, die korpusbasierte Erforschung der gesprochenen Sprache, Mündlichkeitsdidaktik sowie die Nutzung von Korpora im Kontext von Deutsch als Fremd- und Zweitsprache.

Zusammenfassung
Der Beitrag untersucht Mündlichkeit in wissenschaftlichen Vorträgen von Sprecherinnen und Sprechern mit Deutsch als L1 aus dem GeWiss-Korpus und vergleicht diese mit Interaktionsdomänen aus dem Forschungs- und Lehrkorpus Gesprochenes Deutsch (FOLK). Zudem werden ausgewählte Mündlichkeitsphänomene (Abweichungen von der Standardlautung und die Verwendung von Modalpartikeln) in wissenschaftlichen Vorträgen analysiert.
Abstract
This article investigates orality in academic presentations by speakers of German as L1 from the GeWiss corpus and compares them with interactional domains from the Research and Teaching Corpus Spoken German (FOLK). In addition, three oral phenomena in scientific lectures are analysed, namely deviations from standard orthographic phonation, the use of clitics and the use of modal particles.
1 Einleitung
Mit dem GeWiss-Korpus wurde eine empirische Grundlage zur Erforschung von Mündlichkeitsphänomenen in der gesprochenen Wissenschaftssprache geschaffen. Studien auf der Grundlage von GeWiss zeigen, dass die gesprochene Wissenschaftssprache durch eine große Vielfalt an Mündlichkeitsphänomenen geprägt ist, die bislang eher in der gesprochenen Alltagssprache verortet wurden. Allerdings waren mit den bisherigen Zugangswegen zum GeWiss-Korpus auch einige Einschränkungen verbunden, die einer systematischen empirischen Ermittlung von Mündlichkeitsphänomenen in der gesprochenen Wissenschaftssprache im Weg standen. Insbesondere aus der Unterrichtspraxis stammende Fragestellungen ließen sich daher kaum umfassend beantworten, wie etwa:
Wie viel Mündlichkeit steckt eigentlich in wissenschaftlichen Vorträgen?
Welche Wörter werden in wissenschaftlichen Vorträgen abweichend von der Standardlautung realisiert?
Welche Modalpartikeln kommen in Vorträgen besonders häufig vor?
Inzwischen wurden im Rahmen des Projekts ZuMult[1] Zugangswege zu Korpora gesprochener Sprache geschaffen, die gezielt an den Bedürfnissen der Sprachvermittlung ausgerichtet sind. Die hierbei entwickelten Tools eröffnen neue und über das bisherige Maß hinausgehende Möglichkeiten zur Erforschung von Mündlichkeitsphänomenen im GeWiss-Korpus. Hierzu zählen vor allem quantitative Analysen zu deren Vorkommen und Verbreitung.
Im vorliegenden Beitrag werden nach einer Vorstellung des GeWiss-Korpus ausgewählte Befunde zu Mündlichkeitsphänomenen in der gesprochenen Wissenschaftssprache präsentiert, die mithilfe der ZuMult-Tools ermittelt wurden. Im Fokus stehen dabei Abweichungen von der Standardlautung sowie Modalpartikeln. Daran anschließend wird gezeigt, in welcher Form die Ergebnisse für die Vermittlung der gesprochenen Wissenschaftssprache genutzt werden können.
2 Das GeWiss-Korpus als Grundlage zur Erforschung von Mündlichkeitsphänomenen in der gesprochenen Wissenschaftssprache
Das GeWiss-Korpus ist ein Vergleichskorpus und enthält Prüfungsgespräche sowie studentische Referate und Expertenvorträge in deutscher, englischer, italienischer und polnischer Sprache. Die Daten stammen aus philologischen Fächern und wurden in verschiedenen authentischen akademischen Kommunikationssituationen erhoben. Neben Daten, die von Sprechenden stammen, die die jeweiligen Sprachen als Erstsprache (L1) sprechen, liegen für das Deutsche und das Englische auch L2-Daten vor (vgl. Wallner 2023).
Mit dem Korpus werden die Audioaufnahmen zu den einzelnen Sprechereignissen sowie die dazugehörigen Transkriptionen bereitgestellt. Für die deutschsprachigen Daten liegen diese sowohl in aussprachenaher als auch in orthografisch normalisierter Fassung vor. Dies ermöglicht es, Unterschiede zwischen der Standardlautung und der tatsächlichen Realisierung (die sogenannte Normalisierungsrate) systematisch zu erfassen und zu quantifizieren. Zudem sind weitere Annotationen verfügbar – darunter die Annotation von Wortarten für das gesamte Korpus, wobei für die deutschsprachigen Teilkorpora das um gesprochensprachliche Kategorien erweiterte STTS (Westpfahl et al. 2017) zugrunde gelegt wurde. Dies gestattet wiederum die Erfassung von Mündlichkeitsphänomenen, die auf der Ebene der Wortart angesiedelt sind (wie etwa Diskursmarker und Modalpartikeln).
Der Aufbau des Korpus sowie die Beschaffenheit und Struktur der enthaltenen Daten ermöglichen grundsätzlich die Beantwortung vielfältiger Fragestellungen, die sich aus der Praxis der Vermittlung der gesprochenen Wissenschaftssprache ergeben. Derzeit überwiegen hier jedoch qualitativ ausgerichtete Studien, was vor allem auf die bislang vorliegenden Zugriffswege auf die GeWiss-Daten und die damit verbundenen Einschränkungen zurückzuführen ist (vgl. Fandrych/Wallner 2023).
Mit den im Projekt ZuMult geschaffenen Zugangswegen zu Korpora gesprochener Sprache wurden die Möglichkeiten zur systematischen Analyse der GeWissDaten erheblich erweitert. Insbesondere quantitative Fragestellungen zu Vorkommen und Verbreitung von Mündlichkeitsphänomenen können jetzt mithilfe automatisierter und überdies replizierbarer Abfragen bearbeitet werden. Im Folgenden soll dies anhand ausgewählter Analysen demonstriert werden.
3 Korpuslinguistische Befunde zu Mündlichkeitsphänomenen in GeWiss
Im folgenden Abschnitt werden exemplarische Analysen vorgestellt, die sich auf die in Abschnitt 1 formulierten Fragestellungen beziehen. Zunächst werden die dabei verwendeten Daten beschrieben. Daran anschließend werden die Ergebnisse anhand von zwei Mündlichkeitsvariablen (Abweichungen von der standardnahen Lautung und Anteil an Modalpartikeln) gezeigt.
3.1 Datengrundlage und methodisches Vorgehen
Zur Beantwortung der Frage, wie viel Mündlichkeit eigentlich in wissenschaftlichen Vorträgen zu finden ist, wird jeweils anhand der genannten Mündlichkeitsphänomene ein Vergleich von Daten aus dem Forschungs- und Lehrkorpus (FOLK) (vgl. Schmidt 2023) mit Daten aus dem GeWiss-Korpus (studentische und Expertenvorträge mit Deutsch als L1) durchgeführt. FOLK enthält eine Vielzahl von gesprochensprachlichen Sprechereignissen, die unterschiedlichen Interaktionsdomänen zugeordnet werden (Institutionell, Öffentlich, Privat, Sonstiges), welche teilweise auch die Grundlage der Auswertungen in diesem Beitrag bilden. Die gezeigten Analysen beruhen auf der DGD-Version 2.19 und der FOLK-Version 2.18.
Da die Vorträge aus GeWiss nicht ohne Weiteres den Interaktionsdomänen aus FOLK zuzuordnen sind, wird im Folgenden von Gesprächstypen die Rede sein. Die Vorträge werden im vorliegenden Beitrag getrennt in Expertenvorträge und studentische Vorträge betrachtet. Dieser Differenzierung liegt einerseits die Annahme zugrunde, dass sich Vorträge von Studierenden noch recht deutlich von Expertenvorträgen unterscheiden, und andererseits die Überlegung, dass für viele L2-Lernende zunächst studentische Vorträge eine angemessenere Vergleichsfolie bilden. Die GeWiss-Daten umfassen insgesamt 14 Expertenvorträge und elf studentische Vorträge. Die Mediandauer der Expertenvorträge beträgt 43 Minuten und 17 Sekunden, für die studentischen Vorträge 26 Minuten und zehn Sekunden.
Um die Vorträge hinsichtlich ihrer Mündlichkeit einschätzen zu können, wurden sie mit zwei Interaktionsdomänen aus FOLK verglichen, die gleichzeitig relative Endpole auf der Skala von wahrgenommener Mündlichkeit bilden. Einerseits werden private Sprechereignisse in die Analysen aufgenommen, die, so die Annahme, sich durch das größte Maß an Mündlichkeit auszeichnen. Andererseits wurden Sprechereignisse aus der öffentlichen Interaktionsdomäne in die Vergleiche miteinbezogen, da es sich bei diesen um Sprechereignisse handelt, die einem höheren Planungsgrad unterliegen und sich vermutlich eher an schriftsprachlichen Normen orientieren. Die Interaktionsdomänen Institutionell bzw. Sonstiges wurden in den Analysen nicht beachtet, da sie sich konzeptionell eher zwischen den anderen genannten Gesprächstypen einordnen (Institutionell) oder eine so heterogene Gruppe an Sprechereignissen darstellen, dass Ergebnisse nur sehr schwer interpretierbar wären (Sonstige). Insgesamt bildeten 171 Sprechereignisse aus FOLK die Grundlage für die Vergleiche mit den GeWiss-Daten. Dabei handelt es sich um 16 Sprechereignisse (Mediandauer: 1 Stunde, 52 Minuten) aus der öffentlichen und 155 Sprechereignisse aus der privaten Interaktionsdomäne (Mediandauer: 40 Minuten).
Die ausgewählten Gesprächstypen werden im Folgenden hinsichtlich der genannten Mündlichkeitsphänomene verglichen. Für diese Vergleiche werden jeweils deskriptive Statistiken und Violin-Plots aufbereitet. In einem weiteren Schritt wurde mithilfe des nichtparametrischen Kruskal-Wallis-Tests und des Dunn’s Post-hoc-Tests inferenzstatistisch überprüft, ob sich die einzelnen Gesprächstypen hinsichtlich der untersuchten Mündlichkeitsphänomene signifikant unterscheiden. Die Grundlage der Analysen bildeten jeweils die relativen Häufigkeiten der Phänomene berechnet auf 100 Token.
Für die Beantwortung der Frage, welche Wörter in wissenschaftlichen Vorträgen abweichend von der Standardlautung realisiert werden und welche Modalpartikeln in Vorträgen besonders häufig vorkommen, wurde das ZuMult-Werkzeug ZuRecht[2] genutzt. Als Datengrundlage dienten studentische Referate aus dem GeWiss-Korpus von Sprecherinnen und Sprechern mit Deutsch als L1. Die Expertenvorträge wurden hier ausgeklammert, da diese sich aufgrund eines häufig beobachtbaren Expertenhabitus nur bedingt als Orientierung für studentische Referate eignen.
Während zur Beantwortung der ersten Forschungsfrage nur Sprechereignisse mit ausschließlich L1-Sprechenden herangezogen werden, da es sich hier um einen Vergleich von globalen, für ein gesamtes Sprechereignis geltenden Werten handelt, werden die Analysen zur Beantwortung der zweiten und dritten Forschungsfrage mit Bezug auf die Sprechenden durchgeführt. Das heißt, dass eine Auswertung aller Sprecherinnen und Sprecher mit Deutsch als L1 (n=38) erfolgt – auch wenn es sich um Vorträge handelt, in denen sowohl L1- als auch L2-Sprechende Redeanteile besitzen.
3.2 Abweichungen von der standardnahen Lautung
Die Abweichungen von der standardnahen Lautung lassen sich mithilfe einer Gegenüberstellung der aussprachenahen Transkriptionen und der orthografisch normalisierten Fassungen ermitteln. Ein hoher Anteil abweichend realisierter sprachlicher Einheiten wird auch als hohe Normalisierungsrate bezeichnet und deutet darauf hin, dass in einem Transkript viele umgangssprachliche oder dialektal geprägte sprachliche Einheiten vorkommen.
Der Vergleich der einzelnen Gesprächstypen wird hier und im Folgenden einerseits mit deskriptiven Statistiken eingeführt, um die Verteilung der untersuchten Mündlichkeitsphänomene zu verdeutlichen, und andererseits mithilfe von Violin-Plots visualisiert. Violin-Plots zeigen die Verteilung und die Dichte von Daten. Umfangreichere „Violin-Bäuche“ geben einen Hinweis darauf, dass sich in diesem Wertebereich viele Datenpunkte (Kreise) finden. Zusätzlich zu diesen Informationen sind in den Violin-Plots Box-Plot-Elemente integriert, die Aufschluss über die Mediane (dicke schwarze Linie innerhalb der Box) und den Interquartilsabstand (äußerer Rand der Box in den einzelnen Plots) geben. Violin-Plots sind vor allem dann nützlich, wenn wie im vorliegenden Beitrag verschiedene Gruppen anhand einer Variable verglichen werden sollen (vgl. Abbildung 1). Die Skalenniveaus der y-Achse orientieren sich dabei im Folgenden an der Datengrundlage. Für die Normalisierungsrate liegen die maximalen Werte knapp unter 50 Prozent, weswegen die y-Achse sich von 0–0.5 erstreckt, obwohl potenziell natürlich auch höhere Werte möglich wären (bspw. bei zukünftigen Ergänzungen der zugrunde liegenden Korpora).
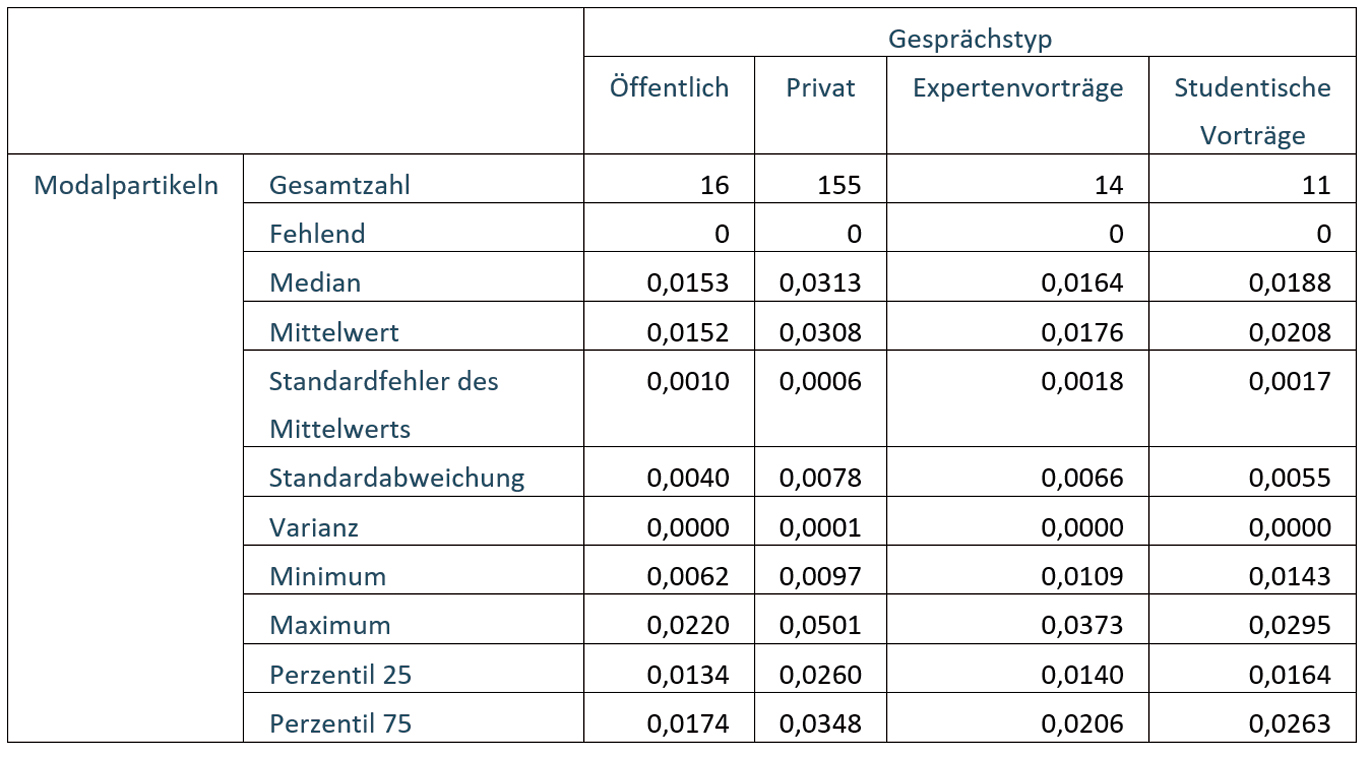
Tabelle 1: Deskriptive Statistik zur Normalisierungsrate in den untersuchten Gesprächstypen
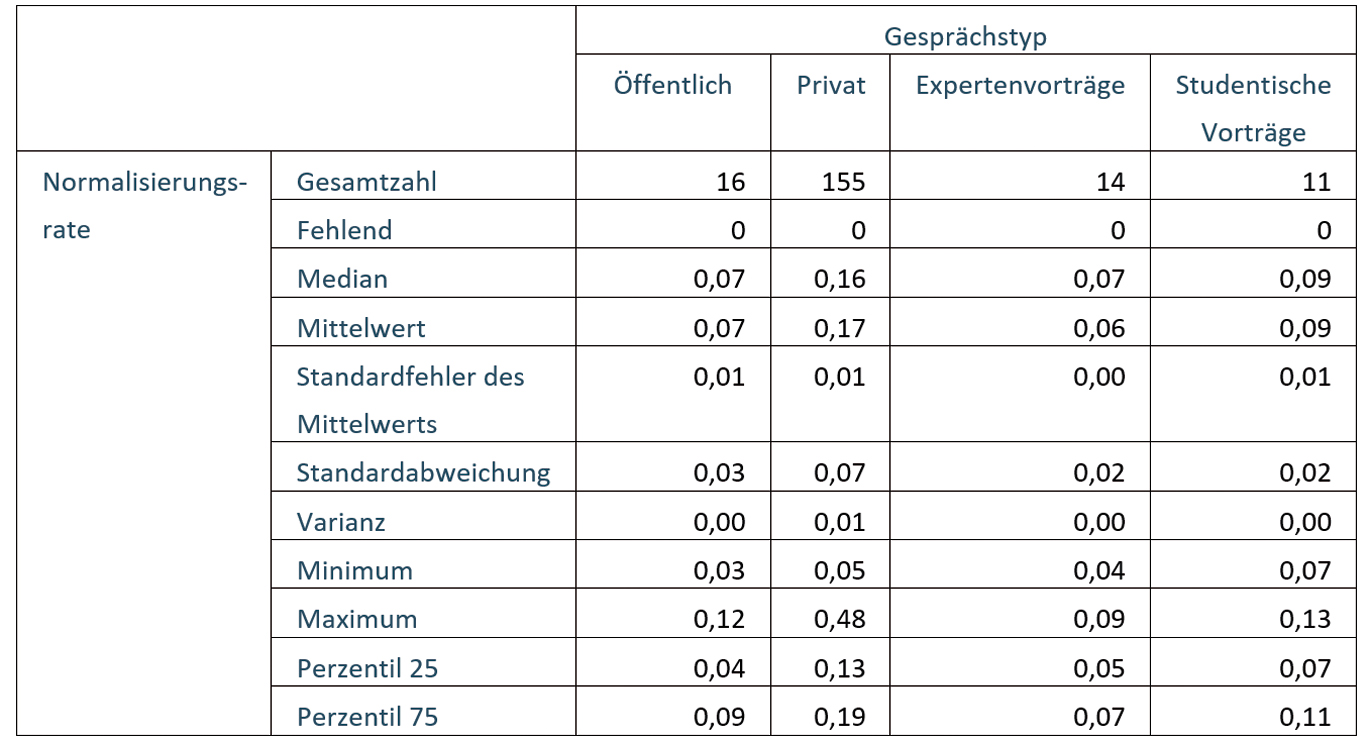
Anhand der deskriptiven Statistik (vgl. Tabelle 1) und des Violin-Plots zur Normalisierungsrate (vgl. Abbildung 1) lässt sich erkennen, dass wissenschaftliche Vorträge hier eher Sprechereignissen der öffentlichen Interaktionsdomäne ähneln. Die Mediane sind fast identisch; zudem besitzen die Expertenvorträge von allen Gesprächstypen die geringste Streuung. Sie scheinen also hinsichtlich der Normalisierungsrate relativ nah am schriftsprachlichen Standard orientiert und als Gruppe von Sprechereignissen relativ homogen zu sein. Der Median der studentischen Vorträge liegt minimal höher. Allerdings unterscheiden sich sowohl die öffentlichen Sprechereignisse als auch die Expertenvorträge und die studentischen Vorträge deutlich von den privaten Gesprächen, die zum Teil eine höhere Normalisierungsrate und vor allem eine deutlich größere Streuung aufweisen.
Da die einzelnen Variablen nicht alle normalverteilt sind, wurde zum Vergleich der Variablenausprägungen in den unterschiedlichen Gesprächstypen für alle Variablen jeweils ein nichtparametrischer Kruskal-Wallis-Test durchgeführt. Für den Vergleich der Normalisierungsraten in den verschiedenen Gesprächstypen zeigt dieser ein signifikantes Ergebnis (χ2 (3) = 79,322; p < 0,00001). Dunn‘s Post-hoc-Vergleiche zeigen zudem, dass hinsichtlich der Normalisierungsrate zwischen den privaten Sprechereignissen und den drei anderen Gesprächstypen signifikante Unterschiede bestehen. Zwischen den drei anderen Gesprächstypen bestehen untereinander keine signifikanten Unterschiede (vgl. Tabelle 5 im Anhang).
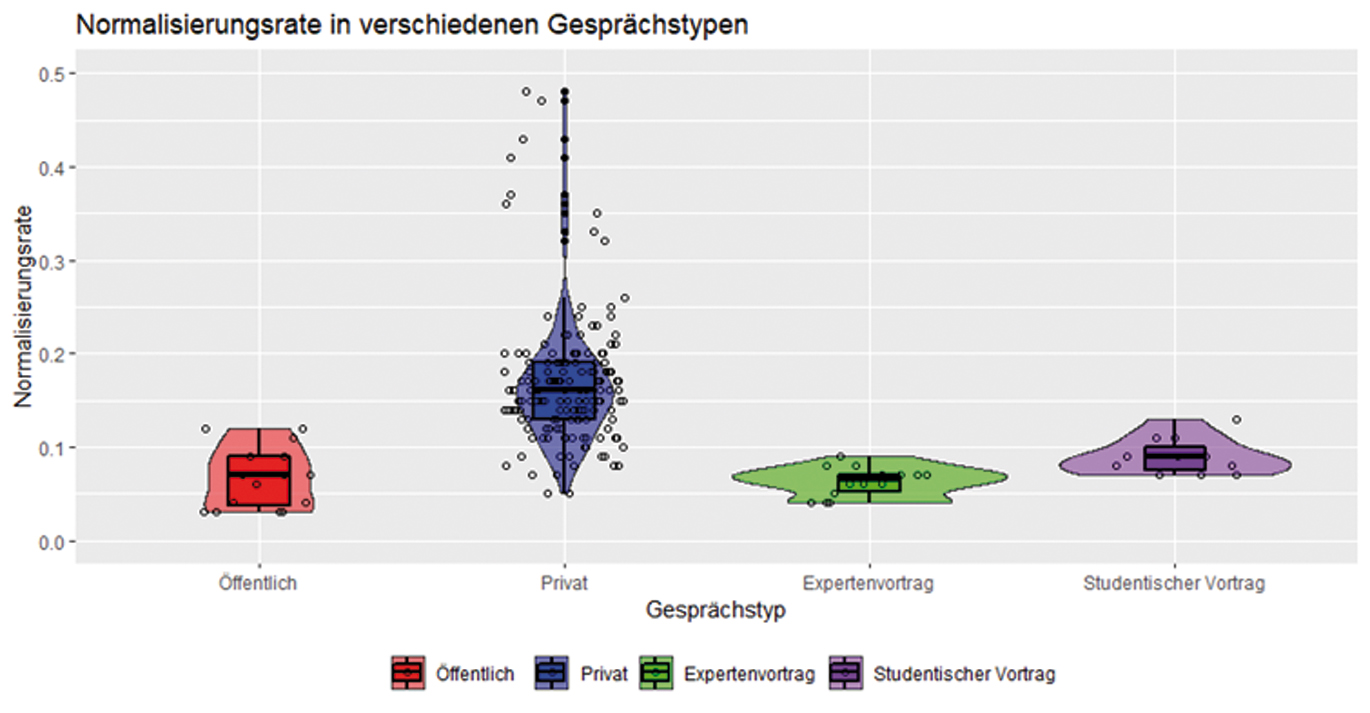
Vergleich der Gesprächstypen anhand der Normalisierungsrate (Darstellung der Abbildung hier und auch im Folgenden mit RStudio: Version 2022.07.2+576)
Eine sprechendenbezogene Betrachtung der studentischen Vorträge lässt erkennen, dass grundsätzlich alle dokumentierten Sprecherinnen und Sprecher Abweichungen von der Standardlautung produzieren. Ähnlich wie bei der auf die Gesprächstypen bezogenen Normalisierungsrate unterscheidet sich bei den Sprecherinnen und Sprechern der Anteil der Normalisierungsfälle, also der standardfern realisierten Einheiten. Dieser liegt zwischen zwei und 22 Prozent.
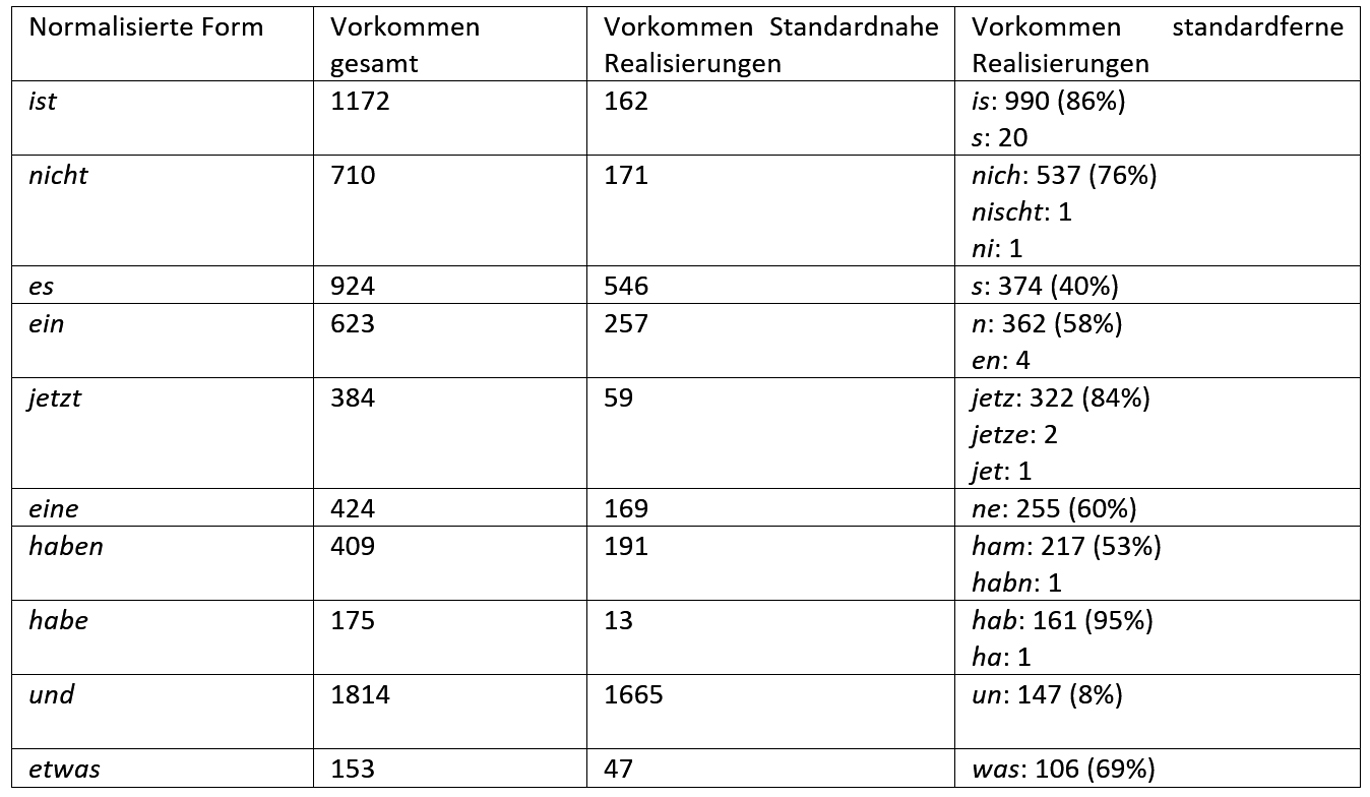
Zu den häufigsten beobachtbaren Normalisierungsfällen gehören Tilgungen wie beispielsweise is, welches 990-mal zu ist normalisiert wurde und bei 93 Prozent der dokumentierten Sprecherinnen und Sprecher zu beobachten ist. Weitere Tilgungen sind nich (537-mal zu nicht normalisiert; beobachtbar bei 93 Prozent der dokumentierten Sprechenden) und n (362-mal zu ein normalisiert; bei 90 Prozent der dokumentierten Sprechenden). Auffällig ist, dass einige dieser Wörter deutlich seltener in ihrer standardnahen Lautung in den studentischen Vorträgen vorkommen. So wird ist lediglich 162-mal standardnah realisiert, d. h. 86 Prozent aller Vorkommen von ist (insgesamt 1.172) wurden abweichend von der standardnahen Lautung ausgesprochen (darunter die oben genannten 990 Vorkommen is sowie weitere 20 Realisierungen als s).
Tabelle 2 gibt einen Überblick über die zehn häufigsten Normalisierungsfälle von studentischen Vortragenden und zeigt an, wie häufig die Formen jeweils in standardnaher Lautung sind.
Tabelle 2: Die zehn häufigsten Normalisierungsfälle bei studentischen Vortragenden
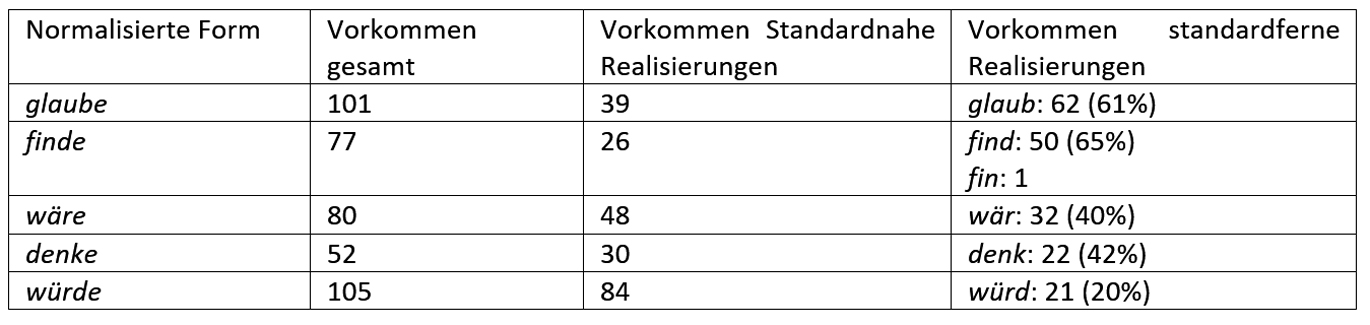
Eine Betrachtung der Normalisierungsfälle nach Wortarten macht deutlich, dass es sich in 2.028 Fällen (37 %) um Verben handelt. Dies sind mit rund 19 Prozent fast ein Fünftel aller Verben. Darunter finden sich vielfach Verbformen auf -e. Auch hier zeigt sich in einigen Fällen die Tendenz, dass die reduzierte Form etwas häufiger gebraucht wird als die standardnahe Realisierung (vgl. Tabelle 3).
Tabelle 3: Häufige normalisierte Verbformen auf -e in den studentischen Vorträgen
Ein Vergleich der in den studentischen Vorträgen vorkommenden Normalisierungsfälle mit anderen Interaktionsdomänen aus dem FOLK macht deutlich, dass es sich vielfach um die gleichen Einheiten handelt, die besonders häufig abweichend von der standardorthografischen Lautung realisiert werden (vgl. hierzu auch Fandrych et al. 2023).
3.3 Modalpartikeln
Die Annotation von Wortarten mithilfe des um mündliche Kategorien erweiterten STTS 2.0 (Westpfahl et al. 2017) ermöglicht die gezielte Suche nach Modalpartikeln in den Sprachdaten. Bei den im Folgenden dargestellten Auswertungen fanden sämtliche als Modalpartikeln annotierten sprachlichen Einheiten Berücksichtigung.[3] Insgesamt sind dies 1.396 in den studentischen Vorträgen mit Deutsch als L1 (n=11) und 1.267 in den Expertenvorträgen mit Deutsch als L1 (n=14).
Auch die deskriptiven Statistiken zu den verwendeten Modalpartikeln (vgl. Tabelle 4) zeigen die bereits bekannten Tendenzen.
Tabelle 4: Deskriptive Statistik zur Verwendung von Modalpartikeln in den untersuchten Gesprächstypen
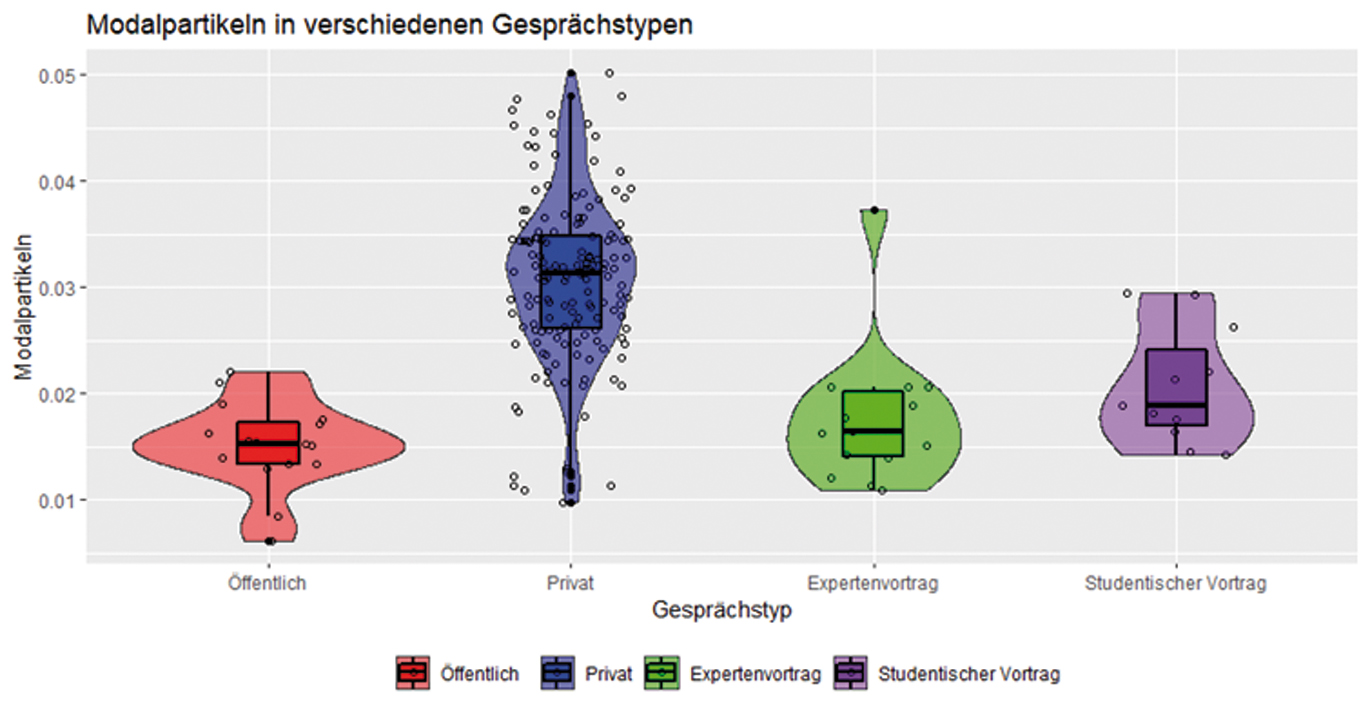
Vergleich der Gesprächstypen anhand der verwendeten Modalpartikeln
Mit Ausnahme von drei Sprechenden (von denen zwei sehr geringe Redeanteile haben, was auch ein Grund dafür sein kann, dass keine Modalpartikeln vorkommen) lässt sich bei allen Sprecherinnen und Sprechern die Verwendung von Modalpartikeln beobachten, wobei erneut deutliche Unterschiede zwischen den Sprechenden bestehen. Der Anteil der Modalpartikeln an den jeweils produzierten Token liegt hier zwischen 0,3 und 2,8 Prozent.
Die beiden häufigsten Modalpartikeln in den studentischen L1-Vorträgen sind ja und eben mit 314 bzw. 307 Vorkommen. Es folgen halt (188 Treffer), einfach (156), mal (109), denn (89), aber (82), schon (72) und doch (71). Es handelt sich dabei ebenfalls um die besonders frequenten Modalpartikeln, die im FOLK ermittelt werden konnten. Lediglich das Ranking unterscheidet sich dort geringfügig.
4 Konsequenzen für die Vermittlung der gesprochenen Wissenschaftssprache
Die Ergebnisse der vorgestellten Analysen zeigen, dass die studentischen Vorträge aus dem GeWiss-Korpus mit Deutsch als L1 eine große Vielfalt an Mündlichkeitsphänomenen enthalten, die im Hinblick auf Ausprägung und Frequenz Ähnlichkeiten zu alltagssprachlichen Kommunikationssituationen aufweisen. Dies bestätigt den Befund, dass es sich bei Vorträgen nicht allein um schriftlich konzipierte und lediglich mündlich realisierte Texte handelt (vgl. auch Slavcheva/Meißner 2014). Für die Vermittlung der gesprochenen Wissenschaftssprache sind diese Ergebnisse hochrelevant. Einerseits aus rezeptiver Perspektive, da studentische Referate im deutschsprachigen akademischen Kontext einen hohen Stellenwert einnehmen und vielfach der Vermittlung relevanter Seminarinhalte an die Mitstudierenden dienen (Guckelsberger 2005). Mit einer Sensibilisierung für erwartbare Phänomene der gesprochenen Sprache in studentischen Vorträgen können die Verstehensleistungen von (angehenden) Studierenden mit Deutsch als L2 gezielt gefördert werden.
Andererseits besitzen die Ergebnisse Relevanz für die Produktion von Referaten. Gerade für Lernende sind Referate in der Fremdsprache Deutsch eine große Herausforderung, was häufig zur Ausformulierung und zum auswendig gelernten Vortragen von Referaten führt. Dies geht dann zulasten der Verständlichkeit, da die für die Schriftsprache typischen komplexen Formulierungen mit einem erhöhten Konzentrations- und Gedächtnisaufwand verbunden sind (Szczepaniak 2015: 109). Zudem zeigen Untersuchungen zur Wirkung von mündlichen Präsentationen, dass das Ablesen häufig mit prosodischer Monotonie einhergeht und als unangemessen oder sogar störend empfunden wird (GrzeszczakowskaPawlikowska 2023).
In der Ratgeberliteratur zum mündlichen Präsentieren wird entsprechend empfohlen, Referate frei zu halten (vgl. u.a. Schäfer und Heinrich 2010 und Bayerlein 2014). Zudem finden sich dort Formulierungshilfen; jedoch handelt es sich dabei zumeist um sprachliche Mittel, die für schriftliche wissenschaftssprachliche Texte als typisch und akzeptabel angesehen werden, beispielsweise von besonderem Interesse ist ..., besonders zu beachten ist ... (Schäfer/Heinrich 2010: 52). Lediglich Lange und Rahn (2017) zeigen anhand von Beispielen, dass in der gesprochenen Wissenschaftssprache Mündlichkeitsphänomene vorkommen. Darunter finden sich Abweichungen von der Standardlautung und Modalpartikeln (vgl. Lange/Rahn 2017: 17, 68 und 72). In Bezug auf mündliche Präsentationen wird explizit empfohlen, Phänomene der gesprochenen Sprache wie Tilgungen (ebd.: 17) und aufmerksamkeitssteuernde Einheiten sowie Gliederungssignale (ebd.: 68 und 99) zu nutzen. Modalpartikeln werden zumindest hinsichtlich ihrer Funktionalisierung in Lehr-Lern-Kontexten thematisiert (ebd.: 35).
Vor dem Hintergrund, dass allein der Hinweis darauf, dass diese Phänomene verwendet werden dürfen, nicht ausreicht, um Lernende dazu zu befähigen, entsprechende Einheiten tatsächlich zu nutzen, erscheint eine umfassende Vorbereitung für den produktiven Gebrauch von besonders verbreiteten Mündlichkeitsphänomenen sinnvoll. Der Fokus könnte dabei auf diejenigen Einheiten gelegt werden, die in Vorträgen besonders häufig beobachtet wurden. Zudem sollten auch wiederkehrende Mechanismen, die in der gesprochenen Sprache zum Tragen kommen (bspw. Tilgungen) thematisiert werden, um Lernenden die eigenständige Bildung entsprechender Formen zu vermitteln. Zu denken wäre etwa an die bei vielen Verbformen in der ersten Person Singular Präsens übliche Tilgung der Endung –e (bspw. habe > hab, sage > sag).
Die hier vorgestellten Untersuchungen können hinsichtlich der Auswahl der zu vermittelnden Einheiten einen wichtigen Beitrag leisten. Da das Repertoire der Phänomene der gesprochenen Sprache in Vorträgen deutlich umfassender als der hier vorgestellte Ausschnitt ist, sollten auch bezüglich anderer Einheiten systematische Analysen zu Vorkommen und Verbreitung durchgeführt werden (bspw. zu Tag Questions und Klitisierungen).
Um unabhängig vom Vorliegen empirischer Studien einen Einblick in die sprachliche Ausgestaltung von studentischen Vorträgen zu erhalten, können die ZuMult-Tools ZuMal (Zugang zu Merkmalsauswahl von Gesprächen) und ZuViel (Zugang zu Visualisierungselementen für Transkripte) genutzt werden.[4] Diese wurden gezielt für sprachdidaktische Kontexte entwickelt und ermöglichen einen niederschwelligen Zugang zu ausgewählten Korpora der gesprochenen Sprache – auch für Personen ohne ausgeprägte korpuslinguistische Expertise. So können mithilfe des Tools ZuMal Sprechereignisse aus dem GeWiss-Korpus nach sprachdidaktisch relevanten Kriterien ausgewählt werden und neben dem GeWissKorpus kann mit diesen Tools auch auf das Forschungs- und Lehrkorpus (FOLK) zugegriffen werden. Dabei stehen verschiedene Filter zur Auswahl, die eine Eingrenzung der Suchergebnisse gestatten. Es ist beispielsweise möglich, gezielt nach studentischen Vorträgen von Sprecherinnen und Sprechern mit Deutsch als L1 zu suchen. Abbildung 3 zeigt in Nr. 1 die hierfür vorzunehmenden Filtereinstellungen.
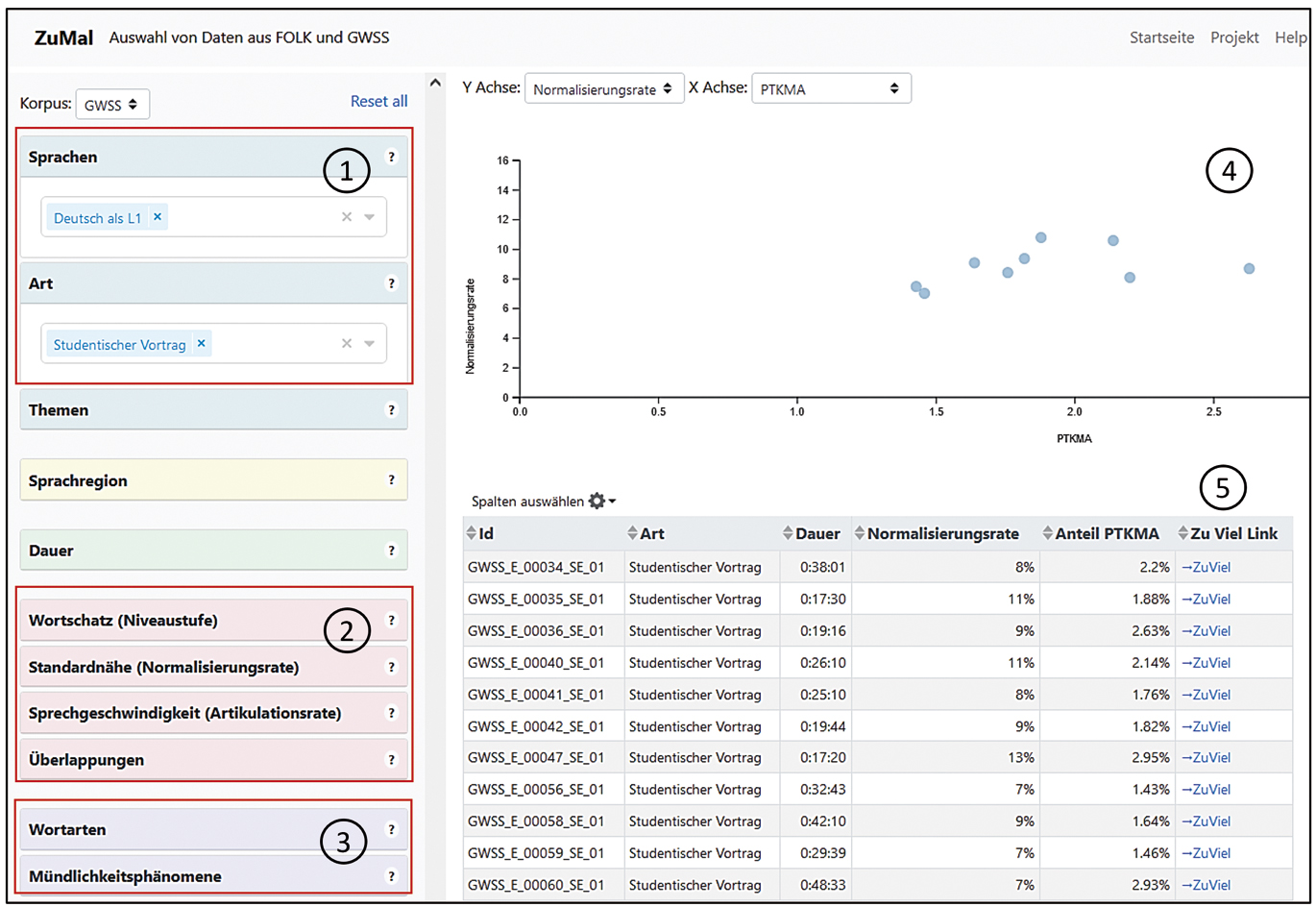
Filtereinstellungen für die Auswahl von studentischen Vorträgen mit Deutsch als L1 in ZuMal
Alternativ lassen sich natürlich auch die anderen im GeWiss-Korpus vertretenen Genres (Expertenvorträge und Prüfungsgespräche) und Gruppen von Sprecherinnen und Sprechern ansteuern.
Zusätzlich sind weitere Filter verfügbar, die sich auf die Schwierigkeit sowie auf die Frequenz bestimmter Phänomene beziehen. Zu den schwierigkeitsbezogenen Filtern (vgl. Abbildung 3, Nr. 2) zählt unter anderem die Standardnähe, welche über die Normalisierungsrate operationalisiert wird. Das bedeutet, dass für jedes Sprechereignis angezeigt wird, wie hoch der Anteil der sprachlichen Einheiten ist, der abweichend von der Standardlautung realisiert wurde. Mithilfe dieses Filters ist es möglich, gezielt Sprechereignisse mit einer hohen, niedrigen oder auch durchschnittlichen Normalisierungsrate auszuwählen. Die Filter, die sich auf die Frequenz bestimmter Phänomene beziehen (vgl. Abbildung 3, Nr. 3), gestatten eine Suche nach Sprechereignissen, die einen hohen, niedrigen oder auch durchschnittlichen Anteil an bestimmten Wortarten und Mündlichkeitsphänomenen aufweisen. Dabei kann beispielsweise nach dem Anteil an Modalpartikeln gefiltert werden. Lehrende haben so die Möglichkeit, gezielt Sprechereignisse auszuwählen, die viele Modalpartikeln enthalten und sich dadurch besonders für eine Veranschaulichung ihres Gebrauchs eignen. Ausführliche Informationen zu den Filtern finden sich in Fandrych et al. (2023).
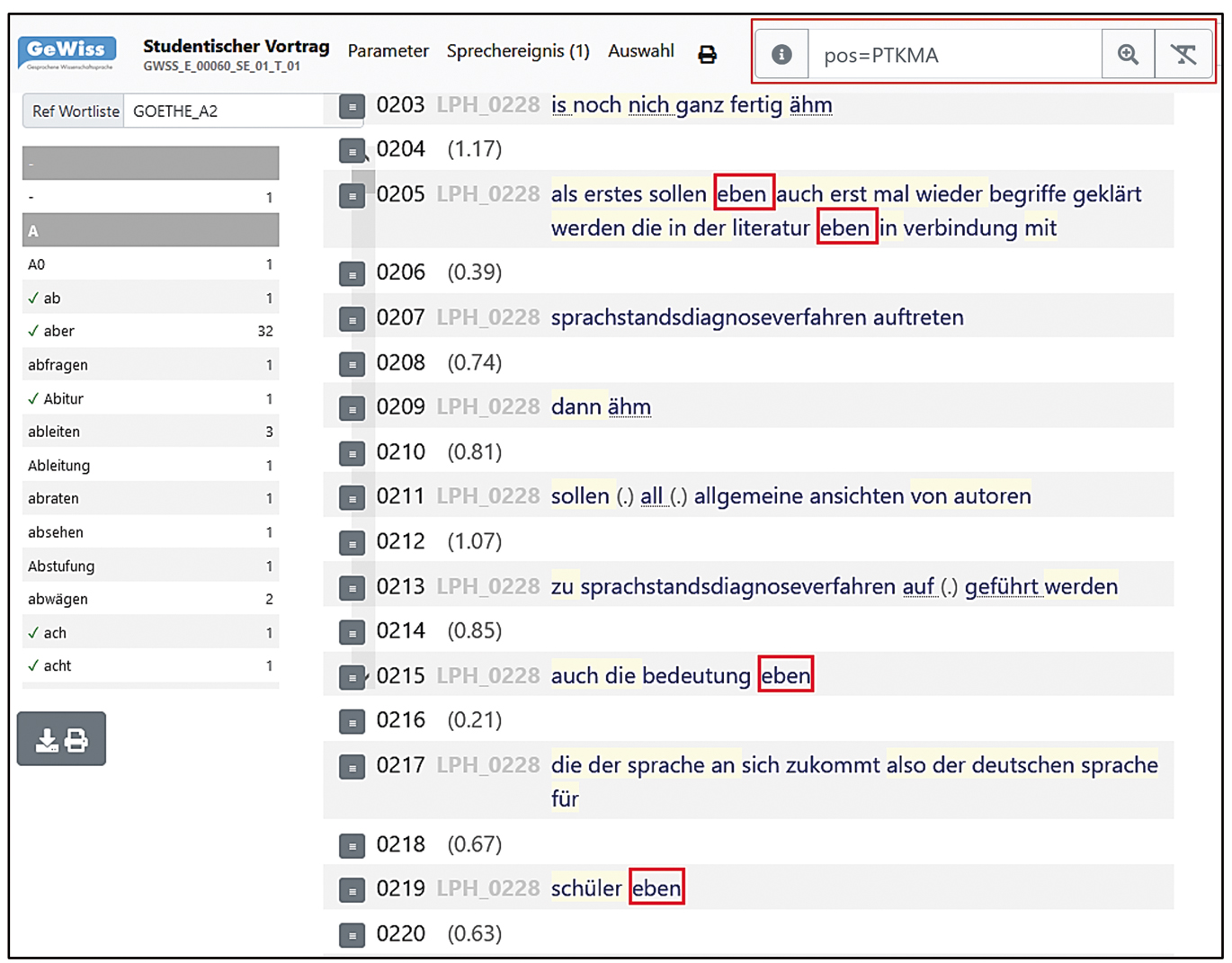
Ausschnitt aus einem studentischen Vortrag in ZuViel (GWSS_E_00060_SE_01)
Da sich die verschiedenen Filter auch kombiniert einsetzen lassen, eröffnen sich für die Suche nach beziehungsweise die Arbeit mit Sprechereignissen vielfältige Auswahloptionen und Vergleichsdimensionen, die im studienvorbereitenden und -begleitenden Sprachunterricht genutzt werden können (vgl. hierzu auch Fandrych/Wallner 2023: 134–135).
Die Ergebnisse der Filterung werden in ZuMal als Streudiagramm und in Form einer tabellarischen Übersicht (vgl. Abbildung 3, Nr. 4 und 5) angezeigt. Ausgehend von der tabellarischen Übersicht lassen sich Sprechereignisse im Tool ZuViel aufrufen. Dort können die Audios der Sprechereignisse abgespielt werden, wobei eine Anpassung der Abspielgeschwindigkeit möglich ist. Dazu lassen sich die Transkripte sowohl in aussprachenaher als auch in orthografisch normalisierter Form anzeigen. Zusätzlich bestehen vielfältige Markierungsoptionen. So können beispielsweise alle abweichend von der Standardlautung realisierten Einheiten durch Unterstreichung hervorgehoben werden. Zudem ist auch die Markierung ausgewählter Wortarten sowie der Niveaustufenzugehörigkeit des Wortschatzes möglich. Abbildung 4 zeigt einen Ausschnitt aus einem studentischen Vortrag in seiner aussprachenahen Fassung. Neben der Unterstreichung aller abweichend von der Standardlautung realisierten Einheiten wurden alle Modalpartikeln umrahmt. Durch diese Hervorhebungen können die jeweiligen Einheiten im Unterricht gezielt fokussiert werden. Gelb unterlegt sind in der Abbildung alle Einheiten, die Bestandteil der GoetheZertifikatswortschatzlisten bis zum Nivea A2 sind. Lehrende können somit den Wortschatz, der ihren Lernenden möglicherweise unbekannt sein könnte, schneller identifizieren.
ZuViel eröffnet damit für Lehrende und Lernende vielfältige Möglichkeiten zur Exploration von authentischen mündlichen Sprachdaten. Es ist daher besonders gut für eine gebrauchsbasierte Sprachdidaktik geeignet und gestattet eine umfassende Auseinandersetzung mit Mündlichkeitsphänomenen in ihrer kontextuellen Einbettung und Funktionalisierung (vgl. hierzu ausführlicher Schmidt/Schwendemann/Wallner 2023).[5]
5 Zusammenfassung
Der Beitrag hat gezeigt, dass in wissenschaftlichen Vorträgen sozusagen viel Mündlichkeit steckt. Anhand der deskriptiven Statistik und der Violin-Plots wurden Unterschiede zwischen den verschiedenen Gesprächstypen herausgearbeitet. Für die untersuchten Mündlichkeitsphänomene hat sich außerdem gezeigt, das Studierende in ihren Vorträgen tendenziell zu mehr Mündlichkeit neigen, als dies in den Expertenvorträgen der Fall ist. Die statistische Überprüfung dieser Beobachtungen ergab allerdings keine signifikanten Unterschiede zwischen den beiden Gruppen. Vielmehr scheinen die Vorträge eher öffentlichen Sprechereignissen zu ähneln, die einen hohen Planungsgrad und deshalb nur geringe Normalisierungsraten und eine überschaubare Anzahl an Modalpartikeln aufweisen. Signifikante Unterschiede ergeben sich jeweils nur zu Sprechereignissen aus der privaten Interaktionsdomäne. In diesem Zusammenhang sollte allerdings beachtet werden, dass die Stichprobengrößen sich sehr stark unterschieden haben und die Ergebnisse daher mit Vorsicht interpretiert werden sollten. Zudem ist anzumerken, dass die hier ausgewählten Phänomene nur einen kleinen Ausschnitt von Mündlichkeit abbilden und diesbezüglich durchaus eine Erweiterung des Fokus notwendig wäre.
Ein deutlich differenzierteres Bild liefern die sprechendenbezogenen Auswertungen. Hier zeigte sich, dass alle untersuchten Sprecherinnen und Sprecher standardferne Aussprachevarianten verwenden und diese in den meisten Fällen frequenter verwendet werden als die standardnahen Varianten. Ein ähnliches Bild ergibt sich für die Verwendung von Modalpartikeln. So enthalten die Äußerungen fast aller Sprechenden Modalpartikeln. Auffällig ist zudem, dass die in den Vorträgen frequentesten Modalpartikeln ebenso in FOLK am häufigsten vorkommen, auch wenn solche Vergleiche aufgrund der unterschiedlichen Stichprobengrößen nur bedingt zulässig sind.
Die Ergebnisse der empirischen Auswertungen sind für sprachdidaktische Kontexte hochrelevant und sollten in der Vermittlung aufgegriffen werden. Für die Veranschaulichung des Gebrauchs der Mündlichkeitsphänomene anhand authentischer Beispiele bieten die im Beitrag vorgestellten Tools aus dem Projekt ZuMult einen niederschwelligen Zugang, der allerdings bislang nur Nutzerinnen und Nutzern in Hochschulkontexten vorbehalten bleibt. Wünschenswert ist, dass perspektivisch weitere Möglichkeiten zur Nutzung authentischer mündlicher Daten in sprachdidaktischen Kontexten geschaffen werden.
Über die Autoren
ist wissenschaftlicher Mitarbeiter im Bereich Linguistik am Herder-Institut der Universität Leipzig. Seine Arbeitsschwerpunkte in Forschung und Lehre liegen in den Bereichen Lexikologie, Wissenschaftssprache und Erwerb und Entwicklung des Deutschen als Fremd- und Zweitsprache sowie der Analyse von Lernersprache.
ist wissenschaftliche Mitarbeiterin am Herder-Institut der Universität Leipzig. Ihre Forschungsschwerpunkte sind unter anderen das Deutsche als fremde Bildungs- und Wissenschaftssprache, die korpusbasierte Erforschung der gesprochenen Sprache, Mündlichkeitsdidaktik sowie die Nutzung von Korpora im Kontext von Deutsch als Fremd- und Zweitsprache.
Literaturverzeichnis
Bayerlein, Oliver (2014): Campus Deutsch. Ismaning: Hueber.10.37307/b.978-3-19-081003-1Search in Google Scholar
Fandrych, Christian; Schwendemann, Matthias; Wallner, Franziska (2021): „,Ich brauch da dringend ein passendes Beispiel ...‘: Sprachdidaktisch orientierte Zugriffsmöglichkeiten auf Korpora der gesprochenen Sprache aus dem Projekt ZuMult“. In: Informationen Deutsch als Fremdsprache 50 (6), 711–729. DOI: https://doi.org/10.1515/infodaf-2021-0077.10.1515/infodaf-2021-0077Search in Google Scholar
Fandrych, Christian; Wallner, Franziska (2023): „Das GeWiss-Korpus: Neue Forschungs- und Vermittlungsperspektiven zur mündlichen Hochschulkommunikation“. In: Deppermann, Arnulf; Fandrych, Christian; Kupietz, Marc; Schmidt, Thomas (Hrsg.): Korpora in der germanistischen Sprachwissenschaft. Mündlich, schriftlich, medial. Berlin: De Gruyter, 129–160.10.1515/9783111085708-007Search in Google Scholar
Fandrych, Christian; Meißner, Cordula; Schwendemann, Matthias; Wallner, Franziska (2023): „ZuMal. Zielgruppenspezifische Gesprächsauswahl aus Korpora gesprochener Sprache“. In: Korpora Deutsch als Fremdsprache 3 (1), 13–43. DOI: https://doi.org.10.48694/kordaf.3725.Search in Google Scholar
Frick, Elena; Helmer, Henrike; Wallner, Franziska (2023): „Zugang zur Recherche in Transkripten mit dem Tool ZuRecht: Nutzungsmöglichkeiten für Forschung und Sprachvermittlung“. In: Korpora Deutsch als Fremdsprache 3 (1), 44–71. DOI: https://doi.org/10.48694/kordaf.3730.Search in Google Scholar
Grzeszczakowska-Pawlikowska, Beata (2023): „Die Rhetorizität von Prosodie in der interkulturellen Wissenschaftskommunikation am Beispiel des Deutschen als Fremdsprache“. In: Deutsch als Fremdsprache 60 (2), 98–106. DOI: https://doi.org/10.37307/j.2198-2430.2023.02.04.10.37307/j.2198-2430.2023.02.04Search in Google Scholar
Guckelsberger, Susanne (2005): Mündliche Referate in universitären Lehrveranstaltungen: Diskursanalytische Untersuchungen im Hinblick auf eine wissenschaftsbezogene Qualifizierung von Studierenden. München: Iudicium.Search in Google Scholar
Lange, Daisy; Rahn, Stefan (2017): Mündliche Wissenschaftssprache. Stuttgart: Ernst Klett Sprachen.Search in Google Scholar
Schäfer, Susanne; Heinrich, Dietmar (2010): Wissenschaftliches Arbeiten an deutschen Universitäten: Eine Arbeitshilfe für ausländische Studierende im geistes- und gesellschaftswissenschaftlichen Bereich. München: Iudicium.Search in Google Scholar
Schiller, Anne; Teufel, Simone; Stöckert, Christine; Thielen, Christine (1999): Guidelines für das Tagging deutscher Textcorpora mit STTS (Kleines und großes Tagset). Online: http://www.sfs.uni-tuebingen.de/resources/stts-1999.pdf (15.02.2023).Search in Google Scholar
Schmidt, Thomas (2023): FOLK – Das Forschungs- und Lehrkorpus für Gesprochenes Deutsch. In: Korpora Deutsch als Fremdsprache 3 (1), 166–169. DOI: https://doi.org/10.48694/kordaf.3737.Search in Google Scholar
Schmidt, Thomas; Schwendemann, Matthias; Wallner, Franziska (2023): „ZuViel: Transkriptvisualisierung und Arbeiten mit Transkripten“. In: Korpora Deutsch als Fremdsprache 3 (1), 72–91. DOI: https://doi.org/10.48694/kordaf.3723.Search in Google Scholar
Selting, Margret; Auer, Peter et al. (2009): „Gesprächsanalytisches Transkriptionssystem 2 (GAT 2)“. In: Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion 10, 353–402. Online: http://www.gespraechsforschung-ozs.de/heft2009/px-gat2.pdf (20.01.2023).Search in Google Scholar
Slavcheva, Adriana; Meißner, Cordula (2014): „Also und so in wissenschaftlichen Vorträgen“. In: Fandrych, Christian; Meißner, Cordula; Slavcheva, Adriana (Hrsg.): Gesprochene Wissenschaftssprache: Korpusmethodische Fragen und empirische Analysen. Heidelberg: Synchron, 113–132.Search in Google Scholar
Szczepaniak, Renata (2015): „Syntaktische Einheitenbildung – typologisch und diachron betrachtet“. In: Dürscheid, Christa; Schneider, Jan Georg (Hrsg.): Handbuch Satz, Äußerung, Schema. Berlin: De Gruyter, 104–124.10.1515/9783110296037-006Search in Google Scholar
Wallner, Franziska (2023): GeWiss – Ein Korpus der Gesprochenen Wissenschaftssprache. In: Korpora Deutsch als Fremdsprache 3 (1), 159–165. DOI: https://doi.org/10.48694/kordaf.3738.Search in Google Scholar
Westpfahl, Swantje; Schmidt, Thomas (2016): „FOLK-Gold – A gold standard for part-of-speech-tagging of spoken German.“ In: Calzolari, Nicoletta; Choukri, Khalid; Declerck, Thierry; Goggi, Sara; Grobelnik, Marko (Hrsg.): Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). Portorož, Slovenia. Paris: European Language Resources Association (ELRA), 1493–1499. Online: https://ids-pub.bsz-bw.de/frontdoor/index/index/docId/5078 (15.2.2023).Search in Google Scholar
Westpfahl, Swantje; Schmidt, Thomas; Jonietz, Jasmin; Borlinghaus, Anton (2017): STTS 2.0: Guidelines für die Annotation von POS-Tags für Transkripte gesprochener Sprache in Anlehnung an das Stuttgart Tübingen Tagset (STTS). Arbeitspapier. IDS Mannheim. Online: https://ids-pub.bsz-bw.de/frontdoor/deliver/index/docId/6063/file/Westpfahl_Schmidt_Jonietz_Borlinghaus_STTS_2_0_2017.pdf (15.02.2023).Search in Google Scholar
ZuMult – Zugänge zu multimodalen Korpora gesprochener Sprache: Vernetzung und zielgruppenspezifische Ausdifferenzierung. (2018): Gefördert von der DFG über das LiS-Programm. Online: https://zumult.org/ (15.2.2023).Search in Google Scholar
Anhang
Tabelle 5: Dunn‘s Post-hoc-Vergleiche mit Bonferroni-Korrektur – Normalisierungsrate/Gesprächstypen
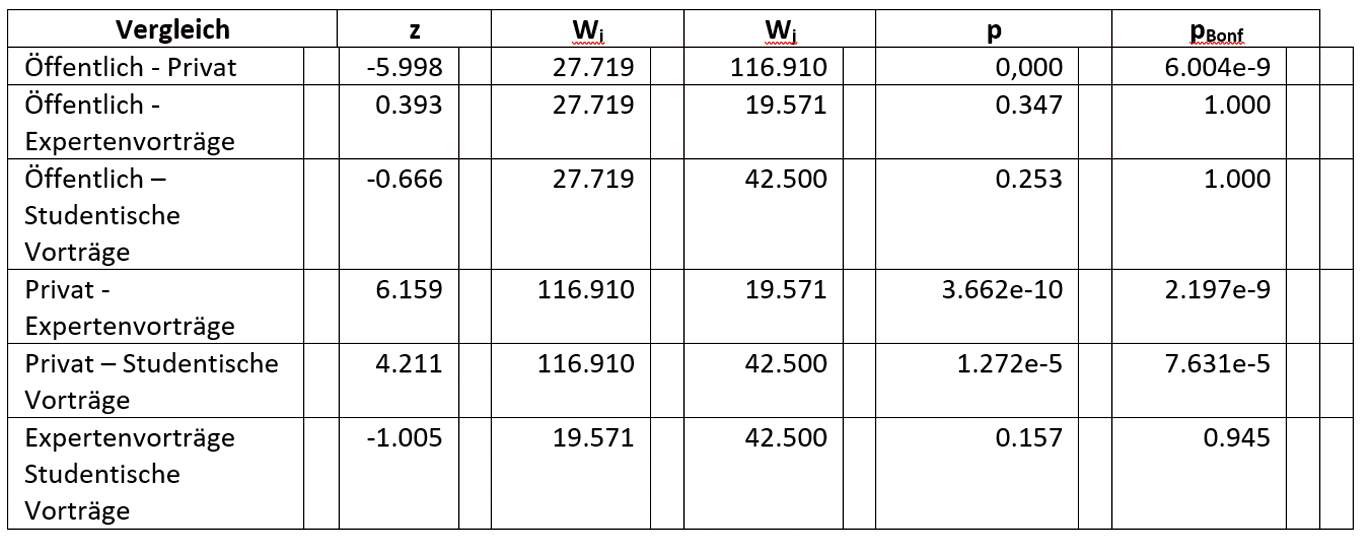
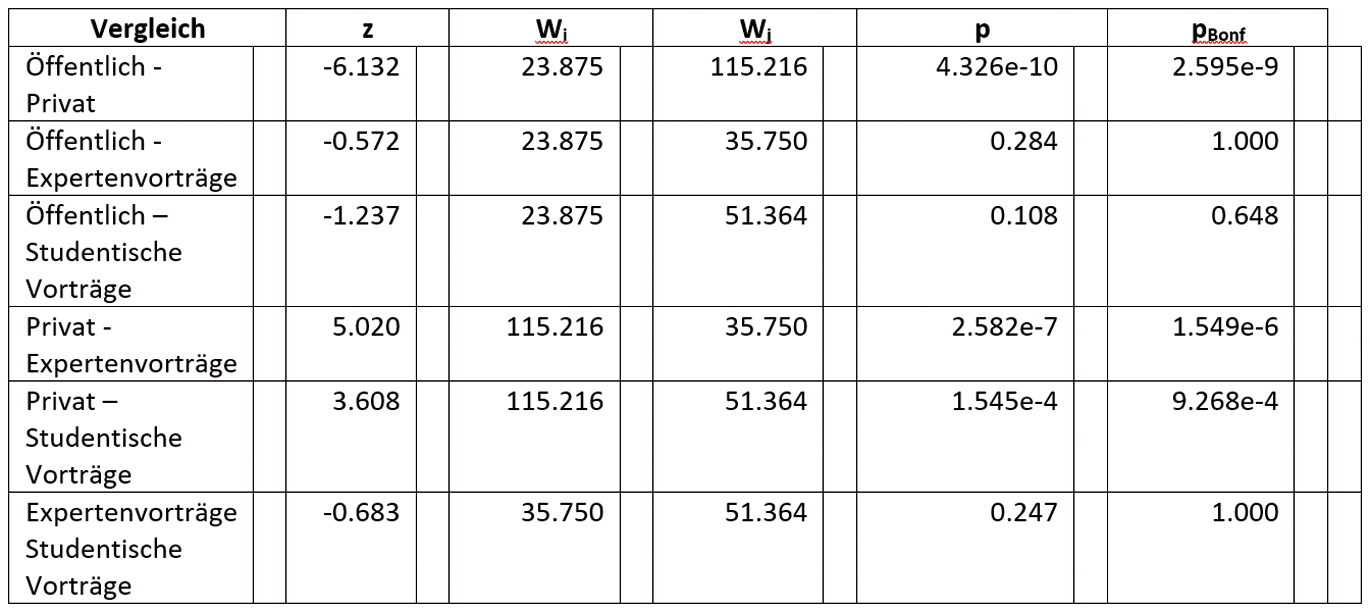
Tabelle 6: Dunn‘s Post-hoc-Vergleiche mit Bonferroni-Korrektur – Modalpartikeln/Gesprächstypen
© 2023 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Frontmatter
- Frontmatter
- Vorwort
- Allgemeiner Beitrag
- „Expect the Unexpected“: Wie kann das Theorie- und Praxisfeld DaF/DaZ auf Krisen reagieren? Ein Debattenbeitrag
- Agilität in der DaF/DaZ-Ausbildung im Kontext der Digitalisierung
- Asynchrone Lernpfade in der Lehrkräftebildung Deutsch als Zweitsprache
- Schreiben im DaF-Unterricht – kommunikative Ziele auf dem Prüfstand
- Formative Beurteilung des Sprechens im DaF-Unterricht: Praktiken und Überzeugungen von Lehrpersonen der Sekundarstufe I
- Mündlichkeitsphänomene in der gesprochenen Wissenschaftssprache: Korpuslinguistische Befunde und didaktische Perspektiven
- Gesprochene Wissenschaftssprache: Die Vorlesung als Gegenstand der Studienvorbereitung?
- Gendersensible Grammatik: Vorschläge zur Vermittlung von Genus und Personenbezeichnungen
Articles in the same Issue
- Frontmatter
- Frontmatter
- Vorwort
- Allgemeiner Beitrag
- „Expect the Unexpected“: Wie kann das Theorie- und Praxisfeld DaF/DaZ auf Krisen reagieren? Ein Debattenbeitrag
- Agilität in der DaF/DaZ-Ausbildung im Kontext der Digitalisierung
- Asynchrone Lernpfade in der Lehrkräftebildung Deutsch als Zweitsprache
- Schreiben im DaF-Unterricht – kommunikative Ziele auf dem Prüfstand
- Formative Beurteilung des Sprechens im DaF-Unterricht: Praktiken und Überzeugungen von Lehrpersonen der Sekundarstufe I
- Mündlichkeitsphänomene in der gesprochenen Wissenschaftssprache: Korpuslinguistische Befunde und didaktische Perspektiven
- Gesprochene Wissenschaftssprache: Die Vorlesung als Gegenstand der Studienvorbereitung?
- Gendersensible Grammatik: Vorschläge zur Vermittlung von Genus und Personenbezeichnungen