
AI agent as a simulated patient for history-taking training in clinical clerkship: an example in stomatology
-
Yongxiang Yuan


Abstract
Objective
This study developed an AI-powered chatbot simulating a patient with acute pulpitis to enhance history-taking training in stomatology, aiming at providing a cost-effective tool that improves diagnostic and communication skills while fostering clinical competence and empathy.
Methods
The study involved 126 undergraduate clinical medicine students who interacted with an AI agent simulating a patient suffering acute pulpitis. The AI agent was created and optimized in a five-step process, including preliminary creation, usability testing with a Chatbot Usability Questionnaire (CUQ), analysis and optimization, retesting, and comparison of pre- and post-optimization results. The platform used was ChatGLM, and statistical analysis was performed using R software.
Results
The pre-optimization group’s CUQ mean score was 64.2, indicating moderate satisfaction. After optimization, the post-optimization group’s mean score improved to 79.3, showing significantly higher satisfaction. Improvements were noted in all aspects, particularly in the chatbot’s personality, user experience, error handling, and onboarding.
Conclusion
The optimized AI agent effectively addresses challenges in history-taking training, improving realism, engagement, and accessibility to diverse scenarios. It demonstrates the potential of AI-powered chatbots as valuable tools for enhancing medical education.
Introduction
The process of taking a comprehensive patient history remains an indispensable initial step within clinical diagnosis, guiding subsequent investigations. Despite the development of abundant sophisticated diagnostic technologies, the fundamental role of detailed history-taking in ensuring patient welfare is indisputable. Globally, the education of healthcare professionals emphasizes the mastery of medical interviewing skills, which are essential not only for diagnostic accuracy but also for fostering a therapeutic relationship between the clinician and patient [1]. Effective communication is a vital determinant of positive patient outcomes, resulting in its widespread integration into medical education mostly through student-patient or standardized patient interactions in their clinical clerkship.
However, conventional history-taking practices in training programs are with their challenges. First, the reliance on real patients or standardized patients may limit the diversity of clinical scenarios encountered by students, potentially compromising their preparedness to handle complex, real-world situations. The cost of recruiting and maintaining standardized patients makes this problem worse. Second, the pressure to perform well in these interactions may shift the focus toward technical proficiency at the expense of genuine empathy and understanding, thereby affecting the quality of patient care. A balanced educational approach is required, one that combines both simulated and real-world experiences to ensure students develop not only clinical skills but also humanistic qualities in medicine. In simpler terms, there is a need for cost-effective training methods that expose students to a variety of complex clinical situations, while simultaneously cultivating empathy and compassion.
Recent advances in natural language processing have led to the development of large language models (LLM)-powered chatbots, such as ChatGPT, which have proved effective in enhancing patient-physician communication [2]. By simulating diverse clinical scenarios, these chatbots can provide students with realistic interactions, fine-tuning their ability to express empathy and deliver bad news with compassion [3]. Compared to traditional interaction with standardized patients, chatbots as simulated patients have distinct advantages: they eliminate potential risks, are not constrained by time or space, and boast high teaching efficiency that allows for repetition and reversibility. Additionally, their ability to engage students in an interactive manner can significantly enhance learning motivation. Nevertheless, after reviewing literature on the application of LLM-powered chatbots as simulated patients, we found several technical barriers are waiting to be overcome:
How can full student participation be ensured within a limited time?
How can the creation of a simulated patient be made easy and accessible to educators without requiring extensive technical expertise?
How can the effectiveness of chatbot-mediated conversations be evaluated?
This manuscript proposes a practical solution by creating an artificial intelligence (AI) agent that simulates a patient with acute pulpitis for history-taking training within clinical clerkship in stomatology.
Materials and methods
Setting and participants
The course of “Stomatology” is offered in the third academic year for five-year undergraduate students majoring in clinical medicine, with theoretical lectures and clinical clerkship lessons conducted in the same semester. There are six clinical clerkship lessons (content of each lesson is listed in Supplementary Table 1), and we built our trial AI agent for the lesson “Differential Diagnosis and Treatment of Toothache” to test its functionality among students and to explore a unified method for future creation of AI agents for other clinical clerkship lessons.
A total of 126 five-year undergraduate students majoring in clinical medicine from the class of 2022 participated in the study, and were divided into two groups, pre-optimization group and post-optimization group. The AI agent, simulating patient consulting online, facilitates students to practice medical history taking and clinical reasoning skills, which constitutes 30 out of 180 min of the lesson chosen. Figure 1 illustrates how the AI agent is used in the lesson.
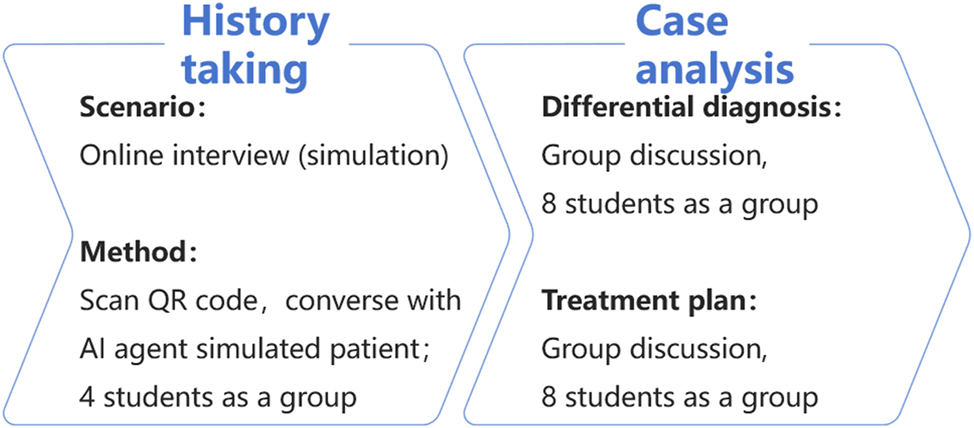
How the AI agent is used in clinical clerkship lessons.
This study includes five steps for the creation and optimization of the AI agent:
Create the preliminary version of the AI agent (see Appendix 1);
Test the preliminary version of the AI agent in the clinical clerkship lesson, and ask students (pre-optimization group) to complete a digital copy of a Chatbot Usability Questionnaire (CUQ), a 16-question survey that assesses various aspects such as the chatbot’s personality and user experience [4], 5];
Analyze the outcome of the CUQ and optimize the AI agent;
Test the optimized version of the AI agent in the clinical clerkship lesson, and ask students (post-optimization group) to complete a CUQ;
Compare the result with the baseline data from the pre-optimization group to evaluate the overall improvement of the AI agent.
AI agent platform
In principle, an AI agent is a chatbot based on LLMs. The difference is that it pre-encapsulates the prompts into the AI agent’s configuration file, so there is no need to re-enter the prompts each time it is called, making it more convenient to use. Nearly every online LLM service provider has the capability to customize AI agents for specific purposes, mostly free of charge. Different online LLM service providers use their own naming conventions for AI agents (e.g. OpenAI refers to its AI as “ChatGPT”, ChatGLM uses its own branding), even though these AI agents are essentially the same in their underlying technology. To ensure each student’s easy access to the AI agent, we chose ChatGLM as the platform to build the AI agent. ChatGLM is an AI Assistant developed on the GLM-4 model by Zhipu AI, China. ChatGLM’s interface allows users to define the agent’s personality, characteristics, and response style, tailoring it to the specific educational needs of medical students. It is friendly to both teachers and students.
Statistical analysis
Statistical analysis and figure generation were performed with R version 4.2.1 (R Core Team 2023) and corresponding packages such as “ggplot2” (version 3.4.4), “stats” (version 4.2.1), “car” (version 3.1–0), etc. For the comparison of CUQ scores between the pre- and post-optimization groups, Student’s t-test was used. For the analysis of each question between the two groups, Wilcoxon rank sum test was used. p-values were calculated, and a p-value less than 0.05 was considered statistically significant.
Results
A total of 126 questionnaires were collected from the students with 63 from the pre-optimization group and 63 from the post-optimization group. The CUQ is a 5-score Likert scale questionnaire with 16 questions, ranging from “strongly disagree” to “strongly agree.” The scores of each question from both groups are listed in mean ± standard deviation (SD) format (Table 1). The CUQ score of each group was calculated using a CUQ Calculation Tool (Appendix 2) according to Holmes et al. [6].
Analysis of the Chatbot Usability Questionnaire (CUQ) results from pre- and post-optimization groups.
| No. | Item | Category | Score (pre-optimization) | Score (post-optimization) | p-Value |
|---|---|---|---|---|---|
| 1 | The chatbot’s personality was realistic and engaging | Personality | 2.7 ± 1.1 | 4.2 ± 0.7 | <0.0001a |
| 2 | The chatbot seemed too robotic | 3.5 ± 1.1 | 2.1 ± 0.9 | <0.0001a | |
| 3 | The chatbot was welcoming during initial setup | 3.9 ± 1.0 | 3.8 ± 1.1 | 0.5136 | |
| 4 | The chatbot seemed very unfriendly | 1.7 ± 0.6 | 1.6 ± 0.7 | 0.1843 | |
| 5 | The chatbot understood me well | 3.8 ± 0.9 | 4.4 ± 0.6 | <0.0001a | |
| 6 | The chatbot was easy to navigate | User experience | 4.0 ± 0.9 | 4.5 ± 0.6 | 0.0009a |
| 7 | It would be easy to get confused when using the chatbot | 2.0 ± 0.9 | 1.8 ± 0.6 | 0.1449 | |
| 8 | The chatbot was very easy to use | 4.0 ± 0.9 | 4.6 ± 0.5 | <0.0001a | |
| 9 | The chatbot was very complex | 1.8 ± 0.7 | 1.5 ± 0.5 | 0.0115a | |
| 10 | The chatbot coped well with any errors or mistakes | Error handling | 2.8 ± 1.2 | 3.3 ± 1.1 | 0.0386* |
| 11 | The chatbot seemed unable to handle any errors | 2.9 ± 1.2 | 2.3 ± 1.1 | 0.0086a | |
| 12 | The chatbot explained its scope and purpose well | Onboarding | 2.8 ± 0.9 | 3.9 ± 0.9 | <0.0001a |
| 13 | The chatbot gave no indication as to its purpose | 3.1 ± 0.8 | 1.9 ± 0.9 | <0.0001a | |
| 14 | The chatbot failed to recognize a lot of my inputs | Other | 1.6 ± 0.6 | 1.4 ± 0.6 | 0.0974 |
| 15 | Chatbot responses were useful, appropriate, and informative | 4.0 ± 0.9 | 4.2 ± 0.6 | 0.2386 | |
| 16 | Chatbot responses were irrelevant | 2.2 ± 1.1 | 1.6 ± 0.6 | 0.0039a | |
| Calculated CUQ score | 64.2 ± 6.1 | 79.3 ± 5.1 | <0.0001a | ||
-
CUQ scores are presented as mean ± standard deviation (SD). aIndicates significant statistical differences.
Analysis of questionnaires from the pre-optimization group
The CUQ examined five aspects as described by its composer, which included personality, user experience, error handling, onboarding, and others. The mean score of the pre-optimization group was calculated to be 64.2 with an SD value of 6.1 (Table 1), indicating students’ moderate satisfaction with the preliminary version. By scrutinizing scores of each question, it was evident that nearly every aspect needs improvement, especially personality, error handling, and onboarding. Relative enhancements were then made by editing the profile of the AI agent (see Appendix 3).
Comparison between the pre- and post-optimization groups
The mean score of the post-optimization group was calculated to be 79.3 with an SD value of 5.1 (Table 1), indicating much higher satisfaction with the optimized version (p<0.0001) compared to that of the pre-optimization group. After optimization, the AI agent has improved significantly in every aspect, with statistically significant difference in the mean score of at least one question belonging to the category (Table 1, Table 2, and Figure 2).
Comparison of the Chatbot Usability Questionnaire (CUQ) answers between the pre- and post-optimization groups.
| Question no. | Group | Strongly disagree, n | Disagree, n | Neutral, n | Agree, n | Strongly agree, n |
|---|---|---|---|---|---|---|
| Q1a | Pre-optimization | 10 | 18 | 19 | 13 | 3 |
| Post-optimization | 0 | 2 | 1 | 37 | 23 | |
| Q2a | Pre-optimization | 0 | 12 | 21 | 15 | 15 |
| Post-optimization | 17 | 32 | 9 | 3 | 2 | |
| Q3 | Pre-optimization | 0 | 5 | 16 | 21 | 21 |
| Post-optimization | 3 | 4 | 16 | 22 | 18 | |
| Q4 | Pre-optimization | 23 | 34 | 6 | 0 | 0 |
| Post-optimization | 31 | 27 | 4 | 1 | 0 | |
| Q5a | Pre-optimization | 0 | 6 | 11 | 34 | 12 |
| Post-optimization | 0 | 0 | 5 | 28 | 30 | |
| Q6a | Pre-optimization | 0 | 4 | 17 | 20 | 22 |
| Post-optimization | 0 | 0 | 4 | 24 | 35 | |
| Q7 | Pre-optimization | 15 | 38 | 4 | 4 | 2 |
| Post-optimization | 19 | 40 | 3 | 1 | 0 | |
| Q8a | Pre-optimization | 0 | 5 | 14 | 23 | 21 |
| Post-optimization | 0 | 0 | 0 | 26 | 37 | |
| Q9a | Pre-optimization | 23 | 30 | 10 | 0 | 0 |
| Post-optimization | 33 | 30 | 0 | 0 | 0 | |
| Q10a | Pre-optimization | 8 | 19 | 17 | 14 | 5 |
| Post-optimization | 0 | 18 | 20 | 15 | 10 | |
| Q11a | Pre-optimization | 9 | 12 | 27 | 6 | 9 |
| Post-optimization | 16 | 22 | 13 | 12 | 0 | |
| Q12a | Pre-optimization | 7 | 13 | 29 | 13 | 1 |
| Post-optimization | 0 | 5 | 16 | 22 | 20 | |
| Q13a | Pre-optimization | 2 | 7 | 39 | 10 | 5 |
| Post-optimization | 24 | 25 | 10 | 4 | 0 | |
| Q14 | Pre-optimization | 30 | 29 | 4 | 0 | 0 |
| Post-optimization | 39 | 22 | 2 | 0 | 0 | |
| Q15 | Pre-optimization | 0 | 4 | 12 | 26 | 21 |
| Post-optimization | 0 | 0 | 6 | 36 | 21 | |
| Q16a | Pre-optimization | 22 | 19 | 12 | 9 | 1 |
| Post-optimization | 30 | 29 | 4 | 0 | 0 |
-
aIndicates significant statistical differences.
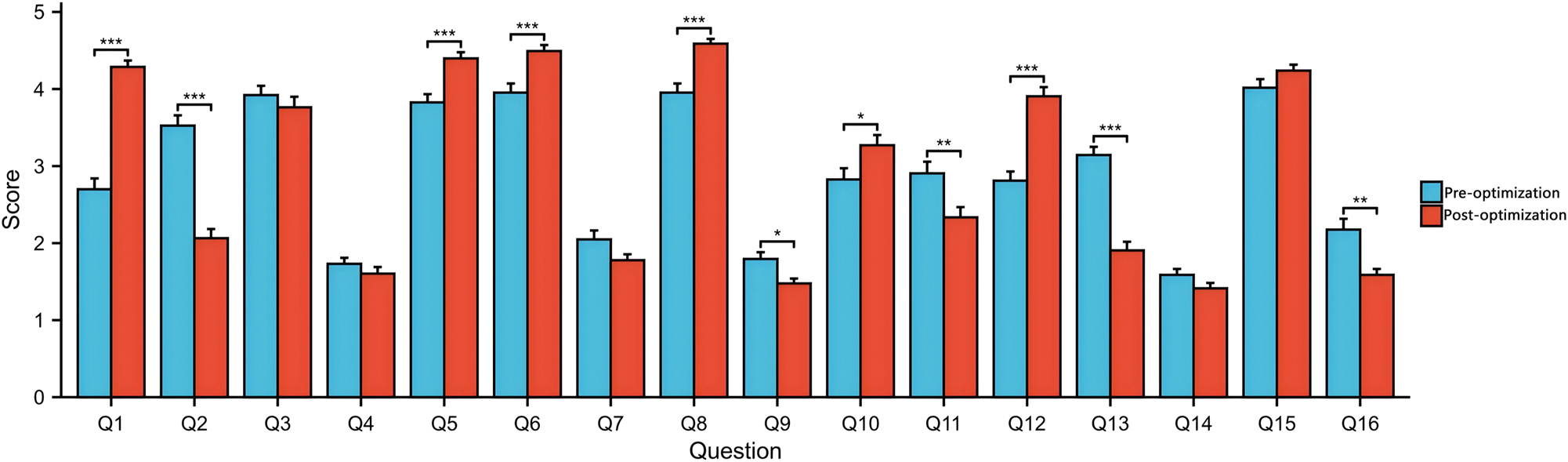
Comparison between the pre- and post-optimization groups. *p<0.05, **p<0.01, ***p<0.001, Student’s t-test.
Notably, the chatbot’s personality, as indicated by a leap in scores from 2.7 to 4.2 (p<0.0001), became more realistic and engaging after optimization. This enhancement suggests that students found the chatbot more relatable and enjoyable to interact with after the improvements were made. In terms of user experience, the chatbot’s ease of navigation saw a notable increase, with scores rising from 4.0 to 4.5 (p=0.0009). The ease of use also improved significantly, as reflected by the scores moving from 4.0 to 4.6 (p<0.0001). These results underscore the success of the optimization in making the chatbot more intuitive and user-friendly. Error handling was another area where significant progress was observed. The scores increased from 2.8 to 3.3 (p=0.0386), indicating that the chatbot became better at coping with errors or mistakes. Conversely, the perception of the chatbot being unable to handle errors decreased significantly, with scores dropping from 2.9 to 2.3 (p=0.0086). Onboarding, which is crucial for first-time users, also saw substantial improvements. The chatbot’s ability to explain its scope and purpose well increased from a score of 2.8 to 3.9 (p<0.0001), while the perception of the chatbot giving no indication of its purpose decreased significantly, with scores dropping from 3.1 to 1.9 (p<0.0001).
Table 2 provides a comparative analysis of user agreement levels before and after the optimization. Questions marked with an asterisk (*) indicate significant statistical differences. After optimization, there was a marked increase in the number of users who “strongly agree” with positive statements about the chatbot, particularly in questions 1, 2, 5, 6, 8, 9, 10, 11, 12, and 13. For instance, in question 1, which pertains to the chatbot’s helpfulness, the number of users selected “strongly agree” increased from 3 to 23, a substantial endorsement of the optimization’s success. In contrast, the number of users who “strongly disagree” or “disagree” with negative statements about the chatbot decreased post-optimization. This is evident in questions 4, 9, and 14, where the number of users who selected “strongly disagree” dropped significantly, aligning with the improvements seen in the quantitative data of Table 1.
Discussion
With the integration of generative AI as a tool in education, it shows the potential to transform the delivery and cultivation of human learning [7], [8], [9], [10], [11]. In the context of virtual simulation, it has brought more humanized elements, making the dialogue-based virtual simulation more realistic. The development of LLMs has been rapid, which has not only enhanced the effectiveness of medical education but also facilitated the training of healthcare professionals in a more immersive and interactive environment [11], [12], [13], [14], [15], [16]. In the field of stomatology, although virtual simulation teaching has shown significant results, no open-access virtual simulation digital resources suitable for clinical clerkship training in stomatology have been found [17], 18]. Here, for the first time, we report a modification on the LLM-powered chatbot tailored to diagnostic training in stomatology.
The first question we posed in the introduction pertains to ensuring full student participation within limited time frames. Our optimized AI agent addressed this by providing a realistic and engaging interaction that could be accomplished conveniently by scanning the QR code with each student’s mobile phone, after which the user interface simulated the scenario of a patient consulting his conditions via the internet. With minimal guidance, students could easily start the history taking process. Traditionally, due to the limitations of teaching duration and the large number of students in a single clinical clerkship lesson, it is hard to ensure that each student experience the whole process of taking medical histories [19], 20]. More importantly, unlike a group of students, usually more than 10, surrounding only one real patient (or standardized patient) in traditional clinical clerkship, our solution ensures each student to converse with the AI agent simultaneously. The CUQ scores highlighted the importance of the chatbot’s personality being realistic and engaging. To this end, we modified the AI agent’s profile to adopt a more natural and responsive tone, ensuring that the simulated patient’s reactions and descriptions are expanded appropriately based on the user’s inquiries. This adjustment aligns with the significant increase in scores for the chatbot’s personality after optimization, indicating that users found the AI more engaging after the changes. To address the perception of the chatbot being too robotic, we focused on making the AI’s responses more human-like. The updated profile (see Appendix 3) includes a detailed medical history and rigorous definitions of how the agent responds, which helps in creating a more authentic patient simulation. This change corresponds with the decrease in scores for the chatbot seeming too robotic, as indicated in the CUQ, suggesting that the optimization made the AI feel less mechanical. The CUQ scores pointed out the need for the chatbot to understand users well and be easy to navigate. We optimized the AI agent’s capabilities to provide detailed symptom descriptions and medical history provisions based on the user’s questions. This enhancement ensures that the AI can keep pace with the user’s line of inquiry, mirroring the significant increase in scores for the chatbot’s understanding and ease of navigation. The original CUQ scores indicated that the chatbot was perceived as complex. In our optimization, we focused on simplifying the AI agent’s responses to be more straightforward and relevant, avoiding the revelation of too much content at once. This change resulted in the decrease in scores for the chatbot being complex, suggesting that users found the AI easier to interact with after the optimization.
The second question addresses the accessibility of creating simulated patients for educators. With the development of generative AI and the emergence of AI agent technology, the creation and application of a simulated patient has become much easier [21], 22]. In this study, we chose ChatGLM as the platform to build the AI agent and provided detailed procedure guiding educators to create their own AI agent. We believe this is the most simple and convenient way of doing so, as no coding or programming skills were required in the process. This democratization of AI use in education ensures that a broader range of educators can enrich their teaching methods, enhancing the diversity of clinical scenarios students can encounter.
The third question involves evaluating the effectiveness of chatbot-mediated conversations. By referencing the CUQ scores and aligning the optimization of our AI agent with the identified areas for improvement, we have successfully enhanced the realism, engagement, and educational value of the AI agent. The modifications to the AI agent’s profile, including its role, medical history, capabilities, and precautions, directly address the feedback from the CUQ. These changes have resulted in a more effective simulated patient that can provide a diverse range of clinical scenarios for medical students, fostering both technical proficiency and empathy in a controlled and safe environment. However, in a minority of instances, the simulated patient’s responses exceeded the bounds of the predefined medical history information, a phenomenon similarly observed in the applications of other researchers [23]. In general, CUQ is a reliable tool to evaluate the effectiveness of chatbot-mediated conversations.
While this study shows promising results, several limitations exist. First, the sample size of 126 students, though reasonable for an initial evaluation, is relatively small. To strengthen the findings, future studies should involve larger and more diverse groups of students across different institutions. Second, the AI agent was tested only for acute pulpitis. Expanding its use to include other medical conditions would make it more versatile and practical for broader clinical training. Third, the evaluation relied on student feedback through the CUQ, which, while helpful, doesn’t fully capture how well the AI agent prepares students for real-world patient interactions. Longer-term studies tracking students’ performance in actual clinical settings would provide a clearer picture of its impact.
There are also opportunities to make the AI agent more realistic and engaging. For example, adding features like voice interaction could make conversations feel more natural, while augmented reality (AR) could create immersive environments that mimic real clinical settings. These enhancements would help bridge the gap between simulation and real patient interactions. Finally, it’s important to address potential ethical concerns, such as ensuring the AI agent’s responses are unbiased, culturally sensitive, and medically accurate, so students can trust it as a reliable training tool.
Conclusions
In conclusion, the optimization of our AI agent demonstrates the potential of AI agents to revolutionize medical education. By providing a platform for full student participation, simplifying the creation of simulated patients, and offering a means to evaluate chatbot-mediated conversations, we have taken significant steps toward overcoming the challenges faced by traditional patient history-taking training methods. The AI agent’s ability to simulate diverse clinical scenarios, coupled with its interactive and evaluative capabilities, positions it as a powerful tool for fostering both clinical skills and humanistic qualities in medical students. As we continue to refine and expand the capabilities of AI in medical education, we move closer to a future where technology and empathy coalesce to enhance patient care [23].
Funding source: Hunan Provincial Department of Education on the 2024 Teaching Reform Research Projects for Ordinary Undergraduate Institutions
Award Identifier / Grant number: 2024jy055
Funding source: Hunan Provincial Department of Education on the 2023 Teaching Reform Research Projects for Continuous Education
Award Identifier / Grant number: HNJG-20230114
Funding source: Educational Reform Project of Central South University
Award Identifier / Grant number: 2024jy139
Funding source: Hunan Provincial Department of Education on the 2023 Teaching Reform Research Projects for Ordinary Undergraduate Institutions
Award Identifier / Grant number: 2023jy170
Funding source: Hunan Province Educational Science ‘14th Five-Year Plan’ 2022 Research
Award Identifier / Grant number: ND227254
Acknowledgments
We would like to thank all the students and teacher of this study from the Central South University. We are grateful to Yiyi Zhang, Yisu Jin, Bin Xie, Jijia Li, Huixin Wang, and Ziqi Yan for their suggestions.
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: Yongxiang Yuan: Conceptualization, methodology, data collection, formal analysis, investigation, writing – original draft, writing – review & editing, visualization, project administration. Jieyu He: Methodology, software, data curation, formal analysis, writing – review & editing. Fang Wang: Data collection, resources, validation, writing – review & editing. Yaping Li: Resources, funding acquisition, writing – review & editing, supervision. Chaxiang Guan: Resources, funding acquisition – review & editing. Canhua Jiang(corresponding author): Data curation, visualization, writing – review & editing, coordination among co-authors. The authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: Large Language Models and AI were used for grammar checking and partial text refinement.
-
Conflict of interest: The authors state no conflict of interest.
-
Research funding: This study was supported by the Hunan Provincial Department of Education on the 2024 Teaching Reform Research Projects for Ordinary Undergraduate Institutions [grant number 2024jy055]; Hunan Provincial Department of Education on the 2023 Teaching Reform Research Projects for Ordinary Undergraduate Institutions [grant number 2023jy170];Hunan Provincial Department of Education on the 2023 Teaching Reform Research Projects for Continuous Education[grant number HNJG-20230114]; Hunan Province Educational Science ‘14th Five-Year Plan’ 2022 Research [grant number ND227254]; Educational Reform Project of Central South University [grant number 2024jy139].
-
Data availability: Not applicable.
References
1. Dang, BN, Westbrook, RA, Njue, SM, Giordano, TP. Building trust and rapport early in the new doctor-patient relationship: a longitudinal qualitative study. BMC Med Educ 2017;17:32. https://doi.org/10.1186/s12909-017-0868-5.Search in Google Scholar PubMed PubMed Central
2. Holderried, F, Stegemann-Philipps, C, Herschbach, L, Moldt, J, Nevins, A, Griewatz, J, et al.. A generative pretrained transformer (GPT)-powered chatbot as a simulated patient to practice history taking: prospective, mixed methods study. JMIR Med Educ 2024;10:e53961. https://doi.org/10.2196/53961.Search in Google Scholar PubMed PubMed Central
3. Holderried, F, Stegemann-Philipps, C, Herrmann-Werner, A, Festl-Wietek, T, Holderried, M, Eickhoff, C, et al.. A language model-powered simulated patient with automated feedback for history taking: prospective study. JMIR Med Educ 2024;10:e59213. https://doi.org/10.2196/59213.Search in Google Scholar PubMed PubMed Central
4. Holmes, S, Moorhead, A, Bond, R, Zheng, H, Coates, V, Mctear, M, et al.. Usability testing of a healthcare chatbot: can we use conventional methods to assess conversational user interfaces? In: 31st European Conference on Cognitive Ergonomics. Belfast, UK; 2019.10.1145/3335082.3335094Search in Google Scholar
5. Holmes, S, Bond, R, Moorhead, A, Zheng, J, Coates, V, McTear, M, et al.. Towards validating a chatbot usability scale. In: 12th International Conference on Design, User Experience, and Usability. DUXU 2023. Copenhagen, Denmark; 2023.10.1007/978-3-031-35708-4_24Search in Google Scholar
6. Holmes, S, Bond, R. Chatbot usability questionnaire (CUQ) calculation tool [online]. https://www.ulster.ac.uk/__data/assets/excel_doc/0010/478810/CUQ-Calculation-Tool.xlsx [Accessed 1 Dec 2024].Search in Google Scholar
7. Kaltenborn, KF, Rienhoff, O. Virtual reality in medicine. Methods Inf Med 1993;32:407–17. https://doi.org/10.1055/s-0038-1634953.Search in Google Scholar
8. Fazlollahi, AM, Yilmaz, R, Winkler-Schwartz, A, Mirchi, N, Ledwos, N, Bakhaidar, M, et al.. AI in surgical curriculum design and unintended outcomes for technical competencies in simulation training. JAMA Netw Open 2023;6:e2334658. https://doi.org/10.1001/jamanetworkopen.2023.34658.Search in Google Scholar PubMed PubMed Central
9. Haupt, CE, Marks, M. AI-generated medical advice-GPT and beyond. JAMA 2023;329:1349–50. https://doi.org/10.1001/jama.2023.5321.Search in Google Scholar PubMed
10. Xi, Z, Chen, W, Guo, X, He, W, Ding, Y, Hong, B, et al.. The rise and potential of large language model based agents: a survey [online]. https://arxiv.org/abs/2309.07864 [Accessed 1 Dec 2024].Search in Google Scholar
11. Waisberg, E, Ong, J, Masalkhi, M, Lee, AG. Large language model (LLM)-driven chatbots for neuro-ophthalmic medical education. Eye (Lond) 2024;38:639–41. https://doi.org/10.1038/s41433-023-02759-7.Search in Google Scholar PubMed PubMed Central
12. Cai, ZR, Chen, ML, Kim, J, Novoa, RA, Barnes, LA, Beam, A, et al.. Assessment of correctness, content omission, and risk of harm in large language model responses to dermatology continuing medical education questions. J Invest Dermatol 2024;144:1877–9. https://doi.org/10.1016/j.jid.2024.01.015.Search in Google Scholar PubMed
13. Huang, Z, Bianchi, F, Yuksekgonul, M, Montine, TJ, Zou, J. A visual-language foundation model for pathology image analysis using medical Twitter. Nat Med 2023;29:2307–16. https://doi.org/10.1038/s41591-023-02504-3.Search in Google Scholar PubMed
14. Lee, H. The rise of ChatGPT: exploring its potential in medical education. Anat Sci Educ 2024;17:926–31. https://doi.org/10.1002/ase.2270.Search in Google Scholar PubMed
15. Betzler, BK, Chen, H, Cheng, C, Lee, CS, Ning, G, Song, SJ, et al.. Large language models and their impact in ophthalmology. Lancet Digit Health 2023;5:e917–24. https://doi.org/10.1016/s2589-7500(23)00201-7.Search in Google Scholar PubMed PubMed Central
16. Jowsey, T, Stokes-Parish, J, Singleton, R, Todorovic, M. Medical education empowered by generative artificial intelligence large language models. Trends Mol Med 2023;29:971–3. https://doi.org/10.1016/j.molmed.2023.08.012.Search in Google Scholar PubMed
17. Nassar, HM, Tekian, A. Computer simulation and virtual reality in undergraduate operative and restorative dental education: a critical review. J Dent Educ 2020;84:812–29. https://doi.org/10.1002/jdd.12138.Search in Google Scholar PubMed
18. Johnson, KS, Schmidt, AM, Bader, JD, Spallek, H, Rindal, DB, Enstad, CJ, et al.. Dental decision simulation (DDSim): development of a virtual training environment. J Dent Educ 2020;84:1284–93. https://doi.org/10.1002/jdd.12303.Search in Google Scholar PubMed
19. Veliz, C, Fuentes-Cimma, J, Fuentes-Lopez, E, Riquelme, A. Adaptation, psychometric properties, and implementation of the Mini-CEX in dental clerkship. J Dent Educ 2021;85:300–10. https://doi.org/10.1002/jdd.12462.Search in Google Scholar PubMed
20. Vrazic, D, Music, L, Barbaric, M, Badovinac, A, Plancak, L, Puhar, I. Dental students’ attitudes and perspectives regarding online learning during the COVID-19 pandemic: a cross-sectional, multi-university study. Acta Stomatol Croat 2022;56:395–404. https://doi.org/10.15644/asc56/4/6.Search in Google Scholar PubMed PubMed Central
21. Garcia Valencia, OA, Thongprayoon, C, Jadlowiec, CC, Mao, SA, Miao, J, Cheungpasitporn, W. Enhancing kidney transplant care through the integration of chatbot. Healthcare (Basel) 2023;11:2518. https://doi.org/10.3390/healthcare11182518.Search in Google Scholar PubMed PubMed Central
22. Wang, A, Qian, Z, Briggs, L, Cole, AP, Reis, LO, Trinh, Q. The use of chatbots in oncological care: a narrative review. Int J Gen Med 2023;16:1591–602. https://doi.org/10.2147/ijgm.s408208.Search in Google Scholar
23. Ayers, JW, Poliak, A, Dredze, M, Leas, EC, Zhu, Z, Kelley, JB, et al.. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med 2023;183:589–96. https://doi.org/10.1001/jamainternmed.2023.1838.Search in Google Scholar PubMed PubMed Central
Supplementary Material
This article contains supplementary material (https://doi.org/10.1515/gme-2024-0025).
© 2025 the author(s), published by De Gruyter on behalf of the Shanghai Jiao Tong University and the Shanghai Jiao Tong University School of Medicine
This work is licensed under the Creative Commons Attribution 4.0 International License.