
ChatAnalysis revisited: can ChatGPT undermine privacy in smart homes with data analysis?
-
Victor Jüttner
 ,
Arthur Fleig
,
Arthur Fleig

Abstract
Large Language Models (LLMs) have demonstrated potential in automating data-driven tasks, enabling non-experts to analyze raw inputs such as tables or sensor data using conversational queries. Advances in Machine Learning (ML) and Human-Computer Interaction (HCI) have further reduced entry barriers, pairing sophisticated model capabilities and background knowledge with user-friendly interfaces like chatbots. While empowering users, this raises critical privacy concerns when used to analyze data from personal spaces, such as smart-home environments. This paper investigates the capabilities of LLMs, specifically GPT-4 and GPT-4o, in analyzing smart-home sensor data to infer human activities, unusual activities, and daily routines. We use datasets from the CASAS project, which include data from connected devices such as motion sensors, door sensors, lamps, and thermometers. Extending our prior work, we evaluate whether advances in model design, prompt engineering, and pre-trained knowledge enhance performance in these tasks and thus increase privacy risks. Our findings reveal that GPT-4 infers daily activities and unusual activities with some accuracy but struggles with daily routines. With our experimental setup, GPT-4o underperforms its predecessor, even when supported by structured CO-STAR prompts and labeled data. Both models exhibit extensive background knowledge about daily routines, underscoring the potential for privacy violations in smart-home contexts.
1 Introduction
Smart homes, equipped with Internet of Things (IoT) devices, significantly enhance home automation. Embedded sensors monitor user-related parameters in real-time, e.g., temperature, humidity, noise, and motion, facilitating automated decision-making, optimizing functions like lighting, climate control, and security, and delivering a personalized living experience tailored to residents’ preferences.
However, smart homes raise significant privacy concerns. 1 Historically, analyzing smart home data required technical expertise and specialized tools, creating a natural barrier against misuse. 2 Advances in ML and LLMs, coupled with HCI research on how to make data processing more accessible in conversations with LLMs, 3 lower this barrier. Simultaneously, the LLM has expert knowledge about powerful ML algorithms, 4 e.g., for inference attacks or de-anonymization. It has also the capabilities to execute them, e.g., in an interactive coding environment like Python REPL. 5 While beneficial in many contexts, this heightens the risk of data misuse, unauthorized behavior monitoring, and privacy invasion. These risks are amplified by these models’ vast body of background knowledge, enabling them to interpret data, make educated guesses on personal activities or habits, and communicate results in plain language.
This paper extends our prior work, 6 which explored GPT-4’s potential for human activity recognition by analyzing smart home sensor data through three proof-of-concept experiments: Inferring Daily Activities (Ex1), Daily Routine (Ex2), and Unusual Activities (Ex3). While results were promising, particularly regarding inference of daily activities, it was unclear how much of the output was driven by genuine data processing versus reliance on pre-trained background knowledge. Furthermore, the impact of factors such as model architecture, prompt structure, and availability of labeled data remained underexplored.
Based on these foundational experiments, we address the research question: To what extent do advances in LLMs, accessible without requiring ML expertise, enable privacy risks through human activity detection from smart home sensor data, particularly via behavior inference and reliance on pre-trained background knowledge?
To investigate this, we evaluate both GPT-4 and its successor, GPT-4o, leveraging datasets from the Center for Advanced Studies in Adaptive Systems (CASAS). 7 We focus on commonly deployed smart home devices, including motion sensors, door sensors, lamps, and thermometers. We include the original experiments Ex1–Ex3 to provide continuity while introducing three new experiments around the most promising original Daily Activities experiment:
Ex4 New Model: We repeat the Daily Activities experiment with GPT-4o to compare its performance to GPT-4.
Ex5 CO-STAR Prompting: We test whether structured CO-STAR prompts and labeled data improve the accuracy of inferred daily activities for both GPT-4 and GPT-4o.
Ex6 Background Knowledge: We analyze how the LLM’s pre-trained knowledge contributes to activity inference.
As our key empirical research contributions, our new experiments clarify the extent to which methodological advancements and model updates enhance or limit the use of LLMs in privacy-sensitive contexts. In particular, we address whether these tools enable privacy violations by making activity detection accessible to non-experts. Our findings reveal that, while GPT-4 infers daily activities and detects unusual activities to some extent, it struggles with identifying the daily routine from extended data. GPT-4o, despite its updated architecture, produced less accurate results than its predecessor in our experiments, even when provided with structured prompts and labeled example data.
The demonstrated limitations of LLMs to analyze smart home data yield key takeaways for HCI researchers striving for user-centric, LLM-based assistants in smart home contexts. While the potential of LLM-driven data analysis could enhance comfort and help educating users about potential privacy risks, our findings suggest that we first have to take a step back and develop hybrid AI approaches that combine language models with specialized ML techniques.
The remainder of the paper is organized as follows: Section 2 reviews the state of the art; Section 3 details the research design and experimental setup; Section 4 presents findings from both the foundational and extended experiments; Section 5 discusses challenges, limitations, and privacy implications; and Section 6 concludes.
2 Background and related work
In this section, we first explore the use of data in smart homes and describe the CASAS dataset. We then derive privacy concerns with smart home data, before reviewing the use of LLMs in data analysis and human activity recognition (HAR). Finally, we list common prompting strategies to optimize the performance of LLMs in data analysis.
2.1 Smart home systems and their data
Smart Home Systems, designed to increase comfort, safety, and efficiency through home automation, enhance modern living. A typical smart home is one that includes consumer smart home devices that enable connectivity and remote control. Examples of these devices include smart thermostats like Nest, 8 which optimize heating and cooling based on user preferences, smart lighting systems like Philips Hue, 9 which can change the color and tone of light (on schedule), and security devices such as Ring Video Doorbells, 10 which provide real-time monitoring and alerts. Central control devices like the Amazon Echo 11 integrate voice-activated assistants to manage other devices and provide additional services. With these devices, a typical smart home generates rich data about energy consumption, security monitoring, and personalized automation.
This Smart Home Data can be distinguished into environmental and behavioral data. 12 Environmental data includes parameters like temperature, humidity, and light levels collected by devices such as thermostats and light meters. This data is used to automate climate control, optimize energy use, and adjust lighting based on occupant preferences. Behavioral data includes monitoring movement patterns with motion sensors and tracking device usage from smart devices. This data enables personalized automation, such as adjusting thermostat settings when no one is home or activating security protocols during unusual activity.
Smart homes continuously collect this multidimensional data, creating a detailed, real-time understanding of the living environment. This comprehensive data collection not only facilitates efficient home management, but also provides insights into occupants’ habits, enhancing the responsiveness and adaptability of smart home systems. 7
First LLM-based approaches that utilize this data are user-centric assistants, which highlight their potential to enhance convenience and accessibility in managing daily tasks. The Sascha approach 13 demonstrates in a hands-on user study how LLMs can interpret unconstrained, user-generated commands like “make it cozy”, showcasing their ability to adapt to natural language inputs. Similarly, GreenIFTTT, a GPT-4-based conversational agent, empowers users to monitor smart devices and create personalized energy optimization routines. 14 While these developments illustrate how LLMs’ intuitive interfaces and adaptability make them valuable tools for end users, they highlight the need to take a step back and critically evaluate their capabilities and limitations in terms of smart home data analysis.
Bouchabou et al. provide a comprehensive evaluation of smart home datasets in their survey on HAR in smart homes based on IoT sensor algorithms. From their survey we focus on real-world datasets due to their representativeness in capturing human activities. Cumin et al.’s Orange4Home dataset 15 includes 236 recorded activities in a single home. Cook et al.’s CASAS dataset 7 covers over 30 apartments, each equipped with approximately 50 sensors, while Alemandar et al.’s ARAS dataset 16 captures multi-resident activity across multiple apartments with 20 sensors per unit. Among these, we selected the CASAS dataset for its balance of scale and detail. It offers a large number of apartments for behavioral comparison, single-resident settings for simplified activity detection, and a representative sensor distribution. These factors make CASAS well-suited for our analysis.
The CASAS architecture, developed by the Center for Advanced Studies in Adaptive Systems, provides smart home capabilities out of the box, with the primary aim of recording datasets of human behavior for research purposes. The CASAS datasets consist of smart home sensor data collected from 30 apartments (HH101–HH130), annotated with activities of the inhabitants. Most apartments have one inhabitant, except for two, which have two inhabitants. Records vary from 10 to 509 days. Most apartments have about 60 days of data. Each apartment dataset was recorded with a different set of sensors, including motion area (MA), light (L), door (D), and temperature (T) sensors (Table 1), providing a comprehensive overview of activities within the apartments. Apartments are equipped with a mean of 46 sensors. Additionally, every apartment dataset includes a layout of the apartment with the positions of the sensors.
Sensor types used in our experiments.
| Sensor type | Function | |
|---|---|---|
| (MA) | Motion area | Detects motion within ∼6 m |
| (L) | Light | “On” or “Off” |
| (D) | Door | “Open” or “Closed” |
| (T) | Temperature | Degree celsius |
2.2 Privacy concerns with smart home data
Advances in machine learning and artificial intelligence (AI) are a driving factor for analyzing smart home data. These technologies enable the interpretation of environmental and behavioral data collected from sensors within the home, transforming raw inputs into actionable insights. By combining diverse data streams, systems can identify patterns and anomalies that inform automation decisions. Current state-of-the-art methods include correlation analysis and predictive models to infer meaningful insights from heterogeneous data sources. 17 , 18
AI algorithms can analyze temperature, humidity, and motion data to optimize energy consumption and improve security by detecting anomalies in real-time. 19 These practices provide insights into daily habits and preferences, enhancing efficiency and responsiveness. This data analysis technology is sufficiently advanced that smart homes are used in human activity recognition. 7 , 20
Significant privacy concerns arise from the collection and analysis of smart home data. Environmental data, such as temperature and light levels, combined with behavioral data like movement patterns, can be used to create detailed profiles of residents’ daily routines. 21 While this information is valuable for enabling automation, it poses considerable risks if accessed by unauthorized parties. Privacy attacks have repeatedly demonstrated the vulnerability of such datasets. For instance, deanonymization attacks can infer the identity of individuals within a dataset, as shown in recent research. 22 Similarly, singling-out attacks, which isolate an individual’s data from an aggregated dataset, are another prominent threat, as highlighted by de Montjoye et al. 23 A comprehensive overview of privacy attacks is provided by Powar et al. 24 detailing various methods that can compromise smart home data. Beyond these known attack vectors, smart home data could also be exploited to track personal habits, predict absences, or infer information about health and lifestyle, raising further privacy issues. Data aggregation in cloud services amplifies these risks, as it becomes a lucrative target for cyberattacks and unauthorized data mining. 1 Addressing these concerns is crucial to maintaining security in smart home environments.
Mitigating privacy risks in smart homes is a complex task. While several protective measures can be implemented, they often have limitations. Educating users about privacy settings and the importance of securing their smart home network is crucial, yet challenging. First approaches such as ChatIDS 25 aim to address this issue. Encryption of data during transmission and storage is fundamental to protecting smart home data against unauthorized access. However, even encrypted data can be vulnerable to advanced traffic analysis techniques, which allow adversaries to infer activities within the home or interactions with smart home devices. 26 , 27 Additionally, smart home system providers may collect this data to analyze it themselves or sell it, posing another privacy risk. While anonymization techniques aim to remove personal identifiers, they also have flaws, as demonstrated by the re-identification of individuals in the Netflix dataset. 28
2.3 LLMs for data analysis and human activity recognition
The application of LLMs to HAR and detecting Activities of Daily Living (ADL) in smart homes is an emerging area of research. Sensor-based HAR has traditionally relied on specialized ML techniques, but is now being reimagined with LLMs. For instance, Hota et al. 29 demonstrate LLMs’ ability to label raw inertial sensor data from wearable devices. They show that GPT-4 provides accurate annotations without requiring computationally expensive fine-tuning. Okita et al. 30 develop an LLM specifically for processing one-dimensional sensor signals, to perform activity recognition and emotion detection. ChatGPT has been used for zero-shot HAR using wearable sensors that record daily object usage. 31 Civitarese et al. 32 take a novel approach by converting raw sensor data into textual representations before feeding it to an LLM for zero-shot ADL detection. Meanwhile, Chen et al. 33 propose LAHAR, a sophisticated LLM-based framework for HAR across multiple users, though its complex prompting system limits accessibility for novices. In contrast, our approach prioritizes simplicity, leveraging structured CO-STAR prompts to enable effective HAR without requiring expertise in machine learning. Finally, Kozama et al. 34 highlight the potential of ChatGPT to empower novices in activity recognition, removing the need for GPU resources and significantly lowering the barrier to entry.
This barrier is further lowered by the LLMs’ shown ability to handle diverse Data Wrangling tasks, such as transforming dates and units into different formats with minimal user input. 35 Systems like InsightPilot leverage LLMs for automated data exploration, enabling users to pose natural language queries and receive actionable insights from datasets. 4 Tools such as LangChain streamline data ingestion, transforming text files, CSVs, and PDFs into formats compatible with LLMs. 36 By allowing users to “tell the computer what they want, not how to do it”, 37 LLMs have expanded the realm of data analysis to a broader audience, democratizing access to powerful analytical tools once reserved for experts.
Yet, Quality Assessment of the LLM’s output in particular without ML knowledge is ongoing research. The seemingly coherent language produced by LLMs can mislead users without background knowledge into thinking that this output is meaningful and unbiased text. 38 In interpreting smart home data, biases in the LLM’s training data can lead to distorted behavioral patterns and incorrect assumptions about occupants’ habits and routines. In particular, the interplay of background knowledge and delivered results from the dataset is underexplored. This paper works towards filling this gap with our assessment of the LLM’s capabilities on smart home data.
2.4 Prompting
An essential technique for optimizing the performance of LLMs in data analysis is Prompting. It involves crafting inputs that guide the model’s reasoning and output generation. While challenging, 39 a wide range of prompt engineering strategies have been developed to enhance the model’s problem-solving capabilities.
Zero-Shot, One-Shot, and Few-Shot Prompting are foundational techniques for guiding LLMs. Zero-Shot prompting is the most basic prompting technique. With this prompting, the model generates an answer based solely on a monolithic task description without any additional examples or external training data. One-Shot prompting goes beyond zero-shopt prompting by providing a single example to offer minimal context, while Few-Shot prompting extends this further by including several examples to improve the model’s understanding and accuracy. 40
Chain-of-Thought (CoT) Prompting is a strategy that guides the LLM to break down complex reasoning tasks into intermediate steps. 41 This approach improves interpretability and enables the model to tackle intricate problems more effectively by encouraging the LLM to employ a sequential reasoning approach.
Decomposition complements CoT by explicitly breaking down complex problems into simpler sub-questions. While CoT often naturally encourages decomposition, explicitly framing sub-tasks within a prompt can further enhance problem-solving capabilities. 42
CO-STAR Prompting is a structured approach to crafting prompts that ensures clarity and precision in AI responses. It includes six elements: Context, to provide background; Objective, to specify the task; Style and Tone, to shape the response’s character; Audience, to tailor content; and Response, to define format and length. This framework reduces ambiguity and aligns outputs with user intent. 43
Verification in this context ensures the LLM understands task instructions by confirming clarity before proceeding. This step involves prompting the model to explicitly acknowledge comprehension, minimizing errors and enhancing alignment with task objectives. 44
3 Research design
Utilizing the CASAS dataset, we conduct proof-of-concept experiments to infer specific daily activities (Ex1), the daily routine (Ex2), and unusual activities that deviate from the everyday routine (Ex3) with GPT-4. We repeat the first experiment with GPT-4o (Ex4) to find out whether the newer model improves the results, and we also test GPT-4 and GPT-4o with a more sophisticated CO-STAR prompt (Ex5). Finally, we test GPT-4o for background knowledge on typical daily activities (Ex6).
3.1 Data selection and preparation
For all experiments, we selected the CASAS dataset [available at available at∼\cite {casas-dataset}, 7]. The data are widely used in research, cover different smart home setups, and capture a wide range of daily activities such as sleeping, eating, and relaxing. We selected data from the apartments HH101 and HH102. Specifically, we used data from August 20, 2012, and the week of July 31 to August 6, 2012, from HH101, and from July 8 to July 15, 2012, from HH102. Our selection criteria focused on ensuring a diverse range of activities and sensor types. The time frame and the number and type of sensors used in the recordings of these apartments are shown in Table 2.
Recording time and sensor count per type in apartments.
| Apartment | Start | End | MA | T | L | D |
|---|---|---|---|---|---|---|
| HH101 | 20.07.2012 | 17.09.2012 | 4 | 4 | 0 | 1 |
| HH102 | 15.06.2011 | 15.08.2011 | 7 | 4 | 5 | 4 |
-
MA: motion area, L: light, D: door, T: temperature.
We prepared the data by removing sensors that only detect light or motion within 1 m, as they are not representative for smart home devices. We also converted the datasets to a wide format, where each sensor has its own column and a new row is created for each sensor event. We cast all values to either binary or integer.
3.2 LLM
For the experiments Ex1–Ex3 in May 2024, we used OpenAI’s GPT-4 via the chat interface. GPT-4 was chosen because of its widespread recognition and strong performance in various fields. In November 2024, we conducted a second series of experiments Ex4–Ex6 with the updated GPT-4o model. Since we wanted to explore privacy risks posed by users without deep ML knowledge, we did not use any preceding prompts or system prompts in our experiments. The chat interface’s default settings were used, with both Top-P and Temperature set to 1, and Frequency and Presence penalties set to 0. The models employed were gpt-4-0125-preview for GPT-4 and gpt-4o-2024-11-20 for GPT-4o, which were the standard models available in the chat interface at the time of our experiments . 45 To isolate the experiments from each other, we started a new chat session for each experiment.
To ensure consistency, we repeated each experiment multiple times until the variance of the results did not increase further, i.e., our termination criterion was the converging result quality. On average, we repeated each experiment 10 times. For all experiments, we provided the prompt, uploaded the dataset with OpenAI’s document loader, 46 , 47 and let the LLM execute the data analysis.
3.3 Prompting
Our starting point is an adversary without in-depth ML expertise, who generates LLM prompts to infer daily activities from time-series of sensor data. To devise prompts for our experiments, we determine the capabilities of this adversary.
Adversary model: We assume an LLM user with access to smart home sensor data. The user has the expertise to write prompts in a trial-and-error style, according to beginner’s prompting tutorials. The user has an intuition of daily patterns, activities and data structures. They do not use LLM APIs or scripting languages, nor fine-tune models. Sophisticated prompting techniques, e.g., Chain-of-Thought or Decomposition, are beyond their abilities. Thus, the user cannot write prompts that specify how the LLM should clean, transform, and analyze time-series data for a defined ML analysis, but relies on the ML knowledge contained in the LLM.
Based on this adversary, we decided to use zero-shot prompts for Ex1–Ex4. Experiment Ex5 tests a slightly more sophisticated CO-STAR prompt, and Ex6 uses both a zero-shot prompt and the CO-STAR prompt.
3.3.1 Zero-shot prompts
We created straightforward zero-shot prompts first. The prompts contain the structure of the sensor data and the expected output format. Figure 1 shows the zero-shot prompt used for Ex1, Ex4, and Ex6. The similar zero-shot prompts for Ex2 and Ex3 can be found in Ref. 6].

Zero-shot prompt for inferring daily activities (Ex1, Ex4).
3.3.2 CO-STAR prompt
To contrast the straightforward zero-shot prompts, for Ex5 and Ex6, we chose a CO-STAR prompt that, while more advanced with its training and test split, allows users without much prompting expertise to refine inputs through trial and error. Our CO-STAR prompt (see Appendix A, Figure 8) instructs the LLM to first use a labeled dataset for training and then use another unlabeled dataset for the experiment. It is structured into the sections Context, Objective, and Response Format.
The Context part of the prompt provides contextual information about the purpose of the analysis, highlighting privacy concerns, and specifying that the household consists of a single resident. The Context introduces two datasets: a “familiarization” dataset containing labeled activity patterns, and an unlabeled single-day dataset to apply these patterns to. Additionally, Context describes the structure of both datasets, its sensors and data types (e.g., temperature, motion, door, and light sensors), and naming conventions.
We recall that the task in Ex5 and Ex6 was to infer daily activities for a single day of unlabeled activities from household HH101. We derived the familiarization dataset from multiple weeks of labeled daily activities of HH101. The single day of unlabeled activities we used so far, a Monday in August, was very similar to many other days in the entire dataset of HH101. A brief test revealed that the inferred activities were rather unreliable and inaccurate, regardless of whether we removed that one day from the familiarization dataset or not. Therefore, we used all data from HH101 in the hope that a degree of overfitting might improve the results.
The Objective part of the prompt specifies two steps: (a) The LLM needs to learn the activity patterns from the familiarization dataset, and (b) must be instructed to apply these patterns to the single-day dataset. Our familiarization dataset contains 35 distinct activity labels. During our prompt design process, we observed that a short summary of the labels (see “Pattern Derivation” in Appendix A, Figure 8) produced similar results to including the entire list of activity labels. To maintain brevity, we opted to include only the short description. The Objective contains explicit instructions for handling the dataset, as well as for circumventing missing data. It also provides clear guidance on interpreting patterns of sensor activity, such as associating movement in the bedroom at night with sleeping, or movement in the kitchen with the lights on with cooking.
In the Response Format part, the prompt specifies that inferred activities should be grouped into meaningful time blocks that span the entire day, while limiting the timeline to 8–12 distinct periods. Each activity must include a reasoning statement to provide transparency. Detailed formatting guidelines are also provided.
3.4 Ground truth
To evaluate how well the LLM can infer activities, we compare its output with an annotated ground truth adapted from the CASAS data set. For example, Figure 2 shows activity (transparent: activity, blue: no activity) in Apt. HH101 on August 20, 2012. The first five rows visualize sensor activities, and the last row shows the activity labels from the CASAS data. As the figure shows, the original labels are inconsistent, non-specific, and oversegmented on the time axis.
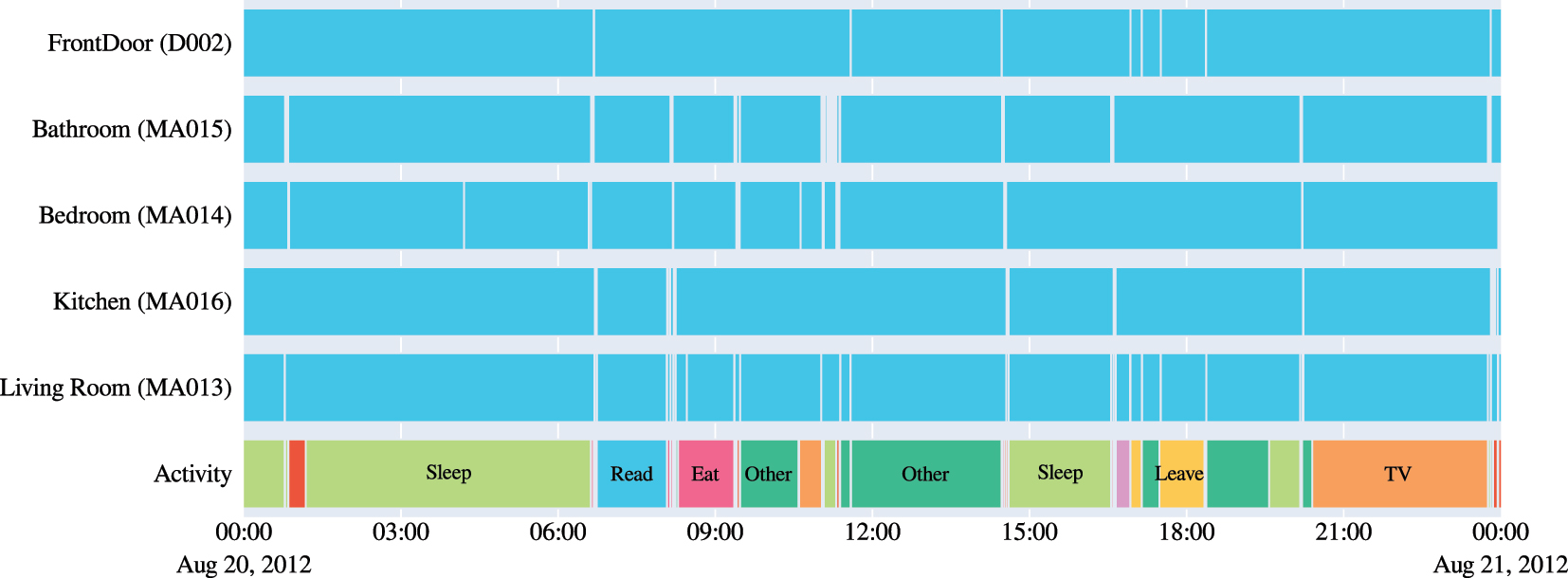
Activity in apartment HH101 on August, 20 2012. The first five rows visualize sensor activity (transparent: activity, blue: no activity), and the last row shows the activity labels from the CASAS data. The labels sometimes lack specificity and display high fragmentation on the time axis.
Thus, we adapted the CASAS labels to the human activities the experiments are supposed to recognize. In particular, we inferred activities that were labeled with “Other”, e.g., we labelled periods without movement and door activity at the beginning and the end as “Away from Home”. We unified the labels of activities that were named differently but represented the same behavior, such as “Various Activities” and “Work/Leisure”. Finally, we filtered out any activity shorter than 5 min, to avoid oversegmentation. The left column in Figure 4 shows our annotation for Figure 2.
4 Experimental results
In this section, we present the results of our experiments. We recall that our concern is a non-specialist in ML being able to use an LLM to carry out privacy attacks on smart home data. Thus, we want to learn the capabilities of GPT-4 to infer daily activities (Ex1), daily routines (Ex2) and unusual activities (Ex3), and observe potential improvements of GPT-4o (Ex4) and sophisticated prompting (Ex5). We also inspect the LLM’s background knowledge (Ex6).
4.1 Daily activities (Ex1)
The goal of Ex1 is to assess how accurately GPT-4 maps sensor readings to daily activities. The experiment mimics the adversary with access to the smart home sensor data of their target apartment, acquired, e.g., by data leaks. The adversary then relies on the LLM to learn about daily activities, e.g., to prepare a burglary or stalking. We use the data of apartment HH101 from August 20, 2012 and the zero-shot prompt from Figure 1, and we repeated this experiment multiple times to ensure consistency. All runs produced similar results, as exemplarily shown in Figure 3.

Inferred daily activity from HH101 for August, 20 2012.
Figure 4 compares our ground truth with the LLM’s inference. Until 11:00, the LLM performs well, with only minor differences. From 12:00 to 20:00, it appears to hallucinate. There’s no evidence for “Lunch” or “Dinner” due to no sensor activity in the kitchen at these times. The “Away from Home” period with no activity was also missed. The LLM appears to correctly infer activities for a total of 14 h, as shown in Table 3. Various days were tested when developing the prompt, sometimes yielding similar or worse results. These inconsistencies highlight the challenges in ensuring reliable performance across different datasets and scenarios.
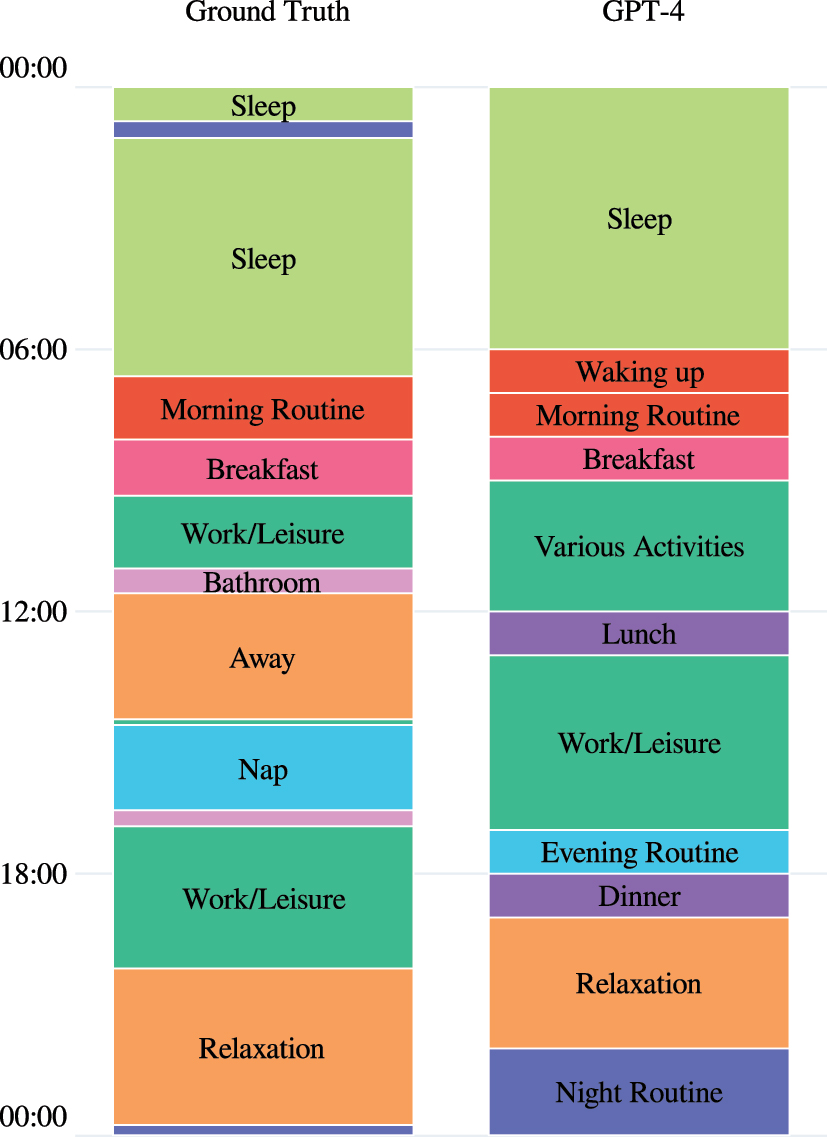
Ground truth versus GPT-4 inferred daily activity in apartment HH101 on August 20, 2012.
Inferred daily activity versus ground truth, Apt. HH101, Aug. 20, 2012.
| Time | Inferred activity | Inferred duration | Correct |
|---|---|---|---|
| 00:00 | |||
| | | Sleep | 6 | 6 |
| 06:00 | |||
| | | Waking up | 1 | 1 |
| 07:00 | |||
| | | Morning routine | 1 | 1 |
| 08:00 | |||
| | | Breakfast | 1 | 1 |
| 09:00 | |||
| | | Various activities | 3 | 2 |
| 12:00 | |||
| | | Lunch | 1 | 0 |
| 13:00 | |||
| | | Work/leisure | 4 | 0 |
| 17:00 | |||
| | | Evening routine | 1 | 0 |
| 18:00 | |||
| | | Dinner | 1 | 0 |
| 19:00 | |||
| | | Relaxation | 3 | 3 |
| 22:00 | |||
| | | Night routine | 2 | 0 |
| 23:59 |
4.2 Daily routine (Ex2)
Next, we explore GPT-4’s capability to identify the daily routine, aiming to evaluate whether it can provide a coherent summary of typical daily activities over a week. Our concern is a privacy concern similar to Ex1, but the adversaries’ objective is to identify recurring behavioral patterns. Ex2 uses data from apartment HH101 from July 31 to August 6, 2012, and a zero-shot prompt similar to the one of Ex1.
Surprisingly, GPT-4 mostly ignored our various prompt attempts to deliver coherent weekly reports without gaps. Instead, GPT-4 yielded nonsensical time frames, such as “12:00–12:00”, excessively fine-grained time frames (e.g., 15-min intervals) that covered only part of the day, and vague descriptions such as “no significant activity”.
We were able to extract and reproduce only one usable weekly behavioral report, and compare it to our ground truth. Table 4 shows each day we evaluated and whether recurring activities were identified correctly. However, most activities inferred by the LLM deviated from our ground truth. This highlights GPT-4’s limitations to infer the daily routine from the data provided, and leaves much room for further improvements.
Inferred daily routine for apartment HH101 (x: incorrect).
| Time | Activity | 31.7. | 1.8. | 2.8. | 3.8. | 4.8. | 5.8. | 6.8. |
|---|---|---|---|---|---|---|---|---|
| 00:00 | Sleep | x | x | x | x | x | x | x |
| 05:00 | Morning | x | x | x | x | x | x | ✓ |
| 06:00 | Breakfast | x | x | x | x | x | x | x |
| 07:00 | Leaving | x | x | x | x | x | x | x |
| 08:00 | Away | x | x | x | x | x | x | x |
| 17:00 | Returning | ✓ | ✓ | x | x | ✓ | ✓ | x |
| 18:00 | Dinner | x | x | x | x | x | x | x |
| 19:00 | relax | ✓ | ✓ | ✓ | x | ✓ | ✓ | ✓ |
| 20:00 | Bathroom | x | x | x | x | x | x | x |
| 21:00 | Sleep prep. | x | x | x | x | x | x | x |
4.3 Unusual activities (Ex3)
The goal of Ex3 is to produce evidence for GPT-4’s ability to identify events that deviate from habitual behavior. This might allow an adversary to exfiltrate private details that are not part of an everyday activity, e.g., going on vacation, having become ill, or giving a party.
In a first experiment, Ex3 uses data from apartment HH102 for the week of August 8 to August 15, 2011. This time period has two anomalies: A door left open for more than an hour and an office light left on for more than 10 h. GPT-4 successfully detected both anomalies, and demonstrated its potential to identify significant deviations in smart home environments. However, when repeating this experiment with data from apartment HH101 and the week from July 31 to August 6, 2012, GPT-4 detected nothing but hallucinations. This suggests that GPT-4’s performance varies, depending on characteristics of the data sets and the unusual activities.
4.4 New model (Ex4)
To examine the impact of LLM model advances on our privacy attacks, we compare the capabilities of GPT-4 (Version: gpt-4-0125-preview) and GPT-4o (Version: gpt-4o-2024-11-20). Therefore, we repeat Ex1 with GPT-4o, i.e., we let the LLM infer daily activities with our zero-shot prompt for apartment HH101 on August 20, 2012.
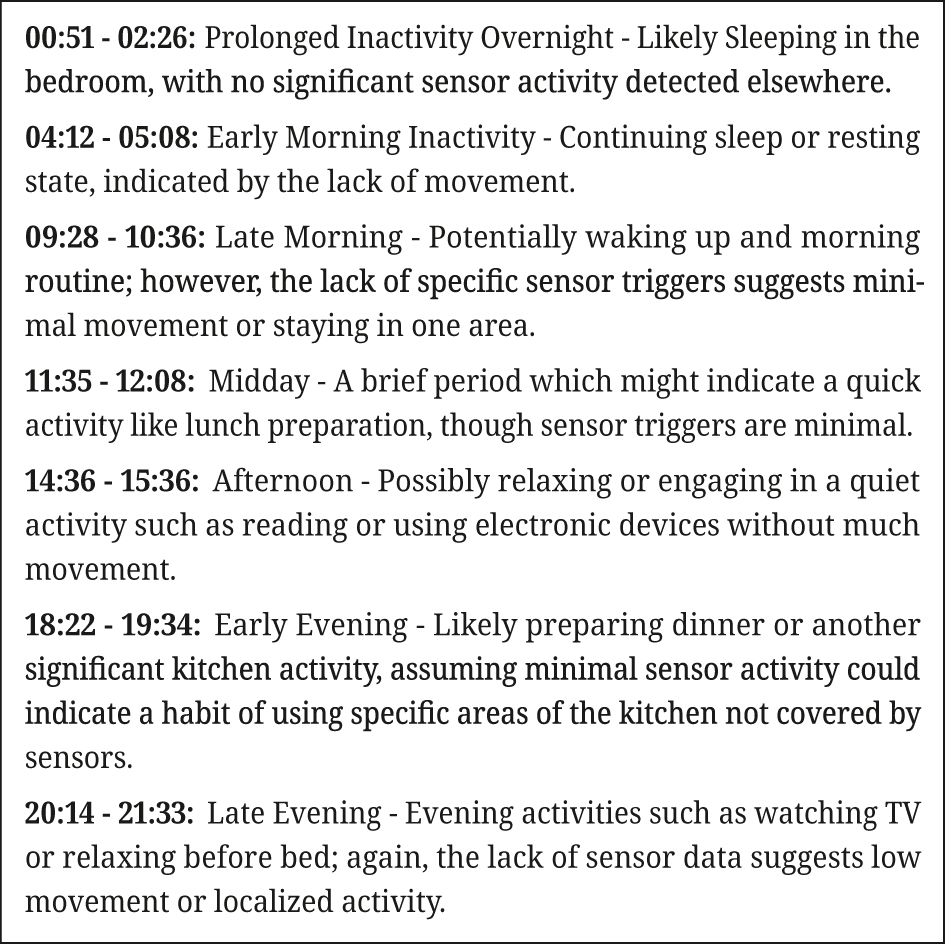
To our surprise, the new GPT-4o model performed much worse than GPT-4 for our daily activity experiment. We repeated our experiment multiple times. Figure 5 shows one of the best daily activity reports we obtained.

GPT-4o inferred daily activity from sensor data.
Frequently, GPT-4o delivered reports with more than 15 activities, as requested by the prompt. Some activities were identified with durations as brief as 1 min, or had identical start and end times. The inferred activities did not cover the whole day, and empty time slots between inferred activities disrupted the continuity of daily timelines. Finally, many labels were ambiguous, such as “Unknown” or “Various.”
4.5 CO-STAR prompting (Ex5)
Ex1–Ex4 used straightforward zero-shot prompts that any adversary could devise without in-depth knowledge about privacy attacks, machine learning or LLMs. With this experiment, we want to learn if a sophisticated CO-STAR prompt and relating training data can increase the accuracy of the inferred daily activities. Our CO-STAR prompt is much longer and more complex than the zero-shot prompt (cf. Appendix A). It instructs the LLM to use a labeled dataset to infer labels for an unlabeled dataset. After receiving this prompt, the LLM asks to upload both data sets and starts processing.
Figure 6 provides a typical result from GPT-4. While literature proposes CO-STAR as a promising prompt design for complex data analysis tasks, 43 we found that in almost all experiment runs, the daily activities were inferred with less accuracy than in the zero-shot prompt in Ex1. Similar to Ex4, GPT-4o performed much worse than GPT-4. Almost all inferred timelines were unrelated to the input data, contained activities that were unlikely at the assigned time, and the activities exceeded our limit of 15 activities we requested in the prompt. We conclude that a sophisticated prompt might actually distract GPT-4 from its analysis tasks, and the GPT-4o model seems to have issues with our prompt design or with understanding the data.
Inferred daily activities for Apt. HH101, Aug 20, 2012 with GPT-4.
4.6 Background knowledge (Ex6)
To assess background knowledge of the LLMs, in Ex6 we did not upload the data set, but told the LLM to execute the prompt without input data. Background knowledge on typical human activities is an enabler for many privacy attacks. It allows the imputation of missing data, and is needed to interpret the results of an analysis of personal data. In order to assess the amount of background knowledge in GPT-4 and GPT-4o, we take the best-working case (GPT-4 with a zero-shot prompt, i.e., Ex1) and the worst-working case (GPT-4o with CO-STAR prompting as part of Ex5), each without providing data. To this end, when the respective LLM asked for the familiarization dataset or the test data set, we instructed it with “Please continue without any dataset” to proceed. We expect that the LLMs generate a typical daily routine from their knowledge on human activities.
We repeated this experiment several times. In most test runs, we obtained results like the one visualized in Figure 7. For comparison, the left column of the figure displays our ground truth, i.e., apartment HH101 on August 20, 2012.
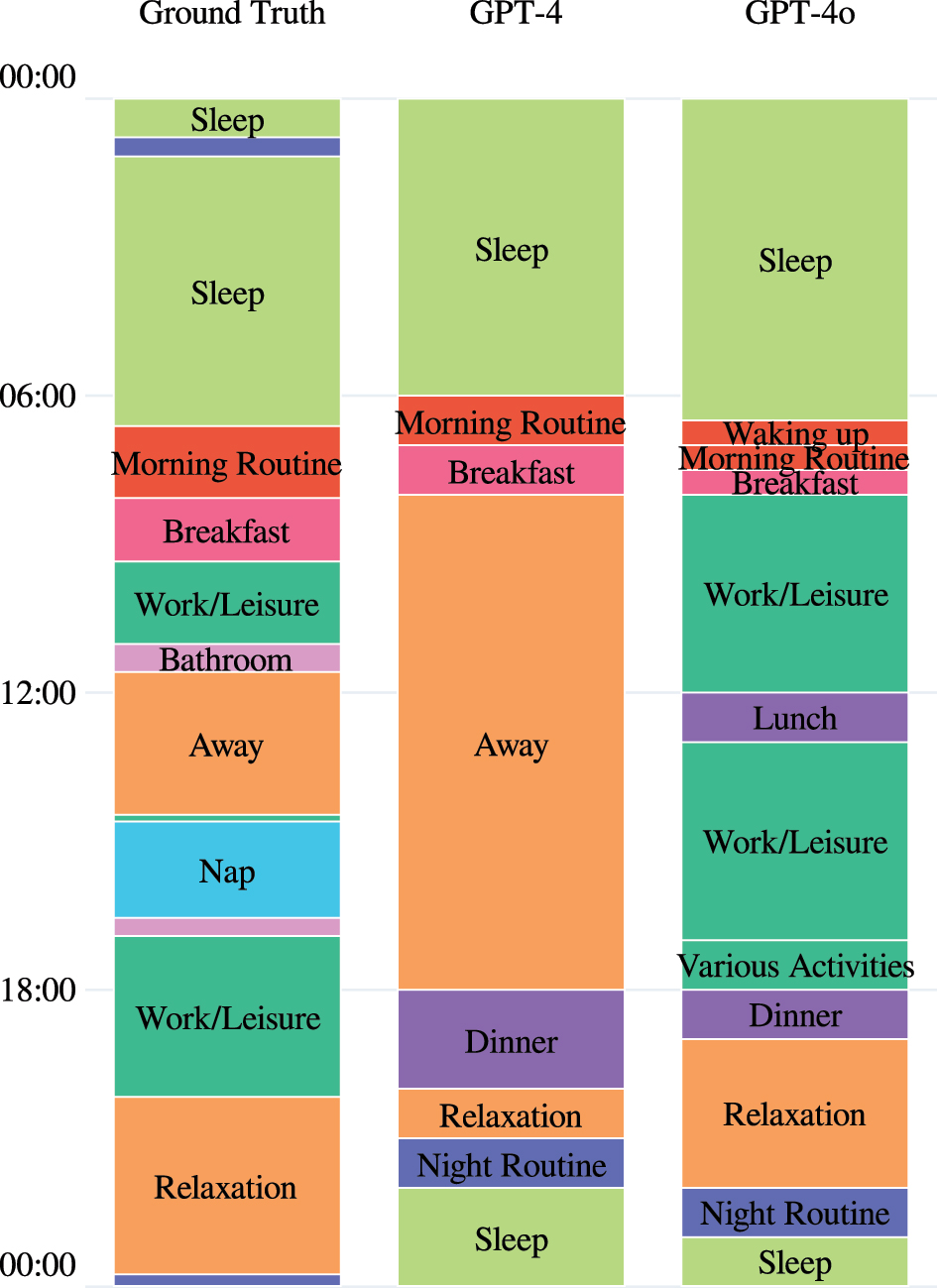
Ground truth versus background knowledge of GPT-4 and GPT-4o.
In addition, we extended the prompts with specific impersonations. For example, we told the LLMs to generate the sequence of daily activities for a baker, a student, a shift worker or an unemployed person. In each case, we obtained daily routines that we deem realistic for both models. For example, Appendix B, Figure 9 contains the routine of a baker, obtained with GPT-4 and our zero-shot prompt. As expected, both GPT-4 and GPT-4o demonstrated very detailed background knowledge about daily routines, regardless of the prompt used. This indicates a robust grasp of human activity patterns, which can help to automatically extrapolate missing data and provide interpretations of the analyzed data. This automation potential highlights potential privacy risks in smart-home contexts.
5 Discussion
Our study investigates to what extent recent advances in LLMs, accessible without requiring ML expertise, enable privacy risks through human activity detection from smart home sensor data, particularly via behavior inference and reliance on pre-trained background knowledge. We evaluated this across multiple tasks: inferring daily activities, the daily routine, and unusual activities. In the following, we contextualize our results (Section 5.1), outline practical implications of our findings (Section 5.2), and discuss further limitations and avenues for future research (Section 5.3).
5.1 Summary of findings
A core concern of this study was whether LLM accessibility would introduce new privacy risks by enabling non-experts to infer behaviors from sensor data. Contrary to expectations that arose from literature (Section 2.3), e.g., Xia et al.’s use of ChatGPT for HAR on data from wearable sensors, 31 our findings suggest that both GPT-4 and GPT-4o, when used with basic prompting techniques, struggle to reliably infer human activities from smart home sensor data.
Across all tasks, our findings yielded mixed results with GPT-4. For example, it could accurately infer certain daily activities, such as morning routines, but struggled with hallucinations and incorrect formatting, especially when identifying the daily routine over a week. Even in the best-performing experiment (Ex1), GPT-4 was underwhelming, only inferring correct activities for the first half of the day.
The introduction of GPT-4o did not yield the expected improvements. It performed worse than GPT-4 in inference of Daily Activities with zero-shot prompts (Ex4), producing fragmented timelines and ambiguous labels. More sophisticated prompting using CO-STAR (Ex5) deteriorated results for both GPT-4 and GPT-4o, and again, the older GPT-4 outperformed GPT-4o. While this might suggest that newer model iterations may not always enhance the result, especially when applied to complex real-world data, the large input size (prompt and document) might have been truncated in the background without notification, leading to ignored instructions. Since we did not explicitly control for the input length of smart home sensor data, the impact of shorter/longer sequences on model output remains an open question that requires further investigation. Future benchmarks, e.g., using RULER, 48 could shed more light on the real context length and to what extent prompt designs have to balance complexity with clarity.
In general, the experiments were difficult to conduct, and the responses by the LLM were often verbose, even though our prompts required a list response. Even with examples as templates, responses sometimes had formatting errors, such as missing or duplicate time periods. In addition, responses were often grouped incorrectly and the same unusual activity was reported multiple times. In some cases, the same model provided different answers for identical data inputs. Without instructions on how to analyze the data, the LLM could not consistently infer accurate information. The LLM frequently encountered errors such as “It appears there was an error in the process” and had to be restarted. Overall, unlike traditional ML approaches that optimize for accuracy using labeled data and statistical modeling, LLMs produced outputs that sounded plausible but lacked reliability. This underscores their limitations in structured data analysis, if used on their own.
LLMs are known to incorporate vast background knowledge, and our experiment Ex6 validated that both models exhibited exceptional background knowledge about daily routines, regardless of the prompt used. This highlights potential privacy risks involved in smart-home contexts, as it could be used to deliver easy-to-understand interpretations to non-experts and automatically compensate for data gaps. However, rather than compensating for missing information, the models seemed to ignore the sensor data and over-rely on their background knowledge. Both GPT-4 and GPT-4o often generated confident but incorrect inferences, demonstrating a susceptibility to hallucination rather than genuine pattern recognition.
5.2 What does this imply?
Given the rather poor LLM performance in our experiments, our findings emphasize the limitations of general-purpose AI tools for structured data analysis rather than their immediate privacy risks. However, this outcome provides important insights into design and practical implications for development and deployment of user-centric LLM-based assistants in smart home contexts (Section 2.1). Similar to enhancing comfort, 14 when empowered to perform data analysis on smart home data, these conversational agents could help educating users about potential privacy risks. For example, implemented in a smart home system, they could demonstrate to the user how much personal information can be inferred from their current smart home data. This enables the user to make a more informed decision about their smart home system (in terms of data collection and sharing data with vendors) and network security.
In this context, on a technical level, we find that designers and programmers should avoid over-reliance on LLMs for structured data analysis (I1). Both GPT-4 and GPT-4o struggled with structured sensor data. We learn that designers and developers should not assume that LLMs can reliably extract insights from structured datasets like time-series sensor data. Instead, our findings reinforce the need for hybrid AI approaches that combine language models with specialized ML techniques (I2). In particular, integrating structured learning models that track long-term patterns and contextualize behaviors over time could improve reliability in behavior inference applications. To this end, one could first develop a working ML pipeline for analyzing the data, then gradually replace parts of this pipeline with complex prompts to evaluate if LLMs can viably replace traditional ML methods. These prompts could then be simplified progressively to assess whether attackers with minimal expertise could still extract meaningful insights, thereby evaluating the real-world privacy risks associated with these models.
Designing interfaces that clearly communicate LLM limitations in data-driven contexts (I3) could prevent users from misinterpreting AI-generated insights. Non-experts using LLMs for structured data analysis in particular may otherwise misinterpret outputs due to the models’ tendency to generate confident but unreliable answers. If coupled with ML techniques, depending on how explainable it is (e.g., decision tree vs. specialized neural networks), explanation and uncertainty indicators or confidence scores could be added, but further research is needed regarding information overload in smart home contexts.
On a policy level beyond LLM-based assistants in smart homes, our findings suggest that AI accessibility does not automatically lead to privacy risks (I4). While AI accessibility raises concerns about misuse, our findings suggest that making LLMs available does not inherently increase privacy risks in structured data analysis. Future discussions on AI governance should differentiate between model accessibility and actual capability when assessing potential threats.
Finally, our results underscore the importance of systematically evaluating LLMs in non-language domains (I5). Future research should establish benchmarking standards for AI output quality in structured data contexts to prevent overestimations of LLM capabilities.
5.3 Further limitations and future work
The dataset used in our study was focused primarily on a single household with a limited range of sensors (motion, door, temperature, and light), and it included a wide array of 35 distinct activities. This setup does not capture the full complexity of modern smart homes and made it difficult for the model to accurately recognize such a high number of activities. To address this limitation, future work should expand datasets to include multiple households, a variety of device types, and more diverse user behaviors. Another promising avenue is to further reduce the number of distinct activities to reduce fragmentation.
While using the chat-based interface resonates well with our assumed adversary model (Section 3.3), API-based prompting provides more control over model behavior, enabling structured and reproducible interactions that might yield different or more reliable inferences. Future work could examine whether API-based adversarial strategies such as iterative refinement or retrieval-augmented techniques enhance inference accuracy.
Our evaluation was constrained to two prompting strategies: zero-shot and CO-STAR prompting. We chose these techniques to capture a reasonable range of prompting styles that align with our adversary model. It remains open to what extent alternative prompting paradigms, such as few-shot learning, chain-of-thought reasoning, and combinations with iterative feedback loops improve results.
Automated testing across multiple models is necessary to better understand how different LLMs perform on sensor data. Our study focused only on GPT-4 and GPT-4o, leaving open questions about output variations across other models. Developing automated testing frameworks to evaluate different LLMs on identical datasets and prompts is a promising research avenue. Additionally, comparisons with AI models designed specifically for sensor-based HAR should be made to determine whether LLMs offer any advantages over traditional methods.
Our findings are framed within an adversarial context, assuming an entity attempting to infer user activities without specialized ML expertise. Shifting the perspective to user-centric LLM-based assistants, i.e., a smart home user with full data access, presents an alternative scenario in which different prompting strategies and LLM interaction models may be more viable. While our results highlight the inherent weaknesses of naive, zero-shot prompting for behavior inference, future work should explore whether more structured, user-driven interactions yield stronger results in practical smart home applications.
6 Conclusions
Smart homes use sensor information linked with user behavior to monitor parameters like temperature, humidity, noise, and motion, etc., enabling automated decision-making for personalized living experiences. While these advancements offer convenience, they also raise significant privacy concerns. Recent advances in LLMs might have lowered the bars for an attacker to infer private details from such data. In particular, this might allow non-experts to analyze and interpret raw data with sophisticated machine learning algorithms through a conversational chatbot interface.
In this work, we used the CASAS datasets to explore the extent to which GPT-4 and GPT-4o can infer daily human activities, daily routines, and activities that deviate from such routines from smart-home sensor data. While GPT-4 showed some accuracy in inferring daily and unusual activities, it was less effective at recognizing daily routines. GPT-4o, even with the aid of structured CO-STAR prompts and labeled data, underperformed GPT-4. However, both models demonstrated an impressive amount of background knowledge about typical daily routines. This emphasizes the potential privacy risks due to the analysis of data from smart-home contexts with LLMs, and underlines the need for advances in model design, prompt engineering, and mitigation strategies to assess and manage these privacy risks effectively.
Acknowledgments
The authors acknowledge financial support from the Federal Ministry of Education and Research of Germany and from the Sächsische Staatsministerium für Wissenschaft, Kultur und Tourismus within the program Center of Excellence for AI Research: “Center for Scalable Data Analytics and Artificial Intelligence Dresden/Leipzig,” project identification number: ScaDS.AI.
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: The LLMs GPT-4 and GPT-4o were used to conduct the experiments in the paper, the use is clearly marked. LLMs were further used to improve language.
-
Conflict of interest: The authors state no conflict of interest.
-
Research funding: None declared.
-
Data availability: The raw data is publicly accessible, sources are in the paper.
Appendix A: CO-STAR prompt

Our CO-STAR prompt for Ex5, Ex6.

(continued)
Appendix B: Baker’s daily routine

Daily routine of a baker, Ex6.
References
1. Geneiatakis, D.; Kounelis, I.; Neisse, R.; Nai-Fovino, I.; Steri, G.; Baldini, G. Security and Privacy Issues for an IoT Based Smart Home. In 2017 40th International Convention on Information and Communication Technology, Electronics and Microelectronics; IEEE: Piscataway, NJ, 2017; pp 1292–1297.10.23919/MIPRO.2017.7973622Suche in Google Scholar
2. Bugeja, J.; Jacobsson, A.; Davidsson, P. PRASH: A Framework for Privacy Risk Analysis of Smart Homes. Sensors 2021, 21, 19. https://doi.org/10.3390/s21196399.Suche in Google Scholar PubMed PubMed Central
3. Todi, K.; Leiva, L. A.; Buschek, D.; Tian, P.; Oulasvirta, A. Conversations with GUIs. In Proceedings of the 2021 ACM Designing Interactive Systems Conference. DIS ‘21. Virtual Event; Association for Computing Machinery: New York, NY, 2021; pp 1447–1457.10.1145/3461778.3462124Suche in Google Scholar
4. Ma, P.; Ding, R.; Wang, S.; Han, S.; Zhang, D. InsightPilot: An LLM-Empowered Automated Data Exploration System. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Stroudsburg, PA, 2023; pp 346–352.10.18653/v1/2023.emnlp-demo.31Suche in Google Scholar
5. LangChain. Python REPL Integration, 2025. https://python.langchain.com/docs/integrations/tools/python/ (accessed 2025-02-26).Suche in Google Scholar
6. Jüttner, V.; Fleig, A.; Buchmann, E. ChatAnalysis: Can GPT-4 Undermine Privacy in Smart Homes with Data Analysis? Mensch und Computer 2024 – Workshopband, 2024.10.1515/icom-2024-0072Suche in Google Scholar
7. Cook, D. J.; Crandall, A. S.; Thomas, B. L.; Krishnan, N. C. CASAS: A Smart Home in a Box. Computer 2013, 46 (7), 62–69. https://doi.org/10.1109/MC.2012.328.Suche in Google Scholar PubMed PubMed Central
8. Google. Nest Thermostat, 2024. https://store.google.com/us/product/nest_thermostat?hl=en-US (accessed 2025-02-26).Suche in Google Scholar
9. Hue, P. Philips Hue Smart Lighting, 2024. https://www.philips-hue.com/en-us (accessed 2025-02-26).Suche in Google Scholar
10. Ring. Ring Video Doorbell, 2024. https://ring.com/products/video-doorbell (accessed 2025-02-26).Suche in Google Scholar
11. Amazon. Amazon Echo (4th Gen), 2024. https://www.amazon.com/Echo-4th-Gen/dp/B07XKF5RM3 (accessed 2025-02-26).Suche in Google Scholar
12. Zhang, H.; Ananda, R.; Fu, X.; Sun, Z.; Wang, X.; Chen, K.; Carroll, J. Multi-Channel Sensor Network Construction, Data Fusion and Challenges for Smart Home. In Proceedings of the Eleventh International Symposium of Chinese CHI. CHCHI ‘23; Association for Computing Machinery: Denpasar, Bali, Indonesia, 2024; pp. 344–351.10.1145/3629606.3629638Suche in Google Scholar
13. King, E.; Yu, H.; Lee, S.; Julien, C. Sasha: Creative Goal-Oriented Reasoning in Smart Homes with Large Language Models. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2024, 8 (1), 1–38. https://doi.org/10.1145/3643505.Suche in Google Scholar
14. Giudici, M.; Padalino, L.; Paolino, G.; Paratici, I.; Pascu, A. I.; Garzotto, F. Designing Home Automation Routines Using an LLM-Based Chatbot. Designs 2024, 8 (3), 43. https://doi.org/10.3390/designs8030043.Suche in Google Scholar
15. Cumin, J.; Lefebvre, G.; Ramparany, F.; Crowley, J. L. A Dataset of Routine Daily Activities in an Instrumented Home. In Ubiquitous Computing and Ambient Intelligence; Ochoa, S. F., Singh, P., Bravo, J., Eds.; Springer International Publishing: Cham, 2017; pp 413–425.10.1007/978-3-319-67585-5_43Suche in Google Scholar
16. Alemdar, H.; Ertan, H.; Incel, O. D.; Ersoy, C. ARAS Human Activity Datasets in Multiple Homes with Multiple Residents. In 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops; IEEE: Piscataway, NJ, 2013; pp 232–235.10.4108/pervasivehealth.2013.252120Suche in Google Scholar
17. Park, S. Machine Learning-Based Cost-Effective Smart Home Data Analysis and Forecasting for Energy Saving. Buildings 2023, 13 (9), 2397. https://doi.org/10.3390/buildings13092397.Suche in Google Scholar
18. Guo, X.; Shen, Z.; Zhang, Y.; Wu, T. Review on the Application of Artificial Intelligence in Smart Homes. Smart Cities 2019, 2 (3), 402–420. https://doi.org/10.3390/smartcities2030025.Suche in Google Scholar
19. Almusaed, A.; Yitmen, I.; Almssad, A. Enhancing Smart Home Design with AI Models: A Case Study of Living Spaces Implementation Review. Energies 2023, 16, 6. https://doi.org/10.3390/en16062636.Suche in Google Scholar
20. Bouchabou, D.; Nguyen, S. M.; Lohr, C.; LeDuc, B.; Kanellos, I. Fully Convolutional Network Bootstrapped by Word Encoding and Embedding for Activity Recognition in Smart Homes. In Deep Learning for Human Activity Recognition; Li, X., Ed., et al..; Springer Singapore: Singapore, 2021.10.1007/978-981-16-0575-8_9Suche in Google Scholar
21. Du, Y.; Lim, Y.; Tan, Y. A Novel Human Activity Recognition and Prediction in Smart Home Based on Interaction. Sensors 2019, 19 (20), 4474. https://doi.org/10.3390/s19204474.Suche in Google Scholar PubMed PubMed Central
22. Creţu, A.-M.; Monti, F.; Marrone, S.; Dong, X.; Bronstein, M.; de Montjoye, Y. A. Interaction Data are Identifiable Even Across Long Periods of Time. Nat. Commun. 2022, 13 (1), 313. https://doi.org/10.1038/s41467-021-27714-6.Suche in Google Scholar PubMed PubMed Central
23. de Montjoye, Y.-A.; Hidalgo, C. A.; Verleysen, M.; Blondel, V. D. Unique in the Crowd: The Privacy Bounds of Human Mobility. Sci. Rep. 2013, 3 (1), 1376. https://doi.org/10.1038/srep01376.Suche in Google Scholar PubMed PubMed Central
24. Powar, J.; Beresford, A. R. SoK: Managing Risks of Linkage Attacks on Data Privacy. Proc. Priv. Enh. Technol. 2023, 2023, 97–116. https://doi.org/10.56553/popets-2023-0043.Suche in Google Scholar
25. Jüttner, V.; Grimmer, M.; Buchmann, E. ChatIDS: Advancing Explainable Cybersecurity Using Generative AI. Int. J. Adv. Secur. 2024, 17 (1), 2.Suche in Google Scholar
26. Copos, B.; Levitt, K.; Bishop, M.; Rowe, J. Is Anybody Home? Inferring Activity from Smart Home Network Traffic. In 2016 IEEE Security and Privacy Workshops (SPW); IEEE: Piscataway, NJ, 2016; pp 245–251.10.1109/SPW.2016.48Suche in Google Scholar
27. Wang, C.; Kennedy, S.; Li, H.; Hudson, K.; Atluri, G.; Wei, X.; Sun, W.; Wang, B. Fingerprinting Encrypted Voice Traffic on Smart Speakers with Deep Learning. In Proceedings of the 13th ACM Conference on Security and Privacy in Wireless and Mobile Networks; ACM: New York, NY, 2020; pp 254–265.10.1145/3395351.3399357Suche in Google Scholar
28. Narayanan, A.; Shmatikov, V. Robust De-Anonymization of Large Sparse Datasets. In Proceedings of the 2008 IEEE Symposium on Security and Privacy, 2008; pp. 111–125.10.1109/SP.2008.33Suche in Google Scholar
29. Hota, A.; Chatterjee, S.; Chakraborty, S. Evaluating Large Language Models as Virtual Annotators for Time-Series Physical Sensing Data. arXiv preprint arXiv: 2403.01133, 2024.10.1145/3696461Suche in Google Scholar
30. Okita, T.; Ukita, K.; Matsuishi, K.; Kagiyama, M.; Hirata, K.; Miyazaki, A. Towards LLMs for Sensor Data: Multi-Task Self-Supervised Learning. In Adjunct Proceedings of the 2023 ACM International Joint Conference on Pervasive and Ubiquitous Computing & the 2023 ACM International Symposium on Wearable Computing. UbiComp/ISWC ‘23 Adjunct; Association for Computing Machinery: Cancun, Quintana Roo: Mexico, 2023; pp. 499–504.10.1145/3594739.3610745Suche in Google Scholar
31. Xia, Q.; Maekawa, T.; Hara, T. Unsupervised Human Activity Recognition Through Two-Stage Prompting with ChatGPT. arXiv preprint arXiv: 2306.02140, 2023.Suche in Google Scholar
32. Civitarese, G.; Fiori, M.; Choudhary, P.; Bettini, C. Large Language Models Are Zero-Shot Recognizers for Activities of Daily Living. arXiv preprint arXiv:2407.01238, 2024.10.1145/3725856Suche in Google Scholar
33. Chen, X.; Cumin, J.; Ramparany, F.; Vaufreydaz, D. Towards LLM-Powered Ambient Sensor Based Multi-Person Human Activity Recognition. In 2024 IEEE 30th International Conference on Parallel and Distributed Systems (ICPADS); IEEE: Piscataway, NJ, 2024; pp. 609–616.10.1109/ICPADS63350.2024.00085Suche in Google Scholar
34. Kazama, K.; Shuzo, M. How ChatGPT Assists Novices in Human Activity Recognition. In Companion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing. UbiComp ‘24; Association for Computing Machinery: Melbourne VIC, Australia, 2024; pp. 575–579.10.1145/3675094.3678459Suche in Google Scholar
35. Jaimovitch-López, G.; Ferri, C.; Hernández-Orallo, J.; Martínez-Plumed, F.; Ramírez-Quintana, M. J. Can Language Models Automate Data Wrangling? Mach. Learn. 2023, 112 (6), 2053–2082. https://doi.org/10.1007/s10994-022-06259-9.Suche in Google Scholar
36. LangChain. Document Loaders, 2024. https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/ (accessed 2025-02-26).Suche in Google Scholar
37. Nielsen, J. AI: First New UI Paradigm in 60 Years, 2023. https://www.nngroup.com/articles/ai-paradigm/ (accessed 2025-02-26).Suche in Google Scholar
38. Bender, E. M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? . In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. FAccT ‘21; Association for Computing Machinery: New York, NY, 2021; pp 610–623.10.1145/3442188.3445922Suche in Google Scholar
39. Zamfirescu-Pereira, J. D.; Wong, R. Y.; Hartmann, B.; Yang, Q. Why Johnny Can’t Prompt: How Non-AI Experts Try (And Fail) to Design LLM Prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. CHI ‘23; Association for Computing Machinery: Hamburg, Germany, 2023.10.1145/3544548.3581388Suche in Google Scholar
40. Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; Agarwal, S.; Herbert-Voss, A.; Krueger, G.; Henighan, T.; Child, R.; Ramesh, A.; Ziegler, D.; Wu, J.; Winter, C.; Hesse, C.; Chen, M.; Sigler, E.; Litwin, M.; Gray, S.; Chess, B.; Clark, J.; Berner, C.; McCandlish, S.; Radford, A.; Sutskever, I.; Amodei, D. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ‘20; Curran Associates Inc.: Red Hook, NY, 2020.Suche in Google Scholar
41. Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q. V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems; Koyejo, S., Ed., et al..; Curran Associates, Inc.: Red Hook, NY, Vol. 35, 2022; pp. 24824–24837. https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf.Suche in Google Scholar
42. Patel, P.; Mishra, S.; Parmar, M.; Baral, C. Is a Question Decomposition Unit All We Need? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 4553–4569.10.18653/v1/2022.emnlp-main.302Suche in Google Scholar
43. GovTech Data Science & AI Division. Prompt Engineering Playbook (Beta), 2023. https://static.launchpad.tech.gov.sg/docs/Prompt20Engineering20Playbook20(Beta).pdf (accessed 2025-02-26).Suche in Google Scholar
44. Reynolds, L.; McDonell, K. Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. CHI EA ‘21; Association for Computing Machinery: Yokohama, Japan, 2021.10.1145/3411763.3451760Suche in Google Scholar
45. OpenAI. Models, 2024. https://platform.openai.com/docs/models (accessed 2025-02-26).Suche in Google Scholar
46. OpenAI. Introducing GPT-4, 2023. https://openai.com/blog/gpt-4 (accessed 2025-02-26).Suche in Google Scholar
47. OpenAI. Hello GPT-4o, 2024. https://openai.com/index/hello-gpt-4o/ (accessed 2025-02-26).Suche in Google Scholar
48. Hsieh, C.-P.; Sun, S.; Kriman, S.; Acharya, S.; Rekesh, D.; Jia, F.; Zhang, Y.; Ginsburg, B.: What's the Real Context Size of Your Long-Context Language Models? arXiv preprint arXiv: 2404.06654, 2024.Suche in Google Scholar
© 2025 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Frontmatter
- Special Issue on “Usable Safety and Security”
- Editorial on Special Issue “Usable Safety and Security”
- The tension of usable safety, security and privacy
- Research Articles
- Keeping the human in the loop: are autonomous decisions inevitable?
- iSAM – towards a cost-efficient and unobtrusive experimental setup for situational awareness measurement in administrative crisis management exercises
- Breaking down barriers to warning technology adoption: usability and usefulness of a messenger app warning bot
- Use of context-based adaptation to defuse threatening situations in times of a pandemic
- Cyber hate awareness: information types and technologies relevant to the law enforcement and reporting center domain
- From usable design characteristics to usable information security policies: a reconceptualisation
- A case study of the MEUSec method to enhance user experience and information security of digital identity wallets
- Evaluating GDPR right to information implementation in automated insurance decisions
- Human-centered design of a privacy assistant and its impact on perceived transparency and intervenability
- ChatAnalysis revisited: can ChatGPT undermine privacy in smart homes with data analysis?
- Special Issue on “AI and Robotic Systems in Healthcare”
- Editorial on Special Issue “AI and Robotic Systems in Healthcare”
- AI and robotic systems in healthcare
- Research Articles
- Exploring technical implications and design opportunities for interactive and engaging telepresence robots in rehabilitation – results from an ethnographic requirement analysis with patients and health-care professionals
- Investigating the effects of embodiment on presence and perception in remote physician video consultations: a between-participants study comparing a tablet and a telepresence robot
- From idle to interaction – assessing social dynamics and unanticipated conversations between social robots and residents with mild cognitive impairment in a nursing home
- READY? – Reflective dialog tool on issues relating to the use of robotic systems for nursing care
- AI-based character generation for disease stories: a case study using epidemiological data to highlight preventable risk factors
- Research Articles
- Towards future of work in immersive environments and its impact on the Quality of Working Life: a scoping review
- A formative evaluation: co-designing tools to prepare vulnerable young people for participating in technology development
Artikel in diesem Heft
- Frontmatter
- Special Issue on “Usable Safety and Security”
- Editorial on Special Issue “Usable Safety and Security”
- The tension of usable safety, security and privacy
- Research Articles
- Keeping the human in the loop: are autonomous decisions inevitable?
- iSAM – towards a cost-efficient and unobtrusive experimental setup for situational awareness measurement in administrative crisis management exercises
- Breaking down barriers to warning technology adoption: usability and usefulness of a messenger app warning bot
- Use of context-based adaptation to defuse threatening situations in times of a pandemic
- Cyber hate awareness: information types and technologies relevant to the law enforcement and reporting center domain
- From usable design characteristics to usable information security policies: a reconceptualisation
- A case study of the MEUSec method to enhance user experience and information security of digital identity wallets
- Evaluating GDPR right to information implementation in automated insurance decisions
- Human-centered design of a privacy assistant and its impact on perceived transparency and intervenability
- ChatAnalysis revisited: can ChatGPT undermine privacy in smart homes with data analysis?
- Special Issue on “AI and Robotic Systems in Healthcare”
- Editorial on Special Issue “AI and Robotic Systems in Healthcare”
- AI and robotic systems in healthcare
- Research Articles
- Exploring technical implications and design opportunities for interactive and engaging telepresence robots in rehabilitation – results from an ethnographic requirement analysis with patients and health-care professionals
- Investigating the effects of embodiment on presence and perception in remote physician video consultations: a between-participants study comparing a tablet and a telepresence robot
- From idle to interaction – assessing social dynamics and unanticipated conversations between social robots and residents with mild cognitive impairment in a nursing home
- READY? – Reflective dialog tool on issues relating to the use of robotic systems for nursing care
- AI-based character generation for disease stories: a case study using epidemiological data to highlight preventable risk factors
- Research Articles
- Towards future of work in immersive environments and its impact on the Quality of Working Life: a scoping review
- A formative evaluation: co-designing tools to prepare vulnerable young people for participating in technology development