A continuous and categorical approach to the L2 acquisition of Spanish voiced stop allophones
-
Rebeka Campos-Astorkiza


Abstract
Previous work on the second language (L2) acquisition of Spanish voiced stop weakening by first language (L1) speakers of English has followed either a categorical or a continuous approach to allophonic production. This study combines both types of analyses to explore the phonetic development of intervocalic voiced stops. In addition, utterance initial voiced stops are examined to compare the development of different allophones, more precisely, approximants, voiced stops, and voiceless stops. Twenty-seven participants were recorded performing a reading task at the beginning and at the end of a semester during which they took a college-level Spanish phonetics course. Voiced stops in intervocalic and utterance initial position were analyzed for type of allophone production, and the consonant-vowel intensity ratio was used as a continuous measure of consonant weakening. Results show that learners develop their production of voiced stop weakening both at the segmental level, with an increase in approximants, and at the subsegmental level, with approximants being produced with increasingly less constriction. Moreover, an asymmetry between the development of intervocalic approximants and utterance initial voiced stops is observed, with the latter displaying a slower pace of acquisition. This finding is discussed within theories of L2 phonology that model the role of similarity in the acquisition process.
1 Introduction
The L2 acquisition of the Spanish voiced stops /b, d, ɡ/ presents a complex scenario for learners whose L1 is American English given the differences in allophones and their distribution between the two languages. Spanish voiced stops present two context-dependent allophones: voiced stops [b, d, ɡ] and approximants [β̞, ð̞, ɣ̞].[1] The latter occur after continuant sounds, a weakening phenomenon known as spirantization that is present in almost all dialects of Spanish, especially after vowels (see Campos-Astorkiza 2018, for dialectal variation and limited spirantization). This weakening process has been shown to be gradient for L1 speakers of Spanish and influenced by several linguistic factors, including place of articulation, stress, surrounding vowels, and position within the word (Carrasco et al. 2012; Cole et al. 1999; Eddington 2011). English has a different set of allophones for /b, d, ɡ/, which are primarily realized as unaspirated, i.e., short-lag, voiceless stops, especially in initial position, and only sporadically as voiced stops with prevoicing (Davidson 2016; Simonet et al. 2014). In contrast, in Spanish, short-lag voiceless stops are allophones of the voiceless stops /p, t, k/. In addition, American English has a flap allophone for /t/ in unstressed positions and the place of articulation of /t/ is dental in Spanish, but alveolar in English. The complexity of these differential patterns, where L2 phonetic development would entail production of new allophones not present in the L1 and also recategorization of L1 allophones to reflect the L2 system, makes the L2 acquisition of Spanish voiced stops a fertile ground for exploring the development of allophonic alternations, namely between approximants, voiced stops and short-lag voiceless stops, and the acquisition of gradient phonetic patterns, in this case the weakening of voiced stops. In fact, there are several studies on L2 Spanish that focus on these sounds and present important findings that expand our understanding of SLA. However, these studies usually focus only on a subset of the possible allophones and explore the development of the allophonic alternations from either a categorical or a gradient/continuous perspective. Building off this earlier work this study follows a combined approach to examine the categorical and the gradient allophonic development of Spanish voiced stops, and considers different types of allophones, including approximants, voiced and voiceless stops, by analyzing both intervocalic and utterance initial contexts.
Previous studies on the acquisition of Spanish voiced stops by L1 English speakers tend to focus on spirantization in intervocalic position. These studies conclude that approximants present a greater challenge for learners than other types of sounds, although learners move towards target-like productions as their proficiency level and experience with Spanish increase (Alvord and Christiansen 2012; Díaz-Campos 2004, 2006; Elliott 1997; Face 2021; Face and Menke 2009; Lord 2010; Shively 2008). Beyond the alternation among different types of allophones, Spanish voiced stop weakening is a gradient phenomenon which allows us to explore the L2 acquisition of gradience in the context of pronunciation. While many studies approach the acquisition of approximant allophones by analyzing them categorically, i.e., voiced stop versus approximant (see references above), some recent studies have used intensity measures to examine voiced stops production and capture their degree of weakening (Bongiovanni et al. 2015; Nagle 2017; Rogers and Alvord 2014; Shea and Curtin 2011). However, only a few studies combine these two methodological approaches (Cabrelli Amaro 2017; Face 2018; Solon 2018). A categorical analysis allows us to explore whether a given allophone, in this case approximants, has been acquired, while a continuous analysis examines whether the acoustic or articulatory target has been acquired, i.e., the degree of constriction. In other words, one analysis examines the L2 acquisition of the target sound, and the other captures any possible variation within that allophone. Furthermore, combining both types of analyses offers the possibility to observe developmental patterns in the continuous analysis that might not be apparent in the categorical one, and vice versa. This would be key to determine whether phonological factors such as stress and place of articulation play a similar role in the two types of acquisition. Thus, our first goal is to expand on those few studies that combine methodological approaches by bringing together a categorical and a continuous analysis of learners’ production of voiced stops, to provide a more comprehensive picture of the L2 development of a phonological process that has been described as gradient.
Beyond the development of spirantization, some other work has examined stop allophones production for both Spanish voiceless and voiced stops focusing on the utterance initial context (Casillas 2020; Face 2021; Face and Menke 2020; González-Bueno 1997; Nagle 2019; Olson 2022; Schuhmann and Huffman 2015; Zampini 1998). However, there is a need for a more comprehensive analysis that considers all allophones of /b, d, ɡ/ in both intervocalic and utterance initial position, to better understand the phonetic development of these sounds and shed light on any potential asymmetries depending on the type of allophone. The Speech Learning Model (SLM, Flege 1995; SLM-r, Flege and Bohn 2021) of second language acquisition of phonology highlights the role of (di)similarity between L1 and L2 sounds in conditioning phonetic development. The basic hypothesis is that learners will face greater difficulty when creating L2 categories for sounds that are similar in the L1 and L2, while more dissimilar sounds would pose less of a challenge. The case of Spanish voiced stops is of interest within this framework given that the expected acquisition path of L1 English learners would include, on the one hand, developing approximants as allophones of voiced stops, a set of sounds that is largely new for L1 English speakers, and, on the other hand, reconfiguring the distribution of short-lag voiceless stops as not being allophones of voiced stops, at the same time as recategorizing the infrequent prevoiced allophones in their L1 as an allophone of Spanish /b, d, g/ according to their contextual distribution. The concept of similarity is relevant in this acquisition scenario since approximants, as new sounds, could be argued to be more dissimilar to any L1 sound than prevoicing and short-lag voiceless stops which are present in L1, albeit with a different distribution. Therefore, our second goal is to compare the development of voiced stop allophones in intervocalic and utterance initial positions, where their expected distribution is different, to examine potential differences based on similarity considerations.
2 Background
2.1 L2 development of Spanish spirantization
Most studies on the L2 acquisition of Spanish voiced stops by L1 English speakers focus on the production of the approximant allophones (Solon 2018) and examine different factors that influence their occurrence. Several studies conclude that approximants take longer to acquire than other sounds (Díaz-Campos 2004, 2006; Elliot 1997). Díaz-Campos (2004) examines the impact of context of learning on the phonetic development of several Spanish sounds by measuring the degree of learners’ accuracy and finds that approximant[2] production shows no improvement, unlike the other sounds which display a change towards target-like realizations. Other studies echo Díaz-Campos’s finding that approximants take longer to acquire than other sounds and attribute this pattern to the cross-linguistic markedness of approximants (Díaz-Campos 2004; Shively 2008), or the lack of positive L1 transfer, since approximants are not part of the allophonic inventory of English (Shively 2008).
However, several studies find higher rates of approximants as learners’ proficiency and experience with Spanish increase (Face 2021; Face and Menke 2009; Shively 2008). Shively (2008) compares two groups of learners, students in a second-semester Spanish language class and students in a Spanish Phonetics class, and finds greater accuracy in intervocalic approximant production among the latter group in a reading task. In addition, Shively identifies a pattern by which the more experience a learner has with Spanish, the higher their rate of approximant production. Similarly, Face and Menke (2009) examine the rate of spirantization in three different groups of Spanish learners, namely fourth-semester Spanish students, graduating Spanish majors, and PhD students, and they find a continuum of approximant production that goes from the lowest to highest rate according to the participants’ level of proficiency. Other studies have found an increase in approximant production after study abroad or immersion experiences (Alvord and Christiansen 2012; Lord 2010; cf. Díaz-Campos 2004) and after explicit phonetic instruction (Elliot 1997; Lord 2005), with Lord (2010) finding a cumulative effect of study abroad and phonetic instruction on approximant rate.
Stylistic and linguistic factors have also been found to impact learner’s production of approximants. Several studies find more approximants in less formal tasks such as conversations (Alvord and Christiansen 2012; Díaz-Campos 2006; Zampini 1994). While this finding seems to run counter to the expectation of a more target-like production when more attention is being paid to speech, this pattern might be explained by the fact that approximants, while sporadic, can occur in conversational American English, especially in unstressed intervocalic position (Zampini 1994). In addition, orthography could explain this task effect since, as Nagle (2017) suggests, the orthographic representation might lead to more hyperarticulated speech while reading that would result in less weakening. Indeed, orthography has been shown to play a role in the production of intervocalic /b/. This sound can be represented with the graphemes <b> or <v> in Spanish, while the two graphemes correspond to different phonemes in English (/b/ and /v/). Face and Menke (2009) find that intervocalic <b> is more often produced as a stop and <v> as an approximant or fricative. Beyond the connection between orthography and the bilabial stop, some studies have found differences in approximant production rate based on the place of articulation of the stop phoneme, although the findings are sometimes contradictory. For example, González-Bueno (1995), Lord (2005) and Face and Menke (2009) report less approximants for /d/ than for /b, g/ and explain this pattern by arguing that the weakened allophone of /d/ in Spanish is the same sound as the voiced fricative /ð/ in English whose phonemic status interferes with its approximant production in Spanish. However, Alvord and Christiansen (2012) find the highest rate of approximant production for /d/. Finally, the linguistic factors of stress and word position have been examined by a couple of studies that find more stops in stressed syllables (Face and Menke 2009; Shively 2008) and more approximants in word-medial versus word-initial position (Face and Menke 2009). The current study will add to these findings by examining the role of stress and place of articulation on a wider range of allophones including voiced and voiceless stops, approximants and taps.
What all the studies discussed so far share is that they follow a categorical analysis by which L2 productions are examined according to the type of allophone produced, usually focusing on the differentiation voiced stop versus approximant or according to the learner’s accuracy in producing the expected allophone. In this sense, the phenomenon under study, i.e., spirantization, is analyzed as a categorical process usually represented as the alternation between a voiced stop and an approximant. However, more recent work has taken a different methodological approach to understand the L2 development of Spanish voiced stop weakening as a gradient process. As mentioned in the introduction, studies on L1 Spanish have shown that spirantization is gradient and there is variation in the degree of constriction of the allophones depending on linguistic, sociolinguistic, and stylistic factors (e.g., Carrasco et al. 2012; Cole et al. 1999; Eddington 2011; Ortega-Llebaria 2004). These L1 studies capture the gradience of the phenomenon by using relative intensity measures of /b, d, ɡ/ to analyze their degree of constriction, namely the consonant-vowel (CV) intensity difference or the CV-intensity ratio, thus performing a continuous analysis of the phenomenon. To clarify, this is how these intensity measures correlate with degree of constriction: For the CV intensity difference, the greater the difference, the greater the constriction; for the CV intensity ratio, the lower the ratio, the greater the constriction. In the context of L2, a couple of studies have used intensity measures to explore the phonetic development of spirantization. Shea and Curtin (2011) compare third-semester versus fifth-semester learners’ CV-intensity ratios for intervocalic /b, d, g/ and find greater intensity ratios, i.e., more weakening, for the higher level. However, Nagle (2017), carrying out a longitudinal study of intervocalic /b/ development across two semesters, finds that his learners, taken as a group, do not show a change in their CV-intensity ratios, although the author identifies individual learners that do display an increase in their ratios, i.e., more weakening.
Other studies have used the CV-intensity difference to explore the effect of context of learning on L2 production of spirantization as a gradient process. Rogers and Alvord (2014) compare learners in an at-home university setting and learners in an abroad context and find that learners abroad present lower intensity differences, i.e., more weakening, than university learners, replicating similar effects of context of learning from studies that look at spirantization categorically (Alvord and Christiansen 2012, see above). However, Bongiovanni et al. (2015) analyze the phonetic development of spirantization using the CV-intensity difference for learners in a 5-week study abroad program and that of learners in an at-home university class and find a very small positive impact of study abroad.
This kind of continuous analysis has been applied to further understand the role of phonological context on L2 spirantization. Shea and Curtin (2011) and Nagle (2017) find that stress conditions the degree of weakening and learners present lower CV-intensity ratios or more constriction in stressed syllables, echoing findings from Shively’s (2008) and Face and Menke’s (2009) categorical analyses discussed earlier. Rogers and Alvord (2014) find smaller CV-intensity differences in word-internal position than in word-initial one, while Shea and Curtin (2011) report an effect of word position only for their more advanced learners. In terms of differences based on place of articulation, Rogers and Alvord (2014) report that /g/ presents the highest CV-intensity difference and /b/ the lowest, indicating that the degree of constriction increases as the place of articulation moves further back in the oral cavity. A similar finding is also reported by Shea and Curtin (2011), but only for the more advanced learners, which leads the authors to conclude that gradience across places of articulation arise with more Spanish experience, suggesting that experience with the L2 is required for subtle, gradient phonetic knowledge to emerge. Finally, the effect of task on spirantization has also been explored from a continuous perspective. Rogers and Alvord (2014) report higher CV-intensity differences or less weakening in a reading task than in an interview, while Bongiovanni et al. (2015) find smaller intensity differences, i.e., more weakening, in a paragraph reading than in a sentence reading one but only for /d/. These results seem to align with earlier categorical studies that find less approximants in more formal contexts such as reading tasks (cf. Nagle 2017).
All in all, these studies bring important insights to better characterize and understand the L2 phonetic development of a gradient phenomenon and that can be seen as complementing findings from categorical studies. In fact, a couple of studies have taken the methodological approach of combining a categorical and a continuous analysis to provide a broader picture of the L2 phonetic development of learners. Cabrelli Amaro (2017) is one of the first to identify a lack of studies that examine the acquisition of spirantization using a gradient and a categorical approach to degree of constriction. While the author states that the two types of analyses allow us to explore “two pieces of the puzzle”, her study focuses mainly on the continuous one and includes a categorical approach only for some of her data, by classifying the productions as stop versus approximant based on the intensity difference.[3] Despite this limitation, Cabrelli Amaro concludes that the continuous analysis allows her to observe differences between groups that might not be apparent in the categorical analysis, highlighting that a combination of both analyses offers a more detailed and complete picture of learners’ production. Mirisis (2020), in a study that focuses on comparing the production and perception of L2 Spanish voiced stops, analyzes these sounds in intervocalic position according to their type of realization and intensity difference. However, in the results discussion, the author explores the intensity difference in detail, while the types of production are presented just in terms of their overall distribution, probably due to the author’s focus on the perception data results and their connection with production.
To the best of our knowledge, since Cabrelli Amaro’s call to expand our analytical approach to L2 spirantization, only two studies have done so fully by looking at production data from a continuous and a categorical lens (Face 2018; Solon et al. 2018). Face (2018) examines ultimate attainment of Spanish spirantization by very advanced learners who are long term residents in Spain. To do this, the author categorizes voiced stops from learners and L1 speakers in three weakening contexts, i.e., intervocalic, postvocalic complex onsets (e.g., /saɡɾado/ ‘sacred’), and following a continuant consonant, according to their manner of articulation: stop, fricative or approximant. In addition, Face calculates the intensity difference for the tokens realized as approximants. The author finds differences in the manner of articulation between learners and L1 speakers in the three contexts under study, with learners systematically producing less approximants than L1 speakers. However, results show an intensity difference between the two groups only in intervocalic position. Face concludes that “[o]verall, then, we see that L1 English speakers may struggle to produce approximants at a native-like rate, but when they do produce them, they are quite good (though not entirely consistent) at producing these with a native-like intensity difference” (Face 2018: 48), highlighting the contribution of combining a categorical and a continuous analysis of the data.
Solon et al. (2018) use a combination of categorical and continuous analyses to examine the acquisition of intervocalic /d/ weakening as a sociolinguistic feature by very advanced learners, compared to L1 speakers, and the role of several linguistic factors. In their analysis procedure, first they perform categorical coding of each token according to their type of realization, i.e., stop, spirant, deleted, or other. Next, they calculate the intensity difference for non-deleted tokens. However, for the statistical treatment of categorical variation, the authors regroup the tokens as deleted or non-deleted, while for the continuous analysis they consider only tokens that were not deleted. Thus, each type of analysis examines one aspect of the phenomenon (approximantization versus deletion). The categorical data shows that native speakers produce more deletion than learners and present a lower intensity difference, indicating that learners’ productions are more constricted overall. In addition, the authors find more similarities between learners and native speakers regarding significant factors in the categorical than in the continuous analysis, which leads them to conclude that learners seem to have acquired the approximants but not the variation of the target forms as manifested in the intensity difference. Similar to Face (2018), this finding is possible because of the analytical approach taken by the authors that combines categorical and continuous measures. In the current study, we build off Face (2018) and Solon et al. (2018) and present a combination of the two types of analyses of intermediate learners’ production of /b, d, ɡ/. As Cabrelli Amaro (2017) suggests, a categorical analysis indicates whether a given allophone, e.g., approximant, has been acquired, while a continuous analysis allow us to see whether the acoustic/articulatory target has been acquired, i.e., degree of constriction (see also Face 2021). In addition, examining the effect of linguistic factors such as stress and place of articulation in both analyses lets us examine whether these factors play a similar role in the two types of acquisition.
2.2 L2 development of Spanish voiced stop allophones
While most studies on the L2 acquisition of Spanish voiced stops focus on the development of approximants, there are some studies that explore voiced stop allophones within the broader context of L2 stop acquisition. Generally, this line of research examines L2 production of Spanish voiced and voiceless stops by using VOT duration as an acoustic cue to capture the possible effect of differences between L1 and L2 allophones (Casillas 2020; Face 2021; Face and Menke 2020; González-Bueno 1997; Nagle 2019; Olson 2022; Schuhmann and Huffman 2015; Zampini 1998). More precisely, they analyze prevoicing of /b, d, ɡ/ in positions where voiced stop allophones would be expected, usually utterance initial position, and compare it to degree of aspiration of /p, t, k/. While these studies show that learners present more prevoicing as their proficiency and experience with Spanish increase (Casillas 2020; Face 2021; Nagle 2019) and as a result of phonetic instruction (González-Bueno 1997) or immersion (Casillas 2020), most of them conclude that VOT duration is closer to the L1 norm for voiceless stop allophones than for voiced stop ones (although see Casillas (2020) who reports the opposite pattern). This asymmetry has been discussed as stemming from the difference in similarity among the categories involve, namely the greater overlap among the voiced stops in the two languages compared to the voiceless stops (Face and Menke 2020; Nagle 2017). Following predictions from the SLM model, this greater similarity would make the acquisition harder for voiced stops. Other authors further attribute this asymmetry to the markedness of prevoicing in stops cross-linguistically (González-Bueno 1997; Shuman and Hufman 2015). Few of these studies have examined the impact of phonological context on pre-voicing, although Nagle (2019) and Face and Menke (2020) report more or longer pre-voicing in stressed contexts compared to unstressed ones. Of note here is also a recent cross-linguistic study by Gorba and Cebrián (2023) that examines L2 Spanish /b, ɡ/ in utterance initial position and where, unlike in previous work, the authors use VOT durations to categorize each token as prevoiced or not, explaining that earlier studies have not looked at L2 voiced stops using a categorical analysis. Gorba and Cebrián (2023) find that, as expected, learners produce fewer prevoiced stops than monolinguals, and among learners those with more experience produce the highest amount of prevoiced tokens.
Few studies consider both L2 voiced stop and approximant allophones and those that do generally do not compare the two allophones directly and present contradictory results that seem to stem from different methodologies. Zampini (1994) reports very few issues with voiced stop allophones post-nasally, except for some orthography effect for /b/, which are by and large realized as such, while approximants show low rates of production. Similarly, Lord (2010) finds that all expected voiced stop allophones are produced as stops in all the contexts explored, i.e., utterance initially, after a nasal, and after /l/ for /d/, but approximants present a very different pattern, as discussed in Section 2.1. The high number of voiced stops reported by Lord (2010) seems surprising given findings from studies that explore VOT of stops summarized above. However, Lord (2010) is mainly interested in stop versus continuant productions, and does not seem to consider a possible difference in voicing for stops, which would explain the author’s results.
Mirisis (2020) includes utterance initial voiced stop and intervocalic approximant allophones. For the stops analysis, the author uses VOT to quantify prevoicing and reports overall little prevoicing, aligning with other studies, and very small differences according to learner’s proficiency level. As mentioned earlier, Mirisis (2020) examines intervocalic approximant allophones; however, the author does not carry out a direct comparison between her results for voiced stop and approximant allophones, since that is not her goal, and the data included in her study does not allow us to evaluate similarities or differences between the allophones. On the other hand, Face (2021), while discussing approximant and voiced stop allophones separately, presents data that allows for comparison of the two allophones. More precisely, the author includes two tables with the percentage of approximant and prevoiced stops produced in the expected contexts, i.e., intervocalically and utterance initially, respectively, and they seem to suggest that learners, long-term residents in Spain, produce more approximants overall than prevoiced stops when comparing the two contexts under study. Although the author does not note this since the focus of the study is elsewhere, the current study builds off this and presents a comparison between allophones of voiced stops in intervocalic and utterance initial positions.
3 The current study
The L2 acquisition of Spanish voiced stop phonemes by L1 English learners presents a complex scenario that has been explored in the literature from either a categorical perspective, mainly focusing on the development of approximant allophones, or a continuous view, examining the degree of weakening. While there have been some efforts to combine both approaches as described above, this study adopts both methodologies to compare what each of them elucidates in relation to the development of a phonological process that has been described as gradient. This project will highlight the benefits of a combined methodological approach to studying L2 development and will present a more thorough understanding of the acquisition of gradient patterns such as consonantal weakening. Furthermore, this study looks at the acquisition of Spanish voiced stops from a rarely taken perspective by examining and comparing a range of allophonic productions, namely approximants, voiced stops, voiceless stops, and taps, to uncover potential asymmetries in their development and thus contribute to theories of L2 phonology such as the SLM that model the role of (dis)similarity in L2 acquisition. This is accomplished by analyzing voiced stops in intervocalic and utterance initial positions. The current study analyzes production data from L2 learners in a college-level Spanish phonetics course to address the following research questions:
How do the types of realization of Spanish L2 voiced stop phonemes in intervocalic position develop over one semester?
How does the L2 degree of weakening of intervocalic Spanish voiced stops as manifested in the CV-intensity ratio develop over one semester?
How do the types of realization of Spanish L2 voiced stops in utterance initial position develop over one semester?
Do the linguistic factors of stress and place of articulation influence the L2 development of voiced stop allophones?
We expect to find development for all the allophones towards the target, i.e., more approximants in intervocalic position and voiced stops in utterance initial position by the end of the semester. However, given the similarity considerations discussed earlier, prevoiced stops are predicted to be harder to acquire than approximants and this would be manifested in a slower development or change in participants’ production for the former. In addition, the factors of stress and place of articulation are expected to play a role, including more approximants in unstressed syllables and taps for the dental voiced stop, although the impact of these factors might change throughout the course of the semester towards a more Spanish-like pattern. In terms of the degree of weakening, while intensity ratios are expected to increase during the semester, indicating less constriction, their patterns might display differences from the development of allophones including distinct effects of stress and place of articulation which would shed light on how gradient phenomena develop in L2 acquisition.
3.1 Data collection
The data for this study was collected using a teaching module called See your Speech that is part of a college-level Spanish phonetics course and students complete twice during the class, i.e., at the beginning and at the end of the semester. The module See your Speech was developed as part of a larger project that combines linguistic research and teaching at a large Midwestern university with the aim of engaging undergraduate students in the research process while building a corpus of linguistic data (Wanjema et al. 2013). As part of this project, several modules were created and integrated into different linguistic courses. See your Speech is a web-based module where students record themselves reading a list of words in Spanish and another list in English. In addition, they complete a demographic questionnaire that includes questions about their age, race, sex, regional background, and experience with Spanish and other languages. Once students complete the recordings and the questionnaire, the module ends with a pedagogical component on vowel production: first, students are presented with basic information regarding vowel production in Spanish and English, including sample vowel spaces for L1 speakers of the two languages, and then, each student is able to see their own vowel space in Spanish. Students’ vowel spaces, a form of instant feedback on their pronunciation, are created by the system which first, automatically segments the recordings at the phoneme level using the Penn Forced Aligner (Yuan and Liberman 2008), and then, extracts the first and second formant of all vowels using Praat (Boersma and Weenink 2012) and fits them to a formant chart (Wanjema et al. 2013). Students complete the module on their own time and record themselves using their personal computers or phones. In addition, at the end of the semester, the aggregated vowel data from students is discussed during an in-class presentation that introduces students to acoustic analysis and SLA research, and highlights vowel production effects that might result from L1 influence. With students’ consent, the module recordings are added to the corpus which serves as the source of data for the present study. Summarizing, this study presents an effort to integrate linguistics teaching and research by using a corpus built through a pedagogical tool.
Participants read a list of 71 words in Spanish of which 21 contain /b, d, g/ in different word and stress positions (see Appendix for the list of read words). Each word was presented individually to avoid word list reading effects. In terms of word location, the target sounds appear intervocalically, a context where weakening to approximant allophones is expected (e.g., /koˈmida/ ‘food’, /paˈɡo/ ‘paid.3sg.’) and word-initially which, given the nature of the data, corresponds to utterance initial position, where weakening is not expected (e.g., /ˈdose/ ‘twelve’, /baˈʝena/ ‘whale’). These two contexts are examined because they are the ones that present less variation across Spanish dialects in terms of approximant and stop productions (Solon 2018). Furthermore, /b, d, ɡ/ are analyzed in stressed and unstressed syllables.
3.2 Participants
Participants in this study are college students taking a Spanish phonetics course as part of their major or minor. This is a 3,000-level course and is part of a group of core courses that form the gateway to the major and minor in Spanish at this institution. While the role of explicit phonetics instruction is not explored in the present study, there is evidence that this kind of instruction can have a positive impact on L2 phonetic and phonological development (Lee et al. 2015). More precisely, several studies on L2 Spanish stops have found that it can speed up the acquisition process (Elliot 1997; González-Bueno 1997; González-López and Counselman 2013; Lord 2010). Participants come from two sections of the course, and all participants were taught the same curriculum with the same pedagogical approach. The two sections had different instructors both of which were L1 English-L2 Spanish speakers with specializations in Spanish phonetics and phonology. While course instructor could have an impact, the data did not show any differential behavior among students from different sections. The phonetics course offers a survey of Spanish sounds, focusing on allophonic alternations and main differences between English and Spanish. In relation to stops, the course includes discussion and practice of all the allophones of /b, d, ɡ/.
Data from 27 participants were analyzed; 16 identified as female and 11 as male. They were all L1 speakers of north American English who had started learning Spanish in middle or high school and considered themselves L2 learners. While a couple of participants had some basic knowledge of a third language, bilingual or heritage speakers of Spanish or any other language (N = 4) were not included in the sample. In addition, some participants were missing one of the two recordings, or their recordings were not of good enough quality for the analysis (N = 17) and were left out from the final sample. Participants in the sample were all in their early twenties, except for one participant who was in their late thirties. Unfortunately, the data collection tool did not provide any more details regarding participants’ background with Spanish. However, the fact that they were all students in the same phonetics class with similar linguistic profiles and of comparable age is taken as an indication that they all had similar experiences with and proficiency levels in Spanish. For example, study abroad tends to take place while students are taking the core courses or after they have completed them, and for this reason, participants are not expected to have studied in a Spanish-speaking country before this class. Although learners’ experience and use of the L2 can impact their phonetic development (Solon 2018), this study does not focus on these aspects and, for this reason, the lack of detailed information of participants’ background with Spanish is not detrimental for the current goals That said, the results will include details on variation across participants.
3.3 Data analysis
The recordings were subject to two types of analysis, namely type of realization and CV-intensity ratio, using Praat (Boersma and Weenink 2012). For the first analysis, tokens of /b, d, ɡ/ were categorized according to their manner of articulation and voicing using acoustic criteria based on visual inspection of spectrograms and waveforms. The different types of production found in the present data include voiced stop, voiceless stop, approximant, fricative, tap, and deletion. Voiced stop productions were identified by the presence of a burst in the waveform and spectrogram and of prevoicing before that burst (see Figure 1). Voiceless stops were also determined based on the presence of a burst but in this case, voicing started after it, i.e., there was no indication of prevoicing (see Figure 2). Approximants were identified as lacking a burst and showing continuous energy during their production with or without presence of formant structure, which depended on the degree of constriction of the approximant (see Figure 3). Fricatives presented frication or noise in their acoustic representation (see Figure 4), and taps were identified by a brief constriction of around 25–35 ms, followed by a release with or without a burst (see Figure 5). Deletions were determined when there was no acoustic evidence of the sound. The categorization based on acoustic criteria was carried out by and split up between three assistants who had been trained on the data analysis protocol. The main author reviewed problematic tokens and 30 % of the data, for which there were very few disagreements.
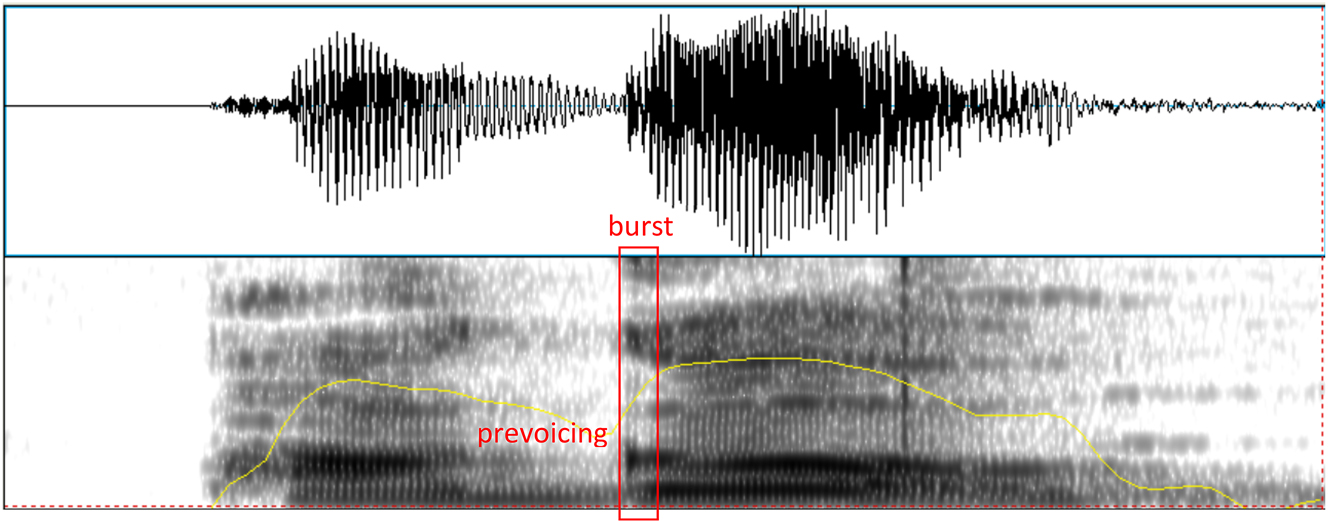
Example of a voiced stop production of /ɡ/ in the word /paˈɡo/ ‘paid.3sg.’ (speaker R). The burst and prevoicing are labeled in the figure.
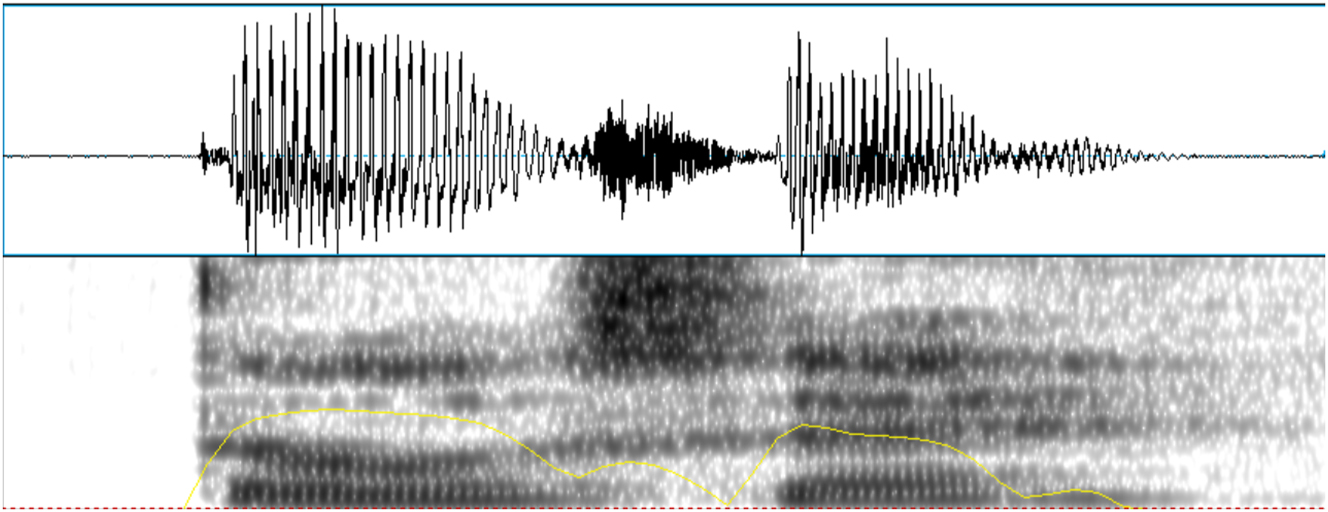
Example of a voiceless stop production of /d/ in the word /ˈdose/ ‘twelve’ (speaker F).
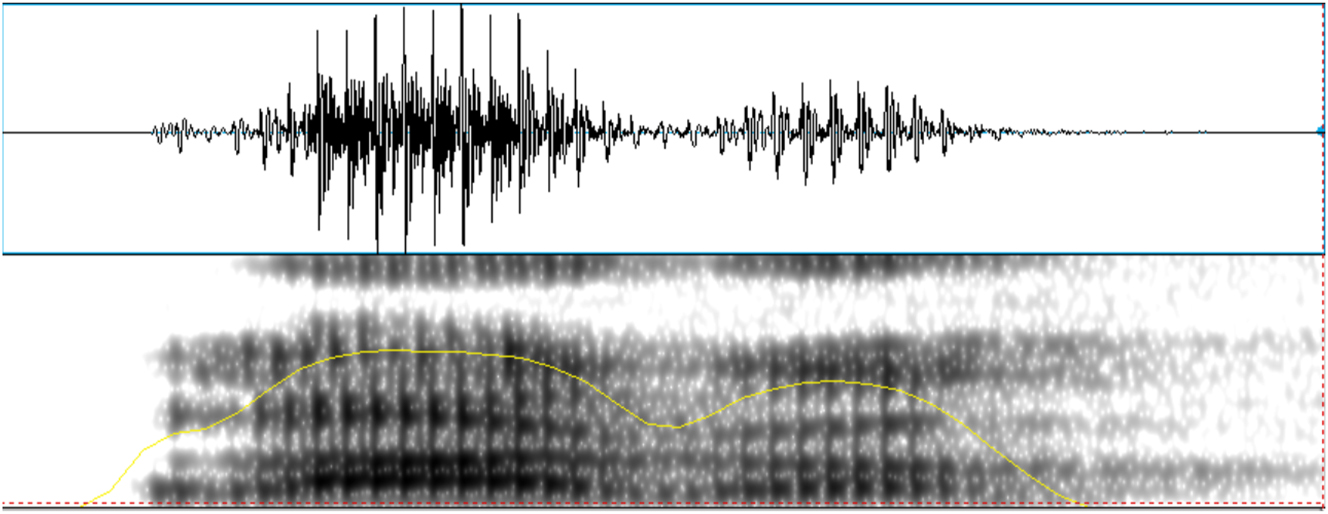
Example of an approximant production of /ɡ/ in the word /ˈlaɡo/ ‘lake’ (speaker B).
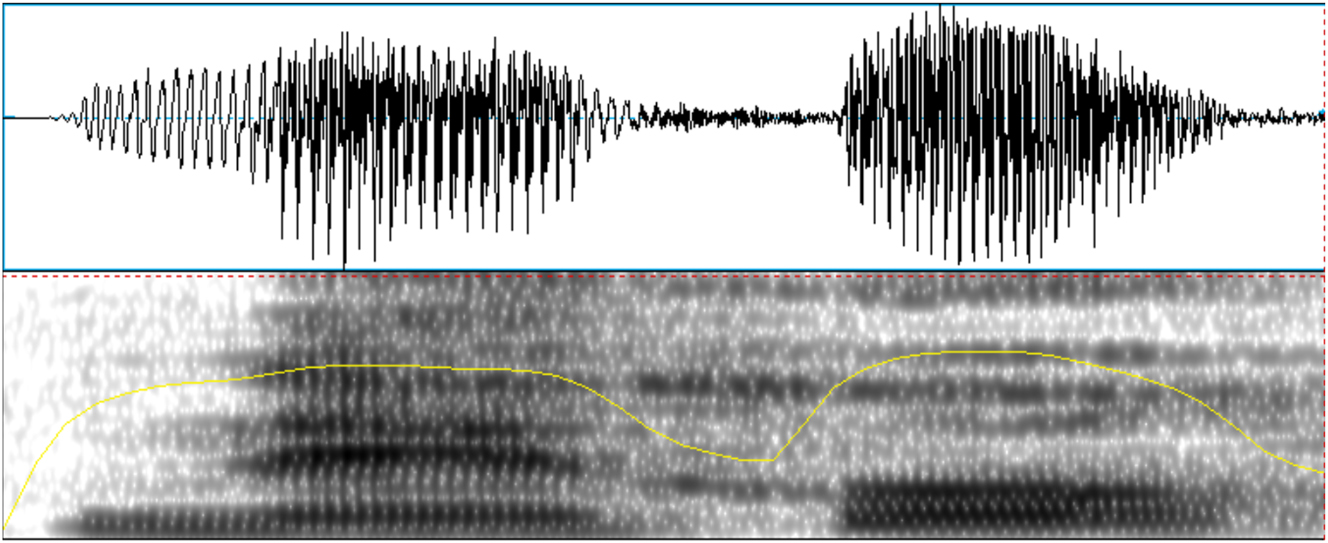
Example of a fricative production of /ɡ/ in the word /neˈɡo/ ‘negated.3sg,’ (speaker S).
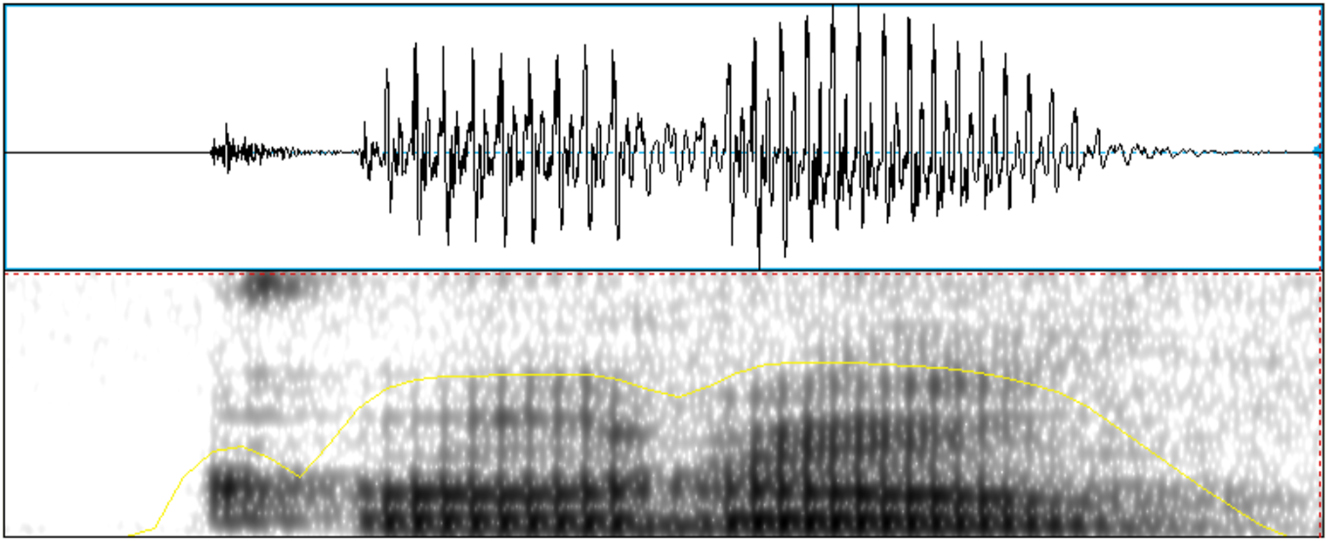
Example of a tap production of /d/ in the word /ˈkodo/ ‘elbow’ (speaker Q).
For the second analysis, following Face (2018) and Mirisis (2020), the CV-intensity ratio was calculated for intervocalic tokens produced as approximants to explore the gradient realization of these allophones in the weakening context. Some previous studies have included other voiced allophones beyond approximants, such as voiced stops or taps, in their analysis of this acoustic measure (e.g., Rogers and Alvord 2014; Bongiovanni et al. 2015; Nagle 2017). However, the present study only considers approximants in this part of the analysis because it distinguishes between the gradient realization of approximants with varying degrees of constriction as reflected in the intensity ratio from the variability in type of allophone as captured by the categorical analysis presented above. This allows us to “tease apart manner of articulation differences from oral constriction differences within a single manner of articulation” (Face 2018: 33–34). This provides for a comparison of the two approaches, as we do in the discussion, to gain a more detailed view of the acquisition process. As Face (2018) explains, these two approaches let us determine learners’ approximant production rate, and also learners’ constriction degree of those approximants. The CV-intensity ratio is the ratio between the consonant minimum intensity and the maximum intensity of the following vowel, and thus captures the degree of oral constriction of approximants (Carrasco et al. 2012). This ratio was calculated by segmenting each approximant production of /b, d, ɡ/ and the following vowel, making sure that the lowest and highest intensity moments for each sound respectively fell within the segmentation boundaries. Next, a Praat script was used to extract these intensity values which were used to compute the ratio.
After leaving 107 tokens out due to speech errors and background noise, there were a total of 1,189 observations, more precisely, 449 tokens for /b/, 391 for /d/, and 349 for /ɡ/. For the statistical analysis, the data was divided according to the position of the voiced stop: intervocalic versus utterance initial. These two locations are examined separately because the allophony of /b, d, ɡ/ is different in each one and because one of the goals of the study is to examine weakening in intervocalic position from a categorical and continuous perspective, which requires us to treat each word location independently. The dependent variables were the type of realization (categorical analysis) and the CV-intensity ratio (continuous variable, only for intervocalic position data), and the following independent factors were considered: timepoint (T1 beginning vs. T2 end of semester), stress (stressed vs. unstressed), place of articulation (/b, d, ɡ/), as well as the interactions between timepoint and the other factors. The variables participant and word were included as random factors. All statistical modelling was carried out in R Statistical Software (v4.1.3; R Core Team 2021) and statistical significance was set at p < 0.05. More details about the relevant models are given in the next section which reports the results from the categorical analysis, by context, first, followed by the results from the continuous analysis.
4 Results
4.1 Results from the categorical analysis
4.1.1 Intervocalic position
As Table 1 shows, in intervocalic position most of the realizations were either approximants or voiced stops, with taps as the third most frequent allophone. There were some voiceless stops, which come mainly from /ɡ/ in stressed position, a few fricatives, and no deletions. The ranges in Table 1 show that there was some variation among participants, supporting including speaker as a random effect in the modelling. As mentioned in Section 3.3, the statistical analysis explores the effect of timepoint, stress, and place of articulation (POA) on the type of realization. The study is also interested in how the role of linguistic factors might develop and for this reason, the statistical modelling also considers the interactions of timepoint and stress and of timepoint and place of articulation. To explore the statistical significance of these factors and interactions, multinomial regression was used (mblogit () function, Elff 2022) on the categorical variable of type of realization which has three levels: voiced stop, approximant and tap. Voiceless stops and fricatives are not included in this analysis due to their low number of tokens. Models were built stepwise by adding each factor and interaction one by one, following the order timepoint, stress, POA and interactions. This order was established based on effect size from a descriptive exploration of the data, with factors that seemed to have a bigger effect added earlier. Models were compared using ANOVA in a pairwise fashion to determine the best-fit model. Table 2 summarizes the results from the best-fit model, which includes equations comparing the voiced stops versus approximants and taps versus approximants. In order to be able to compare voiced stops versus taps, the dependent variable was releveled. The relevant output, i.e., the voiced stops versus taps comparison, of the best-fit model with relevelling is given in Table 3.
Percentage, number of tokens (N) and range across participants for each type of realization in intervocalic position, for T1 and T2 combined.
| Type of realization | Average percentage (N) | Range |
|---|---|---|
| Approximant | 59.42 % (495) | 21.21–100 % |
| Voiced stop | 35.41 % (295) | 0–78.79 % |
| Tap | 3.60 % (30) | 0–20.69 |
| Voiceless stop | 1.20 % (10) | 0–9.38 % |
| Fricative | 0.36 % (3) | 0–6.90 % |
Best-fit model from the multinomial regression analysis for intervocalic position.
| (i) Equation for voiced stop versus approximant | ||||
|---|---|---|---|---|
| Estimate | Std. error | z-value | p-Value | |
| (Intercept) | −0.5859 | 0.3446 | −1.699 | 0.0891 |
| Timepoint (ref. level: T1) | ||||
| T2 | −1.5200 | 0.1829 | −8.309 | <0.001 |
| Stress (ref. level: unstressed) | ||||
| Stressed | 0.9864 | 0.1802 | 5.475 | <0.001 |
| Place of articulation (ref. level: /b/) | ||||
| /d/ | 0.1338 | 0.2365 | 0.566 | 0.5672 |
| /ɡ/ | 0.1303 | 0.2213 | 0.589 | 0.5561 |
| (ii) Equation for tap versus approximant | ||||
|---|---|---|---|---|
| Estimate | Std. error | z-value | p-Value | |
| (Intercept) | −2.624e+01 | 2.825e+04 | −0.001 | 0.99926 |
| Timepoint (ref. level: T1) | ||||
| T2 | −1.239e+00 | 4.252e−01 | −2.914 | 0.00357 |
| Stress (ref. level: unstressed) | ||||
| stressed | 4.938e−01 | 4.153e−01 | 1.189 | 0.23436 |
| Place of articulation (ref. level: /b/) | ||||
| /d/ | 2.486e+01 | 2.825e+04 | 0.001 | 0.99930 |
| /ɡ/ | 9.258e−02 | 3.553e+04 | 0.000 | 1.00000 |
Equation for tap versus voiced stop from the best-fit model from the multinomial regression for intervocalic position with releveling of the dependent variable.
| Estimate | Std. error | z-value | p-Value | |
|---|---|---|---|---|
| (Intercept) | −2.576e+01 | 2.800e+04 | −0.001 | 0.999 |
| Timepoint (ref. level: T1) | ||||
| T2 | 2.022e−01 | 4.309e−01 | 0.469 | 0.639 |
| Stress (ref. level: unstressed) | ||||
| Stressed | −4.295e−01 | 4.176e−01 | −1.029 | 0.304 |
| Place of articulation (ref. level: /b/) | ||||
| /d/ | 2.469e+01 | 2.800e+04 | 0.001 | 0.999 |
| /ɡ/ | −3.561e−02 | 3.522e+04 | 0.000 | 1.000 |
The best-fit model includes the fixed factors of timepoint, stress, and place of articulation, while none of the interactions are part of it. Let us examine each of these factors and illustrate their effects by looking at some descriptive statistics. Table 4 presents the distribution of the three types of realization by timepoint. There is a clear effect of timepoint on the difference in frequency between approximants and voiced stops: the production of voiced stops decreases from 48.18 % in T1, when its frequency is the highest, to 23.59 % in T2, while the number of approximants increases becoming the most frequent allophone with almost 74 % of the data in T2. This effect of timepoint on approximants versus voiced stops is significant in the best-fit multinomial model (estimate = −1.5200, SE = 0.1829, p < 0.001). As for taps, while their frequency is overall low, their production decreases from T1 to T2 and this is reflected as a statistically significant effect of timepoint in the comparison tap versus approximant in the best-fit multinomial model (estimate = −1.239e+00, SE = 4.252e−01, p = 0.00357).
Percentage of each type of realization in intervocalic position by timepoint.
| Type of realization | T1 | T2 |
|---|---|---|
| Approximant | 47.22 % | 73.71 % |
| Voiced stop | 48.18 % | 23.59 % |
| Tap | 4.60 % | 2.70 % |
According to the results from the regression analysis (Tables 2 and 3), stress plays a significant role in the type of realization. As Table 5 shows, approximants are favored by unstressed rather than stressed positions, while the opposite pattern holds for voiced stops (estimate = 0.9864, SE = 0.1802, p < 0.001). This effect of stress for these two types of productions is the same at both timepoints: even in T2, when approximants are the most common realization, voiced stops increase from 16.83 % in unstressed contexts to 30.65 % in stressed ones. On the other hand, overall, tap production does not seem to be influenced by stress. However, while the interaction between stress and timepoint is not significant, indicating a lack of stress effect for taps at both timepoints, Table 5 shows a trend by which taps are more frequent in unstressed than stressed positions in T1, but that effect is not apparent in T2.
Percentage of each type of realization in intervocalic position by stress and timepoint.
| Approximant | Voiced stop | Tap | |
|---|---|---|---|
| Unstressed | 68.30 % | 27.76 % | 3.93 % |
| T1 | 55.28 % | 39.20 % | 5.53 % |
| T2 | 80.77 % | 16.83 % | 2.40 % |
| Stressed | 52.54 % | 44.07 % | 3.39 % |
| T1 | 39.72 % | 56.54 % | 3.74 % |
| T2 | 66.33 % | 30.65 % | 3.02 % |
-
The bold values highlight the percentages for the parent rows in the tables that include values by two factors.
As for place of articulation, the regression analysis does not show a statistically significant effect of this factor. Table 6 shows that /b/ and /ɡ/ present a similar distribution of approximants and voiced stops. However, /d/ does show a difference with respect to the other two places of articulation in that tap realizations occur only for this voiced stop, as expected. The differences between /d/ and /b, ɡ/ are not significant in the regression model (even after releveling) probably because /b, ɡ/ have 0 tokens for taps. In contrast, a chi-square of the types of realization by place of articulation is significant (X-squared = 60.253, df = 4, p-value <0.001) suggesting that the differences between /d/ and the two other POAs are significant. The interaction between POA and timepoint is not significant. However, some patterns emerge in Table 6. /ɡ/ presents the greatest increase in approximant production when comparing T1 versus T2, while /b/ shows the smallest change, likely because this POA has the highest rate of approximant production in T1. We can also see that /d/ presents a smaller change in approximants which seem to be competing with taps, given that the rate of voiced stops for /d/ in T2 is similar to the two other POAs.
Percentage of each type of realization in intervocalic position by place of articulation and timepoint.
| Approximant | Voiced stop | Tap | |
|---|---|---|---|
| /b/ | 64.14 % | 35.86 % | 0.00 % |
| T1 | 52.58 % | 47.42 % | 0.00 % |
| T2 | 75.25 % | 24.75 % | 0.00 % |
| /d/ | 56.58 % | 32.74 % | 10.68 % |
| T1 | 44.44 % | 42.36 % | 13.19 % |
| T2 | 69.34 % | 22.63 % | 8.03 % |
| /ɡ/ | 61.29 % | 38.71 % | 0.00 % |
| T1 | 46.51 % | 53.49 % | 0.00 % |
| T2 | 76.33 % | 23.67 % | 0.00 % |
-
The bold values highlight the percentages for the parent rows in the tables that include values by two factors.
4.1.2 Utterance initial position
The distribution of the different types of realization shows a different pattern in utterance initial position, as Table 7 shows. In this position, voiced stops and voiceless stops are the most common allophones with similar percentages, although voiced stops are 5 % more frequent than voiceless ones. The next most common realization is approximants making less than 8 % of the data, while deletions and fricatives represent only 1 token each, and given this very low number they are left out from the following analyses. The statistical modelling is similar to that for intervocalic position, namely multinominal regression was used to explore the main effects of timepoint, stress, and place of articulation (in this case only /b/ and /d/ due to gaps in the corpus), and the interaction of timepoint by stress and place of articulation on the type of realization. The process of model comparison to obtain the best-fit was the same as for intervocalic position. The best-fit model is summarized in Table 8. Table 9 includes the model with relevelling of the dependent variable.
Percentage, number of tokens (N) and range across participants for each type of realization in word-initial position.
| Type of realization | Average percentage (N) | Range |
|---|---|---|
| Voiced stop | 48.03 % (171) | 0–92.3 % |
| Voiceless stop | 43.54 % (155) | 0–100 % |
| Approximant | 7.87 % (28) | 0–33.33 % |
| Deletion | 0.28 % (1) | 0–7.69 % |
| Fricative | 0.28 % (1) | 0–7.14 % |
Best-fit model from the multinomial regression analysis for utterance initial position.
| (i) Equation for voiced stop versus approximant | ||||
|---|---|---|---|---|
| Estimate | Std. error | z-value | p-Value | |
| (Intercept) | 2.9651 | 1.0347 | 2.866 | 0.00416 |
| Timepoint (ref. level: T1) | ||||
| T2 | −2.6750 | 1.0854 | −2.465 | 0.01372 |
| Stress (ref. level: unstressed) | ||||
| Stressed | −0.4818 | 1.1890 | −0.405 | 0.68532 |
| Place of articulation (ref. level: /b/) | ||||
| /d/ | 1.2856 | 0.7944 | 1.618 | 0.10559 |
| Timepoint*stress | ||||
| T2: stressed | 1.5757 | 1.2836 | 1.228 | 0.21962 |
| (ii) Equation for voiceless stop versus approximant | ||||
|---|---|---|---|---|
| Estimate | Std. error | z-value | p-Value | |
| (Intercept) | 3.0889 | 1.0501 | 2.942 | 0.00327 |
| Timepoint (ref. level: T1) | ||||
| T2 | −2.6516 | 1.0908 | −2.431 | 0.01506 |
| Stress (ref. level: unstressed) | ||||
| Stressed | −0.7934 | 1.1970 | −0.663 | 0.50744 |
| Place of articulation (ref. level: /b/) | ||||
| /d/ | 2.4140 | 0.8123 | 2.972 | 0.00296 |
| Timepoint*stress | ||||
| T2: stressed | 0.3630 | 1.3004 | 0.279 | 0.78011 |
Equation for voiceless stop versus voiced stop from the best-fit model from the multinomial regression for utterance initial position with releveling of the dependent variable.
| Estimate | Std. error | z-value | p-Value | |
|---|---|---|---|---|
| (Intercept) | 0.11417 | 0.46605 | 0.245 | 0.806472 |
| Timepoint (ref. level: T1) | ||||
| T2 | −0.01643 | 0.48935 | −0.034 | 0.973215 |
| Stress (ref. level: unstressed) | ||||
| Stressed | −0.31699 | 0.43363 | −0.731 | 0.464774 |
| Place of articulation (ref. level: /b/) | ||||
| /d/ | 1.13571 | 0.33895 | 3.351 | <0.001 |
| Timepoint*stress | ||||
| T2: stressed | −1.18044 | 0.59179 | −1995 | 0.046075 |
The best-fit model includes the factors of timepoint, stress, and POA, as well as the interaction between timepoint and stress. In terms of timepoint, Table 10 shows that the percentage of voiceless stops, the most common allophone in T1, decreases in T2 while voiced stops and approximants show an increase. In fact, approximants present the greatest increase from 2.27 % to 13.48 %, which is reflected in a significant effect of timepoint in the voiced stop versus approximant and voiceless stop versus approximant equations in the multinomial best-fit model (estimate = −2.6750, SE = 1.0854, p = 0.01372 and estimate = −2.6516, SE = 1.0908, p = 0.01506).
Percentage of each type of realization in utterance initial position by timepoint.
| Type of realization | T1 | T2 |
|---|---|---|
| Voiced stop | 45.45 % | 51.12 % |
| Voiceless stop | 52.27 % | 35.39 % |
| Approximant | 2.27 % | 13.48 % |
The multinomial best-fit model includes a significant interaction between timepoint and stress for the voiceless stop versus voiced stop equation (estimate = −1.18044, SE = 0.59179, p = 0.046075) and Table 11 shows that the interaction is due to stress having a greater effect on the type of realization in T2 than T1. In T2, voiced stops are more frequent in stressed position than in unstressed ones (58.82 % vs. 35.59 %) and voiceless stops and approximants show a higher degree of occurrence in unstressed contexts, with the latter reaching 22 % of the data. In contrast, in T1, the only apparent difference is that there are more voiceless stops in stressed position. Finally, moving on to POA effects, summarized in Table 12, /d/ shows the highest percentage of voiceless stops, while voiced stops and approximants are more frequent for /b/, and these differences are statistically significant (estimate = 1.13571, SE = 0.33895, p < 0.001 and estimate = 2.4140, SE = 0.8123, p = 0.00296).
Percentage of each type of realization in utterance initial position by stress and timepoint.
| Voiced stop | Voiceless stop | Approximant | |
|---|---|---|---|
| Unstressed | 41.67 % | 45.37 % | 12.96 % |
| T1 | 48.98 % | 48.98 % | 2.04 % |
| T2 | 35.59 % | 42.37 % | 22.03 % |
| Stressed | 51.22 % | 43.09 % | 5.69 % |
| T1 | 44.09 % | 53.54 % | 2.36 % |
| T2 | 58.82 % | 31.93 % | 9.24 % |
-
The bold values highlight the percentages for the parent rows in the tables that include values by two factors.
Percentage of each type of realization in utterance initial position by place of articulation and timepoint.
| Voiced stop | Voiceless stop | Approximant | |
|---|---|---|---|
| /b/ | 50.20 % | 39.27 % | 10.53 % |
| T1 | 49.59 % | 47.15 % | 3.25 % |
| T2 | 50.81 % | 31.45 % | 17.74 % |
| /d/ | 43.93 % | 54.21 % | 1.87 % |
| T1 | 35.85 % | 64.15 % | 0.00 % |
| T2 | 51.85 % | 44.44 % | 3.70 % |
-
The bold values highlight the percentages for the parent rows in the tables that include values by two factors.
4.2 Results from the continuous analysis
Recall that the analysis of the CV-intensity ratio includes only intervocalic tokens that were produced as approximants, following Face (2018) and Mirisis (2020). Like for the categorical analysis, the statistical treatment tests the effect of timepoint, stress, place of articulation and the interaction between timepoint and the two other factors but in this case, the response variable is the CV-intensity ratio and mixed-effects linear regression is used (lmer () function, Bates et al. 2015). Model building was carried out in a similar fashion to the categorical analysis, namely fixed factors and interactions were added one by one and models were compared using ANOVA. Table 13 presents the best-fit model from the linear regression analysis.
Best-fit model from the linear regression analysis on the CV-intensity ratio.
| Estimate | Std. error | df | t value | p-Value | |
|---|---|---|---|---|---|
| (Intercept) | 0.884774 | 0.009238 | 45.540164 | 95.772 | <2e−16 |
| Timepoint (ref. level: T1) | |||||
| T2 | 0.023676 | 0.005973 | 242.120710 | 3.964 | <0.001 |
| Stress (ref. level: unstressed) | |||||
| Stressed | −0.046366 | 0.006521 | 280.602843 | −7.111 | <0.001 |
The results in Table 13 show that timepoint and stress were significant factors in determining the CV-intensity ratio for approximants. More precisely, the ratio was higher in T2 compared to T1, which is captured in Figure 6 (left), and indicates a less constricted production. In terms of stress, approximants in stressed position display a lower ratio (Figure 6, right) which corresponds with more constriction, i.e., less weakening, compared to unstressed syllables. POA or the interactions were not significant.
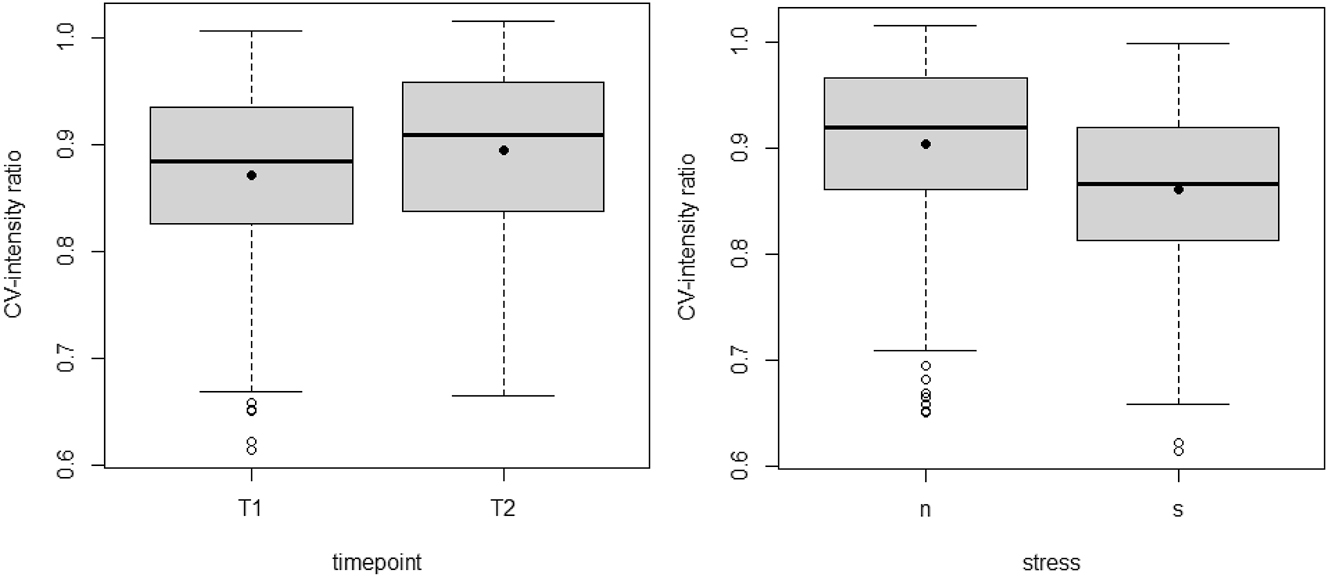
CV-intensity ratio of approximants by timepoint (left) and stress (right; n = unstressed, s = stressed).
5 Discussion
5.1 Development of intervocalic voiced stop allophones
This study examines the phonetic development of L2 Spanish voiced stops in intervocalic position from a categorical and continuous perspective and in utterance initial position among learners taking a Spanish phonetics college class. The first research question asks how the types of realization of intervocalic voiced stops develop throughout the semester. Through a detailed allophonic analysis, our results show that the most common realizations of these stops are approximants, voiced stops, and taps. In addition, the data shows a clear development among participants: there is an increase in approximant productions by the end of the semester that goes hand in hand with a decrease in voiced stops and taps. More precisely, from 47 % of the data at the beginning of the semester, approximants comprise 74 % at the end of the term. This indicates that learners develop the weakening of intervocalic voiced stops and approximants become the most common production. These results can be compared to findings from previous studies, especially those that examine a similar population. Lord (2005) reports an increase from 35 % to 55 % in her study of learners in a phonetics class. While her percentages are lower than ours, possibly because the author included post-consonantal contexts as well, the pattern mirrors the one found in the current study. On the other hand, while the expectation is not for 100 % approximants given that L1 speakers present some variation (Elias-Ulloa 2022; Face 2018), our participants do not produce the same degree of weakening as the very advanced learners that Face (2018) examines in his study on ultimate attainment who present 86 % approximants in intervocalic position. Learners in Face (2018) were long-term residents in Spain, with arguably one of the highest levels of experience with the language, while participants in the current study are college students taking a third-year Spanish class that have limited experience with the language.
Both stress and place of articulation had an impact of the realization of intervocalic voiced stops. Results show that approximants are favored in unstressed position, while voiced stops are more frequent in stressed syllables, and this effect is present at both the beginning and the end of the semester. Few previous studies have examined the role of stress on L2 voiced stop allophones, and their findings align with us since they report more approximants in unstressed syllables (Face and Menke 2009; Shively 2008). Given articulatory considerations, more weakening is expected in unstressed syllables suggesting that learners might be displaying a pattern that results from universal restrictions rather than reflecting L2 acquisition. This might explain why there is no development or change in the effect of stress. While studies on L1 Spanish spirantization that use intensity measures agree that stress leads to less weakening, research on this topic that analyzes type of realization is harder to come by. Elias-Ulloa (2022) finds that stress affects approximant production among L1 speakers from Peru but only in utterance initial position, suggesting the impact of stress for L1 speakers is limited. Relatedly, Face and Menke’s (2009) most advanced learners do not present an effect of stress, and the authors argue that participants might be displaying a ceiling effect. All of this leads us to hypothesize that the effect of stress in the current data possibly stems from language universals that can shape the production of L2 learners (Major 2001), more precisely the tendency for articulation to be weaker in unstressed syllables (Gordon 2011).
As for the effect of place of articulation on type of realization, the main finding is that all taps come from /d/, as we would expect. This type of production, which can be understood as transfer from English, decreases from 13 % to 8 % by the end of the semester. Most previous studies on L2 voiced stop allophones tend to not report details on tap production rates. They usually either combine them with stops as non-target realizations (Díaz-Campos 2006; Shively 2008) or not mentioned them (Face and Menke 2009). However, the current study shows that taps occur in learners’ speech to a considerable degree, especially earlier in the semester, and highlights that the L2 acquisition of Spanish voiced stops involves not only learning approximants and their distribution, but also recategorizing L1 taps. This is echoed in González-Bueno (1995) who reports 32 % taps in her analysis of fourth-semester Spanish students. Earlier work has discussed L2 Spanish intervocalic /d/ in relation to the English voiced fricative phoneme /ð/ and hypothesized a potential interference from this phoneme due to its similarity with the dental approximant [ð̞] (Face and Menke 2009; González-Bueno 1995; Lord 2005). While this similarity might play a role, our findings suggest that the L1 tap allophone of /d/ shows transfer into L2 Spanish and this sets the coronal stop apart from the two other POAs. Furthermore, our results indicate that the nature of the tap in English as a weakened allophone (De Jong 2011) determines its pattern of transfer into Spanish. More precisely, the data shows that taps seem to be competing with approximants, rather than voiced stops, since /d/ has a similar rate of voiced stop production compared to /b, ɡ/, but a lower degree of approximants. This can be understood as L2 speakers’ learning that there is weakening of Spanish /d/ in intervocalic position and producing this weakened sound mainly as an approximant, but sometimes as a tap, the weakened allophone in their L1. Further evidence for this comes from the fact that stress does not have a strong effect on tap realization and there are productions of this allophone with a following stressed vowel (e.g., /muˈdo/ ‘moved.3sg.’), even though English taps are conditioned by stress (De Jong 2011; Eddington and Elzinga 2008). However, despite taps occurring, the preferred weakened allophone among our participants is by and large approximants.
5.2 Development of gradient weakening of voiced stops
Moving on to the second research question that focuses on the gradient production of intervocalic approximants, the intensity ratio results show that learners develop their degree of weakening of approximants during the semester since the ratios become higher by the end of the term indicating more open or weakened realizations. Previous studies that employed intensity measures to explore L2 spirantization usually include realizations other than approximants, mainly voiced stops and sometimes taps, so comparisons with the current data should be made with care. Shea and Curtin (2011) and Cabrelli Amaro (2017) report intensity differences across proficiency levels, suggesting that degree of weakening increases as learners have more experience with the language, which parallels our results, while differences with L1 speakers persist even for the most proficient participants. On the other hand, Bongiovanni et al. (2015) and Nagle (2017) find no development in intensity difference for their participants, although both studies report a significant change towards more weakening for some of the learners. While these studies use relative intensity as a measure of overall spirantization and direct comparison with our results is hard, we should note that Bongiovanni et al. (2015) examine development over a 5-week period and Nagle (2017) analyzes data from learners in second and third semester Spanish classes. This might explain why they find no development, while other studies, like the present one, report significant changes towards more weakening. Mirisis (2020) finds no difference in approximants’ intensity among 1st, 2nd, and 4th year students, although their production is different from L1 speakers, leading the author to conclude that there is no development in degree of approximant weakening. However, Mirisis uses nonce word to elicit production data which could have an impact on the results and explain the author’s different findings compared to the current ones. In addition, our learners were part of a phonetics course, and this type of instruction might have accelerated their change in approximant weakening. In fact, Face (2018), examining relative intensity only for approximants, explains that even though very advanced learners as a group were different from L1 speakers, several individual learners presented intensity differences that were similar to those of monolinguals Spanish speakers, showing that learners can produce degrees of approximant constriction comparable to L1 speakers. In terms of the effect of the linguistic factors, the degree of approximant weakening is influenced by stress since the intensity ratio is lower in unstressed syllables indicating a higher degree of constriction. This echoes findings from other studies that report the same pattern for relative intensity (Shea and Curtin 2011, Solon et al. 2018). The novelty of the current study is that stress is identified as influencing approximants’ constriction, in addition to being a factor on global spirantization.[4]
A goal of this study was to combine a categorical and a continuous analysis of L2 weakening of voiced stops, building off previous efforts (Cabrelli Amaro 2017; Face 2018; Solon et al. 2018). The findings from these two analyses complement each other and offer a more detailed view of the development of the sounds. First, we observe not only an increase in the realization of approximants versus other allophones, by which learners’ production becomes more target-like, but also a change towards more weakening of approximants. This points to a development in categorical and gradient terms highlighting learners’ ability to become more target-like at the segmental and sub-segmental levels. Second, the two analyses allow us to identify similarities or differences in factor effects that might be at play. Our results show that stress affects both levels in a similar fashion: stressed position leads to more weakening, both a higher rate of approximants and more weakening of these, compared to unstressed syllables. This finding highlights the overarching role of stress in L2 weakening of voiced stops which we argue seems to reflect language universals. In fact, the similarity of the effect in both analyses further supports this hypothesis. However, further research would be needed to understand how contextual factors, such as stress, contribute to L2 development.
5.3 Development of utterance initial voiced stop allophones
The third research question shifts the focus to voiced stops in utterance initial position. In this context, the most common allophones are voiced stops, voiceless stops, and approximants. Voiceless stops experience a decrease from 52 % to 35 % by the end of the semester, while voiced stops and approximants become more frequent, although voiced stops, the expected allophone in this initial position, amount to only half of the realizations (51 %) by the end of term. As mentioned earlier, very few studies look at the production of voiced stops in utterance initial position categorically. Lord (2010) reports 100 % accuracy for voiced stops post-nasally and at the beginning of an utterance, which seems to be very different from what we find. However, the author was mainly interested in spirants which suggests that accuracy most likely refers whether the production was a stop and did not take voicing into account. Zampini (1998), who is interested mainly in VOT differences, mentions that her data includes very few observations with prevoicing. Face and Menke (2020, and in Face 2021) also focus on VOT durations but include the percentage of tokens with prevoicing that they found for their very advanced learners: 44 % for /b/, 47 % /d/ and 23 % for /g/. While lower than the rates of voiced stops found in this study, Face and Menke’s results align with our finding that the rate of voiced stop production in utterance initial position remains far from the L1 target. Gorba and Cebrián (2023), the only previous study to adopt a categorical analysis of utterance initial voiced stop similar to ours, find very low rates of voiced stop allophones for their most inexperienced learners (26 % for /b/ and 32 % for /g/), but the rate is higher for more experienced ones, reaching 79 % for /ɡ/.
While our findings further highlight previous studies’ conclusion that voiced stop allophones in utterance initial position are hard to acquire, the present study identifies a new pattern emerging among participants, namely the increase in approximants which comprise 13 % of the data by the end of the semester.[5] Very few earlier studies note approximants in contexts where voiced stops would be expected and they do not provide any details (Elliott 1997; Shively 2008); most previous work has not reported approximants in utterance initial position. This might be because they were concerned with changes in VOT and discarded non-stop productions. The analytical method followed in this study allows us to capture the range of allophones, including non-stop ones. This finding can be interpreted as an overgeneralization of approximants beyond their context of occurrence. Overgeneralization has been described as one of the processes that constitute and shape learners’ interlanguage and it is seen as a development error, rather than a transfer error, since the overgeneralized patterns do not result from the L1 phonology (Major 1986; Tarone 2018). In the present case, approximants in utterance initial position are not transferred from English. Furthermore, overgeneralizations are understood as a sign of progress because learners are moving away from L1 transfer (Tarone 2018) and because they happen late in the acquisition process, only once a new pattern, the one being overproduced, has been learned (Eckman et al. 2013; Major 2001). Among our participants, we observe that by the end of the semester intervocalic approximants have been acquired to a very high rate, and it is then that overgeneralization of these allophones to utterance initial position takes place.
Overgeneralization has been found for other L2 Spanish sounds such as rhotics (Face 2018; Major 1986). However, the case of approximants could be considered from a different perspective by taking the frequency of occurrence of approximant and voiced stop allophones in Spanish into account. More precisely, approximants are much more frequent than voiced stops in the language, something that has led some authors to question the status of the latter as the phonemes or underlying representations (e.g., Baković 1994). In addition, the contexts where voiced stop allophones are found, namely utterance initially, post-nasally and after /l/ for /d/, occur with less frequency in Spanish speech than those that correlate with approximant productions. This means that learners’ input most likely contains more approximants than voiced stops, which could have an impact on how they acquire the different allophones. Another related aspect that could explain the overgeneralization of approximants is that some Spanish words display an alternation between an initial voiced stop and an approximant depending on the preceding context, which means that the same word is pronounced with an initial voiced stop when it occurs utterance initially but with an approximant when preceded by a continuant sound. These frequency effects can be understood and modelled within a usage-based approach to L2 phonology (see Geeslin et al. 2023; Wulff and Ellis 2018 for summaries) based on Exemplar Theory (Bybee 2008). Within this framework, learners build their representations or exemplars of Spanish words and sounds by storing information about the voiced stop and approximant alternation for lexical items that display such alternation. Furthermore, the frequency of the contexts where each allophone occurs would further impact the L2 representation and consequently, the production of utterance initial voiced stops, as has been shown for L1 speakers (Brown 2018). More research is needed to explore the role of contextual and allophone frequency on L2 production to examine some of the predictions made by usage-based models of phonology, and Spanish voiced stops would lend themselves to such examination given their contextual variability in L1 Spanish. Finally, the fact that the current data comes from a phonetics class needs to be considered in relation to any explanation of the observed patterns, including the overgeneralization of approximants, since explicit phonetics instruction might be mediating, i.e., accelerating, the process of acquisition of voiced stops. Learners in a phonetics class not only have the opportunity to practice specific allophones but also develop their phonological awareness. While this study does not directly test the impact of such awareness, there is evidence in the literature an increase in phonological awareness from explicit pronunciation teaching can lead to changes in learners’ production towards the L1 target (Derwing 2017).
The linguistic factors of stress and place of articulation have an effect on the type of realization in utterance initial position. In terms of stress, our results show a change in the direction and the strength of the effect by the end of the semester. At the beginning, while stress does not impact the rate of approximants, voiceless stops are more frequent in stressed positions, favored over voiced stops. This effect could be interpreted as arising from L1 transfer given that in English, stressed syllables are highly correlated with short-lag stop allophones (Gorba and Cebrián 2023) and this might explain why voiceless stops are favored by stress. By the end of the semester, though, this pattern changes and stressed positions favor voiced stops, while unstressed ones correlate with higher rates of voiceless stops and approximants. Comparison with previous studies is limited given that those that explored the effect of stress on utterance initial voiced stops evaluated VOT duration, but the general finding is that there is longer prevoicing in stressed positions (Face and Menke 2020; Nagle 2019). Spanish L1 voiced stops in this position have also been described as having longer prevoicing than in unstressed syllables (Simonet et al. 2014), which means that initial voiced stop allophones are generally longer and thus more salient under stress. This pattern could aid learners in the acquisition of these sounds in stressed syllables and explain the more L1-like productions in that context by the end of the semester. Approximants, on the other hand, as weakened realizations, would be expected to correlate with unstressed syllables, which is what we observe and aligns with results discussed earlier for intervocalic voiced stops. As for the effect of POA, the only apparent pattern is that approximants are more frequent for /b/ than /d/,[6] which correlates with the lower rate of approximants for /d/ in intervocalic position. The role of this linguistic factor, though, would benefit for future research given the limited scope of the current study.
5.4 Asymmetry in the development of intervocalic versus utterance initial allophones
Results from the current study allow us to compare the development of voiced stop allophones in two contexts where their expected distribution is different, i.e., intervocalically and utterance initially. The aim of this comparison is to identify possible asymmetries in the development of the allophones. To this end, Table 14, which combines the results presented in Tables 4 and 10, includes the types of realizations at the beginning and end of the semester for the two contexts under study. Approximants in intervocalic position not only present a much greater development compared to voiced stop allophones utterance initially (26.49 % vs. 5.67 % change for each), but in fact, the former display the biggest change of all allophones. Furthermore, this increase in intervocalic approximant production is accompanied by a similar decrease in voiced stops in this context. On the other hand, utterance initially, the slight increase in voiced stops goes hand in hand with a bigger decrease in voiceless stops (16.88 % change) and, as discussed earlier, a considerable increase in approximants. All of this suggests that, for our participants, voiced stop allophones in utterance initial position are harder to acquire than approximants. In other words, acquiring a new type of allophones seems to pose less of a problem for our learners than recategorizing prevoicing to a new position compared to their L1. The fact that approximants occur even initially further supports this learning asymmetry. While previous studies have not compared these two contexts (see Section 2.2), Face (2021) presents results for allophones in the two positions and if we contrast his data, it shows the same trend as ours, i.e., considerably higher rates of production for intervocalic approximants than initial voiced stops. Furthermore, our finding adds to conclusions from previous studies that examine VOT duration for L2 Spanish voiced and voiceless stops and conclude that VOT is more L1-like for voiceless ones and argue that prevoicing is harder to acquire (see Section 2.2). The current study shows that acquisition of prevoicing, compared to approximants, patterns in a similar way to what these studies report.
Types of realization by timepoint in (a) intervocalic position and (b) utterance initial position.
| (a) Intervocalic position | ||
|---|---|---|
| Type of realization | T1 | T2 |
| Approximant | 47.22 % | 73.71 % |
| Voiced stop | 48.18 % | 23.59 % |
| Tap | 4.60 % | 2.70 % |
| (b) Utterance initial position | ||
|---|---|---|
| Type of realization | T1 | T2 |
| Voiced stop | 45.45 % | 51.12 % |
| Voiceless stop | 52.27 % | 35.39 % |
| Approximant | 2.27 % | 13.48 % |
This asymmetry between approximant and voiced stop allophones can be understood in terms of the similarity between L1 and L2 sounds, following SLM’s proposal to explain L1 transfer patterns (Flege 1995). More precisely, approximants, sounds not present in the learners’ L1, are more dissimilar to any L1 sound, and easier to perceive and consequently to acquire, than prevoiced stop allophones, which occur in the L1 but with a different distribution. Under this account, approximants would have a weaker perceptual link with L1 sounds, compared to voiced stop allophones, that allows them to develop quicker. While this study presents evidence to support a prediction of the SLM model in terms of the role of similarity, note that here, similarity is evaluated by comparing not only L1 and L2 sounds but also their allophonic distribution in the two languages. Prevoiced stops have a stronger link to L1 because they are present in English, however, the distinct distribution between English and Spanish prevoiced stop allophones, and their relationship with voiceless stops makes the mapping between the allophones of the two languages not a direct one, especially compared to approximants. Thus, this study contributes to SLM and our understanding of the relevance of similarity in L2 phonology by showing that reorganizing the allophonic distribution of sounds in the L2 is harder than acquiring a new set of sounds and thus, highlighting the difficulties learners encounter when recategorizing allophones that their L1 and L2 share. Our finding adds to previous studies that find a differential acquisition pattern for voiced and voiceless stops and also recur to similarity to explain their findings arguing that voiced stops in the L1 and L2 have more overlap than voiceless ones and for that reason, they take longer to develop (Face and Menke 2020; Nagle 2019).
However, universal parameters such as markedness might interact with L1 transfer and the role of similarity (Major 2001) and for example, González-Bueno (1997) and Schuhmann and Huffman (2015) state that the greater markedness of voiced stops versus voiceless ones might explain why the former are harder to acquire than the latter. In the case of approximants, markedness considerations are complex. On the one hand, approximants are more marked than voiced stops given typological considerations; however, they are contextually less marked in intervocalic position where lenition is favored (Ohala 1994; Shea and Curtin 2011). It might be that the unmarked status of intervocalic approximants further influences learners’ development. This unmarkedness in intervocalic position could function as an added facilitator for the acquisition of approximants compared to prevoiced stops beyond similarity differences. This approach highlights the complexity of the acquisition process and advocates for explanatory models that are multifaceted and allow for interplay of different factors. Finally, coming back to a usage-based view of L2 phonology, learners have less experience with voiced stops in utterance initial than intervocalic position, given the Spanish language, and this might also explain the reported asymmetry between the two allophones. While previous studies have looked at experience with the L2 as a matter of amount of input or exposure to the language, the suggestion here, within a usage-based approach to L2 phonology, is that also the frequency of different sounds would have an impact on learners, with more frequent sounds allowing for their acquisition to be easier.
6 Conclusions
This study followed a combined categorical and continuous approach to examine the L2 development of Spanish spirantization of intervocalic voiced stops by L1 English speakers. More precisely, a categorical analysis of type of realization and a continuous analysis of the CV-intensity ratio for intervocalic voiced stops show not only that learners develop their production of approximants towards the L1 target, but also that these approximants become weaker, indicating that acquisition of the process takes place at the segmental and subsegmental level. In addition, the realization of utterance initial voiced stops was analyzed and compared to that of intervocalic voiced stops, and an asymmetry was found between intervocalic and utterance initial positions, namely approximants in the latter develop quicker than voiced stops in the former, which adds to our understanding of how different L2 allophones are acquired in distinct ways depending on, we argue, their similarity to L1 sounds. While this study presents group patterns, future research using a similar combined approach could be employed to analyze individual acquisition pathways to further our understanding of factors related to the learner. In fact, participants in the current study present some degree of individual variation, as illustrated in the ranges in Tables 2 and 7, which might be related to differences among learners not explored here.
Acknowledgments
I would like to thank three anonymous reviews for their engagement with the article and their thoughtful feedback. I also want to acknowledge and thank everyone that has been part of the research group Our Voices/Nuestras Voces and assisted in the data analysis.
List of words read by participants (target voiced stops are bolded)
pato ‘duck’
campo ‘field’
papel ‘paper’
papa ‘potato’
lago ‘lake’
peco ‘sin.1sg.’
tomamos ‘take.1pl’
bebé ‘baby’
delta ‘delta’
carro ‘car/cart’
tapó ‘covered.3sg.’
pico ‘peak’
comida ‘food’
taco ‘taco’
total ‘total’
doce ‘twelve’
pitó ‘whistled.3sg.’
tocó ‘touched.3sg.’
paz ‘peace’
dragón ‘dragon’
pagó ‘paid.3sg.’
salto ‘jump’
toga ‘toga’
tapo ‘cover.1sg.’
pita ‘whistle.3sg.’
jugar ‘to play’
sutil ‘subtle’
boda ‘wedding’
teléfono ‘phone’
China ‘China’
milpa ‘cornfield’
mudó ‘moved.3sg.’
picó ‘bit.3sg.’
chupó ‘sucked.3sg.’
estrés ‘stress’
tabú ‘taboo’
azul ‘blue’
sacó ‘took out.3sg.’
caro ‘expensive’
toco ‘touch.1sg.’
ojo ‘eye’
multa ‘ticket’
tope ’buffer’
ballena ‘whale’
pecó ‘sinned.3sg.’
codo ‘elbow’
red ‘net’
frijol ‘bean’
allá ‘there’
champú ‘shampoo’
chupo ‘suck.1sg.’
podó ‘trimmed.3sg.’
yate ‘yacht’
bolsa ‘bag’
baba ‘drool’
misma ‘same’
coca ‘coca/coke’
plátano ‘banana’
capa ‘cape’
maleta ‘suitcase’
mató ‘killed.3sg.’
montañas ‘mountains’
capó ‘neutered.3sg.’
negó ‘negated.3sg.’
experimento ‘experiment’
cabe ‘fits.3sg.’
drogas ‘drugs’
palabra ‘word’
niño ‘kid’
zapato ‘shoe’
todito ‘everything.DIM.’
References
Alvord, Scott. M. & Dianne E. Christiansen. 2012. Factors influencing the acquisition of Spanish voiced stop spirantization during an extended stay abroad. Studies in Spanish and Lusophone Linguistics 6(2). 239–276. https://doi.org/10.1515/shll-2012-1129.Search in Google Scholar
Baković, Eric. 1994. Strong onsets and Spanish fortition. In Chris Giordano & Daniel Ardron (eds.), Proceedings of the 6th Student Conference in Linguistics (SCIL 6), 21–39. Cambridge, MA: MIT Working Papers in Linguistics.Search in Google Scholar
Bates, Douglas, Martin Mächler, Ben Bolker & Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1). 1–48. https://doi.org/10.18637/jss.v067.i01.Search in Google Scholar
Boersma, Paul & David Weenink. 2012. Praat: Doing phonetics by computer.Search in Google Scholar
Bongiovanni, Silvina, Avizia Y. Long, Megan Solon & Erik Willis. 2015. The effect of short-term study abroad on second language Spanish phonetic development. Studies in Hispanic and Lusophone Linguistics 8. 243–282. https://doi.org/10.1515/shll-2015-0010.Search in Google Scholar
Brown, Esther. 2018. Cumulative exposure to phonetic reducing environments marks the lexicon: Spanish /d-/ words spoken in isolation. In K. Aaron Smith & Dawn Nordquist (eds.), Functionalist and usage-based approaches to the study of language: In honor of Joan L. Bybee, 127–153. Amsterdam: John Benjamins.10.1075/slcs.192.06broSearch in Google Scholar
Brown, Esther. 2023. The long-term accrual in memory of contextual conditioning effects. In Manuel Díaz-Campos & Sonia Balasch (eds.), The handbook of usage-based linguistics, 179–195. Malden, MA: Wiley.10.1002/9781119839859.ch10Search in Google Scholar
Bybee, Joan L. 2008. Usage-based grammar and second language acquisition. In Peter Robinson & Nick C. Ellis (eds.), Handbook of cognitive linguistics and second language acquisition, 216–236. London: Routledge.Search in Google Scholar
Cabrelli Amaro, Jennifer. 2017. The role of prosodic structure in L2 Spanish stop lenition. Second Language Research 33. 233–26.10.1177/0267658316687356Search in Google Scholar
Campos-Astorkiza, Rebeka. 2018. Consonants. In Kimberly Geeslin (ed.), Cambridge handbook in Hispanic linguistic, 165–189. Cambridge: Cambridge University Press.10.1017/9781316779194.009Search in Google Scholar
Carrasco, Patricio, Jose Ignacio Hualde & Miquel Simonet. 2012. Dialectal differences in Spanish voiced obstruent allophony: Costa Rican versus Iberian Spanish. Phonetica 69. 149–179. https://doi.org/10.1159/000345199.Search in Google Scholar
Casillas, Joseph. 2020. The longitudinal development of fine-phonetic detail: Stop production in a domestic immersion program. Language Learning 70(3). 768–806. https://doi.org/10.1111/lang.12392.Search in Google Scholar
Cole, Jennifer, Jose Ignacio Hualde & Khalil Iskarous. 1999. Effects of prosodic context on /g/ lenition in Spanish. In Osamu Fujimura, Brian Joseph & Bohumil Palek (eds.), Proceedings of the 4th international linguistics and phonetics conference, 575–589. Prague: The Karolinium Press.Search in Google Scholar
Davidson, Lisa. 2016. Variability in the implementation of voicing in American English obstruents. Journal of Phonetics 54. 35–50. https://doi.org/10.1016/j.wocn.2015.09.003.Search in Google Scholar
de Jong, Kenneth J. 2011. American English Flapping. In Marc van Oostendorp, Colin Ewan, Beth Hume & Keren Rice (eds.), Companion to phonology, 2711–2729. Malden, MA: Wiley-Blackwell.Search in Google Scholar
Derwing, Tracey. 2017. The role of phonological awareness in language learning. In Peter Garrett & Josep Maria Cots (eds.), The Routledge handbook of language awareness, 338–353. London: Routledge.10.4324/9781315676494-21Search in Google Scholar
Díaz-Campos, Manuel. 2004. Context of learning in the acquisition of Spanish second language phonology. Studies in Second Language Acquisition 26. 249–273. https://doi.org/10.1017/s0272263104262052.Search in Google Scholar
Díaz-Campos, Manuel. 2006. The effect of style in second language phonology: An analysis of segmental acquisition in study abroad and regular-classroom students. In Carol A. Klee & Timothy L. Face (eds.), Selected proceedings of the 7th conference on the acquisition of Spanish and Portuguese as first and second languages, 26–39. Somerville, MA: Cascadilla Proceedings Project.Search in Google Scholar
Eckman, Fred R., Gregory K. Iverson & Yae Jung Song. 2013. The role of hypercorrection in the acquisition of L2 phonemic contrasts. Second Language Research 29(3). 257–283. https://doi.org/10.1177/0267658312467029.Search in Google Scholar
Eddington, David. 2011. What are the contextual phonetic variants of /β ð ɣ/ in colloquial Spanish. Probus 23. 1–19. https://doi.org/10.1515/prbs.2011.001.Search in Google Scholar
Eddington, David & Dirk Elzinga. 2008. The phonetic context of American English flapping: Quantitative evidence. Language and Speech 51(3). 245–266. https://doi.org/10.1177/0023830908098542.Search in Google Scholar
Elff, Martin. 2022. Multinomial logit models with or without random effects or overdispersion. R package version 0.9.6. Available at: https://cran.r-project.org/web/packages/mclogit/index.html.Search in Google Scholar
Elias-Ulloa, José. 2022. Influencia prosódica en la espirantización de las oclusivas sonoras del castellano de la ciudad de Lima (Perú). Lexis 46(2). 441–480. https://doi.org/10.18800/lexis.202202.001.Search in Google Scholar
Elliott, A. Raymond. 1997. On the teaching and acquisition of pronunciation within a communicative approach. Hispania 80(1). 95–108. https://doi.org/10.2307/345983.Search in Google Scholar
Face, Timothy L. 2018. Ultimate attainment in Spanish spirantization: The case of US-born immigrants in Spain. Spanish in Context 15(1). 27–53. https://doi.org/10.1075/sic.00002.fac.Search in Google Scholar
Face, Timothy L. 2021. What does advanced L2 pronunciation look like? Evidence from the ultimate attainment of Spanish consonants. In Mandy R. Menke & Paul A. Malovrh (eds.), Advancedness in second language Spanish: Definitions, challenges, and possibilities, 143–169. Amsterdam: John Benjamins.10.1075/ihll.31.07facSearch in Google Scholar
Face, Timothy L. & Mandy R. Menke. 2009. Acquisition of the Spanish voiced spirants by second language learners. In Joseph Collentine, Maryellen García, Barbara Lafford & Francisco Marcos Marín (eds.), Selected proceedings of the 11th Hispanic linguistics symposium, 39–52. Somerville, MA: Cascadilla Proceedings Project.Search in Google Scholar
Face, Timothy L. & Mandy R. Menke. 2020. L2 Acquisition of Spanish VOT by English-speaking immigrants in Spain. Studies in Hispanic and Lusophone linguistics 13(2). 361–389. https://doi.org/10.1515/shll-2020-2034.Search in Google Scholar
Flege, James E. 1995. Second language speech learning. Theory, findings, and problems. In Winifred Strange (ed.), Speech perception and linguistic experience: Issues in cross-language research, 233–277. Timonium, MD: York Press.Search in Google Scholar
Flege, James E. & Ocke-Schwen Bohn. 2021. The revised speech learning model (SLM-r). In Ratree Wayland (ed.), Second language speech learning: Theoretical and empirical progress, 3–83. Cambridge: Cambridge University Press.10.1017/9781108886901.002Search in Google Scholar
Geeslin, Kimberly, Danielle Daidone, Avizia Y. Long & Megan Solon. 2023. Usage-based models of second language acquisition. In Manuel Díaz-Campos & Sonia Balasch (eds.), The handbook of usage-based linguistics, 345–361. Malden, MA: Wiley-Blackwell.10.1002/9781119839859.ch19Search in Google Scholar
González López, Verónica & David Counselman. 2013. L2 acquisition and category formation of Spanish voiceless stops by monolingual English novice learners. In Jennifer Cabrelli Amaro (ed.), Selected proceedings of the 16th Hispanic linguistics symposium, 118–127. Somerville, MA: Cascadilla Proceedings Project.Search in Google Scholar
González-Bueno, Manuela. 1995. Adquisición de los alófonos fricativos de las oclusivas sonoras españolas por aprendices de español como segunda lengua. Estudios de lingüística aplicada 13. 64–79.Search in Google Scholar
González-Bueno, Manuela. 1997. Effects of formal instruction on the improvement in the pronunciation of Spanish stops by second language learners: Changes in voice onset time in initial stops /p, t, k/ and /b, d, g/. State College, PA: The Pennsylvania State University dissertation.Search in Google Scholar
Gorba, Celia & Juli Cebrián. 2023. The acquisition of L2 voiced stops by English learners of Spanish and Spanish learners of English. Speech Communication 146. 93–108. https://doi.org/10.1016/j.specom.2022.12.003.Search in Google Scholar
Gordon, Matthew. 2011. Stress: Phonotactic and phonetic evidence. In Marc Oostendorp, Colin Ewen & Elizabeth Hume (ed.), The Blackwell companion to phonology, 1–25. Malden, MA: Wiley.10.1002/9781444335262.wbctp0039Search in Google Scholar
Hualde, José Ignacio. 2005. The sounds of Spanish. Cambridge: Cambridge University Press.Search in Google Scholar
Lee, Junkyu, Juhyun Jang & Luke Plonsky. 2015. The effectiveness of second language pronunciation instruction: A meta-analysis. Applied Linguistics 36(3). 345–366. https://doi.org/10.1093/applin/amu040.Search in Google Scholar
Lord, Gillian. 2005. (How) can we teach foreign language pronunciation? On the effects of a Spanish phonetics course. Hispania 88(3). 557–567. https://doi.org/10.2307/20063159.Search in Google Scholar
Lord, Gillian. 2010. The combined effects of instruction and immersion on second language pronunciation. Foreign Language Annals 43. 488–503. https://doi.org/10.1111/j.1944-9720.2010.01094.x.Search in Google Scholar
Major, Roy. 1986. The ontogeny model: Evidence from L2 acquisition of Spanish r. Language Learning 36. 453–504. https://doi.org/10.1111/j.1467-1770.1986.tb01035.x.Search in Google Scholar
Major, Roy. 2001. Foreign accent: The ontogeny and phylogeny of second language phonology. Mahwah, NJ: Lawrence Erlbaum Publishers.10.4324/9781410604293Search in Google Scholar
Martínez Celdrán, Eugenio. 1991. Sobre la naturaleza fonética de los alófonos de /b, d, g/ en español y sus distintas denominaciones. Verba 18(1). 235–253.Search in Google Scholar
Mirisis, Christina A. 2020. Production and perception of Spanish voiced stops and approximants by L2 learners. Journal of Second and Multiple Language Acquisition 8(4). 79–110.Search in Google Scholar
Nagle, Charles. 2017. Individual developmental trajectories in the L2 acquisition of Spanish spirantization. Journal of Second Language Pronunciation 3(2). 218–241. https://doi.org/10.1075/jslp.3.2.03nag.Search in Google Scholar
Nagle, Charles. 2019. A longitudinal study of voice onset time development in L2 Spanish stops. Applied Linguistics 40(1). 86–107. https://doi.org/10.1093/applin/amx011.Search in Google Scholar
Ohala, John J. 1994. Speech aerodynamics. In Ron Asher & J. M. Y. Seumas Simpson (eds.), The encyclopedia of language and linguistics, 4144–4148. Oxford: Pergamon.Search in Google Scholar
Olson, Daniel J. 2022. Phonetic feature size in second language acquisition: Examining VOT in voiceless and voiced stops. Second Language Research 38(4). 913–940. https://doi.org/10.1177/02676583211008951.Search in Google Scholar
Ortega-Llebaria, Marta. 2004. Interplay between phonetic and inventory constraints in the degree of spirantization of voiced stops: Comparing intervocalic / b/ and intervocalic /g/ in Spanish and English. In Timothy L. Face (ed.), Laboratory approaches to Spanish phonology, 237–253. Berlin: Mouton de Gruyter.Search in Google Scholar
R Core Team. 2021. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing URL https://www.R-project.org/.Search in Google Scholar
Rogers, Brandon M. A. & Scott M. Alvord. 2014. The gradience of Spirantization: Factors affecting L2 production of intervocalic Spanish [b,d,g]. Spanish in Context 11(3). 402–424. https://doi.org/10.1075/sic.11.3.05rog.Search in Google Scholar
Schuhmann, Katharina S. & Marie K. Huffman. 2015. L1 drift and l2 category formation in second language learning. In The Scottish Consortium for ICPhS 2015 (ed.), Proceedings of the 18th international congress of phonetic sciences, 941–944. Glasgow, Scotland: The University of Glasgow.Search in Google Scholar
Shea, Christine E. & Suzanne Curtin. 2011. Experience, representations and the production of second language allophones. Second Language Research 27. 229–250. https://doi.org/10.1177/0267658310375753.Search in Google Scholar
Shively, Rachel L. 2008. L2 acquisition of [β], [ð], [ɣ] in Spanish: Impact of experience, linguistic environment, and learner variables. Southwest Journal of Linguistics 27(2). 79–114.Search in Google Scholar
Simonet, Miquel, Joseph Casillas & Yamile Díaz. 2014. The effects of stress/accent on VOT depend on language (English, Spanish), consonant (/d/, /t/) and linguistic experience (monolinguals, bilinguals). Speech Prosody 7. 202–206. https://doi.org/10.21437/speechprosody.2014-28.Search in Google Scholar
Solon, Megan. 2018. The acquisition of second language Spanish sounds. In Kimberly Geeslin (ed.), The Cambridge handbook of Spanish linguistics, 668–688. Cambridge, UK: Cambridge University Press.10.1017/9781316779194.031Search in Google Scholar
Solon, Megan, Bret Linford & Kimberly L. Geeslin. 2018. Acquisition of sociophonetic variation: Intervocalic /d/ reduction in native and nonnative Spanish. Spanish Journal of Applied Linguistics 31. 309–344. https://doi.org/10.1075/resla.16028.sol.Search in Google Scholar
Tarone, Elaine. 2018. Interlanguage. In Carol A. Chapelle (ed.), The encyclopedia of applied linguistics, 1–7. Malden, MA: Wiley-Blackwell.10.1002/9781405198431.wbeal0561.pub2Search in Google Scholar
Wanjema, Shontael, Katie Carmichael, Abby Walker & Kathryn Campbell-Kibler. 2013. Integrating teaching and large-scale research through instructional modules. American Speech 88(2). 223–235.10.1215/00031283-2346798Search in Google Scholar
Wulff, Stefanie & Nick C. Ellis. 2018. Usage-based approaches to SLA. In David Miller, Fatih Bayram, Jason Rothman & Ludovica Serratrice (eds.), Bilingual cognition and language: The state of the science across its subfields, 37–56. Amsterdam: John Benjamins.Search in Google Scholar
Yuan, Jiahong & Mark Liberman. 2008. Speaker Identification on the SCOTUS Corpus. In Proceedings of Acoustics ’08 Paris. Paris: Société Francaise d’Acoustique.Search in Google Scholar
Zampini, Mary L. 1994. The role of native language transfer and task formality in the acquisition of Spanish spirantization. Hispania 77. 470–481. https://doi.org/10.2307/344974.Search in Google Scholar
Zampini, Mary L. 1998. The relationship between the production and perception of L2 Spanish stops. Texas Papers in Foreign Language Education 3(3). 85–100.Search in Google Scholar
© 2025 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Research Articles
- Generational change in the conditioning of coda /r/ manner of articulation in Lorain Puerto Rican Spanish
- An initial approximation of the indexical field of creaky voice in Chilean Spanish
- A continuous and categorical approach to the L2 acquisition of Spanish voiced stop allophones
- Testing competing accounts of adjective-noun code-switching in a Spanish-English written corpus
- Gender-inclusive morphology in Spanish: learnability, processing costs, and use
- Exploring factors that influence the accusative/dative experiencer alternation in Spanish psych verbs: data from three types of Spanish–English bilinguals
- Perception of Spanish diphthong /ei/ by second language and heritage speakers of Spanish: findings from two perception tasks
Articles in the same Issue
- Frontmatter
- Research Articles
- Generational change in the conditioning of coda /r/ manner of articulation in Lorain Puerto Rican Spanish
- An initial approximation of the indexical field of creaky voice in Chilean Spanish
- A continuous and categorical approach to the L2 acquisition of Spanish voiced stop allophones
- Testing competing accounts of adjective-noun code-switching in a Spanish-English written corpus
- Gender-inclusive morphology in Spanish: learnability, processing costs, and use
- Exploring factors that influence the accusative/dative experiencer alternation in Spanish psych verbs: data from three types of Spanish–English bilinguals
- Perception of Spanish diphthong /ei/ by second language and heritage speakers of Spanish: findings from two perception tasks