An alternative view of the English alternative embedded passive
-
Daniel Duncan



Abstract
The English alternative embedded passive (AEP), or “needs washed” construction, is a noncanonical morphosyntactic feature found in some American and British Englishes. It involves a matrix verb surfacing immediately before a participle. Previous research has described this construction as only licit with matrix need, want, and like; however, isolated examples of the AEP with additional matrix verbs have surfaced. These rarely attested instances raise questions regarding the basic description of the construction and how matrix verb availability is constrained, as well as whether the AEP is truly the same feature across AmE and BrE varieties. This paper utilizes a large-scale grammaticality judgement survey to obtain as exhaustive a set of AEP matrix verbs as possible. Results show that far more verbs can be used in the AEP than previously attested. Acceptance is constrained by lexical semantics, verbal syntax, and verb productivity. This alternative view of the AEP as a more generalized phenomenon nevertheless shows a strong link between AmE and BrE varieties, as the constraints are nearly identical across the nations. The findings illustrate how attention to rarely attested or non-attested data can inform morphosyntactic and dialectological research.
1 Introduction
This paper is about what is commonly called the “needs washed” construction (Maher and Wood 2011), a noncanonical morphosyntactic feature in some American and British Englishes in which a matrix verb can directly select a past participle as an embedded passive (1). The needs washed construction contrasts with canonical embedded passives (EP, 2), which embed the participle following to be, and concealed passives, in which the embedded participle has progressive morphology (3). These phenomena have similar meanings, and have been analyzed as in variation with one another (e.g., Duncan 2019; Strelluf 2022).
| The car needs washed . |
| The car needs to be washed . |
| The car needs washing . |
The needs washed construction has been strongly attested as occurring with matrix want and like as well (Murray and Simon 1999, 2002):
| The cat wants fed. |
| The baby likes cuddled. |
Because the feature occurs in contexts beyond matrix need, I follow Edelstein (2014) in calling it the alternative embedded passive (AEP) throughout the rest of the paper.
The AEP has been well-studied from both dialectological (Duncan 2019; Murray and Simon 1999, 2002; Murray et al. 1996; Smith et al. 2019; Stabley 1959; Strelluf 2020; Wood et al. 2020, 2022) and syntactic perspectives (Edelstein 2014; Strelluf 2022; Tenny 1998). Such work largely relies on a description of the construction as only permitting the three matrix verbs illustrated above, which stands in sharp contrast to the canonical EP and concealed passive. However, recent work (Duncan 2021; Strelluf 2022; Wood et al. 2022) has observed that the AEP can occur with a wider range of matrix verbs. The goal of this paper is to take this observation seriously as evidence that the wide literature on the feature may be working with an incomplete description of the phenomenon. As I discuss below, the question of which matrix verbs are possible in the AEP is not simply a descriptive question, but rather reopens apparently closed issues concerning constraints on the grammaticality of the construction and its origin and development. In this sense, improving the accuracy of our description of a linguistic phenomenon has the potential to contribute to our analysis of it.
To this end, in this paper I report results of a large-scale grammaticality judgement survey designed to obtain as exhaustive a set of AEP matrix verbs as possible. In doing so, I show that far more verbs can be used in the AEP than previously known. While the distribution of acceptability ratings suggests that at least some users of the AEP will accept most potential matrix verbs in the construction, acceptability of a given verb is nevertheless highly constrained by factors related to lexical semantics, verbal syntax, and verb productivity. By illustrating these effects, this work, like that of Strelluf (2022), aims to rectify misanalysis of the AEP caused by the feature’s low frequency of occurrence. I also contribute strong evidence in favor of claims that the AEP appeared in American Englishes as a result of Scots–Irish migration from the UK (Montgomery 1991, 1997; Murray et al. 1996; Strelluf 2020).
In the pages that follow, I first outline key information about the AEP as currently understood in Section 2. I then introduce examples of the AEP that problematize this understanding in Section 3. Sections 4 and 5 describe the grammaticality judgement survey and its results. Finally, Section 6 summarizes the key outcomes, discusses remaining open questions, and concludes.
2 The alternative embedded passive
The AEP has been most commonly described in the context of American dialectology (Labov et al. 2006; Murray and Simon 1999, 2002; Murray et al. 1996; Stabley 1959; Strelluf 2020, 2022). One key reason for this is that it is one of the few dialect features in American Englishes that offers positive evidence of a Midland dialect (Labov et al. 2006). However, in online surveys Wood et al. (2022) find that residents of much of the US accept the feature as grammatical, with hotspots of acceptance in Arizona and the Pacific Northwest in addition to the Great Plains and traditional Midland. Wood et al.’s surveys find the AEP to be markedly unacceptable in a geographically limited set of regions: New England, California, and the southern half of the Eastern Seaboard. It should be noted that this limited geographical space nonetheless represents a quite large percentage of the US population, and as such the AEP is used by a minority of American English speakers.
Although it is accepted more widely than in the Midland alone, Wood et al. (2022) follow other work in noting that the AEP appears to be more firmly rooted in the Midland than other regions. Wood et al. suggest that acceptance of the AEP is centered on Indiana and Ohio. There has also been a strong association between the Pittsburgh area and the AEP (Edelstein 2014; Johnstone 2009; Tenny 1998) since Stabley’s (1959) observation of the feature in western Pennsylvania. Duncan (2019) shows that the AEP is robustly variable in production on online forums dedicated to Pittsburgh professional sports teams, while Strelluf (2020, 2022 shows that the AEP is consistently produced on Twitter in tweets geotagged within the Pittsburgh metropolitan area. In his study of AEP production on Twitter, Strelluf compares usage in multiple cities. His results support the view that the AEP is more robustly part of the English spoken in the Midland, as it is found within the Midland but is nearly absent from nearby cities outside of the Midland such as Cleveland and Philadelphia. Likewise, Twitter users in more peripheral Midland cities like St. Louis use the feature less than those in core cities like Pittsburgh and Columbus (Strelluf 2020).
The AEP is also robustly attested in the UK. For example, Murray and Simon (2002: 46) note that a handful of survey respondents from Scotland, Northern Ireland, and northern England accepted the construction with matrix like. Montgomery (1991, 1997 describes the AEP as a Scots–Irish feature, implying that it is present at least in Northern Ireland. Strelluf’s (2020, 2022 study of Twitter production confirms this, finding a high rate of usage in Belfast. Acceptability surveys (Smith et al. 2019) and production studies (Strelluf 2020, 2022) additionally find that the AEP is used throughout Scotland. The feature is found much less in England or Wales. However, it is found in Newcastle, albeit at lower rates than in Scotland and Northern Ireland, much like the case of St. Louis in the US (Strelluf 2020, 2022).
Given where the AEP has been attested in both nations, scholars have suggested that the feature appeared in American Englishes as a result of Scots–Irish migration to North America (Kirkham 1997; Montgomery 1991, 1997; Murray and Simon 2002; Murray et al. 1996; Strelluf 2020). Montgomery’s argument is limited to Scots–Irish migrants being early settlers in Appalachia (cf. Mufwene 1996; Zelinsky 1992, 2011) and Appalachian English having the AEP with matrix need. However, the Midland areas such as Pittsburgh also saw a great deal of Scots–Irish migration (Strelluf 2020), and the argumentation would be the same. Murray and Simon (2002) note that if they found positive attestations of the AEP with matrix like in Scotland, this would seem to imply that the feature predates the plantation of Ulster (see also Strelluf 2020: 129), but they were unsuccessful in their search for examples that would prove this conclusively.
In addition to the regional dialectology of the feature, the AEP has also drawn interest from the perspective of formal syntax and semantics (Edelstein 2014; Strelluf 2022; Tenny 1998). The syntactic structure of the feature has been of particular interest; while it varies with the canonical EP (Duncan 2019), diagnostic tests suggest that the AEP is not simply the canonical EP with a silent or deleted to be (Edelstein 2014, although Murray and Simon 1999 outline a deletion argument). One such test involves the kind of participle that may be embedded. Whereas the canonical EP permits a stative or eventive passive to be embedded, the AEP only permits eventive passives (Edelstein 2014; Tenny 1998).
The restricted set of available matrix verbs is relevant to syntactic and semantic accounts as well. The limitation to need, want, and like constitutes a tighter restriction than that found for the canonical EP or concealed passive (Edelstein 2014). Furthermore, acceptability of the AEP is not consistent across these three matrix verbs. Acceptability appears to follow an implicational hierarchy: people accepting the construction as grammatical with matrix like implies them accepting it with matrix want, which implies them accepting it with matrix need (Edelstein 2014; Murray and Simon 2002; Wood et al. 2022). Edelstein (2014) suggests that this hierarchy may be due to verbal syntax. She analyzes the AEP as a Raising construction (see Davies and Dubinsky 2004 for an overview of Raising and Control). Under this view, need is a Raising verb, and can therefore easily fit into the construction. However, want is typically a Control verb, and like certainly is. These verbs must be coerced into the Raising construction, which may be more difficult than simply inserting a Raising verb. In addition to the potential syntactic constraint, the hierarchy has also been attributed to semantic factors (Murray and Simon 1999). For example, Edelstein (2014) notes that the AEP permits the utterance subject to be non-sentient. While this may be attributed to the AEP being a Raising construction (Edelstein 2014: 246), the lexical semantics of the verb could also govern whether this is easily achieved, as it is for need, or whether this must be a coerced reading perhaps with some difficulty, as it is for like.
3 Problem and research aims
As should be clear from the above discussion, the AEP is particularly well-described and well-studied for a noncanonical dialect feature. However, recent work has suggested that the description of the feature may not be as complete as previously believed. Namely, the set of matrix verbs available to the construction does not appear to be limited to need/want/like. For example, footnotes in previous work have attested require and [could] use as AEP matrix verbs:
| Surely Lineker requires fired for that. (Strelluf 2022: 66) |
| Your radiator could use flushed. (Tenny 1998: 596) |
Attestations such as those in (6–7) are not difficult to find with other matrix verbs through online searches (8–11).[1]
| Jimmy Walker was struggling with the amount of people demanding served. (Kielty 2016, accessed via Google Books 19 July 2023) |
| A large warship sent to protect merchant ships sailing in the Mediterranean that risked captured by pirates from the barberry [sic] states of North Africa. (https://www.chegg.com/flashcards/history-6b6e5ec4-e4bc-47b3-b4b7-85fa77883120/deck, accessed 19 July 2023) |
| Lucy is a sweet, well behaved senior who enjoys petted with a gentle hand. (https://www.adoptapet.com/pet/26633006-oro-valley-arizona-cat, accessed 19 July 2023) |
| If you ever see that he wants your attention then give it to him but if he prefers left alone then that would make him happy if he was left alone so he should be happy:) (http://hamsterhideout.com/forum/topic/79995-can-an-untamed-hamster-be-happy/, accessed 22 November 2021) |
Duncan (2021) makes an initial attempt to consider such attestations more systematically, and observes that love and deserve are used as AEP matrix verbs across the United States, primarily in the Midwest and Pacific Northwest (12–13). He also finds online examples of hate as a matrix verb, although these cannot be definitively linked to the US in the same way (14).
| I don’t think he deserves fired. (Duncan 2021: 485) |
| Gretchen loves petted and is a great lap cat. (Duncan 2021: 486) |
| She hates petted and only comes near us when she’s starving. (Duncan 2021: 486) |
Researchers with the Yale Grammatical Diversity Project (Wood et al. 2020, 2022) test whether matrix love is rated as acceptable by American English speakers. They find that acceptance is geographically constrained in a manner consistent with the AEP; there is a hotspot indicating heightened acceptance in the core region of Indiana/Ohio.
These recent results therefore show that non-need/want/like matrix verbs such as love are attested beyond single examples and acceptable to a substantial number of English speakers. This suggests that such matrix verbs are in fact part of the AEP. In light of this, it is clear that the description of the feature as only being acceptable with a small set of matrix verbs is inaccurate. A basic research question thus arises: what is the set of verbs permissible as AEP matrix verbs? In some respects, this is a purely descriptive question, as it does not necessarily bear on the syntactic structure of the feature. However, I argue that the answer to this basic descriptive question interacts with other issues relevant to the syntax, semantics, and dialectological origins of the AEP.
For example, consider that acceptability of AEP matrix verbs is said to follow an implicational hierarchy, perhaps for reasons relating to the syntax of the matrix verb or its lexical meaning. Wood et al. (2022) suggest that this hierarchy holds when love is included as an acceptable matrix verb; acceptability with love implies acceptability with like. However, without knowing the full range of acceptable matrix verbs, it is not possible to know which factors (syntax, lexical semantics, or something else entirely) constrain this implicational hierarchy, or whether there is in fact an implicational hierarchy at all. Knowing the answer to this question is important to a formal understanding of the AEP. Edelstein (2014), for instance, relies in part on the description of the implicational hierarchy and its constraints in arguing for the feature having a particular syntactic structure. In this sense, the basic descriptive question posed here bears on the description of the AEP more broadly, and on any questions of formal structure which depend on this broader description.
Likewise, the claim that the AEP in American Englishes has a Scots–Irish origin is made primarily on the basis of the feature occurring with matrix need in the US and Ulster (Montgomery 1991, 1997; Strelluf 2020). This is by itself compelling evidence, particularly given the relative attested non-usage of the AEP in other Englishes worldwide (Kortmann et al. 2020). However, it is possible that a closer look at the availability of matrix verbs and how they are constrained could show that the AEP in the US and UK is in fact two superficially similar constructions. Following recent sociolinguistic work which argues for a feature appearing in two regions having a shared origin if it has similar constraint rankings in each region (Carmichael and Becker 2018; Chatten et al. 2022; Erker and Otheguy 2021), comparing the set of acceptable matrix verbs and how that acceptability is constrained will shed additional light on whether the AEP indeed is a Scots–Irish import into American Englishes.
The basic question posed here of ascertaining the set of AEP matrix verbs thus offers the prospect of answering three additional questions: (a) what constraints govern matrix verb acceptability in the AEP? (b) does the implicational hierarchy outlined in previous research (Edelstein 2014; Murray and Simon 2002) hold given a more accurate description of the feature? (c) does the available description of the AEP still support a shared origin of the feature in the US and UK? I aim to answer each of these four questions using a large-scale grammaticality judgement survey.
4 Methods
A difficulty in studying the AEP is that embedded passives are rather infrequent on the whole. For example, the Corpus of Contemporary American English (COCA, Davies 2008) has over one billion words, yet within this large dataset are only a little over 100,000 tokens of the canonical embedded passive. Given the source texts in COCA, there are far fewer AEP tokens. At the same time, instances of embedded passives in COCA are strongly skewed toward need (over 40 %) and want (∼15 %) as matrix verbs, with the occurrence of any other matrix verb ranging from being a hapax legomenon to roughly 4 % of embedded passives in the corpus.
Given this, it is not surprising that many production studies of the AEP focus solely on usage with matrix need (Duncan 2019; Strelluf 2020, 2022; Ulrey 2009). Because users of the AEP are a minority of American and British English speakers, this focus can extend to selecting data from specific locations (Strelluf 2020, 2022) or a community linked to a specific location (Duncan 2019). While this approach maximizes the likelihood of obtaining AEP tokens, it also greatly reduces the amount of production data available to the researcher. Because embedded passives skew so strongly to matrix need and want, this effectively means that our research questions cannot be addressed from using corpus or variationist data. For this reason, I use a large-scale acceptability judgement survey to collect data. Such surveys have been shown to effectively replicate linguists’ judgements (Sprouse et al. 2013) and have proven useful in obtaining judgements regarding nonstandard (and thus potentially stigmatized) features as well (Zanuttini et al. 2018).
The aim of survey construction was to test as near-exhaustive a set of potential AEP matrix verbs as possible. Because the AEP is typically described in reference to the canonical EP, I determined this set of potential matrix verbs based on attested usage in the canonical EP. I first used the Penn Treebank 2a guidelines (Taylor 2006) to obtain a list of Raising, Control, and Exceptional Case Marking (ECM) verbs (see Davies and Dubinsky 2004; Wurmbrand 2024, for discussion of these distinctions). This list was modified slightly in three ways. Firstly, I added verbs that were attested in the literature to be AEP matrix verbs (Strelluf 2022; Tenny 1998) but were absent from the initial list ([could] use, require), as well as synonyms to verbs already in the initial list ([could] bear, beg, beseech, demand, enjoin, entreat, exhort, implore, importune, petition, request). Secondly, I removed copular constructions and the modal constructions ought to, have to, and have got to, as the lack of to be in the AEP made it unclear how to construct a test item. Finally, I removed the verbs look, seem, and appear, which select a stative participle and would be expected to be accepted by all participants, regardless of whether they are AEP users or not. In total, the list of potential verbs numbered 142.
With the help of an undergraduate research assistant, attested usage in the canonical EP was determined by searching COCA for embedded passives with each matrix verb. For Raising and Control verbs, we used the following search string and grouped results by lemma:
| VERB_vv to be _v?n |
ECM verbs can only embed a passive when they are themselves passivized; we restricted the search string accordingly:
| VERB_v?n to be _v?n |
In total, there were 116 attested matrix verbs used in the canonical embedded passive. In addition to a binary attested/non-attested determination, we collected each matrix/participle pair, the number of instances for that pair, and representative examples. Representative examples were supplemented by searching the British National Corpus as well (Davies 2004).
Verbs were coded for syntactic type (Raising, Control, ECM) based on their classification in the Treebank 2a guidelines (Taylor 2006).[2] Verbs not listed in these guidelines were coded following diagnostics for distinguishing Raising and Control verbs (Davies and Dubinsky 2004: 7–8). In addition, the matrix/participle pairs and number of instances collected from COCA were used to create a weighted bipartite network model (see Duncan 2023 for details) in R (R Core Team 2020). Unattested verbs were omitted from this model. This model was used to code verbs for additional factors. A verb’s degree centrality (Dodsworth and Benton 2019), effectively the frequency at which it occurred in an embedded passive in COCA, was taken as a measure of verb productivity. Highly frequent verbs which select a wide range of participles will have a higher productivity value than low frequency verbs and/or verbs which select a limited range of participles. Using the bipartite package in R (Dormann et al. 2008), a community detection algorithm was used to group verbs together which select similar sets of participles (Beckett 2016). This algorithm targets a set of communities with the highest modularity value. It selects the set of communities from multiple runs with differing initialization of a two-step process, in which first, the largest number of communities is identified and second, these communities are combined until the modularity cannot increase any more (Beckett 2016: 6). I take these groupings to represent semantic likeness, as shared meaning elements make it more likely that verbs will select similar participles. For example, a child may express sentiment toward a hugging action by liking, loving, or hating (to be) hugged. However, verbs lacking this meaning, such as vote or forget, would be unlikely to co-occur with hugged. Nine semantic likeness groups in total were derived through this process (Table 1). Note that the community detection algorithm merely clustered verbs together; any labeling of their approximate likeness is my interpretation of the output.
Semantic likeness categories from weighted bipartite network model.
| Group and approximate likeness | Verbs in group |
|---|---|
| A: volition, sentiment, intention | Afford, agree, ask, avoid, bear, beg, care, choose, clamor, decide, decline, demand, deny, deserve, elect, enjoy, favor, hate, hesitate, jump, like, love, manage, mind, move, offer, opt, pledge, prefer, push, risk, struggle, vow, want, wish, imagine, suppose |
| B: no future event | Refuse, figure, stop |
| C: permissivity of future event | Apply, come, mean, negotiate, petition, set out, try |
| D: stating, asserting | Attempt, bother, claim, determine, hope, know, press, profess, promise, report, resolve, seek, strive, swear, assume, consider, declare, deem, estimate, find, perceive, repute, rumor, say, see, show, think, believe, happen, prove, tend |
| E: working toward future event | Aim, scramble, remain |
| F: necessity | Admit, concede, flock, request, require, serve, sign, make, need |
| G: forget | Forget |
| H: arranging for future event that will happen | Arrange, begin, discuss, force, intend, learn, proceed, stay, threaten, undertake, vote, wait, allow, hold, judge, continue, fail, start |
| I: arranging for future event that may not happen | Plan, propose, rush, stand, cause, expect, project |
Using the examples found in COCA and the BNC as a template, 348 test sentences were constructed (three per potential matrix verb). In order to clearly test for acceptability of a given matrix verb, stimuli were controlled for grammatical context as much as possible. For most verbs, the test sentences were in present tense, positive declarative contexts (17a). These included a manner adverb and/or by-phrase as necessary in order to force an eventive reading for the participle. Because ECM verbs can only embed a passive when passivized, test sentences including these verbs were passivized as well (17b). The verbs bear and stand predominantly occur with the modal could, and test sentences including these adhered to this template to be more natural-like than the positive declarative context would offer (17c–d).[3]
| This paperwork requires completed. |
| The dangerous package was determined produced by a disgruntled employee. |
| The toddler couldn’t bear parted from her teddy bear. |
| His room could stand cleaned up a bit. |
In addition to the test stimuli, 37 filler sentences were constructed. Because it is quite possible that participants without the AEP in their grammars will reject every test sentence and that even those with the AEP in their grammars will reject the vast majority of test sentences, the fillers were designed to be grammatical for all American and British English speakers. They included examples of the canonical EP, as well as transitive constructions with clefted objects (18). The latter fillers have adjacent matrix verbs and embedded participles and act as an attention check because correctly rating them as grammatical requires reading the sentence carefully.
| The fence needs to be painted. |
| Here is the form that I need filled out. |
The test stimuli and grammatical fillers total 385 items. As this is far too many test items for a single study, the stimuli were divided into four surveys. Each survey included the need, want, and like test stimuli, grammatical fillers, and one quarter of the remaining test stimuli (n = 127–130). Verbs were sorted into surveys by ranking them by productivity, and then assigning verbs to surveys in ranked order in a “snake draft” format. This format of assignment reverses the order in which verbs are assigned to a survey in each pass through the surveys (i.e., survey A has the highest productivity verb and survey D the fourth highest, but survey D has the fifth highest productivity verb and survey A the eighth highest, and so on). In this way, each survey had verbs with a wide range of productivity. The ordering was revised slightly to ensure the verbs were also well-distributed for syntactic type and semantic likeness across surveys. Surveys were compiled into online tasks hosted on the PCIbex Farm (Zehr and Schwartz 2018). In addition to the test stimuli and filler items, surveys included basic demographic information, including gender, education level, ethnicity, date of birth, and the postcode in which they resided most between the ages of six and eighteen.[4] In these tasks, instructions were written to encourage participants to rate acceptability separately from prescriptive norms. Stimuli were presented in a randomized order and set to be rated on a five-point Likert scale.
Surveys were distributed on Prolific, an online platform for academic studies which enables participant screening and recruitment and encourages researchers to pay participants a fair rate (Palan and Schitter 2018; Peer et al. 2017). After confirmation that they passed attention checks through visual inspection of grammatical filler ratings, participants received £2.50 for an estimated 20 min of their time (a £7.50 hourly rate). Participants were recruited from the US and UK. Following Wood et al. (2020), who suggest that roughly 500 participants are required in the US to obtain robust geospatial data, 500 participants per survey (2000 total, 187,500 ratings) were recruited. The 2000 participants were obtained from 2083 engagements with the survey (56 returned the task without submitting, 15 were rejected for failing attention checks, and 12 had missing data due to technical errors). Because the UK is smaller than the US both in population and area, 100 participants per survey (400 total, 37,500 ratings) were recruited from this nation. The 400 participants were obtained from 423 engagements with the survey (19 returned the task without submitting, 1 was rejected for failing attention checks, and 3 had missing data due to technical errors). Participants from the US were permitted from any location. Because in the UK the AEP is most strongly attested in Scotland and Northern Ireland (Strelluf 2020, 2022), which have a quite small population relative to the nation overall, these countries were oversampled to ensure robust data (35 participants from Scotland/Northern Ireland and 65 from England/Wales per survey). All participants were prescreened to report their first language as English and to report fluency in English.
5 Results
Completed surveys included participant-level sentence ratings and demographic information. As one method of testing whether the AEP was brought to the US through Scots–Irish migration, I supplement the US responses with population-level data: for every zip code, the percentage of the 2019 population with German, Irish, Scottish, and Scots–Irish heritage, the local population density, as well as the percentage of the population with a college degree or higher (EASI 2020). I quantitatively analyze the data through linear mixed-effects regression (Bates et al. 2015), as well as geospatial statistics. Regression analysis enables us to examine how language-internal constraints, demographics, and population-level factors affect acceptability ratings. Geospatial statistics enable us to examine how responses are distributed across space. Global Moran’s I, with a Bonferroni correction applied (240 repeated measures across both studies, yielding significance at p = 0.000208), shows whether there is significant clustering of like ratings anywhere, while the Getis-Ord G i * statistic shows whether a particular region rates sentences significantly higher or lower than other regions (Bivand et al. 2013; Grieve 2016; Wood 2019).
One difficulty in conducting the regression analysis is that language-internal constraints and language-external constraints on matrix verb acceptability require different populations. Internal constraints governing matrix verb acceptability should be analyzed among participants with the AEP in their grammars. In contrast, external constraints showing who uses the AEP at all should be analyzed using the entire sample population. The former population must be determined post hoc from the data. Because speakers with the AEP are typically viewed as always accepting matrix need (Edelstein 2014; Murray and Simon 2002), I suggest that participants who rate sentences with matrix need highly can be seen as a proxy for AEP users. Here, I define “accepting” matrix need as having an average rating of 3.67 or higher on the five-point Likert scale. This corresponds to rating at least two of the three test stimuli for the verb as grammatical (i.e., a rating of 4 or 5). Using this definition, we include 210 UK participants (19,686 ratings) and 988 US participants (92,631 ratings) as AEP users.
5.1 Regression analysis: language-internal constraints
Among the participants who most likely have the AEP in their grammars, visual inspection of the acceptability ratings shows that ratings appear to be continuously distributed (Figure 1). Given that so few verbs are attested in the AEP, this is somewhat surprising. While there are clearly unacceptable verbs as well as clearly acceptable verbs, this is not as bifurcated as we may have expected. Rather, at least some participants appear to accept a wide variety of matrix verbs, including rare and previously unattested matrix verbs.
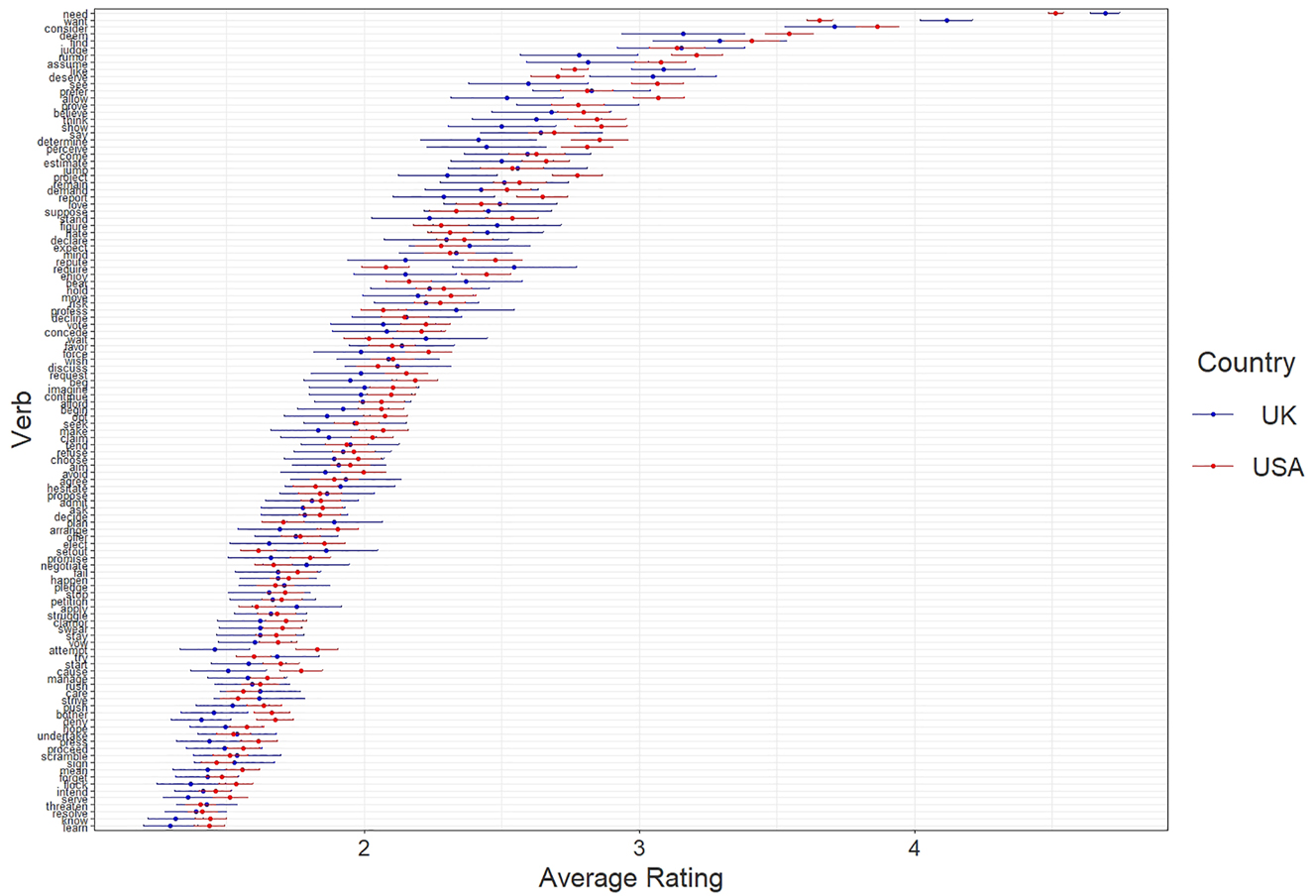
Average rating of each verb by country.
In the same way, there is no clear evidence of a strong implicational hierarchy governing acceptability. Figure 2 shows the percentage of participants rating need, want, and like as acceptable matrix verbs given that they accept a less- or non-attested verb. Here I use the same threshold of an average rating of 3.67 or higher to define acceptance as I do for need and the AEP more generally. As seen in Figure 2, the distribution of acceptance of matrix need/want/like is continuous, with a ceiling effect at 100 % acceptance. Were there a strict implicational hierarchy, we would expect to see a vertical line at 100 % acceptance at least for need and most likely for want and like as well. It is important to note as well that at least one participant accepted every potential matrix verb.
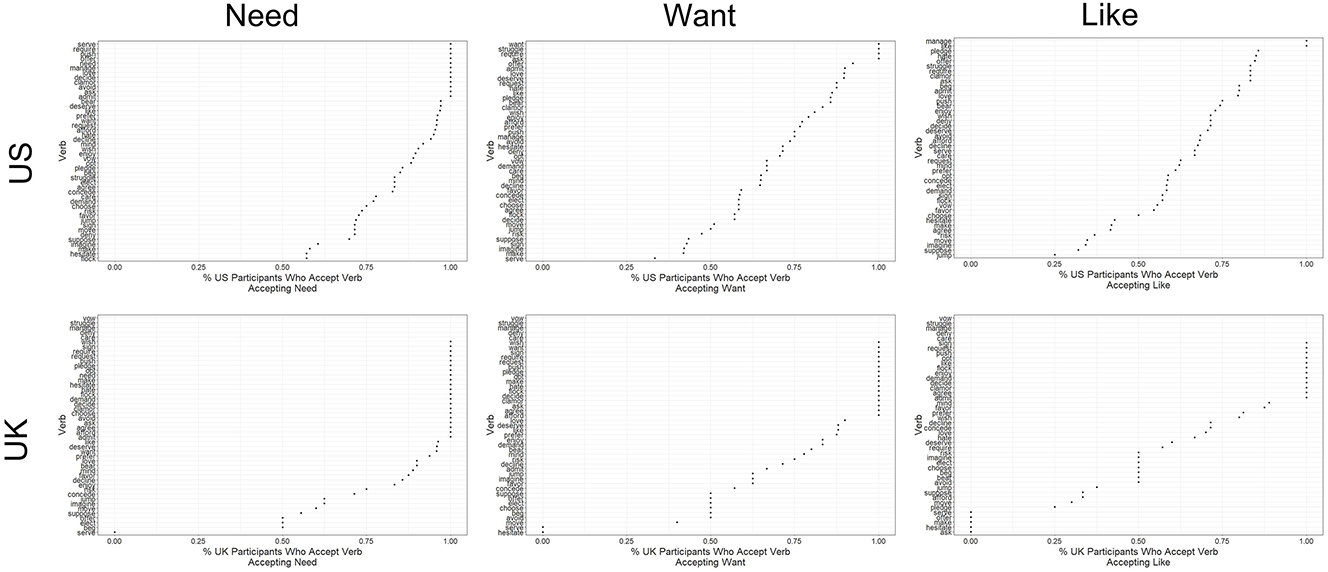
Acceptance of matrix need/want/like given acceptance of other matrix verbs.
Each of the language-internal constraints appears to influence acceptability ratings among the participants taken to have the AEP in their grammars. These effects are quite similar across the UK and US. For example, there is a clear productivity effect in which more productive verbs are rated as more acceptable. As seen in Figure 3, the trendlines for the two nations have near-identical slopes.
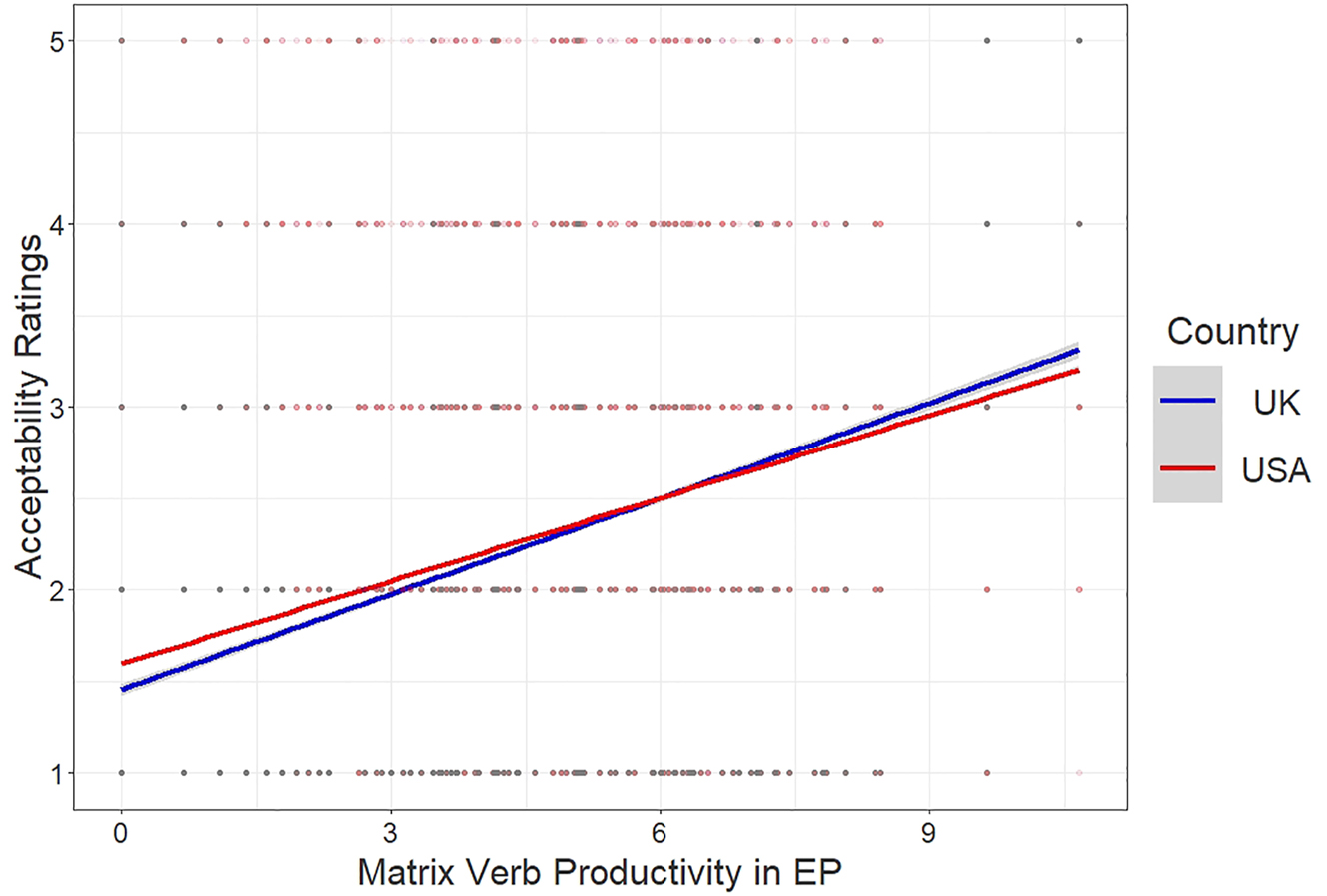
Acceptability ratings by log-scaled productivity.
There is a similar overlap with respect to syntactic type. For both the UK and US, Raising verbs are rated as more acceptable than Control and ECM verbs (Figure 4). The two nations diverge in ratings for ECM verbs, but ratings of Raising and Control verbs are quite alike.
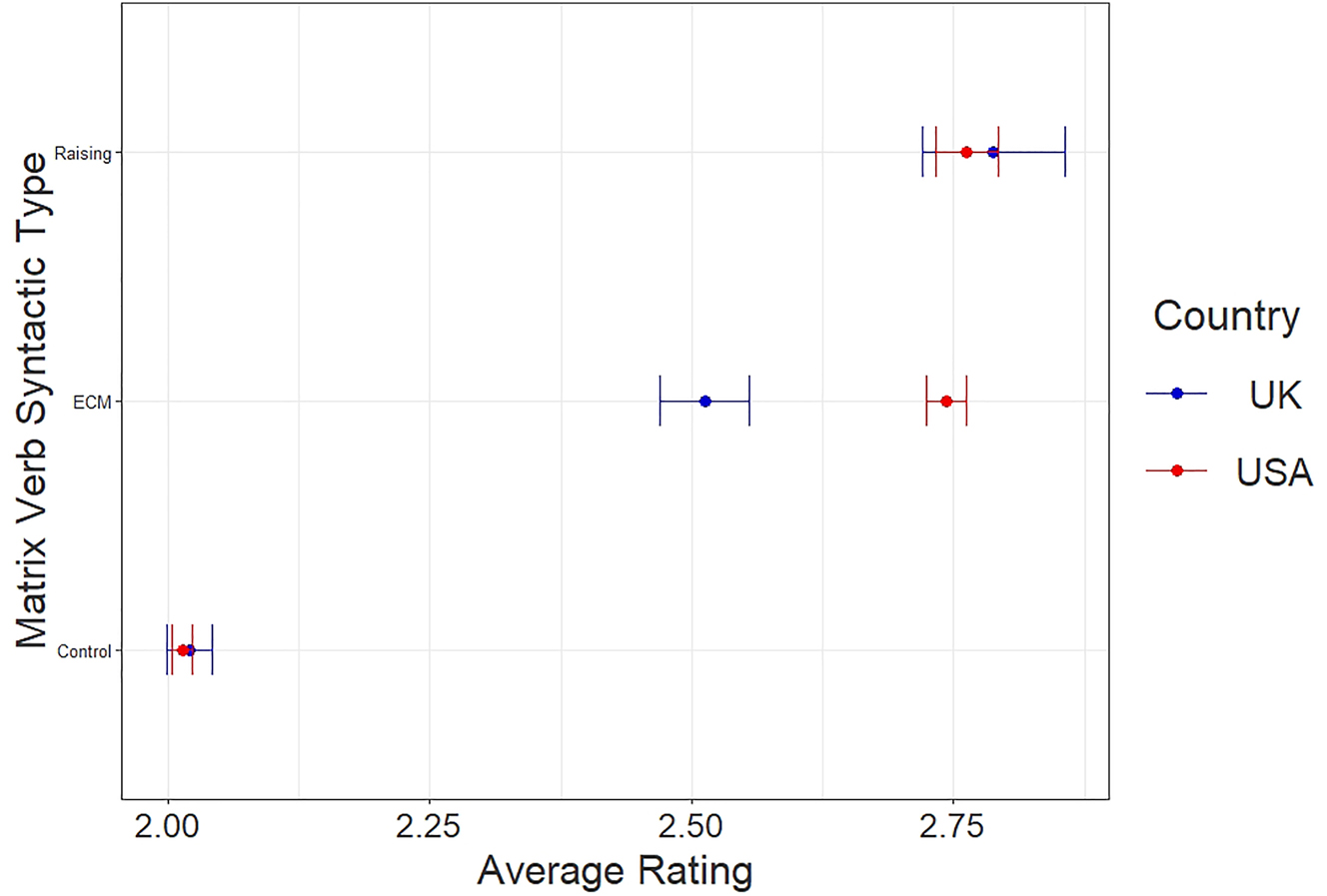
Acceptability ratings by matrix verb syntactic type.
Likewise, there is a clear effect of semantic type. Verbs belonging to groups related to volition and sentiment (A) and necessity (F) are rated higher than those in most other groups (Figure 5). Again, the US and UK appear to have similar effects. Although the nations have a similar overall pattern, the nations’ ratings for any given semantic group overlap to a lesser degree than they do for syntactic type. In particular, US participants rate verbs in groups related to assertion (D), and arranging for future events (H, I) higher than UK participants do. It should be noted that group D contained a comparatively large proportion of ECM verbs that were compatible with stative and eventive passives. In this sense, Figure 5 reflects the observation in Figure 4 of US participants rating ECM verbs higher than UK participants. Figure 5 also shows that several semantic groups are rated similarly to one another. This held strongly after accounting for other factors. For this reason, I recoded the semantic likeness factor into four combined groups: volition and necessity (A/F), permitting or preventing a future event (B/C), assertion or working toward a future event (D/E), and arranging for future events and forget (G/H/I).
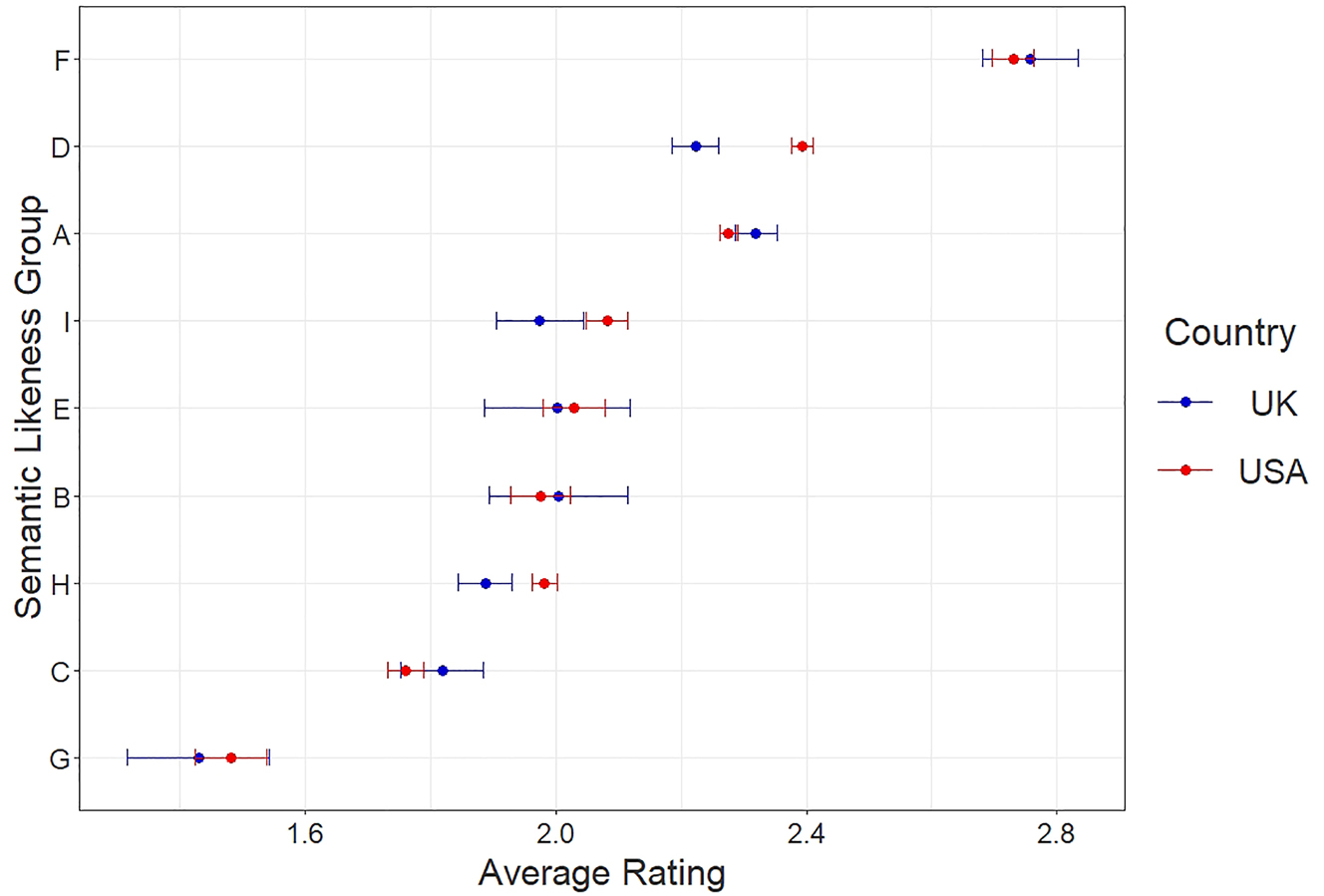
Acceptability ratings by matrix verb semantic likeness group.
Linear mixed-effects regression was conducted separately on ratings from US and UK participants who accepted matrix need. These regressions focused solely on language-internal factors; syntactic type, log-scaled productivity, and semantic likeness were included as fixed effects alongside interactions between semantic likeness and syntactic type/productivity. Random effects included participant and test item as random intercepts, as well as a random slope of the order in which items were presented to individual participants. The step function was used to arrive at a best-fit model through a step-down process. Models for both nations kept all effects except the interaction between semantic likeness and log-scaled productivity. Table 2 summarizes the model for US participants, while Table 3 summarizes the model for UK participants. All factors included in the final models significantly influence matrix verb acceptability. As seen, the models are nearly identical, and paint the same overall picture. The semantic group comprising verbs related to volition and necessity is strongly favored over all other semantic groups, while Raising verbs are strongly favored over Control and ECM verbs. More productive verbs in the canonical EP are more acceptable in the AEP. The interaction between semantic group and syntactic category effectively serves to avoid doubly penalizing non-favored categories. This additionally means that the effect of syntactic type only applies to one semantic group. Overall, the language-internal constraints suggest that there is a broad class of available matrix verbs to the AEP, with acceptability within this class constrained by verb syntax and productivity. Note that while the models are quite similar, the model for US participants consistently has slightly smaller effects for disfavored semantic and syntactic categories, as well as a slightly smaller productivity effect. This may reflect a tendency to accept novel matrix verbs more often than the UK participants.
Linear mixed-effects regression, US participants accepting matrix need.
| Fixed effects: | |||||
|---|---|---|---|---|---|
| Estimate | Std. error | df | t value | Pr(>|t|) | |
| Intercept (raising verbs in groups A/F) | 3.809 | 0.27 | 331.88 | 13.97 | <<0.0001 |
| Semantic group – B/C | −1.987 | 0.32 | 331.60 | −6.29 | <<0.0001 |
| Semantic group – D/E | −2.042 | 0.28 | 329.63 | −7.32 | <<0.0001 |
| Semantic group – G/H/I | −2.358 | 0.28 | 329.50 | −8.45 | <<0.0001 |
| Syntactic type – control | −1.986 | 0.26 | 328.27 | −7.60 | <<0.0001 |
| Syntactic type – ECM | −1.815 | 0.30 | 331.03 | −6.07 | <<0.0001 |
| log(productivity) | 0.063 | 0.01 | 336.55 | 5.86 | <<0.0001 |
| Semantic group – B/C: syntactic type – control | 1.658 | 0.33 | 331.87 | 4.99 | <<0.0001 |
| Semantic group – D/E: syntactic type – control | 1.711 | 0.29 | 330.28 | 5.92 | <<0.0001 |
| Semantic group – G/H/I: syntactic type – control | 2.069 | 0.29 | 330.13 | 7.16 | <<0.0001 |
| Semantic group – D/E: syntactic type – ECM | 2.674 | 0.32 | 331.37 | 8.26 | <<0.0001 |
| Semantic group – G/H/I: syntactic type – ECM | 2.563 | 0.33 | 331.82 | 7.74 | <<0.0001 |
| Random effect: | ||||
|---|---|---|---|---|
| Groups | Name | Variance | Std. dev. | Corr. |
| Sentence | Intercept | 0.18 | 0.43 | |
| Participant | Intercept | 0.36 | 0.60 | |
| z-scaled presentation order slope | 0.02 | 0.14 | 0.38 | |
Linear mixed-effects regression, UK participants accepting matrix need.
| Fixed effects: | |||||
|---|---|---|---|---|---|
| Estimate | Std. error | df | t value | Pr(>|t|) | |
| Intercept (raising verbs in groups A/F) | 3.804 | 0.31 | 317.71 | 12.41 | <<0.0001 |
| Semantic group – B/C | −1.937 | 0.36 | 317.45 | −5.45 | <<0.0001 |
| Semantic group – D/E | −2.186 | 0.31 | 310.60 | −7.00 | <<0.0001 |
| Semantic group – G/H/I | −2.577 | 0.31 | 310.43 | −8.25 | <<0.0001 |
| Syntactic type – control | −2.054 | 0.29 | 305.84 | −7.03 | <<0.0001 |
| Syntactic type – ECM | −1.926 | 0.34 | 314.96 | −5.74 | <<0.0001 |
| log(productivity) | 0.080 | 0.01 | 336.09 | 6.49 | <<0.0001 |
| Semantic group – B/C: syntactic type – control | 1.637 | 0.37 | 318.89 | 4.37 | <<0.0001 |
| Semantic group – D/E: syntactic type – control | 1.790 | 0.32 | 312.77 | 5.52 | <<0.0001 |
| Semantic group – G/H/I: syntactic type – control | 2.262 | 0.32 | 312.53 | 6.98 | <<0.0001 |
| Semantic group – D/E: syntactic type – ECM | 2.577 | 0.36 | 317.26 | 7.08 | <<0.0001 |
| Semantic group – G/H/I: syntactic type – ECM | 2.620 | 0.37 | 318.75 | 7.03 | <<0.0001 |
| Random effects: | ||||
|---|---|---|---|---|
| Groups | Name | Variance | Std. dev. | Corr. |
| Sentence | Intercept | 0.22 | 0.47 | |
| Participant | Intercept | 0.32 | 0.57 | |
| z-scaled presentation order slope | 0.02 | 0.16 | 0.35 | |
5.2 Regression analysis: language-external constraints
To consider whether language-external factors correlate with matrix verb acceptability requires analyzing all participant ratings. This involves including participant demographic data in the analysis of ratings from UK participants, while including participant demographic data and population-level factors in the analysis of ratings from US participants.
The model of UK participant ratings began with the language-internal factors and random effects identified as significant predictors in Section 5.1. To this, I added fixed effects of participant education level, ethnicity, gender, and age. Because acceptability of the AEP was strongest with a single semantic group, I also included interactions between semantic group and each language-external factor. The step function was again used to arrive at a best-fit model. This yielded the same significant language-internal factors as in Section 5.1, but no other factors were included in the final model. As such, the only difference between the model of ratings for UK participants who accept matrix need and the model of all UK ratings is that the inclusion of ratings from participants who do not accept matrix need yields smaller effect sizes. At least in this data set, the only language-external influence on AEP acceptability will be spatial.
The initial model of US participant ratings included the same fixed effects, interaction terms, and random effects as the initial UK model. To this I added the population-level factors of by-zip code German heritage, Scottish heritage, Irish heritage, Scots–Irish heritage, population density, and educational attainment of a Bachelor’s degree or higher, as well as their interactions with semantic group. After using the step function to obtain the best-fit model, the demographic factors, German heritage, Scots–Irish heritage, community educational attainment, and interaction terms for all of these language-external factors except gender were kept in the final model (Table 4).
Linear mixed-effects regression, US participants.
| Fixed effects: | |||||
|---|---|---|---|---|---|
| Estimate | Std. error | df | t value | Pr(>|t|) | |
| Intercept (raising verbs in group A/F, White female participants with HS education or lower) | 3.32900 | 0.49 | 2,160.0 | 6.791 | <<0.0001 |
| Semantic group – B/C | −1.85000 | 0.43 | 1,971.0 | −4.262 | <<0.0001 |
| Semantic group – D/E | −0.65090 | 0.30 | 689.2 | −2.205 | 0.0278 |
| Semantic group – G/H/I | −1.46500 | 0.30 | 735.6 | −4.878 | <<0.0001 |
| Syntactic type – control | −1.25700 | 0.23 | 330.5 | −5.453 | <<0.0001 |
| Syntactic type – ECM | −1.02200 | 0.26 | 332.2 | −3.879 | 0.0001 |
| log(productivity) | 0.03503 | 0.01 | 335.6 | 3.696 | 0.0003 |
| German heritage | 0.00947 | 0.00 | 2023.0 | 5.706 | <<0.0001 |
| Scots–Irish heritage | 0.04564 | 0.02 | 2023.0 | 2.738 | 0.0062 |
| Community university education | −0.00530 | 0.00 | 2027.0 | −5.879 | <<0.0001 |
| Ethnicity – Black/African American | 0.01095 | 0.06 | 2033.0 | 0.184 | 0.8544 |
| Ethnicity – Asian American | 0.01332 | 0.07 | 2028.0 | 0.205 | 0.8379 |
| Ethnicity – Hispanic | −0.09210 | 0.07 | 2031.0 | −1.373 | 0.17 |
| Ethnicity – American Indian/Alaska Native | −0.32210 | 0.21 | 2018.0 | −1.541 | 0.1234 |
| Ethnicity – Native Hawaiian/Pacific Islander | −0.74710 | 0.42 | 2,151.0 | −1.763 | 0.078 |
| Ethnicity – more than one | −0.11510 | 0.07 | 2018.0 | −1.575 | 0.1154 |
| Ethnicity – other | −0.72750 | 0.30 | 2046.0 | −2.462 | 0.0139 |
| Individual education level – some college | −0.07254 | 0.05 | 2028.0 | −1.513 | 0.1304 |
| Individual education level – associate’s degree or technical school | −0.08511 | 0.06 | 2028.0 | −1.526 | 0.1271 |
| Individual education level – bachelor’s degree | −0.09134 | 0.04 | 2028.0 | −2.059 | 0.0397 |
| Individual education level – some graduate school | −0.15410 | 0.08 | 2022.0 | −1.871 | 0.0616 |
| Individual education level – graduate or professional degree | −0.13350 | 0.05 | 2027.0 | −2.555 | 0.0107 |
| Gender – male | 0.08084 | 0.03 | 1908.0 | 2.960 | 0.0031 |
| Gender – non-binary | −0.05905 | 0.08 | 1901.0 | −0.696 | 0.4867 |
| Gender – other | 0.21670 | 0.41 | 1892.0 | 0.528 | 0.5978 |
| Year of birth | −0.00018 | 0.00 | 1998.0 | −0.816 | 0.4147 |
| Semantic group – B/C: syntactic type – control | 0.95410 | 0.29 | 332.6 | 3.257 | 0.0012 |
| Semantic group – D/E: syntactic type – control | 0.91500 | 0.25 | 331.8 | 3.593 | 0.0004 |
| Semantic group – G/H/I: syntactic type – control | 1.30700 | 0.25 | 331.6 | 5.134 | <<0.0001 |
| Semantic group – D/E: syntactic type – ECM | 1.77200 | 0.29 | 332.4 | 6.218 | <<0.0001 |
| Semantic group – G/H/I: syntactic type – ECM | 1.64200 | 0.29 | 332.6 | 5.632 | <<0.0001 |
| Semantic group – B/C: German heritage | −0.00997 | 0.00 | 177,600.0 | −9.760 | <<0.0001 |
| Semantic group – D/E: German heritage | −0.00842 | 0.00 | 177,300.0 | −13.395 | <<0.0001 |
| Semantic group – G/H/I: German heritage | −0.00848 | 0.00 | 177,400.0 | −12.252 | <<0.0001 |
| Semantic group – B/C: Scots–Irish heritage | −0.06401 | 0.01 | 177,600.0 | −6.211 | <<0.0001 |
| Semantic group – D/E: Scots–Irish heritage | −0.04870 | 0.01 | 177,200.0 | −7.724 | <<0.0001 |
| Semantic group – G/H/I: Scots–Irish heritage | −0.04913 | 0.01 | 177,400.0 | −7.074 | <<0.0001 |
| Semantic group – B/C: community university education | 0.00442 | 0.00 | 177,600.0 | 8.103 | <<0.0001 |
| Semantic group – D/E: community university education | 0.00254 | 0.00 | 177,200.0 | 7.461 | <<0.0001 |
| Semantic group – G/H/I: community university education | 0.00313 | 0.00 | 177,500.0 | 8.277 | <<0.0001 |
| Semantic group – B/C: ethnicity – Black/African American | 0.10220 | 0.04 | 177,600.0 | 2.873 | 0.0041 |
| Semantic group – D/E: ethnicity – Black/African American | 0.07830 | 0.02 | 177,200.0 | 3.506 | 0.0005 |
| Semantic group – G/H/I: ethnicity – Black/African American | 0.09726 | 0.03 | 177,500.0 | 3.838 | 0.0001 |
| Semantic group – B/C: ethnicity – Asian American | 0.25930 | 0.04 | 177,500.0 | 6.645 | <<0.0001 |
| Semantic group – D/E: ethnicity – Asian American | 0.00711 | 0.02 | 177,200.0 | 0.287 | 0.7738 |
| Semantic group – G/H/I: ethnicity – Asian American | 0.09353 | 0.03 | 177,300.0 | 3.457 | 0.0005 |
| Semantic group – B/C: ethnicity – Hispanic | 0.12750 | 0.04 | 177,600.0 | 3.160 | 0.0016 |
| Semantic group – D/E: ethnicity – Hispanic | 0.02289 | 0.03 | 177,100.0 | 0.902 | 0.3672 |
| Semantic group – G/H/I: ethnicity – Hispanic | 0.07197 | 0.03 | 177,500.0 | 2.566 | 0.0103 |
| Semantic group – B/C: ethnicity – American Indian/Alaska Native | 0.02978 | 0.12 | 177,400.0 | 0.238 | 0.8116 |
| Semantic group – D/E: ethnicity – American Indian/Alaska Native | 0.43130 | 0.08 | 177,400.0 | 5.582 | <<0.0001 |
| Semantic group – G/H/I: ethnicity – American Indian/Alaska Native | 0.14840 | 0.09 | 176,800.0 | 1.618 | 0.1057 |
| Semantic group – B/C: ethnicity – Native Hawaiian/Pacific Islander | 0.42160 | 0.20 | 176,000.0 | 2.104 | 0.0354 |
| Semantic group – D/E: ethnicity – Native Hawaiian/Pacific Islander | 0.38420 | 0.17 | 176,200.0 | 2.205 | 0.0275 |
| Semantic group – G/H/I: ethnicity – Native Hawaiian/Pacific Islander | 0.29990 | 0.17 | 176,600.0 | 1.771 | 0.0765 |
| Semantic group – B/C: ethnicity – more than one | 0.14450 | 0.05 | 177,300.0 | 3.183 | 0.0015 |
| Semantic group – D/E: ethnicity – more than one | 0.02136 | 0.03 | 177,300.0 | 0.774 | 0.4392 |
| Semantic group – G/H/I: ethnicity – more than one | 0.04920 | 0.03 | 177,300.0 | 1.605 | 0.1084 |
| Semantic group – B/C: ethnicity – other | 0.28180 | 0.16 | 176,600.0 | 1.794 | 0.0729 |
| Semantic group – D/E: ethnicity – other | 0.22070 | 0.12 | 177,700.0 | 1.800 | 0.0719 |
| Semantic group – G/H/I: ethnicity – other | 0.22220 | 0.11 | 176,600.0 | 1.939 | 0.0526 |
| Semantic group – B/C: individual education level – some college | 0.01516 | 0.03 | 177,600.0 | 0.522 | 0.6014 |
| Semantic group – D/E: individual education level – some college | 0.07281 | 0.02 | 177,200.0 | 4.003 | <<0.0001 |
| Semantic group – G/H/I: individual education level – some college | 0.07999 | 0.02 | 177,500.0 | 4.002 | <<0.0001 |
| Semantic group – B/C: individual education level – associate’s degree or technical school | 0.00994 | 0.03 | 177,600.0 | 0.293 | 0.7692 |
| Semantic group – D/E: individual education level – associate’s degree or technical school | 0.03635 | 0.02 | 177,300.0 | 1.718 | 0.0857 |
| Semantic group – G/H/I: individual education level – associate’s degree or technical school | 0.08006 | 0.02 | 177,400.0 | 3.452 | 0.0006 |
| Semantic group – B/C: individual education level – bachelor’s degree | −0.00771 | 0.03 | 177,600.0 | −0.286 | 0.7746 |
| Semantic group – D/E: Individual education level – bachelor’s degree | 0.03118 | 0.02 | 177,200.0 | 1.852 | 0.0641 |
| Semantic group – G/H/I: individual education level – bachelor’s degree | 0.05910 | 0.02 | 177,500.0 | 3.205 | 0.0013 |
| Semantic group – B/C: individual education level – some graduate school | 0.09788 | 0.05 | 177,700.0 | 1.890 | 0.0588 |
| Semantic group – D/E: individual education level – some graduate school | 0.06112 | 0.03 | 177,200.0 | 1.975 | 0.0483 |
| Semantic group – G/H/I: individual education level – some graduate school | 0.09854 | 0.03 | 177,400.0 | 2.868 | 0.0041 |
| Semantic group – B/C: individual education level – graduate or professional degree | 0.01458 | 0.03 | 177,600.0 | 0.457 | 0.648 |
| Semantic group – D/E: individual education level – graduate or professional degree | 0.07418 | 0.02 | 177,200.0 | 3.747 | 0.0002 |
| Semantic group – G/H/I: individual education level – graduate or professional degree | 0.09106 | 0.02 | 177,500.0 | 4.187 | <<0.0001 |
| Semantic group – B/C: year of birth | 0.00037 | 0.00 | 176,600.0 | 2.197 | 0.028 |
| Semantic group – D/E: year of birth | −0.00025 | 0.00 | 177,900.0 | −3.003 | 0.0027 |
| Semantic group – G/H/I: year of birth | −0.00002 | 0.00 | 177,100.0 | −0.234 | 0.8152 |
| Random effects: | ||||
|---|---|---|---|---|
| Groups | Name | Variance | Std. dev. | Corr. |
| Sentence | Intercept | 0.14 | 0.38 | |
| Participant | Intercept | 0.36 | 0.60 | |
| z-scaled presentation order slope | 0.02 | 0.13 | 0.39 | |
Like the model of all UK responses, in the US ratings model the language-internal factors pattern in the same way as when only participants who accept matrix need are analyzed. However, the effect sizes are smaller with all participants included. Male participants were more accepting of test items overall, but this may be a task effect. We find both a main effect of individual education level and an interaction with semantic group in which participants with higher educational attainment accept non-volition/necessity matrix verbs more than participants with a high school education. We see something similar with ethnicity. While there is little main effect of ethnicity, we find that overall, non-White ethnicity interacts with semantic group such that non-White participants accept non-volition/necessity matrix verbs more than White participants. I suggest that these interaction patterns demonstrate that Whites with lower educational attainment tend to be AEP users more than other groups. Overall, this group has a more robust semantic constraint on matrix verb acceptability than other groups. This interpretation is supported by the population-level effects. German and Scots–Irish ancestry correlates positively with ratings of volition/necessity matrix verbs, while university level educational attainment correlates negatively with ratings of these verbs. In the interaction terms, these effects are effectively undone. This suggests that communities with high German and Scots–Irish heritage populations (i.e., White communities) and low educational attainment accept AEP sentences in the broad semantic class shown in Section 5.1 to be highly rated and subject to language-internal constraints. That is, participants from such communities appear to be AEP users. It is important to note, however, that the language-external effects are far weaker than the language-internal effects. The primary constraints on matrix verb acceptability are linguistic.
5.3 Geospatial analysis
An interim summary of the regression analyses is that while matrix verb ratings are distributed continuously, there are clear constraints wherein frequent Raising verbs from a broad class of volition/necessity verbs are most acceptable in the AEP. Constraints on acceptability are nearly identical in the US and UK among participants who accept matrix need. In the US, these matrix verbs are most accepted among White participants with lower levels of educational attainment, evidenced by them growing up in communities with low educational attainment and high German and Scots–Irish ancestry. The correlation with Scots–Irish ancestry, in conjunction with the similar constraints in the US and UK, appears to be evidence in favor of the AEP appearing in American English through Scots–Irish migration.
Here, I contribute additional evidence in favor of this connection by examining geographical patterns in acceptance of potential AEP matrix verbs. Ratings for each verb were averaged by the zip code/postcode that the participant(s) grew up in. I first test whether ratings of individual verbs are distributed evenly or not across the two nations using global Moran’s I. This is a measure of global spatial autocorrelation, the degree to which the entire set of observed values are correlated across all sample locations. Like other geospatial measures, global Moran’s I relies on a spatial weights matrix that defines the relation between the different locations sampled. There are different kinds of spatial weights matrices, and geospatial statistics are sensitive to the kind of spatial weights matrix selected. Unfortunately, as Grieve (2016) and Wood (2019) discuss, there is not a firm guidance for determining how to decide which kind of spatial weights matrix to use. I use a nearest neighbors spatial weights matrix for both nations (Grieve 2018). Under this approach, the relation between zip codes/postcodes is defined as a value between 0 and 1 based on the distance between a zip code/postcode and the k nearest zip codes/postcodes to it. How many zip codes/postcodes are included as neighbors influences the smoothing of the data, and like the choice of spatial weights matrix, there is not a firm criterion for selecting this (Grieve 2018). For the UK, I use k = 15, while for the US I use k = 50. I found that larger values for k smoothed the data too much, while smaller values left it too fragmented to interpret clearly.
A significant p-value using global Moran’s I indicates that values are likely not distributed randomly in space. That is, significant values suggest that there is geographical clustering of data. Because I conduct this test on each potential matrix verb for both nations, I use a Bonferroni-corrected p-value of 0.000208 (0.05/240) as a significance threshold.[5] Even taking this correction into account, the ratings of most verbs were found by global Moran’s I to be distributed non-randomly. The test was significant for 81 verbs in the UK data (70 %) and 104 verbs in the US data (90 %). There was good agreement between the nations; 72 of the verbs had significant results for the UK (89 % of significant results) and the US (69 % of significant results). Of matrix verbs attested in Sections 1 and 2, 10 of 11 (91 %) had significant results in both nations. The one exception, enjoy had a significant result in the US but not the UK.
The global Moran’s I results on the one hand are not particularly informative, because so many results were significant. However, this is not as problematic as it may seem. We found above that the distribution of ratings for all verbs was continuous, that all verbs were rated highly by at least one participant, and that effect sizes in regression analyses were larger among participants who accept matrix need. This suggests that most potential matrix verbs had at least some degree of acceptability among AEP users. Thus, any positive ratings may be geographically marked. At the same time, global Moran’s I does not show that positive ratings are clustered non-randomly. Rather, it shows that there is non-random distribution of any ratings. Even if AEP users are not rating a particular verb highly, there may be locations in which participants rated the verb particularly low for acceptability. Likewise, the statistic may indicate that ratings are dispersed in a regular pattern rather than being clustered in a single region. While a useful start for showing that ratings for most verbs have non-random spatial distributions, more detail is clearly needed.
To obtain this added detail, I use the Getis-Ord G i * statistic as a form of “hotspot” analysis (Grieve 2016; Wood 2019). This statistic measures local spatial autocorrelation: how different a value in one area is from those in surrounding areas. Because this statistic is applied to each measured location, it can be used to determine which regions prefer or disprefer a matrix verb compared to the rest of a nation. To calculate this, I again use a nearest neighbors spatial weight matrix and the same k-values as with global Moran’s I. Getis-Ord G i * results are easily reported on a map. In the following figures, bright red areas will significantly favor a given matrix verb, while dark blue areas will significantly disfavor it. Upon mapping the Getis-Ord G i * analysis, I decide whether a hotspot is found through visual inspection by looking for clusters of zip codes/postcodes which significantly favor the verb compared to the surrounding area. We can see an example of this in Figure 6. This figure maps results of the Getis-Ord G i * analysis across the US and UK for the three widely attested AEP matrix verbs need, want, and like. In the US, we see that the verbs are significantly more favorably rated across the Midwest and in the Pacific Northwest. Likewise, they are significantly less favorably rated in New England and California. We also see that the hotspots are less clearly defined for like than need, with want in between the two. These results replicate the surveys reported in Murray et al. (1996) and Murray and Simon (1999, 2002, as well as the more recent and methodologically similar surveys conducted by Wood et al. (2020) and Wood et al. (2022) quite well with respect to both hot and cold spots. In the UK, we see a similar pattern with the three verbs. Need yields the strongest and largest hotspot, covering Northern Ireland and Scotland in their entirety, and extending into Tyneside in the North East of England. Want and like are also significantly favored in Scotland and Northern Ireland, but Tyneside is less of a hotspot. For all three verbs, there is a strong cold spot in the Greater London area. That Scotland as a whole is a hotspot replicates the fieldwork in Smith et al. (2019), while the overall geographic pattern for need replicates Strelluf’s (2020, 2022 work using data collected from Twitter.
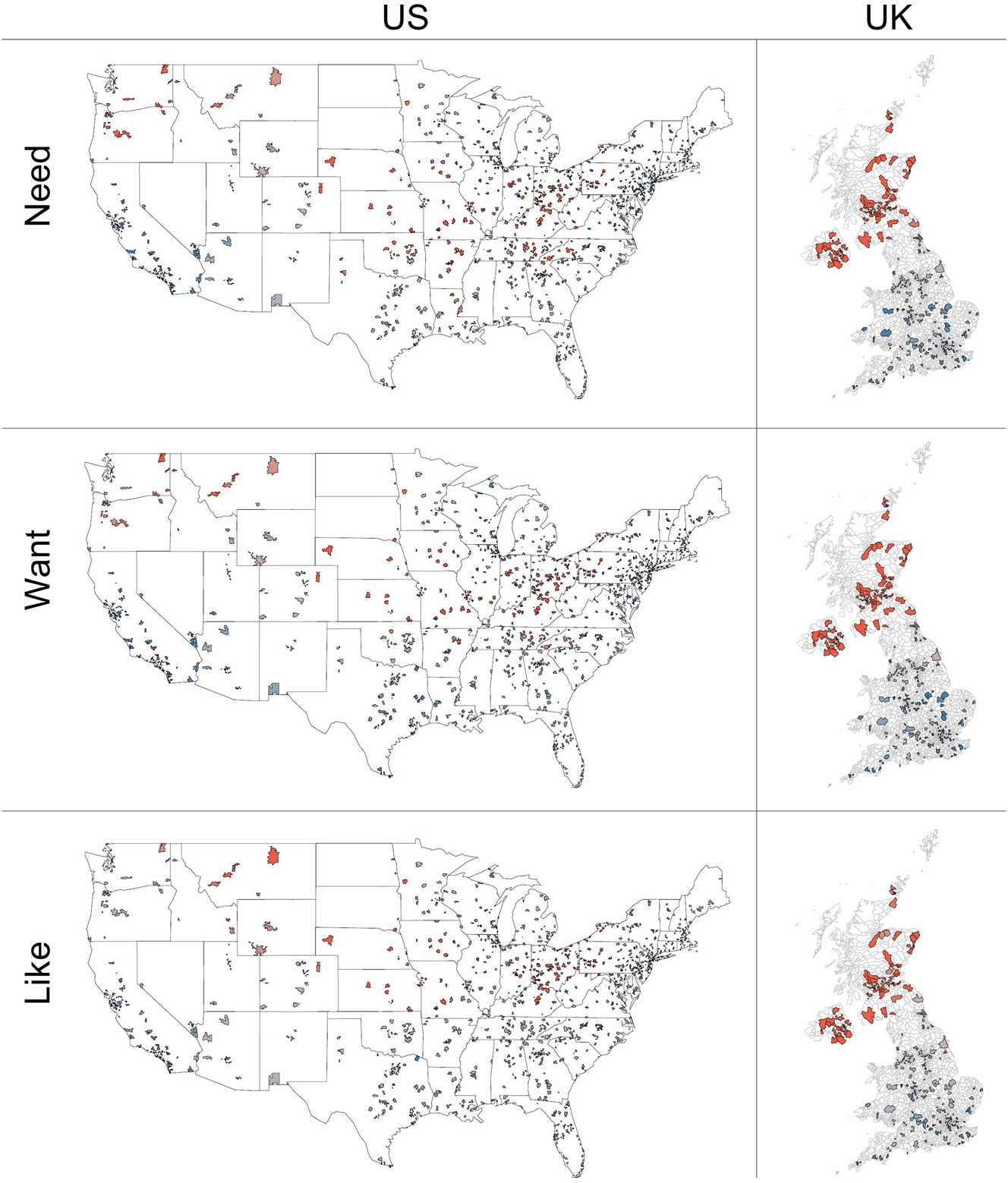
Hotspot analysis of need, want, and like in the US and UK.
A difficulty in conducting this analysis for each potential matrix verb is that like with global Moran’s I, repeated measures risk drawing incorrect conclusions from false positives. Note, however, that the global Moran’s I results are helpful in part: we know for which matrix verbs the results are distributed non-randomly. For these verbs, we expect to see a hot/cold spot somewhere. To improve confidence in interpretation, I focus on these verbs, and additionally limit attention to hotspots in core areas which clearly demonstrate acceptance of the AEP with widely attested matrix verbs. As seen in Figure 6, for the US this is a roughly cohesive region stretching from Indiana to western Pennsylvania (cf. Wood et al. 2022), extending south to eastern Kentucky and West Virginia. For the UK, this is simply Northern Ireland and Scotland. The reasoning here is that although a hotspot in Los Angeles or London, for example, may well be indicative of a novel innovation with the AEP, because the construction is not found in these locations with widely attested verbs, such a hotspot is more likely a false positive. In contrast, a hotspot in Glasgow or Pittsburgh is consistent with these areas accepting the AEP with widely attested verbs.
Of the 116 test matrix verbs, 55 appeared to have a hotspot somewhere in the US and/or UK, and 37 of these were rated as significantly more acceptable in one or more of the core AEP regions than the rest of the US and/or UK (21 had a US core hotspot, 21 had a Northern Ireland hotspot, and 12 had a Scotland hotspot). These 37 matrix verbs include each of the 11 matrix verbs attested in examples (1, 4–14): need, want, like, love, deserve, hate, prefer, enjoy, risk, require, and demand. Of these attested verbs, all but risk have a hotspot in the US’s core region. In contrast, only six attested verbs have a hotspot in Northern Ireland, while seven do in Scotland. In this sense, the results from the core US region appear to encompass the bulk of what are clear true positive hotspots. Figure 7 illustrates the Getis-Ord G i * results for four of the 21 verbs with hotspots in the core US region. There are three key takeaways. Firstly, the size of the US hotspot varies by verb. As seen, love has a far larger hotspot than the others illustrated here. Secondly, the center of the US hotspot varies. For hate, the hotspot is in the Indiana/Ohio region noted by Wood et al. (2022). However, for enjoy and request the (tiny) hotspot is in the region surrounding Pittsburgh. Finally, the degree to which the US hotspot is replicated in the UK also varies. While love has a clear hotspot in Northern Ireland and western Scotland, hate is limited to northeast Scotland and enjoy and request do not have UK hotspots.
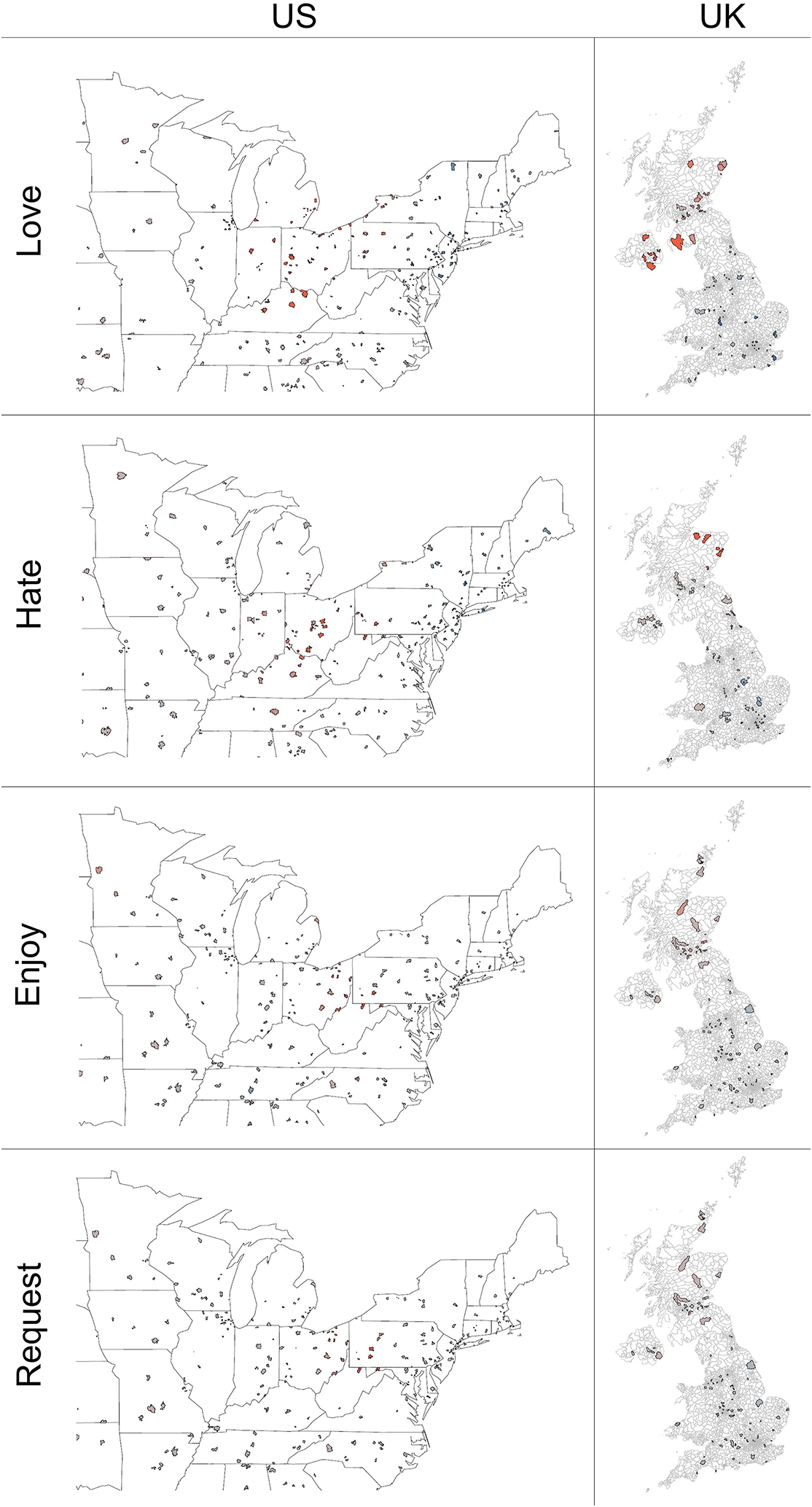
Hotspot analysis of love, hate, and enjoy, and request in the US and UK.
This variation in whether and where UK hotspots are located extends to other verbs as well. There are several verbs with hotspots somewhere in the core US area and part or all of Scotland, but not Northern Ireland (Figure 8).
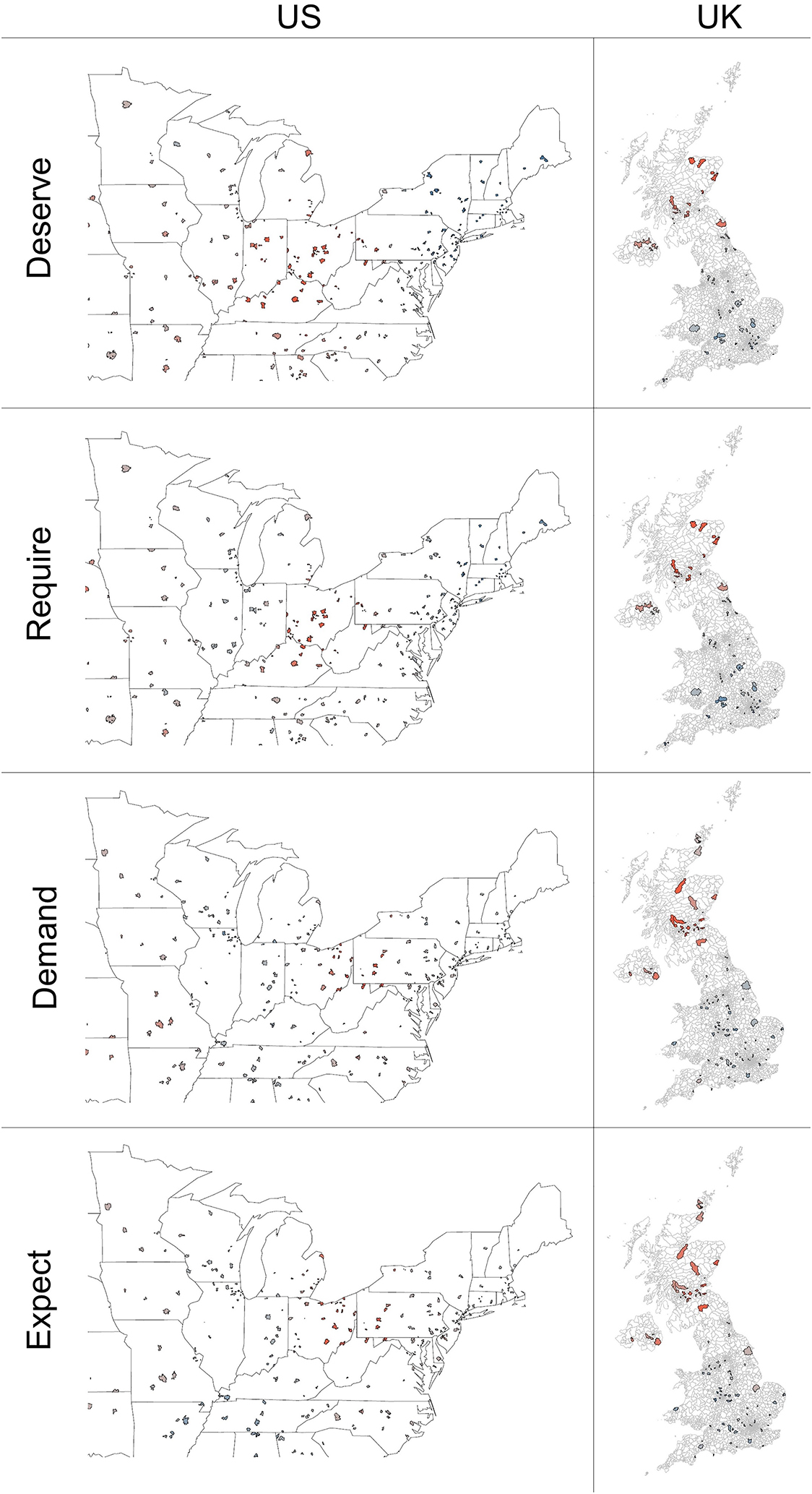
Hotspot analysis of deserve, require, demand, and expect in the US and UK.
At the same time, hotspots for prefer and stand appear somewhere in the core US region as well as Northern Ireland, but are largely absent from Scotland (Figure 9).
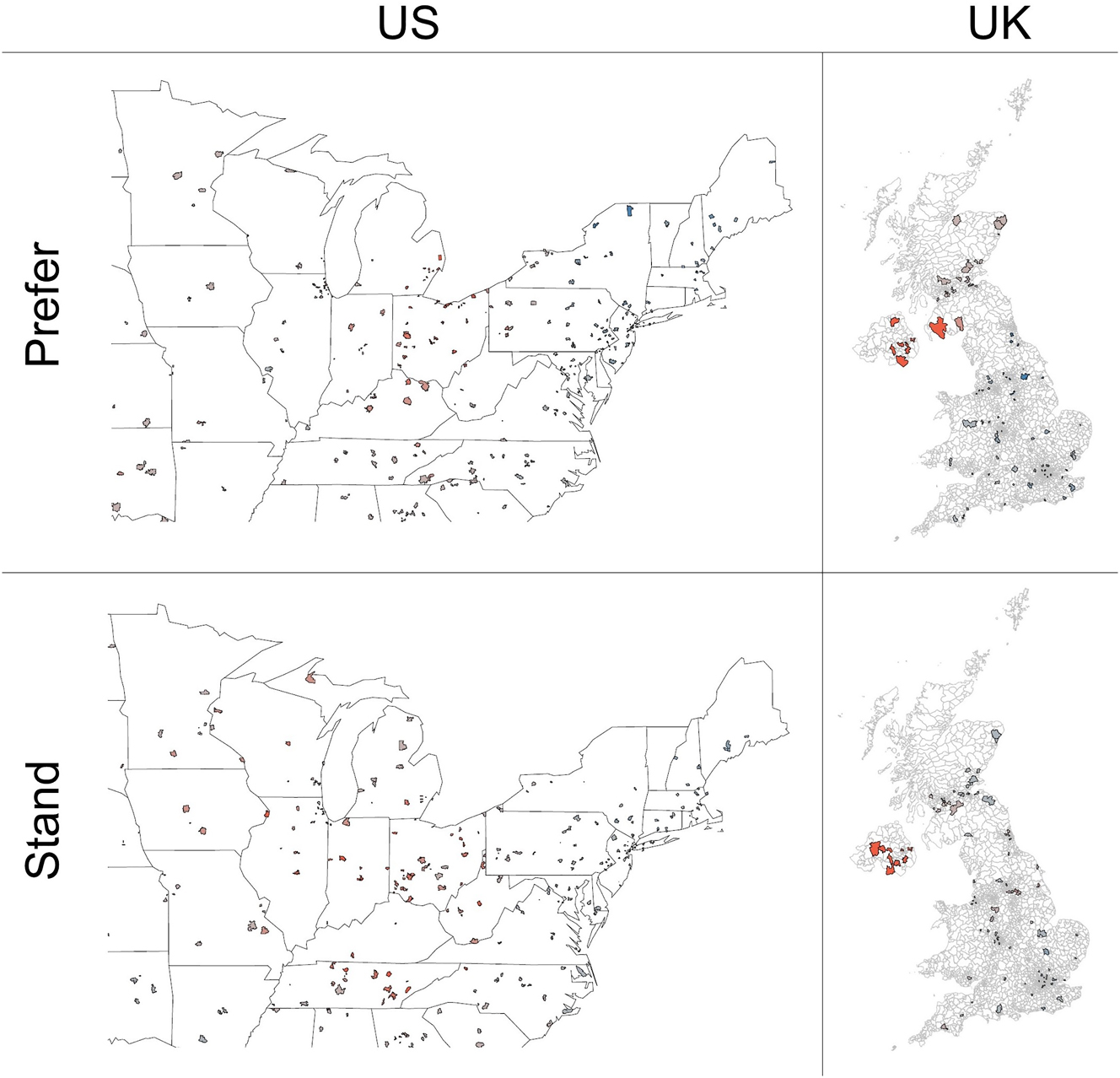
Hotspot analysis of prefer and stand in the US and UK.
The location of hotspots for the 21 matrix verbs with hotspots in the US core region appear to follow an implicational hierarchy (Table 5). As seen, verbs with hotspots in Northern Ireland tend to also have hotspots in Scotland, and those with hotspots in Scotland tend to have hotspots in the US beyond the core region of Indiana/Ohio/western Pennsylvania.
Implicational hierarchy governing regional acceptance of 21 AEP matrix verbs.
| Verb | Hotspot in USA core | Hotspot in US extending beyond or outside of core | Hotspot somewhere in UK | Hotspot in Scotland | Hotspot in Scotland and N. Ireland | Hotspot in N. Ireland |
|---|---|---|---|---|---|---|
| Like | X | X | X | X | X | X |
| Love | X | X | X | X | X | X |
| Need | X | X | X | X | X | X |
| Want | X | X | X | X | X | X |
| Deserve | X | X | X | X | ||
| Require | X | X | X | X | ||
| Prefer | X | X | X | X | ||
| Stand | X | X | X | X | ||
| Allow | X | X | ||||
| Hate | X | X | ||||
| Learn | X | X | ||||
| Demand | X | X | X | |||
| Expect | X | X | X | |||
| Admit | X | |||||
| Attempt | X | |||||
| Claim | X | |||||
| Enjoy | X | |||||
| Flock | X | |||||
| Opt | X | |||||
| Request | X | |||||
| Start | X |
It is important to note that these verbs only comprise a little over half of the 37 verbs with hotspots in a core AEP region. The remaining verbs (15/16) have hotspots primarily in Northern Ireland (Figure 10). The exception, avoid, has a small hotspot centered on Edinburgh, while three others (exemplified by seek and apply here) have hotspots around Glasgow in addition to Northern Ireland. Only three of these 16 verbs, exemplified by seek here, have a hotspot anywhere in the US. The majority of the 16 verbs without hotspots in the core US region, then, are like petition: a hotspot solely in Northern Ireland. One possible conclusion from these results is that Northern Ireland substantially diverges from the US and Scotland with respect to acceptable AEP matrix verbs. That one of these verbs includes risk, for which an attested example exists, may be evidence in favor of this position. However, it is perhaps equally likely that these examples are false positives generated by outlier rating(s) which appear on the northwestern edge of the UK map and which are relatively isolated from the rest of the map. Their existence is worth mention, but I set these, like hotspots elsewhere in the US, England, or Wales, aside as more likely false positives found over the course of many repeated measures.
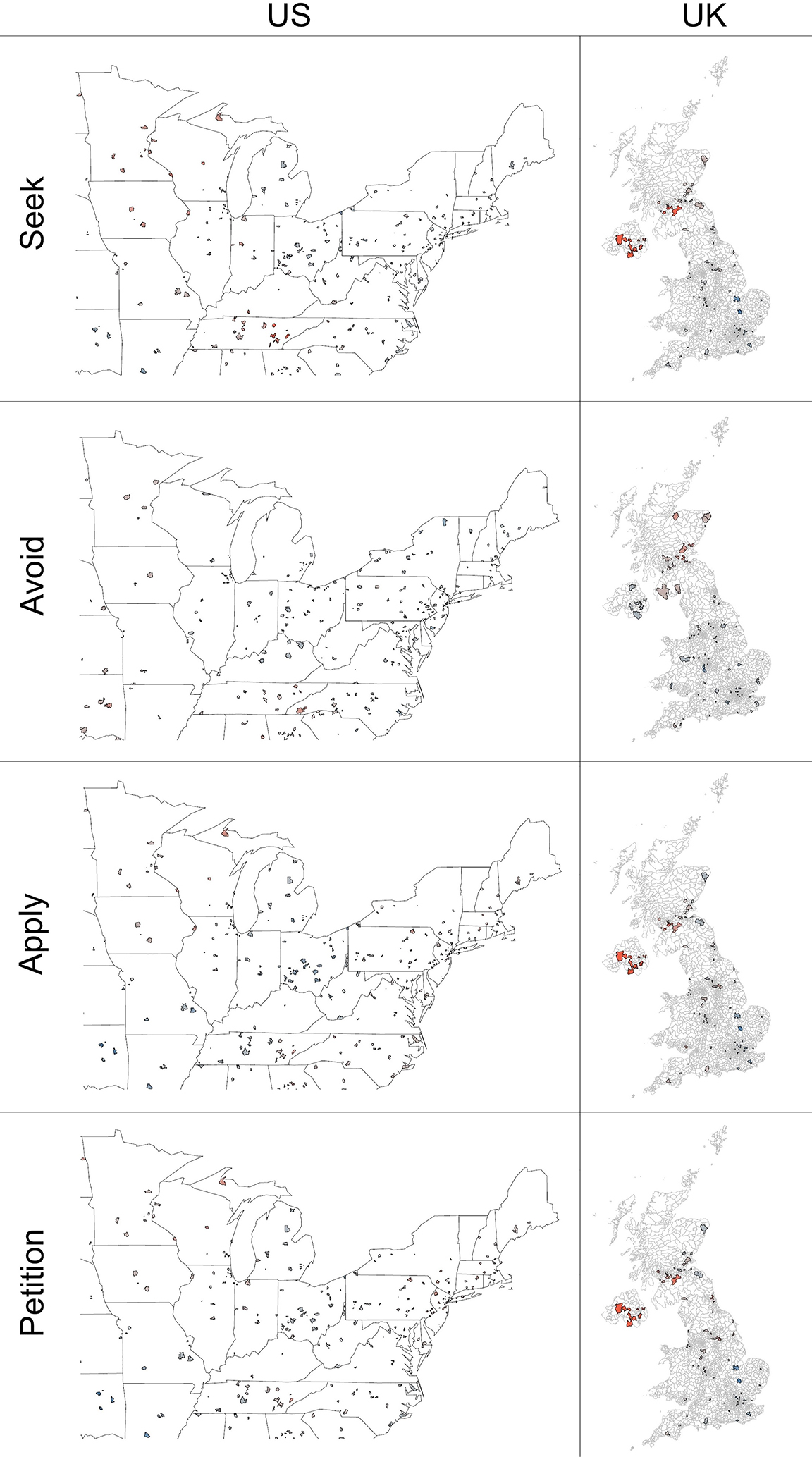
Hotspot analysis of seek, avoid, apply, and petition in the US and UK.
Overall, the geospatial analysis shows that ratings of most verbs have some degree of geographical clustering in both the US and UK. Of these, particularly high ratings are clustered together in hotspots somewhere in one or both nations for roughly half of the verbs (55/116). An intentionally cautious approach to the hotspot analysis finds fewer hotspots, but nonetheless high ratings for far more matrix verbs than previously attested are clustered in core AEP regions. Under this approach, there are more verbs with hotspots in the US than in the UK. This may be an artifact of the study; because there were more participants from the US than the UK, the analysis of the US data may be finding a weaker signal than is possible to find in the UK data. Alternatively, these results may be showing that while the UK and US share a core set of AEP matrix verbs, the US has seen some innovation in the set of possible matrix verbs. It is possible that the UK and US have diverged further, as several verbs have hotspots in Northern Ireland alone. However, it is difficult to assess at this stage whether these are false positives, or evidence that Northern Ireland has a substantially different set of acceptable AEP matrix verbs.
6 Discussion and conclusions
This study utilized a large-scale grammaticality judgement survey in order to ask a deceptively simple question: which verbs can appear as matrix verbs in the AEP? As I noted in Section 3, to ask this question bears on other issues relating to the description of the AEP and the dialectology of it. Regarding the description of the feature, a key question is whether the previously attested implicational hierarchy of matrix verb acceptability holds (Edelstein 2014; Murray and Simon 2002; Wood et al. 2022), and if so, how it is structured and constrained. From a dialectological perspective, the question is whether the feature appears in American and British Englishes as a result of Scots–Irish migration, as previously proposed (Montgomery 1991, 1997; Murray et al. 1996; Strelluf 2020). In this section, I walk through each of these questions in turn, before considering questions that arise or are newly reopened due to these findings.
6.1 Research aims
The regression and geospatial results show that far more verbs are available to the AEP than previously attested. Conservatively, there are hotspots showing spatial clustering of high acceptability ratings for at least 21 matrix verbs. Ratings of many more are distributed non-randomly, although this does not necessarily mean that these verbs are widely accepted in a clear geographic region. Beyond this, ratings of all verbs were distributed continuously among participants who rated matrix need highly, with no clear boundary between acceptable and unacceptable matrix verbs. Indeed, at least one participant rated each potential matrix verb highly. In a general sense, the results suggest that while some verbs are accepted by more participants than others, if a verb is available as a matrix verb in the canonical EP, there are people who will accept it in the AEP. That said, there is a clear class of verbs related to volition, sentiment, and necessity which are more likely to be acceptable. However, this is not a closed class. The community detection algorithm applied to the bipartite network model did not include verbs such as expect and stand in this broad class of verbs, yet they had clear hotspots of high ratings in the US and Scotland (expect) and the US and Northern Ireland (stand).
Like the distribution of potential matrix verb ratings, the distribution of participants rating need, want, or like highly given that they rate another verb highly is continuous. This suggests that there is no implicational hierarchy governing matrix verb acceptability. Rather, the regression models show that acceptability is constrained by lexical semantics, verbal syntax, and verb productivity. As mentioned, there is a strong effect of lexical semantics in which volition and necessity verbs are rated much more highly than other verbs. We also find that Raising verbs and verbs which are highly productive in the canonical EP, that is, highly frequent in COCA, are rated highly for acceptability. Note that these constraints derive the implicational hierarchy suggested in previous research. Need, want, like (and love) are all in the favored volition/necessity class. Of them, need is by far the most productive, followed by want and then like/love. Need is also a Raising verb; the others are Control verbs. Combining these facts together, the constraints found in this study point to need being the most acceptable AEP matrix verb, with productivity governing the ranking of the other primarily attested verbs. In this sense, the previously described implicational hierarchy is an artifact of an incomplete description of possible AEP matrix verbs.
The regression and geospatial analysis strongly support the hypothesis that the AEP appears in American Englishes as the result of Scots–Irish migration. We find that even with the expanded view of the AEP demonstrated here, the feature is effectively the same phenomenon in both nations. Among participants who rate matrix need highly, and thus appear to have the AEP in their grammars, the language-internal constraints on matrix verb acceptability are nearly identical between the nations. At the same time, the geospatial results show a clear relation between hotspots of high ratings in the US and UK; for a set of 21 matrix verbs, acceptability in the UK implies acceptability in the US. This finding greatly expands the number of AEP matrix verbs found to be accepted in both nations. We also find that acceptability ratings in the US correlate with community Scots–Irish ancestry. This is suggestive of a founder, or cultural inertia, effect maintaining the AEP in American regions that saw Scots–Irish migration during the colonizing period (Mufwene 1996; Zelinsky 2011). Note that if the AEP did indeed come to the US through Scots–Irish migration, that the AEP is strongly attested in both Northern Ireland and Scotland suggests that the AEP is an older Scots feature brought over during the plantation of Ulster (cf. Corrigan 2010, 2020a; Strelluf 2020).
6.2 Open issues
While the evidence clearly supports a conclusion that the AEP appeared in American Englishes via British Englishes, the geospatial analysis found some evidence that the US and UK may not share the same set of available matrix verbs. As noted, there were hotspots for some verbs within the US that were not present in the UK. At the same time, several matrix verbs had hotspots in Northern Ireland and nowhere else. More research is necessary to confirm whether these differences are divergent innovations, noisy results due to a weak signal, or simply false positives in the current study. Beyond these potential differences, the raw data appeared to show that ECM verbs which may select either stative or eventive passives were rated surprisingly highly, particularly among US participants. It is unclear whether this is because these participants forced a stative reading of the test items, in which case participants differed in task completion across the two nations, or if there may be an expanding use of the AEP in the US that is not being innovated in the UK.
Given how clear the Scots–Irish migration connection is, one question that emerges is why the AEP is not widely attested in other settler colonial varieties. Although the modern United States was the most common destination, Scottish and Scots–Irish migrants also settled in Canada and Australia (Corrigan 2020a, 2020b; Wilson 1997), for example. However, in the Electronic World Atlas of Varieties of English (eWAVE, Kortmann et al. 2020), the AEP is attested to be absent from Newfoundland English and Aboriginal Australian English, and is said to be impossible in (White) Australian English. In contrast, eWAVE does attest the AEP as “pervasive or obligatory” in Colloquial American English, Scottish English, and English dialects in the North of England, and as “neither pervasive nor extremely rare” in Irish English and Appalachian English. We may have expected Canada and Australia to pattern more like this. New Zealand provides an example which does seem to match the expected pattern, as the AEP is attested there in regions with a high proportion of Scottish settlers (Kortmann et al. 2020; Maclagan and Hay 2009). That Canada and Australia apparently differ from the US and New Zealand is surprising, because sociolinguists often suggest that dialect features brought by early settler populations linger (see Tagliamonte et al. 2005, 2010; cf. Mufwene 1996; Zelinsky 1992). While this lingering effect can fade (Stanford et al. 2012), Denis and D’Arcy (2019) show that it is particularly strong in settler colonial nations such as Canada. Assuming, then, that eWAVE is correct in attesting an absence of the AEP in Canada and Australia, there is a question of why this is the case.
It should be noted that while the US geospatial results replicated past survey work well (Wood et al. 2020, 2022), these researchers find clear effects of participant ethnicity and participant urbanness which are not as clearly replicated (see also Murray et al. 1996 with respect to ethnicity). In effect, Wood et al. find that rural Whites are more likely to accept the AEP. In this study, there was not a clear effect of ethnicity for the volition and necessity verbs, while urbanness was not tested in the same way. However, the correlation between AEP acceptability and community demographics points to the same effect. Participants from zip codes with high degrees of German and Scots–Irish ancestry rated the AEP as more acceptable; this effectively means that participants from communities with larger White populations found the feature more acceptable. The German ancestry correlation is perhaps surprising, but may reflect the AEP being found broadly in White communities across the Midwestern US. Similarly, because rural communities in the US have lower access to higher education (Sowl and Crain 2021), the negative correlation between ratings and community educational attainment may reflect rural communities favoring the AEP.
While beyond the scope of this paper, an important question is what implications, if any, the findings here carry for syntactic analyses of the AEP (Edelstein 2014; Strelluf 2022). For example, a central claim in Edelstein’s (2014) analysis is that the feature is a Raising construction. This appears to be consistent with the strong constraint of syntactic type found here; it would make sense for Raising verbs to be strongly favored in a Raising construction. Beyond this, simply expanding the set of matrix verbs may not bear on formal analyses. However, I suggest that the data here points not only to an expanded set of matrix verbs, but to an expanded set of canonical constructions which the AEP may alternate with. One attested matrix verb not tested here was [could] use, because it did not occur in COCA in the canonical EP. This absence may have arisen because the context would overlap with the semi-modal used to. For me, [could] use seems to embed a passive better in a context such as (19):
| Your radiator could use being flushed. (modified from Tenny 1998: 596) |
However, this preference is not unique to use; indeed, enjoy and prefer, verbs newly attested as AEP matrix verbs in this study, also fit well into the VERB being X’ed frame. It appears, then, that the AEP may alternate not only with the canonical EP and concealed passive (as studied in Strelluf 2022, for example) but with this frame as well. Future research may find considering the VERB being X’ed frame in addition to these fruitful both from a quantitative perspective and for updating a formal analysis.
6.3 Conclusions
Although it is typically attested with a narrow set of matrix verbs, the AEP has been well attested with additional ones. This study takes those attestations seriously, aiming to determine more exhaustively the full set of AEP matrix verbs. In doing so, I provide an alternative view of the feature with an updated description. Matrix verb availability is widespread, yet highly constrained. In this sense, the AEP is more like other constructions that embed passives than previously thought. By examining this question through comparison of the US and UK, we find additional evidence that the American AEP is the same as the British AEP, and that this likely means the AEP was brought from one nation to the other. These findings could not be obtained through attention only to widely attested matrix verbs. Rather, this study serves as an example of how attention to rarely attested or non-attested data can inform morphosyntactic and dialectological research.
Funding source: British Academy
Award Identifier / Grant number: BA/Leverhulme Small Research Grant SRG2021\210047
Acknowledgements
Thank you to Mary Robinson and Karen Corrigan, as well as audiences at the 2022 Linguistics Association of Great Britain and Northern Ireland Annual Meeting and New Ways of Analyzing Variation 50, for helpful feedback and comments. This work was funded by BA/Leverhulme Small Research Grant SRG2021\210047, “This construction deserves (to be) studied further: Innovation and variation of the Alternative Embedded Passive.”
-
Data availability: Materials associated with this study can be found at the public OSF repository https://osf.io/75buw/. These include materials and R code for the construction of the bipartite network used to obtain language-internal factors; experimental design and stimuli; raw survey results; cleaned survey results and R code for regression analysis; and cleaned survey results, R code, and zip code/postcode shapefiles for geospatial analysis.
References
Bates, Douglas, Martin Mächler, Ben Bolker & Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1). 1–48. https://doi.org/10.18637/jss.v067.i01.Search in Google Scholar
Beckett, Stephen J. 2016. Improved community detection in weighted bipartite networks. Royal Society Open Science 3. 140536. https://doi.org/10.1098/rsos.140536.Search in Google Scholar
Bivand, Roger S., Edzer Pebesma & Virgilio Gomez-Rubio. 2013. Applied spatial data analysis with R, 2nd edn. New York: Springer.10.1007/978-1-4614-7618-4Search in Google Scholar
Carmichael, Katie & Kara Becker. 2018. The New York City–New Orleans connection: Evidence from constraint ranking comparison. Language Variation & Change 30(3). 287–314. https://doi.org/10.1017/s0954394518000133.Search in Google Scholar
Chatten, Alicia, Kimberley Baxter, Erwanne Mas, Jailyn Pena, Guy Tabachnick, Daniel Duncan & Laurel MacKenzie. 2022. “I’ve always spoke like this, you see”: Preterite-for-participle leveling in American and British Englishes. American Speech. https://doi.org/10.1215/00031283-9940654.Search in Google Scholar
Corrigan, Karen P. 2010. Irish English, vol. 1: Northern Ireland. Edinburgh: Edinburgh University Press.10.3366/edinburgh/9780748634286.001.0001Search in Google Scholar
Corrigan, Karen P. 2020a. Linguistic communities and migratory processes: Newcomers acquiring sociolinguistic variation in northern Ireland. Berlin: De Gruyter Mouton.10.1515/9783110614190Search in Google Scholar
Corrigan, Karen P. 2020b. From Killycomain to Melbourne: Historical contact and the feature pool. In Karen V. Beaman, Isabelle Buchstaller, Susan Fox & James A. Walker (eds.), Advancing socio-grammatical variation and change, 319–340. New York: Routledge.10.4324/9780429282720-20Search in Google Scholar
Davies, Mark. 2004. British National Corpus (from Oxford University Press). https://www.english-corpora.org/bnc/ (accessed 9 September 2021).Search in Google Scholar
Davies, Mark. 2008. The corpus of contemporary American English (COCA): 520 million words, 1990–present. https://corpus.byu.edu/coca/ (accessed 9 September 2021).Search in Google Scholar
Davies, William D. & Stanley Dubinsky. 2004. The grammar of raising and control: A course in syntactic argumentation. Malden, MA: Blackwell.10.1002/9780470755693Search in Google Scholar
Denis, Derek & Alexandra D’Arcy. 2019. Deriving homogeneity in a settler colonial variety of English. American Speech 94(2). 223–258. https://doi.org/10.1215/00031283-7277054.Search in Google Scholar
Dodsworth, Robin & Richard A. Benton. 2019. Language variation and change in social networks: A bipartite approach. New York: Routledge.10.4324/9781315642000Search in Google Scholar
Dormann, Carsten F., Bernd Gruber & Jochen Fruend. 2008. Introducing the bipartite package: Analysing ecological networks. R News 8(2). 8–11.Search in Google Scholar
Duncan, Daniel. 2019. Grammars compete late: Evidence from embedded passives. University of Pennsylvania Working Papers in Linguistics 25(1). 89–98.Search in Google Scholar
Duncan, Daniel. 2021. A note on the productivity of the alternative embedded passive. American Speech 96(4). 481–490. https://doi.org/10.1215/00031283-9588222.Search in Google Scholar
Duncan, Daniel. 2023. Computationally deriving language-internal factors with bipartite networks. University of Pennsylvania Working Papers in Linguistics 29(2). 79–88.Search in Google Scholar
Easy Analytic Software, Inc. (EASI). 2020. Education attainment, bachelor’s degree (pop 25+); German ancestry; Irish ancestry; Scotch-Irish ancestry; Scottish ancestry. Data prepared by SimplyAnalytics. http://www.simplyanalytics.com (accessed 1 July 2020).Search in Google Scholar
Edelstein, Elspeth. 2014. This syntax needs studied. In Raffaella Zanuttini & Laurence Horn (eds.), Micro-syntactic variation in North American English, 242–268. Oxford: Oxford University Press.10.1093/acprof:oso/9780199367221.003.0008Search in Google Scholar
Erker, Daniel & Ricardo Otheguy. 2021. American myths of linguistic assimilation: A sociolinguistic rebuttal. Language in Society 50(2). 197–233. https://doi.org/10.1017/s0047404520000019.Search in Google Scholar
Grieve, Jack. 2016. Regional variation in written American English. Cambridge: Cambridge University Press.10.1017/CBO9781139506137Search in Google Scholar
Grieve, Jack. 2018. Mapping swearing in the United States using R. osf.io/tvjrp (accessed 4 August 2023).Search in Google Scholar
Johnstone, Barbara. 2009. Pittsburghese shirts: Commodification and the enregisterment of an urban dialect. American Speech 84(2). 157–175. https://doi.org/10.1215/00031283-2009-013.Search in Google Scholar
Kielty, Martin P. 2016. The rule book. Self-published through lulu.com.Search in Google Scholar
Kirkham, Graeme. 1997. Ulster emigration to North America, 1680–1720. In H. Tyler Blethen & Curtis W. WoodJr. (eds.), Ulster and North America: Transatlantic perspectives on the Scotch-Irish, 76–117. Tuscaloosa: University of Alabama Press.Search in Google Scholar
Kortmann, Bernd, Kerstin Lunkenheimer & Katharina Ehret (eds.). 2020. The electronic World Atlas of Varieties of English. http://ewave-atlas.org (accessed 18 July 2023).Search in Google Scholar
Labov, William, Sharon Ash & Charles Boberg. 2006. The Atlas of North American English: Phonetics, phonology and sound change. Berlin: De Gruyter.10.1515/9783110167467Search in Google Scholar
Maclagan, Margaret & Jennifer Hay. 2009. Sociolinguistics in New Zealand. In Martin J. Ball (ed.), The Routledge handbook of sociolinguistics around the world, 159–169. London: Routledge.10.4324/9780203869659-22Search in Google Scholar
Maher, Zach & Jim Wood. 2011. Needs washed. Yale Grammatical Diversity Project: English in North America. Updated by Tom McCoy (2015) and Katie Martin (2018) http://ygdp.yale.edu/phenomena/needs-washed (accessed 28 July 2023).Search in Google Scholar
Montgomery, Michael B. 1991. The roots of Appalachian English: Scotch-Irish or British Southern? Journal of the Appalachian Studies Association 3. 177–191.Search in Google Scholar
Montgomery, Michael B. 1997. The Scotch-Irish element in Appalachian English: How broad? How deep? In H. Tyler Blethen & Curtis W. WoodJr. (eds.), Ulster and North America: Transatlantic perspectives on the Scotch-Irish, 189–212. Tuscaloosa: University of Alabama Press.Search in Google Scholar
Mufwene, Salikoko S. 1996. The founder principle in creole genesis. Diachronica 13(1). 83–134. https://doi.org/10.1075/dia.13.1.05muf.Search in Google Scholar
Murray, Thomas E. & Beth Lee Simon. 1999. Want+past participle in American English. American Speech 74(2). 140–164.Search in Google Scholar
Murray, Thomas E. & Beth Lee Simon. 2002. At the intersection of regional and social dialects: The case of like+past participle in American English. American Speech 77(1). 32–68.10.1215/00031283-77-1-32Search in Google Scholar
Murray, Thomas E., Timothy C. Frazer & Beth Lee Simon. 1996. Need+past participle in American English. American Speech 71(3). 255–271. https://doi.org/10.2307/455549.Search in Google Scholar
Palan, Stefan & Christian Schitter. 2018. Prolific.ac—A subject pool for online experiments. Journal of Behavioral & Experimental Finance 17. 22–27. https://doi.org/10.1016/j.jbef.2017.12.004.Search in Google Scholar
Peer, Eyal, Laura Brandimarte, Sonam Samat & Alessandro Acquisti. 2017. Beyond the Turk: Alternative platforms for crowdsourcing behavioral research. Journal of Experimental Social Psychology 70. 153–163. https://doi.org/10.1016/j.jesp.2017.01.006.Search in Google Scholar
R Core Team. 2020. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/ (accessed 14 January 2021).Search in Google Scholar
Smith, Jennifer, David Adger, Brian Aitken, Caroline Heycock, E Jamieson & Gary Thoms. 2019. The Scots syntax atlas. University of Glasgow. https://scotssyntaxatlas.ac.uk (accessed 28 July 2023).Search in Google Scholar
Sowl, Stephanie & Andrew Crain. 2021. A systematic review of research on rural college access since 2000. Rural Educator 42(2). 16–34. https://doi.org/10.35608/ruraled.v42i2.1239.Search in Google Scholar
Sprouse, Jon, Carson T. Schütze & Diego Almeida. 2013. A comparison of informal and formal acceptability judgments using a random sample from Linguistic Inquiry 2001–2010. Lingua 134. 219–248. https://doi.org/10.1016/j.lingua.2013.07.002.Search in Google Scholar
Stabley, Rhodes R. 1959. “Needs painted,” etc., in western Pennsylvania. American Speech 34(1). 69–70. https://doi.org/10.2307/454165.Search in Google Scholar
Stanford, James N., Thomas A. Leddy-Cecere & Kenneth P. BaclawskiJr. 2012. Farewell to the founders: Major dialect changes along the east-west New England border. American Speech 87(2). 126–169. https://doi.org/10.1215/00031283-1668190.Search in Google Scholar
Strelluf, Christopher. 2020. Needs + past participle in regional Englishes on Twitter. World Englishes 39(1). 119–134. https://doi.org/10.1111/weng.12451.Search in Google Scholar
Strelluf, Christopher. 2022. Regional variation and syntactic derivation of low-frequency NEED-passives on Twitter. Journal of English Linguistics 50(1). 39–71. https://doi.org/10.1177/00754242211066971.Search in Google Scholar
Tagliamonte, Sali, Alexandra D’Arcy & Bridget Jankowski. 2010. Social work and linguistic systems: Marking possession in Canadian English. Language Variation & Change 22(1). 149–173. https://doi.org/10.1017/s0954394510000050.Search in Google Scholar
Tagliamonte, Sali, Jennifer Smith & Helen Lawrence. 2005. No taming the vernacular! Insights from the relatives in Northern Britain. Language Variation & Change 17(1). 75–112. https://doi.org/10.1017/s0954394505050040.Search in Google Scholar
Taylor, Ann. 2006. Treebank 2a guidelines. https://www-users.york.ac.uk/∼lang22/TB2a_Guidelines.htm (accessed 26 January 2023).Search in Google Scholar
Tenny, Carol. 1998. Psych verbs and verbal passives in Pittsburghese. Linguistics 36(3). 591–597.Search in Google Scholar
Ulrey, Kathleen S. 2009. Dinner needs cooked, groceries need bought, diapers need changed, kids need bathed: Tracking the progress of need+past participle across the United States. Muncie, IN: Ball State University MA thesis.Search in Google Scholar
Wilson, Catherine A. 1997. The Scotch-Irish and immigrant culture on Amherst Island, Ontario. In H. Tyler Blethen & Curtis W. WoodJr. (eds.), Ulster and North America: Transatlantic perspectives on the Scotch-Irish, 134–145. Tuscaloosa: University of Alabama Press.Search in Google Scholar
Wood, Jim. 2019. Quantifying geographical variation in acceptability judgments in regional American English dialect syntax. Linguistics 57(6). 1367–1402. https://doi.org/10.1515/ling-2019-0031.Search in Google Scholar
Wood, Jim, Josephine Holubkov, Ian Neidel & Kaija Gahm. 2022. Some notes on the needs washed construction. Yale Working Papers in Grammatical Diversity 4(2). 1–19.Search in Google Scholar
Wood, Jim, Kaija Gahm, Ian Neidel, Sasha Lioutikova, Luke Lindemann, Lydia Lee & Josephine Holubkov. 2020. Mapbook of syntactic variation in American English: Survey results, 2015–2019. Ms.: Yale University. http://lingbuzz.net/lingbuzz/005277 (accessed 24 June 2020).Search in Google Scholar
Wurmbrand, Susanne. 2024. The size of clausal complements. Annual Review of Linguistics 10. 59–83. https://doi.org/10.1146/annurev-linguistics-031522-103802.Search in Google Scholar
Zanuttini, Raffaella, Jim Wood, Jason Zentz & Laurence Horn. 2018. The Yale Grammatical Diversity Project: Morphosyntactic variation in North American English. Linguistics Vanguard 4(1). 1–14. https://doi.org/10.1515/lingvan-2016-0070.Search in Google Scholar
Zelinsky, Wilbur. 1992. The cultural geography of the United States, revised edn. Englewood Cliffs, NJ: Prentice Hall.Search in Google Scholar
Zelinsky, Wilbur. 2011. Not yet a placeless land: Tracking an evolving American geography. Boston: University of Massachusetts Press.Search in Google Scholar
Zehr, Jeremy & Florian Schwartz. 2018. PennController for Internet based experiments (IBEX). https://doi.org/10.17605/OSF.IO/MD832 (accessed 12 April 2022).Search in Google Scholar
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Metaphor forces argument overtness
- Binomials in English and French: ablaut, rhyme and syllable structure
- The interpretation of animate nouns in child and adult Mandarin: from the Universal Grinder to syntactic structure
- Geographic structure of Chinese dialects: a computational dialectometric approach
- Spanish lower and upper bounded change of state verbs: focusing on transitive experiencer object verbs
- Constructional sources of durational shortening in discourse markers
- An alternative view of the English alternative embedded passive
Articles in the same Issue
- Frontmatter
- Metaphor forces argument overtness
- Binomials in English and French: ablaut, rhyme and syllable structure
- The interpretation of animate nouns in child and adult Mandarin: from the Universal Grinder to syntactic structure
- Geographic structure of Chinese dialects: a computational dialectometric approach
- Spanish lower and upper bounded change of state verbs: focusing on transitive experiencer object verbs
- Constructional sources of durational shortening in discourse markers
- An alternative view of the English alternative embedded passive